目录
本章介绍MySQL组复制以及如何安装,配置和监视组。 MySQL Group Replication是一个MySQL Server插件,可用于创建弹性,高可用性,容错复制拓扑。
组可以在具有自动主要选举的单主模式下操作,其中一次只有一个服务器接受更新。 或者,对于更高级的用户,可以在多主模式下部署组,其中所有服务器都可以接受更新,即使它们是同时发布的。
有一个内置的组成员服务,可以在任何给定的时间点保持组的视图一致并可供所有服务器使用。 服务器可以离开并加入组,视图也会相应更新。 有时,服务器可能会意外离开组,在这种情况下,故障检测机制会检测到此情况并通知组该视图已更改。 这都是自动的。
本章的结构如下:
-
第18.1节“组复制背景” 介绍了组以及组复制的工作方式。
-
第18.2节“入门” 解释了如何配置多个MySQL Server实例以创建组。
-
第18.3节“监控组复制” 介绍了如何监控组。
-
第18.4节“组复制操作” 说明了如何使用组。
-
第18.5节“组复制安全性” 解释了如何保护组。
-
第18.7节“升级组复制” 介绍了如何升级组。
-
第18.11节“组复制技术详细信息” 提供有关组复制如何工作的 详细 信息。
本节提供有关MySQL组复制的背景信息。
创建容错系统的最常见方法是使组件冗余,换句话说,组件可以被移除,系统应该继续按预期运行。 这产生了一系列挑战,将这种系统的复杂性提高到了一个完全不同的水平。 具体而言,复制数据库必须处理这样一个事实,即它们需要维护和管理多个服务器而不是一个服务器。 此外,由于服务器正在协同创建该组,因此必须处理若干其他经典分布式系统问题,例如网络分区或分裂脑情景。
因此,最终的挑战是将数据库和数据复制的逻辑与以一致且简单的方式协调多个服务器的逻辑融合。 换句话说,让多个服务器就系统状态和系统经历的每个变化的数据达成一致。 这可以概括为让服务器在每个数据库状态转换时达成一致,以便它们都作为单个数据库进行,或者它们最终收敛到相同的状态。 这意味着它们需要作为(分布式)状态机运行。
MySQL Group Replication通过服务器之间的强大协调提供分布式状态机复制。 当服务器属于同一组时,服务器会自动进行协调。 该组可以在具有自动主要选举的单主模式下操作,其中一次只有一个服务器接受更新。 或者,对于更高级的用户,该组可以以多主模式部署,其中所有服务器都可以接受更新,即使它们是同时发布的。 这种能力的代价是应用程序必须解决此类部署所施加的限制。
有一个内置的组成员服务,可以在任何给定的时间点保持组的视图一致并可供所有服务器使用。 服务器可以离开并加入组,视图也会相应更新。 有时,服务器可能会意外离开组,在这种情况下,故障检测机制会检测到此情况并通知组该视图已更改。 这都是自动的。
对于要提交的事务,该组的大多数人必须就全局事务序列中给定事务的顺序达成一致。 决定提交或中止事务由每个服务器单独完成,但所有服务器都做出相同的决定。 如果存在网络分区,导致成员无法达成协议的分割,则在解决此问题之前系统不会继续进行。 因此,还有一种内置的自动裂脑保护机制。
所有这些都由提供的组通信系统(GCS)协议提供支持。 它们提供故障检测机制,组成员服务以及安全且完全有序的消息传递。 所有这些属性都是创建系统的关键,该系统可确保在服务器组中一致地复制数据。 该技术的核心是Paxos算法的实现。 它充当群组通信引擎。
在深入了解MySQL组复制的细节之前,本节将介绍一些背景概念以及工作原理的概述。 这提供了一些上下文,以帮助理解组复制所需的内容以及经典异步MySQL复制和组复制之间的区别。
传统的MySQL Replication提供了一种简单的Primary-Secondary复制方法。 有一个主要(主),有一个或多个辅助(奴隶)。 主要执行事务,提交事务,然后它们稍后(因此异步)发送到辅助节点,以便重新执行(在基于语句的复制中)或应用(在基于行的复制中)。 它是一个无共享系统,默认情况下所有服务器都拥有完整的数据副本。
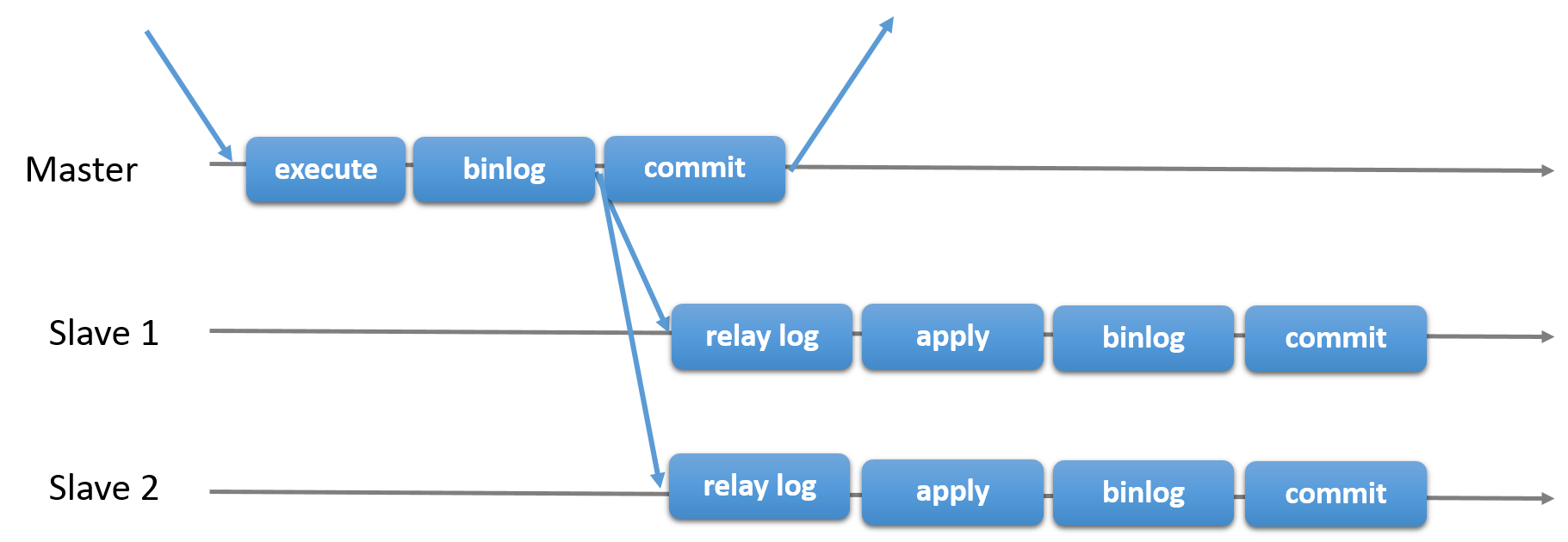
还有半同步复制,它为协议添加了一个同步步骤。 这意味着主服务器在提交时等待辅助服务器确认它已 收到 该事务。 只有这样,主节点才会恢复提交操作。
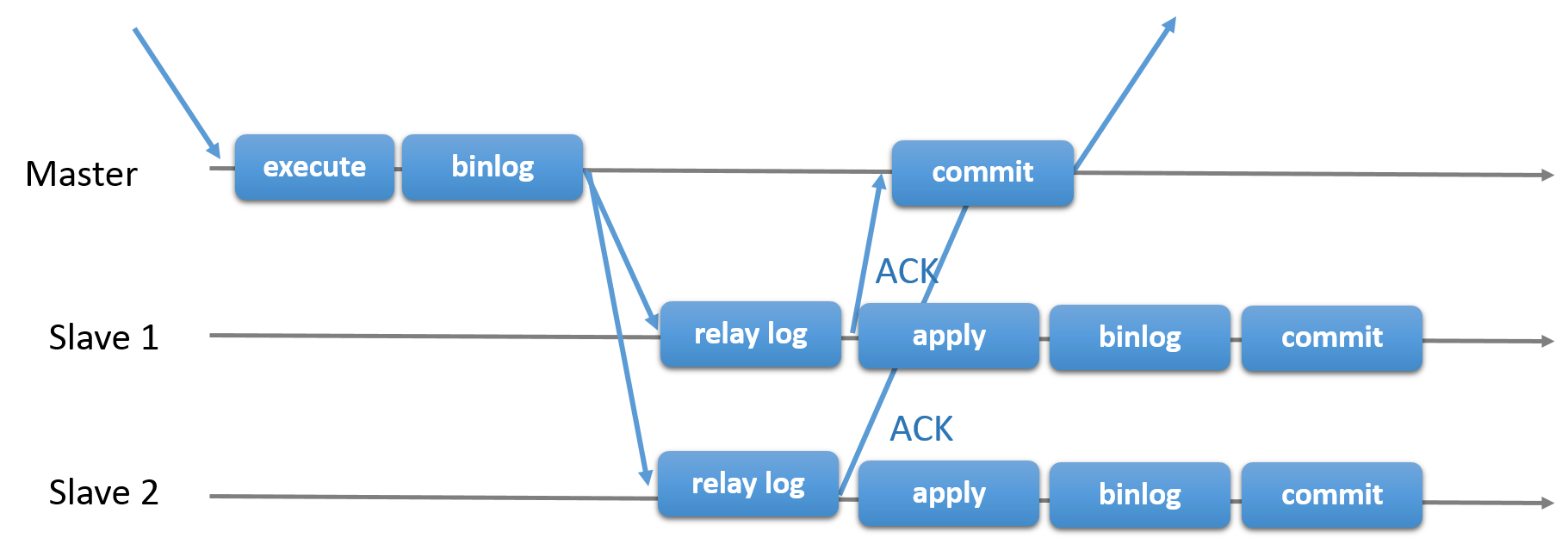
在上面的两张图中,您可以看到经典异步MySQL复制协议(以及它的半同步变体)的图表。 对角箭头表示服务器之间交换的消息或服务器与客户端应用程序之间交换的消息。
组复制是一种可用于实现容错系统的技术。 复制组是一组通过消息传递相互交互的服务器。 通信层提供一组保证,例如原子消息和总订单消息传递。 这些是非常强大的属性,可以转换为非常有用的抽象,可以用来构建更高级的数据库复制解决方案。
MySQL Group Replication构建于此类属性和抽象之上,并实现了多主机更新到处复制协议。 本质上,复制组由多个服务器组成,组中的每个服务器可以独立地执行事务。 但是所有读写(RW)事务只有在得到组的批准后才会提交。 只读(RO)事务在组内不需要协调,因此立即提交。 换句话说,对于任何RW事务,组需要决定它是否提交,因此提交操作不是来自始发服务器的单方面决定。 确切地说,当事务准备好在原始服务器上提交时, 服务器以原子方式广播写入值(已更改的行)和对应的写入集(已更新的行的唯一标识符)。 然后为该交易建立全局总订单。 最终,这意味着所有服务器都以相同的顺序接收相同的事务集。 因此,所有服务器都以相同的顺序应用相同的更改集,因此它们在组内保持一致。
但是,在不同服务器上并发执行的事务之间可能存在冲突。 通过在称为 认证 的过程中检查两个不同和并发事务的写集来检测这种冲突 。 如果在不同服务器上执行的两个并发事务更新同一行,则存在冲突。 解决过程指出,首先订购的事务在所有服务器上提交,而第二个订购的事务在中止,因此在原始服务器上回滚并由组中的其他服务器删除。 这实际上是分布式的第一个提交获胜规则。
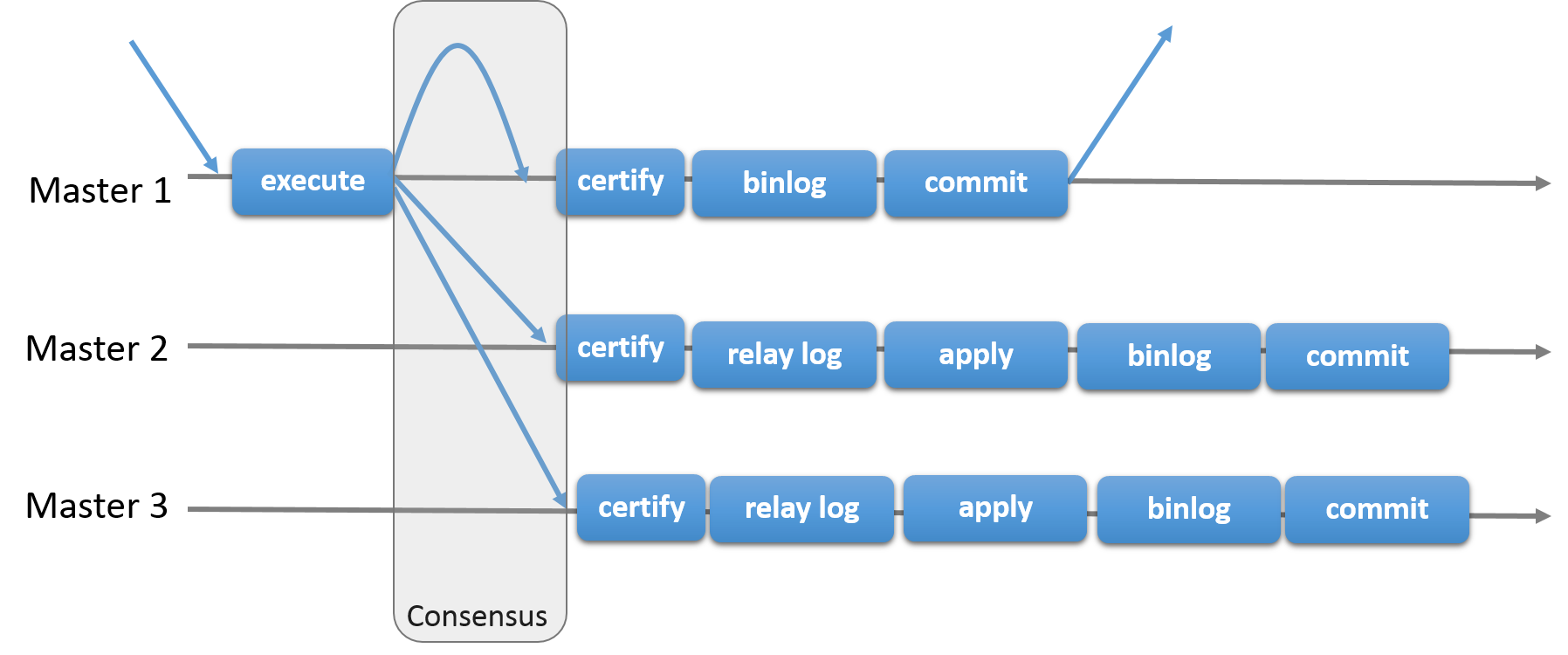
最后,组复制是一种无共享复制方案,其中每个服务器都有自己的整个数据副本。
上图描述了MySQL Group Replication协议,通过将其与MySQL Replication(甚至是MySQL半同步复制)进行比较,您可以看到一些差异。 请注意,为了清楚起见,此图中缺少一些潜在的共识和与Paxos相关的消息。
通过组复制,您可以通过将系统状态复制到一组服务器来创建具有冗余的容错系统。 即使某些服务器随后发生故障,只要它不是全部或大多数,系统仍然可用。 根据失败的服务器数量,该组可能会降低性能或可伸缩性,但它仍然可用。 服务器故障是孤立且独立的。 它们由组成员服务跟踪,该服务依赖于分布式故障检测器,该检测器能够在任何服务器离开组时发出信号,无论是自愿还是由于意外停止。 有一个分布式恢复过程,以确保当服务器加入组时,它们会自动更新。 无需服务器故障转移,并且无处不在的多主机更新可确保在单个服务器发生故障时不会阻止甚至更新。 总而言之,MySQL Group Replication保证数据库服务持续可用。
重要的是要了解尽管数据库服务可用,但在服务器崩溃的情况下,必须将连接到它的客户端重定向或故障转移到其他服务器。 这不是组复制尝试解决的问题。 连接器,负载平衡器,路由器或某种形式的中间件更适合处理此问题。 例如,请参阅 MySQL Router 8.0 。
总而言之,MySQL Group Replication提供了高度可用,高度可靠,可靠的MySQL服务。
本节介绍有关组复制构建的一些服务的详细信息。
组复制包括一种故障检测机制,该机制能够查找并报告哪些服务器是静默的,因此假设已经死机。 在较高级别,故障检测器是一种分布式服务,它提供有关哪些服务器可能已死(怀疑)的信息。 服务器静音时会触发怀疑。 当服务器A在给定时间段内没有从服务器B接收消息时,发生超时并引发怀疑。 稍后,如果小组同意怀疑可能是真的,那么该小组决定给定服务器确实失败了。 这意味着该组中的其余成员采取协调决策以排除给定成员。
如果服务器与组的其余部分隔离,则会怀疑所有其他服务器都已失败。 由于无法与该集团达成协议(因为它无法确保法定人数),其怀疑并没有后果。 当服务器以这种方式与组隔离时,它无法执行任何本地事务。
有关可以配置为指定工作组成员和怀疑发生故障的组成员的响应的组复制系统变量的信息,请参见 第18.6.6节“对故障检测和网络分区的响应” 。
MySQL Group Replication依赖于组成员资格服务。 这是内置于插件中的。 它定义了哪些服务器在线并参与该组。 在线服务器列表通常称为 视图 。 因此,组中的每个服务器都具有一致的视图,其中是在给定时刻主动参与该组的成员。
服务器不仅必须同意事务提交,还要同意当前视图。 因此,如果服务器同意新服务器成为组的一部分,则组本身将重新配置为将该服务器集成在其中,从而触发视图更改。 相反的情况也会发生,如果服务器自愿离开组,则组会动态重新排列其配置并触发视图更改。
请注意,当成员自愿离开时,它首先启动动态组重新配置。 这会触发一个过程,所有成员必须在没有离开服务器的情况下就新视图达成一致。 但是,如果成员不由自主地离开(例如,它已意外停止或网络连接断开),则故障检测机制会实现此事实,并建议重新配置组,这个没有失败的成员。 如上所述,这需要集团中大多数服务器的同意。 如果该组无法达成协议(例如,它以这样的方式进行分区,即没有大多数服务器在线), 那么系统就无法动态改变配置,因此阻止了裂脑情况。 最终,这意味着管理员需要介入并解决此问题。
MySQL Group Replication构建于Paxos分布式算法的实现之上,以在服务器之间提供分布式协调。
因此,它需要大多数服务器处于活动状态才能达到法定人数,从而做出决定。
这直接影响系统可以容忍的故障数量,而不会影响自身及其整体功能。
f
然后
,容忍
失败
所需的服务器数量(n)
n = 2 x f + 1
。
在实践中,这意味着为了容忍一个故障,该组必须具有三个服务器。 因此,如果一个服务器发生故障,仍然有两个服务器构成多数(三个中的两个),并允许系统继续自动做出决策并继续进行。 但是,如果第二个服务器不 自觉地 失败 ,那么该组(剩下一个服务器)会阻塞,因为没有多数人可以做出决定。
以下是说明上述公式的小表。
|
团体规模 |
多数 |
即时失败容忍 |
|---|---|---|
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
五 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
下一章将介绍组复制的技术方面。
MySQL Group Replication作为MySQL服务器的插件提供,组中的每个服务器都需要配置和安装插件。 本节提供详细的教程,其中包含创建具有至少三个服务器的复制组所需的步骤。
组中的每个服务器实例都可以在独立的物理机器上运行,也可以在同一台机器上运行。 本节介绍如何在一台物理计算机上创建具有三个MySQL Server实例的复制组。 这意味着需要三个数据目录,每个服务器实例一个,并且您需要独立配置每个实例。
本教程介绍如何使用组复制插件获取和部署MySQL Server,如何在创建组之前配置每个服务器实例,以及如何使用性能模式监视来验证一切是否正常工作。
第一步是部署三个MySQL服务器实例。
Group Replication是MySQL Server 8.0提供的内置MySQL插件。
有关MySQL插件的更多背景信息,请参见
第5.6节“MySQL服务器插件”
。
此过程假定MySQL Server已下载并解压缩到名为的目录中
mysql-8.0
。
以下过程使用一台物理计算机,因此每个MySQL服务器实例都需要该实例的特定数据目录。
在名为的目录中创建数据目录
data
并初始化每个
目录
。
mkdir datamysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s1mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s2mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s3
里面
data/s1
,
data/s2
,
data/s3
是一个初始化的数据目录,包含了MySQL系统数据库和相关表等等。
要了解有关初始化过程的更多信息,请参见
第2.10.1节“初始化数据目录”
。
不要
--initialize-insecure
在生产环境中
使用
,它仅用于简化教程。
有关安全设置的更多信息,请参见
第18.5节“组复制安全性”
。
本节介绍要用于组复制的MySQL Server实例所需的配置设置。 有关背景信息,请参见 第18.9.2节“组复制限制” 。
要安装和使用组复制插件,必须正确配置MySQL Server实例。 建议将配置存储在实例的配置文件中。 有关 更多信息 , 请参见 第4.2.2.2节“使用选项文件” 。 除非另有说明,否则以下是组中第一个实例的配置, 在此过程中 称为 s1 。 以下部分显示了示例服务器配置。
的[mysqld] #service配置 DATADIR = <full_path_to_data> /数据/ S1 BASEDIR = <full_path_to_bin> /mysql-8.0/ 端口= 24801 插座= <full_path_to_sock_dir> /s1.sock
这些设置将MySQL服务器配置为使用先前创建的数据目录以及服务器应打开的端口并开始侦听传入连接。
使用非默认端口24801是因为在本教程中,三个服务器实例使用相同的主机名。 在具有三台不同机器的设置中,这不是必需的。
组复制需要成员之间的网络连接,这意味着每个成员必须能够解析所有其他成员的网络地址。
例如,在本教程中,所有三个实例都在一台机器上运行,因此为了确保成员可以相互联系,您可以在选项文件中添加一行,例如
report_host=127.0.0.1
。
对于组复制,数据必须存储在InnoDB事务存储引擎中(有关原因的详细信息,请参见
第18.9.1节“组复制要求”
)。
使用其他存储引擎(包括临时
MEMORY
存储引擎)可能会导致组复制出错。
设置
disabled_storage_engines
系统变量如下以防止它们的使用:
disabled_storage_engines = “的MyISAM,BLACKHOLE,FEDERATED,归档,MEMORY”
请注意,在
MyISAM
禁用存储引擎的情况下,当您将MySQL实例升级到
仍使用
mysql_upgrade
的版本时
(在MySQL 8.0.16之前),
mysql_upgrade
可能会失败并显示错误。
要处理此问题,您可以在运行
mysql_upgrade
时重新启用该存储引擎
,然后在重新启动服务器时再次禁用它。
有关更多信息,请参见
第4.4.5节“
mysql_upgrade
- 检查和升级MySQL表”
。
以下设置根据MySQL组复制要求配置复制。
SERVER_ID = 1 gtid_mode = ON enforce_gtid_consistency = ON binlog_checksum = NONE
这些设置将服务器配置为使用唯一标识符编号1,以启用全局事务标识符,以允许仅执行可使用GTID安全记录的语句,以及禁用写入写入二进制日志的事件的校验和。
如果您使用的是早于8.0.3的MySQL版本,其中默认值已针对复制进行了改进,则需要将这些行添加到成员的选项文件中。
log_bin =二进制日志 log_slave_updates = ON binlog_format = ROW master_info_repository =表 relay_log_info_repository =表
这些设置指示服务器打开二进制日志记录,使用基于行的格式,将复制元数据存储在系统表而不是文件中,并禁用二进制日志事件校验和。 有关更多详细信息,请参见 第18.9.1节“组复制要求” 。
此时,该
my.cnf
文件确保配置服务器并指示在给定配置下实例化复制基础结构。
以下部分配置服务器的“组复制”设置。
transaction_write_set_extraction = XXHASH64 group_replication_group_name = “AAAAAAAAAAAA-AAAAAAAA-AAAAAAAAAAAA” group_replication_start_on_boot =关 group_replication_local_address =“127.0.0.1:24901” group_replication_group_seeds =“127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903” group_replication_bootstrap_group =关
-
配置
transaction_write_set_extraction指示服务器对于每个事务,它必须收集写集并使用XXHASH64散列算法将其编码为散列。 从MySQL 8.0.2开始,此设置是默认设置,因此可以省略此行。 -
配置
group_replication_group_name告诉插件它正在加入或创建的组被命名为“aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa值
group_replication_group_name必须是有效的UUID。 在二进制日志中为组复制事件设置GTID时,将在内部使用此UUID。 使用SELECT UUID()生成一个UUID。 -
配置
group_replication_start_on_boot指示插件在服务器启动时不自动启动操作。 这在设置组复制时很重要,因为它确保您可以在手动启动插件之前配置服务器。 配置成员后,您可以设置group_replication_start_on_boot为on,以便在服务器引导时自动启动Group Replication。 -
配置
group_replication_local_address告诉插件使用网络地址127.0.0.1和端口24901与组中的其他成员进行内部通信。重要组复制将此地址用于涉及组通信引擎(XCom,Paxos变体)的远程实例的内部成员到成员连接。 此地址必须与用于SQL的主机名和端口不同,并且不得用于客户端应用程序。 在运行组复制时,必须为组成员之间的内部通信保留它。
配置的网络地址
group_replication_local_address必须可由所有组成员解析。 例如,如果每个服务器实例位于具有固定网络地址的其他计算机上,则可以使用计算机的IP地址,例如10.0.0.1。 如果使用主机名,则必须使用完全限定名称,并确保它可以通过DNS解析,并且配置正确/etc/hosts文件或其他名称解析过程。 从MySQL 8.0.14开始,可以使用IPv6地址(或解析它们的主机名)以及IPv4地址。 组可以包含使用IPv6的成员和使用IPv4的成员的混合。 有关IPv6网络以及混合IPv4和IPv6组的组复制支持的更多信息,请参见 第18.4.6节“支持IPv6以及混合IPv6和IPv4组” 。建议的端口
group_replication_local_address是33061.在本教程中,我们使用在一台计算机上运行的三个服务器实例,因此端口24901到24903用于内部通信网络地址。group_replication_local_addressGroup Replication使用它作为复制组中组成员的唯一标识符。 只要主机名或IP地址都不同,您就可以为复制组的所有成员使用相同的端口,并且如本教程所示,只要具有相同的主机名或IP地址,就可以使用相同的主机名或IP地址。港口都不一样。 -
配置
group_replication_group_seeds设置组成员的主机名和端口,新成员使用它们建立与组的连接。 这些成员称为种子成员。 建立连接后,将列出组成员身份信息performance_schema.replication_group_members。 通常,group_replication_group_seeds列表包含hostname:port每个组成员的列表group_replication_local_address,但这不是强制性的,可以选择组成员的子集作为种子。重要该
hostname:port列在group_replication_group_seeds是种子构件的内部网络地址,由被配置group_replication_local_address,而不是SQLhostname:port用于客户端连接,并且例如在显示performance_schema.replication_group_members表中。启动该组的服务器不使用此选项,因为它是初始服务器,因此,它负责引导组。 换句话说,引导该组的服务器上的任何现有数据都是用作下一个加入成员的数据。 第二个服务器连接要求组中唯一的成员加入,第二个服务器上的任何缺失数据都从引导成员上的施主数据中复制,然后组扩展。 加入的第三个服务器可以要求这两个服务器中的任何一个加入,数据被同步到新成员,然后该组再次扩展。
警告在同时加入多个服务器时,请确保它们指向已在该组中的种子成员。 不要使用也加入该组的成员作为种子,因为他们在联系时可能尚未加入该组。
最好首先启动引导程序成员,然后让它创建组。 然后使其成为正在加入的其余成员的种子成员。 这确保了在连接其余成员时形成的组。
不支持创建组并同时加入多个成员。 它可能有效,但可能是操作竞争,然后加入该组的行为最终会出错或超时。
加入成员必须使用种子成员在
group_replication_group_seeds选项中 通告的相同协议(IPv4或IPv6)与种子成员通信 。 出于组复制的IP地址白名单的目的,种子成员上的白名单必须包含种子成员提供的协议的加入成员的IP地址,或者解析为该协议的地址的主机名。 除了加入成员之外,还必须设置此地址或主机名并列入白名单group_replication_local_address如果该地址的协议与种子成员的通告协议不匹配。 如果加入成员没有适当协议的白名单地址,则拒绝其连接尝试。 有关更多信息,请参见 第18.5.1节“组复制IP地址白名单” 。 -
配置
group_replication_bootstrap_group指示插件是否引导组。重要此选项只能在任何时候在一个服务器实例上使用,通常是第一次引导组时(或者在整个组关闭并重新备份的情况下)。 如果多次引导组,例如当多个服务器实例设置了此选项时,则可以创建一个人工分裂脑情景,其中存在两个具有相同名称的不同组。 在第一个服务器实例联机后禁用此选项。
组中所有服务器的配置非常相似。
您需要更改有关每个服务器的细节(例如
server_id
,
datadir
,
group_replication_local_address
)。
本教程稍后将对此进行说明。
组复制使用异步复制协议来实现
第18.11.5节“分布式恢复”
,在将组成员加入组之前同步组成员。
分布式恢复过程依赖于名为的复制通道
group_replication_recovery
,该
通道
用于将来自供体成员的事务转移到加入该组的成员。
因此,您需要设置具有正确权限的复制用户,以便组复制可以建立直接的成员到成员恢复复制通道。
使用选项文件启动服务器:
mysql-8.0 / bin / mysqld --defaults-file = data / s1 / s1.cnf
使用该
REPLICATION-SLAVE
权限
创建MySQL用户
。
可以在二进制日志中捕获此过程,然后您可以依靠分布式恢复来复制用于创建用户的语句。
或者,您可以禁用二进制日志记录,然后在每个成员上手动创建用户,例如,如果要避免将更改传播到其他服务器实例。
要禁用二进制日志记录,请连接到服务器s1并发出以下语句:
MySQL的> SET SQL_LOG_BIN=0;
在以下示例中
rpl_user
,将
password
显示
具有密码
的用户
。
配置服务器时,请使用合适的用户名和密码。
mysql> mysql> mysql>CREATE USERrpl_user@'%' IDENTIFIED BY 'password';GRANT REPLICATION SLAVE ON *.* TOrpl_user@'%';FLUSH PRIVILEGES;
如果禁用了二进制日志记录,则在创建用户后再次启用它。
MySQL的> SET SQL_LOG_BIN=1;
配置用户后,使用该
CHANGE
MASTER TO
语句将服务器配置为
group_replication_recovery
在下次需要从另一个成员恢复其状态时
使用
复制通道的
给定凭据
。
发出以下,替换
rpl_user
和
password
与创建用户时使用的值。
MySQL的> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' \\
FOR CHANNEL 'group_replication_recovery';
分布式恢复是加入组的服务器采取的第一步,并且没有与组成员相同的事务集。
如果没有为
group_replication_recovery
复制通道
正确设置这些凭据,
并且
rpl_user
如图所示,则服务器无法连接到供体成员并运行分布式恢复过程以与其他组成员同步,因此最终无法加入该组。
同样,如果服务器无法通过服务器正确识别其他成员,
hostname
则恢复过程可能会失败。
建议运行MySQL的操作系统具有正确配置的唯一
hostname
,使用DNS或本地设置。
这
hostname
可以
Member_host
在
performance_schema.replication_group_members
表格
的
列中
进行验证
。
如果多个组成员外部化
hostname
操作系统
的默认
设置,则成员可能无法解析为正确的成员地址而无法加入该组。
在这种情况下,使用
report_host
配置
hostname
由每个服务器外部化
的唯一
。
默认情况下,在MySQL 8中创建的用户使用
第6.4.1.3节“缓存SHA-2可插入身份验证”
。
如果
rpl_user
您为分布式恢复配置使用缓存SHA-2身份验证插件,并且您没有使用
复制通道的
第18.5.2节“组复制安全套接字层(SSL)支持”
,
group_replication_recovery
则使用RSA密钥对进行密码交换,请参见
第6.3.3节“创建SSL和RSA证书和密钥”
。
您可以复制该公钥
rpl_user
应该从组中恢复其状态的成员,或者将捐赠者配置为在请求时提供公钥。
更安全的方法是将公钥复制
rpl_user
到应该从捐赠者恢复组状态的成员。
然后,您需要
group_replication_recovery_public_key_path
在加入组的成员上
配置
系统变量,并为其提供公钥的路径
rpl_user
。
可选地,不太安全的方法是设置
group_replication_recovery_get_public_key=ON
捐赠者,以便他们
rpl_user
在加入组时
提供
成员的
公钥
。
无法验证服务器的身份,因此只有
group_replication_recovery_get_public_key=ON
在您确定没有服务器身份被泄露的风险时
才会设置
,例如通过中间人攻击。
配置并启动服务器s1后,安装组复制插件。 连接到服务器并发出以下命令:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
mysql.session
在加载组复制之前
,
用户必须存在。
mysql.session
在MySQL 8.0.2版中添加了。
如果使用早期版本初始化数据字典,则必须执行MySQL升级过程(请参见
第2.11节“升级MySQL”
)。
如果未运行升级,则组复制无法以错误消息启动
尝试使用用户访问服务器时出现错误:mysql.session@localhost。
确保用户在服务器中,并且在服务器更新后运行了mysql_upgrade。
。
要检查插件是否已成功安装,请发出
SHOW PLUGINS;
并检查输出。
它应该显示如下:
MySQL的> SHOW PLUGINS;
+ ---------------------------- + ---------- + --------- ----------- + ---------------------- + ------------- +
| 名称| 状态| 输入| 图书馆| 许可证|
+ ---------------------------- + ---------- + --------- ----------- + ---------------------- + ------------- +
| binlog | ACTIVE | 存储引擎| NULL | 所有权|
(......)
| group_replication | ACTIVE | 集团复制| group_replication.so | 所有权|
+ ---------------------------- + ---------- + --------- ----------- + ---------------------- + ------------- +
要启动该组,请指示服务器s1引导该组,然后启动组复制。
此引导程序应仅由单个服务器完成,该服务器启动组并且只执行一次。
这就是为什么bootstrap配置选项的值未保存在配置文件中的原因。
如果它保存在配置文件中,则在重新启动时,服务器会自动引导具有相同名称的第二个组。
这将导致两个具有相同名称的不同组。
同样的推理适用于在此选项设置为的情况下停止并重新启动插件
ON
。
SET GLOBAL group_replication_bootstrap_group = ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group = OFF;
一旦
START GROUP_REPLICATION
语句返回,该集团已启动。
您可以检查该组现在是否已创建,并且其中包含一个成员:
MySQL的> SELECT * FROM performance_schema.replication_group_members;
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
| group_replication_applier | ce9be252-2b71-11e6-b8f4-00212844f856 | myhost | 24801 | 在线|
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
此表中的信息确认组中有成员具有唯一标识符
ce9be252-2b71-11e6-b8f4-00212844f856
,它正在
ONLINE
并且正在
myhost
侦听端口上的客户端连接
24801
。
为了证明服务器确实在一个组中并且它能够处理负载,创建一个表并向其添加一些内容。
mysql>CREATE DATABASE test;mysql>USE test;mysql>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);mysql>INSERT INTO t1 VALUES (1, 'Luis');
检查表的内容
t1
和二进制日志。
MySQL的>SELECT * FROM t1;+ ---- + ------ + | c1 | c2 | + ---- + ------ + | 1 | 路易斯| + ---- + ------ + MySQL的>SHOW BINLOG EVENTS;+ --------------- + ----- + ---------------- + ---------- - + ------------- + ---------------------------------- ---------------------------------- + | Log_name | Pos | Event_type | Server_id | End_log_pos | 信息| + --------------- + ----- + ---------------- + ---------- - + ------------- + ---------------------------------- ---------------------------------- + | binlog.000001 | 4 | Format_desc | 1 | 123 | Server ver:8.0.2-gr080-log,Binlog ver:4 | | binlog.000001 | 123 | Previous_gtids | 1 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:1'| | binlog.000001 | 211 | 查询| 1 | 270 | 开始| | binlog.000001 | 270 | View_change | 1 | 369 | view_id = 14724817264259180:1 | | binlog.000001 | 369 | 查询| 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:2'| | binlog.000001 | 495 | 查询| 1 | 585 | CREATE DATABASE测试| | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa:3'| | binlog.000001 | 646 | 查询| 1 | 770 | 用`test`; CREATE TABLE t1(c1 INT PRIMARY KEY,c2 TEXT NOT NULL)| | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:4'| | binlog.000001 | 831 | 查询| 1 | 899 | 开始| | binlog.000001 | 899 | Table_map | 1 | 942 | table_id:108(test.t1)| | binlog.000001 | 942 | Write_rows | 1 | 984 | table_id:108个标志:STMT_END_F | | binlog.000001 | 984 | Xid | 1 | 1011 | COMMIT / * xid = 38 * / | + --------------- + ----- + ---------------- + ---------- - + ------------- + ---------------------------------- ---------------------------------- +
如上所示,创建了数据库和表对象,并将相应的DDL语句写入二进制日志。 此外,数据已插入表中并写入二进制日志。 当组成长并且新成员尝试赶上并联机时执行分布式恢复时,下一节将说明二进制日志条目的重要性。
此时,该组中有一个成员服务器s1,其中包含一些数据。 现在是时候通过添加先前配置的其他两个服务器来扩展组。
为了添加第二个实例,服务器s2,首先为它创建配置文件。
配置类似于用于服务器s1的配置,除了诸如数据目录的位置,s2将要监听的端口或其之外的配置
server_id
。
这些不同的行在下面的列表中突出显示。
的[mysqld] #service配置 DATADIR = <full_path_to_data> /数据/ S2 BASEDIR = <full_path_to_bin> /mysql-8.0/ 端口= 24802 插座= <full_path_to_sock_dir> /s2.sock # #禁用其他存储引擎 # disabled_storage_engines = “的MyISAM,BLACKHOLE,FEDERATED,归档,MEMORY” # #Replication配置参数 # SERVER_ID = 2 gtid_mode = ON enforce_gtid_consistency = ON binlog_checksum = NONE # #组复制配置 # transaction_write_set_extraction = XXHASH64 group_replication_group_name = “AAAAAAAAAAAA-AAAAAAAA-AAAAAAAAAAAA” group_replication_start_on_boot =关 group_replication_local_address =“127.0.0.1:24902” group_replication_group_seeds =“127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903” group_replication_bootstrap_group = off
与服务器s1的过程类似,使用选项文件启动服务器。
mysql-8.0 / bin / mysqld --defaults-file = data / s2 / s2.cnf
然后按如下方式配置恢复凭据。 这些命令与设置服务器s1时使用的命令相同,因为用户在组内共享。 在s2上发布以下语句。
SET SQL_LOG_BIN=0;CREATE USERrpl_user@'%' IDENTIFIED BY 'password';GRANT REPLICATION SLAVE ON *.* TOrpl_user@'%';SET SQL_LOG_BIN=1;CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' \\ FOR CHANNEL 'group_replication_recovery';
如果您使用的是缓存SHA-2身份验证插件(MySQL 8中的默认设置),请参阅 使用组复制和缓存SHA-2用户凭据插件 。
安装组复制插件并开始将服务器加入组的过程。 以下示例以与部署服务器s1时相同的方式安装插件。
mysql> INSTALL PLUGIN group_replication SONAME'group_replication.so';
将服务器s2添加到组中。
mysql> START GROUP_REPLICATION;
与之前的步骤(与s1上执行的步骤相同)不同,此处的区别在于,
在启动组复制之前
不会
发出
SET GLOBAL
group_replication_bootstrap_group=ON;
,因为该组已由服务器s1创建并引导。
此时,只需将服务器s2添加到现有组中。
当组复制成功启动并且服务器加入组时,它会检查
super_read_only
变量。
通过
super_read_only
在成员的配置文件中
设置
为ON,可以确保因任何原因启动组复制时出现故障的服务器不接受事务。
如果服务器应将该组作为读写实例加入,例如作为单主组中的主要组或多主组的成员,则当该
super_read_only
变量设置为ON时,则在加入时将其设置为OFF群组。
performance_schema.replication_group_members
再次
检查
表显示
该组
中现在有两个
ONLINE
服务器。
MySQL的> SELECT * FROM performance_schema.replication_group_members;
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
| group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | myhost | 24801 | 在线|
| group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | myhost | 24802 | 在线|
+ --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
由于服务器s2也标记为ONLINE,它必须已经自动赶上服务器s1。 验证它确实已与服务器s1同步,如下所示。
MySQL的>SHOW DATABASES LIKE 'test';+ ----------------- + | 数据库(测试)| + ----------------- + | 测试| + ----------------- + MySQL的>SELECT * FROM test.t1;+ ---- + ------ + | c1 | c2 | + ---- + ------ + | 1 | 路易斯| + ---- + ------ + MySQL的>SHOW BINLOG EVENTS;+ --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- + | Log_name | Pos | Event_type | Server_id | End_log_pos | 信息| + --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- + | binlog.000001 | 4 | Format_desc | 2 | 123 | Server ver:8.0.3-log,Binlog ver:4 | | binlog.000001 | 123 | Previous_gtids | 2 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:1'| | binlog.000001 | 211 | 查询| 1 | 270 | 开始| | binlog.000001 | 270 | View_change | 1 | 369 | view_id = 14724832985483517:1 | | binlog.000001 | 369 | 查询| 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:2'| | binlog.000001 | 495 | 查询| 1 | 585 | CREATE DATABASE测试| | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa:3'| | binlog.000001 | 646 | 查询| 1 | 770 | 用`test`; CREATE TABLE t1(c1 INT PRIMARY KEY,c2 TEXT NOT NULL)| | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:4'| | binlog.000001 | 831 | 查询| 1 | 890 | 开始| | binlog.000001 | 890 | Table_map | 1 | 933 | table_id:108(test.t1)| | binlog.000001 | 933 | Write_rows | 1 | 975 | table_id:108个标志:STMT_END_F | | binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT / * xid = 30 * / | | binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:5'| | binlog.000001 | 1063 | 查询| 1 | 1122 | 开始| | binlog.000001 | 1122 | View_change | 1 | 1261 | view_id = 14724832985483517:2 | | binlog.000001 | 1261 | 查询| 1 | 1326 | COMMIT | + --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- +
如上所示,第二台服务器已添加到组中,并自动从服务器s1复制了更改。 根据分布式恢复过程,这意味着在加入组之后并且在被声明在线之前,服务器s2已经自动连接到服务器s1并从中获取丢失的数据。 换句话说,它将事务从缺少的s1的二进制日志复制到它加入组的时间点。
向组添加其他实例与添加第二个服务器的步骤顺序基本相同,只是必须更改配置,因为必须更改服务器s2。 总结所需的命令:
1.创建配置文件
的[mysqld] #service配置 DATADIR = <full_path_to_data> /数据/ S3 BASEDIR = <full_path_to_bin> /mysql-8.0/ 端口24803 = 插座= <full_path_to_sock_dir> /s3.sock # #禁用其他存储引擎 # disabled_storage_engines = “的MyISAM,BLACKHOLE,FEDERATED,归档,MEMORY” # #Replication配置参数 # SERVER_ID = 3 gtid_mode = ON enforce_gtid_consistency = ON binlog_checksum = NONE # #组复制配置 # group_replication_group_name = “AAAAAAAAAAAA-AAAAAAAA-AAAAAAAAAAAA” group_replication_start_on_boot =关 group_replication_local_address =“127.0.0.1:24903” group_replication_group_seeds =“127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903” group_replication_bootstrap_group = off
2.启动服务器
mysql-8.0 / bin / mysqld --defaults-file = data / s3 / s3.cnf
3.配置group_replication_recovery通道的恢复凭据。
SET SQL_LOG_BIN = 0; 创建用户rpl_user@'%'标识'password'; 授予复制权限*。*至rpl_user@'%'; FLUSH特权; SET SQL_LOG_BIN = 1; 更改MASTER_USER ='rpl_user',MASTER_PASSWORD ='password'\\ FOR CHANNEL'group_replication_recovery';
4.安装Group Replication插件并启动它。
INSTALL PLUGIN group_replication SONAME'group_replication.so'; START GROUP_REPLICATION;
此时,服务器s3已启动并正在运行,已加入该组并赶上该组中的其他服务器。
performance_schema.replication_group_members
再次
咨询
表证实了这种情况。
mysql> SELECT * FROM performance_schema.replication_group_members; + --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- + | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | + --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- + | group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | myhost | 24801 | 在线| | group_replication_applier | 7eb217ff-6df3-11e6-966c-00212844f856 | myhost | 24803 | 在线| | group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | myhost | 24802 | 在线| + --------------------------- + --------------------- ----------------- + ------------- ------------- + + ---- ----------- +
在服务器s2或服务器s1上发出相同的查询会产生相同的结果。 此外,您可以验证服务器s3是否也赶上了:
MySQL的>SHOW DATABASES LIKE 'test';+ ----------------- + | 数据库(测试)| + ----------------- + | 测试| + ----------------- + MySQL的>SELECT * FROM test.t1;+ ---- + ------ + | c1 | c2 | + ---- + ------ + | 1 | 路易斯| + ---- + ------ + MySQL的>SHOW BINLOG EVENTS;+ --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- + | Log_name | Pos | Event_type | Server_id | End_log_pos | 信息| + --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- + | binlog.000001 | 4 | Format_desc | 3 | 123 | Server ver:8.0.3-log,Binlog ver:4 | | binlog.000001 | 123 | Previous_gtids | 3 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:1'| | binlog.000001 | 211 | 查询| 1 | 270 | 开始| | binlog.000001 | 270 | View_change | 1 | 369 | view_id = 14724832985483517:1 | | binlog.000001 | 369 | 查询| 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:2'| | binlog.000001 | 495 | 查询| 1 | 585 | CREATE DATABASE测试| | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa:3'| | binlog.000001 | 646 | 查询| 1 | 770 | 用`test`; CREATE TABLE t1(c1 INT PRIMARY KEY,c2 TEXT NOT NULL)| | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:4'| | binlog.000001 | 831 | 查询| 1 | 890 | 开始| | binlog.000001 | 890 | Table_map | 1 | 933 | table_id:108(test.t1)| | binlog.000001 | 933 | Write_rows | 1 | 975 | table_id:108个标志:STMT_END_F | | binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT / * xid = 29 * / | | binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:5'| | binlog.000001 | 1063 | 查询| 1 | 1122 | 开始| | binlog.000001 | 1122 | View_change | 1 | 1261 | view_id = 14724832985483517:2 | | binlog.000001 | 1261 | 查询| 1 | 1326 | COMMIT | | binlog.000001 | 1326 | Gtid | 1 | 1387 | SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaa:6'| | binlog.000001 | 1387 | 查询| 1 | 1446 | 开始| | binlog.000001 | 1446 | View_change | 1 | 1585 | view_id = 14724832985483517:3 | | binlog.000001 | 1585 | 查询| 1 | 1650 | COMMIT | + --------------- + ------ + ---------------- + --------- - + ------------- + --------------------------------- ----------------------------------- +
假设 已启用 性能架构 ,请使用Perfomance架构表来监视组复制 。 组复制添加以下表:
这些Perfomance Schema复制表还显示有关组复制的信息:
-
performance_schema.replication_connection_status显示有关组复制的信息,例如,已从组接收并在应用程序队列中排队的事务(中继日志)。 -
performance_schema.replication_applier_status显示与组复制相关的通道和线程的状态如果有许多不同的工作线程应用事务,那么工作表也可用于监视每个工作线程正在执行的操作。
Group Replication插件创建的复制通道命名为:
-
group_replication_recovery- 此通道用于与分布式恢复阶段相关的复制更改。 -
group_replication_applier- 此通道用于来自组的传入更改。 这是用于应用直接来自组的交易的渠道。
以下部分描述了如何解释可用信息。
服务器实例可以处于各种状态。如果服务器正常通信,则所有服务器都报告相同的状态。 但是,如果存在网络分区,或者服务器离开该组,则可以报告不同的信息,具体取决于查询的服务器。 如果服务器已离开该组,则它无法报告有关其他服务器状态的更新信息。 如果存在分区,使得仲裁丢失,则服务器无法在它们之间进行协调。 结果,他们无法猜出不同服务器的状态。 因此,他们报告某些服务器无法访问,而不是猜测他们的状态。
表18.1服务器状态
|
领域 |
描述 |
组同步 |
|---|---|---|
|
|
该成员已准备好充当功能齐全的组成员,这意味着客户端可以连接并开始执行事务。 |
是 |
|
|
该成员正在成为该组织的积极成员,目前正在进行恢复过程,从捐赠者那里接收国家信息。 |
没有 |
|
|
插件已加载但该成员不属于任何组。 |
没有 |
|
|
会员的状态。 只要恢复阶段或应用更改时出现错误,服务器就会进入此状态。 |
没有 |
|
|
每当本地故障检测器怀疑某个服务器无法访问时,例如它被非自愿断开,它就会显示服务器的状态为
|
没有 |
实例进入
ERROR
状态后,该
super_read_only
选项将设置为
ON
。
要离开
ERROR
状态,您必须手动配置实例
super_read_only=OFF
。
请注意,组复制 不是 同步的,但最终是同步的。 更确切地说,事务以相同的顺序传递给所有组成员,但是它们的执行不同步,这意味着在接受提交事务之后,每个成员按照自己的进度提交。
该
performance_schema.replication_group_members
表用于监视作为组成员的不同服务器实例的状态。
只要存在视图更改,就会更新表中的信息,例如,当新成员加入时动态更改组的配置时。
此时,服务器交换一些元数据以使其自身同步并继续一起协作。
信息在作为复制组成员的所有服务器实例之间共享,因此可以从任何成员查询有关所有组成员的信息。
此表可用于获取复制组状态的高级视图,例如通过发出:
SELECT * FROM performance_schema.replication_group_members;
+ --------------------------- + --------------------- ----------------- + -------------- + ------------- + --- ----------- ------------- + ---------------- + +
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+ --------------------------- + --------------------- ----------------- + -------------- + ------------- + --- ----------- ------------- + ---------------- + +
| group_replication_applier | 041f26d8-f3f3-11e8-adff-080027337932 | example1 | 3306 | 在线| 中学| 8.0.13 |
| group_replication_applier | f60a3e10-f3f2-11e8-8258-080027337932 | example2 | 3306 | 在线| 主要| 8.0.13 |
| group_replication_applier | fc890014-f3f2-11e8-a9fd-080027337932 | example3 | 3306 | 在线| 中学| 8.0.13 |
+ --------------------------- + --------------------- ----------------- + -------------- + ------------- + --- ----------- ------------- + ---------------- + +
根据这个结果,我们可以看到该组由三个成员组成,每个成员的主机和端口号,客户端用来连接成员,以及
server_uuid
成员。
该
MEMBER_STATE
列显示了
第18.3.1节“组复制服务器状态”之一
,在这种情况下,它显示该组中的所有三个成员都是
ONLINE
,并且该
MEMBER_ROLE
列显示有两个辅助
节点
和一个主
节点
。
因此,该组必须以单主模式运行。
MEMBER_VERSION
当您升级组并且正在组合运行不同MySQL版本的成员时,
该
列可能很有用。
请参见
第18.3.1节“组Replication Server状态”
欲获得更多信息。
有关
Member_host
值及其对分布式恢复过程的影响的
更多信息
,请参见
第18.2.1.3节“用户凭据”
。
复制组中的每个成员都会验证并应用该组收到的事务。 有关验证者和应用程序过程的统计信息有助于了解应用程序队列的增长情况,已找到的冲突数,检查的事务数,到处提交的事务数等等。
该
performance_schema.replication_group_member_stats
表提供与认证过程相关的组级信息,以及由复制组的每个成员接收和发起的事务的统计信息。
信息在作为复制组成员的所有服务器实例之间共享,因此可以从任何成员查询有关所有组成员的信息。
请注意,刷新远程成员的统计信息由
group_replication_flow_control_period
选项中
指定的消息周期控制
,因此这些信息可能与进行查询的成员的本地收集的统计信息略有不同。
要使用此表监视组复制成员,请发出:
MySQL的> SELECT * FROM performance_schema.replication_group_member_stats\G
这些字段对于监视组中连接的成员的性能很重要。 例如,假设组中的一个成员总是在其队列中报告与其他成员相比的大量事务。 这意味着该成员被延迟,并且无法与该组的其他成员保持同步。 根据此信息,您可以决定从组中删除该成员,或者延迟处理该组其他成员上的事务,以减少排队事务的数量。 此信息还可以帮助您决定如何调整组复制插件的流控制,请参见 第18.6.2节“流控制” 。
本节介绍部署组复制的不同模式,介绍管理组的常用操作,并提供有关如何调整组的信息。 。
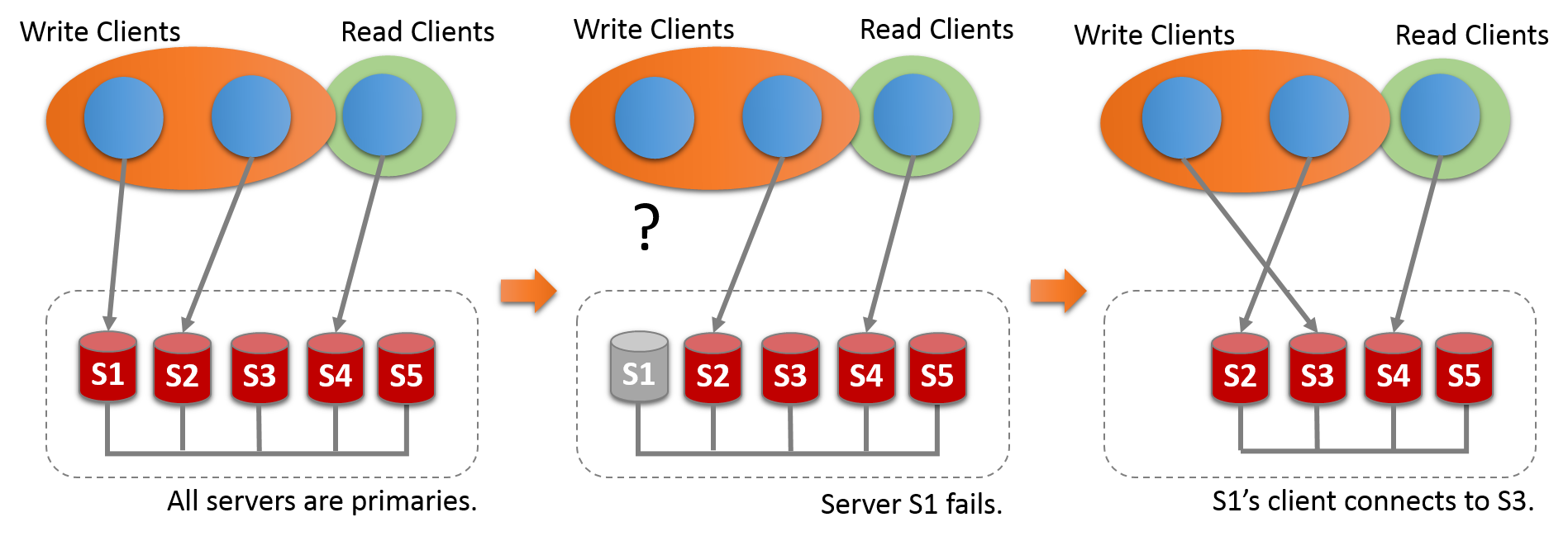
组复制以以下不同模式运行:
-
单主模式
-
多主模式
默认模式是单主模式。 不可能以不同的模式部署组的成员,例如,一个配置为多主模式而另一个配置为单主模式。 要在模式之间切换,需要使用不同的操作配置重新启动组而不是服务器。 无论部署模式如何,组复制都不处理客户端故障转移,必须由应用程序本身,连接器或中间件框架(如代理或 MySQL路由器8.0)处理 。
在多主模式下部署时,会检查语句以确保它们与模式兼容。 在多主模式下部署组复制时,将进行以下检查:
-
如果事务在SERIALIZABLE隔离级别下执行,则在与组同步时其提交失败。
-
如果事务针对具有级联约束的外键的表执行,则在与组同步时事务无法提交。
这些检查可以通过设置选项来禁用
group_replication_enforce_update_everywhere_checks
到
FALSE
。
在单主模式下部署时,
必须
将此选项
设置为
FALSE
。
在此模式下,组具有设置为读写模式的单主服务器。
组中的所有其他成员都设置为只读模式(带
super-read-only=ON
)。
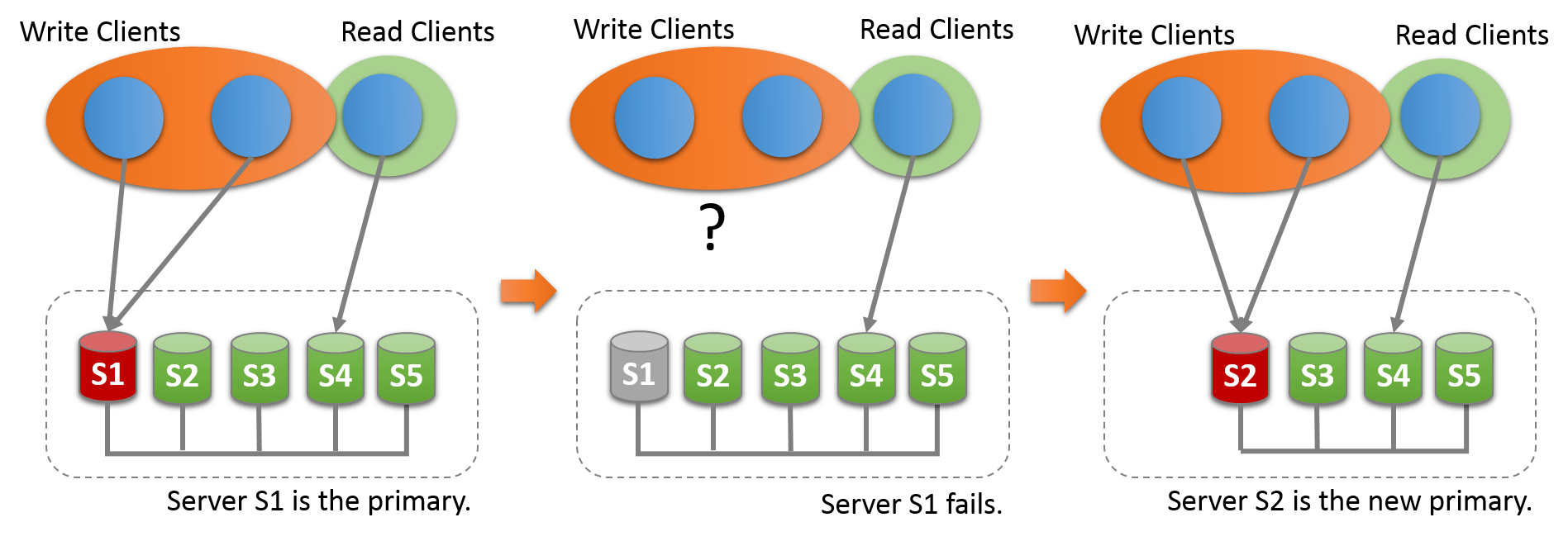
这会自动发生。
主服务器通常是第一个引导组的服务器,所有其他连接的服务器自动了解主服务器并设置为只读。
在单主模式下,部署在多主模式下的某些检查将被禁用,因为系统强制只有一个服务器写入该组。
例如,允许对具有级联外键的表进行更改,而在多主模式下则不允许更改。
在主要成员失败时,自动主要选举机制选择新的主要成员。
选举过程是通过查看新视图,并根据值来订购潜在的新原选
group_replication_member_weight
。
假设该组正在运行所有运行相同MySQL版本的成员,那么具有最高值的成员
group_replication_member_weight
被选为新的小学。
如果多个服务器具有相同
group_replication_member_weight
的服务器,则根据它们
server_uuid
的字典顺序和选择第一个
服务器来确定服务器的优先级
。
选择新的主节点后,它将自动设置为读写,其他辅助节点仍为辅助节点,因此为只读节点。
当选择新主节点时,只有在处理了来自旧主节点的所有事务后,它才可写。 这避免了旧主数据库的旧事务与此成员上执行的新事务之间可能出现的并发问题。 在将客户端应用程序重新路由到它之前,等待新主服务器应用其复制相关的中继日志是一种很好的做法。
如果该组正在运行运行不同版本MySQL的成员,那么选举过程可能会受到影响。
例如,如果任何成员不支持
group_replication_member_weight
,则根据
server_uuid
来自较低主要版本的成员的顺序
选择
主要成员。
或者,如果运行不同MySQL版本的所有成员都支持
group_replication_member_weight
,则根据
group_replication_member_weight
较低主要版本的成员
选择
主要成员。
要在单主模式下部署时找出当前主服务器,请使用
表中
的
MEMBER_ROLE
列
performance_schema.replication_group_members
。
例如:
MySQL的> SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;
+ ------------------------- + ------------- +
| MEMBER_HOST | MEMBER_ROLE |
+ ------------------------- + ------------- +
| remote1.example.com | 主要|
| remote2.example.com | 中学|
| remote3.example.com | 中学|
+ ------------------------- + ------------- +
该
group_replication_primary_member
状态变量已被弃用,并计划在未来的版本中被删除。
或者使用
group_replication_primary_member
状态变量。
MySQL的> SHOW STATUS LIKE 'group_replication_primary_member'
您可以使用一组依赖于组操作协调器的UDF在组复制运行时配置联机组。 这些UDF由版本8.0.13及更高版本中的Group Replication插件安装。 本节介绍如何对正在运行的组以及可用的UDF进行更改。
为使协调器能够在正在运行的组上配置组范围的操作,所有成员必须运行MySQL 8.0.13或更高版本并安装UDF。
要使用UDF,请连接到正在运行的组的成员,并使用该
SELECT
语句
发出UDF
。
Group Replication插件处理操作及其参数,协调器将其发送给您发出UDF的成员可见的所有成员。
如果操作被接受,则所有成员执行操作并在完成时发送终止消息。
一旦所有成员将操作声明为已完成,则调用成员将结果返回给客户端。
配置整个组时,操作的分布式特性意味着它们与Group Replication插件的许多进程交互,因此您应该遵守以下内容:
您可以在任何地方发布配置操作 如果要使成员A成为新的主要成员,则无需在成员A上调用操作。所有操作都以协调的方式发送和执行到所有组成员上。 此外,此操作的分布式执行具有不同的分支:如果调用成员死亡,则任何已在运行的配置过程继续在其他成员上运行。 万一调用成员死亡,您仍然可以使用监视功能来确保其他成员成功完成操作。
所有成员必须在线。 要简化迁移或选举过程并确保它们尽可能快,组不得包含任何恢复成员,否则配置操作将被发出该语句的成员拒绝。
在配置更改期间,任何成员都无法加入组。 在协调配置更改期间尝试加入组的任何成员将离开该组并取消其加入过程。
一次只能配置一个。 正在执行配置更改的组不能接受任何其他组配置更改,因为并发配置操作可能导致成员分歧。
您不能在混合版本组上使用配置功能。 由于这些配置操作的分布式特性,所有成员必须识别它们才能执行它们。 因此,组中不存在旧版本的服务器,否则操作被拒绝。
本节介绍如何更改单主组的哪个成员是主要成员。 用于更改组模式的函数可以在任何成员上运行。
使用
group_replication_set_as_primary()
UDF更改单主组中哪个成员是主要成员。
如果在多主组的成员上发出此功能,则此功能无效。
只有主成员才能写入该组,因此如果该成员上运行异步通道,则在异步通道停止之前不允许任何切换。
server_uuid
通过发出以下内容
传递
您要成为该组新主要成员的成员:
SELECT group_replication_set_as_primary(member_uuid);
当操作运行时,您可以通过发出以下命令来检查其进度:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%";
+ ------------------------------------------------- --------------------------------- + ---------------- + ---------------- +
| event_name | work_completed | work_estimated |
+ ------------------------------------------------- --------------------------------- + ---------------- + ---------------- +
| stage / group_rpl / Primary Election:等待成员打开super_read_only | 3 | 5 |
+ ------------------------------------------------- --------------------------------- + ---------------- + ---------------- +
本节介绍如何更改组运行的模式,单个或多个主要模式。 用于更改组模式的函数可以在任何成员上运行。
使用
group_replication_switch_to_single_primary_mode()
UDF通过发出以下命令将在多主模式下运行的组更改为单主模式:
SELECT group_replication_switch_to_single_primary_mode()
当您更改为单主模式时,还会根据单主模式(
group_replication_enforce_update_everywhere_checks=OFF
)中的
要求禁用所有组成员的严格一致性检查
。
如果未传入任何字符串,则生成的单主组中新主节点的选择由配置的选举权重或UUID字典顺序控制(请参见 第18.4.1.1节“单主模式” )。 当操作运行时,您可以通过发出以下命令来检查其进度:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%";
+ ------------------------------------------------- --------------------------- + ---------------- + ----- ----------- +
| event_name | work_completed | work_estimated |
+ ------------------------------------------------- --------------------------- + ---------------- + ----- ----------- +
| stage / group_rpl / Primary Switch:等待挂起的事务完成| 4 | 20 |
+ ------------------------------------------------- --------------------------- + ---------------- + ----- ----------- +
要覆盖选举过程并将多主要组的特定成员配置为进程中的新主要
server_uuid
成员
,请获取
该成员并将其传递给
group_replication_switch_to_single_primary_mode()
。
例如问题:
SELECT group_replication_switch_to_single_primary_mode(member_uuid);
使用
group_replication_switch_to_multi_primary_mode()
UDF通过发出以下命令将在单主模式下运行的组更改为多主模式:
SELECT group_replication_switch_to_multi_primary_mode()
经过一些协调的小组操作以确保您的数据的安全性和一致性,属于该组的所有成员都成为初选。
当操作运行时,您可以通过发出以下命令来检查其进度:
SELECT event_name,work_completed,work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE“%stage / group_rpl%”; + ------------------------------------------------- --------------------- + ---------------- + ----------- ----- + | event_name | work_completed | work_estimated | + ------------------------------------------------- --------------------- + ---------------- + ----------- ----- + | stage / group_rpl / Multi-primary Switch:应用缓冲事务| 0 | 1 | + ------------------------------------------------- --------------------- + ---------------- + ----------- ----- +
本节介绍如何在任何时间检查和配置组的最大共识实例数。 此最大值称为组的事件范围,是组可以并行执行的最大共识实例数。 这使您可以微调组复制部署的性能。 例如,默认值10适用于LAN上运行的组,但对于通过较慢网络(如WAN)运行的组,请增加此数量以提高性能。
使用
group_replication_get_write_concurrency()
UDF通过发出以下命令在运行时检查组的事件范围值:
SELECT group_replication_get_write_concurrency();
使用
group_replication_set_write_concurrency()
UDF通过发出以下命令来设置系统可以并行执行的最大共识实例数:
SELECT group_replication_set_write_concurrency(instances);
instances
新的最大共识实例数
在哪里
。
GROUP_REPLICATION_ADMIN
使用此UDF需要
该
权限。
从MySQL 8.0.16开始,Group Replication具有该组通信协议的概念。 可以显式管理组复制通信协议版本,并将其设置为容纳您希望该组支持的最旧的MySQL服务器版本。 这使得组可以由不同MySQL Server版本的成员组成,同时确保向后兼容性。 MySQL 5.7.14中的版本允许压缩消息,而MySQL 8.0.16中的版本也允许消息碎片化。 该组的所有成员必须使用相同的通信协议版本,以便组成员可以处于不同的MySQL Server版本,但只发送所有组成员都能理解的消息。
ONLINE
如果组的通信协议版本小于或等于X
,则版本X的MySQL服务器只能加入并达到
复制组中的状态。当新成员加入复制组时,它会检查由该组宣布的通信协议版本。该小组的现有成员。
如果加入成员支持该版本,则它加入该组并使用该组已宣布的通信协议,即使该成员支持其他通信功能。
如果加入成员不支持通信协议版本,则将其从组中驱逐出去。
如果两个成员尝试加入相同的成员资格更改事件,则只有两个成员的通信协议版本已与该组的通信协议版本兼容时,它们才能加入。 来自该组的具有不同通信协议版本的成员必须单独加入。 例如:
-
一个MySQL Server 8.0.16实例可以成功加入使用通信协议版本5.7.24的组。
-
一个MySQL Server 5.7.24实例无法成功加入使用通信协议版本8.0.16的组。
-
两个MySQL Server 8.0.16实例无法同时加入使用通信协议版本5.7.24的组。
-
两个MySQL Server 8.0.16实例可以同时加入使用通信协议版本8.0.16的组。
您可以使用
group_replication_get_communication_protocol()
UDF
检查组使用的通信协议,
UDF返回该组支持的最旧的MySQL服务器版本。
该组的所有现有成员都返回相同的通信协议版本。
例如:
SELECT group_replication_get_communication_protocol(); + ------------------------------------------------ + | group_replication_get_communication_protocol()| + ------------------------------------------------ + | 8.0.16 | + ------------------------------------------------ +
请注意,
group_replication_get_communication_protocol()
UDF返回该组支持的最小MySQL版本,该版本可能与传递给
group_replication_set_communication_protocol()
UDF
的版本号
以及安装在使用UDF的成员上的MySQL Server版本不同。
如果需要更改组的通信协议版本以便早期版本的成员可以加入,请使用
group_replication_set_communication_protocol()
UDF指定要允许的最旧成员的MySQL Server版本。
这使得该组在可能的情况下回退到兼容的通信协议版本。
GROUP_REPLICATION_ADMIN
使用此UDF需要
该
权限,并且在发出语句时所有现有组成员必须联机,且不会丢失多数。
例如:
SELECT group_replication_set_communication_protocol("5.7.25");
如果将复制组的所有成员升级到新的MySQL Server版本,则该组的通信协议版本不会自动升级以匹配。
如果您不再需要在早期版本中支持成员,则可以使用
group_replication_set_communication_protocol()
UDF将通信协议版本设置为已升级成员的新MySQL Server版本。
例如:
SELECT group_replication_set_communication_protocol("8.0.16");
的
group_replication_set_communication_protocol()
UDF被实现为一组动作,所以它是在相同的时间对组的所有成员执行。
组操作开始缓冲消息并等待传递已完成的任何传出消息,然后更改通信协议版本并发送缓冲的消息。
如果成员在更改通信协议版本后随时尝试加入该组,则组成员将公布新协议版本。
只要使用AdminAPI操作更改集群拓扑,MySQL InnoDB集群就会自动且透明地管理其成员的通信协议版本。 InnoDB集群始终使用当前属于集群或加入集群的所有实例都支持的最新通信协议版本。 有关详细信息,请参阅 InnoDB群集和组复制协议 。
分组系统(如组复制)的主要含义之一是它作为一个组提供的一致性保证。 换句话说,跨组成员分布的事务全局同步的一致性。 本节介绍组复制如何根据组中发生的事件处理一致性保证,以及如何最好地配置组的一致性保证。
就分布式一致性保证而言,无论是在正常还是失败的修复操作中,组复制始终是最终的一致性系统。 这意味着只要传入流量减慢或停止,所有组成员都具有相同的数据内容。 与系统一致性相关的事件可以分为控制操作,手动或由故障自动触发; 和数据流操作。
对于组复制,可以根据一致性评估的控制操作是:
-
加入或离开的成员,由Group Replication的 第18.11.5节“分布式恢复” 和写保护 所涵盖 。
-
网络故障,由屏蔽模式覆盖。
-
在单主组中,主要故障转移,也可以是由其触发的操作
group_replication_set_as_primary()。
在单主组中,如果主要故障转移时辅助节点被提升为主节点,则无论复制积压的大小如何,新主节点都可以立即用于应用程序流量,或者可以访问它限制,直到积压已被应用。
使用第一种方法,通过选择新的主数据库,然后在仍然应用来自旧主数据库的任何可能的待办事项时立即允许数据访问,该组花费最少的时间来在主要故障之后保护稳定的组成员资格。
确保写入一致性,但是当新主要应用积压时,读取可以临时检索陈旧数据。
例如,如果客户端C1
A=2 WHERE A=1
在故障发生之前在旧主
服务器上写入
,则当客户端C1重新连接到新主服务器时,它可能会读取,
A=1
直到新主服务器应用其积压日志并在其离开之前赶上旧主服务器的状态。组。
使用第二种方法,系统在主要故障后保护稳定的组成员资格,并以与第一种方案相同的方式选择新的主要成员,但在这种情况下,该组然后等待,直到新的主要应用所有积压,然后才进行允许数据访问。
这确保了在如前所述的情况下,当客户端C1重新连接到新的主要时,它将读取
A=2
。
但是,权衡的是,故障转移所需的时间与积压的大小成正比,积压的大小应该很小。
在MySQL 8.0.14之前,没有办法配置故障转移策略,默认情况下,可用性最大化,如第一种方法中所述。
在具有运行MySQL 8.0.14及更高版本的成员的组中,您可以使用该
group_replication_consistency
变量
配置成员在主要故障转移期间提供的事务一致性保证级别
。
见
一致性对初选的影响
。
由于对组执行的读取和写入,数据流与组一致性保证相关,尤其是当这些操作分布在所有成员上时。
数据流操作适用于组复制的两种模式:单主模式和多主模式,但为了使此解释更清楚,它仅限于单主模式。
在单主组的成员之间拆分传入的读或写事务的常用方法是将写操作路由到主服务器,并将读数均匀地分发给辅助服务器。
由于该组应该表现为单个实体,因此可以合理地预期主要上的写入在辅助节点上即时可用。
虽然组复制是使用实现Paxos算法的组通信系统(GCS)协议编写的,但组复制的某些部分是异步的,这意味着数据异步应用于辅助节点。
这意味着客户端C2可以写入
B=2 WHERE B=1
在主要,立即连接到辅助和阅读
B=1
。
这是因为辅助节点仍在应用积压,并且尚未应用主节点应用的事务。
您可以根据要在组中同步事务的点来配置组的一致性保证。 为了帮助您理解这个概念,本节简化了在读操作时或写操作时将组中的事务同步的要点。 如果在读取时同步数据,则当前客户端会话在其开始执行之前等待直到给定点(即所有先前更新事务已应用的时间点)。 使用此方法,仅影响此会话,所有其他并发数据操作不受影响。
如果在写入时数据已同步,则写入会话将一直等到所有辅助节点都写入其数据。 组复制使用写入的总顺序,因此这意味着要等待这个以及应用辅助队列中的所有先前写入。 因此,在使用此同步点时,写入会话将等待应用所有辅助队列。
任何替代方案都可确保在所描述的情况下,
B=2
即使立即连接到辅助
节点,客户端C2也始终会读取
。
每种替代方案都有其优点和缺点,这些优缺点与您的系统工作负载直接相关。
以下示例描述了不同类型的工作负载,并建议哪个同步点是合适的。
想象一下以下情况:
-
如果不对读取的服务器部署额外限制以避免读取过时数据,则希望对读取进行负载平衡,组写入比组读取少得多。
-
如果您有一个主要是只读数据的组,您希望读写事务一旦提交就应用于任何地方,以便后续读取包括最新写入的最新数据。 这可确保您不为每个RO事务支付同步成本,但仅支持RW事务处理。
在这些情况下,您应该选择在写入时进行同步。
想象一下以下情况:
-
如果不对读取的服务器部署额外限制以避免读取过时数据,则希望对读取进行负载平衡,组写入比组读取更常见。
-
您希望工作负载中的特定事务始终从组中读取最新数据,例如,每当更新敏感数据时(例如文件或类似数据的凭据),并且您希望强制执行读取最多的读取操作日期值。
在这些情况下,您应该选择同步读取。
尽管“ 事务同步点” 部分从概念上解释了有两个同步点,您可以从中选择:在读取或写入时,这些术语是简化的,组复制中使用的术语是: 在 事务执行 之前 和 之后 。 一致性级别可以对组处理的只读(RO)和读写(RW)事务产生不同的影响,如本节所示。
以下列表显示了可以使用
group_replication_consistency
变量
在组复制中配置的可能一致性级别,
以增加事务一致性保证:
-
EVENTUALRO和RW事务都不等待在执行之前应用先前的事务。 这
group_replication_consistency是添加变量 之前组复制的行为 。 RW事务不等待其他成员应用事务。 这意味着事务可以在其他成员之前外部化。 这也意味着在主要故障转移的情况下,新主服务器可以在先前的主要事务全部应用之前接受新的RO和RW事务。 RO事务可能导致过时的值,RW事务可能会因冲突而导致回滚。 -
BEFORE_ON_PRIMARY_FAILOVER在应用任何待办事项之前,将保留(未应用)具有从旧主要应用积压的新选择主要的新RO或RW事务。 这可确保在主要故障转移发生时,无论是否有意,客户端始终会在主服务器上看到最新值。 这保证了一致性,但意味着客户端必须能够在应用积压的情况下处理延迟。 通常这种延迟应该是最小的,但它确实取决于积压的大小。
-
BEFORERW事务在应用之前等待所有先前的事务完成。 RO事务在执行之前等待所有先前的事务完成。 这可确保此事务仅通过影响事务的延迟来读取最新值。 通过确保仅在RO事务上使用同步,这减少了每个RW事务上的同步开销。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。 -
AFTERRW事务等待,直到其更改已应用于所有其他成员。 该值对RO交易没有影响。 此模式确保在本地成员上提交事务时,任何后续事务都会读取任何组成员的写入值或更新值。 将此模式与主要用于RO操作的组一起使用,以确保应用的RW事务在提交后随处应用。 您的应用程序可以使用它来确保后续读取获取包含最新写入的最新数据。 这减少了每个RO事务上的同步开销, 通过确保仅在RW事务上使用同步。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。 -
BEFORE_AND_AFTERRW事务等待1)所有先前的事务在应用之前完成,2)直到其更改已应用于其他成员。 RO事务在执行之前等待所有先前的事务完成。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。
在
BEFORE
与
BEFORE_AND_AFTER
反渗透,RW交易一致性水平可以既使用。
该
AFTER
一致性水平对RO的交易没有影响,因为它们不会产生变化。
不同的一致性级别为DBA提供了灵活性,DBA可以使用它们来设置基础架构; 以及可以使用最适合其应用程序要求的一致性级别的开发人员。 以下方案显示了如何根据您使用组的方式选择一致性保证级别:
-
方案1 您希望对读取进行负载平衡而不必担心过时读取,您的组写操作比组读操作少得多。 在这种情况下,您应该选择
AFTER。 -
方案2 您有一个应用大量写入的数据集,并且您希望偶尔进行读取而不必担心读取陈旧数据。 在这种情况下,您应该选择
BEFORE。 -
方案3 您希望工作负载中的特定事务始终从组中读取最新数据,以便每当更新敏感数据(例如文件或类似数据的凭据)时,您希望强制执行该读取始终读取最新的价值。 在这种情况下,您应该选择
BEFORE。 -
方案4 您有一个主要具有只读(RO)数据的组,您希望读写(RW)事务在提交后随处应用,以便后续读取包括最新数据,包括您的最新写入并且您不会在每个RO事务上支付同步,但仅在RW事务上支付。 在这种情况下,您应该选择
AFTER。 -
方案5 您有一个主要具有只读数据的组,您希望读写(RW)事务始终从组中读取最新数据,并在提交后随处应用,以便后续读取完成包含最新写入的最新数据,并且不在每个只读(RO)事务上支付同步,但仅在RW上执行。 在这种情况下,您应该选择
BEFORE_AND_AFTER。
您可以自由选择强制执行一致性级别的范围。
这很重要,因为如果将其设置为全局范围,则一致性级别可能会对组性能产生负面影响。
因此,您可以使用
group_replication_consistency
不同范围
的
系统变量
来配置组的一致性级别
。
要在当前会话上强制执行一致性级别,请使用会话范围:
> SET @@ SESSION.group_replication_consistency ='BEFORE';
要在所有会话上强制执行一致性级别,请使用全局范围:
> SET @@ GLOBAL.group_replication_consistency ='BEFORE';
在特定会话上设置一致性级别的可能性使您可以利用以下方案:
-
场景6 给定系统处理几个不需要强一致性级别的指令,但是一种指令确实需要强一致性:管理对文档的访问权限; 在这种情况下,系统会更改访问权限,并希望确保所有客户端都能看到正确的权限。 您只需要
SET @@SESSION.group_replication_consistency= ‘AFTER’在这些指令上保留其他指令,以便EVENTUAL在全局范围内 使用 set 运行 。 -
场景7 在场景6中描述的同一系统上,每天一条指令需要进行一些分析处理,因此它需要始终读取最新的数据。 要实现这一点,您只需要执行
SET @@SESSION.group_replication_consistency= ‘BEFORE’该特定指令。
总而言之,您不需要运行具有特定一致性级别的所有事务,特别是如果只有一些事务实际需要它。
请注意,所有读写事务在组复制中完全排序,因此即使您
AFTER
为当前会话
设置一致性级别,
此事务也会等待,直到其更改应用于所有成员,这意味着等待此事务和所有可能的事务在二级队列中。
实际上,一致性级别
AFTER
会等待所有事务,直到并包括此事务。
对一致性级别进行分类的另一种方法是对组的影响,即一致性级别对其他成员的影响。
的
BEFORE
一致性水平,除了被命令在事务流,仅在本地部件上的影响。
也就是说,它不需要与其他成员协调,也不会对其交易产生影响。
换句话说,
BEFORE
仅影响使用它的事务。
在
AFTER
和
BEFORE_AND_AFTER
一致性水平确实有对其他成员执行并发事务的副作用。
如果具有
EVENTUAL
一致性级别的事务在具有
AFTER
或
BEFORE_AND_AFTER
正在执行
的事务中启动,则
这些一致性级别会使其他成员事务处于等待状
其他成员等到该成员
AFTER
提交事务,即使其他成员的事务具有
EVENTUAL
一致性级别。
换句话说,
AFTER
并
BEFORE_AND_AFTER
影响
所有
ONLINE
组成员。
为了进一步说明这一点,想象一个有3个成员的组,M1,M2和M3。 在成员M1上,客户发出:
> SET @@ SESSION.group_replication_consistency = AFTER; >开始; >插入t1值(1); > COMMIT;
然后,在应用上述交易时,在成员M2上,客户发出:
> SET SESSION group_replication_consistency = EVENTUAL;
在这种情况下,即使第二个事务的一致性级别是
EVENTUAL
,因为它在第一个事务已经处于M2的提交阶段时开始执行,第二个事务必须等待第一个事务完成提交,然后才能执行。
您只能使用一致性级别
BEFORE
,
AFTER
并且
BEFORE_AND_AFTER
对于
ONLINE
成员,尝试在其他状态的成员上使用它们会导致会话错误。
一致性级别
EVENTUAL
在超时之前保持执行的
事务
,按
wait_timeout
值
配置
,默认为8小时。
如果达到超时,
ER_GR_HOLD_WAIT_TIMEOUT
则抛出错误。
本节介绍组的一致性级别如何影响已选择新主服务器的单一主组。 这样的组自动检测故障并调整活动成员的视图,换句话说是成员资格配置。 此外,如果组以单主模式部署,则只要组的成员身份发生更改,就会执行检查以检测组中是否还有主成员。 如果没有,则从辅助成员列表中选择一个新的。 通常,这称为二级促销。
鉴于系统检测到故障并自动重新配置自身的事实,用户可能还期望一旦促销发生,新的主要数据处于与数据状态完全相同的状态。 换句话说,一旦用户能够读取和写入新的主要用户,用户可能期望没有积压的复制交易。 实际上,用户可能期望一旦他的应用程序故障转移到新的主服务器,即使是临时的,也没有机会读取旧数据或写入旧数据记录。
当流量控制被激活并在一个组上进行适当调整时,在促销之后立即从新选出的主要数据中暂时读取陈旧数据的可能性很小,因为不应该存在积压,或者如果存在积压,则应该很小。
此外,您可能有一个代理或中间件层来管理升级后对主数据库的应用程序访问,并在该级别强制执行一致性标准。
如果您的组成员使用的是MySQL 8.0.14或更高版本,则可以使用以下命令指定新主要组件的行为
group_replication_consistency
变量,它控制新选择的主要是否在完全应用积压之后阻止读取和写入,或者它是否以运行MySQL 8.0.13或更早版本的成员的方式运行。
如果该
group_replication_consistency
选项设置为
BEFORE_ON_PRIMARY_FAILOVER
新选择的主要应用积压,并且在仍然应用积压的情况下针对新主要发布事务,则会阻止传入事务,直到完全应用积压。
因此,防止了以下异常:
-
对于只读和读写事务,没有过时读取。 这可以防止旧主数据库将过时读取外部化到应用程序。
-
读写事务没有虚假回滚,因为写入写入与仍在等待应用的待办事项中的读写事务冲突。
-
读写事务没有读取偏差,例如:
>开始; > SELECT x FROM t1; - x = 1,因为x = 2在积压中; > INSERT x INTO t2; > COMMIT;
此查询不应导致冲突,而应写入过时的值。
总而言之,当
group_replication_consistency
设置
为何时
,
BEFORE_ON_PRIMARY_FAILOVER
您选择优先考虑可用性的一致性,因为只要选择新的主数据库就会保持读取和写入。
这是配置组时必须考虑的权衡。
还应该记住,如果流量控制正常,积压应该是最小的。
请注意较高的一致性级别
BEFORE
,
AFTER
并且
BEFORE_AND_AFTER
还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER
。
为了保证组无论哪个成员被提升为主要成员都提供相同的一致性级别,该组的所有成员都应该
BEFORE_ON_PRIMARY_FAILOVER
(或更高的一致性级别)持久保存到其配置中。
例如,在每个成员问题上:
> SET PERSIST group_replication_consistency ='BEFORE_ON_PRIMARY_FAILOVER';
这可以确保成员的行为方式相同,并且在重新启动成员后保持配置。
虽然在使用
BEFORE_ON_PRIMARY_FAILOVER
一致性级别
时会保留所有写入
,但并非所有读取都被阻止,以确保在促销发生后应用backlog时仍可以检查服务器。
这对于调试,监视,可观察性和故障排除很有用。
允许一些不修改数据的查询,例如:
事务不能永久保持,如果持有的时间超过
wait_timeout
它,则返回
ER_GR_HOLD_WAIT_TIMEOUT
错误。
每当一个新成员加入一个复制组时,它就会连接到一个合适的捐赠者并获取它已经错过的数据,直到它被声明为在线为止。 组复制中的这一关键组件具有容错能力和可配置性。 以下部分介绍了恢复的工作原理以及如何调整设置
从该组中的现有在线成员中选择随机捐赠者。 这样,当多个成员进入组时,很可能不会多次选择同一服务器。
如果与所选施主的连接失败,则自动尝试向新的候选施主提供新连接。 达到连接重试限制后,恢复过程将终止并显示错误。
从当前视图中的在线成员列表中随机选择捐赠者。
整个复苏的另一个主要关注点是确保它能够应对失败。 因此,Group Replication提供了强大的错误检测机制。 在早期版本的组复制中,当联系捐赠者时,恢复只能检测由于身份验证问题或其他一些问题导致的连接错误。 对这种有问题的情况的反应是切换到新的捐赠者,因此对不同的成员进行了新的连接尝试。
此行为已扩展为还涵盖其他故障情况:
-
清除 数据方案 - 如果选定的供体包含恢复过程所需的一些清除数据,则会发生错误。 恢复检测到此错误,并选择新的捐赠者。
-
重复数据 - 如果加入该组的服务器已经包含一些与恢复期间来自所选捐赠者的数据冲突的数据,则会发生错误。 这可能是由加入该组的服务器中存在的某些错误事务引起的。
有人可能会说,恢复应该失败而不是转移到另一个捐赠者,但在异质群体中,其他成员有可能分享冲突的交易,而其他成员则没有。 出于这个原因,一旦出错,恢复将从该组中选择另一个捐赠者。
-
其他错误 - 如果任何恢复线程失败(接收器或应用程序线程失败),则会发生错误并且恢复切换到新的捐赠者。
如果出现一些持续性故障甚至是瞬态故障,恢复将自动重试连接到相同或新的供体。
恢复数据传输依赖于二进制日志和现有的MySQL复制框架,因此一些瞬态错误可能会导致接收器或应用程序线程中的错误。 在这种情况下,捐赠者切换进程具有重试功能,类似于常规复制中发现的功能。
当尝试从捐赠者池连接到捐赠者时,加入该组的服务器尝试的次数是10.这是通过
group_replication_recovery_retry_count
插件变量
配置的
。
以下命令将连接到捐赠者的最大尝试次数设置为10。
MySQL的> SET GLOBAL group_replication_recovery_retry_count= 10;
请注意,这会考虑加入组的服务器连接到每个合适的捐赠者的全局尝试次数。
该
group_replication_recovery_reconnect_interval
插件变量定义的恢复过程应该需要多少时间供体的连接尝试之间睡觉。
此变量的默认设置为60秒,您可以动态更改此值。
以下命令将恢复施主连接重试间隔设置为120秒。
MySQL的> SET GLOBAL group_replication_recovery_reconnect_interval= 120;
但请注意,每次捐赠者连接尝试后恢复都不会休眠。
由于加入组的服务器连接到不同的服务器而不是一次又一次地连接到同一个服务器,它可以假设影响服务器A的问题不会影响服务器B.因此,只有当它通过所有服务器时,恢复才会暂停可能的捐助者。
一旦加入该组的服务器尝试连接到该组中的所有合适的捐赠者并且没有剩余,则恢复过程将休眠该
group_replication_recovery_reconnect_interval
变量
配置的秒数
。
每当需要复制的更改发生时,该组需要达成共识。 这是常规事务的情况,但也是组成员身份更改和一些使组保持一致的内部消息传递所必需的。 达成共识要求大多数小组成员就特定决定达成一致。 当大多数群体成员丢失时,该群体无法进展和阻止,因为它无法保证多数或法定人数。
当存在多个非自愿故障时,仲裁可能会丢失,导致大多数服务器突然从组中删除。 例如,在一组5台服务器中,如果其中3台服务器立即变为静音,则大多数服务器受到损害,因此无法达到法定人数。 事实上,其余两个服务器无法判断其他3台服务器是否已崩溃,或者网络分区是否已将这两台服务器单独隔离,因此无法自动重新配置该组。
另一方面,如果服务器自愿退出组,它们会指示组应该重新配置自己。 在实践中,这意味着离开的服务器告诉其他人它正在消失。 这意味着其他成员可以正确地重新配置组,保持成员的一致性并重新计算大多数。 例如,在上述5个服务器的场景中,其中3个一次离开,如果3个离开服务器一个接一个地警告组他们要离开,那么成员资格能够从5调整到2,并且同时时间,在发生这种情况时确保法定人数。
法定人数的丧失本身就是不良计划的副作用。 计划组大小以确定预期失败的数量(无论它们是连续的,是一次性发生还是零星发生)。
以下各节说明如果系统以组中的服务器不会自动实现仲裁的方式进行分区,该怎么办。
在多数丢失后重新配置后从组中排除的主要数据库可以包含未包含在新组中的额外事务。 如果发生这种情况,尝试从组中添加回排除的成员会导致错误消息 此成员执行的事务多于组中存在的事务。
在
replication_group_members
性能模式表显示每个服务器在从该服务器的角度来看,当前视图状态。
大多数情况下系统不会进入分区,因此该表显示了组中所有服务器一致的信息。
换句话说,此表上每个服务器的状态在当前视图中由所有人同意。
但是,如果存在网络分区,并且仲裁丢失,则表格将显示
UNREACHABLE
无法联系的服务器
的状态
。
此信息由组复制中内置的本地故障检测器导出。
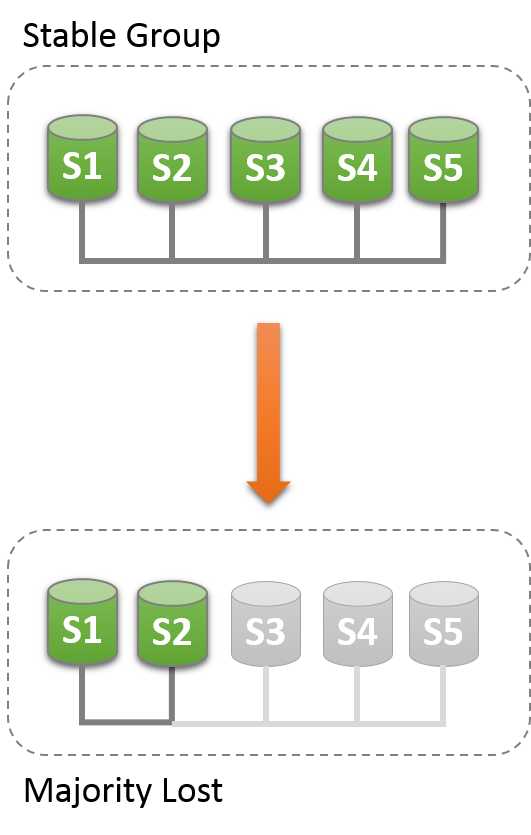
要了解这种类型的网络分区,以下部分描述了最初有5台服务器正确协同工作的情况,以及只有2台服务器在线时才会对组发生的更改。 该场景如图所示。
因此,假设有一个包含这5个服务器的组:
-
带有成员标识符的服务器s1
199b2df7-4aaf-11e6-bb16-28b2bd168d07 -
带有成员标识符的服务器s2
199bb88e-4aaf-11e6-babe-28b2bd168d07 -
带有成员标识符的服务器s3
1999b9fb-4aaf-11e6-bb54-28b2bd168d07 -
带有成员标识符的服务器s4
19ab72fc-4aaf-11e6-bb51-28b2bd168d07 -
带有成员标识符的服务器s5
19b33846-4aaf-11e6-ba81-28b2bd168d07
最初该组运行正常,服务器正在愉快地相互通信。
您可以通过登录s1并查看其
replication_group_members
性能架构表
来验证这一点
。
例如:
MySQL的> SELECT MEMBER_ID,MEMBER_STATE, MEMBER_ROLE FROM performance_schema.replication_group_members;
+ -------------------------------------- + ---------- ---- + ------------- +
| MEMBER_ID | MEMBER_STATE | -MEMBER_ROLE |
+ -------------------------------------- + ---------- ---- + ------------- +
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 在线| 中学|
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 在线| 主要|
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 在线| 中学|
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 在线| 中学|
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 在线| 中学|
+ -------------------------------------- + ---------- ---- + ------------- +
然而,片刻之后发生了灾难性的故障,服务器s3,s4和s5意外停止。
在此之后的几秒钟,再次
replication_group_members
查看s1
上的
表格显示它仍在线,但其他几个成员则没有。
事实上,如下所示,它们被标记为
UNREACHABLE
。
而且,系统无法重新配置自己以改变成员资格,因为大部分已经丢失。
MySQL的> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+ -------------------------------------- + ---------- ---- +
| MEMBER_ID | MEMBER_STATE |
+ -------------------------------------- + ---------- ---- +
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 无法访问|
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 在线|
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 在线|
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 无法访问|
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 无法访问|
+ -------------------------------------- + ---------- ---- +
该表显示s1现在位于没有外部干预的情况下无法进行的组中,因为大多数服务器无法访问。 在这种特殊情况下,需要重置组成员资格列表以允许系统继续进行,本节将对此进行说明。 或者,您也可以选择在s1和s2上停止组复制(或完全停止s1和s2),找出s3,s4和s5发生的情况,然后重新启动组复制(或服务器)。
通过组复制,您可以通过强制执行特定配置来重置组成员身份列表。
例如,在上面的情况中,s1和s2是唯一在线服务器,您可以选择强制仅包含s1和s2的成员资格配置。
这需要检查有关s1和s2的一些信息,然后使用该
group_replication_force_members
变量。
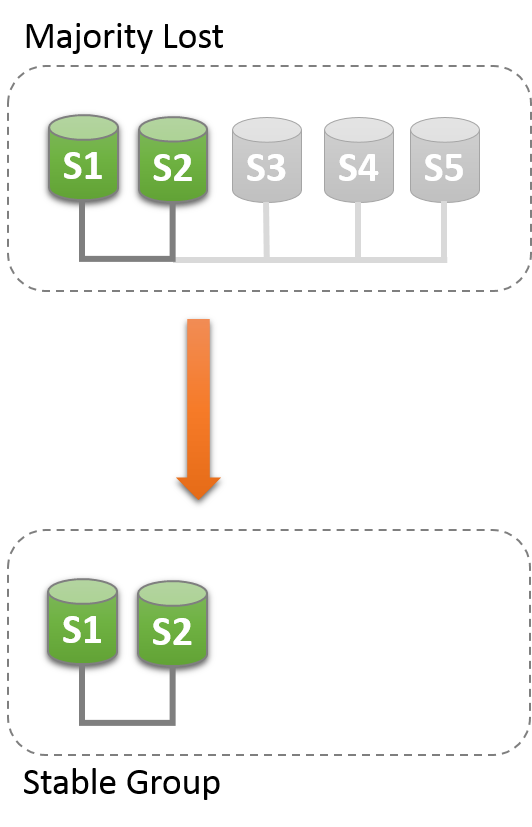
假设您回到s1和s2是组中剩余的唯一服务器的情况。 服务器s3,s4和s5意外离开了该组。 要使服务器s1和s2继续,您需要强制仅包含s1和s2的成员资格配置。
此程序使用
group_replication_force_members
并应被视为最后的补救措施。
必须
非常小心地使用
它
,并且只能用于超越法定人数的损失。
如果误用,它可能会创建一个人工的裂脑情景或完全阻止整个系统。
回想一下系统被阻塞,当前配置如下(正如s1上本地故障检测器所感知的那样):
MySQL的> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+ -------------------------------------- + ---------- ---- +
| MEMBER_ID | MEMBER_STATE |
+ -------------------------------------- + ---------- ---- +
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 无法访问|
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 在线|
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 在线|
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 无法访问|
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 无法访问|
+ -------------------------------------- + ---------- ---- +
首先要检查s1和s2的本地地址(组通信标识符)是什么。 登录s1和s2,获取如下信息。
MySQL的> SELECT @@group_replication_local_address;
一旦知道了s1(
127.0.0.1:10000
)和s2(
127.0.0.1:10001
)
的组通信地址
,就可以在两个服务器之一上使用它来注入新的成员资格配置,从而覆盖已丢失仲裁的现有配置。
要在s1上执行此操作:
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001“;
这会通过强制执行不同的配置来取消阻止该组。
检查
replication_group_members
此更改后,检查s1和s2以验证组成员身份。
首先是s1。
MySQL的> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+ -------------------------------------- + ---------- ---- +
| MEMBER_ID | MEMBER_STATE |
+ -------------------------------------- + ---------- ---- +
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 在线|
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 在线|
+ -------------------------------------- + ---------- ---- +
然后在s2上。
MySQL的> SELECT * FROM performance_schema.replication_group_members;
+ -------------------------------------- + ---------- ---- +
| MEMBER_ID | MEMBER_STATE |
+ -------------------------------------- + ---------- ---- +
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 在线|
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 在线|
+ -------------------------------------- + ---------- ---- +
强制执行新的成员资格配置时,请确保将所有服务器强制退出该组确实已停止。 在上面描述的场景中,如果s3,s4和s5实际上不可达,而是在线,则它们可能已经形成了自己的功能分区(它们是5个中的3个,因此它们占大多数)。 在这种情况下,强制使用s1和s2的组成员列表可能会产生人为的裂脑情况。 因此,在强制执行新的成员资格配置以确保要排除的服务器确实已关闭之前以及如果不是这样,请务必将其关闭,然后再继续执行。
使用
group_replication_force_members
系统变量成功强制新的组成员身份并取消阻止该组后,请确保清除系统变量。
group_replication_force_members
必须为空才能发表
START
GROUP_REPLICATION
声明。
从MySQL 8.0.14开始,组复制组成员可以使用IPv6地址作为IPv4地址的替代方案,以便在组内进行通信。 要使用IPv6地址,必须将服务器主机和MySQL Server实例上的操作系统都配置为支持IPv6。 有关为服务器实例设置IPv6支持的说明,请参见 第5.1.12节“IPv6支持” 。
可以将IPv6地址或解析它们的主机名指定为成员在
group_replication_local_address
其他成员的连接选项中
提供的网络地址
。
使用端口号指定时,必须在方括号中指定IPv6地址,例如:
group_replication_local_address =“[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061”
group_replication_local_address
Group Replication使用
指定的网络地址或主机名
作为复制组中组成员的唯一标识符。
如果指定为服务器实例的组复制本地地址的主机名解析为IPv4和IPv6地址,则IPv4地址始终用于组复制连接。
指定为组复制本地地址的地址或主机名与MySQL服务器SQL协议主机和端口不同,并且未在
bind_address
服务器实例
的
系统变量中
指定
。
出于组复制的IP地址白名单的目的(请参见
第18.5.1节“组复制IP地址白名单”)
),
group_replication_local_address
必须
将为每个组成员指定的地址
添加到
group_replication_ip_whitelist
复制组中其他服务器上的选项
列表中
。
复制组可以包含将IPv6地址显示为其组复制本地地址的成员组合,以及显示IPv4地址的成员。
当服务器加入这样的混合组时,它必须使用种子成员在
group_replication_group_seeds
选项中
通告的协议
(无论是IPv4还是IPv6)
与种子成员进行初始联系
。
如果该组中的任何种子成员列在
group_replication_group_seeds
如果加入成员具有IPv4组复制本地地址,则具有IPv6地址的选项,反之,您还必须为加入成员设置所需协议的备用地址并将其列入白名单(或者解析为地址的主机名)该协议)。
如果加入成员没有适当协议的白名单地址,则拒绝其连接尝试。
备用地址或主机名只需要添加到
group_replication_ip_whitelist
复制组中其他服务器上
的
选项中,而不是添加到
group_replication_local_address
加入成员
的
值(只能包含单个地址)。
例如,服务器A是组的种子成员,并具有以下组复制的配置设置,因此它在
group_replication_group_seeds
选项中
通告IPv6地址
:
group_replication_bootstrap_group =上 group_replication_local_address =“[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061” group_replication_group_seeds =“[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061”
服务器B是该组的加入成员,并具有以下组复制的配置设置,因此它具有IPv4组复制本地地址:
group_replication_bootstrap_group =关 group_replication_local_address =“203.0.113.21:33061” group_replication_group_seeds =“[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061”
服务器B还具有备用IPv6地址
2001:db8:8b0:40:3d9c:cc43:e006:19e8
。
要使服务器B成功加入组,其IPv4组复制本地地址及其备用IPv6地址必须列在服务器A的白名单中,如下例所示:
group replication_ip_whitelist = “203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348, 2001:DB8:8b0:40:3d9c:cc43:E006:19e8"
作为组复制IP白名单的最佳实践,服务器B(以及所有其他组成员)应具有与服务器A相同的白名单,除非安全要求另有要求。
如果复制组的任何或所有成员使用的旧MySQL服务器版本不支持使用IPv6地址进行组复制,则成员无法使用IPv6地址(或解析为一个的主机名)参与该组作为其组复制本地地址。
这适用于至少一个现有成员使用IPv6地址的情况和不支持此尝试加入的新成员,以及新成员尝试使用IPv6地址加入但该组至少包含的情况一个不支持此成员的成员。
在每种情况下,新成员都无法加入。
要使加入成员显示用于组通信的IPv4地址,您可以更改其值
group_replication_local_address
到IPv4地址,或配置DNS以将加入成员的现有主机名解析为IPv4地址。
将每个组成员升级到支持组复制的IPv6的MySQL服务器版本后,可以将
group_replication_local_address
每个成员
的
值
更改
为IPv6地址,或将DNS配置为显示IPv6地址。
更改值
group_replication_local_address
仅在停止并重新启动组复制时生效。
MySQL Enterprise Backup 是MySQL服务器的商业许可备份实用程序,可与 MySQL企业版一起使用 。 本节介绍如何使用MySQL Enterprise Backup备份和随后还原组复制成员。 可以使用相同的技术将新成员快速添加到组中。
使用MySQL Enterprise Backup备份组复制成员
备份组复制成员类似于备份独立的MySQL实例。 以下说明假定您已熟悉如何使用MySQL Enterprise Backup执行备份; 如果不是这种情况,请查看 MySQL Enterprise Backup 8.0用户指南 ,特别是 备份数据库服务器 。 另请注意将 MySQL权限授予备份管理员 和 将MySQL企业备份与组复制一起使用中 描述的要求 。
考虑以下组三名成员
s1
,
s2
以及
s3
,对具有相同名称的主机上运行:
MySQL的> SELECT member_host, member_port, member_state FROM performance_schema.replication_group_members;
+ ------------- ------------- + -------------- + +
| member_host | member_port | member_state |
+ ------------- ------------- + -------------- + +
| s1 | 3306 | 在线|
| s2 | 3306 | 在线|
| s3 | 3306 | 在线|
+ ------------- ------------- + -------------- + +
使用MySQL Enterprise Backup,
s2
通过在其主机上发布
创建备份
,例如,以下命令:
S2> mysqlbackup --defaults-file=/etc/my.cnf --backup-image=/backups/my.mbi_`date +%d%m_%H%M` \
--backup-dir=/backups/backup_`date +%d%m_%H%M` --user=root -p \
--host=127.0.0.1 backup-to-image
-
如果系统变量
sql_require_primary_key设置ON为该组,则MySQL Enterprise Backup将无法在服务器上记录备份进度。 这是因为backup_progress服务器上的表是CSV表,不支持主键。 在这种情况下, mysqlbackup 在备份操作期间发出以下警告:181011 11:17:06主要警告:MySQL查询'CREATE TABLE IF NOT NOT EXISTS mysql.backup_progress(`backup_id` BIGINT NOT NULL,`tool_name` VARCHAR(4096) NOT NULL,`error_code` INT NOT NULL,`error_message` VARCHAR(4096)NOT NULL, `current_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,`current_state` VARCHAR(200)NOT NULL)ENGINE = CSV DEFAULT CHARSET = utf8 COLLATE = utf8_bin':3750,无法创建表格 没有PK时,设置系统变量'sql_require_primary_key'。添加PK 到表或取消设置此变量以避免此消息。请注意表格 没有PK会导致基于行的复制出现性能问题,所以请 在更改此设置之前,请咨询您的DBA。 181011 11:17:06主要警告:此备份操作的进度信息不能 登录。
这并不妨碍 mysqlbackup 完成备份。
-
对于MySQL Enterprise Backup 8.0.11 ,在备份辅助成员时,由于MySQL Enterprise Backup无法将备份状态和元数据写入只读服务器实例,因此在备份操作期间会发出以下警告:
181113 21:31:08主要警告:此备份操作无法写入备份 进展。MySQL服务器使用--super-read-only选项运行。
您可以通过
--no-history-logging在backup命令中 使用该 选项 来避免警告 。 对于MySQL Enterprise Backup 8.0.12及更高版本,这不是问题 - 有关详细信息, 请参阅 将MySQL Enterprise Backup与组复制一起 使用。
恢复失败的成员
假设其中一个成员(
s3
在以下示例中)是不可调和的损坏。
s2
可以使用
组成员的最新备份
进行还原
s3
。
以下是执行还原的步骤:
-
将s2的备份复制到s3的主机上。 复制备份的确切方法取决于您可以使用的操作系统和工具。 在此示例中,我们假设主机都是Linux服务器并使用SCP在它们之间复制文件:
S2 /备份>
scp my.mbi_2206_1429 s3:/backups -
恢复备份。 连接到目标主机(
s3在本例中 为主机 ),并使用MySQL Enterprise Backup还原备份。 以下是步骤:-
如果服务器仍在运行,请停止它。 例如,在使用systemd的Linux发行版上:
s3> systemctl stop mysqld
-
保留损坏的服务器数据目录中的两个配置文件,
auto.cnf以及mysqld-auto.cnf(如果存在),将它们复制到数据目录之外的安全位置。 这用于保留 服务器的UUID 和 第5.1.9.3节“持久系统变量” (如果使用),这些步骤在下面的步骤中是必需的。 -
删除数据目录中的所有内容
s3。 例如:s3> rm -rf / var / lib / mysql / *
如果系统变量
innodb_data_home_dir,innodb_log_group_home_dir并innodb_undo_directory指向除数据目录以外的任何目录,它们也应该为空; 否则,还原操作将失败。 -
将备份还原
s2到主机上s3:S3>
mysqlbackup --defaults-file=/etc/my.cnf \ --datadir=/var/lib/mysql \ --backup-image=/backups/my.mbi_2206_1429 \ --backup-dir=/tmp/restore_`date +%d%m_%H%M` copy-back-and-apply-log注意上面的命令假定二进制日志和中继登录
s2并s3具有相同的基本名称,并且位于两个服务器上的相同位置。 如果不满足这些条件,则应使用--log-bin和--relay-log选项将二进制日志和中继日志还原到其原始文件路径s3。 例如,如果您知道s3二进制日志的基本名称是s3-bin,并且relay-log的基本名称是s3-relay-bin,则restore命令应如下所示:mysqlbackup --defaults-file=/etc/my.cnf \ --datadir=/var/lib/mysql \ --backup-image=/backups/my.mbi_2206_1429 \ --log-bin=s3-bin --relay-log=s3-relay-bin \ --backup-dir=/tmp/restore_`date +%d%m_%H%M` copy-back-and-apply-log能够将二进制日志和中继日志还原到正确的文件路径使得还原过程更加容易; 如果由于某种原因这是不可能的,请参阅 重建失败的成员以重新加入为新成员 。
-
-
恢复
auto.cnfs3 的 文件。 要重新加入复制组,还原的成员 必须 与server_uuid之前用于加入组的 成员 相同 。 通过将auto.cnf上面步骤2中保留 的 文件 复制 到还原成员的数据目录中来 提供旧服务器UUID 。注意如果您无法
server_uuid通过恢复其旧auto.cnf文件将 故障成员的原始文件提供 给已恢复的成员 ,则必须让已还原的成员作为新成员加入该组; 有关如何执行此 操作,请参阅 重建失败成员以重新加入新成员的 说明。 -
恢复
mysqld-auto.cnfs3 的 文件(仅当s3使用持久系统变量时才需要)。 必须将已用于配置故障成员 的 第5.1.9.3节“持久系统变量”的 设置提供给已还原的成员。 这些设置可以在mysqld-auto.cnf故障服务器 的 文件中 找到 ,您应该在上面的步骤2中保留 这些设置 。 将文件还原到还原的服务器的数据目录。 有关 如果没有该文件的副本, 请参阅 还原持久系统变量 。 -
启动已还原的服务器。 例如,在使用systemd的Linux发行版上:
systemctl启动mysqld
注意如果要还原的服务器是主要成员,请 在启动还原的服务器之前 执行 还原主成员中 描述的步骤 。
-
重启组复制。 连接到重新启动的
s3使用,例如, mysql 客户端,并发出以下命令:mysql> START GROUP_REPLICATION;
在恢复的实例可以成为组的在线成员之前,它需要应用备份后发生在组中的任何事务; 这是使用Group Replication的 分布式恢复 机制实现的,并且该过程在 发出 START GROUP_REPLICATION 语句 后 开始 。 要检查已还原实例的成员状态,请发出:
mysql> SELECT member_host,member_port,member_state FROM performance_schema.replication_group_members; + ------------- ------------- + -------------- + + | member_host | member_port | member_state | + ------------- ------------- + -------------- + + | s1 | 3306 | 在线| | s2 | 3306 | 在线| | s3 | 3306 | 恢复| + ------------- ------------- + -------------- + +
这表明
s3正在应用事务来赶上该组。 一旦它赶上了小组的其他成员,它的member_state变化是ONLINE:mysql> SELECT member_host,member_port,member_state FROM performance_schema.replication_group_members; + ------------- ------------- + -------------- + + | member_host | member_port | member_state | + ------------- ------------- + -------------- + + | s1 | 3306 | 在线| | s2 | 3306 | 在线| | s3 | 3306 | 在线| + ------------- ------------- + -------------- + +
注意如果要还原的服务器是主要成员,则一旦它与组成员同步并成为同步
ONLINE,请执行 还原主成员 结束时所述的步骤, 以恢复在启动服务器之前对服务器所做的配置更改。
该成员现已从备份中完全恢复,并作为该组的常规成员发挥作用。
重建失败成员以重新加入新成员
有时,
无法
执行
上面“
还原失败成员”中
概述的步骤
,因为例如二进制日志或中继日志已损坏,或者备份中只丢失了它。
在这种情况下,使用备份重建成员,然后将其作为新成员添加到组中。
在下面的步骤中,我们假设重建的成员将被命名
s3
,就像失败的成员一样,它将在同一主机上运行
s3
:
-
将s2的备份复制到s3的主机上。 复制备份的确切方法取决于您可以使用的操作系统和工具。 在此示例中,我们假设主机都是Linux服务器并使用SCP在它们之间复制文件:
S2 /备份>
scp my.mbi_2206_1429 s3:/backups -
恢复备份。 连接到目标主机(
s3在本例中 为主机 ),并使用MySQL Enterprise Backup还原备份。 以下是步骤:-
如果服务器仍在运行,请停止它。 例如,在使用systemd的Linux发行版上:
s3> systemctl stop mysqld
-
通过将配置文件
mysqld-auto.cnf复制到数据目录之外的安全位置, 保留配置文件 (如果在损坏的服务器的数据目录中找到该文件)。 这是为了保留服务器的 第5.1.9.3节“持久系统变量” ,稍后需要它。 -
删除数据目录中的所有内容
s3。 例如:s3> rm -rf / var / lib / mysql / *
如果系统变量
innodb_data_home_dir,innodb_log_group_home_dir并innodb_undo_directory指向除数据目录以外的任何目录,它们也应该为空; 否则,还原操作将失败。 -
将备份还原
s2到主机上s3。 通过这种方法,我们正在重建s3--skip-binlog和--skip-relaylog选项 将其排除 :S3>
mysqlbackup --defaults-file=/etc/my.cnf \ --datadir=/var/lib/mysql \ --backup-image=/backups/my.mbi_2206_1429 \ --backup-dir=/tmp/restore_`date +%d%m_%H%M` \ --skip-binlog --skip-relaylog \ copy-back-and-apply-log注意如果备份中有健康的二进制日志和中继日志,您可以将其转移到目标主机上而没有任何问题,建议您按照 上面的 还原失败成员中 所述 的更简单的过程进行操作 。
-
-
恢复
mysqld-auto.cnfs3 的 文件(仅当s3使用持久系统变量时才需要)。 必须将已用于配置故障成员 的 第5.1.9.3节“持久系统变量”的 设置提供给已还原的服务器。 这些设置可以在mysqld-auto.cnf故障服务器 的 文件中 找到 ,您应该在上面的步骤2中保留 这些设置 。 将文件还原到还原的服务器的数据目录。 有关 如果没有该文件的副本, 请参阅 还原持久系统变量 。注意不要将损坏的服务器
auto.cnf文件 还原 到新成员的数据目录 - 当重建时s3将组作为新成员加入时,将为其分配新的服务器UUID。 -
启动已还原的服务器。 例如,在使用systemd的Linux发行版上:
systemctl启动mysqld
注意如果要还原的服务器是主要成员,请 在启动还原的服务器之前 执行 还原主成员中 描述的步骤 。
-
重新配置已还原的成员以加入组复制。 使用 mysql 客户端 连接到已还原的服务器, 并使用以下命令重置主从信息:
MySQL的>
RESET MASTER;MySQL的>
RESET SLAVE ALL;要使还原的服务器能够使用Group Replication的内置 分布式恢复 机制自动 恢复 ,请配置服务器的
gtid_executed变量。 要执行此操作,请使用backup_gtid_executed.sql备份中包含 的 文件 ,该 文件s2通常在还原的成员的数据目录下还原。 禁用二进制日志记录,使用该backup_gtid_executed.sql文件进行配置gtid_executed,然后通过向 mysql 客户端 发出以下语句来重新启用二进制日志记录 :mysql>
SET SQL_LOG_BIN=OFF;mysql> mysql>SOURCEdatadir/backup_gtid_executed.sqlSET SQL_LOG_BIN=ON;然后, 在成员上 配置 组复制用户凭据 :
MySQL的>
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' / FOR CHANNEL 'group_replication_recovery'; -
重启组复制。 使用 mysql 客户端 向已还原的服务器发出以下命令 :
MySQL的>
START GROUP_REPLICATION;在恢复的实例可以成为组的在线成员之前,它需要应用备份后发生在组中的任何事务; 这是使用Group Replication的 分布式恢复 机制实现的,并且该过程在 发出 START GROUP_REPLICATION 语句 后 开始 。 要检查已还原实例的成员状态,请发出:
mysql> SELECT member_host,member_port,member_state FROM performance_schema.replication_group_members; + ------------- ------------- + -------------- + + | member_host | member_port | member_state | + ------------- ------------- + -------------- + + | s3 | 3306 | 恢复| | s2 | 3306 | 在线| | s1 | 3306 | 在线| + ------------- ------------- + -------------- + +
这表明
s3正在应用事务来赶上该组。 一旦它赶上了小组的其他成员,它的member_state变化是ONLINE:mysql> SELECT member_host,member_port,member_state FROM performance_schema.replication_group_members; + ------------- ------------- + -------------- + + | member_host | member_port | member_state | + ------------- ------------- + -------------- + + | s3 | 3306 | 在线| | s2 | 3306 | 在线| | s1 | 3306 | 在线| + ------------- ------------- + -------------- + +
注意如果要还原的服务器是主要成员,则一旦它与组成员同步并成为同步
ONLINE,请执行 还原主成员 结束时所述的步骤, 以恢复在启动服务器之前对服务器所做的配置更改。
该成员现已作为新成员恢复到该组。
恢复持久系统变量。
mysqlbackup
不支持备份或保留
第5.1.9.3节“持久系统变量”
- 该文件
mysqld-auto.cnf
不包含在备份中。
要使用其持久变量设置启动已还原的成员,您需要执行以下操作之一:
-
mysqld-auto.cnf从损坏的服务器 保留 文件 的副本 ,并将其复制到还原的服务器的数据目录。 -
mysqld-auto.cnf如果该成员具有与损坏成员相同的持久系统变量设置,则 将该 文件从组复制群集的另一个成员复制到已还原服务器的数据目录中。 -
恢复服务器启动后以及重新启动组复制之前,请通过 mysql 客户端 手动将所有系统变量设置为其持久值 。
恢复主要成员。 如果还原的成员是组中的主要成员,则必须注意防止在组复制恢复阶段写入已还原的数据库:根据客户端访问组的方式,可能会在恢复成员一旦在网络上可以访问,在成员完成其在群组之外错过的活动的追赶之前。 要避免这种情况,请 在启动还原的服务器之前 ,在服务器选项文件中配置以下系统变量:
group_replication_start_on_boot = OFF super_read_only = ON event_scheduler = OFF
这些设置可确保成员在启动时变为只读,并且在成员在恢复阶段赶上组时关闭事件调度程序。 还必须在客户端上配置足够的错误处理,因为它们将在此期间暂时阻止在还原的成员上执行DML操作。 完成还原过程并且还原的成员与组的其余成员同步后,还原这些更改; 重启事件调度程序:
MySQL的> SET global event_scheduler=ON;
在成员的选项文件中编辑以下系统变量,以便为下次启动正确配置:
group_replication_start_on_boot = ON super_read_only = OFF event_scheduler = ON
本节介绍如何保护组,保护组成员之间的连接,或使用地址白名单建立安全边界。
组复制插件具有一个配置选项,用于确定可以从哪些主机接受传入的组通信系统连接。
调用此选项
group_replication_ip_whitelist
。
如果在服务器s1上设置此选项,则当服务器s2与s1建立连接以进行组通信时,s1首先检查白名单,然后再接受来自s2的连接。
如果s2在白名单中,则s1接受连接,否则s1拒绝s2的连接尝试。
如果未明确指定白名单,则组通信引擎(XCom)会自动扫描主机上的活动接口,并识别具有私有子网上地址的接口。
这些地址和
localhost
IPv4
的
IP地址以及(来自MySQL 8.0.14)IPv6用于创建自动组复制白名单。
因此,自动白名单包括在以下范围内为主机找到的任何IP地址:
IPv4(在RFC 1918中定义) 10/8前缀(10.0.0.0 - 10.255.255.255) - A类 172.16 / 12前缀(172.16.0.0 - 172.31.255.255) - B类 192.168 / 16前缀(192.168.0.0 - 192.168.255.255) - C类 IPv6(在RFC 4193和RFC 5156中定义) fc00:/ 7前缀 - 唯一本地地址 fe80 :: / 10前缀 - 链接本地单播地址 127.0.0.1 - IPv4的localhost :: 1 - IPv6的localhost
将在错误日志中添加一个条目,说明已为主机自动列入白名单的地址。
私有地址的自动白名单不能用于来自专用网络外部服务器的连接,因此服务器(即使它具有公共IP上的接口)默认情况下不允许来自外部主机的组复制连接。
对于位于不同计算机上的服务器实例之间的组复制连接,您必须提供公共IP地址并将其指定为显式白名单。
如果您为白名单指定了任何条目,
localhost
则不会自动添加
私有和
地址,因此如果您使用其中
任何条目,则
必须明确指定它们。
要手动指定白名单,请使用该
group_replication_ip_whitelist
选项。
当服务器是复制组的活动成员时,您无法更改服务器上的白名单。
如果该成员处于活动状态,则必须
STOP GROUP_REPLICATION
在更改白名单之前
发出
声明,然后再发出
START GROUP_REPLICATION
声明。
在白名单中,您可以指定以下任意组合:
-
IPv4地址(例如
198.51.100.44) -
带有CIDR表示法的IPv4地址(例如
192.0.2.21/24) -
来自MySQL 8.0.14的IPv6地址(例如
2001:db8:85a3:8d3:1319:8a2e:370:7348) -
来自MySQL 8.0.14的带有CIDR表示法的IPv6地址(例如
2001:db8:85a3:8d3::/64) -
主机名(例如
example.org) -
具有CIDR表示法的主机名(例如,
www.example.com/24)
在MySQL 8.0.14之前,主机名只能解析为IPv4地址。 从MySQL 8.0.14开始,主机名可以解析为IPv4地址,IPv6地址或两者。 如果主机名同时解析为IPv4和IPv6地址,则IPv4地址始终用于组复制连接。 您可以将CIDR表示法与主机名或IP地址结合使用,将具有特定网络前缀的IP地址块列入白名单,但请确保指定子网中的所有IP地址都在您的控制之下。
您必须停止并重新启动成员上的组复制才能更改其白名单。 逗号必须分隔白名单中的每个条目。 例如:
mysql> STOP GROUP_REPLICATION; mysql> SET GLOBAL group_replication_ip_whitelist =“192.0.2.21/24,198.51.100.44,203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348,example.org,www.example.com/24”; mysql> START GROUP_REPLICATION;
白名单必须包含每个成员的
group_replication_local_address
系统变量中
指定的IP地址或主机名
。
此地址与MySQL服务器SQL协议主机和端口不同,并且未在
bind_address
服务器实例
的
系统变量中
指定
。
如果用作服务器实例的组复制本地地址的主机名解析为IPv4和IPv6地址,则IPv4地址优先用于组复制连接。
要加入复制组,服务器需要在其发出加入组请求的种子成员上列入白名单。
通常,这将是复制组的引导程序成员,但它可以是
group_replication_group_seeds
加入该组的服务器的配置中
的
选项
列出的任何服务器
。
如果
group_replication_group_seeds
加入成员具有IPv4
,则在
具有IPv6地址
的
选项
中列出该组的任何种子成员
group_replication_local_address
或者相反,您还必须为种子成员提供的协议(或解析为该协议的地址的主机名)的加入成员设置替代地址并将其列入白名单。
这是因为当服务器加入复制组时,它必须使用种子成员在
group_replication_group_seeds
选项中
通告的协议
(无论是IPv4还是IPv6)
与种子成员进行初始联系
。
如果加入成员没有适当协议的白名单地址,则拒绝其连接尝试。
有关管理混合IPv4和IPv6复制组的更多信息,请参见
第18.4.6节“支持IPv6以及混合IPv6和IPv4组”
。
重新配置复制组时(例如,当选择新主节点或成员加入或离开时),组成员将重新建立它们之间的连接。 如果组成员仅在重新配置后由不再属于复制组的服务器列入白名单,则无法重新连接到复制组中未将其列入白名单的其余服务器。 要完全避免此情况,请为作为复制组成员的所有服务器指定相同的白名单。
可以根据您的安全要求在不同的组成员上配置不同的白名单,例如,以便将不同的子网分开。 如果需要配置不同的白名单以满足安全要求,请确保复制组中的白名单之间存在足够的重叠,以最大限度地提高服务器在没有原始种子成员的情况下重新连接的可能性。
对于主机名,仅当另一个服务器发出连接请求时才会进行名称解析。 无法解析的主机名不会被视为白名单验证,并且会向错误日志写入警告消息。 对已解析的主机名执行前向确认的反向DNS(FCrDNS)验证。
主机名本质上不如白名单中的IP地址安全。 FCrDNS验证提供了良好的保护级别,但可能会受到某些类型的攻击的影响。 仅在严格必要时指定白名单中的主机名,并确保用于名称解析的所有组件(如DNS服务器)都在您的控制之下。 您还可以使用hosts文件在本地实现名称解析,以避免使用外部组件。
MySQL Group Replication支持OpenSSL和MySQL Server的wolfSSL版本。
使用SSL保护组通信连接和恢复连接。 以下部分说明如何配置连接。
通过常规异步复制连接执行恢复。 选择捐赠者后,加入该组的服务器将建立异步复制连接。 这都是自动的。
但是,必须在加入组的服务器连接到捐赠者之前创建需要SSL连接的用户。 通常,这是在配置服务器以加入组时设置的。
donor> SET SQL_LOG_BIN = 0; donor> CREATE USER'rec_ssl_user'@'%'需要SSL; donor> GRANT复制slave ON *。* TO'rec_ssl_user'@'%'; donor> SET SQL_LOG_BIN = 1;
假设组中已有的所有服务器都将复制用户设置为使用SSL,则可以将连接组的服务器配置为在连接到捐赠者时使用这些凭据。 这是根据为Group Replication插件提供的SSL选项的值完成的。
new_member> SET GLOBAL group_replication_recovery_use_ssl = 1; new_member> SET GLOBAL group_replication_recovery_ssl_ca ='... / cacert.pem'; new_member> SET GLOBAL group_replication_recovery_ssl_cert ='... / client-cert.pem'; new_member> SET GLOBAL group_replication_recovery_ssl_key ='... / client-key.pem';
并通过配置恢复通道以使用需要SSL连接的用户的凭据。
new_member> CHANGE MASTER TO MASTER_USER =“rec_ssl_user”FOR CHANNEL“group_replication_recovery”; new_member> START GROUP_REPLICATION;
安全套接字可用于在组中的成员之间建立通信。 此配置取决于服务器的SSL配置。 因此,如果服务器配置了SSL,则组复制插件也配置了SSL。 有关配置服务器SSL的选项的更多信息,请参见 第6.3.2节“加密连接的命令选项” 。 配置组复制的选项如下表所示。
表18.2 SSL选项
|
服务器配置 |
插件配置说明 |
|---|---|
|
ssl_key |
密钥文件的路径。 用作客户端和服务器证书。 |
|
ssl_cert |
证书文件的路径。 用作客户端和服务器证书。 |
|
ssl_ca |
具有受信任的SSL证书颁发机构的文件路径。 |
|
ssl_capath |
包含受信任的SSL证书颁发机构的证书的目录路径。 |
|
ssl_crl |
包含证书吊销列表的文件路径。 |
|
ssl_crlpath |
包含已撤销证书列表的目录路径。 |
|
ssl_cipher |
允许在通过连接加密数据时使用的密码。 |
|
tls_version |
安全通信将使用此版本及其协议。 |
这些选项是组服务器配置选项,组复制依赖于它的配置。 此外,还有以下特定于组复制的选项,用于在插件本身上配置SSL。
-
group_replication_ssl_mode- 指定组复制成员之间连接的安全状态。
表18.3 group_replication_ssl_mode配置值
|
值 |
描述 |
|---|---|
|
禁用 |
建立未加密的连接( 默认 )。 |
|
需要 |
如果服务器支持安全连接,请建立安全连接。 |
|
VERIFY_CA |
与REQUIRED类似,但另外根据配置的证书颁发机构(CA)证书验证服务器TLS证书。 |
|
VERIFY_IDENTITY |
与VERIFY_CA类似,但另外验证服务器证书是否与尝试连接的主机匹配。 |
以下示例显示了用于在服务器上配置SSL以及如何为组复制激活它的示例my.cnf文件部分。
的[mysqld] ssl_ca =“cacert.pem” ssl_capath =“/.../ca_directory” ssl_cert =“server-cert.pem” ssl_cipher =“DHE-RSA-AEs256-SHA” ssl_crl =“crl-server-revoked.crl” ssl_crlpath =“/.../ crl_directory” ssl_key =“server-key.pem” group_replication_ssl_mode = REQUIRED
列出的唯一插件特定配置选项是
group_replication_ssl_mode
。
此选项通过使用
ssl_*
提供给服务器
的
参数
配置SSL框架来激活组成员之间的SSL通信
。
本节介绍如何使用可用的配置选项从复制组中获得最佳性能。
组通信线程(GCT)在加载组复制插件时循环运行。 GCT从组和插件接收消息,处理仲裁和故障检测相关任务,发送一些保持活动消息,并处理来自/到服务器/组的传入和传出事务。 GCT等待队列中的传入消息。 当没有消息时,GCT会等待。 通过在实际进入睡眠状态之前将等待时间设置为稍长(进行主动等待)可以证明在某些情况下是有益的。 这是因为操作系统可以选择从处理器切换GCT并进行上下文切换。
要强制GCT执行活动等待
group_replication_poll_spin_loops
,请在实际轮询队列以查找下一条消息之前
使用该
选项,该选项使GCT循环与配置的循环数无关。
例如:
mysql> SET GLOBAL group_replication_poll_spin_loops = 10000;
组复制可确保事务仅在组中的大多数成员收到事务后提交,并同意所有并发发送的事务之间的相对顺序。 如果对组的写入总数不超过组中任何成员的写入容量,则此方法很有效。 如果确实如此,并且某些成员的写入吞吐量低于其他成员,特别是少于作者成员,那些成员可能会开始落后于作者。
让一些成员落后于该组会带来一些问题后果,特别是对这些成员的读取可能会使非常旧的数据外化。 根据成员滞后的原因,组中的其他成员可能必须保存更多或更少的复制上下文,以便能够满足来自慢成员的潜在数据传输请求。
然而,在复制协议中存在一种机制,以避免在快速和慢速成员之间在应用的事务方面具有太多距离。 这被称为流量控制机制。 它试图解决几个目标:
-
保持成员足够接近,使成员之间的缓冲和去同步成为一个小问题;
-
快速适应不同工作负载或组中更多作者等不断变化的条件;
-
给每个成员公平分享可用的写入能力;
-
不要为了避免浪费资源而严格限制吞吐量。
鉴于集团复制,决定是否扼杀与否可以决定考虑到两项工作队列的设计: (I) 的 认证 队列; (ⅱ) 和二进制日志 施放 队列。 只要其中一个队列的大小超过用户定义的阈值,就会触发限制机制。 仅配置: (i) 是在验证者或应用程序级别进行流量控制,还是两者都进行; 和 (ⅱ) 是什么每个队列的阈值。
流量控制取决于两种基本机制:
-
监督成员收集关于所有小组成员的吞吐量和队列大小的一些统计数据,以便对每个成员应该承受的最大写入压力进行有根据的猜测;
-
试图在每个时刻写出超出其可用容量的公平份额的成员的限制。
监视机制的工作原理是让每个成员部署一组探测器来收集有关其工作队列和吞吐量的信息。 然后,它会定期将该信息传播给该组,以便与其他成员共享该数据。
此类探针分散在整个插件堆栈中,允许建立指标,例如:
-
验证者队列大小;
-
复制应用程序队列大小;
-
经认证的交易总数;
-
成员中应用的远程交易总数;
-
本地交易总数。
一旦成员收到包含来自其他成员的统计信息的消息,它将计算有关在上一个监控期间认证,应用和本地执行的交易数量的其他指标。
监控数据定期与组中的其他人共享。 监视周期必须足够高,以允许其他成员决定当前的写入请求,但足够低,以至于它对组带宽的影响最小。 信息每秒共享一次,这段时间足以解决这两个问题。
根据在组中所有服务器上收集的度量标准,限制机制启动并决定是否限制成员能够执行/提交新事务的速率。
因此,从所有成员获取的指标是计算每个成员容量的基础:如果成员具有大型队列(用于认证或应用程序线程),则执行新事务的能力应接近经认证或应用的成员。最后一期。
组中所有成员的最低容量决定了组的实际容量,而本地事务的数量决定了向其写入的成员数量,因此,可以共享可用容量的成员数量。
这意味着每个成员都具有基于可用容量的已建立的写入配额,换句话说,它可以安全地为下一个时段发布的许多事务。 如果验证者或二进制日志应用程序的队列大小超过用户定义的阈值,则限制机制将强制执行writer-quota。
配额减少了上一期间延迟的事务数,然后进一步减少了10%,以允许触发问题的队列减小其大小。 为了在队列大小超过阈值时避免吞吐量的大幅跳跃,之后每个周期仅允许吞吐量增长相同的10%。
当前的限制机制不会惩罚低于配额的交易,但会延迟完成那些超过它的交易,直到监控期结束。 因此,如果发出的写请求的配额非常小,则某些事务可能具有接近监视时段的延迟。
当网络带宽成为瓶颈时,消息压缩可以在组通信级别提供高达30-40%的吞吐量改进。 这在负载下的大型服务器组的上下文中尤为重要。
组中 N个 参与者 之间的互连的TCP对等性质 使得发送者发送相同数量的数据 N 次。 此外,二进制日志可能表现出高压缩比(见上表)。 这使得压缩成为包含大型事务的工作负载的一个引人注目的功能。
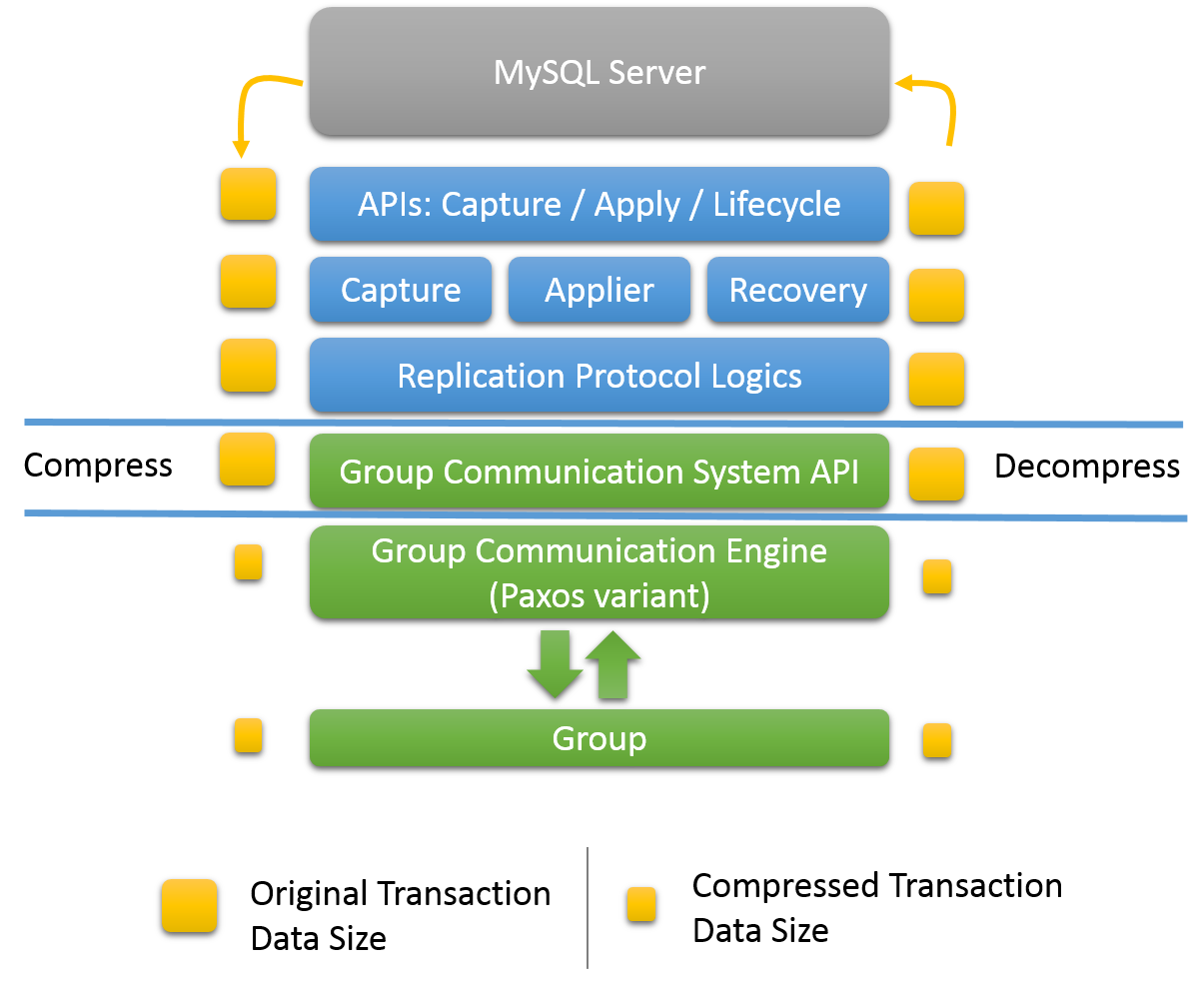
压缩发生在组通信引擎级别,在数据被移交给组通信线程之前,因此它发生在mysql用户会话线程的上下文中。 事务有效载荷可以在被发送到组之前被压缩并且在被接收时被解压缩。 压缩是有条件的,取决于配置的阈值。 默认情况下,启用压缩。
此外,不要求组中的所有服务器都启用压缩以便能够一起工作。 在收到消息后,成员检查消息信封以验证它是否被压缩。 如果需要,该成员在将事务交付给上层之前解压缩该事务。
使用的压缩算法是LZ4。 默认情况下启用压缩,阈值为1000000字节。 压缩阈值(以字节为单位)可以设置为大于默认值的值。 在这种情况下,仅压缩具有大于阈值的有效载荷的事务。 以下是如何设置压缩阈值的示例。
停止GROUP_REPLICATION; SET GLOBAL group_replication_compression_threshold = 2097152; START GROUP_REPLICATION;
这将压缩阈值设置为2MB。 如果事务生成有效负载大于2MB的复制消息,例如大于2MB的二进制日志事务条目,则会对其进行压缩。 禁用压缩设置阈值为0。
当组复制组成员之间发送异常大的消息时,可能会导致某些组成员报告为失败并从组中驱逐。 这是因为Group Replication的组通信引擎(XCom,Paxos变体)使用的单个线程被占用处理消息的时间太长,因此某些组成员可能会将接收器报告为失败。 从MySQL 8.0.16开始,默认情况下,大型邮件会自动拆分为单独发送并由收件人重新组装的片段。
系统变量
group_replication_communication_max_message_size
指定组复制通信的最大邮件大小,超过该邮件会对邮件进行分段。
默认的最大邮件大小为10485760字节(10 MiB)。
允许的最大值与
slave_max_allowed_packet
系统变量
的最大值相同
,即1073741824字节(1 GB)。
设置
group_replication_communication_max_message_size
必须小于
slave_max_allowed_packet
设置,因为应用程序线程无法处理大于的消息片段
slave_max_allowed_packet
。
要关闭碎片,请为其指定零值
group_replication_communication_max_message_size
。
与大多数其他Group Replication系统变量一样,必须重新启动Group Replication插件才能使更改生效。 例如:
停止GROUP_REPLICATION; SET GLOBAL group_replication_communication_max_message_size = 5242880; START GROUP_REPLICATION;
当所有组成员收到并重新组装消息的所有片段时,认为片段消息的消息传递已完成。 分段消息包括其标头中的信息,这些信息使成员在消息传输期间加入以恢复在加入之前发送的早期片段。 如果加入成员无法恢复碎片,则将其从组中驱逐出去。
为了使复制组使用碎片,所有组成员必须处于MySQL 8.0.16或更高版本,并且组使用的组复制通信协议版本必须允许碎片。
您可以使用
group_replication_get_communication_protocol()
UDF
检查组使用的通信协议,
UDF返回该组支持的最旧的MySQL服务器版本。
MySQL 5.7.14中的版本允许压缩消息,而MySQL 8.0.16中的版本也允许消息碎片化。
如果所有组成员都在MySQL 8.0.16或更高版本且没有要求允许早期版本的成员加入,则可以使用
group_replication_set_communication_protocol()
UDF将通信协议版本设置为MySQL 8.0.16或更高版本以允许分段。
有关更多信息,请参见
第18.4.2.4节“设置组的通信协议版本”
。
如果复制组不能使用碎片,因为某些成员不支持碎片,则系统变量
group_replication_transaction_size_limit
可用于限制组接受的事务的最大大小。
在MySQL 8.0中,默认设置大约为143 MB。
回滚此大小以上的交易。
您还可以使用系统变量
group_replication_member_expel_timeout
,以便在怀疑失败的成员被驱逐出组之前允许额外的时间(最多一个小时)。
用于组复制的组通信引擎(XCom,Paxos变体)包括用于在组成员之间交换的消息(及其元数据)的高速缓存,作为共识协议的一部分。 在其他功能中,消息缓存用于在无法与其他组成员通信的时间段之后返回到该组的成员进行恢复。
从MySQL 8.0.16开始,可以使用
group_replication_message_cache_size
系统变量
为XCom的消息缓存设置缓存大小限制
。
此系统变量的默认和最小设置为1 GB,这是MySQL 8.0.16之前的MySQL Server版本中的消息缓存大小。
如果达到缓存大小限制,XCom将删除已决定和交付的最旧条目。
考虑到MySQL Server的其他缓存和对象池的大小,确保系统上有足够的内存用于所选的缓存大小限制。
如果尝试重新连接的无法访问的成员需要恢复消息,但该消息已从消息高速缓存中删除,则该成员无法重新连接。
如果您使用过这种情况,则更有可能发生这种情况
group_replication_member_expel_timeout
系统变量(在MySQL 8.0.13中引入)指定在将可疑成员从组中驱逐之前的额外延迟时间。
组复制的组通信系统(GCS)通过警告消息警告您何时从消息缓存中删除当前无法访问的成员可能需要恢复的消息。
此警告消息记录在所有活动组成员上(每个无法访问的成员只有一次)。
虽然组成员无法确定无法访问的成员看到的最后一条消息是什么消息,但警告消息表明高速缓存大小可能不足以支持在驱逐成员之前所选择的等待时间。
在这种情况下,
group_replication_member_expel_timeout
系统变量,以便缓存包含成员返回成功所需的所有错过的消息。
如果您希望某个成员在一段不寻常的时间内无法访问,您还可以考虑临时增加缓存大小限制。
如果您正在考虑减小缓存大小限制,可以
memory_summary_global_by_event_name
使用以下语句
查询Performance Schema表
:
SELECT * FROM performance_schema.memory_summary_global_by_event_name 在哪里EVENT_NAME喜欢'memory / group_rpl / GCS_XCom :: xcom_cache';
这将返回消息缓存的内存使用情况统计信息,包括当前缓存条目数和缓存的当前大小。 如果减小缓存大小限制,XCom将删除已确定并交付的最旧条目,直到当前大小低于限制。 在此删除过程正在进行时,XCom可能会暂时超出缓存大小限制。
Group Replication的故障检测机制旨在识别不再与该组通信的组成员,并在它们可能发生故障时将其驱逐出去。 具有故障检测机制会增加组包含大多数正确工作成员的可能性,因此可以正确处理来自客户端的请求。
通常,所有小组成员定期与所有其他小组成员交换消息。 如果群组成员在5秒内没有收到来自特定成员的任何消息,则当该检测期结束时,会引起对该成员的怀疑。 当怀疑超时时,假定被怀疑的成员失败,并被驱逐出该组。 被驱逐的成员从其他成员看到的成员列表中删除,但它不知道它已被驱逐出该组,因此它将自己视为在线而其他成员无法访问。 如果该成员实际上没有失败(例如,因为它由于临时网络问题而刚刚断开)并且它能够恢复与其他成员的通信,
可以在流程中的多个点配置组成员(包括失败的成员本身)对这些情况的响应。 默认情况下,如果怀疑某个成员失败,则会发生以下行为:
-
当怀疑被创建时,它会立即超时(其生命周期设置为0),因此一旦发现过期的怀疑,被怀疑的成员就会被驱逐。 该成员可能会在超时后存活几秒钟,因为对过期怀疑的检查会定期进行。
-
如果被驱逐的成员恢复通信并意识到被驱逐,则不会尝试重新加入该组并接受其驱逐。
-
当被驱逐的成员接受其驱逐时,它会切换到超级只读模式并等待操作员注意。 (例外情况是从MySQL 8.0.12到8.0.15的版本,其中默认是成员自行关闭。从MySQL 8.0.16开始,行为被改变以匹配MySQL 5.7中的行为。)
这些默认值设置为优先考虑组的正确操作和正确处理请求。 然而,在较慢的网络或具有高速率的瞬时故障的网络的情况下它们可能是不方便的,因为在这些情况下可能经常需要操作员干预来修复被驱逐的成员。 在预期的网络故障或机器减速的情况下,它们也不允许计划组的持续运行。 您可以使用组复制配置选项永久或临时更改这些行为,以满足系统的要求和优先级,如下所示:
-
您可以使用
group_replication_member_expel_timeoutMySQL 8.0.13中提供 的 系统变量,以便在产生怀疑和驱逐可疑成员之间留出更多时间。 您可以在怀疑超时之前将怀疑的生命周期设置为3600秒(一小时)。 (创建怀疑之前的5秒检测周期是不可配置的。)处于此状态的可疑成员列为UNREACHABLE,但不会从组的成员列表中删除。请记住,虽然组中有无法访问的成员,但您无法添加或删除任何其他成员或选择新的主要成员。 如果您确实想要采取其中一个操作并且无法再次激活可疑成员,则可以通过将
group_replication_member_expel_timeout任何在线成员更改为小于自怀疑创建以来已经过的时间的值 来强制怀疑超时 。 -
你可以使用
group_replication_autorejoin_tries系统变量,可从MySQL 8.0.16获得,使一个能够自动恢复通信的被驱逐成员尝试重新加入该组。 您可以指定该成员重新加入该组的次数,而不是仅在恢复通信后立即接受其驱逐。 当达到成员的驱逐或无法达到的多数超时时,它会尝试重新加入(使用当前插件选项值),然后继续进行进一步的自动重新加入尝试,直到达到指定的尝试次数。 在尝试自动重新加入失败后,该成员在下一次尝试之前等待5分钟。 在自动重新加入过程中,ERROR陈述其对复制组的看法。请记住,虽然成员仍然处于此模式,但是虽然无法对成员进行写入,但读取可能会随着时间的推移而增加过时读取的可能性。 如果您确实想要进行干预以使成员脱机,则可以使用
STOP GROUP_REPLICATION语句或关闭服务器 随时手动停止该成员 。 您可以使用性能架构监视自动重新加入过程。 在执行自动重新加入过程时,性能模式表events_stages_current显示事件 “ 正在进行自动重新加入过程 ” ,在此过程实例中(在 已经尝试过的重试次数 现场)。WORK_COMPLETED领域)。 该events_stages_summary_global_by_event_name表显示服务器实例启动自动重新加入过程的次数(在COUNT_STAR字段中)。 该events_stages_history_long表显示了每个自动重新加入程序的完成时间(在TIMER_END -
你可以使用
group_replication_exit_state_action系统变量,可从MySQL 8.0.12和MySQL 5.7.24获得,用于选择无法重新加入(或不尝试)的被驱逐成员关闭MySQL服务器或将自身切换到超级只读模式。 与自动重新加入过程一样,如果成员进入超级只读模式,则过时读取的可能性会增加。 指示成员自行关闭会结束这种情况,这意味着您不需要主动监视服务器的故障,但这意味着MySQL Server实例不可用,必须重新启动。 无论设置何种退出操作,都需要操作员干预,重要如果在成员成功加入组之前发生故障, 则不会执行 指定的退出操作 。 如果在本地配置检查期间出现故障,或者加入成员的配置与组的配置不匹配,则会出现这种情况。 在这些情况下, 系统变量保留其原始值,服务器不会关闭MySQL。 为确保在组复制未启动时服务器无法接受更新,我们建议您这样做
group_replication_exit_state_actionsuper_read_onlysuper_read_only=ON在启动时在服务器的配置文件中设置,组复制将更改为OFF在主要成员成功启动后。 当服务器配置为在服务器boot(group_replication_start_on_boot=ON) 上启动组复制时,此安全措施尤为重要 ,但在使用START GROUP_REPLICATION命令 手动 启动组复制时,此安全措施 也很有用 。如果后的构件已成功加入组中发生故障,则指定的退出动作 取 。 如果存在应用程序错误,成员被从组中驱逐,或者如果成员被设置为在无法访问多数的情况下超时,则会出现这种情况。 在这些情况下,如果
READ_ONLY是退出操作,super_read_only系统变量设置为ON,或者如果ABORT_SERVER是退出操作,则服务器关闭MySQL。
请注意,如果组成员位于不支持相关设置的旧MySQL服务器版本中,或者在具有不同默认设置的版本中,则它们会根据上述默认行为对自己和其他组成员执行操作。
例如,
group_replication_member_expel_timeout
一旦检测到过期怀疑
,不支持
系统变量的成员就会驱逐其他成员,并且即使它们支持系统变量并且具有更长的超时设置,其他成员也会接受此驱逐。
由于网络分区,未失败的成员可能会与复制组的部分(但不是全部)失去联系。 例如,在一组5个服务器(S1,S2,S3,S4,S5)中,如果(S1,S2)和(S3,S4,S5)之间存在断开,则存在网络分区。 第一组(S1,S2)现在属于少数,因为它不能接触超过一半的组。 由少数群组中的成员处理的任何事务都被阻止,因为该群组的大部分是无法访问的,因此该群组无法达到法定人数。 如果多数组中的服务器仍处于联机状态,则它们可以自动形成自己的功能分区,并继续充当复制组。 有关此方案的详细说明, 第18.4.5节“网络分区” 。
在这种情况下,默认行为是少数和大多数成员保留在组中,继续接受事务(尽管它们在少数成员中被阻止),并等待操作员干预。 第18.4.5节“网络分区”中 描述的干预过程 涉及检查哪些服务器正在运行,并在必要时强制新的组成员身份。
如果您不想主动监控这种情况,并且希望避免由于不适当的干预而产生裂脑情况(具有两个版本的组成员身份)的可能性,您可以指示发现自己的成员少数人在超时后退出该组。
系统变量
group_replication_unreachable_majority_timeout
设置成员在与大多数组成员失去联系后等待的秒数。
在此之后,将回滚该成员和少数群组中其他成员处理的所有待处理事务,并且该组中的服务器将移至该
ERROR
状态,然后按照指定的退出操作执行
group_replication_exit_state_action
。
本节介绍如何升级组复制设置。 升级组成员的基本过程与升级独立实例相同,请参见 第2.11节“升级MySQL” 以了解 升级 的实际过程和可用类型。 在就地升级或逻辑升级之间进行选择取决于组中存储的数据量。 通常,就地升级更快,因此建议使用。 由于组复制的分布式特性,因此需要考虑如何升级组成员的顺序,本节将对此进行介绍。 您还应该参考 第17.4.3节“升级复制设置” 。
如果您的组可以完全脱机,请参见 第18.7.1节“组复制脱机升级” 。 如果您的组需要保持联机(如生产部署中常见的那样),请参见 第18.7.2节“组复制联机升级” ,了解可用于以最短停机时间升级组的不同方法。
要执行组复制组的脱机升级,请从组中删除每个成员,执行成员升级,然后照常重新启动组。 在多主要组中,您可以按任何顺序关闭成员。 在单主组中,首先关闭每个辅助节点,然后最后关闭主节点。 有关 如何从组中删除成员并关闭MySQL , 请参见 第18.7.2.3节“升级组复制成员” 。
组脱机后,升级所有成员。 有关 如何执行升级 , 请参见 第2.11节“升级MySQL” 。 升级所有成员后,重新启动成员。
如果在脱机时升级复制组的所有成员,然后重新启动组,则成员将使用新版本的组复制通信协议版本进行连接,以便成为组的通信协议版本。
如果您要求允许早期版本的成员加入,则可以使用
group_replication_set_communication_protocol()
UDF降级通信协议版本,指定具有最早安装的服务器版本的预期组成员的MySQL Server版本。
如果您要运行要升级的组,但需要使组保持联机以服务于您的应用程序,则需要考虑升级方法。 本节介绍在线升级中涉及的不同元素,以及如何升级组的各种方法。
升级在线组时,您应该考虑以下几点:
-
无论您升级组的方式如何,在组成员准备重新加入组之前禁用对组成员的任何写入都很重要。
-
当成员停止时,该
super_read_only变量将自动设置为on,但不会保留此更改。 -
当MySQL 5.7.22或MySQL 8.0.11尝试加入运行MySQL 5.7.21或更低版本的组时,它无法加入该组,因为MySQL 5.7.21不会发送其值
lower_case_table_names。
升级在线组时,可能需要同时在组中的成员上运行不同版本的MySQL。 根据MySQL版本之间的更改,您可能会遇到不兼容问题。 例如,如果主要版本之间的某个功能已被弃用,则组合这些版本可能会导致依赖已弃用功能的成员失败。 本节介绍在同一组中组合运行不同MySQL版本的成员的最佳实践。
组复制根据插件捆绑的服务器版本进行版本控制,例如,如果某个成员正在运行MySQL 5.7.19,那么这就是插件的版本。 升级组时,特别是在将成员加入组时,此版本号至关重要。 请参见 第2.1.1节“要安装的MySQL版本和分发版本” 。
要检查组成员问题上的MySQL版本:
SELECT MEMBER_HOST,MEMBER_PORT,MEMBER_VERSION FROM performance_schema.replication_group_members;
+ ------------- ------------- + ---------------- + +
| member_host | member_port | member_version |
+ ------------- ------------- + ---------------- + +
| example.com | 3306 | 8.0.13 |
+ ------------- ------------- + ---------------- + +
组合具有不同主要版本的组中的成员的规则是:
-
如果成员运行的旧主要版本低于运行现有组成员的主要版本,则无法将成员加入组。 例如,如果您的组成员运行MySQL版本8.0,则无法添加运行较旧版本的成员,例如MySQL版本5.7。
-
如果成员运行的是比现有组成员运行的主要版本更新的主要版本,则可以将该成员加入组。 例如,如果您有一个运行MySQL 5.7的成员的组,您可以添加运行MySQL 8.0版的成员,但它仍处于只读模式。 当存在运行较旧MySQL版本的读写成员时写入此成员是危险的,必须避免。
组合具有不同次要版本的组中的成员的规则是:
-
您可以将运行较新或较旧版本的成员添加到组中,他们可以执行写入操作。 在单主组中,添加的成员默认为只读。
复制组使用的组复制通信协议版本可能与成员的MySQL Server版本不同。 要检查组的通信协议版本,请对任何成员发出以下语句:
SELECT group_replication_get_communication_protocol();
返回值显示可以加入此组并使用组的通信协议的最早的MySQL Server版本。
MySQL 5.7.14中的版本允许压缩消息,而MySQL 8.0.16中的版本也允许消息碎片化。
请注意,
group_replication_get_communication_protocol()
UDF返回该组支持的最小MySQL版本,该版本可能与传递给
group_replication_set_communication_protocol()
UDF
的版本号
以及安装在使用UDF的成员上的MySQL Server版本不同。
将复制组的所有成员升级到新的MySQL Server版本时,如果仍需要允许早期版本的成员加入,则不会自动升级组复制通信协议版本。
如果您不需要支持较旧的成员并且希望允许升级的成员使用任何添加的通信功能,则在升级之后使用
group_replication_set_communication_protocol()
UDF升级通信协议,指定已升级成员的新MySQL服务器版本。
有关更多信息,请参见
第18.4.2.4节“设置组的通信协议版本”
。
本节介绍升级组成员所需的步骤。 此过程是 第18.7.2.4节“组复制联机升级方法”中 描述的方法的一部分 。 升级组成员的过程对所有方法都是通用的,并首先解释。 加入升级成员的方式取决于您遵循的方法,以及其他因素,例如组是以单主模式还是多主模式运行。 如何使用就地或提供方法升级服务器实例不会影响此处描述的方法。
升级成员的过程包括按照您选择的升级成员的方法将其从组中删除,然后将升级后的成员重新加入组。 升级单主组中成员的建议顺序是升级所有辅助节点,然后升级主节点。 如果在辅助节点之前升级主节点,则选择使用较旧MySQL版本的新主节点,但不需要此步骤。
要升级组的成员:
-
将客户端连接到组成员并发出
STOP GROUP_REPLICATION。 在继续之前,请OFFLINE通过监视replication_group_members表来 确保成员的状态 。 -
禁用组复制自动启动,以便您可以在升级后安全地连接到该成员并进行配置,而无需通过设置重新加入组
group_replication_start_on_boot=0。重要如果已升级的成员已经
group_replication_start_on_boot=1可以重新加入该组,则可以执行MySQL升级过程并可能导致问题。 例如,如果升级失败并且服务器再次重新启动,则可能损坏的服务器可能会尝试加入该组。 -
停止该成员,例如使用 mysqladmin shutdown 或
SHUTDOWN语句。 该组中的任何其他成员继续运行。 -
使用就地或配置方法升级成员。 有关 详细信息 , 请参见 第2.11节“升级MySQL” 。 重新启动已升级的成员时,因为
group_replication_start_on_boot设置为0,组复制不会在实例上启动,因此它不会重新加入该组。 -
在成员上执行MySQL升级过程后,
group_replication_start_on_boot必须将其设置为1以确保重新启动后组复制正确启动。 重启会员。 -
连接到升级的成员并发布
START GROUP_REPLICATION。 这会将该成员重新加入该组。 组复制元数据在升级的服务器上就位,因此通常无需重新配置组复制。 服务器必须赶上服务器脱机时由组处理的任何事务。 一旦它赶上了该组,它就成为该组的在线成员。注意升级服务器所需的时间越长,成员脱机的时间就越长,因此服务器在添加回组时所需的时间就越多。
当升级的成员加入具有运行早期版本的任何成员的组时,升级的成员将加入
super_read_only=on
,无论它是主要成员还是辅助成员。
这可确保在所有成员运行较新版本之前不会对升级的成员进行写入。
在多主组中,一旦确定升级成功并且组已准备好处理事务,就必须手动配置应成为可写主要组件的成员。
连接到每个成员并发出:
SET GLOBAL read_only=off;选择以下升级组复制组的方法之一:
支持此方法,前提是运行较新主要版本的服务器不会为该组生成工作负载,同时仍有服务器中包含旧版本。
换句话说,具有较新主要版本的服务器只能作为辅助服务器加入该组。
在此方法中,只有一个组,每个服务器实例都从组中删除,升级然后重新加入组。
运行较新版本的成员加入该组
super_read_only=ON
。
此方法非常适合单一主要组。
当组以单主模式运行时,主要成员应该是要升级的最后一个成员。
如果在仍有成员运行旧版本的情况下升级主数据库,则从运行旧版本的成员中选择新的主数据库,但不需要这样做。
对于以单主模式运行的组,一旦所有辅助节点都运行较新版本,当主要成员离开要升级的组时,将自动从运行新版本的成员中选择新主节点。
对于在多主模式下运行的组,一旦
升级了
所有
成员,您
必须
手动设置
super_read_only=OFF
应作为主要成员运行的每个成员。
对于在多主模式下操作的组,在此过程中,初级数量减少,导致写入可用性降低。
这不会影响在单主模式下运行的组。
在此方法中,您从组中删除成员,升级它们,然后使用升级的成员创建第二个组。 对于在多主模式下操作的组,在此过程中,初级数量减少,导致写入可用性降低。 这不会影响在单主模式下运行的组。
由于在升级成员时运行旧版本的组处于联机状态,因此您需要运行较新版本的组来跟踪升级成员时执行的任何事务。 因此,新组中的一个服务器配置为较旧组的主服务器的复制从属服务器。 这可确保新组赶上旧组。 因为此方法依赖于异步复制通道,该通道用于将数据从一个组复制到另一个组,所以它在主从复制的相同假设和要求下受支持,请参见 第17章, 复制 。 对于以单主模式运行的组,与旧组的异步复制连接必须将数据发送到新组中的主组,对于多主组,异步复制通道可以连接到任何主组。
过程是:
-
从逐个运行旧服务器版本的原始组中删除成员,请参见 第18.7.2.3节“升级组复制成员”
-
升级在成员上运行的服务器版本,请参见 第2.11节“升级MySQL” 。 您可以按照就地或提供方法进行升级。
-
使用升级的成员创建新组,请参见 第18章, 组复制 。 在这种情况下,您需要在每个成员上配置一个新的组名(因为旧组仍在运行并使用旧名称),引导初始升级的成员,然后添加其余的升级成员。
-
在旧组和新组之间设置异步复制通道,请参见 第17.1.3.4节“使用GTID设置复制” 。 将较旧的主服务器配置为异步复制主服务器,将新的组成员配置为基于GTID的复制从服务器。
在将应用程序重定向到新组之前,必须确保新组具有适当数量的成员,例如,以便该组可以处理成员的故障。
发布
SELECT * FROM
performance_schema.replication_group_members
并比较初始组大小和新组大小。
等待,直到旧组中的所有数据都传播到新组,然后删除异步复制连接并升级所有缺少的成员。
在此方法中,您将创建第二个组,该组由运行较新版本的成员组成,旧组中缺少的数据将复制到较新的组。 这假设您有足够的服务器同时运行这两个组。 由于在该过程期间原始数量 没有 减少 的事实 ,对于在多主模式下操作的组,写入可用性没有降低。 这使得滚动复制升级非常适合在多主模式下运行的组。 这不会影响在单主模式下运行的组。
由于在新组中配置成员时,运行旧版本的组处于联机状态,因此您需要运行较新版本的组来跟踪在配置成员时执行的任何事务。 因此,新组中的一个服务器配置为较旧组的主服务器的复制从属服务器。 这可确保新组赶上旧组。 因为此方法依赖于异步复制通道,该通道用于将数据从一个组复制到另一个组,所以它在主从复制的相同假设和要求下受支持,请参见 第17章, 复制 。 对于以单主模式运行的组,与旧组的异步复制连接必须将数据发送到新组中的主组,对于多主组,异步复制通道可以连接到任何主组。
过程是:
-
部署适当数量的成员,以便运行较新版本的组可以处理成员的故障
-
从组成员中备份现有数据
-
使用旧成员中的备份来配置新组的成员,请参见 第18.7.2.5节“使用 mysqlbackup 进行 组复制升级 ” 一种方法。
注意您必须将备份还原到从中获取备份的相同版本的MySQL,然后执行就地升级。 有关说明,请参见 第2.11节“升级MySQL” 。
-
使用升级的成员创建新组,请参见 第18章, 组复制 。 在这种情况下,您需要在每个成员上配置一个新的组名(因为旧组仍在运行并使用旧名称),引导初始升级的成员,然后添加其余的升级成员。
-
在旧组和新组之间设置异步复制通道,请参见 第17.1.3.4节“使用GTID设置复制” 。 将较旧的主服务器配置为异步复制主服务器,将新的组成员配置为基于GTID的复制从服务器。
一旦新组中丢失的持续数据小到足以快速传输,您必须将写操作重定向到新组。 等待,直到旧组中的所有数据都传播到新组,然后删除异步复制连接。
作为配置方法的一部分,您可以使用MySQL Enterprise Backup将数据从组成员复制和还原到新成员。 但是,您无法使用此技术将运行较旧版本MySQL的成员的备份直接还原到运行较新版本MySQL的成员。 解决方案是将备份还原到新服务器实例,该实例运行与从中获取备份的成员相同版本的MySQL,然后升级实例。 该过程包括:
-
使用 mysqlbackup 从旧组的成员中进行 备份 。 请参见 第18.4.7节“将MySQL企业备份与组复制一起使用” 。
-
部署新的服务器实例,该实例必须与执行备份的旧成员运行相同版本的MySQL。
-
使用 mysqlbackup 将备份从较旧的成员还原到新实例 。
-
在新实例上升级MySQL,请参见 第2.11节“升级MySQL” 。
重复此过程以创建适当数量的新实例,例如,以便能够处理故障转移。 然后加入实例基于A组 第18.7.2.4,“组复制在线升级方法” .`
本节列出了特定于Group Replication插件的系统变量。
每个配置选项都以“
group_replication
”
为前缀
。
组复制的大多数系统变量都被描述为动态,并且可以在服务器运行时更改它们的值。
但是,在大多数情况下,只有在使用
STOP GROUP_REPLICATION
语句后跟
START GROUP_REPLICATION
语句
停止并重新启动组成员上的组复制后,更改才会生效
。
对以下系统变量的更改将在不停止和重新启动组复制的情况下生效:
组复制的大多数系统变量可以在不同的组成员上具有不同的值。 对于以下系统变量,建议在组的所有成员上设置相同的值,以避免不必要的事务回滚,消息传递失败或消息恢复失败:
组复制组成员上的某些系统变量(包括某些特定于组复制的系统变量和一些常规系统变量)是组范围的配置设置。
这些系统变量必须在所有组成员上具有相同的值,在组复制运行时不能更改,并且需要完全重新引导组(服务器的引导程序
group_replication_bootstrap_group=ON
)才能使值更改生效。
这些条件适用于以下系统变量:
从MySQL 8.0.16,你可以使用
group_replication_switch_to_single_primary_mode()
和
group_replication_switch_to_multi_primary_mode()
UDF的改变的值
group_replication_single_primary_mode
和
group_replication_enforce_update_everywhere_checks
,而组仍在运行。
有关更多信息,请参见
第18.4.2.2节“更改组模式”
。
-
如果将组复制的许多系统变量作为命令行参数传递给服务器,则它们在服务器启动期间未完全验证。 这些系统变量包括
group_replication_group_name,group_replication_single_primary_mode,group_replication_force_members,的SSL变量和流量控制系统变量。 它们仅在服务器启动后完全验证。 -
START GROUP_REPLICATION在发出语句 之前,不会验证为组成员指定IP地址或主机名的组复制的系统变量 。 在此之前,组复制的组通信系统(GCS)不可用于验证值。
特定于组复制插件的系统变量如下:
-
group_replication_allow_local_disjoint_gtids_join属性 值 命令行格式 --group-replication-allow-local-disjoint-gtids-join[={OFF|ON}]弃用 是(在8.0.4中删除) 系统变量 group_replication_allow_local_disjoint_gtids_join范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF在8.0.4版中删除。 允许服务器加入组,即使它具有组中不存在的本地事务。
警告启用此选项时请小心,因为不正确的使用可能会导致组中的冲突和事务回滚。 该选项应仅作为最后的方法启用,以允许具有本地事务的服务器加入现有组,然后仅当本地事务不影响组处理的数据时(例如,管理操作)那被写入二进制日志)。 不应在所有组成员上启用该选项。
-
group_replication_allow_local_lower_version_join属性 值 命令行格式 --group-replication-allow-local-lower-version-join[={OFF|ON}]系统变量 group_replication_allow_local_lower_version_join范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF允许当前服务器加入该组,即使它的主要版本低于该组。 使用默认设置时
OFF,如果服务器的主要版本低于现有组成员,则不允许服务器加入复制组。 例如,MySQL 5.7服务器无法加入由MySQL 8.0服务器组成的组。 此标准策略可确保组中的所有成员都能够交换消息并应用事务。 设置group_replication_allow_local_lower_version_join到ON只有在下列情况:-
必须在紧急情况下将服务器添加到组中以提高组的容错能力,并且只有旧版本可用。
-
您希望在不关闭整个组并再次引导它的情况下执行复制组成员的降级。
警告将此选项设置为
ON不会使新成员与组兼容,并允许它加入组,而不对现有成员的不兼容行为进行任何保护。 为确保新成员的正确操作,请采取 以下 两种 预防措施:-
在具有较低主要版本的服务器加入组之前,停止该服务器上的所有写入。
-
从具有较低主要版本的服务器加入组的位置开始,停止对该组中其他服务器的所有写入。
如果没有这些预防措施,主要版本较低的服务器可能会遇到困难并因错误而终止。
-
-
group_replication_auto_increment_increment属性 值 命令行格式 --group-replication-auto-increment-increment=#系统变量 group_replication_auto_increment_increment范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 7最低价值 1最大价值 65535确定在此服务器实例上执行的事务的连续列值之间的间隔。 此系统变量应对所有组成员具有相同的值。 在服务器上启动组复制时,服务器系统变量的值将
auto_increment_increment更改为此值,并且服务器系统变量的auto_increment_offset值将更改为服务器ID。 这些设置可避免为组成员上的写入选择重复的自动增量值,从而导致事务回滚。 停止组复制时,将还原更改。 这些变化只发和恢复,如果auto_increment_increment和auto_increment_offset每个都具有默认值1.如果已从默认值修改其值,则组复制不会更改它们。 从MySQL 8.0开始,当组复制处于单主模式时,系统变量也不会被修改,其中只有一个服务器写入。默认值7表示可用值的数量与复制组的允许的最大大小(9个成员)之间的平衡。 如果您的组具有更多或更少的成员,则可以在启动组复制之前将此系统变量设置为与预期的组成员数匹配。 在组复制运行时,您无法更改设置。
-
group_replication_autorejoin_tries属性 值 命令行格式 --group-replication-autorejoin-tries=#介绍 8.0.16 系统变量 group_replication_autorejoin_tries范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2016指定成员在被驱逐时自动重新加入组的尝试次数,或者在
group_replication_unreachable_majority_timeout达到设置 之前无法联系该组的大多数组的尝试次数 。 默认设置0表示成员不尝试重新加入,并继续执行group_replication_exit_state_action系统变量 指定的操作 。 您最多可以指定2016次尝试。如果您可以容忍过时读取的可能性并且希望最小化手动干预的需要,则激活自动重新加入,尤其是在瞬态网络问题经常导致成员被驱逐的情况下。 如果指定了多次尝试,当达到成员的驱逐或无法访问多数超时时,它会尝试重新加入(使用当前插件选项值),然后继续进行进一步的自动重新加入尝试,直到达到指定的尝试次数。 在尝试自动重新加入失败后,该成员在下一次尝试之前等待5分钟。 在自动重新加入过程中,成员仍处于超级只读模式并显示
ERROR陈述其对复制组的看法。 可以使用STOP GROUP_REPLICATION语句或关闭服务器 随时手动停止该成员 。 如果在没有成员重新加入或停止的情况下指定的尝试次数用尽,则成员将继续执行group_replication_exit_state_action系统变量 指定的操作 ,该操作可以保持超级只读模式或关闭。有关在故障检测情况下配置成员行为的更多信息,请参见 第18.6.6节“对故障检测和网络分区的响应” 。
-
group_replication_bootstrap_group属性 值 命令行格式 --group-replication-bootstrap-group[={OFF|ON}]系统变量 group_replication_bootstrap_group范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF配置此服务器以引导该组。 此选项只能在一台服务器上设置,并且只能在首次启动组或重新启动整个组时设置。 在组引导后,将此选项设置为
OFF。 它应该OFF动态 设置为 配置文件。 在组运行时使用此选项启动两个服务器或重新启动一个服务器可能会导致人为的裂脑情况,其中两个具有相同名称的独立组被引导。 -
group_replication_communication_debug_options属性 值 命令行格式 --group-replication-communication-debug-options=value介绍 8.0.3 系统变量 group_replication_communication_debug_options范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 GCS_DEBUG_NONE有效值 GCS_DEBUG_NONEGCS_DEBUG_BASICGCS_DEBUG_TRACEXCOM_DEBUG_BASICXCOM_DEBUG_TRACEGCS_DEBUG_ALL配置调试消息的级别,以提供不同的组复制组件,例如组通信系统(GCS)和组通信引擎(XCom,Paxos变体)。 调试信息存储在
GCS_DEBUG_TRACE数据目录 中的 文件中。可以组合指定为字符串的可用选项集。 可以使用以下选项:
-
GCS_DEBUG_NONE禁用GCS和XCOM的所有调试级别 -
GCS_DEBUG_BASIC在GCS中启用基本调试信息 -
GCS_DEBUG_TRACE在GCS中启用跟踪信息 -
XCOM_DEBUG_BASIC在XCOM中启用基本调试信息 -
XCOM_DEBUG_TRACE在XCOM中启用跟踪信息 -
GCS_DEBUG_ALL启用GCS和XCOM的所有调试级别
将调试级别设置为
GCS_DEBUG_NONE仅在没有任何其他选项的情况下提供效果。 设置调试级别以GCS_DEBUG_ALL覆盖所有其他选项。 -
-
group_replication_communication_max_message_size属性 值 命令行格式 --group-replication-communication-max-message-size=#介绍 8.0.16 系统变量 group_replication_communication_max_message_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10485760最低价值 0最大价值 1073741824指定组复制通信的最大邮件大小。 大于此大小的邮件会自动拆分为单独发送并由收件人重新组合的片段。 有关更多信息,请参见 第18.6.4节“消息碎片” 。
默认情况下,最大消息大小为10485760字节(10 MiB),这意味着默认情况下在MySQL 8.0.16的发行版中使用碎片。 允许的最大值与
slave_max_allowed_packet系统变量 的最大值相同 ,即1073741824字节(1 GB)。 设置group_replication_communication_max_message_size必须小于slave_max_allowed_packet设置,因为应用程序线程无法处理大于的消息片段slave_max_allowed_packet。 要关闭碎片,请为其指定零值group_replication_communication_max_message_size。group_replication_communication_max_message_size所有组成员 的值 应该相同。为了使复制组的成员使用碎片,组的通信协议版本必须是MySQL 8.0.16或更高版本。 使用
group_replication_get_communication_protocol()UDF查看组的通信协议版本。 如果正在使用较低版本,则组成员不会对邮件进行分段。group_replication_set_communication_protocol()如果所有组成员都支持,则 可以使用 UDF将组的通信协议设置为更高版本。 有关更多信息,请参见 第18.4.2.4节“设置组的通信协议版本” 。 -
group_replication_components_stop_timeout属性 值 命令行格式 --group-replication-components-stop-timeout=#系统变量 group_replication_components_stop_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 31536000最低价值 2最大价值 31536000组复制在关闭时等待每个组件的超时(以秒为单位)。
-
group_replication_compression_threshold属性 值 命令行格式 --group-replication-compression-threshold=#系统变量 group_replication_compression_threshold范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1000000最低价值 0最大价值 4294967295以字节为单位的值,强制执行(LZ4)压缩。 设置为零时,停用压缩。
group_replication_compression_threshold所有组成员 的值 应该相同。 -
属性 值 命令行格式 --group-replication-consistency=value介绍 8.0.14 系统变量 group_replication_consistency范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 列举 默认值 EVENTUAL有效值 EVENTUALBEFORE_ON_PRIMARY_FAILOVERBEFOREAFTERBEFORE_AND_AFTER控制组提供的事务一致性保证。 您可以在全局或每个事务中配置一致性。 还配置单个主要组中新选择的主要使用的防护机制。 对于只读(RO)和读写(RW)事务,必须考虑变量的影响。 以下列表按增加事务一致性保证的顺序显示此变量的可能值:
-
EVENTUALRO和RW事务都不等待在执行之前应用先前的事务。 这是添加此变量之前组复制的行为。 RW事务不等待其他成员应用事务。 这意味着事务可以在其他成员之前外部化。 这也意味着在主要故障转移的情况下,新主服务器可以在先前的主要事务全部应用之前接受新的RO和RW事务。 RO事务可能导致过时的值,RW事务可能会因冲突而导致回滚。
-
BEFORE_ON_PRIMARY_FAILOVER在应用任何待办事项之前,将保留(未应用)具有从旧主要应用积压的新选择主要的新RO或RW事务。 这可确保在主要故障转移发生时,无论是否有意,客户端始终会在主服务器上看到最新值。 这保证了一致性,但意味着客户端必须能够在应用积压的情况下处理延迟。 通常这种延迟应该是最小的,但取决于积压的大小。
-
BEFORERW事务在应用之前等待所有先前的事务完成。 RO事务在执行之前等待所有先前的事务完成。 这可确保此事务仅通过影响事务的延迟来读取最新值。 通过确保仅在RO事务上使用同步,这减少了每个RW事务上的同步开销。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。 -
AFTERRW事务等待,直到其更改已应用于所有其他成员。 该值对RO交易没有影响。 此模式确保在本地成员上提交事务时,任何后续事务都会读取任何组成员的写入值或更新值。 将此模式与主要用于RO操作的组一起使用,以确保应用的RW事务在提交后随处应用。 您的应用程序可以使用它来确保后续读取获取包含最新写入的最新数据。 这减少了每个RO事务上的同步开销, 通过确保仅在RW事务上使用同步。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。 -
BEFORE_AND_AFTERRW事务等待1)所有先前的事务在应用之前完成,2)直到其更改已应用于其他成员。 RO事务在执行之前等待所有先前的事务完成。 此一致性级别还包括由提供的一致性保证
BEFORE_ON_PRIMARY_FAILOVER。
GROUP_REPLICATION_ADMIN需要 该 权限才能更改此系统变量的全局设置。 有关更多信息,请参见 第18.4.3节“事务一致性保证” 。 -
-
group_replication_enforce_update_everywhere_checks属性 值 命令行格式 --group-replication-enforce-update-everywhere-checks[={OFF|ON}]系统变量 group_replication_enforce_update_everywhere_checks范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF在所有位置启用或禁用多主数据更新的严格一致性检查。 默认情况下禁用检查。 在单主模式下,必须在所有组成员上禁用此选项。 在多主模式下,启用此选项时,将按如下方式检查语句,以确保它们与多主模式兼容:
-
如果事务在
SERIALIZABLE隔离级别 下执行 ,则在与组同步时其提交失败。 -
如果事务针对具有级联约束的外键的表执行,则在与组同步时事务无法提交。
此系统变量是组范围的配置设置。 它必须在所有组成员上具有相同的值,在组复制运行时无法更改,并且需要完全重新引导组(服务器的引导程序
group_replication_bootstrap_group=ON)才能使值更改生效。 从MySQL 8.0.16开始,您可以使用group_replication_switch_to_single_primary_mode()和group_replication_switch_to_multi_primary_mode()UDF在组仍在运行时更改此系统变量的值。 有关更多信息,请参见 第18.4.2.2节“更改组模式” 。 -
-
group_replication_exit_state_action属性 值 命令行格式 --group-replication-exit-state-action=value介绍 8.0.12 系统变量 group_replication_exit_state_action范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 (> = 8.0.12,<= 8.0.15) ABORT_SERVER默认值 READ_ONLY有效值 ABORT_SERVERREAD_ONLY配置当服务器实例无意中离开组时的组复制行为,例如在遇到应用程序错误之后,或者在失去多数时,或者由于怀疑超时而驱逐该组的其他成员时。 在失去多数的情况下成员离开组
group_replication_unreachable_majority_timeout的超时时间由group_replication_member_expel_timeout系统变量 设置,怀疑的超时时间由 系统变量 设置 。 请注意,被驱逐的组成员在重新连接到组之前不知道它被驱逐,因此仅当成员设法重新连接时,或者如果该成员对自己提出怀疑并驱逐自己时才采取指定的操作。当成员因怀疑超时或失去多数而被驱逐时,如果该成员将
group_replication_autorejoin_tries系统变量设置为指定多次自动重新加入尝试,则它在超级只读模式下首先进行指定的尝试次数,然后遵循指定的操作group_replication_exit_state_action。 如果出现应用程序错误,则不会进行自动重新加入尝试,因为这些尝试无法恢复。 有关在故障检测情况下配置成员行为的更多信息,请参见 第18.6.6节“对故障检测和网络分区的响应” 。当
group_replication_exit_state_action设置为ABORT_SERVER,如果成员无意中退出组或耗尽其自动重新加入尝试,该实例将关闭MySQL。 当系统变量被添加到MySQL 8.0.15时,此设置是MySQL 8.0.12的默认设置。当
group_replication_exit_state_action设置为READ_ONLY,如果成员无意中退出组或耗尽其自动重新加入尝试,则实例将MySQL切换到超级只读模式(通过将系统变量设置super_read_only为ON)。 此设置是引入系统变量之前MySQL 8.0版本的行为,并从MySQL 8.0.16再次成为默认设置。重要如果在成员成功加入组之前发生故障, 则不会 执行指定的退出操作 。 如果在本地配置检查期间出现故障,或者加入成员的配置与组的配置不匹配,则会出现这种情况。 在这些情况下,
super_read_only系统变量保留其原始值,服务器不会关闭MySQL。 为确保在组复制未启动时服务器无法接受更新,因此我们建议super_read_only=ON在启动时在服务器的配置文件中设置,组复制将更改为OFF在主要成员成功启动后。 当服务器配置为在服务器boot(group_replication_start_on_boot=ON) 上启动组复制时,此安全措施尤为重要 ,但在使用START GROUP_REPLICATION命令 手动 启动组复制时,此安全措施 也很有用 。如果后的构件已成功加入组中发生故障,则指定的退出动作 取 。 如果存在应用程序错误,成员被从组中驱逐,或者如果成员被设置为在无法访问多数的情况下超时,则会出现这种情况。 在这些情况下,如果
READ_ONLY是退出操作,super_read_only系统变量设置为ON,或者如果ABORT_SERVER是退出操作,则服务器关闭MySQL。表18.5组复制失败情况下的退出操作
失败的情况
组复制始于
START GROUP_REPLICATION组复制始于
group_replication_start_on_boot =ON成员未通过本地配置检查
要么
加入成员和组配置不匹配
super_read_only不变MySQL继续运行
super_read_only=ON在启动时 设置 以防止更新super_read_only不变MySQL继续运行
super_read_only=ON在启动时 设置 以防止更新(重要)成员上的Applier错误
要么
被驱逐出集团的成员
要么
无法访问的多数超时
super_read_only调成ON要么
MySQL关闭了
super_read_only调成ON要么
MySQL关闭了
-
group_replication_flow_control_applier_threshold属性 值 命令行格式 --group-replication-flow-control-applier-threshold=#系统变量 group_replication_flow_control_applier_threshold范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 25000最低价值 0最大价值 2147483647指定应用程序队列中触发流控制的等待事务数。 可以在不重置组复制的情况下更改此变量。
-
group_replication_flow_control_certifier_threshold属性 值 命令行格式 --group-replication-flow-control-certifier-threshold=#系统变量 group_replication_flow_control_certifier_threshold范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 25000最低价值 0最大价值 2147483647指定验证者队列中触发流控制的等待事务数。 可以在不重置组复制的情况下更改此变量。
-
group_replication_flow_control_hold_percent属性 值 命令行格式 --group-replication-flow-control-hold-percent=#介绍 8.0.2 系统变量 group_replication_flow_control_hold_percent范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10最低价值 0最大价值 100定义未使用的组配额的百分比,以允许流量控制下的群集赶上积压。 值为0意味着没有保留配额的任何部分来追赶工作积压。
-
group_replication_flow_control_max_commit_quota属性 值 命令行格式 --group-replication-flow-control-max-commit-quota=#介绍 8.0.2 系统变量 group_replication_flow_control_max_commit_quota范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2147483647定义组的最大流量控制配额,或启用流量控制时任何时间段的最大可用配额。 值为0表示没有设置最大配额。 不能小于
group_replication_flow_control_min_quota和group_replication_flow_control_min_recovery_quota。 -
group_replication_flow_control_member_quota_percent属性 值 命令行格式 --group-replication-flow-control-member-quota-percent=#介绍 8.0.2 系统变量 group_replication_flow_control_member_quota_percent范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 100定义在计算配额时成员应该假定的配额百分比。 值为0意味着配额应在上一期间作为作者的成员之间平均分配。
-
group_replication_flow_control_min_quota属性 值 命令行格式 --group-replication-flow-control-min-quota=#介绍 8.0.2 系统变量 group_replication_flow_control_min_quota范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2147483647控制可分配给成员的最低流量控制配额,与上一期间执行的计算最小配额无关。 值为0表示没有最小配额。 不能大于
group_replication_flow_control_max_commit_quota。 -
group_replication_flow_control_min_recovery_quota属性 值 命令行格式 --group-replication-flow-control-min-recovery-quota=#介绍 8.0.2 系统变量 group_replication_flow_control_min_recovery_quota范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2147483647控制可以分配给成员的最低配额,因为组中的另一个恢复成员,与上一个时间段中执行的计算的最小配额无关。 值为0表示没有最小配额。 不能大于
group_replication_flow_control_max_commit_quota。 -
group_replication_flow_control_mode属性 值 命令行格式 --group-replication-flow-control-mode=value系统变量 group_replication_flow_control_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 QUOTA有效值 DISABLEDQUOTA指定用于流控制的模式。 可以在不重置组复制的情况下更改此变量。
-
group_replication_flow_control_period属性 值 命令行格式 --group-replication-flow-control-period=#介绍 8.0.2 系统变量 group_replication_flow_control_period范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1最低价值 1最大价值 60定义流控制迭代之间等待的秒数,其中发送流控制消息并运行流控制管理任务。
-
group_replication_flow_control_release_percent属性 值 命令行格式 --group-replication-flow-control-release-percent=#介绍 8.0.2 系统变量 group_replication_flow_control_release_percent范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 0最大价值 1000定义当流控制不再需要限制编写器成员时应如何释放组配额,此百分比是每个流控制周期的配额增加。 值0表示一旦流量控制阈值在限制范围内,配额就会在单个流量控制迭代中释放。 该范围允许配额以当前配额的10倍释放,因为这允许更大程度的适应,主要是当流量控制周期很大且配额非常小时。
-
group_replication_force_members属性 值 命令行格式 --group-replication-force-members=value系统变量 group_replication_force_members范围 全球 动态 是 SET_VAR提示适用没有 类型 串 对等地址列表,以逗号分隔的列表,例如
host1:port1,host2:port2。 此选项用于强制新的组成员身份,其中被排除的成员不会收到新视图并被阻止。您必须在
group_replication_local_address每个成员 的 选项中 指定地址或主机名和端口 。 必须在方括号中指定IPv6地址。 例如:“198.51.100.44:33061,[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061,example.org:33061”
组复制(XCom)的组通信引擎检查提供的IP地址是否为有效格式,并检查您是否未包含当前无法访问的任何组成员。 否则,不会验证新配置,因此您必须小心只包括该组可访问成员的在线服务器。 列表中的任何不正确的值或无效的主机名都可能导致使用无效配置阻止该组。
在强制执行新成员资格配置之前,确保要排除的服务器已关闭,这一点很重要。 如果不是,请在继续之前关闭它们。 仍在线的组成员可以自动形成新配置,如果已经发生这种情况,强制进一步的新配置可能会为该组创建一个人为的裂脑情况。
使用
group_replication_force_members系统变量成功强制新的组成员身份并取消阻止该组后,请确保清除系统变量。group_replication_force_members必须为空才能发出START GROUP_REPLICATION声明。有关要遵循的过程的详细信息,请参见 第18.4.5节“网络分区” 。
-
属性 值 命令行格式 --group-replication-group-name=value系统变量 group_replication_group_name范围 全球 动态 是 SET_VAR提示适用没有 类型 串 此服务器实例所属的组的名称。 必须是有效的UUID。 在二进制日志中为组复制事件设置GTID时,将在内部使用此UUID。
重要必须使用唯一的UUID。
-
属性 值 命令行格式 --group-replication-group-seeds=value系统变量 group_replication_group_seeds范围 全球 动态 是 SET_VAR提示适用没有 类型 串 一个组成员列表,提供一个成员,该成员将该组加入加入成员所需的数据以与该组同步。 该列表由每个包含的种子成员的单个内部网络地址或主机名组成,在种子成员的
group_replication_local_address系统变量(不是种子成员的SQL主机名和端口)中配置。 种子成员的地址被指定为以逗号分隔的列表,例如host1:port1,host2:port2。 必须在方括号中指定IPv6地址。 例如:group_replication_group_seeds =“198.51.100.44:33061,[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061,example.org:33061”
请注意,在
START GROUP_REPLICATION发出语句并且组通信系统(GCS)可用 之前,不会验证为此变量指定的值 。通常此列表由该组的所有成员组成,但您可以选择组成员的子集作为种子。 该列表必须至少包含一个有效的成员地址。 启动组复制时,将验证每个地址。 如果列表不包含任何有效的成员地址,则发布
START GROUP_REPLICATION失败。当服务器加入复制组时,它会尝试连接到其中列出的第一个种子成员
group_replication_group_seeds系统变量中 。 如果连接被拒绝,则加入成员尝试按顺序连接到列表中的每个其他种子成员。 如果连接成员连接到种子成员但是因此没有添加到复制组(例如,因为种子成员在其白名单中没有加入成员的地址并关闭连接),则加入成员继续按顺序尝试列表中剩余的种子成员。加入成员必须使用种子成员在
group_replication_group_seeds选项中 通告的相同协议(IPv4或IPv6)与种子成员通信 。 出于组复制的IP地址白名单的目的,种子成员上的白名单必须包含种子成员提供的协议的加入成员的IP地址,或者解析为该协议的地址的主机名。 除了加入成员之外,还必须设置此地址或主机名并列入白名单group_replication_local_address如果该地址的协议与种子成员的通告协议不匹配。 如果加入成员没有适当协议的白名单地址,则拒绝其连接尝试。 有关更多信息,请参见 第18.5.1节“组复制IP地址白名单” 。 -
group_replication_gtid_assignment_block_size属性 值 命令行格式 --group-replication-gtid-assignment-block-size=#系统变量 group_replication_gtid_assignment_block_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1000000最低价值 1最大值 (64位平台) 9223372036854775807最大值 (32位平台) 4294967295为每个成员保留的连续GTID数。 每个成员消耗其块并在需要时储备更多。
此系统变量是组范围的配置设置。 它必须在所有组成员上具有相同的值,在组复制运行时无法更改,并且需要完全重新引导组(服务器的引导程序
group_replication_bootstrap_group=ON)才能使值更改生效。 -
group_replication_ip_whitelist属性 值 命令行格式 --group-replication-ip-whitelist=value系统变量 group_replication_ip_whitelist范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 AUTOMATIC指定允许哪些主机连接到该组。 您为每个组成员指定的地址
group_replication_local_address必须在复制组中的其他服务器上列入白名单。 请注意,在START GROUP_REPLICATION发出语句并且组通信系统(GCS)可用 之前,不会验证为此变量指定的值 。默认情况下,此系统变量设置为
AUTOMATIC,允许来自主机上活动的私有子网的连接。 组复制(XCom)的组通信引擎自动扫描主机上的活动接口,并识别具有私有子网上地址的那些接口。 这些地址和localhostIPv4 的 IP地址以及(来自MySQL 8.0.14)IPv6用于创建组复制白名单。 有关地址自动列入白名单的范围列表,请参见 第18.5.1节“组复制IP地址白名单” 。私有地址的自动白名单不能用于来自专用网络外部服务器的连接。 对于位于不同计算机上的服务器实例之间的组复制连接,您必须提供公共IP地址并将其指定为显式白名单。 如果您为白名单指定了任何条目,
localhost则不会自动添加 私有和 地址,因此如果您使用其中 任何条目,则 必须明确指定它们。作为
group_replication_ip_whitelist选项 的值 ,您可以指定以下任意组合:-
IPv4地址(例如
198.51.100.44) -
带有CIDR表示法的IPv4地址(例如
192.0.2.21/24) -
来自MySQL 8.0.14的IPv6地址(例如
2001:db8:85a3:8d3:1319:8a2e:370:7348) -
来自MySQL 8.0.14的带有CIDR表示法的IPv6地址(例如
2001:db8:85a3:8d3::/64) -
主机名(例如
example.org) -
具有CIDR表示法的主机名(例如,
www.example.com/24)
在MySQL 8.0.14之前,主机名只能解析为IPv4地址。 从MySQL 8.0.14开始,主机名可以解析为IPv4地址,IPv6地址或两者。 如果主机名同时解析为IPv4和IPv6地址,则IPv4地址始终用于组复制连接。 您可以将CIDR表示法与主机名或IP地址结合使用,将具有特定网络前缀的IP地址块列入白名单,但请确保指定子网中的所有IP地址都在您的控制之下。
逗号必须分隔白名单中的每个条目。 例如:
“192.0.2.21/24,198.51.100.44,203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348,example.org,www.example.com/24”
如果该组的任何种子成员在
group_replication_group_seeds加入成员具有IPv4时具有IPv6地址 的 选项 中列出group_replication_local_address,或者相反,则还必须为加入成员设置并列入其替代地址的白名单。种子成员(或解析为该协议地址的主机名)。 有关更多信息,请参见 第18.5.1节“组复制IP地址白名单” 。可以根据您的安全要求在不同的组成员上配置不同的白名单,例如,以便将不同的子网分开。 但是,这可能会在重新配置组时导致问题。 如果您没有特定的安全要求,请在组的所有成员上使用相同的白名单。 有关更多详细信息,请参见 第18.5.1节“组复制IP地址白名单” 。
对于主机名,仅当另一个服务器发出连接请求时才会进行名称解析。 无法解析的主机名不会被视为白名单验证,并且会向错误日志写入警告消息。 对已解析的主机名执行前向确认的反向DNS(FCrDNS)验证。
警告主机名本质上不如白名单中的IP地址安全。 FCrDNS验证提供了良好的保护级别,但可能会受到某些类型的攻击的影响。 仅在严格必要时指定白名单中的主机名,并确保用于名称解析的所有组件(如DNS服务器)都在您的控制之下。 您还可以使用hosts文件在本地实现名称解析,以避免使用外部组件。
-
-
group_replication_local_address属性 值 命令行格式 --group-replication-local-address=value系统变量 group_replication_local_address范围 全球 动态 是 SET_VAR提示适用没有 类型 串 成员为其他成员的连接提供的网络地址,指定为
host:port格式化字符串。 该组的所有成员必须可以访问此地址,因为组通信引擎将组地复制(XCom,Paxos变体)用于远程XCom实例之间的TCP通信。 使用共享内存通过输入通道与本地实例进行通信。警告请勿使用此地址与会员进行通信。 这不是MySQL服务器SQL协议主机和端口。
您指定的地址或主机名
group_replication_local_address由Group Replication用作复制组中组成员的唯一标识符。 只要主机名或IP地址都不同,就可以为复制组的所有成员使用相同的端口,只要端口全部不同,就可以对所有成员使用相同的主机名或IP地址。 建议的端口为group_replication_local_address33061.请注意,在START GROUP_REPLICATION发出语句并且组通信系统(GCS)可用 之前,不会验证为此变量指定的值 。配置的网络地址
group_replication_local_address必须可由所有组成员解析。 例如,如果每个服务器实例位于具有固定网络地址的其他计算机上,则可以使用计算机的IP地址,例如10.0.0.1。 如果使用主机名,则必须使用完全限定名称,并确保它可通过DNS,正确配置的/etc/hosts文件或其他名称解析过程进行解析。 从MySQL 8.0.14开始,可以使用IPv6地址(或解析它们的主机名)以及IPv4地址。 必须在方括号中指定IPv6地址才能区分端口号,例如:group_replication_local_address =“[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061”
如果指定为服务器实例的组复制本地地址的主机名解析为IPv4和IPv6地址,则IPv4地址始终用于组复制连接。 有关IPv6网络的组复制支持以及使用IPv4和使用IPv6的成员的混合成员的复制组的更多信息,请参见 第18.4.6节“支持IPv6和混合IPv6和IPv4组” 。
对于组复制的IP地址白名单,
group_replication_local_address必须 将为每个组成员指定的地址 添加到group_replication_ip_whitelist复制组中其他服务器上的选项 列表中 。 如果group_replication_group_seeds该成员具有IPv4时具有IPv6地址 的 选项 中列出了该组的任何种子成员group_replication_local_address,或者相反,则还必须为该成员设置备用地址并将其列入白名单以用于所需协议(或主机)解析为该协议地址的名称。 有关更多信息,请参见 第18.5.1节“组复制IP地址白名单” 。 -
group_replication_member_weight属性 值 命令行格式 --group-replication-member-weight=#介绍 8.0.2 系统变量 group_replication_member_weight范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 0最大价值 100可以分配给成员的百分比权重,以影响成员在发生故障转移时被选为主要成员的可能性,例如当现有主要成员离开单一主要组时。 为成员分配数字权重以确保选择特定成员,例如在主数据库的计划维护期间,或确保在发生故障转移时优先考虑某些硬件。
对于成员配置如下的组:
-
member-1:group_replication_member_weight = 30,server_uuid = aaaa -
member-2:group_replication_member_weight = 40,server_uuid = bbbb -
member-3:group_replication_member_weight = 40,server_uuid = cccc -
member-4:group_replication_member_weight = 40,server_uuid = dddd
新主的选举中的构件上方将被分类为
member-2,member-3,member-4,和member-1。 这导致在member故障转移时-2被选为新的主要。 有关更多信息,请参见 第18.4.1.1节“单主模式” 。 -
-
group_replication_member_expel_timeout属性 值 命令行格式 --group-replication-member-expel-timeout=#介绍 8.0.13 系统变量 group_replication_member_expel_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大值 (> = 8.0.14) 3600最大值 (<= 8.0.13) 31536000组复制组成员在从怀疑失败的成员的组中驱逐之后等待创建怀疑之后等待的时间段(以秒为单位)。 创建怀疑之前的最初5秒检测周期不计入此时间的一部分。 更改
group_replication_member_expel_timeout组成员 的值 会立即生效,以便对该组成员的现有怀疑和将来怀疑。 组中的所有成员不必具有相同的设置,但建议为避免意外驱逐。当其他成员怀疑它(或其自身的怀疑)超时时,团体成员被驱逐出境。 默认情况下,
group_replication_member_expel_timeout设置为0,表示没有等待期,并且可疑成员在5秒检测期结束后立即负责驱逐。 在排出机构检测并实施排出之前可能需要额外的短时间。 如果组成员处于不支持此设置的较旧MySQL服务器版本,则这是对其他成员或其自身的行为。为避免在较慢的网络上进行不必要的驱逐,或者在预期的瞬时网络故障或机器速度降低的情况下,您可以指定大于零的超时值,最长为3600秒(1小时)。 如果可疑成员在怀疑超时之前再次变为活动状态,则它将重新加入该组,应用由其余组成员缓冲的所有消息,并进入
ONLINE状态。 否则,在怀疑超时后立即开除。 有关避免在此系统变量不可用时进行不必要的驱逐的替代缓解策略,请参见 第18.9.2节“组复制限制” 。驱逐成员之前的等待期仅适用于之前在该组中有效的成员。 从未在该组中活动的非成员不会等待这段时间,并且在初始检测期后被删除,因为他们花了太长时间才加入。
驱逐成员时,如果
group_replication_autorejoin_tries系统变量设置为指定多次自动重新加入尝试,则会在超级只读模式下继续进行指定的尝试次数重新加入组。 如果成员没有指定任何自动重新加入尝试,或者它已经用尽指定的尝试次数,则它遵循系统变量指定的操作group_replication_exit_state_action,该操作可以保持在线但处于超级只读模式,或者关闭MySQL的。 有关使用这些选项在故障检测情况下配置成员行为的更多信息,请参见 第18.6.6节“对故障检测和网络分区的响应” 。如果组中的任何成员目前处于怀疑状态,则无法重新配置组成员身份(通过添加或删除成员或选择新的领导者)。 如果在一个或多个成员受到怀疑时需要实施组成员身份更改,并且您希望可疑成员保留在组中,请采取任何必要的操作以使成员再次处于活动状态(如果可能)。 如果你不能让成员再次活跃并且你希望他们被驱逐出小组,你可以强迫怀疑立即超时。 通过改变值来做到这一点
group_replication_member_expel_timeout在任何活动成员上,其值低于自创建怀疑以来已经过去的时间。 然后,嫌疑人立即承担驱逐责任。 -
group_replication_message_cache_size属性 值 命令行格式 --group-replication-message-cache-size=#介绍 8.0.16 系统变量 group_replication_message_cache_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1073741824 (1 GB)最低价值 1073741824 (1 GB)最大值 (64位平台) 18446744073709551615 (16 EiB)最大值 (32位平台) 315360004294967295 (4 GB)组复制(XCom)的组通信引擎中可用于消息高速缓存的最大内存量,它保存作为共识协议一部分在组成员之间交换的消息(及其元数据)。 在其他功能中,消息缓存用于在无法与其他组成员通信的时间段之后返回到该组的成员进行恢复。 该
group_replication_member_expel_timeoutsystem变量确定允许成员返回组而不是被驱逐的时间(最多一小时)。 应该参考此时间段内预期的消息量来设置消息缓存的大小,以便它包含成员成功返回所需的所有错过的消息。group_replication_message_cache_size默认和最小设置为1073741824字节(1 GB)。 应在所有组成员上设置相同的高速缓存大小限制,因为尝试重新连接的无法访问的成员随机选择任何其他成员以恢复丢失的消息。 考虑到MySQL Server的其他缓存和对象池的大小,确保系统上有足够的内存用于所选的缓存大小限制。可以在运行时动态增加或减少高速缓存大小限制。 如果减小缓存大小限制,XCom将删除已确定并交付的最旧条目,直到当前大小低于限制。 组复制的组通信系统(GCS)通过警告消息警告您何时从消息缓存中删除当前无法访问的成员可能需要恢复的消息。 有关调整消息高速缓存大小的更多信息,请参见 第18.6.5节“XCom高速缓存管理” 。
-
group_replication_poll_spin_loops属性 值 命令行格式 --group-replication-poll-spin-loops=#系统变量 group_replication_poll_spin_loops范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295组线程通信线程在线程等待更多传入网络消息之前等待通信引擎互斥锁被释放的次数。
-
group_replication_recovery_complete_at属性 值 命令行格式 --group-replication-recovery-complete-at=value系统变量 group_replication_recovery_complete_at范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 TRANSACTIONS_APPLIED有效值 TRANSACTIONS_CERTIFIEDTRANSACTIONS_APPLIED在状态转移后处理缓存事务时的恢复策略。 此选项指定成员在收到所有在加入组(
TRANSACTIONS_CERTIFIED)之前或在收到并应用它们(TRANSACTIONS_APPLIED) 之后 错过的所有事务后是否在线标记 。 -
group_replication_recovery_get_public_key属性 值 命令行格式 --group-replication-recovery-get-public-key[={OFF|ON}]介绍 8.0.4 系统变量 group_replication_recovery_get_public_key范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF是否向主服务器请求基于RSA密钥对的密码交换所需的公钥。 此变量适用于使用
caching_sha2_password身份验证插件 进行 身份验证的 从属 服务器。 对于该插件,除非请求,否则主服务器不会发送公钥。如果
group_replication_recovery_public_key_path设置为有效的公钥文件,则优先于group_replication_recovery_get_public_key。 -
group_replication_recovery_public_key_path属性 值 命令行格式 --group-replication-recovery-public-key-path=file_name介绍 8.0.4 系统变量 group_replication_recovery_public_key_path范围 全球 动态 是 SET_VAR提示适用没有 类型 文件名 默认值 NULL包含主服务器所需的公钥的从属端副本的文件的路径名,用于基于RSA密钥对的密码交换。 该文件必须采用PEM格式。 此变量适用于使用
sha256_password或caching_sha2_password身份验证插件进行 身份验证的从属 服务器。 (因为sha256_password,group_replication_recovery_public_key_path只有在使用OpenSSL构建MySQL时才适用。)如果
group_replication_recovery_public_key_path设置为有效的公钥文件,则优先于group_replication_recovery_get_public_key。 -
group_replication_recovery_reconnect_interval属性 值 命令行格式 --group-replication-recovery-reconnect-interval=#系统变量 group_replication_recovery_reconnect_interval范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 60最低价值 0最大价值 31536000重新连接尝试之间的休眠时间(以秒为单位),当组中没有发现捐赠者时。
-
group_replication_recovery_retry_count属性 值 命令行格式 --group-replication-recovery-retry-count=#系统变量 group_replication_recovery_retry_count范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10最低价值 0最大价值 31536000在放弃之前,加入的成员尝试连接到可用捐赠者的次数。
-
group_replication_recovery_ssl_ca属性 值 命令行格式 --group-replication-recovery-ssl-ca=value系统变量 group_replication_recovery_ssl_ca范围 全球 动态 是 SET_VAR提示适用没有 类型 串 包含受信任SSL证书颁发机构列表的文件的路径。
-
group_replication_recovery_ssl_capath属性 值 命令行格式 --group-replication-recovery-ssl-capath=value系统变量 group_replication_recovery_ssl_capath范围 全球 动态 是 SET_VAR提示适用没有 类型 串 包含受信任的SSL证书颁发机构证书的目录的路径。
-
group_replication_recovery_ssl_cert属性 值 命令行格式 --group-replication-recovery-ssl-cert=value系统变量 group_replication_recovery_ssl_cert范围 全球 动态 是 SET_VAR提示适用没有 类型 串 用于建立安全连接的SSL证书文件的名称。
-
group_replication_recovery_ssl_cipher属性 值 命令行格式 --group-replication-recovery-ssl-cipher=value系统变量 group_replication_recovery_ssl_cipher范围 全球 动态 是 SET_VAR提示适用没有 类型 串 SSL加密的允许密码列表。
-
group_replication_recovery_ssl_crl属性 值 命令行格式 --group-replication-recovery-ssl-crl=value系统变量 group_replication_recovery_ssl_crl范围 全球 动态 是 SET_VAR提示适用没有 类型 文件名 包含证书吊销列表的文件的目录路径。
-
group_replication_recovery_ssl_crlpath属性 值 命令行格式 --group-replication-recovery-ssl-crlpath=value系统变量 group_replication_recovery_ssl_crlpath范围 全球 动态 是 SET_VAR提示适用没有 类型 目录名称 包含证书吊销列表的文件的目录路径。
-
group_replication_recovery_ssl_key属性 值 命令行格式 --group-replication-recovery-ssl-key=value系统变量 group_replication_recovery_ssl_key范围 全球 动态 是 SET_VAR提示适用没有 类型 串 用于建立安全连接的SSL密钥文件的名称。
-
group_replication_recovery_ssl_verify_server_cert属性 值 命令行格式 --group-replication-recovery-ssl-verify-server-cert[={OFF|ON}]系统变量 group_replication_recovery_ssl_verify_server_cert范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF使恢复过程检查捐赠者发送的证书中的服务器的Common Name值。
-
group_replication_recovery_use_ssl属性 值 命令行格式 --group-replication-recovery-use-ssl[={OFF|ON}]系统变量 group_replication_recovery_use_ssl范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF组复制恢复连接是否应使用SSL。
-
group_replication_single_primary_mode属性 值 命令行格式 --group-replication-single-primary-mode[={OFF|ON}]系统变量 group_replication_single_primary_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指示组自动选择单个服务器作为处理读/写工作负载的服务器。 此服务器是主服务器,所有其他服务器都是SECONDARIES。
此系统变量是组范围的配置设置。 它必须在所有组成员上具有相同的值,在组复制运行时无法更改,并且需要完全重新引导组(服务器的引导程序
group_replication_bootstrap_group=ON)才能使值更改生效。 从MySQL 8.0.16开始,您可以使用group_replication_switch_to_single_primary_mode()和group_replication_switch_to_multi_primary_mode()UDF在组仍在运行时更改此系统变量的值。 有关更多信息,请参见 第18.4.2.2节“更改组模式” 。 -
属性 值 命令行格式 --group-replication-ssl-mode=value系统变量 group_replication_ssl_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 DISABLED有效值 DISABLEDREQUIREDVERIFY_CAVERIFY_IDENTITY指定组复制成员之间的连接的安全状态。
-
group_replication_start_on_boot属性 值 命令行格式 --group-replication-start-on-boot[={OFF|ON}]系统变量 group_replication_start_on_boot范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON服务器启动期间服务器是否应启动组复制。
-
group_replication_transaction_size_limit属性 值 命令行格式 --group-replication-transaction-size-limit=#系统变量 group_replication_transaction_size_limit范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.2) 150000000默认值 (<= 8.0.1) 0最低价值 0最大价值 2147483647配置复制组接受的最大事务大小(以字节为单位)。 大于此大小的事务将由接收成员回滚,并且不会广播给该组。 大型事务可能导致复制组在内存分配方面出现问题,这可能导致系统速度变慢,或者在网络带宽消耗方面,这可能导致成员被怀疑失败,因为它忙于处理大型交易。
当此系统变量设置为0时,组接受的事务大小没有限制。 从MySQL 8.0开始,此系统变量的默认设置为150000000字节(大约143 MB)。 根据组所需的最大消息大小调整此系统变量的值,请记住处理事务所花费的时间与其大小成正比。
group_replication_transaction_size_limit所有组成员 的值 应该相同。 有关大型事务的进一步缓解策略,请参见 第18.9.2节“组复制限制” 。 -
group_replication_unreachable_majority_timeout属性 值 命令行格式 --group-replication-unreachable-majority-timeout=#介绍 8.0.2 系统变量 group_replication_unreachable_majority_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 31536000配置遭受网络分区且无法连接到多数成员的成员在离开组之前等待多长时间。
在一组5个服务器(S1,S2,S3,S4,S5)中,如果在(S1,S2)和(S3,S4,S5)之间存在断开,则存在网络分区。 第一组(S1,S2)现在属于少数,因为它不能接触超过一半的组。 当多数组(S3,S4,S5)保持运行时,少数组等待网络重新连接的指定时间。 少数组处理的任何事务都将被阻止,直到使用
STOP GROUP REPLICATION少数成员 停止使用组复制 。 注意,group_replication_unreachable_majority_timeout如果在检测到多数丢失后在少数群组中的服务器上设置了它,则无效。默认情况下,此系统变量设置为0,这意味着由于网络分区而发现自己处于少数状态的成员将永远等待离开该组。 如果配置为秒数,则成员在离开组之前与大多数成员失去联系后会等待这段时间。 当指定的时间过去后,少数人处理的所有待处理事务都将回滚,少数分区中的服务器将进入ERROR状态。 如果一个成员有
group_replication_autorejoin_tries系统变量设置为指定自动重新加入尝试的次数,它继续在超级只读模式下进行指定的尝试次数以重新加入组。 如果成员没有指定任何自动重新加入尝试,或者它已经耗尽了指定的尝试次数,则它遵循系统变量指定的操作group_replication_exit_state_action,该操作可以保持超级只读模式或关闭MySQL。 有关使用这些选项在故障检测情况下配置成员行为的更多信息,请参见 第18.6.6节“对故障检测和网络分区的响应” 。警告当你有一个对称组时,例如只有两个成员(S0,S2),如果有一个网络分区并且没有多数,则在配置的超时后,所有成员都进入
ERROR状态。
本节介绍提供有关组复制信息的状态变量。 该变量具有以下含义:
-
group_replication_primary_member当组以单主模式运行时,显示主要成员的UUID。 如果该组在多主模式下运行,则显示空字符串。
警告该
group_replication_primary_member状态变量已被弃用,并计划在未来的版本中被删除。请参见 第18.4.1.3节“查找主要内容” 。
本节列出并说明了组复制的要求和限制。
要用于组复制的服务器实例必须满足以下要求。
-
InnoDB存储引擎。 数据必须存储在
InnoDB事务存储引擎中。 事务以乐观方式执行,然后在提交时检查冲突。 如果存在冲突,为了保持整个组的一致性,将回滚一些事务。 这意味着需要事务存储引擎。 此外,InnoDB还提供了一些附加功能,可以在与Group Replication一起操作时更好地管理和处理冲突。 使用其他存储引擎,包括临时存储引擎MEMORY存储引擎,可能会导致组复制错误。 您可以通过disabled_storage_engines在组成员上 设置 系统变量 来阻止使用其他存储引擎 ,例如:disabled_storage_engines = “的MyISAM,BLACKHOLE,FEDERATED,归档,MEMORY”
-
主键。 要由组复制的每个表必须具有已定义的主键或等效的主键,其中等效项是非null唯一键。 这些密钥作为表中每一行的唯一标识符是必需的,使系统能够通过准确识别每个事务已修改的行来确定哪些事务冲突。
-
网络性能。 MySQL Group Replication旨在部署在服务器实例彼此非常接近的集群环境中。 网络延迟和网络带宽都会影响组的性能和稳定性。 所有小组成员之间必须始终保持双向通信。 如果阻止服务器实例的入站或出站通信(例如,通过防火墙或连接问题),则该成员无法在该组中运行,并且组成员(包括有问题的成员)可能无法报告受影响的服务器实例的正确成员状态。
从MySQL 8.0.14开始,您可以使用IPv4或IPv6网络基础结构,或两者的混合,用于远程组复制服务器之间的TCP通信。 也没有什么能阻止Group Replication在虚拟专用网络(VPN)上运行。
同样来自MySQL 8.0.14,其中组复制服务器实例位于同一位置并共享本地组通信引擎(XCom)实例,具有较低开销的专用输入通道用于可能的通信而不是TCP套接字。 对于需要在远程XCom实例之间进行通信的某些组复制任务(例如加入组),仍然使用TCP网络,因此网络性能会影响组的性能。
必须在作为组成员的服务器实例上配置以下选项。
-
二进制日志激活。 设置
--log-bin[=log_file_name]。 MySQL Group Replication复制二进制日志内容,因此二进制日志需要打开才能运行。 默认情况下启用此选项。 请参见 第5.4.4节“二进制日志” 。 -
已记录从属更新。 设置
--log-slave-updates。 服务器需要记录通过复制应用程序应用的二进制日志。 组中的服务器需要记录他们收到的所有事务并从组中应用。 这是必需的,因为恢复是通过依赖组中的参与者的二进制日志来进行的。 因此,每个事务的副本都需要存在于每个服务器上,即使对于那些未在服务器本身上启动的事务也是如此。 默认情况下启用此选项。 -
二进制日志行格式。 设置
--binlog-format=row。 组复制依赖于基于行的复制格式,以在组中的服务器之间一致地传播更改。 它依赖于基于行的基础结构来提取必要的信息,以检测在组中的不同服务器中并发执行的事务之间的冲突。 请参见 第17.2.1节“复制格式” 。 -
二进制日志校验和关闭。 设置
--binlog-checksum=NONE。 由于复制事件校验和的设计限制,组复制无法使用它们,因此必须禁用它们。 -
全局交易标识符。 设置
--gtid-mode=ON。 组复制使用全局事务标识符来准确跟踪在每个服务器实例上已提交的事务,从而能够推断哪些服务器执行的事务可能与其他地方已提交的事务冲突。 换句话说,显式事务标识符是框架的基本部分,以便能够确定哪些事务可能发生冲突。 请参见 第17.1.3节“使用全局事务标识符复制” 。 -
复制信息存储库。 设置
--master-info-repository=TABLE和--relay-log-info-repository=TABLE。 复制应用程序需要将主信息和中继日志元数据写入 系统表mysql.slave_master_info和mysql.slave_relay_log_info系统表。 这可确保组复制插件具有一致的可复制性和复制元数据的事务管理。 从MySQL 8.0.2开始,这些选项TABLE默认 设置为 ,并且从MySQL 8.0.3开始,FILE不推荐使用 该 设置。 请参见 第17.2.4.2节“从站状态日志” 。 -
事务写集提取。 设置
--transaction-write-set-extraction=XXHASH64为在收集行以将其记录到二进制日志时,服务器也会收集写入集。 写集基于每行的主键,是标记的简化紧凑视图,唯一标识已更改的行。 然后,此标记用于检测冲突。 默认情况下启用此选项。 -
多线程应用程序。 组复制成员可以配置为多线程从属,从而可以并行应用事务。 非零值用于
slave_parallel_workers启用成员上的多线程应用程序,并且可以指定多达1024个并行应用程序线程。 设置slave_preserve_commit_order=1确保并行事务的最终提交与原始事务的顺序相同,这是组复制所需的,它依赖于围绕所有参与成员以相同顺序接收和应用已提交事务的保证构建的一致性机制。 最后,设置slave_parallel_type=LOGICAL_CLOCK,指定用于决定允许哪些事务在从服务器上并行执行的策略slave_preserve_commit_order=1。 设置slave_parallel_workers=0禁用并行执行,并为从属设备提供单个应用程序线程,并且没有协调器线程。 使用该设置,slave_parallel_type和slave_preserve_commit_order选项无效并被忽略。
组复制存在以下已知限制。 请注意,针对多主模式组所描述的限制和问题也可以在故障转移事件期间应用于单主模式群集,而新选择的主数据库则从旧主数据库中刷新其应用程序队列。
组复制基于基于GTID的复制,因此您还应了解 第17.1.3.6节“使用GTID进行复制的限制” 。
-
--upgrade=MINIMAL选项。 使用MINIMAL选项(--upgrade=MINIMAL) 的MySQL服务器升级后,无法启动组复制,该选项 不会升级复制内部所依赖的系统表。 -
差距锁定。 认证过程没有考虑 间隙锁定 ,因为在外面没有关于间隙锁定的信息
InnoDB。 有关 详细信息, 请参阅 Gap Locks 。注意除非您依赖
REPEATABLE READ应用程序中的语义, 否则 我们建议将READ COMMITTED隔离级别与Group Replication一起使用。 InnoDB不使用间隙锁定READ COMMITTED,它将InnoDB中的本地冲突检测与Group Replication执行的分布式冲突检测对齐。 -
表锁和命名锁。 认证过程不考虑表锁(请参见 第13.3.6节“LOCK TABLES和UNLOCK TABLES语法” )或命名锁(请 参阅 参考资料
GET_LOCK())。 -
复制事件校验和。 由于复制事件校验和的设计限制,组复制当前无法使用它们。 因此设定
--binlog-checksum=NONE。 -
可串行隔离级别。
SERIALIZABLE默认情况下,多主组不支持隔离级别。 设置事务隔离级别以SERIALIZABLE将组复制配置为拒绝提交事务。 -
并发DDL与DML操作。 使用多主模式时,不支持针对同一对象但在不同服务器上执行的并发数据定义语句和数据操作语句。 在对象上执行数据定义语言(DDL)语句期间,在同一对象上但在不同服务器实例上执行并发数据操作语言(DML)存在在未检测到的不同实例上执行DDL冲突的风险。
-
具有级联约束的外键。 多主模式组(所有配置的成员
group_replication_single_primary_mode=OFF)不支持具有多级外键依赖关系的表,特别是具有已定义CASCADING外键约束的表 。 这是因为导致多主模式组执行级联操作的外键约束可能导致未检测到的冲突,并导致组成员之间的数据不一致。 因此,我们建议设置group_replication_enforce_update_everywhere_checks=ON多主模式组中使用的服务器实例,以避免未检测到的冲突。在单主模式下,这不是问题,因为它不允许并发写入组的多个成员,因此不存在未检测到的冲突的风险。
-
多主模式死锁。 当组以多主模式运行时,
SELECT .. FOR UPDATE语句可能导致死锁。 这是因为锁不在组的成员之间共享,因此可能无法达到对此类语句的期望。 -
复制过滤器。 全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。 -
加密连接。 MySQL服务器自MySQL 8.0.16起可以支持TLSv1.3协议,并且需要使用OpenSSL 1.1.1或更高版本编译MySQL。 组复制当前不支持TLSv1.3,如果使用此支持编译服务器,则在组通信引擎中明确禁用它。
如果单个事务导致消息内容足够大,以至于在5秒钟窗口内无法通过网络在组成员之间复制消息,则可能会怀疑成员失败,然后被驱逐,因为他们正忙于处理交易。 由于内存分配问题,大型事务也可能导致系统速度变慢。 要避免这些问题,请使用以下缓解措施:
-
如果由于大消息而发生不必要的驱逐,请使用系统变量
group_replication_member_expel_timeout以允许在怀疑失败的成员被驱逐之前有额外的时间。 在可疑成员被驱逐出组之前,您可以在最初的5秒检测期后最多一个小时。 -
在可能的情况下,尝试在Group Replication处理事务之前限制事务的大小。 例如,将使用的文件拆分
LOAD DATA为较小的块。 -
使用系统变量
group_replication_transaction_size_limit指定组将接受的最大事务大小。 在MySQL 8.0中,此系统变量默认为最大事务大小为150000000字节(大约143 MB)。 超过此大小的事务将回滚,不会发送到Group Replication的组通信系统(GCS)以分发给该组。 根据组需要容忍的最大消息大小调整此变量的值,请记住处理事务所花费的时间与其大小成正比。 -
使用系统变量
group_replication_compression_threshold指定应用压缩的消息大小。 此系统变量默认为1000000字节(1 MB),因此会自动压缩大型消息。 压缩由Group Replication的组通信系统(GCS)在收到group_replication_transaction_size_limit设置 允许 但超出group_replication_compression_threshold设置的消息时执行。 有关更多信息,请参见 第18.6.3节“消息压缩” 。 -
使用系统变量
group_replication_communication_max_message_size指定消息大小,消息在该消息大小上进行分段。 此系统变量默认为10485760字节(10 MiB),因此大型消息会自动分段。 如果压缩消息仍然超出group_replication_communication_max_message_size限制, GCS会在压缩后执行碎片 。 为了使复制组使用碎片,所有组成员必须处于MySQL 8.0.16或更高版本,并且组使用的组复制通信协议版本必须允许碎片。 有关更多信息,请参见 第18.6.4节“消息碎片” 。
通过为相关系统变量指定零值,可以停用最大事务大小,消息压缩和消息碎片。
如果您已停用所有这些安全措施,则复制组成员上的应用程序线程可以处理的消息的大小上限是该成员的值
slave_max_allowed_packet
系统变量,其默认值和最大值为1073741824字节(1 GB)。
当接收成员尝试处理它时,超过此限制的消息将失败。
组成员可以发起并尝试传输到组的消息的大小上限是4294967295字节(大约4 GB)。
这是组通信引擎为组复制(XCom,Paxos变体)接受的数据包大小的硬限制,它在GCS处理后接收消息。
当原始成员尝试广播它时,超过此限制的消息将失败。
本节提供常见问题的解答。
一个组最多可包含9个服务器。 尝试将另一台服务器添加到具有9个成员的组中会导致拒绝加入请求。 此限制已经从测试和基准测试中确定为安全边界,其中该组在稳定的局域网上可靠地执行。
组中的服务器通过打开对等TCP连接连接到组中的其他服务器。
这些连接仅用于组内服务器之间的内部通信和消息传递。
该地址由
group_replication_local_address
变量
配置
。
引导标志指示成员 创建 组并充当初始种子服务器。 加入组的第二个成员需要询问引导该组的成员动态更改配置,以便将其添加到组中。
成员需要在两种情况下引导该组。 最初创建组时,或关闭并重新启动整个组时。
您可以使用该
CHANGE
MASTER
TO
语句
预配置组复制恢复通道凭据
。
不是直接的,但是MySQL Group复制是一种无共享的完整复制解决方案,其中组中的所有服务器都复制相同数量的数据。 因此,如果组中的一个成员将N个字节写入存储器作为事务提交操作的结果,那么大约N个字节也会写入其他成员的存储器,因为事务在任何地方都被复制。
但是,考虑到其他成员在最初执行事务时不必执行原始成员必须执行的相同处理量,他们会更快地应用更改。 事务以仅用于应用行转换的格式进行复制,而不必再次重新执行事务(基于行的格式)。
此外,假设更改以基于行的格式传播和应用,这意味着它们以优化且紧凑的格式接收,并且可能减少与原始成员相比所需的IO操作的数量。
总而言之,您可以通过在组中的不同成员之间传播无冲突的事务来横向扩展处理。 而且,您可以扩展掉一小部分IO操作,因为远程服务器只接受对稳定存储的读 - 修改 - 写更改所需的必要更改。
预计会有一些额外的负载,因为服务器需要不断地相互交互以实现同步。 很难量化多少数据。 它还取决于组的大小(三个服务器对带宽要求的压力要小于组中的九个服务器)。
此外,内存和CPU占用空间也更大,因为服务器同步部分和组消息传递的工作更复杂。
是的,但每个成员之间的网络连接 必须 可靠且具有合适的性能。 低延迟,高带宽网络连接是获得最佳性能的必要条件。
如果仅存在网络带宽问题,则 可以使用 第18.6.3节“消息压缩” 来降低所需的带宽。 但是,如果网络丢弃数据包,导致重新传输和更高的端到端延迟,则吞吐量和延迟都会受到负面影响。
当任何组成员之间的网络往返时间(RTT)为5秒或更长时,您可能会遇到问题,因为可能会错误地触发内置故障检测机制。
这取决于连接问题的原因。 如果连接问题是暂时的并且重新连接足够快以至于故障检测器不知道它,则可能不会从组中移除服务器。 如果它是“长”连接问题,那么故障检测器最终会怀疑问题并且服务器从组中移除。
从MySQL 8.0开始,您可以激活两个设置以增加成员保留或重新加入组的机会:
-
group_replication_member_expel_timeout增加产生怀疑(在最初的5秒检测期后发生)和驱逐会员之间的时间。 您可以设置最长1小时的等待时间。 -
group_replication_autorejoin_tries使成员尝试在驱逐或无法达到的多数超时后重新加入该组。 该成员使指定数量的自动重新加入尝试间隔五分钟。
如果服务器被驱逐出组并且任何自动重新加入尝试都没有成功,则需要再次将其加入。 换句话说,在从组中显式删除服务器之后,您需要手动重新加入它(或者让脚本自动执行)。
如果成员变为静默,则其他成员将其从组配置中删除。 实际上,当成员崩溃或网络断开时,可能会发生这种情况。
在给定成员的给定超时过去之后检测到故障,并且创建没有静默成员的新配置。
没有方法可以定义何时从组中自动驱逐成员的策略。 您需要找出成员滞后的原因并修复该成员或从该组中删除该成员。 否则,如果服务器太慢而无法触发流量控制,那么整个组也会减慢速度。 可以根据您的需要配置流量控制。
不,组中没有负责触发重新配置的特殊成员。
任何成员都可以怀疑存在问题。 所有成员都需要(自动)同意某个成员失败。 一名成员负责通过触发重新配置将其从组中驱逐出去。 哪个成员负责驱逐该成员不是您可以控制或设置的。
组复制旨在提供高可用性副本集; 数据和写入在组中的每个成员上都是重复的。 要扩展超出单个系统可提供的范围,您需要围绕许多组复制集构建的编排和分片框架,其中每个副本集都维护和管理整个数据集的给定分片或分区。 这种类型的设置(通常称为 “分片 群集 ” )允许您无限制地线性扩展读取和写入。
如果启用了SELinux,您可以使用
sestatus -v
进行验证
,那么您需要启用
group_replication_local_address
对
mysqld
配置的组复制通信端口,
以便它可以绑定到它并在那里监听。
要查看当前允许MySQL使用哪些端口,请发出
semanage port -l |
grep mysqld
。
假设配置的端口是33061,请通过发出
semanage port -a -t mysqld_port_t -p tcp 33061
将必要的端口添加到SELinux允许的
端口
。
如果 启用了 iptables ,则需要打开组复制端口以在计算机之间进行通信。 要查看每台计算机上的当前规则,请发出 iptables -L 。 假设配置的端口是33061,通过发出 iptables -A INPUT -p tcp -dport 33061 -j ACCEPT来 启用必要端口上的通信 。
组复制使用的复制通道的行为方式与主从复制中使用的复制通道的行为方式相同,因此依赖于中继日志。
如果更改了
relay_log
变量,或者未设置选项且主机名更改,则可能会出错。
有关
此情况下的恢复过程,
请参见
第17.2.4.1节“从属中继日志”
。
或者,另一种在Group Replication中专门解决问题的方法是发出一个
STOP GROUP_REPLICATION
语句,然后
发出
一个
START GROUP_REPLICATION
语句来重新启动实例。
Group Replication插件
group_replication_applier
再次
创建
频道。
组复制使用两个绑定地址,以便在客户端用于与成员通信的SQL地址和
group_replication_local_address
组成员内部用于
通信的SQL地址之间拆分网络流量
。
例如,假设一个服务器具有分配给网络地址
203.0.113.1
和的
两个网络接口
198.51.100.179
。
在这种情况下,您可以
203.0.113.1:33061
通过设置用于内部组网络地址
group_replication_local_address=203.0.113.1:33061
。
然后你可以使用
198.51.100.179
for
hostname
和
3306
for
port
。
然后,客户端SQL应用程序将连接到该成员
198.51.100.179:3306
。
这使您可以在不同的网络上配置不同的规则。
类似地,内部组通信可以与用于客户端应用程序的网络连接分开,以提高安全性。
组复制使用成员之间的网络连接,因此其功能直接受配置主机名和端口的影响。
例如,组复制恢复过程基于使用服务器主机名和端口的异步复制。
当成员加入组时,它使用列出的网络地址信息接收组成员资格信息
performance_schema.replication_group_members
。
选择该表中列出的成员之一作为从该组到新成员的缺失数据的捐赠者。
这意味着您使用主机名配置的任何值(例如SQL网络地址或组种子地址)必须是完全限定名称,并且可由组中的每个成员解析。
您可以通过DNS,或正确配置的
/etc/hosts
文件或其他本地进程
来确保这一点
。
如果要
MEMBER_HOST
在服务器上
配置该
值,请在将其
--report-host
加入组之前
使用
服务器上的选项
指定
该
值
。
指定的值直接使用,不受
--skip-name-resolve
选项的
影响
。
要
MEMBER_PORT
在服务器上进行配置,请使用该
--report-port
选项
指定它
。
在服务器上启动组复制时,值
auto_increment_increment
将更改为值
group_replication_auto_increment_increment
,默认值为7,值
auto_increment_offset
更改为服务器ID。
停止组复制时,将还原更改。
这些设置可避免为组成员上的写入选择重复的自动增量值,从而导致事务回滚。
组复制的默认自动增量值7表示可用值的数量与复制组的允许的最大大小(9个成员)之间的平衡。
仅当进行更改
auto_increment_increment
并且
auto_increment_offset
每个
更改
的默认值为1时
,才会进行更改
。如果已从默认值修改其值,则组复制不会更改它们。
从MySQL 8.0开始,当组复制处于单主模式时,系统变量也不会被修改,其中只有一个服务器写入。
如果该组在单主模式下运行,那么找出哪个成员是主要成员会很有用。 请参见 第18.4.1.3节“查找主要内容”
本节提供有关MySQL Group Replication的更多技术细节。
MySQL Group Replication是一个MySQL插件,它基于现有的MySQL复制基础架构,利用二进制日志,基于行的日志记录和全局事务标识符等功能。 它集成了当前的MySQL框架,例如性能模式或插件和服务基础结构。 下图显示了描述MySQL Group Replication整体架构的框图。
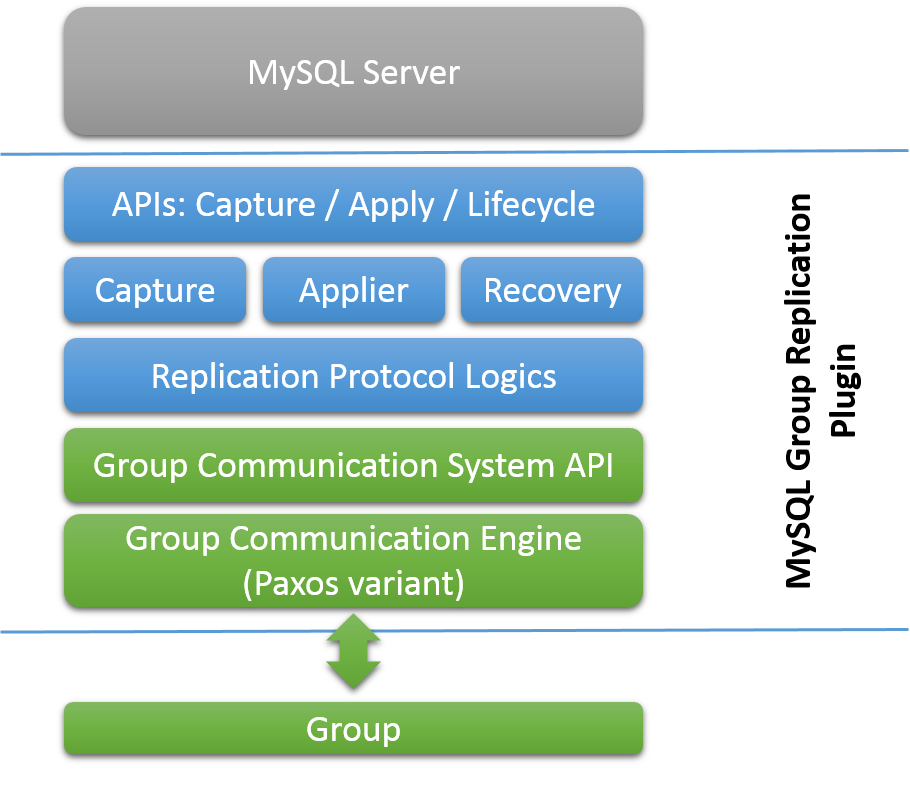
MySQL Group Replication插件包含一组用于捕获,应用和生命周期的API,用于控制插件与MySQL Server的交互方式。 有一些接口可以使信息从服务器流向插件,反之亦然。 这些接口将MySQL服务器核心与Group Replication插件隔离开来,并且主要是放置在事务执行管道中的钩子。 从一个方向,从服务器到插件,有一些事件的通知,例如服务器启动,服务器恢复,服务器准备接受连接,以及服务器即将提交事务。 在另一个方向,插件指示服务器执行诸如提交或中止正在进行的事务之类的操作,
组复制插件体系结构的下一层是一组组件,它们在将通知路由到它们时作出反应。 捕获组件负责跟踪与正在执行的事务相关的上下文。 应用程序组件负责在数据库上执行远程事务。 恢复组件管理分布式恢复,并负责通过选择捐赠者,编排赶上程序并对捐赠者故障作出反应,使加入该组的服务器更新。
继续向下堆栈,复制协议模块包含复制协议的特定逻辑。 它处理冲突检测,并接收事务并将其传播到组。
组复制插件体系结构的最后两层是组通信系统(GCS)API,以及基于Paxos的组通信引擎(XCom)的实现。 GCS API是一个高级API,它抽象了构建复制状态机所需的属性(请参见 第18.1节“组复制背景” )。 因此,它将消息传递层的实现与插件的其余上层分离。 组通信引擎处理与复制组成员的通信。
在MySQL Group Replication中,一组服务器构成一个复制组。 组具有名称,其形式为UUID。 该组是动态的,服务器可以离开(自愿或非自愿)并随时加入。 服务器加入或离开时,该组会自行调整。
如果服务器加入组,它会通过从现有服务器获取丢失状态自动使其自身更新。 此状态通过异步MySQL复制进行传输。 如果服务器离开该组,例如它被取下进行维护,则其余服务器会注意到它已离开并自动重新配置该组。 第18.1.3.2节“组成员身份”中 描述的组成员服务为 所有这些提供了 强制 权。
由于没有任何特定数据集的主服务器(主服务器),因此允许组中的每个服务器随时执行事务,甚至是更改状态的事务(RW事务)。
任何服务器都可以在没有任何 先验 协调的 情况下执行事务 。 但是,在提交时,它与组中的其余服务器协调,以便就该事务的命运做出决定。 这种协调有两个目的:(i)检查交易是否应该提交; (ii)并传播更改,以便其他服务器也可以应用该事务。
当事务通过原子广播发送时,组中的所有服务器都接收该事务,或者不接收任何事务。 如果他们收到它,那么他们都会以与之前发送的其他交易相同的顺序收到它。 通过检查和比较写入事务集来执行冲突检测。 因此,它们在行级检测到。 冲突解决遵循第一个提交者获胜规则。 如果t1和t2在不同的站点同时执行,因为t2在t1之前被排序,并且两者都改变了同一行,那么t2赢得冲突并且t1中止。 换句话说,t1试图改变由t2渲染过时的数据。
如果两个事务经常发生冲突,那么最好在同一台服务器上启动它们。 然后,他们有机会在本地锁管理器上进行同步,而不是稍后在复制协议中中止。
在组复制拓扑中,在执行数据定义语句时也需要小心,通常也称为数据定义语言(DDL)。
MySQL 8.0引入了对原子数据定义语言(DDL)语句的支持,其中完整的DDL语句作为单个原子事务提交或回滚。
但是,原子或其他DDL语句隐式结束当前会话中处于活动状态的任何事务,就好像您
COMMIT
在执行语句之前
完成了
一样。
这意味着DDL语句不能在事务控制语句中的另一个事务中执行,例如
START
TRANSACTION ... COMMIT
,或者与同一事务中的其他语句结合使用。
组复制基于乐观复制范例,其中语句被乐观地执行并在必要时稍后回滚。 每个服务器首先执行和提交而不保护组协议。 因此,在多主模式下复制DDL语句时需要更加小心。 如果您对同一对象进行架构更改(使用DDL)并更改对象包含的数据(使用DML),则需要通过同一服务器处理更改,而架构操作尚未完成并在任何位置进行复制。 如果不这样做,可能会导致操作中断或仅部分完成时数据不一致。 如果该组以单主模式部署,则不会发生此问题,
有关MySQL 8.0中原子DDL支持的详细信息,以及某些语句复制行为的最终更改,请参见 第13.1.1节“原子数据定义语句支持” 。
本节介绍加入组的成员赶上组中其余服务器(称为分布式恢复)的过程。
本节是一个高级摘要。 以下部分通过更详细地描述过程的各个阶段来提供其他详细信息。
组复制分布式恢复可以概括为服务器从组中丢失事务的过程,以便它可以加入已处理与其他组成员相同的事务集的组。 在分布式恢复期间,加入组的服务器会缓冲加入组的服务器正在接收组中所需的事务时发生的任何事务和成员事件。 一旦加入该组的服务器收到了该组的所有事务,它就会应用在恢复过程中缓冲的事务。 在此过程结束时,服务器然后作为在线成员加入组。
在第一阶段,加入该组的服务器选择该组上的一个在线服务器作为 其缺失状态 的 捐赠者 。 捐赠者负责为服务器提供加入该组的所有数据,直到它加入该组为止。 这是通过依靠在捐赠者和加入该组的服务器之间建立的标准异步复制通道来实现的 第17.2.3节“复制通道” 。 通过此复制通道,将复制捐赠者的二进制日志,直到当加入该组的服务器成为该组的一部分时发生视图更改。 加入该组的服务器在收到捐赠者的二进制日志时应用它们。
在复制二进制日志时,加入该组的服务器还会缓存在组内交换的每个事务。 换句话说,它正在监听在加入该组之后发生的交易,同时它正在应用来自捐赠者的缺失状态。 当第一阶段结束并且关闭供体的复制通道时,加入该组的服务器然后开始第二阶段:追赶。
为了使加入组的服务器与捐赠者同步到特定时间点,加入组和捐赠者的服务器利用MySQL全局事务标识符(GTID)机制。 请参见 第17.1.3节“使用全局事务标识符复制” 。 但是,GTIDS仅提供了一种方法来实现加入该组的服务器缺少哪些事务,它们无助于标记加入该组的服务器必须赶上的特定时间点,也无助于传达认证信息。 这是二进制日志视图标记的工作,它标记二进制日志流中的视图更改,还包含其他元数据信息,为服务器加入缺少认证相关数据的组。
要解释视图更改标记的概念,了解视图和视图更改的内容非常重要。
甲 视图 对应于一组在当前配置中积极参与成员,换句话说的在时间上的特定点。 它们在系统中是正确的和在线的。
甲 视图改变 时所述组结构的修改情况,例如构件接合或离开发生。 任何组成员身份更改都会导致在同一逻辑时间点向所有成员传达的独立视图更改。
甲 视图标识符 唯一地标识的图。 只要视图发生更改,就会生成它
在组通信层,视图更改及其关联的视图ID是成员加入之前和之后交换的数据之间的边界。 此概念通过新的二进制日志事件实现:“视图更改日志事件”。 因此,视图id也成为在组成员资格发生变化之前和之后传输的事务的标记。
视图标识符本身由两部分构成: (i) 随机生成的一个和 (ii) 单调递增的整数。 第一部分是在创建组时生成的,并且在组中至少有一个成员时保持不变。 每次视图更改发生时,第二部分都会递增。
构成视图id的这种异构对的原因是需要在成员加入或离开时明确地标记组更改,而且每当所有成员离开组时都没有信息,并且没有关于组所在视图的信息。事实上,单独使用单调增加标识符可能导致在完全组关闭后重用相同的id,从而破坏恢复所依赖的二进制日志数据标记的唯一性。 总而言之,第一部分识别组从一开始就开始,以及当组从那一点开始改变时的增量部分。
本节介绍控制如何将视图更改标识符合并到二进制日志事件并写入日志的过程。执行以下步骤:
每当新成员加入组并因此执行视图更改时,每个联机服务器都会对视图更改日志事件进行排队以执行。 这是排队的,因为在视图更改之前,可以在要应用的服务器上对多个事务进行排队,因此这些事务属于旧视图。 在它们之后对视图更改事件进行排队可确保正确标记何时发生这种情况。
同时,加入该组的服务器通过视图抽象从会员服务所述的在线服务器列表中选择捐赠者。 成员加入视图4,在线成员将查看更改事件写入二进制日志。
一旦加入该组的服务器选择该组中的哪个服务器作为施主,则在两者之间建立新的异步复制连接并且状态转移开始(阶段1)。 这种与捐赠者的交互一直持续到服务器加入组的应用程序线程处理视图更改日志事件,该事件对应于加入组的服务器进入组时触发的视图更改。 换句话说,加入该组的服务器从捐赠者复制,直到它到达具有与其已经存在的视图标记相匹配的视图标识符的标记。
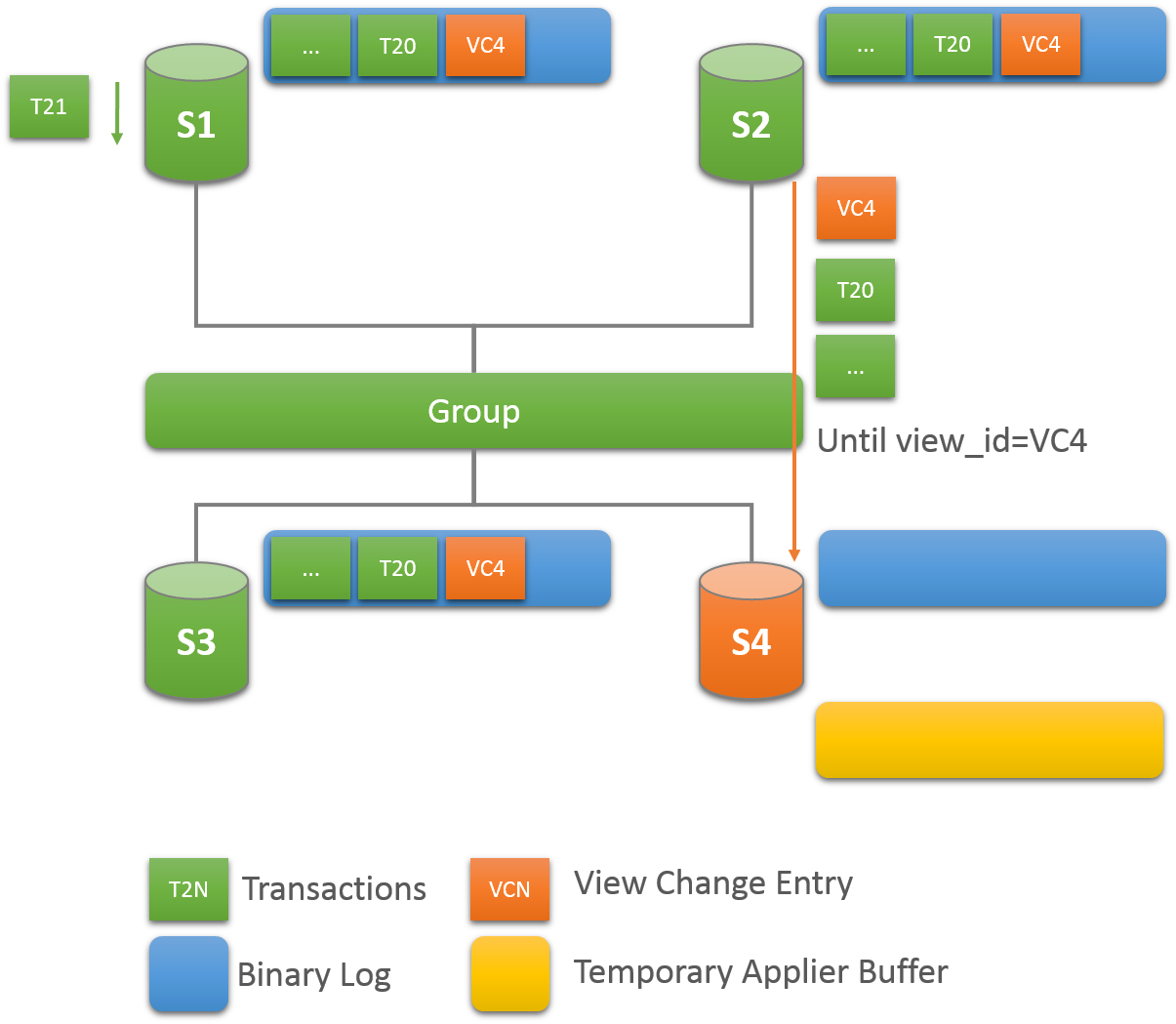
由于视图标识符在相同的逻辑时间被发送到组中的所有成员,因此加入该组的服务器知道它应该停止复制哪个视图标识符。 这避免了复杂的GTID集计算,因为视图ID清楚地标记了哪些数据属于每个组视图。
加入该组的服务器正在从捐赠者复制时,它也会缓存来自该组的传入事务。 最终,它停止从捐赠者复制并切换到应用缓存的那些。
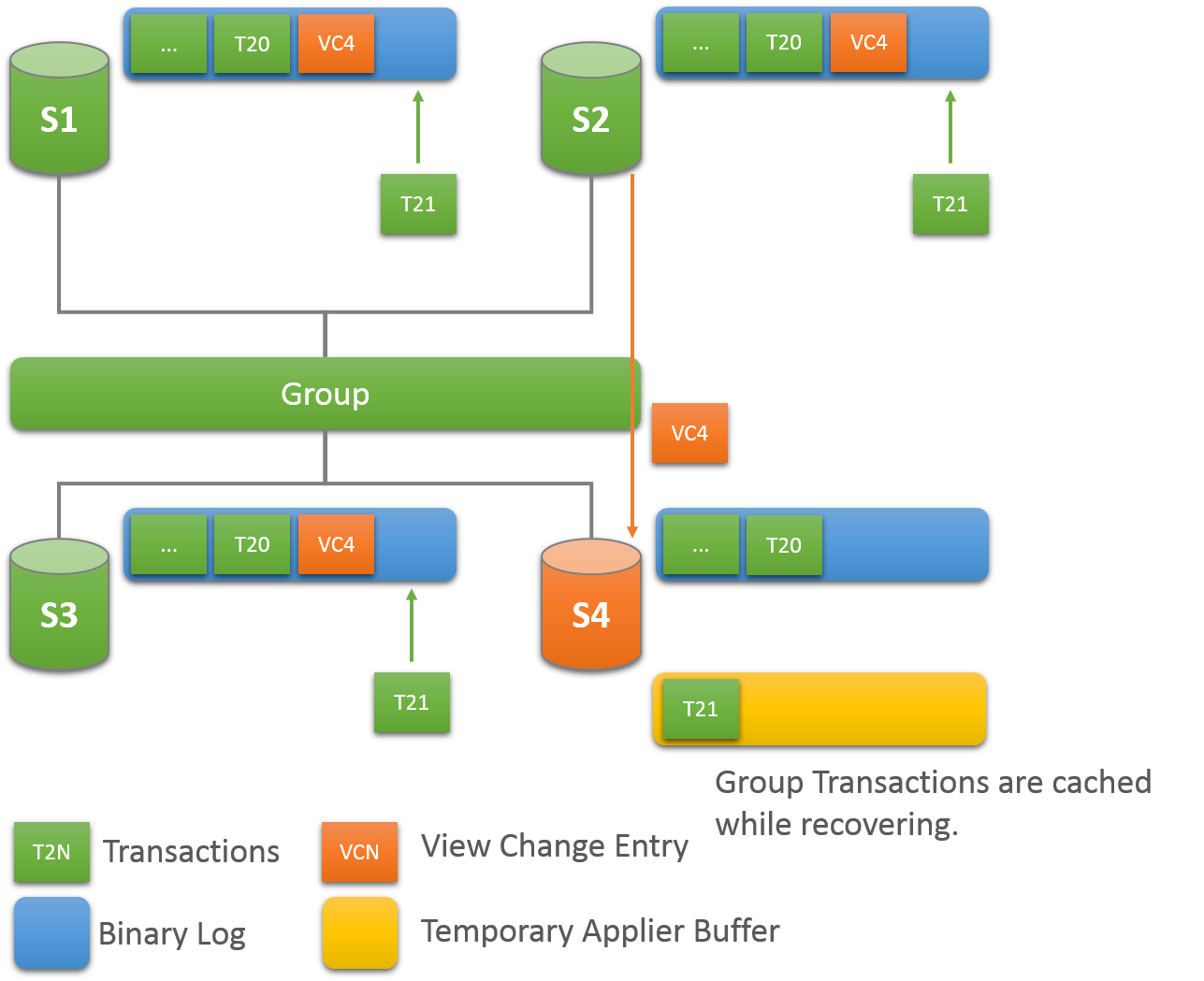
当加入组的服务器识别出具有预期视图标识符的视图更改日志事件时,终止与捐赠者的连接并开始应用缓存的事务。 需要了解的重点是最终的恢复程序。 虽然它在二进制日志中充当标记,但是分隔视图更改,视图更改日志事件也扮演另一个角色。 当加入组的服务器进入组时,它传达所有服务器感知的认证信息,换句话说,最后一次视图改变。 没有它,加入该组的服务器将没有必要的信息来证明(检测冲突)后续事务。
追赶的持续时间(阶段2)不是确定性的,因为它取决于工作量和进入集团的交易的速率。 此过程完全联机,加入组的服务器在捕获时不会阻止组中的任何其他服务器。 因此,当移动到阶段2时,服务器加入该组的事务的数量落后,因此可以根据工作量而变化并因此增加或减少。
当加入组的服务器达到零排队事务并且其存储的数据等于其他成员时,其公共状态将更改为联机。
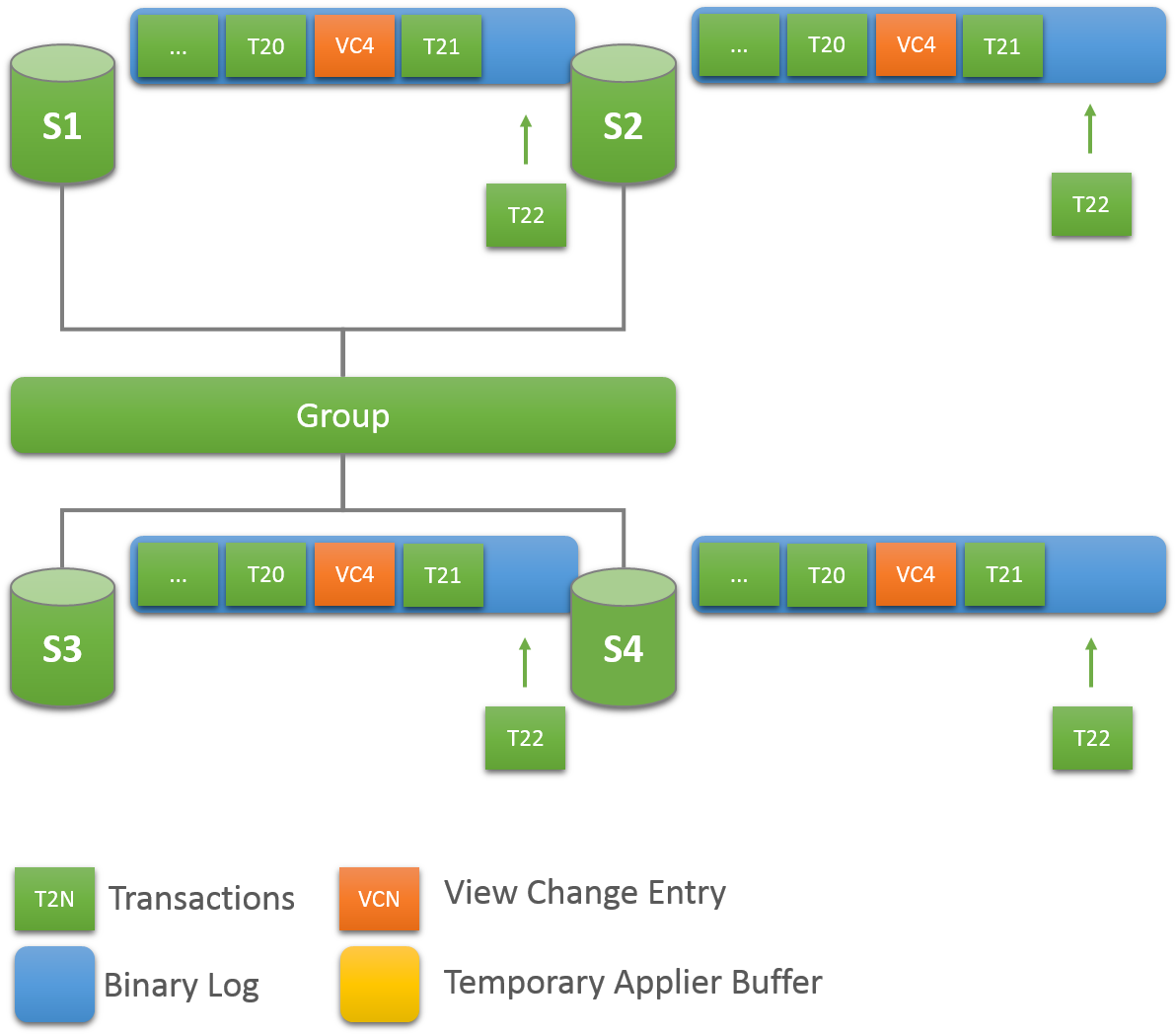
Group Replication插件内置了很多自动化功能。 尽管如此,您有时可能需要了解幕后发生的事情。 这就是组复制和性能模式的工具变得重要的地方。 可以通过performance_schema表查询系统的整个状态(包括视图,冲突统计和服务状态)。 复制协议的分布式特性以及服务器实例同意并因此在事务和元数据上同步这一事实使得检查组的状态变得更加简单。 例如, 您可以通过在与组复制相关的性能架构表上发出select语句来连接到组中的单个服务器并获取本地和全局信息。 有关更多信息,请参阅 第18.3节“监视组复制” 。