复制允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。 默认情况下,复制是异步的 从站不需要永久连接以接收来自主站的更新。 根据配置,您可以复制数据库中的所有数据库,所选数据库甚至选定的表。
MySQL中复制的优点包括:
-
横向扩展解决方案 - 在多个从站之间分配负载以提高性能。 在此环境中,所有写入和更新都必须在主服务器上进行。 但是,读取可能发生在一个或多个从站上。 该模型可以提高写入性能(因为主设备专用于更新),同时显着提高了越来越多的从设备的读取速度。
-
数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
-
分析 - 可以在主服务器上创建实时数据,而信息的分析可以在从服务器上进行,而不会影响主服务器的性能。
-
远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
有关如何在此类方案中使用复制的信息,请参见 第17.3节“复制解决方案” 。
MySQL 8.0支持不同的复制方法。 传统方法基于从主机的二进制日志复制事件,并要求其中的日志文件和位置在主机和从机之间同步。 基于 全局事务标识符 (GTID) 的较新方法 是事务性的,因此不需要处理这些文件中的日志文件或位置,这极大地简化了许多常见的复制任务。 只要在主服务器上提交的所有事务也已应用于从服务器,使用GTID进行复制可确保主服务器和从服务器之间的一致性。 有关MySQL中基于GTID和GTID的复制的更多信息,请参见 第17.1.3节“使用全局事务标识符复制” 。 有关使用基于二进制日志文件位置的复制的信息,请参见 第17.1节“配置复制” 。
MySQL中的复制支持不同类型的同步。 原始类型的同步是单向异步复制,其中一个服务器充当主服务器,而一个或多个其他服务器充当从服务器。 这与 作为NDB Cluster特征 的 同步 复制 形成对比 (参见 第22章, MySQL NDB Cluster 8.0 )。 在MySQL 8.0中,除了内置的异步复制之外,还支持半同步复制。 使用半同步复制,在返回执行事务的会话之前对主块执行提交,直到至少一个从服务器确认已接收并记录事务的事件为止; 看到 第17.3.11节“半同步复制” 。 MySQL 8.0还支持延迟复制,使得从属服务器故意滞后于主服务器至少一段指定的时间; 请参见 第17.3.12节“延迟复制” 。 对于 需要 同步 复制的 方案 ,请使用NDB Cluster(请参阅 第22章, MySQL NDB Cluster 8.0 )。
有许多解决方案可用于在服务器之间设置复制,最佳使用方法取决于您使用的数据和引擎类型的存在。 有关可用选项的更多信息,请参见 第17.1.2节“设置基于二进制日志文件位置的复制” 。
有两种核心类型的复制格式:基于语句的复制(SBR),它复制整个SQL语句,以及基于行的复制(RBR),它仅复制已更改的行。 您还可以使用第三种混合复制(MBR)。 有关不同复制格式的更多信息,请参见 第17.2.1节“复制格式” 。
通过许多不同的选项和变量来控制复制。 有关更多信息,请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。
您可以使用复制来解决许多不同的问题,包括性能,支持不同数据库的备份,以及作为缓解系统故障的更大解决方案的一部分。 有关如何解决这些问题的信息,请参见 第17.3节“复制解决方案” 。
有关如何在复制期间处理不同数据类型和语句的说明和提示,包括复制功能,版本兼容性,升级和潜在问题及其解决方案的详细信息,请参见 第17.4节“复制说明和提示” 。 有关MySQL Replication新手经常提出的一些问题的答案,请参见 第A.13节“MySQL 8.0 FAQ:复制” 。
有关复制实现,复制如何工作,二进制日志的过程和内容,后台线程以及用于决定如何记录和复制语句的规则的详细信息,请参见 第17.2节“复制实现” 。
本节介绍如何配置MySQL中可用的不同类型的复制,并包括复制环境所需的设置和配置,包括创建新复制环境的分步说明。 本节的主要组成部分是:
-
有关使用二进制日志文件位置设置两个或多个服务器进行复制的指南, 第17.1.2节“设置基于二进制日志文件位置的复制”还 介绍了服务器的配置,并提供了在主服务器之间复制数据的方法和奴隶。
-
有关使用GTID事务设置两个或多个服务器进行复制的指南, 第17.1.3节“使用全局事务标识符复制” 处理服务器的配置。
-
二进制日志中的事件使用多种格式记录。 这些被称为基于语句的复制(SBR)或基于行的复制(RBR)。 第三种类型的混合格式复制(MIXED)自动使用SBR或RBR复制,以在适当时利用SBR和RBR格式的优势。 第17.2.1节“复制格式” 中讨论了不同的格式 。
-
有关适用于复制的不同配置选项和变量的详细信息,请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。
-
一旦启动,复制过程应该几乎不需要管理或监视。 但是,有关您可能要执行的常见任务的建议,请参见 第17.1.7节“通用复制管理任务” 。
本节介绍基于二进制日志文件位置方法的MySQL服务器之间的复制,其中作为主服务器运行的MySQL实例(数据库源更改)将更新和更改作为 “ 事件 ” 写入 二进制日志。 二进制日志中的信息根据记录的数据库更改以不同的日志记录格式存储。 从站配置为从主站读取二进制日志,并在从站的本地数据库上执行二进制日志中的事件。
每个从站都会收到二进制日志的全部内容的副本。 从属设备负责决定应该执行二进制日志中的哪些语句。 除非另行指定,否则主从二进制日志中的所有事件都在从站上执行。 如果需要,您可以将从站配置为仅处理适用于特定数据库或表的事件。
您无法将主服务器配置为仅记录特定事件。
每个从站都会记录二进制日志坐标:文件名和文件中它从主站读取和处理的位置。 这意味着可以将多个从站连接到主站并执行同一二进制日志的不同部分。 由于从站控制此过程,因此可以在服务器上连接和断开各个从站,而不会影响主站的操作。 此外,由于每个从站都记录了二进制日志中的当前位置,因此可以断开从站的连接,重新连接然后恢复处理。
必须使用唯一ID配置主站和每个从站(使用该
server-id
选项)。
此外,必须为每个从站配置有关主主机名,日志文件名和该文件中位置的信息。
可以使用
CHANGE
MASTER TO
从属语句在
MySQL会话中控制这些详细信息
。
详细信息存储在从属主信息存储库中(请参见
第17.2.4节“复制中继和状态日志”
)。
本节介绍如何设置MySQL服务器以使用基于二进制日志文件位置的复制。 设置复制有许多不同的方法,确切的使用方法取决于您如何设置复制,以及您是否已在主数据库中拥有数据。
所有设置都有一些通用的通用任务:
-
在主服务器上,您必须确保启用了二进制日志记录,并配置唯一的服务器ID。 这可能需要重新启动服务器。 请参见 第17.1.2.1节“设置复制主配置” 。
-
在要连接到主服务器的每个从服务器上,必须配置唯一的服务器ID。 这可能需要重新启动服务器。 请参见 第17.1.2.2节“设置复制从站配置” 。
-
(可选)在读取二进制日志以进行复制时,为主服务器创建一个单独的用户,以便在与主服务器进行身份验 请参见 第17.1.2.3节“为复制创建用户” 。
-
在创建数据快照或启动复制过程之前,您应该在主服务器上记录二进制日志中的当前位置。 配置从站时需要此信息,以便从站知道二进制日志中的哪个位置开始执行事件。 请参见 第17.1.2.4节“获取复制主二进制日志坐标” 。
-
如果您已经拥有主服务器上的数据并希望使用它来同步从服务器,则需要创建数据快照以将数据复制到从服务器。 您使用的存储引擎会影响您创建快照的方式。 在使用时
MyISAM,必须停止处理主服务器上的语句以获取读锁定,然后获取其当前的二进制日志坐标并转储其数据,然后才允许主服务器继续执行语句。 如果不停止执行语句,则数据转储和主状态信息将不匹配,从而导致从站上的数据库不一致或损坏。 有关复制MyISAM主服务器的 更多信息 ,请参阅 第17.1.2.4节“获取复制主二进制日志坐标” 。 如果您正在使用InnoDB,则不需要读锁定,并且足够长的事务来传输数据快照就足够了。 有关更多信息,请参见 第15.18节“InnoDB和MySQL复制” 。 -
使用用于连接到主服务器的设置配置从服务器,例如主机名,登录凭据和二进制日志文件名和位置。 请参见 第17.1.2.7节“在从站上设置主站配置” 。
设置过程中的某些步骤需要该
SUPER
权限。
如果您没有此权限,则可能无法启用复制。
配置基本选项后,选择您的方案:
-
要为不包含数据的主站和从站的全新安装设置复制,请参见 第17.1.2.6.1节“使用新主站和从站设置复制” 。
-
要使用现有MySQL服务器中的数据 设置新主 服务器的 复制 ,请参见 第17.1.2.6.2节“使用现有数据设置复制” 。
-
要将复制从站添加到现有复制环境,请参见 第17.1.2.8节“将从站添加到复制环境” 。
在管理MySQL复制服务器之前,请阅读整章并尝试 第13.4.1节“用于控制主服务器的SQL语句” 和 第13.4.2节“用于控制从属服务器的SQL语句 ”中 提到的所有语句 。 还要熟悉 第17.1.6节“复制和二进制日志记录选项和变量”中 所述的复制启动选项 。
要将主服务器配置为使用基于二进制日志文件位置的复制,必须确保启用二进制日志记录,并建立唯一的服务器ID。 如果尚未执行此操作,则需要重新启动服务器。
主服务器上需要二进制日志记录,因为二进制日志是将更改从主服务器复制到其从服务器的基础。
默认情况下启用二进制日志记录(
log_bin
系统变量设置为ON)。
该
--log-bin
选项告诉服务器用于二进制日志文件的基本名称。
建议您指定此选项以为二进制日志文件提供非默认基本名称,以便在主机名更改时,您可以轻松地继续使用相同的二进制日志文件名(请参见
第B.4.7节“已知” MySQL中的问题“
)。
必须使用唯一的服务器ID配置复制拓扑中的每个服务器,您可以使用该
--server-id
选项
指定该服务器ID
。
此服务器标识用于标识复制拓扑中的各个服务器,并且必须是介于1和(2
32
)-1
之间的正整数
。
如果在主服务器上设置服务器ID为0,则拒绝来自从服务器的任何连接,如果在从服务器上设置服务器ID为0,则拒绝连接到主服务器。
除此之外,您可以选择如何组织和选择数字,只要每个服务器ID与复制拓扑中任何其他服务器使用的每个其他服务器ID不同即可。
该
server_id
系统变量默认设置为1。
可以使用此默认服务器ID启动服务器,但如果未明确指定服务器ID,则会发出信息性消息。
以下选项也会对复制主机产生影响:
-
为了在使用
InnoDBwith transaction 的复制设置中实现最大的持久性和一致性 ,您应该 在复制主 文件中 使用innodb_flush_log_at_trx_commit=1和 。sync_binlog=1my.cnf -
确保
skip-networking未在复制主机上启用 该 选项。 如果已禁用网络,则从属设备无法与主服务器通信,并且复制失败。
每个复制从站必须具有唯一的服务器ID。 如果尚未完成此操作,则从属设置的这一部分需要重新启动服务器。
如果尚未设置从属服务器ID,或者当前值与您为主服务器选择的值冲突,请关闭从属服务器并编辑
[mysqld]
配置文件
的
部分以指定唯一的服务器ID。
例如:
的[mysqld] 服务器ID = 2
进行更改后,重新启动服务器。
如果要设置多个从站,则每个从站必须具有唯一的非零
server-id
值,该值不同于主站和任何其他从站的
非零
值。
默认情况下,在所有服务器上启用二进制日志记录 从站不需要启用二进制日志记录以进行复制。 但是,从站上的二进制日志记录意味着从站的二进制日志可用于数据备份和崩溃恢复。
启用了二进制日志记录的从站也可以用作更复杂的复制拓扑的一部分。 例如,您可能希望使用此链式排列设置复制服务器:
A - > B - > C.
在这里,
A
作为奴隶的主人
B
,并
B
作为奴隶的主人
C
。
为此,
B
必须是主人
和
奴隶。
收到的更新
A
必须记录
B
到其二进制日志中,以便传递给
C
。
除二进制日志记录外,此复制拓扑还需要
--log-slave-updates
启用
该
选项。
使用此选项,从站将从主服务器接收并由从属SQL线程执行的更新写入从属自己的二进制日志。
--log-slave-updates
默认情况下启用
该
选项。
如果需要在从属服务器上禁用二进制日志记录或从属更新日志记录,则可以通过为从属服务器指定
--skip-log-bin
和
--skip-log-slave-updates
选项
来执行此操作
。
每个从站使用MySQL用户名和密码连接到主站,因此主站上必须有用户帐户,从站可以使用该帐户进行连接。
设置复制从站时
,用户名由
命令
MASTER_USER
上
的
选项
指定
CHANGE
MASTER TO
。
任何帐户都可以用于此操作,只要它已被授予
REPLICATION
SLAVE
特权。
您可以选择为每个从站创建不同的帐户,也可以使用每个从站的相同帐户连接到主站。
虽然您不必专门为复制创建帐户,但您应该知道复制用户名和密码以纯文本形式存储在主信息存储库表中
mysql.slave_master_info
(请参见
第17.2.4.2节“从属状态日志”
)。
因此,您可能希望创建一个仅具有复制过程权限的单独帐户,以最大程度地降低对其他帐户的危害。
要创建新帐户,请使用
CREATE
USER
。
要授予此帐户复制所需的权限,请使用该
GRANT
语句。
如果您仅为复制目的创建帐户,则该帐户仅需要该
REPLICATION SLAVE
权限。
例如,要设置
repl
可以从
example.com
域中的
任何主机连接进行复制
的新用户,请
在主服务器上发出以下语句:
mysql> mysql>CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password';GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com';
有关 操作用户帐户的语句的更多信息 , 请参见 第13.7.1节“帐户管理语句” 。
要使用使用
caching_sha2_password
插件进行
身份验证的用户帐户连接到复制主
服务器,必须按
第17.3.9节“设置复制以使用加密连接”中
所述设置安全连接
,或启用未加密连接以支持密码使用RSA密钥对进行交换。
该
caching_sha2_password
认证插件是从MySQL 8.0中创建新用户的默认(详见
第6.4.1.3,“缓存SHA-2插入式验证”
)。
如果您创建或用于复制的用户帐户(由
MASTER_USER
选项)使用此身份验证插件,并且您没有使用安全连接,必须启用基于RSA密钥对的密码交换才能成功连接。
要将从站配置为在正确的位置启动复制过程,您需要在其二进制日志中记下主站的当前坐标。
此过程使用
FLUSH TABLES
WITH
READ LOCK
,它阻止
表的
COMMIT
操作
InnoDB
。
如果您计划关闭主服务器以创建数据快照,则可以选择跳过此过程,而是存储二进制日志索引文件的副本以及数据快照。 在这种情况下,主服务器会在重新启动时创建新的二进制日志文件。 因此,从属服务器必须启动复制过程的主二进制日志坐标是该新文件的开始,该文件是在复制的二进制日志索引文件中列出的文件之后的主服务器上的下一个二进制日志文件。
要获取主二进制日志坐标,请按照下列步骤操作:
-
通过使用命令行客户端连接到主服务器来启动主服务器上的会话,并通过执行以下
FLUSH TABLES WITH READ LOCK语句 来刷新所有表和阻止写 语句:MySQL的>
FLUSH TABLES WITH READ LOCK;警告让发出
FLUSH TABLES语句 的客户端保持 运行状态,以使读锁定保持有效。 如果退出客户端,则会释放锁定。 -
在master上的不同会话中,使用该
SHOW MASTER STATUS语句确定当前二进制日志文件的名称和位置:mysql>
SHOW MASTER STATUS;+ ------------------ + ---------- + -------------- + ---- -------------- + | 档案| 职位| Binlog_Do_DB | Binlog_Ignore_DB | + ------------------ + ---------- + -------------- + ---- -------------- + | mysql-bin.000003 | 73 | 测试| manual,mysql | + ------------------ + ---------- + -------------- + ---- -------------- +该
File列显示日志文件的名称,列显示文件Position中的位置。 在此示例中,二进制日志文件是mysql-bin.000003,位置为73.记录这些值。 您在以后设置奴隶时需要它们。 它们表示从属服务器应从主服务器开始处理新更新的复制坐标。如果主服务器先前已禁用二进制日志记录,则由 mysqldump
SHOW MASTER STATUS或 master-data 显示的日志文件名和位置值 将为空。 在这种情况下,稍后在指定从属日志文件和位置时需要使用的值是空字符串('')和4。
现在,您可以获得所需的信息,以使从服务器能够从正确的位置开始读取二进制日志以开始复制。
下一步取决于您是否在主服务器上有现有数据。 选择以下选项之一:
-
如果在启动复制之前有现有数据需要与从属设备同步,请保持客户端正常运行,以便锁定保持不变。 这可以防止进行任何进一步的更改,以便复制到从站的数据与主站同步。 继续 第17.1.2.5节“选择数据快照的方法” 。
-
如果要设置新的主从复制组,则可以退出第一个会话以释放读锁定。 有关 如何继续 , 请参见 第17.1.2.6.1节“使用新主站和从站设置复制” 。
如果主数据库包含现有数据,则必须将此数据复制到每个从站。 有多种方法可以从master数据库转储数据。 以下部分描述了可能的选项。
要选择转储数据库的适当方法,请在以下选项之间进行选择:
要在现有主数据库中创建数据的快照,请使用 mysqldump 工具。 完成数据转储后,在开始复制过程之前将此数据导入从属服务器。
以下示例将所有数据库转储到名为的文件
dbdump.db
,并包含一个
--master-data
选项,
该
选项会自动附加
CHANGE MASTER
TO
从属服务器上所需
的
语句以启动复制过程:
外壳> mysqldump --all-databases --master-data > dbdump.db
如果不使用
--master-data
,则需要手动锁定单独会话中的所有表。
请参见
第17.1.2.4节“获取复制主二进制日志坐标”
。
可以使用
mysqldump
工具
从转储中排除某些数据库
。
如果要选择要包含在转储中的数据库,请不要使用
--all-databases
。
选择以下选项之一:
-
使用
--ignore-table选项 排除数据库中的所有表 。 -
仅命名要使用该
--databases选项 转储的数据库 。
有关更多信息,请参见 第4.5.4节“ mysqldump - 数据库备份程序” 。
要导入数据,请将转储文件复制到从站,或者在远程连接到从站时从主站访问该文件。
本节介绍如何使用组成数据库的原始文件创建数据快照。 将此方法与使用具有复杂缓存或记录算法的存储引擎的表一起使用需要额外的步骤来生成完美的 “ 时间点 ” 快照:初始复制命令可能会遗漏缓存信息并记录更新,即使您已获得了全局读锁。 存储引擎如何响应这取决于其崩溃恢复能力。
如果使用
InnoDB
表,则可以使用
MySQL Enterprise Backup组件中
的
mysqlbackup
命令生成一致的快照。
此命令记录与从站上使用的快照对应的日志名称和偏移量。
MySQL Enterprise Backup是一种商业产品,作为MySQL Enterprise订阅的一部分包含在内。
有关
详细信息
,
请参见
第30.2节“MySQL Enterprise备份概述”
。
这种方法还不能可靠地工作,如果主机和从机有不同的价值观
ft_stopword_file
,
ft_min_word_len
或者
ft_max_word_len
你是具有全文索引复制表。
假设上述异常不适用于您的数据库,请使用
冷备份
技术获取
InnoDB
表
的可靠二进制快照
:执行
MySQL服务器
的
慢速关闭
,然后手动复制数据文件。
要
MyISAM
在单个文件系统上存在MySQL数据文件时
创建
表
的原始数据快照
,可以使用标准文件复制工具(如
cp
或
copy)
,远程复制工具(如
scp
或
rsync)
,归档工具(如
zip
或
tar
,或
转储
等文件系统快照工具
。
如果仅复制某些数据库,请仅复制与这些表相关的文件。
对于
InnoDB
,所有数据库中的所有表都存储在
系统表空间中
文件,除非您
innodb_file_per_table
启用
了该
选项。
复制不需要以下文件:
-
与
mysql数据库 相关的 文件。 -
主信息存储库文件
master.info(如果使用); 现在不推荐使用此文件(请参见 第17.2.4节“复制中继和状态日志” )。 -
主服务器的二进制日志文件,但二进制日志索引文件除外,如果您要使用它来定位从服务器的主二进制日志坐标。
-
任何中继日志文件。
根据您是否使用
InnoDB
表,请选择以下选项之一:
如果您正在使用
InnoDB
表,并且还要使用原始数据快照获得最一致的结果,请在此过程中关闭主服务器,如下所示:
-
获取读锁定并获取主控状态。 请参见 第17.1.2.4节“获取复制主二进制日志坐标” 。
-
在单独的会话中,关闭主服务器:
外壳>
mysqladmin shutdown -
制作MySQL数据文件的副本。 以下示例显示了执行此操作的常用方法。 您只需要选择其中一个:
shell> shell> shell>
tar cf/tmp/db.tar./datazip -r/tmp/db.zip./datarsync --recursive./data/tmp/dbdata -
重新启动主服务器。
如果您不使用
InnoDB
表,则可以从主服务器获取系统的快照,而无需按照以下步骤中所述关闭服务器:
-
获取读锁定并获取主控状态。 请参见 第17.1.2.4节“获取复制主二进制日志坐标” 。
-
制作MySQL数据文件的副本。 以下示例显示了执行此操作的常用方法。 您只需要选择其中一个:
shell> shell> shell>
tar cf/tmp/db.tar./datazip -r/tmp/db.zip./datarsync --recursive./data/tmp/dbdata -
在获取读锁定的客户端中,释放锁定:
MySQL的>
UNLOCK TABLES;
创建数据库的存档或副本后,在启动从属复制过程之前将文件复制到每个从属服务器。
以下部分描述了如何设置从站。 在继续之前,请确保您拥有:
-
使用必要的配置属性配置MySQL主服务器。 请参见 第17.1.2.1节“设置复制主配置” 。
-
获取主数据状态信息,或者在关闭数据快照期间生成的主服务器二进制日志索引文件的副本。 请参见 第17.1.2.4节“获取复制主二进制日志坐标” 。
-
在master上,释放了读锁:
MySQL的>
UNLOCK TABLES; -
在slave上,编辑了MySQL配置。 请参见 第17.1.2.2节“设置复制从站配置” 。
接下来的步骤取决于您是否有现有数据导入到从属设备。 有关 更多信息 , 请参见 第17.1.2.5节“为数据快照选择方法” 。 选择以下之一:
-
如果没有要导入的数据库的快照,请参见 第17.1.2.6.1节“使用新主服务器和从服务器设置复制” 。
-
如果要导入数据库的快照,请参见 第17.1.2.6.2节“使用现有数据设置复制” 。
如果没有要导入的先前数据库的快照,请配置从属服务器以从新主服务器启动复制。
要在主服务器和新服务器之间设置复制:
-
启动MySQL slave。
-
执行
CHANGE MASTER TO语句以设置主复制服务器配置。 请参见 第17.1.2.7节“在从站上设置主站配置” 。
在每个从站上执行这些从站设置步骤。
如果要设置新服务器但是要从要加载到复制配置中的其他服务器中转储现有数据库,也可以使用此方法。 通过将数据加载到新主服务器中,数据将自动复制到从服务器。
如果要使用来自其他现有数据库服务器的数据设置新的复制环境以创建新主服务器,请在新主服务器上运行从该服务器生成的转储文件。 数据库更新会自动传播到从属服务器:
外壳> mysql -h master < fulldb.dump
使用现有数据设置复制时,请在开始复制之前将快照从主服务器传输到从服务器。 将数据导入从站的过程取决于您在主站上创建数据快照的方式。
选择以下之一:
如果你使用 mysqldump :
-
使用该
--skip-slave-start选项 启动从站, 以便不启动复制。 -
导入转储文件:
外壳>
mysql < fulldb.dump
如果使用原始数据文件创建了快照:
-
将数据文件解压缩到从属数据目录中。 例如:
外壳>
tar xvf dbdump.tar您可能需要设置文件的权限和所有权,以便从服务器可以访问和修改它们。
-
使用该
--skip-slave-start选项 启动从站, 以便不启动复制。 -
使用主服务器的复制坐标配置从服务器。 这告诉从服务器二进制日志文件和复制需要启动的文件中的位置。 此外,使用主服务器的登录凭据和主机名配置从服务器。 有关
CHANGE MASTER TO所需语句的 更多信息 ,请参见 第17.1.2.7节“在从站上设置主站配置” 。 -
启动从属线程:
MySQL的>
START SLAVE;
执行此过程后,从属设备将连接到主服务器,并复制自拍摄快照以来主服务器上发生的所有更新。 如果由于任何原因无法复制,则会向从属的错误日志发出错误消息。
从站使用记录在其主信息日志和中继日志信息日志中的信息来跟踪它已处理的主站二进制日志的数量。
从MySQL 8.0,默认情况下,这些奴隶状态日志存储库是命名表
slave_master_info
,并
slave_relay_log_info
在
mysql
数据库中。
替代设置
--master-info-repository=FILE
以及
--relay-log-info-repository=FILE
存储库是命名文件
master.info
和
relay-log.info
数据目录
中的文件
现在已弃用,将在以后的版本中删除。
不要
不
删除或修改这些表(或文件,如果使用的话),除非你知道自己在做什么并完全理解的含义。
即使在这种情况下,也最好使用该
CHANGE MASTER
TO
语句来更改复制参数。
从站使用语句中指定的值自动更新从站状态日志。
有关
更多信息
,
请参见
第17.2.4节“复制中继和状态日志”
。
主信息日志的内容会覆盖命令行或中指定的某些服务器选项
my.cnf
。
有关
更多详细信息
,
请参见
第17.1.6节“复制和二进制日志记录选项和变量”
。
主站的单个快照足以满足多个从站的需要。 要设置其他从站,请使用相同的主快照,并按照上述过程的从属部分进行操作。
要将从站设置为与主站通信以进行复制,请使用必要的连接信息配置从站。 为此,请在从站上执行以下语句,将选项值替换为与系统相关的实际值:
mysql>CHANGE MASTER TO- > - > - > - > - >MASTER_HOST='master_host_name',MASTER_USER='replication_user_name',MASTER_PASSWORD='replication_password',MASTER_LOG_FILE='recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;
复制不能使用Unix套接字文件。 您必须能够使用TCP / IP连接到主MySQL服务器。
该
CHANGE MASTER TO
声明还有其他选择。
例如,可以使用SSL设置安全复制。
有关选项的完整列表以及有关字符串值选项的最大允许长度的信息,请参见
第13.4.2.1节“将语法更改为语法”
。
如
第17.1.2.3节“为复制创建用户”中所述
,如果未使用安全连接且
MASTER_USER
选项中
指定的用户帐户
使用
caching_sha2_password
插件进行
身份验证
(默认情况下为MySQL 8.0),则必须指定
MASTER_PUBLIC_KEY_PATH
或
GET_MASTER_PUBLIC_KEY
选项在
CHANGE MASTER TO
语句中启用基于RSA密钥对的密码交换。
您可以将另一个从站添加到现有复制配置,而无需停止主站。 为此,您可以通过复制现有从站的数据目录并为新从站提供不同的服务器ID(由用户指定)和服务器UUID(在启动时生成)来设置新从站。
要复制现有的从属:
-
停止现有从站并记录从站状态信息,尤其是主二进制日志文件和中继日志文件位置。 您可以在性能架构复制表中查看从站状态(请参见 第26.12.11节“性能架构复制表” ),或者按以下方式发出
SHOW SLAVE STATUS以下命令:mysql>
STOP SLAVE;mysql>SHOW SLAVE STATUS\G -
关闭现有的奴隶:
外壳>
mysqladmin shutdown -
将数据目录从现有从站复制到新从站,包括日志文件和中继日志文件。 您可以通过创建归档做到这一点 焦油 或
WinZip,或通过使用工具,如进行直接复制 的cp 或 rsync的 。重要-
在复制之前,请验证与现有从站相关的所有文件是否实际存储在数据目录中。 例如,
InnoDB系统表空间,撤消表空间和重做日志可能存储在备用位置。InnoDB表空间文件和每表文件表空间可能已在其他目录中创建。 从站的二进制日志和中继日志可能位于数据目录之外的自己的目录中。 检查为现有从站设置的系统变量,并查找已指定的任何备用路径。 如果找到任何内容,请同时复制这些目录。 -
在复制期间,如果文件已用于主信息和中继日志信息存储库(请参见 第17.2.4节“复制中继和状态日志” ),请确保还将这些文件从现有从属文件复制到新从属文件。 如果表已用于存储库(默认情况下是MySQL 8.0),则表位于数据目录中。
-
复制后,
auto.cnf从新从属服务器上的数据目录副本中 删除该 文件,以便使用不同的生成服务器UUID启动新从属服务器。 服务器UUID必须是唯一的。
添加新复制从属设备时遇到的一个常见问题是新的从属服务器失败并出现一系列警告和错误消息,如下所示:
071118 16:44:10 [警告]没有使用--relay-log和--relay-log-index; 所以 当此MySQL服务器充当从属服务器并具有其主机名时,复制可能会中断 变!请使用'--relay-log =
new_slave_hostname-relay-bin'来避免此问题。 071118 16:44:10 [错误]无法打开中继日志'./old_slave_hostname-relay-bin.003525' (relay_log_pos 22940879) 071118 16:44:10 [错误]在中继日志初始化期间找不到目标日志 071118 16:44:10 [错误]无法初始化主信息结构如果
--relay-log未指定选项, 则会出现这种情况 ,因为中继日志文件包含主机名作为其文件名的一部分。 如果--relay-log-index未使用 该 选项 ,则中继日志索引文件也是如此 。 有关这些选项的更多信息 , 请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。要避免此问题,请
--relay-log在现有从站上使用的新从站上 使用相同的值 。 如果未在现有从站上明确设置此选项,请使用existing_slave_hostname-relay-bin--relay-log-index选项以匹配现有从站上使用 的 选项。 如果未在现有从站上明确设置此选项,请使用existing_slave_hostname-relay-bin.index-
如果您还没有这样做,请
STOP SLAVE在新的奴隶上发布。如果您已经再次启动现有从站,也可以在现有从站上发出
STOP SLAVE。 -
将现有slave的中继日志索引文件的内容复制到新slave的中继日志索引文件中,确保覆盖该文件中已有的任何内容。
-
继续本节中的其余步骤。
-
-
复制完成后,重新启动现有从站。
-
在新从站上,编辑组态并为新从站提供唯一的服务器ID(使用该
server-id选项),主服务器或任何现有从站未 使用该服务器ID 。 -
启动新的从属服务器,指定该
--skip-slave-start选项,以便尚未启动复制。SHOW SLAVE STATUS与现有从站相比, 使用性能架构复制表或问题 确认新从站具有正确的设置。 还显示服务器ID和服务器UUID,并验证这些对于新从站是否正确且唯一。 -
通过发出
START SLAVE语句 启动从属线程 :MySQL的>
START SLAVE;新的slave现在使用其主信息库中的信息来启动复制过程。
本节介绍使用 全局事务标识符 的基于事务的复制 (GTIDs)。 使用GTID时,可以在原始服务器上提交并由任何从属应用时识别和跟踪每个事务; 这意味着在启动新从站或故障转移到新主站时使用GTID来引用日志文件或这些文件中的位置是不必要的,这极大地简化了这些任务。 由于基于GTID的复制完全基于事务,因此很容易确定主服务器和从服务器是否一致; 只要在主服务器上提交的所有事务也在从服务器上提交,两者之间的一致性就得到保证。 您可以使用基于语句或基于行的复制与GTID(请参见 第17.2.1节“复制格式”) ); 但是,为了获得最佳效果,我们建议您使用基于行的格式。
GTID始终保留在主站和从站之间。 这意味着您始终可以通过检查其二进制日志来确定应用于任何从站的任何事务的源。 此外,一旦在给定服务器上提交具有给定GTID的事务,则该服务器将忽略具有相同GTID的任何后续事务。 因此,在主服务器上提交的事务可以在从服务器上应用不超过一次,这有助于保证一致性。
本节讨论以下主题:
-
如何定义和创建GTID,以及如何在MySQL服务器中表示它们(请参见 第17.1.3.1节“GTID格式和存储” )。
-
GTID的生命周期(见 第17.1.3.2节“GTID生命周期” )。
-
自动定位功能,用于同步使用GTID的从站和主站(参见 第17.1.3.3节“GTID自动定位” )。
-
设置和启动基于GTID的复制的一般过程(请参见 第17.1.3.4节“使用GTID设置复制” )。
-
使用GTID时配置新复制服务器的建议方法(请参见 第17.1.3.5节“使用GTID进行故障转移和扩展” )。
-
使用基于GTID的复制时应注意的限制和限制(请参见 第17.1.3.6节“ 使用GTID进行复制的 限制” )。
-
可用于 处理GTID的存储函数 (请参见 第17.1.3.7节“存储函数示例以处理GTID” )。
有关MySQL服务器选项和与基于GTID的复制相关的变量的信息,请参见 第17.1.6.5节“全局事务ID选项和变量” 。 另请参见 第12.18节“与全局事务标识符(GTID) 一起使用的函数 ” ,其中描述了MySQL 8.0支持的与GTID一起使用的SQL函数。
全局事务标识符(GTID)是创建的唯一标识符,并与在源服务器(主服务器)上提交的每个事务相关联。 此标识符不仅对其发起的服务器是唯一的,而且在给定复制拓扑中的所有服务器上都是唯一的。
GTID分配区分在主服务器上提交的客户端事务和在从服务器上复制的复制事务。 在主服务器上提交客户端事务时,如果事务已写入二进制日志,则会为其分配新的GTID。 保证客户交易具有单调增加的GTID,而生成的数字之间没有间隙。 如果未将客户端事务写入二进制日志(例如,因为事务已被过滤掉,或者事务是只读的),则不会在源服务器上为其分配GTID。
复制的事务保留与分配给源服务器上的事务相同的GTID。
GTID在复制事务开始执行之前存在,并且即使复制的事务未写入从服务器上的二进制日志,或者在从服务器上过滤掉,也会持久存在。
MySQL系统表
mysql.gtid_executed
用于保存MySQL服务器上应用的所有事务的已分配GTID,但存储在当前活动的二进制日志文件中的事务除外。
GTID的自动跳过功能意味着在主服务器上提交的事务可以在从服务器上应用不超过一次,这有助于保证一致性。 一旦在给定服务器上提交了具有给定GTID的事务,则该服务器将忽略使用相同GTID执行后续事务的任何尝试。 不会引发错误,并且不会执行事务中的语句。
如果具有给定GTID的事务已开始在服务器上执行但尚未提交或回滚,则任何在具有相同GTID的服务器上启动并发事务的尝试都将被阻止。 服务器既不开始执行并发事务也不将控制权返回给客户端。 一旦第一次尝试事务提交或回滚,就可以继续在同一GTID上阻塞的并发会话。 如果第一次尝试回滚,则一个并发会话继续尝试该事务,并且在同一GTID上阻塞的任何其他并发会话仍然被阻止。 如果第一次尝试提交,则所有并发会话都将被阻止,并自动跳过事务的所有语句。
GTID表示为一对坐标,用冒号字符(
:
)
分隔
,如下所示:
GTID =source_id:transaction_id
该
source_id
标识的源服务器。
通常,主人
server_uuid
用于此目的。
这
transaction_id
是一个序列号,由在主服务器上提交事务的顺序确定。
例如,要提交的第一个事务具有
1
其
transaction_id
,并且被分配一个相同的始发服务器上被提交第十交易
transaction_id
的
10
。
事务不可能
0
在GTID中具有序列号。
例如,最初在具有UUID的服务器上提交的第二十三个事务
3E11FA47-71CA-11E1-9E33-C80AA9429562
具有以下GTID:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
事务的GTID显示在
mysqlbinlog
的输出中
,例如,它用于标识性能模式复制状态表中的单个事务
replication_applier_status_by_worker
。
gtid_next
系统变量(
@@GLOBAL.gtid_next
)
存储的值
是单个GTID。
GTID集合是包括一个或多个单个GTID或GTID范围的集合。
GTID集以多种方式用于MySQL服务器。
例如,由
系统变量
gtid_executed
和
gtid_purged
系统变量
存储的值
是GTID集。
该
START
SLAVE
条款
UNTIL SQL_BEFORE_GTIDS
并
UNTIL SQL_AFTER_GTIDS
可以用来做一个奴隶交易过程最多只在GTID组第一GTID,或在GTID集中的最后GTID后停止。
内置函数
GTID_SUBSET()
并
GTID_SUBTRACT()
要求GTID集作为输入。
源自同一服务器的一系列GTID可以折叠为单个表达式,如下所示:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
上面的例子表示第一至始发MySQL服务器,其上第五交易
server_uuid
是
3E11FA47-71CA-11E1-9E33-C80AA9429562
。
源自同一服务器的多个单GTID或GTID范围也可以包含在单个表达式中,GTID或范围由冒号分隔,如下例所示:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-3:11:47-49
GTID集可以包括单个GTID和GTID范围的任意组合,并且它可以包括源自不同服务器的GTID。
此示例显示存储在
已从多个主服务器应用事务的从服务器
的
gtid_executed
系统变量(
@@GLOBAL.gtid_executed
)中
的GTID集
:
2174B383-5441-11E8-B90A-C80AA9429562:1-3,24DA167-0C0C-11E8-8442-00059A3C7B00:1-19
当从服务器变量返回GTID集时,UUID按字母顺序排列,并且数值间隔按升序合并。
GTID集的语法如下:
gtid_set:uuid_set[,uuid_set] ...... | “”uuid_set:uuid:interval[:interval] ...uuid:hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhhh: [0-9 | AF]interval:n[ -n] (n> = 1)
GTID存储在
数据库
中名为的表
gtid_executed
中
mysql
。
对于它表示的每个GTID或GTID集合,该表中的一行包含始发服务器的UUID,以及该集合的起始和结束事务ID;
对于仅引用单个GTID的行,这两个最后两个值是相同的。
在
mysql.gtid_executed
创建表(如果它不存在),当MySQL服务器安装或升级,采用了
CREATE
TABLE
如下所示类似的语句:
CREATE TABLE gtid_executed(
source_uuid CHAR(36)NOT NULL,
interval_start BIGINT(20)NOT NULL,
interval_end BIGINT(20)NOT NULL,
PRIMARY KEY(source_uuid,interval_start)
)
与其他MySQL系统表一样,请勿尝试自行创建或修改此表。
该
mysql.gtid_executed
表供MySQL服务器内部使用。
它允许从设备在从设备上禁用二进制日志记录时使用GTID,并且当二进制日志丢失时,它允许保留GTID状态。
该
mysql.gtid_executed
表重置为
RESET
MASTER
。
GTIDs存储在
mysql.gtid_executed
表中,只有当
gtid_mode
是
ON
或
ON_PERMISSIVE
。
存储GTID的点取决于是启用还是禁用二进制日志记录:
-
如果禁用(
log_binisOFF) 二进制日志记录 ,或者 禁用了二进制日志记录log_slave_updates,则服务器将属于每个事务的GTID与表中的事务一起存储。 此外,该表以用户可配置的速率定期压缩; 有关详细信息, 请参阅 mysql.gtid_executed表压缩 。 此情况仅适用于禁用二进制日志记录或从站更新日志记录的复制从站。 它不适用于复制主机,因为在主机上,必须启用二进制日志记录才能进行复制。 -
如果启用了二进制日志记录(
log_bin是ON),则无论何时旋转二进制日志或关闭服务器,服务器都会将写入先前二进制日志的所有事务的GTID写入mysql.gtid_executed表中。 这种情况适用于复制主服务器或启用了二进制日志记录的复制从服务器。如果服务器意外停止,则当前二进制日志文件中的GTID集不会保存在
mysql.gtid_executed表中。 在恢复期间,这些GTID将从二进制日志文件添加到表中。 例外情况是,如果在重新启动服务器时禁用二进制日志记录(使用--skip-log-bin或--disable-log-bin)。 在这种情况下,服务器无法访问二进制日志文件以恢复GTID,因此无法启动复制。启用二进制日志记录后,该
mysql.gtid_executed表不会保存所有已执行事务的GTID的完整记录。 该信息由gtid_executed系统变量 的全局值提供 。 始终使用@@GLOBAL.gtid_executed,在每次提交后更新,以表示MySQL服务器的GTID状态,并且不查询mysql.gtid_executed表。
mysql.gtid_executed
即使服务器处于只读模式或超级只读模式,
MySQL服务器也可以写入
表,这样二进制日志文件仍然可以在这些模式下旋转。
如果
mysql.gtid_executed
无法访问表以进行写入,并且由于除了达到最大文件大小(
max_binlog_size
)
之外的任何原因而旋转
二进制日志文件,则继续使用当前二进制日志文件。
将错误消息返回给请求轮换的客户端,并在服务器上记录警告。
如果
mysql.gtid_executed
无法访问表并进行写入
max_binlog_size
,则服务器将根据其
binlog_error_action
设置进行
响应
。
如果
IGNORE_ERROR
如果设置,则在服务器上记录错误并停止二进制日志记录,或者如果
ABORT_SERVER
设置,则服务器将关闭。
随着时间的推移,
mysql.gtid_executed
表可以填充许多行,这些行指的是源自同一服务器的各个GTID,其事务ID构成一个范围,类似于此处所示:
+ -------------------------------------- + ---------- ------ + -------------- + | source_uuid | interval_start | interval_end | | -------------------------------------- + ---------- ------ + -------------- | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 | ...
为了节省空间,MySQL服务器
mysql.gtid_executed
通过将每个这样的行集替换为跨越整个事务标识符间隔的行来定期
压缩
表,如下所示:
+ -------------------------------------- + ---------- ------ + -------------- + | source_uuid | interval_start | interval_end | | -------------------------------------- + ---------- ------ + -------------- | | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 43 | ...
您可以通过设置
gtid_executed_compression_period
系统变量
来控制压缩表之前允许的事务数,从而控制压缩率
。
此变量的默认值为1000,这意味着默认情况下,在每1000次事务之后执行表的压缩。
设置
gtid_executed_compression_period
为0可以防止执行压缩,如果执行此操作,您应该为
gtid_executed
表
可能需要的磁盘空间量的大幅增加做好准备
。
当启用二进制日志,价值
gtid_executed_compression_period
是
不
使用和
mysql.gtid_executed
表上的每个二进制日志旋转压缩。
mysql.gtid_executed
表的
压缩
由名为的专用前台线程执行
thread/sql/compress_gtid_table
。
此线程未在输出中列出
SHOW
PROCESSLIST
,但可以将其视为
threads
表中
的一行
,如下所示:
MySQL的> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
*************************** 1。排******************** *******
THREAD_ID:26
名称:thread / sql / compress_gtid_table
类型:FOREGROUND
PROCESSLIST_ID:1
PROCESSLIST_USER:NULL
PROCESSLIST_HOST:NULL
PROCESSLIST_DB:NULL
PROCESSLIST_COMMAND:守护进程
PROCESSLIST_TIME:1509
PROCESSLIST_STATE:暂停
PROCESSLIST_INFO:NULL
PARENT_THREAD_ID:1
角色:空
仪表:是的
历史:是的
CONNECTION_TYPE:NULL
THREAD_OS_ID:18677
的
thread/sql/compress_gtid_table
螺纹通常休眠,直到
gtid_executed_compression_period
交易已经被执行,那么唤醒到的执行压缩
mysql.gtid_executed
如前所述表。
然后它休眠直到另一个
gtid_executed_compression_period
事务发生,然后唤醒再次执行压缩,无限期地重复此循环。
禁用二进制日志记录时将此值设置为0意味着线程始终处于休眠状态且从不唤醒。
GTID的生命周期包括以下步骤:
-
事务在主服务器上执行并提交。 此客户端事务被分配一个GTID,该GTID由主服务器的UUID和此服务器上尚未使用的最小非零事务序列号组成。 GTID被写入主服务器的二进制日志(紧接在日志中的事务本身之前)。 如果未将客户端事务写入二进制日志(例如,因为事务已被过滤掉,或者事务是只读的),则不会为其分配GTID。
-
如果为事务分配了GTID,则通过在事务开始时将其写入二进制日志(作为a
Gtid_log_event) ,GTID在提交时保持原子性 。 无论何时旋转二进制日志或关闭服务器,服务器都会将写入先前二进制日志文件的所有事务的GTID写入mysql.gtid_executed表中。 -
如果为事务分配了GTID,则通过将GTID添加到
gtid_executed系统变量(@@GLOBAL.gtid_executed)中 的GTID集合,非原子化(在事务提交后不久)外部化 。 此GTID集包含所有已提交的GTID事务集的表示形式,并在复制中用作表示服务器状态的标记。 启用二进制日志记录(根据主服务器的要求),gtid_executed系统变量中 的GTID集 是应用事务的完整记录,但mysql.gtid_executed表不是,因为最新的历史记录仍在当前的二进制日志文件中。 -
在将二进制日志数据传输到从站并存储在从站的中继日志中之后(使用已建立的此过程机制,请参见 第17.2节“复制实现” ,详细信息),从站读取GTID并设置其
gtid_next系统 的值 变量作为这个GTID。 这告诉从服务器必须使用此GTID记录下一个事务。 重要的是要注意从属设置gtid_next在会话上下文中。 -
从站验证没有线程已经获得GTID的所有权
gtid_next以便处理该事务。 通过首先读取和检查复制事务的GTID,在处理事务本身之前,从设备不仅保证在从设备上没有应用具有此GTID的先前事务,而且还保证没有其他会话已经读取此GTID但尚未提交了相关的交易。 因此,如果多个客户端尝试同时应用同一事务,则服务器只允许其中一个执行,从而解决此问题。 该gtid_owned系统变量(@@GLOBAL.gtid_owned)对于slave,显示当前正在使用的每个GTID以及拥有它的线程的ID。 如果已经使用了GTID,则不会引发错误,并且使用自动跳过功能来忽略该事务。 -
如果尚未使用GTID,则从属应用复制的事务。 因为
gtid_next设置为主设备已分配的GTID,所以从设备不会尝试为此事务生成新的GTID,而是使用存储在其中的GTIDgtid_next。 -
如果在从属设备上启用了二进制日志记录,则GTID会在事务开始时将其写入二进制日志(作为a
Gtid_log_event), 在提交时保持原子状态 。 无论何时旋转二进制日志或关闭服务器,服务器都会将写入先前二进制日志文件的所有事务的GTID写入mysql.gtid_executed表中。 -
如果在从站上禁用二进制日志记录,则通过将GTID直接写入
mysql.gtid_executed表中来 原子性地保留GTID 。 MySQL在事务中附加一条语句,将GTID插入表中。 从MySQL 8.0开始,此操作对于DDL语句和DML语句都是原子操作。 在这种情况下,该mysql.gtid_executed表是从站上应用的事务的完整记录。 -
在从属设备上提交复制事务后不久,GTID通过将其添加到
gtid_executed系统变量(@@GLOBAL.gtid_executed)中的从属 GTID集合而非原子化外部化 。 至于主数据库,此GTID集包含所有已提交的GTID事务集的表示。 如果在从站上禁用二进制日志记录,则该mysql.gtid_executed表也是从站上应用的事务的完整记录。 如果在从站上启用了二进制日志记录,这意味着某些GTID仅记录在二进制日志中,则gtid_executed系统变量中 的GTID集 是唯一的完整记录。
在主服务器上完全过滤掉的客户端事务未分配GTID,因此它们不会添加到
gtid_executed
系统变量中
的事务集中,也不会添加到
mysql.gtid_executed
表中。
但是,在从属设备上完全过滤掉的复制事务的GTID是持久的。
如果在从属设备上启用了二进制日志记录,则过滤掉的事务将作为a
Gtid_log_event
后跟仅包含
BEGIN
和
COMMIT
语句
的空事务
写入二进制日志
。
如果禁用二进制日志记录,则已过滤掉的事务的GTID将写入
mysql.gtid_executed
表中。
为过滤掉的事务保留GTID确保了
mysql.gtid_executed
gtid_executed
可以压缩
表和
系统变量中
的GTID集
。
它还确保如果从站重新连接到主站,则不会再次检索过滤掉的事务,如
第17.1.3.3节“GTID自动定位”中所述
。
在多线程复制从属(带
slave_parallel_workers
> 0
)上,可以并行应用事务,因此复制的事务可以无序提交(除非
slave_preserve_commit_order=1
已设置)。
当发生这种情况时,
gtid_executed
系统变量中的GTID
集
将包含多个GTID范围,它们之间存在间隙。
(在主机或单线程复制从机上,将会有单调增加的GTID,数字之间没有间隙。)多线程复制从机上的间隙仅发生在最近应用的事务中,并在复制过程中填充。
使用时干净地停止复制线程
STOP
SLAVE
语句,应用正在进行的事务以填补空白。如果发生关闭(如服务器故障或使用
KILL
语句停止复制线程),则可能会出现间隙。
典型情况是服务器为已提交的事务生成新的GTID。 但是,除了交易之外,GTID还可以分配给其他变更,在某些情况下,可以为单个交易分配多个GTID。
写入二进制日志的每个数据库更改(DDL或DML)都会分配一个GTID。
这包括自动提交的更改以及使用
BEGIN
和/
COMMIT
或
START TRANSACTION
语句
提交的更改
。
GTID还分配给数据库的创建,更改或删除,以及非表数据库对象,例如过程,函数,触发器,事件,视图,用户,角色或授权。
非事务性更新以及事务性更新都分配了GTID。 此外,对于非事务性更新,如果在尝试写入二进制日志高速缓存时发生磁盘写入故障,因此在二进制日志中创建了间隙,则会为生成的事件日志事件分配GTID。
当二进制日志中的生成语句自动删除表时,会为该语句分配GTID。
当复制从服务器开始应用刚刚启动的主服务器以及基于语句的复制正在使用(
binlog_format=STATEMENT
)和具有打开的临时表断开连接的用户会话时,
将自动删除
临时表。
使用
MEMORY
存储引擎的
表
在服务器启动后第一次访问时会自动删除,因为在关闭期间行可能已丢失。
当事务未写入源服务器上的二进制日志时,服务器不会为其分配GTID。
这包括回滚的事务和在源服务器上禁用二进制日志记录时执行的事务,全局(
--skip-log-bin
在服务器的配置中指定)或会话(
SET @@SESSION.sql_log_bin = 0
)。
当使用基于行的复制时,这还包括无操作事务(
binlog_format=ROW
)。
XA事务被分配单独的GTIDs用于
XA
PREPARE
交易的相位和
XA
COMMIT
或
XA ROLLBACK
交易的阶段。
XA事务是持久准备的,以便用户可以在发生故障时将其提交或回滚(在复制拓扑中可能包括故障转移到另一个服务器)。
因此,事务的两个部分是分开复制的,因此它们必须有自己的GTID,即使回滚的非XA事务没有GTID。
在以下特殊情况下,单个语句可以生成多个事务,因此可以分配多个GTID:
-
调用存储过程以提交多个事务。 为过程提交的每个事务生成一个GTID。
-
多表
DROP TABLE语句删除不同类型的表。 如果任何表使用不支持原子DDL的存储引擎,或者任何表是临时表,则可以生成多个GTID。 -
一个
CREATE TABLE ... SELECT当基于行的复制是在使用语句发出(binlog_format=ROW)。 为该CREATE TABLE动作 生成 一个GTID,并为行插入动作生成一个GTID。
默认情况下,对于在用户会话中提交的新事务,服务器会自动生成并分配新的GTID。
在复制从属服务器上应用事务时,将保留来自原始服务器的GTID。
您可以通过设置
gtid_next
系统变量
的会话值来更改此行为
:
-
如果
gtid_next设置为AUTOMATIC默认值,并且事务已提交并写入二进制日志,则服务器会自动生成并分配新的GTID。 如果由于其他原因而回滚事务或未将事务写入二进制日志,则服务器不会生成并分配GTID。 -
如果设置
gtid_next为有效的GTID(由UUID和事务序列号组成,用冒号分隔),服务器会将GTID分配给您的事务。gtid_executed即使事务未写入二进制日志,或者事务为空 , 也会 分配和添加此GTID 。
请注意,在设置
gtid_next
为特定GTID并且已提交或回滚事务之后,
SET @@SESSION.gtid_next
必须在任何其他语句之前发出
显式
语句。
AUTOMATIC
如果您不想明确分配任何更多
GTID,可以使用此选项将GTID值设置回
。
当复制应用程序线程应用复制事务时,它们使用此技术,
@@SESSION.gtid_next
显式
设置
为在源服务器上分配的复制事务的GTID。
这意味着保留来自原始服务器的GTID,而不是由复制从站生成和分配的新GTID。
这也意味着
gtid_executed
即使在从站上禁用二进制日志记录或从站更新日志记录,或者当事务是无操作或在从站上过滤掉时
,GTID也会添加到
复制从站上。
客户端可以通过
@@SESSION.gtid_next
在执行事务之前
设置
为特定GTID
来模拟复制
的事务。
mysqlbinlog
使用此技术
生成二进制日志的转储,客户端可以重放该转储以保留GTID。
通过客户端提交的模拟复制事务完全等同于通过复制应用程序线程提交的复制事务,并且事后无法区分它们。
该集在GTIDs的
gtid_purged
系统变量(
@@GLOBAL.gtid_purged
)包含已提交在服务器上,但在任何服务器上的二进制日志文件不存在,所有交易的GTIDs。
gtid_purged
是一个子集
gtid_executed
。
以下类别的GTID包括
gtid_purged
:
-
在从站上禁用二进制日志记录时提交的复制事务的GTID。
-
已写入已清除的二进制日志文件的事务的GTID。
-
由语句明确添加到集合中的GTID
SET @@GLOBAL.gtid_purged。
您可以更改值,
gtid_purged
以便在服务器上记录已应用某个GTID集中的事务,尽管它们不存在于服务器上的任何二进制日志中。
当您添加GTID时
gtid_purged
,它们也会被添加到
gtid_executed
。
此操作的示例用例是在服务器上还原一个或多个数据库的备份时,但您没有包含服务器上的事务的相关二进制日志。
在MySQL 8.0之前,你只能改变
gtid_purged
when
的值
gtid_executed
(因此
gtid_purged
)是空的。
从MySQL 8.0开始,此限制不适用,您还可以选择是
gtid_purged
使用指定的GTID集
替换整个
GTID集,还是将指定的GTID集添加到已经存在的GTID中
gtid_purged
。
有关如何执行此操作的详细信息,请参阅说明
gtid_purged
。
在GTIDs的集合
gtid_executed
,并
gtid_purged
在服务器启动时系统变量初始化。
每个二进制日志文件都以事件开头,该事件
Previous_gtids_log_event
包含所有先前二进制日志文件中的GTID集合(由前面文件中的
Previous_gtids_log_event
GTID和
Gtid_log_event
前面文件本身中
的每个GTID组成
)。
的内容
Previous_gtids_log_event
在最早和最近的二进制日志文件来计算的
gtid_executed
,并
gtid_purged
套在服务器启动时:
-
gtid_executed计算为Previous_gtids_log_event最新二进制日志文件中GTID的并集,该二进制日志文件中的事务的GTID以及存储在mysql.gtid_executed表中 的GTID 。 此GTID集包含已gtid_purged在服务器上 使用(或明确添加 )的 所有GTID ,无论它们当前是否位于服务器上的二进制日志文件中。 它不包括当前正在服务器上处理的事务的GTID(@@GLOBAL.gtid_owned)。 -
gtid_purged通过首先Previous_gtids_log_event在最新的二进制日志文件中 添加GTID并 在该二进制日志文件中添加事务的GTID来计算。 此步骤提供当前或曾经记录在服务器上的二进制日志中的GTID集(gtids_in_binlog)。 接下来,从中Previous_gtids_log_event减去最旧的二进制日志文件中 的GTIDgtids_in_binlog。 此步骤提供当前记录在服务器(gtids_in_binlog_not_purged) 上的二进制日志中的一组GTID 。 最后,gtids_in_binlog_not_purged从中减去gtid_executed。 结果是已在服务器上使用的GTID集,但当前未记录在服务器上的二进制日志文件中,并且此结果用于初始化gtid_purged。
如果从MySQL 5.7.7或以上的二进制日志都参与了这些计算,有可能不正确GTID设置要计算的
gtid_executed
,并
gtid_purged
和他们保持,即使服务器重新启动后不正确。
有关详细信息,请参阅
binlog_gtid_simple_recovery
系统变量
的说明,该
变量控制如何迭代二进制日志以计算GTID集。
如果其中描述的某种情况适用于服务器,请进行设置
binlog_gtid_simple_recovery=FALSE
在启动它之前在服务器的配置文件中。
该设置使服务器迭代所有二进制日志文件(不仅是最新和最旧的)以查找GTID事件开始出现的位置。
如果服务器具有大量没有GTID事件的二进制日志文件,则此过程可能需要很长时间。
发出
RESET
MASTER
导致将值
gtid_purged
重置为空字符串,并使全局值(但不是会话值)
gtid_executed
重置为空字符串。
GTID替换先前所需的文件偏移对,以确定启动,停止或恢复主设备和从设备之间的数据流的点。 当使用GTID时,从属设备需要与主设备同步的所有信息都直接从复制数据流中获取。
要使用基于GTID的复制启动从属服务器,请不要
在
用于指示从属服务器从给定主服务器进行复制
的
语句中
包含
MASTER_LOG_FILE
或
MASTER_LOG_POS
选项
CHANGE
MASTER TO
。
这些选项指定日志文件的名称和文件中的起始位置,但是对于GTID,从站不需要此非本地数据。
相反,您需要启用该
MASTER_AUTO_POSITION
选项。
有关使用基于GTID的复制配置和启动主站和从站的完整说明,请参见
第17.1.3.4节“
使用GTID
设置复制”
。
MASTER_AUTO_POSITION
默认情况下禁用
该
选项。
如果在从属设备上启用了多源复制,则需要为每个适用的复制通道设置选项。
禁用
MASTER_AUTO_POSITION
再次选项使从恢复到基于文件的复制,在这种情况下,你还必须指定的一个或两个
MASTER_LOG_FILE
或
MASTER_LOG_POS
选项。
当复制从站启用GTID(
GTID_MODE=ON
,
ON_PERMISSIVE,
或
OFF_PERMISSIVE
)并
MASTER_AUTO_POSITION
启用
该
选项时,将激活自动定位以连接到主站。
必须
GTID_MODE=ON
设置
主服务器
才能使连接成功。
在初始握手中,从站发送一个GTID集,其中包含已经收到,已提交或两者都已完成的事务。
此GTID集等于
gtid_executed
系统变量(
@@GLOBAL.gtid_executed
)中GTID集的并集,以及性能模式
replication_connection_status
表中
记录
为接收事务(语句结果
SELECT RECEIVED_TRANSACTION_SET FROM
PERFORMANCE_SCHEMA.replication_connection_status
)
的GTID集
。
主设备通过发送其二进制日志中记录的所有事务来响应,其GTID不包括在从设备发送的GTID集中。 此交换确保主服务器仅使用从服务器尚未接收或提交的GTID发送事务。 如果从属设备从多个主设备接收事务,如菱形拓扑结构,则自动跳过功能可确保事务不会应用两次。
如果主服务器应发送的任何事务已从主服务器的二进制日志中清除,或
gtid_purged
通过其他方法
添加到
系统变量中
的GTID集中
,则主服务器将错误
ER_MASTER_HAS_PURGED_REQUIRED_GTIDS
发送
给从服务器,并且复制不会开始。
将识别丢失的清除事务的GTID,并在警告消息
ER_FOUND_MISSING_GTIDS
中的主控错误日志中
列出
。
从站无法自动从此错误中恢复,因为已清除了赶上主站所需的部分事务历史记录。
试图重新连接没有
MASTER_AUTO_POSITION
启用选项只会导致从站上清除的事务丢失。
从这种情况中恢复的正确方法是从
服务器
从另一个源
复制
ER_FOUND_MISSING_GTIDS
消息中
列出的丢失事务
,或者从更新的备份创建的新从服务器替换从服务器。
考虑修改主服务器上的二进制日志有效期(
binlog_expire_logs_seconds
)以确保不再发生这种情况。
如果在事务交换期间发现从服务器已经在GTID中接收或提交了与主服务器UUID的事务,但主服务器本身没有它们的记录,则主服务器将错误
ER_SLAVE_HAS_MORE_GTIDS_THAN_MASTER
发送
给从服务器并且复制不会开始。
如果没有的主人可能会发生这种情况
sync_binlog=1
设置遇到电源故障或操作系统崩溃,并丢失尚未同步到二进制日志文件但已由从属设备接收的已提交事务。
如果任何客户端在重新启动后在主服务器上提交事务,则主服务器和从服务器可以发散,这可能导致主服务器和从服务器对不同的事务使用相同的GTID。
从这种情况中恢复的正确方法是手动检查主设备和从设备是否已发散。
如果现在对不同的事务使用相同的GTID,则需要根据需要对各个事务执行手动冲突解决,或者从复制拓扑中删除主服务器或从服务器。
本节介绍在MySQL 8.0中配置和启动基于GTID的复制的过程。 这是一个 “ 冷启动 ” 过程,它假定您是第一次启动复制主服务器,或者可以停止它; 有关使用来自正在运行的主服务器的GTID供应复制从服务器的信息,请参见 第17.1.3.5节“使用GTID进行故障转移和扩展” 。 有关在线更改服务器上的GTID模式的信息,请参见 第17.1.5节“在线服务器上更改复制模式” 。
此启动过程中最简单的GTID复制拓扑的关键步骤(包括一个主服务器和一个从服务器)如下所示:
-
如果复制已在运行,请通过将两个服务器设置为只读来同步它们。
-
停止两台服务器。
-
重启两台服务器并启用GTID并配置正确的选项。
启动服务器所需 的 mysqld 选项将在本节后面的示例中讨论。
-
指示从站使用主站作为复制数据源并使用自动定位。 完成此步骤所需的SQL语句将在本节后面的示例中介绍。
-
采取新的备份。 包含没有GTID的事务的二进制日志不能在启用了GTID的服务器上使用,因此在此之前进行的备份不能与新配置一起使用。
-
启动从属设备,然后在两台服务器上禁用只读模式,以便它们可以接受更新。
在以下示例中,使用MySQL的基于二进制日志位置的复制协议,两个服务器已作为主服务器和从服务器运行。
如果
要从
新服务器启动,请参见
第17.1.2.3节“为复制创建用户”
以获取有关为复制连接添加特定用户
的信息,以及有关设置
变量的
信息
,请参见
第17.1.2.1
节“设置复制主配置”
。
server_id
。
以下示例显示如何
在服务器的选项文件中
存储
mysqld
启动选项,
有关详细信息
,请参见
第4.2.2.2节“使用选项文件”
。
或者,您可以在运行
mysqld
时使用启动选项
。
以下大多数步骤都需要使用MySQL
root
帐户或具有该
SUPER
权限的
其他MySQL用户帐户
。
mysqladmin
shutdown
需要
SUPER
特权或
SHUTDOWN
特权。
第1步:同步服务器。
只有在不使用GTID的情况下复制已经复制的服务器时,才需要执行此步骤。
对于新服务器,请继续执行步骤3.
通过发出以下命令,通过在每台服务器上
设置
read_only
系统变量,
使服务器成为只读
ON
:
MySQL的> SET @@GLOBAL.read_only = ON;
等待所有正在进行的事务提交或回滚。 然后,让奴隶赶上主人。 在继续之前确保从站已处理所有更新非常重要 。
如果将二进制日志用于复制以外的任何其他日志,例如进行即时备份和还原,请等到不需要包含没有GTID的事务的旧二进制日志。 理想情况下,等待服务器清除所有二进制日志,并等待任何现有备份过期。
重要的是要了解包含没有GTID的事务的日志不能在启用了GTID的服务器上使用。 在继续之前,您必须确保拓扑中的任何位置都不存在没有GTID的事务。
第2步:停止两台服务器。
使用
mysqladmin
停止每个服务器
,如下所示,
username
具有足够权限关闭服务器的MySQL用户的用户名
在哪里
:
外壳> mysqladmin -uusername -p shutdown
然后在提示符下提供此用户的密码。
步骤3:启用两台启用了GTID的服务器。
要启用基于GTID的复制,必须通过将
gtid_mode
变量
设置为启用GTID模式来启动每个服务器
ON
,并
enforce_gtid_consistency
启用变量以确保仅记录对基于GTID的复制安全的语句。
例如:
gtid_mode = ON 执行-GTID一致性=真
此外,
--skip-slave-start
在配置从站设置之前
,应该使用该
选项
启动从
站。
有关GTID相关选项和变量的更多信息,请参见
第17.1.6.5节“全局事务ID选项和变量”
。
在使用
mysql.gtid_executed表
时,不必强制启用二进制日志记录以使用GTID
。
主人必须始终启用二进制日志记录才能进行复制。
但是,从服务器可以使用GTID但不使用二进制日志记录。
如果需要在从属服务器上禁用二进制日志记录,可以通过指定从属服务器
--skip-log-bin
和
--skip-log-slave-updates
选项
来执行此操作
。
步骤4:配置从站以使用基于GTID的自动定位。
告诉从属设备使用具有基于GTID的事务的主服务器作为复制数据源,并使用基于GTID的自动定位而不是基于文件的定位。
CHANGE
MASTER TO
在奴隶上
发出
声明,包括
MASTER_AUTO_POSITION
声明中
的
选项,告诉奴隶主人的交易是由GTID识别的。
您可能还需要为主服务器的主机名和端口号提供适当的值,以及复制用户帐户的用户名和密码,从服务器可以使用该帐户连接到主服务器; 如果已经在步骤1之前设置了这些,并且不需要进行进一步的更改,则可以从此处显示的语句中安全地省略相应的选项。
的MySQL>CHANGE MASTER TO> > > > >MASTER_HOST =host,MASTER_PORT =port,MASTER_USER =user,MASTER_PASSWORD =password,MASTER_AUTO_POSITION = 1;
无论是
MASTER_LOG_FILE
选择还是
MASTER_LOG_POS
选择可能与使用
MASTER_AUTO_POSITION
等于1尝试这样做会导致
CHANGE
MASTER
TO
失败,错误陈述。
第5步:进行新备份。 由于您已启用GTID,因此在启用GTID之前创建的现有备份现在无法在这些服务器上使用。 此时进行新备份,这样您就不会没有可用的备份。
例如,您可以
FLUSH
LOGS
在要进行备份的服务器上
执行
。
然后显式地进行备份或等待您可能已设置的任何定期备份例程的下一次迭代。
步骤6:启动从站并禁用只读模式。 像这样启动奴隶:
MySQL的> START SLAVE;
仅当您在步骤1中将服务器配置为只读时,才需要执行以下步骤。要允许服务器再次开始接受更新,请发出以下语句:
MySQL的> SET @@GLOBAL.read_only = OFF;
现在应该正在运行基于GTID的复制,您可以像以前一样在主服务器上开始(或恢复)活动。 第17.1.3.5节“使用GTID进行故障转移和扩展” 讨论了在使用GTID时创建新的从服务器。
将MySQL Replication与全局事务标识符(GTID)一起使用时,有许多技术可用于配置新的从属设备,然后可以将其用于扩展,并根据故障转移的需要提升为主设备。 本节介绍以下技术:
全局事务标识符已添加到MySQL Replication中,以简化复制数据流和特别是故障转移活动的一般管理。 每个标识符唯一地标识一起构成事务的一组二进制日志事件。 GTID在将更改应用于数据库时起着关键作用:服务器自动跳过具有服务器识别为之前已处理的标识符的任何事务。 此行为对于自动复制定位和正确的故障转移至关重要。
在二进制日志中捕获标识符和包括给定事务的事件集之间的映射。 当使用来自另一个现有服务器的数据配置新服务器时,这会带来一些挑战。 要重现在新服务器上设置的标识符,必须将标识符从旧服务器复制到新服务器,并保留标识符与实际事件之间的关系。 这对于恢复立即可用作故障转移或切换成为新主服务器的候选服务器是必要的。
简单的复制。 在新服务器上重现所有标识符和事务的最简单方法是使新服务器成为具有完整执行历史记录的主服务器的从属服务器,并在两个服务器上启用全局事务标识符。 有关 更多信息 , 请参见 第17.1.3.4节“使用GTID设置复制” 。
启动复制后,新服务器将从主服务器复制整个二进制日志,从而获取有关所有GTID的所有信息。
这种方法简单有效,但要求从设备从主设备读取二进制日志; 新的从服务器有时需要相对较长的时间来赶上主服务器,因此这种方法不适合快速故障转移或从备份恢复。 本节介绍如何通过将二进制日志文件复制到新服务器来避免从主服务器获取所有执行历史记录。
将数据和事务复制到从属服务器。 当源服务器先前处理了大量事务时,执行整个事务历史记录可能非常耗时,这可能是设置新复制从站时的主要瓶颈。 为了消除此要求,可以将源服务器包含的数据集快照,二进制日志和全局事务信息导入新从属服务器。 源服务器可以是主服务器,也可以是从服务器,但必须确保源在复制数据之前已处理了所有必需的事务。
这种方法有几种变体,区别在于数据转储和二进制日志中的事务转移到从属的方式,如下所述:
- 数据集
-
-
在源服务器上 使用 mysqldump 创建转储文件 。 设置 mysqldump 选项
--master-data(默认值为1)以包含CHANGE MASTER TO带有二进制日志记录信息 的 语句。 将--set-gtid-purged选项 设置 为AUTO(缺省值)或ON,以包括有关转储中已执行事务的信息。 然后使用 mysql 客户端在目标服务器上导入转储文件。 -
或者,使用原始数据文件创建源服务器的数据快照,然后按照 第17.1.2.5节“选择数据快照的方法”中 的说明将这些文件复制到目标服务器 。 如果使用
InnoDB表,则可以使用 MySQL Enterprise Backup组件中 的 mysqlbackup 命令生成一致的快照。 此命令记录与从站上使用的快照对应的日志名称和偏移量。 MySQL Enterprise Backup是一种商业产品,作为MySQL Enterprise订阅的一部分包含在内。 看到 有关详细信息 ,请参见第30.2节“MySQL企业备份概述” 。 -
或者,停止源服务器和目标服务器,将源数据目录的内容复制到新从属数据目录,然后重新启动从属服务器。 如果使用此方法,则必须为从属服务器配置基于GTID的复制,换句话说
gtid_mode=ON。 有关此方法的说明和重要信息,请参见 第17.1.2.8节“将从站添加到复制环境” 。
-
- 交易历史
-
如果源服务器在其二进制日志中具有完整的事务历史记录(即,GTID集
@@GLOBAL.gtid_purged为空),则可以使用这些方法。-
使用 带有 和 选项的 mysqlbinlog 将二进制日志从源服务器导入新的从服务器 。
--read-from-remote-server--read-from-remote-master -
或者,将源服务器的二进制日志文件复制到从属服务器。 您可以使用 带有 和 选项的 mysqlbinlog 从slave进行复制 。 通过使用 mysqlbinlog (不带 选项)将二进制日志文件导出到SQL文件,然后将这些文件传递给 mysql 客户端进行处理 ,可以将这些文件 读入从属 服务器。 确保使用单个 mysql 进程 处理所有二进制日志文件 ,而不是使用多个连接。 例如:
--read-from-remote-server--raw>file--raw外壳>
mysqlbinlog copied-binlog.000001 copied-binlog.000002 | mysql -u root -p有关更多信息,请参见 第4.6.8.3节“使用mysqlbinlog备份二进制日志文件” 。
-
这种方法的优点是几乎可以立即使用新的服务器; 只有那些在重放快照或转储文件时提交的事务仍需要从现有主服务器获取。 这意味着从属设备的可用性不是即时的,但是从属设备只需要相对较短的时间来赶上这些剩余的事务。
事先将二进制日志复制到目标服务器通常比从主服务器实时读取整个事务执行历史记录更快。 但是,由于大小或其他考虑因素,在需要时将这些文件移动到目标可能并不总是可行的。 本节中讨论的另外两种配置新从站的方法使用其他方法将有关事务的信息传输到新从站。
注入空交易。
master的全局
gtid_executed
变量包含在
master上
执行的所有事务的集合。
在拍摄快照以配置新服务器时,您可以改为记录
gtid_executed
拍摄快照的服务器上的
内容,而不是复制二进制日志
。
在将新服务器添加到复制链之前,只需在新服务器上为主服务器中包含的每个事务标识符提交一个空事务
gtid_executed
,如下所示:
SET GTID_NEXT ='aaa-bbb-ccc-ddd:N'; 开始; 承诺; SET GTID_NEXT ='AUTOMATIC';
使用空事务以这种方式恢复所有事务标识符后,必须刷新并清除slave的二进制日志,如此处所示,其中
N
是当前二进制日志文件名的非零后缀:
FLUSH LOGS;
PURGE BINARY登录N' master-bin.00000 ';
您应该执行此操作以防止此服务器在以后将其提升为主服务器时使用虚假事务充斥复制流。
(该
FLUSH
LOGS
语句强制创建新的二进制日志文件;
PURGE
BINARY LOGS
清除空事务,但保留其标识符。)
此方法创建一个本质上是快照的服务器,但由于其二进制日志历史记录与复制流的历史记录收敛(即,当它赶上主服务器或主服务器时),因此能够及时成为主服务器。 该结果与使用剩余供应方法获得的结果类似,我们将在接下来的几段中讨论。
使用gtid_purged排除交易。
master的全局
gtid_purged
变量包含从主服务器的二进制日志中清除的所有事务的集合。
与前面讨论的方法一样(请参阅
注入空事务
),您可以记录
gtid_executed
从中获取快照的服务器上
的值
(而不是将二进制日志复制到新服务器)。
与以前的方法不同,不需要提交空事务(或发布
PURGE
BINARY LOGS
);
相反,您可以
gtid_purged
根据
gtid_executed
从中获取备份或快照的服务器
上的值直接在从站上
进行设置
。
与使用空事务的方法一样,此方法创建一个功能上为快照的服务器,但由于其二进制日志历史记录与复制主服务器或组的历史记录收敛,因此能够及时成为主服务器。
恢复GTID模式从站。 在遇到错误的基于GTID的复制设置中还原从站时,注入空事务可能无法解决问题,因为事件没有GTID。
使用
mysqlbinlog
查找下一个事务,这可能是事件发生后下一个日志文件中的第一个事务。
将所有内容复制到该
COMMIT
事务,确保包含该事务
SET
@@SESSION.gtid_next
。
即使您不使用基于行的复制,仍可以在命令行客户端中运行二进制日志行事件。
停止从属并运行您复制的事务。
该
mysqlbinlog可以
输出设置的分隔符
/*!*/;
,所以将其设置回:
MySQL的> DELIMITER ;
自动从正确的位置重新启动复制:
mysql>SET GTID_NEXT=automatic;mysql>RESET SLAVE;mysql>START SLAVE;
由于基于GTID的复制依赖于事务,因此在使用时不支持MySQL中可用的某些功能。 本节提供有关使用GTID进行复制的限制和限制的信息。
涉及非事务存储引擎的更新。
使用GTID时,使用非事务性存储引擎对表进行更新(例如,
MyISAM
无法在与使用事务存储引擎(例如)的表更新相同的语句或事务中)
InnoDB
。
这种限制是由于对使用非事务性存储引擎的表的更新与对同一事务中使用事务存储引擎的表的更新混合的事实可能导致将多个GTID分配给同一事务。
当主设备和从设备使用不同的存储引擎用于同一个表的相应版本时,也会发生这样的问题,其中一个存储引擎是事务性的而另一个不是。 还要注意,定义为在非事务性表上运行的触发器可能是导致这些问题的原因。
在刚刚提到的任何一种情况下,事务和GTID之间的一对一对应关系被破坏,结果是基于GTID的复制无法正常运行。
CREATE TABLE ... SELECT语句。
CREATE
TABLE ... SELECT
使用基于GTID的复制时不允许使用语句。
当
binlog_format
设置为STATEMENT时,
CREATE TABLE ... SELECT
语句在二进制日志中记录为具有一个GTID的一个事务,但如果使用ROW格式,则该语句将记录为具有两个GTID的两个事务。
如果主服务器使用STATEMENT格式而从服务器使用ROW格式,
CREATE
TABLE ... SELECT
则从服务器
将无法正确处理事务,因此
GTID不允许使用
该
语句来阻止此情况。
临时表。
何时
binlog_format
设置为
STATEMENT
,
CREATE
TEMPORARY
TABLE
并且
DROP
TEMPORARY
TABLE
当在服务器上使用GTID时(即,当
enforce_gtid_consistency
系统变量设置为
ON
)
时,不能在事务,过程,函数和触发器内使用语句
。
当GTID正在使用时,它们可以在这些上下文之外使用,前提是
autocommit=1
已设置。
从MySQL 8.0.13开始,何时
binlog_format
设置为
ROW
或
MIXED
,
CREATE
TEMPORARY
TABLE
和
DROP
TEMPORARY
TABLE
在使用GTID时,允许在事务,过程,函数或触发器内部使用语句。
这些语句不会写入二进制日志,因此不会复制到从属语句。
使用基于行的复制意味着从属服务器保持同步,而无需复制临时表。
如果从事务中删除这些语句导致空事务,则事务不会写入二进制日志。
防止执行不受支持的语句。
要防止执行会导致基于GTID的复制失败的语句,必须
--enforce-gtid-consistency
在启用GTID时
使用该
选项
启动所有服务器
。
这会导致本节前面讨论的任何类型的语句失败并显示错误。
请注意,
--enforce-gtid-consistency
仅在对语句进行二进制日志记录时才会生效。
如果在服务器上禁用了二进制日志记录,或者由于过滤器删除了语句而未将语句写入二进制日志,则不会对未记录的语句检查或强制执行GTID一致性。
有关启用GTID时其他所需启动选项的信息,请参见 第17.1.3.4节“使用GTID设置复制” 。
跳过交易。
sql_slave_skip_counter
使用GTID时不支持。
如果您需要跳过事务,请使用master的
gtid_executed
变量
值
;
有关详细信息,
请参阅
注入空事务
。
忽略服务器。
CHANGE
MASTER TO
使用GTID时,不推荐使用
该
语句
的IGNORE_SERVER_IDS选项
,因为已经应用的事务会自动被忽略。
在启动基于GTID的复制之前,请检查并清除之前在相关服务器上设置的所有忽略的服务器ID列表。
SHOW SLAVE STATUS
可以为各个通道发出
的
语句显示已忽略的服务器ID列表(如果有)。
如果没有列表,则该
Replicate_Ignore_Server_Ids
字段为空。
GTID模式和mysqldump。 如果 目标服务器的二进制日志中没有GTID ,则可以将使用 mysqldump 创建的转储导入 到启用了GTID模式的MySQL服务器中。
GTID模式和mysql_upgrade。
在MySQL 8.0.16之前,当服务器运行时使用全局事务标识符(GTID)enabled(
gtid_mode=ON
)时,不要通过
mysql_upgrade
启用二进制日志记录
(该
--write-binlog
选项)。
从MySQL 8.0.16开始,服务器执行整个MySQL升级过程,但在升级过程中禁用二进制日志记录,因此没有问题。
MySQL包含一些内置(本机)函数,用于基于GTID的复制。 这些功能如下:
-
GTID_SUBSET(set1,set2) -
由于两套全局事务标识符
set1和set2,如果所有GTIDs返回trueset1也是set2。 否则返回false。 -
GTID_SUBTRACT(set1,set2) -
由于两套全局事务标识符
set1和set2,只返回那些GTIDsset1不在set2。 -
WAIT_FOR_EXECUTED_GTID_SET(gtid_set[,timeout]) -
等到服务器应用了包含全局事务标识符的所有事务
gtid_set。 在指定的秒数过后,可选的超时会使函数停止等待。 -
WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS(gtid_set[,timeout][,channel]) -
喜欢
WAIT_FOR_EXECUTED_GTID_SET(),但是对于单个启动的复制通道。 使用WAIT_FOR_EXECUTED_GTID_SET()而不是保证所有的通道都涵盖所有状态。
有关这些函数的详细信息,请参见 第12.18节“与全局事务标识符(GTID)一起使用的函数” 。
您可以定义自己的存储函数以使用GTID。
有关定义存储函数的信息,请参见
第24章,
存储对象
。
以下示例显示了可以基于内置
函数
GTID_SUBSET()
和
GTID_SUBTRACT()
函数
创建的一些有用的存储
函数。
请注意,在这些存储函数中,delimiter命令已用于将MySQL语句分隔符更改为垂直条,如下所示:
mysql>分隔符|
所有这些函数都将GTID集的字符串表示作为参数,因此GTID集在与它们一起使用时必须始终引用。
如果两个GTID集是相同的集,则此函数返回非零(true),即使它们没有以相同的方式格式化。
创建函数GTID_IS_EQUAL(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT) 退货INT 返回GTID_SUBSET(gtid_set_1,gtid_set_2)和GTID_SUBSET(gtid_set_2,gtid_set_1)|
如果两个GTID集不相交,则此函数返回非零值(true)。
创建函数GTID_IS_DISJOINT(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT) 退货INT 返回GTID_SUBSET(gtid_set_1,GTID_SUBTRACT(gtid_set_1,gtid_set_2))|
如果两个GTID集是不相交的,则此函数返回非零(true),并且
sum
是两个集合的并集。
创建函数GTID_IS_DISJOINT_UNION(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT,总和LONGTEXT)
退货INT
返回GTID_IS_EQUAL(GTID_SUBTRACT(sum,gtid_set_1),gtid_set_2)AND
GTID_IS_EQUAL(GTID_SUBTRACT(sum,gtid_set_2),gtid_set_1)|
此函数以全部大写形式返回GTID集的规范化形式,没有空格且没有重复。 UUID按字母顺序排列,间隔按数字顺序排列。
创建功能GTID_NORMALIZE(g LONGTEXT) 退货长期 返回GTID_SUBTRACT(g,'')|
此函数返回两个GTID集的并集。
创建函数GTID_UNION(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT) 退货长期 返回GTID_NORMALIZE(CONCAT(gtid_set_1,',',gtid_set_2))|
此函数返回两个GTID集的交集。
创建函数GTID_INTERSECTION(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT) 退货长期 返回GTID_SUBTRACT(gtid_set_1,GTID_SUBTRACT(gtid_set_1,gtid_set_2))|
此函数返回两个GTID集之间的对称差异,即存在
gtid_set_1
但不
存在的GTID
gtid_set_2
,以及存在
gtid_set_2
但不
存在的GTID
gtid_set_1
。
创建函数GTID_SYMMETRIC_DIFFERENCE(gtid_set_1 LONGTEXT,gtid_set_2 LONGTEXT) 退货长期 返回GTID_SUBTRACT(CONCAT(gtid_set_1,',',gtid_set_2),GTID_INTERSECTION(gtid_set_1,gtid_set_2))|
此函数从GTID中删除指定原点的所有GTID,并返回剩余的GTID(如果有)。
UUID是发起事务的服务器使用的标识符,通常是
server_uuid
值。
创建函数GTID_SUBTRACT_UUID(gtid_set LONGTEXT,uuid TEXT) 退货长期 返回GTID_SUBTRACT(gtid_set,CONCAT(UUID,':1-',(1 << 63) - 2))|
此函数反转先前列出的函数,以仅返回来自具有指定标识符(UUID)的服务器的GTID集中的那些GTID。
创建函数GTID_INTERSECTION_WITH_UUID(gtid_set LONGTEXT,uuid TEXT) 退货长期 返回GTID_SUBTRACT(gtid_set,GTID_SUBTRACT_UUID(gtid_set,uuid))|
示例17.1验证复制从站是否是最新的
内置的功能
GTID_SUBSET
和
GTID_SUBTRACT
可用于检查复制从具有至少一个主已申请的每个事务应用。
要执行此检查
GTID_SUBSET
,请在从属服务器上执行以下语句:
SELECT GTID_SUBSET(master_gtid_executed,slave_gtid_executed)
如果返回0(false),则某些GTID
master_gtid_executed
不存在
slave_gtid_executed
,因此主机已应用了从站未应用的某些事务,因此从站不是最新的。
要执行检查
GTID_SUBTRACT
,请在从站上执行以下语句:
SELECT GTID_SUBTRACT(master_gtid_executed,slave_gtid_executed)
此语句返回任何
master_gtid_executed
但不在其中的
GTID
slave_gtid_executed
。
如果返回任何GTID,则主站已应用了从站未应用的一些事务,因此从站不是最新的。
示例17.2备份和还原方案
存储的功能
GTID_IS_EQUAL
,
GTID_IS_DISJOINT
以及
GTID_IS_DISJOINT_UNION
可用于验证备份和恢复涉及多个数据库和服务器操作。
在此示例场景中,
server1
包含数据库
db1
,并
server2
包含数据库
db2
。
目标是将数据库复制
db2
到
server1
,并且结果
server1
应该是两个数据库的并集。
使用的过程是
server2
使用
mysqlpump
或
mysqldump
备份,然后恢复此备份
server1
。
如果备份程序的选项
--set-gtid-purged
设置为
ON
或默认值
AUTO
,则程序的输出包含一个
SET
@@GLOBAL.gtid_purged
语句,
该
语句将该
gtid_executed
组
添加
server2
到
gtid_purged
设置中
server1
。
该
gtid_purged
集包含已在服务器上提交但在服务器上的任何二进制日志文件中不存在的所有事务的GTID。
当数据库
db2
被复制到
server1
,犯下交易的GTIDs
server2
,这是不是在二进制日志文件上
server1
,必须添加
server1
的
gtid_purged
设置,使一套完整。
存储的函数可用于协助此方案中的以下步骤:
-
使用
GTID_IS_EQUAL来验证备份操作计算的正确GTID一套SET @@GLOBAL.gtid_purged说法。 在server2,从 mysqlpump 或 mysqldump 输出中 提取该语句 ,并将GTID集存储到本地变量中,例如$gtid_purged_set。 然后执行以下语句:server2> SELECT GTID_IS_EQUAL($ gtid_purged_set,@@ GLOBAL.gtid_executed);
如果结果为1,则两个GTID集相等,并且已正确计算该集。
-
使用
GTID_IS_DISJOINT验证,在设定的GTID mysqlpump 或 mysqldump的 输出不与重叠gtid_executed设置server1。 如果存在任何重叠,由于某种原因在两台服务器上都存在相同的GTID,则在将数据库复制db2到 时会出现错误server1。 要检查,打开server1,提取gtid_purged输出并将输出 存储 到上面的局部变量中,然后执行以下语句:server1> SELECT GTID_IS_DISJOINT($ gtid_purged_set,@@ GLOBAL.gtid_executed);
如果结果为1,则两个GTID集之间没有重叠,因此不存在重复的GTID。
-
使用
GTID_IS_DISJOINT_UNION来验证还原操作导致的正确GTID状态server1。 在恢复备份之前, 通过执行以下语句server1获取现有gtid_executed集:server1> SELECT @@ GLOBAL.gtid_executed;
将结果存储在局部变量中
$original_gtid_executed。 还将gtid_purged集合 存储在 如上所述的局部变量中。 备份来自server2还原后server1,执行以下语句以验证GTID状态:server1> SELECT GTID_IS_DISJOINT_UNION($ original_gtid_executed, $ gtid_purged_set, @@ GLOBAL.gtid_executed);
如果结果是1,存储功能已证实,原来
gtid_executed设定的从server1($original_gtid_executed)和gtid_purged一个从添加组server2($gtid_purged_set)没有重叠,也更新后的gtid_executed设置上server1,现在由以前的gtid_executed一组来自server1加上gtid_purged从集server2,这是理想的结果。 确保在进行任何进一步的事务之前执行此检查server1,否则gtid_executed集合中 的新事务 将导致其失败。
例17.3选择最新的从站进行手动故障转移
存储的函数
GTID_UNION
可用于从一组从属中识别最新的复制从属,以便在复制主机意外停止后执行手动故障转移操作。
如果某些从站遇到复制延迟,则此存储的函数可用于计算最新的从站,而无需等待所有从站应用其现有的中继日志,从而最大限度地缩短故障转移时间。
该函数可以返回
gtid_executed
每个从站上的集合与从站接收的事务集合的并集,该集合记录在性能架构表中
replication_connection_status
。
您可以比较这些结果,以查找哪个奴隶的交易记录是最新的,即使并非所有交易都已提交。
在每个复制从属服务器上,通过发出以下语句来计算完整的事务记录:
SELECT GTID_UNION(RECEIVED_TRANSACTION_SET,@@ GLOBAL.gtid_executed) 来自performance_schema.replication_connection_status WHERE channel_name ='name';
然后,您可以比较每个从站的结果,以查看哪个具有最新的事务记录,并将此从站用作新的复制主站。
示例17.4检查复制从站上的无关事务
存储的函数
GTID_SUBTRACT_UUID
可用于检查复制从站是否已收到不是源自其指定主站或主站的事务。
如果有,则可能是您的复制设置或代理,路由器或负载均衡器存在问题。
此功能的工作原理是从GTID中删除指定始发服务器中的所有GTID,并返回剩余的GTID(如果有)。
对于具有单个主服务器的复制从服务器,请发出以下语句,并提供原始复制主服务器的标识符,该标识符通常为以下
server_uuid
值:
SELECT GTID_SUBTRACT_UUID(@@ GLOBAL.gtid_executed,server_uuid_of_master);
如果结果不为空,则返回的事务是不是源自指定主服务器的额外事务。
对于多主复制拓扑中的从站,请重复该功能,例如:
SELECT GTID_SUBTRACT_UUID(GTID_SUBTRACT_UUID(@@ GLOBAL.gtid_executed, server_uuid_of_master_1) server_uuid_of_master_2);
如果结果不为空,则返回的事务是不是来自任何指定主服务器的额外事务。
示例17.5验证复制拓扑中的服务器是否为只读
存储的函数
GTID_INTERSECTION_WITH_UUID
可用于验证服务器是否未发起任何GTID并且处于只读状态。
该函数仅返回来自GTID集的GTID,这些GTID源自具有指定标识符的服务器。
如果服务器
gtid_executed
集中的
任何事务
具有服务器自己的标识符,则服务器本身会发起这些事务。
您可以在服务器上发出以下语句来检查:
SELECT GTID_INTERSECTION_WITH_UUID(@@ GLOBAL.gtid_executed,my_server_uuid);
例17.6在多主复制设置中验证附加从站
存储的函数
GTID_INTERSECTION_WITH_UUID
可用于查明连接到多主复制设置的从属是否已应用源自一个特定主服务器的所有事务。
在这种情况下,
master1
并且
master2
都是主人和奴隶,并复制到对方。
master2
也有自己的复制奴隶。
master1
如果
master2
配置了
复制从属设备,它也将接收和应用
事务
log_slave_updates=ON
,但如果
master2
使用
则不会这样做
log_slave_updates=OFF
。
无论如何,我们目前只想知道复制从站是否是最新的
master2
。
在这种情况下,存储功能
GTID_INTERSECTION_WITH_UUID
可用于标识
master2
发起的事务,丢弃
master2
已复制
的事务
master1
。
GTID_SUBSET
然后可以使用
内置函数
将结果
gtid_executed
与从站上的设置
进行比较
。
如果从站是最新的
master2
,
gtid_executed
则从站上
的
设置包含交集中的所有事务(源自的事务
master2
)。
要执行此检查,将商店
master2
的
gtid_executed
set,
master2
服务器UUID和slave的
gtid_executed
集合存储到客户端变量中,如下所示:
$ master2_gtid_executed:=
master2> SELECT @@ GLOBAL.gtid_executed;
$ master2_server_uuid:=
master2> SELECT @@ GLOBAL.server_uuid;
$ slave_gtid_executed:=
奴隶> SELECT @@ GLOBAL.gtid_executed;
然后使用
GTID_INTERSECTION_WITH_UUID
和
GTID_SUBSET
将这些变量作为输入,如下所示:
SELECT GTID_SUBSET(GTID_INTERSECTION_WITH_UUID($ master2_gtid_executed,
$ master2_server_uuid)
$ slave_gtid_executed);
来自
master2
(
$master2_server_uuid
)
的服务器标识符
用于
GTID_INTERSECTION_WITH_UUID
识别和返回
源自
master2
的
gtid_executed
集合中的
那些GTID
master2
,省略那些源自
的
集合
master1
。
然后使用得到的GTID集与从站上所有已执行GTID的集合进行比较
GTID_SUBSET
。
如果此语句返回非零(true),则来自
master2
(第一组输入)的
所有标识的GTID
也在从属
gtid_executed
集(第二组输入)中,这意味着从属已复制源自的所有事务
master2
。
本节介绍MySQL多源复制,它允许您并行地从多个直接主站复制。 本节介绍多源复制,以及如何配置,监视和排除故障。
MySQL多源复制使复制从站可以同时从多个源接收事务。 多源复制可用于将多个服务器备份到单个服务器,合并表分片,以及将来自多个服务器的数据合并到单个服务器。 应用事务时,多源复制不会实现任何冲突检测或解决,如果需要,这些任务将留给应用程序。 在多源复制拓扑中,从属服务器为每个应从其接收事务的主服务器创建复制通道。 请参见 第17.2.3节“复制通道” 。 以下部分介绍如何设置多源复制。
本节提供有关如何为多源复制配置主站和从站以及如何启动,停止和重置多源从站的教程。
本节介绍如何配置多源复制拓扑,并提供有关配置主站和从站的详细信息。 这种拓扑需要至少两个主设备和一个从设备配置。
可以将多源复制拓扑中的主服务器配置为使用基于全局事务标识符(GTID)的复制或基于二进制日志位置的复制。 有关 如何使用基于GTID的复制配置主 服务器, 请参见 第17.1.3.4节“ 使用GTID设置复制”。 有关 如何使用基于文件位置的复制配置主 服务器, 请参见 第17.1.2.1节“设置复制主服务器配置” 。
多源复制拓扑中的从站需要
TABLE
主信息日志和中继日志信息日志的存储库,这是MySQL 8.0中的默认日志。
多源复制与
FILE
基于存储库
不兼容,
现在不推荐使用
--master-info-repository
和
--relay-log-info-repository
选项
的FILE设置
。
要修改使用
FILE
存储库以使用从属状态日志来使用
TABLE
存储库
的现有复制从属,请
通过运行以下命令动态转换现有复制存储库:
STOP SLAVE;SET GLOBAL master_info_repository = 'TABLE';SET GLOBAL relay_log_info_repository = 'TABLE';
本节假定您已在主服务器上启用了基于GTID的事务
gtid_mode=ON
,启用了复制用户,并确保从服务器正在使用
TABLE
基于复制的存储库。
使用该
CHANGE
MASTER TO
语句通过使用
子句
将新主服务器添加到通道
。
有关复制通道的更多信息,请参见
第17.2.3节“复制通道”
FOR CHANNEL
channel
例如,要
master1
使用端口
3451
将具有
主机名的新主服务器添加
到名为的通道
master-1
:
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='', \
MASTER_AUTO_POSITION = 1 FOR CHANNEL 'master-1';
多源复制与自动定位兼容。 有关 更多信息 , 请参见 第13.4.2.1节“将语法更改 为 语法” 。
对要添加到通道的每个额外主站重复此过程,根据需要更改主机名,端口和通道。
本节假设在主服务器上启用了二进制日志记录(这是默认设置),从服务器正在使用
TABLE
基于复制的存储库(这是MySQL 8.0中的默认存储库),并且您已启用复制用户并注意到当前的二进制日志位置。
你需要知道当前
MASTER_LOG_FILE
和
MASTER_LOG_POSITION
。
使用该
CHANGE
MASTER TO
语句通过指定
子句
将新主服务器添加到通道
。
例如,要
使用端口
将具有
主机名的新主服务器添加
到名为的通道
:
FOR CHANNEL
channelmaster1
3451
master-1
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='' \
MASTER_LOG_FILE='master1-bin.000006', MASTER_LOG_POS=628 FOR CHANNEL 'master-1';
对要添加到通道的每个额外主站重复此过程,根据需要更改主机名,端口和通道。
添加了要用作复制主服务器的所有通道后,请使用
语句启动复制。
在从站上启用多个通道后,您可以选择启动所有通道,也可以选择要启动的特定通道。
START SLAVE
thread_types
-
要启动所有当前配置的复制通道:
START SLAVEthread_types; -
要仅启动命名通道,请使用以下 子句:
FOR CHANNELchannelSTART SLAVEthread_typesFOR CHANNELchannel;
使用该
thread_types
选项选择您希望上述语句在从站上启动的特定线程。
有关
更多信息
,
请参见
第13.4.2.6节“START SLAVE语法”
。
该
STOP SLAVE
语句可用于停止多源复制从属。
默认情况下,如果
STOP SLAVE
在多源复制从站上
使用该
语句
,则
所有通道都将停止。
(可选)使用该
子句仅停止特定通道。
FOR CHANNEL
channel
-
要停止所有当前配置的复制通道:
STOP SLAVEthread_types; -
要仅停止命名通道,请使用以下 子句:
FOR CHANNELchannelSTOP SLAVEthread_typesFOR CHANNELchannel;
使用该
thread_types
选项选择您希望上述语句在从站上停止的特定线程。
有关
更多信息
,
请参见
第13.4.2.7节“STOP SLAVE语法”
。
该
RESET SLAVE
语句可用于重置多源复制从站。
默认情况下,如果
RESET SLAVE
在多源复制从站上
使用该
语句,则会重置所有通道。
(可选)使用该
子句仅重置特定通道。
FOR CHANNEL
channel
-
要重置所有当前配置的复制通道:
RESET SLAVE; -
要仅重置命名通道,请使用以下 子句:
FOR CHANNELchannelRESET SLAVE FOR CHANNELchannel;
有关 更多信息 , 请参见 第13.4.2.4节“重置从动语法” 。
要监视复制通道的状态,需要以下选项:
-
使用复制性能架构表。 这些表的第一列是
Channel_Name。 这使您可以基于Channel_Name键 来编写复杂查询 。 请参见 第26.12.11节“性能模式复制表” 。 -
用 。 默认情况下,如果 未使用 该 子句,则此语句显示所有通道的从属状态,每个通道一行。 标识符 将作为列添加到结果集中。 如果 提供 了 子句,则结果仅显示指定复制通道的状态。
SHOW SLAVE STATUS FOR CHANNELchannelFOR CHANNELchannelChannel_nameFOR CHANNELchannel
该
SHOW
VARIABLES
语句不适用于多个复制通道。
通过这些变量可用的信息已迁移到复制性能表。
SHOW
VARIABLES
在具有多个通道的拓扑中
使用
语句仅显示默认通道的状态。
本节介绍如何使用复制性能架构表来监视通道。 您可以选择监控所有频道或现有频道的子集。
要监控所有通道的连接状态:
MySQL的> SELECT * FROM replication_connection_status\G;
*************************** 1。排******************** *******
CHANNEL_NAME:master1
团队名字:
SOURCE_UUID:046e41f8-a223-11e4-a975-0811960cc264
THREAD_ID:24
SERVICE_STATE:开
COUNT_RECEIVED_HEARTBEATS:0
LAST_HEARTBEAT_TIMESTAMP:0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET:046e41f8-a223-11e4-a975-0811960cc264:4-37
LAST_ERROR_NUMBER:0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP:0000-00-00 00:00:00
*************************** 2.排******************** *******
CHANNEL_NAME:master2
团队名字:
SOURCE_UUID:7475e474-a223-11e4-a978-0811960cc264
THREAD_ID:26
SERVICE_STATE:开
COUNT_RECEIVED_HEARTBEATS:0
LAST_HEARTBEAT_TIMESTAMP:0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET:7475e474-a223-11e4-a978-0811960cc264:4-6
LAST_ERROR_NUMBER:0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP:0000-00-00 00:00:00
2行(0.00秒)
在上面的输出中,有两个通道被启用,并且如
CHANNEL_NAME
字段
所示,
它们被称为
master1
和
master2
。
通过添加
CHANNEL_NAME
字段,您可以查询特定通道的性能架构表。
要监视命名通道的连接状态,请使用以下
子句:
WHERE
CHANNEL_NAME=
channel
MySQL的> SELECT * FROM replication_connection_status WHERE CHANNEL_NAME='master1'\G
*************************** 1。排******************** *******
CHANNEL_NAME:master1
团队名字:
SOURCE_UUID:046e41f8-a223-11e4-a975-0811960cc264
THREAD_ID:24
SERVICE_STATE:开
COUNT_RECEIVED_HEARTBEATS:0
LAST_HEARTBEAT_TIMESTAMP:0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET:046e41f8-a223-11e4-a975-0811960cc264:4-37
LAST_ERROR_NUMBER:0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP:0000-00-00 00:00:00
1排(0.00秒)
同样,该
子句可用于监视特定通道的其他复制性能架构表。
有关更多信息,请参见
第26.12.11节“性能模式复制表”
。
WHERE
CHANNEL_NAME=
channel
本节介绍如何更改正在使用的复制模式,而无需使服务器脱机。
为了能够安全地配置在线服务器的复制模式,了解一些关键的复制概念非常重要。 本节介绍了这些概念,在尝试修改在线服务器的复制模式之前,它是必不可少的读物。
MySQL中可用的复制模式依赖于识别记录的事务的不同技术。 复制使用的事务类型如下:
-
GTID事务由表单中的全局事务标识符(GTID)标识
UUID:NUMBER。 日志中的每个GTID事务总是以a开头Gtid_log_event。 可以使用GTID或使用文件名和位置来处理GTID事务。 -
匿名事务没有分配GTID,并且MySQL确保日志中的每个匿名事务都以a开头
Anonymous_gtid_log_event。 在以前的版本中,匿名事务之前没有任何特定事件。 匿名事务只能使用文件名和位置来处理。
当使用GTIDs您可以利用自动定位和自动故障转移的,以及使用
WAIT_FOR_EXECUTED_GTID_SET()
,
session_track_gtids
和监控使用Performance模式表复制的事务。
启用GTID后,您无法使用
sql_slave_skip_counter
,而是使用空事务。
从运行MySQL先前版本的主服务器接收的中继日志中的事务可能根本不会出现任何特定事件,但在重放并记录在从属二进制日志中之后,它们前面会有一个
Anonymous_gtid_log_event
。
在线配置复制模式的能力意味着
gtid_mode
和
enforce_gtid_consistency
变量现在都是动态的,并且可以通过具有足以设置全局系统变量的特权的帐户从顶级语句设置。
请参见
第5.1.9.1节“系统变量权限”
。
在MySQL 5.6及更早版本中,这两个变量都只能在服务器启动时使用适当的选项进行配置,这意味着对复制模式的更改需要重新启动服务器。
在所有版本中
gtid_mode
都可以设置为
ON
或
OFF
,这与GTID是否用于识别交易相对应。
什么时候
gtid_mode=ON
无法复制匿名事务,并且
gtid_mode=OFF
只能
复制匿名事务
。
gtid_mode=OFF_PERMISSIVE
然后,
当允许复制的事务为GTID或匿名事务
时,
新
事务是匿名的。
当
gtid_mode=ON_PERMISSIVE
再
新
,同时允许复制的事务事务使用GTIDs是要么GTID或匿名交易。
这意味着可以拥有一个复制拓扑,其中包含使用匿名和GTID事务的服务器。
例如,一个主人
gtid_mode=ON
可以复制到一个奴隶
gtid_mode=ON_PERMISSIVE
。
有效值
gtid_mode
如下并按此顺序:
-
OFF -
OFF_PERMISSIVE -
ON_PERMISSIVE -
ON
重要的是要注意,状态
gtid_mode
只能根据上述顺序一次改变一步。
例如,如果
gtid_mode
当前设置为
OFF_PERMISSIVE
,则可以更改为
OFF
或
ON_PERMISSIVE
不更改
ON
。
这是为了确保服务器正确处理从在线匿名事务更改为GTID事务的过程。
当您在
gtid_mode=ON
和
之间切换时
gtid_mode=OFF
,GTID状态(换句话说,值
gtid_executed
)是持久的。
这可确保始终保留服务器应用的GTID集,而不管类型之间的更改如何
gtid_mode
。
无论当前选择哪个,与GTID相关的字段都会显示正确的信息
gtid_mode
。
这意味着,显示GTID组领域,如
gtid_executed
,
gtid_purged
,
RECEIVED_TRANSACTION_SET
在
replication_connection_status
性能架构表,的GTID相关的结果
SHOW SLAVE STATUS
,现在返回空字符串时,有没有存在GTIDs。
现在,
在未使用GTID事务时
,将显示显示单个GTID的字段,例如
CURRENT_TRANSACTION
性能模式
replication_applier_status_by_worker
表
中的
字段
ANONYMOUS
。
从主服务器进行的复制
gtid_mode=ON
提供了使用自动定位的功能,使用该
CHANGE
MASTER TO MASTER_AUTO_POSITION = 1;
语句进行
配置
。
正在使用的复制拓扑影响是否可以启用自动定位,因为此功能依赖于GTID并且与匿名事务不兼容。
如果启用了自动定位并且遇到匿名事务,则会生成错误。
强烈建议在启用自动定位之前确保拓扑中没有剩余匿名事务,请参见
第17.1.5.2节“在线启用GTID事务”
。
gtid_mode
主站和从站
的有效组合
和自动定位如下表所示,其中主站
gtid_mode
显示在水平上,而从
gtid_mode
站在垂直方向上。
每个条目的含义如下:
表17.1主服务器和从服务器gtid_mode的有效组合
|
主
|
主
|
主
|
主
|
|
|---|---|---|---|---|
|
奴隶
|
ÿ |
ÿ |
ñ |
ñ |
|
奴隶
|
ÿ |
ÿ |
ÿ |
Y * |
|
奴隶
|
ÿ |
ÿ |
ÿ |
Y * |
|
奴隶
|
ñ |
ñ |
ÿ |
Y * |
当前选择的
gtid_mode
也会影响
gtid_next
变量。
下表显示了服务器的不同价值观的行为
gtid_mode
和
gtid_next
。
每个条目的含义如下:
-
ANONYMOUS:生成匿名事务。 -
Error:生成错误并且无法执行SET GTID_NEXT。 -
UUID:NUMBER:使用指定的UUID:NUMBER生成GTID。 -
New GTID:使用自动生成的数字生成GTID。
当二进制日志关闭并
gtid_next
设置
AUTOMATIC
为时,则不会生成GTID。
这与先前版本的行为一致。
本节介绍如何在已联机且使用匿名事务的服务器上启用GTID事务以及(可选)自动定位。 此过程不需要使服务器脱机并且适合在生产中使用。 但是,如果您在启用GTID事务时可以使服务器脱机,则该过程更容易。
在开始之前,请确保服务器满足以下前提条件:
-
拓扑中的 所有 服务器都必须使用MySQL 5.7.6或更高版本。 除非 拓扑中的 所有 服务器都使用此版本, 否则无法在任何单个服务器上联机启用GTID事务 。
-
所有服务器都已
gtid_mode设置为默认值OFF。
以下程序可以随时暂停,之后可以恢复 原状, 或者通过跳转到 第17.1.5.3节“禁用GTID在线交易” 的相应步骤进行 撤销,这是禁用GTID 的在线程序。 这使得该过程具有容错能力,因为可以像往常一样处理可能出现在过程中间的任何不相关的问题,然后该过程在其停止的地方继续。
在继续下一步之前,完成每个步骤至关重要。
要启用GTID交易:
-
在每台服务器上,执行:
SET @@ GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
让服务器在正常工作负载下运行一段时间并监控日志。 如果此步骤导致日志中出现任何警告,请调整应用程序,使其仅使用与GTID兼容的功能,并且不会生成任何警告。
重要这是第一个重要的步骤。 在进行下一步之前,必须确保错误日志中未生成警告。
-
在每台服务器上,执行:
SET @@ GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = OFF_PERMISSIVE;
哪个服务器首先执行此语句无关紧要,但重要的是所有服务器在任何服务器开始下一步之前完成此步骤。
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = ON_PERMISSIVE;
哪个服务器首先执行此语句无关紧要。
-
在每台服务器上,等待状态变量
ONGOING_ANONYMOUS_TRANSACTION_COUNT为零。 可以使用以下方法检查:显示状态如'ONGOING_ANONYMOUS_TRANSACTION_COUNT';
注意在复制从站上,理论上可能会再次显示零然后非零。 这不是问题,它足以显示零一次。
-
等待直到步骤5生成的所有事务都复制到所有服务器。 您可以在不停止更新的情况下执行此操作:唯一重要的是所有匿名事务都会被复制。
有关 检查所有匿名事务是否已复制到所有服务器的一种方法, 请参见 第17.1.5.4节“验证 匿名事务的复制”。
-
如果您将二进制日志用于复制以外的任何其他日志,例如时间点备份和还原,请等到您不需要具有没有GTID的事务的旧二进制日志。
例如,在步骤6完成后,您可以
FLUSH LOGS在要进行备份的服务器上 执行 。 然后显式地进行备份或等待您可能已设置的任何定期备份例程的下一次迭代。理想情况下,等待服务器清除步骤6完成时存在的所有二进制日志。 还要等待在步骤6到期之前进行的任何备份。
重要这是第二个重点。 至关重要的是要了解包含匿名事务的二进制日志,在没有GTID的情况下,在下一步之后无法使用。 完成此步骤后,您必须确保拓扑中的任何位置都不存在没有GTID的事务。
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = ON;
-
在每台服务器上,添加
gtid-mode=ON到my.cnf。现在可以保证所有事务都具有GTID(在步骤5或更早版本中生成的事务已经过处理)。 要开始使用GTID协议以便以后执行自动故障转移,请在每个从站上执行以下操作。 (可选)如果使用多源复制,请对每个通道执行此操作并包含以下 子句:
FOR CHANNELchannelSTOP SLAVE [FOR CHANNEL'channel']; 更改MASTER_AUTO_POSITION = 1 [FOR CHANNEL'channel']; START SLAVE [FOR CHANNEL'channel'];
本节介绍如何在已联机的服务器上禁用GTID事务。 此过程不需要使服务器脱机并且适合在生产中使用。 但是,如果您在禁用GTID模式时可以使服务器脱机,则该过程更容易。
该过程类似于在服务器联机时启用GTID事务,但是反转步骤。 唯一不同的是等待记录的事务复制的点。
在开始之前,请确保服务器满足以下前提条件:
-
拓扑中的 所有 服务器都必须使用MySQL 5.7.6或更高版本。 除非 拓扑中的 所有 服务器都使用此版本, 否则无法在任何单个服务器上联机禁用GTID事务 。
-
所有服务器都
gtid_mode设置为ON。 -
该
--replicate-same-server-id选项未在任何服务器上设置。 如果此选项与--log-slave-updates选项(默认值) 一起设置 并且启用了二进制日志记录(这也是默认值),则 无法禁用GTID事务 。 如果没有GTID,这种选项组合会在循环复制中导致无限循环。
-
在每个从站上执行以下操作,如果使用多源复制,请为每个通道执行此操作并包含
FOR CHANNELchannel子句:STOP SLAVE [FOR CHANNEL'channel']; CHANGE MASTER TO MASTER_AUTO_POSITION = 0,MASTER_LOG_FILE = file,\ MASTER_LOG_POS = position [FOR CHANNEL'channel']; START SLAVE [FOR CHANNEL'channel'];
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = ON_PERMISSIVE;
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = OFF_PERMISSIVE;
-
在每台服务器上,等待变量@@ GLOBAL.GTID_OWNED等于空字符串。 可以使用以下方法检查:
SELECT @@ GLOBAL.GTID_OWNED;
在复制从属设备上,理论上可能是空的,然后再次非空。 这不是问题,只要它是空的一次就足够了。
-
等待任何二进制日志中当前存在的所有事务都复制到所有从属服务器。 有关 检查所有匿名事务是否已复制到所有服务器的一种方法, 请参见 第17.1.5.4节“验证 匿名事务的复制”。
-
如果您将二进制日志用于复制以外的任何其他日志,例如进行时间点备份或还原:请等待,直到您不需要具有GTID事务的旧二进制日志。
例如,在步骤5完成后,您可以
FLUSH LOGS在要进行备份的服务器上 执行 。 然后显式地进行备份或等待您可能已设置的任何定期备份例程的下一次迭代。理想情况下,等待服务器清除步骤5完成时存在的所有二进制日志。 还要等待在步骤5之前进行的任何备份到期。
重要这是此过程中的一个重点。 重要的是要了解包含GTID事务的日志在下一步之后无法使用。 在继续之前,您必须确保拓扑中的任何位置都不存在GTID事务。
-
在每台服务器上,执行:
SET @@ GLOBAL.GTID_MODE = OFF;
-
在每个服务器上,设置
gtid-mode=OFF在my.cnf。如果你想设置
enforce_gtid_consistency=OFF,你现在可以这样做。 设置后,您应该添加enforce_gtid_consistency=OFF到配置文件中。
如果要降级到早期版本的MySQL,可以使用正常的降级程序立即降级。
本节介绍如何监视复制拓扑并验证是否已复制所有匿名事务。 这在联机更改复制模式时很有用,因为您可以验证更改为GTID事务是否安全。
有几种方法可以等待事务复制:
最简单的方法,无论您的拓扑结构如何工作,但依赖于时序如下:如果您确定从站永远不会滞后超过N秒,则只需等待超过N秒。 或者等待一天,或者您认为安全部署的任何时间段。
一种更安全的方法,它不依赖于时间:如果您只有一个或多个从站的主站,请执行以下操作:
-
在主服务器上,执行:
显示主要状态;
记下
File和Position列中 的值 。 -
在每个从站上,使用主站的文件和位置信息执行:
SELECT MASTER_POS_WAIT(文件,位置);
如果您有一个主站和多个级别的从站,或者换句话说您有从站的从站,请在每个级别上重复步骤2,从主站开始,然后是所有直接从站,然后是从站的所有从站,依此类推。
如果使用循环复制拓扑,其中多个服务器可能具有写入客户端,请对每个主从连接执行步骤2,直到完成整个循环。 重复整个过程,以便完成 两次 完整的循环 。
例如,假设您有三个服务器A,B和C,以圆形复制,以便A - > B - > C - > A.过程如下:
-
在A上执行步骤1,在B上执行步骤2。
-
在B上执行步骤1,在C上执行步骤2。
-
在C上执行步骤1,在A上执行步骤2。
-
在A上执行步骤1,在B上执行步骤2。
-
在B上执行步骤1,在C上执行步骤2。
-
在C上执行步骤1,在A上执行步骤2。
以下部分包含有关 在复制和控制二进制日志中使用的 mysqld 选项和服务器变量的 信息 。 复制主服务器和复制从服务器上使用的选项和变量分别包含在内,与二进制日志记录和全局事务标识符(GTID)相关的选项和变量也是如此。 还包括一组快速参考表,提供有关这些选项和变量的基本信息。
特别重要的是
--server-id
选择权。
| 属性 | 值 |
|---|---|
| 命令行格式 | --server-id=# |
| 系统变量 | server_id |
| 范围 | 全球 |
| 动态 | 是 |
SET_VAR
提示适用
|
没有 |
| 类型 | 整数 |
| 默认值 (> = 8.0.3) | 1 |
| 默认值 (<= 8.0.2) | 0 |
| 最低价值 | 0 |
| 最大价值 | 4294967295 |
指定服务器ID。
的
server_id
系统变量被默认设置为1。
可以使用此缺省ID启动服务器,但是启用二进制日志记录时,如果未使用该
--server-id
选项
明确指定服务器标识,则会发出信息性消息
。
对于复制拓扑中使用的服务器,必须为每个复制服务器指定唯一的服务器ID,范围为1到2 32 - 1. “ 唯一 ” 表示每个ID必须与正在使用的每个其他ID不同任何其他复制主机或从机。 有关其他信息,请参见 第17.1.6.2节“复制主选项和变量” 和 第17.1.6.3节“复制从选项和变量” 。
如果服务器ID设置为0,则进行二进制日志记录,但服务器ID为0的主服务器拒绝来自从服务器的任何连接,服务器ID为0的从服务器拒绝连接到主服务器。 请注意,虽然您可以将服务器ID动态更改为非零值,但这样做不会立即启动复制。 您必须更改服务器ID,然后重新启动服务器以初始化复制从站。
有关更多信息,请参见 第17.1.2.2节“设置复制从站配置” 。
除了在
server_id
系统变量中
设置的默认或用户提供的服务器ID之外,MySQL服务器还会生成真正的UUID
。
这可用作全局只读变量
server_uuid
。
所述的存在
server_uuid
系统变量不用于设置一个唯一的改变的要求
--server-id
为每个MySQL服务器作为制备和运行MySQL复制,如前面在本节中描述的组成部分。
| 属性 | 值 |
|---|---|
| 系统变量 | server_uuid |
| 范围 | 全球 |
| 动态 | 没有 |
SET_VAR
提示适用
|
没有 |
| 类型 | 串 |
启动时,MySQL服务器自动获取UUID,如下所示:
该
auto.cnf
文件的格式类似于用于
my.cnf
或
my.ini
文件的格式。
auto.cnf
只有一个
[auto]
部分包含一个
server_uuid
设置和值;
文件的内容与此处显示的内容类似:
[汽车] server_uuid = 8a94f357-aab4-11df-86ab-c80aa9429562
该
auto.cnf
文件是自动生成的;
不要尝试编写或修改此文件。
使用MySQL复制时,主服务器和从服务器知道彼此的UUID。
从属的UUID的值可以在输出中看到
SHOW
SLAVE HOSTS
。
一旦
START
SLAVE
执行,主机的UUID的值在输出中的从机上可用
SHOW
SLAVE STATUS
。
发出
STOP
SLAVE
或
RESET
SLAVE
语句也
不会
重置主人的UUID在从属的使用。
服务器
server_uuid
也在GTID中用于源自该服务器的事务。
有关更多信息,请参见
第17.1.3节“使用全局事务标识符进行复制”
。
启动时,从属I / O线程会生成错误并在其主控器的UUID等于其自身的情况下中止,除非
--replicate-same-server-id
已设置
该
选项。
此外,如果满足以下任一条件,则从属I / O线程会生成警告:
-
没有预期
server_uuid存在的 主人 。 -
server_uuid虽然没有任何CHANGE MASTER TO声明被执行 ,但 主人 已经改变 了。
以下两个列表提供了有关适用于复制的MySQL命令行选项和系统变量以及二进制日志的基本信息。
以下列表中的命令行选项和系统变量与复制主服务器和复制从服务器相关。 第17.1.6.2节“复制主选项和变量” 提供了有关复制主服务器的选项和变量的更多详细信息。 有关与复制从站相关的选项和变量的更多信息,请参见 第17.1.6.3节“复制从站选项和变量” 。
-
abort-slave-event-count:mysql-test用于调试和复制测试的选项 -
binlog_expire_logs_seconds:在这么多秒后清除二进制日志 -
binlog_gtid_simple_recovery:控制在GTID恢复期间迭代二进制日志的方式 -
Com_change_master:CHANGE MASTER TO语句的计数 -
Com_show_master_status:SHOW MASTER STATUS语句的计数 -
Com_show_slave_hosts:SHOW SLAVE HOSTS语句的计数 -
Com_show_slave_status:SHOW SLAVE STATUS语句的计数 -
Com_slave_start:START SLAVE语句的计数 -
Com_slave_stop:STOP SLAVE语句的计数 -
disconnect-slave-event-count:mysql-test用于调试和复制测试的选项 -
enforce-gtid-consistency:防止执行无法以事务安全方式记录的语句 -
enforce_gtid_consistency:防止执行无法以事务安全方式记录的语句 -
expire_logs_days:在这么多天之后清除二进制日志 -
gtid-executed-compression-period:每次发生这么多事务时压缩gtid_executed表。 0表示从不压缩此表。 仅在禁用二进制日志记录时适用。 -
gtid-mode:控制是否启用基于GTID的日志记录以及日志可以包含的事务类型 -
gtid_executed:Global:二进制日志(全局)或当前事务(会话)中的所有GTID。 只读。 -
gtid_executed_compression_period:每次发生这么多事务时压缩gtid_executed表。 0表示从不压缩此表。 仅在禁用二进制日志记录时适用。 -
gtid_mode:控制是否启用基于GTID的日志记录以及日志可以包含的事务类型 -
gtid_next:指定要执行的下一个语句的GTID; 请参阅文档了解详情 -
gtid_owned:此客户端(会话)或所有客户端拥有的GTID集以及所有者的线程ID(全局)。 只读。 -
gtid_purged:已从二进制日志中清除的所有GTID的集合 -
init_slave:从站连接到主站时执行的语句 -
log-bin-trust-function-creators:如果等于0(默认值),则使用--log-bin时,仅允许具有SUPER权限的用户创建存储函数,并且仅当创建的函数不破坏二进制日志记录时才 -
log-slave-updates:告诉slave将其SQL线程执行的更新记录到自己的二进制日志中 -
log_builtin_as_identified_by_password:是否以向后兼容的方式记录CREATE / ALTER USER,GRANT -
log_slave_updates:从属服务器是否应将其SQL线程执行的更新记录到其自己的二进制日志中。 只读; 使用--log-slave-updates服务器选项设置。 -
log_statements_unsafe_for_binlog:禁用错误1592警告写入错误日志 -
master-info-file:记住主服务器的文件的位置和名称以及I / O复制线程在主服务器的二进制日志中的位置 -
master-info-repository:是否将主服务器的二进制日志中的主状态信息和复制I / O线程位置写入文件或表 -
master-retry-count:从站在放弃之前连接到主站的尝试次数 -
master_info_repository:是否将主服务器的二进制日志中的主状态信息和复制I / O线程位置写入文件或表 -
max_relay_log_size:如果非零,则当其大小超过此值时,会自动轮换中继日志。 如果为零,则发生旋转的大小由max_binlog_size的值确定。 -
original_commit_timestamp:在原始主服务器上提交事务的时间 -
immediate_server_version:作为复制拓扑中的直接主服务器的服务器的MySQL服务器版本号 -
original_server_version:最初提交事务的服务器的MySQL Server版本号 -
relay-log:用于中继日志的位置和基本名称 -
relay-log-index:用于保存最后一个中继日志列表的文件的位置和名称 -
relay-log-info-file:记住SQL复制线程在中继日志中的位置的文件的位置和名称 -
relay-log-info-repository:是否将复制SQL线程在中继日志中的位置写入文件或表 -
relay-log-recovery:启用时从主服务器启用自动恢复中继日志文件 -
relay_log_basename:中继日志的完整路径,包括文件名 -
relay_log_index:中继日志索引文件的名称 -
relay_log_info_file:从站记录有关中继日志的信息的文件的名称 -
relay_log_info_repository:是否将复制SQL线程在中继日志中的位置写入文件或表 -
relay_log_purge:确定是否清除中继日志 -
relay_log_recovery:是否启用了在启动时从主服务器自动恢复中继日志文件; 必须启用崩溃安全从站 -
relay_log_space_limit:所有中继日志使用的最大空间 -
replicate-do-db:告诉从属SQL线程限制复制到指定的数据库 -
replicate-do-table:告诉从属SQL线程将复制限制到指定的表 -
replicate-ignore-db:告诉从属SQL线程不要复制到指定的数据库 -
replicate-ignore-table:告诉从属SQL线程不要复制到指定的表 -
replicate-rewrite-db:使用与原始名称不同的名称更新数据库 -
replicate-same-server-id:在复制中,如果启用,请不要跳过具有我们服务器ID的事件 -
replicate-wild-do-table:告诉从属线程将复制限制为与指定通配符模式匹配的表 -
replicate-wild-ignore-table:告诉从属线程不要复制到与给定通配符模式匹配的表 -
report-host:从站注册期间向主站报告的从站的主机名或IP -
report-password:从服务器应向主服务器报告的任意密码。 与MySQL复制用户帐户的密码不同。 -
report-port:从站注册期间连接到从站报告给主站的端口 -
report-user:从服务器应向主服务器报告的任意用户名。 与MySQL复制用户帐户使用的名称不同。 -
Rpl_semi_sync_master_clients:半同步从站的数量 -
rpl_semi_sync_master_enabled:是否在主服务器上启用了半同步复制 -
Rpl_semi_sync_master_net_avg_wait_time:主设备等待从设备回复的平均时间 -
Rpl_semi_sync_master_net_wait_time:主人等待奴隶回复的总时间 -
Rpl_semi_sync_master_net_waits:主服务器等待从服务器回复的总次数 -
Rpl_semi_sync_master_no_times:主服务器关闭半同步复制的次数 -
Rpl_semi_sync_master_no_tx:未成功确认的提交数 -
Rpl_semi_sync_master_status:是否可以在主服务器上运行半同步复制 -
Rpl_semi_sync_master_timefunc_failures:调用时间函数时主服务器失败的次数 -
rpl_semi_sync_master_timeout:等待从机确认的毫秒数 -
rpl_semi_sync_master_trace_level:主服务器上的半同步复制调试跟踪级别 -
Rpl_semi_sync_master_tx_avg_wait_time:主人等待每笔交易的平均时间 -
Rpl_semi_sync_master_tx_wait_time:主服务器等待事务的总时间 -
Rpl_semi_sync_master_tx_waits:主服务器等待事务的总次数 -
rpl_semi_sync_master_wait_for_slave_count:在继续之前,主服务器必须接收多少个从属确认 -
rpl_semi_sync_master_wait_no_slave:即使没有奴隶,主人是否等待超时 -
rpl_semi_sync_master_wait_point:从事交易收据确认的等待点 -
Rpl_semi_sync_master_wait_pos_backtraverse:主服务器等待二进制坐标低于先前等待事件的事件的总次数 -
Rpl_semi_sync_master_wait_sessions:当前正在等待从属回复的会话数 -
Rpl_semi_sync_master_yes_tx:成功确认的提交数 -
rpl_semi_sync_slave_enabled:是否在从属上启用了半同步复制 -
Rpl_semi_sync_slave_status:半同步复制是否可在从站上运行 -
rpl_semi_sync_slave_trace_level:从属服务器上的半同步复制调试跟踪级别 -
rpl_read_size:设置从二进制日志文件和中继日志文件中读取的最小数据量(以字节为单位) -
rpl_stop_slave_timeout:设置STOP SLAVE在超时之前等待的秒数 -
server_uuid:服务器启动时自动(重新)生成的服务器全局唯一ID -
show-slave-auth-info:在此主站的SHOW SLAVE HOSTS中显示用户名和密码 -
skip-slave-start:如果设置,slave不会自动启动 -
slave-checkpoint-group:在调用检查点操作以更新进度状态之前,多线程从属服务器处理的最大事务数。 NDB群集不支持。 -
slave-checkpoint-period:在此毫秒数后更新多线程从站的进度状态并将中继日志信息刷新到磁盘。 NDB群集不支持。 -
slave-load-tmpdir:复制LOAD DATA语句时从属服务器应放置其临时文件的位置 -
slave-max-allowed-packet:可以从复制主服务器发送到从服务器的数据包的最大大小(以字节为单位); 覆盖max_allowed_packet -
slave_net_timeout:在中止读取之前等待来自主/从连接的更多数据的秒数 -
slave-parallel-type:告诉从属服务器使用时间戳信息(LOGICAL_CLOCK)或数据库分区(DATABASE)来并行化事务。 默认值为LOGICAL_CLOCK。 -
slave-parallel-workers:并行执行复制事务的应用程序线程数。 默认值为4个应用程序线程。 设置为0以禁用从属多线程。 MySQL Cluster不支持。 -
slave-pending-jobs-size-max:包含尚未应用的事件的从属工作队列的最大大小 -
slave-rows-search-algorithms:确定用于从站更新批处理的搜索算法。 列表INDEX_SEARCH,TABLE_SCAN,HASH_SCAN中的任何2或3 -
slave-skip-errors:当查询从提供的列表中返回错误时,告诉从属线程继续复制 -
slave_checkpoint_group:在调用检查点操作以更新进度状态之前,多线程从属服务器处理的最大事务数。 NDB群集不支持。 -
slave_checkpoint_period:在此毫秒数后更新多线程从站的进度状态并将中继日志信息刷新到磁盘。 NDB群集不支持。 -
slave_compressed_protocol:在主/从协议上使用压缩 -
slave_exec_mode:允许在IDEMPOTENT模式(键和其他一些被抑制的错误)和STRICT模式之间切换从属线程; STRICT模式是默认设置,但NDB Cluster除外,其中始终使用IDEMPOTENT -
Slave_heartbeat_period:从属的复制心跳间隔,以秒为单位 -
Slave_last_heartbeat:以TIMESTAMP格式显示收到最新心跳信号的时间 -
slave_max_allowed_packet:可以从复制主服务器发送到从服务器的数据包的最大大小(以字节为单位); 覆盖max_allowed_packet -
Slave_open_temp_tables:从属SQL线程当前打开的临时表的数量 -
slave_parallel_type:告诉从属服务器使用时间戳信息(LOGICAL_CLOCK)或数据库分区(DATABASE)来并行化事务。 -
slave_parallel_workers:并行执行复制事务的应用程序线程数。 值为0将禁用从属多线程。 MySQL Cluster不支持。 -
slave_pending_jobs_size_max:包含尚未应用的事件的从属工作队列的最大大小 -
slave_preserve_commit_order:确保从属工作程序的所有提交都与主服务器上的顺序相同,以便在使用并行应用程序线程时保持一致性。 -
Slave_received_heartbeats:自上次重置以来复制从站接收的心跳数 -
Slave_retried_transactions:自启动以来复制从属SQL线程已重试事务的总次数 -
slave_rows_search_algorithms:确定用于从站更新批处理的搜索算法。 列表INDEX_SEARCH,TABLE_SCAN,HASH_SCAN中的任何2或3。 -
Slave_rows_last_search_algorithm_used:此从属服务器最近使用的搜索算法,用于查找基于行的复制(索引,表或散列扫描)的行 -
Slave_running:此服务器的状态作为复制从属(从属I / O线程状态) -
slave_transaction_retries:从属SQL线程重试事务的次数,以防止在发生和停止之前发生死锁或锁定等待超时失败 -
slave_type_conversions:控制复制从属上的类型转换模式。 值是列表中零个或多个元素的列表:ALL_LOSSY,ALL_NON_LOSSY。 设置为空字符串以禁止主服务器和从服务器之间的类型转换。 -
sql_log_bin:控制当前会话的二进制日志记录 -
sql_slave_skip_counter:从服务器应跳过的主服务器的事件数。 与GTID复制不兼容。 -
sync_binlog:每次#th事件后,将二进制日志同步刷新到磁盘 -
sync_master_info:在每个#th事件后将master.info同步到磁盘 -
sync_relay_log:每次#th事件后将中继日志同步到磁盘 -
sync_relay_log_info:在每个#th事件后将relay.info文件同步到磁盘 -
transaction_write_set_extraction:定义用于散列在事务期间提取的写入的算法
以下列表中的命令行选项和系统变量与二进制日志有关。 第17.1.6.4节“二进制日志选项和变量” 提供了有关 二进制日志记录的选项和变量的 更多详细信息。 有关二进制日志的其他一般信息,请参见 第5.4.4节“二进制日志” 。
-
binlog-checksum:启用/禁用二进制日志校验和 -
binlog-do-db:限制二进制日志记录到特定数据库 -
binlog_format:指定二进制日志的格式 -
binlog-ignore-db:告诉主服务器不应将对给定数据库的更新记录到二进制日志中 -
binlog-row-event-max-size:二进制日志最大事件大小 -
binlog_encryption:为此服务器上的二进制日志文件和中继日志文件启用加密 -
binlog_rotate_encryption_master_key_at_startup:在服务器启动时旋转二进制日志主密钥 -
Binlog_cache_disk_use:使用临时文件而不是二进制日志缓存的事务数 -
binlog_cache_size:用于在事务期间保存二进制日志的SQL语句的高速缓存大小 -
Binlog_cache_use:使用临时二进制日志缓存的事务数 -
binlog_checksum:启用/禁用二进制日志校验和 -
binlog_direct_non_transactional_updates:使用语句格式更新非事务引擎直接写入二进制日志。 使用前请参阅文档。 -
binlog_error_action:控制服务器无法写入二进制日志时发生的情况 -
binlog_group_commit_sync_delay:设置在将事务同步到磁盘之前等待的微秒数 -
binlog_group_commit_sync_no_delay_count:设置在中止binlog_group_commit_sync_delay指定的当前延迟之前要等待的最大事务数 -
binlog_max_flush_queue_time:在刷新到二进制日志之前读取事务的时间 -
binlog_order_commits:是否以与写入二进制日志相同的顺序提交 -
binlog_row_image:记录行更改时使用完整或最小图像 -
binlog_row_metadata:配置使用基于行的日志记录时记录的表相关元数据二进制文件的数量。 -
binlog_row_value_options:为基于行的复制启用部分JSON更新的二进制日志记录。 -
binlog_rows_query_log_events:启用时,在使用基于行的日志记录时启用行查询日志事件。 默认情况下禁用。 为5.6之前的从站/阅读器生成日志时不要启用。 -
Binlog_stmt_cache_disk_use:使用临时文件而不是二进制日志语句缓存的非事务性语句的数量 -
binlog_stmt_cache_size:用于在事务期间保存二进制日志的非事务性语句的高速缓存大小 -
Binlog_stmt_cache_use:使用临时二进制日志语句缓存的语句数 -
binlog_transaction_dependency_tracking:依赖关系信息的来源(提交时间戳或事务写入集),从中可以评估slave的多线程应用程序可以并行执行哪些事务。 -
binlog_transaction_dependency_history_size:为查找上次更新某行的事务而保留的行哈希数。 -
Com_show_binlog_events:SHOW BINLOG EVENTS陈述的计数 -
Com_show_binlogs:SHOW BINLOGS语句的计数 -
log-bin-use-v1-row-events:使用版本1二进制日志行事件 -
log_bin_basename:二进制日志文件的路径和基本名称 -
log_bin_use_v1_row_events:显示服务器是否正在使用版本1二进制日志行事件 -
master-verify-checksum:导致master从二进制日志中读取时检查校验和 -
master_verify_checksum:导致master从二进制日志中读取校验和 -
max-binlog-dump-events:mysql-test用于调试和复制测试的选项 -
max_binlog_cache_size:可用于限制用于缓存多语句事务的总大小 -
max_binlog_size:当大小超过此值时,二进制日志将自动旋转 -
max_binlog_stmt_cache_size:可用于限制用于在事务期间缓存所有非事务性语句的总大小 -
slave-sql-verify-checksum:导致slave从中继日志中读取时检查校验和 -
slave_sql_verify_checksum:导致slave从中继日志中读取时检查校验和 -
sporadic-binlog-dump-fail:mysql-test用于调试和复制测试的选项
有关 mysqld 使用 的 所有 命令行选项,系统和状态变量 的列表 ,请参见 第5.1.4节“服务器选项,系统变量和状态变量参考” 。
本节介绍可在复制主服务器上使用的服务器选项和系统变量。
您可以在
命令行
或
选项文件
中指定
选项
。
您可以使用指定系统变量值
SET
。
在主服务器和每个从服务器上,必须使用该
server-id
选项来建立唯一的复制ID。
对于每个服务器,您应该选择1到2
32
- 1
范围内的唯一正整数
,并且每个ID必须与任何其他复制主服务器或从服务器使用的每个其他ID不同。
示例:
server-id=3
。
有关主站用于控制二进制日志 记录的选项 ,请参见 第17.1.6.4节“二进制日志记录选项和变量” 。
以下列表描述了用于控制复制主服务器的启动选项。 与复制相关的系统变量将在本节后面讨论。
-
属性 值 命令行格式 --show-slave-auth-info[={OFF|ON}]类型 布尔 默认值 OFFSHOW SLAVE HOSTS在主服务器 的输出中显示从属用户名和密码, 用于以--report-user和和--report-password选项 启动的从属服务器 。
以下系统变量用于复制主机或由复制主机使用:
-
属性 值 命令行格式 --auto-increment-increment=#系统变量 auto_increment_increment范围 全球,会议 动态 是 SET_VAR提示适用是 类型 整数 默认值 1最低价值 1最大价值 65535auto_increment_increment并且auto_increment_offset旨在用于主 - 主复制,并可用于控制AUTO_INCREMENT列 的操作 。 两个变量都具有全局值和会话值,并且每个变量都可以采用介于1和65,535之间的整数值。 将这两个变量中的任何一个的值设置为0会导致其值设置为1。 尝试将这两个变量中的任何一个的值设置为大于65,535或小于0的整数会导致其值设置为65,535。 试图设置auto_increment_increment或 的值auto_increment_offset到非整数值会产生错误,并且变量的实际值保持不变。从MySQL 8.0.14开始,设置此系统变量的会话值是一种受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
注意auto_increment_increment也支持与NDB表 一起使用 。在服务器上启动组复制时,值
auto_increment_increment将更改为值group_replication_auto_increment_increment,默认值为7,值auto_increment_offset更改为服务器ID。 停止组复制时,将还原更改。 这些变化只发和恢复,如果auto_increment_increment和auto_increment_offset各有如果他们的价值已经从默认修改1.缺省值,组复制不会改变它们。 从MySQL 8.0开始,当组复制处于单主模式时,系统变量也不会被修改,其中只有一个服务器写入。auto_increment_increment并auto_increment_offset影响AUTO_INCREMENT列行为,如下所示:-
auto_increment_increment控制连续列值之间的间隔。 例如:MySQL的>
SHOW VARIABLES LIKE 'auto_inc%';+ -------------------------- + ------- + | Variable_name | 价值| + -------------------------- + ------- + | auto_increment_increment | 1 | | auto_increment_offset | 1 | + -------------------------- + ------- + 2行(0.00秒) mysql>CREATE TABLE autoinc1- >(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);查询正常,0行受影响(0.04秒) MySQL的>SET @@auto_increment_increment=10;查询正常,0行受影响(0.00秒) MySQL的>SHOW VARIABLES LIKE 'auto_inc%';+ -------------------------- + ------- + | Variable_name | 价值| + -------------------------- + ------- + | auto_increment_increment | 10 | | auto_increment_offset | 1 | + -------------------------- + ------- + 2行(0.01秒) MySQL的>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);查询OK,4行受影响(0.00秒) 记录:4个重复:0警告:0 MySQL的>SELECT col FROM autoinc1;+ ----- + | col | + ----- + | 1 | | 11 | | 21 | | 31 | + ----- + 4行(0.00秒) -
auto_increment_offset确定AUTO_INCREMENT列值 的起点 。 请考虑以下情况,假设这些语句在与以下描述中给出的示例相同的会话期间执行auto_increment_increment:MySQL的>
SET @@auto_increment_offset=5;查询正常,0行受影响(0.00秒) MySQL的>SHOW VARIABLES LIKE 'auto_inc%';+ -------------------------- + ------- + | Variable_name | 价值| + -------------------------- + ------- + | auto_increment_increment | 10 | | auto_increment_offset | 5 | + -------------------------- + ------- + 2行(0.00秒) mysql>CREATE TABLE autoinc2- >(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);查询正常,0行受影响(0.06秒) MySQL的>INSERT INTO autoinc2 VALUES (NULL), (NULL), (NULL), (NULL);查询OK,4行受影响(0.00秒) 记录:4个重复:0警告:0 MySQL的>SELECT col FROM autoinc2;+ ----- + | col | + ----- + | 5 | | 15 | | 25 | | 35 | + ----- + 4行(0.02秒)当值
auto_increment_offset大于auto_increment_increment的值时,auto_increment_offset忽略 值 。
如果更改了这些变量中的任何一个,然后将新行插入到包含
AUTO_INCREMENT列 的表中 ,则结果可能看似违反直觉,因为AUTO_INCREMENT计算 一系列 值时不考虑列中已存在的任何值,并且插入的下一个值是系列中的最小值大于AUTO_INCREMENT列中 的最大现有值 。 该系列计算如下:auto_increment_offset+N×auto_increment_incrementwhere
N是系列[1,2,3,...]中的正整数值。 例如:MySQL的>
SHOW VARIABLES LIKE 'auto_inc%';+ -------------------------- + ------- + | Variable_name | 价值| + -------------------------- + ------- + | auto_increment_increment | 10 | | auto_increment_offset | 5 | + -------------------------- + ------- + 2行(0.00秒) MySQL的>SELECT col FROM autoinc1;+ ----- + | col | + ----- + | 1 | | 11 | | 21 | | 31 | + ----- + 4行(0.00秒) MySQL的>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);查询OK,4行受影响(0.00秒) 记录:4个重复:0警告:0 MySQL的>SELECT col FROM autoinc1;+ ----- + | col | + ----- + | 1 | | 11 | | 21 | | 31 | | 35 | | 45 | | 55 | | 65 | + ----- + 8行(0.00秒)显示的值
auto_increment_increment和auto_increment_offset生成系列5 +N×10,即[5,15,25,35,45,...]。 在col列之前 的 列中 出现的最高值为INSERT31,并且该AUTO_INCREMENT系列中 的下一个可用值为 35,因此插入的值col在该点开始,结果如SELECT查询 所示 。不可能将这两个变量的影响限制在一个表中; 这些变量控制 MySQL服务器上 所有 表 中所有
AUTO_INCREMENT列 的行为 。 如果设置了任一变量的全局值,则通过设置会话值或直到 重新启动 mysqld ,其效果将持续到全局值更改或覆盖为止 。 如果设置了本地值,则新值将影响 当前用户在会话期间向其插入新行的所有表的列,除非在该会话期间更改了值。AUTO_INCREMENT默认值为
auto_increment_increment1.请参见 第17.4.1.1节“复制和AUTO_INCREMENT” 。 -
-
属性 值 命令行格式 --auto-increment-offset=#系统变量 auto_increment_offset范围 全球,会议 动态 是 SET_VAR提示适用是 类型 整数 默认值 1最低价值 1最大价值 65535此变量的默认值为1.如果保留其默认值,并且在多主模式下在服务器上启动组复制,则会将其更改为服务器ID。 有关更多信息,请参阅说明
auto_increment_increment。从MySQL 8.0.14开始,设置此系统变量的会话值是一种受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
注意auto_increment_offset也支持与NDB表 一起使用 。 -
属性 值 介绍 8.0.14 系统变量 immediate_server_version范围 会议 动态 是 SET_VAR提示适用没有 类型 整数 供复制内部使用。 此会话系统变量保存服务器的MySQL服务器版本号,该服务器是复制拓扑中的直接主服务器(例如,
80014对于MySQL 8.0.14服务器实例)。 如果此即时服务器处于不支持会话系统变量的发行版中,则该变量的值将设置为0(UNKNOWN_SERVER_VERSION)。变量的值从主服务器复制到从服务器。 利用此信息,从属设备可以通过识别所涉及的版本之间发生语法更改或语义更改的位置并适当地处理这些数据,来正确处理源自旧版本的主数据的数据。 此信息还可以在组复制环境中使用,其中复制组的一个或多个成员处于比其他成员更新的版本。 可以在二进制日志中查看每个事务的变量值(作为
Gtid_log_event,或的 一部分)Anonymous_gtid_log_event如果GTID没有在服务器上使用),并且可能有助于调试跨版本复制问题。设置此系统变量的会话值是受限制的操作。 请参见 第5.1.9.1节“系统变量权限” 。 但是,请注意该变量不是供用户设置的; 它由复制基础结构自动设置。
-
属性 值 介绍 8.0.14 系统变量 original_server_version范围 会议 动态 是 SET_VAR提示适用没有 类型 整数 供复制内部使用。 此会话系统变量保存最初提交事务的服务器的MySQL Server版本号(例如,
80014对于MySQL 8.0.14服务器实例)。 如果此原始服务器处于不支持会话系统变量的发行版中,则该变量的值将设置为0(UNKNOWN_SERVER_VERSION)。 请注意,当原始服务器设置版本号时,如果复制拓扑中的直接服务器或任何其他中间服务器不支持会话系统变量,则变量的值将重置为0,因此不会复制其值。以与
immediate_server_version系统变量 相同的方式设置和使用 变量的值。 如果变量的值与immediate_server_version系统变量 的值相同 ,则只有后者记录在二进制日志中,并指示原始服务器版本相同。在组复制环境中,视图更改日志事件(即新成员加入组时由每个组成员排队的特殊事务)使用排队事务的组成员的服务器版本进行标记。 这确保了加入成员已知原始捐赠者的服务器版本。 由于排队等待特定视图更改的视图更改日志事件在所有成员上具有相同的GTID,因此仅对于此情况,同一GTID的实例可能具有不同的原始服务器版本。
设置此系统变量的会话值是受限制的操作。 请参见 第5.1.9.1节“系统变量权限” 。 但是,请注意该变量不是供用户设置的; 它由复制基础结构自动设置。
-
属性 值 命令行格式 --rpl-semi-sync-master-enabled[={OFF|ON}]系统变量 rpl_semi_sync_master_enabled范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF控制是否在主服务器上启用半同步复制。 要启用或禁用插件,请将此变量 分别 设置为
ON或OFF(或1或0)。 默认是OFF。仅当安装了主端半同步复制插件时,此变量才可用。
-
属性 值 命令行格式 --rpl-semi-sync-master-timeout=#系统变量 rpl_semi_sync_master_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10000一个以毫秒为单位的值,用于控制主机在超时并恢复到异步复制之前等待提交来自从机的确认的时间。 默认值为10000(10秒)。
仅当安装了主端半同步复制插件时,此变量才可用。
-
rpl_semi_sync_master_trace_level属性 值 命令行格式 --rpl-semi-sync-master-trace-level=#系统变量 rpl_semi_sync_master_trace_level范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 32主服务器上的半同步复制调试跟踪级别。 定义了四个级别:
-
1 =一般级别(例如,时间函数失败)
-
16 =详细程度(更详细的信息)
-
32 =净等待级别(有关网络等待的更多信息)
-
64 =功能级别(有关功能进入和退出的信息)
仅当安装了主端半同步复制插件时,此变量才可用。
-
-
rpl_semi_sync_master_wait_for_slave_count属性 值 命令行格式 --rpl-semi-sync-master-wait-for-slave-count=#系统变量 rpl_semi_sync_master_wait_for_slave_count范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1最低价值 1最大价值 65535主服务器必须在继续之前必须接收的从服务确认数。 缺省情况下
rpl_semi_sync_master_wait_for_slave_count是1,这意味着接收一个从机确认之后半同步复制进行。 性能最适合此变量的小值。例如,如果
rpl_semi_sync_master_wait_for_slave_count是2,那么2个从属服务器必须在rpl_semi_sync_master_timeout为半同步复制 配置的超时时间段之前确认收到事务 。 如果较少的从站在超时期间确认收到了该事务,则主站将恢复正常复制。注意这种行为也取决于
rpl_semi_sync_master_wait_no_slave仅当安装了主端半同步复制插件时,此变量才可用。
-
rpl_semi_sync_master_wait_no_slave属性 值 命令行格式 --rpl-semi-sync-master-wait-no-slave[={OFF|ON}]系统变量 rpl_semi_sync_master_wait_no_slave范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON控制主服务器是否等待配置的超时时间
rpl_semi_sync_master_timeout到期,即使从属计数降至小于 超时期间配置 的从属数量rpl_semi_sync_master_wait_for_slave_count。当的值
rpl_semi_sync_master_wait_no_slave是ON(缺省值),用于从属计数下降到小于它是允许rpl_semi_sync_master_wait_for_slave_count在超时期限内。 只要有足够的从服务器在超时期限到期之前确认事务,就会继续进行半同步复制。当的值
rpl_semi_sync_master_wait_no_slave是OFF,如果从计数下降到小于配置在数rpl_semi_sync_master_wait_for_slave_count期间由配置的超时时间段在任何时候rpl_semi_sync_master_timeout,主恢复到正常的复制。仅当安装了主端半同步复制插件时,此变量才可用。
-
rpl_semi_sync_master_wait_point属性 值 命令行格式 --rpl-semi-sync-master-wait-point=value系统变量 rpl_semi_sync_master_wait_point范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 AFTER_SYNC有效值 AFTER_SYNCAFTER_COMMIT此变量控制半同步复制主机在将状态返回到提交事务的客户机之前等待事务接收的从机确认的点。 允许这些值:
-
AFTER_SYNC(默认值):主服务器将每个事务写入其二进制日志和从服务器,并将二进制日志同步到磁盘。 主机在同步后等待从机确认事务接收。 收到确认后,主服务器将事务提交给存储引擎并将结果返回给客户端,然后客户端可以继续。 -
AFTER_COMMIT:主服务器将每个事务写入其二进制日志和从服务器,同步二进制日志,并将事务提交到存储引擎。 提交后,主设备等待事务接收的从设备确认。 收到确认后,主服务器将结果返回给客户端,然后客户端可以继续。
这些设置的复制特征如下:
-
使用时
AFTER_SYNC,所有客户端同时看到已提交的事务:从服务器确认并提交到主服务器上的存储引擎之后。 因此,所有客户端都在主服务器上看到相同的数据。如果主站发生故障,则在主站上提交的所有事务都已复制到从站(保存到其中继日志)。 主服务器和故障转移到从服务器的崩溃是无损的,因为从服务器是最新的。 但请注意,在此方案中无法重新启动主服务器并且必须将其丢弃,因为其二进制日志可能包含未提交的事务,这些事务会在二进制日志恢复后外部化时导致与从服务器冲突。
-
使用
AFTER_COMMIT,发出事务的客户端仅在服务器提交到存储引擎并接收从属确认后才获得返回状态。 在提交之后和从属确认之前,其他客户端可以在提交客户端之前查看已提交的事务。如果出现问题导致从设备不处理事务,那么在主设备崩溃和故障转移到从设备的情况下,这些客户端可能会看到相对于他们在主设备上看到的数据丢失。
仅当安装了主端半同步复制插件时,此变量才可用。
随着
rpl_semi_sync_master_wait_pointMySQL 5.7的增加,创建了版本兼容性约束,因为它增加了半同步接口版本:MySQL 5.7及更高版本的服务器不能与旧版本的半同步复制插件一起使用,旧版本的服务器也不能与半同步复制插件一起使用适用于MySQL 5.7及更高版本。 -
本节介绍适用于从属复制服务器的服务器选项和系统变量,并包含以下内容:
在
命令行
或
选项文件
中指定
选项
。
使用该
CHANGE
MASTER TO
语句
可以在服务器运行时设置许多选项
。
使用指定系统变量值
SET
。
服务器ID。
在主服务器和每个从服务器上,必须使用该
server-id
选项来建立1到2
32
到1之间的唯一复制ID
。
“
唯一
”
表示每个ID必须与任何其他复制主服务器使用的每个其他ID不同或奴隶。
示例
my.cnf
文件:
的[mysqld] 服务器ID = 3
本节介绍用于控制复制从属服务器的启动选项。
通过使用该
CHANGE
MASTER TO
语句,
可以在服务器运行时设置其中许多选项
。
其他
--replicate-*
选项
(例如
选项)只能在从属服务器启动时设置。
与复制相关的系统变量将在本节后面讨论。
-
属性 值 命令行格式 --log-slave-updates[={OFF|ON}]系统变量 log_slave_updates范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 (> = 8.0.3) ON默认值 (<= 8.0.2) OFF此选项使从服务器写入更新,这些更新是从主服务器接收的,并由从服务器的SQL线程执行到从属的自己的二进制日志。
--log-bin必须在从站上启用由选项 控制 并且默认启用的 二进制日志记录,以便记录 更新。--log-slave-updates默认情况下启用,除非您指定--skip-log-bin禁用二进制日志记录,在这种情况下,MySQL还会默认禁用从站更新日志记录。 如果在启用二进制日志记录时需要禁用从站更新日志记录,请指定--skip-log-slave-updates。--log-slave-updates使复制服务器可以链接。 例如,您可能希望使用以下安排设置复制服务器:A - > B - > C.
在这里,
A作为奴隶的主人B,并B作为奴隶的主人C。 为此,B必须是主人 和 奴隶。 通过二进制日志记录和--log-slave-updates启用选项(默认设置),接收到的更新A将记录B到其二进制日志中,因此可以传递给C。 -
属性 值 命令行格式 --master-info-file=file_name类型 文件名 默认值 master.info主信息日志的名称,如果
--master-info-repository=FILE已设置。 默认名称master.info位于数据目录中。--master-info-repository=FILE现已弃用。 有关主信息日志的信息,请参见 第17.2.4.2节“从属状态日志” 。 -
属性 值 命令行格式 --master-retry-count=#弃用 是 类型 整数 默认值 86400最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295在放弃之前,从设备尝试重新连接到主设备的次数。 默认值为86400次。 值0表示 “ 无限 ” ,从站尝试永久连接。 当从站达到其连接超时(由
--slave-net-timeout选项 指定 )而不接收来自主站的数据或心跳信号 时,将触发重新连接尝试 。MASTER_CONNECT_RETRY按照CHANGE MASTER TO语句 选项 设置的间隔尝试重新连接 (默认为每60秒)。此选项已弃用,将在以后的MySQL版本中删除。 请改用 语句
MASTER_RETRY_COUNT选项CHANGE MASTER TO。 -
属性 值 命令行格式 --max-relay-log-size=#系统变量 max_relay_log_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1073741824服务器自动轮换中继日志文件的大小。 如果此值非零,则当其大小超过此值时,将自动轮换中继日志。 如果此值为零(默认值),则中继日志轮换发生的大小由值决定
max_binlog_size。 有关更多信息,请参见 第17.2.4.1节“从站中继日志” 。 -
属性 值 命令行格式 --relay-log=file_name系统变量 relay_log范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 中继日志的基本名称。 服务器通过向基本名称添加数字后缀来按顺序创建中继日志文件。
对于默认复制通道,中继日志的默认基本名称是
host_name-relay-binhost_name-relay-bin-channelchannel中继日志文件的默认位置是数据目录。 您可以使用该
--relay-log选项指定备用位置,方法是在基本名称中添加前导绝对路径名以指定其他目录。复制服务器上的中继日志和中继日志索引的名称不能与二进制日志和二进制日志索引相同,其名称由
--log-bin和--log-bin-index选项 指定 。 服务器发出错误消息,如果二进制日志和中继日志文件基本名称相同,则不会启动。由于MySQL解析服务器选项的方式,如果指定此选项,则必须提供值; 仅当未实际指定选项时才使用默认基本名称 。 如果在
--relay-log未指定值的情况下 使用该 选项,则可能会导致意外行为; 此行为取决于使用的其他选项,指定它们的顺序,以及它们是在命令行还是在选项文件中指定的。 有关MySQL如何处理服务器选项的更多信息,请参见 第4.2.2节“指定程序选项” 。如果指定此选项,则指定的值也将用作中继日志索引文件的基本名称。 您可以通过使用该
--relay-log-index选项 指定其他中继日志索引文件基本名称来覆盖此行为 。当服务器从索引文件中读取条目时,它会检查条目是否包含相对路径。 如果是,则使用该
--relay-log选项 将路径的相对部分替换为设置的绝对路径 。 绝对路径保持不变; 在这种情况下,必须手动编辑索引以启用新路径。 以前,每次重定位二进制日志或中继日志文件时都需要手动干预。 (Bug#11745230,Bug#12133)您可能会发现该
--relay-log选项对执行以下任务很有用:-
创建名称独立于主机名的中继日志。
-
如果您需要将中继日志放在数据目录以外的某个区域,因为您的中继日志往往非常大并且您不想减少
max_relay_log_size。 -
通过在磁盘之间使用负载平衡来提高速度。
您可以从
relay_log_basename系统变量中 获取中继日志文件名(和路径) 。 -
-
属性 值 命令行格式 --relay-log-index=file_name系统变量 relay_log_index范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 中继日志索引文件的名称。 如果未指定该
--relay-log-index选项,但 指定了该 选项,--relay-log则其值将用作中继日志索引文件的缺省基本名称。 如果--relay-log未指定 该 选项,则对于默认复制通道,默认名称为host_name-relay-bin.indexhost_name-relay-bin-channel.indexchannel中继日志文件的缺省位置是数据目录,或使用该
--relay-log选项 指定的任何其他位置 。 您可以使用该--relay-log-index选项指定备用位置,方法是在基本名称中添加前导绝对路径名以指定其他目录。复制服务器上的中继日志和中继日志索引的名称不能与二进制日志和二进制日志索引相同,其名称由
--log-bin和--log-bin-index选项 指定 。 服务器发出错误消息,如果二进制日志和中继日志文件基本名称相同,则不会启动。由于MySQL解析服务器选项的方式,如果指定此选项,则必须提供值; 仅当未实际指定选项时才使用默认基本名称 。 如果在
--relay-log-index未指定值的情况下 使用该 选项,则可能会导致意外行为; 此行为取决于使用的其他选项,指定它们的顺序,以及它们是在命令行还是在选项文件中指定的。 有关MySQL如何处理服务器选项的更多信息,请参见 第4.2.2节“指定程序选项” 。 -
--relay-log-info-file=file_name属性 值 命令行格式 --relay-log-info-file=file_name类型 文件名 默认值 relay-log.info中继日志信息文件的名称,如果
--relay-log-info-repository设置为FILE。 默认名称relay-log.info位于数据目录中。--relay-log-info-repository=FILE现已弃用。 有关中继日志信息日志的信息,请参见 第17.2.4.2节“从属状态日志” 。 -
属性 值 命令行格式 --relay-log-purge[={OFF|ON}]系统变量 relay_log_purge范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON一旦不再需要,就禁用或启用自动清除中继日志。 默认值为1(启用)。 这是一个可以动态更改的全局变量 。 使用该 选项 时禁用中继日志清除 可能会导致数据一致性,因此不会出现崩溃安全问题。
SET GLOBAL relay_log_purge =N--relay-log-recovery -
属性 值 命令行格式 --relay-log-recovery[={OFF|ON}]类型 布尔 默认值 OFF在服务器启动后立即启用自动中继日志恢复。 恢复过程会创建一个新的中继日志文件,将SQL线程位置初始化为此新的中继日志,并将I / O线程初始化为SQL线程位置。 然后继续从主站读取中继日志。 这应该在复制从站崩溃后使用,以确保不会处理可能损坏的中继日志。 默认值为0(禁用)。
要提供防碰撞从站,必须启用此选项(设置为1),
--relay-log-info-repository必须将其设置为TABLE,并且relay-log-purge必须启用 此选项 。 启用--relay-log-recovery选项时,relay-log-purge被禁用的风险从没有清除文件中读取中继日志,从而导致数据不一致,因此是不会崩溃安全。 有关 详细信息, 请参阅 使复制适应意外暂停 。使用多线程从站(换句话说
slave_parallel_workers,大于0)时,从中继日志执行的事务序列中可能会出现间隙等不一致。--relay-log-recovery当存在不一致时 启用该 选项会导致错误,该选项无效。 这种情况下的解决方案是发布START SLAVE UNTIL SQL_AFTER_MTS_GAPS,它使服务器处于更一致的状态,然后发出RESET SLAVE删除中继日志的问题。 有关 更多信息 , 请参见 第17.4.1.33节“复制和事务不一致” 。 -
属性 值 命令行格式 --relay-log-space-limit=#系统变量 relay_log_space_limit范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295此选项对从站上所有中继日志的总大小(以字节为单位)设置上限。 值为0表示 “ 无限制 ” 。 这对于磁盘空间有限的从属服务器主机很有用。 达到限制时,I / O线程将停止从主服务器读取二进制日志事件,直到SQL线程赶上并删除了一些未使用的中继日志。 请注意,此限制不是绝对的:在某些情况下,SQL线程在删除中继日志之前需要更多事件。 在这种情况下,I / O线程超出限制,直到SQL线程可以删除某些中继日志,因为不这样做会导致死锁。 您不应该设置
--relay-log-space-limit为小于--max-relay-log-size(或--max-binlog-size如果) 的值的两倍--max-relay-log-size是0)。 在这种情况下,I / O线程有可能因为--relay-log-space-limit超出而 等待可用空间 ,但SQL线程没有要清除的中继日志,并且无法满足I / O线程。 这会强制I / O线程--relay-log-space-limit暂时 忽略 。 -
属性 值 命令行格式 --replicate-do-db=name类型 串 使用数据库名称创建复制筛选器。 也可以使用这样的过滤器创建
CHANGE REPLICATION FILTER REPLICATE_DO_DB。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-do-db:channel_1:db_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。此复制筛选器的确切效果取决于是使用基于语句还是基于行的复制。
基于语句的复制。 告诉从SQL线程限制复制到报表,其中默认的数据库(即,由选定的一个
USE)是db_name。 要指定多个数据库,请多次使用此选项,每个数据库使用一次; 但是,这样做 不会 复制跨数据库语句,例如 在选择不同的数据库(或没有数据库)时。UPDATEsome_db.some_tableSET foo='bar'警告要指定多个数据库, 必须 使用此选项的多个实例。 因为数据库名称可以包含逗号,所以如果提供以逗号分隔的列表,则该列表将被视为单个数据库的名称。
使用基于语句的复制时无法正常工作的示例:如果从属服务器启动
--replicate-do-db=sales并且您在主服务器上发出以下语句,UPDATE则 不会 复制 语句 :使用价格; 更新sales.january SET金额=金额+ 1000;
这种 “ 仅检查默认数据库 ” 行为的 主要原因 是,仅从语句中就很难知道是否应该复制它(例如,如果您使用多表
DELETE语句或多表UPDATE语句跨多个数据库)。 如果不需要,只检查默认数据库而不是所有数据库也更快。基于行的复制。 告诉从属SQL线程限制复制到数据库
db_name。 只有属于的表db_name被更改; 当前数据库对此没有影响。 假设从属服务器启动--replicate-do-db=sales并且基于行的复制生效,然后在主服务器上运行以下语句:使用价格; UPDATE sales.february SET amount = amount + 100;
从属数据库中 的
february表sales根据UPDATE语句进行 更改 ; 无论USE声明 是否 已发布,都会 发生这种情况 。 但是,在使用基于行的复制时,在主服务器上发出以下语句对从服务器没有影响,并且--replicate-do-db=sales:使用价格; 更新price.march SET金额=金额-25;
即使声明
USE prices改为USE sales,UPDATE声明的效果仍然不会被复制。--replicate-do-db对于引用多个数据库的语句,基于语句的复制与基于行的复制相比,处理方式的 另一个重要区别 。 假设从属服务器启动--replicate-do-db=db1,并在主服务器上执行以下语句:使用db1; UPDATE db1.table1 SET col1 = 10,db2.table2 SET col2 = 20;
如果使用基于语句的复制,则会在从属服务器上更新这两个表。 但是,使用基于行的复制时,只会
table1受到奴隶的影响; 因为table2是在不同的数据库中,table2所以奴隶不会被改变UPDATE。 现在假设 使用USE db1了一个USE db4语句 而不是 语句 :使用db4; UPDATE db1.table1 SET col1 = 10,db2.table2 SET col2 = 20;
在这种情况下,
UPDATE使用基于语句的复制时 ,该 语句对从站没有影响。 但是,如果使用基于行的复制,UPDATE则会table1在从属服务器上进行 更改 ,但不会table2- 但 也就是说,只--replicate-do-db更改 了名为的数据库中的表 ,并且选择默认数据库对此行为没有影响。如果需要跨数据库更新才能工作,请 改用。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。
--replicate-wild-do-table=db_name.%注意此选项以
--binlog-do-db影响二进制日志记录 的相同方式影响复制, 复制格式对--replicate-do-db影响复制行为的影响与对行为的日志记录格式的影响相同--binlog-do-db。 -
属性 值 命令行格式 --replicate-ignore-db=name类型 串 使用数据库名称创建复制筛选器。 也可以使用这样的过滤器创建
CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-ignore-db:channel_1:db_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。要指定要忽略的多个数据库,请多次使用此选项,每个数据库使用一次。 因为数据库名称可以包含逗号,所以如果提供以逗号分隔的列表,则该列表将被视为单个数据库的名称。
与此同时
--replicate-do-db,此过滤的确切效果取决于是使用基于语句还是基于行的复制,并在接下来的几段中进行了描述。基于语句的复制。 告诉slave SQL线程不会复制任何声明,其中默认的数据库(即,由选定的一个
USE)是db_name。基于行的复制。 告诉从属SQL线程不更新数据库中的任何表
db_name。 默认数据库无效。使用基于语句的复制时,以下示例无法正常工作。 假设从属服务器启动
--replicate-ignore-db=sales并在主服务器上发出以下语句:使用价格; 更新sales.january SET金额=金额+ 1000;
该
UPDATE声明 是 在这种情况下复制,因为--replicate-ignore-db只适用于默认数据库(由确定的USE语句)。 由于sales数据库是在语句中显式指定的,因此该语句尚未过滤。 但是,使用基于行的复制时,UPDATE语句的效果 不会 传播到从属,并且表的从属副本sales.january不会更改。 在这种情况下,--replicate-ignore-db=sales导致 对主副本中的表所做的 所有 更改sales数据库被奴隶忽略。如果您使用跨数据库更新并且不希望复制这些更新,则不应使用此选项。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。
如果需要跨数据库更新才能工作,请 改用。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。
--replicate-wild-ignore-table=db_name.%注意此选项以
--binlog-ignore-db影响二进制日志记录 的相同方式影响复制, 复制格式对--replicate-ignore-db影响复制行为的影响与对行为的日志记录格式的影响相同--binlog-ignore-db。 -
--replicate-do-table=db_name.tbl_name属性 值 命令行格式 --replicate-do-table=name类型 串 通过告知从属SQL线程将复制限制到给定表来创建复制筛选器。 要指定多个表,请多次使用此选项,每个表使用一次。 与之相反,这适用于跨数据库更新和默认数据库更新
--replicate-do-db。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。 您还可以通过发出CHANGE REPLICATION FILTER REPLICATE_DO_TABLE语句 来创建此类过滤器 。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-do-table:channel_1:db_name.tbl_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。此选项仅影响适用于表的语句。 它不会影响仅适用于其他数据库对象的语句,例如存储的例程。 要过滤在存储例程上运行的语句,请使用一个或多个
--replicate-*-db选项。 -
--replicate-ignore-table=db_name.tbl_name属性 值 命令行格式 --replicate-ignore-table=name类型 串 通过告知从属SQL线程不复制任何更新指定表的语句来创建复制过滤器,即使任何其他表可能由同一语句更新。 要指定多个要忽略的表,请多次使用此选项,每个表一次。 与之相反,这适用于跨数据库更新
--replicate-ignore-db。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。 您还可以通过发出CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE语句 来创建此类过滤器 。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-ignore-table:channel_1:db_name.tbl_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。此选项仅影响适用于表的语句。 它不会影响仅适用于其他数据库对象的语句,例如存储的例程。 要过滤在存储例程上运行的语句,请使用一个或多个
--replicate-*-db选项。 -
--replicate-rewrite-db=from_name->to_name属性 值 命令行格式 --replicate-rewrite-db=old_name->new_name类型 串 告诉从创建转换的默认数据库复制过滤器(即,通过选择的一个
USE),以to_name如果它是from_name在主。 只有涉及表的语句才会受到影响(不是语句,如CREATE DATABASE,DROP DATABASE和ALTER DATABASE),并且只有from_name在主服务器上是默认数据库时 才会 受到影响 。 要指定多次重写,请多次使用此选项。 服务器使用第一个from_name匹配值 的服务器 。 数据库名称转换在 之前 完成--replicate-*规则经过测试。 您还可以通过发出CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB语句 来创建此类过滤器 。如果在命令行中使用此选项,并且该
>字符对于命令解释程序是特殊的,请引用选项值。 例如:外壳>
mysqld --replicate-rewrite-db="olddb->newdb"此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 指定通道名称后跟冒号,然后指定过滤器规范。 第一个冒号被解释为分隔符,任何后续冒号都被解释为文字冒号。 例如,在名为的通道上配置通道特定的复制筛选器
channel_1,请使用:外壳>
mysqld --replicate-rewrite-db=channel_1:db_name1->db_name2如果使用冒号但未指定通道名称,则该选项会为默认复制通道配置复制筛选器。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。
注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。使用此选项时表名使用数据库名限定的语句不适用于表级复制过滤选项,例如
--replicate-do-table。 假设我们有一个a在master上 命名的数据库 ,一个b在slave上 命名 ,每个包含一个表t,并且已经启动了master--replicate-rewrite-db='a->b'。 在稍后的时间点,我们执行DELETE FROM a.t。 在这种情况下,没有相关的过滤规则有效,原因如下:-
--replicate-do-table=a.t因为slavet在数据库中 有表 , 所以不起作用b。 -
--replicate-do-table=b.t与原始语句不匹配,因此被忽略。 -
--replicate-do-table=*.t处理方式相同--replicate-do-table=a.t,因此也不起作用。
同样,该
--replication-rewrite-db选项不适用于跨数据库更新。 -
-
属性 值 命令行格式 --replicate-same-server-id[={OFF|ON}]类型 布尔 默认值 OFF此选项适用于复制从属服务器。 默认值为0(
FALSE)。 如果将此选项设置为1(TRUE),则从属设备不会跳过具有自己的服务器ID的事件。 此设置通常仅在罕见配置中有用。在复制从站上启用二进制日志记录时, 如果服务器是循环复制拓扑的一部分,则从属服务器上 的
--replicate-same-server-id和--log-slave-updates选项 组合 可能会导致复制中出现无限循环。 (在MySQL 8.0中,默认情况下启用二进制日志记录,启用二进制日志记录时,从属更新日志记录是默认值。)但是,使用全局事务标识符(GTID)可以通过跳过已经执行的事务来防止这种情况应用。 如果gtid_mode=ON在从站上设置,您可以使用此组合选项启动服务器,但在服务器运行时无法更改为任何其他GTID模式。 如果设置了任何其他GTID模式,则服务器不会以此选项组合启动。默认情况下,如果从属I / O线程具有从属服务器ID(此优化有助于节省磁盘使用),则从属I / O线程不会将二进制日志事件写入中继日志。 如果要使用
--replicate-same-server-id,请确保在使从属设备读取您希望从属SQL线程执行的事件之前,使用此选项启动从属设备。 -
--replicate-wild-do-table=db_name.tbl_name属性 值 命令行格式 --replicate-wild-do-table=name类型 串 通过告知从属线程将复制限制为任何更新的表与指定的数据库和表名模式匹配的语句来创建复制过滤器。 模式可以包含 通配符
%和_通配符,其含义与LIKE模式匹配运算符的 含义相同 。 要指定多个表,请多次使用此选项,每个表使用一次。 这适用于跨数据库更新。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。 您还可以通过发出CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE语句 来创建此类过滤器 。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-wild-do-table:channel_1:db_name.tbl_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。此选项适用于表,视图和触发器。 它不适用于存储过程和函数或事件。 要过滤对后一个对象进行操作的语句,请使用一个或多个
--replicate-*-db选项。例如,
--replicate-wild-do-table=foo%.bar%仅复制使用数据库名称以foo表开头且表名开头的表的更新bar。如果表名称模式
%,它匹配任何表名和选项也适用于数据库级的语句(CREATE DATABASE,DROP DATABASE,和ALTER DATABASE)。 例如,如果使用--replicate-wild-do-table=foo%.%,则在数据库名称与模式匹配时复制数据库级语句foo%。要在数据库或表名模式中包含文字通配符,请使用反斜杠对其进行转义。 例如,要复制已命名
my_own%db但不从my1ownAABCdb数据库 复制表的 数据库的 所有表 ,您应该转义_和这样的%字符:--replicate-wild-do-table=my\_own\%db。 如果在命令行上使用该选项,则可能需要将反斜杠加倍或引用选项值,具体取决于命令解释程序。 例如,使用 bash shell,您需要键入--replicate-wild-do-table=my\\_own\\%db。 -
--replicate-wild-ignore-table=db_name.tbl_name属性 值 命令行格式 --replicate-wild-ignore-table=name类型 串 创建一个复制过滤器,使从属线程不会复制任何表与给定通配符模式匹配的语句。 要指定多个要忽略的表,请多次使用此选项,每个表一次。 这适用于跨数据库更新。 请参见 第17.2.5节“服务器如何评估复制过滤规则” 。 您还可以通过发出
CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE语句 来创建此类过滤器 。此选项支持特定于通道的复制过滤器,使多源复制从属服务器可以为不同的源使用特定的过滤器。 在名为
channel_1use 的通道上配置通道特定的复制筛选器 。 在这种情况下,第一个冒号被解释为分隔符,随后的冒号是文字冒号。 有关 更多信息 , 请参见 第17.2.5.4节“基于复制通道的过滤器” 。--replicate-wild-ignore:channel_1:db_name.tbl_name注意全局复制筛选器不能在为组复制配置的MySQL服务器实例上使用,因为在某些服务器上筛选事务会使该组无法就一致状态达成协议。 特定于通道的复制筛选器可用于不直接与组复制相关的复制通道,例如,组成员还充当组外部主服务器的复制从属服务器。 他们不能对使用
group_replication_applier或group_replication_recovery通道。例如,
--replicate-wild-ignore-table=foo%.bar%不复制使用数据库名称以foo表开头且表名开头的表的更新bar。 有关匹配如何工作的信息,请参阅该--replicate-wild-do-table选项 的说明 。 在选项值中包含文字通配符的规则也是相同的--replicate-wild-ignore-table。 -
属性 值 命令行格式 --report-host=host_name系统变量 report_host范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 从站注册期间要向主站报告的从站的主机名或IP地址。 该值显示在
SHOW SLAVE HOSTS主服务器 的输出中 。 如果您不希望从站向主站注册自己,请保留未设置的值。注意主设备在从设备连接后从TCP / IP套接字中简单地读取从设备的IP地址是不够的。 由于NAT和其他路由问题,该IP可能无法从主服务器或其他主机连接到从服务器。
-
属性 值 命令行格式 --report-password=name系统变量 report_password范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 从站注册期间要向主站报告的从站的帐户密码。
SHOW SLAVE HOSTS如果主服务器已启动,则 此值将显示在 主服务器 的输出中--show-slave-auth-info。虽然此选项的名称可能暗示其他情况,
--report-password但未连接到MySQL用户权限系统,因此不一定(甚至可能)与MySQL复制用户帐户的密码相同。 -
属性 值 命令行格式 --report-port=port_num系统变量 report_port范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 [slave_port]最低价值 0最大价值 65535用于连接从站的TCP / IP端口号,在从站注册期间报告给主站。 仅当从站正在侦听非默认端口或者您有从主站或其他客户端到从站的特殊隧道时才设置此项。 如果您不确定,请不要使用此选项。
此选项的默认值是从站实际使用的端口号(Bug#13333431)。 这也是显示的默认值
SHOW SLAVE HOSTS。 -
属性 值 命令行格式 --report-user=name系统变量 report_user范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 从站注册期间要向主站报告的从站的帐户用户名。
SHOW SLAVE HOSTS如果主服务器已启动,则 此值将显示在 主服务器 的输出中--show-slave-auth-info。虽然此选项的名称可能暗示其他情况,
--report-user但未连接到MySQL用户权限系统,因此不一定(甚至可能)与MySQL复制用户帐户的名称相同。 -
属性 值 命令行格式 --slave-checkpoint-group=#类型 整数 默认值 512最低价值 32最大价值 524280块大小 8设置在调用检查点操作以更新其状态之前,多线程从站可以处理的最大事务数,如下所示
SHOW SLAVE STATUS。 设置此选项对未启用多线程的从站没有影响。注意NDB Cluster目前不支持多线程从站,它会静默忽略此选项的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
此选项与
--slave-checkpoint-period选项 结合使用, 以便在超过任一限制时执行检查点,并且计数器跟踪事务数和自上次检查点重置以来经过的时间。除非服务器是使用构建的,否则此选项的最小允许值为32,
-DWITH_DEBUG在这种情况下,最小值为1.有效值始终为8的倍数; 您可以将其设置为不是这样的倍数的值,但是在存储该值之前,服务器将其舍入到下一个较低的8的倍数。 ( 例外 :调试服务器不执行此类舍入。)无论服务器是如何构建的,默认值为512,允许的最大值为524280。 -
属性 值 命令行格式 --slave-checkpoint-period=#类型 整数 默认值 300最低价值 1最大价值 4G设置在调用检查点操作以更新多线程从站的状态之前允许通过的最长时间(以毫秒为单位),如下所示
SHOW SLAVE STATUS。 设置此选项对未启用多线程的从站没有影响。注意NDB Cluster目前不支持多线程从站,它会静默忽略此选项的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
此选项与
--slave-checkpoint-group选项 结合使用, 以便在超过任一限制时执行检查点,并且计数器跟踪事务数和自上次检查点重置以来经过的时间。此选项的最小允许值为1,除非服务器是使用构建的
-DWITH_DEBUG,在这种情况下最小值为0.无论服务器是如何构建的,默认值为300,最大可能值为4294967296(4GB) 。 -
属性 值 命令行格式 --slave-parallel-workers=#类型 整数 默认值 0最低价值 0最大价值 1024在从属设备上启用多线程,并设置从属应用程序线程的数量,以便并行执行复制事务。 当值是大于0的数字时,从属服务器是具有指定数量的应用程序线程的多线程从属服务器,以及用于管理它们的协调器线程。 如果您使用多个复制通道,则每个通道都具有此数量的线程。
在从站上启用多线程时,支持重试事务。 当
slave_preserve_commit_order=1从站上的事务以与从站的中继日志中出现的顺序相同的顺序在从站上外部化时。 在应用程序线程之间分配事务的方式由--slave-parallel-type。要禁用并行执行,请将此选项设置为0,这将为从属设备提供单个应用程序线程,而不是协调器线程。 使用此设置,
--slave-parallel-type和slave_preserve_commit_order选项无效,将被忽略。注意NDB Cluster目前不支持多线程从站,它会静默忽略此选项的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
-
--slave-pending-jobs-size-max=#属性 值 命令行格式 --slave-pending-jobs-size-max=#类型 整数 默认值 (> = 8.0.12) 128M默认值 (<= 8.0.11) 16M最低价值 1024最大价值 16EiB块大小 1024对于多线程从站,此选项设置可用于保存尚未应用的事件的从属工作队列的最大内存量(以字节为单位)。 设置此选项对未启用多线程的从站没有影响。
此选项的最小可能值为1024字节; 默认值为128MB。 最大可能值为18446744073709551615(16 exbibytes)。 在存储之前,不是1024字节的精确倍数的值向下舍入到1024字节的下一个较低倍数。
此变量的值是软限制,可以设置为与正常工作负载匹配。 如果异常大的事件超过此大小,则事务将一直保持到所有从属工作程序都有空队列,然后进行处理。 所有后续交易将持续到大型交易完成为止。
-
属性 值 命令行格式 --skip-slave-start[={OFF|ON}]类型 布尔 默认值 OFF告诉从服务器在服务器启动时不启动从属线程。 要在以后启动线程,请使用
START SLAVE语句。 -
属性 值 命令行格式 --slave-load-tmpdir=dir_name系统变量 slave_load_tmpdir范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 默认值 Value of --tmpdir从站创建临时文件的目录的名称。 默认情况下,此选项等于
tmpdir系统变量 的值 ,或者未指定系统变量时应用的默认值。 当从属SQL线程复制一个LOAD DATA语句,它将要从中继日志加载的文件提取到临时文件中,然后将这些文件加载到表中。 如果主服务器上加载的文件很大,那么从服务器上的临时文件也很庞大。 因此,建议使用此选项告诉从属服务器将临时文件放在位于具有大量可用空间的某个文件系统中的目录中。 在这种情况下,中继日志也很庞大,因此您可能还希望使用该--relay-log选项将中继日志放在该文件系统中。此选项指定的目录应位于基于磁盘的文件系统(而不是基于内存的文件系统)中,以便用于复制的临时文件
LOAD DATA可以在计算机重新启动后继续存在。 该目录也不应该是在系统启动过程中由操作系统清除的目录。 但是,如果已删除临时文件,则重新启动后现在可以继续复制。 -
slave-max-allowed-packet=bytes属性 值 命令行格式 --slave-max-allowed-packet=#类型 整数 默认值 1073741824最低价值 1024最大价值 1073741824此选项设置从属SQL和I / O线程可以处理的最大数据包大小(以字节为单位)。
max_allowed_packet添加事件标头后, 复制主机可以写入比其 设置 更长的二进制日志事件 。 设置slave_max_allowed_packet必须大于max_allowed_packet主服务器上 的 设置,因此使用基于行的复制进行的大型更新不会导致复制失败。相应的服务器变量
slave_max_allowed_packet的值始终为1024的正整数倍; 如果将其设置为某个不是倍数的值,则该值会自动向下舍入到1024的下一个最大倍数。(例如,如果启动服务器--slave-max-allowed-packet=10000,则使用的值为9216;将值设置为0导致1024被使用。)在这种情况下发出截断警告。最大(和默认)值为1073741824(1 GB); 最小值是1024。
-
属性 值 命令行格式 --slave-net-timeout=#系统变量 slave_net_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 60最低价值 1在从站认为连接断开之前等待来自主站的更多数据或心跳信号的秒数,中止读取并尝试重新连接。 默认值为60秒(一分钟)。 超时后立即进行第一次重试。 重试之间的间隔由 语句
MASTER_CONNECT_RETRY选项 控制CHANGE MASTER TO,重新连接尝试次数受 语句MASTER_RETRY_COUNT选项的 限制CHANGE MASTER TO。如果连接仍然良好,则在没有数据的情况下停止连接超时的心跳间隔由 语句 的
MASTER_HEARTBEAT_PERIOD选项 控制CHANGE MASTER TO。 心跳间隔默认为值的一半--slave-net-timeout,并记录在主信息日志中并显示在replication_connection_configuration性能架构表中。 请注意,更改值或默认设置--slave-net-timeout不会自动更改心跳间隔,无论是已明确设置还是使用先前计算的默认值。 如果更改了连接超时,则还必须发出CHANGE MASTER TO将心跳间隔调整为适当的值,以便在连接超时之前发生。 -
属性 值 命令行格式 --slave-parallel-type=type类型 列举 默认值 DATABASE有效值 DATABASELOGICAL_CLOCK使用多线程从站(
slave_parallel_workers大于0)时,此选项指定用于决定允许哪些事务在从站上并行执行的策略。 该选项对未启用多线程的从站没有影响。 可能的值是:-
LOGICAL_CLOCK:作为主服务器上相同二进制日志组提交的一部分的事务在从服务器上并行应用。 根据事务的时间戳跟踪事务之间的依赖关系,以便在可能的情况下提供额外的并行化。 设置此值时,binlog_transaction_dependency_tracking可以在主服务器上使用系统变量来指定写入集用于并行化而不是时间戳,如果写入集可用于事务并且与时间戳相比提供改进的结果。 -
DATABASE:并行应用更新不同数据库的事务。 仅当数据被分区为多个数据库时才适用此值,这些数据库在主服务器上独立且同时更新。 必须没有跨数据库约束,因为可能会在从属设备上违反这些约束。
何时
slave_preserve_commit_order=1设置,您只能使用LOGICAL_CLOCK。如果复制拓扑使用多个级别的从属,则
LOGICAL_CLOCK可能会为每个级别实现较少的并行化,从属远离主服务器。 您可以通过binlog_transaction_dependency_tracking在主服务器上 使用 来指定在可能的情况下使用写集来代替时间戳进行并行化 来减少此影响 。 -
-
slave-rows-search-algorithms=list属性 值 命令行格式 --slave-rows-search-algorithms=list类型 组 默认值 (> = 8.0.2) INDEX_SCAN,HASH_SCAN默认值 (<= 8.0.1) TABLE_SCAN,INDEX_SCAN有效值 TABLE_SCAN,INDEX_SCANINDEX_SCAN,HASH_SCANTABLE_SCAN,HASH_SCANTABLE_SCAN,INDEX_SCAN,HASH_SCAN(相当于INDEX_SCAN,HASH_SCAN)为基于行的日志记录和复制准备批量行时,此选项控制如何搜索行匹配,特别是是否使用散列扫描。 该选项设置
slave_rows_search_algorithms系统变量 的初始值 。指定以逗号分隔的2个值的列表中的以下组合的列表
INDEX_SCAN,TABLE_SCAN,HASH_SCAN。 对于该选项,无需引用列表,但不得包含空格,无论是否使用引号。 推荐的组合(列表)及其效果如下表所示:使用的索引/选项值 INDEX_SCAN,HASH_SCANINDEX_SCAN,TABLE_SCAN主键或唯一键 索引扫描 索引扫描 (其他)关键 哈希扫描索引 索引扫描 没有索引 哈希扫描 表扫描 -
默认值为
INDEX_SCAN,HASH_SCAN。 使用此设置,散列用于任何不使用主键或唯一键的搜索。 指定INDEX_SCAN,HASH_SCAN与 指定 具有相同的效果INDEX_SCAN,TABLE_SCAN,HASH_SCAN,这是允许的。 -
要删除散列,请设置
INDEX_SCAN,TABLE_SCAN。 使用此设置,所有可以使用索引的搜索都会使用它们,而没有任何索引的搜索会使用表扫描。 -
不要使用该组合
TABLE_SCAN,HASH_SCAN。 此设置强制对所有搜索进行散列。 它没有优势INDEX_SCAN,HASH_SCAN,并且 在包含对同一行的多个更新的单个事件或依赖于顺序的更新的情况下, 它可能导致 “ 记录未找到 ” 错误或重复键错误。
在列表中指定算法的顺序不会对它们由
SELECTorSHOW VARIABLES语句 显示的顺序产生任何影响 。可以指定单个值,但这不是最佳值,因为设置单个值会将搜索限制为仅使用该算法。 特别是,
INDEX_SCAN不推荐单独 设置 ,因为在这种情况下,如果不存在索引,则搜索根本无法找到行。 -
-
--slave-skip-errors=[err_code1,err_code2,...|all|ddl_exist_errors]属性 值 命令行格式 --slave-skip-errors=name系统变量 slave_skip_errors范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 OFF有效值 OFF[list of error codes]allddl_exist_errors通常,当从属设备发生错误时复制会停止,这使您有机会手动解决数据中的不一致问题。 当语句返回选项值中列出的任何错误时,此选项会使从属SQL线程继续复制。
除非您完全理解为什么会出现错误,否则请勿使用此选项。 如果复制设置和客户端程序中没有错误,并且MySQL本身没有错误,则永远不会发生停止复制的错误。 不加选择地使用此选项会导致奴隶与主人无法同步,你不知道为什么会发生这种情况。
对于错误代码,您应该使用从错误日志和输出中的错误消息提供的数字
SHOW SLAVE STATUS。 附录B, 错误,错误代码和常见问题 列出了服务器错误代码。速记值
ddl_exist_errors等同于错误代码列表1007,1008,1050,1051,1054,1060,1061,1068,1094,1146。您也可以(但不应该)使用非推荐的值
all来使从属设备忽略所有错误消息并继续运行,无论发生什么。 毋庸置疑,如果您使用all,则无法保证数据的完整性。 如果奴隶的数据与主人的数据不相近,请不要抱怨(或文件错误报告)。 你被警告过了 。例子:
--slave-跳过错误= 1062,1053 --slave-跳过错误= ALL --slave-跳过错误= ddl_exist_errors
-
--slave-sql-verify-checksum={0|1}属性 值 命令行格式 --slave-sql-verify-checksum[={OFF|ON}]类型 布尔 默认值 ON启用此选项后,从站会检查从中继日志中读取的校验和,如果不匹配,从站将停止并显示错误。
MySQL测试套件在内部使用以下选项进行复制测试和调试。 它们不适用于生产环境。
-
属性 值 命令行格式 --abort-slave-event-count=#类型 整数 默认值 0最低价值 0当此选项设置为
value0以外的 某个正整数 (默认值)时,它会影响复制行为,如下所示:从属SQL线程启动后,value允许执行日志事件; 之后,从属SQL线程不再接收任何事件,就像从主服务器的网络连接被切断一样。 从属线程继续运行,并且输出SHOW SLAVE STATUS显示Yes在 列Slave_IO_Running和Slave_SQL_Running列中,但不会从中继日志中读取其他事件。 -
--disconnect-slave-event-count属性 值 命令行格式 --disconnect-slave-event-count=#类型 整数 默认值 0
复制从站状态信息记录到
mysql
数据库中
的InnoDB表
。
在MySQL 8.0之前,此信息也可以记录到数据目录中的文件中,但现在不推荐使用该格式。
可以使用此处列出的两个服务器选项单独配置主信息日志和中继日志信息日志的写入:
-
--master-info-repository={TABLE|FILE}属性 值 命令行格式 --master-info-repository={FILE|TABLE}类型 串 默认值 (> = 8.0.2) TABLE默认值 (<= 8.0.1) FILE有效值 FILETABLE此选项确定从属服务器是否将主状态和连接信息记录到
mysql数据库中 的InnoDB表 或数据目录中的文件。默认设置为
TABLE。 作为InnoDB表,主信息日志被命名mysql.slave_master_info。TABLE配置多个复制通道时,需要进行 此 设置。该
FILE设置已弃用,将在以后的版本中删除。 作为文件,master.info默认情况下 会命名主信息日志 ,您可以使用该--master-info-file选项 更改此名称 。此从属状态日志的位置设置直接影响
sync_master_info系统变量 设置的效果 。 您只能在没有复制线程执行时更改设置。 -
--relay-log-info-repository={TABLE|FILE}属性 值 命令行格式 --relay-log-info-repository={FILE|TABLE}类型 串 默认值 (> = 8.0.2) TABLE默认值 (<= 8.0.1) FILE有效值 FILETABLE此选项确定从属服务器是否将其在中继日志中的位置记录到
mysql数据库中 的InnoDB表 或数据目录中的文件。默认设置为
TABLE。 作为InnoDB表,将命名中继日志信息日志mysql.slave_relay_log_info。TABLE配置多个复制通道时,需要进行 此 设置。 该TABLE还需要中继日志信息的日志设置,使复制抵御意外死机,对此--relay-log-recovery选项也必须启用。 有关 详细信息, 请参阅 使复制适应意外暂停 。该
FILE设置已弃用,将在以后的版本中删除。 作为文件,relay-log.info默认情况下 会命名中继日志信息日志 ,您可以使用该--relay-log-info-file选项 更改此名称 。此从属状态日志的位置设置直接影响
sync_relay_log_info系统变量 设置的效果 。 您只能在没有复制线程执行时更改设置。
从属状态日志表及其内容被视为给定MySQL服务器的本地。 它们不会被复制,对它们的更改不会写入二进制日志。
有关更多信息,请参见 第17.2.4节“复制中继和状态日志” 。
以下列表描述了用于控制复制从属服务器的系统变量。
它们可以在服务器启动时设置,其中一些可以在运行时使用更改
SET
。
本节前面列出了与复制从站一起使用的服务器选项。
-
属性 值 命令行格式 --init-slave=name系统变量 init_slave范围 全球 动态 是 SET_VAR提示适用没有 类型 串 此变量类似于
init_connect,但是每次SQL线程启动时都是从服务器执行的字符串。 字符串的格式与init_connect变量 的格式相同 。 此变量的设置对后续START SLAVE语句 生效 。注意SQL线程在执行之前向客户端发送确认
init_slave。 因此,不保证init_slave在START SLAVE返回 时执行 。 有关 更多信息 , 请参见 第13.4.2.6节“START SLAVE语法” 。 -
属性 值 命令行格式 --log-slow-slave-statements[={OFF|ON}]系统变量 log_slow_slave_statements范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用慢速查询日志时,此变量将启用
long_query_time对从属服务器执行时间 超过 几秒的 查询的日志记录 。 设置此变量不会立即生效。 变量的状态适用于所有后续START SLAVE语句。请注意,即使
log_slow_slave_statements已启用 ,也不会在主服务器的慢速日志中记录主服务器中以行格式记录的所有语句 。 -
属性 值 命令行格式 --master-info-repository={FILE|TABLE}系统变量 master_info_repository范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 (> = 8.0.2) TABLE默认值 (<= 8.0.1) FILE有效值 FILETABLE此变量的设置确定从服务器是否将主状态和连接信息记录到
mysql数据库中 的InnoDB表 或数据目录中的文件。默认设置为
TABLE。 作为InnoDB表,主信息日志被命名mysql.slave_master_info。TABLE配置多个复制通道时,需要进行 此 设置。该
FILE设置已弃用,将在以后的版本中删除。 作为文件,master.info默认情况下 会命名主信息日志 ,您可以使用该--master-info-file选项 更改此名称 。此从属状态日志的位置设置直接影响
sync_master_info系统变量 设置的效果 。 您只能在没有复制线程执行时更改设置。 -
属性 值 命令行格式 --max-relay-log-size=#系统变量 max_relay_log_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1073741824如果复制从属设备写入其中继日志导致当前日志文件大小超过此变量的值,则从属设备将轮换中继日志(关闭当前文件并打开下一个文件)。 如果
max_relay_log_size为0,则服务器将max_binlog_size同时用于二进制日志和中继日志。 如果max_relay_log_size大于0,则会限制中继日志的大小,这使您可以为两个日志设置不同的大小。 必须设置max_relay_log_size为4096字节和1GB(含)之间,或者设置为0.默认值为0.请参见 第17.2.2节“复制实现详细信息” 。 -
属性 值 命令行格式 --relay-log=file_name系统变量 relay_log范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 中继日志文件的基本名称,没有路径,也没有文件扩展名。 对于默认复制通道,中继日志的默认基本名称为
host_name-relay-binhost_name-relay-bin-channelchannel -
属性 值 系统变量 relay_log_basename范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 默认值 datadir + '/' + hostname + '-relay-bin'保存中继日志文件的名称和完整路径。 此变量由服务器设置并且是只读的。
-
属性 值 命令行格式 --relay-log-index=file_name系统变量 relay_log_index范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 默认值 *host_name*-relay-bin.index默认复制通道的中继日志索引文件的名称。 默认名称是
host_name-relay-bin.index -
属性 值 命令行格式 --relay-log-info-file=file_name系统变量 relay_log_info_file范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 默认值 relay-log.inforelay_log_info_repository=FILE设置 时,中继日志信息日志的名称 。 默认名称relay-log.info位于数据目录中。relay_log_info_repository=FILE现已弃用。 -
属性 值 命令行格式 --relay-log-info-repository=value系统变量 relay_log_info_repository范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 (> = 8.0.2) TABLE默认值 (<= 8.0.1) FILE有效值 FILETABLE此变量的设置确定从属服务器是否将其在中继日志中的位置记录到
mysql数据库中 的InnoDB表 或数据目录中的文件。默认设置为
TABLE。 作为InnoDB表,将命名中继日志信息日志mysql.slave_relay_log_info。TABLE配置多个复制通道时,需要进行 此 设置。 该TABLE还需要中继日志信息的日志设置,使复制抵御意外死机,对此--relay-log-recovery选项也必须启用。 有关 详细信息, 请参阅 使复制适应意外暂停 。该
FILE设置已弃用,将在以后的版本中删除。 作为文件,relay-log.info默认情况下 会命名中继日志信息日志 ,您可以使用该--relay-log-info-file选项 更改此名称 。此从属状态日志的位置设置直接影响
sync_relay_log_info系统变量 设置的效果 。 您只能在没有复制线程执行时更改设置。 -
属性 值 命令行格式 --relay-log-purge[={OFF|ON}]系统变量 relay_log_purge范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON一旦不再需要,就禁用或启用自动清除中继日志文件。 默认值为1(
ON)。 -
属性 值 命令行格式 --relay-log-recovery[={OFF|ON}]系统变量 relay_log_recovery范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF在服务器启动后立即启用自动中继日志恢复。 恢复过程会创建一个新的中继日志文件,将SQL线程位置初始化为此新的中继日志,并将I / O线程初始化为SQL线程位置。 然后继续从主站读取中继日志。 这个全局变量是只读的; 可以通过使用
--relay-log-recovery选项 启动从站来更改其值,该 选项应在复制从站发生崩溃后使用,以确保不会处理可能已损坏的中继日志,并且必须使用该选项以保证防碰撞的从站。 默认值为0(禁用)。此变量还与之交互
relay-log-purge,控制在不再需要日志时清除日志。 启用--relay-log-recovery选项时,relay-log-purge被禁用的风险从没有清除文件中读取中继日志,从而导致数据不一致,因此是不会崩溃安全。当
relay_log_recovery被启用,从已停止由于在多线程模式下运行时遇到错误,您可以使用START SLAVE UNTIL SQL_AFTER_MTS_GAPS,以确保所有间隙切换回单线程模式或执行前处理CHANGE MASTER TO的语句。 -
属性 值 命令行格式 --relay-log-space-limit=#系统变量 relay_log_space_limit范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295所有中继日志使用的最大空间量。
-
属性 值 命令行格式 --report-host=host_name系统变量 report_host范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 --report-host选项 的价值 。 -
属性 值 命令行格式 --report-password=name系统变量 report_password范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 --report-password选项 的价值 。 与用于MySQL复制用户帐户的密码不同。 -
属性 值 命令行格式 --report-port=port_num系统变量 report_port范围 全球 动态 没有 SET_VAR提示适用没有 类型 整数 默认值 [slave_port]最低价值 0最大价值 65535--report-port选项 的价值 。 -
属性 值 命令行格式 --report-user=name系统变量 report_user范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 --report-user选项 的价值 。 与MySQL复制用户帐户的名称不同。 -
属性 值 命令行格式 --rpl-read-size=#介绍 8.0.11 系统变量 rpl_read_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 8192最低价值 8192最大价值 4294967295该
rpl_read_size系统变量控制从二进制日志文件和中继日志文件读入字节的数据的最小量。 如果这些文件的大量磁盘I / O活动阻碍了数据库的性能,那么当操作系统当前未缓存文件数据时,增加读取大小可能会减少文件读取和I / O停顿。最小值和默认值为
rpl_read_size8192字节。 该值必须是4KB的倍数。 请注意,为从二进制日志和中继日志文件读取的每个线程分配了此值大小的缓冲区,包括主服务器上的转储线程和从服务器上的协调器线程。 因此,设置较大的值可能会影响服务器的内存消耗。 -
属性 值 命令行格式 --rpl-semi-sync-slave-enabled[={OFF|ON}]系统变量 rpl_semi_sync_slave_enabled范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF控制是否在从站上启用半同步复制。 要启用或禁用插件,请将此变量 分别 设置为
ON或OFF(或1或0)。 默认是OFF。仅当安装了从属端半同步复制插件时,此变量才可用。
-
rpl_semi_sync_slave_trace_level属性 值 命令行格式 --rpl-semi-sync-slave-trace-level=#系统变量 rpl_semi_sync_slave_trace_level范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 32从站上的半同步复制调试跟踪级别。 请参阅
rpl_semi_sync_master_trace_level允许的值。仅当安装了从属端半同步复制插件时,此变量才可用。
-
属性 值 命令行格式 --rpl-stop-slave-timeout=seconds系统变量 rpl_stop_slave_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 31536000最低价值 2最大价值 31536000您可以
STOP SLAVE通过设置此变量 来控制在 超时之前等待 的时间长度(以秒为单位) 。 这可以用来避免它们之间的死锁STOP SLAVE与从属的不同客户端连接 和其他从属SQL语句 。最大值和默认值为
rpl_stop_slave_timeout31536000秒(1年)。 最短为2秒。 对此变量的更改将对后续STOP SLAVE语句 生效 。此变量仅影响发出
STOP SLAVE语句 的客户端 。 达到超时后,发出客户端将返回一条错误消息,指出命令执行不完整。 然后客户端停止等待从属线程停止,但是从属线程继续尝试停止,并且STOP SLAVE指令仍然有效。 一旦从属线程不再忙,STOP SLAVE则执行 该 语句并且从属程序停止。 -
属性 值 命令行格式 --slave-checkpoint-group=#系统变量 slave_checkpoint_group范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 512最低价值 32最大价值 524280块大小 8设置在调用检查点操作以更新其状态之前,多线程从站可以处理的最大事务数,如下所示
SHOW SLAVE STATUS。 设置此变量对未启用多线程的从站没有影响。 设置此变量不会立即生效。 变量的状态适用于所有后续START SLAVE命令。注意NDB Cluster目前不支持多线程从站,它会静默忽略此变量的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
此变量与
slave_checkpoint_period系统变量 结合使用 ,当超过任一限制时,执行检查点并且计数器跟踪事务数和自上次检查点重置以来经过的时间。除非服务器是使用构建的,否则此变量的最小允许值为32,
-DWITH_DEBUG在这种情况下,最小值为1.有效值始终为8的倍数; 您可以将其设置为不是这样的倍数的值,但是在存储该值之前,服务器将其舍入到下一个较低的8的倍数。 ( 例外 :调试服务器不执行此类舍入。)无论服务器是如何构建的,默认值为512,允许的最大值为524280。 -
属性 值 命令行格式 --slave-checkpoint-period=#系统变量 slave_checkpoint_period范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 300最低价值 1最大价值 4G设置在调用检查点操作以更新多线程从站的状态之前允许通过的最长时间(以毫秒为单位),如下所示
SHOW SLAVE STATUS。 设置此变量对未启用多线程的从站没有影响。 设置此变量会立即对所有复制通道生效,包括运行通道。注意NDB Cluster目前不支持多线程从站,它会静默忽略此变量的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
此变量与
slave_checkpoint_group系统变量 结合使用 ,当超过任一限制时,执行检查点并且计数器跟踪事务数和自上次检查点重置以来经过的时间。此变量的最小允许值为1,除非服务器是使用构建的
-DWITH_DEBUG,在这种情况下最小值为0.无论服务器是如何构建的,默认值为300,最大可能值为4294967296(4GB) 。 -
属性 值 命令行格式 --slave-compressed-protocol[={OFF|ON}]系统变量 slave_compressed_protocol范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF如果主设备和从设备都支持,是否使用主/从协议的压缩。 如果禁用此变量(默认值),则连接将被解压缩。 对此变量的更改将对后续连接尝试生效; 这包括在发出
START SLAVE语句之后,以及由正在运行的I / O线程进行的重新连接(例如,在MASTER_RETRY_COUNT为CHANGE MASTER TO语句 设置 选项 之后 )。 另请参见 第4.2.5节“连接压缩控制” 。 -
属性 值 命令行格式 --slave-exec-mode=mode系统变量 slave_exec_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 IDEMPOTENT(NDB)STRICT(其他)有效值 IDEMPOTENTSTRICT控制从属线程在复制期间如何解决冲突和错误。
IDEMPOTENT模式导致重复密钥和无密钥发现错误的抑制;STRICT意味着不会发生这种抑制。IDEMPOTENTmode适用于多主复制,循环复制和NDB Cluster Replication的一些其他特殊复制方案。 (有关详细 信息, 请参见 第22.6.10节“NDB群集复制:多主机和循环复制” 和 第22.6.11节“NDB群集复制冲突解决” 。)NDB群集忽略显式设置的任何值slave_exec_mode,并始终把它视为IDEMPOTENT。在MySQL Server 8.0中,
STRICTmode是默认值。设置此变量会立即生效所有复制通道,包括运行通道。
对于除以外的存储引擎
NDB,IDEMPOTENT只有当您完全确定可以安全地忽略重复键错误和未找到键错误时,才应使用模式 。 它适用于使用多主复制或循环复制的NDB Cluster的故障转移方案,不建议在其他情况下使用。 -
属性 值 命令行格式 --slave-load-tmpdir=dir_name系统变量 slave_load_tmpdir范围 全球 动态 没有 SET_VAR提示适用没有 类型 目录名称 默认值 Value of --tmpdir从站创建临时文件的目录的名称。 设置此变量会立即对所有复制通道生效,包括运行通道。 默认情况下,此系统变量等于系统变量的值
tmpdir,或者未指定系统变量时应用的默认值。当从属SQL线程复制
LOAD DATA语句时,它会将要从中继日志加载的文件提取到临时文件中,然后将这些文件加载到表中。 如果主服务器上加载的文件很大,那么从服务器上的临时文件也很庞大。 因此,建议使用此选项告诉从属服务器将临时文件放在位于具有大量可用空间的某个文件系统中的目录中。 在这种情况下,中继日志也很庞大,因此您可能还希望使用该--relay-log选项将中继日志放在该文件系统中。此选项指定的目录应位于基于磁盘的文件系统(而不是基于内存的文件系统)中,以便用于复制的临时文件
LOAD DATA可以在计算机重新启动后继续存在。 该目录也不应该是在系统启动过程中由操作系统清除的目录。 但是,如果已删除临时文件,则重新启动后现在可以继续复制。 -
属性 值 命令行格式 --slave-max-allowed-packet=#系统变量 slave_max_allowed_packet范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1073741824最低价值 1024最大价值 1073741824此选项设置从属SQL和I / O线程可以处理的最大数据包大小(以字节为单位)。 设置此变量会立即对所有复制通道生效,包括运行通道。
max_allowed_packet添加事件标头后, 复制主机可以写入比其 设置 更长的二进制日志事件 。 设置slave_max_allowed_packet必须大于max_allowed_packet主服务器上 的 设置,因此使用基于行的复制进行的大型更新不会导致复制失败。此全局变量的值始终为1024的正整数倍; 如果将其设置为某个非值的值,则将该值向下舍入为1024的下一个最大倍数,以便存储或使用该值; 设置
slave_max_allowed_packet为0会导致使用1024。 (在所有这些情况下都会发出截断警告。)默认值和最大值为1073741824(1 GB); 最小值是1024。slave_max_allowed_packet也可以在启动时使用该--slave-max-allowed-packet选项 进行设置 。 -
属性 值 命令行格式 --slave-net-timeout=#系统变量 slave_net_timeout范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 60最低价值 1在从站认为连接断开之前等待来自主站的更多数据或心跳信号的秒数,中止读取并尝试重新连接。 设置此变量不会立即生效。 变量的状态适用于所有后续
START SLAVE命令。默认值为60秒(一分钟)。 超时后立即进行第一次重试。 重试之间的间隔由 语句
MASTER_CONNECT_RETRY选项 控制CHANGE MASTER TO,重新连接尝试次数受 语句MASTER_RETRY_COUNT选项的 限制CHANGE MASTER TO。如果连接仍然良好,则在没有数据的情况下停止连接超时的心跳间隔由 语句 的
MASTER_HEARTBEAT_PERIOD选项 控制CHANGE MASTER TO。 心跳间隔默认为值的一半slave_net_timeout,并记录在主信息日志中并显示在replication_connection_configuration性能架构表中。 请注意,更改值或默认设置slave_net_timeout不会自动更改心跳间隔,无论是已明确设置还是使用先前计算的默认值。 如果更改了连接超时,则还必须发出CHANGE MASTER TO将心跳间隔调整为适当的值,以便在连接超时之前发生。 -
属性 值 命令行格式 --slave-parallel-type=type类型 列举 默认值 DATABASE有效值 DATABASELOGICAL_CLOCK使用多线程从站(
slave_parallel_workers大于0)时,此变量指定用于决定允许哪些事务在从站上并行执行的策略。 该变量对未启用多线程的从站没有影响。 可能的值是:-
LOGICAL_CLOCK:作为主服务器上相同二进制日志组提交的一部分的事务在从服务器上并行应用。 根据事务的时间戳跟踪事务之间的依赖关系,以便在可能的情况下提供额外的并行化。 设置此值时,binlog_transaction_dependency_tracking可以在主服务器上使用系统变量来指定写入集用于并行化而不是时间戳,如果写入集可用于事务并且与时间戳相比提供改进的结果。 -
DATABASE:并行应用更新不同数据库的事务。 仅当数据被分区为多个数据库时才适用此值,这些数据库在主服务器上独立且同时更新。 必须没有跨数据库约束,因为可能会在从属设备上违反这些约束。
何时
slave_preserve_commit_order=1设置,您只能使用LOGICAL_CLOCK。如果复制拓扑使用多个级别的从属,则
LOGICAL_CLOCK可能会为每个级别实现较少的并行化,从属远离主服务器。 您可以通过binlog_transaction_dependency_tracking在主服务器上 使用 来指定在可能的情况下使用写集来代替时间戳进行并行化 来减少此影响 。 -
-
属性 值 命令行格式 --slave-parallel-workers=#系统变量 slave_parallel_workers范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1024在从属设备上启用多线程,并设置从属应用程序线程的数量,以便并行执行复制事务。 当值是大于0的数字时,从属服务器是具有指定数量的应用程序线程的多线程从属服务器,以及用于管理它们的协调器线程。 如果您使用多个复制通道,则每个通道都具有此数量的线程。
注意NDB Cluster目前不支持多线程从站,它会静默忽略此变量的设置。 有关 更多信息 , 请参见 第22.6.3节“NDB群集复制中的已知问题” 。
在从站上启用多线程时,支持重试事务。 当
slave_preserve_commit_order=1从站上的事务以与从站的中继日志中出现的顺序相同的顺序在从站上外部化时。 在应用程序线程之间分配事务的方式由--slave-parallel-type。要禁用并行执行,请将此选项设置为0,这将为从属设备提供单个应用程序线程,而不是协调器线程。 使用此设置,
--slave-parallel-type和slave_preserve_commit_order选项无效,将被忽略。设置
slave_parallel_workers没有立即生效。 变量的状态适用于所有后续START SLAVE语句。 -
属性 值 命令行格式 --slave-pending-jobs-size-max=#系统变量 slave_pending_jobs_size_max范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.12) 128M默认值 (<= 8.0.11) 16M最低价值 1024最大价值 16EiB块大小 1024对于多线程从站,此变量设置可用于保存尚未应用的事件的从属工作队列的最大内存量(以字节为单位)。 设置此变量对未启用多线程的从站没有影响。 设置此变量不会立即生效。 变量的状态适用于所有后续
START SLAVE命令。此变量的最小可能值为1024字节; 默认值为128MB。 最大可能值为18446744073709551615(16 exbibytes)。 在存储之前,不是1024字节的精确倍数的值向下舍入到1024字节的下一个较低倍数。
此变量的值是软限制,可以设置为与正常工作负载匹配。 如果异常大的事件超过此大小,则事务将一直保持到所有从属工作程序都有空队列,然后进行处理。 所有后续交易将持续到大型交易完成为止。
-
属性 值 命令行格式 --slave-preserve-commit-order[={OFF|ON}]系统变量 slave_preserve_commit_order范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF对于多线程从站,此变量的设置1确保事务在从站上以与从站的中继日志中出现的顺序相同的顺序外部化,并防止从中继日志执行的事务序列中的间隙。 此变量对未启用多线程的从站没有影响。
slave_preserve_commit_order=1要求--log-bin并--log-slave-updates在从站上启用,并--slave-parallel-type设置为LOGICAL_CLOCK。与
slave_preserve_commit_order启用,执行的线程等待,直到所有以前的事务提交之前提交。 当从属线程正在等待其他工作者提交其事务时,它会将其状态报告为Waiting for preceding transaction to commit。 使用此模式,多线程从站永远不会进入主站不在的状态。这支持使用复制进行读取扩展。 请参见 第17.3.5节“使用复制进行横向扩展” 。在更改此变量之前,必须停止所有复制线程(对于所有复制通道,如果使用多个复制通道)。 如果
slave_preserve_commit_order=0设置,则从属并行应用的事务可能无序。 因此,检查最近执行的事务并不能保证来自主服务器的所有先前事务都已在从服务器上执行。 从从属中继日志执行的事务序列中可能存在间隙。 这对使用多线程从站时的日志记录和恢复有影响。 请注意该设置slave_preserve_commit_order=1防止间隙,但不能防止无间隙的低水位位置(在Exec_master_log_pos执行交易的位置后面)。 有关 更多信息 , 请参见 第17.4.1.33节“复制和事务不一致” 。 -
属性 值 命令行格式 --slave-rows-search-algorithms=value系统变量 slave_rows_search_algorithms范围 全球 动态 是 SET_VAR提示适用没有 类型 组 默认值 (> = 8.0.2) INDEX_SCAN,HASH_SCAN默认值 (<= 8.0.1) TABLE_SCAN,INDEX_SCAN有效值 TABLE_SCAN,INDEX_SCANINDEX_SCAN,HASH_SCANTABLE_SCAN,HASH_SCANTABLE_SCAN,INDEX_SCAN,HASH_SCAN(相当于INDEX_SCAN,HASH_SCAN)为基于行的日志记录和复制准备批量行时,此变量控制如何搜索行匹配,特别是是否使用散列扫描。 设置此变量会立即对所有复制通道生效,包括运行通道。 可以使用
--slave-rows-search-algorithms选项 指定系统变量的初始设置 。指定以逗号分隔的2个值的列表中的以下组合的列表
INDEX_SCAN,TABLE_SCAN,HASH_SCAN。 对于系统变量,该值应为字符串,因此必须引用该值。 此外,该值不得包含任何空格。 推荐的组合(列表)及其效果如下表所示:使用的索引/选项值 INDEX_SCAN,HASH_SCANINDEX_SCAN,TABLE_SCAN主键或唯一键 索引扫描 索引扫描 (其他)关键 哈希扫描索引 索引扫描 没有索引 哈希扫描 表扫描 -
默认值为
INDEX_SCAN,HASH_SCAN。 使用此设置,散列用于任何不使用主键或唯一键的搜索。 指定INDEX_SCAN,HASH_SCAN与 指定 具有相同的效果INDEX_SCAN,TABLE_SCAN,HASH_SCAN,这是允许的。 -
要删除散列,请设置
INDEX_SCAN,TABLE_SCAN。 使用此设置,所有可以使用索引的搜索都会使用它们,而没有任何索引的搜索会使用表扫描。 -
不要使用该组合
TABLE_SCAN,HASH_SCAN。 此设置强制对所有搜索进行散列。 它没有优势INDEX_SCAN,HASH_SCAN,并且 在包含对同一行的多个更新的单个事件或依赖于顺序的更新的情况下, 它可能导致 “ 记录未找到 ” 错误或重复键错误。
在列表中指定算法的顺序不会对它们由
SELECTorSHOW VARIABLES语句 显示的顺序产生任何影响 。可以指定单个值,但这不是最佳值,因为设置单个值会将搜索限制为仅使用该算法。 特别是,
INDEX_SCAN不推荐单独 设置 ,因为在这种情况下,如果不存在索引,则搜索根本无法找到行。 -
-
属性 值 命令行格式 --slave-skip-errors=name系统变量 slave_skip_errors范围 全球 动态 没有 SET_VAR提示适用没有 类型 串 默认值 OFF有效值 OFF[list of error codes]allddl_exist_errors通常,当从属设备发生错误时复制会停止,这使您有机会手动解决数据中的不一致问题。 当语句返回变量值中列出的任何错误时,此变量使从属SQL线程继续复制。
-
属性 值 命令行格式 --slave-sql-verify-checksum[={OFF|ON}]系统变量 slave_sql_verify_checksum范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON导致从属SQL线程使用从中继日志中读取的校验和来验证数据。 如果不匹配,从站会因错误而停止。 设置此变量会立即对所有复制通道生效,包括运行通道。
注意从I / O线程接收来自网络的事件时,如果可能,始终读取校验和。
-
属性 值 命令行格式 --slave-transaction-retries=#系统变量 slave_transaction_retries范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295设置单线程或多线程从属设备上的复制从属SQL线程在停止之前自动重试失败事务的最大次数。 设置此变量会立即对所有复制通道生效,包括运行通道。 默认值为10.将变量设置为0将禁用自动重试事务。
如果复制从SQL线程失败,因为一个来执行事务
InnoDB死锁或因为交易的执行时间超过InnoDB的innodb_lock_wait_timeout或NDB的TransactionDeadlockDetectionTimeout或TransactionInactiveTimeout,它会自动重试slave_transaction_retries与错误停止前的时间。 不会重试具有非临时错误的事务。Performance Schema表
replication_applier_status显示了COUNT_TRANSACTIONS_RETRIES列中 每个复制通道上发生的重试次数 。 性能模式表replication_applier_status_by_worker显示有关单线程或多线程复制从属上的各个应用程序线程的事务重试的详细信息,并标识导致上次事务和当前正在进行的事务被重新尝试的错误。 -
属性 值 命令行格式 --slave-type-conversions=set系统变量 slave_type_conversions范围 全球 动态 没有 SET_VAR提示适用没有 类型 组 默认值 有效值 ALL_LOSSYALL_NON_LOSSYALL_SIGNEDALL_UNSIGNED使用基于行的复制时,控制对从站生效的类型转换模式。 它的值是逗号分隔的集合从列表中零个或多个元素:
ALL_LOSSY,ALL_NON_LOSSY,ALL_SIGNED,ALL_UNSIGNED。 将此变量设置为空字符串以禁止主服务器和从服务器之间的类型转换。 设置此变量会立即对所有复制通道生效,包括运行通道。有关适用于基于 行的复制中的属性提升和降级的 类型转换模式的其他信息,请参阅 基于行的复制:属性提升和降级 。
-
属性 值 系统变量 sql_slave_skip_counter范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 从服务器应跳过的主服务器的事件数。 设置选项不会立即生效。 该变量适用于下一个
START SLAVE语句; 下一个START SLAVE语句也会将值更改回0.当此变量设置为非零值并且配置了多个复制通道时,该START SLAVE语句只能与该 子句 一起使用 。FOR CHANNELchannel此选项与基于GTID的复制不兼容,并且在此时不得设置为非零值
--gtid-mode=ON。 如果您在使用GTID时需要跳过事务,请改为使用gtid_executed主服务器。 有关如何执行此操作的信息, 请参阅 注入空事务 。重要如果通过设置此变量来跳过指定的事件数将导致从属设备在事件组的中间开始,则从属设备将继续跳过,直到找到下一个事件组的开头并从该点开始。 有关更多信息,请参见 第13.4.2.5节“SET GLOBAL sql_slave_skip_counter语法” 。
-
属性 值 命令行格式 --sync-master-info=#系统变量 sync_master_info范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10000最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295此变量对复制从站的影响取决于从站
master_info_repository是否设置为FILE或TABLE,如以下段落中所述。master_info_repository = FILE。 如果值
sync_master_info大于0,则从属设备会 在每个 事件 后将 其master.info文件 同步 到磁盘(使用fdatasync())sync_master_info。 如果为0,则MySQL服务器不执行master.info文件与磁盘的 同步 ; 相反,服务器依赖操作系统定期刷新其内容,就像任何其他文件一样。master_info_repository = TABLE。 如果值
sync_master_info大于0,则从属服务器在每个sync_master_info事件 后更新其主信息存储库表 。 如果为0,则表永远不会更新。默认值为
sync_master_info10000.设置此变量会立即生效所有复制通道,包括运行通道。 -
属性 值 命令行格式 --sync-relay-log=#系统变量 sync_relay_log范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10000最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295如果此变量的值大于0,则MySQL服务器会
fdatasync()在将每个sync_relay_log事件写入中继日志 后将 其中继日志同步到磁盘(使用 ) 。 设置此变量会立即对所有复制通道生效,包括运行通道。设置
sync_relay_log为0会导致不对磁盘进行同步; 在这种情况下,服务器依赖于操作系统来不时刷新中继日志的内容,就像任何其他文件一样。值为1是最安全的选择,因为在发生崩溃时,您最多会从中继日志中丢失一个事件。 但是,它也是最慢的选择(除非磁盘具有电池备份缓存,这使得同步非常快)。
-
属性 值 命令行格式 --sync-relay-log-info=#系统变量 sync_relay_log_info范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 10000最低价值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295默认值为
sync_relay_log_info10000.设置此变量会立即生效所有复制通道,包括运行通道。此变量对复制从站的影响取决于服务器的
relay_log_info_repository设置(FILE或TABLE)。 如果设置为TABLE,则变量的效果还取决于中继日志信息表使用的存储引擎是事务性的(例如InnoDB)还是事务性(MyISAM)。 这些因素对服务器行为的sync_relay_log_info影响为零和大于零的值如下:-
sync_relay_log_info = 0 -
-
如果
relay_log_info_repository设置为FILE,则MySQL服务器不执行relay-log.info文件到磁盘的 同步 ; 相反,服务器依赖操作系统定期刷新其内容,就像任何其他文件一样。 -
如果
relay_log_info_repository设置为TABLE,并且该表的存储引擎是事务性的,则在每次事务后更新表。 (sync_relay_log_info在这种情况下, 该 设置被有效忽略。) -
如果
relay_log_info_repository设置为TABLE,并且该表的存储引擎不是事务性的,则表永远不会更新。
-
-
sync_relay_log_info =N> 0 -
-
如果
relay_log_info_repository设置为FILE,则从属设备 在每次 事务处理 后将 其relay-log.info文件 同步 到磁盘(使用fdatasync())N。 -
如果
relay_log_info_repository设置为TABLE,并且该表的存储引擎是事务性的,则在每次事务后更新表。 (sync_relay_log_info在这种情况下, 该 设置被有效忽略。) -
如果
relay_log_info_repository设置为TABLE,并且该表的存储引擎不是事务性的,则在每个N事件 之后更新表 。
-
-
您可以使用 本节中介绍 的 mysqld 选项和系统变量来影响二进制日志的操作,以及控制将哪些语句写入二进制日志。 有关二进制日志的其他信息,请参见 第5.4.4节“二进制日志” 。 有关使用MySQL服务器选项和系统变量的其他信息,请参见 第5.1.7节“服务器命令选项” 和 第5.1.8节“服务器系统变量” 。
以下列表描述了启用和配置二进制日志的启动选项。 与二进制日志记录一起使用的系统变量将在本节后面讨论。
-
属性 值 命令行格式 --binlog-row-event-max-size=#系统变量 (> = 8.0.14) binlog_row_event_max_size范围 (> = 8.0.14) 全球 动态 (> = 8.0.14) 没有 SET_VAR提示适用 (> = 8.0.14)没有 类型 整数 默认值 8192最低价值 256最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295使用基于行的二进制日志记录时,此设置是对基于行的二进制日志事件的最大大小的软限制(以字节为单位)。 如果可能,存储在二进制日志中的行将分组为大小不超过此设置值的事件。 如果无法拆分事件,则可以超出最大大小。 该值必须(或者向下舍入到)256的倍数。默认值为8192字节。
-
属性 值 命令行格式 --log-bin=file_name类型 文件名 指定用于二进制日志文件的基本名称。 启用二进制日志记录后,服务器会将所有将数据更改的语句记录到二进制日志中,该日志用于备份和复制。 二进制日志是一系列具有基本名称和数字扩展名的文件。 该
--log-bin选项的值是日志序列的基本名称。 服务器通过向基本名称添加数字后缀来按顺序创建二进制日志文件。如果您不提供该
--log-bin选项,MySQL将使用binlog二进制日志文件的默认基本名称。 为了与早期版本兼容,如果提供的--log-bin选项没有字符串或空字符串,则基本名称默认为host_name-bin二进制日志文件的默认位置是数据目录。 您可以使用该
--log-bin选项指定备用位置,方法是在基本名称中添加前导绝对路径名以指定其他目录。 当服务器从二进制日志索引文件中读取条目时,该文件跟踪已使用的二进制日志文件,它会检查条目是否包含相对路径。 如果是,则路径的相对部分将替换为使用的设置的绝对路径--log-bin选项。 二进制日志索引文件中记录的绝对路径保持不变; 在这种情况下,必须手动编辑索引文件以启用新路径。 二进制日志文件基本名称和任何指定的路径都可用作log_bin_basename系统变量。在早期的MySQL版本中,默认情况下禁用二进制日志记录,如果您指定了该
--log-bin选项, 则会启用它 。 从MySQL 8.0开始,默认情况下启用二进制日志记录,无论您是否指定该--log-bin选项。 例外情况是,如果使用 mysqld 通过使用--initializeor--initialize-insecure选项 手动初始化数据目录 ,则默认情况下禁用二进制日志记录。 在这种情况下,可以通过指定--log-bin选项 来启用二进制日志记录 。 启用二进制日志记录时,log_bin系统变量(显示服务器上二进制日志记录的状态)设置为ON。要禁用二进制日志记录,可以 在启动时 指定
--skip-log-bin或--disable-log-bin选项。 如果指定了这些选项中的任何一个并且--log-bin也指定 了这些选项 ,则稍后指定的选项优先。 禁用二进制日志记录时,log_bin系统变量设置为OFF。当GTID在服务器上使用时,如果在异常关闭后重新启动服务器时禁用二进制日志记录,则某些GTID可能会丢失,从而导致复制失败。 在正常关闭时,当前二进制日志文件中的GTID集保存在
mysql.gtid_executed表。 在没有发生这种情况的异常关闭之后,在恢复期间,GTID将从二进制日志文件添加到表中,前提是仍然启用了二进制日志记录。 如果为服务器重新启动禁用二进制日志记录,则服务器无法访问二进制日志文件以恢复GTID,因此无法启动复制。 正常关机后,可以安全禁用二进制日志记录。在
--log-slave-updates和--slave-preserve-commit-order选项需要二进制日志。 如果禁用二进制日志记录,请省略这些选项,或指定--skip-log-slave-updates和--skip-slave-preserve-commit-order。 MySQL时,默认情况下禁用这些选项--skip-log-bin或--disable-log-bin指定的。 如果指定--log-slave-updates或--slave-preserve-commit-order连同--skip-log-bin或者--disable-log-bin,发出警告或错误信息。在MySQL 5.7中,必须在启用二进制日志记录时指定服务器ID,否则服务器将无法启动。 在MySQL 8.0中,
server_id系统变量默认设置为1。 现在,启用二进制日志记录时,可以使用此默认服务器ID启动服务器,但如果未使用该--server-id选项 明确指定服务器标识,则会发出信息性消息 。 对于复制拓扑中使用的服务器,必须为每个服务器指定唯一的非零服务器ID。有关二进制日志的格式和管理的信息,请参见 第5.4.4节“二进制日志” 。
-
属性 值 命令行格式 --log-bin-index=file_name类型 文件名 二进制日志索引文件的名称,其中包含二进制日志文件的名称。 默认情况下,它具有与使用
--log-bin选项和扩展名为 二进制日志文件指定的值相同的位置和基本名称.index。 如果未指定--log-bin,则默认二进制日志索引文件名为binlog.index。 如果指定--log-bin不带字符串或空字符串的选项,则host_name-bin.index有关二进制日志的格式和管理的信息,请参见 第5.4.4节“二进制日志” 。
-
--log-bin-trust-function-creators[={0|1}]属性 值 命令行格式 --log-bin-trust-function-creators[={OFF|ON}]系统变量 log_bin_trust_function_creators范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF此选项设置相应的
log_bin_trust_function_creators系统变量。 如果没有给出参数,则该选项将变量设置为1.log_bin_trust_function_creators影响MySQL如何对存储的函数和触发器创建实施限制。 请参见 第24.7节“存储程序二进制日志记录” 。 -
--log-bin-use-v1-row-events[={0|1}]属性 值 命令行格式 --log-bin-use-v1-row-events[={OFF|ON}]系统变量 log_bin_use_v1_row_events范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFFMySQL 8.0使用版本2二进制日志行事件,MySQL 5.6.6之前的MySQL服务器版本无法读取这些事件。 将此选项设置为1会导致 mysqld 使用版本1日志记录事件编写二进制日志,这是这些版本中使用的唯一二进制日志事件版本,因此会生成可由这些版本的从属服务器读取的二进制日志。 设置
--log-bin-use-v1-row-events为0(默认值)会导致 mysqld 使用版本2二进制日志事件。可以从只读
log_bin_use_v1_row_events系统变量 获取用于此选项的值 。--log-bin-use-v1-row-events在使用NDB$EPOCH_TRANS()冲突检测功能 设置复制冲突检测和解决时,主要是感兴趣 ,这需要版本2二进制日志行事件。 因此,这个选项--ndb-log-transaction-id并不兼容。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
声明选择选项。 以下列表中的选项会影响将哪些语句写入二进制日志,从而将复制主服务器发送到其从属服务器。 还有从属服务器的选项,用于控制从主服务器接收的语句应该被执行或忽略。 有关详细信息,请参见 第17.1.6.3节“复制从选项和变量” 。
-
属性 值 命令行格式 --binlog-do-db=name类型 串 此选项以类似于此方式的方式影响二进制日志记录
--replicate-do-db影响复制 。此选项的效果取决于基于语句或基于行的日志记录格式是否正在使用,其方式与
--replicate-do-db依赖于基于语句或基于行的复制 的效果 是否正在使用的方式相同。 您应该记住,用于记录给定语句的格式可能不一定与值的值相同binlog_format。 例如,DDL语句(如CREATE TABLE和)ALTER TABLE始终记录为语句,而不考虑有效的日志记录格式,因此以下基于语句的规则--binlog-do-db始终适用于确定是否记录该语句。基于语句的日志记录。 只有那些语句被写入二进制日志,其中默认数据库(即选择的那个
USE)是db_name。 要指定多个数据库,请多次使用此选项,每个数据库使用一次; 但是,这样做 不会 导致跨数据库语句,例如UPDATE在选择其他数据库(或没有数据库)时记录 。some_db.some_tableSET foo='bar'警告要指定多个数据库,您 必须 使用此选项的多个实例。 由于数据库名称可以包含逗号,因此如果提供以逗号分隔的列表,则该列表将被视为单个数据库的名称。
使用基于语句的日志记录时无法正常工作的示例:如果服务器启动
--binlog-do-db=sales并发出以下语句, 则不 记录 该UPDATE语句 :使用价格; 更新sales.january SET金额=金额+ 1000;
这种 “ 只检查默认数据库 ” 行为的 主要原因 是,仅从语句中就很难知道是否应该复制它(例如,如果您使用多表
DELETE语句或多表UPDATE语句跨多个数据库)。 如果不需要,只检查默认数据库而不是所有数据库也更快。即使在设置选项时未指定给定数据库,也会发生另一种可能不明显的情况。 如果启动服务器
--binlog-do-db=sales,UPDATE则会记录 以下 语句,即使prices在设置时未包含 该 语句--binlog-do-db:使用销售; UPDATE prices.discounts SET百分比=百分比+10;
因为
sales是UPDATE发出语句 时的默认数据库 ,所以UPDATE会记录 该数据库 。基于行的日志记录。 日志记录仅限于数据库
db_name。 仅db_name记录 对属于的表的更改 ; 默认数据库对此没有影响。 假设服务器已启动--binlog-do-db=sales并且基于行的日志记录生效,然后执行以下语句:使用价格; UPDATE sales.february SET amount = amount + 100;
根据 声明 记录
february对sales数据库 中表 的更改UPDATE; 无论USE声明 是否 已发布,都会 发生这种情况 。 但是,使用基于行的日志记录格式时--binlog-do-db=sales,UPDATE不会记录 以下所做的更改 :使用价格; 更新price.march SET金额=金额-25;
即使
USE prices语句被更改为USE sales,UPDATE语句的效果仍然不会写入二进制日志。--binlog-do-db与基于行的日志记录相比 , 处理基于语句的日志记录的 另一个重要区别 在于引用多个数据库的语句。 假设服务器已启动--binlog-do-db=db1,并执行以下语句:使用db1; UPDATE db1.table1 SET col1 = 10,db2.table2 SET col2 = 20;
如果使用基于语句的日志记录,则两个表的更新都将写入二进制日志。 但是,使用基于行的格式时,仅
table1记录 更改 ;table2在不同的数据库中,所以它不会被更改UPDATE。 现在假设 使用USE db1了一个USE db4语句 而不是 语句 :使用db4; UPDATE db1.table1 SET col1 = 10,db2.table2 SET col2 = 20;
在这种情况下,
UPDATE使用基于语句的日志记录时,不会 将 语句写入二进制日志。 但是,在使用基于行的日志记录时,table1会记录 更改为 ,但不会记录到table2- 换句话说,仅--binlog-do-db记录 对名为的数据库中的表的更改 ,并且选择默认数据库对此行为没有影响。 -
属性 值 命令行格式 --binlog-ignore-db=name类型 串 此选项以类似于
--replicate-ignore-db影响复制 的方式影响二进制日志记录 。此选项的效果取决于基于语句或基于行的日志记录格式是否正在使用,其方式与
--replicate-ignore-db依赖于基于语句或基于行的复制 的效果 是否正在使用的方式相同。 您应该记住,用于记录给定语句的格式可能不一定与值的值相同binlog_format。 例如,DDL语句(如CREATE TABLE和)ALTER TABLE始终记录为语句,而不考虑有效的日志记录格式,因此以下基于语句的规则--binlog-ignore-db始终适用于确定是否记录该语句。基于语句的日志记录。 告诉服务器无法登录任何声明,其中默认的数据库(即,由选定的一个
USE)是db_name。如果没有默认数据库,则不会
--binlog-ignore-db应用 任何 选项,并且始终会记录此类语句。 (Bug#11829838,Bug#60188)基于行的格式。 告知服务器不要将更新记录到数据库中的任何表
db_name。 当前数据库无效。使用基于语句的日志记录时,以下示例无法正常工作。 假设服务器已启动
--binlog-ignore-db=sales并发出以下语句:使用价格; 更新sales.january SET金额=金额+ 1000;
该
UPDATE声明 被 记录在这样的情况下,因为--binlog-ignore-db只适用于默认数据库(由确定的USE语句)。 由于sales数据库是在语句中显式指定的,因此该语句尚未过滤。 但是,使用基于行的日志记录时,UPDATE语句的效果 不会 写入二进制日志,这意味着不会sales.january记录 对 表的 更改 ; 在这种情况下,--binlog-ignore-db=sales导致 对主副本中的表所做的 所有 更改sales为了二进制日志记录而忽略的数据库。要指定要忽略的多个数据库,请多次使用此选项,每个数据库使用一次。 由于数据库名称可以包含逗号,因此如果提供以逗号分隔的列表,则该列表将被视为单个数据库的名称。
如果您使用跨数据库更新并且不希望记录这些更新,则不应使用此选项。
校验和选项。 MySQL支持读写二进制日志校验和。 使用此处列出的两个选项启用它们:
-
--binlog-checksum={NONE|CRC32}属性 值 命令行格式 --binlog-checksum=type类型 串 默认值 CRC32有效值 NONECRC32启用此选项会使主服务器为写入二进制日志的事件编写校验和。 设置为
NONE禁用,或用于生成校验和的算法名称; 目前,仅支持CRC32校验和,并且CRC32是默认值。 您无法在事务中更改此选项的设置。 -
--master-verify-checksum={0|1}属性 值 命令行格式 --master-verify-checksum[={OFF|ON}]类型 布尔 默认值 OFF启用此选项会使主服务器使用校验和来验证来自二进制日志的事件,并在发生不匹配时停止并显示错误。 默认情况下禁用。
要控制从站(来自中继)日志读取校验和,请使用该
--slave-sql-verify-checksum
选项。
测试和调试选项。 以下二进制日志选项用于复制测试和调试。 它们不适用于正常操作。
-
属性 值 命令行格式 --max-binlog-dump-events=#类型 整数 默认值 0MySQL测试套件在内部使用此选项进行复制测试和调试。
-
属性 值 命令行格式 --sporadic-binlog-dump-fail[={OFF|ON}]类型 布尔 默认值 OFFMySQL测试套件在内部使用此选项进行复制测试和调试。
以下列表描述了控制二进制日志记录的系统变量。
它们可以在服务器启动时设置,其中一些可以在运行时使用更改
SET
。
本节前面列出了用于控制二进制日志记录的服务器选项。
-
属性 值 命令行格式 --binlog-cache-size=#系统变量 binlog_cache_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 32768最低价值 4096最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295用于在事务期间保留对二进制日志的更改的缓存大小。 在服务器上启用二进制日志记录(
log_bin系统变量设置为ON)时,如果服务器支持任何事务存储引擎,则为每个客户端分配二进制日志高速缓存。 如果您经常使用大型事务,则可以增加此高速缓存大小以获得更好的性能。 在Binlog_cache_use与Binlog_cache_disk_use状态变量可以用于调整该变量的大小是有用的。 请参见 第5.4.4节“二进制日志” 。binlog_cache_size仅设置事务高速缓存的大小; 语句高速缓存的大小由binlog_stmt_cache_size系统变量控制。 -
属性 值 命令行格式 --binlog-checksum=name系统变量 binlog_checksum范围 全球 动态 是 SET_VAR提示适用没有 类型 串 默认值 CRC32有效值 NONECRC32启用后,此变量会使主服务器为二进制日志中的每个事件写入校验和。
binlog_checksum支持值NONE(禁用)和CRC32。 默认是CRC32。 您无法更改binlog_checksum交易中 的值 。当
binlog_checksum禁用(值NONE)时,服务器通过编写和检查每个事件的事件长度(而不是校验和)来验证它是否只将完整事件写入二进制日志。更改此变量的值会导致二进制日志旋转; 校验和总是写入整个二进制日志文件,永远不会只写入一部分。
将主服务器上的此变量设置为从服务器无法识别的值会导致从服务器将其自己的
binlog_checksum值 设置 为NONE,并通过错误停止复制。 (Bug#13553750,Bug#61096)如果需要考虑与旧版Slave的向后兼容性,则可能需要将值明确设置为NONE。 -
binlog_direct_non_transactional_updates属性 值 命令行格式 --binlog-direct-non-transactional-updates[={OFF|ON}]系统变量 binlog_direct_non_transactional_updates范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF由于并发问题,当事务包含事务和非事务表的更新时,从服务器可能会变得不一致。 MySQL试图通过将非事务性语句写入事务高速缓存来保持这些语句之间的因果关系,事务高速缓存在提交时刷新。 但是,当代表事务对非事务表进行的修改对其他连接立即可见时会出现问题,因为这些更改可能不会立即写入二进制日志。
该
binlog_direct_non_transactional_updates变量为此问题提供了一种可能的解决方法。 默认情况下,禁用此变量。 启用binlog_direct_non_transactional_updates会导致非事务表的更新直接写入二进制日志,而不是写入事务高速缓存。从MySQL 8.0.14开始,设置此系统变量的会话值是一种受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
binlog_direct_non_transactional_updates仅适用于使用基于语句的二进制日志记录格式复制的语句 ; 也就是说,它只能当的值binlog_format是STATEMENT,或者binlog_format是MIXED和一个给定的语句正在使用基于语句的格式复制。 当二进制日志格式为ROW或者binlog_format设置 为时 , 此变量无效 ,MIXED并且使用基于行的格式复制给定语句。重要在启用此变量之前,必须确保事务表和非事务表之间没有依赖关系; 这种依赖的一个例子就是声明
INSERT INTO myisam_table SELECT * FROM innodb_table。 否则,这样的陈述很可能导致奴隶与主人分道扬..当二进制日志格式为
ROW或 时,此变量无效MIXED。 -
属性 值 命令行格式 --binlog-encryption[={OFF|ON}]介绍 8.0.14 系统变量 binlog_encryption范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF为此服务器上的二进制日志文件和中继日志文件启用加密。
OFF是默认值。ON为二进制日志文件和中继日志文件设置加密。 不需要在服务器上启用二进制日志记录以启用加密,因此您可以加密没有二进制日志的从站上的中继日志文件。 要使用加密,必须安装密钥环插件并将其配置为提供MySQL服务器的密钥环服务。 有关执行此操作的说明,请参见 第6.4.4节“MySQL密钥环” 。 任何支持的密钥环插件都可用于存储二进制日志加密密钥。首次启动启用了二进制日志加密的服务器时,会在初始化二进制日志和中继日志之前生成新的二进制日志加密密钥。 此密钥用于加密每个二进制日志文件的文件密码(如果服务器启用了二进制日志记录)和中继日志文件(如果服务器具有复制通道),并且使用文件密码生成的其他密钥来加密数据在文件中。 为所有通道加密中继日志文件,包括组复制应用程序通道和激活加密后创建的新通道。 二进制日志索引文件和中继日志索引文件从不加密。
如果在服务器运行时激活加密,则会在此时生成新的二进制日志加密密钥。 例外情况是先前在服务器上加密已激活然后被禁用,在这种情况下,再次使用之前使用的二进制日志加密密钥。 立即轮换二进制日志文件和中继日志文件,并使用此二进制日志加密密钥加密新文件和所有后续二进制日志文件和中继日志文件的文件密码。 服务器上仍存在的现有二进制日志文件和中继日志文件不会自动加密,但如果不再需要,则可以清除它们。
如果通过将
binlog_encryption系统变量 更改为停用加密,OFF则会立即轮换二进制日志文件和中继日志文件,并且所有后续日志记录都是未加密的。 以前加密的文件不会自动解密,但服务器仍然可以读取它们。 在服务器运行时,需要SUPER特权或BINLOG_ENCRYPTION_ADMIN权限才能激活或取消激活加密。 组复制应用程序通道不包含在中继日志轮换请求中,因此在正常使用中轮换其日志之前,这些通道的未加密日志记录不会启动。有关二进制日志文件和中继日志文件加密的更多信息,请参见 第17.3.10节“加密二进制日志文件和中继日志文件” 。
-
属性 值 命令行格式 --binlog-error-action[=value]系统变量 binlog_error_action范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 ABORT_SERVER有效值 IGNORE_ERRORABORT_SERVER控制当服务器遇到错误时发生的情况,例如无法写入,刷新或同步二进制日志,这可能导致主服务器的二进制日志变得不一致,并且复制从服务器将失去同步。
此变量默认为
ABORT_SERVER,这使服务器在遇到二进制日志的此类错误时停止日志记录并关闭。 重新启动时,恢复将按照意外服务器暂停的情况继续进行(请参见 第17.3.2节“处理意外停止复制从站” )。如果
binlog_error_action设置为IGNORE_ERROR,如果服务器遇到此类错误,它将继续正在进行的事务,记录错误然后暂停日志记录,并继续执行更新。log_bin必须再次启用 恢复二进制日志记录 ,这需要重新启动服务器。 此设置提供与旧版MySQL的向后兼容性。 -
属性 值 命令行格式 --binlog-expire-logs-seconds=#介绍 8.0.1 系统变量 binlog_expire_logs_seconds范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.11) 2592000默认值 (<= 8.0.4) 0最低价值 0最大价值 4294967295以秒为单位设置二进制日志有效期。 在有效期结束后,可以自动删除二进制日志文件。 可能的删除发生在启动时和刷新二进制日志时。 发生日志刷新,如 第5.4节“MySQL服务器日志”中所示 。
默认的二进制日志有效期为2592000秒,等于30天(30 * 24 * 60 * 60秒)。 如果既不
binlog_expire_logs_seconds和已弃用的系统变量 都 没有expire_logs_days在启动时设置值 ,则默认适用 。 如果其中一个变量的非零值binlog_expire_logs_seconds或expire_logs_days在启动时设置,则此值将用作二进制日志有效期。 如果在启动时设置了这两个变量的非零值,则将值forbinlog_expire_logs_seconds用作二进制日志有效期,并expire_logs_days使用警告消息忽略 值for 。要禁用自动清除二进制日志,请为其明确指定值0
binlog_expire_logs_seconds,并且不为其指定值expire_logs_days。 为了与早期版本兼容,如果您明确指定值0expire_logs_days并且未指定值, 则也会禁用自动清除binlog_expire_logs_seconds。 在这种情况下,binlog_expire_logs_seconds不应用 默认值 。要手动删除二进制日志文件,请使用该
PURGE BINARY LOGS语句。 请参见 第13.4.1.1节“PURGE BINARY LOGS语法” 。 -
属性 值 命令行格式 --binlog-format=format系统变量 binlog_format范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 列举 默认值 ROW有效值 ROWSTATEMENTMIXED此变量设置二进制日志格式,并且可以是任何一个
STATEMENT,ROW或MIXED。 请参见 第17.2.1节“复制格式” 。binlog_format可以在启动时或运行时设置,但在某些情况下,无法在运行时更改此变量或导致复制失败,如稍后所述。默认是
ROW。 例外 :在NDB Cluster中,默认为MIXED; NDB群集不支持基于语句的复制。设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
管理此变量的更改何时生效以及效果持续多长时间的规则与其他MySQL服务器系统变量相同。 有关更多信息,请参见 第13.7.5.1节“变量赋值的SET语法” 。
当
MIXED指定,基于语句的复制时,除了仅基于行的复制是保证导致正确的结果的情况。 例如,当语句包含用户定义的函数(UDF)或UUID()函数 时,会发生这种情况 。有关在设置每种二进制日志记录格式时如何处理存储程序(存储过程和函数,触发器和事件)的详细信息,请参见 第24.7节“存储程序二进制日志记录” 。
在运行时无法切换复制格式时有例外:
-
无法从存储的函数或触发器中更改复制格式。
-
如果会话具有打开的临时表,则无法更改会话(
SET @@SESSION.binlog_format) 的复制格式 。 -
如果任何复制通道具有打开的临时表,则无法全局(
SET @@GLOBAL.binlog_format或SET @@PERSIST.binlog_format) 更改复制格式 。 -
如果当前正在运行任何复制通道应用程序线程,则无法全局(
SET @@GLOBAL.binlog_format或SET @@PERSIST.binlog_format) 更改复制格式 。
尝试在任何这些情况下切换复制格式(或尝试设置当前复制格式)都会导致错误。 但是,您可以随时使用
PERSIST_ONLY(SET @@PERSIST_ONLY.binlog_format)更改复制格式,因为此操作不会修改运行时全局系统变量值,并且只有在服务器重新启动后才会生效。当存在任何临时表时,不建议在运行时切换复制格式,因为仅在使用基于语句的复制时记录临时表,而使用基于行的复制和混合复制时,不记录它们。
更改复制主机上的日志记录格式不会导致复制从站更改其日志记录格式以匹配。 如果复制从站启用了二进制日志记录,则在复制过程中切换复制格式会导致问题,并且
STATEMENT在主站正在使用ROW或MIXED格式化日志 记录时, 更改将导致使用 格式日志记录 的从站 。 复制从站无法将以ROW日志记录格式 接收的二进制日志条目 转换为STATEMENT格式以在其自己的二进制日志中使用,因此这种情况可能导致复制失败。 有关更多信息,请参阅 第5.4.4.2节“设置二进制日志格式” 。二进制日志格式会影响以下服务器选项的行为:
在各个选项的描述中详细讨论了这些效果。
-
-
binlog_group_commit_sync_delay属性 值 命令行格式 --binlog-group-commit-sync-delay=#系统变量 binlog_group_commit_sync_delay范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1000000控制二进制日志提交在将二进制日志文件同步到磁盘之前等待的微秒数。 默认
binlog_group_commit_sync_delay设置为0,表示没有延迟。 设置binlog_group_commit_sync_delay为微秒延迟可以使更多事务一次同步到磁盘,从而减少提交一组事务的总时间,因为较大的组每组需要的时间单位较少。当 设置
sync_binlog=0或sync_binlog=1设置时,指定的延迟binlog_group_commit_sync_delay将在同步之前(或在进行之前的情况下sync_binlog=0) 应用于每个二进制日志提交组 。 当sync_binlog设置为 大于1 的值 n时 ,将在每 n个 二进制日志提交组 之后应用延迟 。设置
binlog_group_commit_sync_delay可以增加任何具有(或可能具有故障转移后)复制从属服务器的服务器上的并行提交事务的数量,因此可以增加复制从属服务器上的并行执行。 要从此效果中受益,从属服务器必须已slave_parallel_type=LOGICAL_CLOCK设置,并且在binlog_transaction_dependency_tracking=COMMIT_ORDER设置 时效果更为显着 。 在调整设置时,必须考虑主站的吞吐量和从站的吞吐量binlog_group_commit_sync_delay。设置
binlog_group_commit_sync_delay还可以减少在fsync()具有二进制日志的任何服务器(主服务器或从服务器)上对二进制日志 的 调用 次数 。请注意,设置会
binlog_group_commit_sync_delay增加服务器上事务的延迟,这可能会影响客户端应用程序。 此外,在高度并发的工作负载上,延迟可能会增加争用,从而降低吞吐量。 通常,设置延迟的好处超过了缺点,但应始终进行调整以确定最佳设置。 -
binlog_group_commit_sync_no_delay_count属性 值 命令行格式 --binlog-group-commit-sync-no-delay-count=#系统变量 binlog_group_commit_sync_no_delay_count范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 1000000在中止当前延迟之前要等待的最大事务数
binlog_group_commit_sync_delay。 如果binlog_group_commit_sync_delay设置为0,则此选项无效。 -
属性 值 命令行格式 --binlog-max-flush-queue-time=#弃用 是 系统变量 binlog_max_flush_queue_time范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 0最低价值 0最大价值 100000binlog_max_flush_queue_time已弃用,并标记为在将来的MySQL版本中最终删除。 以前,此系统变量控制以微秒为单位的时间,以便在继续进行组提交之前继续从刷新队列中读取事务。 它不再有任何影响。 -
属性 值 命令行格式 --binlog-order-commits[={OFF|ON}]系统变量 binlog_order_commits范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON在复制主服务器上启用此变量(这是默认设置)时,发布到存储引擎的事务提交指令将在单个线程上序列化,以便事务始终以与写入二进制日志相同的顺序提交。 禁用此变量允许使用多个线程发出事务提交指令。 与二进制日志组提交结合使用,可以防止单个事务的提交率成为吞吐量的瓶颈,因此可能会产生性能提升。
当涉及的所有存储引擎都已确认事务已准备好提交时,事务将写入二进制日志。 然后,二进制日志组提交逻辑在其二进制日志写入发生后提交一组事务。 什么时候
binlog_order_commits被禁用,因为多个线程用于此进程,提交组中的事务可能以与二进制日志中的顺序不同的顺序提交。 (来自单个客户端的事务总是按时间顺序提交。)在许多情况下,这无关紧要,因为在单独的事务中执行的操作应该产生一致的结果,如果不是这种情况,则应该使用单个事务。如果要确保主服务器和多线程复制从属服务器上的事务历史记录保持相同,请
slave_preserve_commit_order=1在复制从服务器上 设置 。 -
binlog_rotate_encryption_master_key_at_startup属性 值 命令行格式 --binlog-rotate-encryption-master-key-at-startup[={OFF|ON}]介绍 8.0.14 系统变量 binlog_rotate_encryption_master_key_at_startup范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF指定在服务器启动时是否轮换二进制日志主密钥。 二进制日志主密钥是二进制日志加密密钥,用于加密服务器上的二进制日志文件和中继日志文件的文件密码。 当第一次启动服务器并启用
binlog_encryption=ON二进制日志加密时,会生成一个新的二进制日志加密密钥并用作二进制日志主密钥。 如果binlog_rotate_encryption_master_key_at_startup系统变量也设置为ON,每当重新启动服务器时,都会生成另一个二进制日志加密密钥,并将其用作所有后续二进制日志文件和中继日志文件的二进制日志主密钥。 如果binlog_rotate_encryption_master_key_at_startup系统变量设置为OFF默认值,则在服务器重新启动后再次使用现有的二进制日志主密钥。 有关二进制日志加密密钥和二进制日志主密钥的更多信息,请参见 第17.3.10节“加密二进制日志文件和中继日志文件” 。 -
属性 值 命令行格式 --binlog-row-event-max-size=#系统变量 (> = 8.0.14) binlog_row_event_max_size范围 (> = 8.0.14) 全球 动态 (> = 8.0.14) 没有 SET_VAR提示适用 (> = 8.0.14)没有 类型 整数 默认值 8192最低价值 256最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295使用基于行的二进制日志记录时,此设置是对基于行的二进制日志事件的最大大小的软限制(以字节为单位)。 如果可能,存储在二进制日志中的行将分组为大小不超过此设置值的事件。 如果无法拆分事件,则可以超出最大大小。 该值必须(或者向下舍入到)256的倍数。默认值为8192字节。
此全局系统变量是只读的,只能在服务器启动时设置。 因此,只能通过 在 语句中 使用
PERSIST_ONLY关键字或@@persist_only限定符 来修改其值SET。 -
属性 值 命令行格式 --binlog-row-image=image_type系统变量 binlog_row_image范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 列举 默认值 full有效值 full(记录所有列)minimal(仅记录更改的列和标识行所需的列)noblob(记录所有列,除了不需要的BLOB和TEXT列)对于基于MySQL的行复制,此变量确定如何将行图像写入二进制日志。
设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
在MySQL基于行的复制中,每个行更改事件包含两个图像,一个 “ 之前 ” 图像,其列在搜索要更新的行时与之匹配,以及 包含更改 的 “ 之后 ” 图像。 通常,MySQL会记录前后图像的完整行(即所有列)。 但是,并不是必须在两个映像中包含每一列,并且我们通常可以通过仅记录实际需要的列来节省磁盘,内存和网络使用。
注意删除行时,仅记录之前的图像,因为删除后没有更改的值要传播。 插入行时,仅记录后映像,因为没有要匹配的现有行。 只有在更新行时,才需要前后映像,并且都写入二进制日志。
对于之前的映像,只需记录唯一标识行所需的最小列集。 如果包含该行的表具有主键,则只将主键列写入二进制日志。 否则,如果表具有所有列的唯一键
NOT NULL,则只需记录唯一键中的列。 (如果表既没有主键也没有唯一键而没有任何NULL列,则必须在之前的映像中使用所有列并进行记录。)在after映像中,只需要记录实际更改的列。您可以使用
binlog_row_image系统变量 使服务器记录完整行或最小行 。 此变量实际上采用三个可能值之一,如以下列表所示:注意NDB Cluster不支持此变量; 设置它对
NDB表 的记录没有影响 。默认值为
full。当 且仅当以下条件对源表和目标表都为真 时,使用
minimal或noblob删除和更新才能保证对给定表正常工作:-
所有列必须以相同的顺序存在; 每列必须使用与其他表中的对应数据类型相同的数据类型。
-
表必须具有相同的主键定义。
(换句话说,这些表必须与不属于表主键的索引的可能异常相同。)
如果不满足这些条件,则目标表中的主键列值可能不足以为删除或更新提供唯一匹配。 在这种情况下,不会发出警告或错误; 主人和奴隶默默地分歧,从而打破了一致性。
当二进制日志记录格式为时,设置此变量无效
STATEMENT。 当binlog_format是MIXED时,设置为binlog_row_image适用于使用基于行的格式记录的变化,但这种设置上记录的语句变化没有影响。设置
binlog_row_image于在全局和会话级不会引起隐式提交; 这意味着可以在事务正在进行时更改此变量,而不会影响事务。 -
-
属性 值 命令行格式 --binlog-row-metadata=metadata_type介绍 8.0.1 系统变量 binlog_row_metadata范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 MINIMAL有效值 FULL(包括所有元数据。)MINIMAL(限制包括元数据。)配置使用基于行的日志记录时添加到二进制日志的表元数据量。 设置为
MINIMAL默认值时,仅记录与SIGNED标志,列字符集和几何类型 相关的元数据 。 设置为FULL完成时,将记录表的元数据,例如列名称ENUM或SET字符串值,PRIMARY KEY信息,等等。扩展元数据用于以下目的:
-
当表的结构与主表结构不同时,从设备使用元数据来传输数据。
-
外部软件可以使用元数据来解码行事件并将数据存储到外部数据库中,例如数据仓库。
-
-
属性 值 命令行格式 --binlog-row-value-options=#介绍 8.0.3 系统变量 binlog_row_value_options范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 组 默认值 ''有效值 PARTIAL_JSON设置为时
PARTIAL_JSON,这允许使用节省空间的二进制日志格式进行更新,这些更新仅修改JSON文档的一小部分,这会导致基于行的复制仅将JSON文档的已修改部分写入后映像二进制日志中的更新(而不是编写完整的文档)。 此作品为UPDATE它修改使用的任何序列的JSON列声明JSON_SET(),JSON_REPLACE()以及JSON_REMOVE()。 如果修改需要比完整文档更多的空间,或者服务器无法生成部分更新,则使用完整文档。设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
PARTIAL_JSON是唯一支持的值; 要取消设置binlog_row_value_options,请将其值设置为空字符串。binlog_row_value_options=PARTIAL_JSON仅在启用二进制日志记录并binlog_format设置为ROW或 时才生效MIXED。 基于语句的复制 始终 仅记录JSON文档的已修改部分,而不管是否设置了任何值binlog_row_value_options。 要最大化节省的空间量,请使用 此选项binlog_row_image=NOBLOB或binlog_row_image=MINIMAL与此选项一起使用。binlog_row_image=FULL由于完整的JSON文档存储在前映像中,因此部分更新仅存储在后映像中,因此比这些中的任何一个都节省更少的空间。binlog_row_value_options=PARTIAL_JSON覆盖log_bin_use_v1_row_events变量的 任何设置 。 如果启用该选项,binlog_row_value_options=PARTIAL_JSON则仍会使用 所需的事件格式 。mysqlbinlog 输出包括使用
BINLOG语句 编码为base-64字符串的事件形式的部分JSON更新 。 如果--verbose指定 了该 选项,则为 mysqlbinlog 使用伪SQL语句将部分JSON更新显示为可读JSON。如果无法将修改应用于从属服务器上的JSON文档,则MySQL Replication会生成错误。 这包括未找到路径。 请注意,即使使用此安全检查和其他安全检查,如果从属设备上的JSON文档与主设备上的JSON文档不同并且应用了部分更新,理论上可以在从设备上生成有效但意外的JSON文档。
复制到较旧的MySQL版本。 当从运行MySQL 8.0.3或更高版本的主服务器复制到使用MySQL 8.0.2或以前版本的从服务器时,
binlog_row_value_options必须禁用(即设置为'')。 这是因为JSON部分更新的日志记录使用MySQL 8.0.3中引入的二进制日志事件类型; 以前版本的MySQL无法识别此事件类型。 -
属性 值 命令行格式 --binlog-rows-query-log-events[={OFF|ON}]系统变量 binlog_rows_query_log_events范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF此系统变量仅影响基于行的日志记录。 启用后,它会使服务器将信息日志事件(如行查询日志事件)写入其二进制日志中。 此信息可用于调试和相关目的,例如,当无法从行更新重建时,获取在主服务器上发出的原始查询。
设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
读取二进制日志的MySQL程序通常会忽略这些信息事件,因此在从备份复制或恢复时不会出现任何问题。 要查看它们,请使用mysqlbinlog
--verbose选项两次 增加详细级别 ,或者为-vv或--verbose --verbose。 -
属性 值 命令行格式 --binlog-stmt-cache-size=#系统变量 binlog_stmt_cache_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 32768最低价值 4096最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295此变量确定二进制日志的高速缓存大小,以保存事务期间发出的非事务性语句。 在服务器上启用二进制日志记录(
log_bin系统变量设置为ON)时,如果服务器支持任何事务存储引擎,则为每个客户端分配单独的二进制日志事务和语句高速缓存。 如果在事务期间经常使用大型非事务性语句,则可以增加此高速缓存大小以获得更好的性能。 在Binlog_stmt_cache_use与Binlog_stmt_cache_disk_use状态变量可以用于调整该变量的大小是有用的。 请参见 第5.4.4节“二进制日志” 。该
binlog_cache_size系统变量设置为事务高速缓存的大小。 -
binlog_transaction_dependency_tracking属性 值 命令行格式 --binlog-transaction-dependency-tracking=value介绍 8.0.1 系统变量 binlog_transaction_dependency_tracking范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 COMMIT_ORDER有效值 COMMIT_ORDERWRITESETWRITESET_SESSION主服务器用于确定哪些事务可以由从属多线程应用程序并行执行的依赖关系信息的来源。 此变量可以采用以下列表中描述的三个值之一:
-
COMMIT_ORDER:从主服务器的提交时间戳生成依赖关系信息。 这是默认值。 此模式也用于没有写集的任何事务,即使此变量是WRITESET或WRITESET_SESSION; 对于没有主键的事务更新表以及更新具有外键约束的表的事务,情况也是如此。 -
WRITESET:从主服务器的写集生成依赖关系信息,并且可以并行化写入不同元组的任何事务。 -
WRITESET_SESSION:从主服务器的写集生成依赖关系信息,但不能重新排序来自同一会话的两个更新。
WRITESET和WRITESET_SESSION模式不提供任何比COMMIT_ORDER模式中 返回的更新的事务依赖项 。此变量的值不能设置为
COMMIT_ORDERif 以外的任何transaction_write_set_extraction值OFF。 你也应该注意,值transaction_write_set_extraction不能改变,如果当前值binlog_transaction_dependency_tracking是WRITESET或WRITESET_SESSION。要保留并检查最新事务以更改给定行的行哈希的数量由值确定
binlog_transaction_dependency_history_size。 -
-
binlog_transaction_dependency_history_size属性 值 命令行格式 --binlog-transaction-dependency-history-size=#介绍 8.0.1 系统变量 binlog_transaction_dependency_history_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 25000最低价值 1最大价值 1000000设置内存中保留的行哈希数的上限,用于查找上次修改给定行的事务。 达到此哈希值后,将清除历史记录。
-
属性 值 命令行格式 --expire-logs-days=#弃用 8.0.3 系统变量 expire_logs_days范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 (> = 8.0.11) 0默认值 (> = 8.0.2,<= 8.0.4) 30默认值 (<= 8.0.1) 0最低价值 0最大价值 99指定自动删除二进制日志文件之前的天数。
expire_logs_days已弃用,将在以后的版本中删除。 而是使用binlog_expire_logs_seconds,它以秒为单位设置二进制日志有效期。 如果未为任一系统变量设置值,则默认有效期为30天。 可能的删除发生在启动时和刷新二进制日志时。 发生日志刷新,如 第5.4节“MySQL服务器日志”中所示 。expire_logs_days如果binlog_expire_logs_seconds还指定 了您指定的任何非零值, 则将 其值binlog_expire_logs_seconds替换为二进制日志有效期。 在这种情况下会发出警告消息。expire_logs_days如果binlog_expire_logs_seconds未指定或指定为0 , 则仅将 非零值 应用为二进制日志有效期 。要禁用自动清除二进制日志,请为其明确指定值0
binlog_expire_logs_seconds,并且不为其指定值expire_logs_days。 为了与早期版本兼容,如果您明确指定值0expire_logs_days并且未指定值, 则也会禁用自动清除binlog_expire_logs_seconds。 在这种情况下,binlog_expire_logs_seconds不应用 默认值 。要手动删除二进制日志文件,请使用该
PURGE BINARY LOGS语句。 请参见 第13.4.1.1节“PURGE BINARY LOGS语法” 。 -
属性 值 系统变量 log_bin范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 显示服务器上二进制日志记录的状态,启用(
ON)或禁用(OFF)。 启用二进制日志记录后,服务器会将所有将数据更改的语句记录到二进制日志中,该日志用于备份和复制。ON表示二进制日志可用,OFF表示它未被使用。 该--log-bin选项可用于指定二进制日志的基本名称和位置。在早期的MySQL版本中,默认情况下禁用二进制日志记录,如果您指定了该
--log-bin选项, 则会启用它 。 从MySQL 8.0开始,默认情况下启用二进制日志记录,log_bin系统变量设置为ON,无论您是否指定--log-bin选项。 例外情况是,如果使用 mysqld 通过使用--initializeor--initialize-insecure选项 手动初始化数据目录 ,则默认情况下禁用二进制日志记录。 在这种情况下,可以通过指定--log-bin选项 来启用二进制日志记录 。如果 在启动时指定 了
--skip-log-binor--disable-log-bin选项,则禁用二进制日志记录,并将log_bin系统变量设置为OFF。 如果指定了这些选项中的任何一个并且--log-bin也指定 了这些选项 ,则稍后指定的选项优先。有关二进制日志的格式和管理的信息,请参见 第5.4.4节“二进制日志” 。
-
属性 值 系统变量 log_bin_basename范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 保存二进制日志文件的基本名称和路径,可以使用
--log-bin服务器选项 进行设置 。 在MySQL 8.0中,如果--log-bin未提供 该 选项,则默认基本名称为binlog。 为了与MySQL 5.7兼容,如果--log-bin选项没有提供字符串或空字符串,则默认基本名称是host_name-bin -
属性 值 命令行格式 --log-bin-index=file_name系统变量 log_bin_index范围 全球 动态 没有 SET_VAR提示适用没有 类型 文件名 保存二进制日志索引文件的基本名称和路径,可以使用
--log-bin-index服务器选项 进行设置 。 -
log_bin_trust_function_creators属性 值 命令行格式 --log-bin-trust-function-creators[={OFF|ON}]系统变量 log_bin_trust_function_creators范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用二进制日志记录时,此变量适用。 它控制是否可以信任存储的函数创建者不创建将导致不安全事件写入二进制日志的存储函数。 如果设置为0(默认值),用户不允许创建或更改存储功能,除非他们有
SUPER除了特权CREATE ROUTINE或ALTER ROUTINE特权。 设置为0还强制执行必须使用DETERMINISTIC特征或使用READS SQL DATA或 声明函数的限制NO SQL特性。 如果变量设置为1,则MySQL不会对存储的函数创建强制实施这些限制。 此变量也适用于触发器创建。 请参见 第24.7节“存储程序二进制日志记录” 。 -
属性 值 命令行格式 --log-bin-use-v1-row-events[={OFF|ON}]系统变量 log_bin_use_v1_row_events范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 OFF显示是否正在使用版本2二进制日志记录。 值为1表示服务器正在使用版本1日志记录事件(以前版本中使用的唯一版本的二进制日志事件)编写二进制日志,从而生成可由较旧的从属服务器读取的二进制日志。 0表示正在使用版本2二进制日志事件。
该变量是只读的。 到版本1和版本2的二进制事件二进制日志之间切换,重新启动它是必要 的mysqld 与
--log-bin-use-v1-row-events选项 。除了在执行NDB群集复制升级时,
--log-bin-use-v1-events主要是在设置复制冲突检测和解决方案时感兴趣NDB$EPOCH_TRANS(),这需要版本2二进制行事件日志记录。 因此,这个选项--ndb-log-transaction-id并不兼容。注意MySQL NDB Cluster 8.0默认使用版本2二进制日志行事件。 在规划升级或降级以及使用NDB群集复制进行设置时,您应该牢记这一点。
有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
log_builtin_as_identified_by_password属性 值 命令行格式 --log-builtin-as-identified-by-password[={OFF|ON}]删除 8.0.11 系统变量 log_builtin_as_identified_by_password范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF在MySQL 8.0.11中删除了此系统变量。
-
属性 值 命令行格式 --log-slave-updates[={OFF|ON}]系统变量 log_slave_updates范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 (> = 8.0.3) ON默认值 (<= 8.0.2) OFF从服务器从主服务器接收的更新是否应记录到从属服务器自己的二进制日志中。 必须在从站上启用二进制日志记录才能使此变量生效。 请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。
默认情况下,此系统变量设置为on,并且是只读的。 如果需要阻止从服务器记录更新,请指定
--skip-log-slave-updates启动从站的时间,或log_slave_updates=OFF在 从站 的配置文件中 指定 。 -
log_statements_unsafe_for_binlog属性 值 命令行格式 --log-statements-unsafe-for-binlog[={OFF|ON}]系统变量 log_statements_unsafe_for_binlog范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON如果遇到错误1592,则控制是否将生成的警告添加到错误日志中。
-
属性 值 命令行格式 --master-verify-checksum[={OFF|ON}]系统变量 master_verify_checksum范围 全球 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 OFF启用此变量会导致主服务器在读取二进制日志时检查校验和。
master_verify_checksum默认情况下禁用; 在这种情况下,主服务器使用二进制日志中的事件长度来验证事件,以便只从二进制日志中读取完整事件。 -
属性 值 命令行格式 --max-binlog-cache-size=#系统变量 max_binlog_cache_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 18446744073709551615最低价值 4096最大价值 18446744073709551615如果事务需要超过这么多字节的内存,则服务器生成的 Multi语句事务需要超过'max_binlog_cache_size'字节的存储 错误。 最小值为4096.最大可能值为16EiB(exbibytes)。 建议的最大值为4GB; 这是因为MySQL目前无法使用大于4GB的二进制日志位置。
max_binlog_cache_size仅设置事务高速缓存的大小; 语句高速缓存的上限由max_binlog_stmt_cache_size系统变量控制。max_binlog_cache_size匹配 会话的可见性 与binlog_cache_size系统变量 的 匹配 ; 换句话说,更改其值只会影响值更改后启动的新会话。 -
属性 值 命令行格式 --max-binlog-size=#系统变量 max_binlog_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1073741824最低价值 4096最大价值 1073741824如果对二进制日志的写入导致当前日志文件大小超过此变量的值,则服务器将轮换二进制日志(关闭当前文件并打开下一个文件)。 最小值为4096字节。 最大值和默认值为1GB。 加密的二进制日志文件有一个额外的512字节标头,包含在其中
max_binlog_size。事务在一个块中写入二进制日志,因此它永远不会在几个二进制日志之间拆分。 因此,如果您有大事务,您可能会看到大于的二进制日志文件
max_binlog_size。如果
max_relay_log_size为0,则为max_binlog_size适用于中继日志。在服务器上使用GTID时
max_binlog_size,如果mysql.gtid_executed无法访问 系统表 以从当前二进制日志文件中写入GTID,则无法轮换二进制日志。 在这种情况下,服务器根据其binlog_error_action设置进行 响应 。 如果IGNORE_ERROR设置,则在服务器上记录错误并停止二进制日志记录,或者如果ABORT_SERVER设置,则服务器将关闭。 -
属性 值 命令行格式 --max-binlog-stmt-cache-size=#系统变量 max_binlog_stmt_cache_size范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 18446744073709547520最低价值 4096最大价值 18446744073709547520如果事务中的非事务性语句需要超过这么多字节的内存,则服务器会生成错误。 最小值为4096. 32位平台上的最大值和默认值为4GB,64位平台上的最大值和默认值为16EB(exabytes)。
max_binlog_stmt_cache_size仅设置语句高速缓存的大小; 事务高速缓存的上限仅由max_binlog_cache_size系统变量控制。 -
属性 值 介绍 8.0.1 系统变量 original_commit_timestamp范围 会议 动态 是 SET_VAR提示适用没有 类型 数字 供复制内部使用。 当在从属服务器上重新执行事务时,将其设置为在原始主服务器上提交事务的时间,以自纪元以来的微秒为单位进行测量。 这允许原始提交时间戳在整个复制拓扑中传播。
设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
-
属性 值 系统变量 sql_log_bin范围 会议 动态 是 SET_VAR提示适用没有 类型 布尔 默认值 ON此变量控制是否为当前会话启用了对二进制日志的记录(假设已启用二进制日志本身)。 默认值为
ON。 要禁用或启用当前会话的二进制日志记录,请将会话sql_log_bin变量 设置 为OFF或ON。将此变量设置
OFF为会话以临时禁用二进制日志记录,同时更改不希望复制到从属服务器的主服务器。设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
无法
sql_log_bin在事务或子查询中 设置会话值 。设置此变量
OFF可防止将GTID分配给二进制日志中的事务 。 如果您使用GTID进行复制,这意味着即使稍后再次启用二进制日志记录,从此处写入日志的GTID也不会考虑同时发生的任何事务,因此实际上这些事务将丢失。 -
属性 值 命令行格式 --sync-binlog=#系统变量 sync_binlog范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1最低价值 0最大价值 4294967295控制MySQL服务器将二进制日志同步到磁盘的频率。
-
sync_binlog=0:禁用MySQL服务器将二进制日志同步到磁盘。 相反,MySQL服务器依赖于操作系统来不时地将二进制日志刷新到磁盘,就像对任何其他文件一样。 此设置提供最佳性能,但在电源故障或操作系统崩溃的情况下,服务器可能已提交尚未同步到二进制日志的事务。 -
sync_binlog=1:在提交事务之前,允许将二进制日志同步到磁盘。 这是最安全的设置,但由于磁盘写入次数增加,可能会对性能产生负面影响。 如果发生电源故障或操作系统崩溃,二进制日志中缺少的事务仅处于准备状态。 这允许自动恢复例程回滚事务,这保证了二进制日志中没有丢失任何事务。 -
sync_binlog=,其中NN是0或1以外的值:N在收集二进制日志提交组 后, 二进制日志将 同步到磁盘 。 如果发生电源故障或操作系统崩溃,服务器可能已提交尚未刷新到二进制日志的事务。 由于磁盘写入次数增加,此设置可能会对性能产生负面影响。 较高的值可提高性能,但会增加数据丢失的风险。
为了在
InnoDB与事务一起使用 的复制设置中尽可能具有持久性和一致性 ,请使用以下设置:警告许多操作系统和一些磁盘硬件欺骗了磁盘到磁盘的操作。 他们可能会告诉 mysqld 已经发生了冲洗,即使它没有。 在这种情况下,即使使用推荐的设置也无法保证事务的持久性,并且在最坏的情况下,断电可能会破坏
InnoDB数据。 在SCSI磁盘控制器或磁盘本身中使用电池供电的磁盘缓存可加快文件刷新速度,并使操作更安全。 您还可以尝试禁用硬件缓存中的磁盘写入缓存。 -
-
transaction_write_set_extraction属性 值 命令行格式 --transaction-write-set-extraction[=value]系统变量 transaction_write_set_extraction范围 全球,会议 动态 是 SET_VAR提示适用没有 类型 列举 默认值 (> = 8.0.2) XXHASH64默认值 OFF有效值 OFFMURMUR32XXHASH64定义用于散列在事务期间提取的写入的算法。 如果使用组复制,则必须将此变量设置为,
XXHASH64因为在所有组成员上进行冲突检测时,需要从事务中提取写入的过程。 请参见 第18.9.1节“组复制要求” 。从MySQL 8.0.14开始,设置此系统变量的会话值是一种受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
注意当
binlog_transaction_dependency_tracking设置为WRITESET或 时,不能更改此变量的值WRITESET_SESSION。
本节中描述的MySQL服务器选项和系统变量用于监视和控制全局事务标识符(GTID)。
有关其他信息,请参见 第17.1.3节“使用全局事务标识符进行复制” 。
以下服务器启动选项与基于GTID的复制一起使用:
-
属性 值 命令行格式 --enforce-gtid-consistency[=value]系统变量 enforce_gtid_consistency范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 OFF有效值 OFFONWARN启用后,服务器通过仅允许执行可使用GTID安全记录的语句来强制执行GTID一致性。 你 必须 将该选项设置为
ON启用基于GTID复制之前。--enforce-gtid-consistency可以配置 的值 是:-
OFF:允许所有交易违反GTID一致性。 -
ON:不允许任何交易违反GTID一致性。 -
WARN:允许所有事务违反GTID一致性,但在这种情况下会生成警告。
--enforce-gtid-consistency没有值的 设置 是别名--enforce-gtid-consistency=ON。 这会影响变量的行为,请参阅enforce_gtid_consistency。只有在
enforce-gtid-consistency设置 为时才能记录可以使用GTID安全语句记录的语句ON,因此此处列出的操作不能与此选项一起使用:-
更新事务和非事务表的事务或语句。 如果所有 非事务性 表都是临时的 ,则会在同一事务或与事务DML相同的语句中允许非事务性DML 。
--enforce-gtid-consistency仅在语句进行二进制日志记录时才生效。 如果在服务器上禁用了二进制日志记录,或者由于过滤器删除了语句而未将语句写入二进制日志,则不会对未记录的语句检查或强制执行GTID一致性。有关更多信息,请参见 第17.1.3.6节“使用GTID进行复制的限制” 。
-
-
属性 值 命令行格式 --gtid-mode=MODE系统变量 gtid_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 OFF有效值 OFFOFF_PERMISSIVEON_PERMISSIVEON此选项指定是否使用全局事务标识符(GTID)来标识事务。 将此选项设置为
--gtid-mode=ON要求enforce-gtid-consistency设置为ON。 该gtid_mode变量是动态的,可以在线配置基于GTID的复制。 在使用此功能之前,请参见 第17.1.5节“在线服务器上更改复制模式” 。 -
--gtid-executed-compression-period属性 值 命令行格式 --gtid-executed-compression-period=#类型 整数 默认值 1000最低价值 0最大价值 4294967295mysql.gtid_executed每次发生这么多交易时都要 压缩 表格。 设置为0表示此表未压缩。 该表没有压缩发生在启用二进制日志,因此该选项无效,除非log_bin是OFF。有关 更多信息, 请参阅 mysql.gtid_executed表压缩 。
以下系统变量与基于GTID的复制一起使用:
-
属性 值 命令行格式 --binlog-gtid-simple-recovery[={OFF|ON}]系统变量 binlog_gtid_simple_recovery范围 全球 动态 没有 SET_VAR提示适用没有 类型 布尔 默认值 ON此变量控制在MySQL启动或重新启动时搜索GTID期间迭代二进制日志文件的方式。
当
binlog_gtid_simple_recovery=TRUE,这是MySQL 8.0中的默认值时gtid_executed,gtid_purged在启动时根据Previous_gtids_log_event最新和最旧的二进制日志文件中 的值计算 和 的值 。 对于计算的说明,请参阅 该gtid_purged系统变量 。 此设置在服务器重新启动期间仅访问两个二进制日志文件。 如果服务器上的所有二进制日志都是使用MySQL 5.7.8或更高版本生成的,binlog_gtid_simple_recovery=TRUE则始终可以安全地使用。如果从MySQL 5.7.7或更老的任何二进制日志是存在于服务器上(例如,下面的较旧服务器的升级到MySQL 8.0)中,用
binlog_gtid_simple_recovery=TRUE,gtid_executed和gtid_purged可能在以下两种情况下不正确地初始化:-
是由MySQL 5.7.5产生的最新的二进制日志或更早版本,并且
gtid_mode是ON对一些二进制日志,但OFF在最新的二进制日志。 -
SET @@GLOBAL.gtid_purged在MySQL 5.7.7或更早版本上发布了 一个 语句,并且SET @@GLOBAL.gtid_purged尚未清除语句 时处于活动状态的二进制日志 。
如果在任一情况下计算出错误的GTID集,即使稍后重新启动服务器,它仍将保持不正确
binlog_gtid_simple_recovery=FALSE。 如果这些情况中的任何一种适用或可能适用于服务器,请binlog_gtid_simple_recovery=FALSE在启动或重新启动服务器之前进行 设置 。当
binlog_gtid_simple_recovery=FALSE被设置时,计算的方法gtid_executed和gtid_purged在被描述为 的gtid_purged系统变量 被改变为迭代二进制日志文件如下:-
不使用
Previous_gtids_log_event来自最新二进制日志文件的GTID日志事件 的值,而是 从最新的二进制日志文件进行gtid_executed迭代 计算 ,并使用Previous_gtids_log_event来自第一个二进制日志文件 的值 和任何GTID日志事件来查找Previous_gtids_log_event值。 如果服务器的最新二进制日志文件没有GTID日志事件,例如,如果gtid_mode=ON已使用但后来服务器已更改为gtid_mode=OFF,则此过程可能需要很长时间。 -
不使用
Previous_gtids_log_event最旧的二进制日志文件的值,计算gtid_purged从最旧的二进制日志文件迭代,并使用Previous_gtids_log_event第一个二进制日志文件 的值, 在该文件中找到非空Previous_gtids_log_event值或至少一个GTID日志事件(表示GTID的使用从那时开始)。 如果服务器的旧二进制日志文件没有GTID日志事件,例如,如果gtid_mode=ON最近才在服务器上设置,则此过程可能需要很长时间。
-
-
属性 值 命令行格式 --enforce-gtid-consistency[=value]系统变量 enforce_gtid_consistency范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 OFF有效值 OFFONWARN根据此变量的值,服务器通过仅允许执行可使用GTID安全记录的语句来强制执行GTID一致性。 您 必须 将此变量设置为
ON启用基于GTID复制之前。enforce_gtid_consistency可以配置 的值 是:-
OFF:允许所有交易违反GTID一致性。 -
ON:不允许任何交易违反GTID一致性。 -
WARN:允许所有事务违反GTID一致性,但在这种情况下会生成警告。
enforce_gtid_consistency仅在语句进行二进制日志记录时才生效。 如果在服务器上禁用了二进制日志记录,或者由于过滤器删除了语句而未将语句写入二进制日志,则不会对未记录的语句检查或强制执行GTID一致性。有关可以使用基于GTID的复制记录的语句的更多信息,请参阅
--enforce-gtid-consistency。在MySQL 5.7之前和该版本系列的早期版本中,布尔值
enforce_gtid_consistency默认为OFF。 为了保持与这些早期版本的兼容性,枚举默认为OFF,而--enforce-gtid-consistency没有值的设置被解释为将值设置为ON。 变量也有价值观的多个文本别名:0=OFF=FALSE,1=ON=TRUE,2=WARN。 这与其他枚举类型不同,但保持与先前版本中使用的布尔类型的兼容性。 这些更改会影响变量返回的内容。 使用SELECT @@ENFORCE_GTID_CONSISTENCY,SHOW VARIABLES LIKE 'ENFORCE_GTID_CONSISTENCY'和SELECT * FROM INFORMATION_SCHEMA.VARIABLES WHERE 'VARIABLE_NAME' = 'ENFORCE_GTID_CONSISTENCY',都返回文本形式,而不是数字形式。 这是一个不兼容的更改,因为@@ENFORCE_GTID_CONSISTENCY返回布尔值的数字形式,但返回SHOW信息架构 的文本格式 。 -
-
属性 值 系统变量 gtid_executed系统变量 gtid_executed范围 全球 范围 全球,会议 动态 没有 动态 没有 SET_VAR提示适用没有 SET_VAR提示适用没有 类型 串 与全局范围一起使用时,此变量包含服务器上执行的所有事务集的表示以及由 语句 设置的GTID 。 这是相同的值 列在的输出 和 。 此变量的值是GTID集, 有关详细信息 ,请参阅 GTID集 。
SETgtid_purgedExecuted_Gtid_SetSHOW MASTER STATUSSHOW SLAVE STATUS服务器启动时,
@@GLOBAL.gtid_executed初始化。 有关binlog_gtid_simple_recovery如何迭代二进制日志以填充的详细信息, 请参阅参考资料gtid_executed。 然后在执行事务时或者如果 执行 任何 语句时将 GTID添加到集合中 。SETgtid_purged在任何给定时间可以在二进制日志中找到的事务集等于
GTID_SUBTRACT(@@GLOBAL.gtid_executed, @@GLOBAL.gtid_purged); 也就是说,二进制日志中尚未清除的所有事务。发出
RESET MASTER会导致此变量的全局值(但不是会话值)重置为空字符串。 除了由于清除集合之外,GTID不会从该集合中移除RESET MASTER。在某些旧版本中,此变量也可以与会话范围一起使用,其中包含在当前会话中写入缓存的事务集的表示。 会话范围现已弃用。
-
gtid_executed_compression_period属性 值 系统变量 gtid_executed_compression_period范围 全球 动态 是 SET_VAR提示适用没有 类型 整数 默认值 1000最低价值 0最大价值 4294967295mysql.gtid_executed每次处理这么多事务时 压缩 表。 设置为0表示此表未压缩。 由于在使用二进制日志时不会对表进行压缩,因此除非禁用二进制日志记录,否则设置变量的值无效。有关 更多信息, 请参阅 mysql.gtid_executed表压缩 。
-
属性 值 系统变量 gtid_mode范围 全球 动态 是 SET_VAR提示适用没有 类型 列举 默认值 OFF有效值 OFFOFF_PERMISSIVEON_PERMISSIVEON控制是否启用基于GTID的日志记录以及日志可以包含的事务类型。 您必须具有足以设置全局系统变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
enforce_gtid_consistency必须是真的才能设置gtid_mode=ON。 在修改此变量之前,请参见 第17.1.5节“在线服务器上更改复制模式” 。记录的事务可以是匿名的,也可以使用GTID。 匿名事务依赖于二进制日志文件和位置来标识特定事务。 GTID事务具有用于引用事务的唯一标识符。 不同的模式是:
-
OFF:新事务和复制事务都必须是匿名的。 -
OFF_PERMISSIVE:新交易是匿名的。 复制的事务可以是匿名或GTID事务。 -
ON_PERMISSIVE:新交易是GTID交易。 复制的事务可以是匿名或GTID事务。 -
ON:新事务和复制事务都必须是GTID事务。
从一个值到另一个值的变化一次只能是一步。 例如,如果
gtid_mode当前设置为OFF_PERMISSIVE,则可以更改为OFF或ON_PERMISSIVE不更改ON。无论值如何 ,
gtid_purged和 的值gtid_executed都是持久的gtid_mode。 因此,即使在更改值之后gtid_mode,这些变量也包含正确的值。 -
-
属性 值 系统变量 gtid_next范围 会议 动态 是 SET_VAR提示适用没有 类型 列举 默认值 AUTOMATIC有效值 AUTOMATICANONYMOUSUUID:NUMBER此变量用于指定是否以及如何获取下一个GTID。
设置此系统变量的会话值是受限制的操作。 会话用户必须具有足以设置受限会话变量的权限。 请参见 第5.1.9.1节“系统变量权限” 。
gtid_next可以采用以下任何值:-
AUTOMATIC:使用下一个自动生成的全局事务ID。 -
ANONYMOUS:事务没有全局标识符,仅由文件和位置标识。 -
全局事务ID, 格式 为
UUID:NUMBER。
上述哪个选项有效取决于设置
gtid_mode, 有关详细信息 ,请参见 第17.1.5.1节“复制模式概念” 。 如果gtid_mode是,则 设置此变量无效OFF。在将此变量设置为
UUID:NUMBER,并且已提交或回滚事务之后,SET GTID_NEXT必须再次在任何其他语句之前发出 显式 语句。DROP TABLE或者DROP TEMPORARY TABLE在非临时表与临时表的组合上使用时出现明显错误,或者使用事务存储引擎与临时表使用非事务性存储引擎的临时表。 -
-
属性 值 系统变量 gtid_owned范围 全球,会议 动态 没有 SET_VAR提示适用没有 类型 串 此只读变量主要供内部使用。 其内容取决于其范围。
-
与全局范围一起使用时,
gtid_owned保存服务器上当前正在使用的所有GTID的列表,以及拥有它们的线程的ID。 此变量主要用于多线程复制从属,以检查事务是否已在另一个线程上应用。 应用程序线程在处理事务时始终拥有事务的GTID,因此@@global.gtid_owned在处理期间显示GTID和所有者。 当事务已提交(或回滚)时,应用程序线程将释放GTID的所有权。 -
与会话范围一起使用时,
gtid_owned保留当前由此会话使用和拥有的单个GTID。 当客户端通过设置为事务明确分配GTID时,此变量主要用于测试和调试GTID的使用gtid_next。 在这种情况下,@@session.gtid_owned在客户端处理事务时始终显示GTID,直到事务已提交(或回滚)。 当客户端处理完事务后,该变量将被清除。 如果gtid_next=AUTOMATIC用于会话,gtid_owned仅在执行事务的commit语句期间短暂填充,因此无法从相关会话中观察到它,尽管如果@@global.gtid_owned在正确的位置读取 它将被列出 。 如果您需要跟踪会话中客户端处理的GTID,则可以启用由session_track_gtids系统变量 控制的会话状态跟踪器 。
-
-
属性 值 系统变量 gtid_purged范围 全球 动态 是 SET_VAR提示适用没有 类型 串 gtid_purged系统变量(@@GLOBAL.gtid_purged) 的全局值 是一个GTID集,它由已在服务器上提交但在服务器上的任何二进制日志文件中不存在的所有事务的GTID组成。gtid_purged是一个子集gtid_executed。 以下类别的GTID包括gtid_purged:-
在从站上禁用二进制日志记录时提交的复制事务的GTID。
-
已写入已清除的二进制日志文件的事务的GTID。
-
由语句明确添加到集合中的GTID
SET @@GLOBAL.gtid_purged。
当服务器启动时,全局值
gtid_purged初始化为一组GTID。 有关此GTID集是如何计算的信息,请参阅 该gtid_purged系统变量 。 如果服务器上存在MySQL 5.7.7或更早版本的二进制日志,则可能需要进行设置binlog_gtid_simple_recovery=FALSE在服务器的配置文件中设置以生成正确的计算。 有关binlog_gtid_simple_recovery需要此设置的情况的详细信息, 请参阅说明 。发行
RESET MASTER会导致值gtid_purged重置为空字符串。您可以设置值
gtid_purged以便在服务器上记录已应用某个GTID集中的事务,尽管它们不存在于服务器上的任何二进制日志中。 此操作的示例用例是在服务器上还原一个或多个数据库的备份时,但您没有包含服务器上的事务的相关二进制日志。从MySQL 8.0开始,有两种方法可以设置值
gtid_purged。 您可以使用gtid_purged指定的GTID集 替换值 ,也可以将指定的GTID集附加到已经保留的GTID集gtid_purged。 如果服务器没有现有的GTID,例如,您使用现有数据库的备份进行配置的空服务器,则两种方法都具有相同的结果。 如果要还原与服务器上已有的事务重叠的备份,例如使用 mysqldump 从主服务器替换已损坏的表和部分转储 (包括服务器上所有事务的GTID,即使转储是部分的),使用第一种替换值的方法gtid_purged。 如果要还原与服务器上已有的事务不相交的备份,例如使用来自两个不同服务器的转储配置多源复制从站,请使用第二种方法来添加值gtid_purged。-
要
gtid_purged使用指定的GTID集 替换值, 请使用以下语句:SET @@ GLOBAL.gtid_purged ='gtid_set'
gtid_set必须是当前值的超集gtid_purged,并且不得与其相交gtid_subtract(gtid_executed,gtid_purged)。 换句话说,新的GTID集 必须 包括已经存在的任何GTIDgtid_purged,并且 不得 包括gtid_executed尚未清除的 任何GTID 。gtid_set也不能包含任何GTID@@global.gtid_owned,即服务器上当前正在处理的事务的GTID。结果是全局值
gtid_purged被设置为等于gtid_set,并且值gtid_executed变为gtid_set和的前一个值的和gtid_executed。 -
要将指定的GTID设置附加到
gtid_purged,请在GTID集之前使用带有加号(+)的以下语句:SET @@ GLOBAL.gtid_purged ='+ gtid_set'
gtid_set不得 与当前值相交gtid_executed。 换句话说,新的GTID集不得包含任何GTIDgtid_executed,包括已经存在的交易gtid_purged。gtid_set也不能包含任何GTID@@global.gtid_owned,即服务器上当前正在处理的事务的GTID。结果是
gtid_set添加到gtid_executed和gtid_purged。
-
如果服务器上存在来自MySQL 5.7.7或更早版本的任何二进制日志(例如,在将旧服务器升级到MySQL 8.0之后),则在发出
SET
@@GLOBAL.gtid_purged
语句之后,您可能需要
binlog_gtid_simple_recovery=FALSE
在重新启动之前
设置
服务器的配置文件。服务器,否则
gtid_purged
可能计算不正确。
有关
binlog_gtid_simple_recovery
需要此设置的情况的详细信息,
请参阅说明
。
一旦启动复制,它就会执行而无需经常管理。 本节介绍如何检查复制的状态以及如何暂停从属。
管理复制过程时最常见的任务是确保正在进行复制,并且从站和主站之间没有错误。
SHOW SLAVE STATUS
必须在每个从站上执行
的
语句提供有关从站服务器和主服务器之间连接的配置和状态的信息。
从MySQL 5.7开始,性能模式具有复制表,以更易于访问的形式提供此信息。
请参见
第26.12.11节“性能模式复制表”
。
该
SHOW
STATUS
声明还提供了一些专门针对复制从属的信息。
从MySQL 5.7开始,
SHOW
STATUS
不推荐
使用先前使用的以下状态变量
并将其移至Performance Schema复制表:
通过性能模式复制表中显示的复制心跳信息,您可以检查复制连接是否处于活动状态,即使主服务器最近未向从服务器发送事件也是如此。
如果二进制日志中没有比心跳间隔更长的更新,并且没有未发送的事件,则主设备向从设备发送心跳信号。
该
MASTER_HEARTBEAT_PERIOD
在主(由所设置的设置
CHANGE
MASTER
TO
语句)指定心跳的频率,默认为用于从属连接超时间隔的一半(
slave_net_timeout
)。
该
replication_connection_status
性能模式表显示复制从站接收到最新心跳信号的时间,以及它收到的心跳信号的数量。
如果您使用该
SHOW SLAVE
STATUS
语句检查单个从站的状态,则该语句提供以下信息:
MySQL的> SHOW SLAVE STATUS\G
*************************** 1。排******************** *******
Slave_IO_State:等待主节点发送事件
Master_Host:master1
Master_User:root
Master_Port:3306
Connect_Retry:60
Master_Log_File:mysql-bin.000004
Read_Master_Log_Pos:931
Relay_Log_File:slave1-relay-bin.000056
Relay_Log_Pos:950
Relay_Master_Log_File:mysql-bin.000004
Slave_IO_Running:是的
Slave_SQL_Running:是的
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno:0
Last_Error:
Skip_Counter:0
Exec_Master_Log_Pos:931
Relay_Log_Space:1365
Until_Condition:无
Until_Log_File:
Until_Log_Pos:0
Master_SSL_Allowed:没有
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:0
Master_SSL_Verify_Server_Cert:没有
Last_IO_Errno:0
Last_IO_Error:
Last_SQL_Errno:0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:0
要检查的状态报告的关键字段是:
-
Slave_IO_State:从站的当前状态。 有关更多 信息, 请参见 第8.14.4节“复制从属I / O线程状态” 和 第8.14.5节“复制从属SQL线程状态” 。 -
Slave_IO_Running:用于读取主机二进制日志的I / O线程是否正在运行。 通常,Yes除非您尚未启动复制或已明确停止复制,否则 您希望这样做STOP SLAVE。 -
Slave_SQL_Running:用于在中继日志中执行事件的SQL线程是否正在运行。 与I / O线程一样,通常应该如此Yes。 -
Last_IO_Error,Last_SQL_Error:处理中继日志时I / O和SQL线程注册的最后一个错误。 理想情况下,这些应为空白,表示没有错误。 -
Seconds_Behind_Master:从属SQL线程处理主二进制日志的秒数。 高数字(或增加数字)可以指示从属设备无法及时处理来自主设备的事件。值0
Seconds_Behind_Master通常可以解释为意味着从属已经赶上了主服务器,但在某些情况下这并非严格正确。 例如,如果主站和从站之间的网络连接断开但从站I / O线程尚未注意到这一点(即slave_net_timeout尚未过去) ,则会发生这种情况 。瞬态值
Seconds_Behind_Master也可能无法准确反映情况。 当从属SQL线程赶上I / O时,Seconds_Behind_Master显示0; 但是当从属I / O线程仍在排队新事件时,Seconds_Behind_Master可能会显示一个较大的值,直到SQL线程完成执行新事件。 当事件具有旧时间戳时,这尤其可能; 在这种情况下,如果您SHOW SLAVE STATUS在相对较短的时间内 执行 多次,您可能会看到此值在0和相对较大的值之间反复来回变化。
几对字段提供有关从主二进制日志读取事件并在中继日志中处理它们的从站进度的信息:
-
(
Master_Log_file,Read_Master_Log_Pos):主二进制日志中的坐标,指示从属I / O线程从该日志读取事件的距离。 -
(
Relay_Master_Log_File,Exec_Master_Log_Pos):主二进制日志中的坐标,指示从属SQL线程执行从该日志接收的事件的距离。 -
(
Relay_Log_File,Relay_Log_Pos):从属中继日志中的坐标,指示从属SQL线程执行中继日志的距离。 这些对应于前面的坐标,但是以从中继日志坐标而不是主二进制日志坐标表示。
在主服务器上,您可以使用检查已连接从服务器的状态
SHOW
PROCESSLIST
来检查正在运行的进程列表。
奴隶联系
Binlog Dump
在
Command
现场:
MySQL的> SHOW PROCESSLIST \G;
****************************排******************** *******
Id:10
用户:root
主持人:slave1:58371
db:NULL
命令:Binlog转储
时间:777
状态:已将所有binlog发送给奴隶; 等待binlog更新
信息:NULL
由于它是驱动复制过程的从属服务器,因此本报告中提供的信息非常少。
对于使用该
--report-host
选项
启动
并连接到主
站的从站,
主站上的
SHOW
SLAVE
HOSTS
语句显示有关从站的基本信息。
输出包括从服务器的ID,
--report-host
选项
的值
,连接端口和主ID:
MySQL的> SHOW SLAVE HOSTS;
+ ----------- + -------- + ------ + ------------------- + - ---------- +
| Server_id | 主持人| 港口| Rpl_recovery_rank | Master_id |
+ ----------- + -------- + ------ + ------------------- + - ---------- +
| 10 | slave1 | 3306 | 0 | 1 |
+ ----------- + -------- + ------ + ------------------- + - ---------- +
1排(0.00秒)
您可以使用
STOP
SLAVE
和
START
SLAVE
语句
停止并启动从站上的复制
。
要停止从主服务器处理二进制日志,请使用
STOP
SLAVE
:
MySQL的> STOP SLAVE;
当复制停止时,从I / O线程停止从主二进制日志读取事件并将它们写入中继日志,并且SQL线程停止从中继日志读取事件并执行它们。 您可以通过指定线程类型单独暂停I / O或SQL线程:
mysql>STOP SLAVE IO_THREAD;mysql>STOP SLAVE SQL_THREAD;
要再次开始执行,请使用以下
START
SLAVE
语句:
MySQL的> START SLAVE;
要启动特定线程,请指定线程类型:
mysql>START SLAVE IO_THREAD;mysql>START SLAVE SQL_THREAD;
对于仅通过处理来自主服务器的事件来执行更新的从服务器,如果要执行备份或其他任务,则仅停止SQL线程可能很有用。 I / O线程将继续从主服务器读取事件,但不会执行它们。 这使得从服务器在重新启动SQL线程时更容易赶上。
仅停止I / O线程使中继日志中的事件能够由SQL线程执行,直到中继日志结束。 当您希望暂停执行以赶上已经从主服务器接收的事件时,当您想要对从服务器执行管理但同时确保它已处理了对特定点的所有更新时,这可能很有用。 当您在主服务器上执行管理时,此方法还可用于暂停从服务器上的事件接收。 停止I / O线程但允许SQL线程运行有助于确保在再次启动复制时不会发生大量事件积压。
复制基于主服务器,在其二进制日志中跟踪其数据库的所有更改(更新,删除等)。
二进制日志用作从服务器启动时起修改数据库结构或内容(数据)的所有事件的书面记录。
通常,
SELECT
不记录语句,因为它们既不修改数据库结构也不修改内容。
连接到主服务器的每个从服务器都请求二进制日志的副本。 也就是说,它从主设备中提取数据,而不是主设备将数据推送到从设备。 从服务器还从它接收的二进制日志中执行事件。 这具有重复原始更改的效果,就像它们在主服务器上进行一样。 创建表或修改其结构,并根据最初在主服务器上进行的更改来插入,删除和更新数据。
由于每个从站都是独立的,因此从主站二进制日志中重放的更改将在连接到主站的每个从站上独立发生。 此外,由于每个从服务器仅通过从主服务器请求二进制日志的副本来接收二进制日志的副本,因此从服务器能够按照自己的进度读取和更新数据库的副本,并且可以随意启动和停止复制过程而不会影响能够在主站或从站上更新到最新的数据库状态。
有关复制实现细节的更多信息,请参见 第17.2.2节“复制实现细节” 。
主人和奴隶定期报告他们在复制过程中的状态,以便您可以监控它们。 有关 所有复制相关状态的说明, 请参见 第8.14节“检查线程信息” 。
在处理之前,主二进制日志将写入从站上的本地中继日志。 从站还使用主站的二进制日志和本地中继日志记录有关当前位置的信息。 请参见 第17.2.4节“复制中继和状态日志” 。
根据根据控制事件评估的各种配置选项和变量应用的一组规则,在从站上过滤数据库更改。 有关如何应用这些规则的详细信息,请参见 第17.2.5节“服务器如何评估复制过滤规则” 。
复制有效,因为写入二进制日志的事件是从主服务器读取的,然后在从服务器上处理。 根据事件的类型,事件以不同的格式记录在二进制日志中。 使用的不同复制格式对应于事件记录在主二进制日志中时使用的二进制日志记录格式。 二进制日志记录格式与复制期间使用的术语之间的关联是:
-
使用基于语句的二进制日志记录时,主服务器会将SQL语句写入二进制日志。 通过在从站上执行SQL语句,将主站复制到从站。 这称为 基于语句的复制 (可以缩写为 SBR ),它对应于基于MySQL语句的二进制日志记录格式。
-
使用基于行的日志记录时,主服务器会将 事件 写入 二进制日志,以指示各个表行的更改方式。 通过将表示表行更改的事件复制到从站,可以将主服务器复制到从服务器。 这称为 基于行的复制 (可以缩写为 RBR )。
基于行的日志记录是默认方法。
-
您还可以将MySQL配置为使用基于语句和基于行的日志记录的混合,具体取决于哪个最适合要记录的更改。 这称为 混合格式日志记录 。 使用混合格式日志记录时,默认情况下使用基于语句的日志。 根据某些语句以及正在使用的存储引擎,在特定情况下,日志会自动切换到基于行的语句。 使用混合格式 的复制 称为 基于混合的复制 或 混合格式复制 。 有关更多信息,请参见 第5.4.4.3节“混合二进制日志格式” 。
NDB集群。
MySQL NDB Cluster 8.0中的默认二进制日志记录格式是
MIXED
。
您应该注意,NDB群集复制始终使用基于行的复制,并且
NDB
存储引擎与基于语句的复制不兼容。
有关
更多信息
,
请参见
第22.6.2节“NDB群集复制的一般要求”
。
使用
MIXED
format时,二进制日志记录格式部分取决于正在使用的存储引擎和正在执行的语句。
有关混合格式日志记录和管理不同日志记录格式支持的规则的更多信息,请参见
第5.4.4.3节“混合二进制日志记录格式”
。
运行MySQL服务器中的日志记录格式通过设置来控制
binlog_format
服务器系统变量。
可以使用会话或全局范围设置此变量。
管理新设置何时以及如何生效的规则与其他MySQL服务器系统变量相同。
为当前会话设置变量仅持续到该会话结束,并且该更改对其他会话不可见。
全局设置变量对更改后连接的客户端生效,但不会对任何当前客户端会话(包括更改变量设置的会话)生效。
要使全局系统变量设置为永久性以便在服务器重新启动时应用,必须在选项文件中进行设置。
有关更多信息,请参见
第13.7.5.1节“变量赋值的SET语法”
。
在某些情况下,您无法在运行时更改二进制日志记录格式,或者这样做会导致复制失败。 请参见 第5.4.4.2节“设置二进制日志格式” 。
更改全局
binlog_format
值需要足以设置全局系统变量的权限。
更改会话
binlog_format
值需要足以设置受限会话系统变量的权限。
请参见
第5.1.9.1节“系统变量权限”
。
基于语句和基于行的复制格式具有不同的问题和限制。 有关它们相对优缺点的比较,请参见 第17.2.1.1节“基于语句和基于行的复制的优点和缺点” 。
使用基于语句的复制,您可能会遇到复制存储的例程或触发器的问题。 您可以通过使用基于行的复制来避免这些问题。 有关更多信息,请参见 第24.7节“存储程序二进制日志记录” 。
每种二进制日志格式都有优点和缺点。 对于大多数用户,混合复制格式应提供数据完整性和性能的最佳组合。 但是,如果您希望在执行某些任务时利用特定于基于语句或基于行的复制格式的功能,则可以使用本节中的信息,该信息提供了它们相对优缺点的摘要,确定哪种最适合您的需求。
基于语句的复制的优点
-
成熟的技术。
-
写入日志文件的数据较少。 当更新或删除影响许多行时,这会导致 日志文件所需的存储空间 大大 减少。 这也意味着可以更快地完成从备份中获取和恢复。
-
日志文件包含进行任何更改的所有语句,因此可用于审计数据库。
基于语句的复制的缺点
-
对SBR不安全的陈述。 不修改该数据的所有语句(如 , 和 语句)可以使用基于语句的复制被复制。 使用基于语句的复制时,很难复制任何非确定性行为。 此类数据修改语言(DML)语句的示例包括以下内容:
INSERTDELETEUPDATEREPLACE-
取决于UDF或非确定性存储程序的语句,因为此类UDF或存储程序返回的值或取决于提供给它的参数以外的因素。 (但是,基于行的复制只是复制UDF或存储程序返回的值,因此它对主表和从表的表行和数据的影响是相同的。)请参见 第17.4.1.16节“调用的 函数的 复制” “ ,了解更多信息。
-
DELETE和UPDATE使用LIMIT没有 a的 子句的 语句ORDER BY是不确定的。 请参见 第17.4.1.18节“复制和限制” 。 -
锁定 使用 或 选项的 read语句(
SELECT ... FOR UPDATE和SELECT ... FOR SHARE) 。 请参阅 使用NOWAIT和SKIP LOCKED锁定读取并发 。NOWAITSKIP LOCKED -
必须在从站上应用确定性UDF。
-
使用基于语句的复制无法正确复制使用以下任何功能的语句:
-
SYSDATE()(除非主服务器和从服务器都是以--sysdate-is-now选项 启动的 )
但是,使用基于语句的复制(包括
NOW()依此类推) 可以正确复制所有其他函数 。有关更多信息,请参见 第17.4.1.14节“复制和系统函数” 。
使用基于语句的复制无法正确复制的语句将记录如下所示的警告:
[警告]语句登录语句格式不安全。
在这种情况下,也会向客户发出类似的警告。 客户端可以使用显示它
SHOW WARNINGS。 -
-
INSERT ... SELECT与基于行的复制相比,需要更多的行级锁。 -
UPDATE需要进行表扫描的语句(因为WHERE子句中 没有使用索引 )必须锁定比基于行的复制更多的行。 -
对于复杂语句,必须在更新或插入行之前在从属服务器上评估和执行该语句。 对于基于行的复制,从属服务器只需修改受影响的行,而不是执行完整语句。
-
如果从站的评估中存在错误,特别是在执行复杂语句时,基于语句的复制可能会逐渐增加受影响行的错误余量。 请参见 第17.4.1.28节“复制期间的从属错误” 。
-
存储的函数使用与
NOW()调用语句 相同的 值 执行 。 但是,存储过程并非如此。 -
必须在从站上应用确定性UDF。
-
表定义在主服务器和从服务器上必须(几乎)相同。 有关 更多信息 , 请参见 第17.4.1.9节“使用主服务器和从服务器上的不同表定义进行复制” 。
基于行的复制的优点
-
可以复制所有更改。 这是最安全的复制形式。
注意更新
mysql系统模式中 的信息的语句 (例如GRANT,REVOKE触发器,存储过程(包括存储过程)和视图的操作)都使用基于语句的复制复制到从属服务器。对于诸如
CREATE TABLE ... SELECT的CREATE语句,从表定义生成语句并使用基于语句的格式进行复制,而使用基于行的格式复制行插入。 -
对于以下类型的语句,主服务器上需要更少的行锁,从而实现更高的并发性:
-
INSERT陈述AUTO_INCREMENT
基于行的复制的缺点
-
RBR可以生成更多必须记录的数据。 要复制DML语句(例如
UPDATE或DELETE语句),基于语句的复制仅将语句写入二进制日志。 相比之下,基于行的复制将每个更改的行写入二进制日志。 如果语句更改了许多行,则基于行的复制可能会将更多数据写入二进制日志; 即使对于回滚的语句也是如此。 这也意味着制作和恢复备份可能需要更多时间。 此外,二进制日志被锁定较长时间来写入数据,这可能会导致并发问题。 使用binlog_row_image=minimal大大减少缺点。 -
BLOB与基于语句的复制相比,使用基于行的复制复制 生成大 值的 确定性UDF 需要更长时间。 这是因为BLOB记录 了 列值,而不是生成数据的语句。 -
您无法在从站上看到从主站接收和执行的语句。 但是,您可以使用 带有选项 和的 mysqlbinlog 查看更改了哪些数据 。
--base64-output=DECODE-ROWS--verbose或者,使用该
binlog_rows_query_log_events变量,如果启用,则 在使用该 选项 时将该Rows_query语句 的 事件 添加 到 mysqlbinlog 输出-vv。 -
对于使用
MyISAM存储引擎的 表 ,INSERT当将它们作为基于行的事件应用于二进制日志而不是将它们作为语句应用时 ,从站上需要更强的锁定 语句。 这意味着MyISAM在使用基于行的复制时不支持 对 表的 并发插入 。
MySQL使用基于语句的日志记录(SBL),基于行的日志记录(RBL)或混合格式日志记录。 使用的二进制日志类型会影响日志记录的大小和效率。 因此,基于行的复制(RBR)或基于语句的复制(SBR)之间的选择取决于您的应用程序和环境。 本节介绍使用基于行的格式日志时的已知问题,并介绍在复制中使用它的一些最佳实践。
有关其他信息,请参见 第17.2.1节“复制格式” 和 第17.2.1.1节“基于语句和基于行的复制的优点和缺点” 。
有关NDB群集复制特定问题(取决于基于行的复制)的信息,请参见 第22.6.3节“NDB群集复制中的已知问题” 。
-
基于行的临时表日志记录。 如 第17.4.1.30节“复制和临时表”中所述 ,使用基于行的格式或(来自MySQL 8.0.4)混合格式时,不会复制临时表。 有关更多信息,请参见 第17.2.1.1节“基于语句和基于行的复制的优点和缺点” 。
使用基于行或混合格式时不会复制临时表,因为没有必要。 此外,因为临时表只能从创建它们的线程中读取,所以即使使用基于语句的格式,也很少从复制它们中获得任何好处。
即使在创建临时表时,您也可以在运行时从基于语句切换到基于行的二进制日志记录格式。 但是,在MySQL 8.0中,您无法在运行时从基于行或混合格式的二进制日志切换到基于语句的格式,因为
CREATE TEMPORARY TABLE在先前模式下的二进制日志中将省略 任何 语句。MySQL服务器跟踪创建每个临时表时生效的日志记录模式。 当给定的客户端会话结束时,服务器会记录
DROP TEMPORARY TABLE IF EXISTS每个临时表 的 语句 ,该 语句仍然存在并且在使用基于语句的二进制日志记录时创建。 如果在创建表时使用了基于行或混合格式的二进制日志记录,DROP TEMPORARY TABLE IF EXISTS则不会记录 该 语句。 在MySQL 8.0.4和5.7.25之前的版本中,DROP TEMPORARY TABLE IF EXISTS无论生效的日志记录模式如何,都会记录 该 语句。binlog_format=ROW只要受语句影响的任何非事务性表都是临时表(Bug#14272672), 在使用时允许涉及临时表的 非事务性 DML语句 。 -
RBL和非事务表的同步。 当许多行受到影响时,更改集将拆分为多个事件; 当语句提交时,所有这些事件都写入二进制日志。 在从站上执行时,会对所涉及的所有表执行表锁定,然后以批处理模式应用这些行。 根据用于副本表的引擎,这可能有效,也可能无效。
-
延迟和二进制日志大小。 RBL将每行的更改写入二进制日志,因此其大小可以非常快速地增加。 这可以显着增加在从站上进行更改以匹配主站上的更改所需的时间。 您应该知道应用程序中可能出现此延迟。
-
读二进制日志。 mysqlbinlog 使用该
BINLOG语句 在二进制日志中显示基于行的事件 (请参见 第13.7.7.1节“BINLOG语法” )。 此语句将事件显示为基本64位编码的字符串,其含义不明显。 当使用--base64-output=DECODE-ROWS和--verbose选项 调用 mysqlbinlog时 将二进制日志的内容格式化为人类可读的。 当二进制日志事件以基于行的格式写入并且您希望从复制或数据库故障中读取或恢复时,可以使用此命令读取二进制日志的内容。 有关更多信息,请参见 第4.6.8.2节“mysqlbinlog行事件显示” 。 -
二进制日志执行错误和slave_exec_mode。 使用
slave_exec_mode=IDEMPOTENT通常仅对MySQL NDB Cluster复制有用,这IDEMPOTENT是默认值。 (请参见 第22.6.10节“NDB集群复制:多主机和循环复制” )。 什么时候slave_exec_mode是IDEMPOTENT,无法从RBL应用更改,因为无法找到原始行不会触发错误或导致复制失败。 这意味着可能未在从站上应用更新,因此主站和从站不再同步。 延迟问题和使用RBR的非事务表时slave_exec_mode,IDEMPOTENT可能会导致主服务器和从服务器进一步分歧。 有关更多信息slave_exec_mode,请参见 第5.1.8节“服务器系统变量” 。对于其他方案,设置
slave_exec_mode于STRICT通常是足够的; 这是除了之外的存储引擎的默认值NDB。 -
不支持基于服务器ID的过滤。 您可以使用 语句
IGNORE_SERVER_IDS选项 基于服务器ID进行筛选CHANGE MASTER TO。 此选项适用于基于语句和基于行的日志记录格式,但在GTID_MODE=ON设置 时不建议使用 。 过滤掉一些从站的变化的另一种方法是使用WHERE包含关系子句 与子句 和 语句。 例如, 。 但是,对于基于行的日志记录,这不能正常工作。 要使用@@server_id <>id_valueUPDATEDELETEWHERE @@server_id <> 1server_id系统变量用于语句过滤,使用基于语句的日志记录。 -
数据库级复制选项。 的影响
--replicate-do-db,--replicate-ignore-db以及--replicate-rewrite-db选择差异很大依赖于基于行或基于语句的日志记录是否被使用。 因此,建议避免使用数据库级选项,而是使用表等级选项,例如--replicate-do-table和--replicate-ignore-table。 有关这些选项以及影响复制格式对其运行方式的更多信息,请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。 -
RBL,非事务性表和停止的从属。 使用基于行的日志记录时,如果从属服务器在从属线程更新非事务性表时停止,则从属数据库可能会达到不一致状态。 因此,建议您使用事务存储引擎,例如
InnoDB使用基于行的格式复制的所有表。 关闭从属MySQL服务器时 使用STOP SLAVE或STOP SLAVE SQL_THREAD之前有助于防止出现问题,无论您使用何种日志格式或存储引擎,都始终建议使用该服务器。
MySQL复制中语句 的 “ 安全性 ” 是指是否可以使用基于语句的格式正确复制语句及其效果。 如果对于该陈述是正确的,我们将该陈述称为 安全 ; 否则,我们称之为 不安全 。
一般来说,如果陈述是确定性的,则是安全的,如果不是,则是不安全的。 但是,某些非确定性函数 不 被视为不安全(请参阅 本节后面的 不确定 不安全 函数 )。 此外,使用浮点数学函数(与硬件相关)的结果的语句始终被认为是不安全的(请参见 第17.4.1.12节“复制和浮点值” )。
处理安全和不安全的陈述。
根据语句是否被认为是安全的,以及二进制日志记录格式(即当前值
binlog_format
)
,对语句的处理方式也不同
。
-
使用基于行的日志记录时,对安全和不安全语句的处理没有区别。
-
使用混合格式日志记录时,使用基于行的格式记录标记为不安全的语句; 使用基于语句的格式记录被视为安全的语句。
-
使用基于语句的日志记录时,标记为不安全的语句会生成对此效果的警告。 正常记录安全语句。
标记为不安全的每个语句都会生成警告。
如果在主服务器上执行了大量此类语句,则可能导致错误日志文件过大。
为了防止这种情况,MySQL有一个警告抑制机制。
每当50个最新
ER_BINLOG_UNSAFE_STATEMENT
警告在任何50秒的时间段内生成超过50次时,都会启用警告抑制。
激活时,这会导致不将这些警告写入错误日志;
相反,对于这种类型的每50个警告,一个注释
The
last warning was repeated
被写入错误日志。
只要在50秒或更短时间内发出50个最近的此类警告,这种情况就会持续下去;
一旦费率降低到此阈值以下,警告将再次正常记录。
警告抑制不会影响如何确定基于语句的日志记录的语句安全性,也不会影响警告如何发送到客户端。
MySQL客户端仍会收到每个此类语句的一个警告。
N times in
last S seconds
有关更多信息,请参见 第17.2.1节“复制格式” 。
声明被认为是不安全的。 具有以下特征的陈述被认为是不安全的:
-
包含可能在从站上返回不同值的系统函数的语句。 这些功能包括
FOUND_ROWS(),GET_LOCK(),IS_FREE_LOCK(),IS_USED_LOCK(),LOAD_FILE(),MASTER_POS_WAIT(),RAND(),RELEASE_LOCK(),ROW_COUNT(),SESSION_USER(),SLEEP(),SYSDATE(),SYSTEM_USER(),USER(),UUID(),和UUID_SHORT()。不确定的功能不被认为是不安全的。 虽然这些功能是不确定的,它们被视为安全的记录和复制的目的:
CONNECTION_ID(),CURDATE(),CURRENT_DATE(),CURRENT_TIME(),CURRENT_TIMESTAMP(),CURTIME(),, ,LAST_INSERT_ID(),LOCALTIME(),LOCALTIMESTAMP(),NOW(),UNIX_TIMESTAMP(),UTC_DATE(),UTC_TIME()和UTC_TIMESTAMP()。有关更多信息,请参见 第17.4.1.14节“复制和系统函数” 。
-
对系统变量的引用。 使用基于语句的格式无法正确复制大多数系统变量。 请参见 第17.4.1.38节“复制和变量” 。 有关例外情况,请参见 第5.4.4.3节“混合二进制日志格式” 。
-
UDF的。 由于我们无法控制UDF的作用,因此我们必须假设它正在执行不安全的语句。
-
全文插件。 此插件在不同的MySQL服务器上的行为可能不同; 因此,取决于它的陈述可能会有不同的结果。 因此,依赖于fulltext插件的所有语句在MySQL中都被视为不安全。
-
触发或存储的程序更新具有AUTO_INCREMENT列的表。 这是不安全的,因为更新行的顺序可能在主服务器和从服务器上不同。
此外,
INSERT具有包含AUTO_INCREMENT不是此复合键的第一列 的 列 的复合主键的表 是不安全的。有关更多信息,请参见 第17.4.1.1节“复制和AUTO_INCREMENT” 。
-
INSERT ...对具有多个主键或唯一键的表的DUPLICATE KEY UPDATE语句。 当针对包含多个主键或唯一键的表执行时,此语句被认为是不安全的,对存储引擎检查键的顺序很敏感,这不是确定性的,并且由此更新了行的选择。 MySQL服务器依赖。
INSERT ... ON DUPLICATE KEY UPDATE针对具有多个唯一键或主键的表 的 语句被标记为基于语句的复制不安全。 (Bug#11765650,Bug#58637) -
使用LIMIT进行更新。 未指定检索行的顺序,因此被视为不安全。 请参见 第17.4.1.18节“复制和限制” 。
-
访问或引用日志表。 主站和从站之间的系统日志表的内容可能不同。
-
交易操作后的非事务操作。 在事务中,允许在任何事务性读取或写入之后执行任何非事务性读取或写入被认为是不安全的。
有关更多信息,请参见 第17.4.1.34节“复制和事务” 。
-
访问或引用自我记录表。 对自记录表的所有读写都被认为是不安全的。 在事务中,读取或写入自记录表之后的任何语句也被视为不安全。
-
LOAD DATA语句。
LOAD DATA被视为不安全,并且binlog_format=MIXED以基于行的格式记录语句。 什么 时候不生成警告,不像其他不安全的语句。binlog_format=STATEMENTLOAD DATA -
XA交易。 如果正在主服务器上以并行顺序准备两个并行提交的XA事务,则无法安全地解决基于语句的复制的锁定依赖关系,并且复制可能会因从服务器上的死锁而失败。 当
binlog_format=STATEMENT设置,XA事务内部DML语句被标记为不安全的,并产生一个警告。 当binlog_format=MIXED或binlog_format=ROW设置,XA事务内的DML语句使用基于行的复制记录,以及潜在的问题是不存在的。 -
DEFAULT引用非确定性函数的子句。 如果表达式默认值引用非确定性函数,则导致表达式计算的任何语句对于基于语句的复制都是不安全的。 这包括语句,如INSERT,UPDATE和ALTER TABLE。 与大多数其他不安全语句不同,此类语句无法以基于行的格式安全地复制。 如果binlog_format设置为STATEMENT,则会记录并执行该语句,但会向错误日志写入警告消息。 何时binlog_format设置为MIXED或ROW,不执行该语句,并将错误消息写入错误日志。 有关显式默认值处理的更多信息,请参阅 MySQL 8.0.13中对显式默认值的处理 。
有关其他信息,请参见 第17.4.1节“复制功能和问题” 。
MySQL复制功能使用三个线程实现,一个在主服务器上,两个在从服务器上:
-
Binlog转储线程。 主设备创建一个线程,以便在从设备连接时将二进制日志内容发送到从设备。 可以
SHOW PROCESSLIST在主服务器 的输出中将此线程标识 为Binlog Dump线程。二进制日志转储线程获取主机二进制日志上的锁,用于读取要发送到从机的每个事件。 一旦读取了事件,即使在事件发送到从站之前,锁也会被释放。
-
从属I / O线程。 在
START SLAVE从属服务器上发出语句时,从属服务器会创建一个I / O线程,该线程连接到主服务器并要求它发送记录在其二进制日志中的更新。从属I / O线程读取主
Binlog Dump线程发送 的更新 (请参阅上一项)并将它们复制到包含从属中继日志的本地文件。此线程的状态显示为
Slave_IO_running输出SHOW SLAVE STATUS或Slave_running输出中的状态SHOW STATUS。 -
从属SQL线程。 从属设备创建一个SQL线程来读取由从属I / O线程写入的中继日志,并执行其中包含的事件。
在前面的描述中,每个主/从连接有三个线程。 具有多个从站的主站为每个当前连接的从站创建一个二进制日志转储线程,每个从站都有自己的I / O和SQL线程。
从站使用两个线程将读取更新与主站分开并将它们执行到独立任务中。 因此,如果语句执行缓慢,则不会减慢读取语句的任务。 例如,如果从服务器尚未运行一段时间,则当从服务器启动时,其I / O线程可以快速从主服务器获取所有二进制日志内容,即使SQL线程远远落后。 如果从服务器在SQL线程执行了所有获取的语句之前停止,则I / O线程至少已获取所有内容,以便语句的安全副本本地存储在从属的中继日志中,准备在下次执行时执行奴隶开始。
该
SHOW
PROCESSLIST
语句提供的信息可以告诉您主服务器和从服务器上有关复制的信息。
有关主状态的信息,请参见
第8.14.3节“复制主线程状态”
。
有关从属状态,请参见
第8.14.4节“复制从属I / O线程状态”
和
第8.14.5节“复制从属SQL线程状态”
。
以下示例说明了三个线程如何显示在输出中
SHOW
PROCESSLIST
。
在主服务器上,输出
SHOW
PROCESSLIST
如下所示:
MySQL的> SHOW PROCESSLIST\G
*************************** 1。排******************** *******
Id:2
用户:root
主持人:localhost:32931
db:NULL
命令:Binlog转储
时间:94
状态:已将所有binlog发送给奴隶; 等待binlog到
得到更新
信息:NULL
这里,线程2是
Binlog Dump
为连接的从属服务的复制线程。
该
State
信息表明所有未完成的更新已发送到从站,并且主站正在等待更多更新发生。
如果
Binlog Dump
在主服务器
上看不到任何
线程,则表示复制未运行;
也就是说,目前没有连接任何从站。
在从属服务器上,输出
SHOW
PROCESSLIST
如下所示:
MySQL的> SHOW PROCESSLIST\G
*************************** 1。排******************** *******
Id:10
用户:系统用户
主办:
db:NULL
命令:连接
时间:11
州:等待主人发送事件
信息:NULL
*************************** 2.排******************** *******
Id:11
用户:系统用户
主办:
db:NULL
命令:连接
时间:11
状态:已读取所有中继日志; 等待从I / O.
线程来更新它
信息:NULL
该
State
信息指示线程10是与主服务器通信的I / O线程,并且线程11是处理存储在中继日志中的更新的SQL线程。
在
SHOW
PROCESSLIST
运行时,两个线程都处于空闲状态,等待进一步更新。
Time
列中
的值
可以显示从站与主站进行比较的时间。
请参见
第A.13节“MySQL 8.0 FAQ:复制”
。
如果主站侧有足够的时间在
Binlog
Dump
线程
上没有活动
,则主站确定从站不再连接。
对于任何其他客户端连接,这样做的超时取决于的值
net_write_timeout
和
net_retry_count
;
有关这些的更多信息,请参见
第5.1.8节“服务器系统变量”
。
该
SHOW
SLAVE STATUS
语句提供有关从属服务器上的复制处理的其他信息。
请参见
第17.1.7.1节“检查复制状态”
。
复制通道表示从主站到从站的事务路径。 本节介绍如何在复制拓扑中使用通道,以及它们对单源复制的影响。
为了提供与先前版本的兼容性,MySQL服务器在启动时自动创建一个名为空字符串(
""
)
的默认通道
。
这个频道总是存在;
它不能被用户创建或销毁。
如果没有创建其他通道(具有非空名称),则复制语句仅作用于缺省通道,以便旧版从属的所有复制语句按预期运行(请参见
第17.2.3.2节“与先前复制语句的兼容性”
。只有当至少有一个命名通道时,才能使用本节所述的复制通道。
复制通道包含从主设备传输到从设备的事务路径。 在多源复制中,从站打开多个通道,每个通道一个,每个通道都有自己的中继日志和应用程序(SQL)线程。 一旦复制通道的接收器(I / O)线程接收到事务,它们就会被添加到通道的中继日志文件中并传递给应用程序线程。 这使通道能够独立运行。
复制通道还与主机名和端口关联。 您可以将多个通道分配给主机名和端口的相同组合。 在MySQL 8.0中,可以在多源复制拓扑中添加到一个从站的最大通道数为256.每个复制通道必须具有唯一(非空)名称(请参见 第17.2.3.4节“复制通道命名约定”) )。 通道可以独立配置。
要使MySQL复制操作能够在单个复制通道上执行操作,请使用
带有以下复制语句
的
子句:
FOR CHANNEL
channel
同样,
channel
为以下函数引入了
一个附加
参数:
该
group_replication_recovery
频道
不允许以下声明
:
该
group_replication_applier
频道
不允许以下声明
:
FLUSH RELAY LOGS
现在允许
group_replication_applier
通道使用,但如果在应用事务时收到请求,则在事务结束后执行请求。
请求者必须在事务完成并等待轮换时等待。
此行为可防止事务被拆分,这是组复制所不允许的。
当复制从站具有多个通道
且未指定选项时,有效语句通常会作用于所有可用通道,但有一些特定的例外情况。
FOR
CHANNEL
channel
例如,除以下某些组复制通道外,以下语句的行为符合预期:
-
START SLAVE为所有通道启动复制线程,除了group_replication_recovery和group_replication_applier通道。 -
STOP SLAVE停止除group_replication_recovery和和group_replication_applier通道 之外的所有通道的复制线程 。 -
SHOW SLAVE STATUS报告除频道外的所有频道的状态group_replication_applier。 -
RESET SLAVE重置所有频道。
请
RESET SLAVE
谨慎
使用
,因为此语句删除所有现有通道,清除其中继日志文件,并仅重新创建默认通道。
某些复制语句无法在所有通道上运行。
在这种情况下,错误1964
从站上存在多个通道。
请提供频道名称作为参数。
生成。
在多源复制拓扑中使用时,以下语句和函数会生成此错误,并且
不使用选项指定要对其执行的通道:
FOR CHANNEL
channel
请注意,默认通道始终存在于单个源复制拓扑中,其中语句和函数的行为与以前版本的MySQL相同。
本节介绍受添加复制通道影响的启动选项。
必须 正确配置 以下启动选项 才能 使用多源复制。
-
必须设置为
TABLE。 如果将此选项设置为FILE,则尝试向从属设备添加更多源将失败ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。 该FILE设置现已弃用,TABLE是默认设置。 -
--master-info-repository必须设置为
TABLE。 如果将此选项设置为FILE,则尝试向从属设备添加更多源将失败ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。 该FILE设置现已弃用,TABLE是默认设置。
以下启动选项现在会影响 复制拓扑中的 所有 通道。
-
从站接收的所有事务(甚至来自多个源)都写入二进制日志中。
-
设置后,每个通道自动清除自己的中继日志。
-
指定数量的事务重试可以在所有通道的所有应用程序线程上进行。
-
没有复制线程在任何通道上启动。
-
继续执行并跳过所有通道的错误。
为以下启动选项设置的值适用于每个通道; 由于这些是 mysqld 启动选项,因此它们适用于每个通道。
-
--max-relay-log-size=size每个通道的单个中继日志文件的最大大小; 达到此限制后,文件将旋转。
-
--relay-log-space-limit=size对于每个单独的通道,所有中继日志的总大小的上限。 对于
N通道,这些日志的组合大小仅限于 。relay_log_space_limit *N -
--slave-parallel-workers=value每个通道的从站并行工作器数。
-
--slave-checkpoint-group每个源的I / O线程等待时间。
-
--relay-log-index=filename每个通道的中继日志索引文件的基本名称。 请参见 第17.2.3.4节“复制通道命名约定” 。
-
--relay-log=filename表示每个通道的中继日志文件的基本名称。 请参见 第17.2.3.4节“复制通道命名约定” 。
-
--slave_net-timeout=N每个通道设置此值,以便每个通道等待
N几秒钟以检查连接是否断开。 -
--slave-skip-counter=N每个通道设置此值,以便每个通道
N从其主 通道中跳过 事件。
本节介绍命名约定如何受复制通道的影响。
每个复制通道都有一个唯一的名称,该名称是一个最大长度为64个字符的字符串,不区分大小写。 由于通道名称用于从属表,因此用于这些的字符集始终为UTF-8。 虽然您通常可以为通道使用任何名称,但保留以下名称:
-
group_replication_applier -
group_replication_recovery
为复制通道选择的名称也会影响多源复制从站使用的文件名。
命名每个通道的中继日志文件和索引文件
,其中
是使用该
选项
指定的基本名称
,并且
是记录到此文件的通道的名称。
如果未指定该
选项,则使用默认文件名,该名称还包括通道的名称。
relay_log_basename-channel.xxxxxxrelay_log_basename
--relay-log
channel
--relay-log
在复制期间,从属服务器会创建多个日志,这些日志包含从主服务器中继到从服务器的二进制日志事件,并记录有关中继日志中当前状态和位置的信息。 此过程中使用了三种类型的日志,如下所示:
-
该 中继日志 由来自主的二进制日志读取和写入由从I / O线程的事件。 作为SQL线程的一部分,中继日志中的事件在从属服务器上执行。
-
该 主信息日志 包含状态和当前的配置信息从服务器的连接到主机。 此日志包含有关主主机名,登录凭据和坐标的信息,这些坐标指示从站从主站的二进制日志中读取了多远。 主信息日志将写入
mysql.slave_master_info表中。 -
该 中继日志信息记录 保存有关从服务器的中继日志中的执行点的状态信息。 中继日志写入
mysql.slave_relay_log_info表中。
在MySQL 8.0中,当 mysqld 无法初始化复制日志记录表 时会发出警告 ,但允许从站继续启动。 从不支持从属日志记录表的MySQL版本升级到支持它们的MySQL版本时,最有可能发生这种情况。
在MySQL 8.0,要求上的任一个或两者写入锁的任何语句的执行
slave_master_info
和
slave_relay_log_info
表是不允许的,而复制正在进行,而仅执行读取在任何时间允许语句。
不要尝试更新或中插入行
slave_master_info
或
slave_relay_log_info
表手动。
这样做可能会导致未定义的行为,并且不受支持。
使复制适应意外停止。
在
mysql.slave_master_info
和
mysql.slave_relay_log_info
表可以使用事务性存储引擎创建
InnoDB
。
中继日志信息日志表的更新与事务一起提交,这意味着记录在该日志中的从属进度信息始终与应用于数据库的内容一致,即使服务器意外停止也是如此。
--relay-log-recovery
必须在从站上启用
该
选项以确保弹性。
有关更多详细信息,请参见
第17.3.2节“处理意外停止复制从站”
。
与二进制日志一样,中继日志由一组编号文件和一个索引文件组成,这些文件包含描述数据库更改的事件,索引文件包含所有使用的中继日志文件的名称。 中继日志文件的默认位置是数据目录。
术语 “ 中继日志文件 ” 通常表示包含数据库事件的单个编号文件。 术语 “ 中继日志 ” 统称为编号的中继日志文件集加上索引文件。
中继日志文件具有与二进制日志文件相同的格式,可以使用 mysqlbinlog 读取 (请参见 第4.6.8节“ mysqlbinlog - 处理二进制日志文件的实用程序” )。
对于默认复制通道,中继日志文件名具有默认形式
,其中
是从属服务器主机的名称,并且
是序列号。
连续的中继日志文件使用连续的序列号创建,从
。
对于非默认复制通道,默认基本名称为
,其中
是中继日志中记录的复制通道的名称。
host_name-relay-bin.nnnnnnhost_name
nnnnnn
000001
host_name-relay-bin-channelchannel
从站使用索引文件来跟踪当前正在使用的中继日志文件。
默认中继日志索引文件名
host_name-relay-bin.indexhost_name-relay-bin-channel.index
可以分别使用
--relay-log
和
--relay-log-index
服务器选项
覆盖缺省中继日志文件和中继日志索引文件名和位置
(请参见
第17.1.6节“复制和二进制日志记录选项和变量”
)。
如果从站使用默认的基于主机的中继日志文件名,则在设置复制后更改从站的主机名可能会导致复制失败,并显示错误
无法打开中继日志,
并且
在中继日志初始化期间无法找到目标日志
。
这是一个已知问题(参见Bug#2122)。
如果您预计将来可能会更改从属主机名(例如,如果在从属服务器上设置了网络,以便可以使用DHCP修改其主机名),则可以完全避免使用
--relay-log
和
--relay-log-index
最初设置从站时显式指定中继日志文件名的选项。
这将使名称独立于服务器主机名更改。
如果在复制已经开始之后遇到问题,解决此问题的一种方法是停止从属服务器,将旧的中继日志索引文件的内容预先添加到新服务器,然后重新启动从属服务器。 在Unix系统上,这可以如下所示完成:
shell> shell>catnew_relay_log_name.index >>old_relay_log_name.indexmvold_relay_log_name.indexnew_relay_log_name.index
从服务器在以下条件下创建新的中继日志文件:
-
每次I / O线程启动时。
-
刷新日志时(例如,使用
FLUSH LOGS或 mysqladmin flush-logs )。 -
当前中继日志文件的大小变得太大时,确定如下:
-
如果值
max_relay_log_size大于0,则表示最大中继日志文件大小。 -
如果值为
max_relay_log_size0,则max_binlog_size确定最大中继日志文件大小。
-
SQL线程在执行文件中的所有事件并且不再需要它之后,会自动删除每个中继日志文件。
没有明确的删除中继日志的机制,因为SQL线程负责这样做。
但是,
FLUSH LOGS
旋转中继日志,这会影响SQL线程何时删除它们。
复制从属服务器
InnoDB
以
mysql
系统模式中
的
表
的形式创建两个从属状态日志
:主信息日志
slave_master_info
和中继日志信息日志
slave_relay_log_info
。
两个从属状态日志包含类似于
SHOW SLAVE
STATUS
语句
输出中显示的信息
,这将在
第13.4.2节“用于控制从属服务器的SQL语句”中讨论
。
从属服务器关闭后,从属状态日志将继续存在。
下一次从站启动时,它会读取两个日志,以确定它在从主站读取二进制日志和处理自己的中继日志之前已经进行了多长时间。
应限制主信息日志表的访问权限,因为它包含用于连接到主服务器的密码。 请参见 第6.1.2.3节“密码和日志记录” 。
在MySQL 8.0之前,要将从属状态日志创建为表,必须
在服务器启动时
指定
--master-info-repository=TABLE
和
--relay-log-info-repository=TABLE
选项。
否则,将被记录在指定的数据目录中的文件创建
master.info
和
relay-log.info
,或由指定的替代名称和位置
--master-info-file
和
--relay-log-info-file
选项。
从MySQL 8.0开始,将从属状态日志创建为表是默认值,并且不建议将从属状态日志创建为文件。
有关更多信息,请参见
第17.1.6节“复制和二进制日志记录选项和变量”
。
在
mysql.slave_master_info
和
mysql.slave_relay_log_info
表可以使用创建的
InnoDB
事务性存储引擎。
中继日志信息日志表的更新与事务一起提交,这意味着记录在该日志中的从属进度信息始终与应用于数据库的内容一致,即使服务器意外停止也是如此。
--relay-log-recovery
必须在从站上启用
该
选项以确保弹性。
有关更多详细信息,请参见
第17.3.2节“处理意外停止复制从站”
。
创建一个主要供内部使用的附加从属状态日志,并保存有关多线程复制从属上的工作线程的状态信息。
此从属工作日志包括每个工作线程的中继日志文件和主二进制日志文件的名称和位置。
如果将从站的中继日志信息日志创建为表(默认值),则将从属工作日志写入
mysql.slave_worker_info
表中。
如果将中继日志信息日志写入文件,则会将从属工作日志写入该
worker-relay-log.info
文件。
对于外部使用,工作线程的状态信息显示在“性能架构”
replication_applier_status_by_worker
表中。
从I / O线程更新主信息日志。
下表显示了
mysql.slave_master_info
表中的列,显示的列
SHOW SLAVE STATUS
和不推荐使用的
master.info
文件中
的行
之间的对应关系
。
slave_master_info
表格列
|
SHOW SLAVE STATUS
柱
|
master.info
文件行
|
描述 |
|---|---|---|---|
Number_of_lines |
[没有] | 1 | 表中的列数(或文件中的行数) |
Master_log_name |
Master_Log_File |
2 | 当前正从主服务器读取的主二进制日志的名称 |
Master_log_pos |
Read_Master_Log_Pos |
3 | 已从主服务器读取的主二进制日志中的当前位置 |
Host |
Master_Host |
4 | 主服务器的主机名 |
User_name |
Master_User |
五 | 用于连接到主服务器的用户名 |
User_password |
密码(未显示
SHOW SLAVE STATUS
)
|
6 | 用于连接主服务器的密码 |
Port |
Master_Port |
7 | 用于连接主站的网络端口 |
Connect_retry |
Connect_Retry |
8 | 在尝试重新连接到主服务器之前,从服务器将等待的时间段(以秒为单位) |
Enabled_ssl |
Master_SSL_Allowed |
9 | 指示服务器是否支持SSL连接 |
Ssl_ca |
Master_SSL_CA_File |
10 | 用于证书颁发机构(CA)证书的文件 |
Ssl_capath |
Master_SSL_CA_Path |
11 | 证书颁发机构(CA)证书的路径 |
Ssl_cert |
Master_SSL_Cert |
12 | SSL证书文件的名称 |
Ssl_cipher |
Master_SSL_Cipher |
13 | SSL连接握手中使用的可能密码列表 |
Ssl_key |
Master_SSL_Key |
14 | SSL密钥文件的名称 |
Ssl_verify_server_cert |
Master_SSL_Verify_Server_Cert |
15 | 是否验证服务器证书 |
Heartbeat |
[没有] | 16 | 复制心跳之间的间隔,以秒为单位 |
Bind |
Master_Bind |
17 | 应使用哪个从属网络接口连接到主服务器 |
Ignored_server_ids |
Replicate_Ignore_Server_Ids |
18 |
要忽略的服务器ID列表。
请注意,对于
Ignored_server_ids
服务器ID列表,前面是要忽略的服务器ID总数。
|
Uuid |
Master_UUID |
19 | 主人的唯一身份证 |
Retry_count |
Master_Retry_Count |
20 | 允许的最大重新连接尝试次数 |
Ssl_crl |
[没有] | 21 | SSL证书吊销列表文件的路径 |
Ssl_crl_path |
[没有] | 22 | 包含SSL证书吊销列表文件的目录的路径 |
Enabled_auto_position |
Auto_position |
23 | 如果自动定位正在使用中 |
Channel_name |
Channel_name |
24 | 复制通道的名称 |
Tls_Version |
Master_TLS_Version |
25 | 主人的TLS版本 |
Master_public_key_path |
Master_public_key_path |
26 | RSA公钥文件的名称 |
Get_master_public_key |
Get_master_public_key |
27 | 是否从master请求RSA公钥 |
从属SQL线程更新中继日志信息日志。
下表显示了
mysql.slave_relay_log_info
表中的列,显示的列
SHOW SLAVE
STATUS
和不推荐使用的
relay-log.info
文件中
的行
之间的对应关系
。
slave_relay_log_info
表格列
|
SHOW SLAVE STATUS
柱
|
行
relay-log.info
文件
|
描述 |
|---|---|---|---|
Number_of_lines |
[没有] | 1 | 表中的列数或文件中的行数 |
Relay_log_name |
Relay_Log_File |
2 | 当前中继日志文件的名称 |
Relay_log_pos |
Relay_Log_Pos |
3 | 中继日志文件中的当前位置; 直到此位置的事件已在从属数据库上执行 |
Master_log_name |
Relay_Master_Log_File |
4 | 读取中继日志文件中事件的主二进制日志文件的名称 |
Master_log_pos |
Exec_Master_Log_Pos |
五 | 主机的二进制日志文件中已经执行的事件的等效位置 |
Sql_delay |
SQL_Delay |
6 | 从站必须滞后主站的秒数 |
Number_of_workers |
[没有] | 7 | 用于并行执行复制事件(事务)的从属应用程序线程数 |
Id |
[没有] | 8 | 用于内部目的的ID; 目前这总是1 |
Channel_name |
CHANNEL_NAME | 9 | 复制通道的名称 |
当您备份复制从服务器的数据,请确保您备份
mysql.slave_master_info
和
mysql.slave_relay_log_info
包含从状态日志,因为他们需要你从从恢复后的数据恢复复制表。
如果丢失了中继日志文件,但仍有中继日志信息日志,则可以检查它以确定SQL线程在主二进制日志中执行了多远。
然后你可以使用
CHANGE
MASTER TO
与
MASTER_LOG_FILE
和
MASTER_LOG_POS
选项告诉奴隶从该点重新读取二进制日志。
当然,这要求主服务器上仍然存在二进制日志。
如果主服务器未将语句写入其二进制日志,则不会复制该语句。 如果服务器记录了该语句,则该语句将发送到所有从站,并且每个从站确定是执行它还是忽略它。
在主服务器上,您可以使用
--binlog-do-db
和
--binlog-ignore-db
选项控制二进制日志记录来控制
要记录更改的数据库
。
有关服务器在评估这些选项时使用的规则的说明,请参见
第17.2.5.1节“数据库级复制和二进制日志记录选项的评估”
。
您不应使用这些选项来控制复制哪些数据库和表。
相反,在从站上使用过滤来控制在从站上执行的事件。
在从属方面,关于是否执行或忽略从主站接收的语句的决定是根据
--replicate-*
从站启动
的
选项进行的。
(请参见
第17.1.6节“复制和二进制日志记录选项和变量”
。)也可以使用该
CHANGE REPLICATION FILTER
语句
动态设置由这些选项控制的过滤器
。
无论是在启动时使用
--replicate-*
选项
创建
还是在从属服务器运行时
创建这些过滤器的规则都是相同
的
CHANGE REPLICATION
FILTER
。
请注意,复制筛选器不能用于为组复制配置的MySQL服务器实例上的特定于组复制的通道,因为在某些服务器上筛选事务会使组无法就一致状态达成协议。
在最简单的情况下,当没有
--replicate-*
选项时,从站执行从主站接收的所有语句。
否则,结果取决于给定的特定选项。
首先检查
数据库级选项(
--replicate-do-db
,
--replicate-ignore-db
);
有关此过程的说明,
请参见
第17.2.5.1节“数据库级复制和二进制日志记录选项的评估”
。
如果未使用任何数据库级选项,则选项检查将继续执行可能正在使用的任何表级选项(
有关这些
选项
的讨论,
请参见
第17.2.5.2节“表级复制选项的评估”
)。
如果使用了一个或多个数据库级选项但未匹配任何选项,则不会复制该语句。
对于仅影响数据库语句(也就是
CREATE
DATABASE
,
DROP
DATABASE
和
ALTER
DATABASE
),数据库级选项总是优先于任何
--replicate-wild-do-table
选项。
换句话说,对于此类语句,
--replicate-wild-do-table
当且仅当没有适用的数据库级选项时,才会检查选项。
为了更容易确定选项 集会 产生什么影响,建议您避免混合使用 “ do ” 和 “ ignore ” 选项,或者使用通配符和非wildcard选项。
如果
--replicate-rewrite-db
指定了
任何
选项,则在
--replicate-*
测试过滤规则
之前应用它们
。
所有复制过滤选项都遵循相同的区分大小写规则,这些规则适用于MySQL服务器中其他位置的数据库和表的名称,包括
lower_case_table_names
系统变量
的影响
。
在评估复制选项时,从属服务器首先检查是否存在任何
--replicate-do-db
或
--replicate-ignore-db
适用的选项。
使用
--binlog-do-db
或时
--binlog-ignore-db
,过程类似,但在主服务器上检查选项。
检查匹配的数据库取决于正在处理的语句的二进制日志格式。
如果使用行格式记录了语句,则要更改数据的数据库是要检查的数据库。
如果使用语句格式记录了语句,则默认数据库(使用
USE
语句
指定
)是要检查的数据库。
只能使用行格式记录DML语句。
DDL语句始终记录为语句,即使是
binlog_format=ROW
。
因此,始终根据基于语句的复制规则筛选所有DDL语句。
这意味着您必须使用
USE
语句
显式选择默认数据库
,以便应用DDL语句。
对于复制,此处列出了所涉及的步骤:
-
使用哪种日志格式?
-
声明。 测试默认数据库。
-
行。 测试受更改影响的数据库。
-
-
有什么
--replicate-do-db选择吗?-
是。 数据库是否匹配其中任何一个?
-
是。 继续第4步。
-
否。 忽略更新并退出。
-
-
不。 继续执行第3步。
-
-
有什么
--replicate-ignore-db选择吗?-
是。 数据库是否匹配其中任何一个?
-
是。 忽略更新并退出。
-
不。 继续执行第4步。
-
-
不。 继续执行第4步。
-
-
继续检查表级复制选项(如果有)。 有关如何检查这些选项的说明,请参见 第17.2.5.2节“表级复制选项的评估” 。
重要在此阶段仍然允许的声明尚未实际执行。 在检查了所有表级选项(如果有)之后,该语句才会执行,并且该进程的结果允许执行该语句。
对于二进制日志记录,此处列出了所涉及的步骤:
-
是否有任何
--binlog-do-db或--binlog-ignore-db选择?-
是。 继续第2步。
-
否。 记录声明并退出。
-
-
是否有默认数据库(已选择任何数据库
USE)?-
是。 继续第3步。
-
不。 忽略声明并退出。
-
-
有一个默认数据库。 有什么
--binlog-do-db选择吗?-
是。 它们中的任何一个都匹配数据库吗?
-
是。 记录该语句并退出。
-
不。 忽略声明并退出。
-
-
不。 继续执行第4步。
-
-
是否有任何
--binlog-ignore-db选项与数据库匹配?-
是。 忽略该语句并退出。
-
否。 记录声明并退出。
-
对于基于语句的日志记录,一个例外是只为给定的规则做
CREATE
DATABASE
,
ALTER
DATABASE
和
DROP
DATABASE
声明。
在这些情况下,
在确定是记录还是忽略更新时
,
正在
创建,更改或删除
的数据库将替换缺省数据库。
--binlog-do-db
有时可能意味着
“
忽略其他数据库
”
。
例如,使用基于语句的日志记录时,仅运行的服务器
--binlog-do-db=sales
不会写入与默认数据库不同的二进制日志语句
sales
。
使用具有相同选项的基于行的日志记录时,服务器仅记录那些更改数据的更新
sales
。
仅当满足以下两个条件之一时,从站才会检查并评估表选项:
-
找不到匹配的数据库选项。
-
找到了一个或多个数据库选项,并 根据上一节中描述的规则 评估它们是否达到 “ 执行 ” 状态(请参见 第17.2.5.1节“数据库级复制和二进制日志记录选项的评估” )。
首先,作为初步条件,从站检查是否启用了基于语句的复制。 如果是,并且语句在存储的函数内发生,则从属执行语句并退出。 如果启用了基于行的复制,则从属服务器不知道是否在主服务器上的存储函数中发生了语句,因此该条件不适用。
对于基于语句的复制,复制事件表示语句(构成给定事件的所有更改都与单个SQL语句相关联);
对于基于行的复制,每个事件表示单个表行中的更改(因此单个语句
UPDATE mytable SET mycol =
1
可能会产生许多基于行的事件)。
从事件角度来看,检查表选项的过程对于基于行和基于语句的复制都是相同的。
达到这一点后,如果没有表选项,则从站只执行所有事件。
如果有任何
--replicate-do-table
或
--replicate-wild-do-table
选项,则事件必须与其中一个匹配(如果要执行);
否则,它会被忽略。
如果有任何
--replicate-ignore-table
或
--replicate-wild-ignore-table
选项,则执行所有事件,但匹配任何这些选项的事件除外。
以下步骤更详细地描述了此评估。 起点是数据库级选项的评估结束,如 第17.2.5.1节“数据库级复制和二进制日志选项的评估”中所述 。
-
有没有表复制选项?
-
是。 继续第2步。
-
否。 执行更新并退出。
-
-
使用哪种日志格式?
-
声明。 执行执行更新的每个语句的剩余步骤。
-
行。 对表行的每次更新执行剩余的步骤。
-
-
有什么
--replicate-do-table选择吗?-
是。 表格是否匹配任何一个?
-
是。 执行更新并退出。
-
不。 继续执行第4步。
-
-
不。 继续执行第4步。
-
-
有什么
--replicate-ignore-table选择吗?-
是。 表格是否匹配任何一个?
-
是。 忽略更新并退出。
-
不。 继续执行第5步。
-
-
不。 继续执行第5步。
-
-
有什么
--replicate-wild-do-table选择吗?-
是。 表格是否匹配任何一个?
-
是。 执行更新并退出。
-
不。 继续执行第6步。
-
-
不。 继续执行第6步。
-
-
有什么
--replicate-wild-ignore-table选择吗?-
是。 表格是否匹配任何一个?
-
是。 忽略更新并退出。
-
不。 继续执行第7步。
-
-
不。 继续执行第7步。
-
-
还有另一张表要测试吗?
-
是。 回到第3步。
-
不。 继续执行第8步。
-
-
是否有任何
--replicate-do-table或--replicate-wild-do-table选择?-
是。 忽略更新并退出。
-
否。 执行更新并退出。
-
如果一个SQL语句上的两个由一个包含一台运行基于语句的复制停止
--replicate-do-table
或
--replicate-wild-do-table
选项,并且由一个忽略另一个表
--replicate-ignore-table
或
--replicate-wild-ignore-table
选项。
slave必须执行或忽略complete语句(形成复制事件),并且它无法在逻辑上执行此操作。
这也适用于DDL语句的基于行的复制,因为DDL语句始终记录为语句,而不考虑有效的日志记录格式。
唯一可以更新包含和被忽略的表并且仍然可以成功复制的语句类型是已记录的DML语句
binlog_format=ROW
。
本节提供了有关复制筛选选项的不同组合的其他说明和用法示例。
下表给出了复制过滤规则类型的一些典型组合:
| 条件(选项类型) | 结果 |
|---|---|
--replicate-*
根本
没有
选择:
|
从站执行从主站接收的所有事件。 |
--replicate-*-db
选项,但没有表选项:
|
从服务器使用数据库选项接受或忽略事件。 它执行这些选项允许的所有事件,因为没有表限制。 |
--replicate-*-table
选项,但没有数据库选项:
|
由于没有数据库条件,因此在数据库检查阶段接受所有事件。 从站仅根据表选项执行或忽略事件。 |
| 数据库和表选项的组合: | 从服务器使用数据库选项接受或忽略事件。 然后,它根据表选项评估这些选项允许的所有事件。 这有时会导致结果看似违反直觉,并且可能会有所不同,具体取决于您使用的是基于语句还是基于行的复制; 请参阅文本以获取示例。 |
接下来是一个更复杂的示例,其中我们检查基于语句和基于行的设置的结果。
假设我们有两个表
mytbl1
的数据库
db1
和
mytbl2
数据库
db2
的主人,从与下面的选项(并且没有其他复制过滤选项)运行:
replicate-ignore-db = db1 replicate-do-table = db2.tbl2
现在我们在master上执行以下语句:
使用db1; INSERT INTO db2.tbl2 VALUES(1);
从站的结果根据二进制日志格式而有很大差异,并且在任何一种情况下都可能与初始期望不匹配。
基于语句的复制。
该
USE
语句导致
db1
默认数据库。
因此
--replicate-ignore-db
选项匹配,
并
INSERT
忽略
该
语句
。
不检查表选项。
基于行的复制。
使用基于行的复制时,缺省数据库对从属服务器读取数据库选项的方式没有影响。
因此,该
USE
语句对如何
--replicate-ignore-db
处理选项
没有区别
:此选项指定的数据库与
INSERT
语句更改数据
的数据库不匹配
,因此从属设备继续检查表选项。
指定
--replicate-do-table
的表与要更新的表匹配,
并插入行
。
本节介绍在存在多个复制通道时如何使用复制筛选器,例如在多源复制拓扑中。 在MySQL 8.0之前,复制过滤器是全局的 - 过滤器应用于所有复制通道。 从MySQL 8.0开始,复制过滤器可以是全局的或通道特定的,使您可以在特定复制通道上配置具有复制过滤器的多源复制从属。 当多个主服务器上存在相同的数据库或表时,通道特定的复制筛选器在多源复制拓扑中特别有用,并且只需要从一个主服务器复制它。
有关更多背景信息,请参见 第17.1.4节“MySQL多源复制” 和 第17.2.3节“复制通道” 。
在为组复制配置的MySQL服务器实例上,可以在不直接与组复制相关的复制通道上使用通道特定的复制筛选器,例如组成员还充当到组外的主服务器的复制从属服务器。组。
他们不能对使用
group_replication_applier
或
group_replication_recovery
通道。
过滤这些渠道会使该小组无法就一致状态达成协议。
当存在多个复制通道时,例如在多源复制拓扑中,复制过滤器的应用方式如下:
-
指定的任何全局复制筛选器都将添加到筛选器类型(
do_db,do_ignore_table等等) 的全局复制筛选器中 。 -
任何特定于通道的复制筛选器都会将筛选器添加到指定筛选器类型的指定通道的复制筛选器中。
-
如果未配置此类型的通道特定复制过滤器,则每个从属复制通道都会将全局复制过滤器复制到其通道特定的复制过滤器
-
每个通道都使用其通道特定的复制过滤器来过滤复制流。
创建特定于通道的复制过滤器的语法扩展了现有的SQL语句和命令选项。
未指定复制通道时,将配置全局复制筛选器以确保向后兼容。
该
CHANGE
REPLICATION FILTER
语句支持
FOR CHANNEL
在线配置通道特定过滤器
的
子句。
--replicate-*
配置筛选器
的
命令选项可以使用表单指定复制通道
。
例如,假设信道
和
存在服务器启动之前,开始与命令行选项从属
将导致:
--replicate-
filter_type=channel_name:filter_detailschannel_1
channel_2
--replicate-do-db=db1
--replicate-do-db=channel_1:db2
--replicate-do-db=db3
--replicate-ignore-db=db4
--replicate-ignore-db=channel_2:db5
-
全局复制过滤器 :do_db = db1,db3,ignore_db = db4
-
channel_1上的通道特定过滤器 :do_db = db2 ignore_db = db4
-
channel_2上的通道特定过滤器 :do_db = db1,db3 ignore_db = db5
要在此类设置中监视复制筛选器,请使用
replication_applier_global_filters
和
replication_applier_filters
表。
与复制过滤器相关的命令选项可以是可选的,
channel
后跟冒号,后跟过滤器规范。
第一个冒号被解释为分隔符,后续冒号被解释为文字冒号。
以下命令选项支持使用以下格式的通道特定复制过滤器:
-
--replicate-do-db=channel:database_id -
--replicate-ignore-db=channel:database_id -
--replicate-do-table=channel:table_id -
--replicate-ignore-table=channel:table_id -
--replicate-rewrite-db=channel:db1-db2 -
--replicate-wild-do-table=channel:table regexid -
--replicate-wild-ignore-table=channel:table regexid
例如,如果使用冒号但未指定
channel
过滤器选项
,则该选项会为默认复制通道配置复制过滤器。
默认复制通道是复制通道,它在启动复制后始终存在,并且与您手动创建的多源复制通道不同。
如果既未
指定
冒号也未
指定
a,
则该选项配置全局复制筛选器,例如
配置全局
筛选器。
--replicate-do-db=:
database_idchannel
--replicate-do-db=
database_id--replicate-do-db
如果
使用相同的
数据库
配置多个
选项,则
所有过滤器将一起添加(放入
列表),第一个
过滤器
生效。
rewrite-db=
from_name->to_namefrom_name
rewrite_do
除了这些
--replicate-*
选项之外,还可以使用该
CHANGE
REPLICATION FILTER
语句
配置复制过滤器
。
这样就无需重新启动服务器,但必须在进行更改时停止从属应用程序线程。
要使此语句将过滤器应用于特定通道,请使用该
子句。
例如:
FOR CHANNEL
channel
CHANGE REPLICATION FILTER REPLICATE_DO_DB =(db1)FOR CHANNEL channel_1;
当
FOR CHANNEL
设置条款,声明作用于指定通道的复制过滤器。
如果有多个类型的过滤器(
do_db
,
do_ignore_table
,
wild_do_table
,等)被指定,只有指定的过滤器类型由语句代替。
在具有多个通道的复制拓扑中,例如在多源复制从属设备上,当未
FOR
CHANNEL
提供子句
时
,该语句将使用与
FOR
CHANNEL
案例
类似的逻辑作用于全局复制过滤器和所有通道的复制过滤器
。
有关更多信息,请参见
第13.4.2.2节“更改复制过滤器语法”
。
如果已配置通道特定的复制筛选器,则可以通过发出空筛选器类型语句来删除筛选器。
例如,
REPLICATE_REWRITE_DB
从名为
channel_1
issue
的复制通道中
删除所有
过滤器
:
CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB =()FOR CHANNEL channel_1;
REPLICATE_REWRITE_DB
使用命令选项或以前配置的
任何
过滤器
CHANGE
REPLICATION FILTER
都将被删除。
该
RESET
SLAVE
ALL
语句删除
在
语句删除的通道上设置的通道特定复制过滤器。
重新创建删除的一个或多个通道时,会为从属服务器指定的任何全局复制过滤器复制到它们,并且不会应用任何特定于通道的复制过滤器。
复制可以在许多不同的环境中用于各种目的。 本节提供有关对特定解决方案类型使用复制的一般说明和建议。
有关在备份环境中使用复制的信息,包括有关设置,备份过程和要备份的文件的说明,请参见 第17.3.1节“使用备份复制” 。
有关在主站和从站上使用不同存储引擎的建议和提示,请参见 第17.3.4节“使用具有不同主站和从站存储引擎的复制” 。
使用复制作为横向扩展解决方案需要对使用该解决方案的应用程序的逻辑和操作进行一些更改。 请参见 第17.3.5节“使用复制进行横向扩展” 。
出于性能或数据分发的原因,您可能希望将不同的数据库复制到不同的复制从属服务器。 请参见 第17.3.6节“将不同的数据库复制到不同的从属服务器”
随着复制从属数量的增加,主服务器上的负载会增加并导致性能降低(因为需要将二进制日志复制到每个从服务器)。 有关提高复制性能的提示(包括将单个辅助服务器用作复制主服务器),请参见 第17.3.7节“提高复制性能” 。
有关切换主站或 将从 站转换为主站作为紧急故障转移解决方案的一部分的指导,请参见 第17.3.8节“在故障转移期间切换主站” 。
要保护复制通信,可以加密通信通道。 有关分步说明,请参见 第17.3.9节“设置复制以使用加密连接” 。
要将复制用作备份解决方案,请将数据从主服务器复制到从服务器,然后备份数据从服务器。 从站可以暂停和关闭,而不会影响主站的运行操作,因此您可以生成 “ 实时 ” 数据 的有效快照, 否则需要关闭主站。
备份数据库的方式取决于其大小以及是仅备份数据,还是备份数据和复制从属状态,以便在发生故障时重建从站。 因此有两种选择:
-
如果您使用复制作为解决方案来使您能够备份主服务器上的数据,并且数据库的大小不是太大,则 mysqldump 工具可能是合适的。 请参见 第17.3.1.1节“使用mysqldump备份从站” 。
-
对于较大的数据库,其中 mysqldump 不切实际或效率低下,您可以备份原始数据文件。 使用原始数据文件选项还意味着您可以备份二进制文件和中继日志,以便在从站发生故障时重新创建从站。 有关更多信息,请参见 第17.3.1.2节“从从站备份原始数据” 。
另一种可用于主服务器或从服务器的备份策略是将服务器置于只读状态。 对只读服务器执行备份,然后将其更改回其通常的读/写操作状态。 请参见 第17.3.1.3节“通过将其设置为只读来备份主设备或从设备” 。
使用 mysqldump 创建数据库副本使您能够以一种格式捕获数据库中的所有数据,该格式使信息能够导入到另一个MySQL服务器实例中(参见 第4.5.4节“ mysqldump - 数据库备份程序”) “ )。 由于信息的格式是SQL语句,因此在紧急情况下需要访问数据时,可以轻松地将文件分发并应用于正在运行的服务器。 但是,如果数据集的大小非常大,则 mysqldump 可能不切实际。
使用 mysqldump时 ,应在启动转储过程之前停止从属服务器上的复制,以确保转储包含一组一致的数据:
-
阻止从服务器处理请求。 您可以使用 mysqladmin 在slave上完全停止复制 :
外壳>
mysqladmin stop-slave或者,您只能停止从属SQL线程以暂停事件执行:
外壳>
mysql -e 'STOP SLAVE SQL_THREAD;'这使从站能够继续从主站的二进制日志接收数据更改事件,并使用I / O线程将它们存储在中继日志中,但阻止从站执行这些事件并更改其数据。 在繁忙的复制环境中,允许I / O线程在备份期间运行可能会在您重新启动从属SQL线程时加快追赶过程。
-
运行 mysqldump 以转储数据库。 您可以转储所有数据库或选择要转储的数据库。 例如,要转储所有数据库:
外壳>
mysqldump --all-databases > fulldb.dump -
转储完成后,再次启动从属操作:
外壳>
mysqladmin start-slave
在前面的示例中,您可能希望向命令添加登录凭据(用户名,密码),并将该过程捆绑到可以每天自动运行的脚本中。
如果使用此方法,请确保监视从属复制过程,以确保运行备份所花费的时间不会影响从属服务器跟上主服务器事件的能力。 请参见 第17.1.7.1节“检查复制状态” 。 如果从站无法跟上,您可能需要添加另一个从站并分发备份过程。 有关如何配置此方案的示例,请参见 第17.3.6节“将不同的数据库复制到不同的从属服务器” 。
为了保证复制文件的完整性,应在从属服务器关闭时备份MySQL复制从属服务器上的原始数据文件。
如果MySQL服务器仍在运行,后台任务可能仍在更新数据库文件,特别是那些涉及具有后台进程的存储引擎的文件
InnoDB
。
有了
InnoDB
这些问题,应该在崩溃恢复期间解决,但由于可以在备份过程中关闭从属服务器而不影响主服务器的执行,因此利用此功能是有意义的。
要关闭服务器并备份文件:
-
关闭从属MySQL服务器:
外壳>
mysqladmin shutdown -
复制数据文件。 您可以使用任何合适的复制或存档实用程序,包括 cp , tar 或 WinZip 。 例如,假设数据目录位于当前目录下,您可以按如下方式归档整个目录:
外壳>
tar cf /tmp/dbbackup.tar ./data -
再次启动MySQL服务器。 在Unix下:
外壳>
mysqld_safe &在Windows下:
C:\>
"C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld"
通常,您应备份从MySQL服务器的整个数据目录。 如果您希望能够恢复数据并作为从设备运行(例如,在从设备发生故障的情况下),除了数据之外,您还需要拥有主信息存储库和中继日志信息存储库,以及中继日志文件。 恢复从属数据后,需要这些项目才能恢复复制。 如果表已用于主信息和中继日志信息存储库(请参见 第17.2.4节“复制中继和状态日志”) ),这是MySQL 8.0中的默认值,这些表与数据目录一起备份。 如果文件已用于存储库,则必须单独备份这些文件。 如果中继日志文件已放置在与数据目录不同的位置,则还必须单独备份它们。
如果丢失了中继日志但仍有
relay-log.info
文件,则可以检查它以确定SQL主线在主二进制日志中执行了多远。
然后你可以使用
CHANGE
MASTER
TO
与
MASTER_LOG_FILE
和
MASTER_LOG_POS
选项告诉奴隶从该点重新读取二进制日志。
这要求主服务器上仍存在二进制日志。
如果您的slave正在复制
LOAD
DATA
语句,则还应备份
SQL_LOAD-*
slave用于此目的的目录中存在的
所有
文件。
从站需要这些文件才能恢复任何中断
LOAD
DATA
操作的
复制
。
此目录的位置是
--slave-load-tmpdir
选项
的值
。
如果未使用该选项启动服务器,则目录位置是
tmpdir
系统变量
的值
。
通过获取全局读锁并
read_only
操作系统变量来更改要备份的服务器的只读状态,可以
在复制设置中备份主服务器或从服务器
:
-
使服务器只读,以便它只处理检索并阻止更新。
-
执行备份。
-
将服务器更改回其正常的读/写状态。
本节中的说明将要备份的服务器置于对从服务器获取数据的备份方法安全的状态,例如 mysqldump (请参见 第4.5.4节“ mysqldump - 数据库备份程序” )。 您不应该尝试使用这些指令通过直接复制文件来进行二进制备份,因为服务器可能仍然将已修改的数据缓存在内存中而不会刷新到磁盘。
以下指示信息描述了如何为主服务器和从属服务器执行此操作。 对于此处讨论的两种方案,假设您具有以下复制设置:
-
主服务器M1
-
从服务器S1以M1为主
-
客户端C1连接到M1
-
客户端C2连接到S1
在任一场景中,语句都获取全局读锁并操纵
read_only
变量
都在要备份的服务器上执行,不会传播到该服务器的任何从属服务器。
方案1:使用只读主服务器备份
通过在主机上执行以下语句将主M1置于只读状态:
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
当M1处于只读状态时,以下属性为真:
-
由C1发送到M1的更新请求将被阻止,因为服务器处于只读模式。
-
C1发送到M1的查询结果请求将成功。
-
在M1上进行备份是安全的。
-
在S1上进行备份是不安全的。 此服务器仍在运行,可能正在处理来自客户端C2的二进制日志或更新请求。
虽然M1是只读的,但请执行备份。 例如,您可以使用 mysqldump 。
在M1上的备份操作完成后,通过执行以下语句将M1恢复到其正常操作状态:
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
尽管在M1上执行备份是安全的(就备份而言),但它不是最佳性能,因为M1的客户端被阻止执行更新。
此策略适用于在复制设置中备份主服务器,但也可用于非复制设置中的单个服务器。
方案2:使用只读从站进行备份
通过在其上执行以下语句将从属S1置于只读状态:
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
当S1处于只读状态时,以下属性为真:
-
主M1将继续运行,因此在主站上进行备份是不安全的。
-
从机S1停止,因此在从机S1上进行备份是安全的。
这些属性为常用备份方案提供了基础:让一个从站忙于执行备份一段时间不是问题,因为它不会影响整个网络,并且系统在备份期间仍在运行。 特别是,客户端仍然可以在主服务器上执行更新,主服务器不受备用服务器上的备份活动的影响。
虽然S1是只读的,但请执行备份。 例如,您可以使用 mysqldump 。
在S1上的备份操作完成后,通过执行以下语句将S1恢复到其正常操作状态:
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
从服务器恢复正常运行后,它会通过从主服务器的二进制日志中获取任何未完成的更新来再次与主服务器同步。
为了使复制能够适应服务器的意外暂停(有时称为崩溃安全),从服务器必须能够在暂停之前恢复其状态。 本节介绍复制期间意外停止从属设备的影响,以及如何配置从属设备以便最好地恢复以继续复制。
在意外停止从属设备后,重启后,从属服务器的SQL线程必须恢复已执行的事务。
恢复所需的信息存储在从属的中继日志信息日志中。
从MySQL 8.0开始,默认情况下会将此日志创建为一个
InnoDB
名为
mysql.slave_relay_log_info
(将系统变量
relay_log_info_repository
设置为默认值的表)
TABLE
)的表。
通过使用此事务存储引擎,信息在重新启动时始终可以恢复。
中继日志信息日志表的更新与事务一起提交,这意味着记录在该日志中的从属进度信息始终与应用于数据库的内容一致,即使服务器意外停止也是如此。
以前,此信息默认存储在应用事务后更新的数据目录中的文件中。
这存在与主服务器失去同步的风险,这取决于从属服务器处理事务的哪个阶段,甚至文件本身的损坏。
该设置
relay_log_info_repository
= FILE
现已弃用,将在以后的版本中删除。
有关从属日志的更多信息,请参阅
第17.2.4节“复制中继和状态日志”
。
当中继日志信息日志存储在
mysql.slave_relay_log_info
表中时,DML事务和原子DDL以原子方式一起进行以下三个更新:
-
在数据库上应用事务。
-
更新
mysql.slave_relay_log_info表中 的复制位置 。 -
更新mysql.gtid_executed表中的GTID(启用GTID并在服务器上禁用二进制日志时)。
在所有其他情况下,包括不完全原子的DDL语句,以及不支持原子DDL的免除存储引擎,
mysql.slave_relay_log_info
如果服务器意外停止
,该
表可能会丢失与复制数据关联的更新。
在这种情况下恢复更新是一个手动过程。
有关MySQL 8.0中原子DDL支持的详细信息,以及复制某些语句的结果行为,请参见
第13.1.1节“原子数据定义语句支持”
。
复制从站从意外停止中恢复的确切方式受所选复制方法的影响,无论是从属服务器是单线程还是多线程,变量的设置
relay_log_recovery
,以及是否
MASTER_AUTO_POSITION
正在使用
诸如此类的功能
。
下表显示了这些不同因素对单线程从站如何从意外停止中恢复的影响。
表17.3影响单线程复制从属恢复的因素
|
GTID |
MASTER_AUTO_POSITION |
崩溃类型 |
保证恢复 |
中继日志影响 |
||
|---|---|---|---|---|---|---|
|
关闭 |
任何 |
1 |
表 |
服务器 |
是 |
丢失 |
|
关闭 |
任何 |
1 |
任何 |
OS |
没有 |
丢失 |
|
关闭 |
任何 |
0 |
表 |
服务器 |
是 |
遗迹 |
|
关闭 |
任何 |
0 |
表 |
OS |
没有 |
遗迹 |
|
上 |
上 |
任何 |
任何 |
任何 |
是 |
丢失 |
|
上 |
关闭 |
0 |
表 |
服务器 |
是 |
遗迹 |
|
上 |
关闭 |
0 |
任何 |
OS |
没有 |
遗迹 |
如表所示,使用单线程从站时,以下配置对于意外停止最具弹性:
-
使用GTID时
MASTER_AUTO_POSITION,设置relay_log_recovery=1。 使用此配置,设置relay_log_info_repository和其他变量不会影响恢复。 请注意,为了保证恢复,sync_binlog=1还必须在从站上设置(这是默认值),以便在每次写入时从站的二进制日志与磁盘同步。 否则,已提交的事务可能不存在于从属的二进制日志中。 -
使用基于文件位置的复制时,请设置
relay_log_recovery=1和relay_log_info_repository=TABLE。注意恢复期间,中继日志丢失。
下表显示了这些不同因素对多线程从站如何从意外停止中恢复的影响。
表17.4影响多线程复制从属恢复的因素
|
GTID |
|
崩溃类型 |
保证恢复 |
中继日志影响 |
|||
|---|---|---|---|---|---|---|---|
|
关闭 |
1 |
任何 |
1 |
表 |
任何 |
是 |
丢失 |
|
关闭 |
> 1 |
任何 |
1 |
表 |
服务器 |
是 |
丢失 |
|
关闭 |
> 1 |
任何 |
1 |
任何 |
OS |
没有 |
丢失 |
|
关闭 |
1 |
任何 |
0 |
表 |
服务器 |
是 |
遗迹 |
|
关闭 |
1 |
任何 |
0 |
表 |
OS |
没有 |
遗迹 |
|
上 |
任何 |
上 |
任何 |
任何 |
任何 |
是 |
丢失 |
|
上 |
1 |
关闭 |
0 |
表 |
服务器 |
是 |
遗迹 |
|
上 |
1 |
关闭 |
0 |
任何 |
OS |
没有 |
遗迹 |
如表所示,使用多线程从站时,以下配置对于意外暂停最具弹性:
-
使用GTID时
MASTER_AUTO_POSITION,设置relay_log_recovery=1。 使用此配置,设置relay_log_info_repository和其他变量不会影响恢复。 -
当使用文件位置基于阵列的复制,设置
relay_log_recovery=1,sync_relay_log=1和relay_log_info_repository=TABLE。注意恢复期间,中继日志丢失。
重要的是要注意其影响
sync_relay_log=1
,这需要写入每个事务的中继日志。
尽管此设置对意外停止的恢复能力最强,但最多会丢失一个未写入的事务,但它也有可能大大增加存储负载。
如果没有
sync_relay_log=1
,意外停止的影响取决于操作系统如何处理中继日志。
另请注意,
relay_log_recovery=0
下次在意外停止后启动从站
时
,中继日志将作为恢复的一部分进行处理。
此过程完成后,将删除中继日志。
使用上面建议的基于文件位置的复制配置意外停止多线程复制从站可能会导致中断日志与事务不一致(事务序列中的间隙)由意外停止引起。 请参见 第17.4.1.33节“复制和事务不一致” 。 如果中继日志恢复过程遇到此类事务不一致,则它们将被填充,并且恢复过程将自动继续。
当您使用多源复制时
relay_log_recovery=1
,由于意外暂停而重新启动后,所有复制通道都会通过中继日志恢复过程。
由于多线程从站的意外停止而在中继日志中发现的任何不一致都被填满。
使用基于行的复制时复制应用程序(SQL)线程的当前进度通过性能架构仪器阶段进行监视,使您能够跟踪操作的处理并检查已完成的工作量和工作量。
启用这些性能架构仪器阶段后,该
events_stages_current
表显示了应用程序线程及其进度的阶段。
有关背景信息,请参见
第26.12.5节“性能架构阶段事件表”
。
要跟踪所有三种基于行的复制事件类型(写入,更新,删除)的进度:
-
通过发出以下命令启用三个性能架构阶段:
mysql>
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'- >WHERE NAME LIKE 'stage/sql/Applying batch of row changes%'; -
等待复制应用程序线程处理某些事件,然后通过查看
events_stages_current表来 检查进度 。 例如,要获取update事件 发展的进度 :mysql>
SELECT WORK_COMPLETED, WORK_ESTIMATED FROM performance_schema.events_stages_current- >WHERE EVENT_NAME LIKE 'stage/sql/Applying batch of row changes (update)' -
如果
binlog_rows_query_log_events启用,则有关查询的信息将存储在二进制日志中,并在processlist_info字段中 公开 。 要查看触发此事件的原始查询:mysql>
SELECT db, processlist_state, processlist_info FROM performance_schema.threads- >WHERE processlist_state LIKE 'stage/sql/Applying batch of row changes%' AND thread_id = N;
对于复制过程,主服务器上的源表和从服务器上的复制表是否使用不同的引擎类型无关紧要。
实际上,
default_storage_engine
系统变量不会被复制。
这在复制过程中提供了许多好处,因为您可以针对不同的复制方案利用不同的引擎类型。
例如,在典型的横向扩展方案中(请参见
第17.3.5节“使用复制进行
横向扩展
”
),您希望使用
InnoDB
主服务器上的表来利用事务功能,但
MyISAM
在事务处理的从服务器上
使用
不需要支持,因为只读取数据。
在数据记录环境中使用复制时,您可能希望使用
Archive
从站上的存储引擎。
在主服务器和从服务器上配置不同的引擎取决于您设置初始复制过程的方式:
-
如果使用 mysqldump 在主服务器上创建数据库快照,则可以编辑转储文件文本以更改每个表上使用的引擎类型。
mysqldump的 另一个替代方法 是在使用转储在从站上构建数据之前禁用您不想在从站上使用的引擎类型。 例如,您可以
--skip-federated在从站上 添加 选项以禁用FEDERATED引擎。 如果要创建的表不存在特定引擎,MySQL通常会使用默认引擎类型MyISAM。 (这要求NO_ENGINE_SUBSTITUTION未启用SQL模式。)如果要以这种方式禁用其他引擎,您可能需要考虑构建一个特殊的二进制文件,以便在仅支持所需引擎的从属服务器上使用。 -
如果使用原始数据文件(二进制备份)来设置从属,则无法更改初始表格式。 而是
ALTER TABLE在从站启动后用于更改表类型。 -
对于主服务器上当前没有表的新主/从复制设置,请避免在创建新表时指定引擎类型。
如果您已在运行复制解决方案并希望将现有表转换为其他引擎类型,请按照下列步骤操作:
-
阻止从服务器运行复制更新:
MySQL的>
STOP SLAVE;这样您就可以在不中断的情况下更改引擎类型。
-
对要更改的每个表 执行一个 。
ALTER TABLE ... ENGINE='engine_type' -
再次启动从属复制过程:
MySQL的>
START SLAVE;
虽然
default_storage_engine
变量是不可复制的,要知道,
CREATE
TABLE
和
ALTER
TABLE
语句包括发动机规格将被正确复制到奴隶。
例如,如果您有CSV表并执行:
MySQL的> ALTER TABLE csvtable Engine='MyISAM';
上述语句将复制到从站,并且从站上的引擎类型将转换为
MyISAM
,即使您之前已将从站上的表类型更改为CSV以外的引擎。
如果要在主服务器和从服务器上保留引擎差异,则
default_storage_engine
在创建新表
时应注意
在主服务器上
使用该
变量。
例如,而不是:
MySQL的> CREATE TABLE tablea (columna int) Engine=MyISAM;
使用以下格式:
mysql>SET default_storage_engine=MyISAM;mysql>CREATE TABLE tablea (columna int);
复制时,
default_storage_engine
将忽略
该
变量,并
CREATE
TABLE
使用从属的默认引擎在从属服务器上执行
该
语句。
您可以将复制用作横向扩展解决方案; 也就是说,在一些合理的限制范围内,您希望在多个数据库服务器之间分配数据库查询的负载。
由于复制从一个主服务器的分发到一个或多个从服务器,因此使用复制进行横向扩展最适合在具有大量读取和较少写入/更新的环境中。 大多数网站都适合此类别,用户浏览网站,阅读文章,发帖或查看产品。 更新仅在会话管理期间,或在购买或向论坛添加评论/消息时发生。
在这种情况下,复制使您可以通过复制从属分发读取,同时仍然允许Web服务器在需要写入时与复制主服务器通信。 您可以在 图17.1“使用复制在横向扩展期间提高性能”中 查看此方案的示例复制布局 。
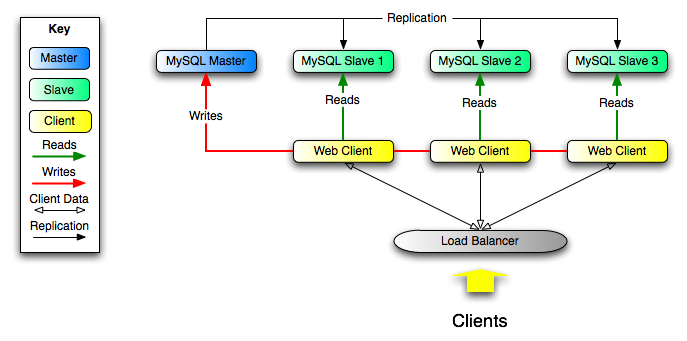
如果代码中负责数据库访问的部分已经被正确抽象/模块化,那么将其转换为使用复制设置运行应该非常顺利和容易。 更改数据库访问的实现,以将所有写入发送到主服务器,并将读取发送到主服务器或从服务器。 如果您的代码没有这种抽象级别,那么设置复制系统会为您提供清理它的机会和动力。 首先创建一个实现以下功能的包装器库或模块:
-
safe_writer_connect() -
safe_reader_connect() -
safe_reader_statement() -
safe_writer_statement()
safe_
在每个函数名称中表示该函数负责处理所有错误条件。
您可以为函数使用不同的名称。
重要的是要有一个统一的接口,用于连接读取,连接写入,读取和写入。
然后转换您的客户端代码以使用包装器库。 起初这可能是一个痛苦而可怕的过程,但从长远来看它会得到回报。 使用上述方法的所有应用程序都能够利用主/从配置,即使涉及多个从站也是如此。 代码更易于维护,添加故障排除选项非常简单。 您只需要修改一个或两个函数(例如,记录每个语句所用的时间,或者发布的语句中的哪个语句会给您一个错误)。
如果您编写了大量代码,则可能需要通过编写转换脚本来自动执行转换任务。 理想情况下,您的代码使用一致的编程样式约定。 如果没有,那么你可能最好还是重写它,或者至少通过并手动调整它以使用一致的风格。
在某些情况下,您可能只有一个主服务器,并且希望将不同的数据库复制到不同的从服务器。 例如,您可能希望将不同的销售数据分发到不同的部门,以帮助在数据分析期间分散负载。 此布局的示例 如图17.2“使用复制将数据库复制到单独的复制从站”所示 。
您可以通过正常配置主站和从站来实现此分离,然后使用
--replicate-wild-do-table
每个从站上
的
配置选项
限制每个从站进程的二进制日志语句
。
你应该
不
使用
--replicate-do-db
使用基于语句的复制时,因为基于语句的复制导致该选项的影响,根据当前选择的数据库来改变这个目的。
这也适用于混合格式复制,因为这样可以使用基于语句的格式复制某些更新。
但是,
--replicate-do-db
如果仅使用基于行的复制
,则应该可以安全地使用
,因为在这种情况下,当前选定的数据库对选项的操作没有影响。
例如,要支持分离,
如图17.2“使用复制将数据库复制到单独的
复制从属”所示,您应该在执行之前按如下方式配置每个复制从属
START
SLAVE
:
-
复制从站1应该使用
--replicate-wild-do-table=databaseA.%。 -
复制从站2应该使用
--replicate-wild-do-table=databaseB.%。 -
复制从属3应该使用
--replicate-wild-do-table=databaseC.%。
此配置中的每个从属服务器从主服务器接收整个二进制日志,但仅执行二进制日志中适用
--replicate-wild-do-table
于该从属服务器上有效选项所
包含的数据库和表的那些事件
。
如果在复制开始之前有必须同步到从属的数据,则有许多选择:
-
将所有数据同步到每个从站,并删除您不想保留的数据库,表或两者。
-
使用 mysqldump 为每个数据库创建单独的转储文件,并在每个从属服务器上加载相应的转储文件。
-
使用原始数据文件转储,仅包括每个从站所需的特定文件和数据库。
注意InnoDB除非您使用 , 否则 这不适用于 数据库innodb_file_per_table。
随着连接到主设备的从设备数量的增加,负载(尽管最小)也会增加,因为每个从设备都使用与主设备的客户端连接。 此外,由于每个从站必须接收主二进制日志的完整副本,因此主站上的网络负载也可能增加并产生瓶颈。
如果您使用连接到一个主服务器的大量从服务器,并且该主服务器也忙于处理请求(例如,作为横向扩展解决方案的一部分),那么您可能希望提高复制过程的性能。
提高复制过程性能的一种方法是创建一个更深层次的复制结构,使主设备只能复制到一个从设备,并使其余从设备连接到该主从设备以满足其各自的复制要求。 图17.3“使用其他复制主机提高性能”中 显示了此结构的示例 。
为此,您必须按如下方式配置MySQL实例:
-
Master 1是主要的主服务器,所有更改和更新都写入数据库。 两个主服务器上都启用了二进制日志记录,这是默认值。
-
Master 2是Master 1的从属设备,它为复制结构中的其余从设备提供复制功能。 Master 2是唯一允许连接到Master 1的机器.Master 2
--log-slave-updates启用 了 选项(这是默认选项)。 使用此选项,Master 1的复制指令也会写入Master 2的二进制日志,以便可以将它们复制到真正的从站。 -
从属1,从属2和从属3充当主2的从属,并复制来自主2的信息,其实际上包括登录在主1上的升级。
上述解决方案减少了主要主服务器上的客户端负载和网络接口负载,这可以在用作直接数据库解决方案时提高主要主服务器的整体性能。
如果您的从服务器无法跟上主服务器上的复制过程,则可以使用多种选项:
-
如果可能,将中继日志和数据文件放在不同的物理驱动器上。 为此,请使用该
--relay-log选项指定中继日志的位置。 -
如果读取二进制日志文件和中继日志文件的重磁盘I / O活动是一个问题,请考虑增加
rpl_read_size系统变量 的值 。 此系统变量控制从日志文件读取的最小数据量,并且当文件数据当前未由操作系统缓存时,增加它可能会减少文件读取和I / O停顿。 请注意,为从二进制日志和中继日志文件读取的每个线程分配了此值大小的缓冲区,包括主服务器上的转储线程和从服务器上的协调器线程。 因此,设置较大的值可能会影响服务器的内存消耗。 -
如果从站明显慢于主站,则可能需要将负责将不同的数据库复制到不同的从站。 请参见 第17.3.6节“将不同的数据库复制到不同的从属服务器” 。
-
如果您的主人使用交易并且您不关心奴隶的交易支持,请使用
MyISAM奴隶上的其他非交易引擎。 请参见 第17.3.4节“使用具有不同主存储引擎和从存储引擎的复制” 。 -
如果您的奴隶不是主人,并且您有可能的解决方案以确保您可以在发生故障时调出主人,那么您可以关闭
--log-slave-updates奴隶。 这可以防止 “ 哑 ”的 奴隶也将他们执行的事件记录到他们自己的二进制日志中。
您可以使用该
CHANGE
MASTER TO
语句
告知从站更改为新的主站
。
从站不检查主站上的数据库是否与从站上的数据库兼容;
它只是从新主控二进制日志中的指定坐标开始读取和执行事件。
在故障转移情况下,组中的所有服务器通常都是从同一个二进制日志文件中执行相同的事件,因此更改事件源不应影响数据库的结构或完整性,前提是您要谨慎操作更改。
应该在启用二进制日志记录(
--log-bin
选项)的情况下
运行从站
,这是默认设置。
如果您不使用GTID进行复制,则还应运行
--skip-log-slave-updates
从站(默认情况下,记录从站更新)。
通过这种方式,从站可以在不重新启动从属
mysqld的
情况下成为主站
。
假设您具有
图17.4“使用复制的冗余,初始结构”
中
所示的结构
。
在此图中,
MySQL Master
保存主数据库,
MySQL Slave
主机是复制从属,并且
Web Client
计算机正在发出数据库读取和写入。
仅显示只读(并且通常将连接到从站)的Web客户端未显示,因为它们在发生故障时无需切换到新服务器。
有关读/写向外扩展复制结构的更详细示例,请参见
第17.3.5节“使用复制进行
横向扩展
”
。
每个MySQL Slave(
Slave 1
,
Slave
2
和
Slave 3
)都是一个运行启用二进制日志记录的从站,并带有
--skip-log-slave-updates
。
由于从主服务器接收的更新未在
--skip-log-slave-updates
指定的二进制日志中记录,因此每个从服务器上的二进制日志最初为空。
如果由于某种原因
MySQL Master
变得不可用,您可以选择其中一个从属设备成为新的主设备。
例如,如果您选择
Slave 1
,
Web Clients
则应将
所有内容
重定向到
Slave 1
,这会将更新写入其二进制日志。
Slave 2
然后
Slave 3
应该复制
Slave 1
。
运行从站的原因
--skip-log-slave-updates
是为了防止从站接收更新两次,以防您使其中一个从站成为新的主站。
如果
Slave 1
已
--log-slave-updates
启用(默认值),则会将
Master
其从其自己的二进制日志中
接收的所有更新写入
。
这意味着,当
Slave 2
从改变
Master
到
Slave 1
它的主人,它可以接收更新
Slave 1
,它已经从收到的
Master
。
确保所有从站都已处理其中继日志中的任何语句。
在每个奴隶上发出问题
STOP SLAVE
IO_THREAD
,然后检查输出,
SHOW
PROCESSLIST
直到你看到
Has read all relay log
。
如果对所有从站都适用,则可以将它们重新配置为新设置。
在奴隶
Slave 1
被提升成为主人,问题
STOP
SLAVE
和
RESET
MASTER
。
在其他从属
Slave 2
和
Slave
3
,使用
STOP
SLAVE
和
CHANGE MASTER TO MASTER_HOST='Slave1'
(其中
'Slave1'
代表真正的主机名
Slave 1
)。
要使用
CHANGE MASTER
TO
,添加有关如何连接到的所有信息
Slave 1
来自
Slave 2
或
Slave 3
(
user
,
password
,
port
)。
在
CHANGE
MASTER TO
此处
发出
语句时,无需指定
Slave 1
二进制日志文件
的名称
或要读取的日志位置,因为第一个二进制日志文件和位置4是默认值。
最后,执行
START
SLAVE
上
Slave
2
和
Slave 3
。
一旦新的复制设置到位,您需要告诉每个
Web Client
人将其语句指向
Slave 1
。
从这一点上来说,通过发送的所有更新语句
Web Client
来
Slave
1
被写入二进制日志
Slave
1
,然后包含发送到每一个更新语句
Slave 1
,因为
Master
死了。
生成的服务器结构 如图17.5“使用复制冗余,主故障后”所示 。
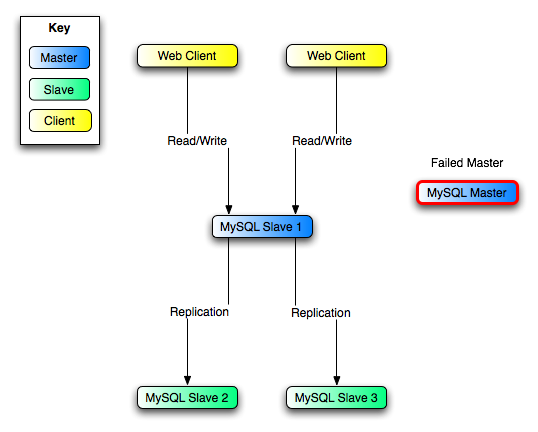
当
Master
再次可用时,你应该让它成为奴隶
Slave 1
。
为此
,请发布
与
之前
和
之前
发布的声明
Master
相同的
CHANGE
MASTER TO
声明
。
然后成为它的奴隶,
并获取
它在离线时错过
的
写入。
Slave
2
Slave 3
Master
S1ave
1
Web Client
要
Master
再次
制作
母版,请使用上述过程,就好像
Slave 1
它不可用并且
Master
是新的母版。
在此过程中,不要忘了运行
RESET
MASTER
在
Master
制作之前
Slave
1
,
Slave 2
和
Slave
3
奴隶
Master
。
如果你没有这样做,那么奴隶们可能会从
Web
Client
应用程序之前的应用程序中
获取陈旧的写入
Master
。
您应该知道,从站之间没有同步,即使它们共享同一个主站,因此某些从站可能远远领先于其他站点。 这意味着在某些情况下,上一个示例中概述的过程可能无法按预期工作。 但实际上,所有从站上的中继日志应该相对靠近。
让应用程序了解主服务器位置的一种方法是为主服务器提供动态DNS条目。
有了
bind
您可以使用
nsupdate
动态更新DNS。
要使用加密连接传输复制期间所需的二进制日志,主服务器和从服务器都必须支持加密的网络连接。 如果任一服务器不支持加密连接(因为它尚未针对它们进行编译或配置),则无法通过加密连接进行复制。
为复制设置加密连接类似于对客户端/服务器连接执行此操作。 您必须获取(或创建)可在主服务器上使用的合适安全证书,以及每个从服务器上的类似证书(来自相同的证书颁发机构)。 您还必须获取合适的密钥文件。
有关为加密连接设置服务器和客户端的更多信息,请参见 第6.3.1节“配置MySQL以使用加密连接” 。
要在主服务器上启用加密连接,您必须创建或获取合适的证书和密钥文件,然后将以下配置选项添加到
[mysqld]
主服务器
my.cnf
文件
部分中的主服务器
配置中
,根据需要更改文件名:
的[mysqld] SSL的CA = cacert.pem SSL证书=服务器cert.pem SSL的密钥=服务器key.pem
文件的路径可以是相对的或绝对的; 我们建议您始终使用完整路径来实现此目的。
选项如下:
-
--ssl-ca:证书颁发机构(CA)证书文件的路径名。 (--ssl-capath类似但指定CA证书文件目录的路径名。) -
--ssl-cert:服务器公钥证书文件的路径名。 可以将此证书发送到客户端,并根据其拥有的CA证书进行身份验证。 -
--ssl-key:服务器私钥文件的路径名。
要在从站上启用加密连接,请使用该
CHANGE
MASTER TO
语句。
您可以在从属文件的
[client]
部分中
为加密连接命名从属证书和SSL私钥
my.cnf
文件,也可以使用该
CHANGE
MASTER
TO
语句
显式指定该信息
。
有关该
CHANGE
MASTER TO
语句的
更多信息
,请参见
第13.4.2.1节“将语法更改为语法”
。
-
要使用选项文件命名从属证书和密钥文件,请将以下行添加到
[client]从属my.cnf文件 的 部分, 根据需要更改文件名:[客户] SSL的CA = cacert.pem SSL证书=客户端 - cert.pem SSL的密钥=客户端 - key.pem
-
使用该
--skip-slave-start选项 重新启动从属服务器, 以防止从属设备连接到主服务器。 使用CHANGE MASTER TO指定的主配置,并添加MASTER_SSL选项,使用加密连接:mysql>
CHANGE MASTER TO- >MASTER_HOST='master_hostname',- >MASTER_USER='repl',- > - >MASTER_PASSWORD='password',MASTER_SSL=1;设置
MASTER_SSL=1复制连接然后不设置其他 选项对应于 客户端的 设置 ,如 第6.3.2节“加密连接的命令选项”中所述 。 使用 ,如果可以建立加密连接,则连接尝试仅成功。 复制连接不会回退到未加密的连接,因此没有与 复制 设置相对应的 设置。 如果 设置,则对应于 。MASTER_SSL_xxx--ssl-mode=REQUIREDMASTER_SSL=1--ssl-mode=PREFERREDMASTER_SSL=0--ssl-mode=DISABLED -
要使用该
CHANGE MASTER TO语句 命名从属证书和SSL私钥文件 ,如果未在从属my.cnf文件中 执行此 操作,请添加适当的 选项:MASTER_SSL_xxx- >
MASTER_SSL_CA = 'ca_file_name',- >MASTER_SSL_CAPATH = 'ca_directory_name',- >MASTER_SSL_CERT = 'cert_file_name',- >MASTER_SSL_KEY = 'key_file_name',这些选项对应于 具有相同名称 的 选项,如 第6.3.2节“加密连接的命令选项”中所述 。 要使这些选项生效, 还必须进行设置。 对于复制连接,指定一个值的任一 或 ,或在从设备的指定这些选项 文件,对应于设置 。 如果使用指定信息找到有效的匹配证书颁发机构(CA)证书,则连接尝试仅成功。
--ssl-xxxMASTER_SSL=1MASTER_SSL_CAMASTER_SSL_CAPATHmy.cnf--ssl-mode=VERIFY_CA -
要激活主机名身份验证,请添加以下
MASTER_SSL_VERIFY_SERVER_CERT选项:- >
MASTER_SSL_VERIFY_SERVER_CERT=1,此选项对应于该
--ssl-verify-server-cert选项,该选项在MySQL 5.7中已弃用,在MySQL 8.0中已删除。 对于复制连接,指定MASTER_SSL_VERIFY_SERVER_CERT=1对应于设置--ssl-mode=VERIFY_IDENTITY,如 第6.3.2节“加密连接的命令选项”中所述 。 要使此选项生效,MASTER_SSL=1还必须设置。 主机名身份验证不适用于自签名证书。 -
要激活证书吊销列表(CRL)检查,请添加
MASTER_SSL_CRL或MASTER_SSL_CRLPATH选项:- >
MASTER_SSL_CRL = 'crl_file_name',- >MASTER_SSL_CRLPATH = 'crl_directory_name',这些选项对应于 具有相同名称 的 选项,如 第6.3.2节“加密连接的命令选项”中所述 。 如果未指定,则不进行CRL检查。
--ssl-xxx -
要指定从属设备允许的用于复制连接的密码和加密协议列表,请添加
MASTER_SSL_CIPHER和MASTER_TLS_VERSION选项:- >
MASTER_SSL_CIPHER = 'cipher_list',- >MASTER_TLS_VERSION = 'protocol_list',该
MASTER_SSL_CIPHER选项指定从属设备允许的用于复制连接的密码列表,其中一个或多个密码名称以冒号分隔。 该MASTER_TLS_VERSION选项指定从属设备允许的复制连接的加密协议。 格式类似于tls_version系统变量 的格式 ,其中一个或多个协议名称以逗号分隔。 您可以在这些列表中使用的协议和密码取决于用于编译MySQL的SSL库。 有关格式和允许值的信息,请参见 第6.3.6节“加密连接协议和密码” 。 -
更新主信息后,启动从属复制过程:
MySQL的>
START SLAVE;您可以使用该
SHOW SLAVE STATUS语句确认已成功建立加密连接。 -
要求从站上的加密连接不能确保主站需要来自从站的加密连接。 如果要确保主服务器仅接受使用加密连接进行连接的复制从服务器,请使用该
REQUIRE SSL选项 在主服务器上创建复制用户帐户 ,然后为该用户授予该REPLICATION SLAVE权限。 例如:mysql> - > mysql> - >CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password'REQUIRE SSL;GRANT REPLICATION SLAVE ON *.*TO 'repl'@'%.example.com';如果主服务器上有现有的复制用户帐户,则可以
REQUIRE SSL使用以下语句 添加 到该 帐户 :MySQL的>
ALTER USER 'repl'@'%.example.com' REQUIRE SSL;
从MySQL 8.0.14开始,可以加密二进制日志文件和中继日志文件,有助于保护这些文件及其中包含的潜在敏感数据不被外部攻击者滥用,以及操作系统用户未经授权查看存储。 用于文件的加密算法AES(高级加密标准)密码算法内置于MySQL服务器中,无法配置。 OpenSSL和MySQL Server的wolfSSL版本支持二进制日志加密。
您可以通过将
binlog_encryption
系统变量
设置为,在MySQL服务器上启用此加密
ON
。
OFF
是默认值。
系统变量为二进制日志文件和中继日志文件设置加密。
不需要在服务器上启用二进制日志记录以启用加密,因此您可以加密没有二进制日志的从站上的中继日志文件。
要使用加密,必须安装密钥环插件并将其配置为提供MySQL服务器的密钥环服务。
有关执行此操作的说明,请参见
第6.4.4节“MySQL密钥环”
。
任何支持的密钥环插件都可用于存储二进制日志加密密钥。
首次启动加密服务器时,会在初始化二进制日志和中继日志之前生成新的二进制日志加密密钥。 此密钥用于加密每个二进制日志文件的文件密码(如果服务器启用了二进制日志记录)和中继日志文件(如果服务器具有复制通道),并且使用文件密码生成的其他密钥来加密数据在文件中。 当前在服务器上使用的二进制日志加密密钥称为二进制日志主密钥。 双层加密密钥体系结构意味着可以根据需要轮换二进制日志主密钥(由新的主密钥替换),并且只需要使用新的主密钥重新加密每个文件的文件密码,而不是整个文件。 为所有通道加密中继日志文件,包括激活加密后创建的新通道。 二进制日志索引文件和中继日志索引文件从不加密。
如果在服务器运行时激活加密,则会在此时生成新的二进制日志加密密钥。 例外情况是先前在服务器上加密已激活然后被禁用,在这种情况下,再次使用之前使用的二进制日志加密密钥。 立即轮换二进制日志文件和中继日志文件,并使用此二进制日志加密密钥加密新文件和所有后续二进制日志文件和中继日志文件的文件密码。 服务器上仍存在的现有二进制日志文件和中继日志文件未加密,但如果不再需要,则可以清除它们。
如果通过将
binlog_encryption
系统变量
更改为停用加密,
OFF
则会立即轮换二进制日志文件和中继日志文件,并且所有后续日志记录都是未加密的。
以前加密的文件不会自动解密,但服务器仍然可以读取它们。
BINLOG_ENCRYPTION_ADMIN
在服务器运行时,需要具有激活或取消激活加密
的
权限。
加密和未加密的二进制日志文件可以使用加密日志文件(
0xFD62696E
)
的文件头开头的幻数来区分
,这与用于未加密日志文件(
0xFE62696E
)的
格式不同
。
该
SHOW
BINARY LOGS
语句显示每个二进制日志文件是加密的还是未加密的。
请注意,当MySQL服务器实例的加密处于活动状态时,只会将写入二进制日志文件和中继日志文件的静态数据加密。
复制事件流中的运动数据(发送到MySQL客户端,包括
mysqlbinlog
)始终采用未加密格式,因此必须使用连接加密保护传输中的数据(请参阅
第6.3节“使用加密连接”)
)。
在事务期间保存在二进制日志事务和语句高速缓存中的正在使用的数据,以及超出这些高速缓存中可用空间并因此存储在磁盘上的临时文件中的任何数据也是未加密的格式。
处理事务的线程结束时,将删除临时文件和高速缓存。
服务器状态变量
Binlog_cache_disk_use
并
Binlog_stmt_cache_disk_use
显示是否已将任何数据存储在临时文件中,如果要在事务期间最小化未加密的临时文件的可能性,则可以增加二进制日志高速缓存或二进制日志语句高速缓存的大小。
当二进制日志文件已加密时,
mysqlbinlog
无法直接读取它们,但可以使用该
--read-from-remote-server
选项
从服务器读取它们
。
从MySQL 8.0.14开始,
如果您尝试直接读取加密的二进制日志文件
,
mysqlbinlog会
返回一个合适的错误,但是旧版本的
mysqlbinlog
根本不会将该文件识别为二进制日志文件。
如果使用
mysqlbinlog
备份加密的二进制日志文件
,请注意使用
mysqlbinlog
生成的文件副本
以未加密的格式存储。
用于加密日志文件的文件密码的二进制日志加密密钥是256位密钥,它们是使用MySQL服务器的密钥环服务专门为每个MySQL服务器实例生成的(请参见 第6.4.4节“MySQL密钥环” )。 密钥环服务处理二进制日志加密密钥的创建,检索和删除。 服务器实例仅创建和删除为其自身生成的密钥,但是如果它们存储在密钥环中,它可以读取为其他实例生成的密钥,如通过文件复制克隆的服务器实例的情况。
MySQL服务器实例的二进制日志加密密钥必须包含在备份和恢复过程中,因为如果解密当前和保留的二进制日志文件或中继日志文件的文件密码所需的密钥丢失,则可能无法启动服务器。
密钥环中二进制日志加密密钥的格式如下:
MySQLReplicationKey_ {} UUID _ {} SEQ_NO
例如:
MySQLReplicationKey_00508583-b5ce-11E8-a6a5-0010e0734796_1
{UUID}
是MySQL服务器生成的真实UUID(
server_uuid
系统变量
的值
)。
{SEQ_NO}
是二进制日志加密密钥的序列号,对于在服务器上生成的每个新密钥,该序列号递增1。
当前在服务器上使用的二进制日志加密密钥称为二进制日志主密钥。 当前二进制日志主密钥的序列号存储在密钥环中。 二进制日志主密钥用于加密每个新日志文件的文件密码,该密码是一个随机生成的32字节文件密码,专用于日志文件,用于加密文件数据。 使用AES-CBC(AES密码块链接模式)使用256位二进制日志加密密钥和随机初始化向量(IV)对文件密码进行加密,并将其存储在日志文件的文件头中。 使用AES-CTR(AES计数器模式)对文件数据进行加密,其中从文件密码生成256位密钥,并且还从文件密码生成随机数。 通过使用OpenSSL加密工具包中提供的工具,如果已知用于加密文件密码的二进制日志加密密钥,则在技术上可以离线解密加密文件。
如果使用文件复制来克隆具有加密活动的MySQL服务器实例,以便对其二进制日志文件和中继日志文件进行加密,请确保还复制了密钥环,以便克隆服务器可以从源读取二进制日志加密密钥服务器。 在克隆服务器上激活加密(在启动时或随后)时,克隆服务器会识别出与复制的文件一起使用的二进制日志加密密钥包括源服务器的生成的UUID。 它使用自己生成的UUID自动生成新的二进制日志加密密钥,并使用它来加密后续二进制日志文件和中继日志文件的文件密码。 使用源服务器继续读取复制的文件
启用二进制日志加密后,您可以在服务器运行时随时通过发出来轮换二进制日志主密钥
ALTER
INSTANCE ROTATE BINLOG MASTER
KEY
。
使用此语句手动旋转二进制日志主密钥时,使用新的二进制日志主密钥加密新文件和后续文件的密码,并重新加密现有加密二进制日志文件和中继日志文件的文件密码使用新的二进制日志主密钥,因此加密完全更新。
您可以定期轮换二进制日志主密钥以符合组织的安全策略,并且如果您怀疑当前或任何以前的二进制日志主密钥可能已被泄露。
手动旋转二进制日志主密钥时,MySQL Server按顺序执行以下操作:
-
生成新的二进制日志加密密钥,其中包含下一个可用的序列号,存储在密钥环上,并用作新的二进制日志主密钥。
-
二进制日志和中继日志文件在所有通道上旋转。
-
新的二进制日志主密钥用于加密新二进制日志和中继日志文件以及后续文件的文件密码,直到再次更改密钥。
-
服务器上现有加密二进制日志文件和中继日志文件的文件密码将使用新的二进制日志主密钥从最新文件开始依次重新加密。 将跳过任何未加密的文件。
-
从密钥环中删除重新加密过程后不再用于任何文件的二进制日志加密密钥。
该
BINLOG_ENCRYPTION_ADMIN
权限才能发出
ALTER
INSTANCE ROTATE BINLOG MASTER KEY
,如果不能用的说法
binlog_encryption
系统变量设置为
OFF
。
作为二进制日志主密钥轮换过程的最后一步,所有不再应用于任何保留的二进制日志文件或中继日志文件的二进制日志加密密钥都将从密钥环中清除。
如果无法初始化保留的二进制日志文件或中继日志文件以进行重新加密,则不会删除相关的二进制日志加密密钥,以防将来恢复文件。
例如,如果二进制日志索引文件中列出的文件当前不可读,或者通道初始化失败,则可能出现这种情况。
如果服务器UUID发生更改,例如因为使用MySQL Enterprise Backup创建的备份用于设置新的复制从站,则发出
ALTER
INSTANCE ROTATE BINLOG MASTER
KEY
在新服务器上不会删除任何包含原始服务器UUID的早期二进制日志加密密钥。
如果无法正确完成二进制日志主密钥轮换过程的前四个步骤中的任何一个,则会发出一条错误消息,说明二进制日志文件和中继日志文件的加密状态的情况和后果。
以前加密的文件始终保持加密状态,但仍可使用旧的二进制日志主密钥对其文件密码进行加密。
如果您看到这些错误,请首先通过
ALTER
INSTANCE ROTATE BINLOG MASTER
KEY
再次
发出来重试该过程
。
然后调查单个文件的状态以查看阻止该进程的内容,尤其是在您怀疑当前或任何以前的二进制日志主密钥可能已被泄露的情况下。
如果无法正确完成二进制日志主密钥轮换过程的最后一步,则会发出一条警告消息,说明该情况。
警告消息标识进程是否无法清除密钥环中用于旋转二进制日志主密钥的辅助密钥,或者无法清除未使用的二进制日志加密密钥。
您可以选择忽略该消息,因为密钥是辅助密钥或不再使用,或者您可以
ALTER
INSTANCE ROTATE BINLOG
MASTER KEY
再次
发出
以重试该过程。
如果服务器停止并重新启动,二进制日志加密仍在
ON
二进制日志主密钥轮换过程中
设置为
,则重新启动后的新二进制日志文件和中继日志文件将使用新的二进制日志主密钥加密。
但是,现有文件的重新加密不会继续,因此在服务器停止之前未重新加密的文件将使用以前的二进制日志主密钥进行加密。
要完成重新加密并清除未使用的二进制日志加密密钥,请
ALTER
INSTANCE
ROTATE BINLOG MASTER KEY
在重新启动后再次
发出
。
ALTER
INSTANCE ROTATE BINLOG MASTER
KEY
操作不会写入二进制日志,也不会在复制从服务器上执行。
因此,二进制日志主密钥轮换可以在包括混合MySQL版本的复制环境中执行。
要在所有适用的主服务器和从属服务器上安排定期轮换二进制日志主密钥,您可以在每台服务器上启用MySQL事件调度程序并
ALTER
INSTANCE ROTATE BINLOG MASTER
KEY
使用
CREATE
EVENT
声明。
如果由于怀疑当前或任何以前的二进制日志主密钥可能已被泄露而旋转二进制日志主密钥,请在每个适用的主从服务器上发出该语句。
在单个服务器上发出语句可确保您可以验证即时合规性,即使是从属于多个复制拓扑的从属服务器,或者在复制拓扑中当前不活动但具有二进制日志和中继日志文件的情况。
在
binlog_rotate_encryption_master_key_at_startup
重新启动服务器时系统变量控制二进制日志主密钥是否是自动旋转。
如果将此系统变量设置为
ON
,则会生成新的二进制日志加密密钥,并在重新启动服务器时将其用作新的二进制日志主密钥。
如果设置为
OFF
,这是默认设置,重新启动后会再次使用现有的二进制日志主密钥。
在启动时轮换二进制日志主密钥时,将使用新密钥对新二进制日志和中继日志文件的文件密码进行加密。
现有加密二进制日志文件和中继日志文件的文件密码未重新加密,因此它们使用旧密钥保持加密,旧密钥仍可在密钥环上使用。
除了内置的异步复制,MySQL 8.0还支持通过插件实现的半同步复制接口。 本节讨论半同步复制是什么以及它是如何工作的。 以下各节介绍了半同步复制的管理界面以及如何安装,配置和监视它。
默认情况下,MySQL复制是异步的。 主设备将事件写入其二进制日志,但不知道从设备是否或何时检索并处理它们。 使用异步复制,如果主服务器崩溃,则它已提交的事务可能尚未传输到任何从服务器。 因此,在这种情况下从主服务器到从服务器的故障转移可能导致故障转移到相对于主服务器丢失事务的服务器。
半同步复制可用作异步复制的替代方法:
-
从站指示当它连接到主站时是否具有半同步能力。
-
如果在主端启用了半同步复制,并且至少有一个半同步从设备,则在主块上执行事务提交的线程等待,直到至少一个半同步从设备确认已收到事务的所有事件,或者直到发生超时。
-
只有在将事件写入其中继日志并刷新到磁盘后,从站才会确认收到事务的事件。
-
如果在没有任何从服务器确认事务的情况下发生超时,则主服务器将恢复为异步复制。 当至少有一个半同步从站赶上时,主站返回半同步复制。
-
必须在主端和从端都启用半同步复制。 如果在主服务器上禁用了半同步复制,或者在主服务器上启用了半同步复制但在没有从服务器上启用了半同步复制,则主服
当主服务器阻塞(等待来自从服务器的确认)时,它不会返回执行事务的会话。 当块结束时,主节点返回到会话,然后可以继续执行其他语句。 此时,事务已在主方面提交,并且至少一个从方已确认其事件的接收。
在继续之前,主服务器必须接收的从服务器确认的数量可以使用
rpl_semi_sync_master_wait_for_slave_count
系统变量
。
默认值为1。
在写入二进制日志的回滚之后也会发生阻塞,这会在回滚修改非事务性表的事务时发生。 即使对事务表没有影响,也会记录回滚事务,因为对非事务表的修改无法回滚并且必须发送到从站。
对于在事务上下文中不发生的语句(即,没有使用
START
TRANSACTION
或
启动任何事务时)
SET
autocommit =
0
),将启用自动提交,并且每个语句都会隐式提交。
使用半同步复制,每个此类语句的主模块就像对显式事务提交一样。
要了解 “ 半 同步复制 ” 中的 “ 半 ” 是什么意思,请将其与异步和完全同步复制进行比较:
-
通过异步复制,主服务器将事件写入其二进制日志,而从服务器在准备就绪时请求它们。 无法保证任何事件都能到达任何奴隶。
-
使用完全同步复制时,当主服务器提交事务时,所有从服务器也将在主服务器返回执行事务的会话之前提交事务。 这样做的缺点是完成交易可能会有很多延迟。
-
半同步复制介于异步和完全同步复制之间。 主设备仅等待至少一个从设备接收并记录事件。 它不会等待所有从站确认收到,并且它只需要接收,而不是事件已在从属端完全执行和提交。
与异步复制相比,半同步复制提供了改进的数据完整性,因为当提交成功返回时,已知数据至少存在于两个位置。
直到半同步主站从配置的从站数量收到确认
rpl_semi_sync_master_wait_for_slave_count
,该事务处于保持状态且未提交。
半同步复制还通过限制二进制日志事件从主服务器发送到从服务器的速度来对繁忙会话设置速率限制。 当一个用户太忙时,这会降低它的速度,这在某些部署情况下很有用。
半同步复制确实会对性能产生一些影响,因为由于需要等待从站,提交速度会变慢。 这是提高数据完整性的权衡。 减速量至少是将提交发送到从站并等待从站确认收到的TCP / IP往返时间。 这意味着半同步复制最适合通过快速网络进行通信的密切服务器,而对于通过慢速网络进行通信的远程服务器则最差。
所述
rpl_semi_sync_master_wait_point
系统变量控制在该状态返回到执行的事务客户端之前一个半同步复制主等待交易收据的从属确认的点。
允许这些值:
-
AFTER_SYNC(默认值):主服务器将每个事务写入其二进制日志和从服务器,并将二进制日志同步到磁盘。 主机在同步后等待从机确认事务接收。 收到确认后,主服务器将事务提交给存储引擎并将结果返回给客户端,然后客户端可以继续。 -
AFTER_COMMIT:主服务器将每个事务写入其二进制日志和从服务器,同步二进制日志,并将事务提交到存储引擎。 提交后,主设备等待事务接收的从设备确认。 收到确认后,主服务器将结果返回给客户端,然后客户端可以继续。
这些设置的复制特征如下:
-
使用时
AFTER_SYNC,所有客户端同时看到已提交的事务:从服务器确认并提交到主服务器上的存储引擎之后。 因此,所有客户端都在主服务器上看到相同的数据。如果主站发生故障,则在主站上提交的所有事务都已复制到从站(保存到其中继日志)。 主服务器和故障转移到从服务器的崩溃是无损的,因为从服务器是最新的。
-
使用
AFTER_COMMIT,发出事务的客户端仅在服务器提交到存储引擎并接收从属确认后才获得返回状态。 在提交之后和从属确认之前,其他客户端可以在提交客户端之前查看已提交的事务。如果出现问题导致从设备不处理事务,那么在主设备崩溃和故障转移到从设备的情况下,这些客户端可能会看到相对于他们在主设备上看到的数据丢失。
半同步复制的管理界面有几个组件:
-
两个插件实现半同步功能。 主侧有一个插件,奴隶侧有一个插件。
-
系统变量控制插件行为。 一些例子:
-
控制是否在主服务器上启用半同步复制。 要启用或禁用插件,请将此变量分别设置为1或0。 默认值为0(关闭)。
-
一个以毫秒为单位的值,用于控制主机在超时并恢复到异步复制之前等待提交来自从机的确认的时间。 默认值为10000(10秒)。
-
类似于
rpl_semi_sync_master_enabled,但控制从属插件。
所有 系统变量在 第5.1.8节“服务器系统变量”中描述 。
rpl_semi_sync_xxx -
-
状态变量启用半同步复制监视。 一些例子:
-
半同步从属的数量。
-
半同步复制当前是否在主服务器上运行。 如果已启用插件且未发生提交确认,则该值为1。 如果未启用插件,或者由于提交确认超时,主服务器已回退到异步复制,则为0。
-
从站未成功确认的提交数。
-
从站成功确认的提交数。
-
半同步复制当前是否在从站上运行。 如果插件已启用且从属I / O线程正在运行,则此值为1,否则为0。
所有 状态变量在 第5.1.10节“服务器状态变量”中描述 。
Rpl_semi_sync_xxx -
仅当安装了相应的主插件或从插件时,系统和状态变量才可用
INSTALL
PLUGIN
。
半同步复制是使用插件实现的,因此必须将插件安装到服务器中才能使它们可用。 安装插件后,您可以通过与之关联的系统变量来控制它。 在安装关联的插件之前,这些系统变量不可用。
本节介绍如何安装半同步复制插件。 有关安装插件的一般信息,请参见 第5.6.1节“安装和卸载插件” 。
要使用半同步复制,必须满足以下要求:
-
安装插件的能力需要支持动态加载的MySQL服务器。 要验证这一点,请检查
have_dynamic_loading系统变量 的值 是否为YES。 二进制分发应支持动态加载。 -
复制必须已经有效,请参见 第17.1节“配置复制” 。
-
一定不能配置多个复制通道。 半同步复制仅与默认复制通道兼容。 请参见 第17.2.3节“复制通道” 。
要设置半同步复制,请使用以下指示信息。
在
INSTALL
PLUGIN
,
SET
GLOBAL
,
STOP
SLAVE
,和
START
SLAVE
这里所说的语句需要
REPLICATION_SLAVE_ADMIN
或
SUPER
特权。
MySQL发行版包括主端和从端的半同步复制插件文件。
要使主服务器或从服务器可以使用,相应的插件库文件必须位于MySQL插件目录(
plugin_dir
系统变量
指定的目录
)中。
如有必要,通过设置
plugin_dir
服务器启动时
的值来配置插件目录位置
。
插件库文件基名是
semisync_master
和
semisync_slave
。
文件名后缀因平台
.so
而异
(例如,
对于Unix和类Unix系统,
.dll
对于Windows)。
主插件库文件必须存在于主服务器的插件目录中。 从属插件库文件必须存在于每个从属服务器的插件目录中。
要加载插件,请使用
INSTALL
PLUGIN
主服务器和每个要半同步的从服务器上
的
语句(
.so
根据需要
调整
平台
的
后缀)。
在主人:
INSTALL PLUGIN rpl_semi_sync_master SONAME'semisync_master.so';
在每个奴隶:
INSTALL PLUGIN rpl_semi_sync_slave SONAME'semisync_slave.so';
如果尝试安装插件导致Linux上出现类似于此处所示的错误,则必须安装
libimf
:
MySQL的> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
ERROR 1126(HY000):无法打开共享库
'/usr/local/mysql/lib/plugin/semisync_master.so'
(错误:22 libimf.so:无法打开共享对象文件:
没有相应的文件和目录)
您可以
libimf
从
https://dev.mysql.com/downloads/os-linux.html
获取
。
要查看已安装的插件,请使用该
SHOW
PLUGINS
语句或查询该
INFORMATION_SCHEMA.PLUGINS
表。
要验证插件安装,请检查
INFORMATION_SCHEMA.PLUGINS
表或使用该
SHOW
PLUGINS
语句(请参见
第5.6.2节“获取服务器插件信息”
)。
例如:
MySQL的>SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE '%semi%';+ ---------------------- + -------- + | PLUGIN_NAME | PLUGIN_STATUS | + ---------------------- + -------- + | rpl_semi_sync_master | ACTIVE | + ---------------------- + -------- +
如果插件无法初始化,请检查服务器错误日志以获取诊断消息。
安装半同步复制插件后,默认情况下会禁用它。 必须在主端和从端都启用插件才能启用半同步复制。 如果仅启用一侧,则复制将是异步的。
要控制是否已启用已安装的插件,请设置相应的系统变量。
您可以在运行时使用
SET
GLOBAL
或在命令行或选项文件中的服务器启动
时设置这些变量
。
在运行时,这些主端系统变量可用:
SET GLOBAL rpl_semi_sync_master_enabled = {0 | 1};
SET GLOBAL rpl_semi_sync_master_timeout = N;
在从属方面,此系统变量可用:
SET GLOBAL rpl_semi_sync_slave_enabled = {0 | 1};
对于
rpl_semi_sync_master_enabled
或
rpl_semi_sync_slave_enabled
,该值应为1以启用半同步复制,或者为0以禁用它。
默认情况下,这些变量设置为0。
对于
rpl_semi_sync_master_timeout
,值
N
以毫秒为单位。
默认值为10000(10秒)。
如果在运行时在从站上启用半同步复制,则还必须启动从站I / O线程(如果它已在运行,则首先将其停止)以使从站连接到主站并注册为半同步从站:
STOP SLAVE IO_THREAD; 开始使用IO_THREAD;
如果I / O线程已在运行且您没有重新启动它,则从站继续使用异步复制。
在服务器启动时,可以将控制半同步复制的变量设置为命令行选项或选项文件。
选项文件中列出的设置将在每次服务器启动时生效。
例如,您可以
my.cnf
按如下方式在主站和从站侧的文件中
设置变量
。
在主人:
的[mysqld] rpl_semi_sync_master_enabled = 1 rpl_semi_sync_master_timeout = 1000#1秒
在每个奴隶:
的[mysqld] rpl_semi_sync_slave_enabled = 1
半同步复制功能的插件公开了几个系统和状态变量,您可以检查这些变量以确定其配置和操作状态。
系统变量反映了如何配置半同步复制。
要检查其值,请使用
SHOW
VARIABLES
:
MySQL的> SHOW VARIABLES LIKE 'rpl_semi_sync%';
状态变量使您可以监视半同步复制的操作。
要检查其值,请使用
SHOW
STATUS
:
MySQL的> SHOW STATUS LIKE 'Rpl_semi_sync%';
当主服务器由于提交阻塞超时或从属服务器追赶而在异步或半同步复制之间切换时,它会相应地设置
Rpl_semi_sync_master_status
状态变量
的值
。
在主服务器上从半同步到异步复制的自动回退意味着
rpl_semi_sync_master_enabled
即使半同步复制此时实际上不可操作,系统变量
也可能
在主服务器端具有值1。
您可以监视
Rpl_semi_sync_master_status
状态变量以确定主服务器当前是使用异步还是半同步复制。
要查看连接了多少个半同步从站,请检查
Rpl_semi_sync_master_clients
。
成功通过从站确认或未成功确认的提交数由
Rpl_semi_sync_master_yes_tx
和
Rpl_semi_sync_master_no_tx
变量
表示
。
在从属端,
Rpl_semi_sync_slave_status
指示半同步复制当前是否可操作。
MySQL支持延迟复制,以便从属服务器至少在指定的时间内故意执行比主服务器更晚的事务。 本节介绍如何在从站上配置复制延迟,以及如何监控复制延迟。
在MySQL 8.0中,延迟复制的方法取决于两个时间戳,
immediate_commit_timestamp
并且
original_commit_timestamp
(请参阅
复制延迟时间戳
)。
如果复制拓扑中的所有服务器都运行MySQL 8.0.1或更高版本,则使用这些时间戳测量延迟复制。
如果直接主服务器或从服务器未使用这些时间戳,则使用从MySQL 5.7执行延迟复制(请参阅
延迟复制
)。
本节介绍使用这些时间戳的服务器之间的延迟复制。
默认复制延迟为0秒。
使用该
CHANGE MASTER TO MASTER_DELAY=N
语句将延迟设置为
N
秒。
从主服务器接收的事务直到至少
N
比直接主服务器上的提交晚几秒才
执行
。
每个事务发生延迟(不是以前MySQL版本中的事件),实际延迟仅在
gtid_log_event
或
上施加
anonymous_gtid_log_event
。
事务中的其他事件始终遵循这些事件,而不会对它们施加任何等待时间。
START
SLAVE
并
STOP
SLAVE
立即生效,忽略任何延迟。
RESET
SLAVE
将延迟重置为0。
在
replication_applier_configuration
性能模式表包含
DESIRED_DELAY
表示采用配置的延迟列
MASTER_DELAY
选项。
的
replication_applier_status
性能模式表包含
REMAINING_DELAY
表示剩余的延迟秒数柱。
延迟复制可用于多种目的:
-
防止用户在主服务器上出错。 延迟时,您可以将延迟的从站回滚到错误之前的时间。
-
测试滞后时系统的行为方式。 例如,在应用程序中,延迟可能是由从属设备上的重负载引起的。 但是,生成此负载级别可能很困难。 延迟复制可以模拟滞后而无需模拟负载。 它还可用于调试与滞后从站相关的条件。
-
要检查数据库过去的样子,而不必重新加载备份。 例如,通过配置延迟为一周的从站,如果您需要在最近几天的开发之前查看数据库的外观,可以检查延迟的从站。
MySQL 8.0提供了一种新方法,用于测量复制拓扑中的延迟(也称为复制滞后),该方法取决于与写入二进制日志的每个事务(而不是每个事件)的GTID相关联的以下时间戳。
-
original_commit_timestamp:从事务写入(提交)到原始主服务器的二进制日志的纪元以来的微秒数。 -
immediate_commit_timestamp:自事务写入(提交)到直接主服务器的二进制日志以来的epoch以来的微秒数。
mysqlbinlog
的输出
以两种格式显示这些时间戳
TIMESTAMP
,即
epoch的
格式
和
格式,这是基于用户定义的时区以获得更好的可读性。
例如:
#170404 10:48:05服务器ID 1 end_log_pos 233 CRC32 0x016ce647 GTID last_committed = 0 \ sequence_number = 1 original_committed_timestamp = 1491299285661130 immediate_commit_timestamp = 1491299285843771 #original_commit_timestamp = 1491299285661130(2017-04-04 10:48:05.661130 WEST) #immediate_commit_timestamp = 1491299285843771(2017-04-04 10:48:05.843771 WEST) / *!80001 SET @@ SESSION.original_commit_timestamp = 1491299285661130 * // *!* /; SET @@ SESSION.GTID_NEXT ='aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa:1'/ *!* /; #233
通常,在
original_commit_timestamp
应用事务的所有副本上始终相同。
在主从复制中,
original_commit_timestamp
(原始)主服务器二进制日志中的事务始终与其相同
immediate_commit_timestamp
。
在从属的中继日志中,
original_commit_timestamp
并
immediate_commit_timestamp
在交易中的相同的主服务器的二进制日志;
而在其自己的二进制日志中,事务
immediate_commit_timestamp
对应于从属提交事务的时间。
在组复制设置中,当原始主服务器是组的成员时,将
original_commit_timestamp
在事务准备好提交时生成。
换句话说,当它在原始主服务器上完成执行并且其写入集准备好发送给该组的所有成员以进行认证时。
因此,将相同的
original_commit_timestamp
内容复制到所有服务器(无论是成员的组成员还是从成员复制)应用事务,并且每个服务器在其二进制日志中存储使用的本地提交时间
immediate_commit_timestamp
。
查看更改事件(特殊于组复制)是一种特殊情况。
包含这些事件的事务由每个服务器生成,但共享相同的GTID(因此,它们不首先在主服务器中执行,然后复制到该组,但该组的所有成员都执行并应用相同的事务)。
由于没有原始主数据,因此这些事务的
original_commit_timestamp
设置为零。
在以前的MySQL版本中监视复制延迟(滞后)的最常见方法之一是依赖于
Seconds_Behind_Master
输出中
的
字段
SHOW SLAVE STATUS
。
但是,当使用比传统主从设置更复杂的复制拓扑(例如组复制)时,此度量标准不适用。
加入的
immediate_commit_timestamp
和
original_commit_timestamp
MySQL的8提供的有关复制延迟信息更精细的程度。
监视支持这些时间戳的拓扑中的复制延迟的推荐方法是使用以下性能架构表。
-
replication_connection_status:与主服务器的连接的当前状态,提供有关连接线程排队到中继日志中的最后和当前事务的信息。 -
replication_applier_status_by_coordinator:协调器线程的当前状态,仅在使用多线程从属设备时显示信息,提供有关协调器线程缓冲到工作队列的最后一个事务的信息,以及当前正在缓冲的事务。 -
replication_applier_status_by_worker:应用从主服务器接收的事务的线程的当前状态,提供有关应用程序线程或每个工作程序在使用多线程从属服务器时应用的事务的信息。
使用这些表,您可以监视有关相应线程处理的最后一个事务以及该线程当前正在处理的事务的信息。 这些信息包括:
-
交易的GTID
-
一个事务,
original_commit_timestamp并immediate_commit_timestamp从从属的中继日志中检索 -
线程开始处理事务的时间
-
对于上次处理的事务,线程完成处理它的时间
除了Performance Schema表之外,
SHOW SLAVE STATUS
还有三个字段
的输出
显示:
-
SQL_Delay:非负整数,表示使用配置的复制延迟CHANGE MASTER TO MASTER_DELAY=N,以秒为单位。 -
SQL_Remaining_Delay:当Slave_SQL_Running_State是Waiting until MASTER_DELAY seconds after master executed event,则此字段包含一个整数指示左延迟的秒数。 在其他时候,这个领域是NULL。 -
Slave_SQL_Running_State:一个字符串,指示SQL线程的状态(类似于Slave_IO_State)。 该值与State显示的SQL线程 的值相同SHOW PROCESSLIST。
当从属SQL线程在执行事件之前等待延迟时间时,将
SHOW
PROCESSLIST
其
State
值
显示
为
Waiting until MASTER_DELAY seconds after
master executed event
。
- 17.4.1.1复制和AUTO_INCREMENT
- 17.4.1.2复制和BLACKHOLE表
- 17.4.1.3复制和字符集
- 17.4.1.4复制和CHECKSUM表
- 17.4.1.5 CREATE SERVER,ALTER SERVER和DROP SERVER的复制
- 17.4.1.6复制CREATE ...如果不是EXISTS声明
- 17.4.1.7复制CREATE TABLE ... SELECT语句
- 17.4.1.8 CURRENT_USER()的复制
- 17.4.1.9在主站和从站上使用不同的表定义进行复制
- 17.4.1.10复制和目录表选项
- 17.4.1.11 DROP的复制......如果EXISTS声明
- 17.4.1.12复制和浮点值
- 17.4.1.13复制和FLUSH
- 17.4.1.14复制和系统功能
- 17.4.1.15复制和小数秒支持
- 17.4.1.16调用特征的复制
- 17.4.1.17 JSON文档的复制
- 17.4.1.18复制和限制
- 17.4.1.19复制和加载数据
- 17.4.1.20复制和max_allowed_packet
- 17.4.1.21复制和MEMORY表
- 17.4.1.22 mysql系统模式的复制
- 17.4.1.23复制和查询优化器
- 17.4.1.24复制和分区
- 17.4.1.25复制和修复表
- 17.4.1.26复制和保留字
- 17.4.1.27复制和主站或从站关闭
- 17.4.1.28复制期间的从站错误
- 17.4.1.29复制和服务器SQL模式
- 17.4.1.30复制和临时表
- 17.4.1.31复制重试和超时
- 17.4.1.32复制和时区
- 17.4.1.33复制和事务不一致
- 17.4.1.34复制和事务
- 17.4.1.35复制和触发器
- 17.4.1.36复制和TRUNCATE表
- 17.4.1.37复制和用户名长度
- 17.4.1.38复制和变量
- 17.4.1.39复制和视图
以下部分提供有关MySQL复制支持什么和不支持什么的信息,以及复制某些语句时可能出现的特定问题和情况。
基于语句的复制取决于主服务器和从服务器之间SQL级别的兼容性。 换句话说,成功的基于语句的复制要求主服务器和从服务器都支持所使用的任何SQL功能。 如果您在主服务器上使用仅在当前版本的MySQL中可用的功能,则无法复制到使用早期版本的MySQL的从服务器。 这种不兼容性也可能发生在版本系列中以及版本之间。
如果您计划在MySQL 8.0和之前的MySQL发行版系列之间使用基于语句的复制,那么最好 参考 与早期版本系列相对应 的 MySQL参考手册 的版本,以获取有关该系列的复制特性的信息。
使用MySQL的基于语句的复制,可能存在复制存储的例程或触发器的问题。 您可以通过使用MySQL的基于行的复制来避免这些问题。 有关问题的详细列表,请参见 第24.7节“存储程序二进制日志记录” 。 有关基于行的日志记录和基于行的复制的更多信息,请参见 第5.4.4.1节“二进制日志格式” 和 第17.2.1节“复制格式” 。
有关复制的其他信息
InnoDB
,请参见
第15.18节“InnoDB和MySQL复制”
。
有关使用NDB Cluster进行复制的信息,请参见
第22.6节“NDB集群复制”
。
基于语句的复制
AUTO_INCREMENT
,
LAST_INSERT_ID()
和
TIMESTAMP
值来执行对符合下列情况除外:
-
AUTO_INCREMENT使用基于语句的复制不会正确复制 调用导致更新 列 的触发器或函数的 语句。 这些陈述被标记为不安全。 (缺陷#45677) -
一个
INSERT成具有包括一个复合主键的表AUTO_INCREMENT列,它是不该组合键的第一列不是基于语句的记录或复制的安全。 这些陈述被标记为不安全。 (Bug#11754117,Bug#45670)此问题不会影响使用
InnoDB存储引擎的InnoDB表 ,因为 具有 AUTO_INCREMENT 列 的 表 至少需要一个键,其中自动增量列是唯一或最左列。 -
向
AUTO_INCREMENT表中 添加 列ALTER TABLE可能不会在从站和主站上生成相同的行顺序。 发生这种情况是因为行的编号顺序取决于用于表的特定存储引擎以及插入行的顺序。 如果在主站和从站上具有相同的顺序很重要,则必须在分配AUTO_INCREMENT号码 之前对行进行排序 。 假设您想将添加AUTO_INCREMENT列一个表t1有列col1和col2,下面的语句产生新表t2相同,t1但有一个AUTO_INCREMENT柱:CREATE TABLE t2 LIKE t1; ALTER TABLE t2 ADD id INT AUTO_INCREMENT PRIMARY KEY; INSERT INTO t2 SELECT * FROM t1 ORDER BY col1,col2;
重要为了保证主服务器和从服务器上的相同顺序,该
ORDER BY子句必须命名 所有 列t1。刚刚给出的指令受以下限制
CREATE TABLE ... LIKE:外键定义被忽略,DATA DIRECTORY而INDEX DIRECTORY表 和 选项也是如此。 如果表定义包含任何这些特性,则t2使用CREATE TABLE与用于 创建 的 语句相同 的 语句创建t1,但添加AUTO_INCREMENT列。无论用于创建和填充具有
AUTO_INCREMENT列 的副本的方法如何 ,最后一步是删除原始表,然后重命名副本:DROP t1; ALTER TABLE t2 RENAME t1;
另请参见 第B.4.6.1节“ALTER TABLE的问题” 。
该
BLACKHOLE
存储引擎接受数据,而是将其丢弃,不存储。
执行二进制日志记录时,无论使用何种日志记录格式,都会记录对此类表的所有插入。
根据是使用基于语句还是基于行的日志记录,更新和删除的处理方式不同。
使用基于语句的日志记录格式,
BLACKHOLE
将记录
影响
表的
所有语句
,但忽略其效果。
使用基于行的日志记录时,只会跳过对这些表的更新和删除 - 它们不会写入二进制日志。
发生这种情况时会记录警告。
因此,我们建议您使用
BLACKHOLE
已将
binlog_format
服务器变量设置为
的
存储引擎
复制到表
STATEMENT
,而不是使用
ROW
或
MIXED
。
以下内容适用于使用不同字符集的MySQL服务器之间的复制:
-
如果主数据库的字符集与全局
character_set_server值 不同 ,则应设计CREATE TABLE语句,以便它们不会隐式依赖数据库缺省字符集。 一个好的解决方法是在CREATE TABLE语句中 明确 说明 字符集和排序规则 。
该声明
CREATE
SERVER
,
ALTER
SERVER
以及
DROP
SERVER
没有写入到二进制日志,无论二进制日志记录格式是在使用中。
MySQL
CREATE ... IF
NOT EXISTS
在复制
各种
语句
时应用这些规则
:
-
CREATE DATABASE IF NOT EXISTS无论数据库是否已存在于主数据库中, 都会 复制 每个 语句。 -
同样, 无论是否已在主服务器上存在该表 ,都会 复制 每个
CREATE TABLE IF NOT EXISTS没有a的语句SELECT。 这包括CREATE TABLE IF NOT EXISTS ... LIKE。 复制CREATE TABLE IF NOT EXISTS ... SELECT遵循一些不同的规则; 有关更多信息 , 请参见 第17.4.1.7节“复制CREATE TABLE ... SELECT语句” 。 -
CREATE EVENT IF NOT EXISTS始终复制,无论语句中指定的事件是否已存在于主服务器上。
MySQL
CREATE
TABLE ... SELECT
在复制语句
时应用这些规则
:
-
CREATE TABLE ... SELECT始终执行隐式提交( 第13.3.3节“导致隐式提交的语句” )。 -
如果目标表不存在,则记录如下。 是否
IF NOT EXISTS存在 无关紧要 。-
STATEMENT或MIXED格式:语句记录为书面形式。 -
ROWformat:该语句记录为CREATE TABLE语句,后跟一系列插入行事件。
-
-
如果
CREATE TABLE ... SELECT语句失败,则不记录任何内容。 这包括目标表存在IF NOT EXISTS且未给出的情况。 -
如果目标表存在并且
IF NOT EXISTS给出,则MySQL 8.0完全忽略该语句; 没有插入或记录任何内容。
当使用基于语句的复制时,MySQL 8.0不允许
CREATE
TABLE ... SELECT
语句在除语句创建的表之外的表中进行任何更改。
使用基于行的复制时,这不是问题,因为该语句记录为一个
CREATE
TABLE
语句,对表数据的任何更改都记录为行插入事件,而不是整个事件
CREATE
TABLE ... SELECT
。
以下语句支持使用该
CURRENT_USER()
函数代替受影响的用户或定义者的名称,可能还有主机:
当启用二进制日志记录和/
CURRENT_USER()
或
CURRENT_USER
在任何这些语句中用作定义器时,MySQL Server确保在复制语句时将语句应用于主服务器和从服务器上的同一用户。
在某些情况下,例如更改密码的语句,函数引用在写入二进制日志之前会进行扩展,因此该语句包含用户名。
对于所有其他情况,主服务器上当前用户的名称将作为元数据复制到从服务器,并且服务器将语句应用于元数据中指定的当前用户,而不是服务于从服务器上的当前用户。
复制的源表和目标表不必相同。 主服务器上的表可以具有比从服务器的表副本更多或更少的列。 此外,主服务器和从服务器上的相应表列可以根据特定条件使用不同的数据类型。
不支持彼此区分的表之间的复制。 请参见 第17.4.1.24节“复制和分区” 。
在源表和目标表没有相同定义的所有情况下,主服务器和从服务器上的数据库和表名称必须相同。 在以下两节中,将通过示例讨论其他条件。
您可以将表从主服务器复制到从服务器,以使表的主副本副本具有不同数量的列,具体取决于以下条件:
-
两个版本的表共有的列必须在主服务器和从服务器上以相同的顺序定义。
(即使两个表的列数相同,也是如此。)
-
必须在任何其他列之前定义表的两个版本共有的列。
这意味着
ALTER TABLE在从属服务器上 执行 语句,其中在两个表共有的列范围内将新列插入表中会导致复制失败,如以下示例所示:假设
t主服务器和从服务器上存在 的表 由以下CREATE TABLE语句 定义 :CREATE TABLE t( c1 INT, c2 INT, c3 INT );假设
ALTER TABLE这里显示 的 语句是在slave上执行的:ALTER TABLE t ADD COLUMN cnew1 INT after c3;
以前
ALTER TABLE是允许的,因为奴隶的列c1,c2以及c3共有的表的两个版本t保留在表中的两个版本组合在一起,即不同的列前。但是,如果
ALTER TABLE不导致复制中断,则无法在从属服务器上执行 以下 语句:ALTER TABLE t ADD COLUMN cnew2 INT after cTER;
在
ALTER TABLE刚刚显示 的 语句 的从属上执行后,复制失败 ,因为新列cnew2位于两个版本的通用 列 之间t。 -
具有更多列的表版本中的 每个 “ 额外 ” 列必须具有默认值。
列的默认值由许多因素决定,包括其类型,是否使用
DEFAULT选项 定义 ,是否声明为NULL,以及创建时生效的服务器SQL模式; 有关更多信息,请参见 第11.7节“数据类型默认值” )。
此外,当从表的副本具有比主副本更多的列时,表的每个列必须在两个表中使用相同的数据类型。
例子。 以下示例说明了一些有效和无效的表定义:
主人上有更多专栏。 以下表定义有效且正确复制:
主人>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);奴隶>CREATE TABLE t1 (c1 INT, c2 INT);
以下表定义会引发错误,因为表的两个版本共有的列的定义在从属服务器上的顺序与在主服务器上的顺序不同:
主人>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);奴隶>CREATE TABLE t1 (c2 INT, c1 INT);
下表定义也会引发错误,因为master上额外列的定义出现在表的两个版本共有的列的定义之前:
主人>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);奴隶>CREATE TABLE t1 (c1 INT, c2 INT);
奴隶上有更多专栏。 以下表定义有效且正确复制:
主人>CREATE TABLE t1 (c1 INT, c2 INT);奴隶>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
以下定义会引发错误,因为表的两个版本共有的列在主服务器和从服务器上的定义顺序不同:
主人>CREATE TABLE t1 (c1 INT, c2 INT);奴隶>CREATE TABLE t1 (c2 INT, c1 INT, c3 INT);
下表定义也会引发错误,因为从表版本的表中额外列的定义出现在表的两个版本共有的列的定义之前:
主人>CREATE TABLE t1 (c1 INT, c2 INT);奴隶>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);
以下表定义失败,因为从属版本的表与主版本相比具有其他列,并且表的两个版本对公共列使用不同的数据类型
c2
:
主人>CREATE TABLE t1 (c1 INT, c2 BIGINT);奴隶>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
主机上的相应列和同一表的从机副本理想情况下应具有相同的数据类型。 但是,只要满足某些条件,并不总是严格执行。
通常可以从给定数据类型的列复制到相同类型和相同大小或宽度的另一列(如果适用)或更大。
例如,您可以从
CHAR(10)
列
复制
到另一个列
CHAR(10)
,或从
CHAR(10)
列
复制
到
CHAR(25)
列而不会出现任何问题。
在某些情况下,也可以从具有一种数据类型(在主服务器上)的列复制到具有不同数据类型的列(在从服务器上);
当主列版本的数据类型被提升为从属大小相同或更大的类型时,这称为
属性提升
。
属性提升可以与基于语句的复制和基于行的复制一起使用,并且不依赖于主服务器或从服务器使用的存储引擎。 但是,日志格式的选择会对允许的类型转换产生影响; 详情将在本节后面讨论。
无论您是使用基于语句还是基于行的复制,如果您希望使用属性提升,则表的从属副本不能包含比主副本更多的列。
基于语句的复制。
当使用基于语句的复制时,一个简单的经验法则是,
“
如果在主服务器上运行的语句也将在从服务器上成功执行,它也应该成功复制
”
。
换句话说,如果语句使用的值与从属服务器上给定列的类型兼容,则可以复制该语句。
例如,您可以将任何适合
TINYINT
列的
值插入
到
BIGINT
列中;
因此,即使您将
TINYINT
表的从属副本中的列
类型更改
为
BIGINT
,成功的主服务器上的那一列中的任何插入也应该在从服务器上成功,因为不可能有
TINYINT
足够大
的合法
值来超过
BIGINT
列。
基于行的复制:属性提升和降级。 基于行的复制支持较小数据类型和较大类型之间的属性提升和降级。 还可以指定是否允许降级列值的有损(截断)或无损转换,如本节后面所述。
有损和无损转换。 如果目标类型不能表示要插入的值,则必须决定如何处理转换。 如果我们允许转换但截断(或以其他方式修改)源值以 在目标列中 实现 “ 拟合 ” ,则我们进行所谓的 有损转换 。 不需要截断或类似修改以适合目标列中的源列值的 转换 是 无损 转换。
类型转换模式(slave_type_conversions变量)。
slave_type_conversions
全局服务器变量
的设置
控制从站上使用的类型转换模式。
此变量从以下列表中获取一组值,该列表描述了每种模式对从属类型转换行为的影响:
- ALL_LOSSY
-
在此模式下,键入允许丢失信息的转换。
这并不意味着允许进行无损转换,只是仅允许需要有损转换或根本不需要转换的情况; 例如, 仅 启用 此模式允许将
INT列转换为TINYINT(有损转换),而不是TINYINT列转换为INT列(无损)。 在这种情况下尝试后一种转换会导致复制停止,从而出现错误。 - ALL_NON_LOSSY
-
此模式允许不需要截断或对源值进行其他特殊处理的转换; 也就是说,它允许目标类型具有比源类型更宽范围的转换。
设置此模式与是否允许有损转换无关; 这是由
ALL_LOSSY模式 控制的 。 如果仅ALL_NON_LOSSY设置,但没有设置,ALL_LOSSY则尝试转换将导致数据丢失(例如INT转到TINYINT或CHAR(25)转移VARCHAR(20))导致从设备因错误而停止。 - ALL_LOSSY,ALL_NON_LOSSY
-
设置此模式后,允许所有支持的类型转换,无论它们是否为有损转换。
- ALL_SIGNED
-
将提升的整数类型视为有符号值(默认行为)。
- ALL_UNSIGNED
-
将提升的整数类型视为无符号值。
- ALL_SIGNED,ALL_UNSIGNED
-
如果可能,将提升的整数类型视为已签名,否则视为无符号。
- [ 空 ]
-
如果
slave_type_conversions没有设置,没有属性升级或降级是允许的; 这意味着源表和目标表中的所有列必须是相同的类型。此模式是默认模式。
提升整数类型时,不保留其签名。
默认情况下,从站将所有此类值视为已签名。
您可以使用控制这种行为
ALL_SIGNED
,
ALL_UNSIGNED
或者两者兼而有之。
ALL_SIGNED
告诉slave将所有提升的整数类型视为signed;
ALL_UNSIGNED
指示它将这些视为无符号。
如果可能,指定两者会导致从属服务器将值视为已签名,否则将其视为无符号;
它们的列出顺序并不重要。
如果至少有一个
或
没有使用,
也
ALL_SIGNED
没有
ALL_UNSIGNED
任何影响
。
ALL_LOSSY
ALL_NONLOSSY
更改类型转换模式需要使用新
slave_type_conversions
设置
重新启动从站
。
支持的转化。 以下列表显示了不同但相似的数据类型之间支持的转换:
-
之间的任意整数类型的
TINYINT,SMALLINT,MEDIUMINT,INT,和BIGINT。这包括这些类型的已签名和未签名版本之间的转换。
通过将源值截断为目标列允许的最大值(或最小值)来进行有损转换。 为了确保从无符号类型转换为有符号类型时的无损转换,目标列必须足够大,以适应源列中的值范围。 例如,您可以
TINYINT UNSIGNED非损失 降级SMALLINT,但不能 降级TINYINT。 -
之间的任何小数类型
DECIMAL,FLOAT,DOUBLE,和NUMERIC。FLOAT到DOUBLE是一个无损转换;DOUBLE到FLOAT只能有损地处理。 转换 到 where 和 )是无损的; 对于其中任何情况下 , 或两者,仅有损转换可。DECIMAL(M,D)DECIMAL(M',D')D'>=D(M'-D') >= (M-DM'<MD'<D对于任何十进制类型,如果要存储的值不适合目标类型,则根据为文档中其他位置为服务器定义的舍入规则对该值进行向下舍入。 有关如何对十进制类型执行此操作的信息 , 请参见 第12.25.4节“舍入行为” 。
-
之间的任何字符串类型
CHAR,VARCHAR以及TEXT,包括不同的宽度之间的转换。的转换
CHAR,VARCHAR或TEXT以一个CHAR,VARCHAR或TEXT列中的相同大小或更大是从未有损耗的。 通过N在从属设备上 仅插入 字符串 的第一个 字符 来处理有损转换 ,其中N是目标列的宽度。重要不支持使用不同字符集的列之间的复制。
-
之间的任何二进制数据类型
BINARY,VARBINARY以及BLOB,包括不同的宽度之间的转换。的转换
BINARY,VARBINARY或BLOB以一个BINARY,VARBINARY或BLOB列中的相同大小或更大是从未有损耗的。 通过仅在N从属设备上 插入 字符串 的第一个 字节 来处理有损转换 ,其中N是目标列的宽度。 -
在任何2
BIT个尺寸的 任何2 列 之间 。将 列中 的值插入 列时,其中列 的最高有效位 被清除(设置为零),并且 值 的 位 被设置为列的最低有效位 。
BIT(M)BIT(M')M'>MBIT(M')MBIT(M)BIT(M')将源 列中 的值插入 目标 列时 ,将 指定列 的最大可能值 ; 换句话说,将 “ 全部设置 ” 值分配给目标列。
BIT(M)BIT(M')M'<MBIT(M')
不允许在不在上一个列表中的类型之间进行转换。
如果
在主服务器上的语句中
使用了
a
DATA DIRECTORY
或
INDEX
DIRECTORY
table选项
CREATE
TABLE
,则表选项也将用于从服务器。
如果从属主机文件系统中不存在相应的目录,或者它存在但从属服务器无法访问,则会导致问题。
这可以通过
NO_DIR_IN_CREATE
在从属服务器上
使用
服务器SQL模式
来覆盖
,这会导致从服务器
在复制
语句
时
忽略
DATA DIRECTORY
和
INDEX
DIRECTORY
表选项
CREATE
TABLE
。
结果是
MyISAM
在表的数据库目录中创建了数据和索引文件。
有关更多信息,请参见 第5.1.11节“服务器SQL模式” 。
的
DROP
DATABASE
IF EXISTS
,
DROP
TABLE IF
EXISTS
和
DROP
VIEW IF
EXISTS
语句总是被复制,即使数据库,表或视图被丢弃在主不存在。
这是为了确保一旦从属设备赶上主设备,主设备或从设备上不再存在要丢弃的对象。
DROP ... IF EXISTS
即使主服务器上不存在要删除的存储程序,也会复制存储程序(存储过程和函数,触发器和事件)的语句。
使用基于语句的复制,值将从十进制转换为二进制。 因为它们的十进制和二进制表示之间的转换可能是近似的,所以涉及浮点值的比较是不精确的。 对于显式使用浮点值的操作或使用隐式转换为浮点的值的操作都是如此。 由于计算机体系结构,用于构建MySQL的编译器等的差异,浮点值的比较可能在主服务器和从服务器上产生不同的结果。 请参见 第12.2节“表达式评估中的类型转换” 和 第B.4.4.8节“浮点值的问题” 。
某些形式的
FLUSH
语句不会被记录,因为如果复制到从站可能会导致问题:
FLUSH LOGS
和
FLUSH TABLES
WITH READ LOCK
。
有关语法示例,请参见
第13.7.7.3节“FLUSH语法”
。
在
FLUSH TABLES
,
ANALYZE
TABLE
,
OPTIMIZE
TABLE
,和
REPAIR
TABLE
语句被写入二进制日志,因此复制到奴隶。
这通常不是问题,因为这些语句不会修改表数据。
但是,这种行为在某些情况下会造成困难。
如果复制
mysql
数据库中
的权限表
并直接更新这些表而不使用
GRANT
,则必须
FLUSH PRIVILEGES
在从属服务器上
发出一个
权限以使新权限生效。
此外,如果
FLUSH TABLES
在重命名作为
MyISAM
表的一部分的
MERGE
表时使用,则必须
FLUSH TABLES
在从站
上
手动
发出
。
除非您指定
NO_WRITE_TO_BINLOG
或使用别名,
否则这些语句将写入二进制日志
LOCAL
。
某些功能在某些情况下不能很好地复制:
-
的
USER(),CURRENT_USER()(或CURRENT_USER)UUID(),VERSION()和LOAD_FILE()功能被复制没有改变,因此并除非基于行的复制功能无法可靠地在从服务器上运行。 (请参见 第17.2.1节“复制格式” 。)USER()并CURRENT_USER()在使用MIXED模式 时使用基于行的复制自动复制 ,并在STATEMENT模式下 生成警告 。 (另请参见 第17.4.1.8节“复制CURRENT_USER()” 。)对于VERSION()和, 也是如此RAND()。 -
对于
NOW(),二进制日志包括时间戳。 这意味着 在主服务器上调用此函数返回 的值 将复制到从服务器。 为避免在不同时区的MySQL服务器之间复制时出现意外结果,请在主服务器和从服务器上设置时区。 另请参见 第17.4.1.32节“复制和时区”要解释在不同时区的服务器之间复制时可能出现的问题,假设主服务器位于纽约,服务器位于斯德哥尔摩,并且两个服务器都使用本地时间。 进一步假设,在master上,你创建一个表
mytable,INSERT在这个表上 执行一个 语句,然后从表中选择,如下所示:MySQL的>
CREATE TABLE mytable (mycol TEXT);查询正常,0行受影响(0.06秒) MySQL的>INSERT INTO mytable VALUES ( NOW() );查询正常,1行受影响(0.00秒) MySQL的>SELECT * FROM mytable;+ --------------------- + | mycol | + --------------------- + | 2009-09-01 12:00:00 | + --------------------- + 1排(0.00秒)斯德哥尔摩当地时间比纽约晚6个小时; 因此,如果您
SELECT NOW()在同一时刻在奴隶上 发出 ,2009-09-01 18:00:00则返回 该值 。 出于这个原因,如果你从奴隶的副本上选择mytable后CREATE TABLE和INSERT刚刚展示的语句已经被复制,您可能希望mycol为包含值2009-09-01 18:00:00。 然而,这种情况并非如此; 当您从奴隶的副本中选择时mytable,您获得的结果与主人的结果完全相同:MySQL的>
SELECT * FROM mytable;+ --------------------- + | mycol | + --------------------- + | 2009-09-01 12:00:00 | + --------------------- + 1排(0.00秒)与此不同
NOW(),该SYSDATE()函数不是复制安全的,因为它不受SET TIMESTAMP二进制日志中 的 语句的 影响, 并且如果使用基于语句的日志记录则不确定。 如果使用基于行的日志记录,这不是问题。另一种方法是使用该
--sysdate-is-now选项使其SYSDATE()成为别名NOW()。 必须在主站和从站上完成此操作才能正常工作。 在这种情况下,此功能仍会发出警告,但只要--sysdate-is-now在主站和从站上都使用,就 可以安全地忽略 。SYSDATE()在使用MIXED模式 时使用基于行的复制自动复制 ,并在STATEMENT模式下 生成警告 。另请参见 第17.4.1.32节“复制和时区” 。
-
以下限制仅适用于基于语句的复制,而不适用于基于行的复制。 的
GET_LOCK(),RELEASE_LOCK(),IS_FREE_LOCK(),和IS_USED_LOCK()其处理用户级锁功能被复制而不会从知道在主并发上下文。 因此,不应使用这些函数插入主表,因为从站上的内容会有所不同。 例如,不要发出诸如的语句INSERT INTO mytable VALUES(GET_LOCK(...))。使用
MIXED模式 时,使用基于行的复制自动复制这些函数 ,并在STATEMENT模式下 生成警告 。
作为基于语句的复制生效时上述限制的解决方法,您可以使用将有问题的函数结果保存在用户变量中并在稍后的语句中引用该变量的策略。
例如,
INSERT
由于引用了
UUID()
函数
,以下单行
存在问题
:
插入值(UUID());
要解决此问题,请执行以下操作:
SET @my_uuid = UUID(); 插入值(@my_uuid);
该语句序列复制,因为它的值
@my_uuid
在
INSERT
语句
之前作为用户变量事件存储在二进制日志中,
并且可以
在
语句中使用
INSERT
。
同样的想法适用于多行插入,但使用起来更麻烦。 对于两行插入,您可以这样做:
SET @ my_uuid1 = UUID(); @ my_uuid2 = UUID(); INSERT IN TO VALUES(@ my_uuid1),(@ my_uuid2);
但是,如果行数很大或未知,则解决方法很难或不切实际。 例如,您无法将以下语句转换为给定的单个用户变量与每行相关联的语句:
INSERT INTO t2 SELECT UUID(),* FROM t1;
在存储函数中,
RAND()
只要在函数执行期间仅调用一次,就可以正确复制。
(您可以将函数执行时间戳和随机数种子视为主服务器和从服务器上相同的隐式输入。)
该
FOUND_ROWS()
和
ROW_COUNT()
功能使用基于语句的复制不可复制的可靠。
解决方法是将函数调用的结果存储在用户变量中,然后在
INSERT
语句中
使用它
。
例如,如果您希望将结果存储在名为的表中
mytable
,通常可以这样执行:
从mytable LIMIT 1中选择SQL_CALC_FOUND_ROWS; 插入mytable VALUES(FOUND_ROWS());
但是,如果要进行复制
mytable
,则应使用
SELECT
... INTO
,然后将变量存储在表中,如下所示:
SELECT SQL_CALC_FOUND_ROWS INTO @found_rows FROM mytable LIMIT 1; 插入mytable VALUES(@found_rows);
通过这种方式,用户变量被复制为上下文的一部分,并正确地应用于从属。
使用
MIXED
模式
时,使用基于行的复制自动复制这些函数
,并在
STATEMENT
模式下
生成警告
。
(Bug#12092,Bug#30244)
复制调用的功能(如用户定义的函数(UDF)和存储的程序(存储过程和函数,触发器和事件))提供以下特征:
-
始终复制该功能的效果。
-
使用基于语句的复制复制以下语句:
但是, 使用基于行的复制可以复制使用这些语句创建,修改或删除的功能 的 效果 。
注意尝试使用基于语句的复制复制调用的功能会产生警告 语句登录语句格式不安全 。 例如,尝试使用基于语句的复制复制UDF会生成此警告,因为MySQL服务器当前无法确定UDF是否具有确定性。 如果您完全确定调用的特征的效果是确定性的,则可以安全地忽略此类警告。
-
在的情况下
CREATE EVENT和ALTER EVENT:-
SLAVESIDE_DISABLED无论指定的状态如何, 事件的状态都设置为 从属(这不适用于DROP EVENT)。 -
创建事件的主服务器在服务器ID上标识在从服务器上。 该
ORIGINATOR列INFORMATION_SCHEMA.EVENTS与originator列mysql.event存储这些信息。 有关更多 信息, 请参见 第25.10节“INFORMATION_SCHEMA事件表” 和 第13.7.6.18节“显示事件语法” 。
-
-
功能实现驻留在可更新状态的从站上,因此如果主站发生故障,从站可以用作主站,而不会丢失事件处理。
要确定在不同服务器(充当复制主服务器)上创建的MySQL服务器上是否存在任何预定事件,请
INFORMATION_SCHEMA.EVENTS
以与此处显示的方式类似的方式
查询
表:
选择EVENT_SCHEMA,EVENT_NAME
来自INFORMATION_SCHEMA.EVENTS
WHERE STATUS ='SLAVESIDE_DISABLED';
或者,您可以使用该
SHOW
EVENTS
语句,如下所示:
展示活动
WHERE STATUS ='SLAVESIDE_DISABLED';
将具有此类事件的复制从属提升到复制主机时,必须使用以下事件启用每个事件
,其中
是事件的名称。
ALTER
EVENT
event_name ENABLEevent_name
如果在此从属服务器上创建事件涉及多个主服务器,并且您希望识别仅在具有服务器ID的给定主服务器上创建的事件
master_id
,请修改
EVENTS
表
上的先前查询
以包括该
ORIGINATOR
列,如下所示:
SELECT EVENT_SCHEMA,EVENT_NAME,ORIGINATOR
来自INFORMATION_SCHEMA.EVENTS
WHERE STATUS ='SLAVESIDE_DISABLED'
AND ORIGINATOR =' master_id'
您可以
以类似的方式
使用
ORIGINATOR
该
SHOW
EVENTS
语句:
展示活动
WHERE STATUS ='SLAVESIDE_DISABLED'
AND ORIGINATOR =' master_id'
在启用从主服务器复制的事件之前,应该禁用从服务器上的MySQL事件调度程序(使用诸如此类的语句
SET GLOBAL event_scheduler =
OFF;
),运行任何必要的
ALTER
EVENT
语句,重新启动服务器,然后在服务器上重新启用事件调度程序(使用一个声明,如
SET GLOBAL event_scheduler = ON;
) -
如果稍后将新主服务器降级为复制从服务器,则必须手动禁用
ALTER
EVENT
语句
启用的所有事件
。
您可以通过在单独的表中存储
SELECT
前面显示
的
语句中
的事件名称
,或使用
ALTER
EVENT
语句重命名具有公共前缀的事件(例如
replicated_
识别它们)来完成此操作。
如果重命名事件,则在将此服务器降级为复制从属时,可以通过查询
EVENTS
表
来标识事件
,如下所示:
SELECT CONCAT(EVENT_SCHEMA,'。',EVENT_NAME)AS'Db.Event'
来自INFORMATION_SCHEMA.EVENTS
在哪里INSTR(EVENT_NAME,'replicated_')= 1;
在MySQL 8.0之前,对JSON列的更新始终作为完整文档写入二进制日志。 在MySQL 8.0中,可以记录对JSON文档的 部分更新 (请参阅 JSON值的部分更新 ),这样更有效。 日志记录行为取决于使用的格式,如下所述:
基于语句的复制。 JSON部分更新始终记录为部分更新。 使用基于语句的日志记录时,无法禁用此功能。
基于行的复制。
默认情况下,JSON部分更新不会记录,而是记录为完整文档。
要启用部分更新的日志记录,请设置
binlog_row_value_options=PARTIAL_JSON
。
如果复制主机设置了此变量,则从该主服务器接收的部分更新将由复制从服务器处理和应用,而不管从服务器自己的变量设置如何。
运行MySQL 8.0.2或更早版本的服务器无法识别用于JSON部分更新的日志事件。
因此,当从运行MySQL 8.0.3或更高版本的服务器复制到此类服务器时,
binlog_row_value_options
必须通过将此变量设置为
''
(空字符串)
来禁用主
服务器上的服务器
。
有关更多信息,请参阅此变量的说明。
基于语句复制
LIMIT
的条款
DELETE
,
UPDATE
以及
INSERT
...
SELECT
因为受影响的行的顺序没有界定的前瞻性声明是不安全的。
(只有
ORDER BY
当这些语句
也包含
子句时,
才可以使用基于语句的复制正确复制这些语句
。)遇到这样的语句时:
-
使用
STATEMENT模式时,现在会发出语句对于基于语句的复制不安全的警告。使用
STATEMENT模式时,会为DML语句发出警告,LIMIT即使它们也有一个ORDER BY子句(因此也是确定的)。 这是一个已知的问题。 (缺陷#42851) -
使用
MIXED模式时,现在使用基于行的模式自动复制语句。
LOAD DATA
基于语句的日志记录被认为是不安全的(参见
第17.2.1.3节“确定二进制日志记录中的安全和不安全语句”
)。
当
binlog_format=MIXED
设置,该语句将记录在基于行的格式。
当
binlog_format=STATEMENT
设置,注意,
LOAD
DATA
不产生警告,不像其他不安全的语句。
当
mysqlbinlog
读取
LOAD
DATA
以基于语句的格式记录的语句的
日志事件时
,将在临时目录中创建生成的本地文件。
mysqlbinlog
或任何其他MySQL程序
不会自动删除这些临时文件
。
如果您使用
LOAD
DATA
基于语句的二进制日志记录的语句,则应在不再需要语句日志后自行删除临时文件。
有关更多信息,请参见
第4.6.8节“
mysqlbinlog
- 处理二进制日志文件的实用程序”
。
max_allowed_packet
设置MySQL服务器和客户端之间任何单个消息大小的上限,包括复制从属。
如果要复制大型列值(例如可能在
列
TEXT
或
BLOB
列中
找到
)并且
max_allowed_packet
在主服务器上太小,则主服务器将失败并显示错误,并且从服务器将关闭I / O线程。
如果
max_allowed_packet
从机上太小,这也会导致从机停止I / O线程。
基于行的复制当前将更新的行的所有列和列值从主服务器发送到从服务器,包括更新未实际更改的列的值。
这意味着,当您使用基于行的复制复制大型列值时,必须注意设置
max_allowed_packet
足够大以容纳要复制的任何表中的最大行,即使您仅复制更新,或者仅插入价值相对较小。
在多线程从站(带
slave_parallel_workers
> 0
)上,确保将
slave_pending_jobs_size_max
系统变量设置为等于或大于
max_allowed_packet
主站上
系统变量设置的值
。
的默认设置
slave_pending_jobs_size_max
,128M,是默认设置两次
max_allowed_packet
,这是64M。
max_allowed_packet
限制主服务器将发送的数据包大小,但添加事件标头可能会产生超过此大小的二进制日志事件。
此外,在基于行的复制中,单个事件可能明显大于
max_allowed_packet
大小,因为该值
max_allowed_packet
仅限制表的每一列。
复制从站实际上接受的数据包达到其
slave_max_allowed_packet
设置设置
的限制
,默认设置为1GB的最大设置,以防止由于大数据包导致复制失败。
但是,值
slave_pending_jobs_size_max
控制从站上可用的内存来保存传入的数据包。
指定的内存在所有从属工作队列之间共享。
值为
slave_pending_jobs_size_max
软限制,如果异常大的事件(由一个或多个数据包组成)超过此大小,则事务将保持到所有从属工作程序都有空队列,然后进行处理。
所有后续交易将持续到大型交易完成为止。
因此,虽然大于
slave_pending_jobs_size_max
可以处理的
异常事件
,但是清除所有从属工作队列的延迟以及等待后续事务的等待可能导致复制从属的延迟并降低从属工作者的并发性。
slave_pending_jobs_size_max
因此应设置得足够高,以适应大多数预期的事件大小。
当主服务器关闭并重新启动时,其
MEMORY
表将变为空。
要将此效果复制到从属服务器,第一次主服务器
MEMORY
在启动后
使用给定的
表,它会记录一个事件,通过将该表的
DELETE
语句
写入
二进制日志
来通知从服务器必须清空
该表。
从服务器关闭并重新启动时,其
MEMORY
表将变为空。
这会导致从站与主站不同步,并可能导致其他故障或导致从站停止:
-
从主服务器接收的行格式更新和删除可能会失败 。
Can't find record in 'memory_table' -
诸如 可以在主服务器和从服务器上插入不同的行集的 语句 。
INSERT INTO ... SELECT FROMmemory_table
重新启动正在复制
MEMORY
表
的从服务器的安全方法
是首先从
MEMORY
主服务器上的表中
删除或删除所有行,
然后等待这些更改复制到从服务器。
然后重新启动从站是安全的。
在某些情况下,可以应用替代的重启方法。
何时
binlog_format=ROW
,如果
slave_exec_mode=IDEMPOTENT
在再次启动从站之前
设置
,
则可以防止从站停止
。
这允许从属设备继续复制,但其
MEMORY
表格仍然与主设备上的表格不同。
如果应用程序逻辑
MEMORY
可以安全地丢失表
的内容
(例如,如果
MEMORY
表用于缓存),这可能没问题。
slave_exec_mode=IDEMPOTENT
全局应用于所有表,因此它可能会隐藏非
MEMORY
表中的
其他复制错误
。
(刚才描述的方法不适用于NDB Cluster,
slave_exec_mode
总是
在哪里
IDEMPOTENT
,不能更改。)
MEMORY
表
的大小
受
max_heap_table_size
系统变量
的值限制,
系统变量
的值
不会被复制(参见
第17.4.1.38节“复制和变量”
)。
更改将在
使用
或
更改后
创建或更新的表
max_heap_table_size
生效
,或者
在服务器重新启动后
对所有
表
生效
。
如果在主服务器上增加此变量的值而不对从服务器执行此操作,则主服务器上的表可能会比从服务器上的表更大,从而导致在主服务器上成功插入但在服务器上失败与
表已满
MEMORY
ALTER TABLE
... ENGINE = MEMORY
TRUNCATE
TABLE
MEMORY
错误。
这是一个已知问题(Bug#48666)。
在这种情况下,必须
max_heap_table_size
在从站和主站上
设置全局值
,然后重新启动复制。
还建议您重新启动主服务器和从服务器MySQL服务器,以确保新值对每个服务器都具有完全(全局)影响。
有关
表的
更多信息
,
请参见
第16.3节“MEMORY存储引擎”
MEMORY
。
对
mysql
模式中的
表进行的数据修改语句将
根据值的值进行复制
binlog_format
。
如果此值为
MIXED
,则使用基于行的格式复制这些语句。
然而,报表通常会更新这些信息间接这样
GRANT
,
REVOKE
和语句操作触发器,存储例程和意见,将被复制到使用基于语句的复制奴隶。
如果以一种数据修改是不确定的方式编写语句,则主服务器和从服务器上的数据可能会不同;
也就是说,留下了查询优化器。
(一般来说,即使在复制之外,这也不是一种好的做法。)非确定性语句的例子包括
DELETE
或
没有
UPDATE
使用
条款的语句;
有关这些内容的详细讨论,
请参见
第17.4.1.18节“复制和限制”
。
LIMIT
ORDER BY
分区表之间支持复制,只要它们使用相同的分区方案,否则具有相同的结构,除非特别允许例外(请参见 第17.4.1.9节“在主服务器和从服务器上使用不同的表定义进行复制” )。
通常不支持具有不同分区的表之间的复制。
这是因为
ALTER
TABLE ... DROP PARTITION
在这种情况下直接作用于分区的
语句(例如
)可能会在主服务器和从服务器上产生不同的结果。
如果表在主服务器上分区但在从服务器上没有分区,则在从服务器主服务器副本上的分区上运行的任何语句都会失败。
当从表的副本被分区但主副本不是分区时,作用于分区的语句不能在主服务器上运行而不会在那里引起错误。
由于这些危险导致复制完全失败(由于语句失败)和不一致(当分区级SQL语句的结果在主服务器和从服务器上产生不同的结果时),我们建议确保任何表的分区要从主服务器复制的数据与这些表的从服务器版本匹配。
在损坏的表或其他损坏的表上使用时,该
REPAIR
TABLE
语句
可能
会删除无法恢复的行。
但是,不会复制此语句执行的表数据的任何此类修改,这可能导致主服务器和从服务器失去同步。
因此,如果主服务器上的表损坏并且您用
REPAIR
TABLE
它来修复它,您应该在使用之前首先停止复制(如果它仍在运行)
REPAIR
TABLE
,然后比较主服务器和从服务器的表副本并且准备在重新启动复制之前手动更正任何差异。
当您尝试从较旧的主服务器复制到较新的主服务器并且您使用主服务器上的标识符时,您可能会遇到问题,这些标识符是在从服务器上运行的较新MySQL版本中的保留字。
例如,
rank
在复制到MySQL 8.0从站的MySQL 5.7主机上
命名的表列
可能会导致问题,因为它
RANK
是从MySQL 8.0开始的保留字。
在这种情况下,复制可能会失败,错误1064
您的SQL语法中出现错误...
,
即使使用保留字命名的数据库或表或具有使用保留字命名的列的表从复制中排除也是如此
。
这是因为每个SQL事件必须在执行之前由从属进行解析,以便从属设备知道哪些数据库对象会受到影响。
只有在事件被解析可从通过应用所定义的任何过滤规则
--replicate-do-db
,
--replicate-do-table
,
--replicate-ignore-db
,和
--replicate-ignore-table
。
要解决主服务器上的数据库,表或列名称问题(从服务器将其视为保留字),请执行以下操作之一:
-
ALTER TABLE在主服务器上 使用一个或多个 语句来更改任何数据库对象的名称,其中这些名称将被视为从服务器上的保留字,并更改使用旧名称的任何SQL语句以使用新名称。 -
在使用这些数据库对象名称的任何SQL语句中,使用反引号字符(
`) 将名称写为带引号的标识符 。
有关MySQL版本的保留字列表,请参阅 MySQL服务器版本参考 中的 保留字 。 有关标识符引用规则,请参见 第9.2节“架构对象名称” 。
关闭主服务器并在以后重新启动它是安全的。
当从设备失去与主设备的连接时,从设备会尝试立即重新连接,如果失败则会定期重试。
默认设置是每60秒重试一次。
这可能会随
CHANGE
MASTER TO
声明
而改变
。
从站也能够处理网络连接中断。
但是,只有在
slave_net_timeout
几秒钟内
没有从主站接收数据后,从站才会注意到网络中断
。
如果您的停电时间很短,您可能希望减少
slave_net_timeout
。
请参见
第17.3.2节“处理意外停止复制从站”
。
由于主二进制日志文件未被刷新,主站侧的不正常关闭(例如,崩溃)可导致主二进制日志的最终位置小于从站读取的最近位置。
这可能导致主服务器重新启动时无法复制从服务器。
sync_binlog=1
主
my.cnf
文件
中的
设置
有助于最大限度地减少此问题,因为它会导致主服务器更频繁地刷新其二进制日志。
为了在使用
InnoDB
事务
的复制设置中实现最大的持久性和一致性
,您还应该进行设置
innodb_flush_log_at_trx_commit=1
。
有了这个设置,内容就是了
InnoDB
每次事务提交时都会将重做日志缓冲区写入日志文件,并将日志文件刷新到磁盘。
请注意,使用此设置仍无法保证事务的持久性,因为操作系统或磁盘硬件可能会告诉
mysqld
已发生刷新到磁盘操作,即使它没有。
干净地关闭一个奴隶是安全的,因为它记录了它从哪里停下来。 但是,要小心奴隶没有打开临时表; 请参见 第17.4.1.30节“复制和临时表” 。 不干净的关闭可能会产生问题,尤其是在问题发生之前磁盘缓存未刷新到磁盘时:
-
对于事务,从属提交然后更新
relay-log.info。 如果在这两个操作之间发生崩溃,则中继日志处理将比信息文件指示的更进一步,并且从服务器将在重新启动后重新执行中继日志中最后一个事务的事件。 -
如果从
relay-log.info服务器 更新 但服务器主机在写入刷新到磁盘之前崩溃, 则会出现类似的问题 。 要最小化发生这种情况的可能性,请sync_relay_log_info=1在从属my.cnf文件中进行 设置 。 设置sync_relay_log_info为0会导致没有写入强制写入磁盘,并且服务器依赖操作系统来不时刷新文件。
如果您拥有良好的不间断电源,系统对这些类型问题的容错能力将大大提高。
如果语句在主服务器和从服务器上产生相同的错误(相同的错误代码),则会记录错误,但会继续复制。
如果语句在主服务器和从服务器上产生不同的错误,则从属SQL线程终止,并且从服务器将消息写入其错误日志,并等待数据库管理员决定如何处理该错误。
这包括语句在主服务器或从服务器上产生错误的情况,但不包括两者。
要解决此问题,请手动连接到从站并确定问题的原因。
SHOW SLAVE STATUS
对此很有用。
然后解决问题并运行
START
SLAVE
。
例如,您可能需要先创建一个不存在的表,然后才能再次启动从属服务器。
如果从站的错误日志中记录了临时错误,则您不必采取引用的错误消息中建议的任何操作。 重试事务的客户端应该处理临时错误。 例如,如果从属SQL线程记录与死锁相关的临时错误,则无需在从属服务器上手动重新启动事务,除非从属SQL线程随后以非临时错误消息终止。
如果不希望出现此错误代码验证行为,则可以使用该
--slave-skip-errors
选项
屏蔽(忽略)部分或全部错误
。
对于非事务性存储引擎(例如,)
MyISAM
,可以使用仅部分更新表并返回错误代码的语句。
例如,这可能发生在多行插入中,其中一行违反了键约束,或者在更新某些行之后杀死了长更新语句。
如果在主服务器上发生这种情况,则从服务器期望执行该语句以产生相同的错误代码。
如果没有,则从属SQL线程如前所述停止。
如果要在主服务器和从服务器上使用不同存储引擎的表之间进行复制,请记住,当针对表的一个版本运行时,相同的语句可能会产生不同的错误,而另一个版本则不会,或者可能导致错误表的版本,但不是另一个。
例如,由于
MyISAM
忽略了外键约束,一个
INSERT
或
UPDATE
声明访问一个
InnoDB
在主表可能会导致外键冲突,但在执行相同的语句
MyISAM
上的从会产生没有这样的错误版本的同一个表,导致复制停止。
在主服务器和从服务器上使用不同的服务器SQL模式设置可能导致在主服务器和从服务器上以不同方式
INSERT
处理
相同的
语句,从而导致主服务器和从服务器发散。
为获得最佳结果,应始终在主服务器和从服务器上使用相同的服务器SQL模式。
无论您使用的是基于语句还是基于行的复制,此建议都适用。
如果要复制分区表,则在主服务器和从服务器上使用不同的SQL模式可能会导致问题。 至少,这可能导致分区之间的数据分布在给定表的主服务器和从服务器副本中不同。 它还可能导致插入到主服务器上成功的分区表中从服务器上失败。
有关更多信息,请参见 第5.1.11节“服务器SQL模式” 。
在MySQL 8.0中,当
binlog_format
设置为
ROW
或时
MIXED
,独占使用临时表的语句不会记录在主服务器上,因此不会复制临时表。
涉及混合临时表和非临时表的语句仅记录在非主表上的操作上,并且不记录临时表上的操作。
这意味着在从站意外关闭的情况下,从站上永远不会丢失任何临时表。
有关基于行的复制和临时表的详细信息,请参阅临时表
的基于行的日志记录
。
如果
binlog_format
设置为
STATEMENT
,则临时表上的操作将记录在主服务器上并在从服务器上复制,前提是可以使用基于语句的格式安全地记录涉及临时表的语句。
在这种情况下,丢失从属服务器上的复制临时表可能是一个问题。
在基于语句的复制模式,
CREATE
TEMPORARY
TABLE
并
DROP
TEMPORARY
TABLE
语句不能交易,程序,函数,或触发器内使用时GTIDs是在服务器上使用(即,当
enforce_gtid_consistency
系统变量被设置为
ON
)。
当GTID正在使用时,它们可以在这些上下文之外使用,前提是
autocommit=1
已设置。
由于基于行或混合复制模式与基于语句的复制模式之间在临时表方面的行为不同,如果更改适用于包含任何打开的临时表的上下文(全局或会话),则无法在运行时切换复制格式表。
有关更多详细信息,请参阅该
binlog_format
选项
的说明
。
使用临时表时安全从站关闭。 在基于语句的复制模式中,将复制临时表,除非您停止从属服务器(不仅仅是从属线程)并且您已复制临时表,这些临时表在尚未在从属服务器上执行的更新中使用。 如果停止从属服务器,则重新启动从属服务器时,这些更新所需的临时表将不再可用。 要避免此问题,请勿在临时表打开时关闭从站。 而是,使用以下过程:
-
发表
STOP SLAVE SQL_THREAD声明。 -
使用
SHOW STATUS检查的数值Slave_open_temp_tables变量。 -
如果该值不为0,请重新启动从属SQL线程,
START SLAVE SQL_THREAD稍后重复该过程。 -
当值为0时,发出 mysqladmin shutdown 命令以停止从站。
临时表和复制选项。
默认情况下,使用基于语句的复制,将复制所有临时表;
这种情况是否不存在任何匹配
--replicate-do-db
,
--replicate-do-table
或
--replicate-wild-do-table
在效果选项。
但是,这些
--replicate-ignore-table
和
--replicate-wild-ignore-table
选项都适用于临时表。
例外是,为了在会话结束时正确删除临时表,复制从站始终复制
DROP TEMPORARY TABLE IF EXISTS
语句,而不管通常适用于指定表的任何排除规则。
使用基于语句的复制时,建议的做法是指定一个前缀,以便在命名您不希望复制的临时表时使用,然后使用一个
--replicate-wild-ignore-table
选项来匹配该前缀。
例如,你可能会给所有这样的表名开头
norep
(如
norepmytable
,
norepyourtable
等),然后使用
--replicate-wild-ignore-table=norep%
,以防止它们被复制。
全局系统变量
slave_transaction_retries
设置单线程或多线程复制从站上的应用程序线程在停止之前自动重试失败事务的最大次数。
当SQL线程由于
InnoDB
死锁
而无法执行
时,或者当事务的执行时间超过该
InnoDB
innodb_lock_wait_timeout
值
时,将自动重试
事务
。
如果事务具有非临时错误,将阻止它成功,则不会重试该事务。
默认设置为
slave_transaction_retries
10,这意味着在应用程序线程停止之前,将重试10次具有明显临时错误的失败事务。
将变量设置为0将禁用自动重试事务。
在多线程从属服务器上,指定数量的事务重试可以在所有通道的所有应用程序线程上进行。
Performance Schema表
replication_applier_status
显示了
COUNT_TRANSACTIONS_RETRIES
列中
每个复制通道上发生的事务重试总数
。
重试事务的过程可能导致复制从属或组复制组成员的延迟,组成员可以配置为单线程或多线程从属。
性能架构表
replication_applier_status_by_worker
显示有关单线程或多线程从站上的应用程序线程的事务重试的详细信息。
此数据包括时间戳,显示应用程序线程从开始到结束应用最后一个事务所花费的时间(以及当前正在进行的事务的开始时间),以及在原始主服务器和直接主服务器上提交之后的时间。
数据还显示最后一个事务和当前正在进行的事务的重试次数,并使您能够识别导致重试事务的瞬态错误。
您可以使用此信息来查看事务重试是否是导致复制滞后的原因,
默认情况下,主服务器和从属服务器假定它们位于同一时区。
如果要在不同时区的服务器之间进行复制,则必须在主服务器和从服务器上设置时区。
否则,将无法正确复制取决于主服务器上本地时间的语句,例如使用
NOW()
或
FROM_UNIXTIME()
函数的
语句
。
使用
脚本
选项
或设置
环境变量
来设置
运行MySQL服务器的时区
。
另请参见
第17.4.1.14节“复制和系统功能”
。
--timezone=
timezone_namemysqld_safe
TZ
根据您的复制配置,可能会发生从中继日志执行的事务序列中的不一致。 本节介绍如何避免不一致并解决它们导致的任何问题。
可能存在以下类型的不一致:
-
半成交 。 更新非事务性表的事务已应用了一些但不是全部更改。
-
差距 。 间隙是尚未(完全)应用的事务,即使已应用某些后续事务。 只有在使用多线程从站时才会出现间隙。 为了避免出现间隙,
slave_preserve_commit_order=1需要 设置 ,并且 还启用slave_parallel_type=LOGICAL_CLOCK了二进制日志记录(log_bin系统变量)和从站更新日志记录(--log-slave-updates)。 -
无间隙低水位位置 。 即使没有差距,也可以
Exec_master_log_pos应用 之后的交易 。 也就是说,N已经应用 了所有直到点的 事务,N并且在应用 之后没有事务 ,但是Exec_master_log_pos具有小于的值。N.这只能在多线程从设备上发生。 启用slave_preserve_commit_order并 不能 阻止无间隙低水印位置。
以下情景与半应用交易的存在,差距和无间隙的低水位位置不一致有关:
-
当从属线程正在运行时,可能存在间隙和半应用事务。
-
mysqld 关闭。 干净和不干净的关闭都会中断正在进行的交易,并可能留下空白和半适用的交易。
-
KILL复制线程(使用单线程从属时的SQL线程,使用多线程从属时的协调器线程)。 这会中断正在进行的交易,并可能留下空白和半应用交易。 -
应用程序线程出错。 这可能会留下空白。 如果错误发生在混合事务中,则该事务处于半应用状态。 使用多线程从站时,未收到错误的工作程序会完成队列,因此停止所有线程可能需要一些时间。
-
STOP SLAVE使用多线程从站时。 发出后STOP SLAVE,奴隶等待填补任何空白然后更新Exec_master_log_pos。 这确保它永远不会留下间隙或无间隙的低水位位置,除非上述任何情况适用(换句话说,在STOP SLAVE完成 之前 ,发生错误,或者另一个线程发出KILL,或者服务器重新启动。在这些情况下,STOP SLAVE返回成功。) -
如果中继日志中的最后一个事务仅半接收并且多线程从协调器已开始将事务调度给工作程序,则
STOP SLAVE等待最多60秒以便接收事务。 超时后,协调员放弃并中止事务。 如果交易混合,可能会完成一半。 -
STOP SLAVE使用单线程从站时。 如果正在进行的事务仅更新事务表,则会回滚并STOP SLAVE立即停止。 如果正在进行的事务是混合的,则STOP SLAVE等待最多60秒以完成事务。 在超时之后,它会中止事务,因此可能会完成一半。
全局变量
rpl_stop_slave_timeout
与停止复制线程的过程无关。
它只会使发出的客户端
STOP
SLAVE
返回到客户端,但复制线程继续尝试停止。
如果复制通道存在间隙,则会产生以下后果:
-
从属数据库处于主机上可能永远不存在的状态。
-
该领域
Exec_master_log_pos中SHOW SLAVE STATUS也只是“低水印”。 换句话说,保证在该头寸之前出现的交易已经提交,但该头寸之后的交易可能已经提交或未提交。 -
CHANGE MASTER TO除非应用程序线程正在运行且CHANGE MASTER TO语句仅设置接收器选项 ,否则该通道的语句将失败并显示错误 。 -
如果 启动了 mysqld
--relay-log-recovery,则不会对该通道进行恢复,并打印警告。 -
如果 mysqldump的 与使用
--dump-slave,它不记录缺口的存在; 因而它打印CHANGE MASTER TO与RELAY_LOG_POS设置为在低水印位置Exec_master_log_pos。在另一台服务器上应用转储并启动复制线程后,将再次复制位置之后出现的事务。 请注意,如果启用了GTID,这将是无害的(但是,在这种情况下,建议不要使用
--dump-slave)。
如果复制通道具有无间隙的低水印位置,则上述情况2至5适用,但情况1不适用。
无间隙低水印位置信息以二进制格式保存在内部表中
mysql.slave_worker_info
。
START
SLAVE
[SQL_THREAD]
始终参考此信息,以便它仅适用于正确的交易。
即使
slave_parallel_workers
已经更改为0
START
SLAVE
,即使
START
SLAVE
与
UNTIL
子句一起
使用,
这仍然是正确的
。
START
SLAVE UNTIL
SQL_AFTER_MTS_GAPS
仅适用于需要的许多交易以填补空白。
如果
START
SLAVE
使用
UNTIL
条款告诉它在消耗所有间隙之前停止,那么它会留下剩余的间隙。
RESET
SLAVE
删除中继日志并重置复制位置。
因此,
RESET
SLAVE
在具有间隙的从设备上
发布
意味着从设备丢失关于间隙的任何信息,而不纠正间隙。
slave-preserve-commit-order
确保没有差距。
但是,
Exec_master_log_pos
在上面的场景1到4中
,它仍然可能
只是一个无间隙的低水位位置。
也就是说,可能存在之后
Exec_master_log_pos
已经应用的
交易
。
因此,即使
slave-preserve-commit-order
启用了
上面编号为2到5(但不是情况1)的情况也适用
。
在同一事务中混合事务和非事务语句。 通常,应避免在复制环境中更新事务和非事务表的事务。 您还应该避免使用任何访问事务(或临时)和非事务表以及写入任何表的语句。
服务器使用这些规则进行二进制日志记录
-
如果事务中的初始语句是非事务性的,则会立即将它们写入二进制日志。 在事务提交之前,事务中的其余语句将被缓存,而不会写入二进制日志。 (如果事务被回滚,则缓存的语句只有在进行无法回滚的非事务性更改时才会写入二进制日志。否则,它们将被丢弃。)
-
对于基于语句的日志记录,非事务性语句的日志记录受
binlog_direct_non_transactional_updates系统变量的 影响 。 当此变量为OFF(默认值)时,记录如上所述。 当这个变量ON出现时,会立即记录事务中任何地方发生的非事务性语句(而不仅仅是初始的非事务性语句)。 其他语句保存在事务高速缓存中,并在事务提交时记录。binlog_direct_non_transactional_updates对行格式或混合格式二进制日志记录没有影响。
事务性,非事务性和混合语句。 要应用这些规则,如果服务器仅更改非事务性表,则会考虑非事务性语句,如果仅更改事务性表,则认为是事务性事务。 引用非事务性表和事务性表以及更新 所涉及的 任何 表的 语句 被视为 “ 混合 ” 语句。 事务提交时,会混淆并记录混合语句(如事务语句)。
如果语句还执行以下任一操作,则更新事务表的混合语句将被视为不安全:
-
更新或读取临时表
-
读取非事务性表,事务隔离级别小于REPEATABLE_READ
如果事务执行以下任一操作,则在事务中更新事务表后的混合语句将被视为不安全:
-
更新任何表并从任何临时表中读取
-
更新非事务表并
binlog_direct_non_transactional_updates关闭
有关更多信息,请参见 第17.2.1.3节“确定二进制日志记录中的安全和不安全语句” 。
混合语句与混合二进制日志记录格式无关。
在事务混合事务和非事务表的更新的情况下,二进制日志中的语句顺序是正确的,即使在a的情况下,所有需要的语句也都写入二进制日志
ROLLBACK
。
但是,当第二个连接在第一个连接事务完成之前更新非事务表时,可以无序地记录语句,因为第二个连接更新在执行后立即写入,而不管第一个连接事务执行的事务状态如何连接。
在主站和从站上使用不同的存储引擎。
可以使用从属上的非事务表在主服务器上复制事务表。
例如,您可以将
InnoDB
主表
复制
为
MyISAM
从属表。
但是,如果执行此操作,如果
从站在
BEGIN
...
COMMIT
块
中间停止,则会出现问题,
因为从站在
BEGIN
块
的开头重新启动
。
将事务从
MyISAM
主表上的
事务复制
到事务表(例如
InnoDB
在从服务器上
使用
存储引擎的
表
)也是安全
的。
在这种情况下,将
AUTOCOMMIT=1
复制在主服务器上发出
的
语句,从而
AUTOCOMMIT
对从服务器
执行
模式。
当从属的存储引擎类型是非事务性时,应避免混合事务和非事务表更新的主服务器上的事务,因为它们可能导致主事务表和从属非事务表之间的数据不一致。 也就是说,此类事务可能导致主存储引擎特定的行为,并且可能导致复制不同步。 MySQL不会对此发出警告,因此在将事务表从主服务器上的非事务表复制到非事务表时应格外小心。
更改事务中的二进制日志记录格式。
该
binlog_format
和
binlog_checksum
系统变量是只读的,只要交易正在进行中。
每个事务(包括
autocommit
事务)都记录在二进制日志中,就好像它以一个
BEGIN
语句
开头一样
,并以a
COMMIT
或a
ROLLBACK
语句结束。
对于影响使用非事务性存储引擎(例如
MyISAM
)的
表的语句,情况甚至如此
。
有关专门适用于XA事务的限制,请参见 第C.6节“XA事务的限制” 。
使用基于语句的复制,在主服务器上执行的触发器也在从服务器上执行。 对于基于行的复制,在主服务器上执行的触发器不会在从服务器上执行。 相反,由触发器执行产生的主服务器上的行更改将被复制并应用于从服务器。
此行为是设计使然。 如果在基于行的复制下,从属设备应用了触发器以及由它们引起的行更改,则实际上这些更改将在从设备上应用两次,从而导致主设备和从设备上的不同数据。
如果希望触发器在主服务器和从服务器上都执行 - 可能是因为主服务器和从服务器上有不同的触发器 - 您必须使用基于语句的复制。 但是,要启用从属端触发器,不必专门使用基于语句的复制。 只对那些需要此效果的语句切换到基于语句的复制,并在其余时间使用基于行的复制就足够了。
AUTO_INCREMENT
使用基于语句的复制不会正确复制
调用导致更新
列
的触发器(或函数)的
语句。
MySQL 8.0将此类语句标记为不安全。
(缺陷#45677)
触发器可以具有用于触发事件的不同组合(触发器
INSERT
,
UPDATE
,
DELETE
)和动作时间(
BEFORE
,
AFTER
),和多个触发器是允许的。
为简洁起见, 这里的 “ 多个触发器 ” 是 “ 具有相同触发事件和动作时间的 多个触发器 ” 的简写 。 ”
升级。 MySQL 5.7之前的版本不支持多个触发器。 如果升级使用早于MySQL 5.7的版本的复制拓扑中的服务器,请先升级复制从属,然后再升级主服务器。 如果升级的复制主服务器仍然使用不支持多个触发器的MySQL版本的旧从服务器,则如果在主服务器上为已经具有相同触发事件和操作时间的触发器的表创建了触发器,则会在这些从服务器上发生错误。
降级。 如果将支持多个触发器的服务器降级到不支持多个触发器的旧版本,则降级具有以下影响:
-
对于每个具有触发器的表,所有触发器定义都在
.TRG表 的 文件中。 但是,如果有多个触发器具有相同的触发事件和操作时间,则在触发事件发生时,服务器仅执行其中一个触发器。 有关.TRG文件的 信息 ,请参阅MySQL Server Doxygen文档的Table Trigger Storage部分,可从 https://dev.mysql.com/doc/index-other.html获取 。 -
如果在降级后添加或删除表的触发器,则服务器会重写表的
.TRG文件。 重写的文件每次触发事件和动作时间组合仅保留一个触发器; 其他人都迷失了。
要避免这些问题,请在降级之前修改触发器。 对于每个触发事件和操作时间组合具有多个触发器的每个表,将每个这样的触发器集转换为单个触发器,如下所示:
-
对于每个触发器,创建一个包含触发器中所有代码的存储例程。 使用
NEW和 访问的值OLD可以使用参数传递给例程。 如果触发器需要代码中的单个结果值,则可以将代码放在存储的函数中并使函数返回该值。 如果触发器需要代码中的多个结果值,则可以将代码放在存储过程中并使用OUT参数 返回值 。 -
删除表的所有触发器。
-
为表调用刚刚创建的存储例程创建一个新触发器。 因此,此触发器的效果与它替换的多个触发器相同。
TRUNCATE
TABLE
通常被视为DML语句,因此当二进制日志记录模式为
ROW
或
时,可以使用基于行的格式记录和复制
MIXED
。
但是,这会在
使用事务存储引擎(例如
事务隔离级别为
或
时)的
表中
记录或复制(
STATEMENT
或
MIXED
模式)
时导致问题
,这会阻止基于语句的日志记录。
InnoDB
READ
COMMITTED
READ UNCOMMITTED
TRUNCATE
TABLE
为了记录和复制而将其视为DDL而不是DML,以便可以将其作为语句进行记录和复制。
但是,适用
InnoDB
于复制从属的其他事务表
的语句的影响
仍然遵循
第13.1.37节“
管理此类表的
TRUNCATE TABLE语法”中
描述的规则
。
(Bug#36763)
MySQL用户名的最大长度为32个字符。 将长度超过16个字符的用户名复制到仅支持较短用户名的MySQL 5.7之前的从属服务器将失败。 但是,只有在从较新的主服务器复制到较旧的主服务器时才会出现这种情况,这不是推荐的配置。
使用
STATEMENT
模式时,
系统变量未正确复制
,但以下变量与会话范围一起使用时除外:
使用
MIXED
mode时,前面列表中的变量与会话作用域一起使用时,会导致从基于语句的日志切换到基于行的日志记录。
请参见
第5.4.4.3节“混合二进制日志格式”
。
sql_mode
也被复制,除了
NO_DIR_IN_CREATE
模式;
NO_DIR_IN_CREATE
无论主服务器上的更改如何,
从服务器始终保留其自身的值
。
对于所有复制格式都是如此。
但是,当
mysqlbinlog
解析
语句
时
,包括
的完整
值
将传递给接收服务器。
因此,
在使用模式
时,复制此类语句可能不安全
。
SET @@sql_mode =
modemode
NO_DIR_IN_CREATE
STATEMENT
所述
default_storage_engine
系统变量是不可复制的,无论记录模式的;
这旨在促进不同存储引擎之间的复制。
该
read_only
系统变量是不可复制的。
此外,启用此变量对于临时表,表锁定和
SET
PASSWORD
不同MySQL版本中
的
语句
具有不同的效果
。
该
max_heap_table_size
系统变量是不可复制的。
在主服务器上增加此变量的值而不在从服务器上执行此操作可能最终导致
在尝试
在主服务器
上的
表上
执行
语句
时,从服务器上的
表是完全
错误
,因此允许其大于服务器上的对应项。
有关更多信息,请参见
第17.4.1.21节“复制和存储器表”
。
INSERT
MEMORY
在基于语句的复制中,在更新表的语句中使用会话变量时,不会正确复制会话变量。 例如,以下语句序列不会在主服务器和从服务器上插入相同的数据:
SET max_join_size = 1000; 插入mytable VALUES(@@ max_join_size);
这不适用于常见的顺序:
SET time_zone = ...; 插入mytable VALUES(CONVERT_TZ(...,...,@@ time_zone));
使用基于行的复制时,会话变量的复制不是问题,在这种情况下,会话变量总是安全地复制。 请参见 第17.2.1节“复制格式” 。
无论日志记录格式如何,以下会话变量都将写入二进制日志并在解析二进制日志时由复制从站进行验证:
即使与字符集和排序规则相关的会话变量写入二进制日志,也不支持在不同字符集之间进行复制。
为了帮助减少可能的混淆,我们建议您始终
lower_case_table_names
在主服务器和从服务器上
使用相同的
系统变量
设置
,尤其是在具有区分大小写的文件系统的平台上运行MySQL时。
lower_case_table_names
只能在初始化服务器时配置
该
设置。
MySQL支持从一个发行版系列到下一个更高版本系列的复制。 例如,您可以从运行MySQL 5.6的主服务器复制到运行MySQL 5.7的从服务器,从运行MySQL 5.7的主服务器复制到运行MySQL 8.0的服务器,依此类推。 但是,如果主服务器使用语句或依赖于从服务器上使用的MySQL版本不再支持的行为,则在从较旧的主服务器复制到较新的主服务器时可能会遇到困难。 例如,MySQL 8.0不再支持超过64个字符的外键名称。
无论主服务器或从服务器MySQL服务器的数量如何,在涉及多个主服务器的复制设置中都不支持使用两个以上的MySQL服务器版本。 此限制不仅适用于发布系列,也适用于同一发行系列中的版本号。 例如,如果您使用的是链式或循环复制设置,则不能同时使用MySQL 8.0.1,MySQL 8.0.2和MySQL 8.0.4,尽管您可以同时使用这两个版本中的任何两个。
强烈建议使用给定MySQL发行版系列中提供的最新版本,因为复制(和其他)功能正在不断改进。 当后者可用于该版本系列时,还建议将使用MySQL早期版本的早期版本升级到GA(生产)版本的主服务器和从服务器。
从MySQL 8.0.14开始,服务器版本记录在最初提交事务(
original_server_version
)
的服务器的每个事务的二进制日志中
,以及复制拓扑(
immediate_server_version
)中
当前服务器的直接主服务器的服务器上
。
可以从较新的主服务器复制到较旧的主服务器,但通常不受支持。 这是由于许多因素造成的:
-
二进制日志格式更改。 二进制日志格式可以在主要版本之间更改。 虽然我们试图保持向后兼容性,但这并不总是可行的。
这对升级复制服务器也有重要意义; 有关更多信息 , 请参见 第17.4.3节“升级复制设置” 。
-
有关基于行的复制的更多信息,请参见 第17.2.1节“复制格式” 。
-
SQL不兼容。 如果要复制的语句使用主服务器上可用的SQL功能但不使用从服务器上的SQL功能,则无法使用基于语句的复制从较新的主服务器复制到较旧的主服务器。
但是,如果主服务器和从服务器都支持基于行的复制,并且没有要复制的数据定义语句依赖于在主服务器上找到但不在从服务器上的SQL功能,则可以使用基于行的复制来复制即使从站上不支持在主站上运行DDL,也会导致数据修改语句的影响。
有关潜在复制问题的更多信息,请参见 第17.4.1节“复制功能和问题” 。
升级参与复制设置的服务器时,升级过程取决于当前服务器版本和要升级的版本。 本节提供有关升级如何影响复制的信息。 有关升级MySQL的一般信息,请参见 第2.11节“升级MySQL”
从早期的MySQL发行版系列中将主服务器升级到8.0时,应首先确保此主服务器的所有从服务器都使用相同的8.0.x版本。 如果不是这种情况,则应首先升级从站。 要升级每个从属服务器,请将其关闭,将其升级到相应的8.0.x版本,重新启动它,然后重新启动复制。 升级后从站创建的中继日志为8.0格式。
影响严格SQL模式(
STRICT_TRANS_TABLES
或
STRICT_ALL_TABLES
)
操作的更改
可能导致升级的从属服务器上的复制失败。
如果使用基于语句的日志记录(
binlog_format=STATEMENT
),如果在主服务器之前升级从服务器,则非升级主服务器将执行无错误的语句,这些语句可能会在从服务器上失败并且复制将停止。
要处理这个问题,请停止主服务器上的所有新语句,并等待从服务器赶上。
然后升级奴隶。
或者,如果您无法停止新语句,请暂时更改为master(
binlog_format=ROW
)
上基于行的日志记录,
并等待所有从属服务器处理所有生成的二进制日志,直到此更改为止。
然后升级奴隶。
默认字符集已从
MySQL 8.0中
更改
latin1
为
utf8mb4
。
在复制设置中,从MySQL 5.7升级到8.0时,建议在升级之前将默认字符集更改回MySQL 5.7中使用的字符集。
升级完成后,可以将默认字符集更改为
utf8mb4
。
假设使用了以前的默认值,保留它们的一种方法是使用
my.cnf
文件中的
这些行启动服务器
:
的[mysqld] 被character_set_server = LATIN1 collation_server的= latin1_swedish_ci
从站升级后,关闭主站,将其升级到与从站相同的8.0.x版本,然后重新启动它。 如果您已暂时将主服务器更改为基于行的日志记录,请将其更改回基于语句的日志记录。 8.0主服务器能够读取升级之前写入的旧二进制日志,并将它们发送到8.0从服务器。 从属设备识别旧格式并正确处理。 升级后主服务器创建的二进制日志格式为8.0。 这些也被8.0奴隶认可。
换句话说,在升级到MySQL 8.0时,从服务器必须是MySQL 8.0才能将主服务器升级到8.0。 请注意,从8.0降级到较旧版本并不是那么简单:必须确保已完全处理任何8.0二进制日志或中继日志,以便在继续降级之前将其删除。
当您从一个MySQL系列移动到下一个MySQL系列时,某些升级可能需要您删除并重新创建数据库对象。 例如,排序规则更改可能需要重建表索引。 如有必要,此类操作详见 第2.11.4节“MySQL 8.0中的更改” 。 最明智的做法是在从站和主站上单独执行这些操作,并禁止从主站到从站的这些操作的复制。 要实现此目的,请使用以下过程:
-
停止所有奴隶并升级它们。 使用该
--skip-slave-start选项 重新启动它们, 以便它们不连接到主服务器。 执行重新创建数据库对象所需的任何表修复或重建操作,例如使用REPAIR TABLEorALTER TABLE,或转储和重新加载表或触发器。 -
禁用主服务器上的二进制日志。 要在不重新启动master的情况下执行此操作,请执行
SET sql_log_bin = OFF语句。 或者,停止主控并使用该--skip-log-bin选项 重新启动它 。 如果重新启动主服务器,则可能还需要禁用客户端连接。 例如,如果所有客户端都使用TCP / IP进行连接,请--skip-networking在重新启动主服务器时 使用该 选项。 -
禁用二进制日志后,执行重新创建数据库对象所需的任何表修复或重建操作。 在此步骤中必须禁用二进制日志,以防止记录这些操作并在以后将其发送到从属服务器。
-
重新启用主服务器上的二进制日志。 如果设置
sql_log_bin为OFF较早,则执行SET sql_log_bin = ON语句。 如果重新启动主服务器以禁用二进制日志,请在不使用的情况下重新启动它--skip-log-bin,--skip-networking以便客户端和从服务器可以连接。 -
重启奴隶,这次没有
--skip-slave-start选项。
如果要将现有复制设置从不支持全局事务标识符的MySQL版本升级到版本,则在确保设置满足GTID的所有要求之前,不应在主服务器或从服务器上启用GTID。基于复制。 请参见 第17.1.3.4节“使用GTID设置复制” ,其中包含有关将现有复制设置转换为使用基于GTID的复制的信息。
在MySQL 8.0.16之前,当服务器运行时使用全局事务标识符(GTID)enabled(
gtid_mode=ON
)时,不要通过
mysql_upgrade
启用二进制日志记录
(该
--write-binlog
选项)。
从MySQL 8.0.16开始,服务器执行整个MySQL升级过程,但在升级过程中禁用二进制日志记录,因此没有问题。
gtid_mode=ON
如果转储文件包含系统表,
则不建议在服务器(
)
上启用GTID时加载转储文件
。
mysqldump
为使用非事务性MyISAM存储引擎的系统表发出DML指令,并且在启用GTID时不允许这种组合。
另请注意,将启用了GTID的服务器中的转储文件加载到启用了GTID的其他服务器中会导致生成不同的事务标识符。
如果您已按照说明操作但复制设置不起作用,则首先要 检查错误日志中的消息 。 许多用户在遇到问题后很快就没有这么做了。
如果您无法从错误日志中判断出问题所在,请尝试以下技术:
-
通过发出
SHOW MASTER STATUS语句 验证主服务器是否启用了二进制日志记录 。 默认情况下启用二进制日志记录。 如果启用了二进制日志记录,Position则为非零。 如果未启用二进制日志记录,请使用禁用二进制日志记录的任何设置(例如--skip-log-bin选项) 验证您是否未运行主服务器 。 -
验证主服务器和从服务器都是使用该
--server-id选项 启动的, 并且每个服务器上的ID值都是唯一的。 -
验证从站是否正在运行。 使用
SHOW SLAVE STATUS检查是否Slave_IO_Running和Slave_SQL_Running值都Yes。 如果没有,请验证启动从属服务器时使用的选项。 例如,--skip-slave-start在发出START SLAVE语句 之前 , 防止从属线程启动 。 -
如果从站正在运行,请检查它是否与主站建立了连接。 使用
SHOW PROCESSLIST,找到I / O和SQL线程并检查其State列以查看它们显示的内容。 请参见 第17.2.2节“复制实现细节” 。 如果I / O线程状态显示Connecting to master,请检查以下内容:-
验证在主服务器上用于复制的用户的权限。
-
检查主服务器的主机名是否正确,以及您使用正确的端口连接到主服务器。 用于复制的端口与用于客户端网络通信的端口相同(默认为
3306)。 对于主机名,请确保名称解析为正确的IP地址。 -
检查主站或从站上是否未禁用网络。
skip-networking在配置文件中 查找该 选项。 如果存在,请将其注释或删除。 -
如果主服务器具有防火墙或IP过滤配置,请确保未过滤用于MySQL的网络端口。
-
检查您是否可以使用
ping或traceroute/tracert到达主机来联系主服务器。
-
-
如果从站先前已经运行但已停止,原因通常是主站上的某个成功语句在从站上失败。 如果您已经获取了主服务器的正确快照,并且从不修改从服务器线程外部的从服务器上的数据,则永远不会发生这种情况。 如果从站意外停止,则表示存在错误,或者您遇到了 第17.4.1节“复制功能和问题” 中所述的已知复制限制之一 。 如果是错误,请参见 第17.4.5节“如何报告复制错误或问题” ,以获取有关如何报告 错误 的说明。
-
如果在主服务器上成功的语句拒绝在从服务器上运行,如果通过删除从服务器的数据库并从主服务器复制新快照来执行完整数据库重新同步是不可行的,请尝试以下过程:
-
确定从站上受影响的表是否与主表不同。 试着了解这是怎么发生的。 然后使slave的表与master的表相同并运行
START SLAVE。 -
如果上一步不起作用或不适用,请尝试了解手动更新是否安全(如果需要),然后忽略来自主服务器的下一个语句。
-
如果您确定从站可以跳过主站的下一个语句,请发出以下语句:
mysql> mysql>
SET GLOBAL sql_slave_skip_counter =N;START SLAVE;N如果来自master的下一个语句不使用AUTO_INCREMENT或, 则 值 应为1LAST_INSERT_ID()。 否则,该值应为2.对于使用AUTO_INCREMENT或者LAST_INSERT_ID()在主服务器的二进制日志中使用两个事件的 语句使用值2的原因 。 -
如果您确定从属服务器与主服务器完全同步,并且没有人更新了从服务器线程之外的表,那么可能是错误是错误的结果。 如果您运行的是最新版本的MySQL,请报告问题。 如果您运行的是旧版本,请尝试升级到最新的生产版本以确定问题是否仍然存在。
-
当您确定没有涉及用户错误,并且复制仍然根本不起作用或不稳定时,是时候向我们发送错误报告了。 我们需要从您那里获取尽可能多的信息,以便能够追踪错误。 请花些时间和精力准备一份好的错误报告。
如果您有一个可重复的测试用例来演示该错误,请使用 第1.7节“如何报告错误或问题”中 给出的说明将其输入我们的错误数据库 。 如果您有 “ 幻像 ” 问题(您无法随意复制),请使用以下过程:
-
确认不涉及用户错误。 例如,如果更新从属线程外部的从属,则数据不同步,并且您可以在更新时具有唯一的密钥违例。 在这种情况下,从属线程会停止并等待您手动清理表以使它们同步。 这不是复制问题。 这是外部干扰导致复制失败的问题。
-
确保从站运行时启用了二进制日志记录(
log_bin系统变量),并--log-slave-updates启用 了 选项,这会使从站将从主站接收的更新记录到其自己的二进制日志中。 这些设置是默认设置。 -
在重置复制状态之前保存所有证据。 如果我们没有信息或只有粗略的信息,我们很难或不可能追查问题。 你应该收集的证据是:
-
来自master的所有二进制日志文件
-
来自从站的所有二进制日志文件
-
SHOW MASTER STATUS您发现问题时主人 的输出 -
SHOW SLAVE STATUS您发现问题时从奴隶 的输出 -
来自主站和从站的错误日志
-
-
使用 mysqlbinlog 检查二进制日志。 以下内容应该有助于找到问题陈述。
log_file和log_pos是Master_Log_File和Read_Master_Log_Pos值从SHOW SLAVE STATUS。外壳>
mysqlbinlog --start-position=log_poslog_file| head
在收集问题的证据后,请先尝试将其作为单独的测试用例进行隔离。 然后使用 第1.7节“如何报告错误或问题”中 的说明将尽可能多的信息输入到我们的错误数据库中 。