目录
- 15.1 InnoDB简介
- 15.2 InnoDB和ACID模型
- 15.3 InnoDB多版本控制
- 15.4 InnoDB架构
- 15.5 InnoDB内存中结构
- 15.6 InnoDB磁盘结构
- 15.7 InnoDB锁定和交易模型
- 15.8 InnoDB配置
- 15.9 InnoDB表和页面压缩
- 15.10 InnoDB行格式
- 15.11 InnoDB磁盘I / O和文件空间管理
- 15.12 InnoDB和在线DDL
- 15.13 InnoDB启动选项和系统变量
- 15.14 InnoDB INFORMATION_SCHEMA表
-
- 15.14.1 InnoDB INFORMATION_SCHEMA关于压缩的表
- 15.14.2 InnoDB INFORMATION_SCHEMA交易和锁定信息
- 15.14.3 InnoDB INFORMATION_SCHEMA模式对象表
- 15.14.4 InnoDB INFORMATION_SCHEMA FULLTEXT索引表
- 15.14.5 InnoDB INFORMATION_SCHEMA缓冲池表
- 15.14.6 InnoDB INFORMATION_SCHEMA度量表
- 15.14.7 InnoDB INFORMATION_SCHEMA临时表信息表
- 15.14.8从INFORMATION_SCHEMA.FILES检索InnoDB表空间元数据
- 15.15 InnoDB与MySQL性能模式的集成
- 15.16 InnoDB监视器
- 15.17 InnoDB备份和恢复
- 15.18 InnoDB和MySQL复制
- 15.19 InnoDB memcached插件
- 15.20 InnoDB故障排除
InnoDB
是一种平衡高可靠性和高性能的通用存储引擎。
在MySQL 8.0中,
InnoDB
是默认的MySQL存储引擎。
除非您配置了不同的默认存储引擎,否则发出
CREATE
TABLE
不带
ENGINE=
子句的语句会创建
InnoDB
表。
InnoDB的主要优势
-
它的 DML 操作遵循 ACID 模型, 具有 提交 , 回滚 和 崩溃恢复 功能的 事务 来保护用户数据。 有关 更多信息 , 请参见 第15.2节“InnoDB和ACID模型” 。
-
行级 锁定 和Oracle风格的 一致性读取可 提高多用户并发性和性能。 有关 更多信息 , 请参见 第15.7节“InnoDB锁定和事务模型” 。
-
InnoDB表格将您的数据排列在磁盘上,以根据 主键 优化查询 。 每个InnoDB表都有一个称为 聚簇索引 的主键索引 ,用于组织数据以最小化主键查找的I / O. 有关 更多信息 , 请参见 第15.6.2.1节“聚簇和二级索引” 。 -
要保持数据 完整性 ,请
InnoDB支持FOREIGN KEY约束。 使用外键,将检查插入,更新和删除,以确保它们不会导致不同表之间的不一致。 有关 更多信息 , 请参见 第15.6.1.5节“InnoDB和FOREIGN KEY约束” 。
表15.1 InnoDB存储引擎功能
| 特征 | 支持 |
|---|---|
| B树索引 | 是 |
| 备份/时间点恢复 (在服务器中实现,而不是在存储引擎中实现。) | 是 |
| 群集数据库支持 | 没有 |
| 聚集索引 | 是 |
| 压缩数据 | 是 |
| 数据缓存 | 是 |
| 加密数据 | 是(通过加密功能在服务器中实现;在MySQL 5.7及更高版本中,支持静态数据表空间加密。) |
| 外键支持 | 是 |
| 全文搜索索引 | 是(在MySQL 5.6及更高版本中可以使用InnoDB对FULLTEXT索引的支持。) |
| 地理空间数据类型支持 | 是 |
| 地理空间索引支持 | 是(在MySQL 5.7及更高版本中可以使用InnoDB对地理空间索引的支持。) |
| 哈希索引 | 否(InnoDB在内部利用哈希索引来实现其自适应哈希索引功能。) |
| 索引缓存 | 是 |
| 锁定粒度 | 行 |
| MVCC | 是 |
| 复制支持 (在服务器中实现,而不是在存储引擎中实现。) | 是 |
| 存储限制 | 64TB |
| T树索引 | 没有 |
| 交易 | 是 |
| 更新数据字典的统计信息 | 是 |
要比较
InnoDB
MySQL提供的其他存储引擎
的功能
,请参阅
第16章
备用存储引擎中
的
存储引擎功能
表
。
InnoDB增强功能和新功能
有关
InnoDB
增强功能和新功能的信息,请参阅:
-
第1.4节“MySQL 8.0中的新
InnoDB功能”中 的 增强功能列表 。 -
该 发行说明 。
额外的InnoDB信息和资源
-
有关
InnoDB相关术语和定义,请参阅 MySQL词汇表 。 -
对于专用于
InnoDB存储引擎的 论坛 ,请参阅 MySQL论坛:: InnoDB 。 -
InnoDB以与MySQL相同的GNU GPL许可证版本2(1991年6月)发布。 有关MySQL许可的更多信息,请 访问http://www.mysql.com/company/legal/licensing/ 。
您可能会发现有
InnoDB
利于以下原因的表:
-
如果您的服务器因硬件或软件问题而崩溃,无论当时数据库中发生了什么,您都无需在重新启动数据库后执行任何特殊操作。
InnoDB崩溃恢复会 自动完成在崩溃之前提交的所有更改,并撤消正在进行但未提交的任何更改。 只需重新启动并继续您离开的地方。 -
该
InnoDB存储引擎维护它自己的 缓冲池 ,当数据被访问主内存中缓存表和索引数据。 经常使用的数据直接从内存中处理。 此缓存适用于许多类型的信息并加快处理速度。 在专用数据库服务器上,通常会将最多80%的物理内存分配给缓冲池。 -
如果将相关数据拆分到不同的表中,则可以设置 强制 引用完整性的 外键 。 更新或删除数据,并自动更新或删除其他表中的相关数据。 尝试将数据插入到辅助表中,而不在主表中显示相应的数据,并且坏数据会自动被踢出。
-
如果数据在磁盘或内存中损坏, 校验和 机制会在您使用之前提醒您伪造数据。
-
使用 每个表的 相应 主键 列 设计数据库时 ,将自动优化涉及这些列的操作。 引用
WHERE子句,ORDER BY子句,GROUP BY子句和 连接 操作中 的主键列非常快 。 -
插入,更新和删除通过称为 更改缓冲 的自动机制进行优化 。
InnoDB不仅允许对同一个表进行并发读写访问,还可以缓存已更改的数据以简化磁盘I / O. -
性能优势不仅限于具有长时间运行查询的巨型表。 当从表中反复访问相同的行时,称为 自适应哈希索引的功能 会接管以使这些查找更快,就像它们来自哈希表一样。
-
您可以压缩表和关联的索引。
-
您可以创建和删除索引,而对性能和可用性的影响要小得多。
-
截断 每个表 的 文件表 空间非常快,并且可以释放磁盘空间以供操作系统重用,而不是释放 系统表空间 中只能
InnoDB重用的 空间 。 -
您可以通过查询 INFORMATION_SCHEMA 表 来监视存储引擎的内部工作方式 。
-
您可以通过查询 性能架构 表 来监控存储引擎的性能详细信息 。
-
您可以自由地将
InnoDB表与来自其他MySQL存储引擎的表 混合 ,甚至可以在同一语句中。 例如,您可以使用 连接 操作来组合 单个查询中的 数据InnoDB和MEMORY表。 -
InnoDB专为处理大量数据时的CPU效率和最高性能而设计。 -
InnoDB表可以处理大量数据,即使在文件大小限制为2GB的操作系统上也是如此。
对于
InnoDB
您可以在应用程序代码中应用特异性调节技术,请参阅
第8.5节,“优化InnoDB表”
。
本节介绍使用
InnoDB
表
时的最佳实践
。
-
根据来自这些表的相同ID值从多个表中提取数据的位置 使用 连接 。 要获得快速连接性能,请 在连接列上 定义 外键 ,并在每个表中声明具有相同数据类型的列。 添加外键可确保对引用的列建立索引,从而提高性能。 外键还会将删除或更新传播到所有受影响的表,如果父表中不存在相应的ID,则会阻止在子表中插入数据。
-
关闭 自动提交 。 每秒承诺数百次会限制性能(受存储设备写入速度的限制)。
-
分组组相关的 DML 操作成 交易 ,通过包围他们
START TRANSACTION和COMMIT报表。 虽然你不想过于频繁地提交,你也不想发出的巨大的批次INSERT,UPDATE或者DELETE,如果没有犯了几个小时运行的语句。 -
不使用
LOCK TABLES语句。InnoDB可以同时处理多个会话,同时读取和写入同一个表,而不会牺牲可靠性或高性能。 要获得对一组行的独占写访问权,请使用SELECT ... FOR UPDATE语法仅锁定要更新的行。 -
启用该
innodb_file_per_table选项或使用通用表空间将表的数据和索引放入单独的文件中,而不是 系统表空间 。innodb_file_per_table默认情况下启用 该 选项。 -
评估您的数据和访问模式是否受益于
InnoDB表或页面 压缩 功能。 您可以在InnoDB不牺牲读/写功能的情况下 压缩 表。 -
使用选项运行服务器,
--sql_mode=NO_ENGINE_SUBSTITUTION以防止在使用ENGINE=子句中 指定的引擎出现问题时使用其他存储引擎创建表CREATE TABLE。
发出
SHOW
ENGINES
语句以查看可用的MySQL存储引擎。
寻找
DEFAULT
在
InnoDB
行。
mysql> SHOW ENGINES;
或者,查询
INFORMATION_SCHEMA.ENGINES
表。
mysql> SELECT * FROM INFORMATION_SCHEMA.ENGINES;
如果
InnoDB
不是您的默认存储引擎,则可以
InnoDB
通过
--default-storage-engine=InnoDB
在命令行中定义
的服务器重新启动服务器
或
default-storage-engine=innodb
在
[mysqld]
MySQL服务器选项文件
的
部分中
定义
来确定数据库服务器或应用程序是否正常工作
。
由于更改默认存储引擎仅会在创建新表时影响新表,因此请运行所有应用程序安装和设置步骤,以确认所有内容都已正确安装。
然后练习所有应用程序功能,以确保所有数据加载,编辑和查询功能都能正常工作。
如果表依赖于特定于另一个存储引擎的功能,您将收到错误;
将该
子句
添加
到
语句中以避免错误。
ENGINE=
other_engine_nameCREATE TABLE
如果您没有对存储引擎做出深思熟虑的决定,并且想要预览某些表在使用时创建的工作方式
InnoDB
,请
ALTER
TABLE
table_name ENGINE=InnoDB;
为每个表
发出命令
。
或者,要在不打扰原始表的情况下运行测试查询和其他语句,请复制:
CREATE TABLE InnoDB_Table(...)ENGINE = InnoDB AS SELECT * FROM other_engine_table;
要在实际工作负载下评估完整应用程序的性能,请安装最新的MySQL服务器并运行基准测试。
测试整个应用程序生命周期,从安装,大量使用和服务器重启。 在数据库忙于模拟电源故障时终止服务器进程,并在重新启动服务器时验证数据是否已成功恢复。
测试任何复制配置,尤其是在主服务器和从服务器上使用不同的MySQL版本和选项时。
该
ACID
模式是一组数据库设计原则强调的是,对于业务数据和关键任务应用重要的可靠性方面。
MySQL包含诸如的组件
InnoDB
存储引擎与ACID模型紧密结合,因此数据不会损坏,并且不会因软件崩溃和硬件故障等特殊情况而导致结果失真。
当您依赖符合ACID的功能时,您无需重新发明一致性检查和崩溃恢复机制。
如果您有其他软件安全措施,超可靠硬件或可以容忍少量数据丢失或不一致的应用程序,您可以调整MySQL设置以交换一些ACID可靠性以获得更高的性能或吞吐量。
以下部分讨论MySQL功能(尤其是
InnoDB
存储引擎)
如何
与ACID模型的类别进行交互:
-
答 :原子性。
-
C :一致性。
-
我 ::隔离。
-
D :耐用性。
原子性
ACID模型
的
原子性
方面主要涉及
InnoDB
交易
。
相关的MySQL功能包括:
一致性
ACID模型
的
一致性
方面主要涉及内部
InnoDB
处理以保护数据免于崩溃。
相关的MySQL功能包括:
隔离
ACID模型
的
隔离
方面主要涉及
InnoDB
事务
,特别
是适用于每个事务
的
隔离级别
。
相关的MySQL功能包括:
耐久力
ACID模型 的 持久性 方面涉及MySQL软件功能与您的特定硬件配置交互。 由于取决于CPU,网络和存储设备的功能的许多可能性,这方面是最复杂的提供具体指导方针。 (这些指南可能采取购买 “ 新硬件 ” 的形式 。)相关的MySQL功能包括:
-
InnoDBdoublewrite buffer ,由innodb_doublewrite配置选项 打开和关闭 。 -
配置选项
sync_binlog。 -
配置选项
innodb_file_per_table。 -
在存储设备中写入缓冲区,例如磁盘驱动器,SSD或RAID阵列。
-
存储设备中的电池备份缓存。
-
用于运行MySQL的操作系统,特别是它对
fsync()系统调用的 支持 。 -
不间断电源(UPS)保护运行MySQL服务器和存储MySQL数据的所有计算机服务器和存储设备的电源。
-
您的备份策略,例如备份的频率和类型以及备份保留期。
-
对于分布式或托管数据应用程序,MySQL服务器的硬件所在的数据中心的特定特征,以及数据中心之间的网络连接。
InnoDB
是一个
多版本的存储引擎
:它保存有关已更改行的旧版本的信息,以支持并发和
回滚
等事务功能
。
此信息存储在表空间中称为
回滚段
的数据结构中(在Oracle中的类似数据结构之后)。
InnoDB
使用回滚段中的信息来执行事务回滚中所需的撤消操作。
它还使用该信息构建行的早期版本以进行
一致读取
。
在内部,
InnoDB
为数据库中存储的每一行添加三个字段。
6字节
DB_TRX_ID
字段指示插入或更新行的最后一个事务的事务标识符。
此外,删除在内部被视为更新,其中行中的特殊位被设置为将其标记为已删除。
每行还包含一个
DB_ROLL_PTR
称为滚动指针
的7字节
字段。
roll指针指向写入回滚段的撤消日志记录。
如果更新了行,则撤消日志记录包含在更新行之前重建行内容所需的信息。
一个6字节的
DB_ROW_ID
字段包含一个行ID,当插入新行时,该行ID会单调增加。
如果
InnoDB
自动生成聚簇索引,索引包含行ID值。
否则,该
DB_ROW_ID
列不会出现在任何索引中。
撤消段中的撤消日志分为插入和更新撤消日志。
只在事务回滚中才需要插入撤消日志,并且可以在事务提交后立即丢弃。
更新撤消日志也用于一致性读取,但只有在没有事务
InnoDB
已分配快照的情况下
才能丢弃它们
,在一致读取中可能需要更新撤消日志中的信息来构建数据库的早期版本行。
定期提交您的交易,包括那些只发出一致读取的交易。
否则,
InnoDB
无法从更新撤消日志中丢弃数据,并且回滚段可能会变得太大,从而填满了表空间。
回滚段中撤消日志记录的物理大小通常小于相应的插入或更新行。 您可以使用此信息计算回滚段所需的空间。
在
InnoDB
多版本控制方案中,使用SQL语句删除行时,不会立即从数据库中物理删除该行。
InnoDB
只有在丢弃为删除写入的更新撤消日志记录时,才会物理删除相应的行及其索引记录。
此删除操作称为
清除
,并且速度非常快,通常与执行删除的SQL语句的时间顺序相同。
如果你在表中以大约相同的速率插入和删除少量批次的行,则清除线程可能开始落后,并且由于所有
“
死
”
行,
表可以变得越来越大
,使得所有磁盘都受到限制慢。
在这种情况下,通过调整
innodb_max_purge_lag
系统变量
来限制新行操作,并将更多资源分配给清除线程
。
有关
更多信息
,
请参见
第15.13节“InnoDB启动选项和系统变量”
。
InnoDB
多版本并发控制(MVCC)以不同于聚簇索引的方式处理二级索引。
聚集索引中的记录就地更新,其隐藏的系统列指向可以重建早期版本记录的撤消日志条目。
与聚簇索引记录不同,二级索引记录不包含隐藏的系统列,也不会就地更新。
更新二级索引列时,旧的二级索引记录将被删除标记,插入新记录,最终清除删除标记的记录。
当二级索引记录被删除标记或二级索引页面由较新的事务更新时,
InnoDB
查找聚簇索引中的数据库记录。
在聚簇索引中,将
DB_TRX_ID
检查记录,如果在启动读取事务后修改了记录,则会从撤消日志中检索正确的记录版本。
如果二级索引记录被标记为删除或二级索引页面由较新的事务更新,
则不使用
覆盖索引
技术。
而不是从索引结构返回值,而是
InnoDB
在聚簇索引中查找记录。
但是,如果
启用
了
索引条件下推(ICP)
优化,并且
WHERE
只能使用索引中的字段来评估条件的
某些部分
,则MySQL服务器仍会将此部分
WHERE
条件下推到存储引擎,在此处使用指数。
如果未找到匹配的记录,则避免聚集索引查找。
如果找到匹配的记录,即使在删除标记的记录中,也会
InnoDB
查找聚簇索引中的记录。
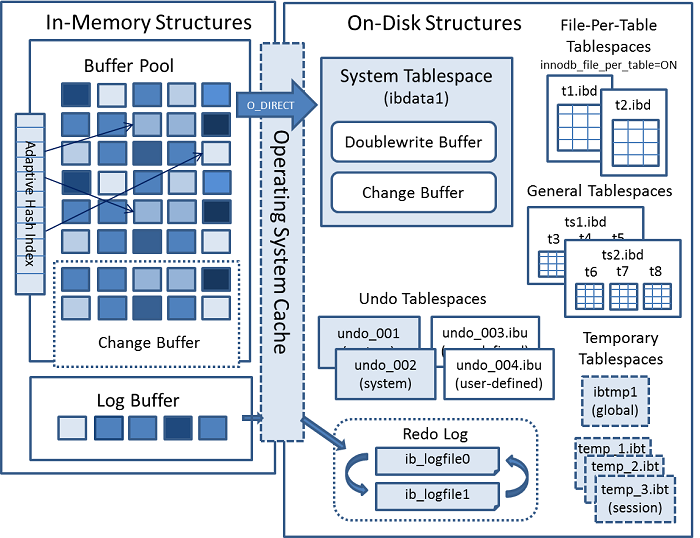
下图显示了构成
InnoDB
存储引擎体系
结构的内存和磁盘结构
。
有关每种结构的信息,请参见
第15.5节“InnoDB内存中结构”
和
第15.6节“InnoDB On-Disk Structures”
。
本节介绍
InnoDB
内存中的结构和相关主题。
缓冲池是主存储器中的一个区域,用于在访问时缓存表和索引数据。 缓冲池允许直接从内存处理常用数据,从而加快处理速度。 在专用服务器上,通常会将最多80%的物理内存分配给缓冲池。
为了提高大容量读取操作的效率,缓冲池被分成 可以容纳多行的 页面 。 为了提高缓存管理的效率,缓冲池被实现为链接的页面列表; 使用 LRU 算法 的变体,很少使用的数据在缓存中老化 。
了解如何利用缓冲池将频繁访问的数据保存在内存中是MySQL调优的一个重要方面。
使用最近最少使用(LRU)算法的变体将缓冲池作为列表进行管理。 当需要空间将新页面添加到缓冲池时,最近最少使用的页面被逐出,并且新页面被添加到列表的中间。 此中点插入策略将列表视为两个子列表:
-
在头部, 最近访问过 的新( “ 年轻 ” )页面 的子列表
-
在尾部,是最近访问的旧页面的子列表
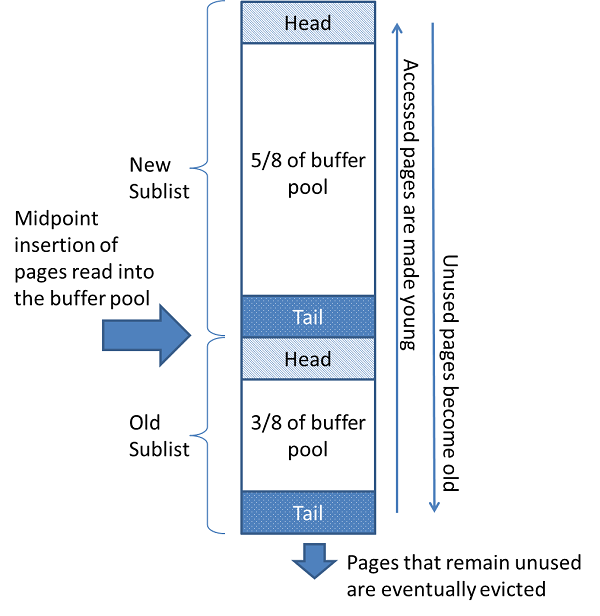
该算法保留新子列表中查询大量使用的页面。 旧子列表包含较少使用的页面; 这些页面是 驱逐的 候选人 。
默认情况下,算法操作如下:
-
3/8的缓冲池专用于旧子列表。
-
列表的中点是新子列表的尾部与旧子列表的头部相交的边界。
-
当
InnoDB将页面读入缓冲池时,它最初将其插入中点(旧子列表的头部)。 可以读取页面,因为它是用户指定的操作(如SQL查询)所必需的,或者是 由自动执行的 预读 操作的 一部分InnoDB。 -
访问旧子列表中的页面使其 “ 年轻 ” ,将其移动到缓冲池的头部(新子列表的头部)。 如果因为需要而读取页面,则会立即进行第一次访问,并使页面变得年轻。 如果由于预读而读取了页面,则第一次访问不会立即发生(并且在页面被逐出之前可能根本不会发生)。
-
随着数据库的运行,在缓冲池的页面没有被访问的 “ 年龄 ” 通过向列表的尾部移动。 新旧子列表中的页面随着其他页面的变化而变旧。 旧子列表中的页面也会随着页面插入中点而老化。 最终,仍然未使用的页面到达旧子列表的尾部并被逐出。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们会更长时间地保留在缓冲池中。
表扫描(例如为
mysqldump
操作执行,或者
SELECT
带有no
WHERE
子句的语句)可以将大量数据带入缓冲池并逐出相同数量的旧数据,即使新数据从未再次使用过。
类似地,由预读后台线程加载然后仅访问一次的页面移动到新列表的头部。
这些情况可以将经常使用的页面推送到旧的子列表中,在那里它们会被驱逐。
有关优化此行为的信息,请参见
第15.8.3.3节“使缓冲池扫描阻止”
和
第15.8.3.4节“配置InnoDB缓冲池预取(预读)”
。
InnoDB
标准监视器输出包含
BUFFER POOL AND MEMORY
有关缓冲池LRU算法操作
的
部分
中的几个字段
。
有关详细信息,请参阅
使用InnoDB标准监视器监视缓冲池
。
您可以配置缓冲池的各个方面以提高性能。
-
理想情况下,您可以将缓冲池的大小设置为尽可能大的值,从而为服务器上的其他进程留出足够的内存,而无需过多的分页。 缓冲池越大,
InnoDB内存数据库 就越多 ,从磁盘读取数据一次,然后在后续读取期间从内存中访问数据。 请参见 第15.8.3.1节“配置InnoDB缓冲池大小” 。 -
在具有足够内存的64位系统上,您可以将缓冲池拆分为多个部分,以最大限度地减少并发操作之间内存结构的争用。 有关详细信息,请参见 第15.8.3.2节“配置多个缓冲池实例” 。
-
您可以将频繁访问的数据保留在内存中,而不管操作中的活动突然出现高峰,这些操作会将大量不经常访问的数据带入缓冲池。 有关详细信息,请参见 第15.8.3.3节“使缓冲池扫描阻止” 。
-
您可以控制何时以及如何执行预读请求,以异步方式将页面预取到缓冲池中,以预期很快就会需要页面。 有关详细信息,请参见 第15.8.3.4节“配置InnoDB缓冲池预取(预读)” 。
-
您可以控制何时发生背景刷新以及是否根据工作负载动态调整刷新率。 有关详细信息,请参见 第15.8.3.5节“配置InnoDB缓冲池刷新” 。
-
您可以微调缓冲池刷新行为的各个方面以提高性能。 有关详细信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
您可以配置如何
InnoDB保留当前缓冲池状态,以避免服务器重新启动后的长时间预热。 有关详细信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
InnoDB
可以使用的标准监视器输出
SHOW
ENGINE INNODB STATUS
提供有关缓冲池操作的指标。
缓冲池指标位于
标准监视器输出
BUFFER POOL AND MEMORY
部分,
InnoDB
显示类似于以下内容:
---------------------- 缓冲池和记忆 ---------------------- 分配的总大内存为2198863872 字典内存分配为776332 缓冲池大小131072 免费缓冲区124908 数据库页面5720 旧数据库页面2071 修改了db页面910 待定读数为0 待写:LRU 0,刷新列表0,单页0 页面年轻4,而不是年轻0 0.10个年轻人/秒,0.00个非年轻人/秒 页面读取197,创建5523,写入5060 0.00读/秒,190.89创建/ s,244.94写/秒 缓冲池命中率1000/1000,年轻率为0/1000没有 0/1000 页面预读0.00 / s,没有访问0.00 / s被逐出,随机读取 提前0.00 / s LRU len:5720,unzip_LRU len:0 I / O sum [0]:cur [0],解压和[0]:cur [0]
下表描述了
InnoDB
标准监视器
报告的缓冲池指标
。
InnoDB
标准监视器输出中
提供的每秒平均值
基于自
InnoDB
上次打印标准监视器输出
以来经过的时间
。
表15.2 InnoDB缓冲池度量标准
| 名称 | 描述 |
|---|---|
| 分配的总内存 | 为缓冲池分配的总内存(以字节为单位)。 |
| 分配的字典内存 |
为
InnoDB
数据字典
分配的总内存(
以字节为单位)。
|
| 缓冲池大小 | 分配给缓冲池的页面的总大小。 |
| 免费缓冲 | 缓冲池空闲列表的页面总大小。 |
| 数据库页面 | 缓冲池LRU列表的页面总大小。 |
| 旧数据库页面 | 缓冲池旧LRU子列表的页面总大小。 |
| 修改了db页面 | 缓冲池中修改的当前页数。 |
| 待读 | 等待读入缓冲池的缓冲池页数。 |
| 待写LRU | 要从LRU列表底部写入的缓冲池中的旧脏页数。 |
| 待处理写入刷新列表 | 在检查点期间要刷新的缓冲池页数。 |
| 待写单页 | 缓冲池中挂起的独立页面写入次数。 |
| 页面变得年轻 | 缓冲池LRU列表中的年轻页总数(移动到 “ 新 ” 页面 的子列表的头部 )。 |
| 页面不年轻 | 缓冲池LRU列表中未完成的页面总数(保留在 “ 旧 ” 子列表 中的页面, 而不是年轻)。 |
| 扬斯/秒 | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致页面变得年轻。 有关详细信息,请参阅此表后面的注释。 |
| 非杨氏/ s的 | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致不使页面变得年轻。 有关详细信息,请参阅此表后面的注释。 |
| 页面已读 | 从缓冲池中读取的总页数。 |
| 页面已创建 | 缓冲池中创建的总页数。 |
| 写的页面 | 从缓冲池写入的总页数。 |
| 读取/秒 | 每秒缓冲池页面读取的平均每秒数。 |
| 创建/秒 | 每秒创建的缓冲池页面的平均每秒数。 |
| 写入/秒 | 每秒缓冲池页面写入的平均每秒数。 |
| 缓冲池命中率 | 从缓冲池内存中读取的页面与从磁盘存储中读取的页面的缓冲池页面命中率。 |
| 年轻人 | 页面访问的平均命中率导致页面变得年轻。 有关详细信息,请参阅此表后面的注释。 |
| 不(年轻率) | 页面访问的平均命中率并未导致页面变得年轻。 有关详细信息,请参阅此表后面的注释。 |
| 页面预读 | 每秒预读操作的平均值。 |
| 被删除的页面无法访问 | 在没有从缓冲池访问的情况下被逐出的页面的每秒平均值。 |
| 随机预读 | 随机预读操作的每秒平均值。 |
| LRU len | 缓冲池LRU列表的页面总大小。 |
| unzip_LRU len | 缓冲池的总页面大小unzip_LRU列表。 |
| I / O总和 | 访问的缓冲池LRU列表页面总数,最近50秒。 |
| I / O cur | 访问的缓冲池LRU列表页面的总数。 |
| I / O解压缩总和 | 访问的缓冲池unzip_LRU列表页面总数。 |
| I / O解压缩 | 访问的缓冲池unzip_LRU列表页面总数。 |
备注 :
-
该
youngs/s指标仅适用于旧页面。 它基于页面访问次数而不是页面数。 可以对给定页面进行多次访问,所有这些访问都被计算在内。 如果youngs/s在没有发生大型扫描时 看到非常低的 值,则可能需要减少延迟时间或增加用于旧子列表的缓冲池的百分比。 增加百分比使旧的子列表变大,因此该子列表中的页面需要更长的时间才能移动到尾部,这增加了再次访问这些页面并使其变得年轻的可能性。 -
该
non-youngs/s指标仅适用于旧页面。 它基于页面访问次数而不是页面数。 可以对给定页面进行多次访问,所有这些访问都被计算在内。 如果non-youngs/s在执行大型表扫描时 没有看到更高的 值(并且youngs/s值 更高 ),请增加延迟值。 -
该
young-making速率考虑了对所有缓冲池页面的访问,而不仅仅是访问旧子列表中的页面。 的young-making速度和not速率通常不加起来的整体缓冲池命中率。 旧子列表中的页面命中会导致页面移动到新的子列表,但是新子列表中的页面命中会导致页面仅在距离头部一定距离时才移动到列表的头部。 -
not (young-making rate)是由于innodb_old_blocks_time未被满足 定义的延迟 ,或者由于新子列表中的页面命中没有导致页面被移动到头部 而导致页面访问没有导致页面年轻化的平均命中率 。 此速率考虑了对所有缓冲池页面的访问,而不仅仅是访问旧子列表中的页面。
缓冲池
服务器状态变量
和
INNODB_BUFFER_POOL_STATS
表提供了许多在
InnoDB
标准监视器输出中
找到的相同缓冲池指标
。
有关更多信息,请参见
例15.10“查询INNODB_BUFFER_POOL_STATS表”
。
更改缓冲区是一种特殊的数据结构,
当这些页面不在
缓冲池中
时
,它会更改
二级索引
页面
。
缓冲的变化,这可能导致从
,
或
当页面被加载到由其他的读操作缓冲池操作(DML),将在后面合并。
INSERT
UPDATE
DELETE
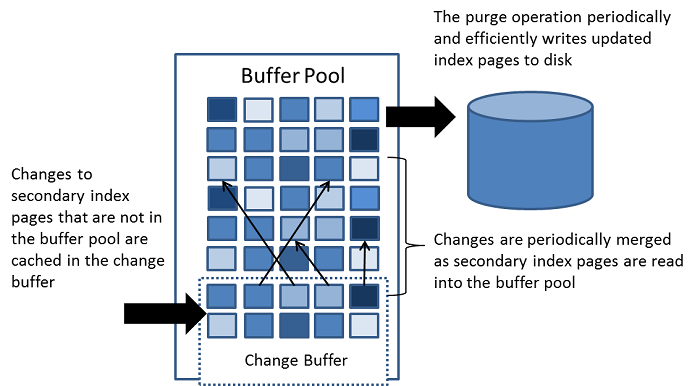
与 聚簇索引 不同 ,二级索引通常不是唯一的,并且插入二级索引的顺序相对随机。 同样,删除和更新可能会影响不在索引树中相邻的二级索引页。 当受影响的页面被其他操作读入缓冲池时,合并缓存的更改,避免了从磁盘读取二级索引页到缓冲池所需的大量随机访问I / O.
系统大部分空闲时或在慢速关闭期间运行的清除操作会定期将更新的索引页写入磁盘。 与每个值立即写入磁盘相比,清除操作可以更有效地为一系列索引值写入磁盘块。
当有许多受影响的行和许多要更新的辅助索引时,更改缓冲区合并可能需要几个小时。 在此期间,磁盘I / O会增加,这会导致磁盘绑定查询显着减慢。 提交事务后,甚至在服务器关闭并重新启动之后,更改缓冲区合并也可能继续发生( 有关更多信息 , 请参见 第15.20.2节“强制InnoDB恢复” )。
在内存中,更改缓冲区占用缓冲池的一部分。 在磁盘上,更改缓冲区是系统表空间的一部分,其中在关闭数据库服务器时缓冲索引更改。
变更缓冲区中缓存的数据类型由
innodb_change_buffering
变量控制。
有关更多信息,请参阅
配置更改缓冲
。
您还可以配置最大更改缓冲区大小。
有关更多信息,请参阅
配置更改缓冲区最大大小
。
如果索引包含降序索引列或主键包含降序索引列,则辅助索引不支持更改缓冲。
有关更改缓冲区的 常见问题解答 ,请参见 第A.15节“MySQL 8.0常见问题解答:InnoDB更改缓冲区” 。
对表执行
何时
INSERT
,
UPDATE
和
DELETE
操作
时
,
索引列的值(特别是辅助键的值)通常按未排序顺序排列,需要大量I / O才能使二级索引更新。
该
变化缓冲区
当相关缓存变为二级索引条目
页面
不在
缓冲池
,从而通过从磁盘上的页面不会立即读避免了昂贵的I / O操作。
当页面加载到缓冲池中时,将合并缓冲的更改,稍后将更新的页面刷新到磁盘。
该
InnoDB
主线程在服务器几乎空闲时以及在
慢速关闭
期间合并缓冲的更改
。
因为它可以减少磁盘读取和写入,所以更改缓冲区功能对于I / O绑定的工作负载最有价值,例如具有大量DML操作的应用程序(如批量插入)。
但是,更改缓冲区占用缓冲池的一部分,从而减少了可用于缓存数据页的内存。 如果工作集几乎适合缓冲池,或者您的表具有相对较少的二级索引,则禁用更改缓冲可能很有用。 如果工作数据集完全适合缓冲池,则更改缓冲不会产生额外开销,因为它仅适用于不在缓冲池中的页面。
您可以
InnoDB
使用
innodb_change_buffering
配置参数
控制
执行更改缓冲
的范围
。
您可以为插入,删除操作(当索引记录最初标记为删除时)和清除操作(物理删除索引记录时)启用或禁用缓冲。
更新操作是插入和删除的组合。
默认
innodb_change_buffering
值为
all
。
允许的
innodb_change_buffering
值包括:
-
all默认值:缓冲区插入,删除标记操作和清除。
-
none不要缓冲任何操作。
-
inserts缓冲插入操作。
-
deletes缓冲区删除标记操作。
-
changes缓冲插入和删除标记操作。
-
purges缓冲后台发生的物理删除操作。
您可以
innodb_change_buffering
在MySQL选项文件(
my.cnf
或
my.ini
)中
设置
参数,
也可以使用
SET GLOBAL
语句
动态更改
该
参数
,该
语句需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
更改设置会影响新操作的缓冲;
现有缓冲条目的合并不受影响。
该
innodb_change_buffer_max_size
变量允许将更改缓冲区的最大大小配置为缓冲池总大小的百分比。
默认情况下,
innodb_change_buffer_max_size
设置为25.最大设置为50。
考虑增加
innodb_change_buffer_max_size
具有大量插入,更新和删除活动的MySQL服务器,其中更改缓冲区合并无法跟上新的更改缓冲区条目,导致更改缓冲区达到其最大大小限制。
考虑
innodb_change_buffer_max_size
使用用于报告的静态数据在MySQL服务器上
减少
,或者如果更改缓冲区消耗了与缓冲池共享的太多内存空间,导致页面比预期更早地超出缓冲池。
使用代表性工作负载测试不同设置以确定最佳配置。
该
innodb_change_buffer_max_size
设置是动态的,允许在不重新启动服务器的情况下修改设置。
以下选项可用于更改缓冲区监视:
-
InnoDB标准监视器输出包括更改缓冲区状态信息 要查看监视器数据,请发出SHOW ENGINE INNODB STATUS语句。MySQL的>
SHOW ENGINE INNODB STATUS\G更改缓冲区状态信息位于
INSERT BUFFER AND ADAPTIVE HASH INDEX标题 下, 并显示类似于以下内容:------------------------------------- 插入缓冲区和自适应哈希索引 ------------------------------------- Ibuf:size 1,free list len 0,seg size 2,0合并 合并后的业务: 插入0,删除标记0,删除0 丢弃的操作: 插入0,删除标记0,删除0 散列表大小4425293,使用单元格32,节点堆有1个缓冲区 13577.57哈希搜索/ s,202.47非哈希搜索/ s
有关更多信息,请参见 第15.16.3节“InnoDB标准监视器和锁定监视器输出” 。
-
该
INFORMATION_SCHEMA.INNODB_METRICS表提供了InnoDB标准监视器输出中的 大多数数据点 以及其他数据点。 要查看更改缓冲区指标及其各自的说明,请发出以下查询:MySQL的>
SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%'\G有关
INNODB_METRICS表用法信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。 -
该
INFORMATION_SCHEMA.INNODB_BUFFER_PAGE表提供有关缓冲池中每个页面的元数据,包括更改缓冲区索引和更改缓冲区位图页面。 更改缓冲区页面由标识PAGE_TYPE。IBUF_INDEX是更改缓冲区索引页IBUF_BITMAP的页面类型,是更改缓冲区位图页的页面类型。警告查询
INNODB_BUFFER_PAGE表可能会带来显着的性能开销。 为避免影响性能,请在测试实例上重现要调查的问题,并在测试实例上运行查询。例如,您可以查询
INNODB_BUFFER_PAGE表以确定大致 缓冲池页面的百分比IBUF_INDEX和IBUF_BITMAP页面 的大致数量 。MySQL的>
SELECT (SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE PAGE_TYPE LIKE 'IBUF%') AS change_buffer_pages,(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ((change_buffer_pages/total_pages)*100))AS change_buffer_page_percentage;+ --------------------- + ------------- ------------- + ------------------ + | change_buffer_pages | total_pages | change_buffer_page_percentage | + --------------------- + ------------- ------------- + ------------------ + | 25 | 8192 | 0.3052 | + --------------------- + ------------- ------------- + ------------------ +有关该
INNODB_BUFFER_PAGE表 提供的其他数据的信息 ,请参见 第25.39.1节“INFORMATION_SCHEMA INNODB_BUFFER_PAGE表” 。 有关相关用法信息,请参见 第15.14.5节“InnoDB INFORMATION_SCHEMA缓冲池表” 。 -
Performance Schema 为高级性能监视提供更改缓冲区互斥等待检测。 要查看更改缓冲区检测,请发出以下查询:
MySQL的>
SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb/ibuf%';+ ------------------------------------------------- ------ + --------- + ------- + | NAME | 启用| 定时| + ------------------------------------------------- ------ + --------- + ------- + | wait / synch / mutex / innodb / ibuf_bitmap_mutex | 是的| 是的| | wait / synch / mutex / innodb / ibuf_mutex | 是的| 是的| | wait / synch / mutex / innodb / ibuf_pessimistic_insert_mutex | 是的| 是的| + ------------------------------------------------- ------ + --------- + ------- +有关监视
InnoDB互斥锁等待的信息,请参见 第15.15.2节“使用性能架构监视InnoDB Mutex等待” 。
自适应散列索引功能使得能够
InnoDB
在具有适当的工作负载组合和缓冲池足够内存的系统上执行更像内存数据库,而不会牺牲事务特性或可靠性。
自适应哈希索引功能由
innodb_adaptive_hash_index
变量
启用
,或在服务器启动时关闭
--skip-innodb-adaptive-hash-index
。
基于观察到的搜索模式,使用索引键的前缀构建哈希索引。 前缀可以是任何长度,并且可能只有B树中的某些值出现在哈希索引中。 哈希索引是根据需要经常访问的索引页面构建的。
如果表几乎完全适合主内存,则哈希索引可以通过启用任何元素的直接查找来加速查询,将索引值转换为一种指针。
InnoDB
有一个监视索引搜索的机制。
如果
InnoDB
通知查询可以从构建哈希索引中受益,则会自动执行此操作。
对于某些工作负载,哈希索引查找的加速大大超过了监视索引查找和维护哈希索引结构的额外工作。
在高负载(例如多个并发连接)下,对自适应哈希索引的访问有时会成为争用的来源。
查询与
LIKE
运营商和
%
通配符也往往不会受益。
对于无法从自适应哈希索引功能中受益的工作负载,将其关闭可减少不必要的性能开销。
由于很难预先预测自适应散列索引功能是否适合特定系统和工作负载,因此请考虑在启用和禁用运行基准测试时运行基准测试。
MySQL 5.6中的体系结构更改使其更适合禁用自适应哈希索引功能,而不是早期版本。
自适应哈希索引功能已分区。
每个索引都绑定到一个特定的分区,每个分区都由一个单独的锁存器保护。
分区由
innodb_adaptive_hash_index_parts
变量
控制
。
innodb_adaptive_hash_index_parts
默认情况下,
该
变量设置为8。
最大设置为512。
您可以在
输出
SEMAPHORES
部分中
监视自适应哈希索引的使用和争用
SHOW
ENGINE INNODB
STATUS
。
如果有许多线程正在等待创建的RW锁存器
btr0sea.c
,请考虑增加自适应哈希索引分区的数量或禁用自适应哈希索引功能。
有关哈希索引的性能特征的信息,请参见 第8.3.9节“B树和哈希索引的比较” 。
日志缓冲区是保存要写入磁盘上日志文件的数据的内存区域。
日志缓冲区大小由
innodb_log_buffer_size
变量
定义
。
默认大小为16MB。
日志缓冲区的内容会定期刷新到磁盘。
大型日志缓冲区使大型事务能够运行,而无需在事务提交之前将重做日志数据写入磁盘。
因此,如果您有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘I / O.
该
innodb_flush_log_at_trx_commit
变量控制如何写入日志缓冲区的内容并刷新到磁盘。
该
innodb_flush_log_at_timeout
变量控制日志刷新频率。
有关相关信息,请参阅 内存配置 和 第8.5.4节“优化InnoDB重做日志记录” 。
本节介绍
InnoDB
磁盘结构和相关主题。
本节介绍与
InnoDB
表
相关的主题
。
要创建
InnoDB
表,请使用该
CREATE
TABLE
语句。
CREATE TABLE t1(INT,b CHAR(20),PRIMARY KEY(a))ENGINE = InnoDB;
ENGINE=InnoDB
如果
InnoDB
定义为默认存储引擎,
则
不需要指定
子句
。
要检查默认存储引擎,请发出以下语句:
MySQL的> SELECT @@default_storage_engine;
+ -------------------------- +
| @@ default_storage_engine |
+ -------------------------- +
| InnoDB |
+ -------------------------- +
ENGINE=InnoDB
如果您计划使用
mysqldump
或复制来重放
CREATE
TABLE
默认存储引擎不在的服务器上的语句,
您仍可以使用
子句
InnoDB
。
一个
InnoDB
表及其索引可以在创建
系统表空间
,在一个
文件中,每个表
的表空间,或在
一般的表空间
。
如果
innodb_file_per_table
启用(默认值),则会
InnoDB
在单个每个表的文件表空间中隐式创建一个表。
相反,
innodb_file_per_table
禁用时,会
InnoDB
在
InnoDB
系统表空间中
隐式创建
表。
要在通用表空间中创建表,请使用
CREATE
TABLE ...
TABLESPACE
语法。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
当您在每个表的文件表空间中创建一个
表时,默认情况下
,MySQL会
在MySQL数据目录下的数据库目录中
创建一个
.ibd
表空间文件。
在
InnoDB
系统表空间中创建的表是在现有的
ibdata文件中
创建的,该
文件
位于MySQL数据目录中。
在通用表空间中创建的表在现有的通用表空间
.ibd文件中创建
。
可以在MySQL数据目录的内部或外部创建常规表空间文件。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
在内部,
InnoDB
将每个表的条目添加到数据字典中。
该条目包括数据库名称。
例如,如果
t1
在
test
数据库中
创建了
表,则数据库名称的数据字典条目为
'test/t1'
。
这意味着您可以
t1
在不同的数据库中
创建具有相同名称(
)的表,并且表名不会在内部发生冲突
InnoDB
。
InnoDB
表
的默认行格式
由
innodb_default_row_format
配置选项
定义
,其默认值为
DYNAMIC
。
Dynamic
和
Compressed
行格式允许您利用
InnoDB
表压缩和长列值的高效页外存储等功能。
要使用这些行格式,
innodb_file_per_table
必须启用(默认值)。
SET GLOBAL innodb_file_per_table = 1; CREATE TABLE t3(INT,b CHAR(20),PRIMARY KEY(a))ROW_FORMAT = DYNAMIC; CREATE TABLE t4(INT,b CHAR(20),PRIMARY KEY(a))ROW_FORMAT = COMPRESSED;
或者,您可以使用
CREATE
TABLE ...
TABLESPACE
语法
InnoDB
在常规表空间中
创建
表。
常规表空间支持所有行格式。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
CREATE TABLE t1(c1 INT PRIMARY KEY)TABLESPACE ts1 ROW_FORMAT = DYNAMIC;
CREATE
TABLE ...
TABLESPACE
语法还可用于
在系统表空间中
创建
InnoDB
具有
Dynamic
行格式的表,以及具有
行
Compact
或
Redundant
行格式的
表
。
CREATE TABLE t1(c1 INT PRIMARY KEY)TABLESPACE = innodb_system ROW_FORMAT = DYNAMIC;
有关
InnoDB
行格式的
更多信息
,请参见
第15.10节“InnoDB行格式”
。
有关如何确定
InnoDB
表
的行格式
和
InnoDB
行格式
的物理特性
,请参见
第15.10节“InnoDB行格式”
。
始终
为
表
定义
主键
InnoDB
,指定以下列:
-
被最重要的查询引用。
-
永远不会留空。
-
永远不会有重复的值。
-
很少,如果一旦插入就改变价值。
例如,在包含有关人员信息的表格中,您不会创建主键,
(firstname,
lastname)
因为多个人可以使用相同的名称,有些人使用空白姓氏,有时人们会更改其姓名。
由于存在如此多的约束,通常没有一组明显的列用作主键,因此您创建一个带有数字ID的新列作为主键的全部或部分。
您可以声明一个
自动增量
列,以便在插入行时自动填充升序值:
#ID的值可以像不同表中相关项之间的指针一样。 CREATE TABLE t5(id INT AUTO_INCREMENT,b CHAR(20),PRIMARY KEY(id)); #主键可以包含多个列。任何autoinc列都必须先行。 CREATE TABLE t6(id INT AUTO_INCREMENT,INT,b CHAR(20),PRIMARY KEY(id,a));
尽管该表在没有定义主键的情况下正常工作,但主键涉及性能的许多方面,并且是任何大型或经常使用的表的关键设计方面。
建议您始终在
CREATE
TABLE
语句中
指定主键
。
如果您创建表,加载数据,然后运行
ALTER
TABLE
以稍后添加主键,则该操作比创建表时定义主键要慢得多。
要查看
InnoDB
表
的属性
,请发出以下
SHOW TABLE STATUS
语句:
MySQL的> SHOW TABLE STATUS FROM test LIKE 't%' \G;
*************************** 1。排******************** *******
姓名:t1
引擎:InnoDB
版本:10
Row_format:紧凑
行:0
Avg_row_length:0
Data_length:16384
Max_data_length:0
Index_length:0
Data_free:0
Auto_increment:NULL
Create_time:2015-03-16 15:13:31
Update_time:NULL
Check_time:NULL
排序规则:utf8mb4_0900_ai_ci
校验和:NULL
Create_options:
评论:
有关
SHOW TABLE
STATUS
输出的
信息
,请参见
第13.7.6.36节“显示表状态语法”
。
InnoDB
也可以使用
InnoDB
Information Schema系统表
查询表属性
:
MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test/t1' \G
*************************** 1。排******************** *******
TABLE_ID:45
姓名:test / t1
标志:1
N_COLS:5
空间:35
ROW_FORMAT:紧凑
ZIP_PAGE_SIZE:0
SPACE_TYPE:单身
有关更多信息,请参见 第15.14.3节“InnoDB INFORMATION_SCHEMA架构对象表” 。
本节介绍将一些或所有
InnoDB
表
移动或复制
到其他服务器或实例的技术。
例如,您可以将整个MySQL实例移动到更大,更快的服务器;
您可以将整个MySQL实例克隆到新的复制从属服务器;
您可以将单个表复制到另一个实例以开发和测试应用程序,或者复制到数据仓库服务器以生成报告。
在Windows上,
InnoDB
始终以小写形式在内部存储数据库和表名。
要以二进制格式将数据库从Unix移动到Windows或从Windows移动到Unix,请使用小写名称创建所有数据库和表。
一种方便的方法是
在创建任何数据库或表之前将以
下行添加到
或
文件
的
[mysqld]
部分
:
my.cnf
my.ini
的[mysqld] 的lower_case_table_names = 1
禁止
lower_case_table_names
使用与初始化
服务器时使用的
设置不同的设置启动服务器。
移动或复制
InnoDB
表格的
技巧
包括:
可传输的表空间
可传输表空间功能用于
FLUSH
TABLES ... FOR EXPORT
准备
InnoDB
表,以便从一个服务器实例复制到另一个服务器实例。
要使用此功能,
InnoDB
必须使用
innodb_file_per_table
set
创建表
,
ON
以便每个
InnoDB
表都有自己的表空间。
有关用法信息,请参见
第15.6.3.7节“将表空间复制到另一个实例”
。
MySQL企业备份
MySQL Enterprise Backup产品允许您备份正在运行的MySQL数据库,同时最大限度地减少对操作的干扰,同时生成数据库的一致快照。 当MySQL Enterprise Backup复制表时,可以继续读取和写入。 此外,MySQL Enterprise Backup可以创建压缩备份文件,并备份表的子集。 结合MySQL二进制日志,您可以执行时间点恢复。 MySQL Enterprise Backup作为MySQL Enterprise订阅的一部分包含在内。
有关MySQL Enterprise Backup的更多详细信息,请参见 第30.2节“MySQL Enterprise Backup概述” 。
复制数据文件(冷备份方法)
InnoDB
只需复制
第15.17.1节“InnoDB备份”中
“冷备份”下列出的所有相关文件,
即可移动
数据库
。
InnoDB
数据和日志文件在具有相同浮点数格式的所有平台上是二进制兼容的。
如果浮点格式不同,但是你有没有使用
FLOAT
或
DOUBLE
在您的表中的数据类型,则过程是一样:简单地拷贝相关文件。
移动或复制每个
.ibd
文件的文件时,源系统和目标系统上的数据库目录名必须相同。
存储在
InnoDB
共享表空间中
的表定义
包括数据库名称。
存储在表空间文件中的事务ID和日志序列号在数据库之间也不同。
要将
.ibd
文件和关联表从一个数据库移动到另一个数据库,请使用以下
RENAME
TABLE
语句:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
如果您对文件进行了
“
干净
”
备份
.ibd
,则可以将其还原到源自它的MySQL安装,如下所示:
-
自复制
.ibd文件 以来,不得删除或截断 该表,因为这样做会更改存储在表空间内的表ID。 -
发出此
ALTER TABLE语句以删除当前.ibd文件:ALTER TABLE
tbl_nameDISCARD TABLESPACE; -
将备份
.ibd文件 复制 到正确的数据库目录。 -
发出此
ALTER TABLE语句告诉InnoDB使用.ibd表 的新 文件:ALTER TABLE
tbl_nameIMPORT TABLESPACE;注意该
ALTER TABLE ... IMPORT TABLESPACE功能不会对导入的数据强制执行外键约束。
在此上下文中,
“
干净
”
.ibd
文件备份是满足以下要求的备份:
-
.ibd文件中 的事务没有未提交的修改 。 -
.ibd文件 中没有未合并的插入缓冲区条目 。 -
Purge已从
.ibd文件中 删除了所有删除标记的索引记录 。 -
mysqld 已将
.ibd文件的 所有已修改页面 从缓冲池 刷新 到文件。
您可以
.ibd
使用以下方法
创建一个干净的备份
文件:
-
停止 mysqld 服务器中的 所有活动 并提交所有事务。
-
等到
SHOW ENGINE INNODB STATUS显示数据库中没有活动事务,并且主线程状态InnoDB为Waiting for server activity。 然后,您可以制作该.ibd文件 的副本 。
制作
.ibd
文件
的干净副本的另一种方法
是使用MySQL Enterprise Backup产品:
-
使用MySQL Enterprise Backup备份
InnoDB安装。 -
在备份上 启动第二个 mysqld 服务器,让它清理备份中的
.ibd文件。
导出和导入(mysqldump)
您可以使用 mysqldump 将表转储到一台计算机上,然后在另一台计算机上导入转储文件。 使用此方法,格式是否不同或表是否包含浮点数据无关紧要。
提高此方法性能的一种方法是 在导入数据时 关闭 自动提交 模式,假设表空间有足够的空间用于导入事务生成的大回滚段。 仅在导入整个表或表的一部分后进行提交。
如果您
MyISAM
要转换表格以
InnoDB
获得更好的可靠性和可扩展性,请在转换之前查看以下指南和提示。
MyISAM
在以前版本的MySQL中创建的
分区
表与MySQL 8.0不兼容。
这些表必须在升级之前准备好,方法是删除分区,或者将它们转换为
InnoDB
。
有关
更多信息
,
请参见
第23.6.2节“分区与存储引擎相关的限制”
。
当您从
MyISAM
表中
转换时
,请将
key_buffer_size
配置选项
的值降低
为释放结果不再需要的空闲内存。
增加
innodb_buffer_pool_size
配置选项
的值,该
选项执行为
InnoDB
表
分配高速缓存的类似角色
。
该
InnoDB
缓冲池
可以缓存表数据和索引数据,加快了查询,查找并保持查询结果在内存中进行再利用。
有关缓冲池大小配置的指导,请参见
第8.12.3.1节“MySQL如何使用内存”
。
因为
MyISAM
表不支持
事务
,所以您可能没有太多关注
autocommit
配置选项和
COMMIT
和
ROLLBACK
语句。
这些关键字对于允许多个会话同时读取和写入
InnoDB
表
非常重要
,从而在写入繁重的工作负载中提供了显着的可伸缩性优势。
当事务处于打开状态时,系统会在事务开始时保留数据的快照,如果系统在杂散事务保持运行时插入,更新和删除数百万行,则会导致大量开销。 因此,请注意避免运行时间过长的事务:
-
如果您正在使用 mysql 会话进行交互式实验,请
COMMIT在完成后 始终 (完成更改)或ROLLBACK(撤消更改)。 关闭交互式会话,而不是让它们长时间保持打开状态,以避免事务长时间保持交易。 -
ROLLBACK是一个相对昂贵的操作,因为INSERT,UPDATE和DELETE操作被写入InnoDB表之前COMMIT,期望大多数更改成功提交并且回滚很少。 在试验大量数据时,请避免对大量行进行更改,然后回滚这些更改。 -
使用一系列
INSERT语句 加载大量数据时 ,请定期COMMIT检查结果,以避免持续数小时的事务。 在数据仓库的典型加载操作中,如果出现问题,则截断表(使用TRUNCATE TABLE)并从头开始而不是执行ROLLBACK。
前面的提示可以节省在过长的事务中可能浪费的内存和磁盘空间。
当事务比它们应该更短时,问题是I / O过多。
对于每个
COMMIT
,MySQL确保每个更改都安全地记录到磁盘,这涉及一些I / O.
-
对于
InnoDB表 上的大多数操作 ,您应该使用该设置autocommit=0。 从效率的角度看,这样就避免了在发出大量连续的不必要的I / OINSERT,UPDATE或DELETE语句。 从安全角度来看,ROLLBACK如果您在 mysql 命令行或应用程序中的异常处理程序中 出错 ,这允许您发出 声明以恢复丢失或乱码的数据 。 -
autocommit=1适用于InnoDB表 的时间 是在运行一系列查询以生成报告或分析统计信息时。 在这种情况下,没有与COMMIT或 相关的I / O代价ROLLBACK,并且InnoDB可以 自动优化只读工作负载 。 -
如果进行了一系列相关更改,请在最后一次完成所有更改
COMMIT。 例如,如果将相关的信息片段插入到多个表中,请COMMIT在进行所有更改后 执行单个操作 。 或者,如果您运行多个连续INSERT语句,请COMMIT在加载所有数据后 执行单个语句 ; 如果您正在进行数百万条INSERT语句,可能会通过发出COMMIT每万或数十万条记录来 分割 大额交易,因此交易不会变得太大。 -
请记住,即使
SELECT语句 也会 打开一个事务,因此在交互式 mysql 会话中 运行某些报表或调试查询后 ,可以发出COMMIT或关闭 mysql 会话。
您可能会
在MySQL错误日志或输出中
看到引用
“
死锁
”的
警告消息
SHOW
ENGINE INNODB
STATUS
。
尽管名称听起来可怕,但
死锁
并不是
InnoDB
表格
的严重问题
,通常不需要任何纠正措施。
当两个事务开始修改多个表,以不同的顺序访问表时,它们可以达到每个事务等待另一个事务的状态,并且两者都不能继续。
当
启用
死锁检测
(默认)时,MySQL立即检测到这种情况并取消(
回滚
)
“
较小
”
交易,让对方继续。
如果使用
innodb_deadlock_detect
配置选项
禁用死锁检测
,则
InnoDB
依赖于
innodb_lock_wait_timeout
设置在发生死锁时回滚事务。
无论哪种方式,您的应用程序都需要错误处理逻辑来重新启动由于死锁而被强制取消的事务。 当您重新发出与以前相同的SQL语句时,原始计时问题不再适用。 另一个事务已经完成,您的事务可以继续,或者另一个事务仍在进行中,您的事务将等待直到完成。
如果持续发生死锁警告,您可以查看应用程序代码以一致的方式重新排序SQL操作,或缩短事务。
您可以使用
innodb_print_all_deadlocks
启用
的
选项
进行测试,
以查看MySQL错误日志中的所有死锁警告,而不仅仅是
SHOW
ENGINE INNODB
STATUS
输出中
的最后一个警告
。
有关更多信息,请参见 第15.7.5节“InnoDB中的死锁” 。
要从
InnoDB
表中
获得最佳性能
,您可以调整与存储布局相关的许多参数。
当您将
MyISAM
是大的,经常访问的,并保持至关重要的数据表,调查和考虑
innodb_file_per_table
和
innodb_page_size
配置选项,以及
ROW_FORMAT
和
KEY_BLOCK_SIZE
条款
中的
CREATE
TABLE
说法。
在最初的实验中,最重要的设置是
innodb_file_per_table
。
启用此设置(默认设置)后,将
InnoDB
在
每个表的文件表
空间
中隐式创建
新
表
。
与
InnoDB
系统表空间相比,每个表的表空间允许在截断或删除表时由操作系统回收磁盘空间。
每个表的文件表空间还支持
DYNAMIC
和
COMPRESSED
行格式以及相关的功能,例如表压缩,长可变长度列的高效页外存储以及大索引前缀。
有关更多信息,请参阅
第15.6.3.2节“每个表的文件表空间”
。
您还可以将
InnoDB
表
存储
在共享通用表空间中,该表空间支持多个表和所有行格式。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
您可以创建一个
InnoDB
表,它是MyISAM表的克隆,而不是
ALTER
TABLE
用于执行转换,以在切换之前并排测试旧表和新表。
创建
InnoDB
具有相同列和索引定义
的空
表。
使用
看到完整的
语句中使用。
将
子句
更改
为
。
SHOW CREATE TABLE
table_name\GCREATE TABLE
ENGINE
ENGINE=INNODB
要将大量数据传输到
InnoDB
如上一节所示创建
的空
表中,请插入行
。
INSERT INTO
innodb_table SELECT * FROM
myisam_table ORDER BY
primary_key_columns
您还可以
InnoDB
在插入数据后
为
表
创建索引
。
从历史上看,创建新的二级索引对InnoDB来说是一个缓慢的操作,但现在您可以在加载数据后创建索引,而索引创建步骤的开销相对较小。
如果您
UNIQUE
对辅助密钥
有
约束,则可以通过在导入操作期间临时关闭唯一性检查来加速表导入:
SET unique_checks = 0;
... import operation ...
SET unique_checks = 1;
对于大表,这可以节省磁盘I / O,因为
InnoDB
可以使用其
更改缓冲区
将二级索引记录作为批处理写入。
确保数据不包含重复键。
unique_checks
允许但不要求存储引擎忽略重复键。
为了更好地控制插入过程,您可以插入大表:
INSERT INTO newtable SELECT * FROM oldtable 你的钥匙>something和你的钥匙<=somethingelse;
插入所有记录后,您可以重命名表。
在转换大表期间,增加
InnoDB
缓冲池
的大小
以减少磁盘I / O,最大为物理内存的80%。
您还可以增加
InnoDB
日志文件
的大小
。
如果您打算
InnoDB
在转换过程中
在
表中创建
数据的多个临时副本,
建议您在每个表的文件表空间中创建表,以便在删除表时可以回收磁盘空间。
当
innodb_file_per_table
配置选项启用(默认),新创建的
InnoDB
表在文件的每个表的表空间隐式创建。
无论是
MyISAM
直接
转换
表还是创建克隆
InnoDB
表,请确保在此过程中有足够的磁盘空间来容纳旧表和新表。
InnoDB
表需要比
MyISAM
表
更多的磁盘空间
。
如果
ALTER
TABLE
操作空间不足,则会启动回滚,如果磁盘受限,则可能需要数小时。
对于插入,
InnoDB
使用插入缓冲区将二级索引记录批量合并到索引中。
这节省了大量的磁盘I / O.
对于回滚,不使用此类机制,并且回滚可能比插入时间长30倍。
在失控回滚的情况下,如果数据库中没有有价值的数据,则建议终止数据库进程,而不是等待数百万个磁盘I / O操作完成。 有关完整的过程,请参见 第15.20.2节“强制InnoDB恢复” 。
该
PRIMARY KEY
子句是影响MySQL查询性能以及表和索引的空间使用的关键因素。
主键唯一标识表中的行。
表中的每一行都必须具有主键值,并且没有两行可以具有相同的主键值。
这些是主键的准则,然后是更详细的解释。
-
PRIMARY KEY为每个表 声明一个 。 通常,它是WHERE查找单行时 在 子句中 引用的最重要的列 。 -
PRIMARY KEY在原始CREATE TABLE语句中 声明该 子句 ,而不是稍后通过ALTER TABLE语句 添加它 。 -
仔细选择列及其数据类型。 首选数字列而不是字符或字符串。
-
如果没有要使用的另一个稳定,唯一,非空的数字列,请考虑使用自动增量列。
-
如果对主键列的值是否可能发生变化有任何疑问,自动增量列也是一个不错的选择。 更改主键列的值是一项昂贵的操作,可能涉及重新排列表中和每个二级索引中的数据。
考虑将 主键 添加 到任何尚未拥有的表中。 根据表格的最大投影尺寸使用最小的实际数字类型。 这可以使每一排稍微紧凑,这可以为大型桌子节省大量空间。 如果表具有任何 二级索引 , 则节省的空间将成倍增加 ,因为主键值在每个二级索引条目中重复。 除了减少磁盘上的数据大小之外,一个小的主键还可以让更多数据适合 缓冲池 ,从而加速各种操作并提高并发性。
如果表已经在某个较长的列(例如a)上具有主键
VARCHAR
,请考虑添加新的无符号
AUTO_INCREMENT
列并将主键切换到该列,即使查询中未引用该列也是如此。
这种设计变更可以在二级指标中节省大量空间。
您可以指定以前的主键列,
UNIQUE NOT NULL
以强制执行与
PRIMARY KEY
子句
相同的约束
,即防止所有这些列中出现重复或空值。
如果跨多个表传播相关信息,通常每个表对其主键使用相同的列。 例如,人员数据库可能有多个表,每个表都有一个员工编号的主键。 销售数据库可能有一些表具有客户编号的主键,而其他表具有订货号的主键。 因为使用主键的查找速度非常快,所以可以为这些表构建有效的连接查询。
如果你
PRIMARY KEY
完全
抛弃该
条款,MySQL会为你创建一个看不见
的
子句。
它是一个6字节的值,可能比您需要的长,因此浪费空间。
因为它是隐藏的,所以您无法在查询中引用它。
可靠性和可伸缩性功能
InnoDB
需要比同等
MyISAM
表
更多的磁盘存储
。
您可以稍微更改列和索引定义,以便在处理结果集时更好地利用空间,减少I / O和内存消耗,以及更有效地使用索引查找的更好的查询优化计划。
如果确实为主键设置了数字ID列,请使用该值与任何其他表中的相关值进行交叉引用,尤其是对于
连接
查询。
例如,不是接受国家/地区名称作为输入并执行搜索相同名称的查询,而是执行一次查找以确定国家/地区ID,然后执行其他查询(或单个连接查询)以在多个表中查找相关信息。
不是将客户或目录项编号存储为数字字符串,而是使用几个字节,将其转换为数字ID以进行存储和查询。
4字节无符号
INT
专栏可以索引超过40亿件物品(美国含义为10亿:1000万)。
有关不同整数类型的范围,请参见
第11.2.1节“整数类型(精确值) - INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT”
。
InnoDB
提供了一种可配置的锁定机制,可以显着提高SQL语句的可伸缩性和性能,从而为具有
AUTO_INCREMENT
列的
表添加行
。
要将该
AUTO_INCREMENT
机制与
InnoDB
表
一起使用
,
AUTO_INCREMENT
必须将列定义为索引的一部分,以便可以
在表上
执行等效的索引
查找以获取最大列值。
通常,这是通过使列成为某些表索引的第一列来实现的。
SELECT
MAX(
ai_col)
本节介绍
AUTO_INCREMENT
锁定模式
的行为,
不同
AUTO_INCREMENT
锁定模式设置的
使用含义
以及如何
InnoDB
初始化
AUTO_INCREMENT
计数器。
本节介绍
AUTO_INCREMENT
用于生成自动增量值
的
锁定模式
的行为
,以及每种锁定模式如何影响复制。
使用
innodb_autoinc_lock_mode
配置参数
在启动时配置自动增量锁定模式
。
以下术语用于描述
innodb_autoinc_lock_mode
设置:
-
“
INSERT似的 ” 陈述在表中生成新的行中的所有语句,包括
INSERT,INSERT ... SELECT,REPLACE,REPLACE ... SELECT,和LOAD DATA。 包括 “ 简单插入 ” , “ 批量插入 ” 和 “ 混合模式 ” 插入。 -
“ 简单插入 ”
可以预先确定要插入的行数的语句(最初处理语句时)。 这包括单行和多行
INSERT以及REPLACE没有嵌套子查询的语句,但不包括INSERT ... ON DUPLICATE KEY UPDATE。 -
“ 批量插入 ”
预先不知道要插入的行数(以及所需的自动增量值的数量)的语句。 这包括
INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA声明,但不是简单的INSERT。 在处理每一行时,一次为列InnoDB分配新值AUTO_INCREMENT。 -
“ 混合模式插入 ”
这些是 “ 简单插入 ” 语句,它指定一些(但不是全部)新行的自动增量值。 下面
c1是一个 示例,其中 是一AUTO_INCREMENT列表t1:INSERT INTO t1(c1,c2)VALUES(1,'a'),(NULL,'b'),(5,'c'),(NULL,'d');
另一种类型的 “ 混合模式插入 ” 是
INSERT ... ON DUPLICATE KEY UPDATE,在最坏的情况下实际上是INSERT后跟aUPDATE,其中AUTO_INCREMENT在更新阶段期间可以使用或不使用列 的分配值 。
innodb_autoinc_lock_mode
配置参数
有三种可能的设置
。
对于
“
传统
”
,
“
连续
”
或
“
交错
”
锁定模式,
设置分别为0,1或2
。
从MySQL 8.0开始,交错锁定模式(
innodb_autoinc_lock_mode=2
)是默认设置。
在MySQL 8.0之前,连续锁定模式是默认值(
innodb_autoinc_lock_mode=1
)。
MySQL 8.0中的交错锁定模式的默认设置反映了从基于语句的复制到基于行的复制的更改,作为默认复制类型。 基于语句的复制需要连续的自动增量锁定模式,以确保为给定的SQL语句序列以可预测和可重复的顺序分配自动增量值,而基于行的复制对SQL语句的执行顺序不敏感。
-
innodb_autoinc_lock_mode = 0( “ 传统 ” 锁定模式)传统的锁定模式提供了与
innodb_autoinc_lock_modeMySQL 5.1中引入配置参数 之前相同的行为 。 传统的锁定模式选项用于向后兼容,性能测试以及解决“混合模式插入”问题,因为语义可能存在差异。在此锁定模式下,所有 “ INSERT-like ” 语句都会获得一个特殊的表级
AUTO-INC锁,以便插入带有AUTO_INCREMENT列的表中。 此锁通常保持在语句的末尾(而不是事务的结尾),以确保为给定的INSERT语句 序列以可预测和可重复的顺序分配自动增量值 ,并确保自动增量值由任何给定的声明分配是连续的。对于基于语句的复制,这意味着在从属服务器上复制SQL语句时,自动增量列使用的值与主服务器上的值相同。 执行多个
INSERT语句 的结果 是确定性的,并且从站再现与主站上相同的数据。 如果多个INSERT语句 生成的自动递增值 是交错的,则两个并发INSERT语句 的结果 将是不确定的,并且无法使用基于语句的复制可靠地传播到从属服务器。为清楚起见,请考虑使用此表的示例:
CREATE TABLE t1( c1 INT(11)NOT NULL AUTO_INCREMENT, c2 VARCHAR(10)DEFAULT NULL, 主要关键(c1) )ENGINE = InnoDB;
假设有两个事务正在运行,每个事务都将行插入带有
AUTO_INCREMENT列 的表中 。 一个事务使用INSERT ... SELECT插入1000行 的 语句, 另一个事务使用 插入一行的简单INSERT语句:Tx1:INSERT INTO t1(c2)从另一个表中选择1000行... Tx2:INSERT INTO t1(c2)VALUES('xxx');
InnoDB事先无法判断从 Tx1SELECT中的INSERT语句中 检索了多少行 ,并且 随着 语句的进行,它会一次分配一个自动增量值。 使用保持在语句末尾的表级锁定,一次只能 执行 一个INSERT引用表的语句t1,并且不会交错生成不同语句的自动增量数。 由Tx1INSERT ... SELECT语句 生成的自动递增值 是连续的,并且由(单个)自动递增值使用INSERTTx2中的语句要小于或大于用于Tx1的语句,具体取决于首先执行的语句。只要SQL语句在从二进制日志重放时(在使用基于语句的复制时或在恢复方案中)以相同的顺序执行,结果与首次运行Tx1和Tx2时的结果相同。 因此,表级锁定一直持续到语句结束时,
INSERT使用自动增量安全 的语句可以 安全地用于基于语句的复制。 但是,当多个事务同时执行insert语句时,这些表级锁限制了并发性和可伸缩性。在前面的示例中,如果没有表级锁定,则用于
INSERTTx2 中的自动增量列的值 取决于语句执行的时间。 如果INSERTTx2在INSERTTx1运行时执行(而不是在启动之前或完成之后),则由两个INSERT语句 分配的特定自动增量值 是不确定的,并且可能因运行而异。在 连续 锁定模式下,
InnoDB可以避免将表级AUTO-INC锁定用于 预先知道行数的 “ 简单插入 ” 语句,并且仍然保留基于语句的复制的确定性执行和安全性。如果您不使用二进制日志作为恢复或复制的一部分重放SQL语句,则 交错 锁定模式可用于消除表级
AUTO-INC锁的 所有使用,从而 实现更高的并发性和性能,但代价是允许自动存在空白 - 由语句分配的增量编号,可能具有由并发执行的语句交错分配的编号。 -
innodb_autoinc_lock_mode = 1( “ 连续 ” 锁定模式)在此模式下, “ 批量插入 ” 使用特殊的
AUTO-INC表级锁定并保持它直到语句结束。 这适用于所有INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句。 只有一个持有AUTO-INC锁的 语句 可以一次执行。 如果批量插入操作的源表与目标表不同,则AUTO-INC在从源表中选择的第一行上执行共享锁之后,将对目标表执行锁定。 如果批量插入操作的源和目标是同一个表,则AUTO-INC在对所有选定的行执行共享锁定后执行锁定。“ 简单插入 ” (预先知道要插入的行数)
AUTO-INC通过在互斥锁(轻量级锁定)的控制下获得所需数量的自动增量值来 避免表级 锁定在分配过程的持续时间内保持, 不 直到语句完成。AUTO-INC除非AUTO-INC另一个事务持有 锁,否则 不使用表级 锁 。 如果另一个事务持有AUTO-INC锁,则 “ 简单插入 ” 等待AUTO-INC锁定,就像它是 “ 批量插入 “ 。此锁定模式确保在存在
INSERT未提前知道行数 的 语句(以及在语句进行时指定自动增量编号)的情况下,由任何 “INSERT-like ” 语句 指定的所有自动增量值 都是连续,并且操作对于基于语句的复制是安全的。简而言之,这种锁定模式显着提高了可伸缩性,同时可以安全地使用基于语句的复制。 此外,与 “ 传统 ” 锁定模式一样,由任何给定语句分配的自动递增数字是 连续的 。 有 没有变化 在语义比较 “ 传统 ” 对于使用自动递增,有一个重要的例外,任何声明模式。
“ 混合模式插入 ” 的例外情况是, 用户为
AUTO_INCREMENT多行 “ 简单插入 ”中的 某些行(但不是所有行) 提供 列的 显式值 。 对于此类插入,请InnoDB分配比要插入的行数更多的自动增量值。 但是,自动分配的所有值都是连续生成(因此高于)最近执行的先前语句生成的自动增量值。 “ 超额 ” 号码丢失了。 -
innodb_autoinc_lock_mode = 2( “ 交错 ” 锁定模式)在此锁定模式下,没有 “
INSERT-like ” 语句使用表级AUTO-INC锁,并且多个语句可以同时执行。 这是最快且最具扩展性的锁定模式,但 在从二进制日志重放SQL语句时使用基于语句的复制或恢复方案时 ,这是 不安全的 。在这种锁定模式下,自动增量值保证是唯一的,并且在所有同时执行的 “
INSERT类似 ” 语句中 单调递增 。 但是,因为多个语句可以同时生成数字(即,数字的分配 在语句之间 交错 ),所以为任何给定语句插入的行生成的值可能不是连续的。如果执行的唯一语句是 “ 简单插入 ” ,其中要插入的行数是提前知道的,则除了 “ 混合模式插入 ” 之外,单个语句生成的数字没有间隙 。 但是,当 执行 “ 批量插入 ” 时 ,任何给定语句分配的自动增量值可能存在间隙。
-
使用复制自动增量
如果使用基于语句的复制,请设置
innodb_autoinc_lock_mode为0或1,并在主服务器及其从服务器上使用相同的值。 如果使用innodb_autoinc_lock_mode= 2( “ 交错 ” )或主站和从站不使用相同锁定模式的配置, 则不确保从站上的自动增量值 与主站上的相同。如果使用基于行或混合格式的复制,则所有自动增量锁定模式都是安全的,因为基于行的复制对SQL语句的执行顺序不敏感(并且混合格式使用基于行的方式)复制任何对基于语句的复制不安全的语句。
-
“ 丢失 ” 自动递增值和序列间隙
在所有锁定模式(0,1和2)中,如果生成自动增量值的事务回滚,则这些自动增量值将 “ 丢失 ” 。 一旦为自动增量列生成了值,就无法回滚它,无论 “
INSERT-like ” 语句是否完成,以及是否回滚包含的事务。 这些丢失的值不会被重用。 因此,存储在AUTO_INCREMENT表 的 列 中的值可能存在间隙 。 -
为
AUTO_INCREMENT列 指定NULL或0在所有的锁模式(0,1,2),如果用户指定NULL或0用于
AUTO_INCREMENT在列INSERT,InnoDB将行仿佛没有指定值,并且生成用于它的新值。 -
为
AUTO_INCREMENT列 指定负值在所有锁定模式(0,1和2)中,如果为
AUTO_INCREMENT列 指定负值,则不会定义自动增量机制的行为 。 -
如果该
AUTO_INCREMENT值大于指定整数类型的最大整数在所有锁定模式(0,1和2)中,如果值大于可以存储在指定整数类型中的最大整数,则不会定义自动增量机制的行为。
-
“ 批量插入 ”的 自动增量值的差距
与
innodb_autoinc_lock_mode设定为0( “ 传统 ” )或1( “ 连续 ” ),通过任何给定语句生成的自动递增的值是连续的,没有间隙,这是因为表级AUTO-INC锁一直保持到该语句的末尾,只有一个这样的语句可以一次执行。与
innodb_autoinc_lock_mode设置为2( “ 交织 ” ),有可能是在所产生的自动递增值间隙 “ 批量插入 , ” 但只有当有同时执行的 “INSERT样 ” 的语句。对于锁定模式1或2,在连续语句之间可能出现间隙,因为对于批量插入,可能不知道每个语句所需的确切数量的自动增量值,并且可能过高估计。
-
由 “ 混合模式插入 ” 指定的自动递增值
考虑 “ 混合模式插入 ” ,其中 “ 简单插入 ” 指定某些(但不是全部)结果行的自动增量值。 这种语句在锁定模式0,1和2中表现不同。例如,假设
c1是一AUTO_INCREMENT列表t1,并且最近自动生成的序列号是100。mysql>
CREATE TABLE t1 (- >c1 INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,- >c2 CHAR(1)- >) ENGINE = INNODB;现在,考虑以下 “ 混合模式插入 ” 语句:
MySQL的>
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');随着
innodb_autoinc_lock_mode设置为0( “ 传统 ” ),这四个新的行是:MySQL的>
SELECT c1, c2 FROM t1 ORDER BY c2;+ ----- + ------ + | c1 | c2 | + ----- + ------ + | 1 | a | | 101 | b | | 5 | c | | 102 | d | + ----- + ------ +下一个可用的自动增量值为103,因为自动增量值一次分配一个,而不是在语句执行开始时一次分配。 无论是否同时执行 “
INSERT-like ” 语句(任何类型), 此结果都是正确的 。随着
innodb_autoinc_lock_mode设置为1( “ 连续 ” ),这四个新行也:MySQL的>
SELECT c1, c2 FROM t1 ORDER BY c2;+ ----- + ------ + | c1 | c2 | + ----- + ------ + | 1 | a | | 101 | b | | 5 | c | | 102 | d | + ----- + ------ +但是,在这种情况下,下一个可用的自动增量值是105,而不是103,因为在处理语句时分配了四个自动增量值,但只使用了两个。 无论是否同时执行 “
INSERT-like ” 语句(任何类型), 此结果都是正确的 。与
innodb_autoinc_lock_mode设定为模式2( “ 交织 ” ),四个新的行是:MySQL的>
SELECT c1, c2 FROM t1 ORDER BY c2;+ ----- + ------ + | c1 | c2 | + ----- + ------ + | 1 | a | |x| b | | 5 | c | |y| d | + ----- + ------ +的值
x和y是独一无二的,比任何先前产生的行大。 然而,具体的数值x,并y依赖于并行执行语句生成自动递增值的数量。最后,考虑以下语句,在最近生成的序列号为100时发出:
MySQL的>
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (101,'c'), (NULL,'d');对于任何
innodb_autoinc_lock_mode设置,此语句将生成重复键错误23000(Can't write; duplicate key in table),因为为行分配了101并且行的(NULL, 'b')插入(101, 'c')失败。 -
AUTO_INCREMENT在一系列INSERT语句 的中间 修改 列值在MySQL 5.7及更早版本中,修改 语句
AUTO_INCREMENT序列中间 的 列值INSERT可能会导致 “ 重复条目 ” 错误。 例如,如果执行的UPDATE操作将AUTO_INCREMENT列值 更改为 大于当前最大自动增量值的值,则INSERT未指定未使用的自动增量值的 后续 操作可能会遇到 “ 重复条目 ” 错误。 在MySQL 8.0及更高版本中,如果您修改了AUTO_INCREMENT如果列值大于当前最大自动增量值,则新值将保持不变,后续INSERT操作将从新的较大值开始分配自动增量值。 以下示例演示了此行为。mysql>
CREATE TABLE t1 (- >c1 INT NOT NULL AUTO_INCREMENT,- >PRIMARY KEY (c1)- >) ENGINE = InnoDB;MySQL的>INSERT INTO t1 VALUES(0), (0), (3);MySQL的>SELECT c1 FROM t1;+ ---- + | c1 | + ---- + | 1 | | 2 | | 3 | + ---- + MySQL的>UPDATE t1 SET c1 = 4 WHERE c1 = 1;MySQL的>SELECT c1 FROM t1;+ ---- + | c1 | + ---- + | 2 | | 3 | | 4 | + ---- + MySQL的>INSERT INTO t1 VALUES(0);MySQL的>SELECT c1 FROM t1;+ ---- + | c1 | + ---- + | 2 | | 3 | | 4 | | 5 | + ---- +
本节介绍如何
InnoDB
初始化
AUTO_INCREMENT
计数器。
如果
AUTO_INCREMENT
为
InnoDB
表
指定
列
,则内存中表对象包含一个称为自动增量计数器的特殊计数器,该计数器在为列分配新值时使用。
在MySQL 5.7及更早版本中,自动增量计数器仅存储在主存储器中,而不存储在磁盘上。
要在服务器重新启动后初始化自动增量计数器,
InnoDB
将在第一次插入到包含
AUTO_INCREMENT
列
的表中执行以下语句的等效语句
。
SELECT MAX(ai_col)FROM table_nameFOR UPDATE;
在MySQL 8.0中,此行为已更改。 每次更改时,当前最大自动增量计数器值将写入重做日志,并保存到每个检查点上的引擎专用系统表中。 这些更改使当前最大自动增量计数器值在服务器重新启动时保持不变。
在正常关闭后重新启动服务器上,
InnoDB
使用存储在数据字典系统表中的当前最大自动增量值初始化内存中自动递增计数器。
在崩溃恢复期间在服务器上重新启动时,
InnoDB
使用存储在数据字典系统表中的当前最大自动增量值初始化内存中自动增量计数器,并扫描重做日志以查找自上一个检查点以来写入的自动增量计数器值。
如果重做日志值大于内存中计数器值,则应用重做日志值。
但是,在服务器崩溃的情况下,无法保证重用先前分配的自动增量值。
每次由于
INSERT
或
更改当前最大自动增量值
UPDATE
操作时,新值将写入重做日志,但如果在重做日志刷新到磁盘之前发生崩溃,则在重新启动服务器后初始化自动增量计数器时,可以重用先前分配的值。
在MySQL 8.0及更高版本中
InnoDB
使用等效
语句来初始化自动增量计数器
的唯一情况
是在
导入
没有
元数据文件
的表空间
时
。
否则,从
元数据文件中
读取当前最大自动增量计数器值
。
SELECT MAX(ai_col) FROM
table_name FOR UPDATE.cfg
.cfg
在MySQL 5.7及更早版本中,服务器重新启动会取消
AUTO_INCREMENT = N
table选项
的效果,该
选项可以在
CREATE TABLE
or
ALTER TABLE
语句中用于设置初始计数器值或分别更改现有计数器值。
在MySQL 8.0中,服务器重新启动不会取消
AUTO_INCREMENT = N
表选项
的效果
。
如果将自动递增计数器初始化为特定值,或者将自动递增计数器值更改为更大的值,则新值将在服务器重新启动时保持不变。
ALTER
TABLE ...
AUTO_INCREMENT = N
只能将自动增量计数器值更改为大于当前最大值的值。
在MySQL 5.7及更早版本中,服务器在
ROLLBACK
操作后
立即重新启动
可能会导致重用先前分配给回滚事务的自动增量值,从而有效地回滚当前的最大自动增量值。
在MySQL 8.0中,当前的最大自动增量值是持久的,从而阻止了以前分配的值的重用。
如果
SHOW TABLE STATUS
语句在初始化自动增量计数器之前检查表,则
InnoDB
打开表并使用存储在数据字典系统表中的当前最大自动增量值初始化计数器值。
该值存储在内存中以供以后插入或更新使用。
计数器值的初始化使用表上的常规异或锁定读取,该读取持续到事务结束。
InnoDB
在为具有用户指定的自动增量值大于0的新创建的表初始化自动增量计数器时,遵循相同的过程。
初始化自动递增计数器后,如果在插入行时未显式指定自动递增值,则
InnoDB
隐式递增计数器并将新值分配给列。
如果插入显式指定自动增量列值的行,并且该值大于当前最大计数器值,则计数器将设置为指定值。
InnoDB
只要服务器运行,就使用内存中的自动增量计数器。
停止并重新启动服务器时,
InnoDB
重新初始化自动增量计数器,如前所述。
的
auto_increment_offset
配置选项确定为起点
AUTO_INCREMENT
列值。
默认设置为1。
的
auto_increment_increment
配置选项控制连续列的值之间的间隔。
默认设置为1。
InnoDB
本节中的以下主题描述
了
存储引擎
如何
处理外键约束:
有关外键使用信息和示例,请参见 第13.1.20.6节“使用FOREIGN KEY约束” 。
InnoDB
表的
外键定义符合
以下条件:
-
InnoDB允许外键引用任何索引列或列组。 但是,在引用的表中,必须有一个索引,其中引用的列是 同一顺序 中的 第一 列。InnoDB还会考虑添加到索引的 隐藏列 (请参见 第15.6.2.1节“聚簇和二级索引” )。 -
InnoDB当前不支持具有用户定义分区的表的外键。 这意味着没有用户分区的InnoDB表可能包含外键引用的外键引用或列。 -
InnoDB允许外键约束引用非唯一键。 这是InnoDB标准SQL 的 扩展。
InnoDB
表的
外键的引用操作
受以下条件限制:
-
虽然
SET DEFAULTMySQL服务器允许,但它被拒绝为无效InnoDB。CREATE TABLE并ALTER TABLE利用这一条款语句不得用于InnoDB表。 -
如果父表中有多个行具有相同的引用键值,则
InnoDB在外键检查中执行操作,就好像其他具有相同键值的父行不存在一样。 例如,如果已定义RESTRICT类型约束,并且存在具有多个父行的子行,InnoDB则不允许删除任何这些父行。 -
InnoDB基于对应于外键约束的索引中的记录,通过深度优先算法执行级联操作。 -
如果
ON UPDATE CASCADE或者ON UPDATE SET NULLrecurses更新 它在级联期间先前已 更新的 同一个表 ,它的作用就像RESTRICT。 这意味着您不能使用自引用ON UPDATE CASCADE或ON UPDATE SET NULL操作。 这是为了防止级联更新导致的无限循环。 自引用的ON DELETE SET NULL,在另一方面,是可能的,因为是自引用ON DELETE CASCADE。 级联操作可能不会嵌套超过15级。 -
与MySQL一样,在一个SQL语句中, 逐行 插入,删除或更新许多行,
InnoDB检查UNIQUE和FOREIGN KEY约束。 执行外键检查时,InnoDB在必须查看的子记录或父记录上设置共享行级锁。InnoDB立即检查外键约束; 检查不会延迟到事务提交。 根据SQL标准,默认行为应该是延迟检查。 也就是说,只有在处理 完整个SQL语句 后才会检查约束 。 直到InnoDB实现延迟约束检查,有些事情是不可能的,例如删除使用外键引用自身的记录。
-
在存储生成列外键约束不能使用
CASCADE,SET NULL或SET DEFAULT作为ON UPDATE参照动作,也不能使用SET NULL或SET DEFAULT作为ON DELETE参照动作。 -
在存储生成列的基本列外键约束不能使用
CASCADE,SET NULL或SET DEFAULT作为ON UPDATE或ON DELETE引用操作。 -
外键约束不能引用 虚拟生成的列 。
-
在MySQL 8.0之前,外键约束不能引用在虚拟生成列上定义的辅助索引。
InnoDB
表中的
限制
在本节的以下主题中描述:
在使用NFS之前
InnoDB
,请查看
使用NFS与MySQL中
概述的潜在问题
。
-
一个表最多可包含1017列。 虚拟生成列包含在此限制中。
-
一个表最多可包含64个 二级索引 。
-
对于
InnoDB使用DYNAMIC或COMPRESSED行格式的 表, 索引键前缀长度限制为3072字节 。对于
InnoDB使用REDUNDANT或COMPACT行格式的 表, 索引键前缀长度限制为767字节 。 例如,您可能会 在一个 或一 列 上使用超过191个字符 的 列前缀 索引 达到此限制 ,假定 为每个字符设置 一个 字符集且最多为4个字节。TEXTVARCHARutf8mb4尝试使用超出限制的索引键前缀长度会返回错误。
适用于索引键前缀的限制也适用于全列索引键。
-
如果 通过 在创建MySQL实例时 指定 选项 将
InnoDB页面大小减小 到8KB或4KBinnodb_page_size,则索引键的最大长度将按比例降低,基于16KB页面大小的3072字节限制。 也就是说,当页面大小为8KB时,最大索引密钥长度为1536字节,当页面大小为4KB时,最大索引密钥长度为768字节。 -
多列索引最多允许16列。 超过限制会返回错误。
ERROR 1070(42000):指定的关键部件太多; 最多允许16件
-
最大行长度,除了可变长度列(
VARBINARY,VARCHAR,BLOB和TEXT),是比对于4KB,8KB,16KB,32KB和页大小的页的一半稍少。 例如,默认innodb_page_size值为16KB 的最大行长度 约为8000字节。 对于InnoDB64KB 的 页面大小,最大行长度约为16000字节。LONGBLOB和LONGTEXT列必须小于4GB,并且总行长度(包括 列BLOB和TEXT列)必须小于4GB。如果一行长度小于半页,则所有行都存储在页面内。 如果它超过半页,则选择可变长度列用于外部页外存储,直到该行适合半页,如 第15.11.2节“文件空间管理”中所述 。
-
虽然
InnoDB内部支持的行大小超过65,535字节,但MySQL本身对所有列的总大小强加了行大小限制为65,535:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),- >c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),- >f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118(42000):行大小太大。最大行大小 使用的表类型,不计算BLOB,是65535.你必须改变一些 列到TEXT或BLOB请参见 第C.10.4节“表列数和行大小的限制” 。
-
在某些较旧的操作系统上,文件必须小于2GB。 这不是
InnoDB自身 的限制 ,但如果您需要大型表空间,请使用几个较小的数据文件而不是一个大型数据文件进行配置。 -
InnoDB日志文件 的总大小 最大可达512GB。 -
最小表空间大小略大于10MB。 最大表空间大小取决于
InnoDB页面大小。
最大表空间大小也是表的最大大小。
-
表空间文件的路径(包括文件名)不能超过
MAX_PATHWindows上 的 限制。 在Windows 10之前,MAX_PATH限制为260个字符。 从Windows 10版本1607开始,MAX_PATH从常见的Win32文件和目录函数中删除了限制,但您必须启用新行为。 -
默认页面大小
InnoDB为16KB。 您可以通过innodb_page_size在创建MySQL实例时 配置 选项 来增加或减少页面大小 。支持32KB和64KB页面大小,但
ROW_FORMAT=COMPRESSED不支持大于16KB的页面大小。 对于32KB和64KB页面大小,最大记录大小为16KB。 对于innodb_page_size=32KB,范围大小为2MB。 对于innodb_page_size=64KB,范围大小是4MB。使用特定
InnoDB页面大小的 MySQL实例 无法使用来自使用不同页面大小的实例的数据文件或日志文件。
-
ANALYZE TABLE通过 对每个索引树 执行 随机潜水 并相应地更新索引基数估计 来确定索引基数(显示在 输出Cardinality列中SHOW INDEX) 。 因为这些只是估计,所以重复运行 会产生不同的数字。 这使得 表格 快速 但不是100%准确,因为它不会考虑所有行。ANALYZE TABLEANALYZE TABLEInnoDB通过打开 配置选项, 您可以 更精确,更稳定地 收集 统计信息 ,如 第15.8.10.1节“配置持久优化器统计信息参数”中所述 。 启用该设置 后,在对索引列数据进行重大更改后 运行非常重要 ,因为不会定期重新计算统计信息(例如在服务器重新启动后)。
ANALYZE TABLEinnodb_stats_persistentANALYZE TABLE如果启用了持久性统计设置,则可以通过修改
innodb_stats_persistent_sample_pages系统变量 来更改随机潜水次数 。 如果禁用持久统计信息设置,请innodb_stats_transient_sample_pages改为 修改 系统变量。MySQL在连接优化中使用索引基数估计。 如果未以正确的方式优化连接,请尝试使用
ANALYZE TABLE。 在少数几个ANALYZE TABLE不能为您的特定表生成足够好的值的 情况下 ,您可以使用FORCE INDEX查询来强制使用特定索引,或者设置max_seeks_for_key系统变量以确保MySQL更喜欢对表扫描进行索引查找。 请参见 第B.4.5节“与优化程序相关的问题” 。 -
如果语句或事务在表上运行,并且
ANALYZE TABLE在同 一个表 上运行,然后执行第二个ANALYZE TABLE操作,则第二个ANALYZE TABLE操作将被阻止,直到语句或事务完成为止。 出现此问题的原因 是ANALYZE TABLE当ANALYZE TABLE完成运行 时将当前加载的表定义标记为已过时 。 新的陈述或交易(包括第二次ANALYZE TABLE必须将新表定义加载到表缓存中,直到当前运行的语句或事务完成并清除旧表定义时才会发生这种情况。 不支持加载多个并发表定义。 -
SHOW TABLE STATUSInnoDB除了表保留的物理大小之外, 没有给出 表的 准确统计信息 。 行计数只是SQL优化中使用的粗略估计。 -
InnoDB不保留表中的内部行数,因为并发事务可能同时 “ 看到 ” 不同数量的行。 因此,SELECT COUNT(*)语句只计算当前事务可见的行。有关信息如何
InnoDB处理SELECT COUNT(*)报表,请参阅COUNT()说明在 第12.20.1,“集合(GROUP BY)功能说明” 。 -
在Windows上,
InnoDB始终以小写形式在内部存储数据库和表名。 要以二进制格式将数据库从Unix移动到Windows或从Windows移动到Unix,请使用小写名称创建所有数据库和表。 -
一
AUTO_INCREMENT列ai_col必须被定义为一个指数,使得它能够进行一个索引的等效的部分 上的表查找以获得最大列值。 通常,这是通过使列成为某些表索引的第一列来实现的。SELECT MAX(ai_col) -
InnoDBAUTO_INCREMENT在初始化AUTO_INCREMENT表上的 先前指定的 列时,在 与 列 关联的索引的末尾设置独占锁 。使用
innodb_autoinc_lock_mode=0,InnoDB使用特殊的AUTO-INC表锁定模式,其中获取锁定并在访问自动增量计数器时保持到当前SQL语句的末尾。 在保持AUTO-INC表锁定 时,其他客户端无法插入表中 。 对于发生相同的行为 “ 批量插入 ” 与innodb_autoinc_lock_mode=1。 表级AUTO-INC锁不用于innodb_autoinc_lock_mode=2。 有关更多信息,请参见 第15.6.1.4节“InnoDB中的AUTO_INCREMENT处理” 。 -
当
AUTO_INCREMENT整数列用完值时,后续INSERT操作将返回重复键错误。 这是一般的MySQL行为。 -
DELETE FROM不会重新生成表,而是逐个删除所有行。tbl_name -
级联外键操作不会激活触发器。
-
不能创建与内部的名称匹配的列名的表
InnoDB列(其中包括DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR,和DB_MIX_ID)。 此限制适用于在任何字母大小写中使用名称。MySQL的>
CREATE TABLE t1 (c1 INT, db_row_id INT) ENGINE=INNODB;错误1166(42000):错误的列名'db_row_id'
-
LOCK TABLES如果innodb_table_locks=1(默认值), 则在每个表上获取两个锁 。 除了MySQL层上的表锁之外,它还获取InnoDB表锁。 4.1.2之前的MySQL版本没有获取InnoDB表锁; 可以通过设置选择旧行为innodb_table_locks=0。 如果未InnoDB获取表锁,LOCK TABLES即使某些表的记录被其他事务锁定 , 也会完成。在MySQL 8.0中,
innodb_table_locks=0对于显式锁定的表没有任何影响LOCK TABLES ... WRITE。 它对通过LOCK TABLES ... WRITE隐式(例如,通过触发器)或通过隐藏(例如,通过触发器) 锁定读取或写入的表有效LOCK TABLES ... READ。 -
InnoDB事务提交或中止时,将释放事务持有的 所有 锁。 因此,它并没有多大意义,调用LOCK TABLES上InnoDB表中autocommit=1模式,因为所获得的InnoDB表锁将被立即释放。 -
您无法在事务中锁定其他表,因为
LOCK TABLES执行隐式COMMIT和UNLOCK TABLES。 -
有关与并发读写事务关联的限制,请参见 第15.6.6节“撤消日志” 。
本节介绍与
InnoDB
索引
相关的主题
。
每个
InnoDB
表都有一个称为
聚簇索引
的特殊索引,
其中存储了行的数据。
通常,聚簇索引与
主键
同义
。
要从查询,插入和其他数据库操作中获得最佳性能,您必须了解如何
InnoDB
使用聚簇索引来优化每个表的最常见查找和DML操作。
-
在
PRIMARY KEY表上 定义a 时,InnoDB将其用作聚簇索引。 为您创建的每个表定义主键。 如果没有逻辑唯一且非空列或列集,请添加一个新的 自动增量 列,其值将自动填充。 -
如果没有
PRIMARY KEY为表 定义一个 ,MySQL将找到UNIQUE所有键列 所在的第一个 索引,NOT NULL并将InnoDB其用作聚簇索引。 -
如果表没有
PRIMARY KEY或 没有 合适的UNIQUE索引,则在InnoDB内部生成一个隐藏的聚簇索引GEN_CLUST_INDEX,该 索引 在包含行ID值的合成列上 命名 。 行按照InnoDB分配给此类表中的行 的ID排序 。 行ID是一个6字节的字段,随着新行的插入而单调增加。 因此,由行ID排序的行在物理上处于插入顺序。
通过聚簇索引访问行很快,因为索引搜索直接指向包含所有行数据的页面。 如果表很大,与使用与索引记录不同的页面存储行数据的存储组织相比,聚簇索引体系结构通常会保存磁盘I / O操作。
除聚簇索引之外的所有索引都称为
辅助索引
。
在
InnoDB
,辅助索引中的每个记录都包含该行的主键列,以及为二级索引指定的列。
InnoDB
使用此主键值来搜索聚簇索引中的行。
如果主键很长,则二级索引使用更多空间,因此使用短主键是有利的。
有关利用
InnoDB
聚簇索引和二级索引的
准则
,请参见
第8.3节“优化和索引”
。
除空间索引外,
InnoDB
索引是
B树
数据结构。
空间索引使用
R树
,
R树
是用于索引多维数据的专用数据结构。
索引记录存储在其B树或R树数据结构的叶页中。
索引页的默认大小为16KB。
将新记录插入
InnoDB
聚簇索引时
,
InnoDB
尝试将页面的1/16保留为可用,以便将来插入和更新索引记录。
如果索引记录按顺序(升序或降序)插入,则生成的索引页大约为15/16。
如果以随机顺序插入记录,则页面从1/2到15/16满。
InnoDB
在创建或重建B树索引时执行批量加载。
这种索引创建方法称为排序索引构建。
该
innodb_fill_factor
配置选项定义的空间作为排序指标构建过程中填充,为今后指数增长预留的剩余空间每个B树页的百分比。
空间索引不支持排序索引构建。
有关更多信息,请参见
第15.6.2.3节“排序索引构建”
。
一个
innodb_fill_factor
100设置叶免费为未来指数增长的聚簇索引页的空间的1/16。
如果
InnoDB
索引页
的填充因子
低于
MERGE_THRESHOLD
默认值(如果未指定则为50%),则
InnoDB
尝试收缩索引树以释放页面。
该
MERGE_THRESHOLD
设置适用于B树和R树索引。
有关更多信息,请参见
第15.8.11节“配置索引页的合并阈值”
。
您可以
通过
在初始化MySQL实例之前
设置
配置选项
来定义
MySQL实例中
所有
表空间
的
页面大小
。
定义实例的页面大小后,如果不重新初始化实例,则无法更改它。
支持的大小为64KB,32KB,16KB(默认),8KB和4KB。
InnoDB
innodb_page_size
使用特定
InnoDB
页面大小的
MySQL实例
无法使用来自使用不同页面大小的实例的数据文件或日志文件。
InnoDB
在创建或重建索引时,执行批量加载而不是一次插入一个索引记录。
这种索引创建方法也称为排序索引构建。
空间索引不支持排序索引构建。
索引构建有三个阶段。 在第一阶段, 扫描 聚簇索引 ,生成索引条目并将其添加到排序缓冲区。 当 排序缓冲区 变满时,条目将被排序并写入临时中间文件。 此过程也称为 “ 运行 ” 。 在第二阶段,将一个或多个运行写入临时中间文件,对文件中的所有条目执行合并排序。 在第三个也是最后一个阶段,已排序的条目将插入到 B树中 。
在引入排序索引构建之前,使用插入API一次将索引条目插入到B树中一条记录。 此方法涉及打开B树 游标 以查找插入位置,然后使用 乐观 插入 将条目插入B树页面 。 如果由于页面已满而导致插入失败, 则将执行 悲观 插入,这涉及打开B树游标并根据需要拆分和合并B树节点以查找条目的空间。 这种 “ 自上而下 ” 的弊端 构建索引的方法是搜索插入位置的成本以及B树节点的常量拆分和合并。
排序索引构建使用 “ 自下而上 ” 构建索引的方法。 使用这种方法,对最右侧叶页的引用保存在B树的所有级别。 分配必要B树深度的最右侧叶页,并根据其排序顺序插入条目。 一旦叶子页面已满,节点指针将附加到父页面,并为下一个插入分配一个兄弟叶页面。 此过程将继续,直到插入所有条目,这可能导致插入到根级别。 分配兄弟页面时,将释放对先前固定的叶子页面的引用,并且新分配的叶子页面将成为最右侧的叶子页面和新的默认插入位置。
为未来指数增长保留B树页面空间
要为将来的索引增长留出空间,可以使用
innodb_fill_factor
配置选项保留B树页面空间的百分比。
例如,
innodb_fill_factor
在排序索引构建期间
,设置
为80可保留B树页面中20%的空间。
此设置适用于B树叶和非叶页。
它不适用于用于
TEXT
或
BLOB
输入的
外部页面
。
保留的空间量可能与配置的不完全相同,因为该
innodb_fill_factor
值被解释为提示而不是硬限制。
排序索引构建和全文索引支持
全文索引 支持排序索引构建 。 以前,SQL用于将条目插入到全文索引中。
排序索引构建和压缩表
对于 压缩表 ,先前的索引创建方法将条目附加到压缩和未压缩页面。 当修改日志(表示压缩页面上的可用空间)变满时,压缩页面将被重新压缩。 如果由于空间不足而导致压缩失败,则页面将被拆分。 对于已排序的索引构建,条目仅附加到未压缩的页面。 当未压缩的页面变满时,它将被压缩。 自适应填充用于确保在大多数情况下压缩成功,但如果压缩失败,则会拆分页面并再次尝试压缩。 此过程将继续,直到压缩成功。 有关压缩B-Tree页面的更多信息,请参阅 第15.9.1.5节“压缩如何用于InnoDB表” 。
排序索引构建和重做日志记录
在排序的索引构建期间禁用 重做日志记录 。 相反,有一个 检查点 可确保索引构建能够承受崩溃或故障。 检查点强制将所有脏页写入磁盘。 在排序索引构建期间, 定期发信号通知 页面清理器 线程以刷新 脏页面 以确保可以快速处理检查点操作。 通常,当清洁页面的数量低于设定阈值时,页面清理器线程会刷新脏页面。 对于排序索引构建,会立即刷新脏页以减少检查点开销并并行化I / O和CPU活动。
排序索引构建和优化程序统计信息
排序索引构建可能导致 优化程序 统计信息与以前的索引创建方法生成的统计信息不同。 统计数据的差异(预计不会影响工作负载性能)是由于用于填充索引的算法不同。
FULLTEXT
索引是在基于文本的列(
CHAR
,
VARCHAR
或
TEXT
列)
上创建的
,
以帮助加快对这些列中包含的数据的查询和DML操作,省略任何定义为停用词的单词。
甲
FULLTEXT
指数被定义为一个的一部分
CREATE
TABLE
说明或使用添加到现有的表
ALTER
TABLE
或
CREATE
INDEX
。
使用
MATCH()
... AGAINST
语法
执行全文搜索
。
有关使用信息,请参见
第12.9节“全文搜索功能”
。
InnoDB FULLTEXT
索引在本节的以下主题中描述:
InnoDB FULLTEXT
索引具有倒排索引设计。
反向索引存储单词列表,并为每个单词存储单词出现的文档列表。为了支持邻近搜索,还存储每个单词的位置信息,作为字节偏移量。
创建
InnoDB
FULLTEXT
索引时,会
创建
一组索引表,如以下示例所示:
MySQL的>CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200),FULLTEXT idx (opening_line)) ENGINE=InnoDB;MySQL的>SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLESWHERE name LIKE 'test/%';+ ---------- + -------------------------------------- -------------- + ------- + | table_id | 名字| 空间| + ---------- + -------------------------------------- -------------- + ------- + | 333 | test / fts_0000000000000147_00000000000001c9_index_1 | 289 | | 334 | test / fts_0000000000000147_00000000000001c9_index_2 | 290 | | 335 | test / fts_0000000000000147_00000000000001c9_index_3 | 291 | | 336 | test / fts_0000000000000147_00000000000001c9_index_4 | 292 | | 337 | test / fts_0000000000000147_00000000000001c9_index_5 | 293 | | 338 | test / fts_0000000000000147_00000000000001c9_index_6 | 294 | | 330 | test / fts_0000000000000147_being_deleted | 286 | | 331 | test / fts_0000000000000147_being_deleted_cache | 287 | | 332 | test / fts_0000000000000147_config | 288 | | 328 | test / fts_0000000000000147_deleted | 284 | | 329 | test / fts_0000000000000147_deleted_cache | 285 | | 327 | test / opening_lines | 283 | + ---------- + -------------------------------------- -------------- + ------- +
前六个表表示反向索引,称为辅助索引表。
当传入文档被标记化时,单个词(也称为
“
标记
”
)与位置信息和关联的文档ID(
DOC_ID
)
一起插入索引表中
。
根据单词第一个字符的字符集排序权重,对六个索引表中的单词进行完全排序和分区。
反向索引被划分为六个辅助索引表以支持并行索引创建。
默认情况下,两个线程对单词和关联数据进行标记,排序和插入索引表。
可以使用该
innodb_ft_sort_pll_degree
选项
配置线程数
。
FULLTEXT
在大型表上
创建
索引
时,请考虑增加线程数
。
辅助索引表名称带有前缀
fts_
和后缀
index_*
。
每个索引表都通过索引表名称中与
table_id
索引表
匹配的十六进制值与索引表相关联
。
例如,
table_id
所述的
test/opening_lines
表是
327
,为此,十六进制值是0x147。
如前面的示例所示,
“
147
”
十六进制值出现在与表关联的索引表的名称中
test/opening_lines
。
表示的十六进制值
index_id
的的
FULLTEXT
索引也出现在辅助索引表名。
例如,在辅助表名称中
test/fts_0000000000000147_00000000000001c9_index_1
,十六进制值
1c9
的十进制值为457.
可以通过查询
表中的值
来识别
opening_lines
table(
idx
)
上定义的索引
INFORMATION_SCHEMA.INNODB_INDEXES
(457)。
MySQL的>SELECT index_id, name, table_id, space from INFORMATION_SCHEMA.INNODB_INDEXESWHERE index_id=457;+ ---------- + ------ + ---------- + ------- + | index_id | 名字| table_id | 空间| + ---------- + ------ + ---------- + ------- + | 457 | idx | 327 | 283 | + ---------- + ------ + ---------- + ------- +
如果主表是在 每个表 的 文件表 空间中 创建的,则索引表存储在它们自己 的表 空间中。
前面示例中显示的其他索引表称为公共索引表,用于删除处理和存储
FULLTEXT
索引
的内部状态
。
与为每个全文索引创建的反向索引表不同,这组表对于在特定表上创建的所有全文索引是通用的。
即使删除了全文索引,也会保留公共辅助表。
删除全文索引时,将
FTS_DOC_ID
保留为索引创建的
FTS_DOC_ID
列
,因为删除
列将需要重建表。
管理
FTS_DOC_ID
色谱柱
需要常见的腋下表
。
-
fts_*_deleted和fts_*_deleted_cache包含已删除但尚未从全文索引中删除其数据的文档的文档ID(DOC_ID)。 这
fts_*_deleted_cache是fts_*_deleted表 的内存版本 。 -
fts_*_being_deleted和fts_*_being_deleted_cache包含已删除文档的文档ID(DOC_ID),其数据当前正在从全文索引中删除。 该
fts_*_being_deleted_cache表是表的内存版本fts_*_being_deleted。 -
fts_*_config存储有关
FULLTEXT索引 内部状态的信息 。 最重要的是,它存储了FTS_SYNCED_DOC_ID标识已解析并刷新到磁盘的文档。 在崩溃恢复的情况下,FTS_SYNCED_DOC_ID值用于标识尚未刷新到磁盘的文档,以便可以重新解析文档并将其添加回FULLTEXT索引缓存。 要查看此表中的数据,请查询该INFORMATION_SCHEMA.INNODB_FT_CONFIG表。
插入文档时,会对其进行标记化,并将单个单词和关联数据插入
FULLTEXT
索引中。
即使对于小型文档,此过程也可能导致在辅助索引表中进行大量小插入,从而使对这些表的并发访问成为争用的焦点。
要避免此问题,请
InnoDB
使用
FULLTEXT
索引缓存临时缓存最近插入的行的索引表插入。
此内存缓存结构保留插入,直到缓存已满,然后批量将它们刷新到磁盘(到辅助索引表)。
您可以查询该
INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE
表以查看最近插入的行的标记化数据。
缓存和批处理刷新行为避免了对辅助索引表的频繁更新,这可能导致繁忙的插入和更新时间期间的并发访问问题。 批处理技术还避免了对同一个单词的多次插入,并最大限度地减少了重复条目。 不是单独刷新每个单词,而是将同一个单词的插入合并并作为单个条目刷新到磁盘,从而提高插入效率,同时保持辅助索引表尽可能小。
该
innodb_ft_cache_size
变量用于配置全文索引缓存大小(基于每个表),这会影响全文索引缓存的刷新频率。
您还可以使用该
innodb_ft_total_cache_size
选项
为给定实例中的所有表定义全局全文索引缓存大小限制
。
全文索引缓存存储与辅助索引表相同的信息。 但是,全文索引缓存仅缓存最近插入的行的标记化数据。 已查询时,已刷新到磁盘(到全文辅助表)的数据不会返回到全文索引缓存中。 直接查询辅助索引表中的数据,并在返回之前将辅助索引表的结果与全文索引缓存的结果合并。
InnoDB
使用称为文档ID(
DOC_ID
)
的唯一文档标识符将
全文索引中的单词映射到单词出现的文档记录。
映射需要
FTS_DOC_ID
索引表上的列。
如果
FTS_DOC_ID
未定义
列,则在创建全文索引时
InnoDB
自动添加隐藏
FTS_DOC_ID
列。
以下示例演示了此行为。
以下表定义不包括
FTS_DOC_ID
列:
MySQL的>CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200)) ENGINE=InnoDB;
使用
CREATE FULLTEXT INDEX
语法
在表上创建全文索引时,将
返回一个警告,报告
InnoDB
正在重建表以添加
FTS_DOC_ID
列。
MySQL的>CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);查询正常,0行受影响,1警告(0.19秒) 记录:0重复:0警告:1 MySQL的>SHOW WARNINGS;+ --------- + ------ + -------------------------------- ------------------ + | 等级| 代码| 消息| + --------- + ------ + -------------------------------- ------------------ + | 警告| 124 | InnoDB重建表添加列FTS_DOC_ID | + --------- + ------ + -------------------------------- ------------------ +
使用
ALTER
TABLE
向没有
FTS_DOC_ID
列
的表添加全文索引
时,会返回相同的警告
。
如果您在
CREATE
TABLE
时间
创建全文索引
并且未指定
FTS_DOC_ID
列,则
InnoDB
添加隐藏
FTS_DOC_ID
列,而不发出警告。
定时
FTS_DOC_ID
列
定义
CREATE
TABLE
比在已加载数据的表上创建全文索引要便宜。
如果
FTS_DOC_ID
在加载数据之前在表上定义
了
列,则不必重建该表及其索引以添加新列。
如果您不关心
CREATE FULLTEXT
INDEX
性能,请忽略该
FTS_DOC_ID
列以便
InnoDB
为您创建它。
InnoDB
在
FTS_DOC_ID
列上
创建一个隐藏
列以及唯一索引(
FTS_DOC_ID_INDEX
)
FTS_DOC_ID
。
如果要创建自己的
FTS_DOC_ID
列,则必须将列定义为
BIGINT UNSIGNED NOT NULL
并命名
FTS_DOC_ID
(全部大写),如下例所示:
该
FTS_DOC_ID
列不需要定义为
AUTO_INCREMENT
列,但
AUTO_INCREMENT
可以使加载数据更容易。
MySQL的>CREATE TABLE opening_lines (FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200)) ENGINE=InnoDB;
如果您选择自己定义
FTS_DOC_ID
列,则负责管理列以避免空值或重复值。
FTS_DOC_ID
值不能重用,这意味着
FTS_DOC_ID
值必须不断增加。
(可选)您可以
FTS_DOC_ID_INDEX
在
FTS_DOC_ID
列
上
创建所需的唯一
(全部大写)
。
MySQL的> CREATE UNIQUE INDEX FTS_DOC_ID_INDEX on opening_lines(FTS_DOC_ID);
如果您不创建
FTS_DOC_ID_INDEX
,
InnoDB
则自动创建。
FTS_DOC_ID_INDEX
不能定义为降序索引,因为
InnoDB
SQL解析器不使用降序索引。
最大使用
FTS_DOC_ID
值与新
FTS_DOC_ID
值
之间的允许间隔
为65535。
为避免重建表,
FTS_DOC_ID
删除全文索引时将保留
该
列。
删除具有全文索引列的记录可能会导致辅助索引表中出现大量小删除,从而使这些表的并发访问成为争用的焦点。
为避免此问题,
每当从索引表中删除
DOC_ID
记录时,已删除文档
的文档ID(
)都会记录在特殊
FTS_*_DELETED
表中,并且索引记录将保留在全文索引中。
在返回查询结果之前,信息在
FTS_*_DELETED
table用于过滤掉已删除的文档ID。
这种设计的好处是删除快速且廉价。
缺点是删除记录后索引的大小不会立即减少。
要删除已删除记录的全文索引条目,请
OPTIMIZE TABLE
在索引表上
运行
innodb_optimize_fulltext_only=ON
以重建全文索引。
有关更多信息,请参阅
优化InnoDB全文索引
。
InnoDB FULLTEXT
由于其缓存和批处理行为,索引具有特殊的事务处理特性。
具体而言,
FULLTEXT
在事务提交时处理索引
上的更新和插入
,这意味着
FULLTEXT
搜索只能看到已提交的数据。
以下示例演示了此行为。
该
FULLTEXT
搜索只返回插入的行被提交之后的结果。
MySQL的>CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200),FULLTEXT idx (opening_line)) ENGINE=InnoDB;MySQL的>BEGIN;MySQL的>INSERT INTO opening_lines(opening_line,author,title) VALUES('Call me Ishmael.','Herman Melville','Moby-Dick'),('A screaming comes across the sky.','Thomas Pynchon','Gravity\'s Rainbow'),('I am an invisible man.','Ralph Ellison','Invisible Man'),('Where now? Who now? When now?','Samuel Beckett','The Unnamable'),('It was love at first sight.','Joseph Heller','Catch-22'),('All this happened, more or less.','Kurt Vonnegut','Slaughterhouse-Five'),('Mrs. Dalloway said she would buy the flowers herself.','Virginia Woolf','Mrs. Dalloway'),('It was a pleasure to burn.','Ray Bradbury','Fahrenheit 451');MySQL的>SELECT COUNT(*) FROM opening_lines WHERE MATCH(opening_line) AGAINST('Ishmael');+ ---------- + | COUNT(*)| + ---------- + | 0 | + ---------- + MySQL的>COMMIT;MySQL的>SELECT COUNT(*) FROM opening_lines WHERE MATCH(opening_line) AGAINST('Ishmael');+ ---------- + | COUNT(*)| + ---------- + | 1 | + ---------- +
您可以
InnoDB FULLTEXT
通过查询以下
INFORMATION_SCHEMA
表
来监视和检查
索引
的特殊文本处理方面
:
您还可以
FULLTEXT
通过查询
INNODB_INDEXES
和
查看
索引和表的
基本信息
INNODB_TABLES
。
有关更多信息,请参见 第15.14.4节“InnoDB INFORMATION_SCHEMA FULLTEXT索引表” 。
本节介绍与
InnoDB
表空间
相关的主题
。
该
InnoDB
系统表空间的双写缓冲区和改变缓冲存储区。
系统表空间还包含在系统表空间中创建的用户创建表的表和索引数据。
在以前的版本中,系统表空间包含
InnoDB
数据字典。
在MySQL 8.0中,
InnoDB
将元数据存储在MySQL数据字典中。
请参见
第14章,
MySQL数据字典
。
系统表空间可以包含一个或多个数据文件。
默认情况下,
ibdata1
在数据目录中创建
一个名为的系统表空间数据文件
。
系统表空间数据文件的大小和数量由
innodb_data_file_path
启动选项
控制
。
有关相关信息,请参阅
系统表空间数据文件配置
。
本节介绍如何增大或减小
InnoDB
系统表空间
的大小
。
增加InnoDB系统表空间的大小
增加
InnoDB
系统表空间
大小的最简单方法
是从头开始配置它以自动扩展。
autoextend
在表空间定义中
指定
最后一个数据文件
的
属性。
然后
InnoDB
在空间不足时以64MB为增量自动增加该文件的大小。
可以通过设置
innodb_autoextend_increment
系统变量
的值来更改增量大小,该值
以兆字节为单位。
您可以通过添加另一个数据文件将系统表空间扩展一个定义的数量:
-
关闭MySQL服务器。
-
如果使用关键字定义了上一个最后一个数据文件
autoextend,请根据实际增长的大小将其定义更改为使用固定大小。 检查数据文件的大小,将其向下舍入到1024×1024字节(= 1MB)的最接近倍数,并明确指定此舍入大小innodb_data_file_path。 -
添加新数据文件到末尾
innodb_data_file_path,可选择使该文件自动扩展。 只能将最后一个数据文件innodb_data_file_path指定为自动扩展。 -
再次启动MySQL服务器。
例如,此表空间只有一个自动扩展数据文件
ibdata1
:
innodb_data_home_dir = innodb_data_file_path = / ibdata / ibdata1:10M:autoextend
假设这个数据文件随着时间的推移已增长到988MB。 以下是修改原始数据文件以使用固定大小并添加新的自动扩展数据文件后的配置行:
innodb_data_home_dir = innodb_data_file_path = / ibdata / ibdata1:988M; / disk2 / ibdata2:50M:autoextend
将新数据文件添加到系统表空间配置时,请确保文件名不引用现有文件。
InnoDB
重新启动服务器时创建并初始化文件。
减小InnoDB系统表空间的大小
您无法从系统表空间中删除数据文件。 要减小系统表空间大小,请使用以下过程:
-
使用 mysqldump 转储所有
InnoDB表,包括InnoDB位于MySQL数据库中的表。MySQL的>
SELECT TABLE_NAME from INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='mysql' and ENGINE='InnoDB';+ --------------------------- + | TABLE_NAME | + --------------------------- + | columns_priv | | 组件| | db | | default_roles | | engine_cost | | func | | global_grants | | gtid_executed | | help_category | | help_keyword | | help_relation | | help_topic | | innodb_dynamic_metadata | | innodb_index_stats | | innodb_table_stats | | 插件| | procs_priv | | proxies_priv | | role_edges | | server_cost | | 服务器| | slave_master_info | | slave_relay_log_info | | slave_worker_info | | tables_priv | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | | 用户| + --------------------------- + -
停止服务器。
-
删除所有现有的表空间文件(
*.ibd),包括ibdata和ib_log文件。 不要忘记删除*.ibd位于MySQL数据库中的表的文件。 -
配置新的表空间。
-
重启服务器。
-
导入转储文件。
如果您的数据库仅使用
InnoDB
引擎,则转储
所有
数据库,停止服务器,删除所有数据库和
InnoDB
日志文件,重新启动服务器以及导入转储文件
可能更简单
。
您可以将原始磁盘分区用作
InnoDB
系统表空间
中的数据文件
。
此技术可在Windows和某些Linux和Unix系统上启用非缓冲I / O,而无需文件系统开销。
使用和不使用原始分区执行测试以验证此更改是否实际上提高了系统性能。
使用原始磁盘分区时,请确保运行MySQL服务器的用户标识具有该分区的读写权限。
例如,如果以
mysql
用户
身份运行服务器
,则该分区必须是可读写的
mysql
。
如果使用该
--memlock
选项
运行服务器
,则必须运行服务器
root
,因此该分区必须是可读写的
root
。
下面描述的过程涉及选项文件修改。 有关其他信息,请参见 第4.2.2.2节“使用选项文件” 。
在Linux和Unix系统上分配原始磁盘分区
-
创建新数据文件时,请在
newraw该innodb_data_file_path选项 的数据文件大小之后立即 指定关键字 。 分区必须至少与指定的大小一样大。 请注意,1MB inInnoDB是1024×1024字节,而磁盘规格中的1MB通常意味着1,000,000字节。的[mysqld] innodb_data_home_dir = innodb_data_file_path中=的/ dev / HDD1:3Gnewraw;的/ dev / HDD2:2Gnewraw
-
重启服务器。
InnoDB注意newraw关键字并初始化新分区。 但是,不要创建或更改任何InnoDB表。 否则,当您下次重新启动服务器时,InnoDB重新初始化分区并且您的更改将丢失。 (作为一种安全措施,InnoDB可防止用户在newraw指定 任何分区时修改数据 。) -
在
InnoDB初始化新分区后,停止服务器,newraw将数据文件规范 更改 为raw:的[mysqld] innodb_data_home_dir = innodb_data_file_path中=的/ dev / HDD1:3Graw;的/ dev / HDD2:2Graw
-
重启服务器。
InnoDB现在允许进行更改。
在Windows上分配原始磁盘分区
在Windows系统上,适用于Linux和Unix系统的相同步骤和附带指南适用,但
innodb_data_file_path
Windows上
的
设置稍有不同。
-
创建新数据文件时,请在
newraw该innodb_data_file_path选项 的数据文件大小之后立即 指定关键字 :的[mysqld] innodb_data_home_dir = innodb_data_file_path中= //。/ d :: 10Gnewraw
该
//./对应于Windows的语法\\.\来访问物理驱动器。 在上面的示例中,D:是分区的驱动器号。 -
重启服务器。
InnoDB注意newraw关键字并初始化新分区。 -
在
InnoDB初始化新分区后,停止服务器,newraw将数据文件规范 更改 为raw:的[mysqld] innodb_data_home_dir = innodb_data_file_path中= //。/ d :: 10Graw
-
重启服务器。
InnoDB现在允许进行更改。
从历史上看,
InnoDB
表存储在
系统表空间中
。
这种单片方法针对专用于数据库处理的机器,精心规划数据增长,其中任何分配给MySQL的磁盘存储都不会用于其他目的。
每个表
的
文件表空间
功能提供了更灵活的替代方案,其中每个
InnoDB
表都存储在自己的表空间数据文件(
.ibd
文件)中。
此功能由
innodb_file_per_table
配置选项
控制
,默认情况下启用
该
选项。
好处
-
截断或删除存储在每个表文件表空间中的表时,可以回收磁盘空间。 截断或删除存储在共享 系统表空间中的表 会在系统表空间数据文件( ibdata文件 ) 内部创建可用空间,该数据文件 只能用于新
InnoDB数据。类似地,
ALTER TABLE驻留在共享表空间中的表上的表 复制 操作可以增加表空间使用的空间量。 此类操作可能需要与表中的数据和索引一样多的额外空间。 表复制ALTER TABLE操作 所需的额外空间 不会像文件每表表空间一样释放回操作系统。 -
TRUNCATE TABLE在存储在每个表文件表空间中的表上运行时 , 操作更快。 -
您可以通过使用语法指定每个表的位置,将特定表存储在单独的存储设备上,进行I / O优化,空间管理或备份 ,如 第15.6.3.6节“在数据目录外创建表空间”中所述“ 。
CREATE TABLE ... DATA DIRECTORY =absolute_path_to_directory -
您可以运行
OPTIMIZE TABLE以压缩或重新创建每个表的文件表空间。 当您运行OPTIMIZE TABLE,InnoDB创建一个新的.ibd具有临时名称的文件,只使用存储的实际数据所需的空间。 优化完成后,InnoDB删除旧.ibd文件并将其替换为新文件。 如果前一个.ibd文件显着增长但实际数据仅占其大小的一部分,则运行OPTIMIZE TABLE可以回收未使用的空间。 -
您可以移动单个
InnoDB表而不是整个数据库。 -
您可以将单个
InnoDB表从一个MySQL实例 复制 到另一个MySQL实例(称为可 传输表空间 功能)。 -
您可以 使用 动态行格式 为具有大型
BLOB或TEXT列的 表启用更高效的存储 。 -
每个表的文件表空间可以提高成功恢复的机会,并在发生损坏,无法重新启动服务器或备份和二进制日志不可用时节省时间。
-
您可以使用MySQL Enterprise Backup产品快速备份或还原单个表,而不会中断其他
InnoDB表 的使用 。 如果您的表需要较少的备份或不同的备份计划,这将非常有用。 有关 详细信息, 请参阅 进行部分备份 。 -
在复制或备份表时,每表文件表空间便于每表状态报告。
-
您可以在不访问MySQL的情况下监视文件系统级别的表大小。
-
当
innodb_flush_method设置为 常用Linux文件系统时,不允许对单个文件进行并发写入O_DIRECT。 因此,在结合使用每表文件表空间时,可能会有性能提升innodb_flush_method。 -
系统表空间存储数据字典和撤消日志,并且受
InnoDB表空间大小限制的限制。 请参见 第15.6.1.6节“InnoDB表的限制” 。 使用每表文件表空间,每个表都有自己的表空间,这为增长提供了空间。
潜在的缺点
-
对于每个表的文件表空间,每个表可能有未使用的空间,只能由同一个表的行使用。 如果管理不当,这可能会导致空间浪费。
-
fsync操作必须在每个打开的表上运行,而不是在单个文件上运行。 由于fsync每个文件 都有单独的 操作,因此不能将多个表上的写操作组合到单个I / O操作中。 这可能需要InnoDB执行更高的fsync操作 总数 。 -
mysqld 必须为每个表保留一个打开的文件句柄,如果在每个表的文件表空间中有许多表,这可能会影响性能。
-
使用更多文件描述符。
-
innodb_file_per_table在MySQL 5.6及更高版本中默认启用。 如果与早期版本的MySQL向后兼容是一个问题,您可以考虑禁用它。 -
如果许多表正在增长,则可能存在更多碎片,这可能会妨碍
DROP TABLE表扫描性能。 但是,在管理碎片时,在自己的表空间中放置文件可以提高性能。 -
删除每个表的文件表空间时会扫描缓冲池,对于数十GB的缓冲池,这可能需要几秒钟。 使用广泛的内部锁执行扫描,这可能会延迟其他操作。 系统表空间中的表不受影响。
-
该
innodb_autoextend_increment变量定义了增量大小(以MB为单位),用于在自动扩展的共享表空间文件变满时扩展其大小,不适用于每个表文件的表空间文件,无论innodb_autoextend_increment设置 如何,这些文件都是自动扩展的 。 初始扩展是少量的,之后扩展以4MB的增量发生。
innodb_file_per_table
默认情况下启用
该
选项。
要
innodb_file_per_table
在启动时
设置
选项,请使用
--innodb_file_per_table
命令行选项
启动服务器
,或将此行添加到以下
[mysqld]
部分
my.cnf
:
的[mysqld] innodb_file_per_table = 1
您还可以
innodb_file_per_table
在服务器运行时动态
设置
:
MySQL的> SET GLOBAL innodb_file_per_table=1;
与
innodb_file_per_table
启用,可以存储
InnoDB
在一个表
tbl_name.ibdMyISAM
存储引擎,与它的独立
tbl_name.MYDtbl_name.MYIInnoDB
在一个单一的数据和索引存储在一起
.ibd
的文件。
如果
innodb_file_per_table
在启动选项中
禁用
并重新启动服务器,或使用该
SET GLOBAL
命令
禁用它,则
InnoDB
在系统表空间内创建新表,除非您已使用该
CREATE
TABLE ...
TABLESPACE
选项
将表显式放置在每表文件表空间或通用表空间中
。
InnoDB
无论每个表的文件设置如何,
您始终可以读写任何
表。
要将表从系统表空间移动到其自己的表空间,请更改
innodb_file_per_table
设置并重建表:
mysql>SET GLOBAL innodb_file_per_table=1;mysql>ALTER TABLEtable_nameENGINE=InnoDB;
使用
CREATE
TABLE ...
TABLESPACE
或
ALTER
TABLE ...
TABLESPACE
语法
添加到系统表空间的表
不受
innodb_file_per_table
设置的
影响
。
要将这些表从系统表空间移动到每个表的文件表空间,必须使用
ALTER
TABLE ...
TABLESPACE
语法
显式移动它们
。
InnoDB
总是需要系统表空间,因为它将内部
数据字典
和
撤消日志
放在
那里。
这些
.ibd
文件不足以
InnoDB
运行。
将表从系统表空间移出到其自己的
.ibd
文件中时,组成系统表空间的数据文件大小保持不变。
以前由表占用的空间可以重新用于新
InnoDB
数据,但不会被回收以供操作系统使用。
将大
InnoDB
表移出磁盘空间有限的系统表空间时,您可能更喜欢
innodb_file_per_table
使用
mysqldump
命令
启用
并重新创建整个实例
。
如上所述,使用
CREATE TABLE ...
TABLESPACE
或
ALTER
TABLE ...
TABLESPACE
语法
添加到系统表空间的表
不受
innodb_file_per_table
设置。
必须单独移动这些表。
通用表空间是
InnoDB
使用
CREATE
TABLESPACE
语法
创建
的共享
表空间
。
本节中的以下主题描述了常规表空间功能和功能:
通用表空间功能提供以下功能:
-
与系统表空间类似,通用表空间是可以存储多个表的数据的共享表空间。
-
与基于 文件的表空间 相比,常规表空间具有潜在的内存优势 。 服务器在表空间的生命周期内将表空间元数据保存在内存中。 较少的通用表空间中的多个表对表空间元数据的内存消耗比单独的每个表文件表空间中的相同数量的表少。
-
通用表空间数据文件可以放在相对于MySQL数据目录或独立于MySQL数据目录的目录中,该目录为您提供了 每个表文件表空间的 许多数据文件和存储管理功能 。 与每表文件表空间一样,将数据文件放在MySQL数据目录之外的功能允许您分别管理关键表的性能,为特定表设置RAID或DRBD,或者将表绑定到特定磁盘。
-
常规表空间支持Antelope和Barracuda文件格式,因此支持所有表格行格式和相关功能。 由于支持这两种文件格式,一般表空间不依赖于
innodb_file_format或innodb_file_per_table设置,这些变量也不会对一般表空间产生任何影响。 -
该
TABLESPACE选项可用于CREATE TABLE在通用表空间,每表文件表空间或系统表空间中创建表。 -
该
TABLESPACE选项可用于ALTER TABLE在常规表空间,每表文件表空间和系统表空间之间移动表。 以前,无法将表从每个表的文件表空间移动到系统表空间。 使用常规表空间功能,您现在可以执行此操作。
使用
CREATE TABLESPACE
语法
创建常规表空间
。
CREATE TABLESPACEtablespace_name[添加数据文件'file_name'] [FILE_BLOCK_SIZE =value] [ENGINE [=]engine_name]
可以在数据目录中或在其外部创建常规表空间。
为避免与隐式创建的每表文件表空间冲突,不支持在数据目录下的子目录中创建常规表空间。
在数据目录之外创建通用表空间时,该目录必须存在,并且必须
InnoDB
在创建表空间之前
知道
。
要创建已知的未知目录
InnoDB
,请将该目录添加到
innodb_directories
参数值。
innodb_directories
是一个只读启动选项。
配置它需要重新启动服务器。
例子:
在数据目录中创建常规表空间:
MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
要么
MySQL的> CREATE TABLESPACE `ts1` Engine=InnoDB;
该
ADD DATAFILE
子句在MySQL 8.0.14中是可选的,在此之前是必需的。
如果
ADD
DATAFILE
在创建表空间时未指定子句,则会隐式创建具有唯一文件名的表空间数据文件。
唯一文件名是128位UUID,格式化为由破折号(
aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee
)
分隔的五组十六进制数字
。
常规表空间数据文件包括
.ibd
文件扩展名。
在复制环境中,在主服务器上创建的数据文件名与在从服务器上创建的数据文件名不同。
在数据目录之外的目录中创建常规表空间:
MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE '/my/tablespace/directory/ts1.ibd' Engine=InnoDB;
只要表空间目录不在数据目录下,就可以指定相对于数据目录的路径。
在此示例中,
my_tablespace
目录与数据目录处于同一级别:
MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE '../my_tablespace/ts1.ibd' Engine=InnoDB;
该
ENGINE = InnoDB
子句必须定义为
CREATE
TABLESPACE
语句的
一部分
,或者
InnoDB
必须定义为默认存储引擎(
default_storage_engine=InnoDB
)。
创建
InnoDB
通用表空间后,可以使用
或
向表空间添加表,如以下示例所示:
CREATE
TABLE
tbl_name ... TABLESPACE [=]
tablespace_nameALTER TABLE
tbl_name TABLESPACE [=]
tablespace_name
MySQL的> CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1;
MySQL的> ALTER TABLE t2 TABLESPACE ts1;
在MySQL 5.7.24中不支持将表分区添加到共享表空间,并在MySQL 8.0.13中删除了。
共享表空间包括
InnoDB
系统表空间和通用表空间。
有关详细语法信息,请参阅
CREATE
TABLE
和
ALTER
TABLE
。
一般的表空间支持所有表行格式(
REDUNDANT
,
COMPACT
,
DYNAMIC
,
COMPRESSED
)与压缩和非压缩表不能在同一个表空间一般共存的警告,由于不同的物理页面大小。
对于包含压缩表(
ROW_FORMAT=COMPRESSED
)
的常规表空间
,
FILE_BLOCK_SIZE
必须指定,并且该
FILE_BLOCK_SIZE
值必须是
与该
值相关的有效压缩页大小
innodb_page_size
。
此外,压缩表(
KEY_BLOCK_SIZE
)
的物理页面大小
必须等于
FILE_BLOCK_SIZE/1024
。
例如,如果
innodb_page_size=16KB
和
FILE_BLOCK_SIZE=8K
,
KEY_BLOCK_SIZE
表的必须为8。
下表显示了允许的
innodb_page_size
,
FILE_BLOCK_SIZE
和
KEY_BLOCK_SIZE
组合。
FILE_BLOCK_SIZE
值也可以以字节为单位指定。
要确定
KEY_BLOCK_SIZE
给定
的有效值
FILE_BLOCK_SIZE
,请将
FILE_BLOCK_SIZE
值除以1024.表压缩不支持32K和64K
InnoDB
页面大小。
有关的更多信息
KEY_BLOCK_SIZE
,请参见
CREATE
TABLE
和
第15.9.1.2节“创建压缩表”
。
表15.4压缩表的允许页大小,FILE_BLOCK_SIZE和KEY_BLOCK_SIZE组合
| InnoDB页面大小(innodb_page_size) | 允许的FILE_BLOCK_SIZE值 | 允许的KEY_BLOCK_SIZE值 |
|---|---|---|
| 64KB | 64K(65536) | 不支持压缩 |
| 32KB | 32K(32768) | 不支持压缩 |
| 16KB | 16K(16384) |
N / A:如果
innodb_page_size
等于
FILE_BLOCK_SIZE
,则表空间不能包含压缩表。
|
| 16KB | 8K(8192) | 8 |
| 16KB | 4K(4096) | 4 |
| 16KB | 2K(2048) | 2 |
| 16KB | 1K(1024) | 1 |
| 8KB | 8K(8192) |
N / A:如果
innodb_page_size
等于
FILE_BLOCK_SIZE
,则表空间不能包含压缩表。
|
| 8KB | 4K(4096) | 4 |
| 8KB | 2K(2048) | 2 |
| 8KB | 1K(1024) | 1 |
| 4KB | 4K(4096) |
N / A:如果
innodb_page_size
等于
FILE_BLOCK_SIZE
,则表空间不能包含压缩表。
|
| 4KB | 2K(2048) | 2 |
| 4KB | 1K(1024) | 1 |
此示例演示如何创建常规表空间并添加压缩表。
该示例假定默认
innodb_page_size
值为16KB。
在
FILE_BLOCK_SIZE
8192要求压缩表有
KEY_BLOCK_SIZE
8个。
MySQL的>CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的>CREATE TABLE t4 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
如果未指定
FILE_BLOCK_SIZE
何时创建常规表空间,则
FILE_BLOCK_SIZE
默认为
innodb_page_size
。
当
FILE_BLOCK_SIZE
等于
innodb_page_size
,表空间可能只包含与未压缩的行格式(表
COMPACT
,
REDUNDANT
和
DYNAMIC
行格式)。
您可以使用
ALTER
TABLE
该
TABLESPACE
选项将表移动到现有的通用表空间,新的每个表文件表空间或系统表空间。
在MySQL 5.7.24中不支持在共享表空间中放置表分区,并删除了MySQL 8.0.13。
共享表空间包括
InnoDB
系统表空间和通用表空间。
要将表从每个表的文件表空间或从系统表空间移动到常规表空间,请指定常规表空间的名称。
通用表空间必须存在。
有关
CREATE TABLESPACE
更多信息,
请参阅
ALTER TABLE tbl_name TABLESPACE [=] tablespace_name;
要将表从通用表空间或每表文件表空间移动到系统表空间,请指定
innodb_system
为表空间名称。
ALTER TABLE tbl_name TABLESPACE [=] innodb_system;
要将表从系统表空间或通用表空间移动到每个表的文件表空间,请指定
innodb_file_per_table
为表空间名称。
ALTER TABLE tbl_name TABLESPACE [=] innodb_file_per_table;
ALTER TABLE ... TABLESPACE
即使
TABLESPACE
属性未从其先前值更改,
操作也始终会导致完整表重建
。
ALTER TABLE ... TABLESPACE
语法不支持将表从临时表空间移动到持久表空间。
该
DATA DIRECTORY
条款是允许的,
CREATE TABLE ...
TABLESPACE=innodb_file_per_table
但不支持与该
TABLESPACE
选项一起使用。
从加密表空间移动表时适用限制。 请参阅 加密限制 。
使用
ALTER
TABLESPACE ... RENAME TO
语法
支持重命名通用表空间
。
ALTER TABLESPACE s1重命名为s2;
CREATE TABLESPACE
重命名常规表空间需要
该
权限。
RENAME TO
autocommit
无论
autocommit
设置
如何,
都以
模式
隐式执行操作
。
甲
RENAME TO
操作不能同时被执行
LOCK TABLES
或者
FLUSH
TABLES WITH READ
LOCK
是在驻留在表空间的表的效果。
在重命名表空间时,会对通用表空间中的表执行 独占 元数据锁定 ,从而防止并发DDL。 支持并发DML。
该
DROP TABLESPACE
语句用于删除
InnoDB
常规表空间。
必须在
DROP TABLESPACE
操作
之前从表空间中删除所有表
。
如果表空间不为空,则
DROP
TABLESPACE
返回错误。
使用类似于以下内容的查询来标识常规表空间中的表。
MySQL的>SELECT a.NAME AS space_name, b.NAME AS table_name FROM INFORMATION_SCHEMA.INNODB_TABLESPACES a,INFORMATION_SCHEMA.INNODB_TABLES b WHERE a.SPACE=b.SPACE AND a.NAME LIKE 'ts1';+ ------------ + ------------ + | space_name | table_name | + ------------ + ------------ + | ts1 | test / t1 | | ts1 | test / t2 | | ts1 | test / t3 | + ------------ + ------------ +
InnoDB
删除表空间中的最后一个表时,不会自动删除
常规
表空间。
必须使用显式删除表空间
。
DROP TABLESPACE
tablespace_name
通用表空间不属于任何特定数据库。
一个
DROP DATABASE
操作可以丢弃属于一般的表空间的表,但它不能删除表空间,即使
DROP
DATABASE
操作下降属于该表空间中的所有表。
必须使用显式删除常规表空间
。
DROP
TABLESPACE
tablespace_name
与系统表空间类似,截断或删除存储在通用表空间中的表会在通用表空间
.ibd数据文件
内部创建可用空间,该
文件
只能用于新
InnoDB
数据。
空间不会释放回操作系统,因为在
DROP
TABLE
操作
期间删除了每表文件表空间
。
此示例演示如何删除
InnoDB
常规表空间。
ts1
使用单个表创建
常规表空间
。
在删除表空间之前必须删除该表。
MySQL的>CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;MySQL的>CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts10 Engine=InnoDB;MySQL的>DROP TABLE t1;MySQL的>DROP TABLESPACE ts1;
tablespace_name
-
生成的或现有的表空间不能更改为常规表空间。
-
不支持创建临时通用表空间。
-
常规表空间不支持临时表。
-
与系统表空间类似,截断或删除存储在通用表空间中的表会在通用表空间 .ibd数据文件 内部创建可用空间,该 文件 只能用于新
InnoDB数据。 空间不会像 文件每表表 空间 一样释放回操作系统 。此外,
ALTER TABLE驻留在共享表空间(通用表空间或系统表空间)中的表上的表 复制 操作可以增加表空间使用的空间量。 此类操作需要与表中的数据和索引一样多的额外空间。 表复制ALTER TABLE操作 所需的额外空间 不会像文件每表表空间一样释放回操作系统。 -
ALTER TABLE ... DISCARD TABLESPACE并且ALTER TABLE ...IMPORT TABLESPACE不支持属于常规表空间的表。 -
支持在一般表空间中放置表分区在MySQL 5.7.24中已弃用,在MySQL 8.0.13中已删除。
撤消表空间包含撤消日志,撤消日志是撤消日志记录的集合,其中包含有关如何撤消事务到聚簇索引记录的最新更改的信息。
撤消日志存在于撤消日志段中,这些日志段包含在回滚段中。
该
innodb_rollback_segments
变量定义分配给每个撤消表空间的回滚段数。
初始化MySQL实例时会创建两个默认的撤消表空间。 在初始化时创建默认的撤消表空间,以便为可以接受SQL语句之前必须存在的回滚段提供位置。 至少需要两个撤消表空间才能支持自动截断撤消表空间。 请参阅 截断撤消表空间 。
在
innodb_undo_directory
变量
定义的位置创建默认的撤消表空间
。
如果
innodb_undo_directory
变量未定义,则在数据目录中创建默认的撤消表空间。
默认的undo表空间数据文件名为
undo_001
and
undo_002
。
数据字典中定义的相应撤消表空间名称是
innodb_undo_001
和
innodb_undo_002
。
从MySQL 8.0.14开始,可以使用SQL在运行时创建其他撤消表空间。 请参阅 添加撤消表空间 。
undo表空间数据文件的初始大小取决于
innodb_page_size
值。
对于默认的16KB页面大小,初始撤消表空间文件大小为10MiB。
对于4KB,8KB,32KB和64KB页面大小,初始撤消表空间文件大小分别为7MiB,8MiB,20MiB和40MiB。
由于在长时间运行的事务期间撤消日志可能会变大,因此创建其他撤消表空间可以帮助防止单个撤消表空间变得过大。
从MySQL 8.0.14开始,可以使用
CREATE UNDO
TABLESPACE
语法
在运行时创建其他撤消表空间
。
创建UNDO TABLESPACEtablespace_name添加数据文件'file_name.ibu'
撤消表空间文件名必须具有
.ibu
扩展名。
在定义撤消表空间文件名时,不允许指定相对路径。
允许使用完全限定的路径,但必须知道路径
InnoDB
。
已知路径是由
innodb_directories
变量
定义的路径
。
在启动时,
innodb_directories
将扫描变量
定义的目录以
获取撤消表空间文件。
(扫描也横穿子目录。)由定义的目录
innodb_data_home_dir
,
innodb_undo_directory
和
datadir
变量被自动添加到
innodb_directories
值,而不管是否
innodb_directories
变量被明确定义。
因此,撤消表空间可以驻留在由任何这些变量定义的路径中。
如果undo表空间文件名不包含路径,则会在
innodb_undo_directory
变量
定义的目录中创建undo表空间
。
如果未定义该变量,则会在数据目录中创建撤消表空间。
在
InnoDB
恢复过程要求撤销表空间文件驻留在已知的目录。
必须在重做恢复之前和打开其他数据文件之前发现并打开撤消表空间文件,以允许回滚未提交的事务和数据字典更改。
无法使用恢复前未找到的撤消表空间,这可能导致数据库不一致。
如果未找到数据字典已知的撤消表空间,则在启动时会报告错误消息。
已知的目录要求还支持撤消表空间可移植性。
请参阅
移动撤消表空间
。
要在相对于数据目录的路径中创建撤消表空间,请将
innodb_undo_directory
变量设置为相对路径,并仅在创建撤消表空间时指定文件名。
要查看撤消表空间名称和路径,请查询
INFORMATION_SCHEMA.FILES
:
来自INFORMATION_SCHEMA.FILES的SELECT TABLESPACE_NAME,FILE_NAME FILE_TYPE喜欢'UNDO LOG';
MySQL实例最多支持127个undo表空间,包括MySQL实例初始化时创建的两个默认undo表空间。
在MySQL 8.0.14之前,通过配置
innodb_undo_tablespaces
启动变量
来创建其他撤消表空间
。
不推荐使用此变量,不再可以从MySQL 8.0.14开始配置。
在MySQL 8.0.14之前,增加
innodb_undo_tablespaces
设置会创建指定数量的撤消表空间,并将它们添加到活动撤消表空间列表中。
减小
innodb_undo_tablespaces
设置会从活动的撤消表空间列表中删除撤消表空间。
从活动列表中删除的撤消表空间保持活动状态,直到现有事务不再使用它们。
所述
innodb_undo_tablespaces
变量可以在运行时使用一被配置
SET
陈述或在配置文件中定义。
在MySQL 8.0.14之前,无法删除已停用的撤消表空间。
在缓慢关闭后可以手动删除撤消表空间文件但不建议这样做,因为如果在关闭服务器时存在打开的事务,则在重新启动服务器后的一段时间内,停用的撤消表空间可能包含活动的撤消日志。
从MySQL 8.0.14开始,可以使用
DROP UNDO
TABALESPACE
语法
删除撤消表空间
。
请参阅
删除撤消表空间
。
从MySQL 8.0.14开始,
CREATE UNDO
TABLESPACE
可以
使用
语法在运行时删除
使用
语法
创建的撤消表空间
DROP UNDO
TABALESPACE
。
撤消表空间在删除之前必须为空。
要清空撤消表空间,必须首先使用
ALTER UNDO
TABLESPACE
语法
将撤消表空间标记为非活动,
以便不再使用表空间将回滚段分配给新事务。
ALTER UNDO TABLESPACE tablespace_nameSET INACTIVE;
将撤消表空间标记为非活动后,允许完成当前在撤消表空间中使用回滚段的事务,以及在这些事务完成之前启动的任何事务。 事务完成后,清除系统将释放撤消表空间中的回滚段,并将撤消表空间截断为其初始大小。 (截断撤消表空间时使用相同的过程。请参阅 截断撤消表空间 。)当撤消表空间为空时,可以删除它。
DROP UNDO TABLESPACE tablespace_name;
或者,撤消表空间可以保留为空状态,并在需要时通过发出
语句
稍后重新激活
。
ALTER UNDO
TABLESPACE
tablespace_name SET
ACTIVE
可以通过查询
INFORMATION_SCHEMA.INNODB_TABLESPACES
表
来监视撤消表空间的状态
。
SELECT NAME,STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
名称在哪里tablespace_name;
的
inactive
状态表示在撤销表空间回滚段不再使用新的交易。
一个
empty
状态指示UNDO表空间是空的,并准备好被丢弃或再使用作出了积极
发言。
尝试删除非空的撤消表空间会返回错误。
ALTER UNDO
TABLESPACE
tablespace_name SET
ACTIVE
无法删除MySQL实例初始化时创建
的默认撤消表空间(
innodb_undo_001
和
innodb_undo_002
)。
但是,可以使用
声明
使它们处于非活动状态
。
在默认撤消表空间可以处于非活动状态之前,必须有一个撤消表空间来取代它。
始终至少需要两个活动的撤消表空间,以支持自动截断撤消表空间。
ALTER UNDO
TABLESPACE
tablespace_name SET
INACTIVE
使用
CREATE UNDO
TABLESPACE
语法
创建的撤消表空间
可以在服务器脱机时移动到任何已知目录。
已知目录是由
innodb_directories
变量
定义的目录
。
无论是否
明确定义变量
,
由
innodb_data_home_dir
,
定义的目录
innodb_undo_directory
,以及
datadir
自动附加到
innodb_directories
值的目录
innodb_directories
。
在启动时扫描这些目录及其子目录以获取撤消表空间文件。
在启动时发现移动到任何这些目录的撤消表空间文件,并假定它是已移动的撤消表空间。
初始化MySQL实例时创建
的默认撤消表空间(
innodb_undo_001
和
innodb_undo_002
)必须始终位于
innodb_undo_directory
变量
定义的目录中
。
如果
innodb_undo_directory
变量未定义,则默认的undo表空间将驻留在数据目录中。
如果在服务器脱机时移动了默认的撤消表空间,则必须使用
innodb_undo_directory
配置到新目录
的
变量
启动服务器
。
撤消日志的I / O模式使撤消表空间成为 SSD 存储的 良好候选者 。
该
innodb_rollback_segments
变量定义
分配给每个撤消表空间和全局临时表空间
的
回滚段
数
。
该
innodb_rollback_segments
变量可以在启动时被配置为或在服务器正在运行。
默认设置为
innodb_rollback_segments
128,也是最大值。
有关回滚段支持的事务数的信息,请参见
第15.6.6节“撤消日志”
。
有两种截断撤消表空间的方法,可以单独使用或组合使用来管理撤消表空间大小。 一种方法是自动化的,使用配置变量启用。 另一种方法是手动,使用SQL语句执行。
自动方法不需要监视撤消表空间大小,并且一旦启用,它就会执行撤消,截断和重新激活撤消表空间,而无需手动干预。 如果要控制撤消表空间何时脱机以进行截断,则手动截断方法可能更为可取。 例如,您可能希望避免在高峰工作负载时间截断撤消表空间。
自动截断
undo表空间的自动截断至少需要两个活动的undo表空间,这样可以确保一个undo表空间保持活动状态,而另一个表空间处于脱机状态以进行截断。 缺省情况下,MySQL实例初始化时会创建两个undo表空间。
要自动截断撤消表空间,请启用该
innodb_undo_log_truncate
变量。
例如:
MySQL的> SET GLOBAL innodb_undo_log_truncate=ON;
当
innodb_undo_log_truncate
被使能可变的,撤消超过由所定义的大小限制表空间
innodb_max_undo_log_size
变量受到截断。
该
innodb_max_undo_log_size
变量是动态的,默认值为1073741824字节(1024 MiB)。
MySQL的> SELECT @@innodb_max_undo_log_size;
+ ---------------------------- +
| @@ innodb_max_undo_log_size |
+ ---------------------------- +
| 1073741824 |
+ ---------------------------- +
当
innodb_undo_log_truncate
启用变量:
-
超出
innodb_max_undo_log_size设置的 默认和用户定义的撤消表空间 标记为截断。 选择用于截断的撤消表空间以循环方式执行,以避免每次都截断相同的撤消表空间。 -
驻留在所选撤消表空间中的回滚段将变为非活动状态,以便不将它们分配给新事务。 允许当前使用回滚段的现有事务完成。
-
该 净化 系统释放回滚段不再使用。
-
释放撤消表空间中的所有回滚段后,将运行truncate操作并将undo表空间截断为其初始大小。 undo表空间的初始大小取决于
innodb_page_size值。 对于默认的16KB页面大小,初始撤消表空间文件大小为10MiB。 对于4KB,8KB,32KB和64KB页面大小,初始撤消表空间文件大小分别为7MiB,8MiB,20MiB和40MiB。由于在操作完成后立即使用,截断操作之后的撤消表空间的大小可能大于初始大小。
该
innodb_undo_directory变量定义了默认undo表空间文件的位置。 如果innodb_undo_directory变量未定义,则默认的undo表空间将驻留在数据目录中。CREATE UNDO TABLESPACE可以通过查询INFORMATION_SCHEMA.FILES表 来确定 所有撤消表空间文件的位置,包括使用 语法 创建的用户定义的撤消表空间 :SELECT TABLESPACE_NAME,FILE_NAME来自INFORMATION_SCHEMA.FILES,其中FILE_TYPE喜欢'UNDO LOG';
-
重新激活回滚段,以便将它们分配给新事务。
手动截断
手动截断撤消表空间至少需要三个活动的撤消表空间。 始终需要两个活动的撤消表空间,以支持启用自动截断的可能性。 至少有三个撤消表空间满足此要求,同时允许撤消表空间手动脱机。
要手动启动撤消表空间的截断,请通过发出以下语句来停用撤消表空间:
ALTER UNDO TABLESPACE tablespace_nameSET INACTIVE;
将撤消表空间标记为非活动后,允许完成当前在撤消表空间中使用回滚段的事务,以及在这些事务完成之前启动的任何事务。
事务完成后,清除系统释放撤消表空间中的回滚段,撤消表空间被截断为其初始大小,撤消表空间状态从更改
inactive
为
empty
。
当
语句停用撤消表空间时,清除线程会在下次机会时查找该撤消表空间。
找到撤消表空间并标记为截断后,清除线程将以更高的频率返回,以快速清空并截断撤消表空间。
ALTER UNDO TABLESPACE
tablespace_name SET
INACTIVE
要检查撤消表空间的状态,请查询该
INFORMATION_SCHEMA.INNODB_TABLESPACES
表。
SELECT NAME,STATE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
名称在哪里tablespace_name;
一旦撤消表空间处于某种
empty
状态,就可以通过发出以下语句来重新激活它:
ALTER UNDO TABLESPACE tablespace_nameSET ACTIVE;
empty
还可以删除状态中
的撤消表空间
。
请参阅
删除撤消表空间
。
加快撤消表空间的自动截断
清除线程负责清空和截断撤消表空间。
默认情况下,清除线程会查找撤消表空间,以便每调用一次清除128次就会截断一次。
清除线程查找撤消表空间以进行截断的频率由
innodb_purge_rseg_truncate_frequency
变量
控制,该
变量的默认设置为128。
MySQL的> SELECT @@innodb_purge_rseg_truncate_frequency;
+ ---------------------------------------- +
| @@ innodb_purge_rseg_truncate_frequency |
+ ---------------------------------------- +
| 128 |
+ ---------------------------------------- +
要增加该频率,请减小
innodb_purge_rseg_truncate_frequency
设置。
例如,要让purge线程每隔32个调用purge的时间一次查找undo tabespaces,设置
innodb_purge_rseg_truncate_frequency
为32。
MySQL的> SET GLOBAL innodb_purge_rseg_truncate_frequency=32;
当清除线程找到需要截断的撤消表空间时,清除线程以更高的频率返回,以快速清空并截断撤消表空间。
截断撤消表空间文件的性能影响
撤消撤消表空间时,撤消表空间中的回滚段将被停用。 其他撤消表空间中的活动回滚段承担整个系统负载的责任,这可能会导致性能略有下降。 性能下降的程度取决于许多因素:
-
撤消表空间的数量
-
撤消日志数
-
撤消表空间大小
-
I / O susbsystem的速度
-
现有的长期运行事务
-
系统负载
截断撤消表空间时避免影响性能的最简单方法是增加撤消表空间的数量。
监视撤消表空间截断
在MySQL 8.0.16中,
undo
和
purge
susbsystem计数器提供用于监视与撤销日志截断相关的后台活动。
对于计数器名称和描述,请查询该
INFORMATION_SCHEMA.INNODB_METRICS
表。
选择名称,子系统,来自INFORMATION_SCHEMA.INNODB_METRICS的评论,其中名称类似'%truncate%';
有关启用计数器和查询计数器数据的信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。
InnoDB
使用会话临时表空间和全局临时表空间。
会话临时表空间存储由优化程序创建的用户创建的临时表和内部临时表,当
InnoDB
配置为磁盘内部临时表的存储引擎时。
从MySQL 8.0.16开始,始终使用用于磁盘内部临时表的存储引擎
InnoDB
。
(以前,存储引擎是由值决定的
internal_tmp_disk_storage_engine
。)
会话临时表空间在第一个请求中从临时表空间池分配给会话,以创建磁盘上的临时表。
最多两个表空间分配给一个会话,一个用于用户创建的临时表,另一个用于由优化器创建的内部临时表。
分配给会话的临时表空间用于会话创建的所有磁盘上临时表。
会话断开连接时,其临时表空间将被截断并释放回池中。
启动服务器时,将创建一个包含10个临时表空间的池。
池的大小永远不会缩小,并且表空间会根据需要自动添加到池中。
临时表空间池在正常关闭或中止初始化时被删除。
会话临时表空间文件在创建时大小为五页,并且具有
.ibt
文件扩展名。
为会话临时表空间保留了40万个空间ID。 由于每次启动服务器时都会重新创建会话临时表空间池,因此当服务器关闭并且可以重用时,会话临时表空间的空间ID不会保留。
该
innodb_temp_tablespaces_dir
变量定义创建会话临时表空间的位置。
默认位置是
#innodb_temp
数据目录中的目录。
如果无法创建临时表空间池,则拒绝启动。
shell> cd BASEDIR/ data /#innodb_temp
shell> ls
temp_10.ibt temp_2.ibt temp_4.ibt temp_6.ibt temp_8.ibt
temp_1.ibt temp_3.ibt temp_5.ibt temp_7.ibt temp_9.ibt
在基于语句的复制(SBR)模式中,在从属服务器上创建的临时表驻留在单个会话临时表空间中,该表空间仅在MySQL服务器关闭时被截断。
该
INNODB_SESSION_TEMP_TABLESPACES
表提供有关会话临时表空间的元数据。
该
INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO
表提供有关在
InnoDB
实例
中处于活动状态的用户创建的临时表的元数据
。
全局临时表空间(
ibtmp1
)存储用于对用户创建的临时表所做更改的回滚段。
该
innodb_temp_data_file_path
变量定义全局临时表空间数据文件的相对路径,名称,大小和属性。
如果没有指定值
innodb_temp_data_file_path
,默认行为是创建一个名为一个自动扩展数据文件
ibtmp1
的
innodb_data_home_dir
目录。
初始文件大小略大于12MB。
在正常关闭或中止初始化时删除全局临时表空间,并在每次启动服务器时重新创建。 全局临时表空间在创建时会收到动态生成的空间ID。 如果无法创建全局临时表空间,则拒绝启动。 如果服务器意外停止,则不会删除全局临时表空间。 在这种情况下,数据库管理员可以手动删除全局临时表空间或重新启动MySQL服务器。 重新启动MySQL服务器会自动删除并重新创建全局临时表空间。
全局临时表空间不能驻留在原始设备上。
INFORMATION_SCHEMA.FILES
提供有关全局临时表空间的元数据。
发出类似于此查询的查询以查看全局临时表空间元数据:
MySQL的> SELECT * FROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME='innodb_temporary'\G
默认情况下,全局临时表空间数据文件是自动扩展的,并根据需要增加大小。
要确定全局临时表空间数据文件是否自动扩展,请检查以下
innodb_temp_data_file_path
设置:
MySQL的> SELECT @@innodb_temp_data_file_path;
+ ------------------------------ +
| @@ innodb_temp_data_file_path |
+ ------------------------------ +
| ibtmp1:12M:autoextend |
+ ------------------------------ +
要检查全局临时表空间数据文件的大小,请
INFORMATION_SCHEMA.FILES
使用与此类似的查询来
查询
表:
MySQL的>SELECT FILE_NAME, TABLESPACE_NAME, ENGINE, INITIAL_SIZE, TOTAL_EXTENTS*EXTENT_SIZEAS TotalSizeBytes, DATA_FREE, MAXIMUM_SIZE FROM INFORMATION_SCHEMA.FILESWHERE TABLESPACE_NAME = 'innodb_temporary'\G*************************** 1。排******************** ******* FILE_NAME:./ ibtmp1 TABLESPACE_NAME:innodb_temporary ENGINE:InnoDB INITIAL_SIZE:12582912 TotalSizeBytes:12582912 DATA_FREE:6291456 MAXIMUM_SIZE:NULL
TotalSizeBytes
显示全局临时表空间数据文件的当前大小。
有关其他字段值的信息,请参见
第25.11节“INFORMATION_SCHEMA文件表”
。
或者,检查操作系统上的全局临时表空间数据文件大小。
全局临时表空间数据文件位于由
innodb_temp_data_file_path
变量
定义的目录中
。
要回收全局临时表空间数据文件占用的磁盘空间,请重新启动MySQL服务器。
重新启动服务器将根据定义的属性删除并重新创建全局临时表空间数据文件
innodb_temp_data_file_path
。
要限制全局临时表空间数据文件的大小,请配置
innodb_temp_data_file_path
以指定最大文件大小。
例如:
的[mysqld] innodb_temp_data_file_path = ibtmp1:12M:自动扩展:最大:500M
配置
innodb_temp_data_file_path
需要重新启动服务器。
该
CREATE
TABLE ...
DATA DIRECTORY
子句允许
在数据目录之外
创建
每表文件表
空间。
例如,您可以使用该
DATA DIRECTORY
子句在具有特定性能或容量特征的单独存储设备上创建表空间,例如快速
SSD
或高容量
HDD
。
确保您选择的位置。
该
DATA
DIRECTORY
子句不能用于
ALTER
TABLE
以后更改位置。
表空间数据文件在指定目录中创建,该目录位于为表所属的模式命名的子目录中。
以下示例演示如何在数据目录之外创建每个表的文件表空间。
假设
innodb_file_per_table
变量已启用。
MySQL的>USE test;数据库已更改 MySQL的>CREATE TABLE t1 (c1 INT PRIMARY KEY) DATA DIRECTORY = '#MySQL在名为的子目录中创建表空间文件 #表示表所属的模式 shell>/remote/directory';cd /remote/directory/testshell>lst1.ibd
在数据目录之外创建表空间时,请确保已知该目录
InnoDB
。
否则,如果服务器在完全刷新表空间数据文件页面之前意外暂停,则在检索已知目录中的表空间数据文件的恢复前发现阶段未找到表空间时启动失败(请参阅
崩溃恢复期间的表空间发现
)。
要使目录已知,请将其添加到
innodb_directories
参数值。
innodb_directories
是一个只读启动选项,用于定义在启动时扫描表空间数据文件的目录。
配置它需要重新启动服务器。
CREATE
TABLE ...
TABLESPACE
语法也可以与
DATA DIRECTORY
子句
结合使用,
以在数据目录之外创建每表文件表空间。
为此,请指定
innodb_file_per_table
为表空间名称。
MySQL的>CREATE TABLE t2 (c1 INT PRIMARY KEY) TABLESPACE = innodb_file_per_tableDATA DIRECTORY = '/remote/directory';
innodb_file_per_table
使用此方法时,不需要启用
该
变量。
使用说明:
-
MySQL最初将表空间数据文件保持打开状态,阻止您卸载设备,但如果服务器繁忙,最终可能会关闭表。 小心不要在MySQL运行时意外卸载外部设备,或在设备断开连接时启动MySQL。 在关联的表空间数据文件丢失时尝试访问表会导致严重错误,需要重新启动服务器。
如果表空间数据文件不在预期路径,则服务器重新启动会发出错误和警告。 在这种情况下,您可以从备份还原表空间数据文件,或删除表以从 数据字典中 删除有关它的 信息 。
-
在将表空间放在已安装NFS的卷上之前,请查看 使用NFS与MySQL中 列出的潜在问题 。
-
如果使用LVM快照,文件副本或其他基于文件的机制来备份表空间数据文件,请始终
FLUSH TABLES ... FOR EXPORT首先 使用该 语句,以确保 在备份发生之前将 内存中缓冲的所有更改 刷新 到磁盘。
本节介绍如何将
每个表
的
文件表
空间从一个MySQL实例
复制
到另一个MySQL实例,也称为可
传输表空间
功能。
此功能还支持分区
InnoDB
表和单个
InnoDB
表分区和子分区。
有关其他
InnoDB
表复制方法的信息,请参见
第15.6.1.2节“移动或复制InnoDB表”
。
将
InnoDB
每个表文件表
空间
复制
到另一个实例的
原因有很多
:
限制和使用说明
-
只有在
innodb_file_per_table启用 时才能使用表空间复制过程 ,这是默认设置。 驻留在共享系统表空间中的表无法停顿。 -
当表静默时,受影响的表上只允许只读事务。
-
导入表空间时,页面大小必须与导入实例的页面大小匹配。
-
ALTER TABLE ... DISCARD TABLESPACE分区InnoDB表ALTER TABLE ... DISCARD PARTITION ... TABLESPACE支持,InnoDB表分区 支持 。 -
DISCARD TABLESPACE不支持与父子时(主键-外键)关系表空间foreign_key_checks设置为1。 在丢弃父子表的表空间之前,请设置foreign_key_checks=0。 分区InnoDB表不支持外键。 -
ALTER TABLE ... IMPORT TABLESPACE不会对导入的数据强制执行外键约束。 如果表之间存在外键约束,则应在相同(逻辑)时间点导出所有表。 分区InnoDB表不支持外键。 -
ALTER TABLE ... IMPORT TABLESPACE并且ALTER TABLE ... IMPORT PARTITION ... TABLESPACE不需要.cfg元数据文件来导入表空间。 但是,在没有.cfg文件 导入时不执行元数据检查 ,并发出类似于以下的警告:消息:InnoDB:IO读取错误:(2,没有这样的文件或目录)错误打开'。\ test \ t.cfg'将尝试导入而不进行模式验证 1排(0.00秒)
.cfg当没有预期的模式不匹配时,没有文件 导入的能力 可能更方便。 此外,在没有.cfg文件的情况下 导入的 功能在崩溃恢复方案中非常有用,在这种情况下无法从.ibd文件中 收集元数据 。如果未
.cfg使用 任何 文件,则InnoDB使用等效的 语句来初始化用于为 列 分配值的内存中自动增量计数器 。 否则,从 元数据文件中 读取当前最大自动增量计数器值 。 有关相关信息,请参阅 InnoDB AUTO_INCREMENT计数器初始化 。SELECT MAX(ai_col) FROMtable_nameFOR UPDATEAUTO_INCREMENT.cfg -
由于
.cfg元数据文件限制,在导入分区表的表空间文件时,不会报告分区类型或分区定义差异的模式不匹配。 报告了列差异。 -
运行
ALTER TABLE ... DISCARD PARTITION ... TABLESPACE和ALTER TABLE ... IMPORT PARTITION ... TABLESPACE在子分区表上时,允许分区和子分区表名称。 指定分区名称时,该分区的子分区将包含在操作中。 -
如果两个实例都具有GA(一般可用性)状态,并且导入文件的服务器实例在同一版本系列中处于相同或更高版本级别,则从另一个MySQL服务器实例导入表空间文件。 不支持将表空间文件导入到运行早期版本的MySQL的服务器实例中。
-
在复制方案中,
innodb_file_per_table必须ON在主服务器和从服务器上都 设置为 。 -
在Windows上,
InnoDB内部以小写形式存储数据库,表空间和表名。 为避免在区分大小写的操作系统(如Linux和UNIX)上导入问题,请使用小写名称创建所有数据库,表空间和表。 完成此操作的一种便捷方法是 在创建数据库,表空间或表之前将以 下行添加到 或 文件 的[mysqld]部分 :my.cnfmy.ini的[mysqld] 的lower_case_table_names = 1
注意禁止
lower_case_table_names使用与初始化 服务器时使用的 设置不同的设置启动服务器。 -
ALTER TABLE ... DISCARD TABLESPACE并且ALTER TABLE ...IMPORT TABLESPACE不支持属于InnoDB常规表空间的表。 有关更多信息,请参阅CREATE TABLESPACE。 -
InnoDB表 的默认行格式 可使用innodb_default_row_format配置选项 进行 配置。 如果 源实例上的设置与目标实例上的设置不同,则 尝试导入未显式定义行format(ROW_FORMAT)或使用的表ROW_FORMAT=DEFAULT可能导致模式不匹配错误innodb_default_row_format。 有关相关信息,请参阅 定义表的行格式 。 -
导出加密表空间时, 除了 元数据文件 外,还会
InnoDB生成 文件。 在 对目标实例 执行 操作 之前, 必须将 文件与文件和表空间文件 一起复制到 目标实例。 该 文件包含传输密钥和加密的表空间密钥。 在导入时, 使用传输密钥来解密表空间密钥。 有关相关信息,请参见 第15.6.3.9节“InnoDB静态数据加密” 。.cfp.cfg.cfp.cfgALTER TABLE ... IMPORT TABLESPACE.cfpInnoDB -
FLUSH TABLES ... FOR EXPORT具有FULLTEXT索引的表不受支持。 不刷新全文搜索辅助表。 导入带FULLTEXT索引 的表后 ,运行OPTIMIZE TABLE以重建FULLTEXT索引。 或者,FULLTEXT在导出操作之前 删除 索引,并在导入目标实例上的表后重新创建它们。
如果要传输使用
InnoDB
表空间加密
进行加密的
表,请
在开始获取其他过程信息之前
参阅
限制和使用说明
。
示例1:将InnoDB表复制到另一个实例
此过程演示如何将常规
InnoDB
表从正在运行的MySQL服务器实例
复制
到另一个正在运行的实例。
可以使用具有微小调整的相同过程在同一实例上执行完整表还原。
-
在源实例上,创建一个表(如果不存在):
mysql>
USE test;mysql>CREATE TABLE t(c1 INT) ENGINE=InnoDB; -
在目标实例上,创建一个表(如果不存在):
mysql>
USE test;mysql>CREATE TABLE t(c1 INT) ENGINE=InnoDB; -
在目标实例上,放弃现有表空间。 (在导入表空间之前,
InnoDB必须丢弃附加到接收表的表空间。)MySQL的>
ALTER TABLE t DISCARD TABLESPACE; -
在源实例上,运行
FLUSH TABLES ... FOR EXPORT以停顿表并创建.cfg元数据文件:mysql>
USE test;mysql>FLUSH TABLES t FOR EXPORT;metadata(
.cfg)在InnoDB数据目录中 创建 。注意该
FLUSH TABLES ... FOR EXPORT语句确保已将对指定表的更改刷新到磁盘,以便在实例运行时可以生成二进制表副本。 当FLUSH TABLES ... FOR EXPORT运行时,InnoDB产生了.cfg在同一个数据库的目录表文件。 该.cfg文件包含导入表空间文件时用于模式验证的元数据。 -
将
.ibd文件和.cfg元数据文件从源实例 复制 到目标实例。 例如:外壳>
scp/path/to/datadir/test/t.{ibd,cfg} destination-server:/path/to/datadir/test注意的
.ibd文件和.cfg文件必须释放共享锁之前如在下一步中所述被复制。 -
在源实例上,用于
UNLOCK TABLES释放通过FLUSH TABLES ... FOR EXPORT以下方式 获取的锁 :mysql>
USE test;mysql>UNLOCK TABLES; -
在目标实例上,导入表空间:
mysql>
USE test;mysql>ALTER TABLE t IMPORT TABLESPACE;注意该
ALTER TABLE ... IMPORT TABLESPACE功能不会对导入的数据强制执行外键约束。 如果表之间存在外键约束,则应在相同(逻辑)时间点导出所有表。 在这种情况下,您将停止更新表,提交所有事务,获取表上的共享锁,然后执行导出操作。
示例2:将InnoDB分区表复制到另一个实例
此过程演示如何将分区
InnoDB
表从正在运行的MySQL服务器实例
复制
到另一个正在运行的实例。
可以使用具有微小调整的相同过程
InnoDB
在同一实例上
执行分区
表
的完全还原
。
-
在源实例上,创建分区表(如果不存在)。 在以下示例中,将创建一个包含三个分区(p0,p1,p2)的表:
mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3;在 目录中, 三个分区中的每个分区 都有一个单独的tablespace( )文件。
/datadir/test.ibdMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd/path/to/datadir/test/ -
在目标实例上,创建相同的分区表:
mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3;在 目录中, 三个分区中的每个分区 都有一个单独的tablespace( )文件。
/datadir/test.ibdMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd/path/to/datadir/test/ -
在目标实例上,丢弃分区表的表空间。 (在可以在目标实例上导入表空间之前,必须丢弃附加到接收表的表空间。)
MySQL的>
ALTER TABLE t1 DISCARD TABLESPACE;.ibd组成分区表的表空间 的三个 文件将从 目录 中丢弃 。/datadir/test -
在源实例上,运行
FLUSH TABLES ... FOR EXPORT以停顿分区表并创建.cfg元数据文件:mysql>
USE test;mysql>FLUSH TABLES t1 FOR EXPORT;在源实例 的 目录 中创建 Metadata(
.cfg)文件,每个tablespace(.ibd)文件 一个 文件 :/datadir/testMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p0.cfg t1#P#p1.cfg t1#P#p2.cfg/path/to/datadir/test/注意FLUSH TABLES ... FOR EXPORT语句确保已将对指定表的更改刷新到磁盘,以便在实例运行时进行二进制表复制。 当FLUSH TABLES ... FOR EXPORT运行时,InnoDB产生.cfg在同一数据库的目录表中的表的表空间文件元数据文件。 这些.cfg文件包含导入表空间文件时用于模式验证的元数据。FLUSH TABLES ... FOR EXPORT只能在表上运行,而不能在单个表分区上运行。 -
将
.ibd和.cfg实例数据库目录中 的 和 文件 复制 到目标实例数据库目录。 例如:壳> SCP
/path/to/datadir/test/t1*.{ibd,cfg} destination-server:/path/to/datadir/test注意的
.ibd和.cfg文件必须释放共享锁之前如在下一步中所述被复制。 -
在源实例上,用于
UNLOCK TABLES释放通过FLUSH TABLES ... FOR EXPORT以下方式 获取的锁 :mysql>
USE test;mysql>UNLOCK TABLES; -
在目标实例上,导入分区表的表空间:
mysql>
USE test;mysql>ALTER TABLE t1 IMPORT TABLESPACE;
示例3:将InnoDB表分区复制到另一个实例
此过程演示如何将
InnoDB
表分区从正在运行的MySQL服务器实例
复制
到另一个正在运行的实例。
可以使用具有微小调整的相同过程
InnoDB
在同一实例上
执行
表分区
的还原
。
在以下示例中,将在源实例上创建具有四个分区(p0,p1,p2,p3)的分区表。
其中两个分区(p2和p3)被复制到目标实例。
-
在源实例上,创建分区表(如果不存在)。 在以下示例中,将创建一个包含四个分区(p0,p1,p2,p3)的表:
mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4;在 目录中, 四个分区中的每个分区 都有一个单独的tablespace( )文件。
/datadir/test.ibdMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd/path/to/datadir/test/ -
在目标实例上,创建相同的分区表:
mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4;在 目录中, 四个分区中的每个分区 都有一个单独的tablespace( )文件。
/datadir/test.ibdMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd/path/to/datadir/test/ -
在目标实例上,丢弃计划从源实例导入的表空间分区。 (可以在目标实例上导入表空间分区之前,必须丢弃附加到接收表的相应分区。)
MySQL的>
ALTER TABLE t1 DISCARD PARTITION p2, p3 TABLESPACE;.ibd从 目标实例上的目录 中删除两个丢弃的分区 的 文件 ,留下以下文件:/datadir/testMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd/path/to/datadir/test/注意当
ALTER TABLE ... DISCARD PARTITION ... TABLESPACE上subpartitioned表上运行,无论分区和子分区表名是允许的。 指定分区名称时,该分区的子分区将包含在操作中。 -
在源实例上,运行
FLUSH TABLES ... FOR EXPORT以停顿分区表并创建.cfg元数据文件。mysql>
USE test;mysql>FLUSH TABLES t1 FOR EXPORT;元数据文件(
.cfg文件) 在源实例 的 目录 中创建 。 有一个 为每个表空间(文件 )文件。/datadir/test.cfg.ibdMySQL的>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd t1#P#p0.cfg t1#P#p1.cfg t1#P#p2.cfg t1#P#p3.cfg/path/to/datadir/test/注意FLUSH TABLES ... FOR EXPORT语句确保已将对指定表的更改刷新到磁盘,以便在实例运行时进行二进制表复制。 当FLUSH TABLES ... FOR EXPORT运行时,InnoDB产生.cfg在同一数据库的目录表中的表的表空间文件元数据文件。 这些.cfg文件包含导入表空间文件时用于模式验证的元数据。FLUSH TABLES ... FOR EXPORT只能在表上运行,而不能在单个表分区上运行。 -
将
.ibd和.cfg实例数据库目录中 的 和 文件 复制 到目标实例数据库目录。 在此示例中,仅将 分区2(p2)和分区3(p3) 的.ibd和.cfg文件复制到data目标实例上的目录。 分区0(p0)和分区1(p1)保留在源实例上。外壳>
scp t1#P#p2.ibd t1#P#p2.cfg t1#P#p3.ibd t1#P#p3.cfg destination-server:/path/to/datadir/test注意的
.ibd文件和.cfg文件必须释放共享锁之前如在下一步中所述被复制。 -
在源实例上,用于
UNLOCK TABLES释放通过FLUSH TABLES ... FOR EXPORT以下方式 获取的锁 :mysql>
USE test;mysql>UNLOCK TABLES; -
在目标实例上,导入表空间分区(p2和p3):
mysql>
USE test;mysql>ALTER TABLE t1 IMPORT PARTITION p2, p3 TABLESPACE;注意当
ALTER TABLE ... IMPORT PARTITION ... TABLESPACE上subpartitioned表上运行,无论分区和子分区表名是允许的。 指定分区名称时,该分区的子分区将包含在操作中。
以下信息描述了常规
InnoDB
表
的可传输表空间复制过程的内部和错误日志消息传递
。
何时
ALTER
TABLE
... DISCARD TABLESPACE
在目标实例上运行:
-
该表被锁定在X模式下。
-
表空间与表分离。
何时
FLUSH
TABLES ... FOR EXPORT
在源实例上运行:
-
刷新导出的表在共享模式下被锁定。
-
清除协调器线程已停止。
-
脏页面与磁盘同步。
-
表元数据被写入二进制
.cfg文件。
此操作的预期错误日志消息:
2013-09-24T13:10:19.903526Z 2 [注意] InnoDB:与“test”同步到磁盘。“t”'开始了。 2013-09-24T13:10:19.903586Z 2 [注意] InnoDB:停止清除 2013-09-24T13:10:19.903725Z 2 [注意] InnoDB:将表格元数据写入'./test/t.cfg' 2013-09-24T13:10:19.904014Z 2 [注意] InnoDB:表'“test”。“t”'刷新到磁盘
何时
UNLOCK
TABLES
在源实例上运行:
-
二进制.cfg文件已删除。
-
将导入要导入的表上的共享锁,并重新启动清除协调程序线程。
此操作的预期错误日志消息:
2013-09-24T13:10:21.181104Z 2 [注意] InnoDB:删除元数据文件'./test/t.cfg' 2013-09-24T13:10:21.181180Z 2 [注意] InnoDB:恢复清除
在
ALTER
TABLE
... IMPORT TABLESPACE
目标实例上运行时,导入算法会为要导入的每个表空间执行以下操作:
-
检查每个表空间页面是否损坏。
-
每页上的空间ID和日志序列号(LSN)都会更新
-
验证标志并更新标题页的LSN。
-
Btree页面已更新。
-
页面状态设置为脏,以便将其写入磁盘。
此操作的预期错误日志消息:
2013-07-18 15:15:01 34960 [注意] InnoDB:导入从主机'ubuntu'导出的表'test / t'的表空间 2013-07-18 15:15:01 34960 [注意] InnoDB:第一阶段 - 更新所有页面 2013-07-18 15:15:01 34960 [注意] InnoDB:同步到磁盘 2013-07-18 15:15:01 34960 [注意] InnoDB:同步到磁盘 - 完成! 2013-07-18 15:15:01 34960 [注意] InnoDB:第三阶段 - 刷新磁盘更改 2013-07-18 15:15:01 34960 [注意] InnoDB:第四阶段 - 冲洗完成
您可能还会收到一个警告,表示已丢弃表空间(如果您丢弃了目标表的表空间),并且收到一条消息,指出由于缺少
.ibd
文件
而无法计算统计信息
:
2013-07-18 15:14:38 34960 [警告] InnoDB:表“test”。“t”表空间被设置为丢弃。 2013-07-18 15:14:38 7f34d9a37700 InnoDB:无法计算表“test”的统计数据。“t” 因为缺少.ibd文件。如需帮助,请参阅 http://dev.mysql.com/doc/refman/8.0/en/innodb-troubleshooting.html
该
innodb_directories
选项定义了在启动时扫描表空间文件的目录,支持在服务器脱机时将表空间文件移动或恢复到新位置。
在启动期间,使用发现的表空间文件而不是数据字典中引用的那些文件,并更新数据字典以引用重定位的文件。
如果扫描发现重复的表空间文件,则启动失败,并显示错误,指示为同一表空间ID找到了多个文件。
由定义的目录
innodb_data_home_dir
,
innodb_undo_directory
和
datadir
配置选项自动附加到
innodb_directories
参数值。
无论是否
innodb_directories
明确指定选项,
都会在启动时扫描这些目录
。
隐式添加这些目录允许移动系统表空间文件,数据目录或撤消表空间文件,而无需配置
innodb_directories
设置。
但是,目录更改时必须更新设置。
例如,重定位数据目录后,必须
--datadir
在重新启动服务器之前
更新该
设置。
该
innodb_directories
选项可以在启动的命令或MySQL选项文件中指定。
参数值周围使用引号,因为否则分号(;)被某些命令解释器解释为特殊字符。
(例如,Unix shell将其视为命令终止符。)
启动命令:
mysqld --innodb-directories =“directory_path_1;directory_path_2”
MySQL选项文件:
的[mysqld] innodb_directories =“directory_path_1;directory_path_2”
以下过程适用于移动单个 file-per-table 和 常规表空间 文件, 系统表空间 文件, undo表空间 文件或数据目录。 在移动文件或目录之前,请查看以下使用说明。
-
停止服务器。
-
移动表空间文件或目录。
-
使新目录为已知
InnoDB。-
如果移动单个 每个 表 文件 或 一般表空间 文件,请将未知目录添加到该
innodb_directories值。-
由定义的目录
innodb_data_home_dir,innodb_undo_directory以及datadir配置选项自动追加到innodb_directories参数值,所以你不需要指定这些。 -
每个表的文件表空间文件只能移动到与模式同名的目录。 例如,如果
actor表属于sakila模式,则actor.ibd数据文件只能移动到名为的目录sakila。 -
通用表空间文件无法移动到数据目录或数据目录的子目录中。
-
-
如果移动系统表空间文件,还原表或数据目录,更新
innodb_data_home_dir,innodb_undo_directory以及datadir为必要的设置。
-
-
重启服务器。
使用说明
-
通配符表达式不能在
innodb_directories参数值中使用。 -
该
innodb_directories扫描还穿越指定目录的子目录。 从要扫描的目录列表中丢弃重复的目录和子目录。 -
该
innodb_directories选项仅支持移动InnoDB表空间文件。InnoDB不支持 移动属于非存储引擎的文件 。 移动整个数据目录时,此限制也适用。 -
该
innodb_directories选项支持在将文件移动到扫描目录时重命名表空间文件。 它还支持将表空间文件移动到其他支持的操作系统。 -
将表空间文件移动到其他操作系统时,请确保表空间文件名不包含目标系统上具有特殊含义的禁止字符或字符。
-
将数据目录从Windows操作系统移动到Linux操作系统时,请修改二进制日志索引文件中的二进制日志文件路径以使用反斜杠而不是正斜杠。 默认情况下,二进制日志索引文件与二进制日志文件具有相同的基本名称,扩展名为“
.index”。 二进制日志索引文件的位置由--log-bin。 定义 。 默认位置是数据目录。 -
如果将表空间文件移动到其他操作系统引入了跨平台复制,则数据库管理员有责任确保正确复制包含特定于平台的目录的DDL语句。 允许指定目录的语句包括
CREATE TABLE ... DATA DIRECTORY和CREATE TABLESPACE。 -
应使用绝对路径或在数据目录之外的位置创建的每个表文件和一般表空间文件的目录应添加到
innodb_directories参数值中。 否则,InnoDB在恢复期间无法找到这些文件。CREATE TABLE ... DATA DIRECTORY并CREATE TABLESPACE允许创建具有绝对路径的表空间文件。CREATE TABLESPACE还允许相对于数据目录的表空间文件目录。 要查看表空间文件位置,请查询INFORMATION_SCHEMA.FILES表:MySQL的>
SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES \G -
CREATE TABLESPACE要求目标目录存在且已知InnoDB。 已知目录包括由innodb_directories选项 隐式和显式定义的目录 。
InnoDB
支持
每表文件表
空间,
常规
表空间,
mysql
系统表空间,重做日志和撤消日志的静态
数据加密
。
从MySQL 8.0.16开始,还支持为模式和通用表空间设置加密默认值,这允许DBA控制在这些模式和表空间中创建的表是否已加密。
InnoDB
本节中的以下主题介绍了静态数据加密功能和功能。
InnoDB
使用双层加密密钥体系结构,包括主加密密钥和表空间密钥。
当表空间被加密时,表空间密钥被加密并存储在表空间头中。
当应用程序或经过身份验证的用户想要访问加密的表空间数据时,
InnoDB
使用主加密密钥来解密表空间密钥。
表空间密钥的解密版本永远不会更改,但可以根据需要更改主加密密钥。
此操作称为
主密钥轮换
。
静态数据加密功能依赖于用于主加密密钥管理的密钥环插件。
所有MySQL版本都提供了一个
keyring_file
插件,它将密钥环数据存储在服务器主机本地的文件中。
MySQL企业版提供额外的密钥环插件:
-
该
keyring_encrypted_file插件将密钥环数据存储在服务器主机本地的加密文件中。 -
该
keyring_okv插件包括KMIP客户端(KMIP 1.1),该客户端使用兼容KMIP的产品作为密钥环存储的后端。 支持KMIP的兼容产品包括集中式密钥管理解决方案,如Oracle Key Vault,Gemalto KeySecure,Thales Vormetric密钥管理服务器和Fornetix Key Orchestration。 -
该
keyring_aws插件与Amazon Web Services密钥管理服务(AWS KMS)通信,作为密钥生成的后端,并使用本地文件进行密钥存储。
在
keyring_file
和
keyring_encrypted file
插件并非意合规性解决方案。
PCI,FIPS等安全标准要求使用密钥管理系统来保护,管理和保护密钥保险库或硬件安全模块(HSM)中的加密密钥。
安全可靠的加密密钥管理解决方案对于安全性和符合各种安全标准至关重要。 当静态数据加密功能使用集中式密钥管理解决方案时,该功能称为 “ MySQL企业透明数据加密(TDE) ” 。
静态数据加密功能支持基于高级加密标准(AES)块的加密算法。 它使用电子密码本(ECB)块加密模式进行表空间密钥加密,使用密码块链接(CBC)块加密模式进行数据加密。
有关 静态 数据加密功能的 常见问题 ,请参见 第A.16节“MySQL 8.0常见问题解答:InnoDB静态数据加密” 。
-
必须安装和配置密钥环插件。 使用该
early-plugin-load选项 在启动时执行密钥环插件安装 。 早期加载可确保在初始化InnoDB存储引擎 之前插件可用 。 有关密钥环插件的安装和配置说明,请参见 第6.4.4节“MySQL密钥环” 。一次只能启用一个密钥环插件。 不支持启用多个密钥环插件。
重要在MySQL实例中创建加密表空间后,创建加密表空间时加载的密钥环插件必须在启动时使用该
early-plugin-load选项 继续加载 。 如果不这样做,则在启动服务器和InnoDB恢复 期间会导致错误 。要验证密钥环插件是否处于活动状态,请使用该
SHOW PLUGINS语句或查询该INFORMATION_SCHEMA.PLUGINS表。 例如:MySQL的>
SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE 'keyring%';+ -------------- + --------------- + | PLUGIN_NAME | PLUGIN_STATUS | + -------------- + --------------- + | keyring_file | ACTIVE | + -------------- + --------------- + -
加密生产数据时,请确保采取措施防止丢失主加密密钥。 如果主加密密钥丢失,则存储在加密表空间文件中的数据将无法恢复。 如果使用
keyring_fileorkeyring_encrypted_fileplugin,请在创建第一个加密表空间之后,主密钥轮换之前以及主密钥轮换之后立即创建密钥环数据文件的备份。 的keyring_file_data配置选项定义了密钥环数据文件位置keyring_file插件。 的keyring_encrypted_file_data配置选项定义了密钥环数据文件位置keyring_encrypted_file插入。 如果使用keyring_okv或keyring_aws插件,请确保已执行必要的配置。 有关说明,请参见 第6.4.4节“MySQL密钥环” 。
从MySQL 8.0.16开始,该
default_table_encryption
变量定义了模式和一般表空间的默认加密设置。
当
未明确指定子句
时
CREATE
TABLESPACE
,
CREATE
SCHEMA
操作将应用该
default_table_encryption
设置
ENCRYPTION
。
ALTER
SCHEMA
和
ALTER
TABLESPACE
操作不适用该
default_table_encryption
设置。
的
ENCRYPTION
条款必须明确指定改变现有模式或一般表空间的加密。
该
default_table_encryption
变量可以为单个客户端连接使用来设置或全局
SET
语法。
例如,以下语句全局启用默认架构和表空间加密:
mysql> SET GLOBAL default_table_encryption = ON;
DEFAULT ENCRYPTION
在创建或更改模式时,
也可以使用
子句
定义模式的默认加密设置
,如下例所示:
mysql> CREATE SCHEMA test DEFAULT ENCRYPTION ='Y';
如果
DEFAULT ENCRYPTION
在创建架构时未指定子句,
default_table_encryption
则应用
该
设置。
DEFAULT ENCRYPTION
必须指定
该
子句以更改现有模式的默认加密。
否则,架构将保留其当前的加密设置。
默认情况下,表继承创建它的模式或常规表空间的加密设置。例如,默认情况下,加密启用模式中创建的表是加密的。 此行为使DBA能够通过定义和实施架构和常规表空间加密默认值来控制表加密使用。
通过启用
table_encryption_privilege_check
变量
来强制执行加密默认值
。
当
table_encryption_privilege_check
启用时,创建或更改架构或一般的表空间与从不同的加密设置时发生特权检查
default_table_encryption
设置,或者创建或更改一个表,从默认模式加密不同的加密设置时。
当
table_encryption_privilege_check
被禁用(默认设置),权限检查不会发生,前面提到的操作被允许用警告继续进行。
启用后,
TABLE_ENCRYPTION_ADMIN
必须具有覆盖默认加密设置
的
权限
table_encryption_privilege_check
。
DBA可以授予此权限,以使用户
default_table_encryption
在创建或更改架构或常规表空间时
偏离
设置,或在创建或更改表时偏离默认架构加密。
在创建或更改表时,此权限不允许偏离通用表空间的加密。
表必须具有与其所在的常规表空间相同的加密设置。
从MySQL 8.0.16开始,每个表的文件表空间继承了创建表的模式的默认加密,除非在
ENCRYPTION
语句中指定了explcitly子句
CREATE
TABLE
。
在MySQL 8.0.16之前,
ENCRYPTION
必须指定
该
子句以启用加密。
MySQL的> CREATE TABLE t1 (c1 INT) ENCRYPTION = 'Y';
要更改现有每个表的表空间的加密,
ENCRYPTION
必须指定
一个
子句。
MySQL的> ALTER TABLE t1 ENCRYPTION = 'Y';
从MySQL 8.0.16开始,如果
table_encryption_privilege_check
启用
了该
变量,则指定
ENCRYPTION
一个设置与默认模式加密不同
的
子句需要该
TABLE_ENCRYPTION_ADMIN
权限。
请参阅
为架构和常规表空间定义加密默认值
。
从MySQL 8.0.16开始,该
default_table_encryption
变量确定新创建的通用表空间的加密,除非
ENCRYPTION
在
CREATE
TABLESPACE
语句中
明确指定
了
子句
。
在MySQL 8.0.16之前,
ENCRYPTION
必须指定
一个
子句来启用加密。
MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' ENCRYPTION = 'Y' Engine=InnoDB;
要更改现有通用表空间的加密,
ENCRYPTION
必须指定
一个
子句。
MySQL的> ALTER TABLESPACE ts1 ENCRYPTION = 'Y';
从MySQL 8.0.16开始,如果
table_encryption_privilege_check
启用
了该
变量,则指定
ENCRYPTION
设置与设置不同
的
子句
default_table_encryption
需要该
TABLE_ENCRYPTION_ADMIN
权限。
请参阅
为架构和常规表空间定义加密默认值
。
mysql
从MySQL 8.0.16开始提供
对
系统表空间的
加密支持
。
该
mysql
系统表空间包含
mysql
系统数据库和MySQL数据字典表。
默认情况下它是未加密的。
要为
mysql
系统表空间
启用加密,请
ENCRYPTION
在
ALTER TABLESPACE
语句中
指定表空间名称和
选项
。
mysql> ALTER TABLESPACE mysql ENCRYPTION ='Y';
要禁用
mysql
系统表空间的
加密
,请
ENCRYPTION = 'N'
使用
ALTER TABLESPACE
语句进行
设置
。
mysql> ALTER TABLESPACE mysql ENCRYPTION ='N';
启用或禁用
mysql
系统表空间的
加密
需要
CREATE TABLESPACE
实例中所有表
的
权限(
CREATE TABLESPACE on
*.*)
。
使用
innodb_redo_log_encrypt
配置选项
启用重做日志数据加密
。
默认情况下禁用重做日志加密。
与表空间数据一样,当重做日志数据写入磁盘时会发生重做日志数据加密,而从磁盘读取重做日志数据时会发生解密。 一旦将重做日志数据读入内存,它就会以未加密的形式出现。 使用表空间加密密钥对重做日志数据进行加密和解密。
当
innodb_redo_log_encrypt
启用时,是存在于磁盘加密重做日志页面未被加密,并且新的重做日志页写入到磁盘加密形式。
同样,
innodb_redo_log_encrypt
禁用时,磁盘上存在的加密重做日志页仍保持加密状态,新的重做日志页以未加密的形式写入磁盘。
重做日志加密元数据(包括表空间加密密钥)存储在第一个重做日志文件(
ib_logfile0
)
的标头中
。
如果删除此文件,则禁用重做日志加密。
启用重做日志加密后,无法在没有密钥环插件或没有加密密钥的情况下正常重启,因为
InnoDB
必须能够在启动期间扫描重做页面,如果重做日志页面已加密则无法进行。
如果没有密钥环插件或加密密钥,则只能在没有重做日志(
SRV_FORCE_NO_LOG_REDO
)的
情况下强制启动
。
请参见
第15.20.2节“强制InnoDB恢复”
。
使用
innodb_undo_log_encrypt
配置选项
启用撤消日志数据加密
。
撤消日志加密适用于驻留在
撤消表空间中的
撤消日志
。
请参见
第15.6.3.4节“撤消表空间”
。
默认情况下禁用撤消日志数据加密。
与表空间数据一样,当撤消日志数据写入磁盘时会发生撤消日志数据加密,而从磁盘读取撤消日志数据时会发生解密。 将撤消日志数据读入内存后,它将以未加密的形式出现。 使用表空间加密密钥对撤消日志数据进行加密和解密。
当
innodb_undo_log_encrypt
启用时,是存在于磁盘加密撤消日志页面未被加密,并且新的撤销日志页写入到磁盘加密形式。
同样,
innodb_undo_log_encrypt
禁用时,磁盘上存在的加密撤消日志页仍保持加密状态,新的撤消日志页以未加密的形式写入磁盘。
撤消日志加密元数据(包括表空间加密密钥)存储在撤消日志文件的标头中。
只要您怀疑密钥已被泄露,就应定期轮换主加密密钥。
主密钥轮换是一种原子的实例级操作。
每次旋转主加密密钥时,MySQL实例中的所有表空间密钥都会重新加密并保存回各自的表空间标头。
作为原子操作,一旦启动旋转操作,所有表空间键的重新加密必须成功。
如果服务器故障导致主密钥轮换中断,
InnoDB
则在服务器重新启动时向前滚动操作。
有关更多信息,请参阅
加密和恢复
。
旋转主加密密钥只会更改主加密密钥并重新加密表空间密钥。 它不会解密或重新加密关联的表空间数据。
旋转主加密密钥需要
ENCRYPTION_KEY_ADMIN
或
SUPER
权限。
要旋转主加密密钥,请运行:
MySQL的> ALTER INSTANCE ROTATE INNODB MASTER KEY;
ALTER
INSTANCE ROTATE INNODB MASTER
KEY
支持并发DML。
但是,它不能与表空间加密操作同时运行,并且会采取锁定来防止可能由并发执行引起的冲突。
如果某个
ALTER
INSTANCE ROTATE
INNODB MASTER KEY
操作正在运行,则必须在表空间加密操作可以继续之前完成,反之亦然。
如果在加密操作期间发生服务器故障,则在重新启动服务器时前滚操作。 对于常规表空间,加密操作在最后处理的页面的后台线程中恢复。
如果在主密钥轮换期间发生服务器故障,请
InnoDB
继续执行服务器重新启动操作。
必须在存储引擎初始化之前加载密钥环插件,以便在
InnoDB
初始化和恢复活动访问表空间数据
之前,可以从表空间头中检索解密表空间数据页所需的信息
。
(请参阅
加密先决条件
。)
当
InnoDB
初始化和恢复开始,主键旋转操作恢复。
由于服务器故障,某些表空间密钥可能已使用新的主加密密钥加密。
InnoDB
从每个表空间头读取加密数据,如果数据表明使用旧的主加密密钥加密了表空间密钥,
InnoDB
则从
密钥环中
检索旧密钥并使用它来解密表空间密钥。
InnoDB
然后使用新的主加密密钥重新加密表空间密钥,并将重新加密的表空间密钥保存回表空间标头。
表空间导出仅支持每个表的文件表空间。
导出加密表空间时,
InnoDB
生成
用于加密表空间键
的
传输
密钥。
加密的表空间密钥和传输密钥存储在
tablespace_name.cfpInnoDB
使用传输密钥来解密
tablespace_name.cfp
-
该
ALTER INSTANCE ROTATE INNODB MASTER KEY语句仅在主服务器和从服务器运行支持表空间加密的MySQL版本的复制环境中受支持。 -
成功的
ALTER INSTANCE ROTATE INNODB MASTER KEY语句将写入二进制日志以便在从属服务器上进行复制。 -
如果
ALTER INSTANCE ROTATE INNODB MASTER KEY语句失败,则不会将其记录到二进制日志中,也不会在从属服务器上复制。 -
ALTER INSTANCE ROTATE INNODB MASTER KEY如果密钥环插件安装在主服务器上而不是从服务器上,则操作 复制将 失败。 -
如果 主服务器和从服务器上都安装 了
keyring_file或者keyring_encrypted_file插件,但是从服务器没有密钥环数据文件,则复制ALTER INSTANCE ROTATE INNODB MASTER KEY语句会在从服务器上创建密钥环数据文件,假设密钥环文件数据未缓存在内存中。ALTER INSTANCE ROTATE INNODB MASTER KEY使用缓存在内存中的密钥环文件数据(如果可用)。
INFORMATION_SCHEMA.INNODB_TABLESPACES
MySQL 8.0.13中引入
的
表包含一个
ENCRYPTION
可用于标识加密表空间的列。
MySQL的>SELECT SPACE, NAME, SPACE_TYPE, ENCRYPTION FROM INFORMATION_SCHEMA.INNODB_TABLESPACESWHERE ENCRYPTION='Y'\G*************************** 1。排******************** ******* 空间:4294967294 名称:mysql SPACE_TYPE:一般 加密:是的 *************************** 2.排******************** ******* 空间:2 姓名:test / t1 SPACE_TYPE:单身 加密:是的 *************************** 3。排******************** ******* 空间:3 姓名:ts1 SPACE_TYPE:一般 加密:是的
当
ENCRYPTION
在
CREATE
TABLE
或
ALTER
TABLE
语句中
指定选项时
,它将记录在
CREATE_OPTIONS
列中
INFORMATION_SCHEMA.TABLES
。
可以查询此列以标识驻留在加密的每个表文件表空间中的表。
MySQL的>SELECT TABLE_SCHEMA, TABLE_NAME, CREATE_OPTIONS FROM INFORMATION_SCHEMA.TABLESWHERE CREATE_OPTIONS LIKE '%ENCRYPTION%';+ -------------- + ------------ + ---------------- + | TABLE_SCHEMA | TABLE_NAME | CREATE_OPTIONS | + -------------- + ------------ + ---------------- + | 测试| t1 | ENCRYPTION =“Y”| + -------------- + ------------ + ---------------- +
查询
INFORMATION_SCHEMA.INNODB_TABLESPACES
以检索与特定架构和表关联的表空间的信息。
MySQL的> SELECT SPACE, NAME, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME='test/t1';
+ ------- + --------- + ------------ +
| 空间| NAME | SPACE_TYPE |
+ ------- + --------- + ------------ +
| 3 | test / t1 | 单身|
+ ------- + --------- + ------------ +
您可以通过查询
INFORMATION_SCHEMA.SCHEMATA
表
来识别启用加密的模式
。
MySQL的>SELECT SCHEMA_NAME, DEFAULT_ENCRYPTION FROM INFORMATION_SCHEMA.SCHEMATAWHERE DEFAULT_ENCRYPTION='YES';+ ------------- + -------------------- + | SCHEMA_NAME | DEFAULT_ENCRYPTION | + ------------- + -------------------- + | 测试| 是的| + ------------- + -------------------- +
SHOW
CREATE SCHEMA
也显示了该
DEFAULT
ENCRYPTION
条款。
您可以
mysql
使用
Performance Schema
监视常规表空间和
系统表空间加密进度
。
该
stage/innodb/alter tablespace
(encryption)
阶段活动的仪器报告
WORK_ESTIMATED
和
WORK_COMPLETED
信息一般表空间加密操作。
以下示例演示如何启用
stage/innodb/alter tablespace (encryption)
stage事件工具和相关的使用者表来监视常规表空间或
mysql
系统表空间加密进度。
有关Performance Schema阶段事件工具和相关使用者的信息,请参见
第26.12.5节“性能模式阶段事件表”
。
-
启用
stage/innodb/alter tablespace (encryption)仪器:mysql>
USE performance_schema;mysql>UPDATE setup_instruments SET ENABLED = 'YES'WHERE NAME LIKE 'stage/innodb/alter tablespace (encryption)'; -
启用舞台活动消费表,其中包括
events_stages_current,events_stages_history,和events_stages_history_long。MySQL的>
UPDATE setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%stages%'; -
运行表空间加密操作。 在此示例中,名为的通用表空间
ts1已加密。MySQL的>
ALTER TABLESPACE ts1 ENCRYPTION = 'Y'; -
通过查询Performance Schema
events_stages_current表 来检查加密操作的进度 。WORK_ESTIMATED报告表空间中的总页数。WORK_COMPLETED报告处理的页数。MySQL的>
SELECT EVENT_NAME, WORK_ESTIMATED, WORK_COMPLETED FROM events_stages_current;+ -------------------------------------------- + ---- ------------ + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + -------------------------------------------- + ---- ------------ + ---------------- + | stage / innodb / alter tablespace(加密)| 1056 | 1407 | + -------------------------------------------- + ---- ------------ + ---------------- +该
events_stages_current如果加密操作已完成表返回一个空集。 在这种情况下,您可以检查events_stages_history表以查看已完成操作的事件数据。 例如:MySQL的>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM events_stages_history;+ -------------------------------------------- + ---- ------------ + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + -------------------------------------------- + ---- ------------ + ---------------- + | stage / innodb / alter tablespace(加密)| 1407 | 1407 | + -------------------------------------------- + ---- ------------ + ---------------- +
-
使用该
ENCRYPTION选项 更改现有的每表文件表空间时,请进行适当规划 。 使用该COPY算法 重建驻留在每表文件表空间中的表 。INPLACE在更改ENCRYPTION通用表空间或mysql系统表空间 的 属性 时使用 该 算法 。 该INPLACE算法允许驻留在通用表空间中的表上的并发DML。 并发DDL被阻止。 -
对通用表空间或
mysql系统表空间进行加密时,驻留在表空间中的所有表都将被加密。 同样,在加密表空间中创建的表也是加密的。 -
如果服务器在正常操作期间退出或停止,建议使用先前配置的相同加密设置重新启动服务器。
-
当第一个新表空间或现有表空间被加密时,将生成第一个主加密密钥。
-
主密钥轮换重新加密表空间密钥,但不会更改表空间密钥本身。 要更改表空间键,必须禁用并重新启用加密。 对于每表文件表空间,重新加密表空间是一种
ALGORITHM=COPY重建表 的 操作。 对于常规表空间和mysql系统表空间,它是一个ALGORITHM=INPLACE操作,不需要重建驻留在表空间中的表。 -
如果使用
COMPRESSION和ENCRYPTION选项 创建表,则在 加密表空间数据之前执行压缩。 -
如果密钥环数据文件(由
keyring_file_dataor 命名的文件keyring_encrypted_file_data)为空或缺失,则首次执行ALTER INSTANCE ROTATE INNODB MASTER KEY会创建主加密密钥。 -
卸载
keyring_file或keyring_encrypted_file插件不会删除现有的密钥环数据文件。 -
建议您不要将密钥环数据文件放在与表空间数据文件相同的目录下。
-
在运行时或重新启动服务器时 修改
keyring_file_data或keyring_encrypted_file_data设置可能导致以前加密的表空间无法访问,从而导致数据丢失。
-
高级加密标准(AES)是唯一受支持的加密算法。
InnoDB表空间加密使用电子密码本(ECB)块加密模式进行表空间密钥加密,并使用密码块链接(CBC)块加密模式进行数据加密。 -
仅对 每个表的文件表 空间, 通用 表空间和
mysql系统表空间 支持加密 。 MySQL 8.0.13中引入了对通用表空间的加密支持。mysql从MySQL 8.0.16开始提供 对 系统表空间的 加密支持 。 其他表空间类型(包括InnoDB系统表空间 )不支持加密 。 -
您不能将表从加密 的每表 空间 表 空间, 通用 表空间或
mysql系统表空间 移动或复制 到不支持加密的表空间类型。 -
您无法将表从加密表空间移动或复制到未加密的表空间。 但是,允许将表从未加密的表空间移动到加密的表空间。 例如,您可以将表从未加密 的每个表 或 一般 表空间 移动或复制 到加密的常规表空间。
-
默认情况下,表空间加密仅适用于表空间中的数据。 可以通过启用
innodb_redo_log_encrypt和 加密重做日志和撤消日志数据innodb_undo_log_encrypt。 请参阅 重做日志加密 和 撤消日志加密 。 二进制日志数据未加密。 -
不允许更改驻留在加密表空间中或之前驻留在加密表空间中的表的存储引擎。
doublewrite缓冲区是位于系统表空间中的存储区域
,在将页面写入数据文件中的正确位置之前
,
InnoDB
写入从
InnoDB
缓冲池中
刷新
的页面。
只有在将页面刷新并写入双写缓冲区后,才能
InnoDB
将页面写入正确的位置。
如果
在页面写入过程中
存在操作系统,存储子系统或
mysqld
进程崩溃,则
InnoDB
可以在崩溃恢复期间从doublewrite缓冲区中找到该页面的良好副本。
尽管数据总是写入两次,但双写缓冲区不需要两倍的I / O开销或两倍的I / O操作。
数据作为一个大的顺序块写入doublewrite缓冲区本身,只需一次
fsync()
调用操作系统。
在大多数情况下,默认情况下启用doublewrite缓冲区。
要禁用双写缓冲区,请设置
innodb_doublewrite
为0。
如果系统表空间文件(
“
ibdata文件
”
)位于支持原子写入的Fusion-io设备上,则会自动禁用双写缓冲,并且Fusion-io原子写入将用于所有数据文件。
由于双写缓冲区设置是全局的,因此对于驻留在非Fusion-io硬件上的数据文件也禁用双写缓冲。
此功能仅在Fusion-io硬件上受支持,仅适用于Linux上的Fusion-io NVMFS。
要充分利用此功能,
建议
进行
innodb_flush_method
设置
O_DIRECT
。
重做日志是在崩溃恢复期间用于纠正由未完成事务写入的数据的基于磁盘的数据结构。 在正常操作期间,重做日志会对更改由SQL语句或低级API调用产生的表数据的请求进行编码。 在初始化期间以及接受连接之前,将在意外关闭之前未完成更新数据文件的修改自动重播。 有关重做日志在崩溃恢复中的作用的信息,请参见 第15.17.2节“InnoDB恢复” 。
默认情况下,重做日志在磁盘上由两个名为
ib_logfile0
和的
文件物理表示
ib_logfile1
。
MySQL以循环方式写入重做日志文件。
重做日志中的数据根据受影响的记录进行编码;
这些数据统称为重做。
通过重做日志的数据传递由不断增加的
LSN
值表示。
有关相关信息,请参阅 重做日志文件配置 和 第8.5.4节“优化InnoDB重做日志记录” 。
有关重做日志的数据 静态加密的信息 ,请参阅 重做日志加密 。
要更改 重做日志 文件 的数量或大小 ,请执行以下步骤:
-
停止MySQL服务器并确保它关闭而没有错误。
-
编辑
my.cnf以更改日志文件配置。 要更改日志文件大小,请进行配置innodb_log_file_size。 要增加日志文件的数量,请进行配置innodb_log_files_in_group。 -
再次启动MySQL服务器。
如果
InnoDB
检测到
innodb_log_file_size
与重做日志文件大小不同,则会写入日志检查点,关闭并删除旧的日志文件,以请求的大小创建新的日志文件,并打开新的日志文件。
InnoDB
与任何其他
符合ACID标准
的数据库引擎一样,在
事务提交之前
刷新
事务
的
重做日志
。
InnoDB
使用
组提交
功能将多个此类刷新请求组合在一起,以避免每次提交一次刷新。
使用组提交,
InnoDB
对日志文件发出单个写入,以便为几乎同时提交的多个用户事务执行提交操作,从而显着提高吞吐量。
有关性能
COMMIT
和其他事务操作的
更多信息
,请参见
第8.5.2节“优化InnoDB事务管理”
。
撤消日志是与单个读写事务关联的撤消日志记录的集合。 撤消日志记录包含有关如何撤消事务到 聚簇索引 记录 的最新更改的信息 。 如果另一个事务需要将原始数据视为一致读取操作的一部分,则从撤消日志记录中检索未修改的数据。 撤消日志存在于 撤消日志段中 ,这些 日志段 包含在 回滚段中 。 回滚段驻留在 撤消表空间 和 全局临时表空间中 。
驻留在全局临时表空间中的撤消日志用于修改用户定义的临时表中的数据的事务。 这些撤消日志不会被重做日志记录,因为它们不是崩溃恢复所必需的。 它们仅用于服务器运行时的回滚。 这种类型的撤消日志通过避免重做日志记录I / O来提高性能。
有关撤消日志的数据静态加密的信息,请参阅 撤消日志加密 。
每个撤消表空间和全局临时表空间分别最多支持128个回滚段。
该
innodb_rollback_segments
变量定义了回滚段的数量。
回滚段支持的事务数取决于回滚段中的撤消槽数和每个事务所需的撤消日志数。
回滚段中的撤消槽数根据
InnoDB
页面大小而
不同
。
| InnoDB页面大小 | 回滚段中的撤消插槽数(InnoDB页面大小/ 16) |
|---|---|
4096 (4KB) |
256 |
8192 (8KB) |
512 |
16384 (16KB) |
1024 |
32768 (32KB) |
2048 |
65536 (64KB) |
4096 |
事务最多分配四个撤消日志,每个日志对应于以下每种操作类型:
根据需要分配撤消日志。
例如,执行交易
INSERT
,
UPDATE
以及
DELETE
定期和临时表操作需要四个撤销日志一个完整的分配。
仅对
INSERT
常规表
执行
操作的
事务
需要单个撤消日志。
在常规表上执行操作的事务将从分配的撤消表空间回滚段中分配撤消日志。 对临时表执行操作的事务将从分配的全局临时表空间回滚段中分配撤消日志。
分配给事务的撤消日志在其持续时间内仍与事务相关联。
例如,为
INSERT
常规表上
的
操作
分配给事务的撤消日志用于该事务
执行的常规表上的所有
INSERT
操作。
鉴于上述因素,可以使用以下公式来估计
InnoDB
能够支持
的并发读写事务的数量
。
在达到
InnoDB
能够支持
的并发读写事务数之前,事务可能会遇到并发事务限制错误
。
当分配给事务的回滚段用完撤消槽时,会发生这种情况。
在这种情况下,请尝试重新运行该事务。
当事务对临时表执行操作时,
InnoDB
能够支持
的并发读写事务
数受限于分配给全局临时表空间的回滚段数,默认情况下为128。
-
如果每个事务执行一个 或 一个 或 一个 或 一个 操作,那么 能够支持 的并发读写事务的数量 是:
INSERTUPDATEDELETEInnoDB(innodb_page_size / 16)* innodb_rollback_segments *撤消表空间的数量
-
如果每个事务执行一个 和 一个 或 一个 或 一个 操作,那么 能够支持 的并发读写事务的数量 是:
INSERTUPDATEDELETEInnoDB(innodb_page_size / 16/2)* innodb_rollback_segments *撤消表空间的数量
-
如果每个事务
INSERT对临时表 执行 操作,InnoDB则能够支持 的并发读写事务的数量 为:(innodb_page_size / 16)* innodb_rollback_segments
-
如果每个交易执行 和 一个 或 操作上的临时表,并发读写的事务的数目 是能够支持的是:
INSERTUPDATEDELETEInnoDB(innodb_page_size / 16/2)* innodb_rollback_segments
要实现大规模,繁忙或高度可靠的数据库应用程序,从不同的数据库系统移植大量代码,或调整MySQL性能,了解
InnoDB
锁定和
InnoDB
事务模型
非常重要
。
本节讨论与
InnoDB
锁定
相关的几个主题
以及
InnoDB
您应该熟悉
的
事务模型。
-
第15.7.1节“InnoDB锁定” 描述了使用的锁类型
InnoDB。 -
第15.7.2节“InnoDB事务模型” 描述了事务隔离级别和每个级别使用的锁定策略。 它还讨论了
autocommit一致的非锁定读取和锁定读取的使用。 -
第15.7.3节“由InnoDB中的不同SQL语句 设置的锁定 ” 讨论了
InnoDB为各种语句 设置的特定锁类型 。 -
第15.7.4节“幻影行” 描述了如何
InnoDB使用下一键锁定来避免幻像行。 -
第15.7.5节“InnoDB中 的死锁 ” 提供了一个死锁示例,讨论了死锁检测和回滚,并提供了最小化和处理死锁的提示
InnoDB。
本节介绍使用的锁类型
InnoDB
。
InnoDB
实现标准的行级锁定,其中有两种类型的锁,
shared(
S
)锁
和
exclusive(
X
)锁
。
如果事务
在行上
T1
持有一个shared(
S
)锁
r
,那么来自某个不同事务
T2
的对行锁的
请求
r
将按如下方式处理:
-
由A请求
T2用于S锁可以立即被授予。 其结果是,无论是T1与T2持有S的锁r。 -
通过请求
T2一个X锁不能立即授予。
如果事务
在行上
T1
持有exclusive(
X
)锁
r
,
则不能立即授予
来自某个不同事务
T2
的锁定任何类型的锁的
请求
r
。
相反,事务
T2
必须等待事务
T1
释放其对行的锁定
r
。
InnoDB
支持
多粒度锁定
,允许行锁和表锁共存。
例如,诸如
在指定表上
LOCK TABLES ...
WRITE
进行独占锁定(
X
锁定)之
类的语句
。
要在多个粒度级别实现锁定,请
InnoDB
使用
意图锁定
。
意图锁是表级锁,它指示事务稍后对表中的行所需的锁(共享或独占)类型。
意图锁有两种类型:
例如,
SELECT
...
FOR SHARE
设置
IS
锁定并
SELECT
... FOR
UPDATE
设置
IX
锁定。
意图锁定协议如下:
-
在事务可以获取表中某行的共享锁之前,它必须首先获取
IS表上的锁或更强。 -
在事务可以获取表中某行的独占锁之前,它必须首先获取
IX表上的锁。
表级锁定类型兼容性总结在以下矩阵中。
X |
IX |
S |
IS |
|
|---|---|---|---|---|
X |
冲突 | 冲突 | 冲突 | 冲突 |
IX |
冲突 | 兼容 | 冲突 | 兼容 |
S |
冲突 | 冲突 | 兼容 | 兼容 |
IS |
冲突 | 兼容 | 兼容 | 兼容 |
如果请求事务与现有锁兼容,则授予锁,但如果它与现有锁冲突则不会。 事务等待,直到释放冲突的现有锁。 如果锁定请求与现有锁定冲突且无法授予,因为它会导致 死锁 ,则会发生错误。
意图锁定不会阻止除完整表请求之外的任何内容(例如,
LOCK
TABLES ... WRITE
)。
意图锁定的主要目的是显示某人正在锁定行,或者要锁定表中的行。
意图锁定的事务数据
SHOW
ENGINE INNODB STATUS
与
InnoDB监视器
输出中
的以下内容类似
:
表LOCK表`test``t` trx id 10080锁定模式IX
记录锁定是对索引记录的锁定。
例如,
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;
可以防止从插入,更新或删除行,其中的值的任何其它交易
t.c1
是
10
。
即使定义了没有索引的表,记录锁也始终锁定索引记录。
对于此类情况,请
InnoDB
创建隐藏的聚簇索引并使用此索引进行记录锁定。
请参见
第15.6.2.1节“聚簇和二级索引”
。
记录锁的事务数据
SHOW
ENGINE INNODB STATUS
与
InnoDB监视器
输出中
的以下内容类似
:
RECORD LOCKS space id 58 page no 3 n bits 72索引`test``t`的`PRIMARY` trx id 10078 lock_mode X锁定rec而不是间隙 记录锁,堆没有2物理记录:n_fields 3; 紧凑格式; 信息位0 0:len 4; hex 8000000a; asc ;; 1:len 6; hex 00000000274f; asc'O ;; 2:len 7; hex b60000019d0110; asc ;;
间隙锁定是锁定索引记录之间的间隙,或锁定在第一个或最后一个索引记录之前的间隙。
例如,
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20
FOR UPDATE;
阻止其他事务将值
15
插入列
t.c1
,无论
列
中是否已存在任何此类值,因为该范围中所有现有值之间的间隙都已锁定。
间隙可能跨越单个索引值,多个索引值,甚至可能为空。
差距锁是性能和并发之间权衡的一部分,用于某些事务隔离级别而不是其他级别。
使用唯一索引锁定行以搜索唯一行的语句不需要间隙锁定。
(这不包括搜索条件仅包含多列唯一索引的某些列的情况;在这种情况下,确实会发生间隙锁定。)例如,如果
id
列具有唯一索引,则以下语句仅使用具有
id
值100
的行的索引记录锁定,
其他会话是否在前一个间隙中插入行无关紧要:
SELECT * FROM child WHERE id = 100;
如果
id
未编入索引或具有非唯一索引,则该语句会锁定前一个间隙。
此处值得注意的是,冲突锁可以通过不同的事务保持在间隙上。 例如,事务A可以在间隙上保持共享间隙锁定(间隙S锁定),而事务B在同一间隙上保持独占间隙锁定(间隙X锁定)。 允许冲突间隙锁定的原因是,如果从索引中清除记录,则必须合并由不同事务保留在记录上的间隙锁定。
间隙锁定
InnoDB
是
“
纯粹抑制
”
,这意味着它们的唯一目的是防止其他事务插入间隙。
差距锁可以共存。
一个事务占用的间隙锁定不会阻止另一个事务在同一个间隙上进行间隙锁定。
共享和独占间隙锁之间没有区别。
它们彼此不冲突,它们执行相同的功能。
可以明确禁用间隙锁定。
如果将事务隔离级别更改为,则会发生这种情况
READ
COMMITTED
。
在这些情况下,对于搜索和索引扫描禁用间隙锁定,并且仅用于外键约束检查和重复键检查。
使用
READ
COMMITTED
隔离级别
还有其他影响
。
在MySQL评估
WHERE
条件
后,将释放非匹配行的记录锁
。
对于
UPDATE
语句,
InnoDB
执行
“
半一致
”
读取,以便将最新提交的版本返回给MySQL,以便MySQL可以确定该行是否符合
WHERE
条件
UPDATE
。
下一键锁定是索引记录上的记录锁定和索引记录之前的间隙上的间隙锁定的组合。
InnoDB
以这样的方式执行行级锁定:当它搜索或扫描表索引时,它会在遇到的索引记录上设置共享锁或排它锁。
因此,行级锁实际上是索引记录锁。
索引记录上的下一键锁定也会影响该
索引记录之前
的
“
间隙
”
。
也就是说,下一键锁定是索引记录锁定加上索引记录之前的间隙上的间隙锁定。
如果一个会话
R
在索引中
具有共享或独占锁定记录
,则另一个会话不能
R
在索引顺序
之前的间隙中插入新索引记录
。
假设索引包含值10,11,13和20.此索引的可能的下一个键锁定覆盖以下间隔,其中圆括号表示排除间隔端点,方括号表示包含端点:
(负无穷大,10] (10,11] (11,13) (13,20) (20,正无穷大)
对于最后一个间隔,下一个键锁定将间隙锁定在索引中最大值之上,而 “ supremum ” 伪记录的值高于索引中实际的任何值。 supremum不是真正的索引记录,因此,实际上,此下一键锁定仅锁定最大索引值之后的间隙。
默认情况下,
InnoDB
以
REPEATABLE
READ
事务隔离级别运行。
在这种情况下,
InnoDB
使用下一键锁进行搜索和索引扫描,这会阻止幻像行(请参见
第15.7.4节“幻影行”
)。
下一键锁的事务数据
SHOW
ENGINE INNODB STATUS
与
InnoDB监视器
输出中
的以下内容类似
:
RECORD LOCKS space id 58 page no 3 n bits 72索引`test``t`的`PRIMARY` trx id 10080 lock_mode X. 记录锁,堆没有1物理记录:n_fields 1; 紧凑格式; 信息位0 0:len 8; hex 73757072656d756d; asc supremum ;; 记录锁,堆没有2物理记录:n_fields 3; 紧凑格式; 信息位0 0:len 4; hex 8000000a; asc ;; 1:len 6; hex 00000000274f; asc'O ;; 2:len 7; hex b60000019d0110; asc ;;
插入意图锁定是一种由
INSERT
行插入之前
的
操作
设置的间隙锁定
。
该锁定表示以这样的方式插入的意图:如果插入到相同索引间隙中的多个事务不插入间隙内的相同位置,则不需要等待彼此。
假设存在值为4和7的索引记录。分别尝试插入值5和6的单独事务,在获取插入行上的排它锁之前,每个锁定4和7之间的间隙和插入意图锁,但是不要互相阻塞因为行是非冲突的。
以下示例演示了在获取插入记录的独占锁之前采用插入意图锁定的事务。 该示例涉及两个客户端,A和B.
客户端A创建一个包含两个索引记录(90和102)的表,然后启动一个事务,该事务对ID大于100的索引记录放置独占锁。独占锁包括记录102之前的间隙锁:
mysql>CREATE TABLE child (id int(11) NOT NULL, PRIMARY KEY(id)) ENGINE=InnoDB;mysql>INSERT INTO child (id) values (90),(102);mysql>START TRANSACTION;mysql>SELECT * FROM child WHERE id > 100 FOR UPDATE;+ ----- + | id | + ----- + | 102 | + ----- +
客户端B开始事务以将记录插入间隙。 该事务在等待获取独占锁时采用插入意图锁。
mysql>START TRANSACTION;mysql>INSERT INTO child (id) VALUES (101);
插入意图锁的事务数据
SHOW
ENGINE INNODB
STATUS
与
InnoDB监视器
输出中
的以下内容类似
:
RECORD LOCKS space id 31 page no 3 n bits 72索引`test``child`的`PRIMARY`
trx id 8731 lock_mode X在rec 插入意图等待之前锁定间隙
记录锁,堆3号物理记录:n_fields 3; 紧凑格式; 信息位0
0:len 4; hex 80000066; asc f ;;
1:len 6; hex 000000002215; asc“;;
2:len 7; hex 9000000172011c; asc r ;; ...
一个
AUTO-INC
锁是通过交易将与表中取得一个特殊的表级锁
AUTO_INCREMENT
列。
在最简单的情况下,如果一个事务正在向表中插入值,则任何其他事务必须等待对该表执行自己的插入,以便第一个事务插入的行接收连续的主键值。
该
innodb_autoinc_lock_mode
配置选项控制用于自动增加锁定的算法。
它允许您选择如何在可预测的自动增量值序列和插入操作的最大并发之间进行权衡。
有关更多信息,请参见 第15.6.1.4节“InnoDB中的AUTO_INCREMENT处理” 。
InnoDB
支持
SPATIAL
对包含空间列的列进行索引(请参见
第11.5.9节“优化空间分析”
)。
要处理涉及
SPATIAL
索引的
操作的锁定
,下一键锁定不能很好地支持
REPEATABLE
READ
或
SERIALIZABLE
事务隔离级别。
多维数据中没有绝对排序概念,因此不清楚哪个是
“
下一个
”
密钥。
要为具有
SPATIAL
索引的
表启用隔离级别
,请
InnoDB
使用谓词锁。
甲
SPATIAL
索引包含最小外接矩形(MBR)值,因此,
InnoDB
通过设置用于查询的MBR值的谓词锁强制上的索引一致的读取。
其他事务无法插入或修改与查询条件匹配的行。
在
InnoDB
事务模型中,目标是将
多版本
数据库
的最佳属性
与传统的两阶段锁定相结合。
InnoDB
在行级别执行锁定,并
以Oracle的样式默认
运行查询作为非锁定
一致性读取
。
锁定信息以
InnoDB
节省空间的方式存储,因此不需要锁定升级。
通常,允许多个用户锁定
InnoDB
表中的
每一行
或
行的
任何随机子集,而不会导致
InnoDB
内存耗尽。
事务隔离是数据库处理的基础之一。 隔离是I的首字母缩写 ACID ; 隔离级别是在多个事务进行更改并同时执行查询时,对结果的性能和可靠性,一致性和可重现性进行微调的设置。
InnoDB
提供由SQL描述的所有四个事务隔离级别:1992标准:
READ
UNCOMMITTED
,
READ
COMMITTED
,
REPEATABLE
READ
,和
SERIALIZABLE
。
InnoDB
is
的默认隔离级别
REPEATABLE
READ
。
用户可以更改单个会话或与
SET
TRANSACTION
语句的
所有后续连接的隔离级别
。
要为所有连接设置服务器的默认隔离级别,请使用
--transaction-isolation
命令行或选项文件中的选项。
有关隔离级别和级别设置语法的详细信息,请参见
第13.3.7节“SET TRANSACTION语法”
。
InnoDB
使用不同的
锁定
策略
支持此处描述的每个事务隔离级别
。
REPEATABLE
READ
对于
ACID
合规性很重要的
关键数据的操作,
您可以强制执行与默认
级别的高度
一致性
。
或者你可以用放松的一致性规则
READ
COMMITTED
,甚至
READ
UNCOMMITTED
在情况下,如散装报告需要精确的一致性和可重复的结果比最小化锁定开销的量更重要。
SERIALIZABLE
执行甚至更严格的规则
REPEATABLE
READ
,主要用于特殊情况,例如
XA
事务和解决并发和
死锁
问题
。
以下列表描述了MySQL如何支持不同的事务级别。 该列表从最常用的级别变为最少使用的级别。
-
这是默认的隔离级别
InnoDB。 同一事务中的 一致读取读取 第一次读取建立 的 快照 。 这意味着如果SELECT在同一事务中 发出多个普通(非锁定) 语句,这些SELECT语句也相互一致。 请参见 第15.7.2.3节“一致的非锁定读取” 。对于 锁定读取 (
SELECT带FOR UPDATE或,FOR SHARE)UPDATE和DELETE语句,锁定取决于语句是使用具有唯一搜索条件的唯一索引还是范围类型搜索条件。-
对于具有唯一搜索条件的唯一索引,
InnoDB仅锁定找到的索引记录,而不是 之前 的 间隙 。 -
对于其他搜索条件,
InnoDB使用 间隙锁 或 下一键锁定锁定 扫描的索引范围, 以阻止其他会话插入范围所覆盖的间隙。 有关间隙锁和下一键锁的信息,请参见 第15.7.1节“InnoDB锁定” 。
-
-
即使在同一事务中,每个一致的读取也会设置和读取自己的新快照。 有关一致性读取的信息,请参见 第15.7.2.3节“一致性非锁定读取” 。
对于锁定读取(
SELECT带FOR UPDATE或FOR SHARE),UPDATE语句和DELETE语句,InnoDB只锁定索引记录,而不是它们之前的间隙,因此允许在锁定记录旁边自由插入新记录。 间隙锁定仅用于外键约束检查和重复键检查。由于禁用了间隙锁定,因此可能会出现幻像问题,因为其他会话可以在间隙中插入新行。 有关 幻像的 信息,请参见 第15.7.4节“幻影行” 。
READ COMMITTED隔离级别 仅支持基于行的二进制日志记录 。 如果使用READ COMMITTED带binlog_format=MIXED时,服务器将自动使用基于行的日志记录。使用
READ COMMITTED还有其他效果:请考虑以下示例,从此表开始:
CREATE TABLE t(INT NOT NULL,b INT)ENGINE = InnoDB; 插入值(1,2),(2,3),(3,2),(4,3),(5,2); 承诺;
在这种情况下,表没有索引,因此搜索和索引扫描使用隐藏的聚簇索引进行记录锁定(请参见 第15.6.2.1节“聚簇和二级索引” )而不是索引列。
假设一个会话
UPDATE使用以下语句 执行 :#会话A. 开始交易; 更新t SET b = 5 WHERE b = 3;
还假设第二个会话
UPDATE通过执行第一个会话的那些语句来执行:#会议B UPDATE t SET b = 4 WHERE b = 2;
当
InnoDB执行每个时UPDATE,它首先获取每行的独占锁,然后确定是否修改它。 如果InnoDB不修改行,则释放锁。 否则,InnoDB保留锁直到事务结束。 这会影响事务处理,如下所示。使用默认
REPEATABLE READ隔离级别时,第UPDATE一个在它读取的每一行上获取一个x锁定,并且不释放它们中的任何一个:X锁(1,2); 保留x锁 X锁(2,3); 更新(2,3)至(2,5); 保留x锁 X锁(3,2); 保留x锁 X锁(4,3); 更新(4,3)至(4,5); 保留x锁 X锁(5,2); 保留x锁
第二个
UPDATE块一旦尝试获取任何锁(因为第一次更新已保留所有行上的锁),并且在第一次UPDATE提交或回滚 之前不会继续 :X锁(1,2); 阻止并等待第一个UPDATE提交或回滚
如果
READ COMMITTED使用 if ,则第UPDATE一个在它读取的每一行上获取一个x-lock,并释放那些不修改的行:X锁(1,2); 解锁(1,2) X锁(2,3); 更新(2,3)至(2,5); 保留x锁 X锁(3,2); 解锁(3,2) X锁(4,3); 更新(4,3)至(4,5); 保留x锁 X锁(5,2); 解锁(5,2)
对于第二个
UPDATE,InnoDB执行 “ 半一致 ” 读取,返回它读取到MySQL的每一行的最新提交版本,以便MySQL可以确定该行是否符合以下WHERE条件UPDATE:X锁(1,2); 更新(1,2)至(1,4); 保留x锁 X锁(2,3); 解锁(2,3) X锁(3,2); 更新(3,2)至(3,4); 保留x锁 X锁(4,3); 解锁(4,3) X锁(5,2); 更新(5,2)至(5,4); 保留x锁
但是,如果
WHERE条件包含索引列并InnoDB使用索引,则在获取和保留记录锁时仅考虑索引列。 在下面的示例中,第一个UPDATE采用并保留每行上的x锁定,其中b = 2.第二个UPDATE阻止它尝试获取相同记录上的x锁定,因为它还使用列b上定义的索引。CREATE TABLE t(INT NOT NULL,b INT,c INT,INDEX(b))ENGINE = InnoDB; 插入值(1,2,3),(2,2,4); 承诺; #会话A. 开始交易; 更新t SET b = 3其中b = 2且c = 3; #会议B UPDATE t SET b = 4 WHERE b = 2且c = 4;
使用
READ COMMITTED隔离级别 的效果 与启用已弃用的innodb_locks_unsafe_for_binlog配置选项相同,但有以下例外:-
启用
innodb_locks_unsafe_for_binlog是全局设置并影响所有会话,而隔离级别可以为所有会话全局设置,也可以为每个会话单独设置。 -
innodb_locks_unsafe_for_binlog只能在服务器启动时设置,而隔离级别可以在启动时设置或在运行时更改。
READ COMMITTED因此提供更精细和更灵活的控制innodb_locks_unsafe_for_binlog。 -
-
SELECT语句以非锁定方式执行,但可能使用行的早期版本。 因此,使用此隔离级别,此类读取不一致。 这也称为 脏读 。 否则,这个隔离级别就像READ COMMITTED。 -
此级别类似
REPEATABLE READ,但InnoDB隐式将所有普通SELECT语句 转换 为SELECT ... FOR SHAREifautocommit被禁用。 如果autocommit启用,则SELECT是它自己的事务。 因此,已知它是只读的,并且如果作为一致(非锁定)读取执行则可以序列化,并且不需要阻止其他事务。 (SELECT如果其他事务已修改所选行,则 强制平面 阻止,禁用autocommit。)
在
InnoDB
,所有用户活动都发生在事务中。
如果
autocommit
启用了mode,则每个SQL语句自己形成一个事务。
默认情况下,MySQL为每个
autocommit
启用的
新连接启动会话
,因此如果该语句没有返回错误,MySQL会在每个SQL语句后执行提交。
如果语句返回错误,则提交或回滚行为取决于错误。
请参见
第15.20.4节“InnoDB错误处理”
。
具有会话
autocommit
启用可以通过显式启动它执行多语句事务
START
TRANSACTION
或
BEGIN
语句,并用它结束
COMMIT
或
ROLLBACK
声明。
请参见
第13.3.1节“START TRANSACTION,COMMIT和ROLLBACK语法”
。
如果
autocommit
在会话中禁用了模式
SET autocommit = 0
,则会话始终打开一个事务。
一个
COMMIT
或
ROLLBACK
语句结束当前事务和一个新的开始。
如果已
autocommit
禁用
的会话在
没有显式提交最终事务的情况下结束,则MySQL将回滚该事务。
某些语句隐式结束事务,就像您
COMMIT
在执行语句之前
完成了
一样。
有关详细信息,请参见
第13.3.3节“导致隐式提交的语句”
。
A
COMMIT
表示当前事务中所做的更改是永久性的,并且对其他会话可见。
一个
ROLLBACK
声明,而另一方面,取消当前事务中的所有修改。
双方
COMMIT
并
ROLLBACK
释放所有
InnoDB
当前事务期间设置的锁。
默认情况下,连接到MySQL服务器开始与 自动提交 模式启用,当你执行它自动提交每个SQL语句。 如果您具有其他数据库系统的经验,则可能不熟悉此操作模式,其中标准做法是发出一系列 DML 语句并将它们提交或一起回滚。
要使用多语句
事务
,请使用SQL语句关闭自动提交,
SET autocommit
= 0
并使用
COMMIT
或
ROLLBACK
根据需要
结束每个事务
。
要启用自动提交,请开始每个事务
START
TRANSACTION
并以
COMMIT
或
结束它
ROLLBACK
。
以下示例显示了两个事务。
第一个承诺;
第二个回滚。
外壳> mysql test
MySQL的>CREATE TABLE customer (a INT, b CHAR (20), INDEX (a));查询正常,0行受影响(0.00秒) mysql>-- Do a transaction with autocommit turned on.mysql>START TRANSACTION;查询正常,0行受影响(0.00秒) MySQL的>INSERT INTO customer VALUES (10, 'Heikki');查询正常,1行受影响(0.00秒) MySQL的>COMMIT;查询正常,0行受影响(0.00秒) mysql>-- Do another transaction with autocommit turned off.mysql>SET autocommit=0;查询正常,0行受影响(0.00秒) MySQL的>INSERT INTO customer VALUES (15, 'John');查询正常,1行受影响(0.00秒) MySQL的>INSERT INTO customer VALUES (20, 'Paul');查询正常,1行受影响(0.00秒) MySQL的>DELETE FROM customer WHERE b = 'Heikki';查询正常,1行受影响(0.00秒) mysql>-- Now we undo those last 2 inserts and the delete.mysql>ROLLBACK;查询正常,0行受影响(0.00秒) MySQL的>SELECT * FROM customer;+ ------ + -------- + | a | b | + ------ + -------- + | 10 | Heikki | + ------ + -------- + 1排(0.00秒) MySQL的>
客户端语言中的事务
在诸如PHP,Perl DBI,JDBC,ODBC或MySQL的标准C调用接口之类的API中,您可以将事务控制语句(例如,
COMMIT
作为字符串)
发送
到MySQL服务器,就像任何其他SQL语句(如
SELECT
或)一样
INSERT
。
某些API还提供单独的特殊事务提交和回滚功能或方法。
甲
一致的读取
该装置
InnoDB
使用多版本呈现给一个查询数据库的快照在一个时间点。
查询将查看在该时间点之前提交的事务所做的更改,并且不会对以后或未提交的事务所做的更改进行更改。
此规则的例外是查询查看同一事务中早期语句所做的更改。
此异常导致以下异常:如果更新表中的某些行,则a
SELECT
查看更新行的最新版本,但它也可能会看到任何行的旧版本。
如果其他会话同时更新同一个表,则异常意味着您可能会看到该表处于从未存在于数据库中的状态。
如果事务
隔离级别
是
REPEATABLE
READ
(缺省级别),则同一事务中的所有一致性读取将读取该事务中第一次此类读取所建立的快照。
您可以通过提交当前事务并在发出新查询之后为查询获取更新的快照。
使用
READ
COMMITTED
隔离级别,事务中的每个一致读取都会设置并读取其自己的新快照。
一致性读取是
InnoDB
进程
SELECT
语句
READ
COMMITTED
和
REPEATABLE
READ
隔离级别
的默认模式
。
一致读取不会对其访问的表设置任何锁定,因此其他会话可以在对表执行一致读取的同时自由修改这些表。
假设您正在以默认
REPEATABLE
READ
隔离级别
运行
。
当您发出一致性读取(即普通
SELECT
语句)时,
InnoDB
为您的事务提供一个时间点,您的查询将根据该时间点查看数据库。
如果另一个事务删除了一行并在分配了您的时间点后提交,则您不会将该行视为已删除。
插入和更新的处理方式类似。
数据库状态的快照适用
SELECT
于事务中的语句,不一定适用于
DML
语句。
如果插入或修改某些行然后提交该事务,
则从另一个并发
事务
发出
的
DELETE
或
UPDATE
语句
REPEATABLE READ
可能会影响那些刚刚提交的行,即使会话无法查询它们。
如果事务确实更新或删除了由其他事务提交的行,则这些更改将对当前事务可见。
例如,您可能会遇到如下情况:
SELECT COUNT(c1)FROM t1 WHERE c1 ='xyz'; - 返回0:没有行匹配。 DELETE FROM t1 WHERE c1 ='xyz'; - 删除最近由其他事务提交的几行。 SELECT COUNT(c2)FROM t1 WHERE c2 ='abc'; - 返回0:没有行匹配。 UPDATE t1 SET c2 ='cba'WHERE c2 ='abc'; - 影响10行:另一个txn只提交了10行,带有'abc'值。 SELECT COUNT(c2)FROM t1 WHERE c2 ='cba'; - 返回10:这个txn现在可以看到它刚刚更新的行。
您可以通过提交您的交易然后再做另一个
SELECT
或
那个来提前您的时间点
START TRANSACTION WITH
CONSISTENT SNAPSHOT
。
这称为 多版本并发控制 。
在以下示例中,会话A仅在B已提交插入且A已提交时才看到由B插入的行,以便时间点超过B的提交。
会议A会议B.
SET autocommit = 0; SET autocommit = 0;
时间
| SELECT * FROM t;
| 空集
| 插入值(1,2);
|
v SELECT * FROM t;
空集
承诺;
SELECT * FROM t;
空集
承诺;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
如果要查看
数据库
的
“
最新
”
状态,请使用
READ
COMMITTED
隔离级别或
锁定读取
:
SELECT * FROM t FOR SHARE;
使用
READ
COMMITTED
隔离级别,事务中的每个一致读取都会设置并读取其自己的新快照。
使用时
FOR SHARE
,会发生锁定读取:
SELECT
直到包含最新行的事务结束的块为止(请参见
第15.7.2.4节“锁定读取”
)。
一致的读取对某些DDL语句不起作用:
-
一致的读取不起作用
DROP TABLE,因为MySQL不能使用已被删除InnoDB的表 并 销毁该表。 -
一致性读取不起作用
ALTER TABLE,因为该语句创建原始表的临时副本,并在构建临时副本时删除原始表。 在事务中重新发出一致读取时,新表中的行不可见,因为在执行事务快照时这些行不存在。 在这种情况下,事务返回一个错误:ER_TABLE_DEF_CHANGED, “ 表的定义发生了变化,请重试交易 ” 。
该类型读为like子句选择不同
INSERT
INTO ...
SELECT
,
UPDATE
... (SELECT)
和
CREATE
TABLE ...
SELECT
没有指定
FOR
UPDATE
或
FOR SHARE
:
-
默认情况下,
InnoDB使用更强的锁,并且该SELECT部分的行为类似于READ COMMITTED,即使在同一事务中,每个一致读取也会设置和读取其自己的新快照。 -
要在这种情况下,读一致性,事务隔离级别设置为
READ UNCOMMITTED,READ COMMITTED或REPEATABLE READ(也就是比其他任何东西SERIALIZABLE)。 在这种情况下,不会对从所选表中读取的行设置锁定。
如果查询数据然后在同一事务中插入或更新相关数据,则常规
SELECT
语句不会提供足够的保护。
其他事务可以更新或删除您刚查询的相同行。
InnoDB
支持两种类型的
锁定读取
,提供额外的安全性:
-
在读取的任何行上设置共享模式锁定。 其他会话可以读取行,但在事务提交之前无法修改它们。 如果这些行中的任何行已被另一个尚未提交的事务更改,则查询将等待该事务结束,然后使用最新值。
注意SELECT ... FOR SHARE是替代SELECT ... LOCK IN SHARE MODE,但LOCK IN SHARE MODE仍可用于向后兼容。 这些陈述是等同的。 然而,FOR SHARE支持 , 和 选项。 请参阅 使用NOWAIT和SKIP LOCKED锁定读取并发 。OFtable_nameNOWAITSKIP LOCKED -
对于搜索遇到的索引记录,锁定行和任何关联的索引条目,就像您
UPDATE为这些行 发出 语句一样。 阻止其他事务更新这些行,执行SELECT ... FOR SHARE或从某些事务隔离级别读取数据。 一致性读取将忽略在读取视图中存在的记录上设置的任何锁定。 (旧版本的记录无法锁定;它们通过 在记录的内存中副本上 应用 撤消日志 来重建 。)
这些子句在处理树形结构或图形结构数据时非常有用,无论是在单个表中还是在多个表中分割。 您将边缘或树枝从一个地方遍历到另一个地方,同时保留返回并更改任何这些 “ 指针 ” 值 的权限 。
提交或回滚事务时,将释放
由设置
FOR SHARE
和
FOR
UPDATE
查询
设置的所有锁
。
只有在禁用自动提交时(通过使用
START
TRANSACTION
或通过设置
autocommit
为0
开始事务处理),才能锁定读取
。
除非在子查询中指定了锁定读取子句,否则外部语句中的锁定读取子句不会锁定嵌套子查询中的表行。
例如,以下语句不会锁定表中的行
t2
。
SELECT * FROM t1 WHERE c1 =(SELECT c1 FROM t2)FOR UPDATE;
要锁定表中的行,
t2
请在子查询中添加一个锁定读取子句:
SELECT * FROM t1 WHERE c1 =(SELECT c1 FROM t2 FOR UPDATE)FOR UPDATE;
假设您要在表中插入新行
child
,并确保子行在表中具有父行
parent
。
您的应用程序代码可确保整个操作序列中的引用完整性。
首先,使用一致性读取来查询表
PARENT
并验证父行是否存在。
你能安全地将子行插入表
CHILD
吗?
不,因为其他一些会话可能会删除您
SELECT
和您
之间的父行,
而您
INSERT
却不知道它。
要避免此潜在问题,请执行以下
SELECT
操作
FOR
SHARE
:
SELECT * FROM parent WHERE NAME ='Jones'FOR SHARE;
在之后
FOR SHARE
的查询返回父
'Jones'
,你可以放心地将孩子记录添加到
CHILD
表并提交事务。
尝试获取
PARENT
表中
适用行的独占锁的任何事务都会
等到完成后,即直到所有表中的数据都处于一致状态。
再举一个例子,考虑表中的整数计数器字段
CHILD_CODES
,用于为添加到表的每个子节点分配唯一的标识符
CHILD
。
不要使用一致读取或共享模式读取来读取计数器的当前值,因为数据库的两个用户可以看到计数器的相同值,并且如果两个事务尝试添加行,则会发生重复键错误
CHILD
表格
的相同标识符
。
这里
FOR SHARE
不是一个好的解决方案,因为如果两个用户同时读取计数器,则当它们尝试更新计数器时,其中至少有一个会陷入死锁。
要实现读取和递增计数器,首先使用计数器执行锁定读取
FOR
UPDATE
,然后递增计数器。
例如:
SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
A
SELECT
... FOR
UPDATE
读取最新的可用数据,在其读取的每一行上设置独占锁。
因此,它设置搜索的SQL
UPDATE
将在行上
设置的相同锁
。
前面的描述仅仅是如何
SELECT
... FOR
UPDATE
工作的
一个例子
。
在MySQL中,生成唯一标识符的具体任务实际上只需对表进行一次访问即可完成:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
该
SELECT
语句仅检索标识符信息(特定于当前连接)。
它不访问任何表。
如果行被事务锁定
,则请求相同锁定行
的事务
SELECT ... FOR
UPDATE
或
SELECT ... FOR SHARE
事务必须等到阻塞事务释放行锁。
此行为可防止事务更新或删除由其他事务查询以进行更新的行。
但是,如果您希望在请求的行被锁定时立即返回查询,或者从结果集中排除锁定的行是可接受的,则无需等待释放行锁定。
为了避免等待其他事务释放行锁,
NOWAIT
并且
SKIP LOCKED
选项可以与
read语句
一起使用
SELECT ... FOR
UPDATE
或
SELECT ... FOR SHARE
锁定。
-
NOWAIT使用
NOWAIT永不等待获取行锁定的 锁定读取 。 查询立即执行,如果请求的行被锁定则失败并显示错误。 -
SKIP LOCKED使用
SKIP LOCKED永不等待获取行锁定的 锁定读取 。 查询立即执行,从结果集中删除锁定的行。注意跳过锁定行的查询会返回数据的不一致视图。
SKIP LOCKED因此不适合一般交易工作。 但是,当多个会话访问同一个类似队列的表时,它可用于避免锁争用。
NOWAIT
并且
SKIP LOCKED
仅适用于行级锁。
对基于语句的复制
使用
NOWAIT
或
SKIP
LOCKED
不安全的语句。
以下示例演示
NOWAIT
和
SKIP LOCKED
。
会话1启动一个事务,该事务对单个记录执行行锁定。
会话2尝试使用该
NOWAIT
选项
对同一记录进行锁定读取
。
由于请求的行被会话1锁定,因此锁定读取会立即返回错误。
在会话3中,锁定读取
SKIP
LOCKED
返回请求的行,但会话1锁定的行除外。
#第1节: MySQL的>CREATE TABLE t (i INT, PRIMARY KEY (i)) ENGINE = InnoDB;MySQL的>INSERT INTO t (i) VALUES(1),(2),(3);MySQL的>START TRANSACTION;MySQL的>SELECT * FROM t WHERE i = 2 FOR UPDATE;+ --- + | 我| + --- + | 2 | + --- + #Session 2: MySQL的>START TRANSACTION;MySQL的>SELECT * FROM t WHERE i = 2 FOR UPDATE NOWAIT;ERROR 3572(HY000):不要等待锁定。 #第3节: MySQL的>START TRANSACTION;MySQL的>SELECT * FROM t FOR UPDATE SKIP LOCKED;+ --- + | 我| + --- + | 1 | | 3 | + --- +
一个
锁定读
,一个
UPDATE
或
DELETE
一般设置纪录是在SQL语句的处理扫描每个索引记录锁定。
WHERE
声明中
是否存在
排除行的条件
并不重要
。
InnoDB
不记得确切的
WHERE
条件,但只知道扫描了哪个索引范围。
锁通常是
下一键锁
,它也会阻止插入到
记录之前的
“
间隙
”中
。
但是,
可以显式禁用
间隙锁定
,这会导致不使用下一键锁定。
有关更多信息,请参阅
第15.7.1节“InnoDB锁定”
。
事务隔离级别也可以影响设置的锁;
请参见
第15.7.2.1节“事务隔离级别”
。
如果在搜索中使用了二级索引,并且要设置的索引记录锁是独占的,则
InnoDB
还会检索相应的聚簇索引记录并对其设置锁定。
如果没有适合您的语句的索引,并且MySQL必须扫描整个表来处理该语句,则表的每一行都会被锁定,这反过来会阻止其他用户对表的所有插入。 创建好的索引非常重要,这样您的查询就不会不必要地扫描很多行。
InnoDB
设置特定类型的锁如下。
-
SELECT ... FROM是一致的读取,读取数据库的快照并设置无锁,除非事务隔离级别设置为SERIALIZABLE。 对于SERIALIZABLE级别,搜索会在遇到的索引记录上设置共享的下一键锁定。 但是,对于使用唯一索引锁定行以搜索唯一行的语句,只需要索引记录锁定。 -
SELECT ... FOR UPDATE和SELECT ... FOR SHARE使用唯一索引的语句获取扫描行的锁,并释放不符合包含在结果集中的行的锁(例如,如果它们不符合WHERE子句中 给出的条件 )。 但是,在某些情况下,行可能不会立即解锁,因为在查询执行期间结果行与其原始源之间的关系会丢失。 例如,在UNION从表中扫描(和锁定)的行可能会在评估它们是否符合结果集之前插入临时表中。 在这种情况下,临时表中的行与原始表中的行的关系将丢失,并且在查询执行结束之前不会解锁后面的行。 -
对于 锁定读取 (
SELECT使用FOR UPDATE或,FOR SHARE)UPDATE和DELETE语句,所采用的锁取决于语句是使用具有唯一搜索条件的唯一索引还是范围类型搜索条件。-
对于具有唯一搜索条件的唯一索引,
InnoDB仅锁定找到的索引记录,而不是 之前 的 间隙 。 -
对于其他搜索条件以及非唯一索引,
InnoDB使用 间隙锁 或 下一键锁 来 锁定 扫描的索引范围, 以阻止其他会话插入范围所涵盖的间隙。 有关间隙锁和下一键锁的信息,请参见 第15.7.1节“InnoDB锁定” 。
-
-
对于搜索遇到的索引记录,
SELECT ... FOR UPDATE阻止其他会话执行SELECT ... FOR SHARE或读取某些事务隔离级别。 一致性读取将忽略在读取视图中存在的记录上设置的任何锁定。 -
UPDATE ... WHERE ...在搜索遇到的每条记录上设置一个独占的下一键锁定。 但是,对于使用唯一索引锁定行以搜索唯一行的语句,只需要索引记录锁定。 -
当
UPDATE修改一个聚集索引记录,隐含的锁被采取对受影响的第二个索引记录。UPDATE在插入新的辅助索引记录之前以及插入新的辅助索引记录时, 该 操作还会在受影响的辅助索引记录上采用共享锁定。 -
DELETE FROM ... WHERE ...在搜索遇到的每条记录上设置一个独占的下一键锁定。 但是,对于使用唯一索引锁定行以搜索唯一行的语句,只需要索引记录锁定。 -
INSERT在插入的行上设置独占锁。 此锁是索引记录锁,而不是下一键锁(即没有间隙锁),并且不会阻止其他会话在插入行之前插入间隙。在插入行之前,设置一种称为插入意图间隙锁定的间隙锁定。 该锁定表示以这样的方式插入的意图:如果插入到相同索引间隙中的多个事务不插入间隙内的相同位置,则不需要等待彼此。 假设存在值为4和7的索引记录。尝试插入值5和6的单独事务在获取插入行上的排它锁之前使用插入意图锁定锁定4和7之间的间隙,但不因为行是非冲突的,所以互相阻塞。
如果发生重复键错误,则设置重复索引记录上的共享锁。 如果有多个会话尝试插入同一行,如果另一个会话已经具有独占锁,则使用共享锁可能导致死锁。 如果另一个会话删除该行,则会发生这种情况。 假设一个
InnoDB表t1具有以下结构:CREATE TABLE t1(i INT,PRIMARY KEY(i))ENGINE = InnoDB;
现在假设三个会话按顺序执行以下操作:
第一节:
开始交易; 插入t1值(1);
第二节:
开始交易; 插入t1值(1);
第3节:
开始交易; 插入t1值(1);
第一节:
ROLLBACK;
会话1的第一个操作获取该行的排他锁。 会话2和3的操作都会导致重复键错误,并且它们都请求该行的共享锁。 当会话1回滚时,它会释放对该行的独占锁定,并且会话2和3的排队共享锁请求被授予。 此时,会话2和3死锁:由于另一个持有共享锁,因此都不能为该行获取排它锁。
如果表已包含键值为1的行并且三个会话按顺序执行以下操作,则会出现类似情况:
第一节:
开始交易; DELETE FROM t1 WHERE i = 1;
第二节:
开始交易; 插入t1值(1);
第3节:
开始交易; 插入t1值(1);
第一节:
承诺;
会话1的第一个操作获取该行的排他锁。 会话2和3的操作都会导致重复键错误,并且它们都请求该行的共享锁。 当会话1提交时,它会释放对该行的独占锁定,并且会话2和3的排队共享锁定请求被授予。 此时,会话2和3死锁:由于另一个持有共享锁,因此都不能为该行获取排它锁。
-
INSERT ... ON DUPLICATE KEY UPDATE不同之处在于,INSERT当发生重复键错误时,在要更新的行上放置独占锁而不是共享锁。 对重复的主键值采用独占索引记录锁定。 对于重复的唯一键值,采用独占的下一键锁定。 -
INSERT INTO T SELECT ... FROM S WHERE ...在插入的每一行上设置一个独占索引记录锁(没有间隙锁)T。 如果事务隔离级别是READ COMMITTED,InnoDB则将搜索S作为一致读取(无锁定)。 否则,InnoDB在行上设置共享的下一键锁定S。InnoDB必须在后一种情况下设置锁定:在使用基于语句的二进制日志的前滚恢复期间,每个SQL语句必须以与最初完成时相同的方式执行。CREATE TABLE ... SELECT ...执行SELECTwith共享的下一键锁定或作为一致读取INSERT ... SELECT。当
SELECT在构建中使用REPLACE INTO t SELECT ... FROM s WHERE ...或UPDATE t ... WHERE col IN (SELECT ... FROM s ...),InnoDB集共享来自表中的行的下键锁s。 -
在初始化
AUTO_INCREMENT表上 的先前指定的 列InnoDB时,在与AUTO_INCREMENT列 关联的索引的末尾设置独占锁 。 在访问自动增量计数器时,InnoDB使用特定的AUTO-INC表锁定模式,其中锁定仅持续到当前SQL语句的末尾,而不是整个事务的结束。 在保持AUTO-INC表锁 时,其他会话无法插入表中 ; 请参见 第15.7.2节“InnoDB事务模型” 。InnoDB获取先前初始化AUTO_INCREMENT列 的值 而不设置任何锁定。 -
如果
FOREIGN KEY在表上定义 了 约束,则需要检查约束条件的任何插入,更新或删除都会在其查看的记录上设置共享记录级锁定以检查约束。InnoDB在约束失败的情况下也设置这些锁。 -
LOCK TABLES设置表锁,但它是InnoDB设置这些锁的 层之上的更高的MySQL层 。InnoDB知道表锁如果innodb_table_locks = 1(默认)和autocommit = 0,以及上面的MySQL层InnoDB知道行级锁。否则,
InnoDB自动死锁检测无法检测涉及此类表锁的死锁。 此外,因为在这种情况下,较高的MySQL层不知道行级锁,所以可以在另一个会话当前具有行级锁的表上获得表锁。 但是,这不会危及事务完整性,如 第15.7.5.2节“死锁检测和回滚”中所述 。 另请参见 第15.6.1.6节“InnoDB表的限制” 。
当同一查询在不同时间产生不同的行集时,
所谓的
幻像
问题发生在事务中。
例如,如果a
SELECT
执行两次,但第二次返回第二次没有返回的行,则该行是
“
幻像
”
行。
假设
表
的
id
列
上有一个索引,
child
并且您要读取并锁定标识符值大于100的表中的所有行,以便稍后更新所选行中的某些列:
SELECT * FROM child WHERE id> 100 FOR UPDATE;
查询从
id
大于100
的第一个记录开始扫描索引
。让表包含
id
值为90和102的行。如果在扫描范围内的索引记录上设置的锁不会锁定在间隙中进行的插入(在这种情况下,90和102之间的差距),另一个会话可以
id
在101中以101的形式
在表中插入一个新行
。如果要在同
SELECT
一个事务中
执行相同
的操作,则会看到一个
id
101
的新行
(一个
“
幽灵
”
)在查询返回的结果集中。
如果我们将一组行视为数据项,则新的幻像子将违反事务应该能够运行的事务的隔离原则,以便它在事务期间读取的数据不会更改。
为了防止幻像,
InnoDB
使用一种称为
下一键锁定
的算法
,
该算法
将索引行锁定与间隙锁定相结合。
InnoDB
以这样的方式执行行级锁定:当它搜索或扫描表索引时,它会在遇到的索引记录上设置共享锁或排它锁。
因此,行级锁实际上是索引记录锁。
此外,索引记录上的下一键锁定也会影响该
索引记录之前
的
“
间隙
”
。
也就是说,下一键锁定是索引记录锁定加上索引记录之前的间隙上的间隙锁定。
如果一个会话在记录中具有共享或独占锁定
R
在索引中,另一个会话不能
R
在索引顺序
之前的间隙中插入新的索引记录
。
当
InnoDB
扫描索引,它也可以锁定在指数的最后一个记录之后的间隙。
恰好在前面的示例中发生:为了防止任何插入到表中
id
大于100的锁,设置的锁
InnoDB
包括在
id
值102之后
的间隙上的锁
。
您可以使用下一键锁定在应用程序中实现唯一性检查:如果您在共享模式下读取数据并且没有看到要插入的行的副本,那么您可以安全地插入行并知道在读取期间在行的后继上设置的下一键锁定可防止任何人同时为您的行插入副本。 因此,下一键锁定使您能够 “ 锁定 ” 表中某些内容的不存在。
可以禁用间隙锁定,如 第15.7.1节“InnoDB锁定”中所述 。 这可能会导致幻像问题,因为其他会话可以在禁用间隙锁定时将新行插入间隙。
死锁是一种情况,其中不同的事务无法继续,因为每个事务都持有另一个需要的锁。 因为两个事务都在等待资源可用,所以它们都不会释放它所拥有的锁。
当事务锁定多个表中的行(通过诸如
UPDATE
或之类的
语句
SELECT
... FOR
UPDATE
)时,
可能会发生死锁
,但顺序相反。
当这样的语句锁定索引记录和间隙的范围时,也会发生死锁,每个事务由于时序问题而获取某些锁而不是其他锁。
有关死锁示例,请参见
第15.7.5.1节“InnoDB死锁示例”
。
要减少死锁的可能性,请使用事务而不是
LOCK TABLES
语句;
保持插入或更新数据足够小的交易,使其长时间不开放;
当不同的事务更新多个表或大范围的行时,
SELECT
... FOR
UPDATE
在每个事务中
使用相同的操作顺序(例如
);
在
SELECT
...
FOR UPDATE
和
UPDATE
... WHERE
语句中
使用的列上创建索引
。
死锁的可能性不受隔离级别的影响,因为隔离级别会更改读取操作的行为,而由于写入操作会发生死锁。
有关避免和从死锁条件中恢复的更多信息,请参阅
第15.7.5.3节“如何最小化和处理死锁”
。
启用死锁检测(默认值)并发生死锁时,
InnoDB
检测条件并回滚其中一个事务(受害者)。
如果使用
innodb_deadlock_detect
配置选项
禁用死锁检测
,则
InnoDB
依赖于
innodb_lock_wait_timeout
设置在发生死锁时回滚事务。
因此,即使您的应用程序逻辑正确,您仍必须处理必须重试事务的情况。
要查看
InnoDB
用户事务中
的最后一个死锁
,请使用该
SHOW
ENGINE INNODB
STATUS
命令。
如果频繁的死锁突出显示事务结构或应用程序错误处理的问题,请运行
innodb_print_all_deadlocks
设置已启用以将有关所有死锁的信息打印到
mysqld
错误日志。
有关如何自动检测和处理死锁的更多信息,请参见
第15.7.5.2节“死锁检测和回滚”
。
以下示例说明了锁定请求导致死锁时如何发生错误。 该示例涉及两个客户端,A和B.
首先,客户端A创建一个包含一行的表,然后开始一个事务。
在事务中,A通过
S
在共享模式中选择它来
获取
该行
的
锁定:
MySQL的>CREATE TABLE t (i INT) ENGINE = InnoDB;查询正常,0行受影响(1.07秒) MySQL的>INSERT INTO t (i) VALUES(1);查询正常,1行受影响(0.09秒) MySQL的>START TRANSACTION;查询正常,0行受影响(0.00秒) MySQL的>SELECT * FROM t WHERE i = 1 FOR SHARE;+ ------ + | 我| + ------ + | 1 | + ------ +
接下来,客户端B开始一个事务并尝试从表中删除该行:
MySQL的>START TRANSACTION;查询正常,0行受影响(0.00秒) MySQL的>DELETE FROM t WHERE i = 1;
删除操作需要
X
锁定。
无法授予
S
锁定,
因为它与
客户端A持有
的
锁
不兼容
,因此请求将进入行和客户端B块的锁定请求队列。
最后,客户端A还尝试从表中删除该行:
MySQL的> DELETE FROM t WHERE i = 1;
ERROR 1213(40001):尝试锁定时发现死锁;
尝试重新启动事务
此处发生死锁,因为客户端A需要
X
锁定才能删除该行。
但是,无法授予该锁定请求,因为客户端B已经有
X
锁定
请求
并且正在等待客户端A释放其
S
锁定。
由于B先前要求锁定,因此
S
A所持有的锁
也不能
升级
X
为
X
锁。
结果,
InnoDB
为其中一个客户端生成错误并释放其锁定。
客户端返回此错误:
ERROR 1213(40001):尝试锁定时发现死锁; 尝试重新启动事务
此时,可以授予其他客户端的锁定请求,并从表中删除该行。
当
死锁检测
被使能(缺省值),
InnoDB
自动检测事务
的死锁
和回退事务或交易打破僵局。
InnoDB
尝试选择要回滚的小事务,其中事务的大小由插入,更新或删除的行数确定。
InnoDB
知道表锁如果
innodb_table_locks = 1
(默认)和
autocommit = 0
,并且它上面的MySQL层知道行级锁。
否则,
InnoDB
无法检测由MySQL
LOCK TABLES
语句
设置的表锁定
或由涉及的存储引擎设置的锁定的死锁
InnoDB
。
通过设置
innodb_lock_wait_timeout
系统变量
的值来解决这些情况
。
当
InnoDB
进行交易的完整回滚,由交易设置的所有锁都被释放。
但是,如果由于错误而仅回滚单个SQL语句,则可能会保留由该语句设置的某些锁定。
发生这种情况是因为
InnoDB
存储行锁的格式使得以后无法知道哪个锁是由哪个语句设置的。
如果a
SELECT
在事务中调用存储函数,并且函数内的语句失败,则该语句将回滚。
此外,如果
ROLLBACK
在此之后执行,则整个事务回滚。
如果
LATEST DETECTED DEADLOCK
第
InnoDB
监视器输出包括一条消息指出,
“
过深或长时间的搜寻锁表WAITS-FOR图中,我们将回滚下面的事务
,
”
这表明交易的所述等待名单上的人数已经达到了限制为200.超过200个事务的等待列表被视为死锁,并且将回滚尝试检查等待列表的事务。
如果锁定线程必须查看等待列表上的事务所拥有的超过1,000,000个锁,则也可能发生相同的错误。
有关组织数据库操作以避免死锁的技术,请参见 第15.7.5节“InnoDB中的死锁” 。
在高并发系统上,当许多线程等待同一个锁时,死锁检测会导致速度减慢。
有时,禁用死锁检测可能更有效,并且在
innodb_lock_wait_timeout
发生死锁时
依赖于
事务回滚
的
设置。
可以使用
innodb_deadlock_detect
配置选项
禁用死锁检测
。
本节基于 第15.7.5.2节“死锁检测和回滚”中 有关死锁的概念性信息 。 它解释了如何组织数据库操作以最大限度地减少死锁以及应用程序中所需的后续错误处理。
死锁 是事务数据库中的一个典型问题,但它们并不危险,除非它们如此频繁以至于根本无法运行某些事务。 通常,您必须编写应用程序,以便在由于死锁而回滚时,它们始终准备重新发出事务。
InnoDB
使用自动行级锁定。
即使只是插入或删除单行的事务,您也可能会遇到死锁。
那是因为这些操作并非真正的
“
原子
”
;
它们会自动设置对插入或删除的行的(可能是几个)索引记录的锁定。
您可以使用以下技术处理死锁并降低其发生的可能性:
-
在任何时候,发出
SHOW ENGINE INNODB STATUS命令以确定最近死锁的原因。 这可以帮助您调整应用程序以避免死锁。 -
如果频繁出现死锁警告,请通过启用
innodb_print_all_deadlocks配置选项 收集更多的调试信息 。 有关每个死锁的信息,而不仅仅是最新的死锁,都记录在MySQL 错误日志中 。 完成调试后禁用此选项。 -
如果由于死锁而失败,请始终准备重新发布事务。 死锁并不危险。 再试一次。
-
保持交易持续时间短且不易发生,以减少交易。
-
在进行一组相关更改后立即提交事务,以使它们不易发生冲突。 特别是,不要 使用未提交的事务 使交互式 mysql 会话长时间保持打开状态。
-
如果使用 锁定读取 (
SELECT ... FOR UPDATE或SELECT ... FOR SHARE),请尝试使用较低的隔离级别,例如READ COMMITTED。 -
在事务中修改多个表或同一个表中的不同行集时,每次都以一致的顺序执行这些操作。 然后事务形成定义良好的队列,不会死锁。 例如,组织数据库操作到功能在应用程序中,或调用存储程序,而不是编码的多个相似序列
INSERT,UPDATE以及DELETE在不同的地方语句。 -
在表中添加精心选择的索引。 然后,您的查询需要扫描更少的索引记录,从而设置更少的锁。 使用
EXPLAIN SELECT以确定哪些索引MySQL认为最适合您的查询。 -
使用较少的锁定。 如果您能够允许
SELECT从旧快照返回数据,请不要添加FOR UPDATE或FOR SHARE使用 该子句 。 在READ COMMITTED这里 使用 隔离级别很好,因为同一事务中的每个一致读取都从其自己的新快照读取。 -
如果没有其他帮助,请使用表级锁定序列化您的事务。
LOCK TABLES与事务表(例如InnoDB表) 一起使用的正确方法是使用SET autocommit = 0(非START TRANSACTION)后跟 开始事务LOCK TABLES,并且UNLOCK TABLES在显式提交事务之前 不调用 。 例如,如果您需要写入表t1并从表中读取t2,则可以执行以下操作:SET autocommit = 0; LOCK TABLES t1 WRITE,t2 READ,...;
... do something with tables t1 and t2 here ...承诺; 解锁表;表级锁可防止对表的并发更新,从而避免死锁,但代价是对繁忙系统的响应性较低。
-
序列化事务的另一种方法是创建一个 只包含一行 的辅助 “ 信号量 ” 表。 让每个事务在访问其他表之前更新该行。 这样,所有事务都以串行方式发生。 请注意,
InnoDB即时死锁检测算法在这种情况下也适用,因为序列化锁定是行级锁定。 使用MySQL表级锁定时,必须使用超时方法来解决死锁。
本节提供有关
存储引擎的
InnoDB
初始化,启动以及各种组件和功能的
配置信息和过程
InnoDB
。
有关优化
InnoDB
表的
数据库操作的信息
,请参见
第8.5节“优化InnoDB表”
。
关于
InnoDB
配置
的第一个决定
涉及数据文件,日志文件,页面大小和内存缓冲区的配置。
建议您在创建
InnoDB
实例
之前定义数据文件,日志文件和页面大小配置
。
修改后的数据文件或日志文件配置
InnoDB
创建实例
可能涉及一个非平凡的过程,并且只能在
InnoDB
首次初始化实例
时定义页面大小
。
除了这些主题之外,本节还提供有关
InnoDB
在配置文件中
指定
选项,查看
InnoDB
初始化信息和重要存储注意事项的信息。
由于MySQL使用数据文件,日志文件和页面大小配置设置来初始化
InnoDB
实例,因此建议您
InnoDB
在初次
化初始化之前在启动时读取的配置文件中定义这些设置
。
InnoDB
MySQL服务器启动时初始化,第一次初始化
InnoDB
通常在第一次启动MySQL服务器时发生。
您可以将
InnoDB
选项放在
[mysqld]
服务器启动时读取的任何选项文件
的
组中。
第4.2.2.2节“使用选项文件”
中介绍了MySQL选项文件的位置
。
要确保
mysqld
仅从特定文件(和
mysqld-auto.cnf
)
读取选项
,请
--defaults-file
在启动服务器时
将该
选项用作命令行上的第一个选项:
mysqld --defaults-file =path_to_configuration_file
要
InnoDB
在启动期间
查看
初始化信息,请
从命令提示符
启动
mysqld
。
当
mysqld的
是从命令提示开始时,初始化信息被打印到控制台。
例如,在Windows上,如果
mysqld的
位于
C:\Program Files\MySQL\MySQL Server
8.0\bin
,启动MySQL服务器这样的:
C:\> "C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld" --console
在类Unix系统上,
mysqld
位于
bin
MySQL安装目录中:
外壳> bin/mysqld --user=mysql &
如果不将服务器输出发送到控制台,请在启动后检查错误日志,以查看
InnoDB
在启动过程中打印
的初始化信息
。
有关使用其他方法启动MySQL的信息,请参见 第2.10.5节“自动启动和停止MySQL” 。
InnoDB
在启动时不会打开所有用户表和关联的数据文件。
但是,
InnoDB
是否检查
*.ibd
数据字典中引用
的表空间文件(
文件)
是否存在
。
如果找不到表空间文件,则
InnoDB
记录错误并继续启动序列。
在重做应用程序的崩溃恢复期间,可能会打开重做日志中引用的表空间文件。
在继续启动配置之前,请查看以下与存储相关的注意事项。
-
在某些情况下,如果数据并非全部放在同一物理磁盘上,则数据库性能会提高。 将日志文件放在与数据不同的磁盘上通常有利于提高性能。 例如,您可以将系统表空间数据文件和日志文件放在不同的磁盘上。 您还可以将原始磁盘分区(原始设备)用于
InnoDB数据文件,这可以加快I / O. 请参阅 为系统表空间使用原始磁盘分区 。 -
InnoDB是一种适用于MySQL的事务安全(ACID兼容)存储引擎,具有提交,回滚和崩溃恢复功能,可保护用户数据。 但是, 如果底层操作系统或硬件不像宣传的那样工作 ,则不能这样做 。 许多操作系统或磁盘子系统可能会延迟或重新排序写入操作以提高性能。 在某些操作系统上,非常fsync()应该等到文件的所有未写入数据都被刷新的系统调用实际上可能在数据被刷新到稳定存储之前返回。 因此,操作系统崩溃或断电可能会破坏最近提交的数据,或者在最坏的情况下,甚至会因为重新排序写入操作而损坏数据库。 如果数据完整性对您很重要,请 在使用生产中的任何内容之前 执行一些 “ 拔插 ” 测试。 在OS X 10.3及更高版本上,InnoDB使用特殊fcntl()文件刷新方法。 在Linux下,建议 禁用回写缓存 。在ATA / SATA磁盘驱动器上,这样的命令
hdparm -W0 /dev/hda可以用于禁用回写高速缓存。 请注意,某些驱动器或磁盘控制器可能无法禁用回写缓存。 -
关于
InnoDB保护用户数据的恢复功能,InnoDB使用涉及称为 doublewrite缓冲区 的结构的文件刷新技术,该结构 默认启用(innodb_doublewrite=ON)。 双写缓冲区可在崩溃或停电后为恢复增加安全性,并通过减少fsync()操作 需求来提高大多数Unix的性能 。innodb_doublewrite如果您担心数据完整性或可能的故障, 建议 保持启用 该 选项。 有关doublewrite缓冲区的其他信息,请参阅 第15.11.1节“InnoDB磁盘I / O” 。 -
在使用NFS之前
InnoDB,请查看 使用NFS与MySQL中 概述的潜在问题 。
的
innodb_data_file_path
配置选项定义的名称,大小,和属性
InnoDB
系统表空间的数据文件。
如果没有为其指定值
innodb_data_file_path
,则默认行为是创建一个名称略大于12MB的自动扩展数据文件
ibdata1
。
要指定多个数据文件,请用分号(
;
)字符
分隔它们
:
innodb_data_file_path =datafile_spec1[;datafile_spec2] ...
以下设置配置一个名为
ibdata1
自动扩展的
12MB数据文件
。
没有给出文件的位置,因此默认情况下,
InnoDB
在MySQL数据目录中创建它:
的[mysqld] innodb_data_file_path中= ibdata1中:12M:自动扩展
文件大小使用
K
,
M
或
G
后缀字母
指定
,
以指示KB,MB或GB的单位。
如果以千字节(KB)指定数据文件大小,请以1024的倍数执行此操作。否则,KB值将四舍五入为最接近的兆字节(MB)边界。
文件大小的总和必须至少略大于12MB。
为第 一个 系统表空间数据文件 强制实施最小文件大小, 以确保有足够的空间用于双写缓冲区页面:
-
对于
innodb_page_size16KB或更小 的 值,最小文件大小为3MB。 -
对于
innodb_page_size32KB 的 值,最小文件大小为6MB。 -
对于
innodb_page_size64KB 的 值,最小文件大小为12MB。
具有固定大小的50MB数据文件
ibdata1
和
名为
50MB自动扩展文件
的系统表空间
ibdata2
可以像这样配置:
的[mysqld] innodb_data_file_path中= ibdata1中:50M; ibdata2:50M:自动扩展
数据文件规范的完整语法包括文件名,文件大小以及可选
autoextend
和
max
属性:
file_name:file_size[:autoextend [:max:max_file_size]]
该
autoextend
和
max
属性只能用于将最后一个指定的数据文件中使用
innodb_data_file_path
的设置。
如果
autoextend
为最后一个数据文件
指定
选项,则
InnoDB
扩展数据文件(如果表空间中的可用空间不足)。
该
autoextend
增量是在默认情况下,时间64MB。
要修改增量,请更改
innodb_autoextend_increment
系统变量。
如果磁盘已满,您可能希望在另一个磁盘上添加另一个数据文件。 有关说明,请参阅 调整系统表空间大小 。
单个文件的大小限制由您的操作系统决定。 您可以在支持大文件的操作系统上将文件大小设置为4GB以上。 您还可以 将原始磁盘分区用作数据文件 。
InnoDB
不知道文件系统的最大文件大小,因此在最大文件大小为2GB的较小值的文件系统上要小心。
要指定自动扩展数据文件的最大大小,请使用
max
属性后面的
autoextend
属性。
max
仅在限制磁盘使用率至关重要的情况下
使用该
属性,因为超出最大大小会导致致命错误,可能导致服务器退出。
以下配置允许
ibdata1
增长到500MB的限制:
的[mysqld] innodb_data_file_path中= ibdata1中:12M:自动扩展:最大:500M
InnoDB
默认情况下(
datadir
)
在MySQL数据目录中创建系统表空间文件
。
要明确指定位置,请使用该
innodb_data_home_dir
选项。
例如,要
在名为的目录中
创建两个名为的文件
ibdata1
,请
ibdata2
按以下方式
myibdata
配置
InnoDB
:
的[mysqld] innodb_data_home_dir = / path / to / myibdata / innodb_data_file_path中= ibdata1中:50M; ibdata2:50M:自动扩展
指定值时,需要使用尾部斜杠
innodb_data_home_dir
。
InnoDB
不创建目录,因此
myibdata
在启动服务器之前,请
确保该
目录存在。
使用Unix或DOS
mkdir
命令创建目录。
确保MySQL服务器具有在数据目录中创建文件的适当访问权限。 更一般地说,服务器必须在需要创建数据文件的任何目录中具有访问权限。
InnoDB
通过以文本方式连接
innodb_data_home_dir
数据文件名
的值
来
形成每个数据文件的目录路径
。
如果
innodb_data_home_dir
未指定
该
选项,则默认值为
“
dot
”
目录
./
,表示MySQL数据目录。
(MySQL服务器在开始执行时将其当前工作目录更改为其数据目录。)
如果指定
innodb_data_home_dir
为空字符串,则可以为
innodb_data_file_path
值中
列出的数据文件指定绝对路径
。
以下示例等效于前一个示例:
的[mysqld] innodb_data_home_dir = innodb_data_file_path中= /路径/到/ myibdata / ibdata1中:50M; /路径/到/ myibdata / ibdata2:50M:自动扩展
默认情况下,
InnoDB
在名为
ib_logfile0
和
的数据目录中创建两个5MB重做日志文件
ib_logfile1
。
以下选项可用于修改默认配置:
-
innodb_log_group_home_dir定义InnoDB日志文件的 目录路径 (重做日志)。 如果未配置此选项,InnoDB则会在MySQL数据目录(datadir) 中创建日志文件 。您可以使用此选项将
InnoDB日志文件放在与InnoDB数据文件 不同的物理存储位置, 以避免潜在的I / O资源冲突。 例如:的[mysqld] innodb_log_group_home_dir = / dr3 / iblogs
注意InnoDB不创建目录,因此请确保在启动服务器之前存在日志目录。 使用Unix或DOSmkdir命令创建任何必要的目录。确保MySQL服务器具有在日志目录中创建文件的适当访问权限。 更一般地说,服务器必须在需要创建日志文件的任何目录中具有访问权限。
-
innodb_log_files_in_group定义日志组中的日志文件数。 默认值和建议值为2。 -
innodb_log_file_size定义日志组中每个日志文件的大小(以字节为单位)。 日志文件的总大小(innodb_log_file_size*innodb_log_files_in_group)不能超过略小于512GB的最大值。 例如,一对255 GB的日志文件接近限制但不超过它。 默认日志文件大小为48MB。 通常,日志文件的总大小应足够大,以便服务器可以消除工作负载活动中的高峰和低谷,这通常意味着有足够的重做日志空间来处理超过一小时的写入活动。 值越大,缓冲池中需要的检查点刷新活动越少,从而节省了磁盘I / O. 有关其他信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
缺省情况下,undo logs驻留在MySQL实例初始化时创建的两个undo表空间中。 撤消日志的I / O模式使撤消表空间成为 SSD 存储的 良好候选者 。
该
innodb_undo_directory
变量定义
InnoDB
创建默认撤消表空间
的路径
。
如果未定义该变量,则在数据目录中创建默认的撤消表空间。
该
innodb_undo_directory
变量不是动态的。
配置它需要重新启动服务器。
有关配置其他还原表空间的信息,请参见 第15.6.3.4节“撤消表空间” 。
全局临时表空间存储用于对用户创建的临时表所做更改的回滚段。
默认情况下,
InnoDB
创建
ibtmp1
在
innodb_data_home_dir
目录中
命名的单个自动扩展全局临时表空间数据文件
。
初始文件大小略大于12MB。
该
innodb_temp_data_file_path
变量指定全局临时表空间数据文件的路径,文件名和文件大小。
通过将K,M或G附加到大小值,以KB,MB或GB指定文件大小。
文件大小的总和必须略大于12MB。
要为全局临时表空间数据文件指定备用位置,请
innodb_temp_data_file_path
在启动时
配置该
变量。
在MySQL 8.0.15及更早版本中,会话临时表空间存储用户创建的临时表和优化器创建的内部临时表,当
InnoDB
配置为内部临时表(
internal_tmp_disk_storage_engine=InnoDB
)
的磁盘存储引擎时
。
在MySQL 8.0.16及更高版本中,
InnoDB
存储引擎始终用于磁盘上的内部临时表。
该
innodb_temp_tablespaces_dir
变量定义
InnoDB
创建会话临时表空间
的位置
。
默认位置是
#innodb_temp
数据目录中的目录。
要为会话临时表空间指定备用位置,请
innodb_temp_tablespaces_dir
在启动时
配置该
变量。
允许相对于数据目录的完全限定路径或路径。
该
innodb_page_size
选项指定
InnoDB
MySQL实例中
所有
表空间
的页面大小
。
该值在创建实例时设置,之后保持不变。
有效值为64KB,32KB,16KB(默认值),8KB和4KB。
或者,您可以指定页面大小(以字节为单位)(65536,32768,16384,8192,4096)。
默认页面大小16KB适用于各种工作负载,特别是涉及表扫描和涉及批量更新的DML操作的查询。
较小的页面大小对于涉及许多小写入的OLTP工作负载可能更有效,其中当单个页面包含许多行时争用可能是一个问题。
较小的页面也可能对SSD存储设备有效,后者通常使用小块大小。
保持
InnoDB
页面大小接近存储设备块大小可以最大限度地减少重写到磁盘的未更改数据量。
MySQL为各种缓存和缓冲区分配内存,以提高数据库操作的性能。
为
InnoDB
内存
分配内存时
,请始终考虑操作系统所需的内存,分配给其他应用程序的内存以及为其他MySQL缓冲区和缓存分配的内存。
例如,如果使用
MyISAM
表,请考虑为密钥缓冲区(
key_buffer_size
)
分配的内存量
。
有关MySQL缓冲区和高速缓存的概述,请参见
第8.12.3.1节“MySQL如何使用内存”
。
InnoDB
使用以下参数配置
特定于的缓冲区
:
-
innodb_buffer_pool_size定义缓冲池的大小,缓冲池是保存InnoDB表,索引和其他辅助缓冲区的 缓存数据的内存区域 。 缓冲池的大小对系统性能很重要,通常建议将innodb_buffer_pool_size其配置为系统内存的50%到75%。 默认缓冲池大小为128MB。 有关其他指导,请参见 第8.12.3.1节“MySQL如何使用内存” 。 有关如何配置InnoDB缓冲池大小的信息,请参见 第15.8.3.1节“配置InnoDB缓冲池大小” 。 可以在启动时或动态配置缓冲池大小。在具有大量内存的系统上,可以通过将缓冲池划分为多个缓冲池实例来提高并发性。 缓冲池实例的数量由by
innodb_buffer_pool_instances选项 控制 。 默认情况下,InnoDB创建一个缓冲池实例。 可以在启动时配置缓冲池实例的数量。 有关更多信息,请参见 第15.8.3.2节“配置多个缓冲池实例” 。 -
innodb_log_buffer_size定义InnoDB用于写入磁盘上日志文件 的缓冲区的大小(以字节为单位) 。 默认大小为16MB。 大型日志缓冲区使大型事务能够运行,而无需在事务提交之前将日志写入磁盘。 如果您有更新,插入或删除许多行的事务,您可以考虑增加日志缓冲区的大小以节省磁盘I / O.innodb_log_buffer_size可以在启动时配置。 有关相关信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
在32位GNU / Linux x86上,请注意不要将内存使用率设置得太高。
glibc
可能允许进程堆在线程堆栈上增长,从而导致服务器崩溃。
如果
为全局和每线程缓冲区和高速缓存
分配给
mysqld
进程
的内存
接近或超过2GB
,则存在风险
。
类似于以下计算MySQL的全局和每线程内存分配的公式可用于估计MySQL内存使用情况。 您可能需要修改公式以考虑MySQL版本和配置中的缓冲区和缓存。 有关MySQL缓冲区和高速缓存的概述,请参见 第8.12.3.1节“MySQL如何使用内存” 。
innodb_buffer_pool_size + key_buffer_size + max_connections *(sort_buffer_size + read_buffer_size + binlog_cache_size) + max_connections * 2MB
每个线程使用一个堆栈(通常为2MB,但在Oracle公司提供的MySQL二进制文件中只有256KB),在最坏的情况下也使用
sort_buffer_size +
read_buffer_size
额外的内存。
在Linux上,如果内核启用了大页面支持,则
InnoDB
可以使用大页面为其缓冲池分配内存。
请参见
第8.12.3.2节“启用大页面支持”
。
现在,您可以
InnoDB
通过
--innodb-read-only
在服务器启动时
启用
配置选项
来查询
MySQL数据目录在只读介质上的表
。
如何启用
要为只读操作准备实例,请确保在
将数据文件存储到只读介质之前将
所有必要信息
刷新
到数据文件中。
在更改缓冲禁用(
innodb_change_buffering=0
)的情况下
运行服务器
并执行
慢速关闭
。
要为整个MySQL实例启用只读模式,请在服务器启动时指定以下配置选项:
-
如果实例位于只读介质(如DVD或CD)上,或者
/var目录不可由所有人写入: 和--pid-file=path_on_writeable_media--event-scheduler=disabled -
--innodb-temp-data-file-path。 此选项指定InnoDB临时表空间数据文件 的路径,文件名和文件大小 。 默认设置为ibtmp1:12M:autoextend,ibtmp1在数据目录中 创建 临时表空间数据文件。 要为只读操作准备实例,请设置innodb_temp_data_file_path为数据目录之外的位置。 路径必须相对于数据目录。 例如:--innodb-TEMP-数据文件路径= .. / .. / .. / TMP / ibtmp1:12M:自动扩展
从MySQL 8.0开始,启用
innodb_read_only
可防止所有存储引擎的表创建和删除操作。
这些操作会修改
mysql
系统数据库
中的数据字典表
,但这些表使用
InnoDB
存储引擎,并且在
innodb_read_only
启用
时无法修改
。
同样的限制适用于修改数据字典表的任何操作,例如
ANALYZE
TABLE
和
。
ALTER
TABLE
tbl_name
ENGINE=engine_name
此外,
mysql
系统数据库
中的其他表
使用
InnoDB
MySQL 8.0中
的
存储引擎。
使这些表只读是导致对修改它们的操作的限制。
例如,
CREATE
USER
,
GRANT
,
REVOKE
,和
INSTALL PLUGIN
操作不在只读模式允许的。
使用场景
这种操作模式适用于以下情况:
-
将MySQL应用程序或一组MySQL数据分发到只读存储介质(如DVD或CD)上。
-
多个MySQL实例同时查询同一数据目录,通常在数据仓库配置中。 您可以使用此技术来避免 在负载很重的MySQL实例中可能出现的 瓶颈 ,或者您可以为各种实例使用不同的配置选项来针对特定类型的查询调整每个实例。
-
查询已出于安全性或数据完整性原因而被置于只读状态的数据,例如归档备份数据。
此功能主要用于分发和部署的灵活性,而不是基于只读方面的原始性能。 有关 调整只读查询性能的方法, 请参见 第8.5.3节“优化InnoDB只读事务” ,这些方法不需要将整个服务器设置为只读。
这个怎么运作
当服务器通过该
--innodb-read-only
选项
以只读模式运行时
,某些
InnoDB
功能和组件将完全减少或关闭:
-
没有进行 更改缓冲 ,特别是没有来自更改缓冲区的合并。 在为只读操作准备实例时,要确保更改缓冲区为空,请先禁用更改缓冲(
innodb_change_buffering=0)并执行 慢速关闭 。 -
由于 重做日志 不用于只读操作,因此可以
innodb_log_file_size在将实例设置为只读之前将其 设置 为可能的最小大小(1 MB)。 -
关闭I / O读取线程以外的所有后台线程。 因此,只读实例不会遇到任何 死锁 。
-
有关死锁,监视器输出等的信息不会写入临时文件。 结果,
SHOW ENGINE INNODB STATUS不产生任何输出。 -
当服务器处于只读模式时,对通常会更改写入操作行为的配置选项设置的更改不起作用。
-
该 撤消日志 不被使用。 禁用
innodb_undo_tablespaces和innodb_undo_directory配置选项的 任何设置 。
本节提供
InnoDB
缓冲池的
配置和调整信息
。
您可以
InnoDB
在服务器运行时离线(启动时)或联机
配置
缓冲池大小。
本节中描述的行为适用于这两种方法。
有关在线配置缓冲池大小的其他信息,请参阅在线
配置InnoDB缓冲池大小
。
当增加或减少时
innodb_buffer_pool_size
,操作以块的形式执行。
块大小由
innodb_buffer_pool_chunk_size
配置选项
定义
,其默认值为
128M
。
有关更多信息,请参阅
配置InnoDB缓冲池块大小
。
缓冲池大小必须始终等于
innodb_buffer_pool_chunk_size
*
的倍数或倍数
innodb_buffer_pool_instances
。
如果配置
innodb_buffer_pool_size
的值不等于
innodb_buffer_pool_chunk_size
*
或
*
的倍数
innodb_buffer_pool_instances
,则缓冲池大小会自动调整为等于
innodb_buffer_pool_chunk_size
*
的倍数或
*
的倍数
innodb_buffer_pool_instances
。
在以下示例中,
innodb_buffer_pool_size
设置为
8G
,并
innodb_buffer_pool_instances
设置为
16
。
innodb_buffer_pool_chunk_size
是
128M
,这是默认值。
8G
是一个有效值,
innodb_buffer_pool_size
因为
8G
是
innodb_buffer_pool_instances=16
*
的倍数
innodb_buffer_pool_chunk_size=128M
,即
2G
。
外壳> mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
MySQL的> SELECT @@innodb_buffer_pool_size/1024/1024/1024;
+ ------------------------------------------ +
| @@ innodb_buffer_pool_size / 1024/1024/1024 |
+ ------------------------------------------ +
| 8.000000000000 |
+ ------------------------------------------ +
在此示例中,
innodb_buffer_pool_size
设置为
9G
,并
innodb_buffer_pool_instances
设置为
16
。
innodb_buffer_pool_chunk_size
是
128M
,这是默认值。
在这种情况下,
9G
不是
innodb_buffer_pool_instances=16
*
的倍数
innodb_buffer_pool_chunk_size=128M
,因此
innodb_buffer_pool_size
调整为
*
10G
,它是
innodb_buffer_pool_chunk_size
*
的倍数
innodb_buffer_pool_instances
。
外壳> mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
MySQL的> SELECT @@innodb_buffer_pool_size/1024/1024/1024;
+ ------------------------------------------ +
| @@ innodb_buffer_pool_size / 1024/1024/1024 |
+ ------------------------------------------ +
| 10.000000000000 |
+ ------------------------------------------ +
innodb_buffer_pool_chunk_size
可以以1MB(1048576字节)为单位增加或减少,但只能在启动时,命令行字符串或MySQL配置文件中进行修改。
命令行:
外壳> mysqld --innodb-buffer-pool-chunk-size=134217728
配置文件:
的[mysqld] innodb_buffer_pool_chunk_size = 134217728
更改时适用以下条件
innodb_buffer_pool_chunk_size
:
-
如果 初始化缓冲池时 新
innodb_buffer_pool_chunk_size值*innodb_buffer_pool_instances大于当前缓冲池大小,则将innodb_buffer_pool_chunk_size其截断为innodb_buffer_pool_size/innodb_buffer_pool_instances。例如,如果缓冲池初始化的大小为
2GB(2147483648字节),4缓冲池实例和块大小1GB(1073741824字节),则块大小将截断为等于innodb_buffer_pool_size/ 的值innodb_buffer_pool_instances,如下所示:外壳>
mysqld --innodb-buffer-pool-size=2147483648 --innodb-buffer-pool-instances=4--innodb-buffer-pool-chunk-size=1073741824;MySQL的>
SELECT @@innodb_buffer_pool_size;+ --------------------------- + | @@ innodb_buffer_pool_size | + --------------------------- + | 2147483648 | + --------------------------- + MySQL的>SELECT @@innodb_buffer_pool_instances;+ -------------------------------- + | @@ innodb_buffer_pool_instances | + -------------------------------- + | 4 | + -------------------------------- + #启动时块大小设置为1GB(1073741824字节)但是 #truncated to innodb_buffer_pool_size / innodb_buffer_pool_instances MySQL的>SELECT @@innodb_buffer_pool_chunk_size;+ --------------------------------- + | @@ innodb_buffer_pool_chunk_size | + --------------------------------- + | 536870912 | + --------------------------------- + -
缓冲池大小必须始终等于
innodb_buffer_pool_chunk_size* 的倍数或倍数innodb_buffer_pool_instances。 如果更改innodb_buffer_pool_chunk_size,innodb_buffer_pool_size则会自动调整为等于innodb_buffer_pool_chunk_size* 的倍数或 * 的倍数innodb_buffer_pool_instances。 初始化缓冲池时会进行调整。 以下示例演示了此行为:#缓冲池的默认大小为128MB(134217728字节) MySQL的>
SELECT @@innodb_buffer_pool_size;+ --------------------------- + | @@ innodb_buffer_pool_size | + --------------------------- + | 134217728 | + --------------------------- + #块大小也是128MB(134217728字节) MySQL的>SELECT @@innodb_buffer_pool_chunk_size;+ --------------------------------- + | @@ innodb_buffer_pool_chunk_size | + --------------------------------- + | 134217728 | + --------------------------------- + #有一个缓冲池实例 MySQL的>SELECT @@innodb_buffer_pool_instances;+ -------------------------------- + | @@ innodb_buffer_pool_instances | + -------------------------------- + | 1 | + -------------------------------- + #启动时块大小减少1MB(1048576字节) #(134217728 - 1048576 = 133169152): 外壳>mysqld --innodb-buffer-pool-chunk-size=133169152MySQL的>SELECT @@innodb_buffer_pool_chunk_size;+ --------------------------------- + | @@ innodb_buffer_pool_chunk_size | + --------------------------------- + | 133169152 | + --------------------------------- + #缓冲池大小从134217728增加到266338304 #缓冲池大小自动调整为等于的值 #或innodb_buffer_pool_chunk_size的倍数* innodb_buffer_pool_instances MySQL的>SELECT @@innodb_buffer_pool_size;+ --------------------------- + | @@ innodb_buffer_pool_size | + --------------------------- + | 266338304 | + --------------------------- +此示例演示了相同的行为,但具有多个缓冲池实例:
#缓冲池的默认大小为2GB(2147483648字节) MySQL的>
SELECT @@innodb_buffer_pool_size;+ --------------------------- + | @@ innodb_buffer_pool_size | + --------------------------- + | 2147483648 | + --------------------------- + #块大小为.5 GB(536870912字节) MySQL的>SELECT @@innodb_buffer_pool_chunk_size;+ --------------------------------- + | @@ innodb_buffer_pool_chunk_size | + --------------------------------- + | 536870912 | + --------------------------------- + #有4个缓冲池实例 MySQL的>SELECT @@innodb_buffer_pool_instances;+ -------------------------------- + | @@ innodb_buffer_pool_instances | + -------------------------------- + | 4 | + -------------------------------- + #启动时块大小减少1MB(1048576字节) #(536870912 - 1048576 = 535822336): 外壳>mysqld --innodb-buffer-pool-chunk-size=535822336MySQL的>SELECT @@innodb_buffer_pool_chunk_size;+ --------------------------------- + | @@ innodb_buffer_pool_chunk_size | + --------------------------------- + | 535822336 | + --------------------------------- + #缓冲池大小从2147483648增加到4286578688 #缓冲池大小自动调整为等于的值 #或innodb_buffer_pool_chunk_size的倍数* innodb_buffer_pool_instances MySQL的>SELECT @@innodb_buffer_pool_size;+ --------------------------- + | @@ innodb_buffer_pool_size | + --------------------------- + | 4286578688 | + --------------------------- +更改时应小心
innodb_buffer_pool_chunk_size,因为更改此值可能会增加缓冲池的大小,如上面的示例所示。 在更改之前innodb_buffer_pool_chunk_size,请计算效果innodb_buffer_pool_size以确保生成的缓冲池大小可接受。
为避免潜在的性能问题,块数(
innodb_buffer_pool_size
/
innodb_buffer_pool_chunk_size
)不应超过1000。
该
innodb_buffer_pool_size
配置选项可以动态使用设置
SET
声明,让您调整缓冲池无需重新启动服务器。
例如:
MySQL的> SET GLOBAL innodb_buffer_pool_size=402653184;
通过执行活动交易和操作
InnoDB
应在调整缓冲池大小之前完成API。
启动调整大小操作时,在完成所有活动事务之前,操作不会启动。
一旦调整大小操作正在进行,需要访问缓冲池的新事务和操作必须等到调整大小操作完成。
规则的例外是,在缓冲池进行碎片整理时允许并发访问缓冲池,并在缓冲池大小减小时撤消页面。
允许并发访问的一个缺点是,当页面被撤销时,它可能导致可用页面暂时短缺。
如果在缓冲池大小调整操作开始后启动,则嵌套事务可能会失败。
该
Innodb_buffer_pool_resize_status
报告缓冲池大小调整的进展。
例如:
MySQL的> SHOW STATUS WHERE Variable_name='InnoDB_buffer_pool_resize_status';
+ ---------------------------------- + -------------- -------------------- +
| Variable_name | 价值|
+ ---------------------------------- + -------------- -------------------- +
| Innodb_buffer_pool_resize_status | 调整其他哈希表的大小。|
+ ---------------------------------- + -------------- -------------------- +
缓冲池大小调整进度也记录在服务器错误日志中。 此示例显示增加缓冲池大小时记录的注释:
[注意] InnoDB:将缓冲池大小从134217728调整为4294967296.(单位= 134217728) [注意] InnoDB:禁用自适应哈希索引。 [注意] InnoDB:缓冲池0:31块(253952块)被添加。 [注意] InnoDB:缓冲池0:调整了哈希表的大小。 [注意] InnoDB:在lock_sys上调整哈希表,自适应哈希索引,字典。 [注意] InnoDB:完成将缓冲池从134217728调整为4294967296。 [注意] InnoDB:重新启用自适应哈希索引。
此示例显示减小缓冲池大小时记录的注释:
[注意] InnoDB:将缓冲池大小从4294967296调整为134217728.(单位= 134217728) [注意] InnoDB:禁用自适应哈希索引。 [注意] InnoDB:缓冲池0:开始撤销最后253952个块。 [注意] InnoDB:缓冲池0:从空闲列表中撤回253952个块。试图重新定位0页。 (253952分之253952) [注意] InnoDB:缓冲池0:撤销目标253952块。 [注意] InnoDB:缓冲池0:31块(253952块)被释放。 [注意] InnoDB:缓冲池0:调整了哈希表的大小。 [注意] InnoDB:在lock_sys上调整哈希表,自适应哈希索引,字典。 [注意] InnoDB:完成将缓冲池的大小从4294967296调整为134217728。 [注意] InnoDB:重新启用自适应哈希索引。
调整大小操作由后台线程执行。 增加缓冲池的大小时,调整大小操作:
-
添加页面
chunks(块大小定义innodb_buffer_pool_chunk_size) -
隐藏在内存中使用新地址的哈希表,列表和指针
-
将新页面添加到空闲列表
当这些操作正在进行时,其他线程将被阻止访问缓冲池。
减小缓冲池的大小时,调整大小操作:
-
对缓冲池进行碎片整理并撤回(释放)页面
-
删除页面
chunks(块大小定义innodb_buffer_pool_chunk_size) -
转换哈希表,列表和指针以在内存中使用新地址
在这些操作中,仅对缓冲池进行碎片整理并撤销页面允许其他线程同时访问缓冲池。
对于具有数千兆字节范围的缓冲池的系统,将缓冲池划分为单独的实例可以通过减少不同线程读取和写入缓存页面时的争用来提高并发性。
此功能通常用于
缓冲池
大小在千兆字节范围内的系统。
使用
innodb_buffer_pool_instances
配置选项
配置多个缓冲池实例
,您也可以调整该
innodb_buffer_pool_size
值。
当
InnoDB
缓冲池很大时,可以通过从内存中检索来满足许多数据请求。
您可能会遇到多个线程尝试一次访问缓冲池的瓶颈。
您可以启用多个缓冲池以最大限度地减少此争用。
存储在缓冲池中或从缓冲池读取的每个页面都使用散列函数随机分配给其中一个缓冲池。
每个缓冲池管理自己的空闲列表,刷新列表,LRU以及连接到缓冲池的所有其他数据结构。
在MySQL 8.0之前,每个缓冲池都由其自己的缓冲池互斥锁保护。
在MySQL 8.0及更高版本中,缓冲池互斥锁被多个列表和散列保护互斥锁替换,以减少争用。
要启用多个缓冲池实例,请将
innodb_buffer_pool_instances
配置选项
设置为
大于1(默认值)的值,最大为64(最大值)。
仅当您设置
innodb_buffer_pool_size
为1GB或更大的大小
时,此选项才会生效
。
您指定的总大小在所有缓冲池之间分配。
为了获得最佳效率,指定的组合
innodb_buffer_pool_instances
和
innodb_buffer_pool_size
,使得每个缓冲池实例是至少为1GB。
有关修改
InnoDB
缓冲池大小的信息,请参见
第15.8.3.1节“配置InnoDB缓冲池大小”
。
而不是使用严格的
LRU
算法,
而是
InnoDB
使用一种技术来最小化带入
缓冲池
并且从不再次访问
的数据量
。
目标是确保频繁访问(
“
热
”
)页面保留在缓冲池中,即使
预读
和
全表扫描
带来了之后可能访问或不访问的新块。
新读取的块将插入LRU列表的中间。
所有新读取的页面都插入到默认位于
3/8
LRU列表尾部的
位置
。
第一次在缓冲池中访问页面时,页面将移动到列表的前面(最近使用的结尾)。
因此,从未访问的页面永远不会进入LRU列表的前部,并且
比使用严格的LRU方法更早地
“
老化
”
。
这种安排将LRU列表分成两个段,其中插入点下游的页面被认为是
“
旧的
”
并且是LRU驱逐的理想受害者。
有关
InnoDB
缓冲池
内部工作原理的说明
以及有关LRU算法的详细信息,请参见
第15.5.1节“缓冲池”
。
您可以控制LRU列表中的插入点,并选择是否
InnoDB
对通过表或索引扫描带入缓冲池的块应用相同的优化。
配置参数
innodb_old_blocks_pct
控制
LRU列表
中
“
旧
”
块
的百分比
。
的默认值
innodb_old_blocks_pct
是
37
,对应于3/8原固定比率。
值范围是
5
(缓冲池中的新页面非常快速地老化)到
95
(只有5%的缓冲池保留用于热页面,使得算法接近熟悉的LRU策略)。
保持缓冲池不被预读搅动的优化可以避免由于表或索引扫描引起的类似问题。
在这些扫描中,数据页面通常连续几次访问,并且永远不会再次触及。
配置参数
innodb_old_blocks_time
指定第一次访问页面之后的时间窗口(以毫秒为单位),在此期间可以访问该时间窗口而不移动到LRU列表的前端(最近使用的端点)。
默认值
innodb_old_blocks_time
是
1000
。
增加此值会使越来越多的块可能从缓冲池中更快地老化。
无论
innodb_old_blocks_pct
并且
innodb_old_blocks_time
可以在MySQL选项文件(指定
my.cnf
或
my.ini
),或在与运行时改变了
SET
GLOBAL
说法。
在运行时更改值需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
为帮助您衡量设置这些参数的效果,该
SHOW ENGINE INNODB STATUS
命令报告缓冲池统计信息。
有关详细信息,请参阅
使用InnoDB标准监视器监视缓冲池
。
由于这些参数的影响可能因您的硬件配置,数据和工作负载的详细信息而有很大差异,因此在任何性能关键或生产环境中更改这些设置之前,始终需要通过基准测试来验证有效性。
在混合工作负载中,大多数活动是OLTP类型,并且定期批量报告查询会导致大量扫描,因此在
innodb_old_blocks_time
批处理运行期间
设置值
可以帮助将正常工作负载的工作集保留在缓冲池中。
扫描不能完全适合缓冲池的大型表时,设置
innodb_old_blocks_pct
为较小的值会使只读取一次的数据占用缓冲池的大部分。
例如,设置
innodb_old_blocks_pct=5
将此数据限制为仅读取一次到缓冲池的5%。
扫描适合内存的小表时,在缓冲池中移动页面的开销较小,因此可以保留
innodb_old_blocks_pct
默认值,甚至更高,例如
innodb_old_blocks_pct=50
。
innodb_old_blocks_time
参数
的效果
比参数更难预测
innodb_old_blocks_pct
,相对较小,并且随工作量变化更大。
要达到最佳值,如果调整后的性能提升
innodb_old_blocks_pct
不充分
,请执行自己的基准测试
。
一个
预读
请求是I / O请求预取的多个页面
缓冲池
异步,在期待这些页面将很快需要。
请求在一个
范围内
引入所有页面
。
InnoDB
使用两个预读算法来提高I / O性能:
线性
预读是一种技术,可以根据顺序访问的缓冲池中的页面来预测很快可能需要的页面。
InnoDB
通过使用配置参数调整触发异步读取请求所需的顺序页面访问次数,
可以控制何时
执行预读操作
innodb_read_ahead_threshold
。
在添加此参数之前,
InnoDB
仅计算在读取当前范围的最后一页时是否对整个下一个范围发出异步预取请求。
配置参数
innodb_read_ahead_threshold
控制
InnoDB
检测顺序页面访问模式的
敏感
程度。
如果从某个范围顺序读取的页数大于或等于
innodb_read_ahead_threshold
,则
InnoDB
启动整个后续范围的异步预读操作。
innodb_read_ahead_threshold
可以设置为0-64之间的任何值。
默认值为56.值越高,访问模式检查越严格。
例如,如果将值设置为48,则
InnoDB
只有在按顺序访问当前范围中的48个页面时才会触发线性预读请求。
如果值为8,
InnoDB
即使在顺序访问范围中只有8个页面,也会触发异步预读。
您可以在MySQL
配置文件中
设置此参数的值
,或使用
SET
GLOBAL
语句
动态更改它,该
语句需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
随机
预读是一种技术,可以根据缓冲池中已有的页面来预测何时很快就需要页面,而不管这些页面的读取顺序如何。
如果在缓冲池中找到来自相同范围的13个连续页面,则
InnoDB
异步发出请求以预取范围的剩余页面。
要启用此功能,请将配置变量设置
innodb_random_read_ahead
为
ON
。
该
SHOW ENGINE INNODB STATUS
命令显示统计信息以帮助您评估预读算法的有效性。
统计信息包括以下全局状态变量的计数器信息:
在微调
innodb_random_read_ahead
设置
时,此信息非常有用
。
有关I / O性能的更多信息,请参见 第8.5.8节“优化InnoDB磁盘I / O” 和 第8.12.1节“优化磁盘I / O” 。
InnoDB
在后台执行某些任务,包括
冲洗
的
脏页
从(那些已更改但尚未写入数据库文件页)
缓冲池
。
InnoDB
当缓冲池中脏页的百分比达到定义的低水位设置时,开始刷新缓冲池页面
innodb_max_dirty_pages_pct_lwm
。
此选项旨在控制缓冲池中脏页的比例,并理想地防止脏页的百分比到达
innodb_max_dirty_pages_pct
。
如果缓冲池中脏页的百分比超过
innodb_max_dirty_pages_pct
,则
InnoDB
开始积极刷新缓冲池页。
InnoDB
根据重做日志生成的速度和当前的刷新率,使用算法估计所需的刷新率。
目的是通过确保缓冲区刷新活动与保持缓冲池
“
干净
”
的需要保持一致来平滑整体性能
。
当过多的缓冲池刷新限制了普通读写活动可用的I / O容量时,自动调整刷新率有助于避免吞吐量突然下降。
InnoDB
以循环方式使用其日志文件。
在重用日志文件的一部分之前,
InnoDB
将所有脏缓冲池页面刷新到磁盘,其重做条目包含在日志文件的该部分中,这个过程称为
尖锐检查点
。
如果工作负载是写密集型的,则会生成大量重做信息,这些信息都写入日志文件。
如果日志文件中的所有可用空间都用完,则会出现尖锐的检查点,从而导致吞吐量暂时降低。
即使
innodb_max_dirty_pages_pct
未达到,
也会发生这种情况
。
InnoDB
使用基于启发式的算法来避免这种情况,方法是测量缓冲池中脏页的数量以及生成重做的速率。
根据这些数字,
InnoDB
决定每秒从缓冲池中刷新多少脏页。
这种自适应算法能够处理工作量的突然变化。
内部基准测试表明,该算法不仅可以保持吞吐量,还可以显着提高整体吞吐量。
由于自适应刷新会显着影响工作负载的I / O模式,因此
innodb_adaptive_flushing
配置参数可让您关闭此功能。
innodb_adaptive_flushing
is
的默认值
ON
,启用自适应刷新算法。
您可以在MySQL选项文件(
my.cnf
或
my.ini
)中
设置此参数的值,
或使用
SET
GLOBAL
语句
动态更改它,该
语句需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
有关微调
InnoDB
缓冲池刷新行为的信息,请参见
第15.8.3.6节“微调InnoDB
缓冲池刷新
”
。
有关
InnoDB
I / O性能的
更多信息
,请参见
第8.5.8节“优化InnoDB磁盘I / O”
。
配置选项
innodb_flush_neighbors
,
innodb_lru_scan_depth
让您微调
缓冲池
的
刷新
过程的
各个方面
。
InnoDB
这些选项主要帮助编写密集型 工作负载 。 如果 DML 活动量 很大 ,如果缓冲不够激烈就会落后,导致缓冲池中内存使用过多; 或者,如果该机制过于激进,由于刷新而导致的磁盘写入可能会使您的I / O容量饱和。 理想的设置取决于您的工作负载,数据访问模式和存储配置(例如,数据是否存储在HDD或SSD设备上)。
对于具有持续繁重
工作负载
或频繁波动的
工作负载的
系统
,可以使用多个配置选项来微调
表
的
刷新
行为
InnoDB
:
这些选项包含在
innodb_adaptive_flushing
选项
使用的公式中
。
的
innodb_adaptive_flushing
,
innodb_io_capacity
和
innodb_max_dirty_pages_pct
选项由以下选项限制或扩展:
该
InnoDB
自适应冲洗
机制并不适合所有的情况。
当
重做日志
有填满的危险
时,它会带来最大的好处
。
该
innodb_adaptive_flushing_lwm
选项指定
重做日志容量
的
“
低水位线
”
百分比;
超过该阈值时,
InnoDB
即使未通过
innodb_adaptive_flushing
选项
指定,也会启用自适应刷新
。
如果冲洗活动远远落后,
InnoDB
可以比指定的更积极地冲洗
innodb_io_capacity
。
innodb_io_capacity_max
表示在此类紧急情况下使用的I / O容量的上限,因此I / O中的峰值不会消耗服务器的所有容量。
InnoDB
尝试从缓冲池中刷新数据,以便脏页的百分比不超过
innodb_max_dirty_pages_pct
。
默认值为
innodb_max_dirty_pages_pct
75。
该
innodb_max_dirty_pages_pct
设置为刷新活动建立了目标。
它不影响潮红的速度。
有关管理刷新率的信息,请参见
第15.8.3.5节“配置InnoDB缓冲池
刷新
”
。
该
innodb_max_dirty_pages_pct_lwm
选项指定
“
低水位线
”
值,该值表示启用预刷新以控制脏页面比率并且理想情况下防止脏页面达到百分比的脏页面百分比
innodb_max_dirty_pages_pct
。
值为
innodb_max_dirty_pages_pct_lwm=0
禁用
“
预刷新
”
行为。
上面引用的大多数选项最适用于长时间运行写入繁重工作负载的服务器,并且几乎没有减少加载时间来赶上等待写入磁盘的更改。
innodb_flushing_avg_loops
定义迭代次数,以
InnoDB
保留先前计算的刷新状态快照,该快照控制自适应刷新对前景负载变化的响应速度。
设置较高的值
innodb_flushing_avg_loops
意味着
InnoDB
保持先前计算的快照更长,因此自适应刷新响应更慢。
较高的值也会减少前台工作和后台工作之间的正反馈,但是当设置较高的值时,确保
InnoDB
重做日志利用率不会达到75%(异步刷新开始时的硬编码限制)以及
innodb_max_dirty_pages_pct
设置将脏页的数量保持在适合工作负载的级别。
具有一致工作负载,大型
innodb_log_file_size
和小型峰值但未达到75%重做日志空间利用率的系统应使用较高
innodb_flushing_avg_loops
值来尽可能保持平滑。
对于具有极端负载峰值的系统或不提供大量空间的日志文件,请考虑较小的
innodb_flushing_avg_loops
值。
较小的值允许刷新以密切跟踪负载,并有助于避免达到75%的重做日志空间利用率。
要
在重新启动服务器后
减少
预热
期,请
InnoDB
在服务器关闭时为每个缓冲池保存最近使用的页面的百分比,并在服务器启动时恢复这些页面。
最近使用的页面的百分比由
innodb_buffer_pool_dump_pct
配置选项
定义
。
重新启动繁忙的服务器后,通常会有一个预热时间逐渐增加的预热期,因为缓冲池中的磁盘页将被带回内存(因为查询,更新等相同的数据)。 启动时恢复缓冲池的能力通过在重新启动之前重新加载缓冲池中的磁盘页而不是等待DML操作来访问相应的行来缩短预热期。 此外,I / O请求可以大批量执行,从而使整体I / O更快。 页面加载发生在后台,并不会延迟数据库启动。
除了在关闭时保存缓冲池状态并在启动时恢复它,您还可以在服务器运行时随时保存和恢复缓冲池状态。 例如,您可以在稳定工作负载下达到稳定吞吐量后保存缓冲池的状态。 您还可以在运行报表或维护作业之后恢复先前的缓冲池状态,这些作业将数据页面放入缓冲池中,这些作业仅针对这些操作进行操作,或者在运行其他非典型工作负载之后。
即使缓冲池的大小可以是几千兆字节,
InnoDB
相比之下
,
保存到磁盘
的缓冲池数据
也很小。
只有找到相应页面所需的表空间ID和页面ID才会保存到磁盘。
此信息来自
表格。
默认情况下,表空间ID和页面ID数据保存在一个名为的文件中
,该
文件
保存到
数据目录中。
可以使用
配置参数
修改文件名和位置
。
INNODB_BUFFER_PAGE_LRU
INFORMATION_SCHEMA
ib_buffer_pool
InnoDB
innodb_buffer_pool_filename
由于数据缓存在缓冲池中并且与常规数据库操作一样老化,因此如果最近更新了磁盘页,或者DML操作涉及尚未加载的数据,则没有问题。 加载机制会跳过不再存在的请求页面。
底层机制涉及调度后台线程以执行转储和装载操作。
压缩表中的磁盘页面以压缩形式加载到缓冲池中。 在DML操作期间访问页面内容时,页面将照常解压缩。 由于解压缩页面是一个CPU密集型进程,因此在并发中更有效地在连接线程中执行操作,而不是在执行缓冲池还原操作的单个线程中执行操作。
以下主题描述了与保存和恢复缓冲池状态相关的操作:
在从缓冲池转储页面之前,可以通过设置
innodb_buffer_pool_dump_pct
选项
来配置要转储的最近使用的缓冲池页面的百分比
。
如果计划在服务器运行时转储缓冲池页面,则可以动态配置该选项:
SET GLOBAL innodb_buffer_pool_dump_pct = 40;
如果计划在服务器关闭时转储缓冲池页面,请
innodb_buffer_pool_dump_pct
在配置文件中进行
设置
。
的[mysqld] innodb_buffer_pool_dump_pct = 40
该
innodb_buffer_pool_dump_pct
默认值是25(转储最近最常使用的网页的25%)。
要在服务器关闭时保存缓冲池的状态,请在关闭服务器之前发出以下语句:
SET GLOBAL innodb_buffer_pool_dump_at_shutdown = ON;
innodb_buffer_pool_dump_at_shutdown
默认情况下启用。
要在服务器启动时恢复缓冲池状态,请在启动服务器时指定
--innodb-buffer-pool-load-at-startup
选项:
mysqld --innodb-buffer-pool-load-at-startup = ON;
innodb_buffer_pool_load_at_startup
默认情况下启用。
要在MySQL服务器运行时保存缓冲池的状态,请发出以下语句:
SET GLOBAL innodb_buffer_pool_dump_now = ON;
要在MySQL运行时恢复缓冲池状态,请发出以下语句:
SET GLOBAL innodb_buffer_pool_load_now = ON;
要在将缓冲池状态保存到磁盘时显示进度,请发出以下语句:
显示状态如'Innodb_buffer_pool_dump_status';
如果操作尚未开始, 则返回 “ 未启动 ” 。 如果操作完成,则打印完成时间(例如,在110505 12:18:02完成)。 如果操作正在进行,则提供状态信息(例如,转储缓冲池5/7,第237/2873页)。
要在加载缓冲池时显示进度,请发出以下语句:
显示状态如'Innodb_buffer_pool_load_status';
如果操作尚未开始, 则返回 “ 未启动 ” 。 如果操作完成,则打印完成时间(例如,在110505 12:23:24完成)。 如果操作正在进行,则提供状态信息(例如,已加载123/22301页)。
您可以使用 Performance Schema 监视缓冲池加载进度 。
以下示例演示如何启用
stage/innodb/buffer pool load
舞台事件工具和相关使用者表以监视缓冲池加载进度。
有关此示例中使用的缓冲池转储和装入过程的信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。 有关Performance Schema阶段事件工具和相关使用者的信息,请参见 第26.12.5节“性能模式阶段事件表” 。
-
启用
stage/innodb/buffer pool load仪器:MySQL的>
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'WHERE NAME LIKE 'stage/innodb/buffer%'; -
启用舞台活动消费表,其中包括
events_stages_current,events_stages_history,和events_stages_history_long。MySQL的>
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'WHERE NAME LIKE '%stages%'; -
通过启用转储当前缓冲池状态
innodb_buffer_pool_dump_now。MySQL的>
SET GLOBAL innodb_buffer_pool_dump_now=ON; -
检查缓冲池转储状态以确保操作已完成。
MySQL的>
SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status'\G*************************** 1。排******************** ******* Variable_name:Innodb_buffer_pool_dump_status 值:缓冲池转储在150202 16:38:58完成 -
通过启用
innodb_buffer_pool_load_now以下内容 加载缓冲池 :MySQL的>
SET GLOBAL innodb_buffer_pool_load_now=ON; -
通过查询Performance Schema
events_stages_current表 来检查缓冲池加载操作的当前状态 。 该WORK_COMPLETED列显示加载的缓冲池页数。 该WORK_ESTIMATED列以页面形式提供剩余工作的估计值。MySQL的>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_current;+ ------------------------------- + ---------------- + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + ------------------------------- + ---------------- + ---------------- + | stage / innodb / buffer pool load | 5353 | 7167 | + ------------------------------- + ---------------- + ---------------- +该
events_stages_current如果缓冲池加载操作已完成表返回一个空集。 在这种情况下,您可以检查events_stages_history表以查看已完成事件的数据。 例如:MySQL的>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_history;+ ------------------------------- + ---------------- + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + ------------------------------- + ---------------- + ---------------- + | stage / innodb / buffer pool load | 7167 | 7167 | + ------------------------------- + ---------------- + ---------------- +
您还可以在启动时使用性能模式监视缓冲池加载进度
innodb_buffer_pool_load_at_startup
。
在这种情况下,
stage/innodb/buffer pool
load
必须在启动时启用仪器和相关的消费者。
有关更多信息,请参见
第26.3节“性能模式启动配置”
。
核心文件记录正在运行的进程的状态和内存映像。 由于缓冲池驻留在主内存中,并且正在运行的进程的内存映像被转储到核心文件,因此当 mysqld 进程终止 时,具有大缓冲池的系统可能会生成大型核心文件 。
大型核心文件可能存在问题,原因有很多,包括编写它们所花费的时间,它们占用的磁盘空间量以及与传输大型文件相关的挑战。
要减小核心文件大小,可以禁用该
innodb_buffer_pool_in_core_file
变量以从核心转储中省略缓冲池页面。
该
innodb_buffer_pool_in_core_file
变量是在MySQL 8.0.14中引入的,默认情况下是启用的。
如果您担心将数据库页面转储到可能在组织内部或外部共享的核心文件以进行调试,则从安全角度来看也可能需要排除缓冲池页面。
在 mysqld 进程死亡 时访问缓冲池页面中的数据 可能在某些调试方案中是有益的。 如果怀疑是否包含或排除缓冲池页面,请咨询MySQL支持。
innodb_buffer_pool_in_core_file
只有在
core_file
启用变量并且操作系统支持
madvise()
系统调用
的
MADV_DONTDUMP
非POSIX扩展时,
禁用
才会生效
,该调用在Linux 3.4及更高版本中受支持。
的
扩展导致在特定范围内的页面从核心转储被排除。
MADV_DONTDUMP
假设操作系统支持
MADV_DONTDUMP
扩展,请使用
--core-file
和
--innodb-buffer-pool-in-core-file=OFF
选项
启动服务器
以生成没有缓冲池页面的核心文件。
shell> mysqld --core-file --innodb-buffer-pool-in-core-file = OFF
该
core_file
变量是只读的,默认情况下禁用。
通过
--core-file
在启动时
指定
选项
来启用它
。
的
innodb_buffer_pool_in_core_file
变量是动态的。
它可以在启动时指定,也可以在运行时使用
SET
语句进行
配置
。
mysql> SET GLOBAL innodb_buffer_pool_in_core_file = OFF;
如果该
innodb_buffer_pool_in_core_file
变量被禁用但
MADV_DONTDUMP
操作系统不支持,或者发生
madvise()
故障,则会向MySQL服务器错误日志写入警告,并
core_file
禁用
该
变量以防止写入无意中包含缓冲池页面的核心文件。
如果
core_file
禁用
只读
变量,则必须重新启动服务器才能再次启用它。
下表显示
MADV_DONTDUMP
了确定是否生成核心文件以及它们是否包含缓冲池页面的
配置和
支持方案。
表15.5核心文件配置方案
core_file
变量
|
innodb_buffer_pool_in_core_file
变量
|
madvise()MADV_DONTDUMP支持 | 结果 |
|---|---|---|---|
| 关(默认) | 与结果无关 | 与结果无关 | 未生成核心文件 |
| 上 | 开(默认) | 与结果无关 | 使用缓冲池页面生成核心文件 |
| 上 | 关闭 | 是 | 生成核心文件时没有缓冲池页面 |
| 上 | 关闭 | 没有 |
未生成核心文件,
core_file
已禁用
核心文件
,并且会向服务器错误日志写入警告
|
通过禁用
innodb_buffer_pool_in_core_file
变量
实现的核心文件大小的减少
取决于缓冲池的大小,但它也受
InnoDB
页面大小的
影响
。
较小的页面大小意味着相同数量的数据需要更多页面,而更多页面意味着更多页面元数据。
下表提供了对于具有不同页面大小的1GB缓冲池可能会看到的缩减示例。
表15.6包含和排除缓冲池页面的核心文件大小
innodb_page_size
设置
|
包含缓冲池页面(
innodb_buffer_pool_in_core_file=ON
)
|
缓冲池页面被排除(
innodb_buffer_pool_in_core_file=OFF
)
|
|---|---|---|
| 4KB | 2.1GB | 0.9GB |
| 64KB | 1.7GB | 0.7GB |
InnoDB
使用操作系统
线程
来处理来自用户事务的请求。
(事务可能会
InnoDB
在提交或回滚之前
发出许多请求
。)在具有多核处理器的现代操作系统和服务器上,上下文切换是高效的,大多数工作负载运行良好,并不限制并发线程数。
在最小化线程之间的上下文切换有帮助的情况下,
InnoDB
可以使用许多技术来限制并发执行的操作系统线程的数量(以及因此在任何时间处理的请求的数量)。
当
InnoDB
从用户会话接收到新请求时,如果同时执行的线程数处于预定义的限制,则新请求在再次尝试之前会休眠一小段时间。
在睡眠之后无法重新安排的请求被放入先进/先出队列并最终被处理。
等待锁的线程不计入并发执行线程的数量。
您可以通过设置配置参数来限制并发线程数
innodb_thread_concurrency
。
一旦执行的线程数达到此限制,其他线程
innodb_thread_sleep_delay
在放入队列之前将
休眠一段时间,由配置参数
设置。
您可以将配置选项设置为
innodb_adaptive_max_sleep_delay
您允许的最高值
innodb_thread_sleep_delay
,并
根据当前的线程调度活动
InnoDB
自动调整
innodb_thread_sleep_delay
。
这种动态调整有助于线程调度机制在系统轻负载和全容量运行时平稳运行。
innodb_thread_concurrency
在各种版本的MySQL和MySQL中,
默认值
和隐含的并发线程数默认限制已经更改
InnoDB
。
默认值
innodb_thread_concurrency
是
0
,那么在默认情况下有上并行执行的线程的数量没有限制。
InnoDB
只有当并发线程数有限时才会导致线程休眠。
当线程数没有限制时,所有线程都同等地进行调度。
也就是说,如果
innodb_thread_concurrency
是
0
,
innodb_thread_sleep_delay
则忽略
值
。
当线程数有限制时(当
innodb_thread_concurrency
> 0时),
InnoDB
通过允许在执行
单个SQL语句
期间发出的多个请求
进入
InnoDB
而不遵守设置的限制
,
减少了上下文切换开销
innodb_thread_concurrency
。
由于SQL语句(例如连接)可能包含多个行操作
InnoDB
,因此
InnoDB
分配指定数量的
“
票证
”
,这些
“
票证
”
允许以最小的开销重复调度线程。
当一个新的SQL语句启动时,一个线程没有票证,它必须遵守
innodb_thread_concurrency
。
一旦线程有权进入
InnoDB
,就会为其分配一些票据,它可以用于随后进入
InnoDB
以执行行操作。
如果票证用完,则线程被逐出,并
innodb_thread_concurrency
再次被观察,这可能将线程放回到等待线程的先进/先出队列中。
当线程再次有权进入时
InnoDB
,再次分配票证。
分配的故障单数由global选项指定
innodb_concurrency_tickets
,默认为5000。
一旦锁定可用,正在等待锁定的线程将获得一个票证。
这些变量的正确值取决于您的环境和工作负载。
尝试使用一系列不同的值来确定适用于您的应用程序的值。
在限制并发执行线程的数量之前,请查看可能会提高
InnoDB
多核和多处理器计算机
性能的配置选项
,例如
innodb_adaptive_hash_index
。
有关MySQL线程处理的一般性能信息,请参见 第8.12.4.1节“MySQL如何处理客户端连接” 。
InnoDB
使用后台
线程
来服务各种类型的I / O请求。
您可以使用
innodb_read_io_threads
和
innodb_write_io_threads
配置参数配置为
数据页上的读写I / O提供服务的后台线程
数。
这些参数分别表示用于读取和写入请求的后台线程数。
它们在所有支持的平台上都有效。
您可以在MySQL选项文件(
my.cnf
或
my.ini
)中
设置这些参数的值
;
您无法动态更改值。
这些参数的默认值为
4
,允许值范围为
1-64
。
这些配置选项的目的是
InnoDB
在高端系统上
实现
更高的可扩展性。
每个后台线程最多可处理256个待处理的I / O请求。
后台I / O的主要来源是
预读
请求。
InnoDB
尝试以大多数后台线程共享工作的方式平衡传入请求的负载。
InnoDB
还尝试将来自相同范围的读取请求分配给同一个线程,以增加合并请求的机会。
如果您有一个高端I / O子系统,并且
innodb_read_io_threads
在
SHOW ENGINE INNODB STATUS
输出中
看到超过64×
挂起的读取请求
,则可以通过增加值来提高性能
innodb_read_io_threads
。
在Linux系统上,
InnoDB
默认情况下使用异步I / O子系统执行数据文件页面的预读和写入请求,这会改变
InnoDB
后台线程为这些类型的I / O请求提供服务
的方式
。
有关更多信息,请参见
第15.8.6节“在Linux上使用异步I / O”
。
有关
InnoDB
I / O性能的
更多信息
,请参见
第8.5.8节“优化InnoDB磁盘I / O”
。
InnoDB
使用Linux上的异步I / O子系统(本机AIO)来执行数据文件页面的预读和写入请求。
此行为由
innodb_use_native_aio
配置选项
控制,该
选项仅适用于Linux系统,默认情况下
处于
启用状态。
在其他类Unix系统上,
InnoDB
仅使用同步I / O.
从历史上看,
InnoDB
仅在Windows系统上使用异步I / O.
在Linux上使用异步I / O子系统需要
libaio
库。
对于同步I / O,查询线程对I / O请求
InnoDB
进行排队
,
后台线程一次检索一个排队请求,为每个请求发出同步I / O调用。
当I / O请求完成并且I / O调用返回时,
InnoDB
处理请求
的
后台线程调用I / O完成例程并返回以处理下一个请求。
可以并行处理的请求数是
n
,
后台线程
n
数
在哪里
InnoDB
。
InnoDB
后台线程
的数量
由
innodb_read_io_threads
和
控制
innodb_write_io_threads
。
请参见
第15.8.5节“配置后台InnoDB I / O线程的数量”
。
使用本机AIO,查询线程直接将I / O请求分派给操作系统,从而消除了后台线程数量限制。
InnoDB
后台线程等待I / O事件发出完成请求的信号。
请求完成后,后台线程调用I / O完成例程并继续等待I / O事件。
本机AIO的优点是可用于大量I / O绑定系统的可伸缩性,这些系统通常在
SHOW ENGINE INNODB STATUS\G
输出中
显示许多挂起的读/写
。
使用本机AIO时并行处理的增加意味着I / O调度程序的类型或磁盘阵列控制器的属性对I / O性能的影响更大。
本地AIO对于大量I / O绑定系统的潜在缺点是缺乏对同时分派给操作系统的I / O写请求数量的控制。 在某些情况下,分配给操作系统进行并行处理的I / O写入请求太多可能会导致I / O读取不足,具体取决于I / O活动量和系统功能。
如果操作系统中的异步I / O子系统出现问题导致
InnoDB
无法启动,则可以使用启动服务器
innodb_use_native_aio=0
。
如果
InnoDB
检测到潜在问题(例如
tmpdir
位置,
tmpfs
文件系统和不支持异步I / O的Linux内核
的组合),
也可能在启动期间自动禁用此选项
tmpfs
。
InnoDB中 的 主线程 是一个在后台执行各种任务的线程。 这些任务中的大多数都与I / O相关,例如从缓冲池中刷新脏页或将更改从插入缓冲区写入适当的二级索引。 主线程尝试以不会对服务器的正常工作产生负面影响的方式执行这些任务。 它试图估计可用的可用I / O带宽并调整其活动以利用此可用容量。 从历史上看,InnoDB使用了100 IOP的硬编码值(每秒输入/输出操作)作为服务器的总I / O容量。
该参数
innodb_io_capacity
表示InnoDB可用的总I / O容量。
此参数应设置为大约系统每秒可执行的I / O操作数。
该值取决于您的系统配置。
当
innodb_io_capacity
设置,主线程估计可根据设定值后台任务的I / O带宽。
将值设置为
100
还原为旧行为。
您可以将值设置
innodb_io_capacity
为任何数字100或更大。
默认值是
200
,反映出典型的现代I / O设备的性能高于MySQL早期的性能。
通常,前一个默认值100左右的值适用于消费级存储设备,例如高达7200 RPM的硬盘驱动器。
更快的硬盘驱动器,RAID配置和SSD可从更高的值中受益。
该
innodb_io_capacity
设置是所有缓冲池实例的总限制。
刷新脏页时,
innodb_io_capacity
限制在缓冲池实例之间平均分配。
有关更多信息,请参阅
innodb_io_capacity
系统变量说明。
您可以在MySQL选项文件(
my.cnf
或
my.ini
)中
设置此参数的值,
或使用
SET GLOBAL
语句
动态更改它,该
语句需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
的
innodb_flush_sync
配置选项使
innodb_io_capacity
发生在检查点I / O活动的脉冲串期间被忽略设置。
innodb_flush_sync
默认情况下启用。
在早期的MySQL版本中,
InnoDB
主线程还执行了任何所需的
清除
操作。
这些I / O操作现在由其他后台线程执行,其编号由
innodb_purge_threads
配置选项
控制
。
有关InnoDB I / O性能的更多信息,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
InnoDB
互斥锁
和
rw-lock
通常保留为短时间间隔。
在多核系统上,线程可以更有效地连续检查它是否可以在睡眠前的一段时间内获取互斥锁或rw-lock。
如果在此期间互斥锁或rw-lock可用,则线程可以在同一时间片中立即继续。
但是,多个线程对共享对象(如互斥锁或rw-lock)进行过于频繁的轮询可能会导致
“
缓存ping pong
”
,从而导致处理器使彼此的缓存部分无效。
InnoDB
通过在轮询之间强制随机延迟来使轮询活动失去同步来最小化此问题。
随机延迟实现为自旋等待循环。
自旋等待循环的持续时间由循环中发生的PAUSE指令的数量决定。
该数字是通过随机选择一个范围从0到但不包括该
innodb_spin_wait_delay
值
的整数生成的
,并将该值乘以50.(乘数值50在MySQL 8.0.16之前是硬编码的,之后可配置。)例如,从以下范围中随机选择一个整数,
innodb_spin_wait_delay
设置为6:
{} 0,1,2,3,4,5
选定的整数乘以50,得到六个可能的PAUSE指令值之一:
{0,50,100,150,200,250}
对于该组值,250是旋转等待循环中可能发生的最大PAUSE指令数。
一个
innodb_spin_wait_delay
的5个结果中的一组的五个可能值的设定
{0,50,100,150,200}
,其中,200是暂停指令的最大数量,等等。
这样,该
innodb_spin_wait_delay
设置控制旋转锁定轮询之间的最大延迟。
在所有处理器内核共享快速高速缓存内存的系统上,您可以通过设置来减少最大延迟或完全禁用忙碌循环
innodb_spin_wait_delay=0
。
在具有多个处理器芯片的系统上,高速缓存失效的影响可能更为显着,您可能会增加最大延迟。
在100MHz奔腾时代,一个
innodb_spin_wait_delay
单元被校准为相当于一微秒。
那个时间等价没有成功,但PAUSE指令持续时间相对于其他CPU指令在处理器周期方面保持相当稳定,直到引入具有相对较长的PAUSE指令的Skylake一代处理器。
该
innodb_spin_wait_pause_multiplier
变量在MySQL 8.0.16中引入,以提供一种方法来解释PAUSE指令持续时间的差异。
该
innodb_spin_wait_pause_multiplier
变量控制PAUSE指令值的大小。
例如,假设
innodb_spin_wait_delay
设置为6,将
innodb_spin_wait_pause_multiplier
值从50(默认值和先前硬编码值)减小到5会生成一组较小的PAUSE指令值:
{0,5,10,15,20,25}
增加或减少PAUSE指令值的能力允许
InnoDB
对不同的处理器体系结构
进行微调
。
例如,较小的PAUSE指令值适用于具有相对较长PAUSE指令的处理器体系结构。
在
innodb_spin_wait_delay
和
innodb_spin_wait_pause_multiplier
变量是动态的。
它们可以在MySQL选项文件中指定,也可以在运行时使用
SET GLOBAL
语句进行
修改
。
在运行时修改变量需要足以设置全局系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
InnoDB自动执行 的 清除 操作(一种垃圾收集)可以由一个或多个单独的线程执行,而不是作为 主线程的 一部分执行 。 使用单独的线程可以通过允许主数据库操作独立于后台执行的维护工作来提高可伸缩性。
要控制此功能,请增加配置选项的值
innodb_purge_threads
。
如果DML操作集中在单个表或几个表上,请将设置保持为低,以便线程不会相互竞争以访问繁忙表。
如果DML操作分布在许多表中,请增加设置。
它的最大值为32.
innodb_purge_threads
是非动态配置选项,这意味着它无法在运行时配置。
还有另一个相关的配置选项,
innodb_purge_batch_size
默认值为300,最大值为5000.此选项主要用于清除操作的实验和调整,对于典型用户来说应该不会感兴趣。
有关InnoDB I / O性能的更多信息,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
本节介绍如何为表配置持久性和非持久性优化程序统计信息
InnoDB
。
持久优化器统计信息在服务器重新启动时 保持 不变 ,从而实现更高的 计划稳定性 和更一致的查询性能。 持久优化器统计信息还提供了控制和灵活性以及这些额外的好处:
-
您可以使用
innodb_stats_auto_recalc配置选项来控制在对表进行实质性更改后是否自动更新统计信息。 -
您可以使用
STATS_PERSISTENT,STATS_AUTO_RECALC以及STATS_SAMPLE_PAGES与条款CREATE TABLE和ALTER TABLE声明配置个别表优化统计。 -
您可以在
mysql.innodb_table_stats和mysql.innodb_index_stats表中 查询优化程序统计数据 。 -
您可以查看 和 表 的
last_update列 以查看上次更新统计信息的时间。mysql.innodb_table_statsmysql.innodb_index_stats -
您可以手动修改
mysql.innodb_table_stats和mysql.innodb_index_stats表以强制执行特定的查询优化计划,或者在不修改数据库的情况下测试备用计划。
默认情况下(
innodb_stats_persistent=ON
)
启用持久优化程序统计信息功能
。
非持久优化器统计信息在每次重新启动服务器和其他一些操作后清除,并在下一个表访问时重新计算。 因此,在重新计算统计数据时可能会产生不同的估计值,从而导致执行计划的不同选择和查询性能的变化。
本节还提供了有关估计
ANALYZE TABLE
复杂性的
信息
,这在尝试实现准确统计和
ANALYZE TABLE
执行时间
之间的平衡时可能很有用
。
持久优化程序统计信息功能 通过将统计信息存储到磁盘并使其在服务器重新启动期间保持 不变 来 提高 计划稳定性 ,以便 优化 程序更有可能每次为给定查询做出一致的选择。
innodb_stats_persistent=ON
当创建或更改单个表
时,优化程序统计信息将持久保存到磁盘
STATS_PERSISTENT=1
。
innodb_stats_persistent
默认情况下启用。
以前,优化器统计信息在每次服务器重新启动时以及在其他一些操作之后被清除,并在下一个表访问时重新计算。 因此,在重新计算统计数据时可能会产生不同的估计值,导致查询执行计划中的选择不同,从而导致查询性能的变化。
持久性统计信息存储在
mysql.innodb_table_stats
和
mysql.innodb_index_stats
表中,如
第15.8.10.1.5节“InnoDB持久性统计表”中所述
。
要恢复使用非持久优化程序统计信息,可以使用
语句
修改表
。
有关相关信息,请参见
第15.8.10.2节“配置非持久优化器统计信息参数”
ALTER TABLE
tbl_name STATS_PERSISTENT=0
innodb_stats_auto_recalc
默认情况下启用
的
配置选项确定是否在表经历实质性更改(超过10%的行)时自动计算统计信息。
您还可以使用
or
语句中
的
STATS_AUTO_RECALC
子句
为各个表配置自动统计信息重新计算
。
默认情况下启用。
CREATE
TABLE
ALTER TABLE
innodb_stats_auto_recalc
由于自动统计信息重新计算的异步性质(在后台发生),在运行影响表的10%以上的DML操作后,即使
innodb_stats_auto_recalc
启用了
统计信息,也不会立即重新计算统计信息
。
在某些情况下,统计重新计算可能会延迟几秒钟。
如果在更改表的重要部分后立即需要最新的统计信息,请运行
ANALYZE TABLE
以启动统计信息的同步(前台)重新计算。
如果
innodb_stats_auto_recalc
已禁用,请在
ANALYZE TABLE
对索引列进行实质性更改后,
通过
为每个适用的表
发出
语句来
确保优化程序统计信息的准确性
。
在将代表性数据加载到表中后,您可以在设置脚本中运行此语句,并在DML操作显着更改索引列的内容之后定期运行此语句,或者在活动较少时按计划运行。
将新索引添加到现有表或添加或删除列时,将计算索引统计信息并将其添加到
innodb_index_stats
表中,而不管其值是多少
innodb_stats_auto_recalc
。
要确保
在创建新索引时
收集统计信息,请启用该
innodb_stats_auto_recalc
选项,或
ANALYZE TABLE
在启用持久统计模式后创建每个新索引后
运行
。
innodb_stats_persistent
,,
innodb_stats_auto_recalc
和
innodb_stats_persistent_sample_pages
是全局配置选项。
要覆盖这些系统的设置和配置单个表优化统计参数,你可以定义
STATS_PERSISTENT
,
STATS_AUTO_RECALC
和
STATS_SAMPLE_PAGES
子句
CREATE
TABLE
或
ALTER
TABLE
语句。
-
STATS_PERSISTENT指定是否 为 表 启用 持久统计信息InnoDB。 该值DEFAULT导致表的持久统计信息设置由innodb_stats_persistent配置选项 确定 。 该值1启用表的持久统计信息,而值0将关闭此功能。 通过CREATE TABLEorALTER TABLE语句 启用持久性统计ANALYZE TABLE信息后,在将代表性数据加载到表中后 ,发出 语句来计算统计信息。 -
STATS_AUTO_RECALC指定是否自动重新计算 持续的统计数据 为InnoDB表。 该值DEFAULT导致表的持久统计信息设置由innodb_stats_auto_recalc配置选项 确定 。1当表中10%的数据发生更改时, 该值 会导致重新计算统计信息。 该值0可防止自动重新计算此表; 使用此设置,发出ANALYZE TABLE声明以在对表进行实质性更改后重新计算统计信息。 -
STATS_SAMPLE_PAGES指定在估计索引列的基数和其他统计信息时要采样的索引页数,例如计算的列ANALYZE TABLE。
以下
CREATE
TABLE
示例
中指定了所有三个子句
:
CREATE TABLE`t1`( `id` int(8)NOT NULL auto_increment, `data` varchar(255), `date` datetime, PRIMARY KEY(`id`), INDEX`DATE_IX`(`date`) )ENGINE = InnoDB, STATS_PERSISTENT = 1, STATS_AUTO_RECALC = 1, STATS_SAMPLE_PAGES = 25;
MySQL查询优化器使用
关于关键分布的
估计
统计
信息,根据
索引
的相对
选择性
为
执行计划
选择
索引。
诸如
ANALYZE
TABLE
导致
InnoDB
从表上的每个索引对随机页面进行采样以估计
索引
的
基数
的操作。
(这种技术称为
随机潜水
。)
为了控制统计估计的质量(以及查询优化器的更好信息),您可以使用参数更改采样页面的数量,该参数
innodb_stats_persistent_sample_pages
可以在运行时设置。
innodb_stats_persistent_sample_pages
默认值为20.作为一般准则,请考虑在遇到以下问题时修改此参数:
-
统计信息不够准确,优化程序选择次优计划 ,如
EXPLAIN输出 所示 。 可以通过比较索引的实际基数(通过SELECT DISTINCT在索引列上 运行返回 )与mysql.innodb_index_stats持久统计表中 提供的估计 来检查统计的准确性 。如果确定统计数据不够准确,
innodb_stats_persistent_sample_pages则应增加 值, 直到统计估计值足够准确。innodb_stats_persistent_sample_pages然而, 增加 太多可能导致ANALYZE TABLE运行缓慢。 -
ANALYZE TABLE太慢了 。 在这种情况下,innodb_stats_persistent_sample_pages应该减少直到ANALYZE TABLE执行时间可以接受。 但是,将值减小太多可能会导致第一个不准确的统计信息和次优查询执行计划的问题。如果在准确的统计信息和
ANALYZE TABLE执行时间 之间无法实现平衡 ,请考虑减少表中索引列的数量或限制分区数以降低ANALYZE TABLE复杂性。 表的主键中的列数也很重要,因为主键列会附加到每个非唯一索引。有关相关信息,请参见 第15.8.10.3节“估算InnoDB表的ANALYZE TABLE复杂度” 。
默认情况下,
InnoDB
在计算统计信息时读取未提交的数据。
对于从表中删除行的未提交事务,
InnoDB
排除在计算行估计和索引统计信息时删除标记的记录,这可能导致对同时使用表执行的其他事务的非最佳执行计划事务隔离级别除外
READ
UNCOMMITTED
。
要避免这种情况,
innodb_stats_include_delete_marked
可以启用此选项以确保
InnoDB
在计算持久优化程序统计信息时包含删除标记的记录。
当
innodb_stats_include_delete_marked
启用时,
ANALYZE TABLE
重新计算统计数据时,会考虑删除标记的记录。
innodb_stats_include_delete_marked
是一个影响所有
InnoDB
表
的全局设置,
它仅适用于持久优化程序统计信息。
持久统计信息功能依赖于
mysql
数据库中
的内部管理表
,名为
innodb_table_stats
和
innodb_index_stats
。
这些表在所有安装,升级和源代码构建过程中自动设置。
表15.7 innodb_table_stats的列
| 列名 | 描述 |
|---|---|
database_name |
数据库名称 |
table_name |
表名,分区名或子分区名 |
last_update |
一个时间戳,指示上次
InnoDB
更新此行的
时间
|
n_rows |
表中的行数 |
clustered_index_size |
主索引的大小,以页为单位 |
sum_of_other_index_sizes |
页面中其他(非主要)索引的总大小 |
表15.8 innodb_index_stats的列
| 列名 | 描述 |
|---|---|
database_name |
数据库名称 |
table_name |
表名,分区名或子分区名 |
index_name |
索引名称 |
last_update |
一个时间戳,指示上次
InnoDB
更新此行的
时间
|
stat_name |
统计信息的名称,其值在
stat_value
列中
报告
|
stat_value |
stat_name
列中
命名的统计信息的值
|
sample_size |
为
stat_value
列中
提供的估算采样的页数
|
stat_description |
stat_name
列中
指定的统计信息的描述
|
无论是
innodb_table_stats
和
innodb_index_stats
表包括一个
last_update
示出了当柱
InnoDB
最后更新索引的统计,如显示在下面的例子:
MySQL的> SELECT * FROM innodb_table_stats \G
*************************** 1。排******************** *******
database_name:sakila
table_name:actor
last_update:2014-05-28 16:16:44
n_rows:200
clustered_index_size:1
sum_of_other_index_sizes:1
...
MySQL的> SELECT * FROM innodb_index_stats \G
*************************** 1。排******************** *******
database_name:sakila
table_name:actor
index_name:PRIMARY
last_update:2014-05-28 16:16:44
stat_name:n_diff_pfx01
stat_value:200
sample_size:1
...
在
innodb_table_stats
和
innodb_index_stats
表是普通表,可以手动更新。
手动更新统计信息的功能可以强制执行特定的查询优化计划或测试备用计划,而无需修改数据库。
如果手动更新统计信息,请发出
命令以使MySQL重新加载更新的统计信息。
FLUSH TABLE
tbl_name
持久性统计信息被视为本地信息,因为它们与服务器实例相关。
在
innodb_table_stats
与
innodb_index_stats
表时自动重新计算统计发生,因此不复制。
如果运行
ANALYZE TABLE
以启动统计信息的同步重新计算,则会复制此语句(除非您禁止对其进行日志记录),并在复制从属服务器上进行重新计算。
该
innodb_table_stats
表包含每个表一行。
收集的数据在以下示例中进行了演示。
表
t1
含有伯指数(列
a
,
b
)二级索引(列
c
,
d
),和唯一索引(列
e
,
f
):
CREATE TABLE t1( a INT,b INT,c INT,d INT,e INT,f INT, 主键(a,b),键i1(c,d),独特键i2uniq(e,f) )ENGINE = INNODB;
插入五行样本数据后,表格如下所示:
MySQL的> SELECT * FROM t1;
+ --- + --- + ------ + ------ + ------ + ------ +
| a | b | c | d | e | f |
+ --- + --- + ------ + ------ + ------ + ------ +
| 1 | 1 | 10 | 11 | 100 | 101 |
| 1 | 2 | 10 | 11 | 200 | 102 |
| 1 | 3 | 10 | 11 | 100 | 103 |
| 1 | 4 | 10 | 12 | 200 | 104 |
| 1 | 5 | 10 | 12 | 100 | 105 |
+ --- + --- + ------ + ------ + ------ + ------ +
要立即更新统计信息,请运行
ANALYZE TABLE
(如果
innodb_stats_auto_recalc
已启用,则假定已达到更改的表行的10%阈值,则会在几秒钟内自动
更新统计信息
):
MySQL的> ANALYZE TABLE t1;
+ --------- + --------- + ---------- + ---------- +
| 表| Op | Msg_type | Msg_text |
+ --------- + --------- + ---------- + ---------- +
| test.t1 | 分析| 状态| 好的
+ --------- + --------- + ---------- + ---------- +
表的统计信息
t1
显示上次
InnoDB
更新表statistics(
2014-03-14 14:36:34
),
表中
的行数(
5
),聚簇索引大小(
1
页面)以及其他索引(
2
页面)
的组合大小
。
MySQL的> SELECT * FROM mysql.innodb_table_stats WHERE table_name like 't1'\G
*************************** 1。排******************** *******
database_name:test
table_name:t1
last_update:2014-03-14 14:36:34
n_rows:5
clustered_index_size:1
sum_of_other_index_sizes:2
该
innodb_index_stats
表包含每个索引的多行。
innodb_index_stats
表
中的每一行都
提供与特定索引统计信息相关的数据,该统计信息在
stat_name
列中
命名并在
列中描述
stat_description
。
例如:
MySQL的>SELECT index_name, stat_name, stat_value, stat_descriptionFROM mysql.innodb_index_stats WHERE table_name like 't1';+ ------------ + -------------- + ------------ + -------- --------------------------- + | index_name | stat_name | stat_value | stat_description | + ------------ + -------------- + ------------ + -------- --------------------------- + | 主要| n_diff_pfx01 | 1 | a | | 主要| n_diff_pfx02 | 5 | a,b | | 主要| n_leaf_pages | 1 | 索引中的叶页数| | 主要| 尺寸| 1 | 索引中的页数| | i1 | n_diff_pfx01 | 1 | c | | i1 | n_diff_pfx02 | 2 | c,d | | i1 | n_diff_pfx03 | 2 | c,d,a | | i1 | n_diff_pfx04 | 5 | c,d,a,b | | i1 | n_leaf_pages | 1 | 索引中的叶页数| | i1 | 尺寸| 1 | 索引中的页数| | i2uniq | n_diff_pfx01 | 2 | e | | i2uniq | n_diff_pfx02 | 5 | e,f | | i2uniq | n_leaf_pages | 1 | 索引中的叶页数| | i2uniq | 尺寸| 1 | 索引中的页数| + ------------ + -------------- + ------------ + -------- --------------------------- +
该
stat_name
列显示以下类型的统计信息:
-
size:Wherestat_name=size,该stat_value列显示索引中的总页数。 -
n_leaf_pages:Wherestat_name=n_leaf_pages,该stat_value列显示索引中的叶页数。 -
n_diff_pfx:WhereNNstat_name=n_diff_pfx01,该stat_value列显示索引第一列中的不同值的数量。 Wherestat_name=n_diff_pfx02,该stat_value列显示索引前两列中的不同值的数量,依此类推。 此外,wherestat_name= ,该 列显示了一个逗号分隔的计数索引列列表。n_diff_pfxNNstat_description
为了进一步说明
提供基数数据
的
统计数据,再次考虑
先前引入
的
表格示例。
如下所示,该
表是用主索引(列而创建
,
),辅指数(列
,
),和唯一索引(列
,
):
n_diff_pfx
NNt1
t1
a
b
c
d
e
f
CREATE TABLE t1( a INT,b INT,c INT,d INT,e INT,f INT, 主键(a,b),键i1(c,d),独特键i2uniq(e,f) )ENGINE = INNODB;
插入五行样本数据后,表格如下所示:
MySQL的> SELECT * FROM t1;
+ --- + --- + ------ + ------ + ------ + ------ +
| a | b | c | d | e | f |
+ --- + --- + ------ + ------ + ------ + ------ +
| 1 | 1 | 10 | 11 | 100 | 101 |
| 1 | 2 | 10 | 11 | 200 | 102 |
| 1 | 3 | 10 | 11 | 100 | 103 |
| 1 | 4 | 10 | 12 | 200 | 104 |
| 1 | 5 | 10 | 12 | 100 | 105 |
+ --- + --- + ------ + ------ + ------ + ------ +
当您查询
index_name
,
stat_name
,
stat_value
,和
stat_description
在那里
stat_name LIKE 'n_diff%'
,下面的返回结果集:
MySQL的>SELECT index_name, stat_name, stat_value, stat_descriptionFROM mysql.innodb_index_statsWHERE table_name like 't1' AND stat_name LIKE 'n_diff%';+ ------------ + -------------- + ------------ + -------- ---------- + | index_name | stat_name | stat_value | stat_description | + ------------ + -------------- + ------------ + -------- ---------- + | 主要| n_diff_pfx01 | 1 | a | | 主要| n_diff_pfx02 | 5 | a,b | | i1 | n_diff_pfx01 | 1 | c | | i1 | n_diff_pfx02 | 2 | c,d | | i1 | n_diff_pfx03 | 2 | c,d,a | | i1 | n_diff_pfx04 | 5 | c,d,a,b | | i2uniq | n_diff_pfx01 | 2 | e | | i2uniq | n_diff_pfx02 | 5 | e,f | + ------------ + -------------- + ------------ + -------- ---------- +
对于
PRIMARY
索引,有两
n_diff%
行。
行数等于索引中的列数。
对于非唯一索引,请
InnoDB
附加主键的列。
-
其中
index_name=PRIMARY和stat_name=n_diff_pfx01,stat_valueis1,表示索引(列a) 的第一列中存在单个不同的值 。a通过查看a表 中列 中 的数据来确认 列中的不同值的数量t1,其中存在单个不同的值(1)。 计数列(a)显示在stat_description结果集 的 列中。 -
其中
index_name=PRIMARY和stat_name=n_diff_pfx02,stat_valueis5,表示index(a,b) 的两列中有五个不同的值 。 的不同值的列数a和b通过查看在列中的数据证实a和b在表t1,其中有五个不同的值:( ),(1,1),(1,21,3),(1,4和)(1,5)。 计算的列(a,b)显示在stat_description结果集 的 列中。
对于二级索引(
i1
),有
n_diff%
四行。
仅为辅助索引(
c,d
)
定义了两列,但辅助索引
有
n_diff%
四行,因为
InnoDB
所有非唯一索引都带有主键后缀。
因此,有
n_diff%
四行而不是两行来考虑二级索引列(
c,d
)和主键列(
a,b
)。
-
其中
index_name=i1和stat_name=n_diff_pfx01,stat_valueis1,表示索引(列c) 的第一列中存在单个不同的值 。c通过查看c表 中列 中 的数据来确认 列中的不同值的数量t1,其中存在单个不同的值:(10)。 计数列(c)显示在stat_description结果集 的 列中。 -
其中
index_name=i1和stat_name=n_diff_pfx02,stat_valueis2,表示index(c,d) 的前两列中有两个不同的值 。 通过查看列 和 表中 的数据来确认 列ca中 的不同值的数量 ,其中有两个不同的值:( )和( )。 计算的列( )显示在 结果集 的 列中。dcdt110,1110,12c,dstat_description -
其中
index_name=i1和stat_name=n_diff_pfx03,stat_valueis2,表示index(c,d,a)的 前三列中有两个不同的值 。 不同的值的列的数量c,d以及a由列查看数据证实c,d和a在表t1,其中有两个不同的值:(10,11,1) 和(10,12,1)。 计算的列(c,d,a)显示在stat_description结果集 的 列中。 -
其中
index_name=i1和stat_name=n_diff_pfx04,stat_valueis5,表示index(c,d,a,b) 的四列中有五个不同的值 。 不同的值的列的数量c,d,a并且b是通过在列查看数据证实c,d,a,和b在表t1,其中有五个不同的值:( ),(10,11,1,1),(10,11,1,2),(10,11,1,310,12,1,4) 和(10,12,1,5)。 计算的列(c,d,a,b)显示在stat_description结果集 的 列中。
对于唯一索引(
i2uniq
),有两
n_diff%
行。
-
其中
index_name=i2uniq和stat_name=n_diff_pfx01,stat_valueis2,表示索引(列e) 的第一列中有两个不同的值 。e通过查看e表 中列 中 的数据来确认 列中不同值的数量t1,其中有两个不同的值:(100)和(200)。 计数列(e)显示在stat_description结果集 的 列中。 -
其中
index_name=i2uniq和stat_name=n_diff_pfx02,stat_valueis5,表示index(e,f) 的两列中有五个不同的值 。 的不同值的列数e和f通过查看在列中的数据证实e和f在表t1,其中有五个不同的值:( ),(100,101),(200,102100,103),(200,104和)(100,105)。 计数列(e,f)显示在stat_description结果集的列。
可以使用
innodb_index_stats
表
检索表,分区或子分区的索引大小
。
在以下示例中,将为表检索索引大小
t1
。
有关表
t1
和相应索引统计信息
的定义
,请参见
第15.8.10.1.6节“InnoDB持久性统计信息表示例”
。
MySQL的>SELECT SUM(stat_value) pages, index_name,SUM(stat_value)*@@innodb_page_size sizeFROM mysql.innodb_index_stats WHERE table_name='t1'AND stat_name = 'size' GROUP BY index_name;+ ------- + ------------ + ------- + | 页面| index_name | 尺寸| + ------- + ------------ + ------- + | 1 | 主要| 16384 | | 1 | i1 | 16384 | | 1 | i2uniq | 16384 | + ------- + ------------ + ------- +
对于分区或子分区,
WHERE
可以使用
带有modified
子句
的相同查询
来检索索引大小。
例如,以下查询检索表的分区的索引大小
t1
:
MySQL的>SELECT SUM(stat_value) pages, index_name,SUM(stat_value)*@@innodb_page_size sizeFROM mysql.innodb_index_stats WHERE table_name like 't1#P%'AND stat_name = 'size' GROUP BY index_name;
本节介绍如何配置非持久优化程序统计信息。
innodb_stats_persistent=OFF
当创建或更改单个表
时,优化程序统计信息不会保留到磁盘
STATS_PERSISTENT=0
。
相反,统计信息存储在内存中,并在服务器关闭时丢失。
某些业务和某些条件下也会定期更新统计数据。
默认情况下,优化程序统计信息将持久保存到磁盘,并由
innodb_stats_persistent
配置选项
启用
。
有关持久优化器统计信息的信息,请参见
第15.8.10.1节“配置持久优化器统计信息参数”
。
优化程序统计信息更新
在以下情况下更新非持久优化程序统计信息:
-
运行
ANALYZE TABLE。 -
在 启用选项的情况下 运行
SHOW TABLE STATUS,SHOW INDEX或查询INFORMATION_SCHEMA.TABLES或INFORMATION_SCHEMA.STATISTICS表innodb_stats_on_metadata。的默认设置
innodb_stats_on_metadata是OFF。 启用innodb_stats_on_metadata可能会降低具有大量表或索引的模式的访问速度,并降低涉及InnoDB表的 查询的执行计划的稳定性 。innodb_stats_on_metadata使用SET语句 全局配置 。SET GLOBAL innodb_stats_on_metadata = ON
注意innodb_stats_on_metadata仅在将优化程序 统计信息 配置为非持久性时innodb_stats_persistent(禁用时) 才适用 。 -
启用启用 了 选项 的 mysql 客户端
--auto-rehash,这是默认设置。 该auto-rehash选项会导致InnoDB打开 所有 表,并且打开表操作会导致重新计算统计信息。要改善 mysql 客户端 的启动时间 并更新统计信息,可以
auto-rehash使用该--disable-auto-rehash选项 关闭 。 该auto-rehash功能为交互式用户启用数据库,表和列名称的自动名称完成。 -
首先打开一个表。
-
InnoDB检测自上次更新统计信息以来已修改1/16的表。
配置采样页数
MySQL查询优化器使用
关于关键分布的
估计
统计
信息,根据
索引
的相对
选择性
为
执行计划
选择
索引。
当
InnoDB
更新优化器统计信息时,它会对表中每个索引的随机页面进行采样,以估计
索引
的
基数
。
(这种技术称为
随机潜水
。)
为了控制统计估计的质量(以及查询优化器的更好信息),您可以使用参数更改采样页面的数量
innodb_stats_transient_sample_pages
。
默认的采样页数为8,这可能不足以产生准确的估计值,导致查询优化器选择的索引较差。
此技术对于
连接中
使用的大型表和表尤其重要
。
对这些表进行
不必要的
全表扫描
可能是一个重大的性能问题。
有关
调整此类查询的提示
,
请参见
第8.2.1.22节“避免全表扫描”
。
innodb_stats_transient_sample_pages
是一个可以在运行时设置的全局参数。
值的大小
innodb_stats_transient_sample_pages
会影响所有
InnoDB
表和索引
的索引采样
innodb_stats_persistent=0
。
更改索引样本大小时,请注意以下潜在的重大影响:
-
像1或2这样的小值可能导致基数估计不准确。
-
增加该
innodb_stats_transient_sample_pages值可能需要更多磁盘读取。 大于8(例如,100)的值可能导致打开表或执行所花费的时间显着减慢SHOW TABLE STATUS。 -
优化器可能会根据索引选择性的不同估计选择非常不同的查询计划。
无论哪种值
innodb_stats_transient_sample_pages
最适合系统,请设置选项并将其保留为该值。
选择一个值,可以对数据库中的所有表进行合理准确的估计,而不需要过多的I / O.
由于统计信息会在执行时的其他时间自动重新计算
ANALYZE TABLE
,因此增加索引样本大小,运行
ANALYZE TABLE
,然后再次减小样本大小
没有意义
。
较小的表通常比较大的表需要更少的索引样本。
如果您的数据库有许多大表,请考虑使用更高的值,而
innodb_stats_transient_sample_pages
不是使用大多数较小的表。
ANALYZE
TABLE
InnoDB
表的
复杂性
取决于:
-
采样的页数,由定义
innodb_stats_persistent_sample_pages。 -
表中索引列的数量
-
分区数量。 如果表没有分区,则分区数被视为1。
使用这些参数,估算
ANALYZE TABLE
复杂性
的近似公式为
:
innodb_stats_persistent_sample_pages
*表中索引列数*
的值
*分区数
通常,结果值越大,执行时间越长
ANALYZE TABLE
。
innodb_stats_persistent_sample_pages
定义在全局级别采样的页数。
要设置单个表的采样页数,请使用
STATS_SAMPLE_PAGES
带
CREATE
TABLE
或
的
选项
ALTER
TABLE
。
有关更多信息,请参见
第15.8.10.1节“配置持久优化器统计信息参数”
。
如果
innodb_stats_persistent=OFF
,采样的页数由定义
innodb_stats_transient_sample_pages
。
有关
其他信息
,
请参见
第15.8.10.2节“配置非持久优化器统计信息参数”
。
有关估算
ANALYZE
TABLE
复杂性
的更深入方法
,请考虑以下示例。
在
Big O表示法中
,
ANALYZE TABLE
复杂性被描述为:
O(n样本
*(n_cols_in_uniq_i
+ n_cols_in_non_uniq_i
+ n_cols_in_pk *(1 + n_non_uniq_i))
* n_part)
哪里:
-
n_sample是采样的页数(定义innodb_stats_persistent_sample_pages) -
n_cols_in_uniq_i是所有唯一索引中所有列的总数(不包括主键列) -
n_cols_in_non_uniq_i是所有非唯一索引中所有列的总数 -
n_cols_in_pk是主键中的列数(如果未定义InnoDB主键,则在内部创建单列主键) -
n_non_uniq_i是表中非唯一索引的数量 -
n_part是分区数。 如果未定义分区,则该表被视为单个分区。
现在,考虑下面的表(表
t
),它有一个主键(2列),一个唯一索引(2列)和两个非唯一索引(每列两列):
CREATE TABLE t( 一个INT, b INT, c INT, d INT, e INT, f INT, g INT, h INT, 主要关键(a,b), UNIQUE KEY i1uniq(c,d), KEY i2nonuniq(e,f), KEY i3nonuniq(g,h) );
对于上述算法所需的列和索引数据,查询
mysql.innodb_index_stats
表
的
持久索引统计信息表
t
。
该
n_diff_pfx%
统计显示,计数每个索引的列。
例如,列
a
和
b
计数主键索引。
对于非唯一索引,除了用户定义的列之外,还会计算主键列(a,b)。
有关
InnoDB
持久性统计信息表的
其他信息
,请参见
第15.8.10.1节“配置持久性优化器统计信息参数”
MySQL的>SELECT index_name, stat_name, stat_descriptionFROM mysql.innodb_index_stats WHEREdatabase_name='test' ANDtable_name='t' ANDstat_name like 'n_diff_pfx%';+ ------------ + -------------- + ------------------ + | index_name | stat_name | stat_description | + ------------ + -------------- + ------------------ + | 主要| n_diff_pfx01 | a | | 主要| n_diff_pfx02 | a,b | | i1uniq | n_diff_pfx01 | c | | i1uniq | n_diff_pfx02 | c,d | | i2nonuniq | n_diff_pfx01 | e | | i2nonuniq | n_diff_pfx02 | e,f | | i2nonuniq | n_diff_pfx03 | e,f,a | | i2nonuniq | n_diff_pfx04 | e,f,a,b | | i3nonuniq | n_diff_pfx01 | g | | i3nonuniq | n_diff_pfx02 | g,h | | i3nonuniq | n_diff_pfx03 | g,h,a | | i3nonuniq | n_diff_pfx04 | g,h,a,b | + ------------ + -------------- + ------------------ +
根据上面显示的索引统计数据和表定义,可以确定以下值:
-
n_cols_in_uniq_i,所有唯一索引中不包括主键列的所有列的总数为2(c和d) -
n_cols_in_non_uniq_i,总数在所有非唯一的索引的所有列的,为4( , ,e和 )fgh -
n_cols_in_pk,主键中的列数为2(a和b) -
n_non_uniq_i,表中非唯一索引的数量是2(i2nonuniq和i3nonuniq)) -
n_part,分区数量为1。
您现在可以计算
innodb_stats_persistent_sample_pages
*(2 + 4 + 2 *(1 + 2))* 1来确定扫描的叶页数。
用
innodb_stats_persistent_sample_pages
设置为默认值
20
,和与16的缺省页大小
KiB
(
innodb_page_size
= 16384),则可以预计,20 * 12 * 16384
bytes
被读取为表
t
,或约4
MiB
。
MiB
可能无法从磁盘读取
所有4个
,因为某些叶页可能已缓存在缓冲池中。
您可以配置
MERGE_THRESHOLD
索引页面
的
值。
如果
索引页面
的
“
页面满
”
百分比低于
MERGE_THRESHOLD
删除行或行
UPDATE
操作
缩短行时的值
,则
InnoDB
尝试将索引页与相邻索引页合并。
默认
MERGE_THRESHOLD
值为50,这是以前的硬编码值。
最小值
MERGE_THRESHOLD
为1,最大值为50。
当
索引页面
的
“
页面满
”
百分比低于50%(这是默认
MERGE_THRESHOLD
设置)时,
InnoDB
尝试将索引页与相邻页合并。
如果两个页面都接近50%已满,则在合并页面后很快就会发生页面拆分。
如果频繁发生此合并拆分行为,则可能会对性能产生负面影响。
为避免频繁的合并拆分,您可以降低该
MERGE_THRESHOLD
值,以便
InnoDB
尝试以较低的
“
页面满
”
百分比
合并
页面
。
以较低页面满百分比合并页面会在索引页面中留出更多空间,并有助于减少合并拆分行为。
该
MERGE_THRESHOLD
索引页面可以为表或个别指标进行定义。
阿
MERGE_THRESHOLD
为单个索引定义的值在一个优先
MERGE_THRESHOLD
的表中定义的值。
如果未定义,则
MERGE_THRESHOLD
默认值为50。
为表设置MERGE_THRESHOLD
您可以
MERGE_THRESHOLD
使用
语句
的
子句
设置
表
的
值
。
例如:
table_option
COMMENT
CREATE TABLE
CREATE TABLE t1( id INT, KEY id_index(id) )COMMENT ='MERGE_THRESHOLD = 45';
您还可以
MERGE_THRESHOLD
使用以下
子句
设置
现有表
的
值
:
table_option COMMENT
ALTER TABLE
CREATE TABLE t1( id INT, KEY id_index(id) ); ALTER TABLE t1 COMMENT ='MERGE_THRESHOLD = 40';
为个别索引设置MERGE_THRESHOLD
要设置
MERGE_THRESHOLD
为单个索引值,则可以使用
与子句
,
或
,如图所示在以下实施例:
index_option COMMENT
CREATE TABLE
ALTER TABLE
CREATE INDEX
-
MERGE_THRESHOLD使用CREATE TABLE以下方式 设置 单个索引 :CREATE TABLE t1( id INT, KEY id_index(id)COMMENT'MERGE_THRESHOLD = 40' );
-
MERGE_THRESHOLD使用ALTER TABLE以下方式 设置 单个索引 :CREATE TABLE t1( id INT, KEY id_index(id) ); ALTER TABLE t1 DROP KEY id_index; ALTER TABLE t1 ADD KEY id_index(id)COMMENT'MERGE_THRESHOLD = 40';
-
MERGE_THRESHOLD使用CREATE INDEX以下方式 设置 单个索引 :CREATE TABLE t1(id INT); CREATE INDEX id_index ON t1(id)COMMENT'MERGE_THRESHOLD = 40';
您无法修改
MERGE_THRESHOLD
索引级别
的
值
GEN_CLUST_INDEX
,即
在没有主键或唯一键索引的情况下创建表
InnoDB
时
创建的聚簇
InnoDB
索引。
您只能
通过设置
表
来修改
MERGE_THRESHOLD
值
。
GEN_CLUST_INDEX
MERGE_THRESHOLD
查询索引的MERGE_THRESHOLD值
MERGE_THRESHOLD
可以通过查询
INNODB_INDEXES
表
来获取索引
的当前
值
。
例如:
MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_INDEXES WHERE NAME='id_index' \G
*************************** 1。排******************** *******
INDEX_ID:91
NAME:id_index
TABLE_ID:68
TYPE:0
N_FIELDS:1
PAGE_NO:4
空间:57
MERGE_THRESHOLD:40
如果使用以下
子句
显式定义,则
可以使用
SHOW CREATE TABLE
查看
MERGE_THRESHOLD
表
的
值
:
table_option COMMENT
MySQL的> SHOW CREATE TABLE t2 \G
*************************** 1。排******************** *******
表:t2
创建表:CREATE TABLE`t2`(
`id` int(11)DEFAULT NULL,
KEY`id_index`(`id`)COMMENT'MERGE_THRESHOLD = 40'
)ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
甲
MERGE_THRESHOLD
在索引级别定义的值在一个优先
MERGE_THRESHOLD
的表定义的值。
如果未定义,则
MERGE_THRESHOLD
默认为50%(
MERGE_THRESHOLD=50
这是以前的硬编码值。
同样,
如果使用以下
子句
显式定义
,您可以使用它
SHOW
INDEX
来查看
MERGE_THRESHOLD
索引
的
值
:
index_option COMMENT
MySQL的> SHOW INDEX FROM t2 \G
*************************** 1。排******************** *******
表:t2
非独特:1
Key_name:id_index
Seq_in_index:1
Column_name:id
整理:A
基数:0
Sub_part:NULL
打包:NULL
空:是的
Index_type:BTREE
评论:
Index_comment:MERGE_THRESHOLD = 40
测量MERGE_THRESHOLD设置的效果
该
INNODB_METRICS
表提供了两个计数器,可用于衡量
MERGE_THRESHOLD
设置对索引页面合并的影响。
MySQL的>SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICSWHERE NAME like '%index_page_merge%';+ ----------------------------- + ------------------- --------------------- + | NAME | 评论| + ----------------------------- + ------------------- --------------------- + | index_page_merge_attempts | 索引页面合并尝试次数| | index_page_merge_successful | 成功索引页面合并的数量| + ----------------------------- + ------------------- --------------------- +
降低
MERGE_THRESHOLD
价值时,目标是:
-
较少数量的页面合并尝试和成功的页面合并
-
相似数量的页面合并尝试和成功的页面合并
一个
MERGE_THRESHOLD
设置过小可能会导致大量的数据文件由于空页空间过量。
有关使用
INNODB_METRICS
计数器的
信息
,请参见
第15.14.6节“InnoDB INFORMATION_SCHEMA度量表”
。
当
innodb_dedicated_server
启用时,
InnoDB
会自动配置以下变量:
仅考虑启用
innodb_dedicated_server
MySQL实例是否位于可以使用所有可用系统资源的专用服务器上。
例如,如果在Docker容器或专用VM中运行MySQL Server,请考虑启用。
innodb_dedicated_server
如果MySQL实例与其他应用程序共享系统资源,则不建议
启用
。
以下信息描述了如何自动配置每个变量。
-
根据服务器上检测到的内存量配置缓冲池大小。
表15.9自动配置的缓冲池大小
检测到的服务器内存 缓冲池大小 不到1GB 128MiB(默认值) 1GB到4GB detected server memory* 0.5大于4GB detected server memory* 0.75
-
从MySQL 8.0.14开始,根据自动配置的缓冲池大小配置日志文件大小。
注意在MySQL 8.0.14之前,
innodb_log_file_size根据服务器上检测到的内存量自动配置变量,如下所示:表15.11自动配置的日志文件大小(MySQL 8.0.13及更早版本)
检测到的服务器内存 日志文件大小 <1GB 48MiB(默认值) <= 4GB 128MiB <= 8GB 为512MiB <= 16GB 1024MiB > 16GB 2048MiB
-
根据自动配置的缓冲池大小(以千兆字节为单位)配置日志文件的数量。
innodb_log_files_in_group在MySQL 8.0.14中添加 了 变量的 自动配置 。表15.12自动配置的日志文件数
缓冲池大小 日志文件数 小于8GB ROUND( buffer pool size)8GB到128GB ROUND( buffer pool size* 0.75)大于128GB 64
-
启用
O_DIRECT_NO_FSYNC时 ,flush方法设置为 wheninnodb_dedicated_server。 如果该O_DIRECT_NO_FSYNC设置不可用,innodb_flush_method则使用 默认 设置。InnoDBO_DIRECT在刷新I / O期间 使用 ,但fsync()在每次写入操作后 跳过 系统调用。警告在MySQL 8.0.14之前,此设置不适用于XFS和EXT4等文件系统,这些文件系统需要
fsync()系统调用来同步文件系统元数据更改。从MySQL 8.0.14开始,
fsync()在创建新文件之后,在增加文件大小之后,以及在关闭文件之后调用,以确保文件系统元数据更改是同步的。 该fsync()系统调用是每次写操作后,仍然跳过。在具有高速缓存的存储设备上,如果数据文件和重做日志文件驻留在不同的存储设备上,则可能会丢失数据,并且在从设备高速缓存刷新数据文件写入之前发生崩溃。 如果您使用或打算为重做日志和数据文件使用不同的存储设备,请
O_DIRECT改用。
如果在选项文件或其他位置显式配置了自动配置选项,则使用显式指定的设置,并将类似于此的启动警告打印到
stderr
:
[警告] [000000] InnoDB:innodb_buffer_pool_size会忽略选项innodb_dedicated_server,因为明确指定了innodb_buffer_pool_size = 134217728。
一个选项的显式配置不会阻止其他选项的自动配置。
例如,if
innodb_dedicated_server
is enabled并
innodb_buffer_pool_size
在选项文件中显式配置,
innodb_log_file_size
并
innodb_log_files_in_group
根据根据服务器上检测到的内存量计算的隐式缓冲池大小自动配置。
每次启动MySQL服务器时,如有必要,将评估并重新配置自动配置的设置。
本节提供有关
InnoDB
表压缩和
InnoDB
页面压缩功能的信息。
页面压缩功能也称为
透明页面压缩
。
使用压缩功能
InnoDB
,您可以创建以压缩形式存储数据的表。
压缩有助于提高原始性能和可伸缩性。
压缩意味着在磁盘和内存之间传输的数据更少,并且在磁盘和内存中占用的空间更少。
对于具有
二级索引的
表,优势会得到放大
,因为索引数据也会被压缩。
压缩对于
SSD
存储设备
尤其重要
,因为它们往往具有比
HDD
设备
更低的容量
。
本节介绍
InnoDB
表压缩,它由
InnoDB
驻留在
file_per_table
表空间或
常规表空间中的表支持
。
使用
ROW_FORMAT=COMPRESSED
带
CREATE
TABLE
或
的
属性
启用表压缩
ALTER
TABLE
。
由于处理器和高速缓存存储器的速度比磁盘存储设备的速度更快,因此许多工作负载都受 磁盘限制 。 数据 压缩 可以实现更小的数据库大小,更少的I / O和更高的吞吐量,同时以较低的CPU利用率降低成本。 对于具有足够RAM的系统,读取密集型应用程序的压缩特别有用,可以将常用数据保存在内存中。
使用
InnoDB
创建
的
表
ROW_FORMAT=COMPRESSED
可以
在磁盘上
使用小于
配置
值的
页面大小
innodb_page_size
。
较小的页面需要较少的I / O来读取和写入磁盘,这对
SSD
设备
尤其有用
。
压缩页面大小通过
CREATE
TABLE
or
参数
指定
。
不同的页面大小要求将表放在
每个表
的
文件表
空间或
通用表空间
而不是
系统表空间中
,因为系统表空间不能存储压缩表。
有关更多信息,请参见
第15.6.3.2节“每个表的文件表空间”
和
第15.6.3.3节“通用表空间”
。
ALTER
TABLE
KEY_BLOCK_SIZE
无论
KEY_BLOCK_SIZE
值
如何,压缩级别都相同
。
在为较小的值指定时
KEY_BLOCK_SIZE
,可以获得越来越小的页面的I / O优势。
但是,如果指定的值太小,则在数据值无法压缩到足以适合每页中的多行时,会有额外的开销重新组织页面。
KEY_BLOCK_SIZE
根据每个索引的键列长度,对表的
小小有一个硬性限制
。
指定一个太小的值,
CREATE
TABLE
或者
ALTER
TABLE
语句失败。
在缓冲池中,压缩数据保存在小页面中,页面大小基于该
KEY_BLOCK_SIZE
值。
为了提取或更新列值,MySQL还使用未压缩的数据在缓冲池中创建未压缩的页面。
在缓冲池中,对未压缩页面的任何更新也会重新写回等效的压缩页面。
您可能需要调整缓冲池的大小以容纳压缩和未压缩页面的其他数据,尽管未压缩的页面在
需要空间时从缓冲池中
逐出
,然后在下次访问时再次解压缩。
可以在 每个表的文件表 空间或 一般 的表 空间中 创建压缩表 。 表压缩不适用于InnoDB 系统表空间 。 系统表空间(空间0, .ibdata文件 )可以包含用户创建的表,但它也包含从不压缩的内部系统数据。 因此,压缩仅适用于存储在每个表文件或一般表空间中的表(和索引)。
在File-Per-Table表空间中创建压缩表
要在每个表的文件表空间中创建压缩表,
innodb_file_per_table
必须启用(默认值)。
您可以
使用
语句
在MySQL配置文件(
my.cnf
或
my.ini
)中动态
设置此参数
SET
。
innodb_file_per_table
配置
该
选项
后
,在
or
语句中
指定
ROW_FORMAT=COMPRESSED
子句或
KEY_BLOCK_SIZE
子句或两者,以
在每个表的文件表空间中创建压缩表。
CREATE
TABLE
ALTER TABLE
例如,您可以使用以下语句:
SET GLOBAL innodb_file_per_table = 1; CREATE TABLE t1 (c1 INT PRIMARY KEY) ROW_FORMAT = COMPRESSED KEY_BLOCK_SIZE = 8;
在常规表空间中创建压缩表
要在通用表空间中创建压缩表,
FILE_BLOCK_SIZE
必须为创建表空间时指定的常规表空间定义。
该
FILE_BLOCK_SIZE
值必须是与
该
值相关的有效压缩页面大小
innodb_page_size
,并且由
CREATE
TABLE
or
子句
定义的压缩表的页面大小
必须等于
。
例如,如果
和
,则
表必须为8.有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
ALTER
TABLE
KEY_BLOCK_SIZE
FILE_BLOCK_SIZE/1024
innodb_page_size=16384
FILE_BLOCK_SIZE=8192
KEY_BLOCK_SIZE
以下示例演示如何创建常规表空间并添加压缩表。
该示例假定默认
innodb_page_size
值为16K。
在
FILE_BLOCK_SIZE
8192要求压缩表有
KEY_BLOCK_SIZE
8个。
MySQL的>CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的>CREATE TABLE t4 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
笔记
-
从MySQL 8.0开始,压缩表的表空间文件是使用物理页面大小而不是
InnoDB页面大小创建的,这使得空压缩表的表空间文件的初始大小比以前的MySQL版本小。 -
如果你指定
ROW_FORMAT=COMPRESSED,你可以省略KEY_BLOCK_SIZE; 该KEY_BLOCK_SIZE设置默认为一半的innodb_page_size价值。 -
如果指定有效值
KEY_BLOCK_SIZE,则可以省略ROW_FORMAT=COMPRESSED; 压缩已自动启用。 -
要确定
KEY_BLOCK_SIZE,通常 的最佳值, 请为此子句创建具有不同值的同一个表的多个副本,然后测量生成的.ibd文件 的大小, 并查看每个文件在实际 工作负载下的 执行情况 。 对于常规表空间,请记住,删除表不会减小常规表空间.ibd文件 的大小 ,也不会将磁盘空间返回给操作系统。 有关更多信息,请参见 第15.6.3.3节“常规表空间” 。 -
该
KEY_BLOCK_SIZE值被视为提示;InnoDB如有必要, 可以使用不同的尺寸 。 对于每表文件表空间,KEY_BLOCK_SIZE只能小于或等于该innodb_page_size值。 如果指定的值大于该innodb_page_size值,则忽略指定的值,发出警告,并将KEY_BLOCK_SIZE其设置为innodb_page_size值的 一半 。 如果innodb_strict_mode=ON指定无效KEY_BLOCK_SIZE值,则返回错误。 对于常规表空间,有效值KEY_BLOCK_SIZE取决于FILE_BLOCK_SIZE表空间 的 设置。 有关更多信息,请参阅 第15.6.3.3节“通用表空间” 。 -
InnoDB支持32KB和64KB页面大小,但这些页面大小不支持压缩。 有关更多信息,请参阅innodb_page_size文档。 -
InnoDB数据 页 的默认未压缩大小 为16KB。 根据选项值的组合,MySQL对表空间数据文件(.ibd文件) 使用1KB,2KB,4KB,8KB或16KB的页面大小 。 实际压缩算法不受该KEY_BLOCK_SIZE值的 影响 ; 该值确定每个压缩块的大小,这反过来又会影响每个压缩页面中可以打包的行数。 -
在每表文件表空间中创建压缩表时,设置
KEY_BLOCK_SIZE等于InnoDB页面大小 通常不会导致太多压缩。 例如,设置KEY_BLOCK_SIZE=16通常不会导致太多压缩,因为正常InnoDB页面大小为16KB。 此设置可能仍然是许多长条桌有用的BLOB,VARCHAR或TEXT列,因为这种价值观往往压缩得很好,因此可能需要较少的 溢出页 中描述 第15.9.1.5,“如何压缩适用于InnoDB表” 。 对于常规表空间, 不允许使用KEY_BLOCK_SIZE等于InnoDB页面大小 的 值 。 有关更多信息,请参见 第15.6.3.3节“常规表空间” 。 -
表的所有索引(包括 聚簇索引 )都使用相同的页面大小进行压缩,如
CREATE TABLEorALTER TABLE语句中 指定的那样 。 表属性如表ROW_FORMAT和KEY_BLOCK_SIZE不是 表 的CREATE INDEX语法的 一部分InnoDB,如果指定了它们将被忽略(尽管如果指定,它们将出现在SHOW CREATE TABLE语句 的输出中 )。 -
有关与性能相关的配置选项,请参见 第15.9.1.3节“调整InnoDB表的压缩” 。
压缩表的限制
-
压缩表无法存储在
InnoDB系统表空间中。 -
常规表空间可以包含多个表,但压缩和未压缩表不能在同一个通用表空间中共存。
-
尽管有子句名称,但压缩适用于整个表及其所有相关索引,而不适用于单个行
ROW_FORMAT。 -
InnoDB不支持压缩的临时表。 当innodb_strict_mode启用(默认值),CREATE TEMPORARY TABLE如果返回错误ROW_FORMAT=COMPRESSED或KEY_BLOCK_SIZE指定。 如果innodb_strict_mode禁用,则发出警告,并使用非压缩行格式创建临时表。 相同的限制适用ALTER TABLE于临时表 上的 操作。
通常, InnoDB数据存储和压缩中 描述的内部优化 确保系统可以很好地运行压缩数据。 但是,由于压缩效率取决于数据的性质,因此您可以做出影响压缩表性能的决策:
使用本节中的指南来帮助进行这些体系结构和配置选择。 当您准备进行长期测试并将压缩表投入生产时,请参见 第15.9.1.4节“在运行时监控InnoDB表压缩” ,以了解在实际条件下验证这些选择的有效性的方法。
何时使用压缩
通常,压缩最适用于包含合理数量的字符串列的表,并且读取数据的频率远远高于写入数据。 由于无法保证预测压缩是否有益于特定情况,因此请始终使用 在代表性配置上运行 的特定 工作负载 和数据集进行 测试 。 在决定要压缩的表时,请考虑以下因素。
数据特征和压缩
减小数据文件大小的压缩效率的关键决定因素是数据本身的性质。
回想一下,压缩的工作原理是识别数据块中重复的字节串。
完全随机化的数据是最糟糕的情况。
典型数据通常具有重复值,因此有效压缩。
字符串经常压缩得很好,在是否定义
CHAR
,
VARCHAR
,
TEXT
或
BLOB
列。
另一方面,主要包含二进制数据(整数或浮点数)的表或先前压缩的数据(例如
JPEG
或
PNG
图像)通常不能很好地压缩,或者根本不压缩。
您可以选择是否为每个InnoDB表打开压缩。 表及其所有索引使用相同(压缩)的 页面大小 。 可能是 主键 (clustered)索引(包含表的所有列的数据)比二级索引更有效地压缩。 对于存在长行的情况,使用压缩可能会导致长列值 “ 离页 ” 存储 ,如 DYNAMIC行格式中所述 。 那些溢出页面可以很好地压缩。 考虑到这些因素,对于许多应用程序,某些表比其他表更有效地压缩,并且您可能会发现只有压缩的表子集才能使您的工作负载表现最佳。
要确定是否压缩特定表格,请进行实验。
通过
在未压缩表
gzip
的
.ibd文件
副本上
使用实现LZ77压缩(例如
或WinZip)
的实用程序,可以粗略估计数据的压缩效率
。
从基于文件的压缩工具开始,您可以从MySQL压缩表中获得较少的压缩,因为MySQL会根据
页面大小
压缩数据块
,默认为16KB。
除用户数据外,页面格式还包括一些未压缩的内部系统数据。
基于文件的压缩实用程序可以检查更大的数据块,因此可能会在庞大的文件中找到比MySQL在单个页面中找到的更多重复的字符串。
在特定表上测试压缩的另一种方法是将一些数据从未压缩的表复制到
每个表
的
文件表
空间中
的类似压缩表(具有所有相同的索引),
并查看生成的
.ibd
文件
的大小
。
例如:
使用测试; SET GLOBAL innodb_file_per_table = 1; SET GLOBAL autocommit = 0; - 创建一个包含一百或两行的未压缩表。 CREATE TABLE big_table AS SELECT * FROM information_schema.columns; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; INSERT INTO big_table SELECT * FROM big_table; 承诺; ALTER TABLE big_table ADD id int unsigned NOT NULL PRIMARY KEY auto_increment; SHOW CREATE TABLE big_table \ G. 从big_table中选择count(id); - 检查未压缩表需要多少空间。 \!ls -l data / test / big_table.ibd CREATE TABLE key_block_size_4 LIKE big_table; ALTER TABLE key_block_size_4 key_block_size = 4 row_format = compressed; INSERT INTO key_block_size_4 SELECT * FROM big_table; 承诺; - 检查压缩表需要多少空间 - 使用特定的压缩设置。 \!ls -l data / test / key_block_size_4.ibd
这个实验产生了以下数字,当然根据您的表结构和数据可能会有很大差异:
-rw-rw ---- 1卷云员工310378496 1月9日13:44 data / test / big_table.ibd -rw-rw ---- 1卷云员工83886080 1月9日15:10 data / test / key_block_size_4.ibd
要查看压缩是否对您的特定 工作负载有效 :
-
对于简单测试,使用没有其他压缩表的MySQL实例并对
INFORMATION_SCHEMA.INNODB_CMP表 运行查询 。 -
对于涉及具有多个压缩表的工作负载的更复杂的测试,请针对该
INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表 运行查询 。 由于INNODB_CMP_PER_INDEX表中 的统计信息 收集起来很昂贵,因此必须innodb_cmp_per_index_enabled在查询该表之前 启用配置选项 ,并且可能会将此类测试限制为开发服务器或非关键 从服务器 。 -
针对您正在测试的压缩表运行一些典型的SQL语句。
-
通过查询
INFORMATION_SCHEMA.INNODB_CMP或INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表,并与之比较COMPRESS_OPS, 检查成功压缩操作与整体压缩操作的比率COMPRESS_OPS_OK。 -
如果高比例的压缩操作成功完成,则该表可能是压缩的良好候选者。
-
如果你得到的高比例 压缩故障 ,您可以调整
innodb_compression_level,innodb_compression_failure_threshold_pct和innodb_compression_pad_pct_max选项中描述 第15.9.1.6,“压缩为OLTP工作负载” ,并尝试进一步的测试。
数据库压缩与应用程序压缩
决定是否压缩应用程序或表格中的数据; 不要对同一数据使用这两种类型的压缩。 压缩应用程序中的数据并将结果存储在压缩表中时,额外节省的空间极不可能,而双重压缩只会浪费CPU周期。
压缩数据库
启用后,MySQL表压缩是自动的,适用于所有列和索引值。
仍然可以使用运算符来测试列
LIKE
,并且即使压缩索引值,排序操作仍然可以使用索引。
由于索引通常是数据库总大小的重要部分,因此压缩可以显着节省存储,I / O或处理器时间。
压缩和解压缩操作发生在数据库服务器上,这可能是一个功能强大的系统,其大小可以处理预期的负载。
在应用程序中压缩
如果在将数据插入数据库之前压缩应用程序中的文本等数据,则可以通过压缩某些列而不是其他列来节省不能很好压缩的数据的开销。 此方法在客户端计算机而不是数据库服务器上使用CPU周期进行压缩和解压缩,这可能适用于具有许多客户端的分布式应用程序,或者客户端计算机具有备用CPU周期的情况。
混合方法
当然,可以组合这些方法。 对于某些应用程序,可能适合使用某些压缩表和一些未压缩表。 最好从外部压缩一些数据(并将其存储在未压缩的表中),并允许MySQL压缩(某些)应用程序中的其他表。 与往常一样,前期设计和现实测试对于做出正确决策很有价值。
工作量特征和压缩
除了选择要压缩的表(以及页面大小)之外,工作负载是性能的另一个关键决定因素。
如果应用程序由读取而不是更新控制,则在索引页面用尽
MySQL为压缩数据维护
的每页
“
修改日志
”
的空间之后,需要重新组织和重新压缩更少的页面
。
如果更新主要更改非索引列或包含
BLOB
恰好存储在
“
页外
”的
s或大字符串的
列
,则压缩的开销可能是可接受的。
如果对表的唯一更改是
INSERT
如果使用单调递增的主键,并且辅助索引很少,则几乎不需要重新组织和重新压缩索引页。
由于MySQL可以
通过修改未压缩数据
来
“
删除标记
”
并在
“
就地
”
删除压缩页面上的行
,因此
DELETE
对表的操作相对有效。
对于某些环境,加载数据所需的时间与运行时检索一样重要。 特别是在数据仓库环境中,许多表可能是只读的或大多数是读取的。 在这些情况下,在增加加载时间方面支付压缩价格可能会或可能不会被接受,除非由此节省的磁盘读取次数或存储成本显着降低。
从根本上说,当CPU时间可用于压缩和解压缩数据时,压缩效果最佳。 因此,如果您的工作负载受I / O限制而非CPU限制,您可能会发现压缩可以提高整体性能。 使用不同的压缩配置测试应用程序性能时,请在类似于生产系统的计划配置的平台上进行测试。
配置特性和压缩
从磁盘 读取和写入数据库 页面 是系统性能最慢的方面。 压缩尝试通过使用CPU时间来压缩和解压缩数据来减少I / O,并且当I / O与处理器周期相比是相对稀缺的资源时最有效。
在具有快速多核CPU的多用户环境中运行时尤其如此。 当压缩表的页面在内存中时,MySQL通常在 缓冲池中 使用额外的内存(通常为16KB) 来获取页面的未压缩副本。 自适应LRU算法尝试平衡压缩页面和未压缩页面之间的内存使用,以考虑工作负载是以I / O绑定还是CPU绑定方式运行。 尽管如此,使用压缩表时,具有更多专用于缓冲池的内存的配置往往比内存受到高度约束的配置更好。
选择压缩页面大小
压缩页面大小的最佳设置取决于表及其索引包含的数据的类型和分布。 压缩页面大小应始终大于最大记录大小,否则操作可能会失败,如 压缩B树页面中所述 。
将压缩页面大小设置得太大会浪费一些空间,但页面不必经常压缩。 如果压缩页面大小设置得太小,则插入或更新可能需要耗时的重新压缩,并且 可能必须更频繁地拆分 B树 节点,从而导致更大的数据文件和更低效的索引。
通常,您将压缩页面大小设置为8K或4K字节。
鉴于InnoDB表的最大行大小约为8K,
KEY_BLOCK_SIZE=8
通常是一个安全的选择。
总体应用程序性能,CPU和I / O利用率以及磁盘文件的大小是压缩对应用程序有效性的良好指标。 本节以 第15.9.1.3节“调整InnoDB表的压缩”中的 性能调优建议为基础 ,并展示了如何查找在初始测试期间可能未出现的问题。
要深入了解压缩表的性能注意事项,可以使用 例15.1“使用压缩信息架构表”中 所述 的 信息架构 表 在运行时监视压缩性能 。 这些表反映了内存的内部使用和整体使用的压缩率。
该
INNODB_CMP
表报告有关
KEY_BLOCK_SIZE
正在使用的
每个压缩页面大小(
)的
压缩活动的信息
。
这些表中的信息是系统范围的:它汇总了数据库中所有压缩表的压缩统计信息。
当没有其他压缩表被访问时,您可以通过检查这些表来使用此数据来帮助决定是否压缩表。
它涉及服务器上相对较低的开销,因此您可以在生产服务器上定期查询它以检查压缩功能的整体效率。
该
INNODB_CMP_PER_INDEX
表报告有关各个表和索引的压缩活动的信息。
此信息更有针对性,对于评估压缩效率和一次诊断一个表或索引的性能问题更有用。
(因为每个
InnoDB
表都表示为聚簇索引,MySQL在此上下文中并没有对表和索引进行大的区分。)该
INNODB_CMP_PER_INDEX
表确实涉及大量开销,因此它更适合开发服务器,您可以在其中比较效果不同的
工作量
,数据和压缩设置是孤立的。
为防止意外强制执行此监视开销,必须先启用
innodb_cmp_per_index_enabled
配置选项,然后才能查询该
INNODB_CMP_PER_INDEX
表。
要考虑的关键统计数据是执行压缩和解压缩操作所花费的时间和数量。
由于MySQL在
B-tree
节点太满而无法在修改后包含压缩数据时
将其拆分
,因此将
“
成功
”
压缩操作的数量与总体上此类操作的数量进行比较。
基于信息
INNODB_CMP
和
INNODB_CMP_PER_INDEX
表和整体应用程序性能和硬件资源利用率,您可以更改硬件配置,调整缓冲池的大小,选择不同的页面大小,或选择要压缩的不同表集。
如果压缩和解压缩所需的CPU时间很长,则更改为更快或多核的CPU可以帮助提高相同数据,应用程序工作负载和压缩表集的性能。 增加缓冲池的大小也可能有助于提高性能,因此更多未压缩的页面可以保留在内存中,从而减少了仅以压缩形式解压缩存在于内存中的页面的需要。
大量的整体压缩操作(与数量
INSERT
,
UPDATE
并
DELETE
在您的应用程序操作和数据库的大小)可能表明你的一些压缩的表都被更新过重的有效压缩。
如果是这样,请选择较大的页面大小,或者更加选择性地压缩哪些表格。
如果
“
成功
”
压缩操作(
COMPRESS_OPS_OK
)的数量占压缩操作总数
(
)的百分比很高
COMPRESS_OPS
,则系统可能表现良好。
如果比率很低,那么MySQL会更频繁地重新组织,重新压缩和拆分B树节点。
在这种情况下,请避免压缩某些表,或者增加
KEY_BLOCK_SIZE
某些压缩表。
您可能会关闭导致
“
压缩失败
”
次数的表的
压缩
在您的申请中,超过总数的1%或2%。
(在诸如数据加载的临时操作期间,这样的故障率可能是可接受的)。
本节介绍有关 InnoDB表 压缩的 一些内部实现细节 。 此处提供的信息可能有助于调整性能,但不必了解压缩的基本用法。
压缩算法
某些操作系统在文件系统级别实施压缩。 文件通常被分成固定大小的块,这些块被压缩成可变大小的块,这很容易导致碎片化。 每次修改块内的某些内容时,整个块在写入磁盘之前会被重新压缩。 这些属性使得此压缩技术不适合在更新密集型数据库系统中使用。
MySQL在众所周知的 zlib库 的帮助下实现压缩,该 库 实现了LZ77压缩算法。 这种压缩算法在CPU利用率和数据大小的减少方面都是成熟,健壮且高效的。 该算法是 “ 无损 ”的 ,因此可以始终从压缩形式重建原始未压缩数据。 LZ77压缩的工作原理是查找在要压缩的数据中重复的数据序列。 数据中的值模式决定了它的压缩程度,但典型的用户数据通常会压缩50%或更多。
InnoDB
支持
zlib
最高版本1.2.11
的
库,这是与MySQL 8.0捆绑在一起的版本。
与应用程序执行的压缩或某些其他数据库管理系统的压缩功能不同,InnoDB压缩既适用于用户数据,也适用于索引。
在许多情况下,索引可占数据库总大小的40-50%或更多,因此这种差异很大。
当压缩对数据集运行良好时,InnoDB数据文件(
每个表的表
空间或
一般表空间
.ibd
文件)的大小是未压缩大小的25%到50%,或者可能更小。
取决于
工作量
这个较小的数据库可以反过来导致I / O的减少和吞吐量的增加,从而在提高CPU利用率方面成本适中。
您可以通过修改
innodb_compression_level
配置选项
来调整压缩级别和CPU开销之间的平衡
。
InnoDB数据存储和压缩
InnoDB表中的所有用户数据都存储在包含 B树 索引( 聚集索引 )的页面中。 在一些其他数据库系统中,这种类型的索引称为 “ 索引组织表 ” 。 索引节点中的每一行都包含(用户指定的或系统生成的) 主键 和表的所有其他列的值。
InnoDB表中的 二级索引 也是B树,包含多对值:索引键和指向聚簇索引中行的指针。 指针实际上是表的主键的值,如果需要除索引键和主键之外的列,则用于访问聚簇索引。 辅助索引记录必须始终适合单个B树页面。
B-树节点的压缩(的集群和二级索引)是从压缩处理方式不同
溢出页
用于存储长
VARCHAR
,
BLOB
或
TEXT
列,如在以下部分中说明。
B树页面的压缩
由于它们经常更新,因此B树页面需要特殊处理。 重要的是最小化B树节点被分割的次数,以及最小化解压缩和重新压缩其内容的需要。
MySQL使用的一种技术是以未压缩的形式在B树节点中维护一些系统信息,从而促进某些就地更新。 例如,这允许在没有任何压缩操作的情况下删除标记和删除行。
此外,MySQL会在更改索引页时尝试避免不必要的压缩和重新压缩。 在每个B树页面中,系统保留未压缩的 “ 修改日志 ” 以记录对页面所做的更改。 可以将小记录的更新和插入写入该修改日志,而不需要完整地重建整个页面。
当修改日志的空间用完时,InnoDB将解压缩页面,应用更改并重新压缩页面。 如果再压缩失败(称为一个的情况 压缩破坏 ),B-树节点被分割,并重复该过程,直到更新或插入成功。
为了避免写入密集型工作负载中的频繁压缩失败,例如对于
OLTP
应用程序,MySQL有时会在页面中保留一些空白空间(填充),以便修改日志尽快填满并且页面被重新压缩,同时仍有足够的空间来避免分裂。
每个页面中留下的填充空间量随着系统跟踪页面拆分的频率而变化。
在频繁写入压缩表的繁忙服务器上,您可以调整
innodb_compression_failure_threshold_pct
和
innodb_compression_pad_pct_max
配置选项以微调此机制。
通常,MySQL要求InnoDB表中的每个B树页面都可以容纳至少两个记录。
对于压缩表,这个要求已经放宽。
B树节点的叶页(无论是主键还是辅助索引)只需要容纳一条记录,但该记录必须以未压缩的形式适合每页修改日志。
如果
innodb_strict_mode
是
ON
,MySQL在
CREATE
TABLE
或
期间检查最大行大小
CREATE
INDEX
。
如果行不适合,则会发出以下错误消息:
ERROR
HY000: Too big row
。
如果在
innodb_strict_mode
OFF
时创建表
,并且后续
INSERT
或
UPDATE
语句尝试创建不符合压缩页大小的索引条目,则操作将失败
ERROR 42000: Row size too
large
。
(此错误消息未指定记录过大的索引,或提及索引记录的长度或该特定索引页上的最大记录大小。)要解决此问题,请使用
ALTER
TABLE
并
重新
选择更大
的表
压缩页面大小(
KEY_BLOCK_SIZE
),缩短任何列前缀索引,或使用
ROW_FORMAT=DYNAMIC
或
完全禁用压缩
ROW_FORMAT=COMPACT
。
innodb_strict_mode
不适用于通用表空间,它也支持压缩表。
一般表空间的表空间管理规则严格执行
innodb_strict_mode
。
有关更多信息,请参见
第13.1.21节“CREATE TABLESPACE语法”
。
压缩BLOB,VARCHAR和TEXT列
在一个InnoDB表,
BLOB
,
VARCHAR
,和
TEXT
列不属于主键的一部分可以被存储在单独分配
溢出页
。
我们将这些列称为
页外列
。
它们的值存储在单个链接的溢出页列表中。
在创建的表
ROW_FORMAT=DYNAMIC
或
ROW_FORMAT=COMPRESSED
,的值
BLOB
,
TEXT
或
VARCHAR
列可以取决于它们的长度和整个行的长度存储完全关闭页。
对于存储在页外的列,聚簇索引记录仅包含指向溢出页的20字节指针,每列一个。
是否在页外存储任何列取决于页面大小和行的总大小。
当行太长而无法完全适合聚簇索引的页面时,MySQL会选择最长的列进行页外存储,直到该行适合聚簇索引页。
如上所述,如果某行在压缩页面上不适合,则会发生错误。
表使用
ROW_FORMAT=REDUNDANT
和
ROW_FORMAT=COMPACT
存储第一个768个字节
BLOB
,
VARCHAR
和
TEXT
列与主键一起聚集索引记录。
768字节前缀后跟一个20字节指针,指向包含列值其余部分的溢出页面。
当表格
COMPRESSED
格式化时,写入溢出页面的所有数据都
“
按原样
”
压缩
;
也就是说,MySQL将zlib压缩算法应用于整个数据项。
除了数据之外,压缩的溢出页面包含未压缩的头部和尾部,其包括页面校验和以及到下一个溢出页面的链接等。
因此,能够更长时间来获得非常显著存储节省
BLOB
,
TEXT
或
VARCHAR
列如果数据是高度可压缩,这是常有的文本数据的情况。
图像数据,如
JPEG
,通常已经被压缩,因此不会因存储在压缩表中而受益很多;
双重压缩可以浪费CPU周期,节省很少或没有空间。
溢出页面与其他页面的大小相同。 包含存储在页外的十列的行占用十个溢出页,即使列的总长度仅为8K字节。 在未压缩的表中,十个未压缩的溢出页占用160K字节。 在页面大小为8K的压缩表中,它们只占用80K字节。 因此,对具有长列值的表使用压缩表格式通常更有效。
对于
文件的每个表
的表空间,采用16K压缩页面大小可以降低存储和I / O开销
BLOB
,
VARCHAR
或
TEXT
列,因为这些数据往往压缩得很好,因此可能需要更少的溢出页,即使在B树节点它们自己占用与未压缩形式一样多的页面。
常规表空间不支持16K压缩页面大小(
KEY_BLOCK_SIZE
)。
有关更多信息,请参阅
第15.6.3.3节“常规表空间”
。
压缩和InnoDB缓冲池
在压缩
InnoDB
表中,每个压缩页面(无论是1K,2K,4K还是8K)都对应于16K字节的未压缩页面(如果
innodb_page_size
设置
了较小的页面
)。
要访问页面中的数据,MySQL会从磁盘读取压缩页面(如果它不在
缓冲池中)
,然后将页面解压缩到其原始格式。
本节介绍如何
InnoDB
管理缓冲池相对于压缩表的页面。
为了最小化I / O并减少解压缩页面的需要,缓冲池有时包含数据库页面的压缩和未压缩形式。 为了为其他所需的数据库页面腾出空间,MySQL可以 从缓冲池中 逐出 一个未压缩的页面,同时将压缩的页面留在内存中。 或者,如果一段时间内未访问某个页面,则可能会将该页面的压缩形式写入磁盘,以释放其他数据的空间。 因此,在任何给定时间,缓冲池可能包含页面的压缩和未压缩形式,或者只包含页面的压缩形式,或者两者都不包含。
MySQL会跟踪要保留在内存中的页面以及使用最近 最少 使用( LRU )列表 逐出的页面 ,以便 热 (经常访问)的数据趋于保留在内存中。 当访问压缩表时,MySQL使用自适应LRU算法来实现内存中压缩和未压缩页面的适当平衡。 此自适应算法对系统是在 I / O绑定 还是 CPU绑定中 敏感 方式。 目标是避免在CPU繁忙时花费太多处理时间解压缩页面,并避免在CPU具有可用于解压缩压缩页面(可能已经在内存中)的备用周期时进行过多的I / O. 当系统受I / O限制时,该算法倾向于逐出页面的未压缩副本而不是两个副本,以便为其他磁盘页面腾出更多空间来成为驻留内存。 当系统受CPU限制时,MySQL更愿意驱逐压缩页面和未压缩页面,这样就可以将更多内存用于 “ 热 ” 页面,并减少仅以压缩形式解压缩内存中数据的需要。
压缩和InnoDB重做日志文件
在将压缩页面写入
数据文件之前
,MySQL会将该页面的副本写入重做日志(如果它自上次写入数据库以来已被重新压缩)。
这样做是为了确保重做日志可用于
崩溃恢复
,即使在
zlib
升级库并且该更改引入压缩数据的兼容性问题的
情况下
也是如此。
因此,
日志文件
的大小会有所增加
,或者需要更频繁的
检查点
,使用压缩时可以预期。
日志文件大小或检查点频率的增加量取决于以需要重组和重新压缩的方式修改压缩页面的次数。
要在每个表的文件表空间中创建压缩表,
innodb_file_per_table
必须启用。
innodb_file_per_table
在通用表空间中创建压缩表时,
不依赖于该
设置。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
传统上,
建议
InnoDB
压缩
功能主要用于只读或大多数读取
工作负载
,例如
数据仓库
配置。
SSD
存储设备的快速
增长
但相对较小且价格昂贵,这使得压缩对
OLTP
工作负载
也具有吸引力
:高流量,交互式网站可以
通过使用压缩表
来降低其存储要求和每秒I / O操作数(
IOPS
)那些频繁的应用程序
INSERT
,
UPDATE
和
DELETE
操作。
通过这些配置选项,您可以调整压缩对特定MySQL实例的工作方式,并强调写入密集型操作的性能和可伸缩性:
-
innodb_compression_level让你上下压缩压缩程度。 较高的值允许您将更多数据放入存储设备,但代价是压缩期间的CPU开销更大。 较低的值可以在存储空间不重要时降低CPU开销,或者您希望数据不是特别可压缩的。 -
innodb_compression_failure_threshold_pct指定 更新压缩表期间 压缩失败 的截止点 。 当此阈值通过时,MySQL开始在每个新的压缩页面中留出额外的可用空间,动态调整可用空间量,直至指定的页面大小百分比。innodb_compression_pad_pct_max -
innodb_compression_pad_pct_max允许您调整每个 页面中 保留的最大空间量, 以记录对压缩行的更改,而无需再次压缩整个页面。 值越高,可以记录的更改越多而不重新压缩页面。 MySQL为每个压缩表中的页面使用可变数量的可用空间,仅当指定百分比的压缩操作 在运行时 “ 失败 ” 时,才需要昂贵的操作来拆分压缩页面。 -
innodb_log_compressed_pages您可以禁用的写入图像 再压缩 页面 到 重做日志 。 当对压缩数据进行更改时,可能会发生重新压缩。 默认情况下启用此选项可防止zlib在恢复期间使用 不同版本的 压缩算法时 可能发生的损坏 。 如果您确定zlib版本不会更改,请禁用innodb_log_compressed_pages以减少修改压缩数据的工作负载的重做日志生成。
因为使用压缩数据有时需要同时在内存中保留页面的压缩和未压缩版本,所以在使用OLTP样式工作负载进行压缩时,请准备增加
innodb_buffer_pool_size
配置选项
的值
。
本节介绍在将表压缩功能与 每表文件表 空间和 常规表空间 一起使用时可能遇到的语法警告和错误 。
每个表文件表空间的SQL压缩语法警告和错误
如果
innodb_strict_mode
启用(默认值),则指定
ROW_FORMAT=COMPRESSED
或
KEY_BLOCK_SIZE
in
CREATE
TABLE
或或
ALTER
TABLE
语句会产生以下错误:
innodb_file_per_table
被禁止。
ERROR 1031(HY000):'t1'的表存储引擎没有此选项
如果当前配置不允许使用压缩表,则不会创建该表。
如果
innodb_strict_mode
禁用,则指定
ROW_FORMAT=COMPRESSED
或
KEY_BLOCK_SIZE
in
CREATE
TABLE
或或
ALTER
TABLE
语句会产生以下警告:
innodb_file_per_table
。
MySQL的> SHOW WARNINGS;
+ --------- + ------ + -------------------------------- ------------------------------- +
| 等级| 代码| 消息|
+ --------- + ------ + -------------------------------- ------------------------------- +
| 警告| 1478 | InnoDB:KEY_BLOCK_SIZE需要innodb_file_per_table。|
| 警告| 1478 | InnoDB:忽略KEY_BLOCK_SIZE = 4。|
| 警告| 1478 | InnoDB:ROW_FORMAT = COMPRESSED需要innodb_file_per_table。|
| 警告| 1478 | InnoDB:假设ROW_FORMAT = DYNAMIC。|
+ --------- + ------ + -------------------------------- ------------------------------- +
这些消息只是警告,而不是错误,并且表是在没有压缩的情况下创建的,就像未指定选项一样。
在
“
非严格的
”
行为可让您导入
mysqldump
文件到不支持压缩表,即使源数据库包含压缩表的数据库。
在这种情况下,MySQL会创建表
ROW_FORMAT=DYNAMIC
而不是阻止操作。
要将转储文件导入新数据库,并在原始数据库中重新创建表,请确保服务器具有正确的
innodb_file_per_table
配置参数
设置
。
KEY_BLOCK_SIZE
仅当
ROW_FORMAT
指定为
COMPRESSED
或被省略
时才允许
该属性
。
KEY_BLOCK_SIZE
使用任何其他
指定a会
ROW_FORMAT
生成可以查看的警告
SHOW WARNINGS
。
但是,该表是非压缩的;
指定
KEY_BLOCK_SIZE
被忽略)。
| 水平 | 码 | 信息 |
|---|---|---|
| 警告 | 1478 | InnoDB: ignoring KEY_BLOCK_SIZE= |
如果您在
innodb_strict_mode
启用时
运行
,则a
KEY_BLOCK_SIZE
与
ROW_FORMAT
其他
任何
组合的组合会
COMPRESSED
生成错误,而不是警告,并且不会创建表。
表15.13“ROW_FORMAT和KEY_BLOCK_SIZE选项”
提供了
与
或
一起使用
的概述
ROW_FORMAT
和
KEY_BLOCK_SIZE
选项
。
CREATE
TABLE
ALTER TABLE
表15.13 ROW_FORMAT和KEY_BLOCK_SIZE选项
| 选项 | 使用说明 | 描述 |
|---|---|---|
ROW_FORMAT=REDUNDANT |
MySQL 5.0.3之前使用的存储格式 |
效率低于
ROW_FORMAT=COMPACT
;
为了向后兼容
|
ROW_FORMAT=COMPACT |
MySQL 5.0.3以来的默认存储格式 | 在聚簇索引页中存储768字节长列值的前缀,其余字节存储在溢出页中 |
ROW_FORMAT=DYNAMIC |
如果值适合,则将值存储在聚集索引页中; 如果没有,只存储一个20字节指针到溢出页面(没有前缀) | |
ROW_FORMAT=COMPRESSED |
使用zlib压缩表和索引 | |
KEY_BLOCK_SIZE= |
指定压缩页面大小为1,2,4,8或16千字节;
暗示
ROW_FORMAT=COMPRESSED
。
对于常规表空间,
不允许使用
KEY_BLOCK_SIZE
等于
InnoDB
页面大小
的
值
。
|
表15.14“InnoDB严格模式关闭时创建/更改表警告和错误”
总结了
CREATE
TABLE
or
ALTER
TABLE
语句中
某些配置参数和选项组合出现的错误情况,以及选项在
输出中的显示方式
SHOW TABLE
STATUS
。
当
innodb_strict_mode
是
OFF
时,MySQL创建或改变该表中,但如下所示忽略某些设置。
您可以在MySQL错误日志中看到警告消息。
如果
innodb_strict_mode
是
ON
,这些指定的选项组合会生成错误,并且不会创建或更改表。
要查看错误条件的完整描述,请发出以下
SHOW ERRORS
语句:example:
mysql>CREATE TABLE x (id INT PRIMARY KEY, c INT)- >ENGINE=INNODB KEY_BLOCK_SIZE=33333;ERROR 1005(HY000):无法创建表'test.x'(错误号:1478) MySQL的>SHOW ERRORS;+ ------- + ------ + ---------------------------------- --------- + | 等级| 代码| 消息| + ------- + ------ + ---------------------------------- --------- + | 错误| 1478 | InnoDB:无效KEY_BLOCK_SIZE = 33333。| | 错误| 1005 | 无法创建表'test.x'(错误号:1478)| + ------- + ------ + ---------------------------------- --------- +
表15.14 InnoDB严格模式为OFF时的CREATE / ALTER TABLE警告和错误
| 句法 | 警告或错误情况 |
结果
ROW_FORMAT
,如图所示
SHOW TABLE
STATUS
|
|---|---|---|
ROW_FORMAT=REDUNDANT |
没有 | REDUNDANT |
ROW_FORMAT=COMPACT |
没有 | COMPACT |
ROW_FORMAT=COMPRESSED
或者
ROW_FORMAT=DYNAMIC
或
KEY_BLOCK_SIZE
指定
|
除非
innodb_file_per_table
已启用,
否则
将
忽略每个表的文件表空间
。
常规表空间支持所有行格式。
请参见
第15.6.3.3节“通用表空间”
。
|
the default row format for file-per-table tablespaces; the
specified row format for general tablespaces |
KEY_BLOCK_SIZE
指定
无效
(不是1,2,4,8或16)
|
KEY_BLOCK_SIZE
被忽略了
|
指定的行格式或默认行格式 |
ROW_FORMAT=COMPRESSED
并
KEY_BLOCK_SIZE
指定
有效
|
没有;
KEY_BLOCK_SIZE
指定使用
|
COMPRESSED |
KEY_BLOCK_SIZE
与指定的
REDUNDANT
,
COMPACT
或
DYNAMIC
行格式
|
KEY_BLOCK_SIZE
被忽略了
|
REDUNDANT
,
COMPACT
或
DYNAMIC
|
ROW_FORMAT
是没有一个
REDUNDANT
,
COMPACT
,
DYNAMIC
或
COMPRESSED
|
如果被MySQL解析器识别,则忽略。 否则,将发出错误。 | 默认行格式或N / A. |
当
innodb_strict_mode
是
ON
时,MySQL拒绝无效
ROW_FORMAT
或
KEY_BLOCK_SIZE
参数问题的错误。
ON
默认情况
下为严格模式
。
当
innodb_strict_mode
是
OFF
时,MySQL发出警告,而不是被忽略的参数无效的错误。
无法看到所选择的
KEY_BLOCK_SIZE
使用
SHOW TABLE
STATUS
。
该语句
SHOW CREATE
TABLE
显示
KEY_BLOCK_SIZE
(即使在创建表时忽略它)。
MySQL无法显示表的实际压缩页面大小。
一般表空间的SQL压缩语法警告和错误
-
如果
FILE_BLOCK_SIZE在创建表空间时未为通用表空间定义,则表空间不能包含压缩表。 如果尝试添加压缩表,则会返回错误,如以下示例所示:MySQL的>
CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;MySQL的>CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8;错误1478(HY000):InnoDB:表空间`ts1`不能包含COMPRESSED表 -
尝试将具有无效的表添加
KEY_BLOCK_SIZE到常规表空间会返回错误,如以下示例所示:MySQL的>
CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的>CREATE TABLE t2 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=4;错误1478(HY000):InnoDB:表空间`ts2`使用块大小8192而不能 包含物理页面大小为4096的表对于常规表空间,
KEY_BLOCK_SIZE表的大小必须等于FILE_BLOCK_SIZE表空间除以1024.例如,如果FILE_BLOCK_SIZE表空间的大小为8192,KEY_BLOCK_SIZE则表的大小必须为8。 -
尝试将具有未压缩行格式的表添加到配置为存储压缩表的常规表空间会返回错误,如以下示例所示:
MySQL的>
CREATE TABLESPACE `ts3` ADD DATAFILE 'ts3.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的>CREATE TABLE t3 (c1 INT PRIMARY KEY) TABLESPACE ts3 ROW_FORMAT=COMPACT;ERROR 1478(HY000):InnoDB:表空间`ts3`使用块大小8192而不能 包含物理页面大小为16384的表
innodb_strict_mode
不适用于一般表空间。
一般表空间的表空间管理规则严格执行
innodb_strict_mode
。
有关更多信息,请参见
第13.1.21节“CREATE TABLESPACE语法”
。
有关将压缩表与通用表空间一起使用的更多信息,请参见 第15.6.3.3节“常规表空间” 。
InnoDB
支持驻留在
每个表文件表
空间中的表的
页级压缩
。
此功能称为
透明页面压缩
。
通过
COMPRESSION
使用
CREATE
TABLE
或
指定
属性
来启用页面压缩
ALTER
TABLE
。
支持的压缩算法包括
Zlib
和
LZ4
。
支持的平台
页面压缩需要稀疏文件和打孔支持。 使用NTFS的Windows支持页面压缩,并且在MySQL支持的Linux平台的以下子集上,内核级别提供打孔支持:
-
RHEL 7和使用内核版本3.10.0-123或更高版本的派生发行版
-
OEL 5.10(UEK2)内核版本2.6.39或更高版本
-
OEL 6.5(UEK3)内核版本3.8.13或更高版本
-
OEL 7.0内核版本3.8.13或更高版本
-
SLE11内核版本3.0-x
-
SLE12内核版本3.12-x
-
OES11内核版本3.0-x
-
Ubuntu 14.0.4 LTS内核版本3.13或更高版本
-
Ubuntu 12.0.4 LTS内核版本3.2或更高版本
-
Debian 7内核版本3.2或更高版本
给定Linux发行版的所有可用文件系统可能都不支持打孔。
页面压缩如何工作
写入页面时,使用指定的压缩算法对其进行压缩。 压缩数据被写入磁盘,其中打孔机构从页面末尾释放空块。 如果压缩失败,则按原样写出数据。
Linux上的打孔大小
在Linux系统上,文件系统块大小是用于打孔的单位大小。
因此,页面压缩仅在页面数据可以压缩到小于或等于
InnoDB
页面大小减去文件系统块大小的大小
时才有效
。
例如,如果
innodb_page_size=16K
文件系统块大小为4K,则页面数据必须压缩到小于或等于12K才能进行打孔。
Windows上的打孔尺寸
在Windows系统上,稀疏文件的底层基础结构基于NTFS压缩。 打孔大小是NTFS压缩单元,是NTFS簇大小的16倍。 群集大小及其压缩单位如下表所示:
仅当页面数据可以压缩到小于或等于
InnoDB
页面大小减去压缩单元大小
的大小时,Windows系统上的页面压缩才有效
。
默认的NTFS簇大小为4KB,压缩单元大小为64KB。
这意味着页面压缩对于开箱即用的Windows NTFS配置没有任何好处,因为最大值
innodb_page_size
也是64KB。
要使页面压缩在Windows上运行,必须使用小于4K的簇大小创建文件系统,并且该文件系统必须
innodb_page_size
至少是压缩单元大小的两倍。
例如,要使页面压缩在Windows上运行,您可以构建文件系统,其簇大小为512字节(压缩单位为8KB),并
InnoDB
使用
innodb_page_size
16K或更大
的
值进行
初始化
。
启用页面压缩
要启用页面压缩,请
COMPRESSION
在
CREATE
TABLE
语句中
指定
属性
。
例如:
CREATE TABLE t1(c1 INT)COMPRESSION =“zlib”;
您还可以在
ALTER
TABLE
语句中
启用页面压缩
。
但是,
ALTER
TABLE ...
COMPRESSION
仅更新表空间压缩属性。
写入设置新压缩算法后出现的表空间使用新设置,但要将新压缩算法应用于现有页面,必须使用重建表
OPTIMIZE TABLE
。
ALTER TABLE t1 COMPRESSION =“zlib”; 优化表t1;
禁用页面压缩
要禁用页面压缩,请
COMPRESSION=None
使用
ALTER
TABLE
。
写入
COMPRESSION=None
不再使用页面压缩
后发生的表空间
。
要解压缩现有页面,必须使用
OPTIMIZE TABLE
设置后
重建表格
COMPRESSION=None
。
ALTER TABLE t1 COMPRESSION =“None”; 优化表t1;
页面压缩元数据
页面压缩元数据位于
INFORMATION_SCHEMA.INNODB_TABLESPACES
表中的以下列中:
-
FS_BLOCK_SIZE:文件系统块大小,用于打孔的单位大小。 -
FILE_SIZE:文件的表观大小,表示文件的最大大小,未压缩。 -
ALLOCATED_SIZE:文件的实际大小,即磁盘上分配的空间量。
在类Unix系统上,
以字节为单位
显示表观文件大小(相当于
)。
要查看磁盘上分配的实际空间量(相当于
),请使用
。
该
选项以字节而不是块打印分配的空间,以便可以将其与
输出
进行比较
。
ls -l
tablespace_name.ibdFILE_SIZE
ALLOCATED_SIZE
du
--block-size=1
tablespace_name.ibd--block-size=1
ls -l
使用
SHOW CREATE TABLE
查看当前页面压缩设置(
Zlib
,
Lz4
,或
None
)。
表格可能包含具有不同压缩设置的混合页面。
在以下示例中,将从表中检索employees表的页面压缩元数据
INFORMATION_SCHEMA.INNODB_TABLESPACES
。
#使用Zlib页面压缩创建employees表
CREATE TABLE员工(
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14)NOT NULL,
last_name VARCHAR(16)NOT NULL,
性别ENUM('M','F')非空,
hire_date DATE NOT NULL,
主键(emp_no)
)COMPRESSION =“zlib”;
#插入数据(未显示)
#在INFORMATION_SCHEMA.INNODB_TABLESPACES中查询页面压缩元数据
MySQL的> SELECT SPACE, NAME, FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE FROM
INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME='employees/employees'\G
*************************** 1。排******************** *******
空间:45
姓名:员工/员工
FS_BLOCK_SIZE:4096
FILE_SIZE:23068672
ALLOCATED_SIZE:19415040
employees表的页面压缩元数据显示表观文件大小为23068672字节,而实际文件大小(页面压缩)为19415040字节。 文件系统块大小为4096字节,这是用于打孔的块大小。
页面压缩限制和使用说明
-
如果文件系统块大小(或Windows上的压缩单元大小)* 2>,则禁用页面压缩
innodb_page_size。 -
驻留在共享表空间中的表不支持页面压缩,这些表包括系统表空间,临时表空间和常规表空间。
-
撤消日志表空间不支持页面压缩。
-
重做日志页面不支持页面压缩。
-
用于空间索引的R树页面不会被压缩。
-
属于压缩表(
ROW_FORMAT=COMPRESSED)的页面保持原样。 -
在恢复期间,更新的页面以未压缩的形式写出。
-
在不支持所使用的压缩算法的服务器上加载页面压缩的表空间会导致I / O错误。
-
在降级到不支持页面压缩的早期版本的MySQL之前,请解压缩使用页面压缩功能的表。 要解压缩表,请运行
ALTER TABLE ... COMPRESSION=None和OPTIMIZE TABLE。 -
如果在两台服务器上都使用所使用的压缩算法,则可以在Linux和Windows服务器之间复制页面压缩的表空间。
-
将页面压缩的表空间文件从一个主机移动到另一个主机时保留页面压缩需要一个保留稀疏文件的实用程序。
-
使用NVMFS的Fusion-io硬件可以在其他平台上实现更好的页面压缩,因为NVMFS旨在利用打孔功能。
-
使用具有大
InnoDB页面大小和相对小的文件系统块大小 的页面压缩特征 可能导致写入放大。 例如,InnoDB具有4KB文件系统块大小的64KB 的最大 页面大小可以改善压缩,但是也可以增加对缓冲池的需求,导致I / O增加和潜在的写入放大。
表的行格式确定其行的物理存储方式,这反过来又会影响查询和DML操作的性能。 随着更多行适合单个磁盘页面,查询和索引查找可以更快地工作,缓冲池中需要的缓存内存更少,并且写出更新值所需的I / O更少。
每个表中的数据分为几页。 组成每个表的页面排列在称为B树索引的树数据结构中。 表数据和二级索引都使用这种类型的结构。 表示整个表的B树索引称为聚簇索引,它是根据主键列组织的。 聚簇索引数据结构的节点包含行中所有列的值。 辅助索引结构的节点包含索引列和主键列的值。
可变长度列是列值存储在B树索引节点中的规则的例外。 太长而不适合B树页面的可变长度列存储在称为溢出页面的单独分配的磁盘页面上。 这些列称为页外列。 页外列的值存储在单个链接的溢出页列表中,每个这样的列具有其自己的一个或多个溢出页面的列表。 根据列长度,可变长度列值的全部或前缀存储在B树中,以避免浪费存储并且必须读取单独的页面。
该
InnoDB
存储引擎支持四名的格式:
REDUNDANT
,
COMPACT
,
DYNAMIC
,和
COMPRESSED
。
表15.16 InnoDB行格式概述
| 行格式 | 紧凑的存储特性 | 增强的可变长度列存储 | 大索引键前缀支持 | 压缩支持 | 支持的表空间类型 |
|---|---|---|---|---|---|
REDUNDANT |
没有 | 没有 | 没有 | 没有 | system,table-per-table,general |
COMPACT |
是 | 没有 | 没有 | 没有 | system,table-per-table,general |
DYNAMIC |
是 | 是 | 是 | 没有 | system,table-per-table,general |
COMPRESSED |
是 | 是 | 是 | 是 | 文件每表,一般 |
以下主题描述行格式存储特征以及如何定义和确定表的行格式。
该
REDUNDANT
格式提供与旧版MySQL的兼容性。
使用
REDUNDANT
行格式的
表将
可变长度列值(
VARCHAR
,
VARBINARY
和,
BLOB
和
TEXT
类型)
的前768个字节存储在
B树节点内的索引记录中,其余部分存储在溢出页面上。
大于或等于768字节的固定长度列被编码为可变长度列,可以在页外存储。
例如,
CHAR(255)
如果字符集的最大字节长度大于3,则列可以超过768字节
utf8mb4
。
如果列的值为768字节或更少,则不使用溢出页,并且可能导致I / O的一些节省,因为该值完全存储在B树节点中。
这适用于相对较短的
BLOB
列值,但可能导致B树节点填充数据而不是键值,从而降低其效率。
具有许多
BLOB
列的表可能导致B树节点变得太满,并且包含的行太少,使得整个索引的效率低于行较短或列值存储在页外的情况。
冗余行格式存储特性
该
REDUNDANT
行格式有如下存储特性:
-
每个索引记录包含一个6字节的标头。 标头用于将连续记录链接在一起,以及用于行级锁定。
-
聚簇索引中的记录包含所有用户定义列的字段。 此外,还有一个6字节的事务ID字段和一个7字节的滚动指针字段。
-
如果没有为表定义主键,则每个聚簇索引记录还包含一个6字节的行ID字段。
-
每个辅助索引记录包含为聚簇索引键定义的所有主键列,这些列不在辅助索引中。
-
记录包含指向记录的每个字段的指针。 如果记录中字段的总长度小于128字节,则指针是一个字节; 否则,两个字节。 指针数组称为记录目录。 指针指向的区域是记录的数据部分。
-
大于或等于768字节的固定长度列被编码为可变长度列,可以在页外存储。 例如,
CHAR(255)如果字符集的最大字节长度大于3,则列可以超过768字节utf8mb4。 -
SQL
NULL值在记录目录中保留一个或两个字节。NULL如果存储在可变长度列中,则 SQL 值将在记录的数据部分中保留零个字节。 对于固定长度的列,列的固定长度保留在记录的数据部分中。 为NULL值 保留固定空间 允许将列从NULL非NULL值 更新 到非 值,而不会导致索引页碎片。
与
COMPACT
行格式相比,行格式减少了大约20%的行存储空间,
REDUNDANT
代价是增加了某些操作的CPU使用。
如果您的工作负载是受缓存命中率和磁盘速度限制的典型工作负载,则
COMPACT
格式可能会更快。
如果工作负载受CPU速度限制,则紧凑格式可能会变慢。
使用
COMPACT
行格式的
表将
可变长度列值(
VARCHAR
,
VARBINARY
和,
BLOB
和
TEXT
类型)
的前768个字节存储在
B树
节点
内的索引记录中
,其余部分存储在溢出页面上。
大于或等于768字节的固定长度列被编码为可变长度列,可以在页外存储。
例如,
CHAR(255)
如果字符集的最大字节长度大于3,则列可以超过768字节
utf8mb4
。
如果列的值为768字节或更少,则不使用溢出页,并且可能导致I / O的一些节省,因为该值完全存储在B树节点中。
这适用于相对较短的
BLOB
列值,但可能导致B树节点填充数据而不是键值,从而降低其效率。
具有许多
BLOB
列的表可能导致B树节点变得太满,并且包含的行太少,使得整个索引的效率低于行较短或列值存储在页外的情况。
紧凑行格式存储特性
该
COMPACT
行格式有如下存储特性:
-
每个索引记录包含一个5字节的头,可以在可变长度头之前。 标头用于将连续记录链接在一起,以及用于行级锁定。
-
记录头的可变长度部分包含用于指示
NULL列 的位向量 。 如果索引中的列数可以NULL是N,则位向量占用 字节。 (例如,如果可以有9到16列的任何位置 ,则位向量使用两个字节。) 不占用此向量中的位以外的空间的 列 。 标题的可变长度部分还包含可变长度列的长度。 每个长度需要一个或两个字节,具体取决于列的最大长度。 如果索引中的所有列都是CEILING(N/8)NULLNULLNOT NULL并且具有固定长度,记录头没有可变长度部分。 -
对于每个非
NULL可变长度字段,记录头包含一个或两个字节的列长度。 如果列的一部分存储在溢出页面的外部,或者最大长度超过255个字节且实际长度超过127个字节,则只需要两个字节。 对于外部存储列,2字节长度表示内部存储部分的长度加上指向外部存储部分的20字节指针。 内部部分为768字节,因此长度为768 + 20。 20字节指针存储列的真实长度。 -
记录头后面是非
NULL列 的数据内容 。 -
聚簇索引中的记录包含所有用户定义列的字段。 此外,还有一个6字节的事务ID字段和一个7字节的滚动指针字段。
-
如果没有为表定义主键,则每个聚簇索引记录还包含一个6字节的行ID字段。
-
每个辅助索引记录包含为聚簇索引键定义的所有主键列,这些列不在辅助索引中。 如果任何主键列是可变长度,则每个辅助索引的记录头都有一个可变长度部分来记录它们的长度,即使在固定长度列上定义了二级索引。
-
在内部,对于非变长字符集,固定长度字符列(例如以
CHAR(10)固定长度格式存储)。尾随空格不会从
VARCHAR列中 截断 。 -
在内部,对于可变长度字符集,例如
utf8mb3和utf8mb4,InnoDB尝试 通过修剪尾随空格 以 字节 存储 。 如果 列值 的字节长度 超过 字节,则将尾随空格调整为列值字节长度的最小值。 列 的最大长度 是最大字符字节长度× 。CHAR(N)NCHAR(N)NCHAR(N)NN保留 最少的 字节数 。 在许多情况下 保留最小空间 可以在不导致索引页碎片的情况下完成列更新。 相比之下, 当使用 行格式 时 , 列占用最大字符字节长度× 。CHAR(N)NCHAR(N)NREDUNDANT大于或等于768字节的固定长度列被编码为可变长度字段,可以在页外存储。 例如,
CHAR(255)如果字符集的最大字节长度大于3,则列可以超过768字节utf8mb4。
该
DYNAMIC
行格式提供相同的存储特性的
COMPACT
行格式,但增加了对长可变长度列增强的存储功能,并支持大型索引键的前缀。
使用时创建表
ROW_FORMAT=DYNAMIC
,
InnoDB
可以
完全在页外
存储长的可变长度列值(for
VARCHAR
,
VARBINARY
和,
BLOB
和
TEXT
类型),聚簇索引记录只包含指向溢出页的20字节指针。
大于或等于768字节的固定长度字段被编码为可变长度字段。
例如,
CHAR(255)
如果字符集的最大字节长度大于3,则列可以超过768字节
utf8mb4
。
列是否存储在页外是否取决于页面大小和行的总大小。
当行太长时,选择最长的列进行页外存储,直到聚簇索引记录适合
B树
页面。
TEXT
并且
BLOB
是小于或等于40个字节的列被存储在线路。
该
DYNAMIC
行格式保持存储在它是否适合的索引节点整个行的效率(如做的
COMPACT
和
REDUNDANT
格式),但是
DYNAMIC
行格式避免填充B-树节点具有大量长列的数据字节的问题。
该
DYNAMIC
行格式是基于这样的思想,如果一个长的数据值的一部分被存储关闭页,它通常是最有效的存储关闭页整个值。
对于
DYNAMIC
格式,较短的列可能保留在B树节点中,从而最小化给定行所需的溢出页数。
该
DYNAMIC
行格式支持索引键的前缀可达3072个字节。
使用
DYNAMIC
行格式的
表
可以存储在系统表空间,每表文件表空间和一般表空间中。
要
DYNAMIC
在系统表空间中
存储
表,请禁用
innodb_file_per_table
和使用常规
CREATE TABLE
或
ALTER
TABLE
语句,或将
TABLESPACE [=]
innodb_system
表选项与
CREATE
TABLE
或一起使用
ALTER TABLE
。
该
innodb_file_per_table
变量不适用于通用表空间,在使用
TABLESPACE [=] innodb_system
table选项
DYNAMIC
在系统表空间中
存储
表
时也不适用
。
动态行格式存储特性
该
DYNAMIC
行格式是一个偏差
COMPACT
行格式。
有关存储特性,请参阅
COMPACT行格式存储特性
。
该
COMPRESSED
行格式提供相同的存储特性和功能的
DYNAMIC
行格式,但增加了对表和索引数据压缩的支持。
该
COMPRESSED
行格式使用类似的内部细节关闭页存储为
DYNAMIC
行格式,从表和索引数据的附加存储和性能的考虑被压缩,并使用较小的页大小。
使用
COMPRESSED
行格式,该
KEY_BLOCK_SIZE
选项控制在聚簇索引中存储的列数据量,以及溢出页面上放置了多少。
有关
COMPRESSED
行格式的
更多信息
,请参见
第15.9节“InnoDB表和页面压缩”
。
该
COMPRESSED
行格式支持索引键的前缀可达3072个字节。
COMPRESSED
可以在每个表的文件表空间或通用表空间中创建
使用
行格式的表。
系统表空间不支持
COMPRESSED
行格式。
要将
COMPRESSED
表
存储
在每个表的文件表空间中,
innodb_file_per_table
必须启用
该
变量。
该
innodb_file_per_table
变量不适用于一般表空间。
一般表空间支持所有行格式,但需要注意的是,由于物理页面大小不同,压缩和未压缩表不能在同一个通用表空间中共存。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
压缩行格式存储特性
该
COMPRESSED
行格式是一个偏差
COMPACT
行格式。
有关存储特性,请参阅
COMPACT行格式存储特性
。
InnoDB
表
的默认行格式
由
innodb_default_row_format
变量
定义
,其默认值为
DYNAMIC
。
如果
ROW_FORMAT
未明确定义表选项或
ROW_FORMAT=DEFAULT
指定
了
表选项,
则使用默认行格式
。
可以使用
or
语句中
的
ROW_FORMAT
table选项
显式定义表的行格式
。
例如:
CREATE
TABLE
ALTER TABLE
CREATE TABLE t1(c1 INT)ROW_FORMAT = DYNAMIC;
显式定义的
ROW_FORMAT
设置将覆盖默认行格式。
指定
ROW_FORMAT=DEFAULT
等同于使用隐式默认值。
所述
innodb_default_row_format
变量可以动态地设置:
MySQL的> SET GLOBAL innodb_default_row_format=DYNAMIC;
有效的
innodb_default_row_format
选项包括
DYNAMIC
,
COMPACT
,和
REDUNDANT
。
COMPRESSED
不支持在系统表空间中使用
的
行格式不能定义为默认值。
它只能在
CREATE
TABLE
或
ALTER
TABLE
语句中
明确指定
。
试图将
innodb_default_row_format
变量
设置
为
COMPRESSED
返回错误:
MySQL的> SET GLOBAL innodb_default_row_format=COMPRESSED;
ERROR 1231(42000):变量'innodb_default_row_format'
不能设置为'COMPRESSED'的值
innodb_default_row_format
当
ROW_FORMAT
未明确指定选项或使用何时,
新创建的表使用由
变量
定义的行格式
ROW_FORMAT=DEFAULT
。
例如,以下
CREATE
TABLE
语句使用
innodb_default_row_format
变量
定义的行格式
。
CREATE TABLE t1(c1 INT);
CREATE TABLE t2(c1 INT)ROW_FORMAT = DEFAULT;
如果
ROW_FORMAT
未明确指定选项或使用何时
ROW_FORMAT=DEFAULT
,则以静默方式重建表的操作会将表的行格式更改为该
innodb_default_row_format
变量
定义的格式
。
表重建操作包括
ALTER
TABLE
使用
ALGORITHM=COPY
或
ALGORITHM=INPLACE
需要表重建的操作。
有关
更多信息
,
请参见
第15.12.1节“在线DDL操作”
。
OPTIMIZE TABLE
也是一个表重建操作。
以下示例演示了一个表重建操作,该操作以静默方式更改未使用显式定义的行格式创建的表的行格式。
MySQL的>SELECT @@innodb_default_row_format;+ ----------------------------- + | @@ innodb_default_row_format | + ----------------------------- + | 动态| + ----------------------------- + MySQL的>CREATE TABLE t1 (c1 INT);MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE 'test/t1' \G*************************** 1。排******************** ******* TABLE_ID:54 姓名:test / t1 旗帜:33 N_COLS:4 空间:35 ROW_FORMAT:动态 ZIP_PAGE_SIZE:0 SPACE_TYPE:单身 MySQL的>SET GLOBAL innodb_default_row_format=COMPACT;MySQL的>ALTER TABLE t1 ADD COLUMN (c2 INT);MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE 'test/t1' \G*************************** 1。排******************** ******* TABLE_ID:55 姓名:test / t1 标志:1 N_COLS:5 空间:36 ROW_FORMAT:紧凑 ZIP_PAGE_SIZE:0 SPACE_TYPE:单身
从改变现有表的行格式之前,请考虑以下潜在的问题
REDUNDANT
或
COMPACT
对
DYNAMIC
。
-
的
REDUNDANT和COMPACT行格式支持的767个字节的最大索引关键字前缀长度而DYNAMIC与COMPRESSED行格式支持的3072个字节的索引关键字前缀长度。 在复制环境中,如果innodb_default_row_format变量设置为DYNAMICmaster,并设置为COMPACTslave,则以下DDL语句(未明确定义行格式)在master上成功但在slave上失败:CREATE TABLE t1(c1 INT PRIMARY KEY,c2 VARCHAR(5000),KEY i1(c2(3070)));
有关相关信息,请参见 第15.6.1.6节“InnoDB表的限制” 。
-
如果
innodb_default_row_format源服务器上的设置与目标服务器上的设置不同,则 导入未显式定义行格式的表会导致模式不匹配错误 。 有关更多信息,请参阅 第15.6.3.7节“将表空间复制到另一个实例”中 概述的限制 。
要确定表的行格式,请使用
SHOW TABLE STATUS
:
MySQL的> SHOW TABLE STATUS IN test1\G
*************************** 1。排******************** *******
姓名:t1
引擎:InnoDB
版本:10
Row_format:动态
行:0
Avg_row_length:0
Data_length:16384
Max_data_length:0
Index_length:16384
Data_free:0
Auto_increment:1
Create_time:2016-09-14 16:29:38
Update_time:NULL
Check_time:NULL
排序规则:utf8mb4_0900_ai_ci
校验和:NULL
Create_options:
评论:
或者,查询
INFORMATION_SCHEMA.INNODB_TABLES
表:
MySQL的> SELECT NAME, ROW_FORMAT FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test1/t1';
+ ---------- + ------------ +
| NAME | ROW_FORMAT |
+ ---------- + ------------ +
| test1 / t1 | 动态|
+ ---------- + ------------ +
作为DBA,您必须管理磁盘I / O以防止I / O子系统饱和,并管理磁盘空间以避免填满存储设备。
该
ACID
设计模型需要一定量的I / O可能似乎是多余的,但有助于确保数据的可靠性。
在这些约束中,
InnoDB
尝试优化数据库工作和磁盘文件的组织,以最大限度地减少磁盘I / O的数量。
有时,I / O会被推迟,直到数据库不忙,或者直到所有内容都需要进入一致状态,例如在
快速关闭
后重新启动数据库期间
。
本节讨论使用默认类型的MySQL表(也称为
InnoDB
表)的
I / O和磁盘空间的主要注意事项
:
-
控制用于提高查询性能的后台I / O量。
-
启用或禁用以额外I / O为代价提供额外持久性的功能。
-
将表组织成许多小文件,一些较大的文件或两者的组合。
-
平衡重做日志文件的大小与日志文件变满时发生的I / O活动。
-
如何重新组织表以获得最佳查询性能。
InnoDB
尽可能使用异步磁盘I / O,通过创建许多线程来处理I / O操作,同时允许其他数据库操作在I / O仍在进行时继续。
在Linux和Windows平台上,
InnoDB
使用可用的OS和库函数来执行
“
本机
”
异步I / O.
在其他平台上,
InnoDB
仍然使用I / O线程,但线程实际上可能等待I / O请求完成;
这种技术称为
“
模拟
”
异步I / O.
如果
InnoDB
可以确定很快就需要数据,它会执行预读操作以将该数据放入缓冲池,以便在内存中可用。
对连续数据进行一些大的读取请求比制作几个小的展开请求更有效。
有两种预读启发式
InnoDB
:
-
在顺序预读中,如果
InnoDB注意到表空间中的段的访问模式是顺序的,则它会预先将一批数据库页的读取发送到I / O系统。 -
在随机预读中,如果
InnoDB注意到表空间中的某些区域似乎正在完全读入缓冲池,则会将剩余的读取发布到I / O系统。
有关配置 预读 启发式的信息,请参见 第15.8.3.4节“配置InnoDB缓冲池预取(预读)” 。
InnoDB
使用一种新颖的文件刷新技术,涉及一种称为
doublewrite缓冲区
的结构
,在大多数情况下默认启用(
innodb_doublewrite=ON
)。
它可以在崩溃或停电后为恢复增加安全性,并通过减少
fsync()
操作
需求来提高大多数Unix的性能
。
在将页面
InnoDB
写入
数据文件之前,
首先将它们写入称为doublewrite缓冲区的连续表空间区域。
只有在写入和刷新到doublewrite缓冲区之后,才会
InnoDB
将页面写入数据文件中的正确位置。
如果
在页面写入过程中
存在操作系统,存储子系统或
mysqld
进程崩溃(导致
页面
状况
破坏
),则
InnoDB
可以在恢复期间从doublewrite缓冲区中找到页面的良好副本。
如果系统表空间文件(
“
ibdata文件
”
)位于支持原子写入的Fusion-io设备上,则会自动禁用双写缓冲,并且Fusion-io原子写入将用于所有数据文件。
由于双写缓冲区设置是全局的,因此对于驻留在非Fusion-io硬件上的数据文件也禁用双写缓冲。
此功能仅在Fusion-io硬件上受支持,仅适用于Linux上的Fusion-io NVMFS。
要充分利用此功能,
建议
进行
innodb_flush_method
设置
O_DIRECT
。
使用
innodb_data_file_path
配置选项
在配置文件中定义的数据文件
构成
InnoDB
系统表空间
。
这些文件在逻辑上连接在一起以形成系统表空间。
使用中没有条纹。
您无法在系统表空间中定义表的分配位置。
在新创建的系统表空间中,
InnoDB
从第一个数据文件开始分配空间。
为了避免在系统表空间中存储所有表和索引所带来的问题,可以启用
innodb_file_per_table
配置选项(默认值),该选项将每个新创建的表存储在单独的表空间文件中(带扩展名
.ibd
)。
对于以这种方式存储的表,磁盘文件中的碎片较少,并且当表被截断时,空间将返回到操作系统,而不是仍由InnoDB在系统表空间中保留。
有关更多信息,请参见
第15.6.3.2节“每个表的文件表空间”
。
您还可以在
一般表空间中
存储表
。
常规表空间是使用
CREATE TABLESPACE
语法
创建的共享表空间
。
它们可以在MySQL数据目录之外创建,能够保存多个表,并支持所有行格式的表。
有关更多信息,请参见
第15.6.3.3节“常规表空间”
。
页面,范围,段和表空间
每个表空间都包含数据库
页面
。
MySQL实例中的每个表空间都具有相同的
页面大小
。
默认情况下,所有表空间的页面大小均为16KB;
通过
innodb_page_size
在创建MySQL实例时
指定
选项,
可以将页面大小减小到8KB或4KB
。
您还可以将页面大小增加到32KB或64KB。
有关更多信息,请参阅
innodb_page_size
文档。
对于最大16KB的页面(64个连续的16KB页面,或128个8KB页面,或256个4KB页面),
页面被分组为
大小为1MB的
范围
。
对于32KB的页面大小,扩展区大小为2MB。
对于64KB的页面大小,扩展区大小为4MB。
在
“
文件
”
表空间内被称为
段
在
InnoDB
。
(这些段与
回滚段
不同
,后者实际上包含许多表空间段。)
当一个段在表空间内增长时,一次一个地
InnoDB
分配前32个页面。
之后,
InnoDB
开始将整个范围分配给段。
InnoDB
最多可以向一个大段添加4个扩展区,以确保数据的良好顺序性。
为每个索引分配两个段
InnoDB
。
一个用于
B树
的非叶节点,另一个用于叶节点。
保持叶子节点在磁盘上连续可以实现更好的顺序I / O操作,因为这些叶节点包含实际的表数据。
表空间中的某些页面包含其他页面的位图,因此
InnoDB
表空间中
的一些范围
不能作为整体分配给段,而只能作为单独的页面。
当您通过发出
SHOW TABLE STATUS
语句
请求表空间中的可用空间时
,
InnoDB
报告表空间中绝对空闲的扩展区。
InnoDB
总是保留一定的范围用于清理和其他内部目的;
这些保留的范围不包含在可用空间中。
从表中删除数据时,会
InnoDB
收缩相应的B树索引。
释放的空间是否可供其他用户使用取决于删除模式是否将单个页面或扩展区释放到表空间。
删除表或删除其中的所有行可以保证将空间释放给其他用户,但请记住,只有
清除
操作
才会删除已删除的行
,这在事务回滚或一致读取不再需要时会自动发生。
(参见
第15.3节“InnoDB多版本”
。)
页面与表格行的关系
对于4KB,8KB,16KB和32KB
innodb_page_size
设置
,最大行长度略小于数据库页面的一半
。
例如,对于默认的16KB
InnoDB
页面大小
,最大行长度略小于8KB
。
对于64KB页面,最大行长度略小于16KB。
如果一行没有超过最大行长度,则所有行都存储在页面内。 如果行超过最大行长度, 则选择 可变长度列 用于外部页外存储,直到该行符合最大行长度限制。 可变长度列的外部页外存储因行格式而异:
-
紧凑和冗余行格式
当为外部页外存储选择可变长度列时
InnoDB,将该行中的前768个字节存储在本地,其余外部存储到溢出页中。 每个这样的列都有自己的溢出页列表。 768字节的前缀伴随着一个20字节的值,该值存储列的真实长度并指向溢出列表,其中存储了值的其余部分。 请参见 第15.10节“InnoDB行格式” 。 -
动态和压缩行格式
当为外部页外存储选择可变长度列时,
InnoDB在该行本地存储一个20字节指针,其余外部存储在溢出页中。 请参见 第15.10节“InnoDB行格式” 。
LONGBLOB
和
LONGTEXT
列必须小于4GB,并且总行长度(包括
列
BLOB
和
TEXT
列)必须小于4GB。
使你的 日志文件 非常大时可以减少磁盘I / O的 检查点 。 将日志文件的总大小设置为与缓冲池一样大甚至更大是有意义的。
检查点处理如何工作
InnoDB
实现了
一种称为
模糊检查点
的
检查点
机制
。
以小批量从缓冲池中刷新已修改的数据库页面。
无需在一个批处理中刷新缓冲池,这会在检查点过程中中断用户SQL语句的处理。
InnoDB
在
崩溃恢复
期间
,
InnoDB
查找写入日志文件的检查点标签。
它知道标签之前对数据库的所有修改都存在于数据库的磁盘映像中。
然后
InnoDB
从检查点向前扫描日志文件,将记录的修改应用于数据库。
从二级索引中随机插入或删除可能会导致索引碎片化。 碎片意味着磁盘上索引页的物理排序不接近页面上记录的索引排序,或者64页块中有许多未使用的页面被分配给索引。
碎片化的一个症状是表格占用的空间比
“
应该
”
占用的
空间多
。
多少确切地说,很难确定。
所有
InnoDB
数据和索引都存储在
B树中
,其
填充因子
可能在50%到100%之间变化。
碎片的另一个症状是像这样的表扫描需要比
“
应该
”
花费更多的时间
:
SELECT COUNT(*)FROM t WHERE non_indexed_column<> 12345;
前面的查询要求MySQL执行全表扫描,这是对大表的最慢类型的查询。
要加速索引扫描,您可以定期执行
“
空
”
ALTER
TABLE
操作,这会导致MySQL重建表:
ALTER TABLE tbl_nameENGINE = INNODB
您还可以使用
执行
重建表
的
“
null
”
更改操作。
ALTER
TABLE
tbl_name FORCE
双方
并
使用
在线DDL
。
有关更多信息,请参见
第15.12节“InnoDB和在线DDL”
。
ALTER
TABLE
tbl_name ENGINE=INNODBALTER TABLE
tbl_name FORCE
执行碎片整理操作的另一种方法是使用 mysqldump 将表转储到文本文件,删除表,然后从转储文件重新加载它。
如果索引中的插入始终是升序的,并且仅从末尾删除记录,则
InnoDB
文件空间管理算法可确保不会发生索引中的碎片。
当回收操作系统的磁盘空间
截断
的
InnoDB
表,该表必须存放在自己的
的.ibd
文件。
要将表存储在其自己的
.ibd
文件中,
innodb_file_per_table
必须在创建表时启用该表。
此外,
被截断的表与其他表之间
不能存在
外键
约束,否则
TRUNCATE TABLE
操作将失败。
但是,允许同一表中两列之间的外键约束。
当表被截断时,它将被删除并在新
.ibd
文件中
重新创建
,并且释放的空间将返回给操作系统。
这与截断
InnoDB
存储在
InnoDB
系统表空间
(
innodb_file_per_table=OFF
存储
时创建的表
)和存储在共享
通用表空间中的
表的表
相反
,后者只能
InnoDB
在截断表后使用释放的空间。
截断表并将磁盘空间返回给操作系统的能力也意味着
物理备份
可以更小。
截断存储在系统表空间(在何时创建的表
innodb_file_per_table=OFF
)或在通用表空间中存储的表会在表空间中留下未使用空间的块。
在线DDL功能支持即时和就地表格更改以及并发DML。 此功能的好处包括:
-
在繁忙的生产环境中提高响应能力和可用性,使得桌子不可用几分钟或几小时是不切实际的。
-
对于就地操作,使用该
LOCK子句 在DDL操作期间调整性能和并发性之间的平衡的能力 。 请参阅 LOCK子句 。 -
与table-copy方法相比,磁盘空间使用和I / O开销更少。
ALGORITHM=INSTANT
支持可用于
ADD COLUMN
MySQL 8.0.12中的其他操作。
通常,您无需执行任何特殊操作即可启用在线DDL。 默认情况下,MySQL会在允许的情况下立即或就地执行操作,并尽可能少地锁定。
您可以使用
语句
的
ALGORITHM
和
LOCK
子句
控制DDL操作的各个方面
ALTER
TABLE
。
这些子句放在语句的末尾,用逗号分隔表和列规范。
例如:
ALTER TABLEtbl_nameADD PRIMARY KEY(column),ALGORITHM = INPLACE,LOCK = NONE;
该
LOCK
子句可用于在适当位置执行的操作,并且可用于在操作期间微调对表的并发访问程度。
仅
LOCK=DEFAULT
支持立即执行的操作。
该
ALGORITHM
子句主要用于性能比较,并作为旧表复制行为的后备,以防您遇到任何问题。
例如:
-
为了避免在就地
ALTER TABLE操作 期间意外地使表不可用于读取,写入或两者,请在 语句上指定一个子句,ALTER TABLE例如LOCK=NONE(允许读取和写入)或LOCK=SHARED(允许读取)。 如果请求的并发级别不可用,则操作立即停止。 -
为了比较算法之间的性能,运行与语句
ALGORITHM=INSTANT,ALGORITHM=INPLACE和ALGORITHM=COPY。 您还可以在old_alter_table启用配置选项的情况下 运行语句 以强制使用ALGORITHM=COPY。 -
为避免使用
ALTER TABLE复制表 的 操作来 捆绑服务器 ,请包含ALGORITHM=INSTANT或ALGORITHM=INPLACE。 如果语句无法使用指定的算法,则语句立即停止。
本节中的以下主题提供了有关DDL操作的联机支持详细信息,语法示例和用法说明。
下表概述了对索引操作的在线DDL支持。 星号表示其他信息,异常或依赖项。 有关详细信息,请参阅 语法和用法说明 。
表15.17索引操作的在线DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
| 创建或添加二级索引 | 没有 | 是 | 没有 | 是 | 没有 |
| 删除索引 | 没有 | 是 | 没有 | 是 | 是 |
| 重命名索引 | 没有 | 是 | 没有 | 是 | 是 |
添加
FULLTEXT
索引
|
没有 | 是* | 没有* | 没有 | 没有 |
添加
SPATIAL
索引
|
没有 | 是 | 没有 | 没有 | 没有 |
| 更改索引类型 | 是 | 是 | 没有 | 是 | 是 |
语法和用法说明
-
创建或添加二级索引
CREATE INDEX
nameONtable(col_list);ALTER TABLE
tbl_nameADD INDEXname(col_list);在创建索引时,该表仍可用于读写操作。 该
CREATE INDEX语句仅在完成访问表的所有事务完成后才结束,因此索引的初始状态反映了表的最新内容。在线DDL支持添加二级索引意味着您通常可以通过创建没有二级索引的表来加速创建和加载表及相关索引的整个过程,然后在加载数据后添加二级索引。
新创建的辅助索引仅包含
CREATE INDEX或在ALTER TABLE语句完成执行 时表中的已提交数据 。 它不包含任何未提交的值,旧版本的值或标记为删除但尚未从旧索引中删除的值。某些因素会影响此操作的性能,空间使用和语义。 有关详细信息,请参见 第15.12.6节“在线DDL限制” 。
-
删除索引
DROP INDEX
nameONtable;ALTER TABLE
tbl_nameDROP INDEXname;在删除索引时,该表仍可用于读取和写入操作。 该
DROP INDEX语句仅在完成访问表的所有事务完成后才结束,因此索引的初始状态反映了表的最新内容。 -
重命名索引
ALTER TABLE
tbl_nameRENAME INDEXold_index_nameTOnew_index_name,ALGORITHM = INPLACE,LOCK = NONE; -
添加一个
FULLTEXT索引name在表格上创建FULLTEXT INDEX (column)上 ;FULLTEXT如果没有用户定义的FTS_DOC_ID列 ,则 添加第一个 索引会重建表 。 额外FULLTEXT可以添加 索引而无需重建表。 -
添加一个
SPATIAL索引CREATE TABLE geom(g GEOMETRY NOT NULL); ALTER TABLE geom ADD SPATIAL INDEX(g),ALGORITHM = INPLACE,LOCK = SHARED;
FULLTEXT如果没有用户定义的FTS_DOC_ID列 ,则 添加第一个 索引会重建表 。FULLTEXT可以添加 其他 索引而无需重建表。 -
更改索引类型(
USING {BTREE | HASH})ALTER TABLE
tbl_nameDROP INDEX i1,ADD INDEX i1(key_part,...)使用BTREE,ALGORITHM = INSTANT;
下表概述了主键操作的联机DDL支持。 星号表示其他信息,异常或依赖项。 请参见 语法和使用说明 。
表15.18主键操作的在线DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
| 添加主键 | 没有 | 是* | 是* | 是 | 没有 |
| 删除主键 | 没有 | 没有 | 是 | 没有 | 没有 |
| 删除主键并添加另一个 | 没有 | 是 | 是 | 是 | 没有 |
语法和用法说明
-
添加主键
ALTER TABLE
tbl_nameADD PRIMARY KEY(column),ALGORITHM = INPLACE,LOCK = NONE;在适当的位置重建表格。 数据进行了大量重组,使其成为一项昂贵的操作。
ALGORITHM=INPLACE如果必须将列转换为特定条件,则不允许使用NOT NULL。重构 聚簇索引 总是需要复制表数据。 因此,最好 在创建表时 定义 主键 ,而不是
ALTER TABLE ... ADD PRIMARY KEY稍后 发布 。当你创建一个
UNIQUE或PRIMARY KEY索引时,MySQL必须做一些额外的工作。 对于UNIQUE索引,MySQL检查表中是否包含密钥的重复值。 对于PRIMARY KEY索引,MySQL还会检查没有PRIMARY KEY列包含NULL。当您使用
ALGORITHM=COPY子句 添加主键时 ,MySQL会将NULL关联列中的值 转换 为默认值:0表示数字,空字符串表示基于字符的列和BLOB,00:00:00表示DATETIME。 这是Oracle建议您不要依赖的非标准行为。ALGORITHM=INPLACE仅当SQL_MODE设置包含strict_trans_tables或strict_all_tables标志 时才允许 使用主键添加 ; 如果SQL_MODE设置是严格的,ALGORITHM=INPLACE则允许,但如果请求的主键列包含,则语句仍然可能失败NULL值。 该ALGORITHM=INPLACE行为更符合标准。如果创建没有主键的表,请
InnoDB为您选择一个 表( 可以是 列上UNIQUE定义 的第一个 键)NOT NULL或系统生成的键。 为避免不确定性以及额外隐藏列的潜在空间要求,请将该PRIMARY KEY子句 指定为 语句的一部分CREATE TABLE。MySQL通过将原始表中的现有数据复制到具有所需索引结构的临时表来创建新的聚簇索引。 将数据完全复制到临时表后,将使用不同的临时表名重命名原始表。 使用原始表的名称重命名包含新聚簇索引的临时表,并从数据库中删除原始表。
适用于二级索引上的操作的联机性能增强不适用于主键索引。 InnoDB表的行存储在 基于 主键 组织 的 聚簇索引中 ,形成一些数据库系统称为 “ 索引组织表 ”的内容 。 由于表结构与主键紧密相关,因此重新定义主键仍需要复制数据。
当主键上的操作使用时
ALGORITHM=INPLACE,即使仍然复制数据,它也比使用更有效,ALGORITHM=COPY因为:-
不需要撤消日志记录或关联的重做日志记录
ALGORITHM=INPLACE。 这些操作会增加使用的DDL语句的开销ALGORITHM=COPY。 -
二级索引条目是预先排序的,因此可以按顺序加载。
-
未使用更改缓冲区,因为没有随机访问插入到二级索引中。
-
-
删除主键
ALTER TABLE
tbl_nameDROP PRIMARY KEY,ALGORITHM = COPY;仅
ALGORITHM=COPY支持删除主键而不在同一ALTER TABLE语句中 添加新主键 。 -
删除主键并添加另一个
ALTER TABLE
tbl_nameDROP PRIMARY KEY,ADD PRIMARY KEY(column),ALGORITHM = INPLACE,LOCK = NONE;数据进行了大量重组,使其成为一项昂贵的操作。
下表概述了对列操作的联机DDL支持。 星号表示其他信息,异常或依赖项。 有关详细信息,请参阅 语法和用法说明 。
表15.19列操作的在线DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
| 添加列 | 是* | 是 | 没有* | 是* | 没有 |
| 删除列 | 没有 | 是 | 是 | 是 | 没有 |
| 重命名列 | 没有 | 是 | 没有 | 是* | 是 |
| 重新排序列 | 没有 | 是 | 是 | 是 | 没有 |
| 设置列默认值 | 是 | 是 | 没有 | 是 | 是 |
| 更改列数据类型 | 没有 | 没有 | 是 | 没有 | 没有 |
扩展
VARCHAR
列大小
|
没有 | 是 | 没有 | 是 | 是 |
| 删除列默认值 | 是 | 是 | 没有 | 是 | 是 |
| 更改自动增量值 | 没有 | 是 | 没有 | 是 | 没有* |
制作专栏
NULL
|
没有 | 是 | 是* | 是 | 没有 |
制作专栏
NOT NULL
|
没有 | 是* | 是* | 是 | 没有 |
修改
ENUM
或
SET
列
的定义
|
是 | 是 | 没有 | 是 | 是 |
语法和用法说明
-
添加列
ALTER TABLE
tbl_nameADD COLUMN ,ALGORITHM = INSTANT;column_namecolumn_definition使用该
INSTANT算法添加列 时,以下限制适用 :-
添加列不能与
ALTER TABLE不支持的 其他 操作 在同一语句中组合ALGORITHM=INSTANT。 -
只能将列添加为表的最后一列。 不支持将列添加到其他列中的任何其他位置。
-
无法将列添加到使用的表中
ROW_FORMAT=COMPRESSED。 -
无法将列添加到包含
FULLTEXT索引的 表中 。 -
列无法添加到临时表。 临时表仅支持
ALGORITHM=COPY。 -
无法将列添加到驻留在数据字典表空间中的表。
-
添加列时不评估行大小限制。 但是,在插入和更新表中的行的DML操作期间会检查行大小限制。
可以在同一
ALTER TABLE语句中 添加多个列 。 例如:ALTER TABLE t1 ADD COLUMN c2 INT,ADD COLUMN c3 INT,ALGORITHM = INSTANT;
INFORMATION_SCHEMA.INNODB_TABLES并INFORMATION_SCHEMA.INNODB_COLUMNS为即时添加的列提供元数据。INFORMATION_SCHEMA.INNODB_TABLES.INSTANT_COLS显示添加第一个即时列之前表中的列数。INFORMATION_SCHEMA.INNODB_COLUMNS.HAS_DEFAULT并DEFAULT_VALUE提供有关即时添加列的默认值的元数据。添加 自动增量 列 时不允许并发DML 。 数据进行了大量重组,使其成为一项昂贵的操作。 至少
ALGORITHM=INPLACE, LOCK=SHARED是必需的。如果
ALGORITHM=INPLACE用于添加列, 则重建该表 。 -
-
删除列
ALTER TABLE
tbl_nameDROP COLUMNcolumn_name,ALGORITHM = INPLACE,LOCK = NONE;数据进行了大量重组,使其成为一项昂贵的操作。
-
重命名列
ALTER TABLE
tblCHANGE ,ALGORITHM = INPLACE,LOCK = NONE;old_col_namenew_col_namedata_type要允许并发DML,请保留相同的数据类型并仅更改列名。
当您保留相同的数据类型和
[NOT] NULL属性时,只更改列名,操作始终可以在线执行。您还可以重命名属于外键约束的列。 外键定义会自动更新以使用新列名称。 重命名参与外键的列仅适用于
ALGORITHM=INPLACE。 如果您使用该ALGORITHM=COPY子句,或某些其他条件导致该命令ALGORITHM=COPY在幕后 使用 ,则该ALTER TABLE语句将失败。ALGORITHM=INPLACE不支持重命名 生成的列 。 -
重新排序列
要重新排序列,请使用
FIRST或AFTERinCHANGE或MODIFY操作。ALTER TABLE
tbl_nameMODIFY COLUMN FIRST,ALGORITHM = INPLACE,LOCK = NONE;col_namecolumn_definition数据进行了大量重组,使其成为一项昂贵的操作。
-
更改列数据类型
ALTER TABLE
tbl_nameCHANGE c1 c1 BIGINT,ALGORITHM = COPY;仅支持更改列数据类型
ALGORITHM=COPY。 -
扩展
VARCHAR列大小ALTER TABLE
tbl_nameCHANGE COLUMN c1 c1 VARCHAR(255),ALGORITHM = INPLACE,LOCK = NONE;VARCHAR列 所需的长度字节数 必须保持不变。 对于VARCHAR大小为0到255字节的列,需要一个长度字节来对值进行编码。 对于VARCHAR大小为256字节或更大的列,需要两个长度字节。 因此,就地ALTER TABLE仅支持将VARCHAR列大小从0增加到255个字节,或从256个字节增加到更大的大小。 就地ALTER TABLE不支持增加a的大小VARCHAR列数小于256个字节,大小等于或大于256个字节。 在这种情况下,所需长度字节数从1变为2,这仅由表副本(ALGORITHM=COPY)支持。 例如,尝试VARCHAR使用in-placeALTER TABLE将 单字节字符集的列大小从VARCHAR(255)更改为VARCHAR(256)会 返回此错误:ALTER TABLE
tbl_nameALGORITHM = INPLACE,CHANGE COLUMN c1 c1 VARCHAR(256); ERROR 0A000:不支持ALGORITHM = INPLACE。原因:无法改变 列类型INPLACE。尝试ALGORITHM = COPY。注意一个的字节长度
VARCHAR列是依赖于字符集的字节长度。不支持
VARCHAR使用就地 减小 大小ALTER TABLE。 减小VARCHAR大小需要表副本(ALGORITHM=COPY)。 -
设置列默认值
ALTER TABLE
tbl_nameALTER COLUMNcolSET DEFAULTliteral,ALGORITHM = INSTANT;仅修改表元数据。 默认列值存储在 数据字典中 。
-
删除列默认值
ALTER TABLE
tblALTER COLUMNcolDROP DEFAULT,ALGORITHM = INSTANT; -
更改自动增量值
ALTER TABLE
tableAUTO_INCREMENT =next_value,ALGORITHM = INPLACE,LOCK = NONE;修改存储在内存中的值,而不是数据文件。
在使用复制或分片的分布式系统中,有时会将表的自动递增计数器重置为特定值。 插入表中的下一行使用其自动增量列的指定值。 您还可以在数据仓库环境中使用此技术,在该环境中,您定期清空所有表并重新加载它们,并从1重新启动自动增量序列。
-
制作专栏
NULLALTER TABLE tbl_name MODIFY COLUMN NULL,ALGORITHM = INPLACE,LOCK = NONE;
column_namedata_type在适当的位置重建表格。 数据进行了大量重组,使其成为一项昂贵的操作。
-
制作专栏
NOT NULLALTER TABLE
tbl_nameMODIFY COLUMN NOT NULL,ALGORITHM = INPLACE,LOCK = NONE;column_namedata_type在适当的位置重建表格。
STRICT_ALL_TABLES或者STRICT_TRANS_TABLESSQL_MODE是手术成功所必需的。 如果列包含NULL值,则操作将失败。 服务器禁止更改可能导致参照完整性丢失的外键列。 请参见 第13.1.9节“ALTER TABLE语法” 。 数据进行了大量重组,使其成为一项昂贵的操作。 -
修改
ENUM或SET列 的定义CREATE TABLE t1(c1 ENUM('a','b','c')); ALTER TABLE t1 MODIFY COLUMN c1 ENUM('a','b','c','d'),ALGORITHM = INSTANT;
通过将新枚举或集合成员添加到 有效成员值列表 的 末尾 来 修改
ENUM或SET列 的定义 可以立即或就地执行,只要数据类型的存储大小不改变即可。 例如,将成员添加到 具有8个成员 的 列会将每个值所需的存储空间从1个字节更改为2个字节; 这需要一个表副本。 在列表中间添加成员会导致重新编号现有成员,这需要表副本。SET
下表概述了对生成的列操作的在线DDL支持。 有关详细信息,请参阅 语法和用法说明 。
表15.20生成列操作的联机DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
添加
STORED
列
|
没有 | 没有 | 是 | 没有 | 没有 |
修改
STORED
列顺序
|
没有 | 没有 | 是 | 没有 | 没有 |
删除
STORED
列
|
没有 | 是 | 是 | 是 | 没有 |
添加
VIRTUAL
列
|
是 | 是 | 没有 | 是 | 是 |
修改
VIRTUAL
列顺序
|
没有 | 没有 | 是 | 没有 | 没有 |
删除
VIRTUAL
列
|
是 | 是 | 没有 | 是 | 是 |
语法和用法说明
-
添加
STORED列更改表t1添加列(c2 INT始终生成(c1 + 1)已存储),算法=复制;
ADD COLUMN不是存储列的就地操作(不使用临时表),因为表达式必须由服务器评估。 -
修改
STORED列顺序ALTER TABLE t1 MODIFY COLUMN c2 INT始终为(c1 + 1)存储的第一个,算法=复制;
在适当的位置重建表格。
-
删除
STORED列ALTER TABLE t1 DROP COLUMN c2,ALGORITHM = INPLACE,LOCK = NONE;
在适当的位置重建表格。
-
添加
VIRTUAL列更改表t1添加列(c2 INT始终为(c1 + 1)VIRTUAL),算法=即时;
对于非分区表,可以立即或就地添加虚拟列。
添加a
VIRTUAL不是分区表的就地操作。 -
修改
VIRTUAL列顺序ALTER TABLE t1 MODIFY COLUMN c2 INT始终为(c1 + 1)VIRTUAL FIRST,算法=复制;
-
删除
VIRTUAL列ALTER TABLE t1 DROP COLUMN c2,ALGORITHM = INSTANT;
VIRTUAL对于非分区表,可以立即或就地 删除 列。
下表概述了对外键操作的在线DDL支持。 星号表示其他信息,异常或依赖项。 有关详细信息,请参阅 语法和用法说明 。
语法和用法说明
-
添加外键约束
禁用
INPLACE时支持 该 算法foreign_key_checks。 否则,仅COPY支持算法。ALTER TABLE
tbl1ADD CONSTRAINTfk_nameFOREIGN KEYindex(col1) 参考文献tbl2(col2)referential_actions; -
删除外键约束
ALTER TABLE
tblDROP FOREIGN KEYfk_name;可以在
foreign_key_checks启用或禁用选项的情况下 在线执行删除外键 。如果您不知道特定表上的外键约束的名称,请发出以下语句并在
CONSTRAINT子句中为每个外键 查找约束名称 :SHOW CREATE TABLE
table\ G.或者,查询
INFORMATION_SCHEMA.TABLE_CONSTRAINTS表并使用CONSTRAINT_NAME和CONSTRAINT_TYPE列来标识外键名称。您还可以在单个语句中删除外键及其关联的索引:
ALTER TABLE
tableDROP FOREIGN KEYconstraint,DROP INDEXindex;
如果
要更改的表中已存在
外键
(即,它是
包含
子句
的
子表
FOREIGN KEY ... REFERENCE
),则其他限制适用于联机DDL操作,即使那些不直接涉及外键列的操作:
-
一个
ALTER TABLE子表上可以等待另一个事务提交,如果更改到父表导致子表通过相关的变化ON UPDATE或ON DELETE条款使用CASCADE或SET NULL参数。 -
以同样的方式,如果表是 父表 的外键关系,即使它不包含任何
FOREIGN KEY条款,它可以等待ALTER TABLE完成如果一个INSERT,UPDATE或DELETE声明引起ON UPDATE或ON DELETE动作子表。
下表提供了对表操作的联机DDL支持的概述。 星号表示其他信息,异常或依赖项。 有关详细信息,请参阅 语法和用法说明 。
表15.22表操作的在线DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
改变了
ROW_FORMAT
|
没有 | 是 | 是 | 是 | 没有 |
改变了
KEY_BLOCK_SIZE
|
没有 | 是 | 是 | 是 | 没有 |
| 设置持久表统计信息 | 没有 | 是 | 没有 | 是 | 是 |
| 指定字符集 | 没有 | 是 | 是* | 没有 | 没有 |
| 转换字符集 | 没有 | 没有 | 是* | 没有 | 没有 |
| 优化表格 | 没有 | 是* | 是 | 是 | 没有 |
使用
FORCE
选项
重建
|
没有 | 是* | 是 | 是 | 没有 |
| 执行空重建 | 没有 | 是* | 是 | 是 | 没有 |
| 重命名表格 | 是 | 是 | 没有 | 是 | 是 |
语法和用法说明
-
改变了
ROW_FORMATALTER TABLE
tbl_nameROW_FORMAT =row_format,ALGORITHM = INPLACE,LOCK = NONE;数据进行了大量重组,使其成为一项昂贵的操作。
有关该
ROW_FORMAT选项的 其他信息 ,请参阅 表选项 。 -
改变了
KEY_BLOCK_SIZEALTER TABLE
tbl_nameKEY_BLOCK_SIZE =value,ALGORITHM = INPLACE,LOCK = NONE;数据进行了大量重组,使其成为一项昂贵的操作。
有关该
KEY_BLOCK_SIZE选项的 其他信息 ,请参阅 表选项 。 -
设置持久表统计信息选项
ALTER TABLE
tbl_nameSTATS_PERSISTENT = 0,STATS_SAMPLE_PAGES = 20,STATS_AUTO_RECALC = 1,ALGORITHM = INPLACE,LOCK = NONE;仅修改表元数据。
持续的统计数据包括
STATS_PERSISTENT,STATS_AUTO_RECALC,和STATS_SAMPLE_PAGES。 有关更多信息,请参见 第15.8.10.1节“配置持久优化器统计信息参数” 。 -
指定字符集
ALTER TABLE
tbl_nameCHARACTER SET =charset_name,ALGORITHM = INPLACE,LOCK = NONE;如果新字符编码不同,则重建表。
-
转换字符集
ALTER TABLE
tbl_nameCONVERT TO CHARACTER SETcharset_name,ALGORITHM = COPY;如果新字符编码不同,则重建表。
-
优化表格
优化表
tbl_name;具有
FULLTEXT索引的 表不支持就地操作 。 该操作使用的INPLACE算法,但ALGORITHM和LOCK语法是不允许的。 -
使用
FORCE选项 重建表ALTER TABLE
tbl_nameFORCE,ALGORITHM = INPLACE,LOCK = NONE;使用
ALGORITHM=INPLACEMySQL 5.6.17。ALGORITHM=INPLACE带FULLTEXT索引的 表不支持 。 -
执行“null”重建
ALTER TABLE
tbl_nameENGINE = InnoDB,ALGORITHM = INPLACE,LOCK = NONE;使用
ALGORITHM=INPLACEMySQL 5.6.17。ALGORITHM=INPLACE带FULLTEXT索引的 表不支持 。 -
重命名表格
ALTER TABLE
old_tbl_nameRENAME TOnew_tbl_name,ALGORITHM = INSTANT;可以立即或就地重命名表格。 MySQL重命名与表对应的文件
tbl_name而不进行复制。 (您也可以使用该RENAME TABLE语句重命名表。请参见 第13.1.36节“RENAME TABLE语法” 。)专门为重命名表授予的权限不会迁移到新名称。 必须手动更改它们。
下表概述了对表空间操作的在线DDL支持。 有关详细信息,请参阅 语法和用法说明 。
表15.23表空间操作的联机DDL支持
| 手术 | 瞬间 | 到位 | 重建表 | 允许并发DML | 仅修改元数据 |
|---|---|---|---|---|---|
| 重命名一般表空间 | 没有 | 是 | 没有 | 是 | 是 |
| 启用或禁用常规表空间加密 | 没有 | 是 | 没有 | 是 | 没有 |
| 启用或禁用每表文件表空间加密 | 没有 | 没有 | 是 | 没有 | 没有 |
语法和用法说明
-
重命名一般表空间
ALTER TABLESPACE
tablespace_nameRENAME TOnew_tablespace_name;ALTER TABLESPACE ... RENAME TO使用该INPLACE算法但不支持该ALGORITHM子句。 -
启用或禁用常规表空间加密
ALTER TABLESPACE
tablespace_nameENCRYPTION ='Y';ALTER TABLESPACE ... ENCRYPTION使用该INPLACE算法但不支持该ALGORITHM子句。有关相关信息,请参见 第15.6.3.9节“InnoDB静态数据加密” 。
-
启用或禁用每表文件表空间加密
ALTER TABLE
tbl_nameENCRYPTION ='Y',ALGORITHM = COPY;有关相关信息,请参见 第15.6.3.9节“InnoDB静态数据加密” 。
除了一些
ALTER
TABLE
分区子句之外,分区
InnoDB
表的
联机DDL操作
遵循适用于常规
InnoDB
表
的相同规则
。
某些
ALTER
TABLE
分区子句不会通过与常规非分区
InnoDB
表
相同的内部联机DDL API
。
因此,对
ALTER
TABLE
分区条款的
在线支持
各不相同。
下表显示了每个
ALTER TABLE
分区语句
的联机状态
。
无论使用何种在线DDL API,MySQL都会尝试尽可能减少数据复制和锁定。
ALTER
TABLE
使用
ALGORITHM=COPY
或仅允许
“
ALGORITHM=DEFAULT,
LOCK=DEFAULT
”的
分区选项,使用
COPY
算法
重新分区表
。
换句话说,使用新的分区方案创建新的分区表。
新创建的表包括
ALTER
TABLE
语句
应用的任何更改
,表数据将复制到新表结构中。
表15.24分区操作的在线DDL支持
| 分区条款 | 瞬间 | 到位 | 允许DML | 笔记 |
|---|---|---|---|---|
PARTITION BY |
没有 | 没有 | 没有 |
许可证
ALGORITHM=COPY
,
LOCK={DEFAULT|SHARED|EXCLUSIVE}
|
ADD PARTITION |
没有 | 是* | 是* | ALGORITHM=INPLACE,
LOCK={DEFAULT|NONE|SHARED|EXCLUSISVE}
支持
RANGE
和
LIST
分区,
ALGORITHM=INPLACE,
LOCK={DEFAULT|SHARED|EXCLUSISVE}
for
HASH
和
KEY
分区以及
ALGORITHM=COPY,
LOCK={SHARED|EXCLUSIVE}
所有分区类型。
不复制由
RANGE
或
分区的表的现有数据
LIST
。
ALGORITHM=COPY
对于由
HASH
or
分区的表
,允许并发查询
LIST
,因为MySQL在保持共享锁的同时复制数据。
|
DROP PARTITION |
没有 | 是* | 是* |
|
DISCARD PARTITION |
没有 | 没有 | 没有 |
只允许
ALGORITHM=DEFAULT
,
LOCK=DEFAULT
|
IMPORT PARTITION |
没有 | 没有 | 没有 |
只允许
ALGORITHM=DEFAULT
,
LOCK=DEFAULT
|
TRUNCATE
PARTITION |
没有 | 是 | 是 | 不复制现有数据。 它只删除行; 它不会改变表本身或其任何分区的定义。 |
COALESCE
PARTITION |
没有 | 是* | 没有 | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE}
得到支持。
|
REORGANIZE
PARTITION |
没有 | 是* | 没有 | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE}
得到支持。
|
EXCHANGE
PARTITION |
没有 | 是 | 是 | |
ANALYZE PARTITION |
没有 | 是 | 是 | |
CHECK PARTITION |
没有 | 是 | 是 | |
OPTIMIZE
PARTITION |
没有 | 没有 | 没有 | ALGORITHM
和
LOCK
条款被忽略。
重建整个表格。
请参见
第23.3.4节“分区维护”
。
|
REBUILD PARTITION |
没有 | 是* | 没有 | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE}
得到支持。
|
REPAIR PARTITION |
没有 | 是 | 是 | |
REMOVE
PARTITIONING |
没有 | 没有 | 没有 |
许可证
ALGORITHM=COPY
,
LOCK={DEFAULT|SHARED|EXCLUSIVE}
|
ALTER
TABLE
分区表上的
非分区联机
操作遵循适用于常规表的相同规则。
但是,
ALTER
TABLE
在每个表分区上执行联机操作,这会导致由于在多个分区上执行操作而对系统资源的需求增加。
有关
ALTER
TABLE
分区子句的
其他信息
,请参阅
分区选项
和
第13.1.9.1节“ALTER TABLE分区操作”
。
有关一般分区的信息,请参见
第23章
分区
。
在线DDL改进了MySQL操作的几个方面:
-
访问该表的应用程序响应更快,因为在DDL操作正在进行时,表上的查询和DML操作可以继续进行。 减少锁定和等待MySQL服务器资源可以实现更高的可伸缩性,即使对于不参与DDL操作的操作也是如此。
-
即时操作仅修改数据字典中的元数据。 表中没有元数据锁,表数据不受影响,使操作瞬间完成。 并发DML不受影响。
-
联机操作可避免与表复制方法关联的磁盘I / O和CPU周期,从而最大限度地减少数据库的总体负载。 最小化负载有助于在DDL操作期间保持良好的性能和高吞吐量。
-
与表复制操作相比,联机操作将更少的数据读入缓冲池,从而减少了从内存中清除频繁访问的数据。 清除频繁访问的数据可能会导致DDL操作后暂时性能下降。
默认情况下,MySQL在DDL操作期间使用尽可能少的锁定。
如果
LOCK
需要,可以为就地操作和一些复制操作指定
该
子句以强制执行更严格的锁定。
如果该
LOCK
子句指定的锁定级别低于特定DDL操作所允许的限制级别,则该语句将失败并显示错误。
LOCK
条款如下所述,按照最少限制的顺序:
-
LOCK=NONE:允许并发查询和DML。
例如,对涉及客户注册或购买的表使用此子句,以避免在冗长的DDL操作期间使表不可用。
-
LOCK=SHARED:允许并发查询但阻止DML。
例如,在数据仓库表中使用此子句,您可以延迟数据加载操作,直到DDL操作完成,但查询不能长时间延迟。
-
LOCK=DEFAULT:允许尽可能多的并发(并发查询,DML或两者)。 省略该
LOCK子句与指定相同LOCK=DEFAULT。当您知道DDL语句的默认锁定级别不会导致表的可用性问题时,请使用此子句。
-
LOCK=EXCLUSIVE:阻止并发查询和DML。
如果主要关注点是在尽可能短的时间内完成DDL操作,则使用此子句,并且不需要并发查询和DML访问。 如果服务器应该处于空闲状态,您也可以使用此子句,以避免意外的表访问。
在线DDL操作可视为分为三个阶段:
-
阶段1:初始化
在初始化阶段,服务器确定在操作期间允许多少并发,同时考虑存储引擎功能,语句中指定的操作以及用户指定的 选项
ALGORITHM和LOCK选项。 在此阶段,将采用共享的可升级元数据锁来保护当前表定义。 -
阶段2:执行
在此阶段,准备并执行该陈述。 元数据锁是否升级为独占取决于初始化阶段评估的因素。 如果需要独占元数据锁定,则仅在语句准备期间进行简要操作。
-
阶段3:提交表定义
在提交表定义阶段,元数据锁升级为独占锁定以驱逐旧表定义并提交新表定义。 授予后,独占元数据锁定的持续时间很短。
由于上面列出的独占元数据锁定要求,联机DDL操作可能必须等待保存表上的元数据锁的并发事务才能提交或回滚。 在DDL操作之前或期间启动的事务可以在要更改的表上保存元数据锁。 在长时间运行或非活动事务的情况下,联机DDL操作可能会超时等待独占元数据锁定。 此外,联机DDL操作请求的挂起的独占元数据锁会阻止表上的后续事务。
以下示例演示了等待独占元数据锁定的联机DDL操作,以及挂起的元数据锁如何阻止表上的后续事务。
第一节:
mysql> CREATE TABLE t1(c1 INT)ENGINE = InnoDB; mysql> START TRANSACTION; mysql> SELECT * FROM t1;
会话1
SELECT
语句在表t1上采用共享元数据锁。
第二节:
mysql> ALTER TABLE t1 ADD COLUMN x INT,ALGORITHM = INPLACE,LOCK = NONE;
会话2中的联机DDL操作(需要对表t1进行独占元数据锁定以提交表定义更改)必须等待会话1事务提交或回滚。
第3节:
mysql> SELECT * FROM t1;
SELECT
会话3中发出
的
语句被阻止,等待
ALTER
TABLE
会话2中
的
操作
请求的独占元数据锁定
被授予。
您可以使用它
SHOW FULL
PROCESSLIST
来确定事务是否在等待元数据锁定。
MySQL的> SHOW FULL PROCESSLIST\G
...
*************************** 2.排******************** *******
Id:5
用户:root
主持人:localhost
db:test
命令:查询
时间:44
状态:等待表元数据锁定
信息:ALTER TABLE t1 ADD COLUMN x INT,ALGORITHM = INPLACE,LOCK = NONE
...
****************************排******************** *******
Id:7
用户:root
主持人:localhost
db:test
命令:查询
时间:5
状态:等待表元数据锁定
信息:SELECT * FROM t1
4行(0.00秒)
元数据锁定信息也通过Performance Schema
metadata_locks
表
公开,该
表提供有关会话之间的元数据锁定依赖关系,会话正在等待的元数据锁定以及当前持有元数据锁定的会话的信息。
有关更多信息,请参见
第26.12.12.3节“metadata_locks表”
。
DDL操作的性能很大程度上取决于操作是否立即执行,是否正确,以及是否重建表。
为了评估一个DDL操作的相对表现,可以比较使用的结果
ALGORITHM=INSTANT
,
ALGORITHM=INPLACE
和
ALGORITHM=COPY
。
也可以在
old_alter_table
启用时
运行语句
以强制使用
ALGORITHM=COPY
。
对于修改表数据的DDL操作,您可以通过查看 命令完成后显示 的 “ 受影响 的 行 ” 值 来确定DDL操作是执行更改还是执行表副本 。 例如:
-
更改列的默认值(快速,不影响表数据):
查询正常,0行受影响(0.07秒)
-
添加索引(需要时间,但
0 rows affected表示不复制表):查询OK,0行受影响(21.42秒)
-
更改列的数据类型(需要大量时间并需要重建表的所有行):
查询OK,受影响的1671168行(1分35.54秒)
在大型表上运行DDL操作之前,请检查操作是快还是慢,如下所示:
-
克隆表结构。
-
使用少量数据填充克隆表。
-
在克隆的表上运行DDL操作。
-
检查 “ 受影响 的 行 ” 值是否为零。 非零值表示操作复制表数据,这可能需要特殊计划。 例如,您可以在计划停机期间执行DDL操作,也可以在每个复制从服务器上执行一次DDL操作。
为了更好地理解与DDL操作相关的MySQL处理,请检查与DDL操作
之前和之后
INFORMATION_SCHEMA
相关的
性能模式和
表,
InnoDB
以查看物理读取,写入,内存分配等的数量。
Performance Schema阶段事件可用于监视
ALTER
TABLE
进度。
请参见
第15.15.1节“使用性能模式监控InnoDB表的ALTER TABLE进度”
。
因为记录由并发DML操作所做的更改所涉及的一些处理工作,然后在最后应用这些更改,所以在线DDL操作可能比阻止来自其他会话的表访问的表复制机制花费更长的时间。 原始性能的降低与使用该表的应用程序的更好响应性相平衡。 在评估更改表结构的技术时,请考虑最终用户对性能的感知,基于诸如网页加载时间等因素。
现场在线DDL操作的空间要求概述如下。 空间要求不适用于立即执行的操作。
-
临时日志文件的空间
当联机DDL操作创建索引或更改表时,临时日志文件记录并发DML。 临时日志文件根据需要扩展,
innodb_sort_buffer_size最大值由指定的最大值innodb_online_alter_log_max_size。 如果临时日志文件超出大小限制,则联机DDL操作将失败,并且将回滚未提交的并发DML操作。 较大的innodb_online_alter_log_max_size设置允许在联机DDL操作期间使用更多DML,但是当表被锁定以应用记录的DML时,它还会延长DDL操作结束时的时间段。如果操作需要很长时间并且并发DML修改表太多以至于临时日志文件的大小超过了值
innodb_online_alter_log_max_size,则联机DDL操作将失败并显示DB_ONLINE_LOG_TOO_BIG错误。 -
临时排序文件的空间
重建表的联机DDL操作将临时排序文件写入MySQL临时目录(
$TMPDIR在Unix上,%TEMP%在Windows上,或由--tmpdir)在索引创建期间。 不会在包含原始表的目录中创建临时排序文件。 每个临时排序文件都足够大,可以容纳所有二级索引列以及聚簇索引的主键列。 一旦将内容合并到最终表或索引中,就会删除临时排序文件。 临时排序文件可能需要的空间等于表中的数据量加上索引。 如果使用数据目录所在的文件系统上的所有可用磁盘空间,则重建表的联机DDL操作将报告错误。如果MySQL临时目录不足以容纳排序文件,请设置
tmpdir为其他目录。 或者,使用在线DDL操作定义单独的临时目录innodb_tmpdir。 引入此选项是为了帮助避免由于大型临时排序文件而可能发生的临时目录溢出。 -
中间表文件的空间
某些重建表的联机DDL操作会在与原始表相同的目录中创建临时中间表文件。 中间表文件可能需要等于原始表大小的空间。 中间表文件名以
#sql-ib前缀 开头, 仅在联机DDL操作期间短暂显示。该
innodb_tmpdir选项不适用于中间表文件。
在引入
在线DDL
之前
,通常的做法是将许多DDL操作组合到一个
ALTER
TABLE
语句中。
因为每个
ALTER
TABLE
语句都涉及复制和重建表,所以一次对同一个表进行多次更改会更有效,因为这些更改都可以通过表的单个重建操作完成。
缺点是涉及DDL操作的SQL代码难以维护并在不同的脚本中重用。
如果每次特定更改都不同,则可能必须
ALTER
TABLE
为每个略有不同的方案
构建新的组合
。
对于可以在线完成的DDL操作,您可以将它们分成单独的
ALTER
TABLE
语句,以便于编写和维护,而不会牺牲效率。
例如,您可能会采用复杂的语句,例如:
ALTER TABLE t1 ADD INDEX i1(c1),ADD UNIQUE INDEX i2(c2), CHANGE c4_old_name c4_new_name INTEGER UNSIGNED;
并将其分解为可以独立测试和执行的更简单的部分,例如:
ALTER TABLE t1 ADD INDEX i1(c1); ALTER TABLE t1 ADD UNIQUE INDEX i2(c2); ALTER TABLE t1 CHANGE c4_old_name c4_new_name INTEGER UNSIGNED NOT NULL;
您仍可以使用多部分
ALTER
TABLE
语句:
-
必须以特定顺序执行的操作,例如创建索引,后跟使用该索引的外键约束。
-
所有使用相同特定
LOCK子句的操作,您希望作为一个组成功或失败。 -
无法在线执行的操作,即仍使用表复制方法的操作。
-
您指定的操作,
ALGORITHM=COPY或者old_alter_table=1如果需要,强制执行表复制行为,以便在特定方案中实现精确的向后兼容性。
在线DDL操作失败通常是由于以下条件之一:
-
一个
ALGORITHM子句指定的算法是不与特定类型的DDL操作或存储引擎的兼容。 -
甲
LOCK子句指定低程度的锁定(的SHARED或NONE),其不与特定类型的DDL操作兼容。 -
等待 表上的 独占锁 时发生超时 ,这可能在DDL操作的初始阶段和最后阶段期间短暂需要。
-
该
tmpdir或innodb_tmpdir文件系统运行的磁盘空间,而MySQL索引的创建过程中,在磁盘上写入临时排序文件。 有关更多信息,请参见 第15.12.3节“在线DDL空间要求” 。 -
该操作需要很长时间,并发DML会对表进行修改,使得临时在线日志的大小超过
innodb_online_alter_log_max_size配置选项 的值 。 这种情况会导致DB_ONLINE_LOG_TOO_BIG错误。 -
并发DML对原始表定义允许的表进行更改,但不对新表进行更改。 当MySQL尝试应用并发DML语句中的所有更改时,操作仅在最后失败。 例如,您可以在创建唯一索引时将重复值插入到列中,也可以
NULL在该列上创建 主键 索引 时 将 值插入 列中。 并发DML所做的更改优先,并且ALTER TABLE操作有效地 回滚 。
以下限制适用于在线DDL操作:
-
在a上创建索引时会复制该表
TEMPORARY TABLE。 -
如果表中存在 或有 约束条件,则 不允许使用 该
ALTER TABLE子句 。LOCK=NONEON...CASCADEON...SET NULL -
在就地联机DDL操作完成之前,它必须等待保存表上的元数据锁的事务提交或回滚。 在线DDL操作可能会在执行阶段短暂地要求对表进行独占元数据锁定,并且在更新表定义时始终需要在操作的最后阶段使用一个。 因此,在表上保存元数据锁的事务可能导致联机DDL操作被阻止。 在表DDL操作之前或期间可能已经启动了在表上保存元数据锁的事务。 在表上保存元数据锁的长时间运行或非活动事务可能导致联机DDL操作超时。
-
运行就地联机DDL操作时,运行该
ALTER TABLE语句 的线程将 应用从其他连接线程在同一表上并发运行的DML操作的联机日志。 应用DML操作时,可能会遇到重复的密钥输入错误( ERROR 1062(23000):重复条目 ),即使重复条目只是临时条目,也会被在线日志中的后续条目恢复。 这类似于外键约束检入的想法,InnoDB其中约束必须在事务期间保持。 -
OPTIMIZE TABLE对于InnoDB表,映射到ALTER TABLE重建表并更新索引统计信息和释放聚簇索引中未使用空间的操作。 辅助索引的创建效率不高,因为密钥是按照它们在主键中出现的顺序插入的。OPTIMIZE TABLE支持添加在线DDL支持以重建常规InnoDB表 和分区 表。 -
在MySQL 5.6之前创建的表包括时间列(
DATE,DATETIME或TIMESTAMP),并且尚未使用ALGORITHM=COPY不支持 重建ALGORITHM=INPLACE。 在这种情况下,ALTER TABLE ... ALGORITHM=INPLACE操作返回以下错误:ERROR 1846(0A000):不支持ALGORITHM = INPLACE。 原因:无法更改列类型INPLACE。尝试ALGORITHM = COPY。
-
以下限制通常适用于涉及重建表的大型表的联机DDL操作:
-
没有机制可以暂停联机DDL操作或限制联机DDL操作的I / O或CPU使用率。
-
如果操作失败,则回滚在线DDL操作可能很昂贵。
-
长时间运行的联机DDL操作可能导致复制滞后。 在从服务器上运行之前,联机DDL操作必须在主服务器上完成运行。 此外,在主服务器上同时处理的DML仅在从服务器上的DDL操作完成后才在从服务器上处理。
有关在大型表上运行联机DDL操作的其他信息,请参见 第15.12.2节“联机DDL性能和并发” 。
-
-
可以在服务器启动时通过命名它们来启用真或假的系统变量,或者使用
--skip-前缀 禁用它们 。 例如,要启用或禁用InnoDB自适应哈希索引,可以使用--innodb-adaptive-hash-index或--skip-innodb-adaptive-hash-index在命令行上,innodb_adaptive_hash_index或skip_innodb_adaptive_hash_index在选项文件中使用。 -
采用数值的系统变量可以 在命令行中或 在选项文件中指定。
--var_name=valuevar_name=value -
许多系统变量可以在运行时更改(请参见 第5.1.9.2节“动态系统变量” )。
-
有关
GLOBAL和SESSION变量范围修饰符的信息,请参阅SET语句文档。 -
某些选项控制
InnoDB数据文件 的位置和布局 。 第15.8.1节“InnoDB启动配置” 解释了如何使用这些选项。 -
您最初可能不会使用的某些选项有助于
InnoDB根据计算机容量和数据库 工作负载 调整 性能特征 。 -
有关指定选项和系统变量的更多信息,请参见 第4.2.2节“指定程序选项” 。
表15.25 InnoDB选项和变量引用
InnoDB命令选项
-
属性 值 命令行格式 --ignore-builtin-innodb[={OFF|ON}]弃用 是(在8.0.3中删除) 系统变量 ignore_builtin_innodb范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 在早期版本的MySQL中,此选项导致服务器的行为就像内置
InnoDB不存在一样,这使得InnoDB Plugin可以使用它。 在MySQL 8.0中,InnoDB是默认存储引擎,InnoDB Plugin未使用。 在MySQL 8.0中删除了此选项。 -
属性 值 命令行格式 --innodb[=value]弃用 是 类型 列举 默认值 ON有效值 OFFONFORCEInnoDB如果服务器是在InnoDB支持 下编译的,则 控制 存储引擎的 加载 。 此选项有三态格式,可能值OFF,ON或FORCE。 请参见 第5.6.1节“安装和卸载插件” 。要禁用
InnoDB,请使用--innodb=OFF或--skip-innodb。 在这种情况下,因为默认存储引擎是InnoDB,服务器不会启动,除非您还使用--default-storage-engine和--default-tmp-storage-engine设置默认值为其他引擎永久和TEMPORARY表的 。该
InnoDB存储引擎可以不再被禁止,并且--innodb=OFF和--skip-innodb选项弃用,没有任何效果。 它们的使用会导致警告。 这些选项将在未来的MySQL版本中删除。 -
属性 值 命令行格式 --innodb-status-file[={OFF|ON}]类型 布尔 默认值 OFF在
--innodb-status-file启动选项控制是否InnoDB创建一个名为文件 在数据目录中,并写入innodb_status.pidSHOW ENGINE INNODB STATUS输出到它每15秒,约。默认情况下不会创建 该 文件。 要创建它,请 使用该 选项 启动 mysqld 。
innodb_status.pid--innodb-status-fileInnoDB在服务器正常关闭时删除文件。 如果发生异常关闭,则可能必须手动删除状态文件。该
--innodb-status-file选项旨在临时使用,因为SHOW ENGINE INNODB STATUS输出生成可能会影响性能,而且innodb_status.文件会随着时间的推移而变得非常大。pid有关相关信息,请参见 第15.16.2节“启用InnoDB监视器” 。
-
禁用
InnoDB存储引擎。 请参阅说明--innodb。
InnoDB系统变量
-
daemon_memcached_enable_binlog属性 值 命令行格式 --daemon-memcached-enable-binlog[={OFF|ON}]系统变量 daemon_memcached_enable_binlog范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF在 主服务器 上启用此选项 以将
InnoDBmemcached 插件(daemon_memcached)与MySQL 二进制日志一起使用 。 此选项只能在服务器启动时设置。 您还必须使用以下命令在主服务器上启用MySQL二进制日志--log-bin选项 。有关更多信息,请参见 第15.19.7节“InnoDB memcached插件和复制” 。
-
daemon_memcached_engine_lib_name属性 值 命令行格式 --daemon-memcached-engine-lib-name=file_name系统变量 daemon_memcached_engine_lib_name范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 默认值 innodb_engine.so指定实现 memcached 的共享库
InnoDB插件 。有关更多信息,请参见 第15.19.3节“设置InnoDB memcached插件” 。
-
daemon_memcached_engine_lib_path属性 值 命令行格式 --daemon-memcached-engine-lib-path=dir_name系统变量 daemon_memcached_engine_lib_path范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 默认值 NULL包含实现
InnoDBmemcached 插件 的共享库的目录的路径 。 默认值为NULL,表示MySQL插件目录。 除非memcached为位于MySQL插件目录之外的其他存储引擎 指定 插件, 否则不需要修改此参数 。有关更多信息,请参见 第15.19.3节“设置InnoDB memcached插件” 。
-
属性 值 命令行格式 --daemon-memcached-option=options系统变量 daemon_memcached_option范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 用于在启动时将空格分隔的memcached选项传递给底层的 memcached 内存对象缓存守护程序。 例如,您可以更改 memcached 的端口 侦听 ,减少最大并发连接数,更改键值对的最大内存大小,或启用错误日志的调试消息。
有关 使用详细信息 , 请参见 第15.19.3节“设置InnoDB memcached插件” 。 有关 memcached 选项的 信息 ,请参阅 memcached 手册页。
-
属性 值 命令行格式 --daemon-memcached-r-batch-size=#系统变量 daemon_memcached_r_batch_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 1指定 在执行 新事务 之前要执行的 memcached 读取操作(
get操作)的数量COMMIT。 对应的daemon_memcached_w_batch_size。默认情况下,此值设置为1,因此通过SQL语句对表所做的任何更改都会立即显示给 memcached 操作。 您可以增加它以减少在仅通过 memcached 接口 访问基础表的系统上频繁提交的开销 。 如果将值设置得太大,则撤消或重做数据的数量可能会产生一些存储开销,就像任何长时间运行的事务一样。
有关更多信息,请参见 第15.19.3节“设置InnoDB memcached插件” 。
-
属性 值 命令行格式 --daemon-memcached-w-batch-size=#系统变量 daemon_memcached_w_batch_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 1指定多少 memcached的 写操作,如
add,set和incr,做一个前执行COMMIT,以启动新的事务。 对应的daemon_memcached_r_batch_size。默认情况下,此值设置为1,前提是存储的数据在发生中断时非常重要,应立即提交。 存储非关键数据时,可以增加此值以减少频繁提交的开销; 但是
N如果发生崩溃 ,最后的 -1次未提交的写操作可能会丢失。有关更多信息,请参见 第15.19.3节“设置InnoDB memcached插件” 。
-
属性 值 命令行格式 --ignore-builtin-innodb[={OFF|ON}]弃用 是(在8.0.3中删除) 系统变量 ignore_builtin_innodb范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 请参阅 本节前面的 “ InnoDB命令选项 ”
--ignore-builtin-innodb下 的说明 。 在MySQL 8.0中删除了此变量。 -
属性 值 命令行格式 --innodb-adaptive-flushing[={OFF|ON}]系统变量 innodb_adaptive_flushing范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指定是否动态调整冲洗速度 脏页 在
InnoDB缓冲池中 ,根据工作负载。 动态调整刷新率旨在避免I / O活动的突发。 默认情况下启用此设置。 有关 更多信息 , 请参见 第15.8.3.5节“配置InnoDB缓冲池刷新” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。 -
属性 值 命令行格式 --innodb-adaptive-flushing-lwm=#系统变量 innodb_adaptive_flushing_lwm范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10最低价值 0最大价值 70定义低水位标记,表示 启用 自适应刷新 的 重做日志 容量的 百分比 。 有关更多信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
属性 值 命令行格式 --innodb-adaptive-hash-index[={OFF|ON}]系统变量 innodb_adaptive_hash_index范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON无论是
InnoDB适应性的散列索引 被启用或禁用。 根据您的工作负载,可能需要动态启用或禁用 自适应哈希索引 以提高查询性能。 由于自适应哈希索引可能对所有工作负载都没有用,因此可以使用实际工作负载来启用和禁用基准测试。 有关 详细信息 , 请参见 第15.5.3节“自适应哈希索引” 。默认情况下启用此变量。 您可以使用该
SET GLOBAL语句 修改此参数 ,而无需重新启动服务器。 在运行时更改设置需要足以设置全局系统变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。 您也可以--skip-innodb-adaptive-hash-index在服务器启动时 使用 它来禁用它。禁用自适应哈希索引会立即清空哈希表。 当哈希表被清空时,正常操作可以继续,并且执行使用哈希表的查询直接访问索引B树。 当重新启用自适应哈希索引时,在正常操作期间再次填充哈希表。
-
innodb_adaptive_hash_index_parts属性 值 命令行格式 --innodb-adaptive-hash-index-parts=#系统变量 innodb_adaptive_hash_index_parts范围 全球 动态 没有 SET_VAR提示适用没有 类型 数字 默认值 8最低价值 1最大价值 512分区自适应哈希索引搜索系统。 每个索引都绑定到一个特定的分区,每个分区都由一个单独的锁存器保护。
自适应哈希索引搜索系统默认分为8个部分。 最大设置为512。
有关相关信息,请参见 第15.5.3节“自适应哈希索引” 。
-
innodb_adaptive_max_sleep_delay属性 值 命令行格式 --innodb-adaptive-max-sleep-delay=#系统变量 innodb_adaptive_max_sleep_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 150000最低价值 0最大价值 1000000允许 根据当前工作负载
InnoDB自动调整innodb_thread_sleep_delay向上或向下 的值 。 任何非零值都可以自动动态调整innodb_thread_sleep_delay值,直到innodb_adaptive_max_sleep_delay选项中 指定的最大值 。 该值表示微秒数。 此选项在繁忙系统中非常有用,超过16个InnoDB线程。 (实际上,对于具有数百或数千个同时连接的MySQL系统,它是最有价值的。)有关更多信息,请参见 第15.8.4节“为InnoDB配置线程并发” 。
-
属性 值 命令行格式 --innodb-api-bk-commit-interval=#系统变量 innodb_api_bk_commit_interval范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 5最低价值 1最大价值 1073741824在几秒钟内 自动提交使用
InnoDBmemcached 接口的 空闲连接的频率 。 有关更多信息,请参见 第15.19.6.4节“控制InnoDB memcached插件的事务行为” 。 -
属性 值 命令行格式 --innodb-api-disable-rowlock[={OFF|ON}]系统变量 innodb_api_disable_rowlock范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF当
InnoDBmemcached 执行DML操作 时,使用此选项禁用行锁 。 默认情况下,innodb_api_disable_rowlock禁用,这意味着 memcached 请求行锁定get和set操作。 当innodb_api_disable_rowlock启用时, 分布式缓存 请求表锁,而不是行锁。innodb_api_disable_rowlock不是动态的。 它必须在 mysqld 命令行中 指定 或输入MySQL配置文件。 安装插件时配置生效,这在MySQL服务器启动时发生。有关更多信息,请参阅 第15.19.6.4节“控制InnoDB memcached插件的事务行为” 。
-
属性 值 命令行格式 --innodb-api-enable-binlog[={OFF|ON}]系统变量 innodb_api_enable_binlog范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF允许您将
InnoDBmemcached 插件与MySQL 二进制日志一起使用 。 有关更多信息,请参阅 启用InnoDB memcached二进制日志 。 -
属性 值 命令行格式 --innodb-api-enable-mdl[={OFF|ON}]系统变量 innodb_api_enable_mdl范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF锁定
InnoDBmemcached 插件 使用的表 ,以便 DDL 不能通过SQL接口 删除或更改它 。 有关更多信息,请参见 第15.19.6.4节“控制InnoDB memcached插件的事务行为” 。 -
属性 值 命令行格式 --innodb-api-trx-level=#系统变量 innodb_api_trx_level范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0控制 memcached 接口 处理的查询 的事务 隔离级别 。 与熟悉的名称对应的常量是:
-
0 =
READ UNCOMMITTED -
1 =
READ COMMITTED -
2 =
REPEATABLE READ -
3 =
SERIALIZABLE
有关更多信息,请参见 第15.19.6.4节“控制InnoDB memcached插件的事务行为” 。
-
-
属性 值 命令行格式 --innodb-autoextend-increment=#系统变量 innodb_autoextend_increment范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 64最低价值 1最大价值 1000增量大小(以兆字节为单位),用于在自动扩展
InnoDB系统表空间 文件变满时 扩展其大小 。 默认值为64.有关相关信息,请参阅 系统表空间数据文件配置 和 调整系统表空间大小 。该
innodb_autoextend_increment设置不会影响 每 表文件 表 空间文件或 常规表空间 文件。 无论innodb_autoextend_increment设置 如何,这些文件都是自动扩展的 。 初始扩展是少量的,之后扩展以4MB的增量发生。 -
属性 值 命令行格式 --innodb-autoinc-lock-mode=#系统变量 innodb_autoinc_lock_mode范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.3) 2默认值 (<= 8.0.2) 1有效值 012用于生成 的 锁定模式 自动增量 值 。 对于传统,连续或交错,允许值分别为0,1或2。
从MySQL 8.0开始,默认设置为2(交错),之前为1(连续)。 将交叉锁定模式更改为默认设置反映了从基于语句的复制到基于行的复制的更改,作为默认复制类型(在MySQL 5.7中发生)。 基于语句的复制需要连续的自动增量锁定模式,以确保为给定的SQL语句序列以可预测和可重复的顺序分配自动增量值,而基于行的复制对SQL语句的执行顺序不敏感。
有关每种锁定模式的特性,请参阅 InnoDB AUTO_INCREMENT锁定模式 。
-
innodb_background_drop_list_empty属性 值 命令行格式 --innodb-background-drop-list-empty[={OFF|ON}]系统变量 innodb_background_drop_list_empty范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用
innodb_background_drop_list_empty调试选项可以通过延迟表创建直到后台下拉列表为空来帮助避免测试用例失败。 例如,如果测试用例A将表t1放在后台下拉列表中,则测试用例B将等待,直到后台下拉列表为空,然后再创建表t1。 -
属性 值 命令行格式 --innodb-buffer-pool-chunk-size=#系统变量 innodb_buffer_pool_chunk_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 134217728最低价值 1048576最大价值 innodb_buffer_pool_size / innodb_buffer_pool_instancesinnodb_buffer_pool_chunk_size定义InnoDB缓冲池大小调整操作 的块大小 。 该innodb_buffer_pool_size参数是动态的,允许您在不重新启动服务器的情况下调整缓冲池的大小。为避免在调整大小操作期间复制所有缓冲池页面,操作以 “ 块 ” 执行 。 默认情况下,
innodb_buffer_pool_chunk_size为128MB(134217728字节)。 块中包含的页数取决于的值innodb_page_size。innodb_buffer_pool_chunk_size可以以1MB(1048576字节)为单位增加或减少。更改
innodb_buffer_pool_chunk_size值 时,以下条件适用 :-
如果 初始化缓冲池时
innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances大于当前缓冲池大小,innodb_buffer_pool_chunk_size则截断为innodb_buffer_pool_size/innodb_buffer_pool_instances。 -
缓冲池大小必须始终等于
innodb_buffer_pool_chunk_size* 的倍数或倍数innodb_buffer_pool_instances。 如果更改innodb_buffer_pool_chunk_size,innodb_buffer_pool_size则会自动舍入为等于或等于innodb_buffer_pool_chunk_size*的值innodb_buffer_pool_instances。 初始化缓冲池时会进行调整。
重要更改时应小心
innodb_buffer_pool_chunk_size,因为更改此值可以自动增加缓冲池的大小。 在更改之前innodb_buffer_pool_chunk_size,请计算它将产生的影响,innodb_buffer_pool_size以确保生成的缓冲池大小可以接受。为避免潜在的性能问题,块数(
innodb_buffer_pool_size/innodb_buffer_pool_chunk_size)不应超过1000。有关 更多信息 , 请参见 第15.8.3.1节“配置InnoDB缓冲池大小” 。
-
-
属性 值 命令行格式 --innodb-buffer-pool-debug[={OFF|ON}]系统变量 innodb_buffer_pool_debug范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF当缓冲池的大小小于1GB时,启用此选项允许多个缓冲池实例,忽略强加的1GB最小缓冲池大小约束
innodb_buffer_pool_instances。 该innodb_buffer_pool_debug选项仅在使用 CMake 选项 编译调试支持时可用 。WITH_DEBUG -
innodb_buffer_pool_dump_at_shutdown属性 值 命令行格式 --innodb-buffer-pool-dump-at-shutdown[={OFF|ON}]系统变量 innodb_buffer_pool_dump_at_shutdown范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指定 在MySQL服务器关闭时 是否记录
InnoDB缓冲池中 缓存的页面 ,以便 在下次重新启动时 缩短 预热 过程。 通常与innodb_buffer_pool_load_at_startup。 结合使用 。 该innodb_buffer_pool_dump_pct选项定义要转储的最近使用的缓冲池页面的百分比。双方
innodb_buffer_pool_dump_at_shutdown并innodb_buffer_pool_load_at_startup默认启用。有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
属性 值 命令行格式 --innodb-buffer-pool-dump-now[={OFF|ON}]系统变量 innodb_buffer_pool_dump_now范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF立即记录
InnoDB缓冲池中 缓存的页面 。 通常与innodb_buffer_pool_load_now。 结合使用 。有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
属性 值 命令行格式 --innodb-buffer-pool-dump-pct=#系统变量 innodb_buffer_pool_dump_pct范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 25最低价值 1最大价值 100指定每个缓冲池最近使用的页面读取和转储的百分比。 范围是1到100.默认值是25.例如,如果有4个缓冲池,每个缓冲池有100个页面,并且
innodb_buffer_pool_dump_pct设置为25,则转储每个缓冲池中最近使用的25个页面。 -
属性 值 命令行格式 --innodb-buffer-pool-filename=file_name系统变量 innodb_buffer_pool_filename范围 全球 动态 是 SET_VAR提示适用没有 类型 文件名 默认值 ib_buffer_pool指定包含由
innodb_buffer_pool_dump_at_shutdownor 生成的表空间ID和页面ID列表的文件的名称innodb_buffer_pool_dump_now。 表空间ID和页面ID以以下格式保存:space, page_id。 默认情况下,该文件已命名ib_buffer_pool并位于InnoDB数据目录中。 必须相对于数据目录指定非默认位置。可以使用以下
SET语句 在运行时指定文件名 :SET GLOBAL innodb_buffer_pool_filename =
'file_name';您还可以在启动时,在启动字符串或MySQL配置文件中指定文件名。 在启动时指定文件名时,该文件必须存在或
InnoDB将返回启动错误,指示没有此类文件或目录。有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
innodb_buffer_pool_in_core_file属性 值 命令行格式 --innodb-buffer-pool-in-core-file[={OFF|ON}]介绍 8.0.14 系统变量 innodb_buffer_pool_in_core_file范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ONinnodb_buffer_pool_in_core_file通过排除InnoDB缓冲池页面来 禁用该 变量可以减小核心文件的大小 。 要使用此变量,core_file必须启用 该变量, 并且操作系统必须支持MADV_DONTDUMP非POSIX扩展madvise(),Linux 3.4及更高版本 支持该 扩展 。 有关更多信息,请参见 第15.8.3.8节“从核心文件中排除缓冲池页面” 。 -
属性 值 命令行格式 --innodb-buffer-pool-instances=#系统变量 innodb_buffer_pool_instances范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 (其他) 8 (or 1 if innodb_buffer_pool_size < 1GB默认值 (Windows,32位平台) (autosized)最低价值 1最大价值 64InnoDB缓冲池 分区 的区域数 。 对于具有数千兆字节范围的缓冲池的系统,将缓冲池划分为单独的实例可以通过减少不同线程读取和写入缓存页面时的争用来提高并发性。 存储在缓冲池中或从缓冲池读取的每个页面都使用散列函数随机分配给其中一个缓冲池实例。 每个缓冲池管理自己的空闲列表, 刷新列表 , LRU 以及连接到缓冲池的所有其他数据结构,并受其自己的缓冲池 互斥锁 保护 。此选项仅在设置
innodb_buffer_pool_size为1GB或更多 时生效 。 总缓冲池大小在所有缓冲池之间划分。 为了获得最佳效率,指定的组合innodb_buffer_pool_instances和innodb_buffer_pool_size,使得每个缓冲池实例是至少为1GB。32位Windows系统上的默认值取决于值
innodb_buffer_pool_size,如下所述:-
如果
innodb_buffer_pool_size大于1.3GB,则默认innodb_buffer_pool_instances值为innodb_buffer_pool_size/ 128MB,每个块具有单独的内存分配请求。 选择1.3GB作为边界,32位Windows无法分配单个缓冲池所需的连续地址空间。 -
否则,默认值为1。
在所有其他平台上,当
innodb_buffer_pool_size大于或等于1GB 时,默认值为8 。 否则,默认值为1。有关相关信息,请参见 第15.8.3.1节“配置InnoDB缓冲池大小” 。
-
-
属性 值 命令行格式 --innodb-buffer-pool-load-abort[={OFF|ON}]系统变量 innodb_buffer_pool_load_abort范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF中断恢复 由 或 触发的
InnoDB缓冲池 内容 的过程 。innodb_buffer_pool_load_at_startupinnodb_buffer_pool_load_now有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
innodb_buffer_pool_load_at_startup属性 值 命令行格式 --innodb-buffer-pool-load-at-startup[={OFF|ON}]系统变量 innodb_buffer_pool_load_at_startup范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 ON指定在MySQL服务器启动时,
InnoDB缓冲池 通过加载较早时保存的相同页面 自动 预热 。 通常与innodb_buffer_pool_dump_at_shutdown。 结合使用 。双方
innodb_buffer_pool_dump_at_shutdown并innodb_buffer_pool_load_at_startup默认启用。有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
属性 值 命令行格式 --innodb-buffer-pool-load-now[={OFF|ON}]系统变量 innodb_buffer_pool_load_now范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF立即 升温 的
InnoDB缓冲池 通过装载一组数据页面,无需等待服务器重新启动。 在基准测试期间将高速缓存存储器恢复到已知状态,或者在运行查询报告或维护后让MySQL服务器恢复正常工作负载可能很有用。有关更多信息,请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
-
属性 值 命令行格式 --innodb-buffer-pool-size=#系统变量 innodb_buffer_pool_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 134217728最低价值 5242880最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1缓冲池 的大小(以字节为单位) ,
InnoDB缓存表和索引数据 的内存区域 。 默认值为134217728字节(128MB)。 最大值取决于CPU架构; 在32位系统上 最大值为4294967295(2 32 -1), 在64位系统上 最大值为 18446744073709551615(2 64 -1)。 在32位系统上,CPU架构和操作系统可能会施加比实际最大值更小的实际最大值。 当缓冲池的大小大于1GB时,设置innodb_buffer_pool_instances为大于1的值可以提高繁忙服务器的可伸缩性。较大的缓冲池需要较少的磁盘I / O来多次访问相同的表数据。 在专用数据库服务器上,您可以将缓冲池大小设置为计算机物理内存大小的80%。 配置缓冲池大小时,请注意以下潜在问题,并准备在必要时缩小缓冲池的大小。
-
物理内存的竞争可能导致操作系统中的分页。
-
InnoDB为缓冲区和控制结构保留额外的内存,以便总分配空间比指定的缓冲池大小大约10%。 -
缓冲池的地址空间必须是连续的,这在带有在特定地址加载的DLL的Windows系统上可能是一个问题。
-
初始化缓冲池的时间大致与其大小成比例。 在具有大缓冲池的实例上,初始化时间可能很长。 要减少初始化时间,可以在服务器关闭时保存缓冲池状态,并在服务器启动时将其还原。 请参见 第15.8.3.7节“保存和恢复缓冲池状态” 。
增大或减小缓冲池大小时,操作将以块的形式执行。 块大小由
innodb_buffer_pool_chunk_size配置选项 定义, 默认值为128 MB。缓冲池大小必须始终等于
innodb_buffer_pool_chunk_size* 的倍数或倍数innodb_buffer_pool_instances。 如果将缓冲池大小更改为不等于innodb_buffer_pool_chunk_size* 或 * 的倍数innodb_buffer_pool_instances,则缓冲池大小将自动调整为等于innodb_buffer_pool_chunk_size* 的倍数或 * 的倍数innodb_buffer_pool_instances。innodb_buffer_pool_size可以动态设置,这允许您在不重新启动服务器的情况下调整缓冲池的大小。 该Innodb_buffer_pool_resize_status状态变量报告在线缓冲池的大小调整操作的状态。 有关 更多信息 , 请参见 第15.8.3.1节“配置InnoDB缓冲池大小” 。如果
innodb_dedicated_server启用,innodb_buffer_pool_size则在未明确定义值的情况下自动配置 该 值。 有关更多信息,请参见 第15.8.12节“为专用MySQL服务器启用自动配置” 。 -
-
属性 值 命令行格式 --innodb-change-buffer-max-size=#系统变量 innodb_change_buffer_max_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 25最低价值 0最大价值 50InnoDB更改缓冲区的 最大大小 ,占 缓冲池 总大小的百分比 。 您可以为具有大量插入,更新和删除活动的MySQL服务器增加此值,或者为具有用于报告的不变数据的MySQL服务器减少该值。 有关更多信息,请参见 第15.5.2节“更改缓冲区” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。 -
属性 值 命令行格式 --innodb-change-buffering=value系统变量 innodb_change_buffering范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 all有效值 noneinsertsdeleteschangespurgesall是否
InnoDB执行 更改缓冲 ,将写操作延迟到二级索引的优化,以便可以按顺序执行I / O操作。 允许的值在下表中描述。 值也可以用数字指定。表15.26 innodb_change_buffering的允许值
值 数值 描述 none0不要缓冲任何操作。 inserts1缓冲插入操作。 deletes2缓冲删除标记操作; 严格地说,标记索引的写入记录以便在清除操作期间稍后删除。 changes3缓冲区插入和删除标记操作。 purges4缓冲后台发生的物理删除操作。 all5默认。 缓冲区插入,删除标记操作和清除。
有关更多信息,请参见 第15.5.2节“更改缓冲区” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-change-buffering-debug=#系统变量 innodb_change_buffering_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最大价值 2设置
InnoDB更改缓冲 的调试标志 。 值为1会强制更改缓冲区的所有更改。 值为2会导致合并时崩溃。 默认值0表示未设置更改缓冲调试标志。 只有在使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-checkpoint-disabled[={OFF|ON}]介绍 8.0.2 系统变量 innodb_checkpoint_disabled范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF这是一个调试选项,仅供专家调试使用。 它禁用检查点,以便故意服务器退出始终启动
InnoDB恢复。 它应该只在短时间间隔内启用,通常在运行DML操作之前,这些操作会写入需要在服务器退出后进行恢复的重做日志条目。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-checksum-algorithm=value系统变量 innodb_checksum_algorithm范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 crc32有效值 innodbcrc32nonestrict_innodbstrict_crc32strict_none指定如何生成和验证 存储在 表空间 磁盘块中 的 校验和 。 is 的默认值 。
InnoDBinnodb_checksum_algorithmcrc32高达3.8.0 的 MySQL Enterprise Backup 版本 不支持备份使用CRC32校验和的表空间。 MySQL Enterprise Backup 在3.8.1中添加了CRC32校验和支持,但有一些限制。 有关更多信息, 请参阅 MySQL Enterprise Backup 3.8.1更改历史记录。
该值
innodb与早期版本的MySQL向后兼容。 该值crc32使用一种算法,该算法可以更快地计算每个已修改块的校验和,并检查每个磁盘读取的校验和。 它一次扫描32位块,这比innodb校验和算法 快 ,后者每次扫描块8位。 该值none在校验和字段中写入常量值,而不是根据块数据计算值。 表空间中的块可以使用旧的,新的和没有校验和值的混合,随着数据的修改逐渐更新; 一旦表空间中的块被修改为使用crc32算法,早期版本的MySQL无法读取关联的表。校验和算法的严格形式如果在表空间中遇到有效但不匹配的校验和值,则报告错误。 建议您仅在新实例中使用严格设置,以便首次设置表空间。 严格的设置有点快,因为它们不需要在磁盘读取期间计算所有校验和值。
下表显示了之间的区别
none,innodb和crc32选项值,和他们同行的严格。none,innodb并将crc32指定类型的校验和值写入每个数据块,但为了兼容性,在读取操作期间验证块时接受其他校验和值。 严格设置也接受有效的校验和值,但在遇到有效的不匹配校验和值时打印错误消息。 如果InnoDB实例中的 所有 数据文件都是在相同的innodb_checksum_algorithm值 下创建的, 则使用strict表单可以加快验证速度 。表15.27允许的innodb_checksum_algorithm值
值 生成的校验和(写入时) 允许的校验和(阅读时) 没有 一个常数。 任何校验的产生通过 none,innodb或crc32。InnoDB的 校验和用软件计算,使用原始算法 InnoDB。任何校验的产生通过 none,innodb或crc32。CRC32 使用 crc32算法 计算的校验和 ,可能使用硬件辅助完成。任何校验的产生通过 none,innodb或crc32。strict_none 一个常数 任何校验的产生通过 none,innodb或crc32。InnoDB如果遇到有效但不匹配的校验和,则会输出错误消息。strict_innodb 校验和用软件计算,使用原始算法 InnoDB。任何校验的产生通过 none,innodb或crc32。InnoDB如果遇到有效但不匹配的校验和,则会输出错误消息。strict_crc32 使用 crc32算法 计算的校验和 ,可能使用硬件辅助完成。任何校验的产生通过 none,innodb或crc32。InnoDB如果遇到有效但不匹配的校验和,则会输出错误消息。
-
属性 值 命令行格式 --innodb-cmp-per-index-enabled[={OFF|ON}]系统变量 innodb_cmp_per_index_enabled范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF在
INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表中 启用与索引压缩相关的统计信息 。 由于这些统计信息的收集成本很高,因此只能在与InnoDB压缩 表 相关的性能调整期间在开发,测试或从属实例上启用此选项 。有关更多信息,请参见 第25.39.7节“INFORMATION_SCHEMA INNODB_CMP_PER_INDEX和INNODB_CMP_PER_INDEX_RESET表” 和 第15.9.1.4节“在运行时监视InnoDB表压缩” 。
-
属性 值 命令行格式 --innodb-commit-concurrency=#系统变量 innodb_commit_concurrency范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1000可以同时 提交 的 线程 数 。 值0(默认值)允许 同时提交 任意数量的 事务 。
innodb_commit_concurrency在运行时不能将 值 从零更改为非零,反之亦然。 该值可以从一个非零值更改为另一个非零值。 -
属性 值 命令行格式 --innodb-compress-debug=value系统变量 innodb_compress_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 none有效值 nonezliblz4lz4hc使用指定的压缩算法压缩所有表,而无需
COMPRESSION为每个表 定义 属性。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG有关相关信息,请参见 第15.9.2节“InnoDB页面压缩” 。
-
innodb_compression_failure_threshold_pct属性 值 命令行格式 --innodb-compression-failure-threshold-pct=#系统变量 innodb_compression_failure_threshold_pct范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 5最低价值 0最大价值 100以百分比形式定义表的压缩失败率阈值,此时MySQL开始在 压缩 页面中 添加填充 以避免昂贵的 压缩失败 。 当此阈值通过时,MySQL开始在每个新压缩页面中留出额外的可用空间,动态调整可用空间量,直至指定的页面大小百分比
innodb_compression_pad_pct_max。 值为零会禁用监视压缩效率并动态调整填充量的机制。有关更多信息,请参见 第15.9.1.6节“OLTP工作负载压缩” 。
-
属性 值 命令行格式 --innodb-compression-level=#系统变量 innodb_compression_level范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 6最低价值 0最大价值 9指定用于
InnoDB压缩 表和索引 的zlib压缩级别 。 较高的值允许您将更多数据放入存储设备,但代价是压缩期间的CPU开销更大。 较低的值可以在存储空间不重要时降低CPU开销,或者您希望数据不是特别可压缩的。有关更多信息,请参见 第15.9.1.6节“OLTP工作负载压缩” 。
-
innodb_compression_pad_pct_max属性 值 命令行格式 --innodb-compression-pad-pct-max=#系统变量 innodb_compression_pad_pct_max范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 0最大价值 75指定可以在每个压缩 页面中 保留为可用空间的最大百分比 ,允许在 更新 压缩 表或索引并且可以重新压缩数据 时重新组织页面内的数据和修改日志 。 仅在
innodb_compression_failure_threshold_pct设置为非零值时应用,并且 压缩失败 率 超过截止点。有关更多信息,请参见 第15.9.1.6节“OLTP工作负载压缩” 。
-
属性 值 命令行格式 --innodb-concurrency-tickets=#系统变量 innodb_concurrency_tickets范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 5000最低价值 1最大价值 4294967295确定 可以 并发 输入 的 线程 数
InnoDB。 如果线程InnoDB数已达到并发限制,则线程 在尝试输入时将进入队列 。 当允许一个线程进入时InnoDB,会给它一些 等于值 的 “ 票证 ”innodb_concurrency_tickets,并且线程可以InnoDB自由 进入和离开 ,直到它用完了票。 在那之后,线程在下次尝试输入时再次受到并发检查(以及可能的排队)的影响InnoDB。 默认值为5000。使用较小的
innodb_concurrency_tickets值,只需要处理几行的小事务就可以与处理多行的较大事务公平竞争。 小innodb_concurrency_tickets值 的缺点 是大型事务必须在完成之前多次遍历队列,这会延长完成任务所需的时间。使用较大的
innodb_concurrency_tickets值时,较大的事务花费较少的时间等待队列末尾的位置(受控制innodb_thread_concurrency)以及更多时间检索行。 大型事务还需要较少的队列访问才能完成任务。 大innodb_concurrency_tickets值 的缺点 是,同时运行的大量事务可能会使较小的事务在执行前等待较长时间而使较小的事务处于饥饿状态。使用非零
innodb_thread_concurrency值时,您可能需要innodb_concurrency_tickets向上或向下 调整 值以找到较大和较小事务之间的最佳平衡。 该SHOW ENGINE INNODB STATUS报告显示执行事务在其当前通过队列时剩余的票数。 该数据也可以从 表格 的TRX_CONCURRENCY_TICKETS列中获得INFORMATION_SCHEMA.INNODB_TRX。有关更多信息,请参见 第15.8.4节“为InnoDB配置线程并发” 。
-
属性 值 命令行格式 --innodb-data-file-path=file_name系统变量 innodb_data_file_path范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 ibdata1:12M:autoextend定义
InnoDB系统表空间 数据文件 的名称,大小和属性 。 如果没有为其指定值innodb_data_file_path,则默认行为是创建一个名称略大于12MB的自动扩展数据文件ibdata1。数据文件规范的完整语法包括文件名,文件大小
autoextend和max属性:file_name:file_size[:autoextend [:max:max_file_size]]文件大小是由附加指定KB,MB或GB(1024MB)
K,M或G到大小值。 如果以千字节(KB)指定数据文件大小,请以1024的倍数执行此操作。否则,KB值将四舍五入为最接近的兆字节(MB)边界。 文件大小的总和必须至少略大于12MB。为第 一个 系统表空间数据文件 强制实施最小文件大小, 以确保有足够的空间用于双写缓冲区页面:
-
对于
innodb_page_size16KB或更小 的 值,最小文件大小为3MB。 -
对于
innodb_page_size32KB 的 值,最小文件大小为6MB。 -
对于
innodb_page_size64KB 的 值,最小文件大小为12MB。
单个文件的大小限制由您的操作系统决定。 您可以在支持大文件的操作系统上将文件大小设置为4GB以上。 您还可以 将原始磁盘分区用作数据文件 。
该
autoextend和max属性只能用于将最后一个指定的数据文件中使用innodb_data_file_path的设置。 例如:的[mysqld] innodb_data_file_path中= ibdata1中:50M; ibdata2:12M:自动扩展:最大:500MB
如果指定该
autoextend选项,则InnoDB在数据文件用尽可用空间时扩展该数据文件。autoextend默认情况下 , 增量为64MB。 要修改增量,请更改innodb_autoextend_increment系统变量。系统表空间数据文件的完整目录路径是通过连接由
innodb_data_home_dir和 定义的路径形成的innodb_data_file_path。有关配置系统表空间数据文件的更多信息,请参见 第15.8.1节“InnoDB启动配置” 。
-
-
属性 值 命令行格式 --innodb-data-home-dir=dir_name系统变量 innodb_data_home_dir范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 InnoDB系统表空间 数据文件 的目录路径的公共部分 。 启用 时, 此设置不会影响 每个表文件表 空间 的位置innodb_file_per_table。 默认值是MySQLdata目录。 如果将值指定为空字符串,则可以为其指定绝对文件路径innodb_data_file_path。指定值时,需要使用尾部斜杠
innodb_data_home_dir。 例如:的[mysqld] innodb_data_home_dir = / path / to / myibdata /
有关相关信息,请参见 第15.8.1节“InnoDB启动配置” 。
-
innodb_ddl_log_crash_reset_debug属性 值 命令行格式 --innodb-ddl-log-crash-reset-debug[={OFF|ON}]介绍 8.0.3 系统变量 innodb_ddl_log_crash_reset_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用此调试选项可将DDL日志崩溃注入计数器重置为1.此选项仅在使用 CMake 选项 编译调试支持时可用 。
WITH_DEBUG -
属性 值 命令行格式 --innodb-deadlock-detect[={OFF|ON}]系统变量 innodb_deadlock_detect范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON此选项用于禁用死锁检测。 在高并发系统上,当许多线程等待同一个锁时,死锁检测会导致速度减慢。 有时,禁用死锁检测可能更有效,并且在
innodb_lock_wait_timeout发生死锁时 依赖于 事务回滚 的 设置。有关相关信息,请参见 第15.7.5.2节“死锁检测和回滚” 。
-
属性 值 命令行格式 --innodb-dedicated-server[={OFF|ON}]介绍 8.0.3 系统变量 innodb_dedicated_server范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF当
innodb_dedicated_server启用时,InnoDB根据所述服务器上检测到的内存量自动配置以下选项:如果您的MySQL实例在MySQL服务器能够使用所有可用系统资源的专用服务器上运行,则只考虑启用此选项。 如果MySQL实例与其他应用程序共享系统资源,则不建议启用此选项。
有关更多信息,请参见 第15.8.12节“为专用MySQL服务器启用自动配置” 。
-
属性 值 命令行格式 --innodb-default-row-format=value系统变量 innodb_default_row_format范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 DYNAMIC有效值 DYNAMICCOMPACTREDUNDANT该
innodb_default_row_format选项定义InnoDB表和用户创建的临时表 的默认行格式 。 默认设置为DYNAMIC。 其他允许的值是COMPACT和REDUNDANT。COMPRESSED不支持在 系统表空间中 使用 的 行格式 不能定义为默认值。新创建的表使用由限定的行格式
innodb_default_row_format时,ROW_FORMAT没有明确指定选项或时ROW_FORMAT=DEFAULT被使用。如果
ROW_FORMAT未明确指定选项或何时ROW_FORMAT=DEFAULT使用,则任何重建表的操作也会以静默方式将表的行格式更改为由其定义的格式innodb_default_row_format。 有关更多信息,请参阅 定义表的行格式 。无论 设置 如何,
InnoDB服务器创建的用于处理查询的 内部 临时表都使用DYNAMIC行格式innodb_default_row_format。 -
属性 值 命令行格式 --innodb-directories=dir_name介绍 8.0.4 系统变量 innodb_directories范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 定义要在启动时扫描表空间文件的目录。 在服务器脱机时将表空间文件移动或还原到新位置时使用此选项。 它还用于指定使用绝对路径创建的表空间文件的目录或位于数据目录之外的表空间文件的目录(请参见 第15.6.3.6节“在数据目录外部创建表空间” )。
崩溃恢复期间的表空间发现依赖于
innodb_directories设置来标识重做日志中引用的表空间。 有关更多信息,请参阅 崩溃恢复期间的表空间发现 。通过定义的目录
innodb_data_home_dir,innodb_undo_directory和datadir被自动附加到innodb_directories参数值,而不管是否的innodb_directories选项被明确指定。innodb_directories可以在启动命令或MySQL选项文件中指定为选项。 参数值周围使用引号,因为否则分号(;)被某些命令解释器解释为特殊字符。 (例如,Unix shell将其视为命令终止符。)启动命令:
mysqld --innodb-directories =“
directory_path_1;directory_path_2”MySQL选项文件:
的[mysqld] innodb_directories =“
directory_path_1;directory_path_2”通配符表达式不能用于指定目录。
该
innodb_directories扫描还遍历指定的目录的子目录。 从要扫描的目录列表中丢弃重复的目录和子目录。有关更多信息,请参见 第15.6.3.8节“在服务器脱机时移动表空间文件” 。
-
innodb_disable_sort_file_cache属性 值 命令行格式 --innodb-disable-sort-file-cache[={OFF|ON}]系统变量 innodb_disable_sort_file_cache范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF为合并排序临时文件禁用操作系统文件系统缓存。 效果是打开相当于的文件
O_DIRECT。 -
属性 值 命令行格式 --innodb-doublewrite[={OFF|ON}]系统变量 innodb_doublewrite范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 ON启用(默认值)时,
InnoDB将所有数据存储两次,首先存储到 双写缓冲区 ,然后存储到实际 数据文件 。--skip-innodb-doublewrite对于基准测试或需要最高性能而不关心数据完整性或可能的故障的情况, 可以关闭此变量 。如果系统表空间数据文件(
ibdata*文件)位于支持原子写入的Fusion-io设备上,则会自动禁用双写缓冲,并且Fusion-io原子写入将用于所有数据文件。 由于双写缓冲区设置是全局的,因此对于驻留在非Fusion-io硬件上的数据文件也禁用双写缓冲。 此功能仅在Fusion-io硬件上受支持,仅在Linux上为Fusion-io NVMFS启用。 要充分利用此功能, 建议 进行innodb_flush_method设置O_DIRECT。有关相关信息,请参见 第15.6.4节“Doublewrite Buffer” 。
-
属性 值 命令行格式 --innodb-fast-shutdown=#系统变量 innodb_fast_shutdown范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1有效值 012在
InnoDB关机 模式。 如果值为0,InnoDB则 在关闭之前 进行 慢速关闭 ,完全 清除 和更改缓冲区合并。 如果值为1(默认值),则InnoDB在关闭时跳过这些操作,这一过程称为 快速关闭 。 如果值为2,则InnoDB刷新其日志并关闭冷,就像MySQL崩溃一样; 没有提交的事务丢失,但 崩溃恢复 操作使下一次启动需要更长时间。在仍然缓冲大量数据的极端情况下,缓慢关闭可能需要几分钟甚至几小时。 在升级或降级MySQL主要版本之前使用慢速关闭技术,以便在升级过程更新文件格式时完全准备好所有数据文件。
使用
innodb_fast_shutdown=2紧急或故障的情况下,获得绝对最快关机,如果数据是在损坏的风险。 -
innodb_fil_make_page_dirty_debug属性 值 命令行格式 --innodb-fil-make-page-dirty-debug=#系统变量 innodb_fil_make_page_dirty_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最大价值 2**32-1默认情况下,设置
innodb_fil_make_page_dirty_debug为表空间的ID会立即弄脏表空间的第一页。 如果innodb_saved_page_number_debug设置为非默认值,则设置innodb_fil_make_page_dirty_debug污染指定的页面。 该innodb_fil_make_page_dirty_debug选项仅在使用 CMake 选项 编译调试支持时可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-file-per-table[={OFF|ON}]系统变量 innodb_file_per_table范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON当
innodb_file_per_table启用时,在文件的每个表的表空间默认创建的表。 禁用时,默认情况下会在系统表空间中创建表。 有关每个表文件表空间的信息,请参见 第15.6.3.2节“每个表的文件表空间” 。 有关InnoDB系统表空间的信息,请参见 第15.6.3.1节“系统表空间” 。所述
innodb_file_per_table变量可以在运行时使用一被配置SET GLOBAL语句,在启动时在命令行上指定,或者指定的选项的文件。 运行时配置需要足以设置全局系统变量的权限(请参见 第5.1.9.1节“系统变量权限” ),并立即影响所有连接的操作。当截断或删除驻留在每个表文件表空间中的表时,释放的空间将返回到操作系统。 截断或删除驻留在系统表空间中的表只会释放系统表空间中的空间。 系统表空间中的释放空间可以再次用于
InnoDB数据,但不会返回到操作系统,因为系统表空间数据文件永远不会缩小。该
innodb_file_per-table设置不会影响临时表的创建。 从MySQL 8.0.14开始,临时表在会话临时表空间中创建,并在之前的全局临时表空间中创建。 请参见 第15.6.3.5节“临时表空间” 。 -
属性 值 命令行格式 --innodb-fill-factor=#系统变量 innodb_fill_factor范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 100最低价值 10最大价值 100InnoDB在创建或重建索引时执行批量加载。 这种索引创建方法称为 “ 排序索引构建 ” 。innodb_fill_factor定义在排序索引构建期间填充的每个B树页面上的空间百分比,其余空间保留用于将来的索引增长。 例如,设置innodb_fill_factor为80可保留每个B树页面上20%的空间,以便将来进行索引增长。 实际百分比可能会有所不同 该innodb_fill_factor设置被解释为提示而不是硬限制。一个
innodb_fill_factor100设置叶免费为未来指数增长的聚簇索引页的空间的1/16。innodb_fill_factor适用于B树叶和非叶页。 它不适用于用于TEXT或BLOB输入的 外部页面 。有关更多信息,请参见 第15.6.2.3节“排序索引构建” 。
-
属性 值 命令行格式 --innodb-flush-log-at-timeout=#系统变量 innodb_flush_log_at_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1最低价值 1最大价值 2700每秒写入并刷新日志
N。innodb_flush_log_at_timeout允许增加刷新之间的超时时间,以减少刷新并避免影响二进制日志组提交的性能。 默认设置为innodb_flush_log_at_timeout每秒一次。 -
innodb_flush_log_at_trx_commit属性 值 命令行格式 --innodb-flush-log-at-trx-commit=#系统变量 innodb_flush_log_at_trx_commit范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 1有效值 012控制 提交 操作的 严格 ACID 合规性 与重新安排和批量完成与提交相关的I / O操作时可能实现的更高性能 之间的平衡 。 您可以通过更改默认值来获得更好的性能,但随后可能会在崩溃中丢失事务。
-
完全符合ACID要求默认设置为1。 在每次事务提交时写入日志并刷新到磁盘。
-
如果设置为0,则每秒写入日志并将其刷新到磁盘一次。 未刷新日志的事务可能会在崩溃中丢失。
-
设置为2时,在每次事务提交后写入日志,并每秒刷新一次磁盘。 未刷新日志的事务可能会在崩溃中丢失。
-
对于设置0和2,每秒一次冲洗不是100%保证。 由于DDL更改和
InnoDB导致日志独立于innodb_flush_log_at_trx_commit设置 而刷新的 其他内部 活动 可能更频繁地发生 刷新 ,并且有时由于调度问题而不常频繁 地刷新 。 如果每秒刷新一次日志,则崩溃中最多可能丢失一秒的事务。 如果日志的刷新次数多于或少于每秒一次,则可丢失的事务量会相应地变化。 -
日志刷新频率由控制
innodb_flush_log_at_timeout,它允许用户设置记录冲洗频率以N秒(其中N是1 ... 2700,为1的默认值)。 但是,任何 mysqld 进程崩溃都可以消除最多N几秒的事务。 -
DDL更改和其他内部
InnoDB活动会独立于innodb_flush_log_at_trx_commit设置 刷新日志 。 -
InnoDB无论innodb_flush_log_at_trx_commit设置 如何, 崩溃恢复都 有效 。 交易要么完全应用,要么完全删除。
对于
InnoDB与事务一起 使用的复制设置的持久性和一致性 :-
如果二进制日志功能被启用,设置
sync_binlog=1。 -
始终设定
innodb_flush_log_at_trx_commit=1。
警告许多操作系统和一些磁盘硬件欺骗了磁盘到磁盘的操作。 他们可能会告诉 mysqld 已经发生了冲洗,即使它没有。 在这种情况下,即使使用推荐的设置也无法保证事务的持久性,并且在最坏的情况下,断电可能会破坏
InnoDB数据。 在SCSI磁盘控制器或磁盘本身中使用电池供电的磁盘缓存可加快文件刷新速度,并使操作更安全。 您还可以尝试禁用硬件缓存中的磁盘写入缓存。 -
-
属性 值 命令行格式 --innodb-flush-method=value系统变量 innodb_flush_method范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 (Windows) unbuffered默认值 (Unix) fsync有效值 (Windows) unbufferednormal有效值 (Unix) fsyncO_DSYNClittlesyncnosyncO_DIRECTO_DIRECT_NO_FSYNC定义用于将 数据 刷新 到
InnoDB数据文件 和 日志文件的方法 ,这可能会影响I / O吞吐量。在类Unix系统上,默认值为
fsync。 在Windows上,默认值为unbuffered。注意在MySQL 8.0中,
innodb_flush_method可以用数字指定选项。innodb_flush_method类Unix系统 的 选项包括:-
fsync或0:InnoDB使用fsync()系统调用来刷新数据和日志文件。fsync是默认设置。 -
O_DSYNC或1:InnoDB用于O_SYNC打开和刷新日志文件,以及fsync()刷新数据文件。InnoDB不O_DSYNC直接 使用 ,因为在很多种Unix上都存在问题。 -
littlesync或2:此选项用于内部性能测试,目前不受支持。 使用风险由您自己承担。 -
nosync或3:此选项用于内部性能测试,目前不受支持。 使用风险由您自己承担。 -
O_DIRECT或4:InnoDB使用O_DIRECT(或directio()在Solaris上)打开数据文件,并用于fsync()刷新数据和日志文件。 某些GNU / Linux版本,FreeBSD和Solaris上提供了此选项。 -
O_DIRECT_NO_FSYNC: 在刷新I / O期间InnoDB使用O_DIRECT,但fsync()在每次写入操作后 跳过 系统调用。在MySQL 8.0.14之前,此设置不适用于XFS和EXT4等文件系统,这些文件系统需要
fsync()系统调用来同步文件系统元数据更改。 如果您不确定文件系统是否需要fsync()系统调用来同步文件系统元数据更改,请O_DIRECT改用。从MySQL 8.0.14开始,
fsync()在创建新文件之后,在增加文件大小之后,以及在关闭文件之后调用,以确保文件系统元数据更改是同步的。 该fsync()系统调用是每次写操作后,仍然跳过。在具有高速缓存的存储设备上,如果数据文件和重做日志文件驻留在不同的存储设备上,则可能会丢失数据,并且在从设备高速缓存刷新数据文件写入之前发生崩溃。 如果您使用或打算为重做日志和数据文件使用不同的存储设备,请
O_DIRECT改用。
innodb_flush_methodWindows系统 的 选项包括:-
unbuffered或0:InnoDB使用模拟异步I / O和非缓冲I / O. -
normal或1:InnoDB使用模拟异步I / O和缓冲I / O.
每个设置如何影响性能取决于硬件配置和工作负载。 对特定配置进行基准测试,以确定要使用的设置,或者是否保留默认设置。 检查
Innodb_data_fsyncs状态变量以查看fsync()每个设置 的总 呼叫 数 。 工作负载中的读写操作混合可能会影响设置的执行方式。 例如,在具有硬件RAID控制器和电池支持的写入缓存的系统上,O_DIRECT可以帮助避免InnoDB缓冲池和操作系统文件系统缓存 之间的双缓冲 。 在某些系统中InnoDB数据和日志文件位于SAN上,默认值或者O_DSYNC对于大多数 的读取繁重工作负载可能更快SELECT声明。 始终使用反映生产环境的硬件和工作负载测试此参数。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。如果
innodb_dedicated_server启用,innodb_flush_method则在未明确定义值的情况下自动配置 该 值。 有关更多信息,请参见 第15.8.12节“为专用MySQL服务器启用自动配置” 。 -
-
属性 值 命令行格式 --innodb-flush-neighbors=#系统变量 innodb_flush_neighbors范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 (> = 8.0.3) 0默认值 (<= 8.0.2) 1有效值 012指定是否 冲洗 从一个页面
InnoDB缓冲池 也可以清空其他 脏页 在相同的 程度 。-
设置为0将
innodb_flush_neighbors关闭,并且不会从缓冲池中刷新其他脏页。 -
设置为1会从缓冲池中刷新相同范围内的连续脏页。
-
设置为2会从缓冲池中刷新相同范围内的脏页。
当表数据存储在传统 HDD 存储设备上时, 与在不同时间刷新各个页面相比,在一次操作中 刷新这些 邻居页面 减少了I / O开销(主要用于磁盘搜索操作)。 对于存储在 SSD 上的表数据 ,查找时间不是一个重要因素,您可以将此选项设置为0以分散写入操作。 有关相关信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
-
属性 值 命令行格式 --innodb-flush-sync[={OFF|ON}]系统变量 innodb_flush_sync范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ONinnodb_flush_sync默认情况下启用 的 参数innodb_io_capacity会导致在 检查点 发生的I / O活动突发时忽略 该 设置 。 要遵守 设置InnoDB定义的后台I / O活动 限制innodb_io_capacity,请禁用innodb_flush_sync。有关相关信息,请参见 第15.8.7节“配置InnoDB主线程I / O速率” 。
-
属性 值 命令行格式 --innodb-flushing-avg-loops=#系统变量 innodb_flushing_avg_loops范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 30最低价值 1最大价值 1000InnoDB保持先前计算的刷新状态快照 的迭代次数 ,控制 自适应刷新 对不断变化的 工作负载的 响应 速度 。 随着 工作量的变化, 增加该值会使 刷新 操作 的速率 平稳地逐渐变化。 降低该值会使自适应刷新快速调整到工作负载变化,如果工作负载突然增加和减少,这可能会导致刷新活动出现峰值。有关相关信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
属性 值 命令行格式 --innodb-force-load-corrupted[={OFF|ON}]系统变量 innodb_force_load_corrupted范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF允许
InnoDB在启动时加载已标记为已损坏的表。 仅在故障排除期间使用,以恢复无法访问的数据。 排除故障后,请禁用此设置并重新启动服务器。 -
属性 值 命令行格式 --innodb-force-recovery=#系统变量 innodb_force_recovery范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 6在 崩溃恢复 模式,通常只有在认真排除故障的情况下更改。 可能的值为0到6.有关这些值的含义和有关的重要信息
innodb_force_recovery,请参见 第15.20.2节“强制InnoDB恢复” 。 -
属性 值 命令行格式 --innodb-fsync-threshold=#介绍 8.0.13 系统变量 innodb_fsync_threshold范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2**64-1默认情况下,在
InnoDB创建新数据文件(例如新日志文件或表空间文件)时,只有在完全写入文件后才会将写入缓冲区的内容刷新到磁盘,这可能导致发生大量磁盘写入活动立刻。 要强制进行较小的定期刷新,请使用innodb_fsync_threshold以字节为单位定义写缓冲区的阈值大小。 达到阈值大小时,写缓冲区的内容将刷新到磁盘。 默认值0强制使用默认行为。在多个MySQL实例使用相同的存储设备的情况下,指定写入缓冲区阈值大小以强制较小的定期刷新可能是有益的。 例如,创建新的MySQL实例及其关联的数据文件可能会导致磁盘写入活动大量涌现,从而影响使用相同存储设备的其他MySQL实例的性能。 配置写入缓冲区阈值大小有助于避免磁盘写入活动中出现此类浪涌。
-
属性 值 系统变量 innodb_ft_aux_table范围 全球 动态 是 SET_VAR提示适用没有 类型 串 指定
InnoDB包含FULLTEXT索引 的 表 的限定名称 。 此变量用于诊断目的,只能在运行时设置。 例如:SET GLOBAL innodb_ft_aux_table ='test / t1';
当您在格式这个变量设置为名称 的 表格 , , , ,和 显示有关指定表的搜索索引信息。
db_name/table_nameINFORMATION_SCHEMAINNODB_FT_INDEX_TABLEINNODB_FT_INDEX_CACHEINNODB_FT_CONFIGINNODB_FT_DELETEDINNODB_FT_BEING_DELETED有关更多信息,请参见 第15.14.4节“InnoDB INFORMATION_SCHEMA FULLTEXT索引表” 。
-
属性 值 命令行格式 --innodb-ft-cache-size=#系统变量 innodb_ft_cache_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 8000000最低价值 1600000最大价值 80000000为
InnoDBFULLTEXT搜索索引缓存 分配的内存(以字节为单位), 在创建InnoDBFULLTEXT索引 时将解析的文档保存在内存中 。 只有innodb_ft_cache_size达到大小限制 时,才会将索引插入和更新提交到磁盘 。innodb_ft_cache_size基于每个表定义高速缓存大小。 要为所有表设置全局限制,请参阅innodb_ft_total_cache_size。有关更多信息,请参阅 InnoDB全文索引缓存 。
-
属性 值 命令行格式 --innodb-ft-enable-diag-print[={OFF|ON}]系统变量 innodb_ft_enable_diag_print范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF是否启用其他全文搜索(FTS)诊断输出。 此选项主要用于高级FTS调试,大多数用户不会感兴趣。 输出将打印到错误日志中,其中包含以下信息:
-
FTS索引同步进度(达到FTS缓存限制时)。 例如:
用于表测试的FTS SYNC,删除计数:100大小:10000字节 同步字:100
-
FTS优化进度。 例如:
FTS开始优化测试 FTS_OPTIMIZE:优化“mysql” FTS_OPTIMIZE:已处理“mysql”
-
FTS索引构建进度。 例如:
处理的doc数:1000
-
对于FTS查询,将打印查询解析树,单词权重,查询处理时间和内存使用情况。 例如:
FTS搜索处理时间:1秒:100毫秒:行10000 全搜索内存:245666(字节),行:10000
-
-
属性 值 命令行格式 --innodb-ft-enable-stopword[={OFF|ON}]系统变量 innodb_ft_enable_stopword范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指定 在创建索引时将 一组 停用词 与
InnoDBFULLTEXT索引 相关联 。 如果innodb_ft_user_stopword_table设置了 该 选项,则从该表中获取停用词。 否则,如果innodb_ft_server_stopword_table设置了 该 选项,则从该表中获取停用词。 否则,使用内置的默认停用词集。有关更多信息,请参见 第12.9.4节“全文停用词” 。
-
属性 值 命令行格式 --innodb-ft-max-token-size=#系统变量 innodb_ft_max_token_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 84最低价值 10最大价值 84存储在
InnoDBFULLTEXT索引中 的单词的最大字符长度 。 设置此值的限制会减少索引的大小,从而通过省略长关键字或不是真实单词且不太可能是搜索项的任意字母集合来加快查询速度。有关更多信息,请参见 第12.9.6节“微调MySQL全文搜索” 。
-
属性 值 命令行格式 --innodb-ft-min-token-size=#系统变量 innodb_ft_min_token_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 3最低价值 0最大价值 16存储在
InnoDBFULLTEXT索引中 的单词的最小长度 。 增加此值会减少索引的大小,从而通过省略在搜索上下文中不太可能重要的常用单词(例如英语单词 “ a ” 和 “ to ”) 来 加速查询 。 对于使用CJK(中文,日文,韩文)字符集的内容,请指定值1。有关更多信息,请参见 第12.9.6节“微调MySQL全文搜索” 。
-
属性 值 命令行格式 --innodb-ft-num-word-optimize=#系统变量 innodb_ft_num_word_optimize范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 2000索引
OPTIMIZE TABLE上 每个 操作 期间要处理的单词数InnoDBFULLTEXT。 由于对包含全文搜索索引的表进行批量插入或更新操作可能需要大量索引维护才能合并所有更改,因此您可能会执行一系列OPTIMIZE TABLE语句,每个语句都会在最后一次保留的位置进行处理。有关更多信息,请参见 第12.9.6节“微调MySQL全文搜索” 。
-
属性 值 命令行格式 --innodb-ft-result-cache-limit=#系统变量 innodb_ft_result_cache_limit范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 2000000000最低价值 1000000最大价值 2**32-1在
InnoDB每全文搜索查询或每个线程全文搜索查询结果高速缓存限制(以字节为单位定义)。 中间和最终InnoDB的全文搜索查询结果在内存中处理。 用于innodb_ft_result_cache_limit对全文搜索查询结果缓存设置大小限制,以避免在非常大InnoDB的全文搜索查询结果(例如,数百万或数亿行)的 情况下过多的内存消耗 。 处理全文搜索查询时,根据需要分配内存。 如果达到结果缓存大小限制,则会返回错误,指示查询超出了允许的最大内存量。innodb_ft_result_cache_limit所有平台类型和位大小 的最大值 为2 ** 32-1。 -
innodb_ft_server_stopword_table属性 值 命令行格式 --innodb-ft-server-stopword-table=db_name/table_name系统变量 innodb_ft_server_stopword_table范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 NULL此选项用于
InnoDBFULLTEXT为所有InnoDB表 指定您自己的 索引停用词列表 。 要为特定InnoDB表 配置自己的停用词列表 ,请使用innodb_ft_user_stopword_table。innodb_ft_server_stopword_table以格式 设置 为包含停用词列表的表的名称 。db_name/table_name配置前必须存在禁用词表
innodb_ft_server_stopword_table。innodb_ft_enable_stopword必须启用,并且innodb_ft_server_stopword_table必须在创建FULLTEXT索引 之前配置选项 。停用词表必须是一个
InnoDB表,包含一个VARCHAR名为的列value。有关更多信息,请参见 第12.9.4节“全文停用词” 。
-
属性 值 命令行格式 --innodb-ft-sort-pll-degree=#系统变量 innodb_ft_sort_pll_degree范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 2最低价值 1最大价值 32InnoDBFULLTEXT构建 搜索索引 时 索引中的索引和标记化文本并行使用的线程数 。有关相关信息,请参见 第15.6.2.4节“InnoDB FULLTEXT索引” 和
innodb_sort_buffer_size。 -
属性 值 命令行格式 --innodb-ft-total-cache-size=#系统变量 innodb_ft_total_cache_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 640000000最低价值 32000000最大价值 1600000000InnoDB为所有表 分配 的全文搜索索引缓存 的总内存(以字节为单位) 。 创建大量表,每个表都有一个FULLTEXT搜索索引,可能占用大量可用内存。innodb_ft_total_cache_size为所有全文搜索索引定义全局内存限制,以帮助避免过多的内存消耗。 如果索引操作达到全局限制,则会触发强制同步。有关更多信息,请参阅 InnoDB全文索引缓存 。
-
属性 值 命令行格式 --innodb-ft-user-stopword-table=db_name/table_name系统变量 innodb_ft_user_stopword_table范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 串 默认值 NULL此选项用于
InnoDBFULLTEXT在特定表上 指定您自己的 索引停用词列表。 要为所有InnoDB表 配置自己的停用词列表 ,请使用innodb_ft_server_stopword_table。innodb_ft_user_stopword_table以格式 设置 为包含停用词列表的表的名称 。db_name/table_name配置前必须存在禁用词表
innodb_ft_user_stopword_table。innodb_ft_enable_stopword必须启用,innodb_ft_user_stopword_table必须在创建FULLTEXT索引 之前进行配置 。停用词表必须是一个
InnoDB表,包含一个VARCHAR名为的列value。有关更多信息,请参见 第12.9.4节“全文停用词” 。
-
属性 值 命令行格式 --innodb-io-capacity=#系统变量 innodb_io_capacity范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 200最低价值 100最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1该
innodb_io_capacity参数设置InnoDB后台任务 每秒执行的I / O操作数的上限 ,例如 从 缓冲池 刷新 页面 和合并来自 更改缓冲区的 数据 。该
innodb_io_capacity限制适用于所有缓冲池实例总限额。 刷新脏页时,限制在缓冲池实例之间平均分配。innodb_io_capacity应设置为大约系统每秒可执行的I / O操作数。 理想情况下,保持设置尽可能低,但不要低到背景活动落后。 如果该值太高,则会从缓冲池中删除数据并过快地插入缓冲区以进行缓存以提供显着的好处。默认值为200.对于具有更高I / O速率的繁忙系统,可以设置更高的值以帮助服务器处理与高速行更改相关的后台维护工作。
通常,您可以根据
InnoDBI / O 使用的驱动器数量增加该值 。 例如,您可以增加使用多个磁盘或固态磁盘(SSD)的系统的值。对于低端SSD,默认设置200通常就足够了。 对于更高端的总线连接SSD,请考虑更高的设置,例如1000。 对于具有单独5400 RPM或7200 RPM驱动器的系统,您可以将值降低到
100,这表示可执行大约100 IOPS的旧一代磁盘驱动器可用的每秒I / O操作(IOPS)的估计比例。虽然您可以指定一个非常高的值,例如一百万,但实际上这样的大值几乎没有任何好处。 通常,建议不要使用20000或更高的值,除非您已经证明较低的值不足以满足您的工作负载。
调整时考虑写入工作负载
innodb_io_capacity。 具有大写入工作负载的系统可能会受益于更高的设置。 对于具有小写入工作负载的系统,较低的设置可能就足够了。您可以将
innodb_io_capacity任意数字 设置 为100或更大,以达到最大值innodb_io_capacity_max。innodb_io_capacity可以在MySQL选项文件(my.cnf或my.ini)中 设置,也可以 使用SET GLOBAL语句 动态更改 ,这需要足以设置全局系统变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。的
innodb_flush_sync配置选项使innodb_io_capacity发生在检查点I / O活动的脉冲串期间被忽略设置。innodb_flush_sync默认情况下启用。更多 信息, 请参见 第15.8.7节“配置InnoDB主线程I / O速率” 。 有关
InnoDBI / O性能的 一般信息 ,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。 -
属性 值 命令行格式 --innodb-io-capacity-max=#系统变量 innodb_io_capacity_max范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 see description最低价值 100最大值 (Windows,64位平台) 2**32-1最大值 (Unix,64位平台) 2**64-1最大值 (32位平台) 2**32-1如果冲洗活动落后,
InnoDB可以比施加的限制更积极地冲洗innodb_io_capacity。 在这种情况下innodb_io_capacity_max,InnoDB后台任务 定义每秒执行的I / O操作数的上限 。该
innodb_io_capacity_max设置是所有缓冲池实例的总限制。如果
innodb_io_capacity在启动时 指定 设置但未指定值innodb_io_capacity_max,则innodb_io_capacity_max默认值为值的两倍innodb_io_capacity,最小值为2000。配置时
innodb_io_capacity_max,两次innodb_io_capacity通常是一个很好的起点。 默认值2000适用于使用固态磁盘(SSD)或多个常规磁盘驱动器的工作负载。 对于不使用SSD或多个磁盘驱动器的工作负载,2000的设置可能太高,并且可能允许过多的刷新。 对于单个常规磁盘驱动器,建议设置介于200和400之间。 对于高端,总线连接的SSD,请考虑更高的设置,例如2500.与innodb_io_capacity设置一样,保持设置尽可能低,但不能太低 ,如果必要,InnoDB不能充分扩展到超出innodb_io_capacity限制。调整时考虑写入工作负载
innodb_io_capacity_max。 具有大写入工作负载的系统可能受益于更高的设置。 对于具有小写入工作负载的系统,较低的设置可能就足够了。innodb_io_capacity_max不能设置为低于该innodb_io_capacity值的值。设置
innodb_io_capacity_max为DEFAULT使用SETstatement(SET GLOBAL innodb_io_capacity_max=DEFAULT)设置innodb_io_capacity_max为最大值。有关相关信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
innodb_limit_optimistic_insert_debug属性 值 命令行格式 --innodb-limit-optimistic-insert-debug=#系统变量 innodb_limit_optimistic_insert_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 2**32-1限制每个 B树 页面 的记录数 。 默认值0表示不施加限制。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。
WITH_DEBUG -
属性 值 命令行格式 --innodb-lock-wait-timeout=#系统变量 innodb_lock_wait_timeout范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 1最大价值 1073741824放弃之前
InnoDB事务 等待 行锁定 的时间长度(以秒 为 单位) 。 默认值为50秒。 尝试访问由另一个InnoDB事务 锁定的行的 事务在发出以下错误之前最多等待这一行以对该行进行写访问:ERROR 1205(HY000):超出锁定等待超时; 尝试重新启动事务
发生锁定等待超时时,将 回滚 当前语句 (而不是整个事务)。 要使整个事务回滚,请使用该
--innodb-rollback-on-timeout选项 启动服务器 。 另请参见 第15.20.4节“InnoDB错误处理” 。您可以为高度交互的应用程序或 OLTP 系统 降低此值 ,以快速显示用户反馈或将更新放入队列以便稍后处理。 您可以为长时间运行的后端操作增加此值,例如等待其他大型插入或更新操作完成的数据仓库中的转换步骤。
innodb_lock_wait_timeout适用于InnoDB行锁。 内部不会发生 MySQL 表锁InnoDB,此超时不适用于等待表锁。启用时(默认值) 锁定等待超时值不适用于 死锁 ,
innodb_deadlock_detect因为InnoDB会立即检测到死锁并回滚其中一个死锁事务。 当innodb_deadlock_detect被禁用,InnoDB依赖于innodb_lock_wait_timeout对事务回滚发生死锁时。 请参见 第15.7.5.2节“死锁检测和回滚” 。innodb_lock_wait_timeout可以使用SET GLOBALorSET SESSION语句 在运行时设置 。 更改GLOBAL设置需要足以设置全局系统变量的权限(请参见 第5.1.9.1节“系统变量权限” ),并影响随后连接的所有客户端的操作。 任何客户端都可以更改SESSION设置innodb_lock_wait_timeout,这仅影响该客户端。 -
属性 值 命令行格式 --innodb-log-buffer-size=#系统变量 (> = 8.0.11) innodb_log_buffer_size系统变量 (<= 8.0.4) innodb_log_buffer_size范围 (> = 8.0.11) 全球 范围 (<= 8.0.4) 全球 动态 (> = 8.0.11) 是 动态 (<= 8.0.4) 没有 SET_VAR提示适用 (> = 8.0.11)没有 SET_VAR提示适用 (<= 8.0.4)没有 类型 整数 默认值 16777216最低价值 1048576最大价值 4294967295InnoDB用于写入 磁盘上 日志文件 的缓冲区的大小(以字节为单位) 。 默认值为16MB。 大型 日志缓冲区 使大型 事务 能够运行,而无需在事务 提交 之前将日志写入磁盘 。 因此,如果您有更新,插入或删除许多行的事务,则使日志缓冲区更大可以节省磁盘I / O. 有关相关信息,请参阅 内存配置 和 第8.5.4节“优化InnoDB重做日志记录” 。 有关常规I / O调优建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。 -
innodb_log_checkpoint_fuzzy_now属性 值 命令行格式 --innodb-log-checkpoint-fuzzy-now[={OFF|ON}]介绍 8.0.13 系统变量 innodb_log_checkpoint_fuzzy_now范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用此调试选项以强制
InnoDB写入模糊检查点。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-log-checkpoint-now[={OFF|ON}]系统变量 innodb_log_checkpoint_now范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用此调试选项以强制
InnoDB写入检查点。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-log-checksums[={OFF|ON}]系统变量 innodb_log_checksums范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON启用或禁用重做日志页面的校验和。
innodb_log_checksums=ON启用CRC-32C重做日志页面 的 校验和算法。 当innodb_log_checksums被禁用时,重做日志页面校验字段的内容被忽略。永远不会禁用重做日志标题页和重做日志检查点页面上的校验和。
-
属性 值 命令行格式 --innodb-log-compressed-pages[={OFF|ON}]系统变量 innodb_log_compressed_pages范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指定是否将 重新压缩 页面的 图像 写入 重做日志 。 当对压缩数据进行更改时,可能会发生重新压缩。
innodb_log_compressed_pages默认情况下启用,以防止zlib在恢复期间使用 不同版本的 压缩算法时 可能发生的损坏 。 如果您确定zlib版本不会更改,则可以禁用innodb_log_compressed_pages以减少修改压缩数据的工作负载的重做日志生成。要衡量启用或禁用的效果,请
innodb_log_compressed_pages在同一工作负载下比较两个设置的重做日志生成。 测量重做日志生成的选项包括观察 输出 部分中 的Log sequence number(LSN) ,或监视 写入重做日志文件的字节数的状态。LOGSHOW ENGINE INNODB STATUSInnodb_os_log_written有关相关信息,请参见 第15.9.1.6节“OLTP工作负载压缩” 。
-
属性 值 命令行格式 --innodb-log-file-size=#系统变量 innodb_log_file_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 50331648最低价值 4194304最大价值 512GB / innodb_log_files_in_group在每个字节大小 日志文件 在 日志组 。 日志文件的总大小(
innodb_log_file_size*innodb_log_files_in_group) 不能超过略小于512GB的最大值。 例如,一对255 GB的日志文件接近限制但不超过它。 默认值为48MB。通常,日志文件的总大小应足够大,以便服务器可以消除工作负载活动中的高峰和低谷,这通常意味着有足够的重做日志空间来处理超过一小时的写入活动。 值越大,缓冲池中需要的检查点刷新活动越少,从而节省磁盘I / O. 较大的日志文件也会使 崩溃恢复 速度变慢,但恢复性能的提高使得日志文件的大小不如早期版本的MySQL那么重要。
最低
innodb_log_file_size为4MB。有关相关信息,请参阅 重做日志文件配置 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
如果
innodb_dedicated_server启用,innodb_log_file_size则在未明确定义值的情况下自动配置 该 值。 有关更多信息,请参见 第15.8.12节“为专用MySQL服务器启用自动配置” 。 -
属性 值 命令行格式 --innodb-log-files-in-group=#系统变量 innodb_log_files_in_group范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 2最低价值 2最大价值 100数 日志文件 中 日志组 。
InnoDB以循环方式写入文件。 默认(和推荐)值为2.文件的位置由innodb_log_group_home_dir。 指定 。 日志文件的总大小(innodb_log_file_size*innodb_log_files_in_group) 可以高达512GB。有关相关信息,请参阅 重做日志文件配置 。
-
属性 值 命令行格式 --innodb-log-group-home-dir=dir_name系统变量 innodb_log_group_home_dir范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 InnoDB重做日志 文件 的目录路径 ,其编号由innodb_log_files_in_group。 如果不指定任何InnoDB日志变量,默认的是创建一个名为两个文件ib_logfile0,并ib_logfile1在MySQL数据目录。 日志文件大小由innodb_log_file_size系统变量 。有关相关信息,请参阅 重做日志文件配置 。
-
属性 值 命令行格式 --innodb-log-spin-cpu-abs-lwm=#介绍 8.0.11 系统变量 innodb_log_spin_cpu_abs_lwm范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 80最低价值 0最大价值 4294967295定义在等待刷新重做时用户线程不再旋转的最小CPU使用量。 该值表示为CPU核心使用量的总和。 例如,默认值80是单个CPU核心的80%。 在具有多核处理器的系统上,值150表示100%使用一个CPU核心加50%使用第二个CPU核心。
有关相关信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
-
属性 值 命令行格式 --innodb-log-spin-cpu-pct-hwm=#介绍 8.0.11 系统变量 innodb_log_spin_cpu_pct_hwm范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 0最大价值 100定义在等待刷新的重做时用户线程不再旋转的最大CPU使用量。 该值表示为所有CPU核心的总处理能力的百分比。 默认值为50%。 例如,两个CPU核心的100%使用率是具有四个CPU核心的服务器上组合CPU处理能力的50%。
的
innodb_log_spin_cpu_pct_hwm配置选项方面处理器的亲和性。 例如,如果服务器有48个内核但 mysqld 进程仅固定为4个CPU内核,则忽略其他44个CPU内核。有关相关信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
-
innodb_log_wait_for_flush_spin_hwm属性 值 命令行格式 --innodb-log-wait-for-flush-spin-hwm=#介绍 8.0.11 系统变量 innodb_log_wait_for_flush_spin_hwm范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 400最低价值 0最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1定义最大平均日志刷新时间,超过该时间,用户线程在等待刷新的重做时不再旋转。 默认值为400微秒。
有关相关信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
-
属性 值 命令行格式 --innodb-log-write-ahead-size=#系统变量 innodb_log_write_ahead_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 8192最低价值 512 (log file block size)最大价值 Equal to innodb_page_size定义重做日志的预写块大小(以字节为单位)。 为避免 “ read-on-write ” ,请设置
innodb_log_write_ahead_size为匹配操作系统或文件系统缓存块大小。 默认设置为8192字节。 由于重做日志的预写块大小与操作系统或文件系统高速缓存块大小不匹配,重做日志块未完全高速缓存到操作系统或文件系统时会发生写入时写入。有效值
innodb_log_write_ahead_size是InnoDB日志文件块大小的 倍数 (2 n )。 最小值是InnoDB日志文件块大小(512)。 指定最小值时不会发生预写。 最大值等于该innodb_page_size值。 如果为该值指定的值innodb_log_write_ahead_size大于该innodb_page_size值,则该innodb_log_write_ahead_size设置将截断为该innodb_page_size值。innodb_log_write_ahead_size相对于操作系统或文件系统高速缓存块大小 设置该 值太低会导致 “ read-on-write ” 。fsync由于一次写入多个块,因此 将值设置得过高可能会对 日志文件写入的性能 产生轻微影响 。有关相关信息,请参见 第8.5.4节“优化InnoDB重做日志记录” 。
-
属性 值 命令行格式 --innodb-lru-scan-depth=#系统变量 innodb_lru_scan_depth范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1024最低价值 100最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1影响 缓冲池 刷新 操作 的算法和启发式的参数 。 主要是对性能专家调整I / O密集型工作负载感兴趣。 它根据缓冲池实例指定页面清理程序线程扫描的缓冲池LRU页面列表向下寻找 要刷新的 脏页的 距离 。 这是每秒执行一次的后台操作。
InnoDB小于默认值的设置通常适用于大多数工作负载。 高于必要值的值可能会影响性能。 如果在典型工作负载下具有备用I / O容量,则仅考虑增加该值。 相反,如果写入密集型工作负载使I / O容量饱和,则减小该值,尤其是在大型缓冲池的情况下。
调整时
innodb_lru_scan_depth,从较低的值开始并向上配置设置,目标是很少看到零空闲页面。 此外,考虑innodb_lru_scan_depth在更改缓冲池实例的数量时进行 调整 ,因为innodb_lru_scan_depth*innodb_buffer_pool_instances定义了页面清理器线程每秒执行的工作量。有关相关信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-max-dirty-pages-pct=#系统变量 innodb_max_dirty_pages_pct范围 全球 动态 是 SET_VAR提示适用没有 类型 数字 默认值 (> = 8.0.3) 90默认值 (<= 8.0.2) 75最低价值 0最大价值 99.99InnoDB尝试 从 缓冲池中 刷新 数据, 以便 脏页 的百分比 不超过此值。该
innodb_max_dirty_pages_pct设置为刷新活动建立了目标。 它不影响潮红的速度。 有关管理刷新率的信息,请参见 第15.8.3.5节“配置InnoDB缓冲池 刷新 ” 。有关相关信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
innodb_max_dirty_pages_pct_lwm属性 值 命令行格式 --innodb-max-dirty-pages-pct-lwm=#系统变量 innodb_max_dirty_pages_pct_lwm范围 全球 动态 是 SET_VAR提示适用没有 类型 数字 默认值 (> = 8.0.3) 10默认值 (<= 8.0.2) 0最低价值 0最大价值 99.99定义代表的比例低水位标记 脏页 ,在其中预冲洗能够控制脏页比例。 值0将完全禁用预冲洗行为。 有关更多信息,请参见 第15.8.3.6节“微调InnoDB缓冲池刷新” 。
-
属性 值 命令行格式 --innodb-max-purge-lag=#系统变量 innodb_max_purge_lag范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 4294967295定义清除队列的最大长度。 默认值0表示无限制(无延迟)。
使用此选项强加延迟
INSERT,UPDATE以及DELETE操作时, 清除 操作滞后(见 第15.3节,“InnoDB的多版本” )。该
InnoDB交易系统认为有通过索引记录删除标记事务的列表UPDATE或DELETE操作。 列表的长度表示purge_lag值。 如果purge_lag超过innodb_max_purge_lag,INSERT,UPDATE,和DELETE操作被延迟。 在MySQL 8.0.14之前,延迟计算是(purge_lag/innodb_max_purge_lag - 0.5) * 10000,这导致最小延迟为5000微秒。 从MySQL 8.0.14开始,延迟计算(purge_lag/innodb_max_purge_lag - 0.9995) * 10000结果 是 ,最小延迟为5微秒。为了防止在极端情况下过度延迟
purge_lag,您可以通过设置来限制延迟innodb_max_purge_lag_delay配置选项 。 延迟是在清除批次开始时计算的。有问题的工作负载的典型设置可能是100万,假设事务很小,只有100字节大小,并且允许有100MB未预订的
InnoDB表行。滞后值显示为 InnoDB Monitor输出
TRANSACTIONS部分中 的历史列表长度 。 在此示例输出中滞后值为20:------------ 交易 ------------ Trx id counter 0 290328385 清除trx的n:o <0 290315608撤消n:o <0 17 历史清单长度20
有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-max-purge-lag-delay=#系统变量 innodb_max_purge_lag_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0指定
innodb_max_purge_lag配置选项 施加的延迟的最大延迟(以微秒为单位) 。 指定值是基于值的公式计算的延迟时间的上限innodb_max_purge_lag。有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-max-undo-log-size=#系统变量 innodb_max_undo_log_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1073741824最低价值 10485760最大价值 2**64-1定义撤消表空间的阈值大小。 如果撤消表空间超过阈值,则可以将其标记为截断
innodb_undo_log_truncate启用 。 默认值为1073741824字节(1024 MiB)。有关更多信息,请参阅 截断撤消表空间 。
-
innodb_merge_threshold_set_all_debug属性 值 命令行格式 --innodb-merge-threshold-set-all-debug=#系统变量 innodb_merge_threshold_set_all_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 1最大价值 50为索引页定义页面满百分比值,该值将覆盖
MERGE_THRESHOLD当前在字典高速缓存中的所有索引 的当前 设置。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。 有关相关信息,请参见 第15.8.11节“配置索引页的合并阈值” 。WITH_DEBUG -
属性 值 命令行格式 --innodb-monitor-disable={counter|module|pattern|all}系统变量 innodb_monitor_disable范围 全球 动态 是 SET_VAR提示适用没有 类型 串 禁用
InnoDB指标计数器 。 可以使用该INFORMATION_SCHEMA.INNODB_METRICS表 查询计数器数据 。 有关使用信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。innodb_monitor_disable='latch'禁用统计信息收集SHOW ENGINE INNODB MUTEX。 有关更多信息,请参见 第13.7.6.15节“SHOW ENGINE语法” 。 -
属性 值 命令行格式 --innodb-monitor-enable={counter|module|pattern|all}系统变量 innodb_monitor_enable范围 全球 动态 是 SET_VAR提示适用没有 类型 串 启用
InnoDB指标计数器 。 可以使用该INFORMATION_SCHEMA.INNODB_METRICS表 查询计数器数据 。 有关使用信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。innodb_monitor_enable='latch'启用统计信息收集SHOW ENGINE INNODB MUTEX。 有关更多信息,请参见 第13.7.6.15节“SHOW ENGINE语法” 。 -
属性 值 命令行格式 --innodb-monitor-reset={counter|module|pattern|all}系统变量 innodb_monitor_reset范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 empty string有效值 countermodulepatternall将
InnoDB度量计数器 的计数值重置 为零。 可以使用该INFORMATION_SCHEMA.INNODB_METRICS表 查询计数器数据 。 有关使用信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。innodb_monitor_reset='latch'重置报告的统计数据SHOW ENGINE INNODB MUTEX。 有关更多信息,请参见 第13.7.6.15节“SHOW ENGINE语法” 。 -
属性 值 命令行格式 --innodb-monitor-reset-all={counter|module|pattern|all}系统变量 innodb_monitor_reset_all范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 empty string有效值 countermodulepatternall重置
InnoDB度量标准计数器的 所有值(最小值,最大值等) 。 可以使用该INFORMATION_SCHEMA.INNODB_METRICS表 查询计数器数据 。 有关使用信息,请参见 第15.14.6节“InnoDB INFORMATION_SCHEMA度量表” 。 -
属性 值 命令行格式 --innodb-numa-interleave[={OFF|ON}]系统变量 innodb_numa_interleave范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用NUMA交错存储器策略以分配
InnoDB缓冲池。 当innodb_numa_interleave启用时,NUMA内存策略设置为MPOL_INTERLEAVE对 mysqld的 进程。InnoDB分配缓冲池 后 ,将NUMA内存策略设置回MPOL_DEFAULT。 要使该innodb_numa_interleave选项可用,必须在支持NUMA的Linux系统上编译MySQL。CMake
WITH_NUMA根据当前平台是否NUMA支持来 设置默认 值 。 有关更多信息,请参见 第2.9.4节“MySQL源配置选项” 。 -
属性 值 命令行格式 --innodb-old-blocks-pct=#系统变量 innodb_old_blocks_pct范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 37最低价值 5最大价值 95指定 用于旧块 子列表 的
InnoDB缓冲池 的近似百分比 。 值的范围是5到95.默认值是37(即池的3/8)。 经常与之结合使用 。innodb_old_blocks_time有关更多信息,请参见 第15.8.3.3节“使缓冲池抗扫描” 。 有关缓冲池管理, LRU 算法和 逐出 策略的信息,请参见 第15.5.1节“缓冲池” 。
-
属性 值 命令行格式 --innodb-old-blocks-time=#系统变量 innodb_old_blocks_time范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1000最低价值 0最大价值 2**32-1非零值可防止 缓冲池 被仅在短时间内引用的数据填充,例如在 全表扫描 期间 。 增加此值可提供更多保护,防止全表扫描干扰缓冲池中缓存的数据。
指定块插入旧块的时间长度(以毫秒为单位) 子列表 在第一次访问后必须保留的 然后才能将其移动到新的子列表。 如果值为0,则无论插入访问后多久发生,插入旧子列表的块在第一次访问时立即移动到新子列表。 如果该值大于0,则块保留在旧子列表中,直到在第一次访问后至少很多毫秒发生访问。 例如,值1000会导致块在第一次访问后保留在旧子列表中1秒钟,然后才有资格移动到新子列表。
默认值为1000。
此配置选项通常与
innodb_old_blocks_pct。 有关更多信息,请参见 第15.8.3.3节“使缓冲池抗扫描” 。 有关缓冲池管理, LRU 算法和 逐出 策略的信息,请参见 第15.5.1节“缓冲池” 。 -
innodb_online_alter_log_max_size属性 值 命令行格式 --innodb-online-alter-log-max-size=#系统变量 innodb_online_alter_log_max_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 134217728最低价值 65536最大价值 2**64-1指定在 表的 联机DDL 操作 期间使用的临时日志文件大小的上限(以字节 为单位)
InnoDB。 每个创建的索引或要更改的表都有一个这样的日志文件。 此日志文件存储在DDL操作期间在表中插入,更新或删除的数据。 临时日志文件在需要时扩展为值innodb_sort_buffer_size,最大为指定的最大值innodb_online_alter_log_max_size。 如果临时日志文件超过了大小上限,则ALTER TABLE操作失败,并回滚所有未提交的并发DML操作。 因此,此选项的较大值允许在联机DDL操作期间发生更多DML,但在表被锁定以应用日志中的数据时,还会延长DDL操作结束时的时间段。 -
属性 值 命令行格式 --innodb-open-files=#系统变量 innodb_open_files范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 -1(表示自动调整大小;不指定此文字值)最低价值 10最大价值 4294967295仅当您使用多个
InnoDB表空间时, 此配置选项才有意义 。 它指定 MySQL一次可以保持打开 的最大.ibd文件 数 。 最小值为10.如果innodb_file_per_table未启用, 则默认值为300;如果 未启用, 则默认值为 300,table_open_cache否则 为300 。用于文件的文件描述符 仅
.ibd用于InnoDB表。 它们独立于open_files_limit系统变量 指定的那些 ,并且不影响表缓存的操作。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。 -
属性 值 命令行格式 --innodb-optimize-fulltext-only[={OFF|ON}]系统变量 innodb_optimize_fulltext_only范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF改变
OPTIMIZE TABLE对InnoDB表格的 操作 方式 。 在InnoDB具有FULLTEXT索引的 表的 维护操作期间,临时启用 。默认情况下,
OPTIMIZE TABLE重新组织 表 的 聚簇索引 中的 数据 。 启用此选项后,将OPTIMIZE TABLE跳过表数据的重组,而是处理InnoDBFULLTEXT索引的 新添加,已删除和已更新的令牌数据 。 有关更多信息,请参阅 优化InnoDB全文索引 。 -
属性 值 命令行格式 --innodb-page-cleaners=#系统变量 innodb_page_cleaners范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 4最低价值 1最大价值 64从缓冲池实例中清除脏页的页清理程序线程数。 页面清除程序线程执行刷新列表和LRU刷新。 当存在多个页面清理器线程时,将每个缓冲池实例的缓冲池刷新任务分派给空闲页面清理器线程。 该
innodb_page_cleaners默认值是4,如果页面清理线程的数量超过缓冲池实例的数量,innodb_page_cleaners将自动设置为相同的值innodb_buffer_pool_instances。如果在将脏页从缓冲池实例刷新到数据文件时您的工作负载是写入IO限制的,并且系统硬件具有可用容量,则增加页面清除线程的数量可能有助于提高写入IO吞吐量。
多线程页面清理器支持扩展到关闭和恢复阶段。
该
setpriority()系统调用是用来在那里它被支持的Linux平台,并且其中 的mysqld 执行用户被授权给page_cleaner线程优先于其他MySQL和InnoDB线程帮助页面刷新保持与当前工作负载的速度。setpriority()此InnoDB启动消息 指示支持 :[注意] InnoDB:如果mysqld执行用户被授权,页面清理 线程优先级可以更改。请参见setpriority()的手册页。
对于不由systemd管理服务器启动和关闭的系统, 可以配置 mysqld 执行用户授权
/etc/security/limits.conf。 例如,如果 在 用户 下运行 mysqld ,则可以通过 将以下行 添加到以下内容来mysql授权mysql用户/etc/security/limits.conf:mysql很难-20 mysql软不错-20
对于systemd受管系统,可以通过
LimitNICE=-20在本地化的systemd配置文件中 指定来实现相同的功能 。 例如,创建一个名为文件override.conf中/etc/systemd/system/mysqld.service.d/override.conf,并添加此项:[服务] LimitNICE = -20
创建或更改后
override.conf,重新加载systemd配置,然后告诉systemd重启MySQL服务:systemctl daemon-reload systemctl重启mysqld #RPM平台 systemctl重启mysql#Debian平台
有关使用本地化systemd配置文件的更多信息,请参阅 为MySQL配置systemd 。
授权 mysqld 执行用户后,使用 cat 命令验证 mysqld 的配置
Nice限制 进程 :shell> cat / proc /
mysqld_pid/ limits | grep很好 Max nice priority 18446744073709551596 18446744073709551596 -
属性 值 命令行格式 --innodb-page-size=#系统变量 innodb_page_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 列举 默认值 16384有效值 40968192163843276865536指定 页面大小 的
InnoDB表空间 。 值可以以字节或千字节为单位指定。 例如,16千字节的页面大小值可以指定为16384,16KB或16k。innodb_page_size只能在初始化MySQL实例之前配置,之后不能更改。 如果未指定任何值,则使用默认页面大小初始化实例。 请参见 第15.8.1节“InnoDB启动配置” 。对于32KB和64KB页面大小,最大行长度约为16000字节。 设置为32KB或64KB
ROW_FORMAT=COMPRESSED时不支持innodb_page_size。 对于innodb_page_size=32KB,范围大小为2MB。 对于innodb_page_size=64KB,范围大小是4MB。innodb_log_buffer_size使用32KB或64KB页面大小时,应设置为至少16M(默认值)。默认的16KB页面大小或更大适用于各种 工作负载 ,特别是涉及表扫描和涉及批量更新的DML操作的查询。 对于 涉及许多小写入的 OLTP 工作负载, 较小的页面大小可能更有效 ,其中当单个页面包含许多行时,争用可能是一个问题。 较小的页面也可能对 SSD 存储设备有效,后者通常使用小块大小。 保持
InnoDB页面大小接近存储设备块大小可以最大限度地减少重写到磁盘的未更改数据量。第一个系统表空间数据文件(
ibdata1) 的最小文件大小因innodb_page_size值而 异 。 有关innodb_data_file_path更多信息, 请参阅 选项说明。有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-parallel-read-threads=#介绍 8.0.14 系统变量 innodb_parallel_read_threads范围 会议 动态 是 SET_VAR提示适用没有 类型 整数 默认值 4最低价值 1最大价值 256定义可用于并行聚簇索引读取的线程数。 并行读取线程可以提高
CHECK TABLE性能。InnoDB在CHECK TABLE操作 期间两次读取聚簇索引 。 第二次读取可以并行执行。 此功能不适用于二级索引扫描。 的innodb_parallel_read_threads会话变量必须被设置为一个大于1的值用于并行聚簇索引读取发生。 用于执行并行聚簇索引读取的实际线程数由innodb_parallel_read_threads设置或要扫描的索引子树的数量,以较小者为准。 在扫描期间读入缓冲池的页面保存在缓冲池LRU列表的尾部,以便在需要空闲缓冲池页面时可以快速丢弃它们。 -
属性 值 命令行格式 --innodb-print-all-deadlocks[={OFF|ON}]系统变量 innodb_print_all_deadlocks范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF当启用该选项,所有信息 死锁 在
InnoDB用户交易被记录在mysqld错误日志 。 否则,您将使用该SHOW ENGINE INNODB STATUS命令 查看有关上次死锁的信息 。 偶尔的InnoDB僵局不一定是个问题,因为InnoDB立即检测到条件并自动回滚其中一个事务。 如果应用程序没有适当的错误处理逻辑来检测回滚并重试其操作,则可以使用此选项来解决发生死锁的原因。 大量死锁可能表明需要重构 为多个表 发出 DML 或SELECT ... FOR UPDATE语句的事务,以便每个事务以相同的顺序访问表,从而避免死锁条件。有关相关信息,请参见 第15.7.5节“InnoDB中的死锁” 。
-
属性 值 命令行格式 --innodb-print-ddl-logs[={OFF|ON}]介绍 8.0.3 系统变量 innodb_print_ddl_logs范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用此选项会导致MySQL将DDL日志写入
stderr。 有关更多信息,请参阅 查看DDL日志 。 -
属性 值 命令行格式 --innodb-purge-batch-size=#系统变量 innodb_purge_batch_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 300最低价值 1最大价值 5000定义从 历史记录列表 中清除一批中的分析和进程的撤消日志页数 。 在多线程吹扫配置中,协调器净化线程分割
innodb_purge_batch_size通过innodb_purge_threads并分配该数量的页的每个吹扫线程。 该innodb_purge_batch_size选项还定义了通过撤消日志每128次迭代后清除释放的撤消日志页数。该
innodb_purge_batch_size选项旨在结合innodb_purge_threads设置 进行高级性能调整 。 大多数MySQL用户无需更改innodb_purge_batch_size其默认值。有关相关信息,请参见 第15.8.9节“配置InnoDB清除调度” 。
-
属性 值 命令行格式 --innodb-purge-threads=#系统变量 innodb_purge_threads范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 4最低价值 1最大价值 32专用于
InnoDB清除 操作 的后台线程数 。 最小值1表示清除操作始终由后台线程执行,而不是作为 主线程的 一部分 。 在一个或多个后台线程中运行清除操作有助于减少内部争用InnoDB,从而提高可伸缩性。 将值增加到大于1会创建许多单独的清除线程,这可以提高 在多个表上执行 DML 操作的 系统的效率 。 最大值为32。有关相关信息,请参见 第15.8.9节“配置InnoDB清除调度” 。
-
innodb_purge_rseg_truncate_frequency属性 值 命令行格式 --innodb-purge-rseg-truncate-frequency=#系统变量 innodb_purge_rseg_truncate_frequency范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 128最低价值 1最大价值 128定义清除系统根据调用清除次数释放回滚段的频率。 在释放其回滚段之前,不能截断撤消表空间。 通常,清除系统每调用一次清除128次就会释放回滚段。 默认值为128.减小此值会增加清除线程释放回滚段的频率。
innodb_purge_rseg_truncate_frequency适用于innodb_undo_log_truncate。 有关更多信息,请参阅 截断撤消表空间 。 -
属性 值 命令行格式 --innodb-random-read-ahead[={OFF|ON}]系统变量 innodb_random_read_ahead范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用随机 预读 技术以优化
InnoDBI / O.有关不同类型的 预读 请求的性能注意事项的详细信息,请参见 第15.8.3.4节“配置InnoDB缓冲池预取(预读)” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-read-ahead-threshold=#系统变量 innodb_read_ahead_threshold范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 56最低价值 0最大价值 64控制线性的灵敏度 预读 的是
InnoDB使用预取页入 缓冲器池 。 如果 从一个 范围 (64页)中 顺序InnoDB读取至少innodb_read_ahead_threshold页面 ,它将启动整个后续范围的异步读取。 允许的值范围是0到64.值0禁用预读。 对于默认值56, 必须从某个范围顺序读取至少56页以启动以下范围的异步读取。InnoDB在微调
innodb_read_ahead_threshold设置 时,了解通过预读机制读取了多少页,以及从缓冲池中驱逐了多少这些页面而无需访问它们 。SHOW ENGINE INNODB STATUS输出显示对抗来自信息Innodb_buffer_pool_read_ahead和Innodb_buffer_pool_read_ahead_evicted全局状态变量,其报告的页数带入 缓冲池 的预读请求,以及这些页面的数量 驱逐 分别从缓冲池而没有被访问。 状态变量报告自上次服务器重新启动以来的全局值。SHOW ENGINE INNODB STATUS还显示了预读页面的读取速率以及未被访问时这些页面被逐出的速率。 每秒平均值基于自上次调用以来收集的统计信息,SHOW ENGINE INNODB STATUS并显示在 输出 的BUFFER POOL AND MEMORY部分中SHOW ENGINE INNODB STATUS。有关更多信息,请参见 第15.8.3.4节“配置InnoDB缓冲池预取(预读)” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
-
属性 值 命令行格式 --innodb-read-io-threads=#系统变量 innodb_read_io_threads范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 4最低价值 1最大价值 64用于读取操作的I / O线程数
InnoDB。 它的写线程对应物是innodb_write_io_threads。 有关更多信息,请参见 第15.8.5节“配置后台InnoDB I / O线程数” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。注意在Linux系统上运行多个MySQL服务器(通常超过12)与默认设置
innodb_read_io_threads,innodb_write_io_threads以及Linux的aio-max-nr设置可以超过系统限制。 理想情况下,增加aio-max-nr设置; 作为解决方法,您可以减少一个或两个MySQL配置选项的设置。 -
属性 值 命令行格式 --innodb-read-only[={OFF|ON}]系统变量 innodb_read_only范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFFInnoDB以只读模式 启动 。 用于在只读介质上分发数据库应用程序或数据集。 也可以在数据仓库中用于在多个实例之间共享相同的数据目录。 有关更多信息,请参见 第15.8.2节“配置InnoDB以进行只读操作” 。以前,启用
innodb_read_only系统变量会阻止仅为InnoDB存储引擎 创建和删除表 。 从MySQL 8.0开始,启用会innodb_read_only阻止所有存储引擎的这些操作。 任何存储引擎的表创建和删除操作都会修改mysql系统数据库 中的数据字典表 ,但这些表使用InnoDB存储引擎,并且在innodb_read_only启用 时无法修改 。 同样的原则适用于需要修改数据字典表的其他表操作。 例子:-
如果
innodb_read_only启用 了 系统变量,则ANALYZE TABLE可能会失败,因为它无法更新数据字典中使用的统计表InnoDB。 对于ANALYZE TABLE更新密钥分发的操作,即使操作更新表本身(例如,如果它是MyISAM表) ,也可能发生故障 。 要获取更新的分布统计信息,请设置information_schema_stats_expiry=0。 -
ALTER TABLE失败,因为它更新了存储在数据字典中的存储引擎名称。tbl_nameENGINE=engine_name
此外,
mysql系统数据库 中的其他表 使用InnoDBMySQL 8.0中 的 存储引擎。 使这些表只读是导致对修改它们的操作的限制。 例子:-
由于授权表使用的 帐户管理语句,例如
CREATE USER和GRANT失败InnoDB。 -
在
INSTALL PLUGIN和UNINSTALL PLUGIN因为插件管理报表失败plugin表使用InnoDB。 -
在
CREATE FUNCTION和DROP FUNCTIONUDF管理报表失败,因为该func表使用InnoDB。
-
-
属性 值 命令行格式 --innodb-redo-log-encrypt[={OFF|ON}]介绍 8.0.1 系统变量 innodb_redo_log_encrypt范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF控制使用
InnoDB表空间加密功能 加密的 表 的重做日志数据的 加密 。 默认情况下禁用重做日志数据的加密。 有关更多信息,请参阅 重做日志加密 。 -
属性 值 命令行格式 --innodb-replication-delay=#系统变量 innodb_replication_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 4294967295innodb_thread_concurrency到达 从属服务器上的复制线程延迟(以毫秒为单位) 。 -
属性 值 命令行格式 --innodb-rollback-on-timeout[={OFF|ON}]系统变量 innodb_rollback_on_timeout范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFFInnoDB默认情况下,仅 回滚 事务超时的最后一个语句。 如果--innodb-rollback-on-timeout指定,则事务超时会导致InnoDB中止并回滚整个事务。注意如果start-transaction语句是
START TRANSACTION或BEGINstatement,则rollback不会取消该语句。 进一步的SQL语句成为交易的一部分,直到发生COMMIT,ROLLBACK或某些SQL语句导致隐式提交。有关更多信息,请参见 第15.20.4节“InnoDB错误处理” 。
-
属性 值 命令行格式 --innodb-rollback-segments=#系统变量 innodb_rollback_segments范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 128最低价值 1最大价值 128innodb_rollback_segments定义 分配给每个撤消表空间 的 回滚段 数 和生成撤消记录的事务的全局临时表空间。 每个回滚段支持的事务数取决于InnoDB页大小和分配给每个事务的撤消日志数。 有关更多信息,请参见 第15.6.6节“撤消日志” 。有关相关信息,请参见 第15.3节“InnoDB多版本控制” 。 有关撤消表空间的信息,请参见 第15.6.3.4节“撤消表空间” 。
-
属性 值 命令行格式 --innodb-scan-directories=dir_name介绍 8.0.2 删除 8.0.4 系统变量 innodb_scan_directories范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 默认值 NULL这个变量
innodb_directories在MySQL 8.0.4中 被替换 。 -
innodb_saved_page_number_debug属性 值 命令行格式 --innodb-saved-page-number-debug=#系统变量 innodb_saved_page_number_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最大价值 2**23-1保存页码。 设置
innodb_fil_make_page_dirty_debug选项会污染定义的页面innodb_saved_page_number_debug。 该innodb_saved_page_number_debug选项仅在使用 CMake 选项 编译调试支持时可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-sort-buffer-size=#系统变量 innodb_sort_buffer_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 1048576最低价值 65536最大价值 67108864指定在创建
InnoDB索引 期间用于对数据进行排序的排序缓冲区的大小 。 指定的大小定义读入内存以进行内部排序然后写入磁盘的数据量。 该过程称为 “ 运行 ” 。 在合并阶段,读取并合并指定大小的缓冲区对。 设置越大,运行和合并越少。此排序区域仅用于索引创建期间的合并排序,而不是在以后的索引维护操作期间。 索引创建完成后,将释放缓冲区。
此选项的值还控制在 联机DDL 期间将临时日志文件扩展为记录并发DML的数量 操作 。
在此设置可配置之前,大小被硬编码为1048576字节(1MB),这仍然是默认值。
在 创建索引 的
ALTER TABLEorCREATE TABLE语句 期间 ,将分配3个缓冲区,每个缓冲区都具有此选项定义的大小。 此外,辅助指针被分配给排序缓冲区中的行,以便排序可以在指针上运行(而不是在排序操作期间移动行)。对于典型的排序操作,可以使用诸如此类的公式来估计内存消耗:
(6 / * FTS_NUM_AUX_INDEX * / *(3 * @@ GLOBAL.innodb_sort_buffer_size) + 2 * number_of_partitions * number_of_secondary_indexes_created *(@@ GLOBAL.innodb_sort_buffer_size / dict_index_get_min_size(index)* /) * 8 / * 64位sizeof * buf-> tuples * /“)
@@GLOBAL.innodb_sort_buffer_size/dict_index_get_min_size(index)表示保持的最大元组。2 * (@@GLOBAL.innodb_sort_buffer_size/*dict_index_get_min_size(index)*/) * 8 /*64-bit size of *buf->tuples*/表示分配的辅助指针。注意对于32位,乘以4而不是8。
对于全文索引的并行排序,请乘以以下
innodb_ft_sort_pll_degree设置:(6 / * FTS_NUM_AUX_INDEX * / * @@ GLOBAL.innodb_ft_sort_pll_degree)
-
属性 值 命令行格式 --innodb-spin-wait-delay=#系统变量 innodb_spin_wait_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 6最低价值 0最大值 (64位平台,<= 8.0.13) 2**64-1最大值 (32位平台,<= 8.0.13) 2**32-1最大值 (> = 8.0.14) 1000旋转 锁定的 轮询之间的最大延迟 。 该机制的低级实现取决于硬件和操作系统的组合,因此延迟不对应于固定的时间间隔。
可以与
innodb_spin_wait_pause_multiplier变量 结合使用, 以更好地控制自旋锁定轮询延迟的持续时间。有关更多信息,请参见 第15.8.8节“配置自旋锁轮询” 。
-
innodb_spin_wait_pause_multiplier属性 值 命令行格式 --innodb-spin-wait-pause-multiplier=#介绍 8.0.16 系统变量 innodb_spin_wait_pause_multiplier范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 50最低价值 1最大价值 100定义乘数值,用于确定线程等待获取互斥锁或rw-lock时发生的自旋等待循环中的PAUSE指令数。
有关更多信息,请参见 第15.8.8节“配置自旋锁轮询” 。
-
属性 值 命令行格式 --innodb-stats-auto-recalc[={OFF|ON}]系统变量 innodb_stats_auto_recalc范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON在表中的数据发生实质性更改后
InnoDB自动重新计算 持久性统计信息的 原因 。 阈值是表中行的10%。 此设置适用于innodb_stats_persistent启用 该 选项 时创建的表 。 还可以通过STATS_PERSISTENT=1在CREATE TABLE或ALTER TABLE语句中 指定来配置自动统计重新计算 。 采样以生成统计信息的数据量由innodb_stats_persistent_sample_pages配置选项 控制 。有关更多信息,请参见 第15.8.10.1节“配置持久优化器统计信息参数” 。
-
innodb_stats_include_delete_marked属性 值 命令行格式 --innodb-stats-include-delete-marked[={OFF|ON}]介绍 8.0.1 系统变量 innodb_stats_include_delete_marked范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF默认情况下,
InnoDB在计算统计信息时读取未提交的数据。 对于从表中删除行的未提交事务,InnoDB排除在计算行估计和索引统计信息时删除标记的记录,这可能导致对同时使用表执行的其他事务的非最佳执行计划事务隔离级别除外READ UNCOMMITTED。 要避免这种情况,innodb_stats_include_delete_marked可以启用此选项以确保InnoDB在计算持久优化程序统计信息时包含删除标记的记录。当
innodb_stats_include_delete_marked启用时,ANALYZE TABLE重新计算统计数据时,会考虑删除标记的记录。innodb_stats_include_delete_marked是一个影响所有InnoDB表 的全局设置 。 它仅适用于持久优化程序统计信息。有关相关信息,请参见 第15.8.10.1节“配置持久优化器统计信息参数” 。
-
属性 值 命令行格式 --innodb-stats-method=value系统变量 innodb_stats_method范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 nulls_equal有效值 nulls_equalnulls_unequalnulls_ignored服务器
NULL在收集 有关 表 的索引值分布的 统计 信息 时 如何处理 值InnoDB。 允许值是nulls_equal,nulls_unequal和nulls_ignored。 因为nulls_equal,所有NULL索引值都被认为是相等的,并形成一个大小等于NULL值 数的单个值组 。 因为nulls_unequal,NULL值被认为是不相等的,并且每个NULL值形成大小为1的不同值组。因为nulls_ignored,NULL值被忽略。用于生成表统计信息的方法会影响优化程序如何选择索引以执行查询,如 第8.3.8节“InnoDB和MyISAM索引统计信息收集”中所述 。
-
属性 值 命令行格式 --innodb-stats-on-metadata[={OFF|ON}]系统变量 innodb_stats_on_metadata范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF此选项仅在优化程序 统计信息 配置为非持久性时适用。
innodb_stats_persistent禁用或创建或更改单个表 时,优化程序统计信息不会保留到磁盘STATS_PERSISTENT=0。 有关更多信息,请参见 第15.8.10.2节“配置非持久优化器统计信息参数” 。当
innodb_stats_on_metadata启用时,InnoDB将更新的非持久性 的统计数据 时,元数据语句,如SHOW TABLE STATUS访问时或INFORMATION_SCHEMA.TABLES或INFORMATION_SCHEMA.STATISTICS表。 (这些更新与发生的情况类似ANALYZE TABLE。)禁用时,InnoDB不会在这些操作期间更新统计信息。 保留禁用的设置可以提高具有大量表或索引的模式的访问速度。 它还可以提高 涉及 表的 查询 的 执行计划 的稳定性InnoDB。要更改设置,请发出语句 ,其中 是 或 (或 或 )。 更改设置需要足以设置全局系统变量的权限(请参见 第5.1.9.1节“系统变量权限” ),并立即影响所有连接的操作。
SET GLOBAL innodb_stats_on_metadata=modemodeONOFF10 -
属性 值 命令行格式 --innodb-stats-persistent[={OFF|ON}]系统变量 innodb_stats_persistent范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON指定
InnoDB索引统计信息是否持久保存到磁盘。 否则,可能会频繁重新计算统计信息,这可能导致 查询执行计划的 变化 。 创建表时,此设置与每个表一起存储。 您可以innodb_stats_persistent在创建表之前在全局级别进行 设置 , 也可以 使用 和 语句 的STATS_PERSISTENT子句 覆盖系统范围的设置并为各个表配置持久统计信息。CREATE TABLEALTER TABLE有关更多信息,请参见 第15.8.10.1节“配置持久优化器统计信息参数” 。
-
innodb_stats_persistent_sample_pages属性 值 命令行格式 --innodb-stats-persistent-sample-pages=#系统变量 innodb_stats_persistent_sample_pages范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 20估计 索引列的 基数 和其他 统计信息 时要采样 的索引 页数 ,例如计算的列 。 增加该值会提高索引统计信息的准确性,从而可以提高 查询执行计划 的执行过程中,在增加的I / O的费用 为 表。 有关更多信息,请参见 第15.8.10.1节“配置持久优化器统计信息参数” 。
ANALYZE TABLEANALYZE TABLEInnoDB注意设置较高的值
innodb_stats_persistent_sample_pages可能会导致ANALYZE TABLE执行时间 过长 。 要估计访问的数据库页数ANALYZE TABLE,请参见 第15.8.10.3节“估算InnoDB表的ANALYZE TABLE复杂度” 。innodb_stats_persistent_sample_pages仅适用innodb_stats_persistent于为表启用的情况; 何时innodb_stats_persistent被禁用,innodb_stats_transient_sample_pages而是适用。 -
innodb_stats_transient_sample_pages属性 值 命令行格式 --innodb-stats-transient-sample-pages=#系统变量 innodb_stats_transient_sample_pages范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 8估计 索引列的 基数 和其他 统计信息 时要采样 的索引 页数 ,例如计算的列 。 默认值为8.增加该值可提高索引统计信息的准确性,这可以改进 查询执行计划 ,但会在打开 表或重新计算统计信息 时增加I / O. 有关更多信息,请参见 第15.8.10.2节“配置非持久优化器统计信息参数” 。
ANALYZE TABLEInnoDB注意设置较高的值
innodb_stats_transient_sample_pages可能会导致ANALYZE TABLE执行时间 过长 。 要估计访问的数据库页数ANALYZE TABLE,请参见 第15.8.10.3节“估算InnoDB表的ANALYZE TABLE复杂度” 。innodb_stats_transient_sample_pages仅适用于innodb_stats_persistent禁用表格的情况; 如果innodb_stats_persistent启用,则innodb_stats_persistent_sample_pages应用。 取而代之innodb_stats_sample_pages。 有关更多信息,请参见 第15.8.10.2节“配置非持久优化器统计信息参数” 。 -
属性 值 命令行格式 --innodb-status-output[={OFF|ON}]系统变量 innodb_status_output范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用或禁用标准
InnoDB监视器的 定期输出 。 还可与组合使用innodb_status_output_locks以启用或禁用InnoDB锁定监视器的 周期性输出 。 有关更多信息,请参见 第15.16.2节“启用InnoDB监视器” 。 -
属性 值 命令行格式 --innodb-status-output-locks[={OFF|ON}]系统变量 innodb_status_output_locks范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用或禁用
InnoDB锁定监视器。 启用后,InnoDB锁定监视器会打印有关SHOW ENGINE INNODB STATUS输出 锁定的附加信息 以及打印到MySQL错误日志的定期输出。InnoDB锁定监视器的 定期输出 作为标准InnoDB监视器输出的 一部分打印 。InnoDB因此,必须启用 标准 监视器,以使InnoDB锁定监视器定期将数据打印到MySQL错误日志。 有关更多信息,请参见 第15.16.2节“启用InnoDB监视器” 。 -
属性 值 命令行格式 --innodb-strict-mode[={OFF|ON}]系统变量 innodb_strict_mode范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON当
innodb_strict_mode启用时,InnoDB将返回错误,而不是警告了一定的条件。严格模式 有助于防止SQL中忽略的拼写错误和语法错误,或操作模式和SQL语句的各种组合的其他意外后果。 当
innodb_strict_mode启用时,InnoDB提出了在某些情况下错误条件,而不是发出警告和处理指定的声明(也许无意的行为)。 这类似于sql_modeMySQL,它控制MySQL接受的SQL语法,并确定它是否默默地忽略错误,或验证输入语法和数据值。该
innodb_strict_mode设置会影响语法错误的处理CREATE TABLE,ALTER TABLE,CREATE INDEX,和OPTIMIZE TABLE语句。innodb_strict_mode还可以启用记录大小检查,以便 由于记录对于所选页面大小而言太大而导致INSERT或UPDATE永远不会失败。Oracle建议使
innodb_strict_mode用时ROW_FORMAT和KEY_BLOCK_SIZE条款中CREATE TABLE,ALTER TABLE和CREATE INDEX语句。 当innodb_strict_mode被禁用,InnoDB忽略了相互矛盾的条款且仅在消息日志警告创建表或索引。 生成的表可能具有与预期不同的特性,例如在尝试创建压缩表时缺少压缩支持。 当innodb_strict_mode启用时,这些问题产生的直接错误,并且不会创建表或索引。您可以
innodb_strict_mode在启动时在命令行上 启用或禁用mysqld,也可以在MySQL 配置文件中 启用或禁用 。 您还可以innodb_strict_mode在运行时使用语句 启用或禁用 ,其中 是 或 。 更改 设置需要足以设置全局系统变量的权限(请参见 第5.1.9.1节“系统变量权限” ),并影响随后连接的所有客户端的操作。 任何客户端都可以更改 设置 ,该设置仅影响该客户端。SET [GLOBAL|SESSION] innodb_strict_mode=modemodeONOFFGLOBALSESSIONinnodb_strict_modeinnodb_strict_mode不适用于 一般表空间 。 一般表空间的表空间管理规则严格执行innodb_strict_mode。 有关更多信息,请参见 第13.1.21节“CREATE TABLESPACE语法” 。 -
属性 值 命令行格式 --innodb-sync-array-size=#系统变量 innodb_sync_array_size范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 1最低价值 1最大价值 1024定义互斥锁/锁定等待数组的大小。 增加该值会拆分用于协调线程的内部数据结构,以便在具有大量等待线程的工作负载中实现更高的并发性。 必须在MySQL实例启动时配置此设置,之后无法更改。 对于经常产生大量等待线程(通常大于768)的工作负载,建议增加该值。
-
属性 值 命令行格式 --innodb-sync-spin-loops=#系统变量 innodb_sync_spin_loops范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 30最低价值 0最大价值 4294967295InnoDB在线程挂起之前 线程等待 释放互斥锁 的次数 。 -
属性 值 命令行格式 --innodb-sync-debug[={OFF|ON}]系统变量 innodb_sync_debug范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用
InnoDB存储引擎的 同步调试检查 。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-table-locks[={OFF|ON}]系统变量 innodb_table_locks范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON如果
autocommit = 0,InnoDB荣誉LOCK TABLES; MySQL不会返回,LOCK TABLES ... WRITE直到所有其他线程都释放了对表的所有锁。 默认值为innodb_table_locks1,这意味着如果LOCK TABLES导致InnoDB在内部锁定表autocommit = 0。在MySQL 8.0中,
innodb_table_locks = 0对于显式锁定的表没有任何影响LOCK TABLES ... WRITE。 它对于为读取或写入而锁定的表有效LOCK TABLES ... WRITE隐式(例如,通过触发器)或通过隐藏(例如,通过触发器)LOCK TABLES ... READ。有关相关信息,请参见 第15.7节“InnoDB锁定和事务模型” 。
-
属性 值 命令行格式 --innodb-temp-data-file-path=file_name系统变量 innodb_temp_data_file_path范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 ibtmp1:12M:autoextend定义全局临时表空间数据文件的相对路径,名称,大小和属性。 全局临时表空间存储用于对用户创建的临时表所做更改的回滚段。
如果没有指定值
innodb_temp_data_file_path,默认行为是创建一个名为一个自动扩展数据文件ibtmp1的innodb_data_home_dir目录。 初始文件大小略大于12MB。全局临时表空间数据文件规范的语法包括文件名,文件大小
autoextend和max属性:file_name:file_size[:autoextend [:max:max_file_size]]全局临时表空间数据文件不能与另一个
InnoDB数据文件 具有相同的名称 。 创建全局临时表空间数据文件的任何无能或错误都被视为致命,并且拒绝服务器启动。文件大小是通过附加在KB,MB,GB或指定
K,M或G对大小值。 文件大小的总和必须略大于12MB。单个文件的大小限制由操作系统确定。 在支持大文件的操作系统上,文件大小可以超过4GB。 不支持将原始磁盘分区用于全局临时表空间数据文件。
该
autoextend和max属性只能在最后一个指定的数据文件中使用innodb_temp_data_file_path的设置。 例如:的[mysqld] innodb_temp_data_file_path = ibtmp1:50M; ibtmp2:12M:自动扩展:最大:500MB
该
autoextend选项会导致数据文件在可用空间不足时自动增大。autoextend默认情况下 , 增量为64MB。 要修改增量,请更改innodb_autoextend_increment变量设置。全局临时表空间数据文件的目录路径是通过连接由
innodb_data_home_dir和 定义的路径形成的innodb_temp_data_file_path。在
InnoDB以只读模式 运行之前 ,请设置innodb_temp_data_file_path为数据目录之外的位置。 路径必须相对于数据目录。 例如:--innodb-TEMP-数据文件路径= .. / .. / .. / TMP / ibtmp1:12M:自动扩展
有关更多信息,请参阅 全局临时表空间 。
-
属性 值 命令行格式 --innodb-temp-tablespaces-dir=dir_name介绍 8.0.13 系统变量 innodb_temp_tablespaces_dir范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 默认值 #innodb_temp定义
InnoDB在启动时创建会话临时表空间池 的位置 。 默认位置是#innodb_temp数据目录中的目录。 允许相对于数据目录的完全限定路径或路径。从MySQL 8.0.16开始,会话临时表空间始终存储由优化器使用创建的用户创建的临时表和内部临时表
InnoDB。 (以前,内部临时表的磁盘存储引擎由internal_tmp_disk_storage_engine系统变量 确定, 不再支持 该 系统变量。请参阅 磁盘内部临时表的存储引擎 。)有关更多信息,请参阅 会话临时表空间 。
-
属性 值 命令行格式 --innodb-thread-concurrency=#系统变量 innodb_thread_concurrency范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1000InnoDB尝试将操作系统线程的数量同时保持在InnoDB小于或等于此变量给定的限制(InnoDB使用操作系统线程来处理用户事务)。 一旦线程数达到此限制,额外的线程被置于等待状态一内 “ 先入先出 ” (FIFO) 队列以供执行。 等待锁的线程不计入并发执行线程的数量。此变量的范围是0到1000.值0(默认值)被解释为无限并发(无并发检查)。 禁用线程并发检查可以
InnoDB根据需要创建 任意数量的线程 。 值0也禁用queries inside InnoDB和queries in queue counters在ROW OPERATIONS第SHOW ENGINE INNODB STATUS输出。如果您的MySQL实例与其他应用程序共享CPU资源,或者您的工作负载或并发用户数量在增长,请考虑设置此变量。 正确的设置取决于工作负载,计算环境以及您运行的MySQL版本。 您需要测试一系列值以确定提供最佳性能的设置。
innodb_thread_concurrency是一个动态变量,它允许您在实时测试系统上试验不同的设置。 如果特定设置表现不佳,您可以快速设置innodb_thread_concurrency回0。使用以下准则来帮助查找和维护适当的设置:
-
如果工作负载的并发用户线程数小于64,请进行设置
innodb_thread_concurrency=0。 -
如果您的工作负载一直很大或偶尔会出现峰值,请先设置
innodb_thread_concurrency=128然后将值降低到96,80,64等,直到找到提供最佳性能的线程数。 例如,假设您的系统通常有40到50个用户,但定期数量会增加到60,70甚至200.您会发现80个并发用户的性能稳定但开始显示高于此数字的回归。 在这种情况下,您将设置innodb_thread_concurrency=80为避免影响性能。 -
如果您不希望
InnoDB为用户线程使用超过一定数量的虚拟CPU(例如,20个虚拟CPU),请设置innodb_thread_concurrency为此数字(或者可能更低,具体取决于性能结果)。 如果您的目标是将MySQL与其他应用程序隔离,则可以考虑将该mysqld进程专门 绑定 到虚拟CPU。 但请注意,如果mysqld进程不是一直很忙 ,则独占绑定可能会导致非最佳硬件使用 。 在这种情况下,您可以绑定mysqld处理虚拟CPU,但也允许其他应用程序使用部分或全部虚拟CPU。注意从操作系统的角度来看,使用资源管理解决方案来管理应用程序之间如何共享CPU时间可能比绑定
mysqld进程 更可取 。 例如,您可以分配90%的虚拟CPU时间给定的应用程序,而其他关键流程 不 运行,而当其他关键流程扩展该值回到40% 的 运行。 -
innodb_thread_concurrency由于对系统内部和资源的争用增加,过高的值会导致性能下降。 -
在某些情况下,最佳
innodb_thread_concurrency设置可能小于虚拟CPU的数量。 -
定期监控和分析您的系统。 工作负载,用户数或计算环境的更改可能需要您调整
innodb_thread_concurrency设置。
有关相关信息,请参见 第15.8.4节“为InnoDB配置线程并发” 。
-
-
属性 值 命令行格式 --innodb-thread-sleep-delay=#系统变量 innodb_thread_sleep_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10000最低价值 0最大价值 1000000InnoDB线程在加入之前睡 多久InnoDB队列 ,以微秒为单位。 默认值为10000.值为0将禁用睡眠。 您可以将配置选项设置为innodb_adaptive_max_sleep_delay您允许的最高值innodb_thread_sleep_delay,并 根据当前的线程调度活动InnoDB自动调整innodb_thread_sleep_delay或调低。 这种动态调整有助于线程调度机制在系统轻载或满负荷运行时平稳运行。有关更多信息,请参见 第15.8.4节“为InnoDB配置线程并发” 。
-
属性 值 命令行格式 --innodb-tmpdir=dir_name系统变量 innodb_tmpdir范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 目录名称 默认值 NULL用于为在线期间创建的临时排序文件定义备用目录
ALTER TABLE重建表的 操作 。ALTER TABLE重建表的 在线 操作也会创建一个 中间件 在与原始表相同的目录中 表文件。 该innodb_tmpdir选项不适用于中间表文件。有效值是除MySQL数据目录路径之外的任何目录路径。 如果值为NULL(默认值),则创建临时文件MySQL临时目录(
$TMPDIR在Unix上,%TEMP%在Windows上,或由--tmpdir配置选项 指定的目录 )。 如果指定了目录,则只有在innodb_tmpdir使用SET语句 配置 时才会检查是否存在目录和权限 。 如果在目录字符串中提供了符号链接,则解析符号链接并将其存储为绝对路径。 路径不应超过512个字节。ALTER TABLE如果innodb_tmpdir设置为无效目录, 则 联机 操作会报告错误 。innodb_tmpdir覆盖MySQLtmpdir设置但仅适用于在线ALTER TABLE操作。该
FILE权限需要配置innodb_tmpdir。innodb_tmpdir引入 该 选项有助于避免溢出位于tmpfs文件系统 上的临时文件目录 。 由于在ALTER TABLE重建表的 联机 操作 期间创建的大型临时排序文件,可能会发生此类溢出 。在复制环境中,
innodb_tmpdir如果所有服务器具有相同的操作系统 环境,则仅考虑复制该 设置。 否则,innodb_tmpdir在运行ALTER TABLE重建表的 联机 操作 时 ,复制该 设置可能会导致复制失败 。 如果服务器操作环境不同,建议您分别innodb_tmpdir在每台服务器上进行 配置 。有关更多信息,请参见 第15.12.3节“在线DDL空间要求” 。 有关在线
ALTER TABLE操作的 信息 ,请参见 第15.12节“InnoDB和在线DDL” 。 -
innodb_trx_purge_view_update_only_debug属性 值 命令行格式 --innodb-trx-purge-view-update-only-debug[={OFF|ON}]系统变量 innodb_trx_purge_view_update_only_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF暂停清除删除标记的记录,同时允许更新清除视图。 此选项人为地创建了一种情况,其中清除视图已更新但尚未执行清除。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。
WITH_DEBUG -
属性 值 命令行格式 --innodb-trx-rseg-n-slots-debug=#系统变量 innodb_trx_rseg_n_slots_debug范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最大价值 1024设置一个调试标志,该标志限制
TRX_RSEG_N_SLOTS为trx_rsegf_undo_find_free查找撤消日志段的空闲插槽 的 函数 的给定值 。 仅当使用 CMake 选项 编译调试支持时,此选项才可用 。WITH_DEBUG -
属性 值 命令行格式 --innodb-undo-directory=dir_name系统变量 innodb_undo_directory范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 路径在哪里
InnoDB创建撤消表空间 。 通常用于将撤消表空间放在不同的存储设备上。没有默认值(它是NULL)。 如果
innodb_undo_directory变量未定义,则在数据目录中创建撤消表空间。初始化MySQL实例时创建 的默认撤消表空间(
innodb_undo_001和innodb_undo_002)始终位于由...定义的目录中innodb_undo_directory变量 。如果未指定其他路径,则 使用
CREATE UNDO TABLESPACE语法创建的 撤消表空间 将在innodb_undo_directory变量 定义的目录中创建 。有关更多信息,请参见 第15.6.3.4节“撤消表空间” 。
-
属性 值 命令行格式 --innodb-undo-log-encrypt[={OFF|ON}]介绍 8.0.1 系统变量 innodb_undo_log_encrypt范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF控制使用
InnoDB表空间加密功能 加密的 表 的撤消日志数据的 加密 。 仅适用于驻留在单独的 撤消表空间中的 撤消日志 。 请参见 第15.6.3.4节“撤消表空间” 。 驻留在系统表空间中的撤消日志数据不支持加密。 有关更多信息,请参阅 撤消日志加密 。 -
属性 值 命令行格式 --innodb-undo-log-truncate[={OFF|ON}]系统变量 innodb_undo_log_truncate范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 (> = 8.0.2) ON默认值 (<= 8.0.1) OFF启用后,撤消超出定义的阈值的表空间
innodb_max_undo_log_size将标记为截断。 只能撤消撤消表空间。 不支持截断驻留在系统表空间中的撤消日志。 要进行截断,必须至少有两个撤消表空间。该
innodb_purge_rseg_truncate_frequency配置选项可用于加速还原表的截断。有关更多信息,请参阅 截断撤消表空间 。
-
属性 值 命令行格式 --innodb-undo-logs=#弃用 是(在8.0.2中删除) 系统变量 innodb_undo_logs范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 128最低价值 1最大价值 128注意innodb_undo_logs已在MySQL 8.0.2中删除。该
innodb_undo_logs选项是别名innodb_rollback_segments。 有关更多信息,请参阅的说明innodb_rollback_segments。 -
属性 值 命令行格式 --innodb-undo-tablespaces=#弃用 8.0.4 系统变量 innodb_undo_tablespaces范围 全球 动态 (> = 8.0.2) 是 动态 (<= 8.0.1) 没有 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.2) 2默认值 (<= 8.0.1) 0最小值 (> = 8.0.3) 2最小值 (<= 8.0.2) 0最大值 (> = 8.0.2) 127最大值 (<= 8.0.1) 95定义的数量 撤销表空间 的使用
InnoDB。 默认值和最小值为2。注意该
innodb_undo_tablespaces变量已弃用,自MySQL 8.0.14起不再可配置。 它将在以后的版本中删除。有关更多信息,请参见 第15.6.3.4节“撤消表空间” 。
-
属性 值 命令行格式 --innodb-use-native-aio[={OFF|ON}]系统变量 innodb_use_native_aio范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 ON指定是否使用Linux异步I / O子系统。 此变量仅适用于Linux系统,在服务器运行时无法更改。 通常,您不需要配置此选项,因为默认情况下已启用此选项。
Linux系统上提供了Windows系统上 的 异步I / O 功能
InnoDB。 (其他类Unix系统继续使用同步I / O调用。)此功能提高了大量I / O绑定系统的可伸缩性,这些系统通常显示许多挂起的读/写SHOW ENGINE INNODB STATUS\G输出中 。使用大量
InnoDBI / O线程运行,尤其是在同一服务器计算机上运行多个此类实例,可能会超出Linux系统的容量限制。 在这种情况下,您可能会收到以下错误:EAGAIN:指定的maxevents超出了用户对可用事件的限制。
您通常可以通过写入更高的限制来解决此错误
/proc/sys/fs/aio-max-nr。但是,如果操作系统中的异步I / O子系统出现问题导致
InnoDB无法启动,则可以使用启动服务器innodb_use_native_aio=0。 如果InnoDB检测到潜在问题(例如 ,不支持AIO 的tmpdir位置,tmpfs文件系统和Linux内核 的组合), 也可以在启动期间自动禁用此选项tmpfs。有关更多信息,请参见 第15.8.6节“在Linux上使用异步I / O” 。
-
该
InnoDB版本号。 在MySQL 8.0中,单独的版本编号InnoDB不适用,此值version与服务器 的 编号 相同 。 -
属性 值 命令行格式 --innodb-write-io-threads=#系统变量 innodb_write_io_threads范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 4最低价值 1最大价值 64用于写入操作的I / O线程数
InnoDB。 默认值为4.读取线程的对应部分是innodb_read_io_threads。 有关更多信息,请参见 第15.8.5节“配置后台InnoDB I / O线程数” 。 有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。注意在Linux系统上运行多个MySQL服务器(通常超过12)与默认设置
innodb_read_io_threads,innodb_write_io_threads以及Linux的aio-max-nr设置可以超过系统限制。 理想情况下,增加aio-max-nr设置; 作为解决方法,您可以减少一个或两个MySQL配置选项的设置。还要考虑
sync_binlog控制二进制日志与磁盘同步的值。有关常规I / O调整建议,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
- 15.14.1 InnoDB INFORMATION_SCHEMA关于压缩的表
- 15.14.2 InnoDB INFORMATION_SCHEMA交易和锁定信息
- 15.14.3 InnoDB INFORMATION_SCHEMA模式对象表
- 15.14.4 InnoDB INFORMATION_SCHEMA FULLTEXT索引表
- 15.14.5 InnoDB INFORMATION_SCHEMA缓冲池表
- 15.14.6 InnoDB INFORMATION_SCHEMA度量表
- 15.14.7 InnoDB INFORMATION_SCHEMA临时表信息表
- 15.14.8从INFORMATION_SCHEMA.FILES检索InnoDB表空间元数据
本节提供
InnoDB
INFORMATION_SCHEMA
表的
信息和用法示例
。
InnoDB INFORMATION_SCHEMA
表提供有关
InnoDB
存储引擎
各个方面的元数据,状态信息和统计信息
。
您可以
InnoDB
INFORMATION_SCHEMA
通过
SHOW
TABLES
在
INFORMATION_SCHEMA
数据库
上
发出
语句
来查看
表
列表
:
MySQL的> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB%';
有关表定义,请参见
第25.39节“INFORMATION_SCHEMA InnoDB表”
。
有关
MySQL
INFORMATION_SCHEMA
数据库的
一般信息
,请参阅
第25章,
INFORMATION_SCHEMA表
。
有两对
InnoDB
INFORMATION_SCHEMA
关于压缩
的
表可以提供有关压缩整体工作情况的信息:
-
INNODB_CMP并INNODB_CMP_RESET提供有关压缩操作数和执行压缩所花费的时间的信息。 -
INNODB_CMPMEM并INNODB_CMP_RESET提供有关为压缩分配内存的方式的信息。
在
INNODB_CMP
与
INNODB_CMP_RESET
表提供有关与压缩表执行的操作,这被描述的状态信息
15.9节,“InnoDB的表和页压缩”
。
该
PAGE_SIZE
列报告压缩
页面大小
。
这两个表具有相同的内容,但读取
INNODB_CMP_RESET
重置压缩和解压缩操作的统计信息。
例如,如果存档
INNODB_CMP_RESET
每60分钟
的输出
,则会看到每个小时的统计信息。
如果您监视输出
INNODB_CMP
(确保永远不会读取
INNODB_CMP_RESET
),您会看到自InnoDB启动以来的累积统计信息。
有关表定义,请参见 第25.39.5节“INFORMATION_SCHEMA INNODB_CMP和INNODB_CMP_RESET表” 。
在
INNODB_CMPMEM
与
INNODB_CMPMEM_RESET
表提供有关驻留在缓冲池中压缩页的状态信息。
有关压缩表和缓冲池使用的更多信息
,
请参见
第15.9节“InnoDB表和页面压缩”
。
在
INNODB_CMP
和
INNODB_CMP_RESET
表格应提供关于压缩的更多有用的统计数据。
内部细节
InnoDB
使用
伙伴分配器
系统来管理分配给
各种大小的页面的
内存
,从1KB到16KB。
这里描述的两个表的每一行对应于单个页面大小。
在
INNODB_CMPMEM
与
INNODB_CMPMEM_RESET
表的内容相同,但是从阅读
INNODB_CMPMEM_RESET
重置迁址操作的统计信息。
例如,如果您每60分钟归档一次输出
INNODB_CMPMEM_RESET
,则会显示每小时统计信息。
如果您从未读过
INNODB_CMPMEM_RESET
并监视过输出
INNODB_CMPMEM
,则会显示自
InnoDB
启动
以来的累积统计信息
。
有关表定义,请参见 第25.39.6节“INFORMATION_SCHEMA INNODB_CMPMEM和INNODB_CMPMEM_RESET表” 。
例15.1使用压缩信息模式表
以下是从包含压缩表(见数据库样本输出
第15.9节,“InnoDB的表和页压缩”
,
INNODB_CMP
,
INNODB_CMP_PER_INDEX
,和
INNODB_CMPMEM
)。
下表显示
INFORMATION_SCHEMA.INNODB_CMP
了轻量级
工作负载
下
的内容
。
缓冲池包含的唯一压缩页面大小为8K。
压缩或解压缩的网页已经消耗不到,因为统计数字重置时间的第二,因为列
COMPRESS_TIME
和
UNCOMPRESS_TIME
为零。
| 页面大小 | 压缩操作 | 压缩操作确定 | 压缩时间 | 解压缩操作 | 解压缩时间 |
|---|---|---|---|---|---|
| 1024 | 0 | 0 | 0 | 0 | 0 |
| 2048 | 0 | 0 | 0 | 0 | 0 |
| 4096 | 0 | 0 | 0 | 0 | 0 |
| 8192 | 1048 | 921 | 0 | 61 | 0 |
| 16384 | 0 | 0 | 0 | 0 | 0 |
根据
INNODB_CMPMEM
,
缓冲池中
有6169个压缩的8KB页面
。
唯一的其他分配块大小为64字节。
最小的
PAGE_SIZE
in
INNODB_CMPMEM
用于那些压缩页面的块描述符,缓冲池中没有未压缩的页面。
我们看到有5910个这样的页面。
间接地,我们看到259(6169-5910)个压缩页面也以未压缩的形式存在于缓冲池中。
下表显示
INFORMATION_SCHEMA.INNODB_CMPMEM
了轻量级
工作负载
下
的内容
。
由于压缩页面的内存分配器碎片,某些内存不可用:
SUM(PAGE_SIZE*PAGES_FREE)=6784
。
这是因为通过使用伙伴分配系统从主缓冲池分配的16K块开始分割更大的块来实现小的存储器分配请求。
碎片很低,因为一些已分配的块已被重新定位(复制)以形成更大的相邻空闲块。
这种
SUM(PAGE_SIZE*RELOCATION_OPS)
字节
复制
消耗不到一秒钟
(SUM(RELOCATION_TIME)=0)
。
本节介绍性能模式
data_locks
和
data_lock_waits
表
公开的锁定信息
,这些信息取代了
MySQL 8.0中的表
INFORMATION_SCHEMA
INNODB_LOCKS
和
INNODB_LOCK_WAITS
表。
对于用旧的条款类似的讨论
INFORMATION_SCHEMA
桌,看到
的InnoDB INFORMATION_SCHEMA交易及锁定信息
中
的MySQL 5.7参考手册
。
通过一个
INFORMATION_SCHEMA
表和两个性能架构表,您可以监视
InnoDB
事务并诊断潜在的锁定问题:
-
INNODB_TRX:此INFORMATION_SCHEMA表提供有关当前正在执行的每个事务的信息InnoDB,包括事务状态(例如,它是否正在运行或等待锁定),事务何时启动以及事务正在执行的特定SQL语句。 -
data_locks:此性能架构表包含每个保持锁的行以及阻止等待释放保持锁的每个锁请求:-
有一排每个持有锁,无论是持有锁的事务的状态(
INNODB_TRX.TRX_STATE是RUNNING,LOCK WAIT,ROLLING BACK或COMMITTING)。 -
InnoDB中等待另一个事务释放锁(
INNODB_TRX.TRX_STATEisLOCK WAIT)的 每个事务 都被一个阻塞锁请求阻止。 阻塞锁定请求是由处于不兼容模式的另一个事务持有的行或表锁定。 锁定请求始终具有与阻止请求的保持锁定模式不兼容的模式(读取与写入,共享与排除)。在另一个事务提交或回滚之前,阻塞的事务无法继续,从而释放所请求的锁。 对于每个被阻止的事务,
data_locks包含一行描述事务已请求的每个锁,以及它正在等待的每个锁。
-
-
data_lock_waits:此性能架构表指示哪些事务正在等待给定锁定,或者指示给定事务正在等待哪个锁定。 此表包含每个被阻止事务的一行或多行,指示它已请求的锁以及阻止该请求的任何锁。 该REQUESTING_ENGINE_LOCK_ID值指的是事务请求的锁,该BLOCKING_ENGINE_LOCK_ID值指的是阻止第一个事务继续进行的锁(由另一个事务持有)。 对于任何给定的阻塞事务,所有行都data_lock_waits具有相同的值REQUESTING_ENGINE_LOCK_ID和不同的值BLOCKING_ENGINE_LOCK_ID。
有关上表的更多信息,请参见 第25.39.29节“INFORMATION_SCHEMA INNODB_TRX表” , 第26.12.12.1节“data_locks表” 和 第26.12.12.2节“data_lock_waits表” 。
本节介绍性能模式
data_locks
和
data_lock_waits
表
公开的锁定信息
,这些信息取代了
MySQL 8.0中的表
INFORMATION_SCHEMA
INNODB_LOCKS
和
INNODB_LOCK_WAITS
表。
对于用旧的条款类似的讨论
INFORMATION_SCHEMA
表,请参见
使用InnoDB的事务和锁定信息
中
的MySQL 5.7参考手册
。
有时识别哪个事务阻止另一个事务是有帮助的。
包含有关
InnoDB
事务和数据锁定
信息的表
使您能够确定哪个事务正在等待另一个事务,以及正在请求哪个资源。
(有关这些表的说明,请参见
第15.14.2节“InnoDB INFORMATION_SCHEMA事务和锁定信息”
。)
假设三个会话同时运行。 每个会话对应一个MySQL线程,并执行一个接一个的事务。 当这些会话发出以下语句时,请考虑系统的状态,但尚未提交其事务:
-
会议A:
开始; 选择FROM t FOR UPDATE; SELECT SLEEP(100);
-
会议B:
SELECT b FROM t FOR UPDATE;
-
会议C:
SELECT c FROM t FOR UPDATE;
在此方案中,使用以下查询来查看正在等待的事务以及阻止它们的事务:
选择 r.trx_id waiting_trx_id, r.trx_mysql_thread_id waiting_thread, r.trx_query waiting_query, b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread, b.trx_query blocking_query FROM performance_schema.data_lock_waits w INNER JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_engine_transaction_id INNER JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_engine_transaction_id;
或者,更简单地说,使用
sys
架构
innodb_lock_waits
视图:
选择 waiting_trx_id, waiting_pid, waiting_query, blocking_trx_id, blocking_pid, blocking_query FROM sys.innodb_lock_waits;
如果为阻止查询报告了NULL值,请参阅 在发出会话变为空闲后识别阻止查询 。
| 等待trx id | 等待线程 | 等待查询 | 阻止trx id | 阻止线程 | 阻止查询 |
|---|---|---|---|---|---|
A4 |
6 |
SELECT b FROM t FOR UPDATE |
A3 |
5 |
SELECT SLEEP(100) |
A5 |
7 |
SELECT c FROM t FOR UPDATE |
A3 |
5 |
SELECT SLEEP(100) |
A5 |
7 |
SELECT c FROM t FOR UPDATE |
A4 |
6 |
SELECT b FROM t FOR UPDATE |
在上表中,您可以通过 “ 等待查询 ” 或 “ 阻止查询 ” 列 来标识会话 。 如你看到的:
-
会话B(trx id
A4,线程6)和会话C(trx idA5,thread7)都在等待会话A(trx idA3,thread5)。 -
会话C正在等待会话B以及会话A.
您可以在
INFORMATION_SCHEMA
INNODB_TRX
表和性能架构
data_locks
和
data_lock_waits
表中
查看基础数据
。
下表显示了该表的一些示例内容
INNODB_TRX
。
| trx id | trx状态 | trx开始了 | trx请求锁定ID | trx等待开始 | trx重量 | trx mysql线程id | trx查询 |
|---|---|---|---|---|---|---|---|
A3 |
RUNNING |
2008-01-15 16:44:54 |
NULL |
NULL |
2 |
5 |
SELECT SLEEP(100) |
A4 |
LOCK WAIT |
2008-01-15 16:45:09 |
A4:1:3:2 |
2008-01-15 16:45:09 |
2 |
6 |
SELECT b FROM t FOR UPDATE |
A5 |
LOCK WAIT |
2008-01-15 16:45:14 |
A5:1:3:2 |
2008-01-15 16:45:14 |
2 |
7 |
SELECT c FROM t FOR UPDATE |
下表显示了该表的一些示例内容
data_locks
。
| 锁定身份证 | 锁定trx id | 锁定模式 | 锁定类型 | 锁定架构 | 锁表 | 锁定指数 | 锁定数据 |
|---|---|---|---|---|---|---|---|
A3:1:3:2 |
A3 |
X |
RECORD |
test |
t |
PRIMARY |
0x0200 |
A4:1:3:2 |
A4 |
X |
RECORD |
test |
t |
PRIMARY |
0x0200 |
A5:1:3:2 |
A5 |
X |
RECORD |
test |
t |
PRIMARY |
0x0200 |
下表显示了该表的一些示例内容
data_lock_waits
。
标识阻塞事务时,如果发出查询的会话已变为空闲,则会为阻止查询报告NULL值。 在这种情况下,请使用以下步骤确定阻止查询:
-
标识阻止事务的进程列表ID。 在
sys.innodb_lock_waits表中,阻塞事务的进程列表ID是blocking_pid值。 -
使用
blocking_pid,查询MySQL Performance Schemathreads表以确定THREAD_ID阻塞事务。 例如,如果blocking_pid为6,则发出以下查询:SELECT THREAD_ID FROM performance_schema.threads WHERE PROCESSLIST_ID = 6;
-
使用
THREAD_ID,查询性能模式events_statements_current表以确定线程执行的最后一个查询。 例如,如果THREAD_ID是28,则发出以下查询:SELECT THREAD_ID,SQL_TEXT FROM performance_schema.events_statements_current 在哪里THREAD_ID = 28 \ G.
-
如果线程执行的最后一个查询不足以确定锁定的原因,则可以查询Performance Schema
events_statements_history表以查看该线程执行的最后10个语句。SELECT THREAD_ID,SQL_TEXT FROM performance_schema.events_statements_history WHERE THREAD_ID = 28按EVENT_ID排序;
有时将内部
InnoDB
锁定信息与MySQL维护的会话级信息
相关联是有用的
。
例如,您可能想知道,对于给定的
InnoDB
事务ID,相应的MySQL会话ID和可能持有锁的会话的名称,从而阻止其他事务。
INFORMATION_SCHEMA
INNODB_TRX
表和性能模式
data_locks
和
data_lock_waits
表
的以下输出来自
有点负载的系统。
可以看出,有几个事务正在运行。
以下
data_locks
和
data_lock_waits
表格显示:
在
INFORMATION_SCHEMA
PROCESSLIST
和
INNODB_TRX
表中
显示的查询之间可能存在不一致
。
有关解释,请参见
第15.14.2.3节“InnoDB事务和锁定信息的持久性和一致性”
。
下表显示了
PROCESSLIST
运行繁重
工作负载
的系统
的
表
的内容
。
| ID | 用户 | 主办 | D B | 命令 | 时间 | 州 | 信息 |
|---|---|---|---|---|---|---|---|
384 |
root |
localhost |
test |
Query |
10 |
update |
INSERT INTO t2 VALUES … |
257 |
root |
localhost |
test |
Query |
3 |
update |
INSERT INTO t2 VALUES … |
130 |
root |
localhost |
test |
Query |
0 |
update |
INSERT INTO t2 VALUES … |
61 |
root |
localhost |
test |
Query |
1 |
update |
INSERT INTO t2 VALUES … |
8 |
root |
localhost |
test |
Query |
1 |
update |
INSERT INTO t2 VALUES … |
4 |
root |
localhost |
test |
Query |
0 |
preparing |
SELECT * FROM PROCESSLIST |
2 |
root |
localhost |
test |
Sleep |
566 |
|
NULL |
下表显示了
INNODB_TRX
运行繁重
工作负载
的系统
的
表
的内容
。
| trx id | trx状态 | trx开始了 | trx请求锁定ID | trx等待开始 | trx重量 | trx mysql线程id | trx查询 |
|---|---|---|---|---|---|---|---|
77F |
LOCK WAIT |
2008-01-15 13:10:16 |
77F |
2008-01-15 13:10:16 |
1 |
876 |
INSERT INTO t09 (D, B, C) VALUES … |
77E |
LOCK WAIT |
2008-01-15 13:10:16 |
77E |
2008-01-15 13:10:16 |
1 |
875 |
INSERT INTO t09 (D, B, C) VALUES … |
77D |
LOCK WAIT |
2008-01-15 13:10:16 |
77D |
2008-01-15 13:10:16 |
1 |
874 |
INSERT INTO t09 (D, B, C) VALUES … |
77B |
LOCK WAIT |
2008-01-15 13:10:16 |
77B:733:12:1 |
2008-01-15 13:10:16 |
4 |
873 |
INSERT INTO t09 (D, B, C) VALUES … |
77A |
RUNNING |
2008-01-15 13:10:16 |
NULL |
NULL |
4 |
872 |
SELECT b, c FROM t09 WHERE … |
E56 |
LOCK WAIT |
2008-01-15 13:10:06 |
E56:743:6:2 |
2008-01-15 13:10:06 |
5 |
384 |
INSERT INTO t2 VALUES … |
E55 |
LOCK WAIT |
2008-01-15 13:10:06 |
E55:743:38:2 |
2008-01-15 13:10:13 |
965 |
257 |
INSERT INTO t2 VALUES … |
19C |
RUNNING |
2008-01-15 13:09:10 |
NULL |
NULL |
2900 |
130 |
INSERT INTO t2 VALUES … |
E15 |
RUNNING |
2008-01-15 13:08:59 |
NULL |
NULL |
5395 |
61 |
INSERT INTO t2 VALUES … |
51D |
RUNNING |
2008-01-15 13:08:47 |
NULL |
NULL |
9807 |
8 |
INSERT INTO t2 VALUES … |
下表显示了
data_lock_waits
运行繁重
工作负载
的系统
的
表
的内容
。
| 请求trx id | 请求锁定ID | 阻止trx id | 阻止锁定ID |
|---|---|---|---|
77F |
77F:806 |
77E |
77E:806 |
77F |
77F:806 |
77D |
77D:806 |
77F |
77F:806 |
77B |
77B:806 |
77E |
77E:806 |
77D |
77D:806 |
77E |
77E:806 |
77B |
77B:806 |
77D |
77D:806 |
77B |
77B:806 |
77B |
77B:733:12:1 |
77A |
77A:733:12:1 |
E56 |
E56:743:6:2 |
E55 |
E55:743:6:2 |
E55 |
E55:743:38:2 |
19C |
19C:743:38:2 |
下表显示了
data_locks
运行繁重
工作负载
的系统
的
表
的内容
。
| 锁定身份证 | 锁定trx id | 锁定模式 | 锁定类型 | 锁定架构 | 锁表 | 锁定指数 | 锁定数据 |
|---|---|---|---|---|---|---|---|
77F:806 |
77F |
AUTO_INC |
TABLE |
test |
t09 |
NULL |
NULL |
77E:806 |
77E |
AUTO_INC |
TABLE |
test |
t09 |
NULL |
NULL |
77D:806 |
77D |
AUTO_INC |
TABLE |
test |
t09 |
NULL |
NULL |
77B:806 |
77B |
AUTO_INC |
TABLE |
test |
t09 |
NULL |
NULL |
77B:733:12:1 |
77B |
X |
RECORD |
test |
t09 |
PRIMARY |
supremum pseudo-record |
77A:733:12:1 |
77A |
X |
RECORD |
test |
t09 |
PRIMARY |
supremum pseudo-record |
E56:743:6:2 |
E56 |
S |
RECORD |
test |
t2 |
PRIMARY |
0, 0 |
E55:743:6:2 |
E55 |
X |
RECORD |
test |
t2 |
PRIMARY |
0, 0 |
E55:743:38:2 |
E55 |
S |
RECORD |
test |
t2 |
PRIMARY |
1922, 1922 |
19C:743:38:2 |
19C |
X |
RECORD |
test |
t2 |
PRIMARY |
1922, 1922 |
本节介绍性能模式
data_locks
和
data_lock_waits
表
公开的锁定信息
,这些信息取代了
MySQL 8.0中的表
INFORMATION_SCHEMA
INNODB_LOCKS
和
INNODB_LOCK_WAITS
表。
对于用旧的条款类似的讨论
INFORMATION_SCHEMA
桌,看到
InnoDB的锁锁等待信息
中
的MySQL 5.7参考手册
。
当一个事务在一个表中更新了一行,或将其锁定
SELECT FOR UPDATE
,
InnoDB
建立在该行锁的列表或队列。
同样,
InnoDB
在表上维护表级锁的列表。
如果第二个事务要在不兼容模式下更新行或锁定先前事务已锁定的表
InnoDB
,则将该行的锁定请求添加到相应的队列。
对于要由事务获取的锁,必须删除先前输入到该行或表的锁队列中的所有不兼容的锁请求(当持有或请求这些锁的事务提交或回滚时发生)。
事务可以对不同的行或表具有任意数量的锁请求。
在任何给定时间,事务可以请求由另一个事务持有的锁,在这种情况下,它被该另一个事务阻止。
请求事务必须等待持有阻塞锁的事务提交或回滚。
如果事务没有等待锁定,则它处于某种
RUNNING
状态。
如果事务正在等待锁定,则它处于某种
LOCK WAIT
状态。
(该
INFORMATION_SCHEMA
INNODB_TRX
表指示事务状态值。)
Performance Schema
data_locks
表为每个
LOCK
WAIT
事务
保存一行或多行
,指示阻止其进度的任何锁定请求。
此表还包含一行,用于描述对于给定行或表的挂起锁定队列中的每个锁。
性能模式
data_lock_waits
表显示事务已经保留的锁是阻止其他事务请求的锁。
本节介绍性能模式
data_locks
和
data_lock_waits
表
公开的锁定信息
,这些信息取代了
MySQL 8.0中的表
INFORMATION_SCHEMA
INNODB_LOCKS
和
INNODB_LOCK_WAITS
表。
对于用旧的条款类似的讨论
INFORMATION_SCHEMA
表,请参见
持久性和InnoDB事务的一致性和锁定信息
中
的MySQL 5.7参考手册
。
事务和锁定表(
INFORMATION_SCHEMA
INNODB_TRX
表,性能模式
data_locks
和
data_lock_waits
表)
公开的数据
代表了快速变化的数据的一瞥。
这与用户表不同,用户表仅在发生应用程序启动的更新时才更改数据。
底层数据是内部系统管理的数据,可以非常快速地更改:
-
数据可能不是之间是一致的
INNODB_TRX,data_locks和data_lock_waits表。在
data_locks与data_lock_waits从表中公开的实时数据InnoDB存储引擎,提供有关的交易锁定inormationINNODB_TRX表。 从锁表中检索的数据在SELECT执行 时存在 ,但在客户端使用查询结果时可能会消失或更改。加入
data_locks与data_lock_waits可显示的行中data_lock_waits,在确定父行data_locks不再存在或不存在。 -
事务和锁定表中的数据可能与
INFORMATION_SCHEMAPROCESSLIST表或性能模式threads表 中的数据不一致 。例如,在将
InnoDB事务和锁定表中的数据与表中的数据 进行比较时应该小心PROCESSLIST。 即使你发出一个SELECT(加盟INNODB_TRX和PROCESSLIST,例如),这些表的内容一般是不相符的。 这是可能的INNODB_TRX,以引用不存在于行PROCESSLIST或用于示出的事务的当前正在执行的SQL查询INNODB_TRX.TRX_QUERY,以从所述一个中不同PROCESSLIST.INFO。
您可以提取有关
InnoDB
使用
InnoDB
INFORMATION_SCHEMA
表
管理的架构对象的元数据
。
此信息来自数据字典。
传统上,您将使用
第15.16节“InnoDB监视器”中
的技术获取此类信息
,设置
InnoDB
监视器并解析
SHOW
ENGINE INNODB
STATUS
语句
的输出
。
该
InnoDB
INFORMATION_SCHEMA
表界面允许您使用SQL查询数据。
InnoDB INFORMATION_SCHEMA
模式对象表包括下面列出的表。
INNODB_DATAFILES INNODB_TABLESTATS INNODB_FOREIGN INNODB_COLUMNS INNODB_INDEXES INNODB_FIELDS INNODB_TABLESPACES INNODB_TABLESPACES_BRIEF INNODB_FOREIGN_COLS INNODB_TABLES
表名表示所提供的数据类型:
-
INNODB_TABLES提供有关InnoDB表的 元数据 。 -
INNODB_COLUMNS提供有关InnoDB表列的 元数据 。 -
INNODB_INDEXES提供有关InnoDB索引的 元数据 -
INNODB_FIELDS提供有关InnoDB索引 的键列(字段)的元数据 。 -
INNODB_TABLESTATS提供有关InnoDB从内存数据结构派生的表 的低级状态信息的视图 。 -
INNODB_DATAFILES提供InnoDB每表文件和一般表空间的 数据文件路径信息 。 -
INNODB_TABLESPACES提供有关InnoDB每个表文件,常规表和撤消表空间的 元数据 。 -
INNODB_TABLESPACES_BRIEF提供有关InnoDB表空间 的元数据子集 。 -
INNODB_FOREIGN提供有关在InnoDB表上 定义的外键的元数据 。 -
INNODB_FOREIGN_COLS提供有关在表上定义的外键列的元数据InnoDB。
InnoDB INFORMATION_SCHEMA
方案对象表可以通过领域,如连接在一起
TABLE_ID
,
INDEX_ID
和
SPACE
,让您轻松检索所有可用的数据,你想学习或监视的对象。
有关每个表的列的信息,
请参阅
InnoDB
INFORMATION_SCHEMA
文档。
例15.2 InnoDB INFORMATION_SCHEMA模式对象表
此示例使用
t1
带有单个索引(
i1
)
的简单table(
)
来演示在
InnoDB
INFORMATION_SCHEMA
架构对象表中
找到的元数据类型
。
-
创建测试数据库和表
t1:MySQL的>
CREATE DATABASE test;MySQL的>USE test;MySQL的>CREATE TABLE t1 (col1 INT,col2 CHAR(10),col3 VARCHAR(10))ENGINE = InnoDB;MySQL的>CREATE INDEX i1 ON t1(col1); -
创建表后
t1,查询INNODB_TABLES以查找以下内容的元数据test/t1:MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test/t1' \G*************************** 1。排******************** ******* TABLE_ID:71 姓名:test / t1 标志:1 N_COLS:6 空间:57 ROW_FORMAT:紧凑 ZIP_PAGE_SIZE:0 INSTANT_COLS:0表的
t1aTABLE_ID为71.该FLAG字段提供有关表格式和存储特征的位级信息。 有六列,其中三个是通过创建隐藏的列InnoDB(DB_ROW_ID,DB_TRX_ID,和DB_ROLL_PTR)。 表的IDSPACE是57(值0表示表位于系统表空间中)。 该ROW_FORMAT紧凑。ZIP_PAGE_SIZE仅适用于具有Compressed行格式的 表 。INSTANT_COLS显示使用ALTER TABLE ... ADD COLUMNwith 添加第一个即时列之前表中的列数ALGORITHM=INSTANT。 -
使用
TABLE_ID来自 的 信息INNODB_TABLES,查询INNODB_COLUMNS表以获取有关表的列的信息。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_COLUMNS where TABLE_ID = 71\G*************************** 1。排******************** ******* TABLE_ID:71 名称:col1 POS:0 MTYPE:6 PRTYPE:1027 LEN:4 HAS_DEFAULT:0 DEFAULT_VALUE:NULL *************************** 2.排******************** ******* TABLE_ID:71 名称:col2 POS:1 MTYPE:2 PRTYPE:524542 LEN:10 HAS_DEFAULT:0 DEFAULT_VALUE:NULL *************************** 3。排******************** ******* TABLE_ID:71 名称:col3 POS:2 MTYPE:1 PRTYPE:524303 LEN:10 HAS_DEFAULT:0 DEFAULT_VALUE:NULL除了
TABLE_ID和列之外NAME,INNODB_COLUMNS还提供了POS每列 的序号位置( )(从0开始并按顺序递增),列MTYPE或 “ 主要类型 ” (6 = INT,2 = CHAR,1 = VARCHAR),PRTYPE或者 “ 精确” type “ (带有表示MySQL数据类型,字符集代码和可为空性的位的二进制值)和列长度(LEN)。 在HAS_DEFAULT与DEFAULT_VALUE列仅适用于使用即时添加的列ALTER TABLE ... ADD COLUMN用ALGORITHM=INSTANT。 -
再次 使用该
TABLE_ID信息INNODB_TABLES,查询INNODB_INDEXES有关与表关联的索引的信息t1。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_INDEXES WHERE TABLE_ID = 71 \G*************************** 1。排******************** ******* INDEX_ID:111 名称:GEN_CLUST_INDEX TABLE_ID:71 类型:1 N_FIELDS:0 PAGE_NO:3 空间:57 MERGE_THRESHOLD:50 *************************** 2.排******************** ******* INDEX_ID:112 姓名:i1 TABLE_ID:71 TYPE:0 N_FIELDS:1 PAGE_NO:4 空间:57 MERGE_THRESHOLD:50INNODB_INDEXES返回两个索引的数据。 第一个索引是GEN_CLUST_INDEX,InnoDB如果表没有用户定义的聚簇索引 , 则 创建 聚簇索引。 第二个索引(i1)是用户定义的二级索引。它
INDEX_ID是索引的标识符,在实例中的所有数据库中都是唯一的。 在TABLE_ID识别出索引与相关联的表。 索引TYPE值表示 索引 的类型(1 =聚簇索引,0 =辅助索引)。 该N_FILEDS值是构成索引的字段数。PAGE_NO是索引B-tree的根页码,SPACE是索引所在的表空间的ID。 非零值表示索引不驻留在系统表空间中。MERGE_THRESHOLD定义索引页中数据量的百分比阈值。 如果删除行或更新操作缩短行时索引页中的数据量低于此值(默认值为50%),InnoDB尝试将索引页与相邻索引页合并。 -
使用
INDEX_ID来自 的 信息INNODB_INDEXES,查询INNODB_FIELDS有关索引字段的信息i1。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FIELDS where INDEX_ID = 112 \G*************************** 1。排******************** ******* INDEX_ID:112 名称:col1 POS:0INNODB_FIELDS提供NAME索引字段及其在索引中的序数位置。 如果已在多个字段上定义索引(i1),INNODB_FIELDS则将为每个索引字段提供元数据。 -
利用
SPACE从信息INNODB_TABLES,查询INNODB_TABLESPACES表中有关表的表空间信息。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE SPACE = 57 \G*************************** 1。排******************** ******* 空间:57 姓名:test / t1 标记:16417 ROW_FORMAT:动态 PAGE_SIZE:16384 ZIP_PAGE_SIZE:0 SPACE_TYPE:单身 FS_BLOCK_SIZE:4096 FILE_SIZE:114688 ALLOCATED_SIZE:98304 SERVER_VERSION:8.0.4 SPACE_VERSION:1 加密:N除了
SPACE表空间 的 ID和NAME关联表 的 ID 之外 ,INNODB_TABLESPACES还提供表空间FLAG数据,这是有关表空间格式和存储特性的位级信息。 还提供的表空间ROW_FORMAT,PAGE_SIZE和其他几个表空间元数据项。 -
再次 使用该
SPACE信息INNODB_TABLES,查询INNODB_DATAFILES表空间数据文件的位置。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_DATAFILES WHERE SPACE = 57 \G*************************** 1。排******************** ******* 空间:57 路径:./ test / t1.ibd数据文件位于
testMySQL目录下的data目录中。 如果 使用 语句 的 子句 在MySQL数据目录之外的位置创建了 每表文件表 空间 ,则表空间 将是完全限定的目录路径。DATA DIRECTORYCREATE TABLEPATH -
最后一步,在table
t1(TABLE_ID = 71)中 插入一行 并查看INNODB_TABLESTATS表中 的数据 。 MySQL优化器使用此表中的数据来计算查询InnoDB表 时使用的索引 。 此信息源自内存数据结构。MySQL的>
INSERT INTO t1 VALUES(5, 'abc', 'def');查询正常,1行受影响(0.06秒) MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLESTATS where TABLE_ID = 71 \G*************************** 1。排******************** ******* TABLE_ID:71 姓名:test / t1 STATS_INITIALIZED:已初始化 NUM_ROWS:1 CLUST_INDEX_SIZE:1 OTHER_INDEX_SIZE:0 MODIFIED_COUNTER:1 AUTOINC:0 REF_COUNT:1该
STATS_INITIALIZED字段指示是否已为该表收集统计信息。NUM_ROWS是表中当前估计的行数。 在CLUST_INDEX_SIZE与OTHER_INDEX_SIZE场报告后,分别存储集群和二级指标对表在磁盘上的页面数。 该MODIFIED_COUNTER值显示DML操作修改的行数和外键的级联操作。 该AUTOINC值是为基于自动增量的操作发出的下一个数字。 表中没有定义自动增量列t1,因此值为0REF_COUNT价值是一个柜台。 当计数器达到0时,表示可以从表缓存中逐出表元数据。
例15.3外键INFORMATION_SCHEMA模式对象表
在
INNODB_FOREIGN
和
INNODB_FOREIGN_COLS
表格提供了有关外键关系数据。
此示例使用具有外键关系的父表和子表来演示在
INNODB_FOREIGN
和
INNODB_FOREIGN_COLS
表中
找到的
数据。
-
使用父表和子表创建测试数据库:
MySQL的>
CREATE DATABASE test;MySQL的>USE test;MySQL的>CREATE TABLE parent (id INT NOT NULL,PRIMARY KEY (id)) ENGINE=INNODB;MySQL的>CREATE TABLE child (id INT, parent_id INT,INDEX par_ind (parent_id),CONSTRAINT fk1FOREIGN KEY (parent_id) REFERENCES parent(id)ON DELETE CASCADE) ENGINE=INNODB; -
创建父表和子表后,查询
INNODB_FOREIGN并找到外键test/child和test/parent外键关系 的外键数据 :MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FOREIGN \G*************************** 1。排******************** ******* ID:test / fk1 FOR_NAME:测试/孩子 REF_NAME:测试/家长 N_COLS:1 类型:1元数据包括外键
ID(fk1),它以CONSTRAINT在子表上定义的 名称命名 。 的FOR_NAME就是外键定义子表的名称。REF_NAME是父表的名称( “ 引用 ” 表)。N_COLS是外键索引中的列数。TYPE是表示提供有关外键列的附加信息的位标志的数值。 在这种情况下,TYPE值为1,表示 该 值ON DELETE CASCADE为外键指定了选项。INNODB_FOREIGN有关TYPE值的 更多信息, 请参阅 表定义 。 -
使用外键
ID,查询INNODB_FOREIGN_COLS以查看有关外键列的数据。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FOREIGN_COLS WHERE ID = 'test/fk1' \G*************************** 1。排******************** ******* ID:test / fk1 FOR_COL_NAME:parent_id REF_COL_NAME:id POS:0FOR_COL_NAME是子表中外键列REF_COL_NAME的名称,是父表中引用列的名称。 该POS值是外键索引中键字段的序号位置,从零开始。
例15.4加入InnoDB INFORMATION_SCHEMA模式对象表
此示例演示如何连接三个
InnoDB INFORMATION_SCHEMA
架构对象表(
INNODB_TABLES
,
INNODB_TABLESPACES
和
INNODB_TABLESTATS
)以收集有关employees示例数据库中的表的文件格式,行格式,页面大小和索引大小信息。
以下表名称别名用于缩短查询字符串:
一个
IF()
控制流功能用于解释压缩的表。
如果压缩表,则使用
ZIP_PAGE_SIZE
而不是
计算索引大小
PAGE_SIZE
。
CLUST_INDEX_SIZE
并且
OTHER_INDEX_SIZE
,以字节为单位报告,除以
1024*1024
提供以兆字节(MB)为单位的索引大小。
使用该
ROUND()
函数
将MB值四舍五入为零小数空格
。
MySQL的>SELECT a.NAME, a.ROW_FORMAT,@page_size :=IF(a.ROW_FORMAT='Compressed',b.ZIP_PAGE_SIZE, b.PAGE_SIZE)AS page_size,ROUND((@page_size * c.CLUST_INDEX_SIZE)/(1024*1024)) AS pk_mb,ROUND((@page_size * c.OTHER_INDEX_SIZE)/(1024*1024)) AS secidx_mbFROM INFORMATION_SCHEMA.INNODB_TABLES aINNER JOIN INFORMATION_SCHEMA.INNODB_TABLESPACES b on a.NAME = b.NAMEINNER JOIN INFORMATION_SCHEMA.INNODB_TABLESTATS c on b.NAME = c.NAMEWHERE a.NAME LIKE 'employees/%'ORDER BY a.NAME DESC;+ ------------------------ + ------------ + ----------- + ------- + ----------- + | NAME | ROW_FORMAT | page_size | pk_mb | secidx_mb | + ------------------------ + ------------ + ----------- + ------- + ----------- + | 员工/职称| 动态| 16384 | 20 | 11 | | 员工/薪水| 动态| 16384 | 93 | 34 | | 员工/员工| 动态| 16384 | 15 | 0 | | employees / dept_manager | 动态| 16384 | 0 | 0 | | employees / dept_emp | 动态| 16384 | 12 | 10 | | 员工/部门| 动态| 16384 | 0 | 0 | + ------------------------ + ------------ + ----------- + ------- + ----------- +
下表提供了
FULLTEXT
索引的
元数据
:
MySQL的> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_FT%';
+ ------------------------------------------- +
| Tables_in_INFORMATION_SCHEMA(INNODB_FT%)|
+ ------------------------------------------- +
| INNODB_FT_CONFIG |
| INNODB_FT_BEING_DELETED |
| INNODB_FT_DELETED |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_INDEX_TABLE |
| INNODB_FT_INDEX_CACHE |
+ ------------------------------------------- +
表概述
-
INNODB_FT_CONFIG:提供有关表的FULLTEXT索引和关联处理的 元数据InnoDB。 -
INNODB_FT_BEING_DELETED:提供INNODB_FT_DELETED表 的快照 ; 它仅在OPTIMIZE TABLE维护操作 期间 使用。 当OPTIMIZE TABLE运行时,该INNODB_FT_BEING_DELETED表被清空,并且DOC_ID值是从除去INNODB_FT_DELETED表。 由于内容INNODB_FT_BEING_DELETED通常具有较短的生命周期,因此该表对监视或调试的实用性有限。 有关OPTIMIZE TABLE在带有FULLTEXT索引的 表上 运行的信息 ,请参见 第12.9.6节“微调MySQL全文搜索” 。 -
INNODB_FT_DELETED:存储从 表 的FULLTEXT索引 中删除的行InnoDB。 为了避免在索引的DML操作期间进行昂贵的索引重组InnoDBFULLTEXT,有关新删除的单词的信息将单独存储,在执行文本搜索时从搜索结果中过滤掉,并且仅在您OPTIMIZE TABLE为InnoDB表 发出 语句 时从主搜索索引中删除 。 -
INNODB_FT_DEFAULT_STOPWORD:保存 在 表 上 创建 索引 时默认使用 的 停用词 列表 。FULLTEXTInnoDB有关该
INNODB_FT_DEFAULT_STOPWORD表的 信息 ,请参见 第12.9.4节“全文停用词” 。 -
INNODB_FT_INDEX_TABLE:提供有关用于处理针对 表 的FULLTEXT索引的 文本搜索的反向索引的信息InnoDB。 -
INNODB_FT_INDEX_CACHE:提供有关FULLTEXT索引中 新插入行的标记信息 。 为了避免在DML操作期间进行昂贵的索引重组,有关新索引词的信息将单独存储,并且仅在OPTIMIZE TABLE运行时,服务器关闭时或者当缓存大小超过由innodb_ft_cache_size或 定义的限制时 与主搜索索引组合。innodb_ft_total_cache_size系统变量。
除
INNODB_FT_DEFAULT_STOPWORD
表外,这些表最初都是空的。
在查询其中任何一个之前,请将
innodb_ft_aux_table
系统变量
的值设置为
包含
FULLTEXT
索引
的表的名称(包括数据库名称)
(例如,
test/articles
)。
例15.5 InnoDB FULLTEXT索引INFORMATION_SCHEMA表
此示例使用带
FULLTEXT
索引
的表
来演示
FULLTEXT
索引
INFORMATION_SCHEMA
表中
包含的
数据。
-
创建一个带
FULLTEXT索引 的表 并插入一些数据:MySQL的>
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)) ENGINE=InnoDB;MySQL的>INSERT INTO articles (title,body) VALUES('MySQL Tutorial','DBMS stands for DataBase ...'),('How To Use MySQL Well','After you went through a ...'),('Optimizing MySQL','In this tutorial we will show ...'),('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),('MySQL vs. YourSQL','In the following database comparison ...'),('MySQL Security','When configured properly, MySQL ...'); -
将
innodb_ft_aux_table变量 设置为 包含FULLTEXT索引 的表的名称 。 如果未设置此变量,则InnoDBFULLTEXTINFORMATION_SCHEMA表为空,但除外INNODB_FT_DEFAULT_STOPWORD。MySQL的>
SET GLOBAL innodb_ft_aux_table = 'test/articles'; -
查询
INNODB_FT_INDEX_CACHE表,该表显示有关FULLTEXT索引中 新插入行的信息 。 为避免在DML操作期间进行昂贵的索引重组,新插入行的数据将保留在FULLTEXT索引缓存中,直到OPTIMIZE TABLE运行(或直到服务器关闭或超出缓存限制为止)。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE LIMIT 5;+ ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- + | WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | 位置| + ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- + | 1001 | 5 | 5 | 1 | 5 | 0 | | 之后| 3 | 3 | 1 | 3 | 22 | | 比较| 6 | 6 | 1 | 6 | 44 | | 配置| 7 | 7 | 1 | 7 | 20 | | 数据库| 2 | 6 | 2 | 2 | 31 | + ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- + -
启用
innodb_optimize_fulltext_only系统变量并OPTIMIZE TABLE在包含FULLTEXT索引 的表上 运行 。 此操作将FULLTEXT索引缓存 的内容刷新 到主FULLTEXT索引。innodb_optimize_fulltext_only更改OPTIMIZE TABLE语句对InnoDB表 操作 的方式 ,并且在InnoDB具有FULLTEXT索引的 表的 维护操作期间,临时启用 。MySQL的>
SET GLOBAL innodb_optimize_fulltext_only=ON;MySQL的>OPTIMIZE TABLE articles;+ --------------- + ---------- + ---------- + ---------- + | 表| Op | Msg_type | Msg_text | + --------------- + ---------- + ---------- + ---------- + | test.articles | 优化| 状态| 好的 + --------------- + ---------- + ---------- + ---------- + -
查询
INNODB_FT_INDEX_TABLE表以查看有关主FULLTEXT索引中数据的信息,包括有关刚从FULLTEXT索引缓存 刷新的数据的信息 。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE LIMIT 5;+ ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- + | WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | 位置| + ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- + | 1001 | 5 | 5 | 1 | 5 | 0 | | 之后| 3 | 3 | 1 | 3 | 22 | | 比较| 6 | 6 | 1 | 6 | 44 | | 配置| 7 | 7 | 1 | 7 | 20 | | 数据库| 2 | 6 | 2 | 2 | 31 | + ------------ + -------------- + ------------- + ------- ---- + -------- + ---------- +INNODB_FT_INDEX_CACHE由于OPTIMIZE TABLE操作刷新了FULLTEXT索引缓存, 因此该 表现在为空 。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE LIMIT 5;空集(0.00秒) -
从
test/articles表中 删除一些记录 。MySQL的>
DELETE FROM test.articles WHERE id < 4; -
查询
INNODB_FT_DELETED表格。 此表记录从FULLTEXT索引 中删除的行 。 为避免在DML操作期间进行昂贵的索引重组,有关新删除记录的信息将单独存储,在执行文本搜索时从搜索结果中过滤掉,并在运行时从主搜索索引中删除OPTIMIZE TABLE。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DELETED;+ -------- + | DOC_ID | + -------- + | 2 | | 3 | | 4 | + -------- + -
运行
OPTIMIZE TABLE以删除已删除的记录。MySQL的>
OPTIMIZE TABLE articles;+ --------------- + ---------- + ---------- + ---------- + | 表| Op | Msg_type | Msg_text | + --------------- + ---------- + ---------- + ---------- + | test.articles | 优化| 状态| 好的 + --------------- + ---------- + ---------- + ---------- +该
INNODB_FT_DELETED表现在应为空。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DELETED;空集(0.00秒) -
查询
INNODB_FT_CONFIG表格。 该表包含有关FULLTEXT索引和相关处理的 元数据 :-
optimize_checkpoint_limit:OPTIMIZE TABLE运行停止 的秒数 。 -
synced_doc_id:下一个DOC_ID要发行。 -
stopword_table_name:database/table用户定义的停用词表的名称。VALUE如果没有用户定义的停用词表,则 该 列为空。 -
use_stopword:指示是否使用停用词表,该表是在FULLTEXT创建索引 时定义的 。
MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_CONFIG;+ --------------------------- + ------- + | KEY | 价值| + --------------------------- + ------- + | optimize_checkpoint_limit | 180 | | synced_doc_id | 8 | | stopword_table_name | | | use_stopword | 1 | + --------------------------- + ------- + -
-
禁用
innodb_optimize_fulltext_only,因为它只是暂时启用:MySQL的>
SET GLOBAL innodb_optimize_fulltext_only=OFF;
该
InnoDB
INFORMATION_SCHEMA
缓冲池表提供了有关内页缓冲池的状态信息和元数据
InnoDB
缓冲池。
该
InnoDB
INFORMATION_SCHEMA
缓冲池表包括那些列举如下:
MySQL的> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_BUFFER%';
+ ----------------------------------------------- +
| Tables_in_INFORMATION_SCHEMA(INNODB_BUFFER%)|
+ ----------------------------------------------- +
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_POOL_STATS |
+ ----------------------------------------------- +
表概述
-
INNODB_BUFFER_PAGE:保存有关InnoDB缓冲池中 每个页面的信息 。 -
INNODB_BUFFER_PAGE_LRU:保存有关InnoDB缓冲池中 页面的信息 ,特别是它们在LRU列表中的排序方式,它确定哪些页面在缓冲池变满时从缓冲池中逐出。 该INNODB_BUFFER_PAGE_LRU表与表具有相同的列INNODB_BUFFER_PAGE,但该INNODB_BUFFER_PAGE_LRU表具有LRU_POSITION列而不是BLOCK_ID列。 -
INNODB_BUFFER_POOL_STATS:提供缓冲池状态信息。 许多相同的信息由SHOW ENGINE INNODB STATUS输出 提供 ,或者可以使用InnoDB缓冲池服务器状态变量获得。
查询
INNODB_BUFFER_PAGE
或
INNODB_BUFFER_PAGE_LRU
表可能会影响性能。
除非您了解性能影响并确定它是可接受的,否则不要在生产系统上查询这些表。
为避免影响生产系统的性能,请重现要调查的问题并在测试实例上查询缓冲池统计信息。
例15.6查询INNODB_BUFFER_PAGE表中的系统数据
此查询通过排除
TABLE_NAME
值为
NULL
或者包含
表名中
的斜杠
/
或句点
的页面来提供包含系统数据的页面的近似计数
.
,表示用户定义的表。
MySQL的>SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);+ ---------- + | COUNT(*)| + ---------- + | 1516 | + ---------- +
此查询返回包含系统数据的大致页数,缓冲池页的总数以及包含系统数据的页的大致百分比。
MySQL的>SELECT(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0)) AS system_pages,(SELECT COUNT(*)FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ROUND((system_pages/total_pages) * 100)) AS system_page_percentage;+ -------------- + ------------- + -------------------- ---- + | system_pages | total_pages | system_page_percentage | + -------------- + ------------- + -------------------- ---- + | 295 | 8192 | 4 | + -------------- + ------------- + -------------------- ---- +
可以通过查询
PAGE_TYPE
值
来确定缓冲池中的系统数据类型
。
例如,以下查询
PAGE_TYPE
在包含系统数据的页面中
返回八个不同的
值:
MySQL的>SELECT DISTINCT PAGE_TYPE FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);+ ------------------- + | PAGE_TYPE | + ------------------- + | 系统| | IBUF_BITMAP | | 未知| | FILE_SPACE_HEADER | | INODE | | UNDO_LOG | | 分配| + ------------------- +
例15.7查询INNODB_BUFFER_PAGE表中的用户数据
此查询通过计算
TABLE_NAME
值为
NOT
NULL
和
的页面来提供包含用户数据的页面的近似计数
NOT LIKE
'%INNODB_TABLES%'
。
MySQL的>SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NOT NULL AND TABLE_NAME NOT LIKE '%INNODB_TABLES%';+ ---------- + | COUNT(*)| + ---------- + | 7897 | + ---------- +
此查询返回包含用户数据的大致页数,缓冲池页面的总数以及包含用户数据的页面的大致百分比。
MySQL的>SELECT(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME不是NULL和(INSTR(TABLE_NAME,'/')> 0 OR INSTR(TABLE_NAME,'。')> 0)) AS user_pages,(SELECT COUNT(*)FROM information_schema.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ROUND((user_pages/total_pages) * 100)) AS user_page_percentage;+ ------------ + ------------- + ---------------------- + | user_pages | total_pages | user_page_percentage | + ------------ + ------------- + ---------------------- + | 7897 | 8192 | 96 | + ------------ + ------------- + ---------------------- +
此查询使用缓冲池中的页面标识用户定义的表:
MySQL的>SELECT DISTINCT TABLE_NAME FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NOT NULL AND (INSTR(TABLE_NAME, '/') > 0 OR INSTR(TABLE_NAME, '.') > 0)AND TABLE_NAME NOT LIKE '`mysql`.`innodb_%';+ ------------------------- + | TABLE_NAME | + ------------------------- + | `employees``salaries` | | `employees``employees` | + ------------------------- +
例15.8查询INNODB_BUFFER_PAGE表中的索引数据
有关索引页的信息,请
INDEX_NAME
使用索引名称
查询
列。
例如,以下查询返回
表中
emp_no
定义
的
索引
的页数和页面总数据大小
employees.salaries
:
MySQL的>SELECT INDEX_NAME, COUNT(*) AS Pages,ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))/1024/1024)AS 'Total Data (MB)'FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE INDEX_NAME='emp_no' AND TABLE_NAME = '`employees`.`salaries`';+ ------------ + ------- + ----------------- + | INDEX_NAME | 页面| 总数据(MB)| + ------------ + ------- + ----------------- + | emp_no | 1609 | 25 | + ------------ + ------- + ----------------- +
此查询返回
employees.salaries
表中
定义的所有索引的页数和页面总数据大小
:
MySQL的>SELECT INDEX_NAME, COUNT(*) AS Pages,ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@GLOBAL.innodb_page_size, COMPRESSED_SIZE))/1024/1024)AS 'Total Data (MB)'FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME = '`employees`.`salaries`'GROUP BY INDEX_NAME;+ ------------ + ------- + ----------------- + | INDEX_NAME | 页面| 总数据(MB)| + ------------ + ------- + ----------------- + | emp_no | 1608 | 25 | | 主要| 6086 | 95 | + ------------ + ------- + ----------------- +
例15.9查询INNODB_BUFFER_PAGE_LRU表中的LRU_POSITION数据
该
INNODB_BUFFER_PAGE_LRU
表包含有关
InnoDB
缓冲池中
页面的信息
,特别是它们的排序方式,用于确定哪些页面在缓冲池变满时从缓冲池中逐出。
此页面的定义与for相同
INNODB_BUFFER_PAGE
,但此表包含
LRU_POSITION
列而不是
BLOCK_ID
列。
此查询计算
employees.employees
表
的页面占用的LRU列表中特定位置的位置数
。
MySQL的>SELECT COUNT(LRU_POSITION) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE_LRUWHERE TABLE_NAME='`employees`.`employees`' AND LRU_POSITION < 3072;+ --------------------- + | COUNT(LRU_POSITION)| + --------------------- + | 548 | + --------------------- +
例15.10查询INNODB_BUFFER_POOL_STATS表
该
INNODB_BUFFER_POOL_STATS
表提供类似于
SHOW
ENGINE INNODB
STATUS
和
InnoDB
缓冲池状态变量的信息。
MySQL的> SELECT * FROM information_schema.INNODB_BUFFER_POOL_STATS \G
*************************** 1。排******************** *******
POOL_ID:0
POOL_SIZE:8192
FREE_BUFFERS:1
DATABASE_PAGES:8173
OLD_DATABASE_PAGES:3014
MODIFIED_DATABASE_PAGES:0
PENDING_DECOMPRESS:0
PENDING_READS:0
PENDING_FLUSH_LRU:0
PENDING_FLUSH_LIST:0
PAGES_MADE_YOUNG:15907
PAGES_NOT_MADE_YOUNG:3803101
PAGES_MADE_YOUNG_RATE:0
PAGES_MADE_NOT_YOUNG_RATE:0
NUMBER_PAGES_READ:3270
NUMBER_PAGES_CREATED:13176
NUMBER_PAGES_WRITTEN:15109
PAGES_READ_RATE:0
PAGES_CREATE_RATE:0
PAGES_WRITTEN_RATE:0
NUMBER_PAGES_GET:33069332
HIT_RATE:0
YOUNG_MAKE_PER_THOUSAND_GETS:0
NOT_YOUNG_MAKE_PER_THOUSAND_GETS:0
NUMBER_PAGES_READ_AHEAD:2713
NUMBER_READ_AHEAD_EVICTED:0
READ_AHEAD_RATE:0
READ_AHEAD_EVICTED_RATE:0
LRU_IO_TOTAL:0
LRU_IO_CURRENT:0
UNCOMPRESS_TOTAL:0
UNCOMPRESS_CURRENT:0
为了进行比较,
SHOW
ENGINE INNODB
STATUS
输出和
InnoDB
缓冲池状态变量输出如下所示,基于相同的数据集。
有关
SHOW
ENGINE INNODB
STATUS
输出的
更多信息
,请参见
第15.16.3节“InnoDB标准监视器和锁定监视器输出”
。
MySQL的> SHOW ENGINE INNODB STATUS \G
...
----------------------
缓冲池和记忆
----------------------
分配的总大内存为137428992
字典内存分配579084
缓冲池大小8192
免费缓冲区1
数据库页面8173
旧数据库页面3014
修改了db页面0
待定读数为0
待写:LRU 0,刷新列表0,单页0
页面年轻15907年,而不是年轻的3803101
0.00个年轻人/秒,0.00个非年轻人/秒
页面读取3270,创建13176,写成15109
0.00读/秒,0.00创建/ s,0.00写/秒
自上次打印输出以来没有缓冲池页面
页面预读0.00 / s,没有访问0.00 / s被逐出,随机预读0.00 / s
LRU len:8173,unzip_LRU len:0
I / O sum [0]:cur [0],解压和[0]:cur [0]
...
有关状态变量的说明,请参见 第5.1.10节“服务器状态变量” 。
MySQL的> SHOW STATUS LIKE 'Innodb_buffer%';
+ --------------------------------------- + --------- ---- +
| Variable_name | 价值|
+ --------------------------------------- + --------- ---- +
| Innodb_buffer_pool_dump_status | 没开始|
| Innodb_buffer_pool_load_status | 没开始|
| Innodb_buffer_pool_resize_status | 没开始|
| Innodb_buffer_pool_pages_data | 8173 |
| Innodb_buffer_pool_bytes_data | 133906432 |
| Innodb_buffer_pool_pages_dirty | 0 |
| Innodb_buffer_pool_bytes_dirty | 0 |
| Innodb_buffer_pool_pages_flushed | 15109 |
| Innodb_buffer_pool_pages_free | 1 |
| Innodb_buffer_pool_pages_misc | 18 |
| Innodb_buffer_pool_pages_total | 8192 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 2713 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 33069332 |
| Innodb_buffer_pool_reads | 558 |
| Innodb_buffer_pool_wait_free | 0 |
| Innodb_buffer_pool_write_requests | 11985961 |
+ --------------------------------------- + --------- ---- +
该
INNODB_METRICS
表提供了有关的信息
InnoDB
性能和资源相关计数器的信息。
INNODB_METRICS
表格列如下所示。
有关列说明,请参阅
第25.39.22节“INFORMATION_SCHEMA INNODB_METRICS表”
。
MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts" \G
*************************** 1。排******************** *******
名称:dml_inserts
SUBSYSTEM:dml
COUNT:46273
MAX_COUNT:46273
MIN_COUNT:NULL
AVG_COUNT:492.2659574468085
COUNT_RESET:46273
MAX_COUNT_RESET:46273
MIN_COUNT_RESET:NULL
AVG_COUNT_RESET:NULL
TIME_ENABLED:2014-11-28 16:07:53
TIME_DISABLED:NULL
TIME_ELAPSED:94
TIME_RESET:NULL
状态:已启用
TYPE:status_counter
注释:插入的行数
启用,禁用和重置计数器
您可以使用以下变量启用,禁用和重置计数器:
-
innodb_monitor_enable:启用计数器。SET GLOBAL innodb_monitor_enable = [counter-name | module_name | pattern | all];
-
innodb_monitor_disable:禁用计数器。SET GLOBAL innodb_monitor_disable = [counter-name | module_name | pattern | all];
-
innodb_monitor_reset:将计数器值重置为零。SET GLOBAL innodb_monitor_reset = [counter-name | module_name | pattern | all];
-
innodb_monitor_reset_all:重置所有计数器值。 使用前必须禁用计数器innodb_monitor_reset_all。SET GLOBAL innodb_monitor_reset_all = [counter-name | module_name | pattern | all];
使用MySQL服务器配置文件也可以在启动时启用计数器和计数器模块。
例如,要启用
log
模块
metadata_table_handles_opened
和
metadata_table_handles_closed
计数器,请
[mysqld]
在MySQL服务器配置文件
的
部分中
输入以下行
。
的[mysqld] innodb_monitor_enable = module_recovery,metadata_table_handles_opened,metadata_table_handles_closed
在配置文件中启用多个计数器或模块时,请指定
innodb_monitor_enable
变量,后跟由逗号分隔的计数器和模块名称,如上所示。
只能
innodb_monitor_enable
在配置文件中使用
该
变量。
在
innodb_monitor_disable
和
innodb_monitor_reset
变量仅支持在命令行上。
因为每个计数器都会增加一定程度的运行时开销,所以在生产服务器上保守地使用计数器来诊断特定问题或监视特定功能。 建议使用测试或开发服务器以更广泛地使用计数器。
计数器
可用计数器列表可能会有所变化。
查询
INFORMATION_SCHEMA.INNODB_METRICS
表中MySQL服务器版本中可用的计数器。
默认情况下启用的计数器对应于
SHOW
ENGINE INNODB
STATUS
输出中
显示的计数器
。
SHOW
ENGINE INNODB
STATUS
输出中
显示的计数器
始终在系统级别启用,但可以对
INNODB_METRICS
表格
禁用
。
计数器状态不是持久的。
除非另行配置,否则在重新启动服务器时,计数器将恢复为其默认启用或禁用状态。
如果您运行的程序会受到添加或删除计数器的影响,建议您查看发行说明并查询
INNODB_METRICS
表以在升级过程中识别这些更改。
MySQL的> SELECT name, subsystem, status FROM INFORMATION_SCHEMA.INNODB_METRICS ORDER BY NAME;
------------------------------------------ + ------ + --------------- + ---------- +
| 名字| 子系统| 状态|
------------------------------------------ + ------ + --------------- + ---------- +
| adaptive_hash_pages_added | adaptive_hash_index | 禁用|
| adaptive_hash_pages_removed | adaptive_hash_index | 禁用|
| adaptive_hash_rows_added | adaptive_hash_index | 禁用|
| adaptive_hash_rows_deleted_no_hash_entry | adaptive_hash_index | 禁用|
| adaptive_hash_rows_removed | adaptive_hash_index | 禁用|
| adaptive_hash_rows_updated | adaptive_hash_index | 禁用|
| adaptive_hash_searches | adaptive_hash_index | 启用|
| adaptive_hash_searches_btree | adaptive_hash_index | 启用|
| buffer_data_reads | 缓冲区| 启用|
| buffer_data_written | 缓冲区| 启用|
| buffer_flush_adaptive | 缓冲区| 禁用|
| buffer_flush_adaptive_avg_pass | 缓冲区| 禁用|
| buffer_flush_adaptive_avg_time_est | 缓冲区| 禁用|
| buffer_flush_adaptive_avg_time_slot | 缓冲区| 禁用|
| buffer_flush_adaptive_avg_time_thread | 缓冲区| 禁用|
| buffer_flush_adaptive_pages | 缓冲区| 禁用|
| buffer_flush_adaptive_total_pages | 缓冲区| 禁用|
| buffer_flush_avg_page_rate | 缓冲区| 禁用|
| buffer_flush_avg_pass | 缓冲区| 禁用|
| buffer_flush_avg_time | 缓冲区| 禁用|
| buffer_flush_background | 缓冲区| 禁用|
| buffer_flush_background_pages | 缓冲区| 禁用|
| buffer_flush_background_total_pages | 缓冲区| 禁用|
| buffer_flush_batches | 缓冲区| 禁用|
| buffer_flush_batch_num_scan | 缓冲区| 禁用|
| buffer_flush_batch_pages | 缓冲区| 禁用|
| buffer_flush_batch_scanned | 缓冲区| 禁用|
| buffer_flush_batch_scanned_per_call | 缓冲区| 禁用|
| buffer_flush_batch_total_pages | 缓冲区| 禁用|
| buffer_flush_lsn_avg_rate | 缓冲区| 禁用|
| buffer_flush_neighbor | 缓冲区| 禁用|
| buffer_flush_neighbor_pages | 缓冲区| 禁用|
| buffer_flush_neighbor_total_pages | 缓冲区| 禁用|
| buffer_flush_n_to_flush_by_age | 缓冲区| 禁用|
| buffer_flush_n_to_flush_requested | 缓冲区| 禁用|
| buffer_flush_pct_for_dirty | 缓冲区| 禁用|
| buffer_flush_pct_for_lsn | 缓冲区| 禁用|
| buffer_flush_sync | 缓冲区| 禁用|
| buffer_flush_sync_pages | 缓冲区| 禁用|
| buffer_flush_sync_total_pages | 缓冲区| 禁用|
| buffer_flush_sync_waits | 缓冲区| 禁用|
| buffer_LRU_batches_evict | 缓冲区| 禁用|
| buffer_LRU_batches_flush | 缓冲区| 禁用|
| buffer_LRU_batch_evict_pages | 缓冲区| 禁用|
| buffer_LRU_batch_evict_total_pages | 缓冲区| 禁用|
| buffer_LRU_batch_flush_avg_pass | 缓冲区| 禁用|
| buffer_LRU_batch_flush_avg_time_est | 缓冲区| 禁用|
| buffer_LRU_batch_flush_avg_time_slot | 缓冲区| 禁用|
| buffer_LRU_batch_flush_avg_time_thread | 缓冲区| 禁用|
| buffer_LRU_batch_flush_pages | 缓冲区| 禁用|
| buffer_LRU_batch_flush_total_pages | 缓冲区| 禁用|
| buffer_LRU_batch_num_scan | 缓冲区| 禁用|
| buffer_LRU_batch_scanned | 缓冲区| 禁用|
| buffer_LRU_batch_scanned_per_call | 缓冲区| 禁用|
| buffer_LRU_get_free_loops | 缓冲区| 禁用|
| buffer_LRU_get_free_search | 缓冲区| 禁用|
| buffer_LRU_get_free_waits | 缓冲区| 禁用|
| buffer_LRU_search_num_scan | 缓冲区| 禁用|
| buffer_LRU_search_scanned | 缓冲区| 禁用|
| buffer_LRU_search_scanned_per_call | 缓冲区| 禁用|
| buffer_LRU_single_flush_failure_count | 缓冲区| 禁用|
| buffer_LRU_single_flush_num_scan | 缓冲区| 禁用|
| buffer_LRU_single_flush_scanned | 缓冲区| 禁用|
| buffer_LRU_single_flush_scanned_per_call | 缓冲区| 禁用|
| buffer_LRU_unzip_search_num_scan | 缓冲区| 禁用|
| buffer_LRU_unzip_search_scanned | 缓冲区| 禁用|
| buffer_LRU_unzip_search_scanned_per_call | 缓冲区| 禁用|
| buffer_pages_created | 缓冲区| 启用|
| buffer_pages_read | 缓冲区| 启用|
| buffer_pages_written | 缓冲区| 启用|
| buffer_page_read_blob | buffer_page_io | 禁用|
| buffer_page_read_fsp_hdr | buffer_page_io | 禁用|
| buffer_page_read_ibuf_bitmap | buffer_page_io | 禁用|
| buffer_page_read_ibuf_free_list | buffer_page_io | 禁用|
| buffer_page_read_index_ibuf_leaf | buffer_page_io | 禁用|
| buffer_page_read_index_ibuf_non_leaf | buffer_page_io | 禁用|
| buffer_page_read_index_inode | buffer_page_io | 禁用|
| buffer_page_read_index_leaf | buffer_page_io | 禁用|
| buffer_page_read_index_non_leaf | buffer_page_io | 禁用|
| buffer_page_read_other | buffer_page_io | 禁用|
| buffer_page_read_system_page | buffer_page_io | 禁用|
| buffer_page_read_trx_system | buffer_page_io | 禁用|
| buffer_page_read_undo_log | buffer_page_io | 禁用|
| buffer_page_read_xdes | buffer_page_io | 禁用|
| buffer_page_read_zblob | buffer_page_io | 禁用|
| buffer_page_read_zblob2 | buffer_page_io | 禁用|
| buffer_page_written_blob | buffer_page_io | 禁用|
| buffer_page_written_fsp_hdr | buffer_page_io | 禁用|
| buffer_page_written_ibuf_bitmap | buffer_page_io | 禁用|
| buffer_page_written_ibuf_free_list | buffer_page_io | 禁用|
| buffer_page_written_index_ibuf_leaf | buffer_page_io | 禁用|
| buffer_page_written_index_ibuf_non_leaf | buffer_page_io | 禁用|
| buffer_page_written_index_inode | buffer_page_io | 禁用|
| buffer_page_written_index_leaf | buffer_page_io | 禁用|
| buffer_page_written_index_non_leaf | buffer_page_io | 禁用|
| buffer_page_written_other | buffer_page_io | 禁用|
| buffer_page_written_system_page | buffer_page_io | 禁用|
| buffer_page_written_trx_system | buffer_page_io | 禁用|
| buffer_page_written_undo_log | buffer_page_io | 禁用|
| buffer_page_written_xdes | buffer_page_io | 禁用|
| buffer_page_written_zblob | buffer_page_io | 禁用|
| buffer_page_written_zblob2 | buffer_page_io | 禁用|
| buffer_pool_bytes_data | 缓冲区| 启用|
| buffer_pool_bytes_dirty | 缓冲区| 启用|
| buffer_pool_pages_data | 缓冲区| 启用|
| buffer_pool_pages_dirty | 缓冲区| 启用|
| buffer_pool_pages_free | 缓冲区| 启用|
| buffer_pool_pages_misc | 缓冲区| 启用|
| buffer_pool_pages_total | 缓冲区| 启用|
| buffer_pool_reads | 缓冲区| 启用|
| buffer_pool_read_ahead | 缓冲区| 启用|
| buffer_pool_read_ahead_evicted | 缓冲区| 启用|
| buffer_pool_read_requests | 缓冲区| 启用|
| buffer_pool_size | 服务器| 启用|
| buffer_pool_wait_free | 缓冲区| 启用|
| buffer_pool_write_requests | 缓冲区| 启用|
| compression_pad_decrements | 压缩| 禁用|
| compression_pad_increments | 压缩| 禁用|
| compress_pages_compressed | 压缩| 禁用|
| compress_pages_decompressed | 压缩| 禁用|
| ddl_background_drop_indexes | ddl | 禁用|
| ddl_background_drop_tables | ddl | 禁用|
| ddl_log_file_alter_table | ddl | 禁用|
| ddl_online_create_index | ddl | 禁用|
| ddl_pending_alter_table | ddl | 禁用|
| ddl_sort_file_alter_table | ddl | 禁用|
| dml_deletes | dml | 启用|
| dml_inserts | dml | 启用|
| dml_reads | dml | 禁用|
| dml_updates | dml | 启用|
| file_num_open_files | file_system | 启用|
| ibuf_merges | change_buffer | 启用|
| ibuf_merges_delete | change_buffer | 启用|
| ibuf_merges_delete_mark | change_buffer | 启用|
| ibuf_merges_discard_delete | change_buffer | 启用|
| ibuf_merges_discard_delete_mark | change_buffer | 启用|
| ibuf_merges_discard_insert | change_buffer | 启用|
| ibuf_merges_insert | change_buffer | 启用|
| ibuf_size | change_buffer | 启用|
| icp_attempts | icp | 禁用|
| icp_match | icp | 禁用|
| icp_no_match | icp | 禁用|
| icp_out_of_range | icp | 禁用|
| index_page_discards | 指数| 禁用|
| index_page_merge_attempts | 指数| 禁用|
| index_page_merge_successful | 指数| 禁用|
| index_page_reorg_attempts | 指数| 禁用|
| index_page_reorg_successful | 指数| 禁用|
| index_page_splits | 指数| 禁用|
| innodb_activity_count | 服务器| 启用|
| innodb_background_drop_table_usec | 服务器| 禁用|
| innodb_checkpoint_usec | 服务器| 禁用|
| innodb_dblwr_pages_written | 服务器| 启用|
| innodb_dblwr_writes | 服务器| 启用|
| innodb_dict_lru_count | 服务器| 禁用|
| innodb_dict_lru_usec | 服务器| 禁用|
| innodb_ibuf_merge_usec | 服务器| 禁用|
| innodb_log_flush_usec | 服务器| 禁用|
| innodb_master_active_loops | 服务器| 禁用|
| innodb_master_idle_loops | 服务器| 禁用|
| innodb_master_purge_usec | 服务器| 禁用|
| innodb_master_thread_sleeps | 服务器| 禁用|
| innodb_mem_validate_usec | 服务器| 禁用|
| innodb_page_size | 服务器| 启用|
| innodb_rwlock_sx_os_waits | 服务器| 启用|
| innodb_rwlock_sx_spin_rounds | 服务器| 启用|
| innodb_rwlock_sx_spin_waits | 服务器| 启用|
| innodb_rwlock_s_os_waits | 服务器| 启用|
| innodb_rwlock_s_spin_rounds | 服务器| 启用|
| innodb_rwlock_s_spin_waits | 服务器| 启用|
| innodb_rwlock_x_os_waits | 服务器| 启用|
| innodb_rwlock_x_spin_rounds | 服务器| 启用|
| innodb_rwlock_x_spin_waits | 服务器| 启用|
| lock_deadlocks | 锁定| 启用|
| lock_rec_locks | 锁定| 禁用|
| lock_rec_lock_created | 锁定| 禁用|
| lock_rec_lock_removed | 锁定| 禁用|
| lock_rec_lock_requests | 锁定| 禁用|
| lock_rec_lock_waits | 锁定| 禁用|
| lock_row_lock_current_waits | 锁定| 启用|
| lock_row_lock_time | 锁定| 启用|
| lock_row_lock_time_avg | 锁定| 启用|
| lock_row_lock_time_max | 锁定| 启用|
| lock_row_lock_waits | 锁定| 启用|
| lock_table_locks | 锁定| 禁用|
| lock_table_lock_created | 锁定| 禁用|
| lock_table_lock_removed | 锁定| 禁用|
| lock_table_lock_waits | 锁定| 禁用|
| lock_timeouts | 锁定| 启用|
| log_checkpoints | 恢复| 禁用|
| log_lsn_buf_pool_oldest | 恢复| 禁用|
| log_lsn_checkpoint_age | 恢复| 禁用|
| log_lsn_current | 恢复| 禁用|
| log_lsn_last_checkpoint | 恢复| 禁用|
| log_lsn_last_flush | 恢复| 禁用|
| log_max_modified_age_async | 恢复| 禁用|
| log_max_modified_age_sync | 恢复| 禁用|
| log_num_log_io | 恢复| 禁用|
| log_padded | 恢复| 启用|
| log_pending_checkpoint_writes | 恢复| 禁用|
| log_pending_log_flushes | 恢复| 禁用|
| log_waits | 恢复| 启用|
| log_writes | 恢复| 启用|
| log_write_requests | 恢复| 启用|
| metadata_table_handles_closed | 元数据| 禁用|
| metadata_table_handles_opened | 元数据| 禁用|
| metadata_table_reference_count | 元数据| 禁用|
| os_data_fsyncs | os | 启用|
| os_data_reads | os | 启用|
| os_data_writes | os | 启用|
| os_log_bytes_written | os | 启用|
| os_log_fsyncs | os | 启用|
| os_log_pending_fsyncs | os | 启用|
| os_log_pending_writes | os | 启用|
| os_pending_reads | os | 禁用|
| os_pending_writes | os | 禁用|
| purge_del_mark_records | 清除| 禁用|
| purge_dml_delay_usec | 清除| 禁用|
| purge_invoked | 清除| 禁用|
| purge_resume_count | 清除| 禁用|
| purge_stop_count | 清除| 禁用|
| purge_undo_log_pages | 清除| 禁用|
| purge_upd_exist_or_extern_records | 清除| 禁用|
| trx_active_transactions | 交易| 禁用|
| trx_commits_insert_update | 交易| 禁用|
| trx_nl_ro_commits | 交易| 禁用|
| trx_rollbacks | 交易| 禁用|
| trx_rollbacks_savepoint | 交易| 禁用|
| trx_rollback_active | 交易| 禁用|
| trx_ro_commits | 交易| 禁用|
| trx_rseg_current_size | 交易| 禁用|
| trx_rseg_history_len | 交易| 启用|
| trx_rw_commits | 交易| 禁用|
| trx_undo_slots_cached | 交易| 禁用|
| trx_undo_slots_used | 交易| 禁用|
------------------------------------------ + ------ + --------------- + ---------- +
235行(0.01秒)
计数器模块
每个计数器与特定模块相关联。
模块名称可用于启用,禁用或重置特定子系统的所有计数器。
例如,用于
module_dml
启用与
dml
子系统
关联的所有计数器
。
MySQL的>SET GLOBAL innodb_monitor_enable = module_dml;MySQL的>SELECT name, subsystem, status FROM INFORMATION_SCHEMA.INNODB_METRICSWHERE subsystem ='dml';+ ------------- ----------- + + --------- + | 名字| 子系统| 状态| + ------------- ----------- + + --------- + | dml_reads | dml | 启用| | dml_inserts | dml | 启用| | dml_deletes | dml | 启用| | dml_updates | dml | 启用| + ------------- ----------- + + --------- +
模块名称可以
innodb_monitor_enable
与相关变量
一起使用
。
模块名称和相应的
SUBSYSTEM
名称如下所示。
-
module_adaptive_hash(子系统=adaptive_hash_index) -
module_buffer(子系统=buffer) -
module_buffer_page(子系统=buffer_page_io) -
module_compress(子系统=compression) -
module_ddl(子系统=ddl) -
module_dml(子系统=dml) -
module_file(子系统=file_system) -
module_ibuf_system(子系统=change_buffer) -
module_icp(子系统=icp) -
module_index(子系统=index) -
module_innodb(子系统=innodb) -
module_lock(子系统=lock) -
module_log(子系统=recovery) -
module_metadata(子系统=metadata) -
module_os(子系统=os) -
module_purge(子系统=purge) -
module_trx(子系统=transaction) -
module_undo(子系统=undo)
示例15.11使用INNODB_METRICS表计数器
此示例演示启用,禁用和重置计数器,以及查询
INNODB_METRICS
表中的
计数器数据
。
-
创建一个简单的
InnoDB表:MySQL的>
USE test;数据库已更改 MySQL的>CREATE TABLE t1 (c1 INT) ENGINE=INNODB;查询OK,0行受影响(0.02秒) -
启用
dml_inserts计数器。MySQL的>
SET GLOBAL innodb_monitor_enable = dml_inserts;查询OK,0行受影响(0.01秒)dml_inserts计数器 的描述 可以COMMENT在INNODB_METRICS表格 的 列中 找到 :MySQL的>
SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts";+ ------------- + ------------------------- + | NAME | 评论| + ------------- + ------------------------- + | dml_inserts | 插入的行数| + ------------- + ------------------------- + -
查询
INNODB_METRICS表中的dml_inserts计数器数据。 由于未执行任何DML操作,因此计数器值为零或NULL。 该TIME_ENABLED和TIME_ELAPSED值表明,当计数器最后一次启用,自那时以来,多少秒的流逝。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts" \G*************************** 1。排******************** ******* 名称:dml_inserts SUBSYSTEM:dml COUNT:0 MAX_COUNT:0 MIN_COUNT:NULL AVG_COUNT:0 COUNT_RESET:0 MAX_COUNT_RESET:0 MIN_COUNT_RESET:NULL AVG_COUNT_RESET:NULL TIME_ENABLED:2014-12-04 14:18:28 TIME_DISABLED:NULL TIME_ELAPSED:28 TIME_RESET:NULL 状态:已启用 TYPE:status_counter 注释:插入的行数 -
在表中插入三行数据。
MySQL的>
INSERT INTO t1 values(1);查询正常,1行受影响(0.00秒) MySQL的>INSERT INTO t1 values(2);查询正常,1行受影响(0.00秒) MySQL的>INSERT INTO t1 values(3);查询正常,1行受影响(0.00秒) -
INNODB_METRICS再次 查询 表以获取dml_inserts计数器数据。 许多计数器值现在已经增加,包括COUNT,MAX_COUNT,AVG_COUNT,和COUNT_RESET。INNODB_METRICS有关这些值的说明, 请参阅 表定义。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1。排******************** ******* 名称:dml_inserts SUBSYSTEM:dml COUNT:3 MAX_COUNT:3 MIN_COUNT:NULL AVG_COUNT:0.046153846153846156 COUNT_RESET:3 MAX_COUNT_RESET:3 MIN_COUNT_RESET:NULL AVG_COUNT_RESET:NULL TIME_ENABLED:2014-12-04 14:18:28 TIME_DISABLED:NULL TIME_ELAPSED:65 TIME_RESET:NULL 状态:已启用 TYPE:status_counter 注释:插入的行数 -
重置
dml_inserts计数器并INNODB_METRICS再次 查询 表以获取dml_inserts计数器数据。%_RESET之前报告 的 值(例如COUNT_RESET和MAX_RESET)将重新设置为零。 值,如COUNT,MAX_COUNT和AVG_COUNT,其累计从柜台启用时间收集数据,是由复位影响。MySQL的>
SET GLOBAL innodb_monitor_reset = dml_inserts;查询正常,0行受影响(0.00秒) MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1。排******************** ******* 名称:dml_inserts SUBSYSTEM:dml COUNT:3 MAX_COUNT:3 MIN_COUNT:NULL AVG_COUNT:0.03529411764705882 COUNT_RESET:0 MAX_COUNT_RESET:0 MIN_COUNT_RESET:NULL AVG_COUNT_RESET:0 TIME_ENABLED:2014-12-04 14:18:28 TIME_DISABLED:NULL TIME_ELAPSED:85 TIME_RESET:2014-12-04 14:19:44 状态:已启用 TYPE:status_counter 注释:插入的行数 -
要重置所有计数器值,必须先禁用计数器。 禁用计数器将
STATUS值 设置 为disabled。MySQL的>
SET GLOBAL innodb_monitor_disable = dml_inserts;查询正常,0行受影响(0.00秒) MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1。排******************** ******* 名称:dml_inserts SUBSYSTEM:dml COUNT:3 MAX_COUNT:3 MIN_COUNT:NULL AVG_COUNT:0.030612244897959183 COUNT_RESET:0 MAX_COUNT_RESET:0 MIN_COUNT_RESET:NULL AVG_COUNT_RESET:0 TIME_ENABLED:2014-12-04 14:18:28 TIME_DISABLED:2014-12-04 14:20:06 TIME_ELAPSED:98 TIME_RESET:NULL 状态:已禁用 TYPE:status_counter 注释:插入的行数注意计数器和模块名称支持通配符匹配。 例如,
dml_inserts您可以指定 ,而不是指定完整的 计数器名称dml_i%。 您还可以使用通配符匹配一次启用,禁用或重置多个计数器或模块。 例如,指定dml_%启用,禁用或重置以所有开头的所有计数器dml_。 -
禁用计数器后,您可以使用该
innodb_monitor_reset_all选项 重置所有计数器值 。 所有值都设置为零或NULL。MySQL的>
SET GLOBAL innodb_monitor_reset_all = dml_inserts;查询正常,0行受影响(0.00秒) MySQL的>SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1。排******************** ******* 名称:dml_inserts SUBSYSTEM:dml COUNT:0 MAX_COUNT:NULL MIN_COUNT:NULL AVG_COUNT:NULL COUNT_RESET:0 MAX_COUNT_RESET:NULL MIN_COUNT_RESET:NULL AVG_COUNT_RESET:NULL TIME_ENABLED:NULL TIME_DISABLED:NULL TIME_ELAPSED:NULL TIME_RESET:NULL 状态:已禁用 TYPE:status_counter 注释:插入的行数
INNODB_TEMP_TABLE_INFO
提供有关
InnoDB
在
InnoDB
实例
中处于活动状态的
用户创建的
临时表的
信息
。
它不提供有关
InnoDB
优化程序使用的
内部
临时表的
信息
。
MySQL的> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_TEMP%';
+ --------------------------------------------- +
| Tables_in_INFORMATION_SCHEMA(INNODB_TEMP%)|
+ --------------------------------------------- +
| INNODB_TEMP_TABLE_INFO |
+ --------------------------------------------- +
有关表定义,请参见 第25.39.28节“INFORMATION_SCHEMA INNODB_TEMP_TABLE_INFO表” 。
例15.12 INNODB_TEMP_TABLE_INFO
此示例演示了
INNODB_TEMP_TABLE_INFO
表的
特征
。
-
创建一个简单的
InnoDB临时表:MySQL的>
CREATE TEMPORARY TABLE t1 (c1 INT PRIMARY KEY) ENGINE=INNODB; -
查询
INNODB_TEMP_TABLE_INFO以查看临时表元数据。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G*************************** 1。排******************** ******* TABLE_ID:194 姓名:#sql7a79_1_0 N_COLS:4 空间:182它
TABLE_ID是临时表的唯一标识符。 该NAME列显示临时表的系统生成的名称,前缀为 “ #sql ” 。 列(数N_COLS)为4,而不是1,因为InnoDB总是创建三个隐藏的表列(DB_ROW_ID,DB_TRX_ID,和DB_ROLL_PTR)。 -
重启MySQL并查询
INNODB_TEMP_TABLE_INFO。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G返回空集,因为
INNODB_TEMP_TABLE_INFO当服务器关闭时,其数据不会持久保存到磁盘。 -
创建一个新的临时表。
MySQL的>
CREATE TEMPORARY TABLE t1 (c1 INT PRIMARY KEY) ENGINE=INNODB; -
查询
INNODB_TEMP_TABLE_INFO以查看临时表元数据。MySQL的>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G*************************** 1。排******************** ******* TABLE_ID:196 姓名:#sql7b0e_1_0 N_COLS:4 空间:184所述
SPACEID可以是不同的,因为当在服务器启动它是动态生成的。
该
INFORMATION_SCHEMA.FILES
表提供有关所有
InnoDB
表空间类型的
元数据,
包括
每表文件表空间
,
通用表空间
,
系统表空间
,
临时表表空间
和
撤消表空间
(如果存在)。
本节提供了
InnoDB
特定的用法示例。
有关
INFORMATION_SCHEMA.FILES
表
提供的数据的更多信息
,请参见
第25.11节“INFORMATION_SCHEMA文件表”
。
所述
INNODB_TABLESPACES
和
INNODB_DATAFILES
表还提供有关的元数据
InnoDB
的表空间,但数据被限制到文件每次表,一般情况下,和撤消表空间。
此查询
InnoDB
从
INFORMATION_SCHEMA.FILES
表的与
InnoDB
表空间
相关的
字段中
检索有关
系统表空间的
元数据
。
INFORMATION_SCHEMA.FILES
与
InnoDB
总是返回NULL
无关的字段,
从查询中排除。
MySQL的>SELECT FILE_ID, FILE_NAME, FILE_TYPE, TABLESPACE_NAME, FREE_EXTENTS,TOTAL_EXTENTS, EXTENT_SIZE, INITIAL_SIZE, MAXIMUM_SIZE, AUTOEXTEND_SIZE, DATA_FREE, STATUS ENGINEFROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME LIKE 'innodb_system' \G*************************** 1。排******************** ******* FILE_ID:0 FILE_NAME:./ ibdata1 FILE_TYPE:TABLESPACE TABLESPACE_NAME:innodb_system FREE_EXTENTS:0 TOTAL_EXTENTS:12 EXTENT_SIZE:1048576 INITIAL_SIZE:12582912 MAXIMUM_SIZE:NULL AUTOEXTEND_SIZE:67108864 DATA_FREE:4194304 发动机:正常
此查询检索
每个表文件和一般表空间
的
FILE_ID
(相当于空间ID)和
FILE_NAME
(包括路径信息)
InnoDB
。
每个表的
.ibd
文件
和一般表空间都有一个
文件扩展名。
MySQL的>SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%.ibd%' ORDER BY FILE_ID;+ --------- + --------------------------------------- + | FILE_ID | FILE_NAME | + --------- + --------------------------------------- + | 2 | ./mysql/plugin.ibd | | 3 | ./mysql/servers.ibd | | 4 | ./mysql/help_topic.ibd | | 5 | ./mysql/help_category.ibd | | 6 | ./mysql/help_relation.ibd | | 7 | ./mysql/help_keyword.ibd | | 8 | ./mysql/time_zone_name.ibd | | 9 | ./mysql/time_zone.ibd | | 10 | ./mysql/time_zone_transition.ibd | | 11 | ./mysql/time_zone_transition_type.ibd | | 12 | ./mysql/time_zone_leap_second.ibd | | 13 | ./mysql/innodb_table_stats.ibd | | 14 | ./mysql/innodb_index_stats.ibd | | 15 | ./mysql/slave_relay_log_info.ibd | | 16 | ./mysql/slave_master_info.ibd | | 17 | ./mysql/slave_worker_info.ibd | | 18 | ./mysql/gtid_executed.ibd | | 19 | ./mysql/server_cost.ibd | | 20 | ./mysql/engine_cost.ibd | | 21 | ./sys/sys_config.ibd | | 23 | ./test/t1.ibd | | 26 | /home/user/test/test/t2.ibd | + --------- + --------------------------------------- +
该查询检索
FILE_ID
和
FILE_NAME
对
InnoDB
全局临时表空间。
全局临时表空间文件名以前缀为前缀
ibtmp
。
MySQL的>SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%ibtmp%';+ --------- + ----------- + | FILE_ID | FILE_NAME | + --------- + ----------- + | 22 | ./ibtmp1 | + --------- + ----------- +
同样,
InnoDB
undo表空间文件名以前缀为前缀
undo
。
以下查询返回
FILE_ID
和
FILE_NAME
for
InnoDB
表空间。
MySQL的>SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%undo%';
本节简要介绍
InnoDB
与Performance Schema的集成。
有关全面的性能架构文档,请参见
第26章,
MySQL性能架构
。
您可以
InnoDB
使用MySQL
Performance Schema功能
分析某些内部
操作
。
此类调整主要面向评估优化策略以克服性能瓶颈的专家用户。
DBA还可以使用此功能进行容量规划,以查看其典型工作负载是否遇到任何性能瓶颈,特定的CPU,RAM和磁盘存储组合;
如果是的话,判断是否可以通过增加系统某些部分的容量来改善性能。
要使用此功能来检查
InnoDB
性能:
-
您必须大致熟悉如何使用 性能架构功能 。 例如,您应该知道如何启用仪器和使用者,以及如何查询
performance_schema表以检索数据。 有关介绍性概述,请参见 第26.1节“性能架构快速入门” 。 -
您应该熟悉可用的性能模式工具
InnoDB。 要查看InnoDB相关的仪器,您可以在setup_instruments表格中 查询 包含'innodb'的 仪器名称 。MySQL的>
SELECT *FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%innodb%';+ ------------------------------------------------- ------ + --------- + ------- + | NAME | 启用| 定时| + ------------------------------------------------- ------ + --------- + ------- + | wait / synch / mutex / innodb / commit_cond_mutex | 没有| 没有| | wait / synch / mutex / innodb / innobase_share_mutex | 没有| 没有| | wait / synch / mutex / innodb / autoinc_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_zip_mutex | 没有| 没有| | wait / synch / mutex / innodb / cache_last_read_mutex | 没有| 没有| | wait / synch / mutex / innodb / dict_foreign_err_mutex | 没有| 没有| | wait / synch / mutex / innodb / dict_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / recalc_pool_mutex | 没有| 没有| ... | wait / io / file / innodb / innodb_data_file | 是的| 是的| | wait / io / file / innodb / innodb_log_file | 是的| 是的| | wait / io / file / innodb / innodb_temp_file | 是的| 是的| | stage / innodb / alter table(结束)| 是的| 是的| | stage / innodb / alter table(flush)| 是的| 是的| | stage / innodb / alter table(insert)| 是的| 是的| | stage / innodb / alter table(log apply index)| 是的| 是的| | stage / innodb / alter table(log apply table)| 是的| 是的| | stage / innodb / alter table(合并排序)| 是的| 是的| | stage / innodb / alter table(读取PK和内部排序)| 是的| 是的| | stage / innodb / buffer pool load | 是的| 是的| | 记忆/ innodb / buf_buf_pool | 没有| 没有| | memory / innodb / dict_stats_bg_recalc_pool_t | 没有| 没有| | memory / innodb / dict_stats_index_map_t | 没有| 没有| | memory / innodb / dict_stats_n_diff_on_level | 没有| 没有| | 记忆/ innodb /其他| 没有| 没有| | memory / innodb / row_log_buf | 没有| 没有| | memory / innodb / row_merge_sort | 没有| 没有| | 记忆/ innodb / std | 没有| 没有| | memory / innodb / sync_debug_latches | 没有| 没有| | memory / innodb / trx_sys_t :: rw_trx_ids | 没有| 没有| ... + ------------------------------------------------- ------ + --------- + ------- + 155行(0.00秒)有关已检测
InnoDB对象的 其他信息 ,可以查询性能模式 实例表 ,这些 表 提供有关已检测对象的其他信息。 与之相关的实例表InnoDB包括:-
该
mutex_instances表 -
该
rwlock_instances表 -
该
cond_instances表 -
该
file_instances表
注意与
InnoDB缓冲池 相关的互斥锁和RW锁 不包含在此coverage中; 这同样适用于SHOW ENGINE INNODB MUTEX命令 的输出 。例如,要查看
InnoDB执行文件I / O检测时性能模式所见的 检测 文件对象的 信息 ,可以发出以下查询:MySQL的>
SELECT *FROM performance_schema.file_instancesWHERE EVENT_NAME LIKE '%innodb%'\G*************************** 1。排******************** ******* FILE_NAME:/path/to/mysql-8.0/data/ibdata1 EVENT_NAME:wait / io / file / innodb / innodb_data_file OPEN_COUNT:3 *************************** 2.排******************** ******* FILE_NAME:/path/to/mysql-8.0/data/ib_logfile0 EVENT_NAME:wait / io / file / innodb / innodb_log_file OPEN_COUNT:2 *************************** 3。排******************** ******* FILE_NAME:/path/to/mysql-8.0/data/ib_logfile1 EVENT_NAME:wait / io / file / innodb / innodb_log_file OPEN_COUNT:2 ****************************排******************** ******* FILE_NAME:/path/to/mysql-8.0/data/mysql/engine_cost.ibd EVENT_NAME:wait / io / file / innodb / innodb_data_file OPEN_COUNT:3 ... -
-
您应该熟悉
performance_schema存储InnoDB事件数据的 表 。 与InnoDB相关事件相关的 表格 包括:-
在 等待事件 表,其存储等待事件。
-
该 汇总 表,提供随时间终止事件的汇总信息。 摘要表包括 文件I / O摘要表 ,它汇总了有关I / O操作的信息。
-
Stage Event 表,用于存储事件数据
InnoDBALTER TABLE和缓冲池加载操作。 有关更多信息,请参见 第15.15.1节“使用性能模式 监控 InnoDB表的ALTER TABLE进度” 和 使用性能模式 监控缓冲池负载进度 。
如果您只对
InnoDB相关对象 感兴趣,请 在查询这些表时 使用子句WHERE EVENT_NAME LIKE '%innodb%'或WHERE NAME LIKE '%innodb%'(根据需要)。 -
您可以
使用
Performance Schema
监视
表的
ALTER
TABLE
进度
。
InnoDB
有七个阶段事件代表不同阶段
ALTER
TABLE
。
每个阶段事件报告在
其不同阶段中
进行的整个
操作的
总计
WORK_COMPLETED
和
总计
操作。
使用一个公式来计算,该公式考虑了所有
执行
的工作
,并且可以在
处理
期间进行修改
。
和
值是由所执行的所有工作的抽象表示
。
WORK_ESTIMATED
ALTER TABLE
WORK_ESTIMATED
ALTER TABLE
ALTER TABLE
WORK_COMPLETED
WORK_ESTIMATED
ALTER TABLE
按发生顺序,
ALTER
TABLE
舞台活动包括:
-
stage/innodb/alter table (read PK and internal sort):当ALTER TABLE处于读取 - 主键阶段 时,此阶段处于活动 状态。 它从 主键 开始WORK_COMPLETED=0并WORK_ESTIMATED设置为估计的主页数。 阶段完成后,WORK_ESTIMATED将更新为主键中的实际页数。 -
stage/innodb/alter table (merge sort):对ALTER TABLE操作 添加的每个索引重复此阶段 。 -
stage/innodb/alter table (insert):对ALTER TABLE操作 添加的每个索引重复此阶段 。 -
stage/innodb/alter table (log apply index):此阶段包括ALTER TABLE运行时 生成的DML日志的应用程序 。 -
stage/innodb/alter table (flush):在此阶段开始之前WORK_ESTIMATED,根据刷新列表的长度更新更准确的估计。 -
stage/innodb/alter table (log apply table):此阶段包括ALTER TABLE运行时 生成的并发DML日志的应用程序 。 此阶段的持续时间取决于表更改的范围。 如果没有在表上运行并发DML,则此阶段是即时的。 -
stage/innodb/alter table (end):包括在刷新阶段之后出现的任何剩余工作,例如重新应用ALTER TABLE在运行时 在表上执行的DML 。
InnoDB ALTER
TABLE
阶段事件目前不考虑添加空间索引。
使用性能架构的ALTER TABLE监控示例
以下示例演示如何启用
stage/innodb/alter table%
舞台事件工具和相关的使用者表以监视
ALTER
TABLE
进度。
有关Performance Schema阶段事件工具和相关使用者的信息,请参见
第26.12.5节“性能模式阶段事件表”
。
-
启用
stage/innodb/alter%仪器:MySQL的>
UPDATE performance_schema.setup_instrumentsSET ENABLED = 'YES'WHERE NAME LIKE 'stage/innodb/alter%';查询OK,7行受影响(0.00秒) 匹配的行数:7已更改:7警告:0 -
启用舞台活动消费表,其中包括
events_stages_current,events_stages_history,和events_stages_history_long。MySQL的>
UPDATE performance_schema.setup_consumersSET ENABLED = 'YES'WHERE NAME LIKE '%stages%';查询OK,3行受影响(0.00秒) 匹配的行数:3已更改:3警告:0 -
运行一个
ALTER TABLE操作。 在此示例中,将一middle_name列添加到employees示例数据库的employees表中。MySQL的>
ALTER TABLE employees.employees ADD COLUMN middle_name varchar(14) AFTER first_name;查询正常,0行受影响(9.27秒) 记录:0重复:0警告:0 -
ALTER TABLE通过查询Performance Schemaevents_stages_current表 来 检查 操作 的进度 。 显示的阶段事件根据ALTER TABLE当前正在进行的阶段而 不同 。 该WORK_COMPLETED列显示已完成的工作。 该WORK_ESTIMATED列提供剩余工作的估计值。MySQL的>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_current;+ ------------------------------------------------- ----- + ---------------- + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + ------------------------------------------------- ----- + ---------------- + ---------------- + | stage / innodb / alter table(读取PK和内部排序)| 280 | 1245 | + ------------------------------------------------- ----- + ---------------- + ---------------- + 1排(0.01秒)events_stages_current如果ALTER TABLE操作已完成, 该 表将返回一个空集 。 在这种情况下,您可以检查events_stages_history表以查看已完成操作的事件数据。 例如:MySQL的>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_history;+ ------------------------------------------------- ----- + ---------------- + ---------------- + | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | + ------------------------------------------------- ----- + ---------------- + ---------------- + | stage / innodb / alter table(读取PK和内部排序)| 886 | 1213 | | stage / innodb / alter table(flush)| 1213 | 1213 | | stage / innodb / alter table(log apply table)| 1597 | 1597 | | stage / innodb / alter table(结束)| 1597 | 1597 | | stage / innodb / alter table(log apply table)| 1981年| 1981年| + ------------------------------------------------- ----- + ---------------- + ---------------- + 5行(0.00秒)如上所示,
WORK_ESTIMATED在ALTER TABLE处理 期间修改 了该 值 。 初始阶段完成后的估计工作是1213.ALTER TABLE处理完成后,WORK_ESTIMATED设定为实际值,即1981年。
互斥体是代码中使用的同步机制,用于强制在给定时间只有一个线程可以访问公共资源。 当在服务器中执行的两个或多个线程需要访问相同的资源时,线程相互竞争。 获取互斥锁上的锁的第一个线程会导致其他线程等待,直到释放锁。
对于
InnoDB
已检测的互斥锁,可以使用
性能模式
监视互斥等待
。
例如,在Performance Schema表中收集的等待事件数据可以帮助识别具有最多等待或最长总等待时间的互斥锁。
以下示例演示了如何启用
InnoDB
互斥等待工具,如何启用关联的使用者以及如何查询等待事件数据。
-
要查看可用的
InnoDB互斥等待工具,请查询性能模式setup_instruments表。InnoDB默认情况下, 所有 互斥等待仪器都被禁用。MySQL的>
SELECT *FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb%';+ ------------------------------------------------- -------- + --------- + ------- + | NAME | 启用| 定时| + ------------------------------------------------- -------- + --------- + ------- + | wait / synch / mutex / innodb / commit_cond_mutex | 没有| 没有| | wait / synch / mutex / innodb / innobase_share_mutex | 没有| 没有| | wait / synch / mutex / innodb / autoinc_mutex | 没有| 没有| | wait / synch / mutex / innodb / autoinc_persisted_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_flush_state_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_LRU_list_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_free_list_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_zip_free_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_zip_hash_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_pool_zip_mutex | 没有| 没有| | wait / synch / mutex / innodb / cache_last_read_mutex | 没有| 没有| | wait / synch / mutex / innodb / dict_foreign_err_mutex | 没有| 没有| | wait / synch / mutex / innodb / dict_persist_dirty_tables_mutex | 没有| 没有| | wait / synch / mutex / innodb / dict_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / recalc_pool_mutex | 没有| 没有| | wait / synch / mutex / innodb / fil_system_mutex | 没有| 没有| | wait / synch / mutex / innodb / flush_list_mutex | 没有| 没有| | wait / synch / mutex / innodb / fts_bg_threads_mutex | 没有| 没有| | wait / synch / mutex / innodb / fts_delete_mutex | 没有| 没有| | wait / synch / mutex / innodb / fts_optimize_mutex | 没有| 没有| | wait / synch / mutex / innodb / fts_doc_id_mutex | 没有| 没有| | wait / synch / mutex / innodb / log_flush_order_mutex | 没有| 没有| | wait / synch / mutex / innodb / hash_table_mutex | 没有| 没有| | wait / synch / mutex / innodb / ibuf_bitmap_mutex | 没有| 没有| | wait / synch / mutex / innodb / ibuf_mutex | 没有| 没有| | wait / synch / mutex / innodb / ibuf_pessimistic_insert_mutex | 没有| 没有| | wait / synch / mutex / innodb / log_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / log_sys_write_mutex | 没有| 没有| | wait / synch / mutex / innodb / mutex_list_mutex | 没有| 没有| | wait / synch / mutex / innodb / page_zip_stat_per_index_mutex | 没有| 没有| | wait / synch / mutex / innodb / purge_sys_pq_mutex | 没有| 没有| | wait / synch / mutex / innodb / recv_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / recv_writer_mutex | 没有| 没有| | wait / synch / mutex / innodb / redo_rseg_mutex | 没有| 没有| | wait / synch / mutex / innodb / noredo_rseg_mutex | 没有| 没有| | wait / synch / mutex / innodb / rw_lock_list_mutex | 没有| 没有| | wait / synch / mutex / innodb / rw_lock_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_dict_tmpfile_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_innodb_monitor_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_misc_tmpfile_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_monitor_file_mutex | 没有| 没有| | wait / synch / mutex / innodb / buf_dblwr_mutex | 没有| 没有| | wait / synch / mutex / innodb / trx_undo_mutex | 没有| 没有| | wait / synch / mutex / innodb / trx_pool_mutex | 没有| 没有| | wait / synch / mutex / innodb / trx_pool_manager_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / lock_mutex | 没有| 没有| | wait / synch / mutex / innodb / lock_wait_mutex | 没有| 没有| | wait / synch / mutex / innodb / trx_mutex | 没有| 没有| | wait / synch / mutex / innodb / srv_threads_mutex | 没有| 没有| | wait / synch / mutex / innodb / rtr_active_mutex | 没有| 没有| | wait / synch / mutex / innodb / rtr_match_mutex | 没有| 没有| | wait / synch / mutex / innodb / rtr_path_mutex | 没有| 没有| | wait / synch / mutex / innodb / rtr_ssn_mutex | 没有| 没有| | wait / synch / mutex / innodb / trx_sys_mutex | 没有| 没有| | wait / synch / mutex / innodb / zip_pad_mutex | 没有| 没有| | wait / synch / mutex / innodb / master_key_id_mutex | 没有| 没有| + ------------------------------------------------- -------- + --------- + ------- + -
某些
InnoDB互斥锁实例是在服务器启动时创建的,仅在服务器启动时启用了关联的仪器时才会进行检测。 要确保InnoDB检测并启用 所有 互斥锁实例,请将以下performance-schema-instrument规则 添加 到MySQL配置文件中:性能架构仪器= '等待/同步/互斥/ innodb的/%= ON'
如果您不需要所有
InnoDB互斥锁的 等待事件数据 ,则可以通过向performance-schema-instrumentMySQL配置文件 添加其他 规则来 禁用特定仪器 。 例如,要禁用InnoDB与全文搜索相关的互斥等待事件工具,请添加以下规则:性能架构仪器= '等待/同步/互斥/ innodb的/ FTS(%)= OFF'
注意具有较长前缀的规则,例如
wait/synch/mutex/innodb/fts%优先于具有较短前缀的规则,例如wait/synch/mutex/innodb/%。将
performance-schema-instrument规则 添加 到配置文件后,重新启动服务器。InnoDB除启用与全文搜索相关 的 互斥锁外, 所有 互斥锁均已启用。 要验证,请查询setup_instruments表。 在ENABLED与TIMED列应设置YES为您启用的工具。MySQL的>
SELECT *FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb%';+ ------------------------------------------------- ------ + --------- + ------- + | NAME | 启用| 定时| + ------------------------------------------------- ------ + --------- + ------- + | wait / synch / mutex / innodb / commit_cond_mutex | 是的| 是的| | wait / synch / mutex / innodb / innobase_share_mutex | 是的| 是的| | wait / synch / mutex / innodb / autoinc_mutex | 是的| 是的| ... | wait / synch / mutex / innodb / master_key_id_mutex | 是的| 是的| + ------------------------------------------------- ------ + --------- + ------- + 49行(0.00秒) -
通过更新
setup_consumers表 启用等待事件使用者 。 默认情况下禁用等待事件使用者。MySQL的>
UPDATE performance_schema.setup_consumersSET enabled = 'YES'WHERE name like 'events_waits%';查询OK,3行受影响(0.00秒) 匹配的行数:3已更改:3警告:0您可以通过查询
setup_consumers表 来验证是否启用了等待事件使用者 。 的events_waits_current,events_waits_history和events_waits_history_long消费者应该启用。MySQL的>
SELECT * FROM performance_schema.setup_consumers;+ ---------------------------------- + --------- + | NAME | 启用| + ---------------------------------- + --------- + | events_stages_current | 没有| | events_stages_history | 没有| | events_stages_history_long | 没有| | events_statements_current | 是的| | events_statements_history | 是的| | events_statements_history_long | 没有| | events_transactions_current | 是的| | events_transactions_history | 是的| | events_transactions_history_long | 没有| | events_waits_current | 是的| | events_waits_history | 是的| | events_waits_history_long | 是的| | global_instrumentation | 是的| | thread_instrumentation | 是的| | statements_digest | 是的| + ---------------------------------- + --------- + 15行(0.00秒) -
启用仪器和使用者后,运行要监视的工作负载。 在此示例中, mysqlslap 加载仿真客户端用于模拟工作负载。
外壳>
./mysqlslap --auto-generate-sql --concurrency=100 --iterations=10--number-of-queries=1000 --number-char-cols=6 --number-int-cols=6; -
查询等待事件数据。 在这个例子中,等待事件数据从查询
events_waits_summary_global_by_event_name,其聚合中找到的数据表events_waits_current,events_waits_history和events_waits_history_long表。 数据由事件名称(EVENT_NAME) 汇总,事件名称( )是生成事件的工具的名称。 汇总数据包括:-
COUNT_STAR汇总的等待事件数。
-
SUM_TIMER_WAIT汇总的定时等待事件的总等待时间。
-
MIN_TIMER_WAIT汇总的定时等待事件的最短等待时间。
-
AVG_TIMER_WAIT汇总的定时等待事件的平均等待时间。
-
MAX_TIMER_WAIT汇总的定时等待事件的最长等待时间。
以下查询返回仪器名称(
EVENT_NAME),等待事件数(COUNT_STAR)以及该仪器事件的总等待时间(SUM_TIMER_WAIT)。 因为默认情况下等待的时间间隔为皮秒(万亿分之一秒),所以等待时间除以1000000000以显示等待时间(以毫秒为单位)。 数据按汇总等待事件数(COUNT_STAR)的 降序显示 。 您可以调整ORDER BY子句以按总等待时间对数据进行排序。MySQL的>
SELECT EVENT_NAME, COUNT_STAR, SUM_TIMER_WAIT/1000000000 SUM_TIMER_WAIT_MSFROM performance_schema.events_waits_summary_global_by_event_nameWHERE SUM_TIMER_WAIT > 0 AND EVENT_NAME LIKE 'wait/synch/mutex/innodb/%'ORDER BY COUNT_STAR DESC;+ ------------------------------------------------- -------- + ------------ + ------------------- + | EVENT_NAME | COUNT_STAR | SUM_TIMER_WAIT_MS | + ------------------------------------------------- -------- + ------------ + ------------------- + | wait / synch / mutex / innodb / trx_mutex | 201111 | 23.4719 | | wait / synch / mutex / innodb / fil_system_mutex | 62244 | 9.6426 | | wait / synch / mutex / innodb / redo_rseg_mutex | 48238 | 3.1135 | | wait / synch / mutex / innodb / log_sys_mutex | 46113 | 2.0434 | | wait / synch / mutex / innodb / trx_sys_mutex | 35134 | 1068.1588 | | wait / synch / mutex / innodb / lock_mutex | 34872 | 1039.2589 | | wait / synch / mutex / innodb / log_sys_write_mutex | 17805 | 1526.0490 | | wait / synch / mutex / innodb / dict_sys_mutex | 14912 | 1606.7348 | | wait / synch / mutex / innodb / trx_undo_mutex | 10634 | 1.1424 | | wait / synch / mutex / innodb / rw_lock_list_mutex | 8538 | 0.1960 | | wait / synch / mutex / innodb / buf_pool_free_list_mutex | 5961 | 0.6473 | | wait / synch / mutex / innodb / trx_pool_mutex | 4885 | 8821.7496 | | wait / synch / mutex / innodb / buf_pool_LRU_list_mutex | 4364 | 0.2077 | | wait / synch / mutex / innodb / innobase_share_mutex | 3212 | 0.2650 | | wait / synch / mutex / innodb / flush_list_mutex | 3178 | 0.2349 | | wait / synch / mutex / innodb / trx_pool_manager_mutex | 2495 | 0.1310 | | wait / synch / mutex / innodb / buf_pool_flush_state_mutex | 1318 | 0.2161 | | wait / synch / mutex / innodb / log_flush_order_mutex | 1250 | 0.0893 | | wait / synch / mutex / innodb / buf_dblwr_mutex | 951 | 0.0918 | | wait / synch / mutex / innodb / recalc_pool_mutex | 670 | 0.0942 | | wait / synch / mutex / innodb / dict_persist_dirty_tables_mutex | 345 | 0.0414 | | wait / synch / mutex / innodb / lock_wait_mutex | 303 | 0.1565 | | wait / synch / mutex / innodb / autoinc_mutex | 196 | 0.0213 | | wait / synch / mutex / innodb / autoinc_persisted_mutex | 196 | 0.0175 | | wait / synch / mutex / innodb / purge_sys_pq_mutex | 117 | 0.0308 | | wait / synch / mutex / innodb / srv_sys_mutex | 94 | 0.0077 | | wait / synch / mutex / innodb / ibuf_mutex | 22 | 0.0086 | | wait / synch / mutex / innodb / recv_sys_mutex | 12 | 0.0008 | | wait / synch / mutex / innodb / srv_innodb_monitor_mutex | 4 | 0.0009 | | wait / synch / mutex / innodb / recv_writer_mutex | 1 | 0.0005 | + ------------------------------------------------- -------- + ------------ + ------------------- +注意前面的结果集包括在启动过程中产生的等待事件数据。 要排除此数据,可以
events_waits_summary_global_by_event_name在启动后和运行工作负载之前立即 截断 表。 但是,截断操作本身可能会产生可忽略不计的等待事件数据。MySQL的>
TRUNCATE performance_schema.events_waits_summary_global_by_event_name; -
InnoDB
监视器提供有关
InnoDB
内部状态的信息。
此信息对性能调整很有用。
有两种类型的
InnoDB
监视器:
-
标准
InnoDB监视器显示以下类型的信息:-
主要后台主题完成的工作
-
信号量等待
-
有关最新外键和死锁错误的数据
-
Lock等待事务
-
活动事务持有的表和记录锁
-
待处理的I / O操作和相关统计信息
-
插入缓冲区和自适应哈希索引统计
-
重做日志数据
-
缓冲池统计信息
-
行操作数据
-
-
该
InnoDB锁监控打印附加锁信息作为标准的一部分InnoDB监视器输出。
当
InnoDB
监视器启用定期输出时
,大约每15秒
InnoDB
将
输出
写入
mysqld
服务器标准错误输出(
stderr
)。
InnoDB
发送监视器输出
stderr
而不是
stdout
或固定大小的内存缓冲区,以避免潜在的缓冲区溢出。
在Windows上,
stderr
除非另行配置,否则将定向到默认日志文件。
如果要将输出定向到控制台窗口而不是错误日志,请在控制台窗口中使用该
--console
选项
从命令提示符启动服务器
。
有关更多信息,请参阅
Windows上的错误日志记录
。
在Unix和类Unix系统上,
stderr
除非另有配置,否则通常指向终端。
有关更多信息,请参阅
Unix和类Unix系统上的错误记录
。
InnoDB
只有在您真正想要查看监视器信息时才应启用监视器,因为输出生成会导致某些性能下降。
此外,如果将监视器输出定向到错误日志,如果您以后忘记禁用监视器,则日志可能会变得非常大。
为了帮助进行故障排除,
在某些条件下
InnoDB
临时启用标准
InnoDB
监视器输出
有关更多信息,请参见
第15.20节“InnoDB故障排除”
。
InnoDB
监视器输出以包含时间戳和监视器名称的标头开头。
例如:
===================================== 2014-10-16 18:37:29 0x7fc2a95c1700 INNODB MONITOR OUTPUT =====================================
标准
InnoDB
Monitor(
INNODB MONITOR OUTPUT
)
的标头
也用于锁定监视器,因为后者通过添加额外的锁定信息产生相同的输出。
该
innodb_status_output
和
innodb_status_output_locks
系统变量用于启用标准的
InnoDB
监控和
InnoDB
锁定监控。
PROCESS
启用或禁用
InnoDB
监视器
需要
该
权限
。
启用标准InnoDB监视器
InnoDB
通过将
innodb_status_output
系统变量
设置为
启用标准
监视器
ON
。
SET GLOBAL innodb_status_output = ON;
要禁用标准
InnoDB
监视器,请设置
innodb_status_output
为
OFF
。
关闭服务器时,该
innodb_status_output
变量将设置为默认
OFF
值。
启用InnoDB锁定监视器
InnoDB
使用
InnoDB
标准监视器输出
打印锁定监视器数据
。
无论是
InnoDB
标准监视器和
InnoDB
锁显示器必须能够具有
InnoDB
锁定监控数据定期打印。
要启用
InnoDB
锁定监视器,请将
innodb_status_output_locks
系统变量
设置
为
ON
。
无论是
InnoDB
标准的监控和
InnoDB
锁定显示器必须能够有
InnoDB
定期打印锁监视器数据:
SET GLOBAL innodb_status_output = ON; SET GLOBAL innodb_status_output_locks = ON;
要禁用
InnoDB
锁定监视器,请设置
innodb_status_output_locks
为
OFF
。
设置
innodb_status_output
为
OFF
也禁用
InnoDB
标准监视器。
关闭服务器时,
innodb_status_output
和
innodb_status_output_locks
变量将设置为默认
OFF
值。
要启用
InnoDB
锁定监视器
SHOW
ENGINE INNODB
STATUS
输出,只需启用
innodb_status_output_locks
。
获得标准的InnoDB监视器按需输出
作为启用标准
InnoDB
Monitor for periodic output
的替代方法
,您可以
InnoDB
使用
SHOW
ENGINE
INNODB STATUS
SQL语句
按需
获取标准
Monitor输出,该
语句将输出提取到客户端程序。
如果您使用的是
mysql
交互式客户端,那么如果您将通常的分号语句终止符替换为以下内容,则输出更具可读性
\G
:
MySQL的> SHOW ENGINE INNODB STATUS\G
SHOW
ENGINE INNODB
STATUS
InnoDB
如果
InnoDB
启用
了
锁定监视器,则
输出还包括
锁定监视器数据
。
将标准InnoDB监视器输出定向到状态文件
InnoDB
通过
--innodb-status-file
在启动时
指定
选项,
可以启用
标准
监视器输出并将其定向到状态文件
。
使用此选项时,将
InnoDB
创建一个
在数据目录中
命名的文件
,并每隔15秒将输出写入其中。
innodb_status.
pid
InnoDB
正常关闭服务器时删除状态文件。
如果发生异常关闭,则可能必须手动删除状态文件。
该
--innodb-status-file
选项用于临时使用,因为输出生成可能会影响性能,并且
文件会随着时间的推移而变得非常大。
innodb_status.
pid
锁定监视器与标准监视器相同,只是它包含其他锁定信息。 启用任一监视器以定期输出会打开同一输出流,但如果启用了锁定监视器,则流包含额外信息。 例如,如果启用“标准监视器”和“锁定监视器”,则会打开单个输出流。 在您禁用锁定监视器之前,该流包含额外的锁定信息。
使用该
SHOW
ENGINE INNODB
STATUS
语句
生成时,标准监视器输出限制为1MB
。
此限制不适用于写入服务器标准错误输出(
stderr
)的
输出
。
示例标准监视器输出:
MySQL的> SHOW ENGINE INNODB STATUS\G
*************************** 1。排******************** *******
类型:InnoDB
名称:
状态:
=====================================
2018-04-12 15:14:08 0x7f971c063700 INNODB MONITOR OUTPUT
=====================================
从最后4秒计算的每秒平均值
-----------------
背景线
-----------------
srv_master_thread循环:15 srv_active,0 srv_shutdown,1122 srv_idle
srv_master_thread日志刷新并写入:0
----------
SEMAPHORES
----------
操作系统等待阵列信息:预订计数24
OS WAIT ARRAY INFO:信号计数24
RW共享的旋转4,第8轮,OS等待4
RW-excl旋转2,轮60,OS等待2
RW-sx旋转0,舍入0,OS等待0
每次等待旋转轮次:2.00 RW-shared,30.00 RW-excl,0.00 RW-sx
------------------------
最新的外国关键错误
------------------------
2018-04-12 14:57:24 0x7f97a9c91700交易:
TRANSACTION 7717,有效0秒插入
mysql表在使用1,锁定1
4个锁定结构,堆大小1136,3个行锁,撤消日志条目3
MySQL线程id 8,OS线程句柄140289365317376,查询id 14 localhost root update
INSERT INTO子VALUES(NULL,1),(NULL,2),(NULL,3),(NULL,4),(NULL,5),(NULL,6)
表`test` .child`的外键约束失败:
,
CONSTRAINT`child_ibfk_1` FOREIGN KEY(`parent_id`)REFERENCES` parent`(`id`)ON DELETE
CASCADE ON UPDATE CASCADE
尝试在索引par_ind元组中添加子表:
DATA TUPLE:2个字段;
0:len 4; hex 80000003; asc ;;
1:len 4; hex 80000003; asc ;;
但是在父表`test` .parent`中,在索引PRIMARY中,
我们能找到的最接近的匹配是记录:
物理记录:n_fields 3; 紧凑格式; 信息位0
0:len 4; hex 80000004; asc ;;
1:len 6; hex 000000001e19; asc ;;
2:len 7; hex 81000001110137; asc 7 ;;
------------
交易
------------
Trx id计数器7748
清除trx的n:o <7747撤消n:o <0状态:正在运行但空闲
历史清单长度19
每届会议的交易清单:
--- TRANSACTION 421764459790000,未启动
0个锁定结构,堆大小1136,0行锁定
--- TRANSACTION 7747,ACTIVE 23秒开始索引读取
mysql表在使用1,锁定1
LOCK WAIT 2 lock struct(s),堆大小1136,1行锁
MySQL线程id 9,OS线程句柄140286987249408,查询id 51 localhost root更新
DELETE FROM t WHERE i = 1
------- TRX已被23美元等待获得此锁定:
RECORD LOCKS空格id 4页第4位n位72索引GEN_CLUST_INDEX表`test``t`
trx id 7747 lock_mode X等待
记录锁,堆3号物理记录:n_fields 4; 紧凑格式; 信息位0
0:len 6; hex 000000000202; asc ;;
1:len 6; hex 000000001e41; asc A ;;
2:len 7; hex 820000008b0110; asc ;;
3:len 4; hex 80000001; asc ;;
------------------
表LOCK表`test``t` trx id 7747锁定模式IX
RECORD LOCKS空格id 4页第4位n位72索引GEN_CLUST_INDEX表`test``t`
trx id 7747 lock_mode X等待
记录锁,堆3号物理记录:n_fields 4; 紧凑格式; 信息位0
0:len 6; hex 000000000202; asc ;;
1:len 6; hex 000000001e41; asc A ;;
2:len 7; hex 820000008b0110; asc ;;
3:len 4; hex 80000001; asc ;;
--------
文件I / O.
--------
I / O线程0状态:等待I / O请求(插入缓冲线程)
I / O线程1状态:等待I / O请求(日志线程)
I / O线程2状态:等待I / O请求(读取线程)
I / O线程3状态:等待I / O请求(读取线程)
I / O线程4状态:等待I / O请求(读取线程)
I / O线程5状态:等待I / O请求(读取线程)
I / O线程6状态:等待I / O请求(写线程)
I / O线程7状态:等待I / O请求(写线程)
I / O线程8状态:等待I / O请求(写线程)
I / O线程9状态:等待I / O请求(写线程)
等待正常的aio读取:[0,0,0,0],aio写道:[0,0,0,0],
ibuf aio读取:,log i / o's :, sync i / o's:
待刷新(fsync)log:0; 缓冲池:0
833 OS文件读取,605 OS文件写入,208 OS fsyncs
0.00读/秒,0 avg字节/读,0.00写/ s,0.00 fsyncs / s
-------------------------------------
插入缓冲区和自适应哈希索引
-------------------------------------
Ibuf:size 1,free list len 0,seg size 2,0合并
合并后的业务:
插入0,删除标记0,删除0
丢弃的操作:
插入0,删除标记0,删除0
哈希表大小为553253,节点堆有0个缓冲区
哈希表大小为553253,节点堆有1个缓冲区
哈希表大小为553253,节点堆有3个缓冲区
哈希表大小为553253,节点堆有0个缓冲区
哈希表大小为553253,节点堆有0个缓冲区
哈希表大小为553253,节点堆有0个缓冲区
哈希表大小为553253,节点堆有0个缓冲区
哈希表大小为553253,节点堆有0个缓冲区
0.00哈希搜索/ s,0.00非哈希搜索/秒
---
LOG
---
日志序列号19643450
分配最多19643450的日志缓冲区
日志缓冲区已完成,最长可达19643450
记录最多19643450
日志刷新到19643450
添加了最多19643450的脏页
页面刷新到19643450
最后一个检查站在19643450
129 log i / o完成,0.00 log i / o /秒
----------------------
缓冲池和记忆
----------------------
分配的总大内存为2198863872
字典内存分配409606
缓冲池大小131072
免费缓冲130095
数据库页面973
旧数据库页面0
修改了db页面0
待定读数为0
待写:LRU 0,刷新列表0,单页0
页面年轻0,而不是年轻0
0.00个年轻人/秒,0.00个非年轻人/秒
页面读取810,创建163,写入404
0.00读/秒,0.00创建/ s,0.00写/秒
缓冲池命中率1000/1000,年轻率0/1000不是0/1000
页面预读0.00 / s,没有访问0.00 / s被逐出,随机预读0.00 / s
LRU len:973,unzip_LRU len:0
I / O sum [0]:cur [0],解压和[0]:cur [0]
----------------------
个人缓冲池信息
----------------------
--- BUFFER POOL 0
缓冲池大小65536
免费缓冲65043
数据库页面491
旧数据库页面0
修改了db页面0
待定读数为0
待写:LRU 0,刷新列表0,单页0
页面年轻0,而不是年轻0
0.00个年轻人/秒,0.00个非年轻人/秒
页面读取411,创建80,写入210
0.00读/秒,0.00创建/ s,0.00写/秒
缓冲池命中率1000/1000,年轻率0/1000不是0/1000
页面预读0.00 / s,没有访问0.00 / s被逐出,随机预读0.00 / s
LRU len:491,unzip_LRU len:0
I / O sum [0]:cur [0],解压和[0]:cur [0]
--- BUFFER POOL 1
缓冲池大小65536
免费缓冲65052
数据库页面482
旧数据库页面0
修改了db页面0
待定读数为0
待写:LRU 0,刷新列表0,单页0
页面年轻0,而不是年轻0
0.00个年轻人/秒,0.00个非年轻人/秒
页面读取399,创建83,写入194
0.00读/秒,0.00创建/ s,0.00写/秒
自上次打印输出以来没有缓冲池页面
页面预读0.00 / s,没有访问0.00 / s被逐出,随机预读0.00 / s
LRU len:482,unzip_LRU len:0
I / O sum [0]:cur [0],解压和[0]:cur [0]
--------------
行操作
--------------
InnoDB内部有0个查询,队列中有0个查询
在InnoDB内部打开0个读取视图
进程ID = 5772,主线程ID = 140286437054208,state = sleeping
插入的行数57,更新354,删除4,读4421
0.00插入/秒,0.00更新/秒,0.00删除/秒,0.00读数/秒
----------------------------
INNODB MONITOR OUTPUT结束
============================
有关标准监视器报告的每个度量标准的说明,请参阅 “ Oracle企业管理器for MySQL数据库用户指南”中的“ 度量标准” 一章 。
-
Status此部分显示时间戳,监视器名称以及每秒平均值所基于的秒数。 秒数是当前时间与上次
InnoDB打印监视器输出 之间经过的时间 。 -
BACKGROUND THREAD这些
srv_master_thread行显示了主后台线程完成的工作。 -
SEMAPHORES此部分报告等待信号量的线程以及有关线程在互斥锁或rw-lock信号量上需要旋转或等待的次数的统计信息。 等待信号量的大量线程可能是磁盘I / O或内部争用问题的结果
InnoDB。 争用可能是由于查询的严重并行性或操作系统线程调度中的问题。innodb_thread_concurrency在这种情况下, 将 系统变量 设置为 小于默认值可能会有所帮助。 该Spin rounds per wait行显示每个OS等待互斥锁的自旋锁轮数。互斥指标由报告
SHOW ENGINE INNODB MUTEX。 -
LATEST FOREIGN KEY ERROR本节提供有关最新外键约束错误的信息。 如果没有发生这样的错误,则不存在。 内容包括失败的语句以及有关失败的约束以及引用和引用表的信息。
-
LATEST DETECTED DEADLOCK本节提供有关最近死锁的信息。 如果没有发生死锁,则不存在。 内容显示涉及哪些事务,每个尝试执行的语句,他们拥有和需要的锁,以及
InnoDB决定回滚以打破死锁的 事务 。 本节中报告的锁定模式在 第15.7.1节“InnoDB锁定”中 进行了解释 。 -
TRANSACTIONS如果此部分报告锁等待,则您的应用程序可能存在锁争用。 输出还可以帮助跟踪事务死锁的原因。
-
FILE I/O本节提供有关
InnoDB用于执行各种类型I / O的 线程的信息 。 其中前几个专门用于一般InnoDB处理。 内容还显示待处理I / O操作的信息和I / O性能的统计信息。这些线程的数量由
innodb_read_io_threads和innodb_write_io_threads参数 控制 。 请参见 第15.13节“InnoDB启动选项和系统变量” 。 -
INSERT BUFFER AND ADAPTIVE HASH INDEX此部分显示
InnoDB插入缓冲区(也称为 更改缓冲区 )和自适应哈希索引的状态。有关相关信息,请参见 第15.5.2节“更改缓冲区” 和 第15.5.3节“自适应哈希索引” 。
-
LOG此部分显示有关
InnoDB日志的 信息 。 内容包括当前日志序列号,日志刷新到磁盘的距离以及InnoDB最后一次检查点 的位置 。 (请参见 第15.11.3节“InnoDB检查点” 。)该部分还显示有关挂起写入和写入性能统计信息的信息。 -
BUFFER POOL AND MEMORY本节为您提供有关读取和写入页面的统计信息。 您可以根据这些数字计算您的查询当前正在执行的数据文件I / O操作数。
有关缓冲池统计信息描述,请参阅 使用InnoDB标准监视器监视缓冲池 。 有关缓冲池操作的其他信息,请参见 第15.5.1节“缓冲池” 。
-
ROW OPERATIONS此部分显示主线程正在执行的操作,包括每种类型的行操作的数量和性能速率。
本节介绍与
InnoDB
备份和恢复
相关的主题
。
-
有关适用的备份技术的信息
InnoDB,请参见 第15.17.1节“InnoDB备份” 。 -
有关时间点恢复,磁盘故障或损坏的
InnoDB恢复 以及如何 执行崩溃恢复的信息,请参见 第15.17.2节“InnoDB恢复” 。
安全数据库管理的关键是定期备份。 根据您的数据量,MySQL服务器数量和数据库工作负载,您可以单独或组合使用这些备份技术: 使用 MySQL Enterprise Backup进行 热备份 ; 在MySQL服务器关闭时通过复制文件进行 冷备份 ; 使用 mysqldump 进行 逻辑备份 以 用于较小的数据卷或记录模式对象的结构。 冷热备份是 复制实际数据文件的 物理备份 ,可以由 mysqld 服务器 直接使用, 以便更快地进行恢复。
使用
MySQL Enterprise Backup
是备份
InnoDB
数据
的推荐方法
。
InnoDB
不支持使用第三方备份工具还原的数据库。
热备份
该
mysqlbackup
命令,MySQL企业备份组件的一部分,让您备份运行MySQL实例,包括
InnoDB
表,以最小的中断操作,同时生产数据库的一致性快照。
当
mysqlbackup
复制
InnoDB
表时,
InnoDB
可以继续
读取和写入
表。
MySQL Enterprise Backup还可以创建压缩备份文件,并备份表和数据库的子集。
结合MySQL二进制日志,用户可以执行时间点恢复。
MySQL Enterprise Backup是MySQL Enterprise订阅的一部分。
有关更多详细信息,请参见
第30.2节“MySQL Enterprise Backup概述”
。
冷备份
如果可以关闭MySQL服务器,则可以进行物理备份,该备份包含
InnoDB
管理其表
所使用的所有文件
。
使用以下过程:
-
执行 MySQL服务器 的 慢速关闭 并确保它没有错误地停止。
-
将所有
InnoDB数据文件(ibdata文件和.ibd文件) 复制 到安全的地方。 -
将所有
InnoDB日志文件(ib_logfile文件) 复制 到安全的位置。 -
将
my.cnf配置文件复制到安全的位置。
使用mysqldump进行逻辑备份
除物理备份外,建议您通过使用
mysqldump
转储表来定期创建逻辑备份
。
二进制文件可能已损坏而您没有注意到它。
转储表存储在人类可读的文本文件中,因此定位表损坏变得更容易。
此外,由于格式更简单,严重数据损坏的可能性更小。
mysqldump
还有一个
--single-transaction
选项,可以在不锁定其他客户端的情况下创建一致的快照。
请参见
第7.3.1节“建立备份策略”
。
复制适用于
InnoDB
表,因此您可以使用MySQL复制功能在需要高可用性的数据库站点上保留数据库的副本。
请参见
第15.18节“InnoDB和MySQL复制”
。
本节介绍
InnoDB
恢复。
主题包括:
要从
InnoDB
进行物理备份时
将
数据库
恢复
到当前状态,必须在启用二进制日志记录的情况下运行MySQL服务器,甚至在进行备份之前。
要在还原备份后实现时间点恢复,可以应用备份后发生的二进制日志中的更改。
请参见
第7.5节“使用二进制日志进行时间点(增量)恢复”
。
如果数据库损坏或发生磁盘故障,则必须使用备份执行恢复。 在损坏的情况下,首先找到未损坏的备份。 还原基本备份后,使用 mysqlbinlog 和 mysql 从二进制日志文件执行时间点恢复, 以还原备份后发生的更改。
在某些数据库损坏的情况下,转储,删除和重新创建一个或几个损坏的表就足够了。
您可以使用该
CHECK
TABLE
语句来检查表是否已损坏,但
CHECK
TABLE
自然无法检测到每种可能的损坏类型。
在某些情况下,明显的数据库页面损坏实际上是由于操作系统破坏了自己的文件缓存,磁盘上的数据可能没问题。
最好先尝试重新启动计算机。
这样做可能会消除似乎是数据库页面损坏的错误。
如果MySQL由于
InnoDB
一致性问题
仍然无法启动
,请参见
第15.20.2节“强制InnoDB恢复”,
了解在恢复模式下启动实例的步骤,该模式允许您转储数据。
要从MySQL服务器崩溃中恢复,唯一的要求是重启MySQL服务器。
InnoDB
自动检查日志并执行数据库前滚到现在。
InnoDB
自动回滚崩溃时出现的未提交的事务。
在恢复期间,
mysqld
显示类似于此的输出:
InnoDB:系统表空间中的日志序列号664050266不匹配 ib_logfiles中的日志序列号685111586! InnoDB:数据库没有正常关闭! InnoDB:开始崩溃恢复。 InnoDB:使用'tablespaces.open.2'最大LSN:664075228 InnoDB:执行恢复:扫描到日志序列号690354176 InnoDB:执行恢复:扫描到日志序列号695597056 InnoDB:执行恢复:扫描到日志序列号700839936 InnoDB:执行恢复:扫描到日志序列号706082816 InnoDB:执行恢复:扫描到日志序列号711325696 InnoDB:执行恢复:扫描到日志序列号713458156 InnoDB:应用一批1467个重做日志记录...... InnoDB:10% InnoDB:20% InnoDB:30% InnoDB:40% InnoDB:50% InnoDB:60% InnoDB:70% InnoDB:80% InnoDB:90% InnoDB:100% InnoDB:申请批量完成! InnoDB:1个交易,必须回滚或清理总共561887行 要撤消的操作 InnoDB:Trx id计数器是4096 ... InnoDB:8.0.1开始; 日志序列号713458156 InnoDB:等待清除开始 InnoDB:从后台开始回滚未提交的事务 InnoDB:回滚trx,id为3596,要撤消561887行 ... ./mysqld:准备连接....
InnoDB
崩溃恢复
包括几个步骤:
-
表空间发现
表空间发现是
InnoDB用于标识需要重做日志应用程序的表空间 的过程 。 请参阅 崩溃恢复期间的表空间发现 。 -
重做日志 应用程序
在接受任何连接之前,在初始化期间执行重做日志应用程序。 如果所有更改都从中刷新 在关闭或崩溃时将 缓冲池 到 表空间 (
ibdata*和*.ibd文件),则会跳过重做日志应用程序。InnoDB如果启动时缺少重做日志文件,也会跳过重做日志应用程序。-
每次值更改时,当前最大自动增量计数器值都会写入重做日志,这使其具有防崩溃性。 在恢复期间,
InnoDB扫描重做日志以收集计数器值更改并将更改应用于内存中的表对象。有关如何更多信息
InnoDB处理自动递增值的 ,请参见 第15.6.1.4节“InnoDB中的AUTO_INCREMENT处理” 和 InnoDB AUTO_INCREMENT计数器初始化 。 -
遇到索引树损坏时,
InnoDB将损坏标志写入重做日志,这会使损坏标志崩溃安全。InnoDB还将内存中损坏标志数据写入每个检查点上的引擎专用系统表。 在恢复期间,InnoDB从两个位置读取损坏标志并在将内存表和索引对象标记为损坏之前合并结果。 -
即使可以接受某些数据丢失,也不建议删除重做日志以加快恢复。 只有在干净关闭后才能考虑删除重做日志,
innodb_fast_shutdown设置为0或1。
-
-
不完整的事务是在崩溃或 快速关闭 时处于活动状态的任何事务 。 回滚未完成事务所花费的时间可以是事务在中断之前处于活动状态的时间量的三倍或四倍,具体取决于服务器负载。
您无法取消正在回滚的事务。 在极端情况下,回滚事务时,预计将需要一个非常长的时间,它可能会更快开始
InnoDB用innodb_force_recovery的设置3或更大。 请参见 第15.20.2节“强制InnoDB恢复” 。 -
更改缓冲区 合并
将更改缓冲区( 系统表空间的 一部分)中的更改应用于 二级索引的叶页,因为索引页将读取到缓冲池。
-
删除活动事务不再可见的删除标记记录。
重做日志应用程序之后的步骤不依赖于重做日志(除了用于记录写入),并且与正常处理并行执行。 其中,仅回滚未完成的事务对于崩溃恢复是特殊的。 插入缓冲区合并和清除在正常处理期间执行。
重做日志应用程序后,
InnoDB
尝试尽早接受连接,以减少停机时间。
作为崩溃恢复的一部分,
InnoDB
回滚
XA
PREPARE
服务器崩溃时
未提交或处于
状态的
事务
。
回滚由后台线程执行,与新连接的事务并行执行。
在回滚操作完成之前,新连接可能会遇到与已恢复事务的锁定冲突。
在大多数情况下,即使MySQL服务器在繁重活动中意外终止,恢复过程也会自动发生,并且不需要DBA执行任何操作。
如果硬件故障或严重的系统错误损坏了
InnoDB
数据,MySQL可能会拒绝启动。
在这种情况下,请参见
第15.20.2节“强制InnoDB恢复”
。
有关二进制日志和
InnoDB
崩溃恢复的信息,请参见
第5.4.4节“二进制日志”
。
如果在恢复期间
InnoDB
遇到自上一个检查点以来写入的重做日志,则必须将重做日志应用于受影响的表空间。
在恢复期间标识受影响的表空间的过程称为
表空间发现
。
表空间发现依赖于该
innodb_directories
设置,该设置定义在启动时为表空间文件扫描的目录。
无论是否
显式配置选项
,
由
innodb_data_home_dir
,
定义的目录
innodb_undo_directory
,以及
datadir
自动附加到
innodb_directories
参数值
innodb_directories
。
使用绝对路径定义的表空间文件或驻留在自动附加到
innodb_directories
设置
的目录之外的表空间文件
应添加到
innodb_directories
设置中。
如果先前未发现重做日志中引用的任何表空间文件,则终止恢复。
MySQL复制适用于
InnoDB
表,就像对
MyISAM
表一样。
也可以以从属设备上的存储引擎与主设备上的原始存储引擎不同的方式使用复制。
例如,您可以
InnoDB
将主服务器上的
MyISAM
表的
修改复制到从服务器
上的
表。
有关更多信息,请参见
第17.3.4节“使用具有不同主存储引擎和从存储引擎的复制”
。
有关为主站设置新从站的信息,请参见 第17.1.2.6节“设置复制从站” 和 第17.1.2.5节“为数据快照选择方法” 。 要在不关闭主服务器或现有从服务器的情况下创建新的从服务器,请使用 MySQL Enterprise Backup 产品。
在主服务器上失败的事务根本不会影响复制。 MySQL复制基于二进制日志,MySQL编写修改数据的SQL语句。 失败的事务(例如,由于外键冲突,或因为它被回滚)不会写入二进制日志,因此不会发送到从属服务器。 请参见 第13.3.1节“START TRANSACTION,COMMIT和ROLLBACK语法” 。
复制和CASCADE。
仅
当共享外键关系的表
在主服务器和从服务器上
使用时
,
才会
InnoDB
在从服务器上复制主服务器上表的
级联操作
。
无论您使用的是基于语句的复制还是基于行的复制,都是如此。
假设您已经开始复制,然后使用以下
语句
在master上创建两个表
:
InnoDB
CREATE TABLE
CREATE TABLE fc1(
我是INT主要的关键,
j INT
)ENGINE = InnoDB;
CREATE TABLE fc2(
m INT PRIMARY KEY,
n INT,
外键ni(n)参考文献fc1(i)
ON DELETE CASCADE
)ENGINE = InnoDB;
假设从站没有
InnoDB
启用支持。
如果是这种情况,则会创建从属表上的表,但它们使用
MyISAM
存储引擎,并
FOREIGN KEY
忽略
该
选项。
现在我们在master上的表中插入一些行:
高手>INSERT INTO fc1 VALUES (1, 1), (2, 2);查询正常,2行受影响(0.09秒) 记录:2个重复:0个警告:0 高手>INSERT INTO fc2 VALUES (1, 1), (2, 2), (3, 1);查询OK,3行受影响(0.19秒) 记录:3个重复:0个警告:0
此时,在主服务器和从服务器上,表
fc1
包含2行,表
fc2
包含3行,如下所示:
高手>SELECT * FROM fc1;+ --- + ------ + | 我| j | + --- + ------ + | 1 | 1 | | 2 | 2 | + --- + ------ + 2行(0.00秒) 高手>SELECT * FROM fc2;+ --- + ------ + | m | n | + --- + ------ + | 1 | 1 | | 2 | 2 | | 3 | 1 | + --- + ------ + 3组(0.00秒) 从>SELECT * FROM fc1;+ --- + ------ + | 我| j | + --- + ------ + | 1 | 1 | | 2 | 2 | + --- + ------ + 2行(0.00秒) 从>SELECT * FROM fc2;+ --- + ------ + | m | n | + --- + ------ + | 1 | 1 | | 2 | 2 | | 3 | 1 | + --- + ------ + 3组(0.00秒)
现在假设您
DELETE
在master上
执行以下
语句:
高手> DELETE FROM fc1 WHERE i=1;
查询正常,1行受影响(0.09秒)
由于级联,
fc2
master上的表现在只包含1行:
高手> SELECT * FROM fc2;
+ --- + --- +
| m | n |
+ --- + --- +
| 2 | 2 |
+ --- + --- +
1排(0.00秒)
但是,级联不会在从站上传播,因为在从站上,
DELETE
for
fc1
不会删除任何行
fc2
。
slave的副本
fc2
仍然包含最初插入的所有行:
从> SELECT * FROM fc2;
+ --- + --- +
| m | n |
+ --- + --- +
| 1 | 1 |
| 3 | 1 |
| 2 | 2 |
+ --- + --- +
3组(0.00秒)
这种差异是由于级联删除由
InnoDB
存储引擎
在内部处理
,这意味着没有记录任何更改。
的
InnoDB
分布式缓存
插件(
daemon_memcached
)提供了一个集成
的memcached
守护程序自动存储和检索从数据
InnoDB
表,把MySQL服务器到快速
“
键值存储
”
。
而不是在SQL中制定查询,你可以使用简单的
get
,
set
和
incr
操作,从而避免使用SQL解析和构造查询优化计划相关的性能开销。
您还可以
InnoDB
通过SQL
访问相同的
表,以方便,复杂查询,批量操作以及传统数据库软件的其他优势。
这个
“
NoSQL风格
”的
接口使用
memcached
API来加速数据库操作,让我们
InnoDB
使用其
缓冲池
机制
来处理内存缓存
。
通过修改的数据
分布式缓存
操作,诸如
add
,
set
以及
incr
被存储到磁盘,在
InnoDB
表中。
的组合
分布式缓存
的简单性和
InnoDB
可靠性和一致性提供两全其美的用户,如在解释
第15.19.1“InnoDB的的好处的memcached插件”
。
有关体系结构概述,请参见
第15.19.2节“InnoDB memcached体系结构”
。
本节概述了
daemon_memcached
插件的
优点
。
InnoDB
表和
memcached
的组合
提供了优于
单独
使用它们的优点。
-
直接访问
InnoDB存储引擎可以避免SQL的解析和规划开销。 -
在与MySQL服务器相同的进程空间中 运行 memcached 可以避免来回传递请求的网络开销。
-
使用 memcached 协议 写入的数据 透明地写入
InnoDB表,而不通过MySQL SQL层。 您可以控制写入频率,以便在更新非关键数据时实现更高的原始性能。 -
通过 memcached 协议 请求的数据 从
InnoDB表中 透明地查询 ,而不通过MySQL SQL层。 -
从
InnoDB缓冲池 提供对相同数据的后续请求 。 缓冲池处理内存中缓存。 您可以使用InnoDB配置选项 调整数据密集型操作的性能 。 -
数据可以是非结构化的或结构化的,具体取决于应用程序的类型。 您可以为数据创建新表,也可以使用现有表。
-
InnoDB可以处理组合和将多个列值分解为单个 memcached 项值,从而减少应用程序中所需的字符串解析和连接量。 例如,您可以将字符串值存储2|4|6|8在 memcached 缓存中,并InnoDB根据分隔符将值拆分,然后将结果存储在四个数字列中。 -
内存和磁盘之间的传输是自动处理的,简化了应用程序逻辑。
-
数据存储在MySQL数据库中,以防止崩溃,中断和损坏。
-
您可以
InnoDB通过SQL 访问基础 表,以进行报告,分析,即席查询,批量加载,多步事务计算,联合和交集等集合操作,以及适合SQL的表达性和灵活性的其他操作。 -
通过将 主服务器
daemon_memcached上 的 插件 与MySQL复制结合 使用,可以确保高可用性 。
-
memcached 与MySQL 的集成 提供了一种使内存数据持久化的方法,因此您可以将它用于更重要的数据类型。 您可以 在应用程序中 使用更多
add,incr类似的写入操作,而无需担心数据可能会丢失。 您可以停止并启动 memcached 服务器,而不会丢失对缓存数据的更新。 为了防止意外中断,您可以利用InnoDB崩溃恢复,复制和备份功能。 -
该方法
InnoDB确实快速 的主键 查找是天作之合 memcached的 单项查询。daemon_memcached与同等的SQL查询相比 , 插件 使用的直接低级数据库访问路径 对于键值查找更有效。 -
memcached 的序列化功能 可以将复杂的数据结构,二进制文件甚至代码块转换为可存储的字符串,这提供了一种将这些对象转换为数据库的简单方法。
-
因为你可以通过SQL访问底层数据,可以生成报告,在多个搜索键或更新,并调用功能,如
AVG()与MAX()上 memcached的 数据。 使用 memcached 本身 所有这些操作都很昂贵或复杂 。 -
您无需 在启动时 手动将数据加载到 memcached 中。 由于应用程序请求特定键,因此将自动从数据库中检索值,并使用
InnoDB缓冲池 将值缓存在内存中 。 -
因为 memcached 消耗相对较少的CPU,并且其内存占用容易控制,所以它可以在同一系统上与MySQL实例一起舒适地运行。
-
由于数据一致性是由用于常规
InnoDB表 的机制强制执行的, 因此在丢失密钥的情况下 ,您不必担心过时的 memcached 数据或回退逻辑来查询数据库。
的
InnoDB
分布式缓存
插件实现
的memcached
作为访问一个MySQL插件守护程序
InnoDB
直接存储引擎,绕过MySQL的SQL层。
下图说明了
daemon_memcached
与SQL相比,
应用程序如何通过
插件
访问数据
。
该功能
daemon_memcached
插件:
-
memcached 作为 mysqld 的守护进程插件 。 双方 的mysqld 和 memcached的 在同一个进程空间中运行,具有非常低的延迟对数据的访问。
-
直接访问
InnoDB表,绕过SQL解析器,优化器,甚至是Handler API层。 -
标准的 memcached 协议,包括基于文本的协议和二进制协议。 该
daemon_memcached插件通过了 memcapable 命令的 所有55个兼容性测试 。 -
多列支持。 您可以将多个列映射到 键值存储 的 “ 值 ” 部分,其中列值由用户指定的分隔符分隔。
-
默认情况下, memcached 协议用于直接读取和写入数据
InnoDB,让MySQL使用InnoDB缓冲池 管理内存缓存 。 默认设置代表了高可靠性和数据库应用程序最少惊喜的组合。 例如,默认设置可以避免数据库端的未提交数据,也可以避免为 memcachedget请求 返回过时数据 。 -
高级用户可以将系统配置为传统的 memcached 服务器,所有数据仅缓存在 memcached 引擎中(内存缓存),或者使用 “ memcached 引擎 ” (内存缓存)和
InnoDBmemcached 引擎(InnoDB作为后端持久性)的组合存储)。
-
控制多久数据来回传递之间
InnoDB和 memcached的 通过操作innodb_api_bk_commit_interval,daemon_memcached_r_batch_size以及daemon_memcached_w_batch_size配置选项。 批量大小选项默认值为1以获得最大可靠性。 -
通过 配置参数 指定 memcached 选项的功能
daemon_memcached_option。 例如,您可以更改 memcached 侦听 的端口 ,减少最大并发连接数,更改键值对的最大内存大小,或启用错误日志的调试消息。 -
的
innodb_api_trx_level配置选项控制事务 隔离级别 上通过处理的查询 分布式缓存 。 尽管 memcached 没有 事务 概念 ,但您可以使用此选项来控制 memcached 查看 daemon_memcached 插件 使用的表上发出的SQL语句引起的更改的 时间 。 默认情况下,innodb_api_trx_level设置为READ UNCOMMITTED。 -
该
innodb_api_enable_mdl选项可用于在MySQL级别锁定表,以便 DDL 不能通过SQL接口 删除或更改映射表 。 如果没有锁定,表可以从MySQL层中删除,但保留在InnoDB存储中直到 memcached 或其他一些用户停止使用它。 “ MDL ” 代表 “ 元数据锁定 ” 。
您可能已经熟悉使用
MySQL的
memcached
,如
使用MySQL和
memcached中所述
。
本节介绍集成
InnoDB
memcached
插件的功能与传统插件的不同之处
memcached
。
-
安装: memcached 库随MySQL服务器一起提供,使安装和设置相对容易。 安装包括运行
innodb_memcached_config.sql脚本以创建 要使用的 memcached 的demo_test表 ,发出 启用 插件 的 语句 ,以及将所需的 memcached 选项 添加 到MySQL配置文件或启动脚本。 您可能仍会 为其他实用程序 安装传统的 memcached 发行版,例如 memcp , memcat 和 memcapableINSTALL PLUGINdaemon_memcached。与传统的 memcached 相比 ,请参阅 安装 memcached 。
-
部署:使用传统的 memcached ,通常运行大量低容量的 memcached 服务器。
daemon_memcached但是,插件的 典型部署 涉及较少数量的已经运行MySQL的中等或高性能服务器。 此配置的好处在于提高单个数据库服务器的效率,而不是利用未使用的内存或在大量服务器上分发查找。 在默认配置中, memcached 使用的 内存 非常少 , 缓冲池中 提供了内存中查找InnoDB,自动缓存最近和常用的数据。 与传统的MySQL服务器实例一样,保持innodb_buffer_pool_size配置选项 的值 尽可能高(不会在OS级别引起分页),以便在内存中执行尽可能多的工作。与传统的 memcached 相比 ,请参阅 memcached 部署 。
-
到期:默认情况下(即使用
innodb_only缓存策略),InnoDB始终返回表中 的最新数据 ,因此到期选项没有实际效果。 如果您将缓存策略更改为caching或cache_only,则到期选项将照常工作,但如果在从内存缓存到期之前在基础表中更新了请求的数据,则所请求的数据可能已过时。与传统的 memcached 相比 ,请参阅 数据过期 。
-
命名空间: memcached 就像一个大型目录,您可以使用前缀和后缀为文件提供精心设计的名称,以防止文件冲突。 该
daemon_memcached插件允许您对键使用类似的命名约定,只需添加一个。 格式中的键名称 。 使用来自 表的 映射数据解码以引用特定的 表。 该 被查找或写入到指定的表。@@table_id.keytable_idinnodb_memcache.containerskey该
@@符号只适用于个别呼叫get,add和set功能,而不是其他如incr或delete。 要为 会话中的 后续 memcached 操作 指定默认表,get请使用@@带有atable_id得到@@
table_id随后
get,set,incr,delete,等操作使用由指定的表table_idinnodb_memcache.containers.name列。要与传统的 memcached 进行比较 ,请参阅 使用命名空间 。
-
散列和分发:使用
innodb_only缓存策略 的默认配置 适用于所有服务器上都可用的传统部署配置,例如一组复制从属服务器。如果您在物理上划分数据(如在分片配置中),则可以在运行
daemon_memcached插件的 多台计算机之间拆分数据 ,并使用传统的 memcached 散列机制将请求路由到特定计算机。 在MySQL方面,您通常会通过add对 memcached 的 请求 插入所有数据 , 以便将适当的值存储在相应服务器上的数据库中。与传统的 memcached 相比 ,请参阅 memcached Hashing / Distribution Types 。
-
内存使用情况:默认情况下(使用
innodb_only缓存策略), memcached 协议使用InnoDB表 来回传递信息 ,InnoDB缓冲池处理内存中查找而不是 memcached 内存使用量增长和收缩。 memcached 端 使用相对较少的内存 。如果将缓存策略切换为
caching或cache_only,则 适用 memcached 内存使用 的常规规则 。 memcached 数据值的 内存 按 “ slabs ” 分配 。 您可以控制用于 memcached的 slab大小和最大内存 。无论哪种方式,您都可以
daemon_memcached使用熟悉的 统计 系统 监控 插件 并对其进行故障排除 ,例如 ,通过标准协议访问,通过 telnet 会话。daemon_memcached插件 中不包含额外的实用程序 。 您可以使用该memcached-tool脚本 安装完整的 memcached 分发。为了与传统的比较 memcached的 ,见 内内存分配 的memcached 。
-
线程使用:MySQL线程和 memcached 线程共存于同一服务器上。 操作系统对线程施加的限制适用于线程总数。
与传统的 memcached 相比 ,请参阅 memcached Thread Support 。
-
日志的使用:由于 memcached的 守护程序同时运行MySQL服务器和写入
stderr的-v,-vv和-vvv选项日志输出写入MySQL的 错误日志 。与传统的 memcached 相比 ,请参阅 memcached Logs 。
-
memcached的 操作:熟悉 memcached的 操作,例如
get,set,add,和delete可用。 序列化(即表示复杂数据结构的确切字符串格式)取决于语言接口。与传统的 memcached 相比 ,请参阅 基本的 memcached 操作 。
-
使用 memcached 作为MySQL前端:这是
InnoDBmemcached 插件 的主要目的 。 集成的 memcached 守护程序可提高应用程序性能,并且InnoDB处理内存和磁盘之间的数据传输可简化应用程序逻辑。与传统的 memcached 相比 ,请参阅 将 memcached 用作MySQL缓存层 。
-
实用程序:MySQL服务器包括
libmemcached库,但没有其他命令行实用程序。 要使用 memcp , memcat 和 memcapable 命令等命令,请安装完整的 memcached 发行版。 当 memrm 和 memflush 从缓存中删除项目时,这些项目也会从基础InnoDB表中 删除 。与传统的 memcached 进行比较 ,请参阅 libmemcached 命令行实用程序 。
-
编程接口:您可以
daemon_memcached使用所有支持的语言 通过 插件 访问MySQL服务器 : C和C ++ , Java , Perl , Python , PHP 和 Ruby 。 与传统的 memcached 服务器 一样,指定服务器主机名和端口 。 默认情况下,daemon_memcached插件侦听端口11211。 您可以使用 文本和二进制协议 。 您可以自定义 行为 的 memcached 函数在运行时。 序列化(即表示复杂数据结构的确切字符串格式)取决于语言接口。有关与传统 memcached的 比较 ,请参阅 开发 memcached 应用程序 。
-
常见问题:MySQL有一个广泛的传统 memcached 常见问题解答 。 常见问题解答主要适用,除了使用
InnoDB表作为 memcached 数据 的存储介质 意味着您可以将 memcached 用于比以前更多的写密集型应用程序,而不是作为只读缓存。请参阅 memcached FAQ 。
本节介绍如何
daemon_memcached
在MySQL服务器上
设置
插件。
由于
memcached
守护程序与MySQL服务器紧密集成以避免网络流量并最大程度地减少延迟,因此您可以在使用此功能的每个MySQL实例上执行此过程。
在设置
daemon_memcached
插件
之前
,请参阅
第15.19.5节“InnoDB memcached插件的安全注意事项”,
以了解防止未经授权访问所需的安全过程。
-
该
daemon_memcached插件仅在Linux,Solaris和OS X平台上受支持。 不支持其他操作系统。 -
从源代码构建MySQL时,必须使用
-DWITH_INNODB_MEMCACHED=ON。 此构建选项在MySQL插件目录(plugin_dir)中 生成两个 运行daemon_memcached插件 所需的 共享库 :-
libmemcached.so: MySQL 的 memcached 守护进程插件。 -
innodb_engine.so: memcached 的InnoDBAPI插件 。
-
-
libevent必须安装。-
如果您没有从源代码构建MySQL,则该
libevent库不包含在您的安装中。 使用操作系统的安装方法安装libevent1.4.12或更高版本。 例如,根据操作系统,您可以使用apt-get,yum或port install。 例如,在Ubuntu Linux上,使用:sudo apt-get install libevent-dev
-
如果您从源代码版本安装了MySQL,则
libevent1.4.12与该软件包捆绑在一起,位于MySQL源代码目录的顶层。 如果使用捆绑版本libevent,则无需执行任何操作。 如果要使用本地系统版本libevent,则必须在-DWITH_LIBEVENT构建选项设置为system或的情况下 构建MySQLyes。
-
-
配置
daemon_memcached插件,使其可以InnoDB通过运行位于的innodb_memcached_config.sql配置脚本 与 表进行 交互MYSQL_HOME/shareinnodb_memcache有三个需要的表数据库(cache_policies,config_options,和containers)。 它还将demo_test示例表 安装 在test数据库中。MySQL的>
sourceMYSQL_HOME/share/innodb_memcached_config.sql运行
innodb_memcached_config.sql脚本是一次性操作。 如果您稍后卸载并重新安装daemon_memcached插件 ,表将保留在原位 。mysql>
USE innodb_memcache;mysql>SHOW TABLES;+ --------------------------- + | Tables_in_innodb_memcache | + --------------------------- + | cache_policies | | config_options | | 容器| + --------------------------- + mysql>USE test;mysql>SHOW TABLES;+ ---------------- + | Tables_in_test | + ---------------- + | demo_test | + ---------------- +在这些表中,
innodb_memcache.containers表格是最重要的。containers表中的 条目 提供了到InnoDB表列 的映射 。InnoDB与daemon_memcached插件 一起使用的 每个 表都 需要表中的条目containers。该
innodb_memcached_config.sql脚本在containers表中 插入一个条目,该 表提供表的映射demo_test。 它还将单行数据插入demo_test表中。 此数据允许您在设置完成后立即验证安装。MySQL的>
SELECT * FROM innodb_memcache.containers\G*************************** 1。排******************** ******* 名称:aaa db_schema:test db_table:demo_test key_columns:c1 value_columns:c2 标志:c3 cas_column:c4 expire_time_column:c5 unique_idx_name_on_key:PRIMARY MySQL的>SELECT * FROM test.demo_test;+ ---- + ------------------ + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ---- + ------------------ + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | + ---- + ------------------ + ------ + ------ + ------ +有关
innodb_memcache表和demo_test示例表的 更多信息 ,请参见 第15.19.8节“InnoDB memcached插件内部” 。 -
daemon_memcached通过运行INSTALL PLUGIN语句 激活 插件 :MySQL的>
INSTALL PLUGIN daemon_memcached soname "libmemcached.so";安装插件后,每次重启MySQL服务器时都会自动激活它。
要验证
daemon_memcached
插件设置,请使用
telnet
会话发出
memcached
命令。
默认情况下,
memcached
守护程序侦听端口11211。
-
从
test.demo_test表中 检索数据 。 表中的单行数据demo_test的键值为AA。telnet localhost 11211试试127.0.0.1 ...... 连接到localhost。 逃脱角色是'^]'。get AA价值AA 8 12 你好你好 结束 -
使用
set命令 插入数据 。set BB 10 0 16GOODBYE, GOODBYESTORED哪里:
-
set是存储值的命令 -
BB是关键 -
10是操作的旗帜; memcached 忽略 但客户端可以使用它来指示任何类型的信息; 指定0是否未使用 -
0是到期时间(TTL); 指定0是否未使用 -
16是以字节为单位的提供值块的长度 -
GOODBYE, GOODBYE是存储的值
-
-
通过连接MySQL服务器并查询
test.demo_test表, 验证插入的数据是否存储在MySQL 中。MySQL的>
SELECT * FROM test.demo_test;+ ---- + ------------------ + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ---- + ------------------ + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | | BB | GOODBYE,GOODBYE | 10 | 1 | 0 | + ---- + ------------------ + ------ + ------ + ------ + -
返回到telnet会话并使用key检索先前插入的数据
BB。get BB价值BB 10 16 GOODBYE,GOODBYE 结束quit
如果关闭MySQL服务器(也关闭集成的
memcached
服务器),则进一步尝试访问
memcached
数据会因连接错误而失败。
通常,
memcached
数据此时也会消失,并且当
重新启动
memcached
时,您需要应用程序逻辑将数据加载回内存
。
但是,
InnoDB
memcached
插件会为您自动执行此过程。
重新启动MySQL时,
get
操作将再次返回存储在先前
memcached
会话
中的键值对
。
当请求密钥并且关联的值不在内存缓存中时,将从MySQL
test.demo_test
表中
自动查询该值
。
此示例显示如何
InnoDB
使用
daemon_memcached
插件
设置自己的
表
。
-
创建一个
InnoDB表。 该表必须具有带唯一索引的键列。 city表的键列是city_id,它被定义为主键。 该表还必须包括列flags,cas和expiry值。 可能有一个或多个值列。 该city表有三个值列(name,state,country)。注意对列名称没有特殊要求,因为有效映射已添加到
innodb_memcache.containers表中。mysql> )CREATE TABLE city (city_id VARCHAR(32),name VARCHAR(1024),state VARCHAR(1024),country VARCHAR(1024),flags INT,cas BIGINT UNSIGNED,expiry INT,primary key(city_id)ENGINE=InnoDB; -
在
innodb_memcache.containers表中 添加一个条目, 以便daemon_memcached插件知道如何访问该InnoDB表。 该条目必须满足innodb_memcache.containers表定义。 有关每个字段的说明,请参见 第15.19.8节“InnoDB memcached插件内部” 。MySQL的>
DESCRIBE innodb_memcache.containers;+ ------------------------ + -------------- + ------ + - --- + --------- + ------- + | 领域| 输入| 空| 钥匙| 默认| 额外的| + ------------------------ + -------------- + ------ + - --- + --------- + ------- + | 名字| varchar(50)| 没有| PRI | NULL | | | db_schema | varchar(250)| 没有| | NULL | | | db_table | varchar(250)| 没有| | NULL | | | key_columns | varchar(250)| 没有| | NULL | | | value_columns | varchar(250)| 是的| | NULL | | | 旗帜| varchar(250)| 没有| | 0 | | | cas_column | varchar(250)| 是的| | NULL | | | expire_time_column | varchar(250)| 是的| | NULL | | | unique_idx_name_on_key | varchar(250)| 没有| | NULL | | + ------------------------ + -------------- + ------ + - --- + --------- + ------- +innodb_memcache.containerscity表 的 表条目定义为:MySQL的>
INSERT INTO `innodb_memcache`.`containers` (`name`, `db_schema`, `db_table`, `key_columns`, `value_columns`,`flags`, `cas_column`, `expire_time_column`, `unique_idx_name_on_key`)VALUES ('default', 'test', 'city', 'city_id', 'name|state|country','flags','cas','expiry','PRIMARY');-
default为containers.name列配置,以将city表 配置 为InnoDB与daemon_memcached插件 一起使用 的默认 表 。 -
多
InnoDB表列(name,state,country)映射到containers.value_columns使用 “ | “ 分隔符。 -
的
flags,cas_column以及expire_time_column该领域innodb_memcache.containers表通常不使用的应用程序显著daemon_memcached插件。 但是,InnoDB每个都需要 指定的 表格列。 插入数据时,0如果未使用这些列 ,请指定 这些列。
-
-
更新
innodb_memcache.containers表后,重新启动daemon_memcache插件以应用更改。MySQL的>
UNINSTALL PLUGIN daemon_memcached;MySQL的>INSTALL PLUGIN daemon_memcached soname "libmemcached.so"; -
使用telnet,
city使用 memcachedset命令 将数据插入 表中 。telnet localhost 11211试试127.0.0.1 ...... 连接到localhost。 逃脱角色是'^]'。set B 0 0 22BANGALORE|BANGALORE|INSTORED -
使用MySQL,查询
test.city表以验证您插入的数据是否已存储。MySQL的>
SELECT * FROM test.city;+ --------- + ----------- ----------- + + --------- + ----- - + ------ + -------- + | city_id | 名字| 州| 国家| 旗帜| cas | 到期| + --------- + ----------- ----------- + + --------- + ----- - + ------ + -------- + | B | 班加罗尔| 班加罗尔| IN | 0 | 3 | 0 | + --------- + ----------- ----------- + + --------- + ----- - + ------ + -------- + -
使用MySQL,将其他数据插入
test.city表中。mysql>
INSERT INTO city VALUES ('C','CHENNAI','TAMIL NADU','IN', 0, 0 ,0);mysql>INSERT INTO city VALUES ('D','DELHI','DELHI','IN', 0, 0, 0);mysql>INSERT INTO city VALUES ('H','HYDERABAD','TELANGANA','IN', 0, 0, 0);mysql>INSERT INTO city VALUES ('M','MUMBAI','MAHARASHTRA','IN', 0, 0, 0);注意建议您指定的值
0的flags,cas_column和expire_time_column领域,如果他们不使用。 -
使用telnet,发出 memcached
get命令以检索使用MySQL插入的数据。get H价值H 0 22 海得拉巴|特兰伽纳| IN 结束
memcached
可以
在
配置参数
的参数中编码
的MySQL配置文件或
mysqld
启动字符串中
指定
传统
配置选项
daemon_memcached_option
。
memcached
配置选项在加载插件时生效,每次启动MySQL服务器时都会发生这种情况。
例如,要使
端口11222上的
memcached
侦听而不是默认端口11211,请指定
配置选项
-p11222
的参数
daemon_memcached_option
:
mysqld ....--daemon_memcached_option =“ - p11222”
其他
memcached
选项可以在
daemon_memcached_option
字符串中
编码
。
例如,您可以指定选项以减少最大并发连接数,更改键值对的最大内存大小,或为错误日志启用调试消息,等等。
还有特定于
daemon_memcached
插件的
配置选项
。
这些包括:
-
daemon_memcached_engine_lib_name:指定实现InnoDBmemcached 插件 的共享库 。 默认设置为innodb_engine.so。 -
daemon_memcached_engine_lib_path:包含实现InnoDBmemcached 插件 的共享库的目录的路径 。 默认值为NULL,表示插件目录。 -
daemon_memcached_r_batch_size:定义读取操作的批量提交大小(get)。 它指定 发生 提交 之后 的 memcached 读取操作 的数量 。 默认情况下设置为1,以便每个 请求访问 表中 最近提交的数据 ,无论数据是通过 memcached 还是通过SQL 更新的 。 当该值大于1时,每次 调用时 ,读操作的计数器都会递增 。 一个 调用重置读取和写入计数器。daemon_memcached_r_batch_sizegetInnoDBgetflush_all -
daemon_memcached_w_batch_size:定义批提交大小写操作(set,replace,append,prepend,incr,decr,等)。daemon_memcached_w_batch_size默认情况下设置为1,以便在发生中断时不会丢失未提交的数据,以便基础表上的SQL查询访问最新的数据。 当该值大于1时,用于写入操作的计数器被递增为每个add,set,incr,decr,和delete调用。 一个flush_all调用重置读取和写入计数器。
默认情况下,您无需修改
daemon_memcached_engine_lib_name
或
daemon_memcached_engine_lib_path
。
例如,如果要为
memcached
使用不同的存储引擎
(例如NDB
memcached
引擎)
,则可以配置这些选项
。
daemon_memcached
插件配置参数可以在MySQL配置文件或
mysqld
启动字符串中指定。
它们在您加载
daemon_memcached
插件
时生效
。
更改
daemon_memcached
插件配置时,请重新加载插件以应用更改。
为此,请发出以下声明:
MySQL的>UNINSTALL PLUGIN daemon_memcached;MySQL的>INSTALL PLUGIN daemon_memcached soname "libmemcached.so";
重新启动插件时,将保留配置设置,所需的表和数据。
有关启用和禁用插件的其他信息,请参见 第5.6.1节“安装和卸载插件” 。
该
daemon_memcached
插件支持多个get操作(在单个
memcached
查询中
获取多个键值对
)和范围查询。
多次获取操作
在单个
memcached
查询中
获取多个键值对的
能力通过减少客户端和服务器之间的通信流量来提高读取性能。
因为
InnoDB
,这意味着更少的事务和开放表操作。
以下示例演示了多get支持。
该示例使用
创建新表和列映射
test.city
中描述的
表
。
mysql>USE test;mysql>SELECT * FROM test.city;+ --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- + | city_id | 名字| 州| 国家| 旗帜| cas | 到期| + --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- + | B | 班加罗尔| 班加罗尔| IN | 0 | 1 | 0 | | C | CHENNAI | TAMIL NADU | IN | 0 | 0 | 0 | | D | DELHI | DELHI | IN | 0 | 0 | 0 | | H | 海得拉巴| TELANGANA | IN | 0 | 0 | 0 | | M | 孟买| MAHARASHTRA | IN | 0 | 0 | 0 | + --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- +
运行
get
命令以从
city
表中
检索所有值
。
结果以键值对序列返回。
telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。get B C D H M价值B 0 22 |班加罗尔| IN 价值C 0 21 CHENNAI | TAMIL NADU | IN 价值D 0 14 新德里|新德里| IN 价值H 0 22 海得拉巴|特兰伽纳| IN 价值M 0 21 孟买| MAHARASHTRA | IN 结束
在单个
get
命令中
检索多个值时
,可以切换表(使用
表示法)来检索第一个键的值,但不能为后续键切换表。
例如,此示例中的表开关有效:
@@
containers.name
get @@aaa.AA BB
VALUE @@ aaa.AA 8 12
你好你好
价值BB 10 16
GOODBYE,GOODBYE
结束
不支持尝试在同一
get
命令中
再次切换表
以从其他表中检索键值。
范围查询
对于范围查询,该
daemon_memcached
插件支持下列比较运算符:
<
,
>
,
<=
,
>=
。
运算符前面必须有
@
符号。
当范围查询找到多个匹配的键 - 值对时,将在键 - 值对序列中返回结果。
以下示例演示了范围查询支持。
这些示例使用
创建新表和列映射
test.city
中描述的
表
。
MySQL的> SELECT * FROM test.city;
+ --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- +
| city_id | 名字| 州| 国家| 旗帜| cas | 到期|
+ --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- +
| B | 班加罗尔| 班加罗尔| IN | 0 | 1 | 0 |
| C | CHENNAI | TAMIL NADU | IN | 0 | 0 | 0 |
| D | DELHI | DELHI | IN | 0 | 0 | 0 |
| H | 海得拉巴| TELANGANA | IN | 0 | 0 | 0 |
| M | 孟买| MAHARASHTRA | IN | 0 | 0 | 0 |
+ --------- + ----------- ------------- + + --------- + --- ---- + ------ + -------- +
打开telnet会话:
telnet 127.0.0.1 11211
试试127.0.0.1 ......
连接到127.0.0.1。
逃脱角色是'^]'。
要获得大于的所有值
B
,请输入
get @>B
:
get @>B
价值C 0 21
CHENNAI | TAMIL NADU | IN
价值D 0 14
新德里|新德里| IN
价值H 0 22
海得拉巴|特兰伽纳| IN
价值M 0 21
孟买| MAHARASHTRA | IN
结束
要获得小于的所有值
M
,请输入
get @<M
:
get @<M
价值B 0 22
|班加罗尔| IN
价值C 0 21
CHENNAI | TAMIL NADU | IN
价值D 0 14
新德里|新德里| IN
价值H 0 22
海得拉巴|特兰伽纳| IN
结束
要获得小于和包括的所有值
M
,请输入
get @<=M
:
get @<=M
价值B 0 22
|班加罗尔| IN
价值C 0 21
CHENNAI | TAMIL NADU | IN
价值D 0 14
新德里|新德里| IN
价值H 0 22
海得拉巴|特兰伽纳| IN
价值M 0 21
孟买| MAHARASHTRA | IN
要获得大于
B
但小于的
值
M
,请输入
get @>B@<M
:
get @>B@<M
价值C 0 21
CHENNAI | TAMIL NADU | IN
价值D 0 14
新德里|新德里| IN
价值H 0 22
海得拉巴|特兰伽纳| IN
结束
最多可以解析两个比较运算符,一个是'小于'(
@<
)或'小于或等于'(
@<=
)运算符,另一个是'大于'(
@>
)或'大于或等于'到'(
@>=
)运算符。
假设任何其他运算符都是密钥的一部分。
例如,如果发出
get
包含三个运算符
的
命令,则第三个operator(
@>C
)将被视为键的一部分,并且该
get
命令将搜索小于
M
和大于的
值
B@>C
。
get @<M@>B@>C
价值C 0 21
CHENNAI | TAMIL NADU | IN
价值D 0 14
新德里|新德里| IN
价值H 0 22
海得拉巴|特兰伽纳| IN
daemon_memcached
在生产服务器上
部署
插件
之前,请参阅此部分
,如果MySQL实例包含敏感数据,则甚至在测试服务器上。
因为
默认情况下
memcached
不使用身份验证机制,并且可选的SASL身份验证不如传统的DBMS安全措施那么强,所以只在使用该
daemon_memcached
插件
的MySQL实例中保留非敏感数据
,并阻止使用此配置的任何服务器来自潜在的入侵者。
不允许
从Internet访问这些服务器的
memcached
;
只允许从防火墙内部网内访问,最好是从可以限制其成员资格的子网中进行访问。
SASL支持提供了通过
memcached
客户端
保护MySQL数据库免受未经身份验证的访问的功能
。
本节介绍如何使用该
daemon_memcached
插件
启用SASL
。
这些步骤几乎与为传统的
memcached
服务器
启用SASL所执行的步骤相同
。
SASL代表 “ 简单身份验证和安全层 ” ,这是一种为基于连接的协议添加身份验证支持的标准。 memcached 在1.4.3版本中添加了SASL支持。
只有二进制协议支持SASL身份验证。
memcached
客户端只能访问在
InnoDB
表中注册的
innodb_memcache.containers
表。
即使DBA可以对此类表进行访问限制,
也无法控制
通过
memcached
应用程序的
访问
。
因此,提供了SASL支持来控制对
InnoDB
与
daemon_memcached
插件
关联的表的
访问
。
以下部分显示如何构建,启用和测试支持SASL的
daemon_memcached
插件。
默认情况下,启用SASL的
daemon_memcached
插件不包含在MySQL发行包中,因为启用SASL的
daemon_memcached
插件需要
使用SASL库
构建
memcached
。
要启用SASL支持,请
daemon_memcached
在下载SASL库后下载
MySQL源并重新
构建插件:
-
安装SASL开发和实用程序库。 例如,在Ubuntu上,使用 apt-get 获取库:
sudo apt-get -f install libsasl2-2 sasl2-bin libsasl2-2 libsasl2-dev libsasl2-modules
-
daemon_memcached通过添加ENABLE_MEMCACHED_SASL=1到 cmake 选项, 使用SASL功能 构建 插件共享库 。 memcached 还提供 简单的明文密码支持 ,便于测试。 要启用简单的明文密码支持,请指定ENABLE_MEMCACHED_SASL_PWDB=1cmake 选项。总之,添加以下三个 cmake 选项:
cmake ... -DWITH_INNODB_MEMCACHED = 1 -DENABLE_MEMCACHED_SASL = 1 -DENABLE_MEMCACHED_SASL_PWDB = 1
-
安装
daemon_memcached插件,如 第15.19.3节“设置InnoDB memcached插件”中所述 。 -
配置用户名和密码文件。 (此示例使用 memcached 简单的明文密码支持。)
-
在文件中,创建一个名为的用户并将
testname密码定义为testpasswd:echo“testname:testpasswd :::::::”> / home / jy / memcached-sasl-db
-
配置
MEMCACHED_SASL_PWDB环境变量以通知memcached用户名和密码文件:export MEMCACHED_SASL_PWDB = / home / jy / memcached-sasl-db
-
通知
memcached使用明文密码:echo“mech_list:plain”> /home/jy/work2/msasl/clients/memcached.conf export SASL_CONF_PATH = / home / jy / work2 / msasl / clients
-
-
通过使用 配置参数中 编码 的 memcached
-S选项 重新启动MySQL服务器来启用SASLdaemon_memcached_option:mysqld ... --daemon_memcached_option =“ - S”
-
要测试设置,请使用支持SASL的客户端,例如 启用SASL的libmemcached 。
memcp --servers = localhost:11211 --binary --username = testname --password =
passwordmyfile.txt memcat --servers = localhost:11211 --binary --username = testname --password =passwordmyfile.txt如果指定了错误的用户名或密码,则会拒绝该操作并显示
memcache error AUTHENTICATION FAILURE消息。 在这种情况下,请检查memcached-sasl-db文件中 设置的明文密码, 以验证您提供的凭据是否正确。
还有其他方法可以使用 memcached 测试SASL身份验证 ,但上述方法最直接。
通常,为
InnoDB
memcached
插件
编写应用程序
涉及某种程度的重写或调整使用MySQL或
memcached
API的
现有代码
。
-
使用该
daemon_memcached插件,而不是 在低功耗机器上运行 的许多传统 memcached 服务器,您拥有与 MySQL服务器 相同数量的 memcached 服务器,在具有大量磁盘存储和内存的相对高功率的计算机上运行。 您可以重用一些与 memcached API 一起使用的现有代码 ,但由于服务器配置不同,可能需要进行调整。 -
通过
daemon_memcached插件 存储的数据 进入VARCHAR,TEXT或BLOB列,必须转换为数字操作。 您可以在应用程序端执行转换,也可以CAST()在查询中 使用该 函数。 -
来自数据库背景,您可能习惯于具有许多列的通用SQL表。 由 memcached 代码 访问的表 可能只有几个甚至一个列保存数据值。
-
您可以调整应用程序中执行单行查询,插入,更新或删除的部分,以提高代码关键部分的性能。 两个 查询 (读取)和 DML (写)操作可以通过执行时更快基本上
InnoDB分布式缓存 接口。 写入的性能改进通常大于读取的性能改进,因此您可能会专注于调整在网站上执行日志记录或记录交互式选择的代码。
以下部分更详细地探讨了这些要点。
在调整现有MySQL架构或应用程序以使用
插件
时,
请考虑
memcached
应用程序的
这些方面
daemon_memcached
:
-
memcached 键不能包含空格或换行符,因为这些字符在ASCII协议中用作分隔符。 如果您使用包含空格的查找值,在调用使用它们作为键来变换前或将它们散列到值没有空格
add(),set(),get(),等等。 虽然理论上这些字符在使用二进制协议的程序中的密钥中是允许的,但您应该限制密钥中使用的字符以确保与广泛的客户端兼容。 -
如果表中有一个短的数字 主键 列
InnoDB,则 通过将整数转换为字符串值,将其 用作 memcached 的唯一查找键 。 如果 memcached 服务器用于多个应用程序或多个InnoDB表,请考虑修改名称以确保它是唯一的。 例如,在数值之前添加表名,数据库名和表名。注意该
daemon_memcached插件支持对InnoDB已INTEGER定义为主键的 映射 表进行 插入和读取 。 -
您不能将分区表用于使用 memcached 查询或存储的数据 。
-
的 分布式缓存 协议围绕经过数字值作为字符串。 要在基础
InnoDB表中 存储数值 ,要实现可在SQL函数中使用的计数器, 例如:SUM()或者AVG():-
使用
VARCHAR具有足够字符的列来保存最大预期数字的所有数字(如果适用于负号,小数点或两者,则包含其他字符)。 -
在使用列值执行算术的任何查询中,使用该
CAST()函数将值从字符串转换为整数,或转换为其他一些数字类型。 例如:#字母条目返回为零。 SELECT CAST(c2为无符号整数)FROM demo_test; #由于数字值可能为0,因此无法取消它们的资格。 #测试字符串值以查找整数,并仅对其进行平均。 SELECT AVG(强制转换(c2为无符号整数))FROM demo_test '在'0'和'9999999999'之间; #Views让您隐藏查询的复杂性。结果已经转换; #每次都不需要重复转换函数和WHERE子句。 创建视图编号作为选择c1 KEY,CAST(c2 AS UNSIGNED INTEGER)val FROM demo_test WHERE c2 BETWEEN'0'和'9999999999'; SELECT SUM(val)FROM数字;
注意通过调用将结果集中的任何字母值转换为0
CAST()。 当使用诸如AVG()取决于结果集中的行数的 函数时 ,包括WHERE用于过滤掉非数字值的子句。
-
-
如果
InnoDB用作键 的 列的值可能超过250个字节,则将该值散列为小于250个字节。 -
要将现有表与
daemon_memcached插件 一起 使用,请在表中为其定义条目innodb_memcache.containers。 要使该表成为所有 memcached 请求 的默认 值,请default在name列中 指定值 ,然后重新启动MySQL服务器以使更改生效。 如果对不同类型的 memcached 数据 使用多个表,请 在innodb_memcache.containers表中使用name您选择的值 设置多个条目 ,然后 以 或者 的形式 发出 memcached 请求get @@nameset @@在应用程序中指定要用于后续 memcached 请求 的表 。name有关使用预定义
test.demo_test表 以外的 表的 示例 ,请参见 例15.13“将自己的表与InnoDB memcached应用程序一起使用” 。 有关所需的表格布局,请参见 第15.19.8节“InnoDB memcached插件内部” 。 -
要将多个
InnoDB表列值与 memcached 键值对一起使用,请 在 表value_columns的innodb_memcache.containers条目 字段中 指定由逗号,分号,空格或管道字符分隔的列名InnoDB。 例如,指定col1,col2,col3或col1|col2|col3在value_columns字段中。在将字符串传递给 memcached
add或set调用 之前,使用管道字符作为分隔符将列值连接成单个字符串 。 该字符串将自动解压缩到正确的列中。 每次get调用都返回一个包含列值的字符串,该列值也由管道符号分隔。 您可以使用适当的应用程序语言语法解压缩值。
例15.13将自己的表与InnoDB memcached应用程序一起使用
此示例显示如何将自己的表与
memcached
用于数据操作
的示例Python应用程序一起使用
。
该示例假定
daemon_memcached
插件的安装如
第15.19.3节“设置InnoDB memcached插件”中所述
。
它还假定您的系统配置为运行使用该
python-memcache
模块
的Python脚本
。
-
创建
multicol存储国家/地区信息 的 表格,包括人口,区域和驾驶员侧数据('R'右侧和'L'左侧)。MySQL的>
USE test;MySQL的>CREATE TABLE `multicol` (`country` varchar(128) NOT NULL DEFAULT '',`population` varchar(10) DEFAULT NULL,`area_sq_km` varchar(9) DEFAULT NULL,`drive_side` varchar(1) DEFAULT NULL,`c3` int(11) DEFAULT NULL,`c4` bigint(20) unsigned DEFAULT NULL,`c5` int(11) DEFAULT NULL,PRIMARY KEY (`country`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -
将记录插入
innodb_memcache.containers表中,以便daemon_memcached插件可以访问该multicol表。MySQL的>
INSERT INTO innodb_memcache.containers(name,db_schema,db_table,key_columns,value_columns,flags,cas_column,expire_time_column,unique_idx_name_on_key)VALUES('bbb','test','multicol','country','population,area_sq_km,drive_side','c3','c4','c5','PRIMARY');MySQL的>COMMIT;-
该 表 的
innodb_memcache.containers记录multicol指定了name值'bbb',即表标识符。注意如果将单个
InnoDB表用于所有 memcached 应用程序,则name可以 将该 值设置default为避免使用@@表示法来切换表。 -
该
db_schema列设置为test,这是multicol表所在 的数据库的名称 。 -
该
db_table列设置为multicol,即InnoDB表 的名称 。 -
key_columns设置为唯一country列。 该country列被定义为multicol表定义中 的主键 。 -
而不是单一的
InnoDB表列,以保存的复合数据值,数据由三个表中的列之间划分(population,area_sq_km,和drive_side)。 为了容纳多个值列,在value_columns字段中 指定了以逗号分隔的列列表 。 字段中定义value_columns的列是存储或检索值时使用的列。 -
对值
flags,expire_time以及cas_column字段基于在所使用的值demo.test的示例表。 这些字段在使用daemon_memcached插件的 应用程序中通常不重要, 因为MySQL使数据保持同步,并且无需担心数据过期或变得陈旧。 -
该
unique_idx_name_on_key字段设置为PRIMARY,表示country在multicol表中 唯一 列 上定义的主索引 。
-
-
将示例Python应用程序复制到文件中。 在此示例中,示例脚本将复制到名为的文件中
multicol.py。示例Python应用程序将数据插入
multicol表中并检索所有键的数据,演示如何InnoDB通过daemon_memcached插件 访问 表 。import sys,os 导入memcache def connect_to_memcached(): memc = memcache.Client(['127.0.0.1:11211'],debug = 0); 打印“连接到memcached。” 返回记忆库 def banner(消息): 打印 print“=”* len(消息) 打印消息 print“=”* len(消息) country_data = [ ( “加拿大”, “34820000”, “9984670”, “R”), ( “USA”, “314242000”, “9826675”, “R”), ( “爱尔兰”, “6399152”, “84421”, “L”), ( “英国”, “62262000”, “243610”, “L”), ( “墨西哥”, “113910608”, “1972550”, “R”), ( “丹麦”, “5543453”, “43094”, “R”), ( “挪威”, “5002942”, “385252”, “R”), ( “UAE”, “8264070”, “83600”, “R”), ( “印”, “1210193422”, “3287263”, “L”), ( “中国”, “1347350000”, “9640821”, “R”), ] def switch_table(memc,table): key =“@@”+ table 打印“通过发出GET for'”+ key +“'将默认表格切换为'”+ table +“'。” result = memc.get(key) def insert_country_data(memc): banner(“通过memcached接口插入初始数据”) 对于country_data中的项目: country = item [0] population = item [1] area = item [2] drive_side = item [3] key =国家 value =“|”。join([population,area,drive_side]) 打印“Key =”+键 打印“值=”+值 如果memc.add(键,值): print“添加了新的密钥,值对。” 其他: print“更新现有密钥的值”。 memc.set(键,值) def query_country_data(memc): banner(“检索所有密钥的数据(国家/地区名称)”) 对于country_data中的项目: key = item [0] result = memc.get(key) print“这是从数据库中检索到的键”+ key +“的结果:” 打印结果 (m_population,m_area,m_drive_side)= result.split(“|”) print“Unpacked population value:”+ m_population 打印“未打包区域值:”+ m_area 打印“未打开的驱动器侧值:”+ m_drive_side 如果__name__ =='__ main__': memc = connect_to_memcached() switch_table(MEMC, “BBB”) insert_country_data(MEMC) query_country_data(MEMC) sys.exit(0)示例Python应用程序说明:
-
运行应用程序不需要数据库授权,因为数据操作是通过 memcached 接口 执行的 。 唯一需要的信息是 memcached 守护程序侦听 的本地系统上的端口号 。
-
为了确保应用程序使用该
multicol表,switch_table()调用 该 函数 ,该 函数 使用 表示法 执行虚拟get或set请求@@。name请求中 的 值是bbb,该 字段中multicol定义 的 表标识符innodb_memcache.containers.name。name可以在实际应用程序中使用 更具描述性的 值。 此示例仅说明指定了表标识符,而不是get @@...请求中 的表名 。 -
用于插入和查询数据的实用程序函数演示了如何将Python数据结构转换为管道分隔值,以便使用
add或set请求 将数据发送到MySQL ,以及如何解压由get请求 返回的管道分隔值 。 仅当将单个 memcached 值 映射 到多个MySQL表列 时,才需要此额外处理 。
-
-
运行示例Python应用程序。
外壳>
python multicol.py如果成功,示例应用程序将返回此输出:
连接到memcached。 通过发出'@@ bbb'的GET将默认表切换为'bbb'。 ============================================== 通过memcached接口插入初始数据 ============================================== 关键=加拿大 值= 34820000 | 9984670 | R. 添加了新的密钥,值对。 关键=美国 值= 314242000 | 9826675 | R. 添加了新的密钥,值对。 关键=爱尔兰 值= 6399152 | 84421 | L. 添加了新的密钥,值对。 关键=英国 值= 62262000 | 243610 | L. 添加了新的密钥,值对。 Key =墨西哥 值= 113910608 | 1972550 | R. 添加了新的密钥,值对。 关键=丹麦 值= 5543453 | 43094 | R. 添加了新的密钥,值对。 关键=挪威 值= 5002942 | 385252 | R. 添加了新的密钥,值对。 关键=阿联酋 值= 8264070 | 83600 | R. 添加了新的密钥,值对。 关键=印度 值= 1210193422 | 3287263 | L. 添加了新的密钥,值对。 关键=中国 值= 1347350000 | 9640821 | R. 添加了新的密钥,值对。 ============================================ 检索所有密钥(国家/地区名称)的数据 ============================================ 以下是从加拿大关键数据库中检索到的结果: 34820000 | 9984670 | R 未包装人口价值:34820000 未包装区域值:9984670 未包装的驱动器侧值:R 以下是从关键美国数据库中检索到的结果: 314242000 | 9826675 | R 未打包人口价值:314242000 未包装区域值:9826675 未包装的驱动器侧值:R 以下是从爱尔兰主要数据库中检索到的结果: 6399152 | 84421 | L 未打包人口价值:6399152 未包装区域值:84421 未包装的驱动器侧值:L 以下是从英国关键数据库中检索到的结果: 62262000 | 243610 | L 未打包人口价值:62262000 拆包面积值:243610 未包装的驱动器侧值:L 以下是从关键墨西哥数据库中检索到的结果: 113910608 | 1972550 | R 未拆包人口价值:113910608 拆包面积值:1972550 未包装的驱动器侧值:R 以下是从丹麦主要数据库中检索到的结果: 5543453 | 43094 | R 未打包人口价值:5543453 未包装区域值:43094 未包装的驱动器侧值:R 以下是从关键挪威数据库中检索到的结果: 5002942 | 385252 | R 未打包人口价值:5002942 未包装区域值:385252 未包装的驱动器侧值:R 以下是从关键阿联酋数据库中检索到的结果: 8264070 | 83600 | R 未打包人口价值:8264070 拆包面积值:83600 未包装的驱动器侧值:R 以下是从关键印度数据库中检索到的结果: 1210193422 | 3287263 | L 未打包人口价值:1210193422 未包装区域值:3287263 未包装的驱动器侧值:L 以下是从关键中国数据库中检索到的结果: 1347350000 | 9640821 | R 未拆包人口价值:1347350000 未包装区域值:9640821 未包装的驱动器侧值:R
-
查询
innodb_memcache.containers表以查看先前为multicol表 插入的记录 。 第一个记录是demo_test在初始daemon_memcached插件设置 期间创建 的 表 的示例条目 。 第二条记录是您为multicol表格 插入的条目 。MySQL的>
SELECT * FROM innodb_memcache.containers\G*************************** 1。排******************** ******* 名称:aaa db_schema:test db_table:demo_test key_columns:c1 value_columns:c2 标志:c3 cas_column:c4 expire_time_column:c5 unique_idx_name_on_key:PRIMARY *************************** 2.排******************** ******* 名称:bbb db_schema:test db_table:multicol key_columns:country value_columns:population,area_sq_km,drive_side 标志:c3 cas_column:c4 expire_time_column:c5 unique_idx_name_on_key:PRIMARY -
查询
multicol表以查看示例Python应用程序插入的数据。 这些数据可用于MySQL 查询 ,它演示了如何使用SQL或应用程序(使用适当的 MySQL连接器或API ) 访问相同的数据 。MySQL的>
SELECT * FROM test.multicol;+ --------- + ------------ + ------------ + ------------ + ------ + ------ + ------ + | 国家| 人口| area_sq_km | drive_side | c3 | c4 | c5 | + --------- + ------------ + ------------ + ------------ + ------ + ------ + ------ + | 加拿大| 34820000 | 9984670 | R | 0 | 11 | 0 | | 中国| 1347350000 | 9640821 | R | 0 | 20 | 0 | | 丹麦| 5543453 | 43094 | R | 0 | 16 | 0 | | 印度| 1210193422 | 3287263 | L | 0 | 19 | 0 | | 爱尔兰| 6399152 | 84421 | L | 0 | 13 | 0 | | 墨西哥| 113910608 | 1972550 | R | 0 | 15 | 0 | | 挪威| 5002942 | 385252 | R | 0 | 17 | 0 | | 阿联酋| 8264070 | 83600 | R | 0 | 18 | 0 | | 英国| 62262000 | 243610 | L | 0 | 14 | 0 | | 美国| 314242000 | 9826675 | R | 0 | 12 | 0 | + --------- + ------------ + ------------ + ------------ + ------ + ------ + ------ +注意在定义被视为数字的列的长度时,始终允许足够的大小来保存必要的数字,小数点,符号字符,前导零等。 字符串列中的太长值(例如a)
VARCHAR会通过删除某些字符而被截断,这可能会产生无意义的数值。 -
(可选)在
InnoDB存储 memcached 数据 的 表 上运行报表类型查询 。您可以通过SQL查询生成报告,跨任何列执行计算和测试,而不仅仅是
country关键列。 (由于以下示例仅使用来自少数国家/地区的数据,因此这些数字仅用于说明目的。)以下查询返回人们在右侧行驶的国家/地区的平均人口数,以及名称以 “ U ” 开头的国家/地区的平均大小 “ :MySQL的>
SELECT AVG(population) FROM multicol WHERE drive_side = 'R';+ ------------------- + | 平均(人口)| + ------------------- + | 261304724.7142857 | + ------------------- + MySQL的>SELECT SUM(area_sq_km) FROM multicol WHERE country LIKE 'U%';+ ----------------- + | sum(area_sq_km)| + ----------------- + | 10153885 | + ----------------- +因为
population和area_sq_km列存储字符数据,而不是强类型的数字数据,功能,如AVG()和SUM()由第一各值转换为数字工作。 该方法 不工作 为运营商,如<或>,例如,比较基于字符的值时,9 > 1000,这是不能从子句预期如ORDER BY population DESC。 要获得最准确的类型处理,请对将数字列强制转换为适当类型的视图执行查询。 这种技术让你发行简单SELECT *来自数据库应用程序的查询,同时确保转换,过滤和排序是正确的。 以下示例显示了一个视图,可以查询以按人口降序查找前三个国家/地区,其结果反映了multicol表中 的最新数据 ,并将人口和区域数字视为数字:MySQL的>
CREATE VIEW populous_countries ASSELECTcountry,cast(population as unsigned integer) population,cast(area_sq_km as unsigned integer) area_sq_km,drive_side FROM multicolORDER BY CAST(population as unsigned integer) DESCLIMIT 3;MySQL的>SELECT * FROM populous_countries;+ --------- + ------------ + ------------ + ------------ + | 国家| 人口| area_sq_km | drive_side | + --------- + ------------ + ------------ + ------------ + | 中国| 1347350000 | 9640821 | R | | 印度| 1210193422 | 3287263 | L | | 美国| 314242000 | 9826675 | R | + --------- + ------------ + ------------ + ------------ + MySQL的>DESC populous_countries;+ ------------ + --------------------- + ------ + ------ + - -------- ------- + + | 领域| 输入| 空| 钥匙| 默认| 额外的| + ------------ + --------------------- + ------ + ------ + - -------- ------- + + | 国家| varchar(128)| 没有| | | | | 人口| bigint(10)unsigned | 是的| | NULL | | | area_sq_km | int(9)unsigned | 是的| | NULL | | | drive_side | varchar(1)| 是的| | NULL | | + ------------ + --------------------- + ------ + ------ + - -------- ------- + +
InnoDB
在调整现有的
memcached
应用程序以使用
daemon_memcached
插件
时,
请考虑MySQL和
表的
这些方面
:
-
如果有键值超过几个字节,它可能是更有效地使用数字自动增量列作为 主键 的的
InnoDB表格,并创造了独特的 二次指数 在包含列 memcached的 键值。 这是因为InnoDB如果按排序顺序添加主键值(因为它们具有自动增量值),则对大规模插入执行效果最佳。 主键值包含在二级索引中,如果主键是长字符串值,则会占用不必要的空间。 -
如果使用 memcached 存储多个不同类别的信息 ,请考虑
InnoDB为每种类型的数据 设置单独的 表。 在innodb_memcache.containers表中 定义其他表标识符 ,并使用该 表示法来存储和检索来自不同表的项。 通过物理划分不同类型的信息,您可以调整每个表的特性,以获得最佳的空间利用率,性能和可靠性。 例如,您可以启用 压缩@@用于保存博客帖子的表,但不包含用于保存缩略图图像的表。 您可能会比另一个表更频繁地备份一个表,因为它包含关键数据。 您可以 在经常用于使用SQL生成报告的表上 创建其他 二级索引 。table_id.key -
最好配置一组稳定的表定义,以便与 daemon_memcached 插件一起使用,并永久保留表。 对
innodb_memcache.containers表的 更改将在 下次innodb_memcache.containers查询 表时生效 。 容器表中的条目在启动时处理,只要containers.name使用@@符号 请求 无法识别的表标识符(由定义 ), 就会查询这些条目 。 因此,只要您使用关联的表标识符,就会看到新条目,但是对现有条目的更改需要服务器重新启动才能生效。 -
当您使用默认的
innodb_only缓存策略,调用add(),set(),incr(),等能成功,但依旧会触发调试消息如while expecting 'STORED', got unexpected response 'NOT_STORED。 发生调试消息是因为新InnoDB缓存 值和更新值 由于innodb_only缓存策略 而 直接发送到 表而不保存在内存缓存中 。
因为
InnoDB
与
memcached
结合使用
涉及将所有数据写入磁盘,无论是立即还是稍后,原始性能预计比使用
memcached
本身
要慢一些
。
使用
InnoDB
memcached
插件时,请关注
memcached
操作的
调优目标,
以实现比等效SQL操作更好的性能。
基准测试表明, 使用 memcached 接口的 查询和 DML 操作(插入,更新和删除) 比传统SQL更快。 DML操作通常会看到更大的改进。 因此,请考虑 首先 使用写密集型应用程序来使用 memcached 接口。 还要考虑使用缺乏可靠性的快速,轻量级机制的写密集型应用程序的优先级。
调整SQL查询
最适合简单
GET
请求
的查询类型是
AND
在
WHERE
子句中
具有单个子句或一组
条件的查询
:
SQL: SELECT col FROM tbl WHERE key ='key_value'; memcached的: 获取key_value SQL: SELECT col FROM tbl WHERE col1 = val1 and col2 = val2 and col3 = val3; memcached的: #由于您必须始终知道这3个值才能查找密钥, #将它们组合成一个唯一的字符串并将其用作键 #用于所有ADD,SET和GET操作。 key_value = val1 +“:”+ val2 +“:”+ val3 获取key_value SQL: SELECT'键存在!' 从tbl WHERE EXISTS(SELECT col1 FROM tbl WHERE KEY ='key_value')LIMIT 1; memcached的: #通过询问密钥并检查呼叫是否成功来测试密钥是否存在, #忽略值本身。对于存在检查,您通常只存储一个 #短值,例如“1”。 获取key_value
使用系统内存
为获得最佳性能,请将
daemon_memcached
插件
部署在
配置为典型数据库服务器的计算机上,其中大部分系统RAM
通过
配置选项
专用于
InnoDB
缓冲池
innodb_buffer_pool_size
。
对于具有多千兆字节缓冲池的系统,
innodb_buffer_pool_instances
当大多数操作涉及已缓存在内存中的数据时
,请考虑提高
最大吞吐量
的值
。
减少冗余I / O.
InnoDB
有许多设置可让您选择高可靠性(如果发生崩溃)和高写入工作负载期间的I / O开销量之间的平衡。
例如,考虑设置
innodb_doublewrite
to
0
和
innodb_flush_log_at_trx_commit
to
2
。
使用不同的
innodb_flush_method
设置
测量性能
。
有关减少或调整表操作的I / O的其他方法,请参见 第8.5.8节“优化InnoDB磁盘I / O” 。
减少交易开销
的1为默认值
daemon_memcached_r_batch_size
,并
daemon_memcached_w_batch_size
适用于结果的最大的可靠性和存储或更新的数据的安全性。
根据应用程序的类型,您可以增加其中一个或两个设置,以减少频繁
提交
操作
的开销
。
在繁忙的系统上,您可能会增加
daemon_memcached_r_batch_size
,因为
您
知道通过SQL进行的数据更改可能不会
立即
对
memcached
可见
(即,直到
处理
N
更多
get
操作)。
处理必须可靠存储每个写操作的数据时,请将
daemon_memcached_w_batch_size
设置
保留
为
1
。
处理大量仅用于统计分析的更新时增加设置,其中丢失
N
崩溃中
的最后
更新是可接受的风险。
例如,想象一个系统监控穿过繁忙桥梁的交通,每天记录大约100,000辆车的数据。
如果应用程序统计不同类型的车辆来分析流量模式,改变
daemon_memcached_w_batch_size
从
1
以
100
减少99%提交操作的I / O开销。
如果发生中断,最多会丢失100条记录,这可能是可接受的误差范围。
相反,如果应用程序进行自动收费为每一辆汽车,您将设置
daemon_memcached_w_batch_size
以
1
确保每个收费记录被立即保存到磁盘。
由于
在磁盘上
InnoDB
组织
memcached
键值
的方式
,如果要创建大量键,则可以更快地按应用程序中的键值对数据项进行排序,并按
add
排序顺序排序,而不是按任意顺序创建键。
的
memslap
命令,这是常规的一部分,
分布式缓存
分布,但不包含在
daemon_memcached
插件,可以进行基准测试的不同配置是有用的。
它还可用于生成样本键值对,以用于您自己的基准测试。
有关
详细信息,
请参阅
libmemcached
命令行实用程序
。
不同于传统的
分布式缓存
,该
daemon_memcached
插件可以让你控制通过将呼叫产生的数据值的耐用性
add
,
set
,
incr
,等等。
默认情况下,通过
memcached
接口
写入的数据
存储到磁盘,并调用以
get
从磁盘返回最新值。
虽然默认行为不能提供最佳的原始性能,但与
InnoDB
表
的SQL接口相比仍然很快
。
随着您获得使用
daemon_memcached
插件的
经验
,您可以考虑为非关键数据类放松持久性设置,冒着在中断时丢失一些更新值或返回稍微过时的数据的风险。
提交频率
耐久性和原始性能之间的一个折衷是 提交 新数据和更改数据的频率 。 如果数据很关键,应立即提交,以便在发生崩溃或中断时保证安全。 如果数据不太重要,例如在崩溃后重置的计数器或记录您可能丢失的数据,则可能更倾向于提交较低的原始吞吐量。
当
memcached
操作在基础
InnoDB
表中
插入,更新或删除数据时
,更改可能会
InnoDB
立即(如果
daemon_memcached_w_batch_size=1
)或稍后(如果
daemon_memcached_w_batch_size
值大于1)
提交到
表
。
在任何一种情况下,都无法回滚更改。
如果增加值
daemon_memcached_w_batch_size
以避免繁忙时间的高I / O开销,则在工作负载减少时,提交可能会很少发生。
作为安全措施,后台线程会
定期
自动提交通过
memcached
API
进行的更改
。
间隔由。控制
innodb_api_bk_commit_interval
配置选项,默认设置为
5
秒。
当
memcached
操作在基础
InnoDB
表中
插入或更新数据时
,更改的数据立即对其他
memcached
请求
可见,
因为新值保留在内存缓存中,即使它尚未在MySQL端提交。
交易隔离
当
对基础
表
执行
memcached
操作(例如
get
或
incr
导致查询或DML操作)时
InnoDB
,您可以控制操作是否查看写入表的最新数据,仅查看已提交的数据或事务
隔离级别的
其他变体
。
使用
innodb_api_trx_level
配置选项可以控制此功能。
为此选项指定的数值对应于隔离级别,例如
REPEATABLE
READ
。
innodb_api_trx_level
有关其他设置的信息,
请参阅该
选项
的说明
。
严格的隔离级别可确保您检索的数据不会回滚或突然更改,从而导致后续查询返回不同的值。 但是,严格的隔离级别需要更大的 锁定 开销,这可能导致等待。 对于不使用长时间运行事务的NoSQL样式应用程序,通常可以使用默认隔离级别或切换到不太严格的隔离级别。
禁用memcached DML操作的行锁
innodb_api_disable_rowlock
当
通过
插件的
memcached
请求
daemon_memcached
导致DML操作
时,
该
选项可用于禁用行锁
。
默认情况下,
innodb_api_disable_rowlock
设置为
OFF
表示
memcached
请求行锁定
get
和
set
操作。
当
innodb_api_disable_rowlock
设置
为时
ON
,
memcached
请求表锁而不是行锁。
该
innodb_api_disable_rowlock
选项不是动态的。
它必须在
mysqld
命令行
启动时指定
或输入MySQL配置文件。
允许或禁止DDL
默认情况下,您可以执行
DDL
操作,例如
插件
ALTER
TABLE
使用的表
daemon_memcached
。
为避免在将这些表用于高吞吐量应用程序时可能出现的速度减慢,请
innodb_api_enable_mdl
在启动时
启用对这些表禁用DDL操作
。
通过
memcached
和SQL
访问相同的表时,此选项不太合适
,因为它会阻止
CREATE
INDEX
表上的语句,这对于运行报表查询很重要。
将数据存储在磁盘,内存或两者中
该
innodb_memcache.cache_policies
表指定是否将通过
memcached
接口
写入的数据存储
到磁盘(
innodb_only
默认值);
仅在内存中,与传统的
memcached
(
cache_only
)一样;
或两者(
caching
)。
使用该
caching
设置,如果
memcached
在内存中找不到密钥,它将在
InnoDB
表中
搜索该值
。
如果值已在
表中的
磁盘上更新
但尚未从内存缓存中过期,则从该
设置
get
下的调用
返回的值
caching
可能
InnoDB
已过时。
缓存策略可以独立设定
get
,
set
(包括
incr
和
decr
),
delete
和
flush
操作。
例如,您可以允许
get
和
set
操作来查询或更新表和
memcached
(使用在同一时间内存缓存
caching
设置),同时使
delete
,
flush
或(使用上都在内存中拷贝只能操作
cache_only
设置)。
这样,删除或刷新项目只会使项目从缓存中过期,并且
InnoDB
在下次请求项目时
从
表格
返回最新值
。
MySQL的>SELECT * FROM innodb_memcache.cache_policies;+ -------------- + ------------- ------------- + ------ + --------- + -------------- + | policy_name | get_policy | set_policy | delete_policy | flush_policy | + -------------- + ------------- ------------- + ------ + --------- + -------------- + | cache_policy | innodb_only | innodb_only | innodb_only | innodb_only | + -------------- + ------------- ------------- + ------ + --------- + -------------- + MySQL的>UPDATE innodb_memcache.cache_policies SET set_policy = 'caching'WHERE policy_name = 'cache_policy';
innodb_memcache.cache_policies
值仅在启动时读取。
更改此表中的值后,卸载并重新安装
daemon_memcached
插件以确保更改生效。
MySQL的>UNINSTALL PLUGIN daemon_memcached;MySQL的>INSTALL PLUGIN daemon_memcached soname "libmemcached.so";
基准测试表明,
daemon_memcached
插件加速
DML
操作(插入,更新和删除)比加快查询速度更快。
因此,考虑将初始开发工作集中在I / O绑定的写密集型应用程序上,并寻找机会将MySQL与
daemon_memcached
插件一起用于新的写密集型应用程序。
单行DML语句是转换为
memcached
操作
的最简单语句类型
。
INSERT
变
add
,
UPDATE
变
set
,
incr
还是
decr
和
DELETE
成为
delete
。
保证这些操作仅在通过
memcached
接口
发出时影响一行
,因为
key
它在表中是唯一的。
在以下SQL示例中,
t1
根据表中
的配置
引用用于
memcached
操作的
innodb_memcache.containers
表。
key
是指下面列出的列
key_columns
,并
val
引用下面列出的列
value_columns
。
INSERT INTO t1(key,val)VALUES(some_key,some_value); SELECT val FROM t1 WHERE key =some_key; UPDATE t1 SET val =new_valueWHERE key =some_key; UPDATE t1 SET val = val + x WHERE key =some_key; DELETE FROM t1 WHERE key =some_key;
以下
TRUNCATE TABLE
和
DELETE
语句从表中删除所有行,对应于
flush_all
操作,其中
t1
配置为
memcached
操作
的表
,如上例所示。
TRUNCATE TABLE t1; 从t1删除;
您可以
通过标准SQL接口
访问基础
InnoDB
表(
test.demo_test
默认情况下)。
但是,有一些限制:
-
查询也通过 memcached 接口 访问的表时 ,请记住 可以将 memcached 操作配置为定期提交,而不是在每次写操作之后。 此行为由
daemon_memcached_w_batch_size选项 控制 。 如果将此选项设置为大于的值1,请使用READ UNCOMMITTED查询查找刚刚插入的行。MySQL的>
SET SESSSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;MySQL的>SELECT * FROM demo_test;+ ------ + ------ + ------ + ------ + ----------- ------ + + - ---- + ------ + ------ + ------ + ------ + | cx | cy | c1 | cz | c2 | ca | CB | c3 | cu | c4 | C5 | + ------ + ------ + ------ + ------ + ----------- ------ + + - ---- + ------ + ------ + ------ + ------ + | NULL | NULL | a11 | NULL | 123456789 | NULL | NULL | 10 | NULL | 3 | NULL | + ------ + ------ + ------ + ------ + ----------- ------ + + - ---- + ------ + ------ + ------ + ------ + -
使用也通过 memcached 接口 访问的SQL修改表时 ,可以配置 memcached 操作以定期启动新事务,而不是每次读取操作。 此行为由
daemon_memcached_r_batch_size选项 控制 。 如果将此选项设置为大于的值1,则使用SQL对表进行的更改不会立即显示给 memcached 操作。 -
该
InnoDB表是针对事务中的所有操作锁定的IS(意图共享)或IX(意图排他)。 如果增加daemon_memcached_r_batch_size并daemon_memcached_w_batch_size从它们的默认值显着1,该表是最有可能的每个操作之间的锁定,防止 DDL 语句在表。
由于
daemon_memcached
插件支持MySQL
二进制日志
,
因此可以复制
通过
memcached
接口
在
主服务器上
进行的
更新以
进行备份,平衡密集读取工作负载和高可用性。
二进制日志记录支持
所有
memcached
命令。
您不需要
daemon_memcached
在
从属服务器
上
设置
插件
。
此配置的主要优点是增加了主服务器上的写入吞吐量。
复制机制的速度不受影响。
以下部分显示了在将
daemon_memcached
插件与MySQL复制一起
使用时如何使用二进制日志功能
。
假设您已完成
第15.19.3节“设置InnoDB memcached插件”中所述的设置
。
-
要将
daemon_memcached插件与MySQL 二进制日志一起使用 ,请innodb_api_enable_binlog在 主服务器 上 启用 配置选项 。 此选项只能在服务器启动时设置。 您还必须使用该--log-bin选项 在主服务器上启用MySQL二进制日志 。 您可以将这些选项添加到MySQL配置文件或 mysqld 命令行。mysqld ... --log-bin --innodb_api_enable_binlog = 1
-
配置主服务器和从属服务器,如 第17.1.2节“设置基于二进制日志文件位置的复制”中所述 。
-
使用 mysqldump 创建主数据快照,并将快照同步到从属服务器。
主shell>
mysqldump --all-databases --lock-all-tables > dbdump.db从属shell>mysql < dbdump.db -
在主服务器上,发出
SHOW MASTER STATUS以获取主二进制日志坐标。MySQL的>
SHOW MASTER STATUS; -
在从属服务器上,使用
CHANGE MASTER TO语句使用主二进制日志坐标设置从属服务器。MySQL的>
CHANGE MASTER TOMASTER_HOST='localhost',MASTER_USER='root',MASTER_PASSWORD='',MASTER_PORT = 13000,MASTER_LOG_FILE='0.000001,MASTER_LOG_POS=114; -
启动奴隶。
MySQL的>
START SLAVE;如果错误日志打印输出类似于以下内容,则从站已准备好进行复制。
2013-09-24T13:04:38.639684Z 49 [注意]从站I / O线程:连接到 master'root @ localhost:13000',复制在log'0.000001'中开始 在第114位
此示例演示如何
使用
memcached
和telnet
测试
InnoDB
memcached
复制配置
以插入,更新和删除数据。
MySQL客户端用于验证主服务器和从属服务器上的结果。
该示例使用
demo_test
表,该表是在
插件
innodb_memcached_config.sql
的初始设置期间
由
配置脚本
创建的
daemon_memcached
。
该
demo_test
表包含单个示例记录。
-
使用该
set命令插入一个记录,其密钥为test1,标志值为10,到期值为0,cas值为1,值为t1。telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。set test1 10 0 1t1STORED -
在主服务器上,检查记录是否已插入
demo_test表中。 假设该demo_test表先前未被修改,则应该有两个记录。 带有键的示例记录AA,以及刚插入的记录,带有键test1。 的c1列映射到键时,c2列的值,该c3列的标志值,该c4列的值CAS,和c5列的到期时间。 到期时间设置为0,因为它未使用。MySQL的>
SELECT * FROM test.demo_test;+ ------- + -------------- + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ------- + -------------- + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | | test1 | t1 | 10 | 1 | 0 | + ------- + -------------- + ------ + ------ + ------ + -
检查以验证是否已将同一记录复制到从属服务器。
MySQL的>
SELECT * FROM test.demo_test;+ ------- + -------------- + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ------- + -------------- + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | | test1 | t1 | 10 | 1 | 0 | + ------- + -------------- + ------ + ------ + ------ + -
使用此
set命令将键更新为值new。telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。set test1 10 0 2newSTORED更新将复制到从属服务器(请注意该
cas值也已更新)。MySQL的>
SELECT * FROM test.demo_test;+ ------- + -------------- + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ------- + -------------- + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | | test1 | 新的| 10 | 2 | 0 | + ------- + -------------- + ------ + ------ + ------ + -
test1使用delete命令 删除 记录 。telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。delete test1DELETED将
delete操作复制到从站时,test1也会删除从站上的记录。MySQL的>
SELECT * FROM test.demo_test;+ ---- + -------------- + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ---- + -------------- + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | + ---- + -------------- + ------ + ------ + ------ + -
使用该
flush_all命令 从表中删除所有行 。telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。flush_all好MySQL的>
SELECT * FROM test.demo_test;空集(0.00秒) -
Telnet到主服务器并输入两个新记录。
telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'set test2 10 0 4againSTOREDset test3 10 0 5again1STORED -
确认两个记录已复制到从属服务器。
MySQL的>
SELECT * FROM test.demo_test;+ ------- + -------------- + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ------- + -------------- + ------ + ------ + ------ + | test2 | 再次| 10 | 4 | 0 | | test3 | again1 | 10 | 5 | 0 | + ------- + -------------- + ------ + ------ + ------ + -
使用该
flush_all命令 从表中删除所有行 。telnet 127.0.0.1 11211试试127.0.0.1 ...... 连接到127.0.0.1。 逃脱角色是'^]'。flush_all好 -
检查以确保
flush_all在从属服务器上复制操作。MySQL的>
SELECT * FROM test.demo_test;空集(0.00秒)
二进制日志格式:
-
大多数 memcached 操作都映射到 DML 语句(类似于插入,删除,更新)。 由于MySQL服务器没有处理实际的SQL语句,因此所有 memcached 命令(除外
flush_all)都使用基于行的复制(RBR)日志记录,该日志记录独立于任何服务器binlog_format设置。 -
该 memcached的
flush_all命令被映射到TRUNCATE TABLE在MySQL 5.7和更早版本的命令。 由于 DDL 命令只能使用基于语句的日志记录,因此flush_all通过发送TRUNCATE TABLE语句 来复制 该 命令 。 在MySQL 8.0及更高版本中,flush_all映射到DELETE但仍通过发送TRUNCATE TABLE语句进行 复制 。
交易方式:
-
事务 的概念 通常不是 memcached 应用程序的 一部分 。 出于性能方面的考虑,
daemon_memcached_r_batch_size以及daemon_memcached_w_batch_size用于控制读取和写入数据的批量大小。 这些设置不会影响复制。InnoDB成功完成后,将复制 基础 表 上的每个SQL操作 。 -
默认值为
daemon_memcached_w_batch_sizeis1,表示 立即提交 每个 memcached 写入操作。 此默认设置会产生一定的性能开销,以避免主服务器和从属服务器上可见的数据不一致。 复制的记录始终可在从属服务器上立即使用。 如果设置daemon_memcached_w_batch_size为大于的值1,则通过 memcached 插入或更新的记录 不会立即显示在主服务器上; 在提交之前查看主服务器上的记录,问题SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED。
在
InnoDB
分布式缓存
引擎访问
InnoDB
过
InnoDB
的API,其中大部分是直接从嵌入式采纳
InnoDB
。
InnoDB
API函数
作为回调函数
传递给
InnoDB
memcached
引擎。
InnoDB
API函数
InnoDB
直接
访问
表,主要是DML操作,但不包括
TRUNCATE TABLE
。
memcached
命令通过
InnoDB
memcached
API实现。
下表概述了
memcached
命令
如何
映射到DML或DDL操作。
表15.28 memcached命令和关联的DML或DDL操作
| memcached命令 | DML或DDL操作 |
|---|---|
get |
读/取命令 |
set |
搜索后跟一个
INSERT
或
UPDATE
(取决于是否存在密钥)
|
add |
搜索后跟一个
INSERT
或
UPDATE
|
replace |
搜索后跟一个
UPDATE
|
append |
搜索后跟a
UPDATE
(将数据附加到结果之前
UPDATE
)
|
prepend |
搜索后跟一个
UPDATE
(在之前的数据前面添加数据
UPDATE
)
|
incr |
搜索后跟一个
UPDATE
|
decr |
搜索后跟一个
UPDATE
|
delete |
搜索后跟a
DELETE
|
flush_all |
TRUNCATE TABLE
(DDL)
|
本节介绍
daemon_memcached
插件
使用的配置表
。
该
cache_policies
表,
config_options
表,
containers
表是由创建
innodb_memcached_config.sql
的配置脚本
innodb_memcache
数据库。
MySQL的>USE innodb_memcache;数据库已更改 MySQL的>SHOW TABLES;+ --------------------------- + | Tables_in_innodb_memcache | + --------------------------- + | cache_policies | | config_options | | 容器| + --------------------------- +
该
cache_policies
表定义了
InnoDB
memcached
安装
的缓存策略
。
您可以
在单个缓存策略中
为
get
,
set
和
delete
,以及
flush
操作
指定单独的
策略。
所有操作的默认设置是
innodb_only
。
-
innodb_only:InnoDB用作数据存储。 -
cache_only:使用 memcached 引擎作为数据存储。 -
caching:使用两者InnoDB和 memcached 引擎作为数据存储。 在这种情况下,如果 memcached 在内存中找不到密钥,它将在InnoDB表中 搜索该值 。 -
disable:禁用缓存。
表15.29 cache_policies列
| 柱 | 描述 |
|---|---|
policy_name |
缓存策略的名称。
默认缓存策略名称是
cache_policy
。
|
get_policy |
get操作的缓存策略。
有效值是
innodb_only
,
cache_only
,
caching
,或
disabled
。
默认设置为
innodb_only
。
|
set_policy |
设置操作的缓存策略。
有效值是
innodb_only
,
cache_only
,
caching
,或
disabled
。
默认设置为
innodb_only
。
|
delete_policy |
删除操作的缓存策略。
有效值是
innodb_only
,
cache_only
,
caching
,或
disabled
。
默认设置为
innodb_only
。
|
flush_policy |
刷新操作的缓存策略。
有效值是
innodb_only
,
cache_only
,
caching
,或
disabled
。
默认设置为
innodb_only
。
|
该
config_options
表存储了与
memcached
相关的设置,这些设置可以在运行时使用SQL进行更改。
支持的配置选项是
separator
和
table_map_delimiter
。
表15.30 config_options列
| 柱 | 描述 |
|---|---|
Name |
memcached
相关配置选项的
名称
。
config_options
表
支持以下配置选项
:
|
Value |
分配给 memcached 相关配置选项的值。 |
该
containers
表是三个配置表中最重要的一个。
InnoDB
用于存储
memcached
值的
每个
表都
必须在
containers
表中
包含一个条目
。
该条目提供了
InnoDB
表列和容器表列
之间的映射
,这是
memcached
处理
InnoDB
表
所必需的
。
该
containers
表包含表的缺省条目,该条目
test.demo_test
由
innodb_memcached_config.sql
配置脚本
创建
。
要将
daemon_memcached
插件与您自己的
InnoDB
表一起使用,您必须在
containers
表中
创建一个条目
。
表15.31容器列
| 柱 | 描述 |
|---|---|
name |
给容器的名称。
如果
InnoDB
使用
@@
表示法
未按名称请求表
,则
daemon_memcached
插件使用
值为
的
InnoDB
表
。
如果没有这样的条目,表中的第一个条目
按字母顺序排序
(升序),则确定默认
表。
containers.name
default
containers
name
InnoDB
|
db_schema |
InnoDB
表所在
的数据库的名称
。
这是必需的值。
|
db_table |
InnoDB
存储
memcached
值
的
表
的名称
。
这是必需的值。
|
key_columns |
InnoDB
表中包含
memcached
操作的
查找键值
的列
。
这是必需的值。
|
value_columns |
InnoDB
存储
memcached
数据
的
表列(一个或多个)
。
可以使用表中指定的分隔符来指定多个列
innodb_memcached.config_options
。
默认情况下,分隔符是管道符(
“
|
”
)。
要指定多个列,请使用定义的分隔符分隔它们。
例如:
col1|col2|col3
。
这是必需的值。
|
flags |
InnoDB
用作
memcached的
标志(用户定义的数值,与主值一起存储和检索)
的
表列
。
如果将
memcached
值映射到多个列,则
可以将标志值用作某些操作(例如
incr
,
prepend
)
的列说明符
,以便对指定的列执行操作。
例如,如果已映射
到三个
表列,并且只希望对一列执行增量操作,请使用该
列指定列。
如果你不使用
value_columns
InnoDB
flags
flags
列,设置值
0
以指示它未使用。
|
cas_column |
InnoDB
存储比较和交换(cas)值
的
表列。
该
cas_column
值与
memcached
对不同服务器的哈希请求和缓存内存中数据
的方式有关
。
因为
InnoDB
memcached
插件与单个
memcached
守护程序
紧密集成
,并且内存缓存机制由MySQL和
InnoDB缓冲池处理
,所以很少需要此列。
如果不使用此列,请设置一个值
0
以指示它未使用。
|
expire_time_column |
InnoDB
存储过期值
的
表列。
该
expire_time_column
值与
memcached
对不同服务器的哈希请求和缓存内存中数据
的方式有关
。
因为
InnoDB
memcached
插件与单个
memcached
守护程序
紧密集成
,并且内存缓存机制由MySQL和
InnoDB缓冲池处理
,所以很少需要此列。
如果不使用此列,请设置值
0
以指示该列未使用。
最大过期时间定义为
INT_MAX32
或2147483647秒(约68年)。
|
unique_idx_name_on_key |
键列上的索引名称。
它必须是唯一的索引。
它可以是
主键
或
辅助索引
。
优选地,使用
InnoDB
表
的主键
。
使用主键可避免使用二级索引时执行的查找。
您无法
为
memcached
查找
创建
覆盖索引
;
如果您尝试在键列和值列上定义复合二级索引,则会返回错误。
InnoDB
|
容器表列限制
-
你必须提供一个值
db_schema,db_name,key_columns,value_columns和unique_idx_name_on_key。 指定0forflags,cas_column以及expire_time_column它们是否未使用。 如果不这样做可能会导致您的设置失败。 -
key_columns: memcached 键 的最大限制为 250个字符,由 memcached 强制执行 。 映射的键必须是非NullCHAR或VARCHAR类型。 -
value_columns:必须被映射到CHAR,VARCHAR或者BLOB柱。 没有长度限制,值可以为NULL。 -
cas_column:该cas值是64位整数。 它必须映射到BIGINT至少8个字节的a。 如果不使用此列,请设置一个值0以指示它未使用。 -
expiration_time_column:必须映射到INTEGER至少4个字节。 到期时间定义为Unix时间的32位整数(自1970年1月1日以来的秒数,为32位值),或从当前时间开始的秒数。 对于后者,秒数不得超过60 * 60 * 24 * 30(30天内的秒数)。 如果客户端发送的数字较大,则服务器认为它是真正的Unix时间值而不是当前时间的偏移量。 如果不使用此列,请设置一个值0以指示它未使用。 -
flags:必须映射到INTEGER至少32位,并且可以为NULL。 如果不使用此列,请设置一个值0以指示它未使用。
在插件加载时执行预检查以强制执行列约束。 如果找到不匹配,则不加载插件。
多值列映射
-
在插件初始化期间,当
InnoDBmemcached 配置了containers表中 定义的信息时,将containers.value_columns根据映射InnoDB表 验证 定义的每个映射列 。 如果InnoDB映射了 多个 表列,则会进行检查以确保每个列都存在且类型正确。 -
在运行时,对于
memcached插入操作,如果分隔的值多于映射列的数量,则仅采用映射值的数量。 例如,如果有六个映射列,并且提供了七个分隔值,则仅采用前六个分隔值。 第七个分隔值被忽略。 -
如果分隔值少于映射列,则未填充列将设置为NULL。 如果未填充的列不能设置为NULL,则插入操作将失败。
-
如果表的列数多于映射值,则额外的列不会影响结果。
该
innodb_memcached_config.sql
配置脚本创建一个
demo_test
表中的
test
数据库,它可以用来验证
InnoDB
memcached的
设置完成后立即安装插件。
该
innodb_memcached_config.sql
配置脚本还创建了一个条目
demo_test
表中的
innodb_memcache.containers
表。
MySQL的>SELECT * FROM innodb_memcache.containers\G*************************** 1。排******************** ******* 名称:aaa db_schema:test db_table:demo_test key_columns:c1 value_columns:c2 标志:c3 cas_column:c4 expire_time_column:c5 unique_idx_name_on_key:PRIMARY MySQL的>SELECT * FROM test.demo_test;+ ---- + ------------------ + ------ + ------ + ------ + | c1 | c2 | c3 | c4 | c5 | + ---- + ------------------ + ------ + ------ + ------ + | AA | 你好,你好| 8 | 0 | 0 | + ---- + ------------------ + ------ + ------ + ------ +
本节介绍使用
InnoDB
memcached
插件
时可能遇到的问题
。
-
如果在MySQL错误日志中遇到以下错误,则服务器可能无法启动:
无法为打开的文件设置rlimit。 尝试以root身份运行或请求较小的maxconns值。
错误消息来自 memcached 守护程序。 一种解决方案是提高打开文件数量的操作系统限制。 用于检查和增加打开文件限制的命令因操作系统而异。 此示例显示Linux和OS X的命令:
#Linux 外壳>
ulimit -n1024 shell>ulimit -n 4096shell>ulimit -n4096 #OS X. 外壳>ulimit -n256 shell>ulimit -n 4096shell>ulimit -n4096另一种解决方案是减少 memcached 守护程序 允许的并发连接数 。 为此,请 在MySQL配置文件 的 配置参数中对
-cmemcached 选项 进行编码daemon_memcached_option。 该-c选项的默认值为1024。的[mysqld] ... loose-daemon_memcached_option =' - c 64'
-
要解决 memcached 守护程序无法存储或检索
InnoDB表数据的问题,请 在MySQL配置文件 的 配置参数中对-vvvmemcached 选项 进行编码daemon_memcached_option。 检查MySQL错误日志以获取与 memcached 相关的调试输出 操作 。的[mysqld] ... 松daemon_memcached_option = ' - VVV'
-
如果指定用于保存 memcached 值的 列 是错误的数据类型(例如数字类型而不是字符串类型),则存储键值对的尝试将失败,并且不会显示特定的错误代码或消息。
-
如果
daemon_memcached插件导致MySQL服务器启动问题,您可以daemon_memcached通过[mysqld]在MySQL配置文件中 的 组 下添加此行 来暂时禁用 插件 :daemon_memcached = OFF
例如,如果
INSTALL PLUGIN在运行innodb_memcached_config.sql配置脚本 之前运行语句 以设置必要的数据库和表,则服务器可能会崩溃并无法启动。 如果您错误地配置表中的条目,服务器也可能无法启动innodb_memcache.containers。要卸载 MySQL实例 的 memcached 插件,请发出以下语句:
MySQL的>
UNINSTALL PLUGIN daemon_memcached; -
如果在同一台计算机上运行多个MySQL实例且
daemon_memcached每个实例都启用 了 插件,请使用daemon_memcached_option配置参数 为每个 插件 指定唯一的 memcached 端口daemon_memcached。 -
如果SQL语句找不到
InnoDB表或 在 表中找不到数据,但是 memcached API调用检索到了预期的数据,则可能缺少InnoDB表中表 的条目innodb_memcache.containers,或者您可能没有InnoDB通过发布 切换到正确的 表aget或set使用 表示法的 请求 。 如果您更改表中的现有条目 而不重新启动MySQL服务器, 也可能会出现此问题 。 自由格式存储机制足够灵活,可以存储或检索多列值的请求,例如@@table_idinnodb_memcache.containerscol1|col2|col3即使守护程序正在使用test.demo_test将值存储在单个列中 的 表,它 仍然可以工作 。 -
在定义自己的
InnoDB表以供daemon_memcached插件 使用时 ,表中的列定义为NOT NULL,确保NOT NULL在将表的记录插入表时 为 列 提供值innodb_memcache.containers。 如果 记录 的INSERT语句innodb_memcache.containers包含的分隔值少于映射列,则未填充的列将设置为NULL。 尝试将NULL值插入NOT NULL列会导致INSERT失败,这可能只有在重新初始化daemon_memcached插件以将更改应用于innodb_memcache.containers表 后才会变得明显 。 -
如果 表的 字段
cas_column和expire_time_column字段innodb_memcached.containers设置为NULL,则在尝试加载 memcached 插件 时会返回以下错误 :InnoDB_Memcached:配置表'containers'的条目中的第6列 数据库'innodb_memcache'具有无效的NULL值。
该 memcached的 插件拒绝的使用
NULL在cas_column与expire_time_column列。0在未使用 列 时将 这些列的值设置为 。 -
随着 memcached 键 的长度 和值的增加,您可能会遇到大小和长度限制。
-
当密钥超过250个字节时, memcached 操作会返回错误。 这是目前 memcached中 的固定限制 。
-
InnoDB如果值超过768字节大小,3072字节大小或innodb_page_size值的 一半,则可能遇到表限制 。 如果您打算在值列上创建索引以使用SQL在该列上运行生成报表的查询,则这些限制主要适用。 有关 详细信息 , 请参见 第15.6.1.6节“InnoDB表的限制” 。 -
键值组合的最大大小为1 MB。
-
-
如果您在不同版本的MySQL服务器之间共享配置文件,则使用
daemon_memcached插件 的最新配置选项 可能会导致较旧MySQL版本的启动错误。 要避免兼容性问题,请使用loose带有选项名称 的 前缀。 例如,使用loose-daemon_memcached_option='-c 64'而不是daemon_memcached_option='-c 64'。 -
验证字符集设置没有限制或检查。 memcached 以字节为单位存储和检索键和值,因此不是字符集敏感的。 但是,您必须确保 memcached 客户端和MySQL表使用相同的字符集。
-
阻止 memcached 连接访问包含索引虚拟列的表。 访问索引虚拟列需要回调服务器,但 memcached 连接无权访问服务器代码。
以下一般准则适用于故障排除
InnoDB
问题:
-
当操作失败或您怀疑有错误时,请查看MySQL服务器错误日志(请参见 第5.4.2节“错误日志” )。 第B.3.1节“服务器错误消息参考” 提供
InnoDB了您可能遇到的 一些常见 错误的 故障排除信息 。 -
如果失败与 死锁 相关 ,请在
innodb_print_all_deadlocks启用 该 选项的情况下 运行, 以便将有关每个死锁的详细信息打印到MySQL服务器错误日志中。 有关死锁的信息,请参见 第15.7.5节“InnoDB中的死锁” 。 -
如果问题与
InnoDB数据字典有关,请参见 第15.20.3节“对InnoDB数据字典操作进行故障排除” 。 -
进行故障排除时,通常最好从命令提示符运行MySQL服务器,而不是通过 mysqld_safe 或Windows服务。 然后,您可以看到 mysqld 打印到控制台的内容,因此可以更好地掌握正在发生的事情。 在Windows上,启动 mysqld 并
--console选择将输出定向到控制台窗口。 -
启用
InnoDB监视器以获取有关问题的信息(请参见 第15.16节“InnoDB监视器” )。 如果问题与性能相关,或者您的服务器似乎挂起,则应启用标准监视器以打印有关内部状态的信息InnoDB。 如果问题出在锁定中,请启用锁定监视器。 如果问题出在表创建,表空间或数据字典操作上,请参阅 InnoDB信息模式系统表 以检查InnoDB内部数据字典的内容。InnoDBInnoDB在以下条件下 临时启用标准 监视器输出:-
一个长信号量等待
-
InnoDB在缓冲池中找不到空闲块 -
超过67%的缓冲池被锁堆或自适应哈希索引占用
-
-
如果您怀疑某个表已损坏,请
CHECK TABLE在该表上 运行 。
InnoDB
I / O问题
的故障排除步骤
取决于问题发生的时间:MySQL服务器启动期间,或者由于文件系统级别的问题导致DML或DDL语句失败时的正常操作期间。
初始化问题
如果在
InnoDB
尝试初始化其表空间或其日志文件时出现问题,请删除由
InnoDB
以下
文件创建的
所有
ibdata
文件
:所有
文件和所有
ib_logfile
文件。
如果您已经创建了一些
InnoDB
表,还要
.ibd
从MySQL数据库目录中
删除任何
文件。
然后
InnoDB
再次
尝试
创建数据库。
要进行最简单的故障排除,请从命令提示符启动MySQL服务器,以便查看发生的情况。
运行时问题
如果
InnoDB
在文件操作期间打印操作系统错误,通常问题具有以下解决方案之一:
-
确保存在
InnoDB数据文件目录和InnoDB日志目录。 -
确保 mysqld 具有在这些目录中创建文件的访问权限。
-
确保 mysqld 可以读取正确的
my.cnf或my.ini选项文件,以便它以您指定的选项开头。 -
确保磁盘未满,并且您没有超过任何磁盘配额。
-
确保为子目录和数据文件指定的名称不会发生冲突。
-
仔细检查
innodb_data_home_dir和innodb_data_file_path值 的语法 。 特别是, 选项中的 任何MAX值innodb_data_file_path都是硬限制,超过该限制会导致致命错误。
要调查数据库页面损坏,您可以使用从数据库转储表
SELECT ... INTO
OUTFILE
。
通常,以这种方式获得的大多数数据是完整的。
严重损坏可能导致
语句或
后台操作崩溃或断言,甚至导致前
滚恢复崩溃。
在这种情况下,您可以使用该
选项强制
启动存储引擎,同时防止后台操作运行,以便您可以转储表。
例如,您可以
在重新启动服务器之前将以
下行添加到
选项文件
的
部分:
SELECT * FROM
tbl_nameInnoDB
InnoDB
innodb_force_recovery
InnoDB
[mysqld]
的[mysqld] innodb_force_recovery = 1
有关使用选项文件的信息,请参见 第4.2.2.2节“使用选项文件” 。
仅
innodb_force_recovery
在紧急情况下
设置
为大于0的值,以便您可以启动
InnoDB
和转储表。
在此之前,请确保您拥有数据库的备份副本,以备需要重新创建时使用。
值为4或更高可能会永久损坏数据文件。
innodb_force_recovery
在成功测试数据库的单独物理副本上的设置后,
仅
在生产服务器实例上
使用
4或更高的设置。
在强制
InnoDB
恢复时,您应该始终以
innodb_force_recovery=1
并且仅在必要时递增地增加值。
innodb_force_recovery
默认为0(没有强制恢复的正常启动)。
允许的非零值为
innodb_force_recovery
1到6.较大的值包括较小值的功能。
例如,值3包括值1和2的所有功能。
如果您能够以
innodb_force_recovery
3或更小
的
值
转储表
,那么相对安全的是,只有损坏的单个页面上的某些数据会丢失。
值为4或更高被认为是危险的,因为数据文件可能会永久损坏。
值6被认为是激烈的,因为数据库页面处于过时状态,这反过来可能会在
B树
和其他数据库结构中
引入更多损坏
。
作为安全措施,
InnoDB
防止
INSERT
,
UPDATE
或
DELETE
操作时,
innodb_force_recovery
是大于0的较大
innodb_force_recovery
的4米以上的地方设置
InnoDB
在只读模式。
-
1(SRV_FORCE_IGNORE_CORRUPT)即使检测到损坏的 页面, 也允许服务器运行 。 尝试 跳过损坏的索引记录和页面,这有助于转储表。
SELECT * FROMtbl_name -
2(SRV_FORCE_NO_BACKGROUND) -
3(SRV_FORCE_NO_TRX_UNDO) -
4(SRV_FORCE_NO_IBUF_MERGE)阻止 插入缓冲区 合并操作。 如果它们会导致崩溃,则不会这样做。 不计算表 统计信息 。 此值可能会永久损坏数据文件。 使用此值后,请准备删除并重新创建所有二级索引。 设置
InnoDB为只读。 -
5(SRV_FORCE_NO_UNDO_LOG_SCAN)启动数据库时 不查看 撤消日志 :
InnoDB甚至将未完成的事务视为已提交。 此值可能会永久损坏数据文件。 设置InnoDB为只读。 -
6(SRV_FORCE_NO_LOG_REDO)不执行与 恢复相关的重做日志前 滚。 此值可能会永久损坏数据文件。 使数据库页面处于过时状态,这反过来可能会在B树和其他数据库结构中引入更多损坏。 设置
InnoDB为只读。
您可以
SELECT
从表中转储它们。
使用
innodb_force_recovery
3或更小
的
值,您可以
DROP
或
CREATE
表。
DROP
TABLE
也支持
innodb_force_recovery
大于3
DROP
TABLE
的
innodb_force_recovery
值。大于4
的
值
不允许
。
如果您知道给定的表导致回滚崩溃,则可以删除它。
如果遇到由大量导入失败导致的失控回滚,或者
ALTER
TABLE
您可以
终止mysqld
进程并设置
innodb_force_recovery
为
3
在没有回滚的情况下启动数据库,然后
DROP
启动导致失控回滚的表。
如果表数据中的损坏阻止您转储整个表内容,则带有
子句
的查询
可能能够在损坏的部分之后转储表的一部分。
ORDER BY
primary_key DESC
如果一个高
innodb_force_recovery
值是必需的开始
InnoDB
,有可能是,可能导致(含有查询的复杂查询损坏的数据结构
WHERE
,
ORDER
BY
或其它条款)失败。
在这种情况下,您可能只能运行基本
SELECT * FROM t
查询。
有关表定义的信息存储在InnoDB 数据字典中 。 如果移动数据文件,字典数据可能会变得不一致。
如果数据字典损坏或一致性问题阻止您启动
InnoDB
,请参见
第15.20.2节“强制InnoDB恢复”
以获取有关手动恢复的信息。
随着
innodb_file_per_table
启用(默认值),下面的消息可能会在启动时出现,如果一个
文件的每个表的
表空间文件(
.ibd
文件)是丢失:
[错误] InnoDB:文件操作中的操作系统错误号2。 [错误] InnoDB:错误表示系统找不到指定的路径。 [错误] InnoDB:无法以只读方式打开数据文件:'。/ test / t1.ibd'OS错误:71 [警告] InnoDB:忽略表空间`test / t1`,因为它无法打开。
要解决这些消息,请发出
DROP
TABLE
语句以从数据字典中删除有关缺失表的数据。
此过程描述如何将
每个文件的
orphan
文件
还原
.ibd
到另一个MySQL实例。
如果系统表空间丢失或不可恢复,并且您希望
.ibd
在新的MySQL实例上
恢复
文件备份,
则可以使用此过程
。
一般表空间
.ibd
文件
不支持该过程
。
该过程假定您只有
.ibd
文件备份,您正在恢复到最初创建孤立
.ibd
文件
的相同版本的MySQL
,并且该
.ibd
文件备份是干净的。
有关创建干净备份的信息
,
请参见
第15.6.1.2节“移动或复制InnoDB表”
。
第15.6.3.7节“将表空间复制到另一个实例” 中 概述的表空间复制限制 适用于此过程。
-
在新的MySQL实例上,在同名的数据库中重新创建表。
MySQL的>
CREATE DATABASE sakila;MySQL的>USE sakila;MySQL的>CREATE TABLE actor (actor_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,first_name VARCHAR(45) NOT NULL,last_name VARCHAR(45) NOT NULL,last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (actor_id),KEY idx_actor_last_name (last_name))ENGINE=InnoDB DEFAULT CHARSET=utf8; -
丢弃新创建的表的表空间。
MySQL的>
ALTER TABLE sakila.actor DISCARD TABLESPACE; -
将
.ibd备份目录中 的孤立 文件 复制 到新数据库目录。外壳>
cp /backup_directory/actor.ibdpath/to/mysql-5.7/data/sakila/ -
确保该
.ibd文件具有必要的文件权限。 -
导入孤立
.ibd文件。 将发出警告,指示InnoDB将尝试导入文件而不进行架构验证。MySQL的>
ALTER TABLE sakila.actor IMPORT TABLESPACE; SHOW WARNINGS;查询正常,0行受影响,1警告(0.15秒) 警告| 1810年| InnoDB:IO读错误:(2,没有这样的文件或目录) 打开'./sakila/actor.cfg'时出错,将尝试导入 没有架构验证 -
查询表以验证
.ibd文件是否已成功还原。MySQL的>
SELECT COUNT(*) FROM sakila.actor;+ ---------- + | count(*)| + ---------- + | 200 | + ---------- +
以下各项描述了如何
InnoDB
执行错误处理。
InnoDB
有时只会回滚失败的语句,有时会回滚整个事务。
-
如果 表 空间中的文件空间
Table is full不足,则会发生 MySQL 错误并InnoDB回滚SQL语句。 -
一个事务 死锁 导致
InnoDB要 回滚 整个 事务 。 发生这种情况时重试整个事务。锁定等待超时导致
InnoDB仅回滚等待锁定并遇到超时的单个语句。 (要使整个事务回滚,请使用该--innodb-rollback-on-timeout选项 启动服务器 。)如果使用当前行为,则重试该语句,如果使用,则重试整个事务--innodb-rollback-on-timeout。在繁忙的服务器上,死锁和锁定等待超时都是正常的,应用程序必须知道它们可能会发生并通过重试来处理它们。 您可以通过在事务和提交期间对数据的第一次更改之间尽可能少的工作来降低它们的可能性,因此锁可以保持最短的时间和最小的行数。 有时,在不同交易之间分配工作可能是实际且有用的。
当由于死锁或锁等待超时而发生事务回滚时,它会取消事务中语句的效果。 但是如果start-transaction语句是
START TRANSACTION或者BEGIN语句,则回滚不会取消该语句。 进一步的SQL语句成为交易的一部分,直到发生COMMIT,ROLLBACK或某些SQL语句导致隐式提交。 -
如果未
IGNORE在语句中 指定 选项 ,则重复键错误将回滚SQL 语句。 -
A
row too long error回滚SQL语句。 -
其他错误主要由MySQL代码层(在
InnoDB存储引擎级别 之上 ) 检测到 ,并且它们回滚相应的SQL语句。 锁定不会在单个SQL语句的回滚中释放。
在隐式回滚期间以及在执行显式
ROLLBACK
SQL语句期间,
将
在相关连接
的
列中
SHOW PROCESSLIST
显示
。
Rolling back
State