目录
- 22.1 NDB群集概述
- 22.2 NDB群集安装
- 22.3 NDB集群的配置
- 22.4 NDB群集程序
-
- 22.4.1 ndbd - NDB集群数据节点守护程序
- 22.4.2 ndbinfo_select_all - 从ndbinfo表中选择
- 22.4.3 ndbmtd - NDB簇数据节点守护进程(多线程)
- 22.4.4 ndb_mgmd - NDB群集管理服务器守护程序
- 22.4.5 ndb_mgm - NDB集群管理客户端
- 22.4.6 ndb_blob_tool - 检查并修复NDB集群表的BLOB和TEXT列
- 22.4.7 ndb_config - 提取NDB群集配置信息
- 22.4.8 ndb_delete_all - 从NDB表中删除所有行
- 22.4.9 ndb_desc - 描述NDB表
- 22.4.10 ndb_drop_index - 从NDB表中删除索引
- 22.4.11 ndb_drop_table - 删除NDB表
- 22.4.12 ndb_error_reporter - NDB错误报告实用程序
- 22.4.13 ndb_import - 将CSV数据导入NDB
- 22.4.14 ndb_index_stat - NDB索引统计工具
- 22.4.15 ndb_move_data - NDB数据复制实用程序
- 22.4.16 ndb_perror - 获取NDB错误消息信息
- 22.4.17 ndb_print_backup_file - 打印NDB备份文件内容
- 22.4.18 ndb_print_file - 打印NDB磁盘数据文件内容
- 22.4.19 ndb_print_frag_file - 打印NDB片段列表文件内容
- 22.4.20 ndb_print_schema_file - 打印NDB模式文件内容
- 22.4.21 ndb_print_sys_file - 打印NDB系统文件内容
- 22.4.22 ndb_redo_log_reader - 检查并打印群集重做日志的内容
- 22.4.23 ndb_restore - 恢复NDB群集备份
- 22.4.24 ndb_select_all - 从NDB表打印行
- 22.4.25 ndb_select_count - 打印NDB表的行计数
- 22.4.26 ndb_setup.py - 为NDB群集启动基于浏览器的自动安装程序
- 22.4.27 ndb_show_tables - 显示NDB表的列表
- 22.4.28 ndb_size.pl - NDBCLUSTER大小要求估算器
- 22.4.29 ndb_top - 查看NDB线程的CPU使用情况信息
- 22.4.30 ndb_waiter - 等待NDB群集到达给定状态
- 22.4.31 NDB群集程序常用选项 - NDB群集程序常用选项
- 22.5 NDB集群管理
-
- 22.5.1 NDB集群启动阶段摘要
- 22.5.2 NDB集群管理客户端中的命令
- 22.5.3 NDB集群的在线备份
- 22.5.4 NDB集群的MySQL服务器使用情况
- 22.5.5执行NDB集群的滚动重新启动
- 22.5.6在NDB集群中生成的事件报告
- 22.5.7 NDB集群日志消息
- 22.5.8 NDB集群单用户模式
- 22.5.9快速参考:NDB集群SQL语句
- 22.5.10 ndbinfo:NDB群集信息数据库
- 22.5.11 NDB集群的INFORMATION_SCHEMA表
- 22.5.12 NDB群集安全问题
- 22.5.13 NDB群集磁盘数据表
- 22.5.14在NDB集群中使用ALTER TABLE进行在线操作
- 22.5.15在线添加NDB集群数据节点
- 22.5.16分布式MySQL权限(不支持)
- 22.5.17 NDB API统计计数器和变量
- 22.6 NDB群集复制
- 22.7 NDB群集发行说明
MySQL
NDB Cluster
是适用于分布式计算环境的高可用性,高冗余版本的MySQL。
最近的NDB Cluster版本系列使用版本8的
NDB
存储引擎(也称为
NDBCLUSTER
)来支持在群集中运行带有MySQL服务器和其他软件的多台计算机。
NDB Cluster 8.0现已作为开发人员里程碑版本(DMR)从版本8.0.13开始提供,它包含了8.0版的
NDB
存储引擎。
NDB Cluster 7.6是当前的GA版本,使用7.6版本
NDB
。
以前的GA版本仍然可用于生产,NDB Cluster 7.5和NDB Cluster 7.4合并
NDB
版本分别为7.5和7.4。
使用
NDB
存储引擎
版本7.2的NDB Cluster 7.2
是以前仍在维护的GA版本;
7.2鼓励用户升级到NDB 7.5或NDB 7.6。
不再支持或维护NDB 7.1和以前的发行版系列
。
NDB
Oracle构建的标准MySQL Server 8.0二进制文件中不包含
对
存储引擎的
支持
。
相反,来自Oracle的NDB Cluster二进制文件的用户应升级到支持平台的NDB Cluster的最新二进制版本 -
这些版本包括适用于大多数Linux发行版的RPM。
从源构建的NDB Cluster 8.0用户应使用为MySQL 8.0提供的源,并使用提供NDB支持所需的选项进行构建。
(可以获得源的位置将在本节后面列出。)
MySQL NDB Cluster不支持InnoDB集群,必须使用带有
InnoDB
存储引擎的
MySQL Server 8.0
以及NDB集群分发中未包含的其他应用程序
进行部署
。
MySQL Server 8.0二进制文件不能与MySQL NDB Cluster一起使用。
有关部署和使用InnoDB集群的更多信息,请参阅
第21章,
InnoDB集群
。
22.1.6节,“MySQL服务器使用的是InnoDB与NDB集群相比”
,论述之间的差异
NDB
和
InnoDB
存储引擎。
本章包含有关通过8.0.17-ndb-8.0.17发布的NDB Cluster 8.0版本的信息,该版本目前作为开发人员预览版提供。 NDB Cluster 7.6是最新的通用可用性版本,建议用于新部署; 有关NDB Cluster 7.6的信息,请参阅 NDB Cluster 7.6中的新增功能 。 有关NDB Cluster 7.5的类似信息,请参阅 NDB Cluster 7.5中的新增功能 。 NDB Cluster 7.4和7.3是以前在生产中仍然支持的GA版本; 请参阅 MySQL NDB Cluster 7.3和NDB Cluster 7.4 。 NDB Cluster 7.2是之前的GA版本系列,仍然可以维护,但我们建议新的生产部署使用NDB Cluster 7.6。 有关NDB Cluster 7.2的更多信息,请参阅 MySQL NDB Cluster 7.2 。
支持的平台。 NDB Cluster目前可在许多平台上使用和支持。 有关操作系统版本,操作系统分发版和硬件平台的特定组合的可用支持级别,请参阅 https://www.mysql.com/support/supportedplatforms/cluster.html 。
可用性。 NDB Cluster二进制和源代码包可从 https://dev.mysql.com/downloads/cluster/ 获得支持的平台 。
NDB群集版本号。
NDB 8.0遵循与MySQL Server 8.0系列发行版相同的发布模式,从MySQL 8.0.13和MySQL NDB Cluster 8.0.13开始。
在本
手册
和其他MySQL文档中,我们使用以
“
NDB
”
开头的版本号标识这些以及后来的NDB Cluster版本
。
此版本号是
NDBCLUSTER
NDB 8.0版本中使用
的
存储引擎的版本号,与NDB Cluster 8.0版本所基于的MySQL 8.0服务器版本相同。
NDB Cluster软件中使用的版本字符串。 MySQL NDB Cluster发行 版 提供 的 mysql 客户端 显示的版本字符串 使用以下格式:
mysql- mysql_server_version-cluster
mysql_server_version
表示NDB Cluster发行版所基于的MySQL Server的版本。
对于所有NDB簇8.0版本,这是
,这里
是版本号。
从源代码构建
或使用等效项将
后缀
添加
到版本字符串。
(请参见
第22.2.2.4节“在Linux上从源代码构建NDB集群”
和
第22.2.3.2节“在Windows上从源代码编译和安装NDB集群”
。)您可以在
mysql
客户端中
看到此格式
,如此处所示:
8.0.
nn
-DWITH_NDBCLUSTER
-cluster
外壳>mysql欢迎使用MySQL监视器。命令以;结尾; 或\ g。 您的MySQL连接ID是2 服务器版本:8.0.17-群集源分发 输入'help;' 或'\ h'寻求帮助。输入'\ c'清除缓冲区。 MySQL的>SELECT VERSION()\G*************************** 1。排******************** ******* VERSION():8.0.17-cluster 1排(0.00秒)
使用MySQL 8.0的NDB Cluster的第一个版本是NDB 8.0.13,它使用MySQL 8.0.13。
其他NDB Cluster程序显示的版本字符串通常不包含在MySQL 8.0发行版中,使用以下格式:
mysql-mysql_server_versionndb-ndb_engine_version
mysql_server_version
表示NDB Cluster发行版所基于的MySQL Server的版本。
对于所有NDB簇8.0版本,这是
,这里
是版本号。
是
此版本的NDB Cluster软件使用
的
存储引擎
的版本
。
对于所有NDB 8.0版本,此编号与MySQL Server版本相同。
您可以
在
ndb_mgm
客户端
中看到
命令
输出中使用的此格式
,如下所示:
8.0.
nn
ndb_engine_version
NDB
SHOW
ndb_mgm> SHOW
连接到Management Server:localhost:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 10.0.10.6(mysql-8.0.18 ndb-8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 10.0.10.8(mysql-8.0.18 ndb-8.0.17-ndb-8.0.17,Nodegroup:0)
[ndb_mgmd(MGM)] 1个节点
id = 3 @ 10.0.10.2(mysql-8.0.18 ndb-8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 4 @ 10.0.10.10(mysql-8.0.18 ndb-8.0.17-ndb-8.0.17)
id = 5(未连接,接受来自任何主机的连接)
与标准MySQL 8.0版本的兼容性。
虽然许多标准的MySQL模式和应用程序可以使用NDB Cluster,但使用NDB Cluster运行时,未修改的应用程序和数据库模式可能会略微不兼容或性能不佳(请参见
第22.1.7节“NDB集群的已知限制”)
)。
大多数问题都可以克服,但这也意味着您不太可能切换现有的应用程序数据存储区 - 例如,
MyISAM
或者
InnoDB
- 使用
NDB
存储引擎而不允许更改模式的可能性,查询和应用程序。
没有编译
的
mysqld
NDB
支持(即,没有
-DWITH_NDBCLUSTER_STORAGE_ENGINE
或它的别名
构建
-DWITH_NDBCLUSTER
)不能作为
使用它构建
的
mysqld的
替代品
。
NDB Cluster开发源代码树。 也可以从 https://github.com/mysql/mysql-server 访问NDB Cluster开发树 。
维护在 https://github.com/mysql/mysql-server 的NDB Cluster开发源 是根据GPL许可的。 有关使用Git获取MySQL源代码并自行构建它们的信息,请参见 第2.9.3节“使用开发源代码树安装MySQL” 。
与MySQL Server 8.0一样,NDB Cluster 8.0版本是使用 CMake 构建的 。
NDB Cluster 7.5和NDB Cluster 7.6可作为通用可用性(GA)版本提供; 建议将NDB 7.6用于新部署。 NDB Cluster 7.4和NDB Cluster 7.3是以前的GA版本,在生产中仍然受支持。 NDB 7.2是以前的GA版本系列,仍然保留; 不再建议用于新部署。 有关NDB 7.6中添加的主要功能的概述,请参阅 NDB Cluster 7.6中的新增功能 。 有关NDB Cluster 7.5的类似信息,请参阅 NDB Cluster 7.5中的新增功能 。 有关以前的NDB Cluster版本的信息,请参阅 MySQL NDB Cluster 7.3和NDB Cluster 7.4 以及 MySQL NDB Cluster 7.2 。
随着NDB Cluster不断发展,本章内容可能会进行修订。 有关NDB Cluster的更多信息,请访问MySQL网站 http://www.mysql.com/products/cluster/ 。
其他资源。 有关NDB Cluster的更多信息,请访问以下位置:
-
有关NDB Cluster的一些常见问题的解答,请参见 第A.10节“MySQL 8.0 FAQ:NDB Cluster” 。
-
NDB Cluster邮件列表: http : //lists.mysql.com/cluster 。
-
许多NDB Cluster用户和开发人员都在博客上介绍他们使用NDB Cluster的经验,并通过 PlanetMySQL 提供这些 经验 。
NDB Cluster 是一种在无共享系统中实现内存数据库 集群 的技术。 无共享架构使系统能够使用非常便宜的硬件,并且对硬件或软件的特定要求最低。
NDB Cluster的设计不会出现任何单点故障。 在无共享系统中,每个组件都应具有自己的内存和磁盘,并且不建议或不支持使用共享存储机制,如网络共享,网络文件系统和SAN。
NDB Cluster将标准MySQL服务器与称为内存的集群存储引擎
NDB
(代表
“
N
etwork
D
ata
B
ase
”
)
集成在一起
。
在我们的文档中,该术语
NDB
指的是特定于存储引擎的设置部分,而
“
MySQL NDB Cluster
”
指的是一个或多个MySQL服务器与
NDB
存储引擎的组合。
NDB群集由一组称为 主机 的计算机组成 ,每台 计算机 运行一个或多个进程。 这些称为 节点的 过程 可以包括MySQL服务器(用于访问NDB数据),数据节点(用于存储数据),一个或多个管理服务器,以及可能的其他专用数据访问程序。 这里显示了NDB集群中这些组件的关系:
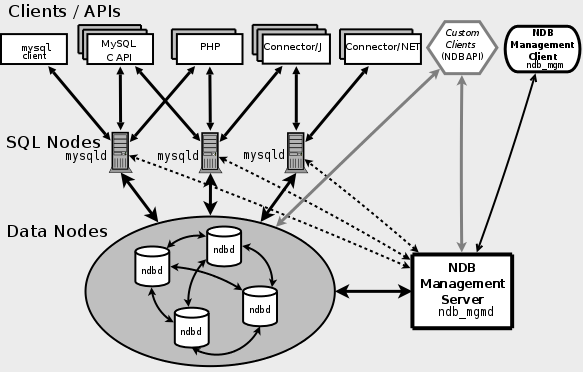
所有这些程序共同构成一个NDB集群(参见
第22.4节“NDB集群程序”
。当数据由
NDB
存储引擎存储时,表(和表数据)存储在数据节点中。这些表可直接从集群中的所有其他MySQL服务器(SQL节点)。因此,在集群中存储数据的工资单应用程序中,如果一个应用程序更新了员工的工资,则查询此数据的所有其他MySQL服务器都可以立即看到此更改。
尽管NDB Cluster SQL节点使用 mysqld 服务器守护程序,但它在许多关键方面 与MySQL 8.0发行版提供 的 mysqld 二进制文件不同,并且两个版本的 mysqld 不可互换。
此外,未连接到NDB群集的MySQL服务器无法使用
NDB
存储引擎,也无法访问任何NDB群集数据。
存储在NDB Cluster的数据节点中的数据可以进行镜像; 群集可以处理单个数据节点的故障,而不会因为丢失事务状态而导致少量事务中止。 由于事务性应用程序需要处理事务失败,因此这不应成为问题的根源。
可以停止并重新启动各个节点,然后可以重新加入系统(群集)。 滚动重启(其中所有节点依次重新启动)用于进行配置更改和软件升级(请参见 第22.5.5节“执行NDB群集的滚动重新启动” )。 滚动重启也用作在线添加新数据节点的过程的一部分(请参见 第22.5.15节“在线添加NDB群集数据节点” )。 有关数据节点的详细信息,它们在NDB集群中的组织方式以及它们如何处理和存储NDB集群数据,请参见 第22.1.2节“NDB集群节点,节点组,副本和分区” 。
可以使用
NDB
NDB群集管理客户端中的
-native
功能和
NDB群集分发中包含
的
ndb_restore
程序
来完成备份和还原NDB群集数据库
。
有关更多信息,请参见
第22.5.3节“NDB集群的在线备份”
和
第22.4.23节“
ndb_restore
- 还原NDB集群备份”
。
您还可以在
mysqldump
和MySQL服务器中
使用为此目的提供的标准MySQL功能
。
有关
更多信息
,
请参见
第4.5.4节“
mysqldump
- 数据库备份程序”
。
NDB Cluster节点可以采用不同的传输机制进行节点间通信; 在大多数实际部署中使用TCP / IP超过标准100 Mbps或更快的以太网硬件。
NDBCLUSTER
(也称为
NDB
)是一种内存存储引擎,提供高可用性和数据持久性功能。
的
NDBCLUSTER
存储引擎可以与一系列故障切换和负载平衡选项进行配置,但最简单的是开始在集群级别的存储引擎。
NDB Cluster的
NDB
存储引擎包含一整套数据,仅依赖于集群内部的其他数据。
NDB Cluster 的 “ Cluster ” 部分是独立于MySQL服务器配置的。 在NDB群集中,群集的每个部分都被视为一个 节点 。
在许多情况下,术语 “ 节点 ” 用于表示计算机,但在讨论NDB群集时,它意味着一个 过程 。 可以在一台计算机上运行多个节点; 对于运行一个或多个群集节点的计算机,我们使用术语 群集主机 。
有三种类型的集群节点,在最小的NDB集群配置中,将至少有三个节点,每种节点中的一种:
-
管理节点 :此类 节点 的作用是管理NDB集群中的其他节点,执行诸如提供配置数据,启动和停止节点以及运行备份等功能。 由于此节点类型管理其他节点的配置,因此应首先在任何其他节点之前启动此类型的节点。 使用命令 ndb_mgmd 启动MGM节点 。
-
数据节点 :此类节点存储群集数据。 存在与副本一样多的数据节点,乘以片段的数量(请参见 第22.1.2节“NDB群集节点,节点组,副本和分区” )。 例如,如果有两个副本,每个副本有两个片段,则需要四个数据节点。 一个副本足以用于数据存储,但不提供冗余; 因此,建议使用2个(或更多)副本来提供冗余,从而提供高可用性。 使用命令 ndbd 启动数据节点 (请参见 第22.4.1节“ ndbd - NDB集群数据节点守护程序” )或 ndbmtd (参见 第 22.4.3 节“ ndbmtd - NDB集群数据节点守护进程(多线程)” )。
NDB Cluster表通常完全存储在内存中而不是磁盘上(这就是我们将NDB Cluster称为 内存 数据库的原因)。 但是,一些NDB Cluster数据可以存储在磁盘上; 有关更多信息 , 请参见 第22.5.13节“NDB集群磁盘数据表” 。
-
SQL节点 :这是一个访问集群数据的节点。 对于NDB Cluster,SQL节点是使用
NDBCLUSTER存储引擎 的传统MySQL服务器 。 SQL节点是 使用 和 选项 启动 的 mysqld 进程 ,本章的其他地方对此进行了解释,可能还有其他MySQL服务器选项。--ndbcluster--ndb-connectstringSQL节点实际上只是一种特殊类型的 API节点 ,它指定访问NDB集群数据的任何应用程序。 API节点的另一个示例 是用于还原群集备份 的 ndb_restore 实用程序。 可以使用NDB API编写此类应用程序。 有关NDB API的基本信息,请参阅NDB API 入门 。
期望在生产环境中使用三节点设置是不现实的。 这种配置不提供冗余; 要从NDB Cluster的高可用性功能中受益,您必须使用多个数据和SQL节点。 强烈建议使用多个管理节点。
有关 NDB群集中节点,节点组,副本和分区 之间关系的简要介绍,请参见 第22.1.2节“NDB群集节点,节点组,副本和分区” 。
群集的配置涉及配置群集中的每个单独节点以及在节点之间设置各个通信链路。 NDB Cluster目前的设计目的是使数据节点在处理器功率,内存空间和带宽方面是同质的。 此外,为了提供单点配置,集群的所有配置数据作为一个整体位于一个配置文件中。
管理服务器管理群集配置文件和群集日志。 集群中的每个节点都从管理服务器检索配置数据,因此需要一种方法来确定管理服务器所在的位置。 当数据节点中发生有趣事件时,节点将有关这些事件的信息传输到管理服务器,然后管理服务器将信息写入集群日志。
此外,可以有任意数量的集群客户端进程或应用程序。
这些包括标准MySQL客户端,
NDB
特定API程序和管理客户端。
这些将在接下来的几段中描述。
标准MySQL客户端。 NDB Cluster可以与用PHP,Perl,C,C ++,Java,Python,Ruby等编写的现有MySQL应用程序一起使用。 此类客户端应用程序将SQL语句发送到作为NDB Cluster SQL节点的MySQL服务器并从其接收响应,其方式与它们与独立MySQL服务器交互的方式非常相似。
可以修改使用NDB群集作为数据源的MySQL客户端,以利用与多个MySQL服务器连接的能力来实现负载平衡和故障转移。
例如,使用Connector / J 5.0.6及更高版本的Java客户端可以使用
jdbc:mysql:loadbalance://
URL(在Connector / J 5.1.7中进行了改进)来透明地实现负载平衡;
有关将Connector / J与NDB Cluster一起使用的更多信息,请参阅
将Connector / J与NDB Cluster一起使用
。
NDB客户端程序。
可以编写客户端程序
NDBCLUSTER
,使用
NDB API
(高级C ++ API)
直接从
存储引擎
访问NDB Cluster数据
,绕过可能连接到群集的任何MySQL服务器
。
此类应用程序可能对于不需要SQL数据接口的专用目的很有用。
有关更多信息,请参阅
NDB API
。
NDB
也可以使用
NDB Cluster Connector for Java
为NDB Cluster编写特定的Java应用程序
。
此NDB集群连接器包括
ClusterJ
,这是一种高级数据库API,类似于对象关系映射持久性框架,如Hibernate和JPA,它们直接连接
NDBCLUSTER
,因此不需要访问MySQL服务器。
NDB Cluster for
ClusterJPA
也提供支持
,一个利用ClusterJ和JDBC优势的NDB集群的OpenJPA实现;
使用ClusterJ(绕过MySQL服务器)执行ID查找和其他快速操作,而使用JDBC通过MySQL服务器发送可以从MySQL的查询优化器中受益的更复杂的查询。
有关
详细信息
,
请参阅
Java和NDB Cluster
以及
ClusterJ API和数据对象模型
。
NDB Cluster还支持使用Node.js用JavaScript编写的应用程序。
MySQL Connector for JavaScript包括用于直接访问
NDB
存储引擎和MySQL服务器的
适配器
。
使用此连接器的应用程序通常是事件驱动的,并且使用与ClusterJ采用的方式类似的域对象模型。
有关更多信息,请参阅
适用于JavaScript的MySQL NoSQL Connector
。
用于NDB群集的Memcache API,作为 memcached 1.6及更高版本 的可加载 ndbmemcache 存储引擎实现,可用于提供使用memcache协议访问的持久NDB群集数据存储。
标准的 memcached 缓存引擎包含在NDB Cluster 8.0发行版中。 每个 memcached 服务器都可以直接访问存储在NDB Cluster中的数据,但也能够在本地缓存数据并从本地缓存中提供(某些)请求。
有关更多信息,请参阅 NDB群集的ndbmemcache-Memcache API 。
管理客户。 这些客户端连接到管理服务器,并提供用于正常启动和停止节点,启动和停止消息跟踪(仅限调试版本),显示节点版本和状态,启动和停止备份等命令。 此类程序的一个示例是 随NDB Cluster提供 的 ndb_mgm 管理客户端(请参见 第22.4.5节“ ndb_mgm - NDB群集管理客户端” )。 可以使用 MGM API 编写此类应用程序, MGM API 是一种直接与一个或多个NDB Cluster管理服务器通信的C语言API。 有关更多信息,请参阅 MGM API 。
Oracle还提供了MySQL Cluster Manager,它提供了一个高级命令行界面,简化了许多复杂的NDB Cluster管理任务,例如重新启动具有大量节点的NDB Cluster。 MySQL Cluster Manager客户端还支持用于获取和设置大多数节点配置参数的值的命令,以及 与NDB Cluster相关的 mysqld 服务器选项和变量。 有关 更多信息, 请参阅“ MySQL™Cluster Manager 1.4.7用户手册” 。
事件日志。 NDB群集按类别(启动,关闭,错误,检查点等),优先级和严重性记录事件。 有关所有可报告事件的完整列表,请参见 第22.5.6节“在NDB群集中生成的事件报告” 。 事件日志属于此处列出的两种类型:
-
群集日志 :记录整个群集的所有所需可报告事件。
-
节点日志 :为每个单独节点保留的单独日志。
在正常情况下,仅保留和检查群集日志是必要且充分的。 只需要为应用程序开发和调试目的查阅节点日志。
检查点。
一般来说,当数据保存到磁盘时,据说
已到达
检查点
。
更具体的是NDB Cluster,检查点是所有已提交事务存储在磁盘上的时间点。
关于
NDB
存储引擎,有两种类型的检查点一起工作以确保维持集群数据的一致视图。
这些显示在以下列表中:
-
本地检查点(LCP) :这是一个特定于单个节点的检查点; 但是,LCP或多或少同时发生在集群中的所有节点上。 LCP通常每隔几分钟发生一次; 精确的间隔会有所不同,并取决于节点存储的数据量,群集活动的级别以及其他因素。
NDB 8.0支持部分LCP,可以在某些条件下显着提高性能。 请参阅 启用部分LCP并控制其使用的存储量的配置
EnablePartialLcp和RecoveryWork配置参数 的说明 。 -
全局检查点(GCP) :每隔几秒就会发生一次GCP,此时所有节点的事务都已同步,并且重做日志被刷新到磁盘。
有关本地检查点和全局检查点创建的文件和目录的详细信息,请参阅 NDB群集数据节点文件系统目录文件 。
本节讨论NDB群集分割和复制数据以进行存储的方式。
在接下来的几段中将讨论一些理解这一主题的核心概念。
数据节点。 一个 ndbd 或 ndbmtd 进程,它存储一个或多个 副本 - 即 分配给该节点所属的节点组 的 分区 副本 (本节稍后讨论)。
每个数据节点应位于单独的计算机上。 虽然也可以在一台计算机上托管多个数据节点进程,但通常不建议这样的配置。
当引用 ndbd 或 ndbmtd 进程 时 ,术语 “ 节点 ” 和 “ 数据节点 ” 通常可互换使用 ; 如上所述,管理节点( ndb_mgmd 进程)和SQL节点( mysqld 进程)在本讨论中如此指定。
节点组。 节点组由一个或多个节点组成,并存储分区或 副本 集 (请参阅下一项)。
NDB群集中的节点组数量不能直接配置;
它是数据节点数量和副本数量(
NoOfReplicas
配置参数)的函数,如下所示:
[节点组数] = [数据节点数] / NoOfReplicas
因此,具有4个数据节点的NDB簇如果
NoOfReplicas
在
config.ini
文件中
设置为1
则具有4个节点组
,2个节点组if
NoOfReplicas
设置为2,并且1个节点组if
NoOfReplicas
设置为4.副本将在本节稍后讨论;
有关更多信息
NoOfReplicas
,请参见
第22.3.3.6节“定义NDB集群数据节点”
。
NDB群集中的所有节点组必须具有相同数量的数据节点。
您可以在线将新节点组(以及新数据节点)添加到正在运行的NDB集群中; 有关更多信息 , 请参见 第22.5.15节“在线添加NDB集群数据节点” 。
划分。 这是群集存储的数据的一部分。 每个节点负责保留分配给它的任何分区的至少一个副本(即,至少一个副本)。
NDB Cluster默认使用的分区数取决于数据节点的数量和数据节点使用的LDM线程数,如下所示:
[分区数] = [数据节点数] * [LDM线程数]
使用运行
ndbmtd的
数据节点时
,LDM线程的数量由设置控制
MaxNoOfExecutionThreads
。
使用
ndbd时
,只有一个LDM线程,这意味着与参与集群的节点一样多的集群分区。
这也是使用时的情况下
ndbmtd
与
MaxNoOfExecutionThreads
设置为3或更小。
(您应该知道LDM线程的数量随着此参数的值而增加,但不是严格线性的,并且在设置它时还有其他限制;
MaxNoOfExecutionThreads
有关详细信息
,请参阅说明
。)
NDB和用户定义的分区。
NDB群集通常会
NDBCLUSTER
自动
分区
表。
但是,也可以对表使用用户定义的分区
NDBCLUSTER
。
这受到以下限制:
-
生产中只 支持
KEY和LINEAR KEY分区方案NDB。 -
可以为任何
NDB表 显式定义的最大分区数 是 ,NDB群集中的节点组数量正如本节前面所讨论的那样确定。 将 ndbd 用于数据节点进程时,设置 无效; 在这种情况下,为了执行该计算,可以将其视为等于1。8 * MaxNoOfExecutionThreads * [number of node groups]MaxNoOfExecutionThreads
有关NDB集群和用户定义分区的更多信息,请参见 第22.1.7节“NDB集群的已知限制” 和 第23.6.2节“分区与存储引擎相关的限制” 。
复制品。 这是群集分区的副本。 节点组中的每个节点都存储一个副本。 有时也称为 分区副本 。 副本数等于每个节点组的节点数。
副本完全属于单个节点; 节点可以(通常会)存储多个副本。
下图说明了一个NDB集群,其中四个数据节点运行 ndbd ,分别安排在两个节点组中,每个节点包含两个节点; 节点1和2属于节点组0,节点3和4属于节点组1。
这里只显示数据节点; 尽管有效的NDB群集需要 ndb_mgmd 进程进行群集管理,并且至少有一个SQL节点需要访问群集存储的数据,但为清楚起见,这些已从图中省略。
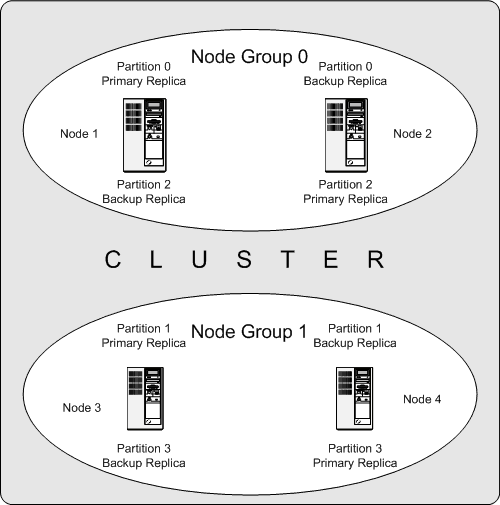
群集存储的数据分为四个分区,编号为0,1,2和3.每个分区在同一节点组中存储多个副本。 分区存储在备用节点组中,如下所示:
-
分区0存储在节点组0上; 一个 主副本 (主副本)被存储在节点1和一个 备份副本 (分区的备份副本)被存储在节点2上。
-
分区1存储在另一个节点组(节点组1)上; 此分区的主副本位于节点3上,其备份副本位于节点4上。
-
分区2存储在节点组0上。但是,它的两个副本的放置与分区0的放置相反; 对于分区2,主副本存储在节点2上,备份存储在节点1上。
-
分区3存储在节点组1上,并且其两个副本的放置与分区1的位置相反。即,其主副本位于节点4上,备份在节点3上。
对于NDB集群的持续运行,这意味着:只要参与集群的每个节点组至少有一个节点运行,集群就拥有所有数据的完整副本并且仍然可行。 这将在下图中说明。
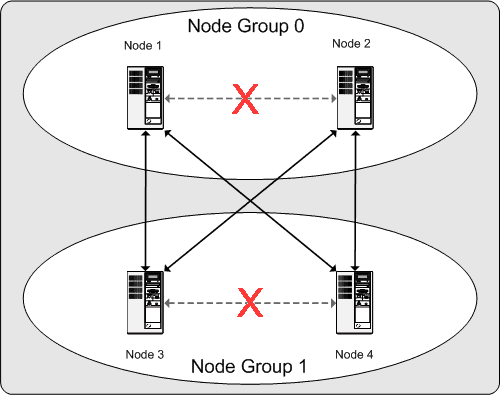
在此示例中,群集由两个节点组组成,每个节点组由两个数据节点组成。 每个数据节点都运行 ndbd 的实例 。 来自节点组0的至少一个节点和来自节点组1的至少一个节点的任何组合足以使群集保持 “ 活动 ” 。 但是,如果来自单个节点组的两个节点都发生故障,则由另一个节点组中的其余两个节点组成的组合是不够的。 在这种情况下,群集已丢失整个分区,因此无法再提供对所有NDB群集数据的完整集合的访问。
单个NDB群集实例支持的最大节点组数为48。
NDB Cluster的优势之一是它可以在商用硬件上运行,除了大量RAM之外,在这方面没有任何异常要求,因为所有实时数据存储都是在内存中完成的。 (可以使用磁盘数据表减少此要求 - 有关这些内容的更多信息, 请参见 第22.5.13节“NDB群集磁盘数据表” 。)当然,多个更快的CPU可以提高性能。 其他NDB Cluster进程的内存要求相对较小。
NDB Cluster的软件要求也不高。 主机操作系统不需要任何不寻常的模块,服务,应用程序或配置来支持NDB群集。 对于支持的操作系统,标准安装应该足够了。 MySQL软件要求很简单:所需要的只是NDB Cluster的生产版本。 仅仅为了能够使用NDB集群,自己编译MySQL并不是绝对必要的。 我们假设您使用的是适用于您平台的二进制文件,可从NDB Cluster软件下载页面获取, 网址 为 https://dev.mysql.com/downloads/cluster/ 。
对于节点之间的通信,NDB Cluster支持任何标准拓扑中的TCP / IP网络,每个主机的最低预期值是标准的100 Mbps以太网卡,以及交换机,集线器或路由器,以便为整个集群提供网络连接。 我们强烈建议NDB群集在其自己的子网上运行,该子网不与不构成群集一部分的计算机共享,原因如下:
-
安全。 NDB群集节点之间的通信不以任何方式加密或屏蔽。 保护NDB群集内传输的唯一方法是在受保护的网络上运行NDB群集。 如果您打算将NDB Cluster用于Web应用程序,则群集应该位于防火墙之后,而不是位于网络的 非军事 区( DMZ )或其他地方。
有关 更多信息 , 请参见 第22.5.12.1节“NDB群集安全性和网络问题” 。
-
效率。 在专用或受保护的网络上设置NDB群集使群集可以独占集群主机之间的带宽。 为NDB群集使用单独的交换机不仅有助于防止未经授权访问NDB群集数据,还可确保NDB群集节点免受网络上其他计算机之间传输的干扰。 为了提高可靠性,您可以使用双交换机和双卡将网络作为单点故障排除; 许多设备驱动程序支持此类通信链接的故障转移。
网络通信和延迟。 NDB Cluster需要数据节点和API节点(包括SQL节点)之间以及数据节点和其他数据节点之间的通信,以执行查询和更新。 这些进程之间的通信延迟可直接影响观察到的用户查询的性能和延迟。 此外,为了在节点无声故障的情况下保持一致性和服务,NDB Cluster使用心跳和超时机制,将来自节点的通信的延长丢失视为节点故障。 这可以减少冗余。 回想一下,为了保持数据一致性,当节点组中的最后一个节点发生故障时,NDB集群会关闭。 因此,为避免增加强制关机的风险,
数据或API节点的故障导致涉及故障节点的所有未提交事务的中止。 数据节点恢复需要在数据节点恢复服务之前,从幸存的数据节点同步故障节点的数据,并重新建立基于磁盘的重做和检查点日志。 此恢复可能需要一些时间,在此期间群集以减少的冗余运行。
心跳依赖于所有节点及时生成心跳信号。 如果节点过载,由于与其他程序共享导致机器CPU不足,或者由于交换而出现延迟,则可能无法执行此操作。 如果心跳生成被充分延迟,则其他节点会将响应缓慢的节点视为失败。
在某些情况下,将慢节点作为故障节点的这种处理可能是或可能不是合乎需要的,这取决于节点的慢速操作对集群其余部分的影响。
当设置超时值等
HeartbeatIntervalDbDb
和
HeartbeatIntervalDbApi
对NDB集群,必须小心照顾,以实现快速检测,故障转移和恢复工作,同时避免潜在的昂贵误报。
如果预期数据节点之间的通信延迟高于LAN环境中预期的通信延迟(大约100μs),则必须增加超时参数以确保任何允许的延迟时段都在配置的超时内。 以这种方式增加超时对于检测故障的最坏情况时间以及因此服务恢复的时间具有相应的影响。
LAN环境通常可以配置稳定的低延迟,并且可以通过快速故障转移提供冗余。 可以从TCP级别可见的最小和受控延迟(NDB群集正常运行)中恢复单个链路故障。 WAN环境可能会提供一系列延迟,以及冗余和较慢的故障转移时间。 单个链路故障可能需要在端到端连接恢复之前传播路由更改。 在TCP级别,这可能表现为各个通道上的大延迟。 在这些情况下观察到的最坏情况的TCP延迟与IP层在故障周围重新路由的最坏情况时间有关。
以下部分描述了与早期版本系列相比,MySQL NDB Cluster 8.0到8.0.17中NDB Cluster实现的更改。 NDB Cluster 8.0目前在Developer Preview版本中可用。 NDB Cluster 7.6作为通用可用性版本提供,NDB Cluster 7.5也是如此。有关NDB Cluster 7.6中的添加和其他更改的信息,请参阅 NDB Cluster 7.5中的新增功能 ; 有关NDB Cluster 7.5中的新功能和其他更改的信息,请参阅 NDB Cluster 7.6中的 新增功能 。
NDB Cluster 7.4和7.3是最新的通用版本,仍然受支持。 NDB Cluster 7.2是以前的GA版本,在现有部署的生产中仍然受支持。 生产中不再维护或支持NDB 7.1及更早版本系列 。 我们建议新部署使用NDB Cluster 7.6或NDB Cluster 7.5。 有关NDB 7.4和NDB 7.3的信息,请参阅 MySQL NDB Cluster 7.3和NDB Cluster 7.4 。 有关NDB 7.2和以前的NDB版本的信息,请参阅 MySQL NDB Cluster 7.2 。
NDB Cluster 8.0的新增功能
可能感兴趣的NDB Cluster 8.0中的主要更改和新功能显示在以下列表中:
-
INFORMATION_SCHEMA更改。 在表中显示有关磁盘数据文件的信息时进行了以下更改
INFORMATION_SCHEMA.FILES:-
表空间和日志文件组不再在
FILES表中 表示 。 (这些结构实际上不是文件。) -
现在,每个数据文件都由
FILES表中的 一行表示 。 现在,每个撤消日志文件也仅在此表中以一行表示。 (以前,每个数据节点上的每个文件的每个副本都显示一行。) -
对于与数据文件或撤消日志文件对应的行,节点ID和撤消日志缓冲区信息不再显示在 表 的
EXTRA列中FILES。
此外,
INFORMATION_SCHEMA现在使用MySQL Cluster表的表空间统计信息填充表。 (缺陷#27167728) -
-
ndb_perror的错误信息。 删除了 perror 的已弃用
--ndb选项 。 使用 ndb_perror 从 错误代码中 获取错误消息信息 。 (Bug#81704,Bug#81705,Bug#23523926,Bug#23523957)NDB -
与MySQL服务器并行开发。 从此版本开始,MySQL NDB Cluster正在与标准MySQL 8.0服务器并行开发,具有以下功能的新统一版本模型:
-
NDB 8.0是在MySQL 8.0源代码树中开发,构建和发布的。
-
NDB Cluster 8.0版本的编号方案遵循MySQL 8.0的方案,从当前的MySQL版本(8.0.13)开始。
-
使用NDB支持构建源会附加
-cluster到 mysql 返回的版本字符串-V,如下所示:shell»
mysql -V适用于x86_64的Linux的mysql Ver 8.0.13-cluster(源代码分发)NDB二进制文件继续显示MySQL Server版本和NDB引擎版本,如下所示:
外壳>
ndb_mgm -VMySQL distrib mysql-8.0.13 ndb-8.0.13-dmr,适用于Linux(x86_64)在MySQL Cluster NDB 8.0中,这两个版本号始终相同。
要使用NDB Cluster支持构建MySQL 8.0.13(或更高版本)源,请使用CMake选项
-DWITH_NDBCLUSTER。 -
-
离线多线程索引构建。 现在可以指定一组内核用于执行有序索引的脱机多线程构建的I / O线程,而不是正常的I / O任务,如文件I / O,压缩或解压缩。 此上下文中的 “ 脱机 ” 是指在未写入父表时执行的有序索引的构建; 当
NDB集群执行节点或系统重新启动时,或者作为使用 ndb_restore 从备份还原集群的一部分 时,会发生此类构建--rebuild-indexes。此外,还修改了脱机索引构建工作的默认行为,以使用 ndbmtd 可用的所有核心 ,而不是将其自身限制为为I / O线程保留的核心。 这样做可以改善重新启动和恢复时间以及性能,可用性和用户体验。
此增强功能实现如下:
-
默认值
BuildIndexThreads从0更改为128.这意味着默认情况下,脱机排序索引构建现在是多线程的。 -
默认值
TwoPassInitialNodeRestartCopy从更改false为true。 这意味着初始节点重新启动首先将所有数据从 “ 活动 ” 节点 复制 到正在启动的节点,而不创建任何索引 - 构建有序索引脱机,然后再次将其数据与活动节点同步,即同步两次,在两个同步之间离线构建索引。 这会导致初始节点重新启动的行为更像是节点的正常重启,并减少构建索引所需的时间。 -
idxbld为ThreadConfig配置参数 定义了 新的线程类型( ) ,以允许将脱机索引构建线程锁定到特定的CPU。
此外,
NDB现在 通过以下两个条件 区分 “ ThreadConfig ” 可访问的线程类型 :-
线程是否是执行线程。 的类型的线
main,ldm,recv,rep,tc,和send是执行线程; 线程类型io,watchdog而idxbld不是。 -
将线程分配给给定任务是永久性的还是临时性的。 目前所有线程类型除了
idxbld是永久性的。
有关其他信息,请参阅手册中参数的说明。 (Bug#25835748,Bug#26928111)
-
-
logbuffers表备份进程信息。 执行NDB备份时,该
ndbinfo.logbuffers表现在显示有关每个数据节点上备份过程的缓冲区使用情况的信息。 这是作为行反映,除了两个新的日志类型REDO和DD-UNDO。 其中一行具有日志类型BACKUP-DATA,该 类型 显示备份期间将片段复制到备份文件时使用的数据缓冲区数量。 另一行具有日志类型BACKUP-LOG,该 类型 显示备份期间用于记录备份开始后所做更改的日志缓冲区数量。 这些log_type行中的 每一 行都显示在logbuffers表中的每个数据节点。 仅当NDB备份当前正在进行时,具有这两种日志类型的行才会出现在表中。 (虫号#25822988) -
Windows上的进程表。 Windows平台上
RESTART用于生成和重新启动 mysqld 的监视器进程的进程ID 现在在ndbinfo.processes表中显示为angel_pid。 -
ODirectSyncFlag。 添加了
ODirectSyncFlag数据节点 的 配置参数。 启用后,数据节点会将所有已完成的文件系统写入视为重做日志,就好像它们已使用执行一样fsync。(缺陷号25428560)
-
数据节点日志缓冲区大小控制。 添加了 ndbd 和 ndbmtd
--logbuffer-size选项 ,用于调试大量日志消息。 这可以控制数据节点日志缓冲区的大小; 默认(32K)用于正常操作。 (Bug#89679,Bug#27550943) -
字符串哈希改进。 在NDB 8.0之前,所有字符串散列都是基于首先将字符串转换为规范化形式,然后对生成的二进制映像进行MD5散列。 这可能会导致一些性能问题,原因如下:
-
规范化的字符串始终以空格填充到其全长。 对于a
VARCHAR,这通常涉及添加比原始字符串中的字符更多的空格。 -
字符串库未针对此空间填充进行优化,并且在某些用例中增加了相当大的开销。
-
填充语义在字符集之间变化,其中一些字符集没有填充到它们的全长。
-
即使没有空间填充,转换后的字符串也会变得非常大; 某些Unicode 9.0排序规则可以将单个代码点转换为100个字节或更多字符数据。
-
随后的MD5散列主要由带空格的填充组成,并且不是特别有效,可能通过刷新L1高速缓存的重要部分而导致额外的性能损失。
排序规则提供自己的哈希函数,直接对字符串进行哈希处理,而无需先创建规范化字符串。 此外,对于Unicode 9.0归类,散列是在没有填充的情况下计算的。
NDB现在,只要对标识为使用Unicode 9.0排序规则的字符串进行散列,就可以利用此内置函数。因为,对于其他排序规则,现有的数据库在转换后的字符串上进行散列分区,
NDB继续使用前面的方法来散列使用这些字符串的字符串,以保持兼容性。 (Bug#89590,Bug#89604,Bug#89609,Bug#27515000,Bug#27523758,Bug#27522732)(也可以看看。)
-
-
使用.frm文件即时升级表。 在NDB 7.6及更早版本中创建的表包含压缩
.frm文件 形式的元数据 ,MySQL 8.0不再支持该文件。 为了便于在线升级到NDB 8.0,NDB执行此元数据的即时转换并将其写入MySQL服务器的数据字典,这使得 NDB Cluster 8.0中 的 mysqld 能够与表一起使用,而不会阻止随后使用该表。以前的NDB软件 版本 。重要一旦在NDB 8.0中修改了表的结构,就会使用数据字典存储其元数据,并且NDB 7.6及更早版本无法再访问它。
此增强功能还可以将
NDB使用早期版本创建 的 备份 还原 到运行NDB 8.0(或更高版本)的群集。 -
表空间对象的模式同步。 当MySQL服务器作为SQL节点连接到NDB集群时,它会将其数据字典与字典中的信息同步
NDB。以前,
NDB在连接新SQL节点时同步 的唯一 对象是数据库和表; MySQL NDB Cluster 8.0.14及更高版本还实现了磁盘数据对象(包括表空间和日志文件组)的模式同步。 除了其他好处之外,这消除了在本NDB机备份和恢复之后 MySQL数据字典和 字典 之间不匹配的可能性 ,其中表空间和日志文件组被还原到NDB字典,而不是MySQL服务器的数据字典。 -
处理mysqld选项文件中的NO_AUTO_CREATE_USER。 当 选项文件中 存在 选项
NO_AUTO_CREATE_USER值sql_mode阻止 mysqld 启动 时,现在会将错误写入服务器日志 。 -
处理对不存在的表空间的引用。 不再可能发出
CREATE TABLE引用不存在的表空间 的 语句。 这样的声明现在失败并出现错误。 -
重置MASTER更改。 由于MySQL服务器现在
RESET MASTER使用全局读锁 执行 ,因此与NDB Cluster一起使用时此语句的行为在以下两个方面发生了变化:-
它不再保证是同步的; 也就是说,现在可能
RESET MASTER不会记录之前发出 的读取, 直到旋转二进制日志之后。 -
无论语句是在写入二进制日志的同一SQL节点上发布,还是在同一集群中的不同SQL节点上发布,它现在的行为都相同。
注意SHOW BINLOG EVENTS,FLUSH LOGS和大多数数据定义语句一样,在先前NDB版本中 继续,以 同步方式运行。 -
-
NDB表额外的元数据更改。 在NDB 8.0.14及更高版本中,表的额外元数据属性
NDB用于存储来自MySQL数据字典的序列化元数据,而不是像先前版本一样存储表的二进制表示。 (这是一个.frm文件,MySQL服务器不再使用它 - 请参阅 第14章, MySQL数据字典 。)作为支持此更改的工作的一部分,表的额外元数据的可用大小已增加。 这意味着NDB在NDB Cluster 8.0.14及更高版本中创建的表与以前的NDB Cluster版本不兼容。 在先前版本中创建的表可以与NDB 8.0.14及更高版本一起使用,但之后的版本不能打开。有关更多信息,请参见 第22.2.8节“升级和降级NDB集群” 。
-
磁盘数据文件分发。 从NDB Cluster 8.0.14开始,
NDB使用MySQL数据字典确保磁盘数据文件和相关结构(如表空间和日志文件组)在所有连接的SQL节点之间正确分布。 -
ndb_restore选项。 从NDB 8.0.16开始, 调用 ndb_restore 时都需要
--nodeid和--backupid选项 。 -
ndb_log_bin系统变量。 从NDB 8.0.16开始,
ndb_log_bin系统变量 的默认值 已从TRUEto 更改 为FALSE。 -
NDB元数据更改检测。 NDB 8.0.16实现了一种新机制,用于使用MySQL数据字典检测数据对象(如表,表空间和日志文件组)的元数据更新。 这是使用线程(
NDB元数据更改监视器线程)完成的,该线程在后台运行并定期检查NDB字典和MySQL数据字典 之间的不一致 。默认情况下,监视器每60秒执行一次元数据检查。 轮询间隔可以通过设置
ndb_metadata_check_interval系统变量 的值来调整 ; 通过将ndb_metadata_check系统变量 设置 为OFF, 可以完全禁用轮询 。 状态变量,Ndb_metadata_detected_count显示自 mysqld 上次启动以来检测到不一致 的次数 。 -
不再支持NDB 7.x分布式权限。 大多数
NDB支持在连接到NDB集群的MySQL服务器之间分配特权的代码,如NDB 7.6及更早版本中所实现的(参见 NDB集群的分布式MySQL权限 )已被删除。 这是因为这样的特权表在NDB 8.0中无法正常运行,并且是MySQL服务器特权系统更改的结果(参见 第6.2.3节“授权表” )。保留使用
NDB存储引擎并在先前版本中创建的 权限表是安全的,但不是必需的 ,但它们不再用于NDB Cluster 8.0中的访问控制。 在NDB 8.0.16及更高版本中,当一个 充当SQL节点 的 mysqld 检测到这样的表时NDB,它会向MySQL服务器日志写一个警告,并创建InnoDB自己的本地影子表; 在连接到NDB群集的每个MySQL服务器上创建此类影子表。 从NDB 7.6或更早版本执行升级时,NDB可以使用 ndb_drop_table 安全地删除 权限表 一旦所有充当SQL节点的MySQL服务器都已升级。该 ndb_restore 实用程序的
--restore-privilege-tables选项,继续NDB 8.0兑现,并且仍可以用于恢复存在于NDB簇的先前版本带到运行NDB 8.0集群备份分布式权限表。 这些表按照前一段中的描述进行处理。有关从以前的NDB Cluster版本升级到NDB 8.0的其他信息,请参见 第22.2.8节“升级和降级NDB群集” 。
-
动态事务资源分配。 现在使用动态内存池执行 事务corrdinator中的资源分配(请参阅 DBTC块 )。 这意味着由数据节点的配置参数,例如确定资源分配
MaxDMLOperationsPerTransaction,MaxNoOfConcurrentIndexOperations,MaxNoOfConcurrentOperations,MaxNoOfConcurrentScans,MaxNoOfConcurrentTransactions,MaxNoOfFiredTriggers,MaxNoOfLocalScans,和TransactionBufferMemory现在以这样的方式完成:如果由这些参数中的每一个表示的负载在所有这些资源的目标负载内,则可以限制这些资源中的其他资源以便不超过可用的总资源。作为此项工作的一部分,添加了几个控制
DBTC此处列出的 事务资源的新数据节点参数 : -
每个数据节点使用多个LDM进行备份。
NDB现在可以使用多个本地数据管理器(LDM)在各个数据节点上以并行方式执行备份。 (以前,备份是跨数据节点并行完成的,但在数据节点进程中始终是串行的。) ndb_mgm 客户端中 的START BACKUP命令 不需要特殊语法 来启用此功能,但所有数据节点都必须使用多个LDM。 这意味着数据节点必须运行 ndbmtd ( ndbd 是单线程的,因此总是只有一个LDM),并且它们必须配置为在进行备份之前使用多个LDM; 可以通过选择用于多线程数据节点的配置参数中的一个适当的设定为此MaxNoOfExecutionThreads或ThreadConfig。使用多个LDM的备份在 目录 下创建子目录,每个LDM一个 。 ndb_restore 现在自动检测这些子目录,如果存在,则尝试并行恢复备份; 有关详细信息 , 请参见 第22.4.23.2节“从并行备份中恢复” 。 (恢复单线程备份与以前版本相同 。)还可以 通过修改通常的恢复过程, 使用 先前版本的NDB Cluster中 的 ndb_restore 二进制文件 并行恢复备份 。 第22.4.23.2.2节“串行恢复并行备份”
BACKUP/BACKUP-backup_id/NDB,提供有关如何执行此操作的信息。 -
条件下推增强功能。 以前,条件下推仅限于谓词术语,这些术语指的是推送条件的同一个表中的列值。 在NDB 8.0.16中,删除了此限制,以便查询计划中较早的表中的列值也可以从推送条件中引用。
按下条件的较大部分允许数据节点过滤掉更多行,从而减少 mysqld 在连接处理期间必须处理 的行数 。 这种增强的另一个好处是可以在LDM线程中并行执行过滤,而不是在SQL节点上的单个mysqld进程中执行; 这有可能显着提高查询性能。
所比较的列值之间的类型兼容性的现有规则继续适用(参见 第8.2.1.4节“引擎条件下推优化” )。
-
ndb_mgm SHOW命令和单用户模式。 从NDB 8.0.17开始,当群集处于单用户模式时,管理客户端
SHOW命令 的输出 指示在此模式生效时具有独占访问权限的API或SQL节点。 -
架构分发增强功能。
NDB处理模式操作并跟踪其进度 的 模式分发协调器已在NDB 8.0.17中进行了扩展,以确保在模式操作期间使用的资源在结束时被释放。 以前,这项工作的一部分是由架构分发客户端完成的; 这已经发生了变化,因为客户端并不总是拥有所有需要的状态信息,当客户端决定在完成之前放弃模式操作并且没有通知协调器时,这可能导致资源泄漏。为了帮助解决此问题,已将架构操作超时检测从架构分发客户端移至协调器,从而为协调器提供了清除架构操作期间使用的任何资源的机会。 协调器现在定期检查正在进行的模式操作是否超时,并在检测到超时时将尚未完成给定模式操作的参与者标记为失败。 每当发生模式操作超时时,它还会提供合适的警告。 (应该注意,在检测到这样的超时之后,模式操作本身继续。
作为这项工作的另一部分,新的 mysqld 选项
--ndb-schema-dist-timeout可以设置等待架构操作被标记为超时的时间长度。
接下来的几节包含有关
NDB
配置参数和NDB特定的
mysqld
选项以及已在NDB 8.0中添加,弃用或删除的变量的信息。
NDB 8.0中添加了以下节点配置参数。
-
ReservedConcurrentIndexOperations:在一个数据节点上具有专用资源的同时索引操作的数量。 在NDB 8.0.16中添加。 -
ReservedConcurrentOperations:在一个数据节点上的事务协调器中具有专用资源的同时操作的数量。 在NDB 8.0.16中添加。 -
ReservedConcurrentScans:在一个数据节点上具有专用资源的同时扫描数。 在NDB 8.0.16中添加。 -
ReservedConcurrentTransactions:在一个数据节点上具有专用资源的同时事务的数量。 在NDB 8.0.16中添加。 -
ReservedFiredTriggers:在一个数据节点上具有专用资源的触发器数。 在NDB 8.0.16中添加。 -
ReservedLocalScans:在一个数据节点上具有专用资源的同时片段扫描的数量。 在NDB 8.0.16中添加。 -
ReservedTransactionBufferMemory:分配给每个数据节点的密钥和属性数据的动态缓冲区空间(以字节为单位)。 在NDB 8.0.16中添加。
在NDB 8.0中添加了 以下 mysqld 系统变量,状态变量和选项。
-
Ndb_metadata_detected_count:NDB元数据更改监视器线程检测到更改的次数。 在NDB 8.0.16中添加。 -
ndb-schema-dist-timeout:在架构分发期间检测到超时之前等待多长时间。 在NDB 8.0.17中添加。 -
ndb_metadata_check:启用与MySQL数据字典相关的NDB元数据更改的自动检测; 默认启用。 在NDB 8.0.16中添加。 -
ndb_metadata_check_interval:以秒为单位的间隔,用于检查与MySQL数据字典相关的NDB元数据更改。 在NDB 8.0.16中添加。 -
ndbinfo:如果支持,启用ndbinfo插件。 在NDB 8.0.13中添加。
MySQL Server在存储引擎中提供了许多选择。
由于双方
NDB
并
InnoDB
可以作为事务的MySQL存储引擎,MySQL服务器的用户有时会感兴趣的NDB集群。
他们认为
NDB
可以替代或升级到
InnoDB
MySQL 8.0中
的默认
存储引擎。
虽然
NDB
并且
InnoDB
具有共同特征,但在体系结构和实现方面存在差异,因此一些现有的MySQL服务器应用程序和使用方案可以很好地适用于NDB
Cluster,但不是所有这些都适用。
在本节中,我们将讨论和比较
NDB
NDB 8.0
InnoDB
使用
的
存储引擎与
MySQL 8.0中
使用的
一些特性
。
接下来的几节提供了技术比较。
在许多情况下,必须根据具体情况决定何时何地使用NDB Cluster,并考虑所有因素。
虽然为每个可能的使用场景提供细节超出了本文档的范围,但我们还尝试提供一些关于一些常见类型的应用程序
NDB
相对于
InnoDB
后端
的相对适用性的非常一般的指导
。
NDB Cluster 8.0使用
基于MySQL 8.0
的
mysqld
,包括对
InnoDB
1.1的
支持
。
虽然可以将
InnoDB
表与NDB Cluster
一起使用
,但这些表不是群集的。
也无法使用带有MySQL Server 8.0的NDB Cluster 8.0发行版中的程序或库,反之亦然。
虽然某些类型的常见业务应用程序也可以在NDB Cluster或MySQL Server上运行(最有可能使用
InnoDB
存储引擎),但是存在一些重要的架构和实现差异。
第22.1.6.1节“NDB和InnoDB存储引擎之间的差异”
提供了这些差异的摘要。
由于存在差异,一些使用场景显然更适合于一个引擎或另一个引擎;
请参见
第22.1.6.2节“NDB和InnoDB工作负载”
。
这反过来又对类型的应用,更好地适合用于有冲击
NDB
或
InnoDB
。
请参见
第22.1.6.3节“NDB和InnoDB功能使用摘要”
,用于比较每种用于常见类型的数据库应用程序的相对适用性。
有关
存储引擎
NDB
和
MEMORY
存储引擎
的相对特性的信息
,请参阅
何时使用MEMORY或NDB群集
。
有关MySQL存储引擎的其他信息 , 请参见 第16章, 备用 存储引擎。
该
NDB
存储引擎采用分布式,无共享架构,这会导致它从行为不同的方式实现
InnoDB
在多种方式。
对于那些不习惯使用的人来说
NDB
,由于其在交易,外键,表格限制和其他特征方面的分布性,可能会出现意外行为。
这些如下表所示:
表22.1 InnoDB和NDB存储引擎之间的差异
| 特征 | InnoDB
(MySQL 8.0)
|
NDB
8
|
|---|---|---|
| MySQL服务器版 | 8 | 8 |
InnoDB
版
|
InnoDB
8.0.18
|
InnoDB
8.0.18
|
| NDB群集版本 | N / A | NDB
8.0.17 / 8.0.17
|
| 存储限制 | 64TB | 128TB |
| 外键 | 是 | 是 |
| 交易 | 所有标准类型 | READ
COMMITTED |
| MVCC | 是 | 没有 |
| 数据压缩 | 是 | 否(可以压缩NDB检查点和备份文件) |
| 大排支撑(> 14K) |
支持
VARBINARY
,
VARCHAR
,
BLOB
,和
TEXT
列
|
仅
支持
BLOB
和
TEXT
列(使用这些类型存储大量数据可以降低NDB性能)
|
| 复制支持 | 使用MySQL Replication进行异步和半同步复制; MySQL 组复制 | NDB集群内的自动同步复制; NDB群集之间的异步复制,使用MySQL Replication(不支持半同步复制) |
| 读取操作的扩展 | 是(MySQL复制) | 是(NDB群集中的自动分区; NDB群集复制) |
| 写入操作的扩展 | 需要应用程序级分区(分片) | 是(NDB群集中的自动分区对应用程序是透明的) |
| 高可用性(HA) | 内置,来自InnoDB集群 | 是(设计用于99.999%的正常运行时间) |
| 节点故障恢复和故障转移 | 来自MySQL Group Replication | 自动(NDB架构中的关键元素) |
| 节点故障恢复的时间 | 30秒或更长时间 | 通常<1秒 |
| 实时性能 | 没有 | 是 |
| 内存表 | 没有 | 是(某些数据可以选择存储在磁盘上;内存和磁盘数据存储都是耐用的) |
| NoSQL访问存储引擎 | 是 | 是(多个API,包括Memcached,Node.js / JavaScript,Java,JPA,C ++和HTTP / REST) |
| 并发和并行写入 | 是 | 最多48个写入器,针对并发写入进行了优化 |
| 冲突检测和解决方案(多个复制主机) | 是(MySQL组复制) | 是 |
| 哈希索引 | 没有 | 是 |
| 在线添加节点 | 使用MySQL Group Replication读/写副本 | 是(所有节点类型) |
| 在线升级 | 是(使用复制) | 是 |
| 在线架构修改 | 是的,作为MySQL 8.0的一部分 | 是 |
NDB Cluster具有一系列独特属性,非常适合为需要高可用性,快速故障转移,高吞吐量和低延迟的应用程序提供服务。
由于其分布式架构和多节点实现,NDB Cluster还具有特定约束,可能会使某些工作负载无法正常运行。
关于一些常见类型的数据库驱动的应用程序工作负载
NDB
,
InnoDB
存储引擎
之间的行为存在许多主要差异,
如下表所示::
在将应用程序功能要求与使用功能进行比较
InnoDB
时
NDB
,有些显然与一个存储引擎的兼容性要高于另一个存储引擎。
下表列出了根据每个功能通常更适合的存储引擎支持的应用程序功能。
表22.3根据每个功能通常更适合的存储引擎支持的应用程序功能
首选应用要求
InnoDB
|
首选应用要求
NDB
|
|---|---|
|
|
在接下来的部分中,我们将讨论当前版本的NDB Cluster与使用
MyISAM
和
InnoDB
存储引擎
时可用功能相比的已知限制
。
如果选中
“
群集
”
在MySQL的缺陷数据库类别
http://bugs.mysql.com
,你可以找到以下类别下的已知错误
“
MySQL服务器
: ”
在MySQL的缺陷数据库
的http://错误.mysql.com
,我们打算在即将发布的NDB Cluster版本中纠正:
-
NDB集群
-
Cluster Direct API(NDBAPI)
-
群集磁盘数据
-
群集复制
-
ClusterJ
该信息旨在完成所述条件。 您可以使用 第1.7节“如何报告错误或问题”中 给出的说明向MySQL错误数据库报告您遇到的任何差异 。 如果我们不打算在NDB Cluster 8.0中解决问题,我们会将其添加到列表中。
请参阅 NDB Cluster 7.3中已解决的先前NDB群集问题 ,以获取已在NDB Cluster 8.0中解决的早期版本中的问题列表。
第22.6.3节“NDB群集复制中的已知问题” 中介绍了NDB群集复制特有的限制和其他问题 。
某些与某些MySQL功能相关的SQL语句在与
NDB
表一起
使用时会产生错误
,如以下列表中所述:
-
临时表。 不支持临时表。 尝试创建使用
NDB存储引擎 的临时表 或更改要使用的现有临时表NDB失败,错误 表存储引擎'ndbcluster'不支持创建选项'TEMPORARY' 。 -
NDB表中的索引和键。 NDB群集表上的键和索引受以下限制:
-
列宽。 尝试在
NDB宽度大于3072字节 的 表列 上创建索引 成功,但实际上只有前3072个字节用于索引。 在这种情况下,警告 指定密钥太长; 发出 最大密钥长度为3072字节 ,并且SHOW CREATE TABLE语句将索引的长度显示为3072。 -
FULLTEXT索引。 该
NDB存储引擎不支持FULLTEXT索引,这是可能的MyISAM和InnoDB唯一的表。 -
使用HASH键和NULL。 在唯一键和主键中使用可空列意味着使用这些列的查询将作为全表扫描进行处理。 要解决此问题,请创建列
NOT NULL,或重新创建没有USING HASH选项 的索引 。 -
前缀。 没有前缀索引; 只能对整列进行索引。 (
NDB列索引 的大小 始终与列的宽度相同,以字节为单位,最多包括3072字节,如本节前面所述。另请参见 第22.1.7.6节“NDB集群中不支持或缺少的功能” ,了解更多信息。) -
BIT专栏。 甲
BIT列不能是一个主键,唯一键,或指数,也不能是复合主键,唯一键,或索引的一部分。 -
AUTO_INCREMENT列。 与其他MySQL存储引擎一样,
NDB存储引擎AUTO_INCREMENT每个表 最多可处理一 列。 但是,如果NDB表没有显式主键,AUTO_INCREMENT则会自动定义 一 列并将其用作 “ 隐藏 ” 主键。 因此,AUTO_INCREMENT除非使用该PRIMARY KEY选项 声明该列,否则 无法定义具有显式 列 的表 。 试图用一个表创建一个表AUTO_INCREMENT不是表的主键并使用NDB存储引擎的列失败并显示错误。
-
-
外键限制。 NDB 8.0中对外键约束的支持与提供的内容相当
InnoDB,但受以下限制:-
引用为外键的每一列都需要显式唯一键(如果它不是表的主键)。
-
ON UPDATE CASCADE引用是父表的主键时不支持。这是因为主键的更新实现为删除旧行(包含旧主键)以及新行的插入(使用新主键)。 这对于
NDB内核 是不可见的, 内核将这两行视为相同,因此无法知道此更新应该是级联的。 -
SET DEFAULT不受支持。 (也不支持InnoDB。) -
该
NO ACTION关键字被接受,但作为治疗RESTRICT。 (也和InnoDB。 一样 。) -
在早期版本的NDB Cluster中,当创建一个外键引用另一个表中的索引的表时,即使索引中列的顺序不匹配,有时也可能创建外键,这是因为内部并不总是返回适当的错误。 对此问题的部分修复改进了内部使用的错误,在大多数情况下都可以使用; 但是,如果父索引是唯一索引,则仍可能发生这种情况。 (缺陷号18094360)
有关更多信息,请参见 第13.1.20.6节“使用FOREIGN KEY约束” 和 第1.8.3.2节“FOREIGN KEY约束” 。
-
-
NDB集群和几何数据类型。 表 支持 几何数据类型(
WKT和WKB)NDB。 但是,不支持空间索引。 -
字符集和二进制日志文件。 目前, 使用 (ASCII)字符集 创建
ndb_apply_status和ndb_binlog_index表latin1。 由于二进制日志的名称记录在此表中,因此在这些表中未正确引用使用非拉丁字符命名的二进制日志文件。 这是一个已知问题,我们正在努力解决这个问题。 (缺陷号码#50226)要解决此问题,命名二进制日志文件或设置任何时候只使用Latin-1字符
--basedir,--log-bin或--log-bin-index选择。 -
使用用户定义的分区创建NDB表。 NDB群集中对用户定义分区的支持仅限于[
LINEAR]KEY分区。 使用其他的分区类型用ENGINE=NDB或ENGINE=NDBCLUSTER在CREATE TABLE一个错误的语句的结果。可以覆盖此限制,但不支持在生产设置中使用此限制。 有关详细信息,请参阅 用户定义的分区和NDB存储引擎(NDB群集) 。
默认分区方案。 默认情况下,所有NDB Cluster表都
KEY使用表的主键作为分区键进行分区。 如果没有为表显式设置 主键, 则使用 由 存储引擎 自动创建 的 “ 隐藏 ” 主键NDB。 有关这些问题和相关问题的其他讨论,请参见 第23.2.5节“KEY分区” 。CREATE TABLE和ALTER TABLE不会导致用户分区NDBCLUSTER表不满足以下两个要求之一或两者的 语句 ,并且失败并显示错误:-
该表必须具有显式主键。
-
表的分区表达式中列出的所有列都必须是主键的一部分。
例外。 如果
NDBCLUSTER使用空列列表(即使用PARTITION BY [LINEAR] KEY()) 创建 用户分区 表 ,则不需要显式主键。NDBCLUSTER表的最大分区数。
NDBCLUSTER使用用户定义的分区时 可以为 表定义的最大分区数是每个节点组8个。 (有关 NDB群集节点组 的详细信息 , 请参见 第22.1.2节“NDB群集节点,节点组,副本和分区”) 。DROP PARTITION不受支持。 无法
NDB使用表 从 表中 删除分区ALTER TABLE ... DROP PARTITION。 对于NDB表支持的ALTER TABLE-ADD PARTITION,REORGANIZE PARTITION和COALESCE PARTITION- 的其他分区扩展 ,但是使用复制等都没有进行优化。 请参见 第23.3.1节“RANGE和LIST分区的管理” 和 第13.1.9节“ALTER TABLE语法” 。 -
-
基于行的复制。 在NDB Cluster中使用基于行的复制时,无法禁用二进制日志记录。 也就是说,
NDB存储引擎忽略了它的值sql_log_bin。 -
JSON数据类型。 随NDB 8.0提供 的 mysqld中的 表
JSON支持 MySQL 数据类型 。NDB一个
NDB表最多可以包含3JSON列。NDB API没有用于处理
JSON数据的 特殊规定 ,它只是将BLOB数据 视为 数据。 处理数据JSON必须由应用程序执行。
在本节中,我们列出了在NDB Cluster中找到的限制,这些限制要么与标准MySQL中找到的限制不同,要么在标准MySQL中找不到限制。
内存使用和恢复。
将数据插入
NDB
表中
时消耗的内存
在删除时不会自动恢复,与其他存储引擎一样。
相反,以下规则适用:
-
一
DELETE上声明NDB表使得以前只在同一个表使用通过重新利用现有的已删除的行通过插入记忆。 但是,通过执行,可以使该存储器可用于一般的重复使用OPTIMIZE TABLE。滚动重新启动群集还可以释放已删除行使用的所有内存。 请参见 第22.5.5节“执行NDB集群的滚动重新启动” 。
-
甲
DROP TABLE或TRUNCATE TABLE上的操作NDB表释放的是使用由该表用于通过任何再使用所述存储器NDB或者由同一个表或由另一个表,NDB表中。注意回想一下,
TRUNCATE TABLE丢弃并重新创建表。 请参见 第13.1.37节“TRUNCATE TABLE语法” 。 -
群集配置强加的限制。 存在许多可配置的硬限制,但集群中可用的主存储器设置了限制。 请参见 第22.3.3节“NDB集群配置文件” 中的配置参数的完整列表 。 大多数配置参数都可以在线升级。 这些硬限制包括:
-
数据库存储器大小和索引存储器大小(
DataMemory和IndexMemory,分别地)。DataMemory被分配为32KB页面。 在使用每个DataMemory页面时,它被分配给特定的表; 一旦分配,除了丢弃表之外,不能释放该内存。有关 更多信息 , 请参见 第22.3.3.6节“定义NDB集群数据节点” 。
-
可以使用配置参数
MaxNoOfConcurrentOperations和 设置每个事务可以执行的最大操作数MaxNoOfLocalOperations。注意批量加载,
TRUNCATE TABLE并ALTER TABLE通过运行多个事务作为特殊情况处理,因此不受此限制。 -
与表和索引相关的不同限制。 例如,群集中有序索引的最大数量由
MaxNoOfOrderedIndexes,并且每个表的有序索引的最大数量为16。
-
-
节点和数据对象的最大值。 以下限制适用于群集节点和元数据对象的数量:
-
最大数据节点数为48。
数据节点必须具有1到48(包括1和48)范围内的节点ID。 (管理和API节点可以使用1到255范围内的节点ID。)
-
NDB群集中的最大节点总数为255.此数字包括所有SQL节点(MySQL服务器),API节点(访问除MySQL服务器以外的群集的应用程序),数据节点和管理服务器。
-
当前版本的NDB群集中的元数据对象的最大数量是20320.此限制是硬编码的。
有关 详细信息, 请参阅 NDB Cluster 7.3中已解决的先前NDB群集问题 。
-
在处理事务方面,NDB Cluster存在许多限制。 这些包括以下内容:
-
事务隔离级别。 该
NDBCLUSTER存储引擎只支持READ COMMITTED事务隔离级别。 (InnoDB,例如,支持READ COMMITTED,READ UNCOMMITTED,REPEATABLE READ,和SERIALIZABLE。)你应该记住,NDB实现READ COMMITTED在每行的基础; 当读取请求到达存储该行的数据节点时,返回的是此时该行的最后提交的版本。永远不会返回未提交的数据,但是当修改多个行的事务与读取相同行的事务同时提交时,执行读取的事务可以观察到 “ 之前 ” 值, “ 之后 ” 值或两者之间的不同行由于可以在提交另一个事务之前或之后处理给定行读取请求的事实。
要确保给定事务仅在值之前或之后读取,可以使用强制执行行锁定
SELECT ... LOCK IN SHARE MODE。 在这种情况下,锁定一直持续到拥有的事务被提交。 使用行锁还可能导致以下问题:-
锁定等待超时错误的频率增加,并发性降低
-
由于读取需要提交阶段而增加了事务处理开销
-
耗尽可用数量的并发锁定的可能性受限于
MaxNoOfConcurrentOperations
NDB使用READ COMMITTED用于所有读取,除非改性剂如LOCK IN SHARE MODE或FOR UPDATE使用。LOCK IN SHARE MODE导致使用共享行锁;FOR UPDATE导致使用独占行锁。 唯一的密钥读取会自动升级其锁定,NDB以确保自我读取;BLOB读取还使用额外锁定来保持一致性。有关 NDB Cluster实现事务隔离级别如何影响 数据库 备份和还原的信息 , 请参见 第22.5.3.4节“NDB集群备份故障排除”
NDB。 -
-
事务和BLOB或TEXT列。
NDBCLUSTER只存储使用MySQL 可见的表中 任何MySQLBLOB或TEXT数据类型 的列值的一部分 ; 其余部分BLOB或TEXT存储在MySQL无法访问的单独内部表中。 这会产生两个相关的问题,每当SELECT在包含这些类型的列的表上 执行 语句 时,您应该注意 这些问题:-
对于
SELECT来自NDB Cluster表的 任何 表:如果SELECT包含aBLOB或TEXT列,则READ COMMITTED事务隔离级别将转换为具有读锁定的读取。 这样做是为了保证一致性。 -
对于
SELECT使用唯一键查找来检索任何使用任何BLOB或TEXT数据类型并在事务中执行的 列的任何列, 在事务持续时间内,表上会保留共享读锁,即直到事务已提交或已中止。对于使用索引或表扫描的查询,即使对于
NDB具有BLOB或TEXT列的 表, 也不会发生此问题 。例如,考虑
t以下CREATE TABLE语句 定义 的表 :CREATE TABLE t( INT NOT NOT AUTO_INCREMENT PRIMARY KEY, b INT NOT NULL, c INT NOT NULL, d TEXT, INDEX i(b), 独特的钥匙u(c) )ENGINE = NDB,以下任一查询
t都会导致共享读锁定,因为第一个查询使用主键查找而第二个查询使用唯一键查找:SELECT * FROM t WHERE a = 1; SELECT * FROM t WHERE c = 1;
但是,此处显示的四个查询都不会导致共享读锁:
SELECT * FROM t WHERE b = 1; SELECT * FROM t WHERE d ='1'; SELECT * FROM t; SELECT b,c WHERE a = 1;
这是因为,在这四个查询中,第一个使用索引扫描,第二个和第三个使用表扫描,第四个使用主键查找时,不检索任何
BLOB或TEXT列 的值 。通过避免使用检索
BLOB或TEXT列的 唯一键查找的查询 ,或者在无法避免此类查询的情况下,通过尽快提交事务, 可以帮助最大限度地减少共享读锁的问题 。
-
-
回滚。 没有部分事务,也没有部分事务回滚。 重复键或类似错误会导致整个事务回滚。
此行为与其他事务存储引擎的行为不同,例如
InnoDB可能会回滚单个语句。 -
事务和内存使用情况。 如本章其他部分所述,NDB Cluster不能很好地处理大型事务; 最好是执行一些只有少量操作的小事务,而不是尝试包含大量操作的单个大事务。 除其他考虑因素外,大型事务需要非常大量的内存。 因此,许多MySQL语句的事务行为会受到影响,如下面的列表所述:
-
TRUNCATE TABLE在NDB表上 使用时不是事务性的 。 如果aTRUNCATE TABLE无法清空表,则必须重新运行该表才能成功。 -
DELETE FROM(即使没有WHERE条款) 是 交易性的。 对于包含大量行的表,你会发现性能得到了几种改进的DELETE FROM ... LIMIT ...语句 “ 块 ” 的删除操作。 如果您的目标是清空表格,那么您可能希望改为使用TRUNCATE TABLE。 -
ALTER TABLE和事务。 复制
NDB表作为a的一部分时ALTER TABLE,副本的创建是非事务性的。 (在任何情况下,删除副本时都会回滚此操作。)
-
-
事务和COUNT()函数。 使用NDB群集复制时,无法保证
COUNT()从站上的功能 的事务一致性 。 换句话说,当在主服务器上执行一系列 更改单个事务中的表中行数 的语句(INSERT,DELETE或两者)时, 对从服务器 执行 查询可能会产生中间结果。 这是因为 可能执行脏读操作,并且不是 存储引擎中 的错误 。 (有关更多信息,请参阅Bug#31321。)SELECT COUNT(*) FROMtableSELECT COUNT(...)NDB
启动,停止或重新启动节点可能会导致临时错误,从而导致某些事务失败。 这些包括以下情况:
-
暂时的错误。 首次启动节点时,您可能会看到错误1204 临时故障,分发已更改 以及类似的临时错误。
-
节点故障导致的错误。 任何数据节点的停止或失败都可能导致许多不同的节点故障错误。 (但是,在执行计划的群集关闭时,应该没有中止的事务。)
在任何一种情况下,必须在应用程序中处理生成的任何错误。 这应该通过重试事务来完成。
使用
NDBCLUSTER
存储引擎
时,某些数据库对象(如表和索引)具有不同的限制
:
-
数据库和表名。 使用
NDB存储引擎时,数据库名称和表名称的最大允许长度为63个字符。 使用长度超过此限制的数据库名称或表名称的语句将失败并显示相应的错误。 -
数据库对象的数量。 单个NDB群集(包括数据库,表和索引) 中 所有
NDB数据库对象 的最大数量 限制为20320。 -
每个表的属性。 可以属于给定表的最大属性数(即列和索引)为512。
-
每个键的属性。 每个键的最大属性数为32。
-
行大小。 任何一行的最大允许大小为14000字节。 每个
BLOB或TEXT列贡献256 + 8 = 264个字节。另外,
NDB表 的固定宽度列的最大偏移量 是8188字节; 尝试创建违反此限制的表失败,出现NDB错误851 超出固定大小列的最大偏移量 。 对于基于内存的列,您可以通过使用可变宽度列类型(例如VARCHAR将列定义 为)来解决此限制COLUMN_FORMAT=DYNAMIC; 这不适用于存储在磁盘上的列。 对于基于磁盘的列,您可以通过重新排序一个或多个表的基于磁盘的列来实现此目的,以便除了最后定义的基于磁盘的列之外的所有列的组合宽度。CREATE TABLE用于创建表的语句不超过8188个字节,减去对某些数据类型执行的任何可能的舍入,例如CHAR或VARCHAR; 否则,有必要为一个或多个违规列或列使用基于内存的存储。 -
每个表的BIT列存储。
BIT给定NDB表中 使用的 所有 列 的最大组合宽度为 4096。 -
固定列存储。 NDB Cluster 8.0支持
FIXED列中 每个数据片段最多128 TB 。
NDB
表
不支持其他存储引擎支持的许多功能
。
尝试在NDB群集中使用这些功能中的任何一个都不会导致错误;
但是,在期望支持或强制执行功能的应用程序中可能会发生错误。
引用这些特征的语句,即使被有效忽略
NDB
,也必须在语法上和其他方面都有效。
-
索引前缀。
NDB表 不支持索引的前缀 。 如果前缀是在声明用作索引规范的一部分,例如CREATE TABLE,ALTER TABLE,或CREATE INDEX,不被创建的前缀NDB。包含索引前缀以及创建或修改
NDB表 的语句 仍必须在语法上有效。 例如,以下语句始终失败,错误1089 错误的前缀键; 使用的关键部分不是字符串,使用的长度比关键部分长,或者存储引擎不支持唯一的前缀键 ,无论存储引擎如何:CREATE TABLEt1( c1 INT NOT NULL, c2 VARCHAR(100), INDEX i1(c2(500)) );这是因为SQL语法规则没有索引可能具有大于其自身的前缀。
-
保存点和回滚。 保存点和回滚到保存点将被忽略,如
MyISAM。 -
提交的持久性。 磁盘上没有持久提交。 提交已复制,但无法保证在提交时将日志刷新到磁盘。
-
复制。 不支持基于语句的复制。 设置群集复制时 使用
--binlog-format=ROW(或--binlog-format=MIXED)。 有关 更多信息 , 请参见 第22.6节“NDB群集复制” 。使用全局事务标识符(GTID)的复制与NDB Cluster不兼容,并且在NDB Cluster 8.0中不受支持。 使用
NDB存储引擎 时不要启用GTID ,因为这很可能会导致问题,包括NDB群集复制失败。NDB群集不支持半同步复制。
-
生成的列。 该
NDB存储引擎不支持虚拟生成列的索引。与其他存储引擎一样,您可以在存储的生成列上创建索引,但是您应该记住
NDB使用DataMemory存储生成的列以及IndexMemory索引。 有关 示例, 请参阅 NDB群集中的JSON列和间接索引 。NDB群集将存储的生成列中的更改写入二进制日志,但不记录对虚拟列的更改。 这不应影响NDB群集复制或
NDB其他MySQL存储引擎 之间的复制 。
有关事务处理
限制的更多信息
,
请参见
第22.1.7.3节“与NDB集群中的事务处理
相关的限制”
NDB
。
以下性能问题在NDB群集中特定或特别明显:
-
范围扫描。 由于对
NDB存储引擎的 顺序访问,存在查询性能问题 ; 与其中任何一个MyISAM或 多个扫描相比,进行多次扫描也相对更昂贵InnoDB。 -
范围内记录的可靠性。 该
Records in range统计是有的,但没有完全测试或正式支持。 在某些情况下,这可能会导致非最佳查询计划。 如有必要,您可以使用USE INDEX或FORCE INDEX更改执行计划。 有关 如何执行此操作的详细信息 , 请参见 第8.9.4节“索引提示” 。 -
唯一的哈希索引。
USING HASH如果NULL作为密钥的一部分给出, 则使用 创建的唯一哈希索引 不能用于访问表 。
以下是
NDB
存储引擎
特有的限制
:
-
机器架构。 群集中使用的所有计算机必须具有相同的体系结构。 也就是说,托管节点的所有计算机必须是big-endian或little-endian,并且不能同时使用两者。 例如,您不能在PowerPC上运行管理节点,该节点指示在x86计算机上运行的数据节点。 此限制不适用于仅运行 mysql 或可能正在访问群集的SQL节点的其他客户端的 计算机 。
-
二进制日志。 NDB Cluster在二进制日志记录方面具有以下限制或限制:
-
sql_log_bin对数据操作没有影响; 但是,它支持模式操作。 -
NDB Cluster无法为具有
BLOB列但没有主键的 表生成二进制日志 。 -
在群集二进制日志中仅记录以下模式操作,该日志 不在 执行语句 的 mysqld上 :
-
-
任何数据节点重新启动时都会拒绝架构操作(DDL语句)。
-
副本数量。 由
NoOfReplicas数据节点配置参数 确定的副本 数是NDB Cluster存储的所有数据的副本数。 将此参数设置为1表示只有一个副本; 在这种情况下,不提供冗余,并且数据节点的丢失导致数据丢失。 为了保证冗余,即使数据节点出现故障也能保存数据,请将此参数设置为2,这是生产中的默认值和建议值。可以设置
NoOfReplicas为大于2的值(最多为4),但不必防止数据丢失。 此外, 生产中不支持此参数的大于2的值 。
另请参见 第22.1.7.10节“与多个NDB群集节点相关的限制” 。
磁盘数据对象的最大值和最小值。 磁盘数据对象受以下最大值和最小值的限制:
-
最大表空间数:2 32 (4294967296)
-
每个表空间的最大数据文件数:2 16 (65536)
-
表空间数据文件的最小和最大可能大小分别为32K和2G。 有关 更多信息 , 请参见 第13.1.21节“CREATE TABLESPACE语法” 。
此外,在使用NDB磁盘数据表时,您应该了解有关数据文件和扩展区的以下问题:
-
数据文件使用
DataMemory。 用法与内存中数据的用法相同。 -
数据文件使用文件描述符。 请务必记住,数据文件始终处于打开状态,这意味着文件描述符始终在使用中,不能重复用于其他系统任务。
-
范围要求足够
DiskPageBufferMemory; 您必须为此参数保留足够的内容以考虑所有扩展区使用的所有内存(扩展区数乘以扩展区大小)。
磁盘数据表和无盘模式。 在无盘模式下运行群集时,不支持使用磁盘数据表。
多个SQL节点。
以下是与使用多个MySQL服务器作为NDB Cluster SQL节点相关的问题,并且特定于
NDBCLUSTER
存储引擎:
-
没有分布式表锁。 A
LOCK TABLES仅适用于发出锁定的SQL节点; 群集中没有其他SQL节点 “ 看到 ” 此锁定。 对于锁定表作为其操作一部分的任何语句发出的锁也是如此。 (有关示例,请参阅下一项。) -
ALTER TABLE操作。
ALTER TABLE运行多个MySQL服务器(SQL节点)时没有完全锁定。 (如前一项所述,NDB Cluster不支持分布式表锁。)
-
如果任何管理服务器在同一主机上运行,则必须在连接字符串中为节点提供显式ID,因为节点ID的自动分配在同一主机上的多个管理服务器上不起作用。 如果每个管理服务器驻留在不同的主机上,则不需要这样做。
-
管理服务器启动时,它首先检查同一NDB群集中的任何其他管理服务器,并在成功连接到其他管理服务器时使用其配置数据。 这意味着 将忽略 管理服务器
--reload和--initial启动选项,除非管理服务器是唯一运行的服务器。 这还意味着,当执行具有多个管理节点的NDB群集的滚动重新启动时,管理服务器将读取其自己的配置文件(如果(仅当)它是此NDB群集中运行的唯一管理服务器)。 请参见 第22.5.5节“执行NDB集群的滚动重新启动” , 欲获得更多信息。
多个网络地址。 不支持每个数据节点的多个网络地址。 使用这些可能会导致问题:如果数据节点发生故障,SQL节点会等待确认数据节点已关闭但从未收到它,因为到该数据节点的另一个路由仍保持打开状态。 这可以有效地使群集无法运行。
可以
为单个数据节点
使用多个网络硬件
接口
(例如以太网卡),但这些必须绑定到同一地址。
这也意味着
文件中
[tcp]
每个连接
不可能使用多个
部分
config.ini
。
有关
更多信息
,
请参见
第22.3.3.10节“NDB集群TCP / IP连接”
。
本节介绍规划,安装,配置和运行NDB群集的基础知识。 第22.3节“NDB群集的配置”中 的示例 提供了有关各种群集选项和配置的更深入信息,遵循此处概述的准则和过程的结果应该是可用的NDB群集,其满足 最低 要求可用性和数据保护。
本节介绍硬件和软件要求; 网络问题; 安装NDB集群; 基本配置问题; 启动,停止和重新启动集群; 加载示例数据库; 并执行查询。
NDB Cluster还提供NDB Cluster Auto-Installer,这是一个基于Web的图形安装程序,作为NDB Cluster分发的一部分。 自动安装程序可用于在一台(用于测试)或更多主机上执行NDB群集的基本安装和设置。 有关 更多信息 , 请参见 第22.2.1节“NDB集群自动安装程序” 。
假设。 以下部分对集群的物理和网络配置做出了许多假设。 这些假设将在接下来的几段中讨论。
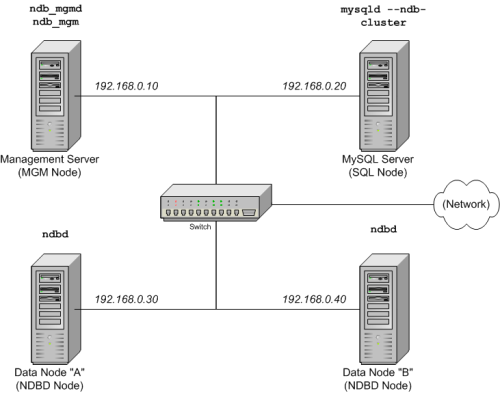
群集节点和主机。 该集群由四个节点组成,每个节点位于一台独立的主机上,每个节点在典型的以太网网络上具有固定的网络地址,如下所示:
此设置也显示在下图中:
网络寻址。
在简单(和可靠性)的利益,这种
操作方法
仅使用数字IP地址。
但是,如果网络上有DNS解析,则可以在配置群集时使用主机名代替IP地址。
或者,您可以使用该
hosts
文件(通常
/etc/hosts
用于Linux和其他类Unix操作系统,
C:\WINDOWS\system32\drivers\etc\hosts
在Windows上,或操作系统的等效操作系统),以提供进行主机查找的方法(如果可用)。
潜在的主机文件问题。
尝试为群集节点使用主机名时出现的常见问题是由于某些操作系统(包括某些Linux发行版)
/etc/hosts
在安装期间
设置系统自己的主机名的方式
。
考虑两台具有主机名的计算机,
ndb1
并且
ndb2
都在
cluster
网络域中。
Red Hat Linux(包括一些衍生产品,如CentOS和Fedora)将以下条目放在这些机器的
/etc/hosts
文件中:
#ndb1 /etc/hosts:
127.0.0.1 ndb1.cluster ndb1 localhost.localdomain localhost
#ndb2 /etc/hosts:
127.0.0.1 ndb2.cluster ndb2 localhost.localdomain localhost
SUSE Linux(包括OpenSUSE)将这些条目放在计算机的
/etc/hosts
文件中:
#ndb1 /etc/hosts:
127.0.0.1 localhost
127.0.0.2 ndb1.cluster ndb1
#ndb2 /etc/hosts:
127.0.0.1 localhost
127.0.0.2 ndb2.cluster ndb2
在这两种情况下,
ndb1
路由
ndb1.cluster
到环回IP地址,但从DNS获取公共IP地址
ndb2.cluster
,同时
ndb2
路由
ndb2.cluster
到环回地址并获取公共地址
ndb1.cluster
。
结果是每个数据节点都连接到管理服务器,但无法判断任何其他数据节点何时连接,因此数据节点在启动时似乎挂起。
您不能混合使用
localhost
其他主机名或IP地址
config.ini
。
出于这些原因,在这种情况下的解决方案(除了对
所有
config.ini HostName
条目
使用IP地址之外
)是从中删除全限定主机名,
/etc/hosts
并将其
config.ini
用于所有群集主机。
主机类型。 我们安装方案中的每台主机都是基于Intel的台式PC,运行支持的操作系统,以标准配置安装到磁盘,并且不运行任何不必要的服务。 具有标准TCP / IP网络功能的核心操作系统应该足够了。 同样为了简单起见,我们还假设所有主机上的文件系统都设置相同。 如果不是,您应该相应地调整这些说明。
网络硬件。 每台计算机上都安装了标准的100 Mbps或1千兆位以太网卡,以及卡的正确驱动程序,并且所有四台主机都通过标准问题以太网网络设备(如交换机)连接。 (所有机器都应该使用具有相同吞吐量的网卡。也就是说,群集中的所有四台机器应该有100 Mbps卡, 或者 所有四台机器都应该有1 Gbps卡。)NDB群集在100 Mbps网络中工作; 但是,千兆以太网可提供更好的性能。
NDB群集 不适 用于吞吐量低于100 Mbps或经历高延迟的网络。 出于这个原因(等等),尝试在诸如因特网之类的广域网上运行NDB集群不太可能成功,并且在生产中不支持。
样本数据。
我们使用
world
可从MySQL网站下载的数据库(参见
https://dev.mysql.com/doc/index-other.html
)。
我们假设每台机器都有足够的内存来运行操作系统,需要NDB集群进程,以及(在数据节点上)存储数据库。
有关安装MySQL的一般信息,请参阅 第2章, 安装和升级MySQL 。 有关在Linux和其他类Unix操作系统上安装NDB Cluster的信息,请参见 第22.2.2节“在Linux上安装NDB Cluster” 。 有关在Windows操作系统上安装NDB Cluster的信息,请参见 第22.2.3节“在Windows上安装NDB Cluster” 。
有关NDB Cluster硬件,软件和网络要求的一般信息,请参见 第22.1.3节“NDB群集硬件,软件和网络要求” 。
本节介绍作为NDB Cluster分发的一部分包含的基于Web的图形配置安装程序。 讨论的主题包括安装程序及其部件的概述,运行安装程序的软件和其他要求,浏览GUI以及使用安装程序在一台或多台主机上设置和启动或停止NDB群集。
NDB群集自动安装程序由两个组件组成。 前端是一个GUI客户端,实现为一个Web页面,可以在标准的Web浏览器(如Firefox或Microsoft Internet Explorer)中加载和运行。 后端是服务器进程( ndb_setup.py ),它在本地计算机或您有权访问的其他主机上运行。
这两个组件(客户端和服务器)使用标准HTTP请求和响应相互通信。 后端可以在后端用户授予访问权限的任何主机上管理NDB Cluster软件程序。 如果NDB Cluster软件位于不同的主机上,则后端依赖SSH进行访问,使用 Paramiko 库远程执行命令(请参见 第22.2.1.1节“NDB群集自动安装程序要求” )。
本节提供有关支持的操作平台和软件,所需软件以及运行NDB Cluster Auto-Installer的其他先决条件的信息。
支持的平台。 NDB群集自动安装程序适用于最新版本的Linux,Windows,Solaris和MacOS X的NDB 8.0发行版。有关NDB群集和NDB群集自动安装程序的平台支持的更多详细信息,请参阅 https:// www .mysql.com / support / supportedplatforms / cluster.html 。
支持的Web浏览器。 最新版本的Firefox和Microsoft Internet Explorer支持基于Web的安装程序。 它也适用于Opera,Safari和Chrome的最新版本,尽管我们还没有彻底测试这些浏览器的兼容性。
必需的软件设置主机。 必须在运行自动安装程序的主机上安装以下软件:
-
Python 2.6或更高版本。 Auto-Installer需要Python解释器和标准库。 如果系统上尚未安装这些,您可以使用系统的软件包管理器添加它们。 否则,您可以从 http://python.org/download/ 下载它们 。
-
Paramiko 2或更高。 这是使用SSH与远程主机通信所必需的。 您可以从 http://www.lag.net/paramiko/ 下载 。 Paramiko也可以从您系统的包管理器中获得。
-
Pycrypto版本1.9或更高版本。 Paramiko需要此加密模块,并且可以使用它进行安装
pip install cryptography。 如果pip未安装,并且使用系统的软件包管理无法使用该模块,则可以从 https://www.dlitz.net/software/pycrypto/ 下载该模块 。
上面列表中的所有软件都包含在Windows版本的配置工具中,不需要单独安装。
只有在打算在远程主机上部署NDB Cluster节点时才需要Paramiko和Pycrypto库,如果所有节点都在运行安装程序的同一主机上,则不需要Paramiko和Pycrypto库。
必需的软件远程主机。 您希望部署NDB Cluster节点的远程主机所需的唯一软件是SSH服务器,它通常默认安装在Linux和Solaris系统上。 有几种替代方案适用于Windows; 有关这些的概述,请参阅 http://en.wikipedia.org/wiki/Comparison_of_SSH_servers 。
使用多个主机时的另一个要求是,可以使用SSH和正确的密钥或用户凭据对任何远程主机进行身份验证,如下几段所述:
身份验证和安全。 Auto-Installer提供了三种用于远程访问的基本安全或身份验证机制,我们在此列出并描述:
-
SSH。 安全shell连接用于使后端能够在远程主机上执行操作。 因此,必须在远程主机上运行SSH服务器。 此外,运行安装程序的操作系统用户必须具有访问远程服务器的权限,可以使用用户名和密码,也可以使用公钥和私钥。
重要您永远不应该使用系统
root帐户进行远程访问,因为这是非常不安全的。 另外, mysqld 通常不能由系统启动root。 出于这些原因和其他原因,您应该为目标系统上的常规用户帐户提供SSH凭据,而不是系统root。 有关此问题的更多信息,请参见 第6.1.5节“如何以普通用户身份运行MySQL” 。 -
HTTPS。 默认情况下,Web浏览器前端和后端之间的远程通信不会加密,这意味着用户的SSH密码等信息将以任何人都可读的明文形式传输。 对于要加密的远程客户端的通信,后端必须具有证书,并且前端必须使用HTTPS而不是HTTP与后端进行通信。 通过颁发自签名证书,可以最轻松地完成启用HTTPS。 颁发证书后,您必须确保使用证书。 您可以通过启动 ndb_setup.py 来完成此 操作 从命令行使用
--use-https(-S)和--cert-file(-c)选项。cfg.pem包含 示例证书文件 ,默认情况下使用。 该文件位于mcc安装共享目录下的目录中; 在Linux上,通常是文件的完整路径/usr/share/mysql/mcc/cfg.pem。 在Windows系统上,这通常是C:\Program Files\MySQL\MySQL Server 8.0\share\mcc\cfg.pem。 设置默认值意味着,出于测试目的,您只需启动安装程序,并-S选择在浏览器和后端之间使用HTTPS连接。自动安装程序保存给定群集的配置文件,
mycluster01如mycluster01.mcc调用 ndb_setup.py 可执行文件 的用户的主目录中 所示 。 该文件使用用户提供的密码加密(使用 Fernet ); 因为HTTP以明文形式传输密码, 强烈建议您始终使用HTTPS连接来访问远程主机上的自动安装程序 。 -
基于证书的身份验证。 后端 ndb_setup.py 进程可以在本地主机和远程主机上执行命令。 这意味着连接到后端的任何人都可以负责命令的执行方式。 要拒绝到后端的不需要的连接,可能需要证书来验证客户端。 在这种情况下,证书必须由用户发布,安装在浏览器中,并且可用于后端以进行身份验证。 您可以通过启动 ndb_setup.py 来制定此要求(与密码或密钥验证一起或代替密码或密钥验证) 使用
--ca-certs-file(-a)选项。
当客户端浏览器与自动安装程序后端运行在同一主机上时,不需要或不需要安全身份验证。
另请参见 第22.5.12节“NDB群集安全性问题” ,其中讨论了在部署NDB群集时要考虑的安全性注意事项,以及 第6章“ 安全性” ,以获取更一般的MySQL安全性信息。
NDB群集自动安装程序界面由多个页面组成,每个页面对应于用于配置和部署NDB群集的过程中的一个步骤。 这些页面按顺序列在此处:
NDB群集安装程序设置和帮助菜单
除 欢迎 屏幕 外,所有屏幕上都会显示这些菜单 。 它们提供对安装程序设置和信息的访问。 此处显示 “ 菜单的详细信息:
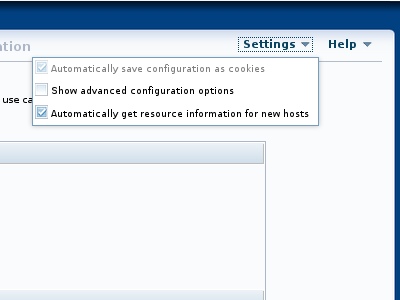
“ 菜单包含以下条目:
-
:将配置信息(如主机名,过程数据和参数值)保存为浏览器中的cookie。 选择此选项后,将保存除SSH密码之外的所有信息。 这意味着您可以退出并重新启动浏览器,并继续使用上一个会话结束时从中断处继续的相同配置。 默认情况下启用此选项。
永远不会保存SSH密码; 如果您使用一个,则必须在每个新会话开始时提供。
-
:默认显示高级配置参数(如果可用)。
设置后,高级参数将继续在配置文件中使用,直到显式更改或重置为止。 这与安装程序中当前是否显示高级参数无关; 换句话说,禁用菜单项不会重置任何这些参数的值。
您还可以在“ 定义参数” 屏幕 上切换各个过程的高级参数的显示 。
默认情况下禁用此选项。
-
:自动查询新主机以获取硬件资源信息,以预先填充许多配置选项和值。 在这种情况下,建议值不是必需的,但除非使用安装程序中的相应编辑选项进行显式更改,否则将使用它们。
默认情况下启用此选项。
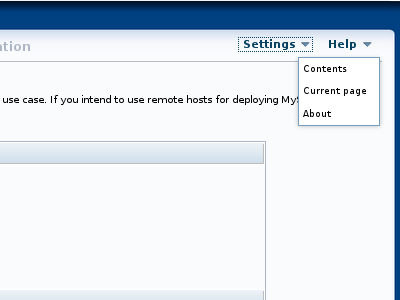
安装程序“ 菜单如下所示:
“ 菜单提供了几个选项,如以下列表中所述:
-
:显示内置用户指南。 这是在单独的浏览器窗口中打开的,因此可以与安装程序同时使用,而不会中断工作流程。
-
:打开描述安装程序中当前显示页面的部分的内置用户指南。
-
:打开一个对话框,显示安装程序名称和提供它的NDB Cluster分发版本号。
Auto-Installer还以大多数输入窗口小部件的工具提示的形式提供上下文相关帮助。
此外,大多数NDB配置参数的名称都链接到在线文档中的描述。 文档显示在单独的浏览器窗口中。
下一节将讨论启动自动安装程序。 紧随其后的部分以前面列出的顺序更详细地描述了每个页面的目的和功能。
自动安装程序与NDB Cluster软件一起提供。
.deb
许多Linux发行版也可以使用
单独的RPM和
仅包含自动安装程序的软件包。
(请参见
第22.2节“NDB群集安装”
。)
本节介绍如何启动安装程序。 您可以通过调用 ndb_setup.py 可执行文件来完成。
您应该
以普通用户身份
运行
ndb_setup.py
;
这样做不需要特殊权限。
你应该
不
运行该程序的
mysql
用户,或使用系统
root
或管理员帐户;
这样做可能会导致安装失败。
ndb_setup.py
在发现
bin
NDB簇安装目录中;
典型位置可能
/usr/local/mysql/bin
位于Linux系统或
C:\Program Files\MySQL\MySQL Server
8.0\bin
Windows系统上。
这可能因系统上安装NDB Cluster软件的位置和安装方法而异。
在Windows上,您还可以通过 在NDB Cluster安装目录中 运行 setup.bat 来 启动安装程序 。 从命令行调用时,此批处理文件接受与 ndb_setup.py 相同的选项 。
ndb_setup.py 可以使用影响其操作的几个选项中的任何一个来启动,但通常允许使用默认设置,在这种情况下,您可以 通过以下两种方法之一 启动 ndb_setup.py :
-
导航到
bin终端中 的NDB Cluster 目录并从命令行调用它,不需要任何其他参数或选项,如下所示:外壳>
ndb_setup.py用完安装目录:/ usr / local / mysql / bin 在端口8081上启动Web服务器 URL为https:// localhost:8081 / welcome.html deathkey = 627876 按CTRL + C以停止Web服务器。 该应用程序现在应该在您的浏览器中运行。 (或者您可以导航到https:// localhost:8081 / welcome.html来启动它)无论操作平台如何,这都有效。
-
导航到
bin文件浏览器(例如Windows上的Windows资源管理器或Linux上的Konqueror,Dolphin或Nautilus)中 的NDB Cluster 目录,并激活(通常通过双击) ndb_setup.py 文件图标。 这适用于Windows,也适用于大多数常见的Linux桌面。在Windows上,您还可以导航到NDB Cluster安装目录并激活 setup.bat 文件图标。
在任何一种情况下,一旦
调用
ndb_setup.py
,自动安装程序的
欢迎
屏幕
应该在系统的默认Web浏览器中打开。
如果没有,您应该能够打开页面
http://localhost:8081/welcome.html
或
https://localhost:8081/welcome.html
在浏览器中手动
打开
。
在某些情况下,你可能希望使用安装程序非默认设置,如指定的HTTPS连接,或不同端口的自动安装程序自带的Web服务器上运行,在这种情况下,你必须调用
ndb_setup.py
与一个或多个启动选项,其值覆盖必要的默认值。
使用
setup.bat
可以在Windows系统上使用相同的启动选项
在NDB Cluster软件分发中为此类平台提供的文件。
这可以使用命令行完成,但如果您希望或需要在使用这些选项中的一个或多个时从桌面或文件浏览器启动安装程序,则还可以创建包含正确调用的脚本或批处理文件,然后双击文件浏览器中的文件图标以启动安装程序。
(在Linux系统上,您可能还需要首先使脚本文件可执行。)如果您计划从远程主机使用自动安装程序,则应该开始使用该
-S
选项。
有关NDB Cluster Auto-Installer的此选项和其他高级启动选项的信息,请参阅
第22.4.26节“
ndb_setup.py
- 启动基于浏览器的NDB集群自动安装程序”
。
调用 ndb_setup.py 时 , 欢迎 屏幕将加载到默认浏览器中 。 第一次运行自动安装程序(或者由于某些其他原因没有现有配置),此屏幕如下所示:
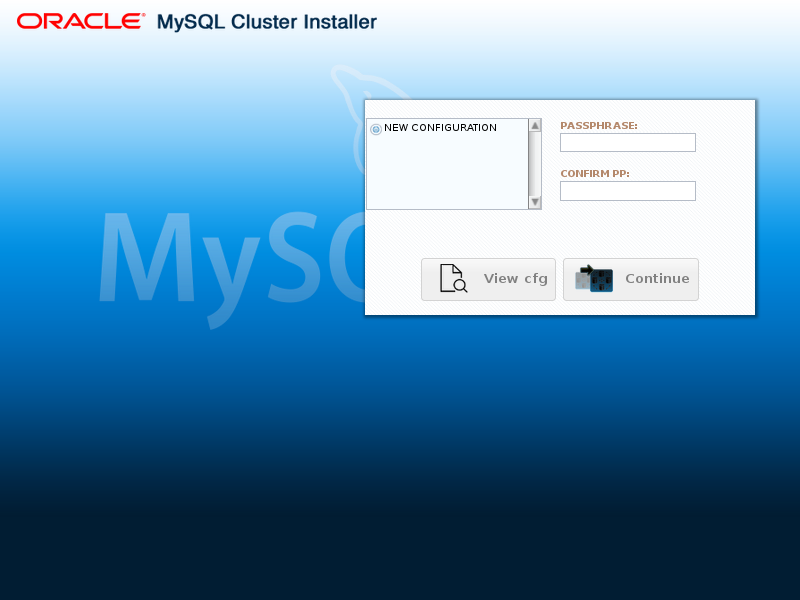
在这种情况下,列出的集群的唯一选择是配置新集群,并且 和 按钮都处于非活动状态。
要创建新配置,请在提供的文本框中输入并确认密码。 完成此操作后,可以单击“ 以进入“ 定义群集” 屏幕,您可以在其中为新群集指定名称。
如果您之前使用自动安装程序创建了一个或多个群集,则会按名称列出它们。
此示例显示了一个名为的现有集群
mycluster-1
:
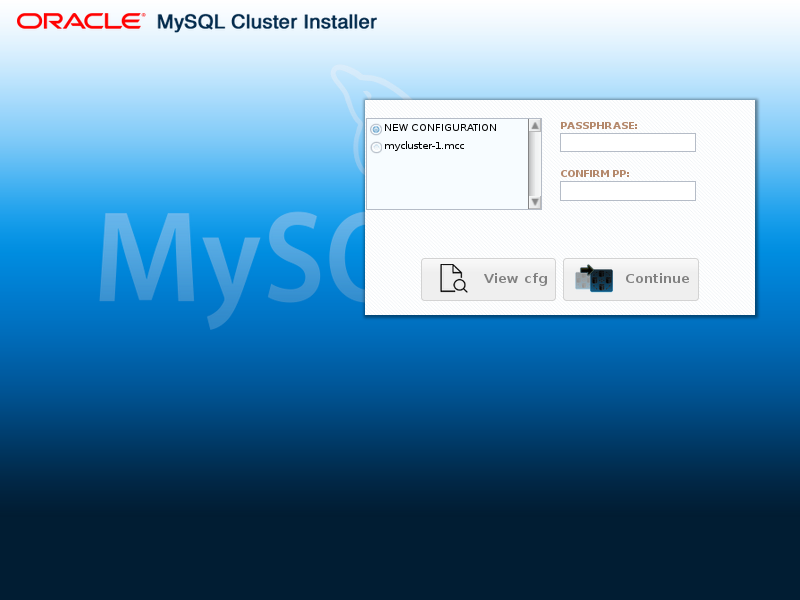
要查看给定群集的配置并使用它,请在列表中选择其名称旁边的radiobutton,然后输入并确认用于创建它的密码。 正确完成此操作后,可以单击“ 以查看和编辑此群集的配置。
“ 定义群集” 屏幕将显示在“ 欢迎” 屏幕之后 ,用于设置群集的常规属性。 Define Cluster 屏幕 的布局 如下所示:
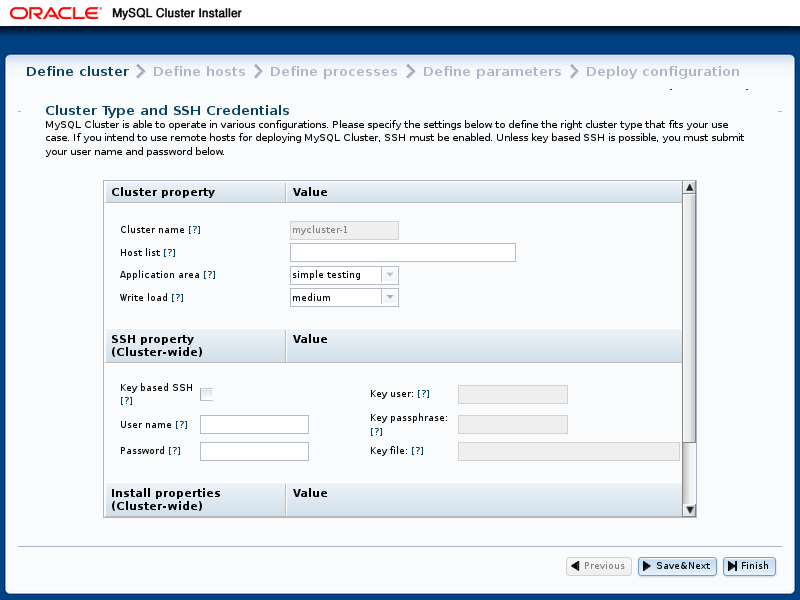
此屏幕和后续屏幕还包括 设置 和 帮助 菜单,本节稍后将对其进行介绍; 请参阅 NDB群集安装程序设置和帮助菜单 。
“ 定义群集” 屏幕允许您为 群集 设置三种属性:群集属性,SSH属性和安装属性。
此处列出了可在此屏幕上设置的群集属性:
-
群集名称 :标识 群集的名称 ; 在这个例子中,这是
mycluster-1。 名称在前一个屏幕上设置,无法在此处更改。 -
主机列表 :应运行集群进程的一个或多个主机的逗号分隔列表。 默认情况下,这是
127.0.0.1。 如果将远程主机添加到列表中,则必须能够使用作为SSH属性提供的凭据连接到它们。 -
应用程序类型 :选择以下选项之一:
-
:小规模测试的最小资源使用。 这是默认值。 不适用于生产环境 。
-
:最大化给定硬件的性能。
-
:最大化性能,同时最大限度地提高对超时的敏感度,以最大限度地缩短检测故障群集过程所需的时间。
-
-
写入负载 :为整个群集选择预期写入次数的级别。 您可以选择以下任何一个级别:
-
:预期负载包括少于100次写入事务。
-
:预期负载包括每秒100到1000次写入事务; 这是默认值。
-
:预期负载包括每秒超过1000次写入事务。
-
SSH属性在以下列表中描述:
-
基于密钥的SSH :选中此框以使用启用密钥的登录到远程主机。 如果选中,则还必须提供密钥用户和密码短语; 否则,需要远程登录帐户的用户和密码。
-
用户 :具有远程登录访问权限的用户的名称。
-
密码 :远程用户的密码。
-
关键用户 :密钥有效的用户名,如果与操作系统用户不同。
-
密钥密码 :如果需要, 密钥的密码 。
-
密钥文件 : 密钥文件的 路径。 默认是
~/.ssh/id_rsa。
此页面上设置的SSH属性适用于群集中的所有主机。 可以通过在“ 定义主机” 屏幕 上编辑主机的属性来覆盖给定主机的它们 。
也可以在此屏幕上设置两个安装属性:
-
安装MySQL群集 :此设置确定自动安装程序在群集主机上安装NDB群集软件(如果有)的源。 这里列出了可能的值及其影响:
-
DOCKER:尝试从https://hub.docker.com/r/mysql/mysql-cluster/每个主机上 安装MySQL Cluster Docker镜像 -
REPO:尝试从 每个主机上 的 MySQL存储库 安装NDB Cluster软件 -
BOTH:尝试从每个主机上的存储库安装Docker映像或软件,优先考虑存储库 -
NONE:不要在主机上安装NDB Cluster软件; 这是默认值
-
-
打开FW端口 :选中此复选框可让安装程序尝试在所有主机上打开NDB CLuster进程所需的端口。
下图显示了“
定义群集”
页面,其中包含运行所有节点的小型测试群集的设置
localhost
:
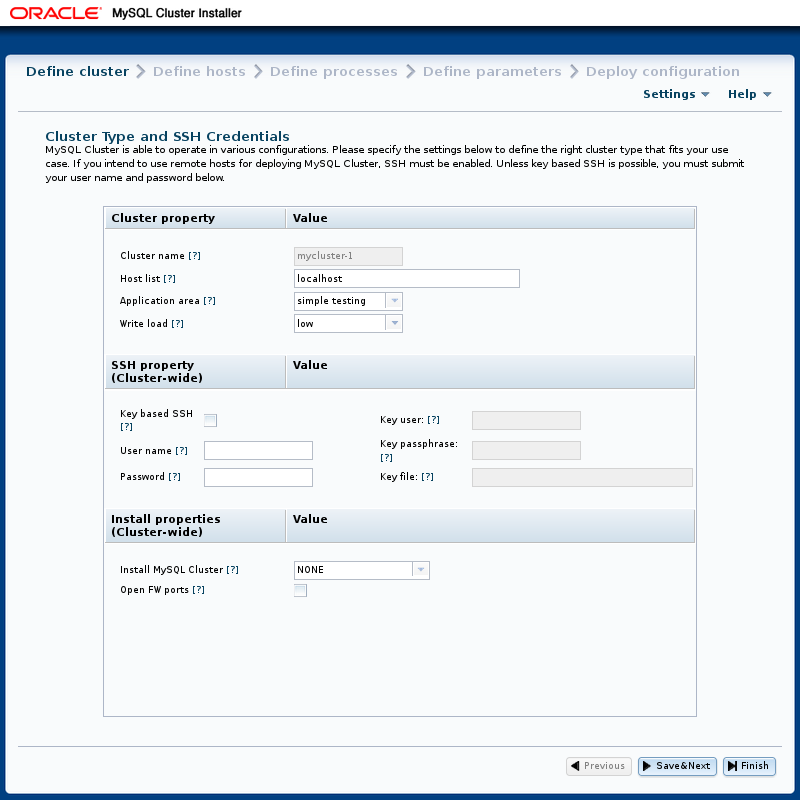
进行所需设置后,可以将它们保存到配置文件中, 然后单击“ 单击 按钮 进入“ 定义主机” 屏幕 。
如果在未保存的情况下退出安装程序,则不会对配置文件进行任何更改。
此处显示的 “ 定义主机” 屏幕提供了查看和指定每个群集主机的几个关键属性的方法:
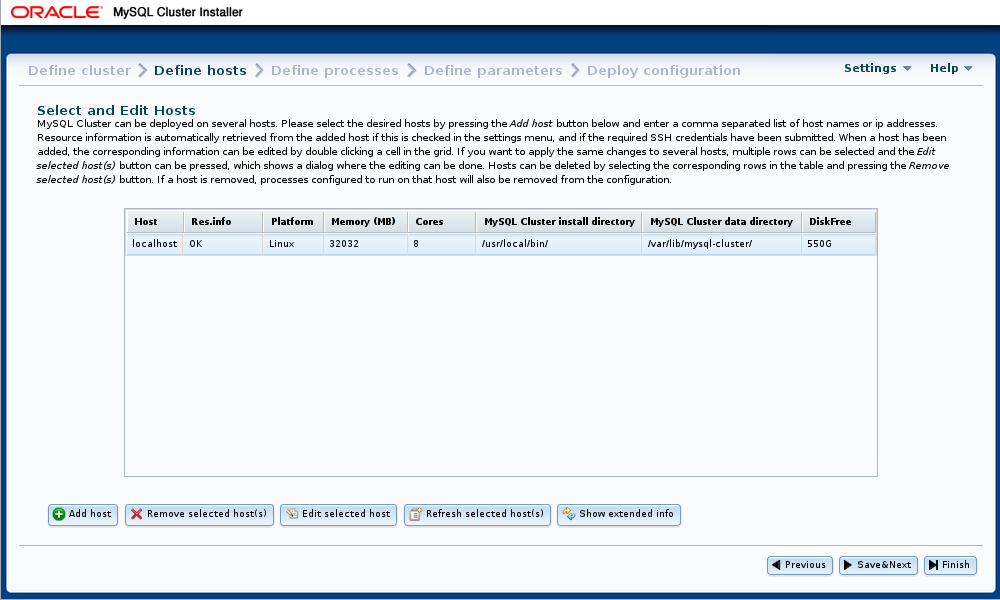
显示的属性包括以下内容:
-
主机 :该主机的名称或IP地址
-
Res.info :显示
OK安装程序是否能够从该主机检索所请求的资源信息 -
平台 :操作系统或平台
-
内存(MB) :此主机上的RAM量
-
核心 :此主机上可用的CPU核心数
-
MySQL Cluster安装目录 :在此主机上安装NDB Cluster软件的 目录的 路径; 默认为
/usr/local/bin -
MySQL Cluster数据目录 :此主机上NDB Cluster进程用于 数据的目录 路径; 默认为
/var/lib/mysql-cluster。 -
DiskFree :可用磁盘空间(以字节为单位)
对于具有多个磁盘的主机,仅显示用于数据目录的磁盘上的可用空间。
此屏幕还为每个主机提供包含以下属性的扩展视图:
-
FDQN :此主机的完全限定域名,由安装程序用于连接它,向其分发配置信息,以及在其上启动和停止集群进程。
-
内部IP :用于与在其他位置运行的进程在此主机上运行的集群进程进行通信的IP地址。
-
OS详细信息 :详细的操作系统名称和版本信息。
-
打开固件 :如果启用此复选框,安装程序将尝试打开集群进程所需的主机防火墙中的端口。
-
REPO URL :MySQL NDB Cluster存储库的URL
-
DOCKER URL :MySQL NDB CLuster Docker镜像的URL; 对于NDB 8.0,这是
mysql/mysql-cluster:8.0。 -
安装 :如果启用此复选框,则自动安装程序会尝试在此主机上安装NDB Cluster软件
扩展视图如下所示:
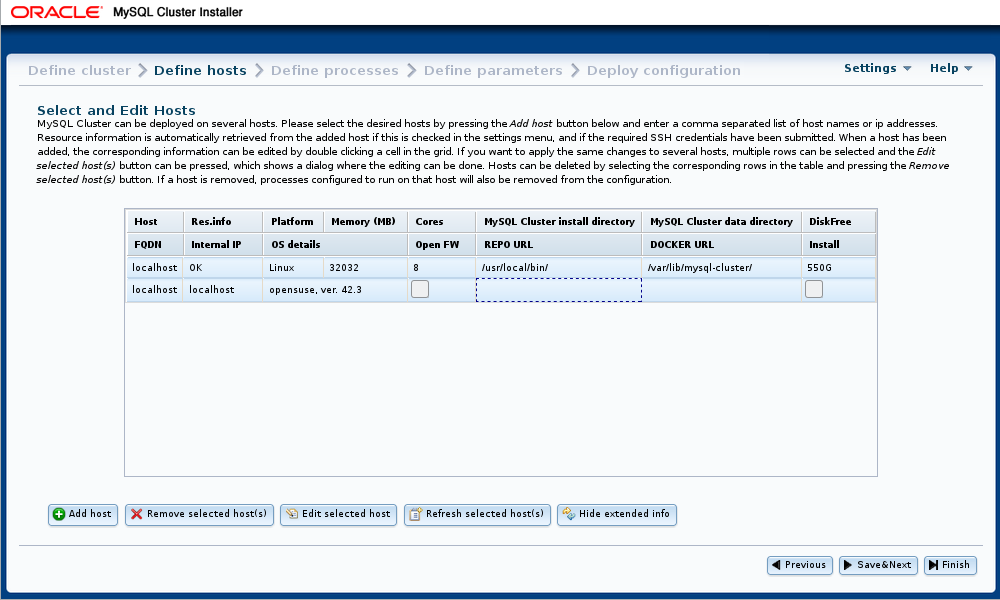
显示中的所有单元格都是可编辑的,但 Host , Res.info 和 FQDN 列中的 单元格除外 。
请注意,从远程主机检索信息可能需要一些时间。
可以检索无值的字段用省略号(
…
)表示。
您可以通过选择列表中的主机,然后单击“
刷新所选主机”
按钮,
重试从一个或多个主机获取资源信息
。
添加和删除主机
您可以通过单击“ 按钮并输入“ 添加新主机” 对话框 中指示的所需属性 来添加一个或多个主机 ,如下所示:
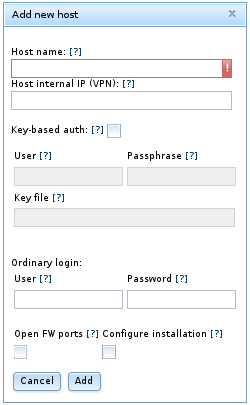
该对话框包括以下字段:
-
主机名 :以逗号分隔的一个或多个主机名,IP地址或两者的列表。 这些必须可以从运行自动安装程序的主机访问。
-
主机内部IP(VPN) :如果要将群集设置为在VPN或其他内部网络上运行,请输入用于其他主机上的群集节点联系的IP地址。
-
基于密钥的身份验证 :如果选中,则启用基于密钥的身份验证。 您可以在“ 用户” ,“ 密码 ”和“ 密钥文件” 字段中 输入任何其他所需信息 。
-
普通登录 :如果使用基于密码的登录访问此主机,请在“ 用户” 和“ 密码” 字段中 输入相应的信息 。
-
打开FW端口 :选中此复选框允许安装程序尝试打开此主机防火墙中集群进程所需的任何端口。
-
配置安装 :选中此选项允许自动安装尝试在此主机上设置NDB群集软件。
要保存新主机及其属性,请单击“ 添加” 。 如果您希望取消而不保存任何更改,请单击 取消 。
同样,您可以使用标记为 的按钮删除一个或多个主机 。 删除主机时,也会删除为该主机配置的任何进程 。
立即 。 没有确认对话框。 如果错误地删除了主机,则必须使用“ 手动重新输入其名称和属性 。
如果 更改 了“ 定义群集” 屏幕 上的SSH用户凭据 ,则自动安装程序会尝试从缺少信息的任何主机刷新资源信息。
您可以通过单击网格中的相应单元格,选择一个或多个主机并单击标记为 编辑所选主机 的按钮来编辑主机的平台名称,硬件资源信息,安装目录和数据目录 。 这会导致出现一个对话框,可以在其中编辑这些字段,如下所示:
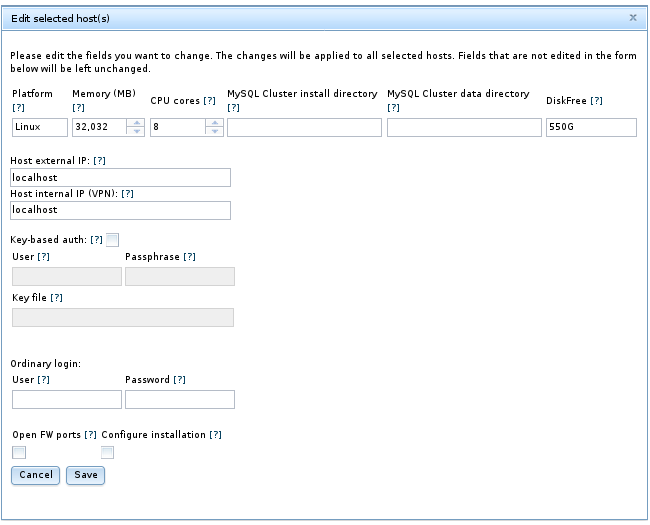
选择多个主机时,任何已编辑的值都将应用于所有选定的主机。
输入所有所需的主机信息后,可以使用 按钮将信息保存到群集的配置文件,然后进入 Define Processes 屏幕 ,您可以在其中设置一个或多个主机上的NDB Cluster进程。
此处显示 的 Define Processes 屏幕提供了一种将NDB Cluster进程(节点)分配给集群主机的方法:
![Content is described in the surrounding text. The example process tree topology includes "Any host" and "localhost", as defined earlier. The localhost tree includes the following processes: Management mode 1, API node 1, API node 2, API node 3, SQL node 1, SQL node 2, Multi threaded data node 1, and Multi threaded data node 2. This panel also includes "Add process" and "Del[ete] process" buttons.](static/picture/define-processes-start.png)
此屏幕包含一个进程树,显示集群主机和设置为在每个主机上运行的进程,以及一个显示有关树中当前所选项目的信息的面板。
当第一次访问给定群集的此屏幕时,将根据主机数量为您定义一组默认进程。 如果稍后返回“ 定义主机” 屏幕 ,删除所有主机并添加新主机,这也会导致定义新的默认进程集。
NDB群集进程具有此列表中描述的类型:
有关进程(节点)类型的更多信息,请参见 第22.1.1节“NDB集群核心概念” 。
在树中所示的处理是由类型顺序编号,对每台主机,例如,
SQL node
1
,
SQL node 2
,等等-简化鉴别。
必须将每个管理节点,数据节点或SQL进程分配给特定主机,并且不允许在任何其他主机上运行。 可以 将 API节点 分配给单个主机,但这不是必需的。 相反,您可以将其分配给 除了任何其他主机之外树还包含 的特殊 条目,并充当允许在任何主机上运行的进程的占位符。 只有API进程可以使用此 条目 。
添加流程。 要向给定主机添加新进程,请右键单击树中该主机的条目,然后 在出现时 选择“ 添加进程” 弹出窗口,或者在进程树中选择主机,然后按 进程树下面的 “ 按钮。 执行这些操作之一将打开“添加进程”对话框,如下所示:
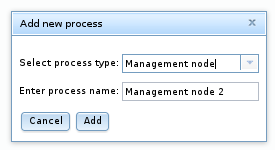
在这里,您可以从本节前面介绍的可用流程类型中进行选择; 如果需要,您还可以输入任意进程名称来代替建议值。
在流程树中选择流程时,信息面板中会显示有关该流程的信息,您可以在其中更改流程名称及其类型。 您可以将多线程数据节点( ndbmtd )更改为单线程数据节点( ndbd ),反之亦然; 不允许其他进程类型更改。 如果要在任何其他流程类型之间进行更改,则必须先删除原始流程,然后添加所需类型的新流程 。
与“ 定义流程” 屏幕一样 ,此屏幕包含一个流程树; “ 定义参数” 流程树按流程或节点类型组织在标记为“ ,“ ,“ ”和“ 。 信息面板显示有关当前所选项目的信息。 “ 定义属性” 屏幕如下所示:
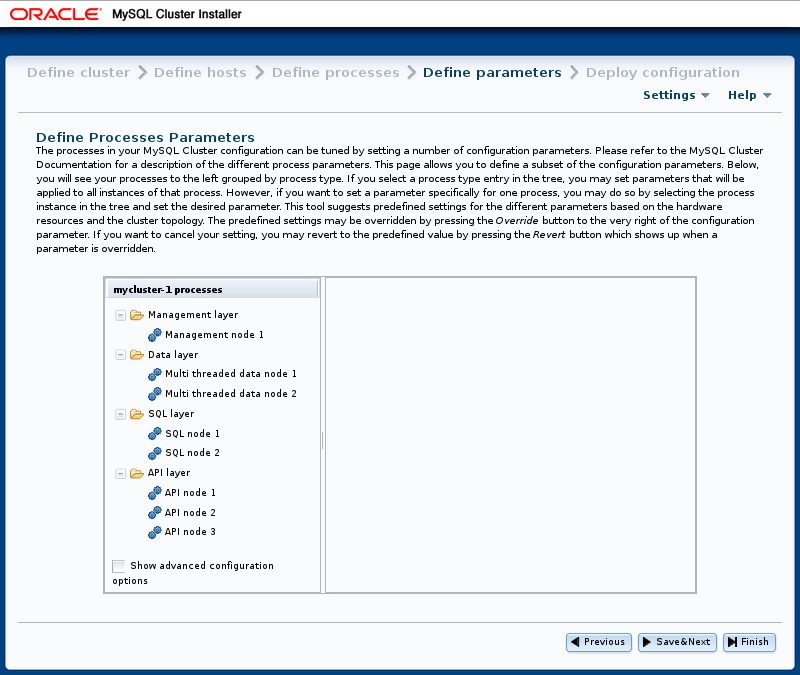
标记为“ 显示高级配置 ”的复选框 在选中时,会在信息窗格中显示数据节点和SQL节点进程的高级选项。 无论它们是否可见,都会设置和使用这些选项。 您还可以通过选中 设置” 下的 “ ”来 全局启用此行为 (请参阅 NDB群集安装程序设置和帮助菜单 )。
您可以通过从树中选择该进程来编辑单个进程的属性,也可以通过选择其中一个 文件夹 来编辑群集中相同类型的所有进程 。 为给定属性设置的每个进程值将覆盖该属性的任何每个组设置,否则这些设置将应用于相关进程。 此处显示了此类信息面板(用于SQL进程)的示例:

可以覆盖其值的属性将显示在信息面板中,并带有带加号的按钮。 此 按钮可激活属性的输入窗口小部件,使您可以更改其值。 覆盖该值后,此按钮将变为显示 的按钮 。 的 按钮撤消给定属性,它立即恢复成预定义值的任何更改。
所有配置属性都具有安装程序计算的预定义值,这些值基于主机名,节点ID,节点类型等因素。 在大多数情况下,这些值可以保持不变。 如果您不熟悉它,强烈建议您在更改任何属性值之前阅读适用的文档。 为了更容易地查找此信息,信息面板中显示的每个属性名称都链接到在线NDB Cluster文档中的描述。
此屏幕允许您执行以下任务:
-
查看要应用的进程启动命令和配置文件
-
通过在所有群集主机上创建任何必需的文件和目录来分发配置文件,即 按照当前配置 部署 群集
-
启动和停止群集
“ 部署配置” 屏幕显示在此处:
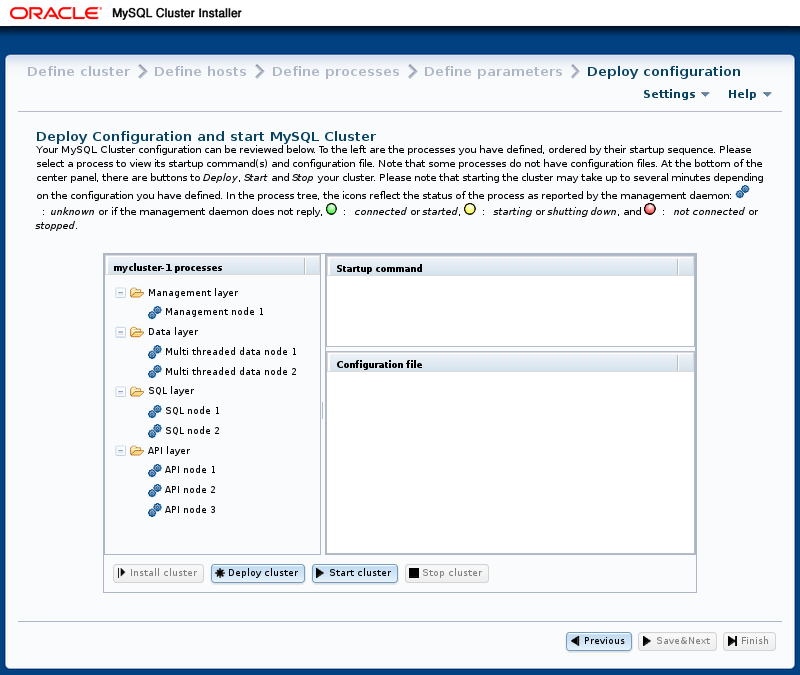
与“
定义参数”
屏幕
类似
,此屏幕具有按流程类型组织的流程树。
树中每个进程旁边都有一个状态图标,指示进程的当前状态:connected(
CONNECTED
),starting(
STARTING
),running(
STARTED
),stops(
STOPPING
)或disconnected(
NO_CONTACT
)。
如果进程已连接或正在运行,则图标显示绿色;
如果它正在启动或停止,则为黄色;
如果进程停止或管理服务器无法联系,则为红色。
此屏幕还包含两个信息面板,一个显示启动所选进程所需的启动命令或命令。 (对于某些进程,可能需要多个命令 - 例如,如果需要初始化。)另一个面板显示给定进程的配置文件的内容(如果有)。
此屏幕还包含四个按钮,标记为并执行以下列表中描述的功能:
-
:此版本中无效; 旨在用于未来版本的实现。
-
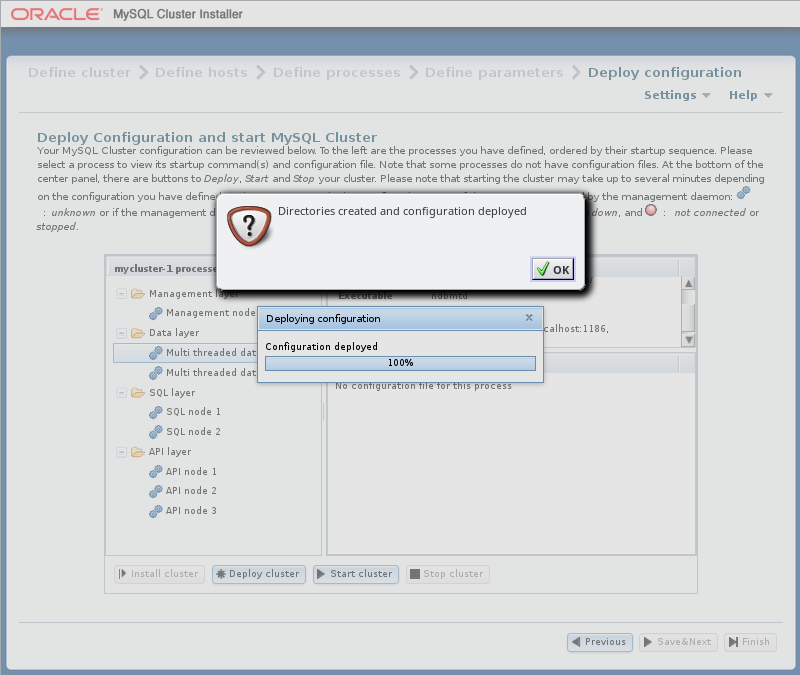
:验证配置是否有效。 创建群集主机上所需的任何目录,并将配置文件分发到主机上。 进度条显示部署的进度,如此处所示,并在部署完成时显示一个对话框,如下所示:
-
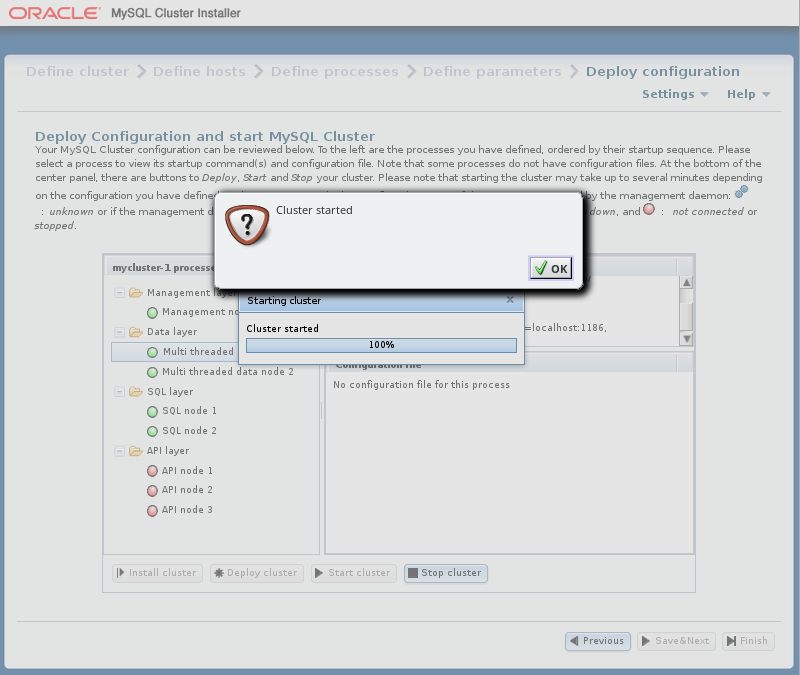
:与 一样 ,然后以正确的顺序启动所有集群进程。
启动这些过程可能需要一些时间。 如果估计的完成时间太长,则安装程序提供取消或继续启动过程的机会。 进度条指示启动过程的当前状态,如下所示:
进程树中显示的项旁边的进程状态图标也会随每个进程的状态一起更新。
启动过程完成后会显示确认对话框,如下所示:
-
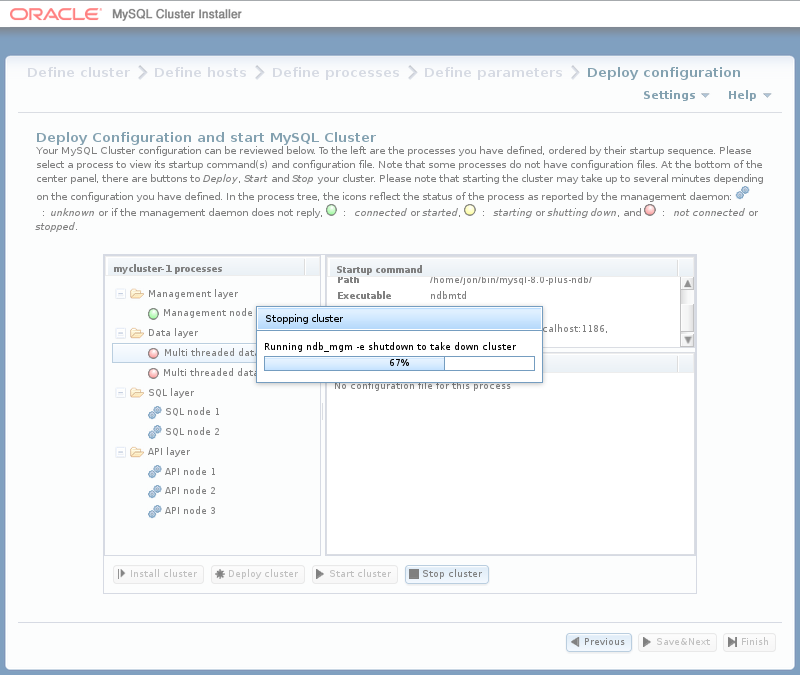
:集群启动后,您可以使用它停止它。 与启动集群一样,集群关闭不是即时的,可能需要一些时间才能完成。 类似于群集启动期间显示的进度条显示群集关闭过程的大致当前状态,与进程树相邻的进程状态图标也是如此。 进度条如下所示:
确认对话框指示关闭过程何时完成:

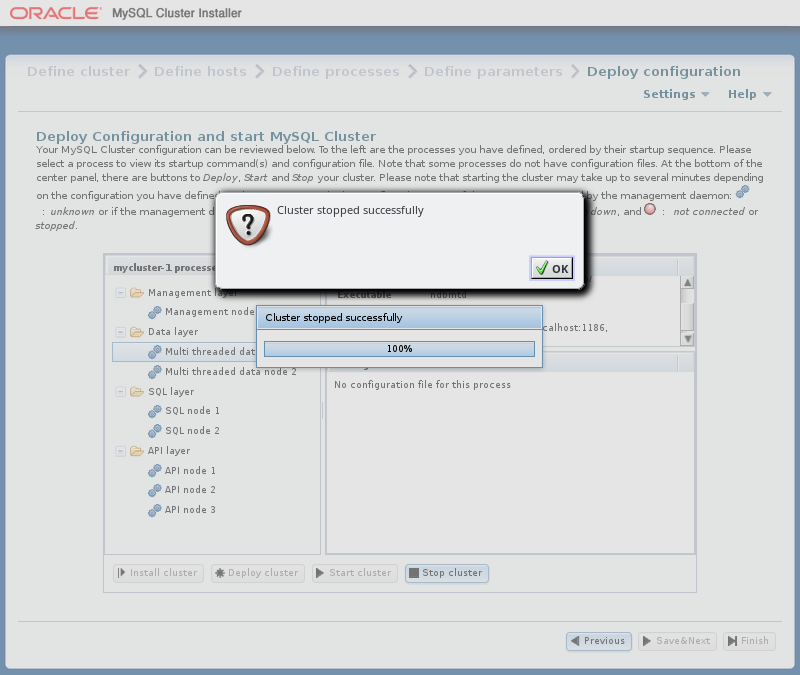
自动安装程序
config.ini
为每个管理节点
生成
包含NDB节点参数
的
文件,以及
my.cnf
包含
集群中
每个
mysqld
进程
的相应选项
的
文件
。
没有为数据节点或API节点创建配置文件。
本节介绍Linux和其他类Unix操作系统上的NDB Cluster的安装方法。 虽然接下来的几节涉及Linux操作系统,但其中的指令和程序应该很容易适应其他受支持的类Unix平台。 有关Windows系统特定的手动安装和设置说明,请参见 第22.2.3节“在Windows上安装NDB群集” 。
每个NDB群集主机必须安装正确的可执行程序。 运行SQL节点的主机必须在其上安装MySQL Server二进制文件( mysqld )。 管理节点需要管理服务器守护程序( ndb_mgmd ); 数据节点需要数据节点守护程序( ndbd 或 ndbmtd )。 没有必要在管理节点主机和数据节点主机上安装MySQL Server二进制文件。 建议您还在 管理服务器主机上 安装管理客户端( ndb_mgm )。
在Linux上安装NDB Cluster可以使用Oracle的预编译二进制文件(下载为.tar.gz存档),RPM软件包(也可从Oracle获得)或源代码完成。 所有这三种安装方法都在下面的部分中描述。
无论使用何种方法,在启动集群之前,仍然需要在安装NDB Cluster二进制文件之后为所有集群节点创建配置文件。 请参见 第22.2.4节“NDB集群的初始配置” 。
本节介绍了为Oracle提供的预编译二进制文件为每种类型的Cluster节点安装正确的可执行文件所需的步骤。
要使用预编译的二进制文件设置集群,每个集群主机的安装过程的第一步是从
NDB集群下载页面
下载二进制存档
。
(对于最新的64位NDB 8.0版本,这是
mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64.tar.gz
。)我们假设您已将此文件放在每个计算机的
/var/tmp
目录中。
如果需要自定义二进制文件,请参见 第2.9.3节“使用开发源代码树安装MySQL” 。
完成安装后,还没有启动任何二进制文件。 我们将在配置节点后向您展示如何执行此操作(请参见 第22.2.4节“NDB集群的初始配置” )。
SQL节点。
在指定用于承载SQL节点的每台计算机上,以系统
root
用户
身份执行以下步骤
:
-
检查您的
/etc/passwd和/etc/group文件(或使用操作系统提供的任何工具来管理用户和组),以查看系统上是否已有mysql组和mysql用户。 某些操作系统发行版将这些作为操作系统安装过程的一部分创建。 如果它们尚不存在,请创建一个新mysql用户组,然后将mysql用户 添加 到该组:shell>
groupadd mysqlshell>useradd -g mysql -s /bin/false mysqluseradd 和 groupadd 的语法 在不同版本的Unix上可能略有不同,或者它们可能有不同的名称,如 adduser 和 addgroup 。
-
将位置更改为包含下载文件的目录,解压缩归档文件,并创建一个名为
mysql该mysql目录 的符号链接 。注意实际的文件和目录名称根据NDB Cluster版本号而有所不同。
shell>
cd /var/tmpshell>tar -C /usr/local -xzvf mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64.tar.gzshell>ln -s /usr/local/mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64 /usr/local/mysql -
将位置更改为
mysql目录并使用 mysqld 设置系统数据库--initialize,如下所示:shell>
cd mysqlshell>mysqld --initialize这会为MySQL
root帐户 生成一个随机密码 。 如果你 不 希望被生成的随机密码,您可以替换--initialize-insecure的选项--initialize。 在任何一种情况下,您都应该 在执行此步骤之前 查看 第2.10.1节“初始化数据目录” 以获取其他信息。 另请参见 第4.4.2节“ mysql_secure_installation - 改进MySQL安装安全性” 。 -
设置MySQL服务器和数据目录的必要权限:
shell>
chown -R root .shell>chown -R mysql datashell>chgrp -R mysql . -
将MySQL启动脚本复制到相应的目录,使其可执行,并将其设置为在启动操作系统时启动:
shell>
cp support-files/mysql.server /etc/rc.d/init.d/shell>chmod +x /etc/rc.d/init.d/mysql.servershell>chkconfig --add mysql.server(启动脚本目录可能因操作系统和版本而异 - 例如,在某些Linux发行版中,它是
/etc/init.d。)在这里,我们使用Red Hat的 chkconfig 创建启动脚本的链接; 在您的平台上使用适用于此目的的任何方法,例如 Debian上的 update-rc.d 。
请记住,必须在要驻留SQL节点的每台计算机上重复上述步骤。
数据节点。
安装数据节点不需要
mysqld
二进制文件。
只需要NDB Cluster数据节点可执行
ndbd
(单线程)或
ndbmtd
(多线程)。
这些二进制文件也可以在
.tar.gz
存档中
找到
。
同样,我们假设您已将此存档放入
/var/tmp
。
作为系统
root
(即,在使用
sudo
,
su root
或系统等效用于暂时承担系统管理员帐户的权限之后),执行以下步骤在数据节点主机上安装数据节点二进制文件:
-
将位置更改为
/var/tmp目录,并将 存档中 的 ndbd 和 ndbmtd 二进制文件解压缩到合适的目录中,例如/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64.tar.gzshell>cd mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64shell>cp bin/ndbd /usr/local/bin/ndbdshell>cp bin/ndbmtd /usr/local/bin/ndbmtd(你可以安全地删除通过解压缩下载的存档创建的目录,它包含的文件,从
/var/tmp一次 ndb_mgm 和 ndb_mgmd 已经被复制到可执行文件目录。) -
将位置更改为复制文件的目录,然后使它们都可执行:
shell>
cd /usr/local/binshell>chmod +x ndb*
应在每个数据节点主机上重复上述步骤。
虽然只需要一个数据节点可执行文件来运行NDB Cluster数据节点,但我们已经向您展示了如何 在前面的说明中 安装 ndbd 和 ndbmtd 。 我们建议您在安装或升级NDB群集时执行此操作,即使您计划仅使用其中一个,因为如果您以后决定从一个更改为另一个,这将节省时间和麻烦。
托管数据节点的每台机器上的数据目录是
/usr/local/mysql/data
。
配置管理节点时,此信息是必不可少的。
(请参见
第22.2.4节“NDB集群的初始配置”
。)
管理节点。
安装管理节点不需要
mysqld
二进制文件。
只需要NDB群集管理服务器(
ndb_mgmd
);
您最有可能也想安装管理客户端(
ndb_mgm
)。
这两个二进制文件也可以在
.tar.gz
存档中
找到
。
同样,我们假设您已将此存档放入
/var/tmp
。
作为系统
root
,执行以下步骤以
在管理节点主机上
安装
ndb_mgmd
和
ndb_mgm
:
-
将位置更改为
/var/tmp目录,并将 存档中 的 ndb_mgm 和 ndb_mgmd 解压缩到合适的目录中,例如/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64.tar.gzshell>cd mysql-cluster-gpl-8.0.17-linux-glibc2.12-x86_64shell>cp bin/ndb_mgm* /usr/local/bin(你可以安全地删除通过解压缩下载的存档创建的目录,它包含的文件,从
/var/tmp一次 ndb_mgm 和 ndb_mgmd 已经被复制到可执行文件目录。) -
将位置更改为复制文件的目录,然后使它们都可执行:
shell>
cd /usr/local/binshell>chmod +x ndb_mgm*
在 第22.2.4节“NDB集群的初始配置”中 ,我们为示例NDB集群中的所有节点创建配置文件。
本节介绍使用Oracle提供的RPM软件包为每种类型的NDB Cluster 8.0节点安装正确的可执行文件所需的步骤。 有关以前版本的NDB Cluster的RPM的信息,请参阅 使用旧式RPM(NDB 7.5.3及更早版本)进行安装 。
作为本节中描述的方法的替代方案,Oracle为NDB群集提供了与许多常见Linux发行版兼容的MySQL存储库。 此处列出的两个repostories可用于基于RPM的发行版:
-
对于使用 yum 或 dnf的发行版 ,您可以使用MySQL Yum存储库进行NDB集群。 有关 说明和其他信息, 请参阅 使用Yum存储库安装MySQL NDB群集 。
-
对于SLES,您可以使用MySQL SLES Repository for NDB Cluster。 有关 说明和其他信息, 请参阅 使用SLES存储库安装MySQL NDB群集 。
RPM可用于32位和64位Linux平台。 这些RPM的文件名使用以下模式:
MySQL的集群社区数据节点,8.0.17-1.el7.x86_64.rpm mysql-cluster-license-component-ver-rev。distro。arch的.rpmlicense:= {commercial | 社区}component:{management-server | 数据节点| 服务器| 客户|other—see text}ver:major。minor。releaserev:major[。minor]distro:{el6 | el7 | sles12}arch:{i686 | x86_64的}
license
指示RPM是否是NDB群集的商业版或社区版的一部分。
在本节的其余部分中,我们假设您正在安装社区版本的示例。
component
可以在下表中找到带描述的
可能值
:
表22.5 NDB Cluster RPM分发的组件
| 零件 | 描述 |
|---|---|
auto-installer |
NDB Cluster Auto Installer程序; 有关用法 , 请参见 第22.2.1节“NDB集群自动安装程序” |
client |
MySQL和
NDB
客户端程序;
包括
mysql
客户端,
ndb_mgm
客户端和其他客户端工具
|
common |
MySQL服务器所需的字符集和错误消息信息 |
data-node |
ndbd 和 ndbmtd 数据节点二进制文件 |
devel |
MySQL客户端开发所需的头文件和库文件 |
embedded |
嵌入式MySQL服务器 |
embedded-compat |
向后兼容的嵌入式MySQL服务器 |
embedded-devel |
用于开发嵌入式MySQL应用程序的头文件和库文件 |
java |
支持ClusterJ应用程序所需的JAR文件 |
libs |
MySQL客户端库 |
libs-compat |
向后兼容的MySQL客户端库 |
management-server |
NDB群集管理服务器( ndb_mgmd ) |
memcached |
需要支持的文件
ndbmemcache
|
minimal-debuginfo |
包server-minimal的调试信息; 在开发使用此包的应用程序或调试此包时有用 |
ndbclient |
NDB
用于运行NDB API和MGM API应用程序的客户端库(
libndbclient
)
|
ndbclient-devel |
开发NDB API和MGM API应用程序所需的标头和其他文件 |
nodejs |
设置Node.JS支持NDB Cluster所需的文件 |
server |
包含
存储引擎支持
的MySQL服务器(
mysqld
)
NDB
以及相关的MySQL服务器程序
|
server-minimal |
为NDB和相关工具最小化安装MySQL服务器 |
test |
mysqltest ,其他MySQL测试程序和支持文件 |
.tar
还提供针对给定平台和体系结构的所有NDB Cluster RPM
的单个捆绑(
文件)。
此文件的名称遵循此处显示的模式:
mysql-cluster-license-ver-rev。distro。arch的.rpm,bundle.tar
您可以使用 tar 或首选工具 从此文件中提取单个RPM文件 以提取存档。
以下列表中给出了安装三种主要类型的NDB Cluster节点所需的组件:
-
管理节点 :
management-server -
数据节点 :
data-node -
SQL节点 :
server和common
此外,
client
应安装RPM以
在至少一个管理节点上
提供
ndb_mgm
管理客户端。
您可能还希望在SQL节点上安装它,以便
在这些
节点上提供
mysql
和其他MySQL客户端程序。
我们将在本节后面讨论按类型安装节点。
ver
表示
NDB
8.0中
的三部分
存储引擎版本号。
x
格式,如
8.0.17
示例中
所示
。
rev
提供RPM修订号
major
。
minor
格式。
在本节所示的示例中,我们使用
1.1
此值。
的
distro
(Linux发行)是一个
rhel5
(甲骨文Linux 5时,红帽企业Linux 4和5),
el6
(
甲骨文Linux 6中,红帽企业Linux 6),
el7
(
甲骨文的Linux 7,红帽企业Linux 7),或
sles12
(SUSE企业Linux 12)。
对于本节中的示例,我们假设主机运行Oracle Linux 7,Red Hat Enterprise Linux 7或等效项(
el7
)。
arch
适用
i686
于32位RPM和
x86_64
64位版本。
在此处显示的示例中,我们假设使用64位平台。
RPM文件名中的NDB Cluster版本号(此处显示为
8.0.17
)可能会根据您实际使用的版本而有所不同。
非常重要的是,要安装的所有Cluster RPM都具有相同的版本号
。
该体系结构也应该适合安装RPM的机器;
特别是,您应该记住,64位RPM(
x86_64
)不能与32位操作系统一起使用(
i686
用于后者)。
数据节点。
在要承载NDB群集数据节点的计算机上,只需安装
data-node
RPM。
为此,请将此RPM复制到数据节点主机,并以系统root用户身份运行以下命令,根据需要替换为RPM显示的名称,以匹配从MySQL网站下载的RPM的名称:
外壳> rpm -Uhv mysql-cluster-community-data-node-8.0.17-1.el7.x86_64.rpm
这将安装
ndbd
和
ndbmtd
数据节点二进制文件
/usr/sbin
。
这些中的任何一个都可用于在此主机上运行数据节点进程。
SQL节点。
将
RPM
server
和
common
RPM
复制
到用于托管NDB Cluster SQL节点的每台计算机(
server
需要
common
)。
server
通过以系统root用户身份执行以下命令来
安装
RPM,根据需要替换为RPM显示的名称,以匹配从MySQL网站下载的RPM的名称:
外壳> rpm -Uhv mysql-cluster-community-server-8.0.17-1.el7.x86_64.rpm
这将
在
目录中
安装
具有
存储引擎支持
的MySQL服务器二进制文件(
mysqld
)
。
它还安装了所有需要的MySQL服务器支持文件和有用的MySQL服务器程序,包括
mysql.server
和
mysqld_safe
启动脚本(
分别
在
和中
)。
RPM安装程序应自动处理常规配置问题(如创建
用户和组,如果需要)。
NDB
/usr/sbin
/usr/share/mysql
/usr/bin
mysql
您必须使用为NDB Cluster发布的这些RPM的版本;
那些为标准MySQL服务器发布的版本不支持
NDB
存储引擎。
要管理SQL节点(MySQL服务器),还应安装
client
RPM,如下所示:
外壳> rpm -Uhv mysql-cluster-community-client-8.0.17-1.el7.x86_64.rpm
这将安装
MySQL的
客户端和其他MySQL客户端程序,如
中mysqladmin
和
mysqldump的
,对
/usr/bin
。
管理节点。
要安装NDB Cluster管理服务器,只需使用
management-server
RPM。
将此RPM复制到用于托管管理节点的计算机,然后通过以系统root用户身份运行以下命令来安装它(根据需要替换为RPM显示的名称以匹配
management-server
从MySQL网站下载
的RPM的名称
):
外壳> rpm -Uhv mysql-cluster-commercial-management-server-8.0.17-1.el7.x86_64.rpm
此RPM
在
目录中
安装管理服务器二进制文件
ndb_mgmd
/usr/sbin
。
虽然这是运行管理节点实际需要的唯一程序,但同样也可以使用
ndb_mgm
NDB集群管理客户端。
您可以
通过安装
RPM
来获取此程序以及其他
NDB
客户端程序(如
ndb_desc
和
ndb_config)
,
client
如前所述。
有关 使用Oracle 提供的RPM安装MySQL的一般信息 , 请参见 第2.5.4节“使用Oracle的RPM软件包在Linux上安装MySQL” 。
从RPM安装后,您仍然需要配置集群; 有关信息, 请参见 第22.2.4节“NDB群集的初始配置” 。
非常重要的是,要安装的所有Cluster RPM都具有相同的版本号
。
该
architecture
名称也应适用于安装RPM的机器;
特别是,您应该记住,64位RPM不能与32位操作系统一起使用。
数据节点。
在要托管群集数据节点的计算机上,只需安装
server
RPM。
为此,请将此RPM复制到数据节点主机,并以系统root用户身份运行以下命令,根据需要替换为RPM显示的名称,以匹配从MySQL网站下载的RPM的名称:
外壳> rpm -Uhv MySQL-Cluster-server-gpl-8.0.17-1.sles11.i386.rpm
虽然这会安装所有NDB Cluster二进制文件,但
实际上只需要
程序
ndbd
或
ndbmtd
(都在其中
/usr/sbin
)来运行NDB Cluster数据节点。
SQL节点。
在用于托管群集SQL节点的每台计算机上,
server
通过以系统root用户身份执行以下命令来
安装
RPM,根据需要替换为RPM显示的名称,以匹配从MySQL网站下载的RPM的名称:
外壳> rpm -Uhv MySQL-Cluster-server-gpl-8.0.17-1.sles11.i386.rpm
这将
在
目录中
安装
具有
存储引擎支持
的MySQL服务器二进制文件(
mysqld
)
,以及所有需要的MySQL服务器支持文件。
它还安装了
mysql.server
和
mysqld_safe
启动脚本(
分别
在
和中
)。
RPM安装程序应自动处理常规配置问题(如创建
用户和组,如果需要)。
NDB
/usr/sbin
/usr/share/mysql
/usr/bin
mysql
要管理SQL节点(MySQL服务器),还应安装
client
RPM,如下所示:
外壳> rpm -Uhv MySQL-Cluster-client-gpl-8.0.17-1.sles11.i386.rpm
这将安装 mysql 客户端程序。
管理节点。
要安装NDB Cluster管理服务器,只需使用
server
RPM。
将此RPM复制到用于托管管理节点的计算机,然后通过以系统root用户身份运行以下命令来安装它(根据需要替换为RPM显示的名称以匹配
server
从MySQL网站下载
的RPM的名称
):
外壳> rpm -Uhv MySQL-Cluster-server-gpl-8.0.17-1.sles11.i386.rpm
虽然此RPM安装了许多其他文件,但
实际上只需要
管理服务器二进制文件
ndb_mgmd
(在
/usr/sbin
目录中)来运行管理节点。
该
server
RPM还安装
ndb_mgm
,在
NDB
管理客户端。
有关 使用Oracle 提供的RPM安装MySQL的一般信息 , 请参见 第2.5.4节“使用Oracle的RPM软件包在Linux上安装MySQL” 。 有关所需的安装后配置的信息 , 请参见 第22.2.4节“NDB群集的初始配置” 。
本节提供有关在Debian和相关Linux发行版(如Ubuntu)上安装NDB Cluster的信息,使用
.deb
Oracle提供
的
文件来实现此目的。
Oracle还为Debian和其他发行版提供了NDB Cluster APT存储库。 有关 说明和其他信息, 请参阅 使用APT存储库安装MySQL NDB群集 。
Oracle
.deb
为32位和64位平台的NDB Cluster
提供
安装程序文件。
对于基于Debian的系统,只需要一个安装程序文件。
根据适用的NDB Cluster版本,Debian版本和体系结构,使用此处显示的模式命名此文件:
mysql-cluster-gpl-ndbver-debiandebianver-arch.deb
这里
ndbver
是3部分
NDB
引擎版本号,
debianver
是Debian(
8
或
9
)
的主要版本
,
arch
是
i686
或者之一
x86_64
。
在下面的示例中,我们假设您希望在64位Debian 9系统上安装NDB 8.0.17;
在这种情况下,安装程序文件被命名
mysql-cluster-gpl-8.0.17-debian9-x86_64.deb-bundle.tar
。
下载完相应的
.deb
文件后,您可以解压缩它,然后使用命令行安装它
dpkg
,如下所示:
外壳> dpkg -i mysql-cluster-gpl-8.0.17-debian9-i686.deb
您也可以使用
dpkg
如下所示
删除它
:
外壳> dpkg -r mysql
安装程序文件还应与大多数使用
.deb
文件的
图形包管理器兼容
,例如
GDebi
Gnome桌面。
该
.deb
文件安装了NDB Cluster
,其中
包含MySQL服务器的2部分版本系列版本。
对于NDB 8.0,这始终是
。
目录布局与通用Linux二进制发行版的目录布局相同(
参见表2.3,“通用Unix / Linux二进制包的MySQL安装布局”
),但是找到启动脚本和配置文件
而不是
。
所有NDB Cluster可执行文件(例如
ndb_mgm
,
ndbd
和
ndb_mgmd
)都放在
目录中。
/opt/mysql/server-
version/version
5.7
support-files
share
bin
本节提供有关在Linux和其他类Unix平台上编译NDB Cluster的信息。 从源代码构建NDB集群类似于构建标准MySQL服务器,尽管它在这里讨论的几个关键方面有所不同。 有关从源代码构建MySQL的一般信息,请参见 第2.9节“从源代码安装MySQL” 。 有关在Windows平台上编译NDB群集的信息,请参见 第22.2.3.2节“在Windows上从源代码编译和安装NDB群集” 。
构建MySQL NDB Cluster 8.0需要使用MySQL Server 8.0源代码。
这些可以从MySQL下载页面获得,
网址
为
https://dev.mysql.com/downloads/
。
存档的源文件应具有类似的名称
mysql-8.0.17.tar.gz
。
您还可以从
launchpad.net
获取MySQL开发源代码
。
在以前的版本中,不支持从标准MySQL服务器源构建NDB Cluster。 在MySQL 8.0和NDB Cluster 8.0中,情况已不再如此 - 这两种产品现在都是从相同的源构建的 。
CMake
的
WITH_NDBCLUSTER
选项
导致构建管理节点,数据节点和其他NDB Cluster程序的二进制文件;
它还会导致
mysqld
与
存储引擎支持
一起编译
。
此选项(其别名或一个
和
)需要建立NDB簇时。
NDB
WITH_NDBCLUSTER_STORAGE_ENGINE
WITH_PLUGIN_NDBCLUSTER
WITH_NDB_JAVA
默认情况下启用
该
选项。
这意味着,默认情况下,如果
CMake
无法在系统上找到Java的位置,则配置过程将失败;
如果您不希望启用Java和ClusterJ支持,则必须通过使用配置构建来明确指出
-DWITH_NDB_JAVA=OFF
。
用于
WITH_CLASSPATH
在需要时提供Java类路径。
有关 特定于构建NDB群集的 CMake 选项的 更多信息 ,请参阅 编译NDB群集的选项 。
运行 make && make install (或系统的等效)后,结果类似于将预编译二进制文件解压缩到同一位置所获得的结果。
管理节点。
从源构建并运行默认的
make install时
,
可以在中找到
管理服务器和管理客户端二进制文件(
ndb_mgmd
和
ndb_mgm
)
/usr/local/mysql/bin
。
管理节点主机上
只
需要
ndb_mgmd
;
但是,
在同一主机上
存在
ndb_mgm
也是一个好主意
。
这些可执行文件都不需要主机文件系统上的特定位置。
数据节点。
数据节点主机上唯一需要的可执行文件是数据节点二进制文件
ndbd
或
ndbmtd
。
(
例如,
mysqld
不必存在于主机上。)默认情况下,从源构建时,此文件将放在目录中
/usr/local/mysql/bin
。
要在多个数据节点主机上安装,只需要
ndbd
或
ndbmtd
需要复制到其他主机或机器。
(这假设所有数据节点主机使用相同的体系结构和操作系统;否则您可能需要为每个不同的平台单独编译。)数据节点二进制文件不必位于主机文件系统上的任何特定位置,只要位置已知。
从源代码编译NDB Cluster时,构建多线程数据节点二进制文件不需要特殊选项。
使用
NDB
存储引擎支持
配置构建
会导致
自动构建
ndbmtd
;
make install
将
ndbmtd
二进制
bin
文件与
mysqld
,
ndbd
和
ndb_mgm
一起
放在安装
目录中
。
SQL节点。
如果您使用群集支持编译MySQL,并执行默认安装(使用
make install
作为系统
root
用户),
则放置
mysqld
/usr/local/mysql/bin
。
按照
第2.9节“从源安装MySQL”中
给出的步骤
使
mysqld
可以使用。
如果要运行多个SQL节点,可以
在多台计算机上
使用相同
mysqld
可执行文件及其关联支持文件
的副本
。
最简单的方法是复制整个
/usr/local/mysql
目录及其中包含的所有目录和文件到其他SQL节点主机,然后重复
每台计算机上的
第2.9节“从源安装MySQL”中
的步骤
。
如果使用非默认
PREFIX
选项
配置构建
,则必须相应地调整目录。
在 第22.2.4节“NDB集群的初始配置”中 ,我们为示例NDB集群中的所有节点创建配置文件。
本节介绍Windows主机上NDB Cluster的安装过程。 适用于Windows的NDB Cluster 8.0二进制文件可从 https://dev.mysql.com/downloads/cluster/获取 。 有关从Oracle提供的二进制版本在Windows上安装NDB Cluster的信息,请参见 第22.2.3.1节“从二进制版本在Windows上安装NDB群集” 。
也可以使用Microsoft Visual Studio在Windows上从源代码编译和安装NDB Cluster。 有关更多信息,请参见 第22.2.3.2节“在Windows上从源代码编译和安装NDB集群” 。
本节介绍使用 Oracle提供 的二进制 “ 无安装 ” NDB Cluster版本 在Windows上基本安装NDB Cluster ,使用本节开头概述的相同的4节点设置(请参见 第22.2节“NDB群集安装”) ),如下表所示:
与其他平台一样,运行SQL节点的NDB Cluster主机必须在其上安装MySQL Server二进制文件( mysqld.exe )。 您还应该 在此主机上 安装MySQL客户端( mysql.exe )。 对于管理节点和数据节点,没有必要安装MySQL Server二进制文件; 但是,每个管理节点都需要管理服务器守护程序( ndb_mgmd.exe ); 每个数据节点都需要数据节点守护程序( ndbd.exe 或 ndbmtd.exe )。 对于此示例,我们将 ndbd.exe 称为数据节点可执行文件,但您可以安装 ndbmtd.exe ,这个程序的多线程版本,完全相同的方式。 您还应该 在管理服务器主机上 安装管理客户端( ndb_mgm.exe )。 本节介绍为每种类型的NDB Cluster节点安装正确的Windows二进制文件所需的步骤。
与其他Windows程序一样,NDB Cluster可执行文件以
.exe
文件扩展名
命名
。
但是,
.exe
从命令行调用这些程序时,
不必包含
扩展名。
因此,我们通常只是将本文档中的这些程序称为
mysqld
,
mysql
,
ndb_mgmd
等。
您应该明白,无论我们引用(例如)
mysqld
还是
mysqld.exe
,任何一个名称都意味着相同的东西(MySQL Server程序)。
要使用Oracles的
no-install
二进制文件
设置NDB集群
,安装过程的第一步是从
https://dev.mysql.com/downloads/cluster/
下载最新的NDB集群Windows ZIP二进制存档
。
此存档具有文件名
,其中
是
存储引擎版本(例如
),并且
是体系结构(
对于32位二进制文件和
64位二进制文件)。
例如,命名了64位Windows系统的NDB Cluster 8.0.17存档
。
mysql-cluster-gpl-
ver-winarch.zipver
NDB
8.0.17
arch
32
64
mysql-cluster-gpl-8.0.17-win64.zip
您可以在32位和64位版本的Windows上运行32位NDB Cluster二进制文件; 但是,64位NDB Cluster二进制文件只能用于64位版本的Windows。 如果在具有64位CPU的计算机上使用32位版本的Windows,则必须使用32位NDB群集二进制文件。
要最小化需要从Internet下载或在计算机之间复制的文件数,我们从您打算运行SQL节点的计算机开始。
SQL节点。
我们假设您已将存档的副本放在
IP地址为198.51.100.20的计算机上的
目录中
,其中
是当前用户的名称。
(您可以
在命令行上
使用此名称
。)要将NDB Cluster可执行文件安装并运行为Windows服务,此用户应该是该
组
的成员
。
C:\Documents and
Settings\
username\My
Documents\Downloadsusername
ECHO
%USERNAME%
Administrators
从存档中提取所有文件。
与Windows资源管理器集成的提取向导足以完成此任务。
(如果使用其他存档程序,请确保它从存档中提取所有文件和目录,并保留存档的目录结构。)当系统要求您输入目标目录时,请输入
C:\
,这会导致提取向导提取存档到目录
。
将此目录重命名为
。
C:\mysql-cluster-gpl-
ver-winarchC:\mysql
可以将NDB Cluster二进制文件安装到除以外的目录
C:\mysql\bin
;
但是,如果这样做,则必须相应地修改此过程中显示的路径。
特别是,如果将MySQL服务器(SQL节点)二进制文件安装到
C:\mysql
or
之外的位置
C:\Program
Files\MySQL\MySQL Server 8.0
,或者如果SQL节点的数据目录位于
C:\mysql\data
or
之外的位置
C:\Program
Files\MySQL\MySQL Server 8.0\data
,则必须在命令行上使用额外的配置选项或将其添加到
my.ini
或
my.cnf
启动SQL节点时的文件。
有关配置MySQL服务器以在非标准位置运行的更多信息,请参见
第2.3.5节“在Microsoft Windows上使用
noinstall
ZIP存档“
。
对于具有NDB群集支持的MySQL服务器作为NDB群集的一部分运行,必须使用选项
--ndbcluster
和
启动它
--ndb-connectstring
。
虽然您可以在命令行上指定这些选项,但将它们放在选项文件中通常更方便。
为此,请在记事本或其他文本编辑器中创建新的文本文件。
在此文件中输入以下配置信息:
的[mysqld] #mysqld进程的选项: ndbcluster#运行NDB存储引擎 ndb-connectstring = 198.51.100.10#管理服务器的位置
如果需要,您可以添加此MySQL服务器使用的其他选项(请参见
第2.3.5.2节“创建选项文件”
),但文件必须至少包含显示的选项。
将此文件另存为
C:\mysql\my.ini
。
这样就完成了SQL节点的安装和设置。
数据节点。
Windows主机上的NDB群集数据节点只需要一个可执行文件,即
ndbd.exe
或
ndbmtd.exe之一
。
对于此示例,我们假设您使用的是
ndbd.exe
,但使用
ndbmtd.exe
时应用相同的说明
。
在这里你想运行一个数据节点(具有IP电脑地址198.51.100.30和198.51.100.40)每台计算机上,创建目录
C:\mysql
,
C:\mysql\bin
和
C:\mysql\cluster-data
;
然后,在计算机上,您下载并提取
no-install
档案,找到
ndbd.exe
在
C:\mysql\bin
目录。
将此文件复制到
C:\mysql\bin
两个数据节点主机中的每个主机上
的
目录中。
要充当NDB群集的一部分,必须为每个数据节点提供管理服务器的地址或主机名。
在启动每个数据节点进程时,可以
使用
--ndb-connectstring
or
-c
选项在
命令行上提供此信息
。
但是,通常最好将此信息放在选项文件中。
为此,请在记事本或其他文本编辑器中创建新的文本文件,然后输入以下文本:
[mysql_cluster] #数据节点进程选项: ndb-connectstring = 198.51.100.10#管理服务器的位置
将此文件另存为
C:\mysql\my.ini
数据节点主机上。
创建包含相同信息的另一个文本文件,并将其保存
C:mysql\my.ini
在其他数据节点主机上,或将my.ini文件从第一个数据节点主机复制到第二个数据节点主机,确保将副本放在第二个数据节点的
C:\mysql
目录中。
现在,两个数据节点主机都可以在NDB群集中使用,只留下要安装和配置的管理节点。
管理节点。
用于托管NDB群集管理节点的计算机上所需的唯一可执行程序是管理服务器程序
ndb_mgmd.exe
。
但是,为了在NDB群集启动后对其进行管理,
还应
在与管理服务器相同的计算机上
安装NDB群集管理客户端程序
ndb_mgm.exe
。
在下载和解
no-install
压缩归档
的机器上找到这两个程序
;
这应该是
C:\mysql\bin
SQL节点主机上
的目录
。
创建目录
C:\mysql\bin
在具有IP地址198.51.100.10的计算机上,然后将两个程序复制到此目录。
您现在应该创建两个配置文件供以下用户使用
ndb_mgmd.exe
:
-
本地配置文件,用于提供特定于管理节点本身的配置数据。 通常,此文件只需提供NDB Cluster全局配置文件的位置(请参阅第2项)。
要创建此文件,请在记事本或其他文本编辑器中启动新文本文件,然后输入以下信息:
[mysql_cluster] #管理节点进程的选项 配置文件中= C:/mysql/bin/config.ini
将此文件另存为文本文件
C:\mysql\bin\my.ini。 -
一个全局配置文件,管理节点可以从中获取整个NDB集群的配置信息。 此文件至少必须包含NDB群集中每个节点的一个部分,以及管理节点和所有数据节点的IP地址或主机名(
HostName配置参数)。 还建议包括以下附加信息:-
任何SQL节点的IP地址或主机名
-
分配给每个数据节点的数据存储器和索引存储器(
DataMemory以及IndexMemory配置参数) -
使用
NoOfReplicas配置参数 的副本数量 (请参见 第22.1.2节“NDB群集节点,节点组,副本和分区” ) -
每个数据节点存储数据和日志文件的目录,以及管理节点保存其日志文件的目录(在两种情况下,
DataDir配置参数)
使用文本编辑器(如记事本)创建新的文本文件,并输入以下信息:
[ndbd默认] #影响所有数据节点上的ndbd进程的选项: NoOfReplicas = 2#副本数 DataDir = C:/ mysql / cluster-data#每个数据节点的数据文件的目录 #目录路径中使用的正斜杠, #而不是反斜杠。这是对的; #参见文本中的重要说明 DataMemory = 80M#分配给数据存储的内存 IndexMemory = 18M#内存分配给索引存储 #对于DataMemory和IndexMemory,我们使用了 # 默认值。由于“世界”数据库占用了 #只有大约500KB,这应该足够了 #此示例群集设置。 [ndb_mgmd] #管理流程选项: HostName = 198.51.100.10#管理节点的主机名或IP地址 DataDir = C:/ mysql / bin / cluster-logs#管理节点日志文件的目录 [NDBD] #数据节点“A”的选项: #(每个数据节点一个[ndbd]部分) HostName = 198.51.100.30#主机名或IP地址 [NDBD] #数据节点“B”的选项: HostName = 198.51.100.40#主机名或IP地址 的[mysqld] #SQL节点选项: HostName = 198.51.100.20#主机名或IP地址将此文件另存为文本文件
C:\mysql\bin\config.ini。 -
\
在Windows上的NDB Cluster使用的程序选项或配置文件中指定目录路径时,不能使用
单个反斜杠字符(
)。
相反,您必须使用第二个反斜杠(
\\
)
转义每个反斜杠字符
,或者使用正斜杠字符(
/
)
替换反斜杠
。
例如,
[ndb_mgmd]
NDB群集
config.ini
文件
部分中
的以下行
不起作用:
DATADIR = C:\ MySQL的\ BIN \群集日志
相反,您可以使用以下任一方法:
DataDir = C:\\ mysql \\ bin \\ cluster-logs #Eascaped反斜杠
DataDir = C:/ mysql / bin / cluster-logs#正斜杠
出于简洁和易读的原因,我们建议您在Windows上的NDB群集程序选项和配置文件中使用的目录路径中使用正斜杠。
Oracle为Windows提供了预编译的NDB Cluster二进制文件,这对大多数用户来说应该是足够的。 但是,如果您愿意,也可以从源代码编译NDB Cluster for Windows。 执行此操作的过程几乎与用于编译Windows的标准MySQL Server二进制文件的过程相同,并使用相同的工具。 但是,有两个主要区别:
-
要构建NDB Cluster 8.0,请使用MySQL Server 8.0源,您可以从 https://dev.mysql.com/downloads/ 获取这些源 。
以前,NDB Cluster使用自己的源代码。 在MySQL 8.0和NDB Cluster 8.0中,情况已不再如此, 现在这两种产品都是从同一个源构建的 。
-
WITH_NDBCLUSTER除了要与 CMake 一起使用的任何其他构建选项之外,还 必须使用该 选项 配置构建 。WITH_NDBCLUSTER_STORAGE_ENGINE并WITH_PLUGIN_NDBCLUSTER作为别名支持WITH_NDBCLUSTER,并以完全相同的方式工作。
WITH_NDB_JAVA
默认情况下启用
该
选项。
这意味着,默认情况下,如果
CMake
无法在系统上找到Java的位置,则配置过程将失败;
如果您不希望启用Java和ClusterJ支持,则必须通过使用配置构建来明确指出
-DWITH_NDB_JAVA=OFF
。
(缺陷号12379735)用于
WITH_CLASSPATH
在需要时提供Java类路径。
有关 特定于构建NDB群集的 CMake 选项的 更多信息 ,请参阅 编译NDB群集的选项 。
构建过程完成后,您可以创建包含已编译二进制文件的Zip存档;
第2.9.2节“使用标准源分发安装MySQL”
提供了在Windows系统上执行此任务所需的命令。
NDB集群二进制文件可以
bin
在生成的归档
的
目录中
找到,该
目录等同于
no-install
归档,并且可以以相同的方式安装和配置。
有关更多信息,请参见
第22.2.3.1节“从二进制发行版在Windows上安装NDB集群”
。
一旦NDB群集可执行文件和所需的配置文件到位,执行群集的初始启动只需启动群集中所有节点的NDB群集可执行文件。 每个群集节点进程必须单独启动,并在其所在的主机上启动。 应首先启动管理节点,然后启动数据节点,最后启动任何SQL节点。
-
在管理节点主机上,从命令行发出以下命令以启动管理节点进程。 输出应该类似于此处显示的内容:
C:\ mysql的\ BIN>
ndb_mgmd2010-06-23 07:53:34 [MgmtSrvr] INFO - NDB集群管理服务器。的mysql-8.0.17-NDB-8.0.17 2010-06-23 07:53:34 [MgmtSrvr] INFO - 从'config.ini'读取集群配置管理节点进程继续将日志记录输出打印到控制台。 这是正常现象,因为管理节点未作为Windows服务运行。 (如果你在类似Unix的平台上使用NDB Cluster,你可能会注意到管理节点在Windows上的这方面的默认行为实际上与它在Unix系统上的行为相反,在Unix系统上它默认运行为Unix守护程序进程。在Windows上运行的NDB集群数据节点进程也是如此。)因此,请不要关闭 运行 ndb_mgmd.exe 的窗口 ; 这样做会杀死管理节点进程。 (看到 第22.2.3.4节“将NDB集群进程安装为Windows服务” ,其中显示如何将NDB集群进程安装和运行为Windows服务。)
required
-f选项告诉管理节点在哪里可以找到全局配置文件(config.ini)。 这个选项的长形式是--config-file。重要NDB群集管理节点缓存从中读取的配置数据
config.ini; 一旦它创建了配置缓存,它将config.ini在后续启动 时忽略该 文件,除非强制执行其他操作。 这意味着,如果管理节点由于此文件中的错误而无法启动,则必须config.ini在更正 管理节点中的 任何错误后 重新读取管理节点 。 您可以通过 在命令行上 使用 或 选项 启动 ndb_mgmd.exe 来执行此操作 。 这些选项中的任何一个都可用于刷新配置缓存。--reload--initial在管理节点的
my.ini文件中 使用这些选项之一是不必要或不可取的 。有关可与 ndb_mgmd 一起使用的选项的其他信息 ,请参见 第22.4.4节“ ndb_mgmd - NDB集群管理服务器守护程序” ,以及 第22.4.31节“NDB集群程序常用选项 - NDB集群通用选项”节目“ 。
-
在每个数据节点主机上,运行此处显示的命令以启动数据节点进程:
C:\ mysql的\ BIN>
ndbd2010-06-23 07:53:46 [ndbd] INFO - 从'localhost:1186'获取的配置,代:1在每种情况下,数据节点进程的第一行输出应类似于前面示例中显示的内容,然后是其他日志输出行。 与管理节点进程一样,这是正常的,因为数据节点未作为Windows服务运行。 因此,请不要关闭运行数据节点进程的控制台窗口; 这样做会杀死 ndbd.exe 。 (有关更多信息,请参见 第22.2.3.4节“将NDB集群进程安装为Windows服务” 。)
-
不要启动SQL节点; 在数据节点完成启动之前,它无法连接到群集,这可能需要一些时间。 而是在管理节点主机上的新控制台窗口中,启动NDB群集管理客户端 ndb_mgm.exe ,该 客户端 应位于
C:\mysql\bin管理节点主机上。 (不要尝试 通过键入 CTRL + C 来重新使用 运行 ndb_mgmd.exe 的控制台窗口 ,因为这会导致管理节点死亡。)结果输出应如下所示:C:\ mysql的\ BIN>
ndb_mgm- NDB群集 - 管理客户端 - ndb_mgm>出现提示时
ndb_mgm>,这表示管理客户端已准备好接收NDB群集管理命令。 您可以通过ALL STATUS在管理客户端提示符处 输入来 查看 数据节点开始时的状态 。 此命令导致数据节点的启动顺序的运行报告,其应如下所示:ndb_mgm>
ALL STATUS连接到Management Server:localhost:1186 节点2:启动(上次完成阶段3)(mysql-8.0.17-ndb-8.0.17) 节点3:启动(上次完成阶段3)(mysql-8.0.17-ndb-8.0.17) 节点2:启动(上次完成阶段4)(mysql-8.0.17-ndb-8.0.17) 节点3:启动(上次完成阶段4)(mysql-8.0.17-ndb-8.0.17) 节点2:已启动(版本8.0.17) 节点3:已启动(版本8.0.17) ndb_mgm>注意管理客户端中发出的命令不区分大小写; 我们使用大写作为这些命令的规范形式,但在将它们输入到 ndb_mgm 客户端 时,不需要遵守此约定 。 有关更多信息,请参见 第22.5.2节“NDB集群管理客户端中的命令” 。
ALL STATUS根据数据节点能够启动的速度,您正在使用的NDB Cluster软件的发行版本号以及其他因素, 产生的输出 可能与此处显示的不同。 重要的是,当您看到两个数据节点都已启动时,您就可以启动SQL节点了。你可以让 ndb_mgm.exe 运行; 它对NDB集群的性能没有负面影响,我们在下一步中使用它来验证SQL节点在启动后是否已连接到集群。
-
在指定为SQL节点主机的计算机上,打开控制台窗口并导航到解压缩NDB群集二进制文件的目录(如果您按照我们的示例,这是
C:\mysql\bin)。通过 从命令行 调用 mysqld.exe 来 启动SQL节点 ,如下所示:
C:\ mysql的\ BIN>
mysqld --console该
--console选项会将日志记录信息写入控制台,这在出现问题时非常有用。 (一旦您对SQL节点以令人满意的方式运行感到满意,您可以停止它并在没有该--console选项的 情况下重新启动它 ,以便正常执行日志记录。)在 管理节点主机上运行 管理客户机( ndb_mgm.exe ) 的控制台窗口中 ,输入
SHOW命令,该命令应生成类似于此处所示的输出:ndb_mgm>
SHOW连接到Management Server:localhost:1186 群集配置 --------------------- [ndbd(NDB)] 2个节点 id = 2 @ 198.51.100.30(版本:8.0.17-ndb-8.0.17,节点组:0,*) id = 3 @ 198.51.100.40(版本:8.0.17-ndb-8.0.17,节点组:0) [ndb_mgmd(MGM)] 1个节点 id = 1 @ 198.51.100.10(版本:8.0.17-ndb-8.0.17) [mysqld(API)] 1个节点 id = 4 @ 198.51.100.20(版本:8.0.17-ndb-8.0.17)您还可以 使用该 语句 验证SQL节点是否已连接到 mysql 客户端( mysql.exe )中 的NDB群集
SHOW ENGINE NDB STATUS。
您现在应该已准备好使用NDB Cluster的
NDBCLUSTER
存储引擎
处理数据库对象和数据
。
有关
更多信息和示例
,
请参见
第22.2.6节“带表和数据的NDB集群示例”
。
您还可以将 ndb_mgmd.exe , ndbd.exe 和 ndbmtd.exe 安装 为Windows服务。 有关如何执行此操作的信息,请参见 第22.2.3.4节“将NDB集群进程安装为Windows服务” 。
一旦您对NDB Cluster按需运行感到满意,就可以将管理节点和数据节点安装为Windows服务,以便在Windows启动或停止时自动启动和停止这些进程。 这也使得可以使用适当的 SC START 和 SC STOP 命令 从命令行控制这些进程 ,或使用Windows图形 服务 实用程序。 也可以使用 NET START 和 NET STOP 命令。
通常,必须使用具有系统管理员权限的帐户来安装程序作为Windows服务。
要在Windows上将管理节点作为服务安装
,请使用
选项
从托管管理节点的计算机上的命令行
调用
ndb_mgmd.exe
--install
,如下所示:
C:\> C:\mysql\bin\ndb_mgmd.exe --install
安装服务'NDB Cluster Management Server'
as'“C:\ mysql \ bin \ ndbd.exe”“ - service = ndb_mgmd”'
服务已成功安装。
将NDB Cluster程序安装为Windows服务时,应始终指定完整路径; 否则服务安装可能会失败并显示错误 系统找不到指定的文件 。
--install
必须首先使用
该
选项,优先于可能为
ndb_mgmd.exe
指定的任何其他选项
。
但是,最好在选项文件中指定此类选项。
如果您的选项文件不在
ndb_mgmd.exe
输出中显示的默认位置之一,则
--help
可以使用该
--config-file
选项
指定位置
。
现在您应该可以像这样启动和停止管理服务器:
C:\>SC START ndb_mgmdC:\>SC STOP ndb_mgmd
如果使用 NET 命令,您还可以使用描述性名称将管理服务器作为Windows服务启动或停止,如下所示:
C:\>NET START 'NDB Cluster Management Server'NDB Cluster Management Server服务正在启动。 NDB Cluster Management Server服务已成功启动。 C:\>NET STOP 'NDB Cluster Management Server'NDB群集管理服务器服务正在停止.. NDB群集管理服务器服务已成功停止。
指定短服务名称或允许在安装服务时使用默认服务名称,然后在启动或停止服务时引用该名称通常更简单。
要指定除以外的服务名称
ndb_mgmd
,请将其附加到
--install
选项,如以下示例所示:
C:\> C:\mysql\bin\ndb_mgmd.exe --install=mgmd1
安装服务'NDB Cluster Management Server'
as'“C:\ mysql \ bin \ ndb_mgmd.exe”“ - service = mgmd1”'
服务已成功安装。
现在,您应该能够使用您指定的名称启动或停止服务,如下所示:
C:\>SC START mgmd1C:\>SC STOP mgmd1
要删除管理节点服务,请使用
SC DELETE
service_name
:
C:\> SC DELETE mgmd1
或者,
使用
选项
调用
ndb_mgmd.exe
--remove
,如下所示:
C:\> C:\mysql\bin\ndb_mgmd.exe --remove
删除服务'NDB Cluster Management Server'
服务已成功删除。
如果使用非默认服务名称安装服务,请将服务名称作为
ndb_mgmd.exe
--remove
选项
的值传递
,如下所示:
C:\> C:\mysql\bin\ndb_mgmd.exe --remove=mgmd1
删除服务'mgmd1'
服务已成功删除。
使用
ndbd.exe
(或
ndbmtd.exe
)
--install
选项,
可以以类似的方式安装NDB Cluster数据节点进程作为Windows服务
,如下所示:
C:\> C:\mysql\bin\ndbd.exe --install
将服务'NDB Cluster Data Node Daemon'安装为'“C:\ mysql \ bin \ ndbd.exe”“ - service = ndbd”'
服务已成功安装。
现在,您可以启动或停止数据节点,如以下示例所示:
C:\>SC START ndbdC:\>SC STOP ndbd
要删除数据节点服务,请使用
SC DELETE
service_name
:
C:\> SC DELETE ndbd
或者,
使用
选项
调用
ndbd.exe
--remove
,如下所示:
C:\> C:\mysql\bin\ndbd.exe --remove
删除服务'NDB群集数据节点守护程序'
服务已成功删除。
与
ndb_mgmd.exe
(和
mysqld.exe
)一样,在将
ndbd.exe
作为Windows服务
安装时
,您还可以将服务的名称指定为值
--install
,然后在启动或停止服务时使用它,如下所示:
C:\>C:\mysql\bin\ndbd.exe --install=dnode1将服务'dnode1'安装为'“C:\ mysql \ bin \ ndbd.exe”“ - service = dnode1”' 服务已成功安装。 C:\>SC START dnode1C:\>SC STOP dnode1
如果在安装数据节点服务时指定了服务名称,则在删除它时也可以使用此名称,如下所示:
C:\> SC DELETE dnode1
或者,您可以将服务名称作为
ndbd.exe
--remove
选项
的值传递
,如下所示:
C:\> C:\mysql\bin\ndbd.exe --remove=dnode1
删除服务'dnode1'
服务已成功删除。
使用
mysqld
--install
,
SC START
,
SC STOP
和
SC DELETE
(或
mysqld
--remove
)
以类似的方式安装SQL节点作为Windows服务,启动服务,停止服务和删除服务
。
NET
命令也可用于启动或停止服务。
有关其他信息,请参见
第2.3.5.8节“将MySQL作为Windows服务启动”
。
在本节中,我们将通过创建和编辑配置文件来讨论已安装的NDB群集的手动配置。
NDB Cluster还提供GUI安装程序,可用于执行配置,而无需在单独的应用程序中编辑文本文件。 有关更多信息,请参见 第22.2.1节“NDB集群自动安装程序” 。
对于我们的四节点,四主机NDB集群(请参阅 集群节点和主机 ),有必要编写四个配置文件,每个节点主机一个。
-
每个数据节点或SQL节点都需要一个
my.cnf提供两条信息 的 文件:一个 告诉节点在哪里找到管理节点 的 连接字符串 ,以及一条告诉该主机(托管数据节点的机器)上的MySQL服务器的线路该NDBCLUSTER存储引擎。有关连接字符串的更多信息,请参见 第22.3.3.3节“NDB集群连接字符串” 。
-
管理节点需要一个
config.ini文件,告诉它要维护多少个副本,为每个数据节点分配数据和索引的内存量,在哪里查找数据节点,在每个数据节点上将数据保存到磁盘的位置以及在哪里查找任何SQL节点。
配置数据节点和SQL节点。
my.cnf
数据节点所需
的
文件非常简单。
配置文件应位于
/etc
目录中,并可使用任何文本编辑器进行编辑。
(如果文件不存在,则创建该文件。)例如:
外壳> vi /etc/my.cnf
我们 在这里使用 vi 来创建文件,但任何文本编辑器都应该可以正常工作。
对于我们的示例设置中的每个数据节点和SQL节点,
my.cnf
应如下所示:
的[mysqld] #mysqld进程的选项: ndbcluster#运行NDB存储引擎 [mysql_cluster] #NDB Cluster进程的选项: ndb-connectstring = 198.51.100.10#管理服务器的位置
输入上述信息后,保存该文件并退出文本编辑器。 对托管数据节点 “ A ” ,数据节点 “ B ” 和SQL节点 的计算机执行此操作 。
一旦你开始
的mysqld
与过程
ndbcluster
,并
ndb-connectstring
在参数
[mysqld]
和
[mysql_cluster]
该路段
my.cnf
的文件如前所示,你不能执行
CREATE
TABLE
或者
ALTER
TABLE
不具有实际开始集群语句。
否则,这些语句将失败并显示错误。
这是设计的。
配置管理节点。
配置管理节点的第一步是创建可以在其中找到配置文件的目录,然后创建文件本身。
例如(运行为
root
):
shell>mkdir /var/lib/mysql-clustershell>cd /var/lib/mysql-clustershell>vi config.ini
对于我们的代表性设置,该
config.ini
文件应如下所示:
[ndbd默认]
#影响所有数据节点上的ndbd进程的选项:
NoOfReplicas = 2#副本数
DataMemory = 98M#为数据存储分配多少内存
[ndb_mgmd]
#管理流程选项:
HostName = 198.51.100.10 #MAMM节点的主机名或IP地址
DataDir = / var / lib / mysql-cluster #MaM节点日志文件的目录
[NDBD]
#数据节点“A”的选项:
#(每个数据节点一个[ndbd]部分)
HostName = 198.51.100.30#主机名或IP地址
NodeId = 2#此数据节点的节点ID
DataDir = / usr / local / mysql / data#此数据节点的数据文件的目录
[NDBD]
#数据节点“B”的选项:
HostName = 198.51.100.40#主机名或IP地址
NodeId = 3#此数据节点的节点ID
DataDir = / usr / local / mysql / data#此数据节点的数据文件的目录
的[mysqld]
#SQL节点选项:
HostName = 198.51.100.20#主机名或IP地址
#(其他mysqld连接可以是
#为此节点指定各种
#目的,如运行ndb_restore)
该
world
数据库可以从
https://dev.mysql.com/doc/index-other.html
下载
。
在创建所有配置文件并指定了这些最小选项之后,您就可以继续启动集群并验证所有进程是否正在运行。 我们将在 第22.2.5节“NDB集群的初始启动”中 讨论如何完成此操作 。
有关可用NDB群集配置参数及其用法的更多详细信息,请参见 第22.3.3节“NDB群集配置文件” 和 第22.3 节“NDB群集的配置 ” 。 有关与备份相关的NDB Cluster的配置,请参见 第22.5.3.3节“NDB集群备份的配置” 。
Cluster管理节点的默认端口是1186; 数据节点的默认端口是2202.但是,群集可以自动为那些已经空闲的数据节点分配端口。
配置后启动集群并不是很困难。 每个群集节点进程必须单独启动,并在其所在的主机上启动。 应首先启动管理节点,然后启动数据节点,最后启动任何SQL节点:
-
在管理主机上,从系统shell发出以下命令以启动管理节点进程:
外壳>
ndb_mgmd -f /var/lib/mysql-cluster/config.ini第一次启动时, 必须使用 或 选项 告诉 ndb_mgmd 在哪里找到其配置文件 。 (有关详细 信息, 请参见 第22.4.4节“ ndb_mgmd - NDB群集管理服务器守护程序” 。)
-f--config-file有关可与 ndb_mgmd 一起使用的其他选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
-
在每个数据节点主机上,运行此命令以启动 ndbd 进程:
外壳>
ndbd -
如果您使用RPM文件在SQL节点所在的群集主机上安装MySQL,则可以(并且应该)使用提供的启动脚本在SQL节点上启动MySQL服务器进程。
如果一切顺利,并且群集已正确设置,则群集现在应该可以运行。 您可以通过调用 ndb_mgm 管理节点客户端 来测试它 。 输出应该如下所示,尽管您可能会看到输出略有不同,具体取决于您使用的MySQL的确切版本:
外壳>ndb_mgm- NDB群集 - 管理客户端 - ndb_mgm>SHOW连接到Management Server:localhost:1186 群集配置 --------------------- [ndbd(NDB)] 2个节点 id = 2 @ 198.51.100.30(版本:8.0.17-ndb-8.0.17,节点组:0,*) id = 3 @ 198.51.100.40(版本:8.0.17-ndb-8.0.17,节点组:0) [ndb_mgmd(MGM)] 1个节点 id = 1 @ 198.51.100.10(版本:8.0.17-ndb-8.0.17) [mysqld(API)] 1个节点 id = 4 @ 198.51.100.20(版本:8.0.17-ndb-8.0.17)
此处引用SQL节点
[mysqld(API)]
,这反映了
mysqld
进程充当NDB Cluster API节点
的事实
。
为输出中的给定NDB Cluster SQL或其他API节点显示的IP地址
SHOW
是SQL或API节点用于连接到群集数据节点而不是任何管理节点的地址。
您现在应该已准备好使用NDB Cluster中的数据库,表和数据。 有关 简要讨论, 请参见 第22.2.6节“带表和数据的NDB集群示例” 。
本节中的信息适用于在Unix和Windows平台上运行的NDB Cluster。
在NDB Cluster中使用数据库表和数据与在标准MySQL中这样做没有太大区别。 要记住两点要点:
-
对于要在群集中复制的表,它必须使用
NDBCLUSTER存储引擎。 要指定此项,请 在创建表时 使用ENGINE=NDBCLUSTER或ENGINE=NDB选项:CREATE TABLE
tbl_name()ENGINE = NDBCLUSTER;col_namecolumn_definitions或者,对于使用不同存储引擎的现有表,使用
ALTER TABLE更改要使用的表NDBCLUSTER:ALTER TABLE
tbl_nameENGINE = NDBCLUSTER; -
每个
NDBCLUSTER表都有一个主键。 如果在创建表时用户未定义主键,则NDBCLUSTER存储引擎会自动生成隐藏的 主键 。 这样的密钥占用空间就像任何其他表索引一样。 (由于内存不足以容纳这些自动创建的索引,因此遇到问题的情况并不少见。)
如果使用
mysqldump
的输出从现有数据库导入表
,则可以在文本编辑器中打开SQL脚本,并将该
ENGINE
选项
添加
到任何表创建语句,或替换任何现有
ENGINE
选项。
假设您
world
在另一台不支持NDB Cluster的MySQL服务器上
安装了
示例数据库,并且您想要导出该
City
表:
外壳> mysqldump --add-drop-table world City > city_table.sql
生成的
city_table.sql
文件将包含此表创建语句(以及
INSERT
导入表数据所需
的
语句):
DROP TABLE IF EXISTS`City`;
CREATE TABLE`City`(
`ID` int(11)NOT NULL auto_increment,
`Name` char(35)NOT NULL default'',
`CountryCode` char(3)NOT NULL default'',
`District` char(20)NOT NULL default'',
`population` int(11)NOT NULL默认为'0',
主键(`ID`)
)ENGINE = MyISAM DEFAULT CHARSET = latin1;
插入“城市”价值观(1,'喀布尔','AFG','卡博尔',1780000);
插入“城市”价值观(2,'坎大哈','AFG','坎大哈',237500);
插入“城市”价值观(3,'赫拉特','AFG','赫拉特',186800);
(remaining INSERT statements omitted)
您需要确保MySQL使用
NDBCLUSTER
此表
的
存储引擎。
有两种方法可以实现。
其中之一是在将表定义
导入Cluster数据库
之前
修改表定义
。
以
City
表格为例,修改
ENGINE
定义选项,如下所示:
DROP TABLE IF EXISTS`City`;
CREATE TABLE`City`(
`ID` int(11)NOT NULL auto_increment,
`Name` char(35)NOT NULL default'',
`CountryCode` char(3)NOT NULL default'',
`District` char(20)NOT NULL default'',
`population` int(11)NOT NULL默认为'0',
主键(`ID`)
)ENGINE = NDBCLUSTER DEFAULT CHARSET = latin1;
插入“城市”价值观(1,'喀布尔','AFG','卡博尔',1780000);
插入“城市”价值观(2,'坎大哈','AFG','坎大哈',237500);
插入“城市”价值观(3,'赫拉特','AFG','赫拉特',186800);
(remaining INSERT statements omitted)
必须对要成为集群数据库一部分的每个表的定义执行此操作。
完成此操作的最简单方法是对包含定义的文件执行搜索和替换,并替换所有
或
带有的
实例
。
如果您不想修改文件,可以使用未修改的文件创建表,然后使用
更改其存储引擎。
详情将在本节后面给出。
TYPE=
engine_nameENGINE=
engine_nameENGINE=NDBCLUSTER
ALTER TABLE
假设您已经创建了一个
world
在集群的SQL节点上
命名的数据库
,那么您可以使用
mysql
命令行客户端来读取
city_table.sql
,并以通常的方式创建和填充相应的表:
外壳> mysql world < city_table.sql
请记住,必须在运行SQL节点的主机上执行上述命令(在本例中,在具有IP地址的计算机上
198.51.100.20
)
,这一点非常重要
。
要
world
在SQL节点上
创建整个
数据库
的副本,请在
非群集服务器上
使用
mysqldump
将数据库导出到名为的文件
world.sql
(例如,在
/tmp
目录中)。
然后修改刚才描述的表定义,并将文件导入到集群的SQL节点,如下所示:
外壳> mysql world < /tmp/world.sql
如果将文件保存到其他位置,请相应地调整前面的说明。
SELECT
在SQL节点上
运行
查询与在MySQL服务器的任何其他实例上
运行
查询没有什么不同。
要从命令行运行查询,首先需要以通常的方式登录MySQL Monitor(
root
在
Enter
password:
提示符下
指定
密码
):
外壳> mysql -u root -p
输入密码:
欢迎使用MySQL监视器。命令以;结尾; 或\ g。
您的MySQL连接ID为1到服务器版本:8.0.17-ndb-8.0.17
输入'help;' 或'\ h'寻求帮助。输入'\ c'清除缓冲区。
MySQL的>
我们只是使用MySQL服务器的
root
帐户,并假设您已遵循安装MySQL服务器的标准安全预防措施,包括设置强
root
密码。
有关更多信息,请参见
第2.10.4节“保护初始MySQL帐户”
。
值得考虑的是,NDB Cluster节点
在访问彼此时
不
使用MySQL权限系统。
设置或更改MySQL用户帐户(包括
root
帐户)只会影响访问SQL节点的应用程序,而不会影响节点之间的交互。
有关
更多信息
,
请参见
第22.5.12.2节“NDB集群和MySQL权限”
。
如果
ENGINE
在导入SQL脚本之前未修改表定义中
的
子句,则此时应运行以下语句:
mysql>USE world;mysql>ALTER TABLE City ENGINE=NDBCLUSTER;mysql>ALTER TABLE Country ENGINE=NDBCLUSTER;mysql>ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
选择数据库并 对该数据库中的表 运行 SELECT 查询也是以通常的方式完成的,就像退出MySQL Monitor一样:
mysql>USE world;mysql>SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;+ ----------- ------------ + + | 名称| 人口| + ----------- ------------ + + | 孟买| 10500000 | | 首尔| 9981619 | | 圣保罗| 9968485 | | 上海| 9696300 | | 雅加达| 9604900 | + ----------- ------------ + + 5行(0.34秒) MySQL的>\q再见 外壳>
使用MySQL的应用程序可以使用标准API来访问
NDB
表。
请务必记住,您的应用程序必须访问SQL节点,而不是管理或数据节点。
这个简短的例子展示了我们如何
SELECT
通过使用在
mysqli
网络上其他地方的Web服务器上运行
的PHP 5.X
扩展
来
执行
刚刚显示
的
语句
:
<!DOCTYPE HTML PUBLIC“ - // W3C // DTD HTML 4.01 Transitional // EN”
“http://www.w3.org/TR/html4/loose.dtd”>
<HTML>
<HEAD>
<meta http-equiv =“Content-Type”
content =“text / html; charset = iso-8859-1”>
<title> SIMPLE mysqli SELECT </ title>
</ HEAD>
<BODY>
<?PHP
#connect to SQL node:
$ link = new mysqli('198.51.100.20','root',' root_password','world');
mysqli构造函数的#参数是:
#host,user,password,database
if(mysqli_connect_errno())
死(“连接失败:”。mysqli_connect_error());
$ query =“SELECT Name,Population
来自城市
按人口数量排序
限制5“;
#如果没有错误......
if($ result = $ link-> query($ query))
{
?>
<table border =“1”width =“40%”cellpadding =“4”cellspacing =“1”>
<TBODY>
<TR>
<th width =“10%”>城市</ th>
<TH>人口</次>
</ TR>
<?
#然后显示结果......
while($ row = $ result-> fetch_object())
printf(“<tr> \ n <td align = \”center \“>%s </ td> <td>%d </ td> \ n </ tr> \ n”,
$ row-> Name,$ row-> Population);
?>
</ TBODY
</ TABLE>
<?
#...并验证检索的行数
printf(“<p>受影响的行:%d </ p> \ n”,$ link-> affected_rows);
}
其他
#否则,告诉我们出了什么问题
echo mysqli_error();
#释放结果集和mysqli连接对象
$ result->接近();
$链路>接近();
?>
</ BODY>
</ HTML>
我们假设在Web服务器上运行的进程可以到达SQL节点的IP地址。
以类似的方式,您可以使用MySQL C API,Perl-DBI,Python-mysql或MySQL Connectors来执行数据定义和操作任务,就像通常使用MySQL一样。
要关闭群集,请在托管管理节点的计算机上的shell中输入以下命令:
外壳> ndb_mgm -e shutdown
-e
此处
的
选项用于将命令
从shell
传递到
ndb_mgm
客户端。
(
有关此选项的详细信息
,
请参见
第22.4.31节“NDB群集程序的通用选项 - NDB群集程序的通用
选项”。)该命令使
ndb_mgm
,
ndb_mgmd
以及任何
ndbd
或
ndbmtd
进程正常终止。
可以使用
mysqladmin shutdown
和其他方法
终止任何SQL节点
。
在Windows平台上,假设您已将SQL节点安装为Windows服务,则可以使用
SC STOP
service_name
或
NET STOP
service_name
。
要在Unix平台上重新启动集群,请运行以下命令:
-
在管理主机上(
198.51.100.10在我们的示例设置中):外壳>
ndb_mgmd -f /var/lib/mysql-cluster/config.ini -
在每个数据节点主机(
198.51.100.30和198.51.100.40)上:外壳>
ndbd -
使用 ndb_mgm 客户端验证两个数据节点是否已成功启动。
-
在SQL主机(
198.51.100.20)上:外壳>
mysqld_safe &
在Windows平台上,假设您已使用默认服务名称将所有NDB Cluster进程安装为Windows服务(请参见 第22.2.3.4节“将NDB集群进程安装为Windows服务” ),您可以按如下方式重新启动集群:
-
在管理主机上(
198.51.100.10在我们的示例设置中),执行以下命令:C:\>
SC START ndb_mgmd -
在每个数据节点主机上(
198.51.100.30和198.51.100.40)上,执行以下命令:C:\>
SC START ndbd -
在管理节点主机上,使用 ndb_mgm 客户端验证管理节点和两个数据节点是否已成功启动(请参见 第22.2.3.3节“Windows上的NDB群集的初始启动” )。
-
在SQL节点主机上(
198.51.100.20)上,执行以下命令:C:\>
SC START mysql
在生产环境中,通常不希望完全关闭集群。 在许多情况下,即使在进行配置更改或执行需要关闭单个主机的群集硬件或软件(或两者)的升级时,也可以在不通过执行 滚动来 关闭整个群集的情况下执行此操作 重新启动 群集。 有关执行此操作的更多信息,请参见 第22.5.5节“执行NDB集群的滚动重新启动” 。
本节提供有关NDB Cluster软件和不同NDB Cluster 8.0版本之间关于执行升级和降级以及兼容性矩阵和注释的表文件兼容性的信息。 在尝试升级或降级之前,您应该熟悉安装和配置NDB群集。 请参见 第22.3节“NDB集群的配置” 。
本节仅考虑MySQL版本之间的兼容性
NDBCLUSTER
,并且可能还有其他问题需要考虑。
与任何其他MySQL软件升级或降级一样,强烈建议您在尝试升级或降级NDB
Cluster软件之前,查看MySQL手册中有关您要迁移的MySQL版本的相关部分
。
请参见
第2.11节“升级MySQL”
。
已知的问题。 升级到NDB 8.0版本或在NDB 8.0版本之间发生以下问题时会发生以下问题:
-
不支持从NDB 8.0.14到以前版本的在线降级。 在NDB 8.0.14中创建的表与以前的版本不向后兼容。 这是由于实现的额外元数据属性的使用情况发生了变化
NDB表 以提供对MySQL数据字典的完全支持。有关更多信息,请参阅 NDB表额外的元数据更改 。 另见 第14章, MySQL数据字典 。
-
NDB Cluster 8.0不支持在 先前版本系列中实现的MySQL服务器之间共享的分布式权限(请参阅 NDB群集的分布式MySQL权限 )。 启动时, 随NDB 8.0.16提供 的 mysqld 检查是否存在使用
NDB存储引擎 的任何授权表 ; 如果找到任何,它会 使用这些 创建本地副本( “ 影子表 ” )InnoDB。 对于连接到NDB Cluster的每个MySQL服务器都是如此。 在充当NDB Cluster SQL节点的所有MySQL服务器上执行此操作后,可以使用 NDB Cluster分发提供 的 ndb_drop_table 实用程序 安全地删除NDB授权表 。 (保留NDB授权表是安全的,但它们不用于访问控制,并且实际上被忽略。)有关NDB 8.0中使用的MySQL权限系统的更多信息,请参见 第6.2.3节“授权表” 。
作为NDB集群的一部分的MySQL服务器在一个主要方面与普通(非集群)MySQL服务器不同,因为它使用
NDB
存储引擎。
该发动机有时也被称为
NDBCLUSTER
,尽管
NDB
是优选的。
为避免不必要的资源分配,默认情况下会配置服务器并
NDB
禁用存储引擎。
要启用
NDB
,您必须修改服务器的
my.cnf
配置文件,或使用该
--ndbcluster
选项
启动服务器
。
此MySQL服务器是群集的一部分,因此它还必须知道如何访问管理节点以获取群集配置数据。
默认行为是查找管理节点
localhost
。
但是,如果您需要指定其位置在其他位置,可以
my.cnf
在
mysql
客户端中
完成
,
也可以
使用
mysql
客户端。
之前
NDB
可以使用存储引擎
,至少一个管理节点必须是可操作的,以及任何期望的数据节点。
有关
NDB Cluster特定的
--ndbcluster
其他
mysqld
选项的
更多信息
,请参见
第22.3.3.9.1节“NDB集群的MySQL服务器选项”
。
您还可以使用NDB Cluster Auto-Installer使用基于浏览器的GUI在一个或多个主机上设置和部署NDB Cluster。 有关更多信息,请参阅 NDB群集自动安装程序(NDB 7.5) 。
有关安装NDB Cluster的一般信息,请参见 第22.2节“NDB群集安装” 。
为了使您熟悉基础知识,我们将描述功能性NDB群集的最简单配置。 在此之后,您应该能够根据本章其他相关章节中提供的信息设计所需的设置。
首先,您需要创建一个配置目录,例如
/var/lib/mysql-cluster
,通过以系统
root
用户
身份执行以下命令
:
外壳> mkdir /var/lib/mysql-cluster
在此目录中,创建一个
config.ini
包含以下信息
的文件
。
为系统
替换适当的值
HostName
并
DataDir
根据需要
替换
。
#file“config.ini” - 显示由1个数据节点组成的最小设置, #1管理服务器和3台MySQL服务器。 #空的默认部分不是必需的,仅显示为 #完整的缘故。 #数据节点必须提供主机名,但不需要MySQL服务器 #这样做。 #如果您不知道计算机的主机名,请使用localhost。 #DataDir参数也有一个默认值,但建议使用 #明确设置它。 #注意:[db],[api]和[mgm]是[ndbd],[mysqld]和[ndb_mgmd]的别名, # 分别。[db]已弃用,不应在新安装中使用。 [ndbd默认] NoOfReplicas = 1 [mysqld默认] [ndb_mgmd默认] [tcp默认] [ndb_mgmd] HostName = myhost.example.com [NDBD] HostName = myhost.example.com DataDir = / var / lib / mysql-cluster 的[mysqld] 的[mysqld] 的[mysqld]
您现在可以启动
ndb_mgmd
管理服务器。
默认情况下,它会尝试读取
config.ini
当前工作目录中
的
文件,因此将位置更改为文件所在的目录,然后调用
ndb_mgmd
:
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
然后通过运行 ndbd 启动单个数据节点 :
外壳> ndbd
有关在启动 ndbd 时可以使用的命令行选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
默认情况下,
ndbd
localhost
在端口1186上
查找管理服务器
。
最后,将位置更改为MySQL数据目录(通常
/var/lib/mysql
或
/usr/local/mysql/data
),并确保
my.cnf
文件包含启用NDB存储引擎所需的选项:
的[mysqld] NDBCLUSTER
您现在可以照常启动MySQL服务器:
外壳> mysqld_safe --user=mysql &
稍等片刻,确保MySQL服务器正常运行。
如果看到该通知
mysql ended
,请检查服务器
.err
文件以找出问题所在。
如果到目前为止一切顺利,您现在可以开始使用群集了。
连接到服务器并验证
NDBCLUSTER
已启用存储引擎:
外壳>mysql欢迎使用MySQL监视器。命令以;结尾; 或\ g。 您的MySQL连接ID为1到服务器版本:8.0.18 输入'help;' 或'\ h'寻求帮助。输入'\ c'清除缓冲区。 MySQL的>SHOW ENGINES\G... *************************** 12.排******************** ******* 引擎:NDBCLUSTER 支持:是的 注释:集群,容错,基于内存的表 *************************** 13.排******************** ******* 引擎:NDB 支持:是的 评论:NDBCLUSTER的别名 ...
前面示例输出中显示的行号可能与系统上显示的行号不同,具体取决于服务器的配置方式。
尝试创建一个
NDBCLUSTER
表:
shell>mysqlmysql>USE test;数据库已更改 MySQL的>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;查询正常,0行受影响(0.09秒) MySQL的>SHOW CREATE TABLE ctest \G*************************** 1。排******************** ******* 表:ctest 创建表:CREATE TABLE`ctest`( `i`int(11)默认为NULL )ENGINE = ndbcluster DEFAULT CHARSET = latin1 1排(0.00秒)
要检查节点是否已正确设置,请启动管理客户端:
外壳> ndb_mgm
使用 管理客户端中 的 SHOW 命令获取有关群集状态的报告:
ndb_mgm> SHOW
群集配置
---------------------
[ndbd(NDB)] 1个节点
id = 2 @ 127.0.0.1(版本:8.0.17-ndb-8.0.17,节点组:0,*)
[ndb_mgmd(MGM)] 1个节点
id = 1 @ 127.0.0.1(版本:8.0.17-ndb-8.0.17)
[mysqld(API)] 3个节点
id = 3 @ 127.0.0.1(版本:8.0.17-ndb-8.0.17)
id = 4(未连接,接受来自任何主机的连接)
id = 5(未连接,接受来自任何主机的连接)
此时,您已成功设置可运行的NDB群集。
您现在可以使用使用
ENGINE=NDBCLUSTER
其别名
创建的任何表将数据存储在集群中
ENGINE=NDB
。
接下来的几节提供了
config.ini
文件中
使用的NDB Cluster节点配置参数的汇总表,用于
管理节点行为的各个方面,以及
mysqld
my.cnf
在作为NDB集群进程运行时
从
文件或命令行
读取的选项和变量
。
每个节点参数表列出对于给定类型的参数(
ndbd
,
ndb_mgmd
,
mysqld
,
computer
,
tcp
,
shm
,或
sci
)。
所有表都包括参数,选项或变量的数据类型,以及适用的默认值,最小值和最大值。
重新启动节点时的注意事项。
对于节点参数,这些表还指示需要何种类型的重新启动(节点重新启动或系统重新启动) - 以及是否必须使用
--initial
-to更改给定配置参数的值
来完成重新启动
。
执行节点重新启动或初始节点重新启动时,必须依次重新启动所有群集的数据节点(也称为
滚动重新启动
)。
可以更新标记为
node
在线的
群集配置参数
,即不以此方式关闭群集。
初始节点重新启动需要
使用该
选项
重新启动每个
ndbd
进程
--initial
。
系统重新启动需要完全关闭并重新启动整个群集。 初始系统重新启动需要备份群集,在关闭后擦除群集文件系统,然后在重新启动后从备份进行恢复。
在任何群集重新启动时,必须重新启动所有群集的管理服务器才能读取更新的配置参数值。
数值集群参数的值通常可以毫无问题地增加,但建议逐步进行,以相对较小的增量进行此类调整。 其中许多可以使用滚动重启在线增加。
但是,减少这些参数的值 - 无论是使用节点重启,节点初始重启,还是集群的完整系统重启 - 都不能轻易进行;
建议您仅在仔细规划和测试后才这样做。
这是对于那些与内存使用和磁盘空间参数,如尤其如此
MaxNoOfTables
,
MaxNoOfOrderedIndexes
,和
MaxNoOfUniqueHashIndexes
。
另外,通常情况是可以使用简单的节点重启来提高与存储器和磁盘使用有关的配置参数,但是它们需要降低初始节点重启。
由于其中一些参数可用于配置多种类型的群集节点,因此它们可能出现在多个表中。
4294967039
通常在这些表中显示为最大值。
此值在
NDBCLUSTER
源中
定义
为
MAX_INT_RNIL
和等于
0xFFFFFEFF
或
。
232 −
28 − 1
本节中的列表提供有关
用于配置NDB Cluster数据节点
的
文件
[ndbd]
或
[ndbd default]
部分中
使用的参数的信息
config.ini
。
有关每个参数的详细说明和其他附加信息,请参见
第22.3.3.6节“定义NDB集群数据节点”
。
这些参数也适用于 ndbmtd , ndbd 的多线程版本 。 有关更多信息,请参见 第 22.4.3 节“ ndbmtd - NDB集群数据节点守护程序(多线程)” 。
-
Arbitration:如何在节点发生故障时执行仲裁以避免裂脑问题。 -
ArbitrationTimeout:数据库分区等待仲裁信号的最长时间(毫秒) -
BackupDataBufferSize:备份的数据缓冲区的默认大小(以字节为单位) -
BackupDataDir:存储备份的位置的路径。 请注意,字符串'/ BACKUP'始终附加到此设置,因此* effective * default是FileSystemPath / BACKUP。 -
BackupDiskWriteSpeedPct:设置启动abackup时为LCP保留的数据节点分配的最大写入速度(MaxDiskWriteSpeed)的百分比。 -
BackupLogBufferSize:备份的日志缓冲区的默认大小(以字节为单位) -
BackupMaxWriteSize:备份所做的文件系统写入的最大大小(以字节为单位) -
BackupMemory:为每个节点的备份分配的总内存(以字节为单位) -
BackupReportFrequency:备份期间备份状态报告的频率,以秒为单位 -
BackupWriteSize:备份所做的文件系统写入的默认大小(以字节为单位) -
BatchSizePerLocalScan:用于计算使用保持锁定进行扫描的锁定记录数 -
BuildIndexThreads:在系统或节点重新启动期间用于构建有序索引的线程数。 在运行ndb_restore --rebuild-indexes时也适用。 将此参数设置为0将禁用有序索引的多线程构建。 -
CompressedBackup:使用zlib在写入时压缩备份 -
CompressedLCP:使用zlib编写压缩的LCP -
ConnectCheckIntervalDelay:数据节点连接检查阶段之间的时间。 数据节点在1个间隔后被认为是可疑的,并且在2个间隔之后死亡,没有响应。 -
CrashOnCorruptedTuple:启用时,强制节点在检测到损坏的元组时关闭。 -
DataDir:此节点的数据目录 -
DataMemory:分配用于存储数据的每个数据节点上的字节数; 取决于可用的系统RAM。 -
DefaultHashMapSize:设置用于表哈希映射的大小(在桶中)。 支持三个值:0,240和3840.主要用于NDB 7.2中的升级和降级。 -
DictTrace:启用DBDICT调试; 用于NDB开发 -
DiskIOThreadPool:文件访问的未绑定线程数(当前仅适用于磁盘数据); 在MySQL Cluster NDB 6.4.3之前称为IOThreadPool。 -
Diskless:不使用磁盘运行 -
DiskPageBufferEntries:DiskPageBufferMemory中要分配的32K页条目数。 非常大的磁盘事务可能需要增加此值。 -
DiskPageBufferMemory:为磁盘页缓冲区高速缓存分配的每个数据节点上的字节数 -
DiskSyncSize:强制同步之前写入文件的数据量 -
EnablePartialLcp:启用部分LCP(true); 如果禁用(false),则所有LCP都会写入完整的检查点。 -
EnableRedoControl:启用自适应检查点速度以控制重做日志使用 -
EventLogBufferSize:数据节点内NDB日志事件的循环缓冲区大小。 -
ExecuteOnComputer:引用先前定义的COMPUTER的字符串 -
ExtraSendBufferMemory:除了由TotalSendBufferMemory或SendBufferMemory分配的内存之外,还用于发送缓冲区的内存。 默认(0)允许最多16MB。 -
FileSystemPath:数据节点存储其数据的目录的路径(目录必须存在) -
FileSystemPathDataFiles:数据节点存储其磁盘数据文件的目录的路径。 默认值为FilesystemPathDD,如果设置; 否则,如果设置了则使用FilesystemPath; 否则,使用DataDir的值。 -
FileSystemPathDD:数据节点存储其磁盘数据和撤消文件的目录的路径。 默认值为FileSystemPath,如果设置; 否则,使用DataDir的值。 -
FileSystemPathUndoFiles:数据节点存储其磁盘数据的撤消文件的目录的路径。 默认值为FilesystemPathDD,如果设置; 否则,如果设置了则使用FilesystemPath; 否则,使用DataDir的值。 -
FragmentLogFileSize:每个重做日志文件的大小 -
HeartbeatIntervalDbApi:API节点 - 数据节点心跳之间的时间。 (3次错过心跳后API连接关闭) -
HeartbeatIntervalDbDb:数据节点到数据节点心跳之间的时间; 数据节点在3次错过心跳后被认为死亡 -
HeartbeatOrder:设置数据节点检查彼此的心跳以确定给定节点是否仍处于活动状态并连接到群集的顺序。 对于所有数据节点必须为零或对于所有数据节点必须为不同的非零值; 请参阅文档以获取进一步指 -
HostName:此数据节点的主机名或IP地址。 -
IndexMemory:已弃用。 -
IndexStatAutoCreate:创建索引时启用/禁用自动统计信息收集。 -
IndexStatAutoUpdate:监视更改的索引并触发自动统计信息更新 -
IndexStatSaveScale:用于确定存储的索引统计信息的大小的缩放系数。 -
IndexStatSaveSize:每个索引保存的统计信息的最大大小(字节)。 -
IndexStatTriggerPct:索引统计信息更新的DML操作中的阈值百分比更改。 该值按IndexStatTriggerScale缩小。 -
IndexStatTriggerScale:对于大型索引,按此量向下缩放IndexStatTriggerPct,乘以索引大小的基数2对数。 设置为0以禁用缩放。 -
IndexStatUpdateDelay:给定索引的自动索引统计信息更新之间的最小延迟。 0表示没有延迟。 -
InitFragmentLogFiles:初始化片段日志文件(稀疏/完整) -
InitialLogFileGroup:描述在初始启动期间创建的日志文件组。 请参阅文档格式。 -
InitialNoOfOpenFiles:每个数据节点打开的初始文件数。 (每个文件创建一个线程) -
InitialTablespace:描述在初始启动期间创建的表空间。 请参阅文档格式。 -
InsertRecoveryWork:用于插入行的RecoveryWork的百分比; 除非使用部分本地检查点,否则无效。 -
LateAlloc:在建立与管理服务器的连接后分配内存。 -
LcpScanProgressTimeout:在节点关闭之前可以停止本地检查点碎片扫描的最长时间,以确保系统范围的LCP进度。 使用0禁用。 -
LockExecuteThreadToCPU:逗号分隔的CPU ID列表 -
LockMaintThreadsToCPU:CPU ID,指示哪个CPU运行维护线程 -
LockPagesInMainMemory:0 =禁用锁定,1 =内存分配后锁定,2 =内存分配前锁定 -
LogLevelCheckpoint:打印到stdout的本地和全局检查点信息的日志级别 -
LogLevelCongestion:打印到stdout的拥塞级别信息 -
LogLevelConnection:节点连接/断开信息的级别打印到stdout -
LogLevelError:转运,心跳错误打印到标准输出 -
LogLevelInfo:打印到stdout的心跳和日志信息 -
LogLevelNodeRestart:节点重新启动级别和节点故障信息打印到stdout -
LogLevelShutdown:打印到stdout的节点关闭信息级别 -
LogLevelStartup:打印到stdout的节点启动信息的级别 -
LogLevelStatistic:打印到stdout的交易,操作和运输商信息的级别 -
LongMessageBuffer:内部长消息在每个数据节点上分配的字节数 -
MaxAllocate:为表分配内存时要使用的最大分配大小 -
MaxBufferedEpochs:允许订阅节点可以滞后的编号的时期(未处理的时期)。 超出将导致滞后的用户断开连接。 -
MaxBufferedEpochBytes:为缓冲时期分配的总字节数。 -
MaxDiskWriteSpeed:当没有重新启动时,LCP和备份可以写入的每秒最大字节数。 -
MaxDiskWriteSpeedOtherNodeRestart:当另一个节点重新启动时,LCP和备份可以写入的每秒最大字节数。 -
MaxDiskWriteSpeedOwnRestart:此节点重新启动时LCP和备份可写入的每秒最大字节数。 -
MaxFKBuildBatchSize:用于构建外键的最大扫描批处理大小。 增加此值可能会加快外键的构建速度,但也会影响正在进行的流量。 -
MaxDMLOperationsPerTransaction:限制交易的大小; 如果事务需要的不仅仅是这么多DML操作,那么就会中止事务。 设置为0以禁用。 -
MaxLCPStartDelay:LCP轮询检查点互斥锁(允许其他数据节点完成元数据同步)的时间(以秒为单位),然后将其置于锁定队列中以便并行恢复表数据。 -
MaxNoOfAttributes:建议存储在数据库中的属性总数(所有表的总和) -
MaxNoOfConcurrentIndexOperations:可以在一个数据节点上同时执行的索引操作的总数 -
MaxNoOfConcurrentOperations:事务协调器中的最大操作记录数 -
MaxNoOfConcurrentScans:数据节点上并发执行的最大扫描数 -
MaxNoOfConcurrentSubOperations:最大并发订户操作数 -
MaxNoOfConcurrentTransactions:在此数据节点上并发执行的最大事务数,可以并发执行的事务总数是此值乘以群集中的数据节点数。 -
MaxNoOfFiredTriggers:可以在一个数据节点上同时触发的触发器总数 -
MaxNoOfLocalOperations:此数据节点上定义的最大操作记录数 -
MaxNoOfLocalScans:此数据节点上并行的最大片段扫描数 -
MaxNoOfOpenFiles:每个数据节点打开的最大文件数。(每个文件创建一个线程) -
MaxNoOfOrderedIndexes:可以在系统中定义的有序索引的总数 -
MaxNoOfSavedMessages:要在错误日志中写入的最大错误消息数以及要保留的最大跟踪文件数 -
MaxNoOfSubscribers:最大订户数(默认0 = MaxNoOfTables * 2) -
MaxNoOfSubscriptions:最大订阅数(默认为0 = MaxNoOfTables) -
MaxNoOfTables:建议存储在数据库中的NDB表总数 -
MaxNoOfTriggers:可以在系统中定义的触发器总数 -
MaxNoOfUniqueHashIndexes:可以在系统中定义的唯一哈希索引的总数 -
MaxParallelCopyInstances:节点重新启动期间的并行副本数。 默认值为0,它使用两个节点上的LDM数量,最多为16。 -
MaxParallelScansPerFragment:每个片段的最大并行扫描数。 达到此限制后,将扫描序列化。 -
MaxReorgBuildBatchSize:用于重组表分区的最大扫描批量大小。 增加此值可能会加快表分区重组速度,但也会影响正在进行的流量。 -
MaxStartFailRetries:数据节点在启动时失败时的最大重试次数,需要StopOnError = 0.设置为0会导致启动尝试无限期地继续。 -
MaxUIBuildBatchSize:用于构建唯一键的最大扫描批量大小。 增加此值可能会加快唯一键的构建速度,但也会影响正在进行的流量。 -
MemReportFrequency:内存频率报告,以秒为单位; 0 =仅在超过百分比限制时报告 -
MinDiskWriteSpeed:LCP和备份可写入的最小每秒字节数。 -
MinFreePct:为重新启动保留的内存资源百分比。 -
NodeGroup:数据节点所属的节点组; 仅在群集的初始启动期间使用。 -
NodeId:唯一标识集群中所有节点之间的数据节点的编号。 -
NoOfFragmentLogFiles:属于数据节点的4个文件集中每个文件集中的16 MB重做日志文件数 -
NoOfReplicas:数据库中所有数据的副本数量; 建议值为2(默认值)。 生产中不支持大于2的值。 -
Numa:(仅限Linux;需要libnuma)控制NUMA支持。 设置为0允许系统通过数据节点过程确定交织的使用; 1表示它由数据节点确定。 -
ODirect:尽可能使用O_DIRECT文件读写。 -
ODirectSyncFlag:O_DIRECT写入被视为同步写入; 在未启用ODirect时,InitFragmentLogFiles设置为SPARSE或两者都被忽略。 -
RealtimeScheduler:如果为true,则将数据节点线程调度为实时线程。 默认值为false。 -
RecoveryWork:LCP文件的存储开销百分比:值越大意味着正常操作中的工作量越少,恢复期间的工作量越多 -
RedoBuffer:分配用于写入重做日志的每个数据节点上的字节数 -
RedoOverCommitCounter:当多次超过RedoOverCommitLimit时,事务将中止,并按DefaultOperationRedoProblemAction指定的方式处理操作 -
RedoOverCommitLimit:每次刷新当前重做缓冲区所需的时间都超过这么多秒,将发生这种情况的次数与RedoOverCommitCounter进行比较。 -
ReservedConcurrentIndexOperations:在一个数据节点上具有专用资源的同时索引操作的数量 -
ReservedConcurrentOperations:在一个数据节点上的事务协调器中具有专用资源的同时操作的数量 -
ReservedConcurrentScans:在一个数据节点上具有专用资源的同时扫描数 -
ReservedConcurrentTransactions:在一个数据节点上具有专用资源的同时事务的数量 -
ReservedFiredTriggers:在一个数据节点上具有专用资源的触发器数 -
ReservedLocalScans:在一个数据节点上具有专用资源的同时片段扫描的数量 -
ReservedTransactionBufferMemory:分配给每个数据节点的密钥和属性数据的动态缓冲区空间(以字节为单位) -
RestartOnErrorInsert:控制插入错误导致的重启类型(启用StopOnError时) -
SchedulerExecutionTimer:发送前在调度程序中执行的微秒数 -
SchedulerResponsiveness:设置NDB调度程序响应优化0-10; 值越高,响应时间越长,但吞吐量越低 -
SchedulerSpinTimer:睡眠前在调度程序中执行的微秒数 -
ServerPort:端口用于为来自API节点的传入连接设置传输器 -
SharedGlobalMemory:为任何使用分配的每个数据节点上的总字节数 -
StartFailRetryDelay:重试前启动失败后的延迟时间; 需要StopOnError = 0。 -
StartFailureTimeout:终止前等待的毫秒数。 (0 =永远等待) -
StartNoNodeGroupTimeout:在尝试启动之前等待没有节点组的节点的时间(0 =永远) -
StartPartialTimeout:在没有所有节点的情况下尝试启动之前等待的毫秒数。 (0 =永远等待) -
StartPartitionedTimeout:尝试启动分区之前等待的毫秒数。 (0 =永远等待) -
StartupStatusReportFrequency:启动期间状态报告的频率 -
StopOnError:设置为0时,数据节点会自动重新启动并在节点故障后恢复 -
StringMemory:字符串内存的默认大小(0到100 =最大值的百分比,101 + =实际字节) -
TcpBind_INADDR_ANY:绑定IP_ADDR_ANY以便可以从任何地方建立连接(对于自动生成的连接) -
TimeBetweenEpochs:纪元之间的时间(用于复制的同步) -
TimeBetweenEpochsTimeout:时间段之间的超时时间。 超过将导致节点关闭。 -
TimeBetweenGlobalCheckpoints:组事务提交到磁盘之间的时间 -
TimeBetweenGlobalCheckpointsTimeout:将事务组提交到磁盘的最小超时 -
TimeBetweenInactiveTransactionAbortCheck:检查非活动事务之间的时间 -
TimeBetweenLocalCheckpoints:获取数据库快照之间的时间(以2的字节对数表示) -
TimeBetweenWatchDogCheck:数据节点内执行检查之间的时间 -
TimeBetweenWatchDogCheckInitial:数据节点内执行检查之间的时间(分配内存时的早期启动阶段) -
TotalSendBufferMemory:用于所有传输器发送缓冲区的总内存。 -
TransactionBufferMemory:为每个数据节点分配的密钥和属性数据的动态缓冲区空间(以字节为单位) -
TransactionDeadlockDetectionTimeout:时间事务可以花费在数据节点内执行。 这是事务协调器等待参与事务的每个数据节点执行请求的时间。 如果数据节点花费的时间超过此时间,则中止事务。 -
TransactionInactiveTimeout:应用程序在执行事务的另一部分之前等待的毫秒数。 这是事务协调器等待应用程序执行或发送事务的另一部分(查询,语句)的时间。 如果应用程序花费太多时间,则中止事务。 超时= 0表示应用程序永远不会超时。 -
TwoPassInitialNodeRestartCopy:在初始节点重新启动期间复制数据2次,从而为这种重新启动启用有序索引的多线程构建。 -
UndoDataBuffer:分配用于写入数据撤消日志的每个数据节点上的字节数 -
UndoIndexBuffer:分配用于写入索引撤消日志的每个数据节点上的字节数 -
UseShm:在此数据节点和也在此主机上运行的API节点之间使用共享内存连接
以下参数特定于 ndbmtd :
-
MaxNoOfExecutionThreads:仅对于ndbmtd,指定最大执行线程数 -
NoOfFragmentLogParts:属于此数据节点的重做日志文件组的数量; value必须是4的偶数倍。 -
ThreadConfig:用于配置多线程数据节点(ndbmtd)。 默认为空字符串; 请参阅文档以获取语法和其他信息。
本节中的列表提供了有关
用于配置NDB群集管理节点
的
文件
[ndb_mgmd]
或
[mgm]
部分中
使用的参数的信息
config.ini
。
有关每个参数的详细说明和其他附加信息,请参见
第22.3.3.5节“定义NDB集群管理服务器”
。
-
ArbitrationDelay:当被要求仲裁时,仲裁员在投票前等待很长时间(毫秒) -
ArbitrationRank:如果为0,则管理节点不是仲裁者。 内核按顺序选择仲裁器1,2 -
DataDir:此节点的数据目录 -
ExecuteOnComputer:引用先前定义的COMPUTER的字符串 -
ExtraSendBufferMemory:除了由TotalSendBufferMemory或SendBufferMemory分配的内存之外,还用于发送缓冲区的内存。 默认(0)允许最多16MB。 -
HeartbeatIntervalMgmdMgmd:管理节点到管理节点心跳之间的时间; 3次错过心跳后,管理节点之间的连接被认为丢失。 -
HeartbeatThreadPriority:为管理节点设置心跳线程策略和优先级; 有关允许的值,请参见手册 -
HostName:此管理节点的主机名或IP地址。 -
Id:标识管理节点(Id)的编号。 现已弃用; 请改用NodeId。 -
LogDestination:发送日志消息的位置:控制台,系统日志或指定的日志文件 -
NodeId:唯一标识集群中所有节点之间的管理节点的编号。 -
PortNumber:用于向管理服务器发送命令和从管理服务器获取配置的端口号 -
PortNumberStats:用于从管理服务器获取统计信息的端口号 -
TotalSendBufferMemory:用于所有传输器发送缓冲区的总内存 -
wan:使用WAN TCP设置作为默认设置
在管理节点的配置中进行更改后,必须执行群集的滚动重新启动才能使新配置生效。 有关 更多信息 , 请参见 第22.3.3.5节“定义NDB群集管理服务器” 。
要将新的管理服务器添加到正在运行的NDB群集,还必须在修改任何现有
config.ini
文件
后执行所有群集节点的滚动重新启动
。
有关使用多个管理节点时出现的问题的更多信息,请参见
第22.1.7.10节“与多个NDB群集节点相关的限制”
。
本节中的列表提供了有关
用于配置NDB Cluster SQL节点和API节点
的
文件
[mysqld]
和
[api]
部分中
使用的参数的信息
config.ini
。
有关每个参数的详细说明和其他附加信息,请参见
第22.3.3.7节“在NDB集群中定义SQL和其他API节点”
。
-
ApiVerbose:启用NDB API调试; 用于NDB开发 -
ArbitrationDelay:当被要求仲裁时,仲裁员在投票前等待这么多毫秒 -
ArbitrationRank:如果为0,则API节点不是仲裁者。 内核按顺序选择仲裁器1,2 -
AutoReconnect:指定在与群集断开连接时,API节点是否应完全重新连接 -
BatchByteSize:默认批量大小(以字节为单位) -
BatchSize:记录数的默认批处理大小 -
ConnectBackoffMaxTime:指定此API节点在任何给定数据节点的连接尝试之间允许的最长时间(以毫秒为单位)(~100ms分辨率)。 排除连接尝试正在进行时经过的时间,在最坏的情况下可能需要几秒钟。 通过设置为0禁用。如果当前没有数据节点连接到此API节点,则使用StartConnectBackoffMaxTime。 -
ConnectionMap:指定要连接的数据节点 -
DefaultHashMapSize:设置用于表哈希映射的大小(在桶中)。 支持三个值:0,240和3840.主要用于NDB 7.2中的升级和降级。 -
DefaultOperationRedoProblemAction:如果超出RedoOverCommitCounter,将如何处理操作 -
ExecuteOnComputer:引用先前定义的COMPUTER的字符串 -
ExtraSendBufferMemory:除了由TotalSendBufferMemory或SendBufferMemory分配的内存之外,还用于发送缓冲区的内存。 默认(0)允许最多16MB。 -
HeartbeatThreadPriority:为API节点设置心跳线程策略和优先级; 有关允许的值,请参见手册 -
HostName:此SQL或API节点的主机名或IP地址。 -
Id:标识MySQL服务器或API节点(Id)的编号。 现已弃用; 请改用NodeId。 -
MaxScanBatchSize:一次扫描的最大集合批量大小 -
NodeId:唯一标识集群中所有节点之间的SQL节点或API节点的编号。 -
StartConnectBackoffMaxTime:与ConnectBackoffMaxTime相同,但如果没有数据节点连接到此API节点,则使用此参数。 -
TotalSendBufferMemory:用于所有传输器发送缓冲区的总内存 -
wan:使用WAN TCP设置作为默认设置
有关NDB Cluster的MySQL服务器选项的讨论,请参见 第22.3.3.9.1节“NDB集群的MySQL服务器选项” 。 有关与NDB群集相关的MySQL服务器系统变量的信息,请参见 第22.3.3.9.2节“NDB群集系统变量” 。
要将新的SQL或API节点添加到正在运行的NDB群集的配置中,必须在向
文件
添加新的
[mysqld]
或
[api]
部分
之后执行所有群集节点的滚动重新启动
config.ini
(或者,如果您使用多个管理服务器,则为文件) 。
必须在新的SQL或API节点连接到群集之前完成此操作。
这是 不 必要执行群集的任何重新启动,如果新的SQL或API节点可以使用以前未使用的API槽在群集配置以连接到群集。
本节中的清单提供有关在使用的参数信息
[computer]
,
[tcp]
,
[shm]
,和
[sci]
一的部分
config.ini
文件进行配置NDB集群。
有关各个参数的详细说明和其他信息,请参见
第22.3.3.10节“NDB集群TCP / IP连接”
,
第22.3.3.12节“NDB集群共享内存连接”
或
第22.3.3.13节“SCI传输连接”。 NDB Cluster“
,视情况而定。
以下参数适用于
config.ini
文件的
[computer]
部分:
以下参数适用于
config.ini
文件的
[tcp]
部分:
-
Checksum:如果启用了校验和,则会检查节点之间的所有信号是否有错误 -
Group:用于群组接近; 较小的值被解释为更接近 -
NodeId1:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeId2:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeIdServer:设置TCP连接的服务器端 -
OverloadLimit:如果发送缓冲区中有多个未发送的字节,则认为连接过载。 -
PreSendChecksum:如果同时启用此参数和校验和,请执行预发送校验和检查,并检查节点之间的所有TCP信号是否存在错误 -
Proxy: -
ReceiveBufferMemory:此节点接收的信号的缓冲区字节数 -
SendBufferMemory:TCP缓冲区的字节,用于从此节点发送的信号 -
SendSignalId:在每个信号中发送ID。 用于跟踪文件。 在调试版本中默认为true。 -
TCP_MAXSEG_SIZE:用于TCP_MAXSEG的值 -
TCP_RCV_BUF_SIZE:用于SO_RCVBUF的值 -
TCP_SND_BUF_SIZE:用于SO_SNDBUF的值 -
TcpBind_INADDR_ANY:绑定InAddrAny而不是服务器部分连接的主机名
以下参数适用于
config.ini
文件的
[shm]
部分:
-
Checksum:如果启用了校验和,则会检查节点之间的所有信号是否有错误 -
Group: -
NodeId1:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeId2:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeIdServer:设置SHM连接的服务器端 -
OverloadLimit:如果发送缓冲区中有多个未发送的字节,则认为连接过载。 -
PreSendChecksum:如果同时启用此参数和校验和,请执行预发送校验和检查,并检查节点之间的所有SHM信号是否存在错误 -
SendBufferMemory:共享内存缓冲区中的字节,用于从此节点发送的信号 -
SendSignalId:在每个信号中发送ID。 用于跟踪文件。 -
ShmKey:共享内存密钥; 设置为1时,由NDB计算 -
ShmSpinTime:接收时,睡眠前旋转的微秒数 -
ShmSize:共享内存段的大小 -
Signum:用于信令的信号编号
以下参数适用于
config.ini
文件的
[sci]
部分:
-
Checksum:如果启用了校验和,则会检查节点之间的所有信号是否有错误 -
Group: -
Host1SciId0:Host1上的适配器0的SCI节点ID(计算机可以有两个适配器) -
Host1SciId1:Host1上的适配器1的SCI节点ID(计算机可以有两个适配器) -
Host2SciId0:Host2上的适配器0的SCI节点ID(计算机可以有两个适配器) -
Host2SciId1:Host2上的适配器1的SCI节点ID(计算机可以有两个适配器) -
NodeId1:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeId2:连接一侧的节点(数据节点,API节点或管理节点)的ID -
NodeIdServer: -
OverloadLimit:如果发送缓冲区中有多个未发送的字节,则认为连接过载。 -
SendLimit:当缓冲此字节数时,将发送传输器发送缓冲区内容 -
SendSignalId:在每个信号中发送ID。 用于跟踪文件。 -
SharedBufferSize:共享内存段的大小
下表提供了
mysqld
在NDB群集中作为SQL节点运行时
适用的命令行选项,服务器和状态变量的列表
。
有关
可用于
mysqld的
所有
命令行选项,服务器和状态变量
的表
,请参见
第5.1.4节“服务器选项,系统变量和状态变量参考”
。
-
Com_show_ndb_status:SHOW NDB STATUS语句的计数 -
Handler_discover:已发现表的次数 -
ndb-batch-size:用于NDB事务批处理的大小(以字节为单位) -
ndb-blob-read-batch-bytes:指定应批量处理大型BLOB读取的大小(以字节为单位)。 0 =没有限制。 -
ndb-blob-write-batch-bytes:指定应批量处理大型BLOB写入的大小(以字节为单位)。 0 =没有限制。 -
ndb-cluster-connection-pool:MySQL使用的集群的连接数 -
ndb-cluster-connection-pool-nodeids:以逗号分隔的节点ID列表,用于连接MySQL使用的集群; 列表中的节点数必须与为--ndb-cluster-connection-pool设置的值相同 -
ndb-connectstring:指向分发群集配置的管理服务器 -
ndb-default-column-format:在创建列或向表添加列时,默认情况下为COLUMN_FORMAT和ROW_FORMAT选项使用此值(FIXED或DYNAMIC)。 -
ndb-deferred-constraints:指定对唯一索引(支持这些索引)的约束检查应该延迟到提交时间。 通常不需要或使用; 仅用于测试目的。 -
ndb-distribution:NDBCLUSTER中新表的默认分布(KEYHASH或LINHASH,默认为KEYHASH) -
ndb-log-apply-status:导致MySQL服务器充当从属服务器,使用自己的服务器ID记录从其直接主服务器接收的mysql.ndb_apply_status更新。 仅在使用--ndbcluster选项启动服务器时有效。 -
ndb-log-empty-epochs:启用时,即使启用了--log-slave-updates,也会将没有更改的时期写入ndb_apply_status和ndb_binlog_index表。 -
ndb-log-empty-update:启用时,即使启用了--log-slave-updates,也会导致无法将更改生成的更新写入ndb_apply_status和ndb_binlog_index表。 -
ndb-log-exclusive-reads:使用独占锁定记录主键读取; 允许基于读取冲突解决冲突 -
ndb-log-orig:在mysql.ndb_binlog_index表中记录始发服务器ID和纪元 -
ndb-log-transaction-id:在二进制日志中写入NDB事务ID。 需要--log-bin-v1-events = OFF。 -
ndb-log-update-as-write:在更新(OFF)和写入(ON)之间切换主服务器上更新的日志记录 -
ndb-mgmd-host:设置主机(和端口,如果需要)以连接到管理服务器 -
ndb-nodeid:此MySQL服务器的NDB群集节点ID -
ndb-recv-thread-activation-threshold:接收线程接管群集连接轮询时的激活阈值(在并发活动线程中测量) -
ndb-recv-thread-cpu-mask:用于将接收器线程锁定到特定CPU的CPU掩码; 指定为十六进制。 请参阅文档了解详细信 -
ndb-transid-mysql-connection-map:启用或禁用ndb_transid_mysql_connection_map插件; 也就是说,启用或禁用具有该名称的INFORMATION_SCHEMA表 -
ndb-wait-connected:MySQL服务器在接受MySQL客户端连接之前等待连接到群集管理和数据节点的时间(以秒为单位) -
ndb-wait-setup:MySQL服务器等待NDB引擎设置完成的时间(以秒为单位) -
ndb-allow-copying-alter-table:设置为OFF以防止ALTER TABLE在NDB表上使用复制操作 -
Ndb_api_bytes_received_count:此MySQL服务器(SQL节点)从数据节点接收的数据量(以字节为单位) -
Ndb_api_bytes_received_count_session:从此客户端会话中的数据节点接收的数据量(以字节为单位) -
Ndb_api_bytes_received_count_slave:此从站从数据节点接收的数据量(以字节为单位) -
Ndb_api_bytes_sent_count:此MySQL服务器(SQL节点)发送到数据节点的数据量(以字节为单位) -
Ndb_api_bytes_sent_count_session:在此客户端会话中发送到数据节点的数据量(以字节为单位) -
Ndb_api_bytes_sent_count_slave:此从站发送到数据节点的数据量(以字节为单位) -
Ndb_api_event_bytes_count:此MySQL服务器(SQL节点)接收的事件的字节数 -
Ndb_api_event_bytes_count_injector:NDB二进制日志注入器线程接收的事件的字节数 -
Ndb_api_event_data_count:此MySQL服务器(SQL节点)收到的行更改事件数 -
Ndb_api_event_data_count_injector:NDB二进制日志注入器线程收到的行更改事件数 -
Ndb_api_event_nondata_count:此MySQL服务器(SQL节点)收到的事件数(行更改事件除外) -
Ndb_api_event_nondata_count_injector:NDB二进制日志注入器线程接收的事件数,而不是行更改事件 -
Ndb_api_pk_op_count:此MySQL服务器基于或使用主键的操作数(SQL节点) -
Ndb_api_pk_op_count_session:此客户端会话中基于或使用主键的操作数 -
Ndb_api_pk_op_count_slave:此从站基于或使用主键的操作数 -
Ndb_api_pruned_scan_count:此MySQL服务器(SQL节点)已修剪到单个分区的扫描数 -
Ndb_api_pruned_scan_count_session:已在此客户端会话中修剪到单个分区的扫描数 -
Ndb_api_pruned_scan_count_slave:此从属程序已修剪到单个分区的扫描数 -
Ndb_api_range_scan_count:此MySQL服务器(SQL节点)启动的范围扫描数 -
Ndb_api_range_scan_count_session:已在此客户端会话中启动的范围扫描数 -
Ndb_api_range_scan_count_slave:此从站已启动的范围扫描数 -
Ndb_api_read_row_count:此MySQL服务器(SQL节点)已读取的总行数 -
Ndb_api_read_row_count_session:此客户端会话中已读取的总行数 -
Ndb_api_read_row_count_slave:此从属服务器已读取的总行数 -
Ndb_api_scan_batch_count:此MySQL服务器(SQL节点)收到的行批次数 -
Ndb_api_scan_batch_count_session:此客户端会话中收到的行批次数 -
Ndb_api_scan_batch_count_slave:此从属接收的批次行数 -
Ndb_api_table_scan_count:此MySQL服务器(SQL节点)已启动的表扫描数,包括内部表的扫描数 -
Ndb_api_table_scan_count_session:此客户端会话中已启动的表扫描数,包括内部表的扫描数 -
Ndb_api_table_scan_count_slave:此从属服务器已启动的表扫描数,包括内部表的扫描数 -
Ndb_api_trans_abort_count:此MySQL服务器中止的事务数(SQL节点) -
Ndb_api_trans_abort_count_session:此客户端会话中中止的事务数 -
Ndb_api_trans_abort_count_slave:此从站中止的事务数 -
Ndb_api_trans_close_count:此MySQL服务器(SQL节点)中止的事务数(可能大于TransCommitCount和TransAbortCount的总和) -
Ndb_api_trans_close_count_session:此客户端会话中止的事务数(可能大于TransCommitCount和TransAbortCount的总和) -
Ndb_api_trans_close_count_slave:此从站中止的事务数(可能大于TransCommitCount和TransAbortCount的总和) -
Ndb_api_trans_commit_count:此MySQL服务器(SQL节点)提交的事务数 -
Ndb_api_trans_commit_count_session:此客户端会话中提交的事务数 -
Ndb_api_trans_commit_count_slave:此从属服务器提交的事务数 -
Ndb_api_trans_local_read_row_count:此MySQL服务器(SQL节点)已读取的总行数 -
Ndb_api_trans_local_read_row_count_session:此客户端会话中已读取的总行数 -
Ndb_api_trans_local_read_row_count_slave:此从属服务器已读取的总行数 -
Ndb_api_trans_start_count:此MySQL服务器启动的事务数(SQL节点) -
Ndb_api_trans_start_count_session:此客户端会话中启动的事务数 -
Ndb_api_trans_start_count_slave:此从属服务器启动的事务数 -
Ndb_api_uk_op_count:此MySQL服务器基于或使用唯一键的操作数(SQL节点) -
Ndb_api_uk_op_count_session:此客户端会话中基于或使用唯一键的操作数 -
Ndb_api_uk_op_count_slave:此从站基于或使用唯一键的操作数 -
Ndb_api_wait_exec_complete_count:等待执行此MySQL服务器完成的操作时阻塞线程的次数(SQL节点) -
Ndb_api_wait_exec_complete_count_session:等待执行在此客户端会话中完成的操作时线程被阻止的次数 -
Ndb_api_wait_exec_complete_count_slave:等待执行此从站完成的操作时线程被阻止的次数 -
Ndb_api_wait_meta_request_count:此MySQL服务器(SQL节点)阻止线程等待基于元数据的信号的次数 -
Ndb_api_wait_meta_request_count_session:在此客户端会话中线程被阻止等待基于元数据的信号的次数 -
Ndb_api_wait_meta_request_count_slave:线程被此从站等待基于元数据的信号被阻止的次数 -
Ndb_api_wait_nanos_count:此MySQL服务器(SQL节点)等待来自数据节点的某种类型信号所花费的总时间(以纳秒为单位) -
Ndb_api_wait_nanos_count_session:在此客户端会话中等待来自数据节点的某种类型信号所花费的总时间(以纳秒为单位) -
Ndb_api_wait_nanos_count_slave:此从站等待来自数据节点的某种类型信号所花费的总时间(以纳秒为单位) -
Ndb_api_wait_scan_result_count:此MySQL服务器(SQL节点)等待基于扫描的信号时线程被阻止的次数 -
Ndb_api_wait_scan_result_count_session:在此客户端会话中等待基于扫描的信号时线程被阻止的次数 -
Ndb_api_wait_scan_result_count_slave:此从站等待基于扫描的信号时线程被阻止的次数 -
ndb_autoincrement_prefetch_sz:NDB自动增加预取大小 -
ndb_cache_check_time:MySQL查询缓存对集群SQL节点进行检查之间的毫秒数 -
ndb_clear_apply_status:导致RESET SLAVE清除ndb_apply_status表中的所有行; 默认为ON -
Ndb_cluster_node_id:如果服务器充当NDB群集节点,则此变量的值为群集中的节点ID -
Ndb_config_from_host:群集管理服务器的主机名或IP地址以前是Ndb_connected_host -
Ndb_config_from_port:用于连接到群集管理服务器的端口。 以前是Ndb_connected_port -
Ndb_conflict_fn_epoch:NDB $ EPOCH()冲突检测函数在冲突中找到的行数 -
Ndb_conflict_fn_epoch2:NDB $ EPOCH2()冲突检测功能在冲突中发现的行数 -
Ndb_conflict_fn_epoch2_trans:NDB $ EPOCH2_TRANS()冲突检测功能在冲突中发现的行数 -
Ndb_conflict_fn_epoch_trans:NDB $ EPOCH_TRANS()冲突检测功能在冲突中发现的行数 -
Ndb_conflict_fn_max:如果服务器是群集复制中涉及的NDB群集的一部分,则此变量的值指示已应用基于“更大时间戳获胜”的冲突解决的次数 -
Ndb_conflict_fn_old:如果服务器是群集复制中涉及的NDB群集的一部分,则此变量的值指示已应用“相同时间戳获胜”冲突解决的次数 -
Ndb_conflict_last_conflict_epoch:这个奴隶的最新NDB纪元,其中检测到冲突 -
Ndb_conflict_last_stable_epoch:事务冲突函数发现冲突的行数 -
Ndb_conflict_reflected_op_discard_count:由于执行期间的错误而未应用的反射操作数 -
Ndb_conflict_reflected_op_prepare_count:已准备好执行的已接收操作数 -
Ndb_conflict_refresh_op_count:已准备的刷新操作数 -
Ndb_conflict_trans_conflict_commit_count:在要求事务冲突处理之后提交的纪元事务的数量 -
Ndb_conflict_trans_detect_iter_count:提交epoch事务所需的内部迭代次数。 应该(略微)大于或等于Ndb_conflict_trans_conflict_commit_count -
Ndb_conflict_trans_reject_count:由事务冲突函数发现冲突后被拒绝的事务数 -
Ndb_conflict_trans_row_conflict_count:事务冲突函数冲突中发现的行数。 包括冲突事务中包含或依赖于冲突事务的任何行。 -
Ndb_conflict_trans_row_reject_count:由事务冲突函数发现冲突后重新排列的行总数。 包括Ndb_conflict_trans_row_conflict_count以及冲突事务中包含或依赖于冲突事务的任何行。 -
ndb_data_node_neighbour:指定与此MySQL服务器“最接近”的集群数据节点,用于事务提示和完全复制的表 -
ndb_default_column_format:设置用于新NDB表的默认行格式和列格式(FIXED或DYNAMIC) -
ndb_deferred_constraints:指定应延迟约束检查(支持这些检查)。 通常不需要或使用; 仅用于测试目的。 -
ndb_distribution:NDBCLUSTER中新表的默认分布(KEYHASH或LINHASH,默认为KEYHASH) -
Ndb_conflict_delete_delete_count:检测到删除 - 删除冲突的数量(应用删除操作,但行不存在) -
ndb_eventbuffer_free_percent:在达到ndb_eventbuffer_max_alloc设置的限制之后,在恢复缓冲之前应该在事件缓冲区中可用的可用内存百分比 -
ndb_eventbuffer_max_alloc:NDB API可以为缓冲事件分配的最大内存。 默认为0(无限制)。 -
Ndb_execute_count:提供由操作产生的NDB内核往返次数 -
ndb_extra_logging:控制MySQL错误日志中的NDB群集架构,连接和数据分发事件的日志记录 -
ndb_force_send:强制立即向NDB发送缓冲区,而不等待其他线程 -
ndb_fully_replicated:是否完全复制了新的NDB表 -
ndb_index_stat_enable:在查询优化中使用NDB索引统计信息 -
ndb_index_stat_option:以逗号分隔的NDB索引统计信息可调选项列表; 列表不应包含空格 -
ndb_join_pushdown:允许将联接下推到数据节点 -
ndb_log_apply_status:作为从属服务器的MySQL服务器是否使用自己的服务器ID记录从其直接主服务器接收的mysql.ndb_apply_status更新 -
ndb_log_bin:在二进制日志中写入NDB表的更新。 仅当使用--log-bin启用二进制日志记录时才有效。 -
ndb_log_binlog_index:将时期和二进制日志位置之间的映射插入到ndb_binlog_index表中。 默认为ON。 仅在服务器上启用二进制日志记录时有效。 -
ndb_log_empty_epochs:启用后,即使启用了log_slave_updates,也会向ndb_apply_status和ndb_binlog_index表写入没有更改的纪元 -
ndb_log_empty_update:启用后,即使启用了log_slave_updates,也会将未产生更改的更新写入ndb_apply_status和ndb_binlog_index表 -
ndb_log_exclusive_reads:使用独占锁定记录主键读取; 允许基于读取冲突解决冲突 -
ndb_log_orig:始发服务器的id和epoch是否记录在mysql.ndb_binlog_index表中。 启动mysqld时使用--ndb-log-orig选项进行设置。 -
ndb_log_transaction_id:是否将NDB事务ID写入二进制日志(只读)。 -
ndb-log-update-minimal:以最小格式记录更新。 -
ndb_log_updated_only:记录完整行(ON)或仅更新(OFF) -
ndb_metadata_check:启用NDB元数据更改的自动检测以与数据字典同步 -
ndb_metadata_check_interval:执行检查NDB元数据更改以与数据字典同步的时间间隔(秒) -
Ndb_metadata_detected_count:NDB元数据更改监视器线程检测到更改的次数 -
Ndb_number_of_data_nodes:如果服务器是NDB群集的一部分,则此变量的值是群集中的数据节点数 -
ndb-optimization-delay:设置NDB表上OPTIMIZE TABLE处理行集之间等待的毫秒数 -
ndb_optimized_node_selection:确定SQL节点如何选择要用作事务协调器的集群数据节点 -
Ndb_pruned_scan_count:自上次启动集群以来NDB执行的扫描数,可以使用分区修剪 -
Ndb_pushed_queries_defined:API节点尝试下推到数据节点的联接数 -
Ndb_pushed_queries_dropped:API节点尝试下推但失败的连接数 -
Ndb_pushed_queries_executed:成功下推并在数据节点上执行的联接数 -
Ndb_pushed_reads:通过下推连接在数据节点上执行的读取次数 -
ndb_read_backup:启用从任何副本读取 -
ndb_recv_thread_activation_threshold:接收线程接管群集连接轮询时的激活阈值(在并发活动线程中测量) -
ndb_recv_thread_cpu_mask:用于将接收器线程锁定到特定CPU的CPU掩码; 指定为十六进制。 请参阅文档了解详细信 -
ndb_report_thresh_binlog_epoch_slip:NDB 7.5.4及更高版本:完全缓冲但尚未被binlog注入器线程消耗的时期数的阈值,当超过时生成BUFFERED_EPOCHS_OVER_THRESHOLD事件缓冲区状态消息; 在NDB 7.5.4之前:在报告二进制日志状态之前滞后的时期数的阈值 -
ndb_report_thresh_binlog_mem_usage:这是报告二进制日志状态之前剩余可用内存百分比的阈值 -
ndb_row_checksum:启用时,设置行校验和; 默认启用 -
Ndb_scan_count:自上次启动集群以来NDB执行的扫描总数 -
ndb_show_foreign_key_mock_tables:显示用于支持foreign_key_checks = 0的模拟表 -
ndb_slave_conflict_role:奴隶在冲突检测和解决方面的作用。 值是PRIMARY,SECONDARY,PASS或NONE(默认值)之一。 只有在从属SQL线程停止时才能更改。 有关详细信息,请参阅文档 -
Ndb_slave_max_replicated_epoch:这个奴隶上最近提交的NDB纪元。 当此值大于或等于Ndb_conflict_last_conflict_epoch时,尚未检测到任何冲突。 -
Ndb_system_name:已配置的集群系统名称; 如果服务器未连接到NDB,则为空 -
ndb_table_no_logging:启用此设置时创建的NDB表不会检查点到磁盘(尽管创建了表模式文件)。 创建表或使用NDBCLUSTER更改表时生效的设置在表的生命周期内仍然存在。 -
ndb_table_temporary:NDB表在磁盘上不持久:不创建任何模式文件,也不记录表 -
ndb_use_exact_count:在规划查询时使用确切的行计数 -
ndb_use_transactions:强制NDB在SELECT COUNT(*)查询计划期间使用记录计数来加速此类查询 -
ndb_version:将构建和NDB引擎版本显示为整数 -
ndb_version_string:显示构建信息,包括ndb-xyz格式的NDB引擎版本 -
ndbcluster:启用NDB群集(如果此版本的MySQL支持它)禁用--skip-ndbcluster -
ndbinfo_database:用于NDB信息数据库的名称; 只读 -
ndbinfo_max_bytes:仅用于调试 -
ndbinfo_max_rows:仅用于调试 -
ndbinfo_offline:将ndbinfo数据库置于脱机模式,其中不从表或视图返回任何行 -
ndbinfo_show_hidden:是否在mysql客户端中显示ndbinfo内部基表。 默认为OFF。 -
ndbinfo_table_prefix:用于命名ndbinfo内部基表的前缀 -
ndbinfo_version:ndbinfo引擎的版本; 只读 -
server-id-bits:设置实际用于标识服务器的server_id中的最低有效位数,允许NDB API应用程序以最高有效位存储应用程序数据。 server_id必须小于此值的2的幂。 -
slave_allow_batching:为复制从站打开和关闭更新批处理 -
transaction_allow_batching:允许在事务中批处理语句。 禁用AUTOCOMMIT使用。
- 22.3.3.1 NDB群集配置:基本示例
- 22.3.3.2 NDB集群的推荐启动配置
- 22.3.3.3 NDB群集连接字符串
- 22.3.3.4在NDB集群中定义计算机
- 22.3.3.5定义NDB群集管理服务器
- 22.3.3.6定义NDB集群数据节点
- 22.3.3.7在NDB集群中定义SQL和其他API节点
- 22.3.3.8定义系统
- 22.3.3.9 NDB集群的MySQL服务器选项和变量
- 22.3.3.10 NDB群集TCP / IP连接
- 22.3.3.11使用直接连接的NDB群集TCP / IP连接
- 22.3.3.12 NDB群集共享内存连接
- 22.3.3.13 NDB集群中的SCI传输连接
- 22.3.3.14配置NDB集群发送缓冲区参数
配置NDB群集需要使用两个文件:
-
my.cnf:指定所有NDB Cluster可执行文件的选项。 您之前使用MySQL时应该熟悉的此文件必须可由群集中运行的每个可执行文件访问。 -
config.ini:此文件(有时称为 全局配置文件 )仅由NDB群集管理服务器读取,然后NDB群集管理服务器将其中包含的信息分发给参与群集的所有进程。config.ini包含集群中涉及的每个节点的描述。 这包括数据节点的配置参数和集群中所有节点之间的连接的配置参数。 对于一个快速参考可以出现在这个文件中,哪些类型的配置参数的部分可以被放置在每个部分,看到 的各款config.ini文件 。
缓存配置数据。
NDB
使用
有状态配置
。
管理服务器不会在每次重新启动管理服务器时读取全局配置文件,而是在第一次启动时缓存配置,此后,只有在满足下列条件之一时才会读取全局配置文件:
-
使用--initial选项启动管理服务器。 当
--initial使用时,全局配置文件重新读取,任何现有的缓存文件被删除,管理服务器创建一个新的配置缓存。 -
使用--reload选项启动管理服务器。 该
--reload选项使管理服务器将其缓存与全局配置文件进行比较。 如果它们不同,管理服务器将创建新的配置缓存; 保留任何现有配置缓存,但不使用。 如果管理服务器的缓存和全局配置文件包含相同的配置数据,则使用现有缓存,并且不会创建新缓存。 -
使用--config-cache = FALSE启动管理服务器。 此禁用
--config-cache(默认情况下启用),可用于强制管理服务器完全绕过配置缓存。 在这种情况下,管理服务器会忽略可能存在的任何配置文件,config.ini而是 始终从 文件中 读取其配置数据 。 -
找不到配置缓存。 在这种情况下,管理服务器读取全局配置文件并创建包含与文件中相同的配置数据的缓存。
配置缓存文件。
默认情况下,管理服务器
mysql-cluster
在MySQL安装目录
中指定的目录中创建配置缓存文件
。
(如果在Unix系统上从源构建NDB Cluster,则默认位置为
/usr/local/mysql-cluster
。)可以通过使用该
--configdir
选项
启动管理服务器在运行时覆盖此项
。
配置缓存文件是根据模式命名的二进制文件
,其中
是集群中管理服务器的节点ID,并且
是缓存标识符。
缓存文件使用顺序编号
ndb_
node_id_config.bin.seq_idnode_id
seq_id
seq_id
,按照创建顺序。
管理服务器使用由...确定的最新缓存文件
seq_id
。
可以通过删除以后的配置缓存文件或通过重命名先前的缓存文件以使其具有更高的值来回滚到先前的配置
seq_id
。
但是,由于配置缓存文件是以二进制格式编写的,因此不应尝试手动编辑其内容。
有关更多信息
--configdir
,
--config-cache
,
--initial
,和
--reload
为NDB集群管理服务器选项,请参见
第22.4.4,“
ndb_mgmd
- NDB簇管理服务器守护程序”
。
我们不断改进群集配置并尝试简化此过程。 尽管我们努力保持向后兼容性,但有时可能会引入不兼容的更改。 在这种情况下,如果更改不向后兼容,我们将尝试让群集用户提前知道。 如果您发现了这样的更改并且我们没有记录它,请使用 第1.7节“如何报告错误或问题”中 给出的说明在MySQL错误数据库 中报告 。
要支持NDB群集,您需要更新
my.cnf
,如以下示例所示。
您还可以在调用可执行文件时在命令行上指定这些参数。
此处显示的选项不应与
config.ini
全局配置文件
中使用的选项混淆
。
全局配置选项将在本节后面讨论。
#my.cnf #ne.cnf for NDB Cluster的示例添加 #(在MySQL 8.0中有效) #enable ndbcluster存储引擎,并为其提供连接字符串 #management server host(默认端口为1186) 的[mysqld] NDBCLUSTER NDB-CONNECTSTRING = ndb_mgmd.mysql.com #为管理服务器主机提供连接字符串(默认端口:1186) [NDBD] 连接串= ndb_mgmd.mysql.com #为管理服务器主机提供连接字符串(默认端口:1186) [ndb_mgm] 连接串= ndb_mgmd.mysql.com #提供集群配置文件的位置 [ndb_mgmd] 配置文件中=的/ etc / config.ini中
(有关连接字符串的更多信息,请参见 第22.3.3.3节“NDB集群连接字符串” 。)
#my.cnf #ne.cnf for NDB Cluster的示例添加 #(适用于所有版本) #enable ndbcluster存储引擎,并提供管理连接字符串 #server host到默认端口1186 的[mysqld] NDBCLUSTER NDB-CONNECTSTRING = ndb_mgmd.mysql.com:1186
一旦
用
如前所示
的
文件中
的
和
参数
启动了
mysqld
进程
,就不能在
没有实际启动集群的情况下
执行任何
或
语句。
否则,这些语句将失败并显示错误。
这是设计的
。
NDBCLUSTER
ndb-connectstring
[mysqld]
my.cnf
CREATE TABLE
ALTER TABLE
您还可以
[mysql_cluster]
在群集
my.cnf
文件中
使用单独的
部分,
以便所有可执行文件读取和使用设置:
#cluster特定设置 [mysql_cluster] NDB-CONNECTSTRING = ndb_mgmd.mysql.com:1186
有关
NDB
可在
my.cnf
文件中
设置的
其他
变量
,请参见
第22.3.3.9.2节“NDB集群系统变量”
。
NDB Cluster全局配置文件按约定命名
config.ini
(但这不是必需的)。
如果需要,它
在启动时
由
ndb_mgmd
读取,
并且可以放置在可以由其读取的任何位置。
配置的位置和名称使用指定
与
ndb_mgmd
在命令行上。
此选项没有默认值,如果
ndb_mgmd
使用配置缓存
,则会忽略该选项
。
--config-file=
path_name
NDB Cluster的全局配置文件使用INI格式,其中包含以节标题开头的节(由方括号括起),后跟相应的参数名称和值。
与标准INI格式的一个偏差是参数名称和值可以用冒号(
:
)和等号(
=
)
分隔
;
但是,等号是首选。
另一个偏差是部分名称不能唯一标识部分。
相反,唯一的部分(例如两个相同类型的不同节点)由在该部分中指定为参数的唯一ID标识。
默认值是为大多数参数定义的,也可以在中指定
config.ini
。
要创建默认值部分,只需将该单词添加
default
到部分名称即可。
例如,一个
[ndbd]
部分包含适用于特定数据节点的
[ndbd
default]
参数
,而一个
部分包含适用于所有数据节点的参数。
假设所有数据节点都应使用相同的数据内存大小。
要全部配置它们,请创建一个
[ndbd
default]
包含
DataMemory
指定数据内存大小
的
行
的
部分
。
在某些旧版本的NDB Cluster中,没有默认值
NoOfReplicas
,必须在该
[ndbd
default]
部分中
明确指定
。
虽然此参数现在具有默认值2(这是大多数常见使用方案中的建议设置),但仍建议您明确设置此参数。
全局配置文件必须定义群集中涉及的计算机和节点以及这些节点所在的计算机。 此处显示了由一个管理服务器,两个数据节点和两个MySQL服务器组成的集群的简单配置文件示例:
#file“config.ini” - 2个数据节点和2个SQL节点 #这个文件放在ndb_mgmd的启动目录中( #management server) #可以从任何主机启动第一个MySQL服务器。第二 #只能在主机mysqld_5.mysql.com上启动 [ndbd默认] NoOfReplicas = 2 DataDir = / var / lib / mysql-cluster [ndb_mgmd] 主机名= ndb_mgmd.mysql.com DataDir = / var / lib / mysql-cluster [NDBD] HostName = ndbd_2.mysql.com [NDBD] HostName = ndbd_3.mysql.com 的[mysqld] 的[mysqld] HostName = mysqld_5.mysql.com
前面的示例旨在作为熟悉NDB Cluster的最小起始配置,并且几乎可以肯定不足以进行生产设置。 请参见 第22.3.3.2节“NDB群集的推荐启动配置” ,它提供了更完整的示例启动配置。
每个节点在
config.ini
文件中
都有自己的部分
。
例如,此集群有两个数据节点,因此前面的配置文件包含
[ndbd]
定义这些节点的
两个
部分。
不要将注释放在与
config.ini
文件中
的节标题相同的行上
;
这会导致管理服务器无法启动,因为在这种情况下它无法解析配置文件。
config.ini文件的部分
您可以在
config.ini
配置文件中
使用六个不同的部分
,如以下列表中所述:
-
[computer]:定义群集主机。 这不是配置可行的NDB群集所必需的,但在设置大型群集时可以方便使用。 有关 更多信息 , 请参见 第22.3.3.4节“在NDB集群中定义计算机” 。 -
[ndbd]:定义集群数据节点( ndbd 进程)。 有关详细 信息, 请参见 第22.3.3.6节“定义NDB集群数据节点” 。 -
[mysqld]:定义集群的MySQL服务器节点(也称为SQL或API节点)。 有关SQL节点配置的讨论,请参见 第22.3.3.7节“在NDB集群中定义SQL和其他API节点” 。 -
[mgm]或[ndb_mgmd]:定义集群管理服务器(MGM)节点。 有关管理节点配置的信息,请参见 第22.3.3.5节“定义NDB群集管理服务器” 。 -
[tcp]:定义群集节点之间的TCP / IP连接,TCP / IP是默认连接协议。 通常,[tcp]或者[tcp default]不需要部分来设置NDB群集,因为群集会自动处理此问题; 但是,在某些情况下可能需要覆盖群集提供的默认值。 有关可用TCP / IP配置参数及其使用方法的信息 , 请参见 第22.3.3.10节“NDB集群TCP / IP连接” 。 ( 在某些情况下 , 您可能还会发现 第22.3.3.11节“使用直接连接的NDB群集TCP / IP连接” 。) -
[shm]:定义节点之间的共享内存连接。 在MySQL 8.0中,它默认启用,但仍应被视为实验性的。 有关SHM互连的讨论,请参见 第22.3.3.12节“NDB集群共享内存连接” 。 -
[sci]:定义集群数据节点之间的可伸缩相干接口连接。 NDB 8.0不支持。
您可以
default
为每个部分
定义
值。
除非在MySQL服务器
my.cnf
或
my.ini
文件中
指定,否则NDB群集参数名称不区分大小写
。
从NDB群集获得最佳性能取决于许多因素,包括:
-
NDB Cluster软件版本
-
数据节点和SQL节点的数量
-
硬件
-
操作系统
-
要存储的数据量
-
集群运行的负载大小和类型
因此,获得最佳配置可能是一个迭代过程,其结果可能因每个NDB群集部署的细节而有很大差异。 在运行集群的平台或使用NDB集群数据的应用程序中进行更改时,也可能会指示配置更改。 由于这些原因,不可能提供适合所有使用场景的单一配置。 但是,在本节中,我们提供了建议的基本配置。
启动config.ini文件。
以下
config.ini
文件是配置运行NDB Cluster 8.0的集群的建议起点:
#TCP参数 [tcp默认]SendBufferMemory= 2MReceiveBufferMemory= 2M #将这两个缓冲区的大小增加到超出默认值 #有助于防止因磁盘I / O速度慢导致的瓶颈。 #MANAGEMENT NODE PARAMETERS [ndb_mgmd默认]DataDir=path/to/management/server/data/directory#可以为每个管理使用不同的数据目录 #server,但为了便于管理,最好是 #一致。 [ndb_mgmd]HostName=management-server-A-hostname#NodeId=management-server-A-nodeid[ndb_mgmd]HostName=management-server-B-hostname#NodeId=management-server-B-nodeid#使用2个管理服务器有助于保证始终存在 在网络分区的情况下#arbitrator,等等 #建议用于高可用性。每个管理服务器必须是 #由HostName标识。您可以为方便起见指明 #a任何管理服务器的NodeId,尽管将分配一个 #自动; 如果你这样做,它必须在1-255范围内 #inclusive,在为群集指定的所有ID中必须是唯一的 #个节点。 #DATA NODE PARAMETERS [ndbd默认]NoOfReplicas= 2 #建议使用2个副本以保证数据的可用性; #仅使用1个副本不提供任何冗余,这意味着 #单个数据节点的故障导致整个集群 # 关掉。我们不建议使用超过2个副本,因为2是 #足以提供高可用性,我们目前不测试 #具有此参数的更大值。LockPagesInMainMemory= 1 #在Linux和Solaris系统上,设置此参数会锁定数据节点 #进入内存。这样做可以防止它们交换到磁盘, #会严重降低群集性能。DataMemory= 3456M #为DataMemory提供的值假定为4 GB RAM #每个数据节点。但是,为了获得最佳效果,您应该先计算 #将根据您实际计划的数据使用的内存#store (您可能会发现ndb_size.pl实用程序对估算有帮助 #this),然后比计算值多出20%。自然, #您应该确保每个数据节点主机至少具有相同的数量 #物理内存作为这两个值的总和。 #ODirect= 1 #启用此参数会导致NDBCLUSTER尝试使用O_DIRECT #写入本地检查点和重做日志; 这可以减少负荷 #CPU。我们建议在运行的系统上使用NDB Cluster时这样做 #Linux kernel 2.6或更高版本。NoOfFragmentLogFiles= 300DataDir= = 100000path/to/data/node/data/directoryMaxNoOfConcurrentOperationsSchedulerSpinTimer= 400SchedulerExecutionTimer= 100RealTimeScheduler= 1 #设置这些参数可以利用实时调度 使用ndbd时增加吞吐量的NDB线程数。他们 使用ndbmtd时不需要#; 特别是,你不应该设置 #RealTimeScheduler为ndbmtd数据节点。TimeBetweenGlobalCheckpoints= 1000TimeBetweenEpochs= 200RedoBuffer= 32M #CompressedLCP= 1 #CompressedBackup= 1 #启用CompressedLCP和CompressedBackup分别导致本地 要压缩的检查点文件和备份文件,这可能会产生空间 与非压缩LCP和备份相比可节省高达50%的成本。 #MaxNoOfLocalScans= 64MaxNoOfTables= 1024MaxNoOfOrderedIndexes= 256 [NDBD]HostName=data-node-A-hostname#NodeId=data-node-A-nodeidLockExecuteThreadToCPU= 1LockMaintThreadsToCPU= 0 #在具有多个CPU的系统上,这些参数可用于锁定NDBCLUSTER #特定CPU的线程 [NDBD]HostName=data-node-B-hostname#NodeId=data-node-B-nodeidLockExecuteThreadToCPU= 1LockMaintThreadsToCPU= 0 #您必须为群集中的每个数据节点都有一个[ndbd]部分; #这些部分中的每一部分都必须包含HostName。每个部分都可以 #为方便起见,可选地包括NodeId,但在大多数情况下,它是 #足以允许集群动态分配节点ID。如果 #您确实指定了数据节点的节点ID,它必须在1的范围内 #到48(包括),并且必须在指定的所有ID中唯一 #cluster节点。 #SQL NODE / API NODE PARAMETERS 的[mysqld] #HostName=sql-node-A-hostname#NodeId=sql-node-A-nodeid的[mysqld] 的[mysqld] #连接到群集的每个API或SQL节点都需要[mysqld] #或[api]部分。每个这样的部分定义一个连接 #“ slot ” ; 你应该至少拥有这些部分 #config.ini文件作为API节点和SQL节点的总数 #您希望在任何给定时间连接到群集。有 #没有可用的额外插槽的性能或其他惩罚 #case您稍后会发现您想要或需要更多API或SQL节点 #同时连接到群集。 #如果没有为给定的[mysqld]或[api]部分指定HostName, #然后任何 API或SQL节点都可以使用该插槽连接到 #cluster。您可能希望为一个连接槽使用显式HostName #以保证来自该主机的API或SQL节点始终可以 #连接到群集。如果您希望阻止API或SQL节点 #从所需主机或主机之外连接,然后使用 #config.ini文件中每个[mysqld]或[api]部分的HostName。 #如果您希望为任何API定义节点ID(NodeId参数),您可以 #SQL节点,但这不是必需的; 如果你这样做,它必须在 #范围1到255(包括1和255),并且在指定的所有ID中必须唯一 #用于群集节点。
推荐用于SQL节点的my.cnf选项。
充当NDB群集SQL节点的MySQL服务器必须始终使用
--ndbcluster
和
--ndb-connectstring
选项
启动
,无论是在命令行还是在
my.cnf
。
此外,为
群集中的
所有
mysqld
进程
设置以下选项
,除非您的设置另有要求:
-
--ndb-use-exact-count=0 -
--ndb-index-stat-enable=0 -
--ndb-force-send=1 -
--engine-condition-pushdown=1
除NDB群集管理服务器( ndb_mgmd ) 之外,属于NDB群集的 每个节点都需要一个 指向管理服务器位置 的 连接字符串 。 此连接字符串用于建立与管理服务器的连接以及执行其他任务,具体取决于节点在集群中的角色。 连接字符串的语法如下:
[nodeid =node_id,]host-definition[,host-definition[,...]]host-definition:host_name[:port_number]
node_id
是一个大于或等于1的整数,用于标识节点
config.ini
。
host_name
是表示有效Internet主机名或IP地址的字符串。
port_number
是一个指向TCP / IP端口号的整数。
示例1(长):“nodeid = 2,myhost1:1100,myhost2:1100,198.51.100.3:1200” 例2(短):“myhost1”
localhost:1186
如果未提供,则用作默认连接字符串值。
如果
port_num
从连接字符串中省略,则默认端口为1186.此端口应始终在网络上可用,因为IANA已为此目的分配该端口(请参阅
http://www.iana.org/assignments/port-numbers
详情)。
通过列出多个主机定义,可以指定多个冗余管理服务器。 NDB群集数据或API节点尝试按指定的顺序联系每台主机上的连续管理服务器,直到建立成功连接。
还可以在连接字符串中指定一个或多个绑定地址,以供具有多个网络接口的节点用于连接到管理服务器。 绑定地址由主机名或网络地址和可选端口号组成。 此连接字符串的增强语法如下所示:
[nodeid =node_id,] [bind-address =host-definition,]host-definition[; bind-address =host-definition]host-definition[; bind-address =host-definition] [,...]]host-definition:host_name[:port_number]
如果在
指定任何管理主机
之前
在连接字符串中使用单个绑定地址
,则此地址将用作
连接
到其中任何管理主机的默认地址(除非为给定的管理服务器覆盖;请参阅本节后面的示例) 。
例如,以下连接字符串会导致节点使用,
198.51.100.242
无论它连接到哪个管理服务器:
bind-address = 198.51.100.242,poseidon:1186,perch:1186
如果指定了绑定地址 下列 一个管理主机定义,则它仅用于连接到该管理节点。 请考虑以下连接字符串:
poseidon:1186; bind-address = localhost,perch:1186; bind-address = 198.51.100.242
在这种情况下,节点用于
localhost
连接到在命名主机上运行的管理服务器,
poseidon
并
198.51.100.242
连接到在名为的主机上运行的管理服务器
perch
。
您可以指定默认绑定地址,然后为一个或多个特定管理主机覆盖此默认值。
在以下示例中,
localhost
用于连接到在主机上运行的管理服务器
poseidon
;
自从
198.51.100.242
首先指定(在任何管理服务器定义之前),它是默认的绑定地址,因此用于连接到主机上的管理服务器,
perch
并且
orca
:
绑定地址= 198.51.100.242,波塞冬:1186;绑定地址=本地主机,鲈鱼:1186,ORCA:2200
指定连接字符串有多种不同的方法:
-
每个可执行文件都有自己的命令行选项,可以在启动时指定管理服务器。 (请参阅相应可执行文件的文档。)
-
也可以通过将其放在
[mysql_cluster]管理服务器my.cnf文件的 某个 部分中 ,立即为集群中的所有节点设置连接字符串 。 -
为了向后兼容,可以使用相同的语法提供另外两个选项:
-
设置
NDB_CONNECTSTRING环境变量以包含连接字符串。 -
将每个可执行文件的连接字符串写入一个名为的文本文件
Ndb.cfg,并将此文件放在可执行文件的启动目录中。
但是,这些现已弃用,不应用于新安装。
-
指定连接字符串的推荐方法是在命令行或
my.cnf
每个可执行文件的文件中
设置它
。
该
[ndb_mgmd]
部分用于配置管理服务器的行为。
如果使用多个管理服务器,则可以在一个
[ndb_mgmd default]
部分中
指定所有这些服务器共有的参数
。
[mgm]
并且
[mgm default]
是这些的较旧别名,支持向后兼容性。
以下列表中的所有参数都是可选的,并且如果省略则采用其默认值。
如果既不存在
ExecuteOnComputer
也不存在
HostName
参数,
localhost
则将假定两者都具有
默认值
。
-
群集中的每个节点都具有唯一标识。 对于管理节点,这由1到255(包括1和255)范围内的整数值表示。 所有内部群集消息都使用此ID来寻址节点,因此无论节点类型如何,每个NDB群集节点都必须是唯一的。
注意数据节点ID必须小于49.如果计划部署大量数据节点,最好将管理节点(和API节点)的节点ID限制为大于48的值。
使用的
Id识别管理节点参数赞成不赞成NodeId。 尽管Id继续支持向后兼容性,但它现在会生成警告,并且在未来版本的NDB Cluster中可能会被删除。 -
群集中的每个节点都具有唯一标识。 对于管理节点,这由1到255(包括1和255)范围内的整数值表示。 所有内部群集消息都使用此ID来寻址节点,因此无论节点类型如何,每个NDB群集节点都必须是唯一的。
注意数据节点ID必须小于49.如果计划部署大量数据节点,最好将管理节点(和API节点)的节点ID限制为大于48的值。
NodeId是标识管理节点时使用的首选参数名称。 虽然旧版本Id继续支持向后兼容性,但现在不推荐使用它,并在使用时生成警告; 它也将在未来的NDB Cluster版本中删除。 -
表22.11此表提供ExecuteOnComputer管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 名称 默认 [没有] 范围 ... 重启类型 小号
这指 的是 文件 一部分中
Id定义的计算机之一 的 集合 。[computer]config.ini重要不推荐使用此参数,并且在将来的版本中将删除此参数。 请改用
HostName参数。 -
这是管理服务器侦听配置请求和管理命令的端口号。
-
指定此参数定义管理节点所驻留的计算机的主机名。 要指定除此
localhost参数 之外的主机名 ,或者ExecuteOnComputer是必需的。 -
将管理节点分配 给云中 的特定 可用性域 (也称为可用区)。 通过告知
NDB哪些节点位于哪些可用域中,可以通过以下方式在云环境中提高性能:-
如果在同一节点上找不到请求的数据,则可以将读取定向到同一可用性域中的另一个节点。
-
保证不同可用域中的节点之间的通信使用
NDB传输器的WAN支持,而无需任何进一步的手动干预。 -
传输器的组编号可以基于使用的可用域,使得SQL和其他API节点也尽可能与同一可用性域中的本地数据节点通信。
-
可以从没有数据节点的可用性域中选择仲裁器,或者如果没有找到这样的可用域,则可以从第三可用性域中选择仲裁器。
LocationDomainId取0到16之间的整数值,其中0是默认值; 使用0与保留参数unset相同。 -
-
表22.15此表提供LogDestination管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 {CONSOLE | SYSLOG | FILE} 默认 [见文] 范围 ... 重启类型 ñ
此参数指定发送群集日志记录信息的位置。 有三个选项在此顾及─
CONSOLE,SYSLOG和FILE-withFILE是默认值:-
CONSOLE将日志输出到stdout:安慰
-
SYSLOG日志发送到syslog设施,可能的值是以下之一auth,authpriv,cron,daemon,ftp,kern,lpr,mail,news,syslog,user,uucp,local0,local1,local2,local3,local4,local5,local6,或local7。注意并非每个设施都必须受到每个操作系统的支持。
SYSLOG:设备=系统日志
-
FILE将群集日志输出通过管道传输到同一台计算机上的常规文件。 可以指定以下值:-
filename:日志文件的名称。在这种情况下使用的默认日志文件名是 。
ndb_nodeid_cluster.log -
maxsize:记录转到新文件之前文件可以增长的最大大小(以字节为单位)。 发生这种情况时,将通过附加.N到文件名来 重命名旧的日志文件 ,其中N下一个数字尚未与此名称一起使用。 -
maxfiles:最大日志文件数。
FILE:文件名= cluster.log,MAXSIZE = 1000000,MAXFILES = 6
FILE参数 的默认值 是 ,其中 是节点的ID。FILE:filename=ndb_node_id_cluster.log,maxsize=1000000,maxfiles=6node_id -
可以指定由分号分隔的多个日志目标,如下所示:
CONSOLE; SYSLOG:设施= LOCAL0; FILE:文件名= /无功/日志/ mgmd
-
-
此参数用于定义哪些节点可以充当仲裁器。 只有管理节点和SQL节点可以是仲裁者。
ArbitrationRank可以采用以下值之一:-
0:该节点永远不会用作仲裁程序。 -
1:节点具有高优先级; 也就是说,它将优先作为低优先级节点上的仲裁器。 -
2:表示仅在具有较高优先级的节点不可用于此目的时才用作仲裁器的低优先级节点。
通常,应将管理服务器配置为仲裁程序,方法是将其设置
ArbitrationRank为1(管理节点的缺省值),将所有SQL节点的值设置为0(SQL节点的缺省值)。您可以通过
ArbitrationRank在所有管理和SQL节点上 设置 为0或通过 在 全局配置文件Arbitration的[ndbd default]部分中 设置 参数 来 完全禁用仲裁config.ini。 设置Arbitration会导致ArbitrationRank忽略 任何设置 。 -
-
表22.17此表提供ArbitrationDelay管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
一个整数值,它使管理服务器对仲裁请求的响应延迟该毫秒数。 默认情况下,此值为0; 通常没有必要改变它。
-
这指定了将放置管理服务器的输出文件的目录。 这些文件包括集群日志文件,进程输出文件和守护程序的进程ID(PID)文件。 (对于日志文件,可以通过设置
FILE参数 来覆盖此位置 ,LogDestination如本节前面所述。)此参数的默认值是 ndb_mgmd 所在 的目录 。
-
表22.19此表提供PortNumberStats管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 [没有] 范围 0 - 64K 重启类型 ñ
此参数指定用于从NDB群集管理服务器获取统计信息的端口号。 它没有默认值。
-
使用WAN TCP设置作为默认设置。
-
表22.21此表提供HeartbeatThreadPriority管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 串 默认 [没有] 范围 ... 重启类型 小号
为管理和API节点设置心跳线程的调度策略和优先级。
设置此参数的语法如下所示:
HeartbeatThreadPriority =
policy[,priority]policy: {FIFO | RR}设置此参数时,必须指定策略。 这是
FIFO(先进先出)或RR(循环赛)之一。 策略值可选地由优先级(整数)跟随。 -
表22.22此表提供TotalSendBufferMemory管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 256K - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数用于确定在此节点上为所有已配置的传输器之间的共享发送缓冲区内存分配的内存总量。
如果设置了此参数,则其最小允许值为256KB; 0表示尚未设置参数。 有关更多详细信息,请参见 第22.3.3.14节“配置NDB集群发送缓冲区参数” 。
-
表22.23此表提供HeartbeatIntervalMgmdMgmd管理节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 1500 范围 100 - 4294967039(0xFFFFFEFF) 重启类型 ñ
指定用于确定另一个管理节点是否与此节点联系的心跳消息之间的间隔。 管理节点在这些间隔中的3个之后等待以声明连接已死; 因此,1500毫秒的默认设置使管理节点在超时之前等待大约1600毫秒。
在管理节点的配置中进行更改后,必须执行群集的滚动重新启动才能使新配置生效。
要将新的管理服务器添加到正在运行的NDB群集,还需要在修改任何现有
config.ini
文件
后执行所有群集节点的滚动重新启动
。
有关使用多个管理节点时出现的问题的更多信息,请参见
第22.1.7.10节“与多个NDB群集节点相关的限制”
。
在
[ndbd]
与
[ndbd
default]
部分用于配置簇数据节点的行为。
[ndbd]
并且
[ndbd default]
始终用作节名称,无论您是使用
ndbd
还是
ndbmtd
二进制文件进行数据节点进程。
有许多参数可以控制缓冲区大小,池大小,超时等。
唯一的强制性的参数是的任一个
ExecuteOnComputer
或
HostName
;
这必须在本地
[ndbd]
部分
定义
。
该参数
NoOfReplicas
应在该
[ndbd default]
部分中
定义
,因为它对所有Cluster数据节点都是通用的。
设置并非绝对必要
NoOfReplicas
,但最好明确设置它。
大多数数据节点参数都在该
[ndbd
default]
部分
中设置
。
只允许在该
[ndbd]
部分中
更改那些明确声明为能够设置本地值的参数
。
如果存在,
HostName
,
NodeId
并
ExecuteOnComputer
必须
在本地进行定义
[ndbd]
部分,而不是在其他任何部分
config.ini
。
换句话说,这些参数的设置特定于一个数据节点。
对于那些影响内存使用或缓冲区大小的参数,可以使用
K
,,
M
或
G
作为后缀来指示1024,1024×1024或1024×1024×1024的单位。
(例如,
100K
表示100×1024 = 102400.)
参数名称和值不区分大小写,除非在MySQL服务器
my.cnf
或
my.ini
文件中使用,在这种情况下它们区分大小写。
有关特定于NDB群集磁盘数据表的配置参数的信息,请参阅本节后面的内容(请参阅 磁盘数据配置参数 )。
所有这些参数也适用于
ndbmtd
(
ndbd
的多线程版本
)。
另外三个数据节点配置参数
MaxNoOfExecutionThreads
-
ThreadConfig
,和 -
仅
NoOfFragmentLogParts
适用于
ndbmtd
;
与
ndbd一起
使用时,这些没有效果
。
有关更多信息,请参阅
多线程配置参数(ndbmtd)
。
另请参见
第
22.4.3
节“
ndbmtd
- NDB集群数据节点守护程序(多线程)”
。
识别数据节点。
的
NodeId
或
Id
值(即,数据节点标识符)可以在命令行上,当启动节点在配置文件中进行分配。
-
唯一节点ID用作所有集群内部消息的节点地址。 对于数据节点,这是1到48(包括1和48)范围内的整数。 群集中的每个节点都必须具有唯一标识符。
NodeId是标识数据节点时唯一支持的参数名称。 -
表22.25此表提供ExecuteOnComputer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 名称 默认 [没有] 范围 ... 重启类型 小号
这是指
Id一个[computer]部分中 定义的计算机之一 的 集合 。重要不推荐使用此参数,并且在将来的版本中将删除此参数。 请改用
HostName参数。 -
指定此参数定义数据节点所在的计算机的主机名。 要指定除此
localhost参数 之外的主机名 ,或者ExecuteOnComputer是必需的。 -
群集中的每个节点都使用端口连接到其他节点。 默认情况下,此端口是动态分配的,以确保同一主机上没有两个节点接收相同的端口号,因此通常不需要为此参数指定值。
但是,如果您需要能够在防火墙中打开特定端口以允许数据节点和API节点(包括SQL节点)之间的通信,则可以将此参数设置为
[ndbd]节中 所需端口的编号 或(如果需要)为多个数据节点执行此操作) 文件 的[ndbd default]部分config.ini,然后打开具有该编号的端口,用于来自SQL节点,API节点或两者的传入连接。注意从数据节点到管理节点的连接是使用 ndb_mgmd 管理端口(管理服务器
PortNumber)完成的,因此应始终允许从任何数据节点到该端口的传出连接。 -
将此参数设置为
TRUE或1绑定,IP_ADDR_ANY以便可以从任何位置进行连接(对于自动生成的连接)。 默认值为FALSE(0)。 -
此参数可用于将数据节点分配给特定节点组。 它仅在首次启动集群时才会被读取,并且不能用于在线将数据节点重新分配给其他节点组。 通常不希望
[ndbd default]在config.ini文件 的 部分中 使用该参数 ,并且必须注意不要将节点分配给节点组,使得将无效数量的节点分配给任何节点组。该
NodeGroup参数主要用于将新节点组添加到正在运行的NDB群集,而无需执行滚动重新启动。 为此,您应将其设置为65536(最大值)。 您不需要NodeGroup为所有群集数据节点 设置 值,仅适用于那些要在以后启动并作为新节点组添加到群集的节点。 有关更多信息,请参见 第22.5.15.3节“在线添加NDB集群数据节点:详细示例” 。 -
将数据节点分配 给云中 的特定 可用性域 (也称为可用区)。 通过告知
NDB哪些节点位于哪些可用域中,可以通过以下方式在云环境中提高性能:-
如果在同一节点上找不到请求的数据,则可以将读取定向到同一可用性域中的另一个节点。
-
保证不同可用域中的节点之间的通信使用
NDB传输器的WAN支持,而无需任何进一步的手动干预。 -
传输器的组编号可以基于使用的可用域,使得SQL和其他API节点也尽可能与同一可用性域中的本地数据节点通信。
-
可以从没有数据节点的可用性域中选择仲裁器,或者如果没有找到这样的可用域,则可以从第三可用性域中选择仲裁器。
LocationDomainId取0到16之间的整数值,其中0是默认值; 使用0与保留参数unset相同。 -
-
此全局参数只能在
[ndbd default]节中 设置 ,并定义存储在集群中的每个表的副本数。 此参数还指定节点组的大小。 节点组是一组节点,它们都存储相同的信息。节点组是隐式形成的。 第一节点组由具有最低节点ID的一组数据节点形成,下一个节点组由下一个最低节点标识的集合形成,等等。 举例来说,假设我们有4个数据节点并且
NoOfReplicas设置为2.四个数据节点具有节点ID 2,3,4和5.然后第一个节点组由节点2和3形成,第二个节点组由节点2和3形成。节点组由节点4和5组成。以这样的方式配置集群非常重要,即同一节点组中的节点不会放在同一台计算机上,因为单个硬件故障会导致整个集群失败。如果未提供节点ID,则数据节点的顺序将是节点组的决定因素。 无论是否进行显式分配,都可以在管理客户端
SHOW命令 的输出中查看它们 。默认值为
NoOfReplicas2. 这是大多数生产环境的建议值 。重要虽然 此参数 的最大 可能 值为4,但 生产中不支持将值 设置
NoOfReplicas为大于2 。警告设置
NoOfReplicas为1表示只有一个所有Cluster数据的副本; 在这种情况下,丢失单个数据节点会导致集群失败,因为该节点不存储其他数据副本。此参数的值必须均匀分配到群集中的数据节点数。 例如,如果有两个数据节点,则
NoOfReplicas必须等于1或2,因为2/3和2/4都产生小数值; 如果有四个数据节点,则NoOfReplicas必须等于1,2或4。 -
此参数指定放置跟踪文件,日志文件,pid文件和错误日志的目录。
默认值是数据节点进程工作目录。
-
此参数指定为元数据,REDO日志,UNDO日志(用于磁盘数据表)和数据文件创建的所有文件的目录。 默认值是指定的目录
DataDir。注意在 启动 ndbd 进程 之前,此目录必须存在 。
NDB Cluster的推荐目录层次结构包括
/var/lib/mysql-cluster在其下创建节点文件系统的目录。 该子目录的名称包含节点ID。 例如,如果节点ID为2,则命名此子目录ndb_2_fs。 -
此参数指定放置备份的目录。
重要字符串'
/BACKUP'始终附加到此值。 例如,如果将值设置BackupDataDir为/var/lib/cluster-data,则所有备份都存储在/var/lib/cluster-data/BACKUP。 这也意味着 有效的 默认备份位置是BACKUP在FileSystemPath参数 指定的位置下指定 的目录 。
数据存储器,索引存储器和字符串存储器
DataMemory
并且
IndexMemory
是
[ndbd]
指定用于存储实际记录及其索引的内存段大小的参数。
在设置这些值时,了解如何
DataMemory
使用
非常重要
,因为它通常需要更新以反映群集的实际使用情况。
IndexMemory
已弃用,并且将在未来版本的NDB Cluster中删除。
有关详细信息,请参阅以下说明。
-
此参数定义可用于存储数据库记录的空间量(以字节为单位)。 此值指定的总量在内存中分配,因此机器有足够的物理内存来容纳它是非常重要的。
分配的内存
DataMemory用于存储实际记录和索引。 每条记录有16字节的开销; 每个记录会产生额外的金额,因为它存储在一个32KB的页面中,页面开销为128字节(见下文)。 由于每条记录仅存储在一页中,因此每页还浪费了少量资金。对于可变大小的表属性,数据存储在从中分配的单独数据页上
DataMemory。 可变长度记录使用固定大小的部分,额外的4字节开销来引用可变大小的部分。 可变大小的部分有2个字节的开销加上每个属性2个字节。最大记录大小为14000字节。
分配的资源
DataMemory用于存储所有数据和索引。 (配置为的任何内存IndexMemory都会自动添加到用于DataMemory形成公共资源池的 内存中 。)目前,NDB Cluster可以为每个分区使用最多512 MB的哈希索引,这意味着在某些情况下, 即使 ndb_mgm -e“ALL REPORT MEMORYUSAGE” 显示出显着的空闲 ,也可能 在MySQL客户端应用程序中 获得 Table是完整 错误 。 这也可能会导致数据节点在负载很重的数据的节点上重新启动时出现问题。
DataMemory可以通过设置控制每个本地数据管理分区给定表的数量
NDB_TABLE的选项PARTITION_BALANCE中的值中的一个FOR_RA_BY_LDM,FOR_RA_BY_LDM_X_2,FOR_RA_BY_LDM_X_3,或FOR_RA_BY_LDM_X_4,1,2,3,或每LDM 4个分区,分别创建表时(见 第13.1.20.11节“设置NDB_TABLE选项” )。注意在以前版本的NDB Cluster中,可以为NDB Cluster表创建额外的分区,因此可以使用for
MAX_ROWS选项为 哈希索引提供更多内存CREATE TABLE。 虽然仍支持向后兼容性,但不建议使用MAX_ROWS此目的; 你应该用PARTITION_BALANCE。您还可以使用
MinFreePct配置参数来帮助避免节点重新启动时出现问题。分配的内存空间
DataMemory由32KB页面组成,这些页面分配给表格片段。 每个表通常被划分为与集群中的数据节点相同数量的片段。 因此,对于每个节点,存在与设置的相同数量的片段NoOfReplicas。分配页面后,除了删除表格外,目前无法将其返回到空闲页面池。 (这也意味着
DataMemory页面一旦分配给给定的表,就不能被其他表使用。)执行数据节点恢复也会压缩分区,因为所有记录都插入到其他活动节点的空分区中。该
DataMemory内存空间也包含UNDO信息:对于每一更新,未改变记录的副本将被分配DataMemory。 还有一个对有序表索引中的每个副本的引用。 仅在更新唯一索引列时才更新唯一哈希索引,在这种情况下,将插入索引表中的新条目,并在提交时删除旧条目。 因此,还需要分配足够的内存来处理使用群集的应用程序执行的最大事务。 在任何情况下,执行一些大型事务与使用许多较小事务相比没有任何优势,原因如下:-
大型交易并不比小型交易快
-
大型事务会增加丢失的操作数,并且必须在事务失败时重复
-
大型事务使用更多内存
DataMemoryNDB 8.0中 的默认值为 98MB。 最小值为1MB。 没有最大尺寸,但实际上必须调整最大尺寸,以便在达到限制时过程不会开始交换。 此限制取决于计算机上可用的物理RAM量以及操作系统可能为任何一个进程提交的内存量。 32位操作系统通常限制为每个进程2-4GB; 64位操作系统可以使用更多。 对于大型数据库,出于这个原因,最好使用64位操作系统。 -
-
该
IndexMemory参数已弃用(并将在以后删除); 分配给的任何内存都IndexMemory被分配给同一个池DataMemory,它独自负责在内存中存储数据和索引所需的所有资源。 在NDB 8.0中,IndexMemory在群集配置文件中使用会触发来自管理服务器的警告。您可以使用以下公式估计哈希索引的大小:
size =((
fragments* 32K)+(rows* 18)) *replicasfragments片段的数量,replicas是副本的数量(通常为2),并且rows是行数。 如果一个表有一百万行,8个片段和2个副本,则预计的索引内存使用量计算如下所示:((8 * 32K)+(1000000 * 18))* 2 =((8 * 32768)+(1000000 * 18))* 2 =(262144 + 18000000)* 2 = 18262144 * 2 = 36524288字节= ~35MB
有序索引的索引统计信息(启用时)存储在
mysql.ndb_index_stat_sample表中。 由于此表具有哈希索引,因此会增加索引内存使用量。 给定有序索引的行数的上限可以如下计算:sample_size = key_size +((key_attributes + 1)* 4) sample_rows =
IndexStatSaveSize*((0.01 *IndexStatSaveScale* log 2(rows * sample_size))+ 1) / sample_size在上面的公式中,
key_size是有序索引键的大小(以字节key_attributes为 单位), 是 有序索引键中的 属性rows数,是基表中的行数。假设该表
t1有100万行和一个以ix1两个四字节整数 命名的有序索引 。 另外假设IndexStatSaveSize和IndexStatSaveScale设置为默认值(分别为32K和100)。 使用前两个公式,我们可以计算如下:sample_size = 8 +((1 + 2)* 4)= 20个字节 sample_rows = 32K *((0.01 * 100 * log 2(1000000 * 20))+ 1) / 20 = 32768 *((1 * ~16.811)+1)/ 20 = 32768 * ~17.811 / 20 = ~29182行因此,预期的索引存储器使用量为2 * 18 * 29182 = ~1050550字节。
在NDB 8.0中,此参数的最小值和默认值为0(零)。
-
表22.36此表提供StringMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 %或字节 默认 25 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 小号
此参数确定为表名等字符串分配的内存量,并 在 文件的 一个
[ndbd]或[ndbd default]一部分中 指定config.ini。 介于0和 之间的值100被解释为最大默认值的百分比,该最大默认值是根据许多因素计算的,包括表的数量,最大表名称大小,.FRM文件的 最大大小MaxNoOfTriggers,最大列名称大小和最大默认值列值。大于的值
100被解释为字节数。默认值为25,即默认最大值的25%。
在大多数情况下,默认值应该足够了,但是当你有很多
NDB表(1000或更多)时,可能会得到错误773 超出字符串内存,请修改StringMemory配置参数:永久错误:架构错误 ,在在哪种情况下你应该增加这个值。25(25%)并不过分,并应防止此错误在除最极端条件之外的所有情况下重复出现。
以下示例说明了如何将内存用于表。 考虑这个表定义:
CREATE TABLE示例( INT NOT NULL, b INT NOT NULL, c INT NOT NULL, 主要关键(a), UNIQUE(b)中 )ENGINE = NDBCLUSTER;
对于每条记录,有12个字节的数据加上12个字节的开销。
没有可空列可以节省4个字节的开销。
此外,我们对列中的两个有序索引
a
和
b
消耗大约每记录10个字节。
基表上有一个主键哈希索引,每个记录大约使用29个字节。
唯一约束由具有
b
主键和
a
列
的单独表实现
。
该另一个表在
example
表中
每个记录消耗额外的29个字节的索引存储器
以及8个字节的记录数据加上12个字节的开销。
因此,对于一百万条记录,我们需要58MB的索引内存来处理主键和唯一约束的哈希索引。 我们还需要64MB的基表和唯一索引表的记录,以及两个有序的索引表。
您可以看到哈希索引占用了大量的内存空间; 但是,它们可以非常快速地访问数据。 它们还用于NDB Cluster以处理唯一性约束。
目前,唯一的分区算法是散列,有序索引是每个节点的本地。 因此,在一般情况下,有序索引不能用于处理唯一性约束。
两个重要的一点
IndexMemory
和
DataMemory
是总数据库大小为所有数据存储器和用于在每个节点组中的所有索引存储器的总和。
每个节点组用于存储复制的信息,因此如果有四个节点具有两个副本,则将有两个节点组。
因此,
DataMemory
对于每个数据节点,
可用的总数据存储器是2×
。
强烈建议
DataMemory
,并
IndexMemory
设置为所有节点的相同值。
数据分布甚至在群集中的所有节点上,因此任何节点可用的最大空间量不能大于群集中最小节点的空间量。
DataMemory
可以改变,但减少它可能是有风险的;
这样做很容易导致节点甚至整个NDB集群由于内存空间不足而无法重启。
增加这些值应该是可以接受的,但建议以与软件升级相同的方式执行此类升级,从更新配置文件开始,然后重新启动管理服务器,然后依次重新启动每个数据节点。
MinFreePct。
DataMemory
保留一定
比例(默认为5%)的数据节点资源
,以确保数据节点在执行重启时不耗尽其内存。
这可以使用
MinFreePct
数据节点配置参数
进行调整
(默认值为5)。
更新不会增加使用的索引内存量。 插入物立即生效; 但是,在提交事务之前,实际上不会删除行。
交易参数。
[ndbd]
我们讨论
的下几个
参数很重要,因为它们会影响并行事务的数量以及系统可以处理的事务的大小。
MaxNoOfConcurrentTransactions
设置节点中可能的并行事务数。
MaxNoOfConcurrentOperations
设置可以处于更新阶段或同时锁定的记录数。
这两个参数(特别是
MaxNoOfConcurrentOperations
)可能是用户设置特定值而不使用默认值的目标。
为使用小事务的系统设置默认值,以确保这些不使用过多内存。
MaxDMLOperationsPerTransaction
设置可在给定事务中执行的最大DML操作数。
-
表22.38此表提供MaxNoOfConcurrentTransactions数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 4096 范围 32 - 4294967039(0xFFFFFEFF) 重启类型 ñ
每个群集数据节点都需要群集中每个活动事务的事务记录。 协调事务的任务分布在所有数据节点中。 集群中的事务记录总数是任何给定节点中的事务数乘以集群中的节点数。
事务记录分配给各个MySQL服务器。 与MySQL服务器的每个连接都需要至少一个事务记录,以及该连接访问的每个表的附加事务对象。 这意味着集群中事务总数的合理最小值可表示为
TotalNoOfConcurrentTransactions = (在任何单个事务中访问的最大表数+ 1) * SQL节点数假设有10个SQL节点使用该集群。 涉及10个表的单个连接需要11个事务记录; 如果一个事务中有10个这样的连接,则每个MySQL服务器需要10 * 11 = 110个事务记录,或者总共110 * 10 = 1100个事务记录。 可以期望每个数据节点处理TotalNoOfConcurrentTransactions /数据节点数。 对于具有4个数据节点的NDB群集,这将意味着设置
MaxNoOfConcurrentTransactions在每个数据节点上为1100/4 = 275.此外,您应该通过确保单个节点组可以容纳所有并发事务来提供故障恢复; 换句话说,每个数据节点的MaxNoOfConcurrentTransactions足以覆盖等于TotalNoOfConcurrentTransactions /节点组数量的多个事务。 如果此群集具有单个节点组,MaxNoOfConcurrentTransactions则应设置为1100(与整个群集的并发事务总数相同)。此外,每笔交易至少涉及一次操作; 因此,设置的值
MaxNoOfConcurrentTransactions应始终不超过MaxNoOfConcurrentOperations。必须将此参数设置为所有群集数据节点的相同值。 这是因为,当数据节点发生故障时,最老的幸存节点会重新创建故障节点中正在进行的所有事务的事务状态。
可以使用滚动重新启动来更改此值,但是群集上的流量必须使得在发生这种情况时不会发生比新旧级别更低的事务更多的事务。
默认值为4096。
-
表22.39此表提供MaxNoOfConcurrentOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 32K 范围 32 - 4294967039(0xFFFFFEFF) 重启类型 ñ
最好根据事务的大小和数量调整此参数的值。 执行仅涉及少量操作和记录的事务时,此参数的默认值通常就足够了。 执行涉及许多记录的大型事务通常需要增加其值。
在事务协调器和执行实际更新的节点中,为每个事务更新集群数据保留记录。 这些记录包含查找UNDO记录以进行回滚,锁定队列和其他目的所需的状态信息。
此参数应设置为最小值,以便在事务中同时更新的记录数除以群集数据节点的数量。 例如,在具有四个数据节点且预计使用事务处理一百万个并发更新的群集中,应将此值设置为1000000/4 = 250000.为了帮助提供针对故障的弹性,建议您设置此参数的值足够高,以允许单个数据节点处理其节点组的负载。 换句话说,您应该将值设置为等于
total number of concurrent operations / number of node groups。 (在存在单个节点组的情况下,这与整个群集的并发操作总数相同。)因为每个事务总是涉及至少一个操作,所以值
MaxNoOfConcurrentOperations应始终大于或等于值MaxNoOfConcurrentTransactions。读取设置锁定的查询也会导致创建操作记录。 在各个节点内分配一些额外的空间,以适应在节点上分布不完美的情况。
当查询使用唯一哈希索引时,事务中每条记录实际上使用了两条操作记录。 第一个记录表示索引表中的读取,第二个记录表示基表上的操作。
默认值为32768。
此参数实际处理可以单独配置的两个值。 第一个指定将与事务协调器放置多少操作记录。 第二部分指定数据库的本地操作记录数。
在八节点集群上执行的非常大的事务需要事务协调器中的操作记录与事务中涉及的读取,更新和删除一样多。 但是,它的操作记录遍布所有八个节点。 因此,如果需要为一个非常大的事务配置系统,最好分别配置这两个部分。
MaxNoOfConcurrentOperations将始终用于计算节点的事务协调器部分中的操作记录数。了解操作记录的内存要求也很重要。 这些消耗大约每个记录1KB。
-
表22.40此表提供MaxNoOfLocalOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 未定义 范围 32 - 4294967039(0xFFFFFEFF) 重启类型 ñ
默认情况下,此参数计算为1.1×
MaxNoOfConcurrentOperations。 这适用于具有许多同时交易的系统,它们都不是非常大。 如果需要一次处理一个非常大的事务并且有许多节点,最好通过显式指定此参数来覆盖默认值。 -
MaxDMLOperationsPerTransaction表22.41此表提供MaxDMLOperationsPerTransaction数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 运营(DML) 默认 4294967295 范围 32 - 4294967295 重启类型 ñ
此参数限制事务的大小。 如果事务需要的不仅仅是这么多DML操作,那么事务就会中止。 每笔交易的最小操作次数为32; 但是,您可以设置
MaxDMLOperationsPerTransaction为0以禁用对每个事务的DML操作数的任何限制。 最大值(默认值)为4294967295。此参数的值不能超过为此设置的值
MaxNoOfConcurrentOperations。
交易临时存储。
下一组
[ndbd]
参数用于在执行属于Cluster事务的语句时确定临时存储。
语句完成且集群正在等待提交或回滚时,将释放所有记录。
这些参数的默认值适用于大多数情况。 但是,需要支持涉及大量行或操作的事务的用户可能需要增加这些值以在系统中实现更好的并行性,而应用程序需要相对较小的事务的用户可以减少值以节省内存。
-
MaxNoOfConcurrentIndexOperations表22.42此表提供MaxNoOfConcurrentIndexOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 8K 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
对于使用唯一哈希索引的查询,在查询的执行阶段使用另一组临时操作记录。 此参数设置该记录池的大小。 因此,仅在执行查询的一部分时分配该记录。 一旦执行此部分,记录就会被释放。 处理中止和提交所需的状态由正常操作记录处理,其中池大小由参数设置
MaxNoOfConcurrentOperations。此参数的默认值为8192.只有在使用唯一哈希索引的极高并行度的极少数情况下,才需要增加此值。 如果DBA确定群集不需要高度并行性,则可以使用较小的值并节省内存。
-
表22.43此表提供MaxNoOfFiredTriggers数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 4000 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
默认值为
MaxNoOfFiredTriggers4000,足以满足大多数情况。 在某些情况下,如果DBA确定群集中的并行性需求不高,甚至可以减少它。执行影响唯一哈希索引的操作时会创建记录。 在具有唯一哈希索引的表中插入或删除记录或更新属于唯一哈希索引的列会在索引表中触发插入或删除。 生成的记录用于表示此索引表操作,同时等待触发它完成的原始操作。 此操作是短暂的,但对于在包含一组唯一哈希索引的基表上具有许多并行写入操作的情况,仍可在其池中需要大量记录。
-
表22.44此表提供TransactionBufferMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 1M 范围 1K - 4294967039(0xFFFFFEFF) 重启类型 ñ
受此参数影响的内存用于跟踪更新索引表和读取唯一索引时触发的操作。 此内存用于存储这些操作的密钥和列信息。 很少需要从默认值更改此参数的值。
默认值为
TransactionBufferMemory1MB。正常的读写操作使用类似的缓冲区,其使用寿命更短。 编译时参数
ZATTRBUF_FILESIZE(找到ndb/src/kernel/blocks/Dbtc/Dbtc.hpp)设置为4000×128字节(500KB)。 用于密钥信息的类似缓冲区ZDATABUF_FILESIZE(也在Dbtc.hpp)包含4000×16 = 62.5KB的缓冲区空间。Dbtc是处理事务协调的模块。
事务资源分配参数。
以下列表中的参数用于在事务协调器中分配事务资源(
DBTC
请参阅
DBTC块
)。
将这些设置中的任何一个设置为默认值(0)将事务存储器专用于相应资源的估计总数据节点使用量的25%。
这些参数的实际最大可能值通常受数据节点可用内存量的限制;
设置它们对分配给数据节点的内存总量没有影响。
此外,你应该记住,他们控制的保留内部记录号码倚赖任何设置数据节点
MaxDMLOperationsPerTransaction
,
MaxNoOfConcurrentIndexOperations
,
MaxNoOfConcurrentOperations
,
MaxNoOfConcurrentScans
,
MaxNoOfConcurrentTransactions
,
MaxNoOfFiredTriggers
,
MaxNoOfLocalScans
,或
TransactionBufferMemory
(参见
事务参数
和
事务临时存储
)。
-
ReservedConcurrentIndexOperations表22.45此表提供ReservedConcurrentIndexOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个数据节点上具有专用资源的同时索引操作的数量。
-
表22.46此表提供ReservedConcurrentOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个数据节点上的事务协调器中具有专用资源的同时操作的数量。
-
表22.47此表提供ReservedConcurrentScans数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个数据节点上具有专用资源的同时扫描数。
-
ReservedConcurrentTransactions表22.48此表提供ReservedConcurrentTransactions数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个数据节点上具有专用资源的同时事务的数量。
-
表22.49此表提供ReservedFiredTriggers数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个ndbd(DB)节点上具有专用资源的触发器数。
-
表22.50此表提供ReservedLocalScans数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在一个数据节点上具有专用资源的同时片段扫描的数量。
-
ReservedTransactionBufferMemory表22.51此表提供ReservedTransactionBufferMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.16 类型或单位 数字 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
分配给每个数据节点的密钥和属性数据的动态缓冲区空间(以字节为单位)。
扫描和缓冲。
模块
中的其他
[ndbd]
参数
Dblqh
(in
ndb/src/kernel/blocks/Dblqh/Dblqh.hpp
)会影响读取和更新。
这些包括
ZATTRINBUF_FILESIZE
,默认设置为10000×128字节(1250KB)
ZDATABUF_FILE_SIZE
,默认设置为10000 * 16字节(大约156KB)的缓冲区空间。
到目前为止,既没有来自用户的任何报告,也没有来自我们自己的广泛测试的任何结果,表明应该增加这些编译时限制中的任何一个。
-
表22.52此表提供BatchSizePerLocalScan数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 256 范围 1 - 992 重启类型 ñ
此参数用于计算用于处理并发扫描操作的锁记录数。
BatchSizePerLocalScanBatchSize与SQL节点中定义的 连接很强 。 -
表22.53此表提供LongMessageBuffer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 64M 范围 512K - 4294967039(0xFFFFFEFF) 重启类型 ñ
这是一个内部缓冲区,用于在各个节点内和节点之间传递消息。 默认值为64MB。
此参数很少需要从默认值更改。
-
表22.54此表提供MaxFKBuildBatchSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 64 范围 16 - 512 重启类型 小号
用于构建外键的最大扫描批量大小。 增加为此参数设置的值可以加快构建外键构建,但代价是对正在进行的流量产生更大的影响。
-
表22.55此表提供MaxNoOfConcurrentScans数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 256 范围 2 - 500 重启类型 ñ
此参数用于控制可在群集中执行的并行扫描数。 每个事务协调器都可以处理为此参数定义的并行扫描数。 通过并行扫描所有分区来执行每个扫描查询。 每个分区扫描使用分区所在节点中的扫描记录,记录的数量是此参数的值乘以节点数。 群集应该能够
MaxNoOfConcurrentScans从群集中的所有节点同时 维持 扫描。扫描实际上是在两种情况下进行的。 当没有散列或有序索引来处理查询时,会出现第一种情况,在这种情况下,通过执行全表扫描来执行查询。 当没有哈希索引来支持查询但是有一个有序索引时遇到第二种情况。 使用有序索引意味着执行并行范围扫描。 订单仅保留在本地分区上,因此必须在所有分区上执行索引扫描。
默认值为
MaxNoOfConcurrentScans256.最大值为500。 -
表22.56此表提供MaxNoOfLocalScans数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 [见文] 范围 32 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果许多扫描未完全并行化,则指定本地扫描记录的数量。 如果未提供本地扫描记录的数量,则计算如下所示:
4 *
MaxNoOfConcurrentScans* [#data nodes] + 2最小值为32。
-
表22.57此表提供MaxParallelCopyInstances数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 64 重启类型 小号
此参数设置在节点重新启动或系统重新启动的复制阶段中使用的并行化,此时当前刚启动的节点通过从最新节点复制任何已更改的记录与已具有当前数据的节点同步。 因为在这种情况下完全并行可能导致过载情况,
MaxParallelCopyInstances提供了减少它的方法。 此参数的默认值为0.此值表示有效并行度等于刚刚启动的节点中的LDM实例数以及更新它的节点数。 -
表22.58此表提供MaxParallelScansPerFragment数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 256 范围 1 - 4294967039(0xFFFFFEFF) 重启类型 ñ
可以在开始排队进行串行处理之前 配置允许的最大并行扫描数(
TUP扫描和TUX扫描)。 您可以增加此功能,以便在并行执行大量扫描时利用任何未使用的CPU并提高其性能。此参数的默认值为256。
-
表22.59此表提供MaxReorgBuildBatchSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 64 范围 16 - 512 重启类型 小号
用于重组表分区的最大扫描批量大小。 增加为此参数设置的值可能会加快重组速度,但会对正在进行的流量产生更大的影响。
-
表22.60此表提供MaxUIBuildBatchSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 64 范围 16 - 512 重启类型 小号
用于构建唯一键的最大扫描批量大小。 增加为此参数设置的值可能会加速此类构建,但会对正在进行的流量产生更大的影响。
内存分配
这是为表分配内存时要使用的内存单元的最大大小。
在情况下,
NDB
给出了
内存不足的
错误,但它通过检查群集日志或输出是显而易见的
DUMP
1000
所有可用内存还未被使用,可以增加这个参数的值(或
MaxNoOfTables
,或两者),使
NDB
使足够的内存可用。
哈希地图大小
表22.62此表提供DefaultHashMapSize数据节点配置参数的类型和值信息
| 属性 | 值 |
|---|---|
| 版本(或更高版本) | NDB 8.0.13 |
| 类型或单位 | LDM线程 |
| 默认 | 3840 |
| 范围 | 0 - 3840 |
| 重启类型 | ñ |
使用的表哈希映射的大小
NDB
可使用此参数进行配置。
DefaultHashMapSize
可以采用三个可能的值中的任何一个(0,240,380)。
这些值及其影响如下表所述:
表22.63 DefaultHashMapSize参数
| 值 | 描述/效果 |
|---|---|
0 |
在集群中的所有数据节点和API节点中使用此参数的最小值集(如果有); 如果未在任何数据或API节点上设置,请使用默认值。 |
240 |
原始哈希映射大小(用于较旧的NDB群集版本) |
3840 |
较大的哈希映射大小(默认情况下在NDB 8.0中使用) |
此参数的最初预期用途是促进升级,特别是降级到具有不同默认哈希映射大小的旧版本的升级。 从NDB Cluster 7.6升级到NDB Cluster 8.0时,这不是问题。
记录和检查点。
以下
[ndbd]
参数控制日志和检查点行为。
-
表22.64此表提供FragmentLogFileSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 16M 范围 4M - 1G 重启类型 在
通过设置此参数,您可以直接控制重做日志文件的大小。 这在NDB Cluster在高负载下运行并且在尝试打开新的文件之前无法快速关闭片段日志文件的情况下非常有用(一次只能打开2个片段日志文件); 在必须打开每个新的片段日志文件之前,增加片段日志文件的大小会为集群提供更多时间。 此参数的默认值为16M。
有关片段日志文件的详细信息,请参阅说明
NoOfFragmentLogFiles。 -
表22.65此表提供InitialNoOfOpenFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 档 默认 27 范围 20 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置为打开文件分配的内部线程的初始数量。
默认值为27。
-
表22.66此表提供InitFragmentLogFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 [见价值] 默认 疏 范围 SPARSE,FULL 重启类型 在
默认情况下,在执行数据节点的初始启动时,稀疏地创建片段日志文件 - 也就是说,根据所使用的操作系统和文件系统,并非所有字节都必须写入磁盘。 但是,可以通过此参数覆盖此行为并强制写入所有字节,而不管所使用的平台和文件系统类型如何。
InitFragmentLogFiles采用以下两个值之一:-
SPARSE。 碎片日志文件是稀疏创建的。 这是默认值。 -
FULL。 强制将片段日志文件的所有字节写入磁盘。
根据您的操作系统和文件系统,设置
InitFragmentLogFiles=FULL可能有助于消除写入REDO日志时的I / O错误。 -
-
当
true,让部分本地检查点:这意味着每个LCP仅记录完整的数据库的一部分,再加上含有自上次LCP改变行的任何记录; 如果没有更改行,则LCP仅更新LCP控制文件,并且不更新任何数据文件。如果
EnablePartialLcp禁用(false),则每个LCP仅使用单个文件并写入完整检查点; 这需要LCP的最小磁盘空间,但会增加每个LCP的写入负载。 默认值为enabled(true)。 partiaL LCPS使用的空间比例可以通过RecoveryWork配置参数 的设置进行修改 。设置此参数
false还会禁用自适应LCP控制机制使用的磁盘写入速度的计算。 -
表22.68此表提供LcpScanProgressTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 第二 默认 60 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
本地检查点片段扫描监视程序定期检查作为本地检查点的一部分执行的每个碎片扫描没有进展,并且如果在给定的时间量过去之后没有进展则关闭该节点。 可以使用
LcpScanProgressTimeout数据节点配置参数 设置此时间间隔 ,该参数设置在LCP片段扫描看门狗关闭节点之前可以停止本地检查点的最长时间。默认值为60秒(提供与先前版本的兼容性)。 将此参数设置为0会完全禁用LCP片段扫描监视程序。
-
表22.69此表提供MaxNoOfOpenFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 20 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置为打开文件分配的内部线程数的上限。 任何需要更改此参数的情况都应报告为错误 。
默认值为0.但是,可以设置此参数的最小值为20。
-
表22.70此表提供MaxNoOfSavedMessages数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 25 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置在错误日志中写入的最大错误数以及在覆盖现有错误之前保留的最大跟踪文件数。 无论出于何种原因,节点崩溃时都会生成跟踪文件。
默认值为25,它将这些最大值设置为25个错误消息和25个跟踪文件。
-
在并行数据节点恢复中,仅实际复制和同步表数据; 诸如字典和检查点信息之类的元数据的同步以串行方式完成。 此外,字典和检查点信息的恢复不能与执行本地检查点并行执行。 这意味着,当同时启动或重新启动许多数据节点时,可能会强制数据节点在执行本地检查点时等待,这可能导致更长的节点恢复时间。
可以在本地检查点中强制延迟以允许更多(可能所有)数据节点完成元数据同步; 一旦每个数据节点的元数据同步完成,即使在执行本地检查点时,所有数据节点也可以并行恢复表数据。 要强制执行此类延迟,请设置
MaxLCPStartDelay,这将确定群集在数据节点继续同步元数据时等待开始本地检查点的秒数。 此参数应[ndbd default]在config.ini文件 的 部分中 设置 ,以便所有数据节点都相同。 最大值为600; 默认值为0。 -
表22.72此表提供NoOfFragmentLogFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 16 范围 3 - 4294967039(0xFFFFFEFF) 重启类型 在
此参数设置节点的REDO日志文件数,从而设置分配给REDO日志记录的空间量。 因为REDO日志文件是按环组织的,所以集合中的第一个和最后一个日志文件非常重要(有时称为 “ 头” ” 和 “ tail ” 日志文件)不符合非常重要。 当这些方法过于接近时,节点开始中止由于缺少新日志记录空间而包含更新的所有事务。
一个
REDO日志记录不会被删除,直到两个要求各地检查站已完成自认为插入日志记录。 检查点频率由本章其他地方讨论的配置参数集决定。默认参数值为16,默认情况下为16组4个16MB文件,总计1024MB。 可以使用
FragmentLogFileSize参数 配置各个日志文件的大小 。 在需要大量更新的场景中,NoOfFragmentLogFiles可能需要 将值 设置为高达300或甚至更高,以便为REDO日志提供足够的空间。如果检查点很慢并且对数据库的写入太多以至于日志文件已满并且日志尾部无法在不危及恢复的情况下被切断,则所有更新事务都将中止,内部错误代码为410(
Out of log file space temporarily) 。 这种情况一直存在,直到检查点完成并且日志尾部可以向前移动。重要此参数不能改变 “ 对飞 ” ; 您必须使用重新启动节点
--initial。 如果要为正在运行的集群中的所有数据节点更改此值,可以使用滚动节点重新启动(--initial在启动每个数据节点时 使用 )。 -
LCP文件的存储开销百分比。 仅当
EnablePartialLcptrue为true时, 此参数才有效 ,即仅在启用了部分本地检查点时才有效。 更高的值意味着:-
为每个LCP编写的记录较少,LCP使用更多空间
-
重启期间需要做更多的工作
较低的
RecoveryWork均值:-
在每个LCP期间写入更多记录,但LCP需要更少的磁盘空间。
-
在重新启动期间减少工作量,从而加快重启速度,但在正常操作期间需要付出更多工作
例如,设置
RecoveryWork为60意味着LCP的总大小大约是要检查点数据大小的1 + 0.6 = 1.6倍。 这意味着,与使用完整检查点的重新启动期间完成的工作相比,在重新启动的恢复阶段需要多做60%的工作。 (这在重启的其他阶段得到了补偿,使得在使用部分LCP时整个重启仍然比使用完整LCP时更快。)为了不填写重做日志,有必要写入RecoveryWork检查点期间数据变化率的 1 +(1 / )倍 - 因此,何时RecoveryWork= 60,有必要以大约1 +(1 / 0.6)= 2.67倍的变化率写入。 换句话说,如果以每秒10 MB的速度写入更改,则需要以大约26.7 MByte /秒的速度写入检查点。设置
RecoveryWork= 40意味着只需要总LCP大小的1.4倍(因此恢复阶段需要10到15%的时间。在这种情况下,检查点写入速率是变化率的3.5倍。NDB源代码分发包括用于模拟LCP的测试程序。
lcp_simulator.cc可以找到storage/ndb/src/kernel/blocks/backup/。 要在Unix平台上编译并运行它,请执行以下命令:shell>
gcc lcp_simulator.ccshell>./a.out此程序除了以外没有依赖关系
stdio.h,并且不需要连接到NDB集群或MySQL服务器。 默认情况下,它模拟300个LCP(三组100个LCP,每个LCP依次包含插入,更新和删除),在每个LCP之后报告LCP的大小。 您可以通过改变值改变的模拟recovery_work,insert_work以及delete_work在源和重新编译。 有关更多信息,请参阅该程序的来源。 -
-
表22.74此表提供InsertRecoveryWork数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 40 范围 0 - 70 重启类型 ñ
RecoveryWork用于插入行的 百分比 。 较高的值会增加本地检查点期间的写入次数,并会减小LCP的总大小。 较低的值会减少LCP期间的写入次数,但会导致更多的空间用于LCP,这意味着恢复需要更长的时间。 仅当EnablePartialLcptrue为true时, 此参数才有效 ,即仅在启用了部分本地检查点时才有效。 -
启用自适应检查点速度以控制重做日志使用。 设置为
false禁用(默认值)。 设置EnablePartialLcp到false还可以禁用自适应计算。启用时,
EnableRedoControl允许数据节点在将LCP写入磁盘的速率方面具有更大的灵活性。 更具体地说,启用此参数意味着可以使用更高的写入速率,以便LCP可以完成并且可以更快地修整重做日志,从而减少恢复时间和磁盘空间要求。 此功能允许数据节点更好地利用现有固态存储设备和协议(例如使用非易失性存储器快速(NVMe)的固态驱动器(SSD))提供的更高I / O速率和更大带宽。该参数当前默认为
false(禁用),因为它NDB仍然广泛部署在I / O或带宽相对于采用固态技术的系统(例如使用传统硬盘(HDD)的系统)受到限制的系统上。 在这些设置中,EnableRedoControl机制很容易导致I / O子系统饱和,增加了数据节点输入和输出的等待时间。 特别是,这可能会导致NDB磁盘数据表出现问题,这些表具有表空间或日志文件组,这些表共享带有数据节点LCP和重做日志文件的约束IO子系统; 此类问题可能包括由于GCP停止错误导致的节点或群集故障。
元数据对象。
下一组
[ndbd]
参数定义元数据对象的池大小,用于定义索引,事件和集群之间复制所使用的属性,表,索引和触发器对象的最大数量。
这些仅仅作为 群集的 “ 建议 ” ,任何未指定的都会恢复为显示的默认值。
-
表22.76此表提供MaxNoOfAttributes数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 1000 范围 32 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置可在群集中定义的建议最大属性数; 比如
MaxNoOfTables,它不打算作为硬上限。(在较旧的NDB Cluster版本中,此参数有时被视为某些操作的硬限制。这会导致NDB群集复制出现问题,因为可能会创建比可复制的更多的表,有时会导致混乱。 [或根据具体情况不可能]创建超过
MaxNoOfAttributes属性。)默认值为1000,最小可能值为32.最大值为4294967039.由于所有元数据都在服务器上完全复制,每个属性每个节点占用大约200字节的存储空间。
设置时
MaxNoOfAttributes,必须事先准备好ALTER TABLE您将来可能要执行的 任何 语句。 这是因为ALTER TABLE在Cluster表上 执行期间, 使用的原始数量是原始表中的3倍,并且一个好的做法是允许将此数量加倍。 例如,如果具有最大数量的属性(greatest_number_of_attributes) 的NDB Cluster表具有 100个属性,则值的良好起点MaxNoOfAttributes将是 。6 *greatest_number_of_attributes= 600您还应该估算每个表的平均属性数并将其乘以
MaxNoOfTables。 如果此值大于上一段中获得的值,则应使用较大的值。假设您可以毫无问题地创建所有需要的表,您还应该
ALTER TABLE在配置参数后 尝试实际验证此数字是否足够 。 如果这不是成功的,增加MaxNoOfAttributes的另一个多个MaxNoOfTables,并再次测试。 -
表22.77此表提供MaxNoOfTables数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 128 范围 8 - 20320 重启类型 ñ
为每个表和集群中的每个唯一哈希索引分配一个表对象。 此参数设置整个群集的建议最大表对象数; 比如
MaxNoOfAttributes,它不打算作为硬上限。(在较旧的NDB Cluster版本中,此参数有时被视为某些操作的硬限制。这会导致NDB群集复制出现问题,因为可能会创建比可复制的更多的表,有时会导致混乱。 [或根据具体情况不可能]创建多个
MaxNoOfTables表格。)对于具有
BLOB数据类型的 每个属性, 使用额外的表来存储大多数BLOB数据。 在定义表的总数时,还必须考虑这些表。此参数的默认值为128.最小值为8,最大值为20320.每个表对象每个节点消耗大约20KB。
注意的总和
MaxNoOfTables,MaxNoOfOrderedIndexes和MaxNoOfUniqueHashIndexes不得超过 (4294967294)。232 − 2 -
表22.78此表提供MaxNoOfOrderedIndexes数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 128 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
对于集群中的每个有序索引,将分配一个对象,描述要编制索引的内容及其存储段。 默认情况下,如此定义的每个索引还定义了一个有序索引。 每个唯一索引和主键都有一个有序索引和一个哈希索引。
MaxNoOfOrderedIndexes设置任何时候系统中可以使用的有序索引的总数。此参数的默认值为128.每个索引对象每个节点消耗大约10KB的数据。
注意的总和
MaxNoOfTables,MaxNoOfOrderedIndexes和MaxNoOfUniqueHashIndexes不得超过 (4294967294)。232 − 2 -
表22.79此表提供MaxNoOfUniqueHashIndexes数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 64 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
对于不是主键的每个唯一索引,将分配一个特殊表,用于将唯一键映射到索引表的主键。 默认情况下,还为每个唯一索引定义有序索引。 要防止这种情况,您必须
USING HASH在定义唯一索引时 指定该 选项。默认值为64.每个索引每个节点消耗大约15KB。
注意的总和
MaxNoOfTables,MaxNoOfOrderedIndexes和MaxNoOfUniqueHashIndexes不得超过 (4294967294)。232 − 2 -
表22.80此表提供MaxNoOfTriggers数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 768 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
为每个唯一哈希索引分配内部更新,插入和删除触发器。 (这意味着为每个唯一的哈希索引创建了三个触发器。)但是, 有序 索引只需要一个触发器对象。 备份还为群集中的每个普通表使用三个触发器对象。
集群之间的复制也使用内部触发器。
此参数设置群集中的最大触发器对象数。
默认值为768。
-
表22.81此表提供MaxNoOfSubscriptions数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
NDBNDB群集中的 每个 表都需要在NDB内核中进行订阅。 对于某些NDB API应用程序,可能需要或希望更改此参数。 但是,对于MySQL服务器充当SQL节点的正常使用,没有必要这样做。默认值为
MaxNoOfSubscriptions0,被视为等于MaxNoOfTables。 每个订阅消耗108个字节。 -
表22.82此表提供MaxNoOfSubscribers数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
仅在使用NDB群集复制时,此参数才有意义。 默认值为0,被视为
2 * MaxNoOfTables; 也就是说,NDB对于两个MySQL服务器中的 每一个,每个 表 有一个订阅 (一个充当复制主服务器,另一个充当从服务器)。 每个订户使用16个字节的内存。当使用循环复制,多主复制和涉及2个以上MySQL服务器的其他复制设置时,您应该将此参数增加到 复制中包含 的 mysqld 进程 数 (这通常但不总是与数量相同)集群)。 例如,如果您使用三个NDB Cluster进行循环复制设置 ,并且每个集群都附加 一个 mysqld ,并且每个 mysqld 进程充当主服务器和从服务器,则应将其设置为
MaxNoOfSubscribers等于3 * MaxNoOfTables。有关更多信息,请参见 第22.6节“NDB集群复制” 。
-
MaxNoOfConcurrentSubOperations表22.83此表提供MaxNoOfConcurrentSubOperations数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 256 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置一次可由群集中的所有API节点执行的操作数的上限。 默认值(256)足以用于正常操作,并且可能仅需要在存在大量API节点的情况下进行调整,每个API节点同时执行大量操作。
布尔参数。
数据节点的行为也受到一组具有
[ndbd]
布尔值
的
参数的
影响
。
这些参数可以
TRUE
通过将它们设置为等于
1
或
指定
Y
,并
FALSE
通过将它们设置为等于
0
或来指定
N
。
-
启用此参数会导致压缩备份文件。 使用的压缩等同于 gzip --fast ,并且可以节省数据节点上所需空间的50%或更多,以存储未压缩的备份文件。 可以为单个数据节点或所有数据节点启用压缩备份(通过
[ndbd default]在config.ini文件 的 部分中 设置此参数 )。重要您无法将压缩备份还原到运行不支持此功能的MySQL版本的群集。
默认值为
0(禁用)。 -
设置此参数可
1导致压缩本地检查点文件。 使用的压缩等同于 gzip --fast ,并且可以节省数据节点上所需空间的50%或更多,以存储未压缩的检查点文件。 可以为单个数据节点或所有数据节点启用压缩LCP(通过[ndbd default]在config.ini文件 的 部分中 设置此参数 )。重要您无法将压缩的本地检查点还原到运行不支持此功能的MySQL版本的群集。
默认值为
0(禁用)。 -
表22.86此表提供CrashOnCorruptedTuple数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 布尔 默认 真正 范围 真假 重启类型 小号
启用此参数(默认值)时,它会强制数据节点在遇到损坏的元组时关闭。
-
可以将NDB Cluster表指定为 无盘 ,这意味着表不会检查到磁盘,也不会记录日志。 这些表仅存在于主存中。 使用无盘表的结果是表和这些表中的记录都不会崩溃。 但是,在无盘模式下运行时,可以 在无盘计算机上 运行 ndbd 。
重要此功能使 整个 群集在无盘模式下运行。
启用此功能后,将禁用群集联机备份。 此外,无法部分启动群集。
Diskless默认情况下禁用。 -
在建立与管理服务器的连接后,为此数据节点分配内存。 默认情况下启用。
-
表22.89此表提供LockPagesInMainMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 0 范围 0 - 2 重启类型 ñ
对于许多操作系统,包括Solaris和Linux,可以将进程锁定到内存中,从而避免任何交换到磁盘。 这可用于帮助保证群集的实时特征。
此参数采用整数值之一
0,1或2,其行为如下列表所示:-
0:禁用锁定。 这是默认值。 -
1:为进程分配内存后执行锁定。 -
2:在分配进程的内存之前执行锁定。
如果操作系统未配置为允许非特权用户锁定页面,则使用此参数的数据节点进程可能必须以系统根目录运行。 (
LockPagesInMainMemory使用该mlockall功能。从Linux内核2.6.9开始,非特权用户可以锁定内存受限制max locked memory。有关更多信息,请参阅 ulimit -l 和 http://linux.die.net/man/2/mlock )。注意在较旧的NDB Cluster版本中,此参数是布尔值。
0或者false是默认设置,并禁用锁定。1或者true在分配内存后启用锁定。 NDB簇8.0治疗true或false此参数为错误的值。重要从
glibc2.10 开始 ,glibc使用每线程竞技场来减少共享池上的锁争用,这会占用实际内存。 通常,数据节点进程不需要每线程竞技场,因为它在启动后不执行任何内存分配。 (分配器的这种差异似乎不会显着影响性能。)该
glibc行为旨在通过MALLOC_ARENA_MAX环境变量 进行配置 ,但glibc2.16 之前的此机制中的错误 意味着此变量不能设置为小于8,因此无法回收浪费的内存。 (Bug#15907219; 有关此问题的更多信息 ,另请参阅 http://sourceware.org/bugzilla/show_bug.cgi?id=13137 。)此问题的一种可能的解决方法是使用
LD_PRELOAD环境变量来预加载jemalloc内存分配库以取代提供 的 内存分配库glibc。 -
-
启用此参数会导致
NDB尝试O_DIRECT对LCP,备份和重做日志 使用 写入,这通常会降低 kswapd 和CPU使用率。 在Linux上使用NDB Cluster时,ODirect如果使用的是2.6或更高版本的内核 ,请启用 。ODirect默认情况下禁用。 -
启用此参数后,将执行重做日志写入,以便将每个已完成的文件系统写入作为调用进行处理
fsync。 如果满足以下条件中的至少一个,则忽略此参数的设置:-
ODirect未启用。 -
InitFragmentLogFiles设置为SPARSE。
默认情况下禁用。
-
-
表22.92此表提供RestartOnErrorInsert数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 错误代码 默认 2 范围 0 - 4 重启类型 ñ
只有在构建调试版本时才能访问此功能,其中可以在执行单个代码块时插入错误作为测试的一部分。
默认情况下禁用此功能。
-
此参数指定在遇到错误情况时数据节点进程是应退出还是执行自动重新启动。
该参数的默认值为1; 这意味着,默认情况下,错误会导致数据节点进程暂停。
遇到错误且
StopOnError为0时,将重新启动数据节点进程。MySQL Cluster Manager的用户应该注意,当
StopOnError等于1时,这会阻止MySQL Cluster Manager代理在执行自己的重启和恢复后重新启动任何数据节点。 有关 详细信息, 请参阅 在Linux上启动和停止代理 。 -
在此数据节点与也在此主机上运行的API节点之间启用共享内存连接。 设置为1以启用。
控制超时,间隔和磁盘分页
有许多
[ndbd]
参数指定群集数据节点中各种操作之间的超时和间隔。
大多数超时值以毫秒为单位指定。
如果适用,可以提及任何例外情况。
-
表22.95此表提供TimeBetweenWatchDogCheck数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 6000 范围 70 - 4294967039(0xFFFFFEFF) 重启类型 ñ
为防止主线程在某个时刻卡在无限循环中, “ 看门狗 ” 线程会检查主线程。 此参数指定检查之间的毫秒数。 如果在三次检查后进程保持相同状态,则监视程序线程将终止它。
为了实验或适应当地条件,可以轻松更改此参数。 它可以在每个节点的基础上指定,尽管似乎没有理由这样做。
默认超时为6000毫秒(6秒)。
-
TimeBetweenWatchDogCheckInitial表22.96此表提供TimeBetweenWatchDogCheckInitial数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 6000 范围 70 - 4294967039(0xFFFFFEFF) 重启类型 ñ
这类似于
TimeBetweenWatchDogCheck参数,除了TimeBetweenWatchDogCheckInitial控制在分配内存的早期启动阶段内在存储节点内执行检查之间经过的时间量。默认超时为6000毫秒(6秒)。
-
表22.97此表提供StartPartialTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 30000 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指定在调用集群初始化例程之前,集群等待所有数据节点出现的时间。 此超时用于尽可能避免部分群集启动。
执行集群的初始启动或初始重新启动时,将覆盖此参数。
默认值为30000毫秒(30秒)。 0禁用超时,在这种情况下,只有所有节点都可用时,群集才可以启动。
-
表22.98此表提供StartPartitionedTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 60000 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果群集在等待
StartPartialTimeout毫秒 后准备好启动 但仍可能处于分区状态,则群集将等待,直到此超时也已过去。 如果StartPartitionedTimeout设置为0,则群集将无限期等待。执行集群的初始启动或初始重新启动时,将覆盖此参数。
默认超时为60000毫秒(60秒)。
-
表22.99此表提供StartFailureTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果数据节点未在此参数指定的时间内完成其启动序列,则节点启动失败。 将此参数设置为0(默认值)意味着不应用数据节点超时。
对于非零值,此参数以毫秒为单位。 对于包含极大量数据的数据节点,应增加此参数。 例如,在包含几千兆字节数据的数据节点的情况下,执行节点重启可能需要长达10-15分钟(即600000到1000000毫秒)的时间段。
-
表22.100此表提供StartNoNodeGroupTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 15000 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
配置数据节点时
Nodegroup = 65536,视为未分配给任何节点组。 完成后,集群等待StartNoNodegroupTimeout毫秒,然后将这些节点视为已添加到传递给--nowait-nodes选项 的列表中 ,并启动。 默认值为15000(即管理服务器等待15秒)。 将此参数设置为等于0表示群集无限期等待。StartNoNodegroupTimeout对于集群中的所有数据节点必须相同; 出于这个原因,你应该总是在它的[ndbd default]部分 设置它config.ini文件 ,而不是单个数据节点中。有关 更多信息 , 请参见 第22.5.15节“在线添加NDB集群数据节点” 。
-
表22.101此表提供HeartbeatIntervalDbDb数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 5000 范围 10 - 4294967039(0xFFFFFEFF) 重启类型 ñ
发现故障节点的主要方法之一是使用心跳。 此参数指示心跳信号的发送频率以及预期接收心跳信号的频率。 心跳不能被禁用。
在连续丢失四个心跳间隔后,该节点被宣布为死亡。 因此,通过心跳机制发现故障的最长时间是心跳间隔的五倍。
默认心跳间隔为5000毫秒(5秒)。 此参数不得大幅更改,并且不应在节点之间广泛变化。 如果一个节点使用5000毫秒并且观察它的节点使用1000毫秒,显然该节点将很快被宣布为死亡。 在线软件升级期间可以更改此参数,但只能以较小的增量进行更改。
另请参阅 网络通信和延迟 ,以及
ConnectCheckIntervalDelay配置参数 的说明 。 -
表22.102此表提供HeartbeatIntervalDbApi数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 1500 范围 100 - 4294967039(0xFFFFFEFF) 重启类型 ñ
每个数据节点都向每个MySQL服务器(SQL节点)发送心跳信号,以确保它保持联系。 如果MySQL服务器未能及时发送心跳,则会将其声明为 “ 已死 ”, 在这种情况下,所有正在进行的事务都已完成并且所有资源都已释放。 在完成前一个MySQL实例启动的所有活动之前,SQL节点无法重新连接。 该确定的三心跳标准与所描述的相同
HeartbeatIntervalDbDb。默认时间间隔为1500毫秒(1.5秒)。 此间隔可能因各个数据节点而异,因为每个数据节点都会监视与其连接的MySQL服务器,而与所有其他数据节点无关。
有关更多信息,请参阅 网络通信和延迟 。
-
表22.103此表提供HeartbeatOrder数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 0 范围 0 - 65535 重启类型 小号
数据节点以循环方式彼此发送心跳,由此每个数据节点监视前一个数据节点。 如果给定数据节点未检测到心跳,则此节点将圆圈中的先前数据节点声明为 “ 死 ” (即群集不再可访问)。 全局完成数据节点死亡的确定; 换一种说法; 一旦数据节点被宣布为死亡,集群中的所有节点都将其视为死亡。
与其他节点对之间的心跳相比,驻留在不同主机上的数据节点之间的心跳可能太慢(例如,由于非常低的心跳间隔或临时连接问题),因此数据节点被宣布为死亡,即使该节点仍然可以作为群集的一部分。 。
在这种情况下,可能是在数据节点之间传输心跳的顺序对于特定数据节点是否被宣告为死有所不同。 如果此声明不必要地发生,则这又可能导致节点组的不必要丢失,从而导致集群故障。
考虑一个设置,其中有4个数据节点A,B,C,和d 2台的主机计算机上运行的
host1和host2,并且这些数据节点弥补2个节点组,如图所示,在下表中:表22.104在两台主机host1,host2上运行的四个数据节点A,B,C,D; 每个数据节点属于两个节点组之一。
节点组 运行的节点 host1运行的节点 host2节点组0 : 节点A. 节点B. 节点组1 : 节点C. 节点D.
假设心跳按照A-> B-> C-> D-> A的顺序传输。 在这种情况下,主机之间的心跳丢失导致节点B声明节点A死亡,节点C声明节点B死亡。 这会导致节点组0丢失,因此群集将失败。 另一方面,如果传输顺序是A-> B-> D-> C-> A(并且所有其他条件保持如前所述),则心跳的丢失导致节点A和D被宣告死亡; 在这种情况下,每个节点组都有一个幸存节点,并且群集仍然存在。
所述
HeartbeatOrder配置参数使得心跳发送用户可配置的顺序。 默认值HeartbeatOrder为零; 允许在所有数据节点上使用默认值导致心跳传输的顺序由下式确定NDB。 如果使用此参数,则必须将其设置为群集中每个数据节点的非零值(最大值为65535),并且此值对于每个数据节点必须是唯一的; 这会导致心跳传输从数据节点到数据节点按其HeartbeatOrder值从最低到最高 的顺序进行 (然后直接从具有最高值的数据节点开始)HeartbeatOrder到具有最低值的数据节点,以完成圆圈)。 值不必是连续的。 例如,要在前面概述的方案中强制心跳传输顺序A-> B-> D-> C-> A,您可以设置HeartbeatOrder如下所示 的 值:
要使用此参数更改正在运行的NDB群集中的心跳传输顺序,必须首先
HeartbeatOrder在全局配置(config.ini)文件(或文件) 中为群集中的每个数据节点 设置 。 要使更改生效,您必须执行以下任一操作:-
完全关闭并重新启动整个群集。
-
2连续滚动重启群集。 在两次滚动重启中,必须以相同的顺序重新启动所有节点 。
您可以使用
DUMP 908此方法在数据节点日志中观察此参数的效果。 -
-
表22.106此表提供ConnectCheckIntervalDelay数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数启用数据节点之间的连接检查,其中一个节点检测到心跳检测失败,最多间隔为5
HeartbeatIntervalDbDb毫秒。这种在
ConnectCheckIntervalDelay毫秒 间隔内未能响应的数据节点 被认为是可疑的,并且在两个这样的间隔之后被认为是死的。 这在具有已知延迟问题的设置中非常有用。此参数的默认值为0(禁用)。
-
表22.107此表提供TimeBetweenLocalCheckpoints数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 4字节字的数量,作为基数2的对数 默认 20 范围 0 - 31 重启类型 ñ
此参数是一个例外,因为它没有指定在开始新的本地检查点之前等待的时间。 相反,它用于确保不会在发生相对较少更新的群集中执行本地检查点。 在大多数具有高更新速率的群集中,很可能在完成上一个检查点之后立即启动新的本地检查点。
添加自先前本地检查点开始以来执行的所有写入操作的大小。 此参数也是例外,因为它被指定为4字节字数的基数2对数,因此默认值20表示4MB(4×2 20 )的写操作,21表示8MB,所以最大值为31,相当于8GB的写入操作。
群集中的所有写入操作都会一起添加。 设置
TimeBetweenLocalCheckpoints为6或更小意味着本地检查点将连续执行而不会暂停,与群集的工作负载无关。 -
表22.108此表提供TimeBetweenGlobalCheckpoints数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 2000 范围 20 - 32000 重启类型 ñ
提交事务时,它将在镜像数据的所有节点的主内存中提交。 但是,事务日志记录不会作为提交的一部分刷新到磁盘。 这种行为背后的原因是,在至少两台自主主机上安全地提交事务应该符合合理的耐久性标准。
确保即使是最糟糕的情况 - 集群的完全崩溃 - 也能得到妥善处理也很重要。 为了保证这种情况发生,在给定时间间隔内发生的所有事务都被放入一个全局检查点,可以将其视为已刷新到磁盘的一组已提交事务。 换句话说,作为提交过程的一部分,事务将放置在全局检查点组中。 稍后,此组的日志记录将刷新到磁盘,然后整个事务组将安全地提交到群集中所有计算机上的磁盘。
此参数定义全局检查点之间的间隔。 默认值为2000毫秒。
-
TimeBetweenGlobalCheckpointsTimeout表22.109此表提供TimeBetweenGlobalCheckpointsTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 120000 范围 10 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数定义全局检查点之间的最小超时。 默认值为120000毫秒。
-
表22.110此表提供TimeBetweenEpochs数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 100 范围 0 - 32000 重启类型 ñ
此参数定义NDB群集复制的同步时期之间的间隔。 默认值为100毫秒。
TimeBetweenEpochs是 “ 微GCP ” 实施的一部分, 可用于提高NDB集群复制的性能。 -
表22.111此表提供TimeBetweenEpochsTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 0 范围 0 - 256000 重启类型 ñ
此参数定义NDB群集复制的同步时期的超时。 如果节点在此参数确定的时间内未能参与全局检查点,则该节点将关闭。 默认值为0; 换句话说,超时被禁用。
TimeBetweenEpochsTimeout是 “ 微GCP ” 实施的一部分, 可用于提高NDB集群复制的性能。只要GCP保存时间超过1分钟或GCP提交时间超过10秒,此参数的当前值和警告就会写入群集日志。
将此参数设置为零可以禁用由保存超时,提交超时或两者引起的GCP停止。 此参数的最大可能值为256000毫秒。
-
表22.112此表提供MaxBufferedEpochs数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 时代 默认 100 范围 0 - 100000 重启类型 ñ
订阅节点可以滞后的未处理时期的数量。 超过此数字会导致滞后的用户断开连接。
对于大多数正常操作,默认值100就足够了。 如果订阅节点确实滞后足以导致断开连接,则通常是由于与进程或线程有关的网络或调度问题。 (在极少数情况下,问题可能是由于
NDB客户端中 的错误引起的 。)当纪元较长时,可能需要将值设置为低于默认值。断开连接可防止客户端问题影响数据节点服务,内存不足以缓冲数据,并最终关闭。 相反,只有客户端因断开连接而受到影响(例如,通过二进制日志中的间隙事件),迫使客户端重新连接或重新启动进程。
-
表22.113此表提供MaxBufferedEpochBytes数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 26214400 范围 26214400(0x01900000) - 4294967039(0xFFFFFEFF) 重启类型 ñ
此节点为缓冲时期分配的总字节数。
-
TimeBetweenInactiveTransactionAbortCheck表22.114此表提供TimeBetweenInactiveTransactionAbortCheck数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 1000 范围 1000 - 4294967039(0xFFFFFEFF) 重启类型 ñ
通过针对此参数指定的每个间隔检查每个事务的计时器来执行超时处理。 因此,如果此参数设置为1000毫秒,则将检查每个事务每秒超时一次。
默认值为1000毫秒(1秒)。
-
表22.115此表提供TransactionInactiveTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 [见文] 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指出在事务中止之前允许在同一事务中的操作之间经过的最长时间。
此参数的默认值为
4G(也是最大值)。 对于需要确保没有事务长时间保持锁定的实时数据库,应将此参数设置为相对较小的值。 将其设置为0意味着应用程序永远不会超时。 单位是毫秒。 -
TransactionDeadlockDetectionTimeout表22.116此表提供TransactionDeadlockDetectionTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 1200 范围 50 - 4294967039(0xFFFFFEFF) 重启类型 ñ
当节点执行涉及事务的查询时,该节点在继续之前等待集群中的其他节点响应。 此参数设置事务可在数据节点内执行的时间量,即事务协调器等待参与事务的每个数据节点执行请求的时间。
由于以下任何原因,都可能无法响应:
-
节点 “ 死了 ”
-
该操作已进入锁定队列
-
请求执行操作的节点可能会严重超载。
此超时参数指示事务协调器在中止事务之前等待另一个节点执行查询的时间,并且对于节点故障处理和死锁检测都很重要。
默认超时值为1200毫秒(1.2秒)。
此参数的最小值为50毫秒。
-
-
表22.117此表提供DiskSyncSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 4M 范围 32K - 4294967039(0xFFFFFEFF) 重启类型 ñ
这是在将数据刷新到本地检查点文件之前要存储的最大字节数。 这样做是为了防止写入缓冲,这可能会严重影响性能。 此参数 不是 为了取代
TimeBetweenLocalCheckpoints。注意当
ODirect启用时,它是没有必要设置DiskSyncSize; 事实上,在这种情况下,它的价值被忽略了。默认值为4M(4兆字节)。
-
表22.118此表提供MaxDiskWriteSpeed数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 20M 范围 1M - 1024G 重启类型 小号
在此NDB群集中没有重新启动(由此数据节点或任何其他数据节点)时,通过本地检查点和备份操作设置写入磁盘的最大速率(以每秒字节数为单位)。
要设置此数据节点重新启动时允许的最大磁盘写入速率,请使用
MaxDiskWriteSpeedOwnRestart。 要设置其他数据节点重新启动时允许的最大磁盘写入速率,请使用MaxDiskWriteSpeedOtherNodeRestart。 可以通过设置来调整所有LCP和备份操作的磁盘写入的最低速度MinDiskWriteSpeed。 -
MaxDiskWriteSpeedOtherNodeRestart表22.119此表提供MaxDiskWriteSpeedOtherNodeRestart数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 50公尺 范围 1M - 1024G 重启类型 小号
设置当此NDB群集中的一个或多个数据节点重新启动时本地检查点和备份操作写入磁盘的最大速率(以每秒字节数为单位),而不是此节点。
要设置此数据节点重新启动时允许的最大磁盘写入速率,请使用
MaxDiskWriteSpeedOwnRestart。 要设置当没有数据节点在群集中的任何位置重新启动时允许的最大磁盘写入速率,请使用MaxDiskWriteSpeed。 可以通过设置来调整所有LCP和备份操作的磁盘写入的最低速度MinDiskWriteSpeed。 -
表22.120此表提供MaxDiskWriteSpeedOwnRestart数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 200M 范围 1M - 1024G 重启类型 小号
在此数据节点重新启动时,通过本地检查点和备份操作设置写入磁盘的最大速率(以每秒字节数为单位)。
要设置其他数据节点重新启动时允许的最大磁盘写入速率,请使用
MaxDiskWriteSpeedOtherNodeRestart。 要设置当没有数据节点在群集中的任何位置重新启动时允许的最大磁盘写入速率,请使用MaxDiskWriteSpeed。 可以通过设置来调整所有LCP和备份操作的磁盘写入的最低速度MinDiskWriteSpeed。 -
表22.121此表提供MinDiskWriteSpeed数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 10M 范围 1M - 1024G 重启类型 小号
通过本地检查点和备份操作设置写入磁盘的最小速率(以每秒字节数为单位)。
允许用于在各种条件下的LCP和备份磁盘写入的最大速率是可调节的使用参数
MaxDiskWriteSpeed,MaxDiskWriteSpeedOwnRestart以及MaxDiskWriteSpeedOtherNodeRestart。 有关更多信息,请参阅这些参数的说明。 -
表22.122此表提供ArbitrationTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 7500 范围 10 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指定数据节点等待仲裁器对仲裁消息的响应的时间。 如果超出此范围,则假定网络已拆分。
默认值为7500毫秒(7.5秒)。
-
该
Arbitration参数允许选择仲裁方案,对应于此参数的3个可能值之一:-
默认。 这使仲裁能够正常进行,这由
ArbitrationRank管理和API节点 的 设置 决定 。 这是默认值。 -
禁用。
Arbitration = Disabled在 文件[ndbd default]部分中进行 设置config.ini以完成与ArbitrationRank在所有管理和API节点上 设置 为0 相同的任务 。 当Arbitration以这种方式设置,任何ArbitrationRank设置将被忽略。 -
WaitExternal。 该
Arbitration参数还使得可以以这样的方式配置仲裁:集群等待直到经过确定的时间之后,ArbitrationTimeout外部集群管理器应用程序执行仲裁而不是在内部处理仲裁。 这可以通过Arbitration = WaitExternal在 文件 的[ndbd default]部分中 进行设置来完成config.ini。 为了获得最佳效果,WaitExternal建议使用ArbitrationTimeout是外部集群管理器执行仲裁所需间隔的2倍。
重要此参数仅应
[ndbd default]在群集配置文件 的 部分中使用。 当Arbitration为各个数据节点设置不同的值时, 未指定集群的行为 。 -
-
RestartSubscriberConnectTimeout表22.124此表提供RestartSubscriberConnectTimeout数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 女士 默认 12000 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 小号
此参数确定数据节点等待订阅API节点连接的时间。 一旦此超时到期,任何 “ 缺失 ”的 API节点都将与群集断开连接。 要禁用此超时,请设置
RestartSubscriberConnectTimeout为0。虽然此参数以毫秒为单位指定,但超时本身将解析为下一个最大的整秒。
缓冲和记录。
一些
[ndbd]
配置参数使高级用户能够更好地控制节点进程使用的资源,并根据需要调整各种缓冲区大小。
将日志记录写入磁盘时,这些缓冲区用作文件系统的前端。
如果节点在无盘模式下运行,则可以将这些参数设置为其最小值而不会受到惩罚,因为磁盘写入
由
存储引擎的文件系统抽象层
“
伪造
”
NDB
。
-
表22.125此表提供UndoIndexBuffer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 2M 范围 1M - 4294967039(0xFFFFFEFF) 重启类型 ñ
UNDO索引缓冲区的大小由此参数设置,在本地检查点期间使用。 该
NDB存储引擎使用基于结合运算REDO日志检查点稠度的恢复方案。 要生成一致的检查点而不阻止整个系统进行写入,UNDO日志记录将在执行本地检查点时完成。 一次在单个表片段上激活UNDO日志记录。 这种优化是可能的,因为表完全存储在主存储器中。UNDO索引缓冲区用于主键哈希索引的更新。 插入和删除重新排列哈希索引; NDB存储引擎写入UNDO日志记录,将所有物理更改映射到索引页,以便在系统重新启动时撤消它们。 它还会在本地检查点的开头记录每个片段的所有活动插入操作。
读取和更新设置锁定位并更新哈希索引条目中的标头。 这些更改由页面编写算法处理,以确保这些操作不需要UNDO日志记录。
此缓冲区默认为2MB。 最小值为1MB,足以满足大多数应用的需求。 对于执行极大或大量插入和删除以及大事务和大主键的应用程序,可能需要增加此缓冲区的大小。 如果此缓冲区太小,NDB存储引擎会发出内部错误代码677(
Index UNDO buffers overloaded)。重要在滚动重启期间减小此参数的值是不安全的。
-
表22.126此表提供UndoDataBuffer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 16M 范围 1M - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置UNDO数据缓冲区的大小,该缓冲区执行类似于UNDO索引缓冲区的功能,但UNDO数据缓冲区用于数据存储器而不是索引存储器。 在片段的本地检查点阶段使用此缓冲区进行插入,删除和更新。
因为记录更多操作时UNDO日志条目会变得更大,所以此缓冲区也大于其索引内存对应项,默认值为16MB。
对于某些应用程序,此大小的内存可能不必要地大。 在这种情况下,可以将此大小减小到最小1MB。
很少需要增加此缓冲区的大小。 如果有这种需要,最好检查磁盘是否可以实际处理由数据库更新活动引起的负载。 通过增加此缓冲区的大小无法克服缺少足够的磁盘空间。
如果此缓冲区太小并且变得拥塞,则NDB存储引擎会发出内部错误代码891( Data UNDO缓冲区已过载 )。
重要在滚动重启期间减小此参数的值是不安全的。
-
表22.127此表提供RedoBuffer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 32M 范围 1M - 4294967039(0xFFFFFEFF) 重启类型 ñ
还需要记录所有更新活动。 REDO日志可以在重新启动系统时重放这些更新。 NDB恢复算法使用数据的 “ 模糊 ” 检查点和UNDO日志,然后应用REDO日志来回放直到恢复点的所有更改。
RedoBuffer设置写入REDO日志的缓冲区的大小。 默认值为32MB; 最小值为1MB。如果此缓冲区太小,则
NDB存储引擎会发出错误代码1221( REDO日志缓冲区已过载 )。 因此,如果您尝试降低RedoBuffer群集配置中在线更改 的值,则应小心谨慎 。ndbmtd 为每个LDM线程分配一个单独的缓冲区(请参阅 参考资料
ThreadConfig)。 例如,对于4个LDM线程, ndbmtd 数据节点实际上有4个缓冲区并RedoBuffer为每个 缓冲区分配 字节,总计4 * RedoBuffer字节数。 -
表22.128此表提供EventLogBufferSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 8192 范围 0 - 64K 重启类型 小号
控制用于数据节点内的NDB日志事件的循环缓冲区的大小。
控制日志消息。
在管理群集时,能够控制为各种事件类型发送的日志消息的数量非常重要
stdout
。
对于每个事件类别,有16个可能的事件级别(编号为0到15)。
将给定事件类别的事件报告设置为级别15意味着将该类别中的所有事件报告发送到
stdout
;
将其设置为0表示该类别中不会生成事件报告。
默认情况下,仅将启动消息发送到
stdout
,其余事件报告级别默认值设置为0.原因是这些消息也会发送到管理服务器的群集日志。
可以为管理客户端设置一组类似的级别,以确定要在群集日志中记录的事件级别。
-
流程启动期间生成的事件的报告级别。
默认级别为1。
-
作为节点正常关闭的一部分生成的事件的报告级别。
默认级别为0。
-
表22.131此表提供LogLevelStatistic数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 15 重启类型 ñ
统计事件的报告级别,例如主键读取次数,更新次数,插入次数,与缓冲区使用相关的信息等。
默认级别为0。
-
表22.132此表提供LogLevelCheckpoint数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 日志级别 默认 0 范围 0 - 15 重启类型 ñ
本地和全球检查点生成的事件的报告级别。
默认级别为0。
-
表22.133此表提供LogLevelNodeRestart数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 15 重启类型 ñ
节点重新启动期间生成的事件的报告级别。
默认级别为0。
-
表22.134此表提供LogLevelConnection数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 15 重启类型 ñ
群集节点之间的连接生成的事件的报告级别。
默认级别为0。
-
整个群集由错误和警告生成的事件的报告级别。 这些错误不会导致任何节点故障,但仍被认为值得报告。
默认级别为0。
-
表22.136此表提供LogLevelCongestion数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 水平 默认 0 范围 0 - 15 重启类型 ñ
拥塞产生的事件的报告级别。 这些错误不会导致节点故障,但仍被认为值得报告。
默认级别为0。
-
为有关群集的一般状态的信息生成的事件的报告级别。
默认级别为0。
-
表22.138此表提供MemReportFrequency数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数控制在群集日志中记录数据节点内存使用情况报告的频率; 它是一个整数值,表示报告之间的秒数。
每个数据节点的数据存储器和索引存储器使用情况都记录为 文件中
DataMemory设置 的百分比和32 KB页面的数量config.ini。 例如,如果DataMemory等于100 MB,并且给定数据节点使用50 MB进行数据内存存储,则群集日志中的相应行可能如下所示:2006-12-24 01:18:16 [MgmSrvr] INFO - 节点2:数据使用率为50%(1280个32K页,总计2560个)
MemReportFrequency不是必需参数。 如果使用,则可以为该[ndbd default]部分中的 所有集群数据节点设置,config.ini也可以为[ndbd]配置文件 的相应 部分中的 各个数据节点设置或覆盖它 。 最小值 - 也是默认值 - 为0,在这种情况下,仅当内存使用率达到某个百分比(80%,90%和100%)时才会记录内存报告,如 章节 中统计事件的讨论中所述 22.5.6.2,“NDB集群日志事件” 。 -
表22.139此表提供StartupStatusReportFrequency数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
当使用数据节点启动数据节点时
--initial,它会在启动阶段4期间初始化重做日志文件(请参见 第22.5.1节“NDB集群启动阶段摘要” )。 设置非常大的值时NoOfFragmentLogFiles,FragmentLogFileSize或两者 ,则此初始化可能需要很长时间。您可以通过StartupStatusReportFrequency配置参数 强制定期记录有关此过程进度的报告 。 在这种情况下,根据文件数和已初始化的空间量,在集群日志中报告进度,如下所示:2009-06-20 16:39:23 [MgmSrvr] INFO - 节点1:本地重做日志文件初始化状态: #Total files:80,已完成:60 #Total MBytes:20480,已完成:15557 2009-06-20 16:39:23 [MgmSrvr] INFO - 节点2:本地重做日志文件初始化状态: #Total files:80,已完成:60 #Total MBytes:20480,已完成:15570
StartupStatusReportFrequency在开始阶段4期间每秒 记录这些报告。 如果StartupStatusReportFrequency为0(默认值),则仅在重做日志文件初始化过程开始和完成时将报告写入群集日志。
数据节点调试参数
以下参数旨在用于测试或调试数据节点,而不是用于生产。
-
可以使用创建和删除表生成的事件记录跟踪
DictTrace。 此参数仅在调试NDB内核代码时有用。DictTrace取整数值。 0是默认值,表示不执行日志记录; 1启用跟踪日志记录,2启用其他DBDICT调试输出的 日志记录 。 -
表22.141此表提供WatchDogImmediateKill数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 布尔 默认 假 范围 真假 重启类型 小号
通过启用
WatchdogImmediateKill数据节点配置参数 ,可以在发生看门狗问题时立即终止线程 。 此参数仅在调试或故障排除时使用,以获取跟踪文件,以准确报告执行停止的瞬间发生的情况。
备份参数。
[ndbd]
本节中讨论
的
参数定义了为执行在线备份而预留的内存缓冲区。
-
表22.142此表提供BackupDataBufferSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 16M 范围 512K - 4294967039(0xFFFFFEFF) 重启类型 ñ
在创建备份时,有两个缓冲区用于将数据发送到磁盘。 备份数据缓冲区用于填充通过扫描节点表记录的数据。 一旦此缓冲区填充到指定的级别
BackupWriteSize,页面将被发送到磁盘。 在将数据刷新到磁盘时,备份过程可以继续填充此缓冲区,直到它用完空间。 发生这种情况时,备份过程会暂停扫描并等待,直到某些磁盘写入完成释放内存,以便继续扫描。此参数的默认值为16MB。 最低为512K。
-
表22.143此表提供BackupDiskWriteSpeedPct数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 百分 默认 50 范围 0 - 90 重启类型 ñ
在正常操作期间,数据节点尝试最大化用于本地检查点和备份的磁盘写入速度,同时保持在由
MinDiskWriteSpeed和 设置的范围内MaxDiskWriteSpeed。 磁盘写入限制为每个LDM线程提供了总预算的相等份额。 这允许在不超过磁盘I / O预算的情况下进行并行LCP。 因为备份仅由一个LDM线程执行,这有效地导致预算削减,导致备份完成时间更长,并且 - 如果更改率足够高 - 当备份日志缓冲区填充率为时,无法完成备份高于可实现的写入速率。可以使用
BackupDiskWriteSpeedPct配置参数 来解决此问题 ,该参数采用0-90(含)范围内的值,该值被解释为在共享预算剩余部分之前保留的节点最大写入速率预算的百分比LCP的LDM线程。 运行备份的LDM线程接收备份的整个写入速率预算,以及本地检查点的写入速率预算的(减少的)份额。此参数的默认值为50(解释为50%)。
-
表22.144此表提供BackupLogBufferSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 16M 范围 2M - 4294967039(0xFFFFFEFF) 重启类型 ñ
备份日志缓冲区履行与备份数据缓冲区类似的角色,但它用于生成在执行备份期间进行的所有表写入的日志。 与备份数据缓冲区一样,编写这些页面的原则相同,只是当备份日志缓冲区中没有更多空间时,备份将失败。 因此,备份日志缓冲区的大小必须足够大,以便在进行备份时处理由写入活动引起的负载。 请参见 第22.5.3.3节“NDB集群备份的配置” 。
对于大多数应用程序,此参数的默认值应该足够。 事实上,磁盘写入速度不足导致备份失败的可能性大于备份日志缓冲区变满的可能性。 如果没有为应用程序引起的写入负载配置磁盘子系统,则群集不太可能执行所需的操作。
最好以处理器成为瓶颈而不是磁盘或网络连接的方式配置群集节点。
此参数的默认值为16MB。
-
表22.145此表提供BackupMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 32M 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
不推荐使用此参数,并且在将来的NDB Cluster版本中将其删除。 对其进行的任何设置都将被忽略。
-
表22.146此表提供BackupReportFrequency数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数控制在备份期间在管理客户端中发布备份状态报告的频率,以及此类报告写入群集日志的频率(提供的群集事件日志记录配置为允许它 - 请参阅 日志记录和检查点 )。
BackupReportFrequency表示备份状态报告之间的时间(秒)。默认值为0。
-
表22.147此表提供BackupWriteSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 256K 范围 32K - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指定备份日志和备份数据缓冲区写入磁盘的消息的默认大小。
此参数的默认值为256KB。
-
表22.148此表提供BackupMaxWriteSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 1M 范围 256K - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指定备份日志和备份数据缓冲区写入磁盘的消息的最大大小。
此参数的默认值为1MB。
备份文件的位置由
BackupDataDir
数据节点配置参数
确定
。
其他要求。 指定这些参数时,以下关系必须成立。 否则,数据节点将无法启动。
-
BackupDataBufferSize >= BackupWriteSize + 188KB -
BackupLogBufferSize >= BackupWriteSize + 16KB -
BackupMaxWriteSize >= BackupWriteSize
NDB群集实时性能参数
[ndbd]
本节中讨论
的
参数用于调度和锁定多处理器数据节点主机上的特定CPU的线程。
要使用这些参数,必须以系统根目录运行数据节点进程。
-
表22.149此表提供LockExecuteThreadToCPU数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 一组CPU ID 默认 0 范围 ... 重启类型 ñ
与 ndbd一起 使用时 ,此参数(现在为字符串)指定分配用于处理
NDBCLUSTER执行线程 的CPU的ID 。 与 ndbmtd一起 使用时 ,此参数的值是分配给处理执行线程的以逗号分隔的CPU ID列表。 列表中的每个CPU ID应为0到65535(含)范围内的整数。指定的ID数应与确定的执行线程数相匹配
MaxNoOfExecutionThreads。 但是,使用此参数时,无法保证以任何给定顺序将线程分配给CPU。 您可以使用获得更细粒度的此类控件ThreadConfig。LockExecuteThreadToCPU没有默认值。 -
表22.150此表提供LockMaintThreadsToCPU数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 CPU ID 默认 0 范围 0 - 64K 重启类型 ñ
此参数指定分配用于处理
NDBCLUSTER维护线程 的CPU的ID 。该参数的取值范围为0~65535(含)之间的整数。 没有默认值 。
-
将此参数设置为1可以实现数据节点线程的实时调度。
默认值为0(禁用调度)。
-
表22.152此表提供SchedulerExecutionTimer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 微秒 默认 50 范围 0 - 11000 重启类型 ñ
此参数指定在发送之前在调度程序中执行的线程的时间(以微秒为单位)。 将其设置为0可以最大限度地缩短响应时间; 为了实现更高的吞吐量,您可以以更长的响应时间为代价来增加价值。
默认值为50微秒,我们的测试显示在高负载情况下略微增加吞吐量而不会大幅延迟请求。
-
表22.153此表提供SchedulerResponsiveness数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 五 范围 0 - 10 重启类型 小号
NDB在速度和吞吐量之间 设置 调度程序中 的余额 。 此参数采用整数,其值在0-10(含)范围内,默认值为5。 较高的值相对于吞吐量提供更好的响应时间。 较低的值以较长的响应时间为代价提供了增加的吞吐量。 -
表22.154此表提供SchedulerSpinTimer数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 微秒 默认 0 范围 0 - 500 重启类型 ñ
此参数指定在休眠之前在调度程序中执行的线程的时间(以微秒为单位)。
默认值为0。
-
表22.155此表提供BuildIndexThreads数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 128 范围 0 - 128 重启类型 小号
此参数确定在系统或节点启动期间以及运行 ndb_restore 时重建有序索引时要创建的线程数
--rebuild-indexes。 仅当每个数据节点的表有多个片段时才支持它(例如,何时COMMENT="NDB_TABLE=PARTITION_BALANCE=FOR_RA_BY_LDM_X_2"使用CREATE TABLE)。将此参数设置为0(默认值)将禁用有序索引的多线程构建。
您可以通过将
TwoPassInitialNodeRestartCopy数据节点配置参数 设置为,在数据节点初始重新启动期间启用多线程构建TRUE。 -
表22.156此表提供TwoPassInitialNodeRestartCopy数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 布尔 默认 真正 范围 真假 重启类型 ñ
通过将此配置参数设置为
true(默认值),可以 为数据节点的初始重新启动启用有序索引的多线程构建 ,从而在初始节点重新启动期间启用数据的双向复制。你还必须设置
BuildIndexThreads为非零值。 -
此参数确定非统一内存访问(NUMA)是由操作系统还是由数据节点进程控制,无论数据节点是使用 ndbd 还是 ndbmtd 。 默认情况下,
NDB尝试在主机操作系统提供NUMA支持的任何数据节点上使用交叉NUMA内存分配策略。设置
Numa = 0意味着datanode进程本身不会尝试设置内存分配策略,并允许操作系统确定此行为,这可能会由单独的 numactl 工具 进一步指导 。 也就是说,Numa = 0产生系统默认行为,可以通过 numactl 自定义 。 对于许多Linux系统,系统默认行为是在分配时为任何给定进程分配套接字本地内存。 使用 ndbmtd 时可能会出现问题 ; 这是因为 nbdmtd 在启动时分配所有内存,导致不平衡,为不同的套接字提供不同的访问速度,尤其是在主内存中锁定页面时。设置
Numa = 1意味着数据节点进程用于libnuma请求交叉存取器分配。 (这也可以在操作系统级别使用 numactl 手动完成 。)使用交错分配实际上告诉数据节点进程忽略非统一内存访问但不尝试利用快速本地内存; 相反,数据节点进程试图避免由于远程内存缓慢导致的不平衡。 如果不需要交叉分配,请设置Numa为0,以便可以在操作系统级别确定所需的行为。该
Numa配置参数只在Linux系统中支持libnuma.so可用。
多线程配置参数(ndbmtd)。
ndbmtd
默认运行为单线程进程,必须使用两种方法之一配置为使用多个线程,这两种方法都需要在
config.ini
文件中
设置配置参数
。
第一种方法是简单地为
MaxNoOfExecutionThreads
配置参数
设置适当的值
。
第二种方法可以为
ndbmtd
使用多线程
设置更复杂的规则
ThreadConfig
。
接下来的几段提供了有关这些参数及其与多线程数据节点一起使用的信息。
在数据节点上使用并行性的备份要求在进行备份之前,在群集中的所有数据节点上使用多个LDM。 有关更多信息,请参见 第22.5.3.5节“使用并行数据节点建立NDB” ,以及 第22.4.23.2节“从并行备份中恢复” 。
-
表22.158此表提供MaxNoOfExecutionThreads多线程数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 2 范围 2 - 72 重启类型 小号
此参数直接控制 ndbmtd 使用的执行线程数, 最多为72.虽然此参数设置在 文件的 部分
[ndbd]或[ndbd default]部分中config.ini,但它是 ndbmtd 独有的, 不适用于 ndbd 。设置
MaxNoOfExecutionThreads设置每种类型的线程数,由文件中的矩阵确定storage/ndb/src/kernel/vm/mt_thr_config.cpp。 此表显示了可能值的这些线程数MaxNoOfExecutionThreads。表22.159按线程类型(LQH,TC,发送,接收)的MaxNoOfExecutionThreads值和相应的线程数。
MaxNoOfExecutionThreads值LDM线程 TC线程 发送主题 接收线程 0 .. 3 1 0 0 1 4 .. 6 2 0 0 1 7 .. 8 4 0 0 1 9 4 2 0 1 10 4 2 1 1 11 4 3 1 1 12 6 2 1 1 13 6 3 1 1 14 6 3 1 2 15 6 3 2 2 16 8 3 1 2 17 8 4 1 2 18 8 4 2 2 19 8 五 2 2 20 10 4 2 2 21 10 五 2 2 22 10 五 2 3 23 10 6 2 3 24 12 五 2 3 25 12 6 2 3 26 12 6 3 3 27 12 7 3 3 28 12 7 3 4 29 12 8 3 4 三十 12 8 4 4 31 12 9 4 4 32 16 8 3 3 33 16 8 3 4 34 16 8 4 4 35 16 9 4 4 36 16 10 4 4 37 16 10 4 五 38 16 11 4 五 39 16 11 五 五 40 20 10 4 4 41 20 10 4 五 42 20 11 4 五 43 20 11 五 五 44 20 12 五 五 45 20 12 五 6 46 20 13 五 6 47 20 13 6 6 48 24 12 五 五 49 24 12 五 6 50 24 13 五 6 51 24 13 6 6 52 24 14 6 6 53 24 14 6 7 54 24 15 6 7 55 24 15 7 7 56 24 16 7 7 57 24 16 7 8 58 24 17 7 8 59 24 17 8 8 60 24 18 8 8 61 24 18 8 9 62 24 19 8 9 63 24 19 9 9 64 32 16 7 7 65 32 16 7 8 66 32 17 7 8 67 32 17 8 8 68 32 18 8 8 69 32 18 8 9 70 32 19 8 9 71 32 20 8 9 72 32 20 8 10
总有一个SUMA(复制)线程。
NoOfFragmentLogParts应设置为等于 ndbmtd 使用的LDM线程数, 由此参数的设置决定。 该比例不应大于4:1; 特别是不允许这种情况的配置。LDM线程的数量还决定了
NDB未明确分区 的 表 使用的 分区数; 这是LDM线程数乘以集群中数据节点数。 (如果 在数据节点而不是 ndbmtd 上使用 ndbd ,那么总会有一个LDM线程;在这种情况下,自动创建的分区数简单地等于数据节点数。请参见 第22.1.2节“NDB群集节点,节点组,副本和分区“ ,以获取更多信息。如果磁盘页面缓冲区不够大,则在使用超过默认数量的LDM线程时为磁盘数据表添加大型表空间可能会导致资源和CPU使用问题;
DiskPageBufferMemory有关详细信息, 请参阅 配置参数 的说明 。线程类型将在本节后面介绍(请参阅参考资料
ThreadConfig)。将此参数设置在允许的值范围之外会导致管理服务器在启动时中止,并显示错误 错误行
number:value参数MaxNoOfExecutionThreads的 非法值 。对于
MaxNoOfExecutionThreads,值0或1在内部向上舍入NDB为2,因此2被视为此参数的默认值和最小值。MaxNoOfExecutionThreads通常旨在将其设置为等于可用的CPU线程数,并分配适合于典型工作负载的每种类型的多个线程。 它不会将特定线程分配给指定的CPU。 对于需要改变所提供的设置或将线程绑定到CPU的情况,您应该使用ThreadConfig,这允许您将每个线程直接分配给所需的类型,CPU或两者。多线程数据节点进程始终至少生成此处列出的线程:
-
1个本地查询处理程序(LDM)线程
-
1接收线程
-
1个订阅管理器(SUMA或复制)线程
对于
MaxNoOfExecutionThreads值8或更小,不创建TC线程,而是由主线程执行TC处理。更改LDM线程的数量通常需要重新启动系统,无论是使用此参数更改还是
ThreadConfig,但是如果 满足以下两个条件 ,则可以使用节点初始重启( NI ) 来实现更改 :-
每个LDM线程最多处理8个片段,并且
-
表碎片的总数是LDM线程数的整数倍。
在NDB 8.0,在初始重新启动 不 要求以实现该参数的变化,因为它是在一些老版本的NDB集群。
-
-
表22.160此表提供NoOfFragmentLogParts多线程数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 4 范围 4,8,12,16,24,32 重启类型 在
设置属于此 ndbmtd的 重做日志的日志文件组数 。 最大值为32; 值集必须是4的偶数倍。
NoOfFragmentLogParts应设置为等于 ndbmtd 使用的LDM线程数, 由设置确定MaxNoOfExecutionThreads。 不允许每个LDM使用超过4个重做日志部分的配置。有关
MaxNoOfExecutionThreads详细信息, 请参阅说明 。 -
此参数与 ndbmtd 一起 使用, 以将不同类型的线程分配给不同的CPU。 它的值是一个字符串,其格式具有以下语法:
ThreadConfig:=
entry[,entry[,...]]entry:=type= {param[,param[,...]]}type:= ldm | 主要| recv | 发送| rep | io | tc | 看门狗| idxbldparam:= count =number| cpubind =cpu_list| cpuset =cpu_list| spintime =number| 实时= {0 | 1} | 是nosend = {0 | 1} | thread_prio = {0..10} | cpubind_exclusive =cpu_list| cpuset_exclusive =cpu_list即使列表中只有一个参数,也需要围绕参数列表 的花括号(
{...})。A
param(参数)指定以下任何或所有信息:-
给定类型(
count) 的线程数 。 -
给定类型的线程非独占地绑定到的CPU集合。 这由
cpubindorcpuset)中的 任何一个确定 。cpubind导致每个线程被绑定(非独占)到集合中的CPU;cpuset表示每个线程绑定(非独占)到指定的CPU集合。在Solaris上,您可以指定一组CPU,将给定类型的线程专门绑定到这些CPU。
cpubind_exclusive导致每个线程专门绑定到集合中的CPU;cpuset_exclsuive表示每个线程专门绑定到指定的CPU集。仅一个
cpubind,cpuset,cpubind_exclusive,或cpuset_exclusive可以在一个单一的结构提供。 -
spintime确定线程在进入休眠状态之前旋转的等待时间(以微秒为单位)。默认值为 数据节点配置参数
spintime的值SchedulerSpinTimer。spintime不适用于I / O线程,看门狗或脱机索引构建线程,因此无法为这些线程类型设置。 -
realtime可以设置为0或1.如果设置为1,则线程以实时优先级运行。 这也意味着thread_prio无法设置。该
realtime参数默认设置为RealtimeScheduler数据节点配置参数 的值 。realtime无法为脱机索引构建线程设置。 -
通过设置
nosend为1,可以阻止main,ldm,rep,或tc线程协助发送线程。 默认情况下,此参数为0,不能与其他类型的线程一起使用。 -
thread_prio是一个线程优先级,可以设置为0到10,其中10表示最高优先级。 默认值为5.此参数的精确效果是特定于平台的,将在本节后面介绍。无法为脱机索引构建线程设置线程优先级。
thread_prio设置和平台效果。
thread_prioLinux / FreeBSD,Solaris和Windows之间 的实现 有所不同。 在下面的列表中,我们依次讨论它对每个平台的影响:-
Linux和FreeBSD :我们映射
thread_prio到要提供给nice系统调用的值。 由于进程的较低的niceness值表示较高的进程优先级,因此增加thread_prio具有降低该nice值 的效果 。表22.162在Linux和FreeBSD上将thread_prio映射到nice值
thread_prio值nice值0 19 1 16 2 12 3 8 4 4 五 0 6 -4 7 -8 8 -12 9 -16 10 -20
某些操作系统可能提供20的最大进程良好级别,但并非所有目标版本都支持此级别; 因此,我们选择19作为
nice可以设置 的最大值 。 -
Solaris :
thread_prioSolaris上的设置使用如下表所示的映射设置Solaris FX优先级:表22.163 Solaris上thread_prio到FX优先级的映射
thread_prio值Solaris FX优先级0 15 1 20 2 25 3 三十 4 35 五 40 6 45 7 50 8 55 9 59 10 60
一个
thread_prio9设置映射在Solaris上的特殊FX优先级值59,这意味着操作系统还试图强行线程处理自己的CPU核心单独运行。 -
Windows :我们映射
thread_prio到传递给Windows APISetThreadPriority()函数 的Windows线程优先级值 。 此映射如下表所示:表22.164 thread_prio到Windows线程优先级的映射
thread_prio值Windows线程优先级 0 - 1 THREAD_PRIORITY_LOWEST2 - 3 THREAD_PRIORITY_BELOW_NORMAL4 - 5 THREAD_PRIORITY_NORMAL6 - 7 THREAD_PRIORITY_ABOVE_NORMAL8 - 10 THREAD_PRIORITY_HIGHEST
该
type属性表示NDB线程类型。count以下列表中提供了 支持的线程类型以及 每个 类型的允许 值 范围 :-
ldm:DBLQH处理数据的 本地查询处理程序( 内核块)。 使用的LDM线程越多,数据的分区越高。 每个LDM线程都维护自己的数据和索引分区集,以及它自己的重做日志。 设置的值ldm必须是值1,2,4,6,8,12,16,24或32中的一个。更改LDM线程数通常需要重新启动系统才能有效且安全地进行集群操作,在某些情况下会放宽此要求,如本节后面所述。 使用时也是如此
MaxNoOfExecutionThreads。当使用超过默认数量的LDM时,为磁盘数据表添加大型表空间(数百千兆字节或更多)可能会导致资源和CPU使用问题,如果
DiskPageBufferMemory不够大。 -
tc:事务协调器线程(DBTC内核块),包含正在进行的事务的状态。 TC线程的最大数量为32。最理想的是,每个新事务都可以分配给新的TC线程。 在大多数情况下,每2个LDM线程1个TC线程足以保证可以发生这种情况。 在与读取次数相比写入次数相对较少的情况下,可能每4 LQH线程仅需要1个TC线程来维持事务状态。 相反,在执行大量更新的应用程序中,TC线程与LDM线程的比率可能需要接近1(例如,3个TC线程到4个LDM线程)。
设置
tc为0会导致TC处理由主线程完成。 在大多数情况下,这实际上与将其设置为1相同。范围:0 - 32
-
main:数据字典和事务协调器(DBDIH和DBTC内核块),提供模式管理。 这总是由一个专用线程处理。范围:仅限1。
-
recv:接收线程(CMVMI内核块)。 每个接收线程处理一个或多个套接字,用于与NDB集群中的其他节点通信,每个节点有一个套接字。 NDB Cluster支持多个接收线程; 最多是16个这样的线程。范围:1 - 16
-
send:发送线程(CMVMI内核块)。 为了提高吞吐量,可以从一个或多个单独的专用线程(最多8个)执行发送。以前,所有线程都直接处理自己的发送; 这仍然可以通过将发送线程数设置为0来实现(当
MaxNoOfExecutionThreads设置小于10 时也会发生这种情况 )。 虽然这样做会对吞吐量产生重大影响,但在某些情况下也可以减少延迟。范围:0 - 16
-
rep:复制线程(SUMA内核块)。 异步复制操作始终由单个专用线程处理。范围:仅限1。
-
io:文件系统和其他杂项操作。 这些不是要求苛刻的任务,并且始终由单个专用I / O线程作为一个组进行处理。范围:仅限1。
-
watchdog:与此类型关联的参数设置实际上应用于多个线程,每个线程都有特定用途。 这些线程包括SocketServer线程,它接收来自其他节点的连接设置; 的SocketClient螺纹,它试图建立至其它节点的连接; 以及检查线程正在进行的线程监视程序线程。范围:仅限1。
-
idxbld:脱机索引构建线程。 与先前列出的永久性线程类型不同,这些是临时线程,仅在节点或系统重新启动期间或运行 ndb_restore 时创建和使用--rebuild-indexes。 它们可能绑定到与集合到永久线程类型的CPU集重叠的CPU集。thread_prio,realtime和,spintime无法为脱机索引构建线程设置值。 另外,count对于这种类型的线程会被忽略。如果
idxbld未指定,则默认行为如下:-
如果I / O线程也未绑定,则不绑定脱机索引构建线程,并且这些线程使用任何可用的核心。
-
如果绑定了I / O线程,则脱机索引构建线程将绑定到整个绑定线程集,因为这些线程不应执行其他任务。
范围:0 - 1。
-
-
ThreadCOnfig
正常
更改
需要系统初始重启,但在某些情况下可以放宽此要求:
-
如果在更改之后,LDM线程的数量保持与以前相同,则只需要简单的节点重新启动(滚动重启或 N )即可实现更改。
-
否则(即,如果LDM线程的数量发生变化),如果 满足以下两个条件 ,仍可以使用节点初始重启( NI ) 来实现更改 :
-
每个LDM线程最多处理8个片段,并且
-
表碎片的总数是LDM线程数的整数倍。
-
在任何其他情况下,需要系统初始重启才能更改此参数。
NDB
可以通过以下两个标准区分线程类型:
-
线程是否是执行线程。 类型的线程
main,ldm,recv,rep,tc,和send是执行线程;io,watchdog和idxbld线程不被视为执行线程。 -
是否为给定任务分配线程是永久性的还是临时性的。 目前除了
idxbld被认为是永久性的 所有线程类型idxbld线程被视为临时线程。
简单的例子:
#例1。
threadconfig.vi可= LDM = {计数= 2,cpubind = 1,2},主要= {cpubind = 12},代表= {cpubind = 11}
#例2。
threadconfig.vi可=主= {cpubind = 0},LDM = {计数= 4,cpubind = 1,2,5,6},IO = {cpubind = 3}
在为数据节点主机配置线程使用时,通常需要为操作系统和其他任务保留一个或多个CPU。
因此,对于具有24个CPU的主机,您可能需要使用20个CPU线程(其余4个用于其他用途),8个LDM线程,4个TC线程(LDM线程数量的一半),3个发送线程,3个接收线程,每个1个线程用于模式管理,异步复制和I
/ O操作。
(这与
MaxNoOfExecutionThreads
设置为20
时使用的线程分布几乎相同。
)以下
ThreadConfig
设置执行这些分配,另外将所有这些线程绑定到特定CPU:
ThreadConfig = ldm {count = 8,cpubind = 1,2,3,4,5,6,7,8},main = {cpubind = 9},io = {cpubind = 9},\
rep = {cpubind = 10},tc {count = 4,cpubind = 11,12,13,14},recv = {count = 3,cpubind = 15,16,17},\
发送{计数= 3,cpubind = 18,19,20}
在大多数情况下,应该可以将主(模式管理)线程和I / O线程绑定到同一个CPU,就像我们在刚刚显示的示例中所做的那样。
下面的示例结合使用这两种定义CPU的基团
cpuset
和
cpubind
,以及使用线程优先级的。
ThreadConfig = ldm = {count = 4,cpuset = 0-3,thread_prio = 8,spintime = 200},\
ldm = {count = 4,cpubind = 4-7,thread_prio = 8,spintime = 200},\
tc = {count = 4,cpuset = 8-9,thread_prio = 6},send = {count = 2,thread_prio = 10,cpubind = 10-11},\
主= {计数= 1,cpubind = 10},代表= {计数= 1,cpubind = 11}
在这种情况下,我们创建了两个LDM组;
第一次使用
cpubind
和第二次使用
cpuset
。
thread_prio
并
spintime
为每个组设置相同的值。
这意味着总共有8个LDM线程。
(您应该确保
NoOfFragmentLogParts
也设置为8.)四个TC线程仅使用两个CPU;
使用时
cpuset
可以指定比组中的线程更少的CPU。
(但事实并非如此
cpubind
。)发送线程使用两个线程
cpubind
将这些线程绑定到CPU 10和11.主线程和副线程可以重用这些CPU。
此示例显示了如何
ThreadConfig
以及
NoOfFragmentLogParts
可能为具有超线程的24-CPU主机设置,使CPU 10,11,22和23可用于操作系统功能和中断:
NoOfFragmentLogParts = 10
ThreadConfig = ldm = {count = 10,cpubind = 0-4,12-16,thread_prio = 9,spintime = 200},\
tc = {count = 4,cpuset = 6-7,18-19,thread_prio = 8},send = {count = 1,cpuset = 8},\
recv = {count = 1,cpuset = 20},main = {count = 1,cpuset = 9,21},rep = {count = 1,cpuset = 9,21},\
IO = {计数= 1,cpuset = 9,21,thread_prio = 8},看门狗= {计数= 1,cpuset = 9,21,thread_prio = 9}
接下来的几个例子包括的设置
idxbld
。
前两个演示了如何
idxbld
为其他(永久)线程类型指定
的CPU集合
重叠,第一个使用
cpuset
,第二个使用
cpubind
:
ThreadConfig = main,ldm = {count = 4,cpuset = 1-4},tc = {count = 4,cpuset = 5,6,7},\
IO = {cpubind = 8},idxbld = {cpuset = 1-8}
threadconfig.vi可=主,LDM = {计数= 1,cpubind = 1},idxbld = {计数= 1,cpubind = 1}
下一个示例指定I / O线程的CPU,但不指定索引构建线程的CPU:
ThreadConfig = main,ldm = {count = 4,cpuset = 1-4},tc = {count = 4,cpuset = 5,6,7},\
IO = {cpubind = 8}
由于
ThreadConfig
刚刚显示
的
设置将线程锁定到编号为1到8的八个核心,因此它等效于此处显示的设置:
ThreadConfig = main,ldm = {count = 4,cpuset = 1-4},tc = {count = 4,cpuset = 5,6,7},\
IO = {cpubind = 8},idxbld = {cpuset = 1,2,3,4,5,6,7,8}
为了利用提供的增强的稳定性,
ThreadConfig
有必要确保CPU是隔离的,并且它们不会受到中断,或者被操作系统安排用于其他任务。
在许多Linux系统,你可以通过设置这样做
IRQBALANCE_BANNED_CPUS
的
/etc/sysconfig/irqbalance
到
0xFFFFF0
,并通过使用
isolcpus
在启动选项
grub.conf
。
有关具体信息,请参阅操作系统或平台文档。
-
表22.165此表提供DiskPageBufferEntries数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 32K页 默认 10 范围 1 - 1000 重启类型 ñ
这是要分配的页面条目(页面引用)的数量。 它被指定为32K页的数量
DiskPageBufferMemory。 对于大多数情况,默认值已足够,但如果在磁盘数据表上遇到非常大的事务问题,则可能需要增加此参数的值。 每个页面条目大约需要100个字节。 -
表22.166此表提供DiskPageBufferMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 64M 范围 4M - 1T 重启类型 ñ
这决定了用于在磁盘上缓存页面的空间量,并 在 文件 的
[ndbd]或[ndbd default]部分中设置config.ini。 它以字节为单位。 每页占用32 KB。 这意味着NDB群集磁盘数据存储始终使用N* 32 KB内存,其中N是一些非负整数。此参数的默认值为
64M(2000页,每页32 KB)。如果将值
DiskPageBufferMemory设置得太低并且使用超过默认数量的LDM线程ThreadConfig(例如{ldm=6...}),则在尝试将大型(例如500G)数据文件添加到基于磁盘的NDB表时会出现问题,其中占用其中一个CPU内核时,该过程会无限期地持续。这是因为,作为向表空间添加数据文件的一部分,扩展页面被锁定到额外PGMAN工作线程的内存中,以便快速访问元数据。 添加大文件时,此工作程序没有足够的内存用于所有数据文件元数据。 在这种情况下,您应该增加
DiskPageBufferMemory或添加较小的表空间文件。 您可能还需要调整DiskPageBufferEntries。您可以查询该
ndbinfo.diskpagebuffer表以帮助确定是否应该增加此参数的值以最小化不必要的磁盘搜索。 有关 更多信息 , 请参见 第22.5.10.20节“ndbinfo diskpagebuffer表” 。 -
表22.167此表提供SharedGlobalMemory数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 128M 范围 0 - 64T 重启类型 ñ
此参数确定用于日志缓冲区,磁盘操作(如页面请求和等待队列)的内存量,以及表空间,日志文件组,
UNDO文件和数据文件的 元 数据。 共享全局内存池还提供用于满足UNDO_BUFFER_SIZE与CREATE LOGFILE GROUP和ALTER LOGFILE GROUP语句 一起使用 的 选项 的内存要求的内存 ,包括通过设置InitialLogFileGroup数据节点配置参数 对此选项隐含的任何默认值 。SharedGlobalMemory可以设置在。[ndbd]或[ndbd default]部分config.ini配置文件,以字节为单位。默认值为
128M。 -
表22.168此表提供DiskIOThreadPool数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 线程 默认 2 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数确定用于磁盘数据文件访问的未绑定线程数。 在
DiskIOThreadPool介绍 之前 ,每个磁盘数据文件只生成一个线程,这可能导致性能问题,尤其是在使用非常大的数据文件时。 使用DiskIOThreadPool,您可以 - 例如 - 使用多个并行工作的线程访问单个大型数据文件。此参数仅适用于磁盘数据I / O线程。
此参数的最佳值取决于您的硬件和配置,并包括以下因素:
-
磁盘数据文件的物理分布。 通过将数据文件,撤消日志文件和数据节点文件系统放在不同的物理磁盘上,可以获得更好的性能。 如果对部分或全部这些文件集执行此操作,则可以设置
DiskIOThreadPool更高级别以启用单独的线程来处理每个磁盘上的文件。 -
磁盘性能和类型。 磁盘数据文件处理可容纳的线程数也取决于磁盘的速度和吞吐量。 更快的磁盘和更高的吞吐量允许更多的磁盘I / O线程。 我们的测试结果表明,固态磁盘驱动器可以处理比传统磁盘更多的磁盘I / O线程,因此更高的值
DiskIOThreadPool。
此参数的默认值为2。
-
-
磁盘数据文件系统参数。 以下列表中的参数可以将NDB Cluster Disk Data文件放在特定目录中,而无需使用符号链接。
-
表22.169此表提供FileSystemPathDD数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 文件名 默认 [见文] 范围 ... 重启类型 在
如果指定了此参数,则NDB Cluster Disk Data数据文件和撤消日志文件将放置在指定的目录中。 这可以被改写为数据文件,撤消日志文件,或两者,通过用于指定值
FileSystemPathDataFiles,FileSystemPathUndoFiles或二者,作为这些参数说明。 它也可以通过在指定路径覆盖数据文件ADD DATAFILE的条款CREATE TABLESPACE或ALTER TABLESPACE语句,并撤消日志文件被在指定路径ADD UNDOFILE的条款CREATE LOGFILE GROUP或ALTER LOGFILE GROUP语句。 如果FileSystemPathDD未指定,则FileSystemPath使用。如果
FileSystemPathDD为给定数据节点指定 了 目录(包括在 文件[ndbd default]部分中 指定参数的情况config.ini),则启动该数据节点--initial会导致删除目录中的所有文件。 -
表22.170此表提供FileSystemPathDataFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 文件名 默认 [见文] 范围 ... 重启类型 在
如果指定了此参数,则NDB Cluster Disk Data数据文件将放置在指定的目录中。 这将覆盖为其设置的任何值
FileSystemPathDD。 通过在 用于创建该数据文件ADD DATAFILE的CREATE TABLESPACE或ALTER TABLESPACE语句 的 子句中 指定路径,可以为给定数据文件覆盖此参数 。 如果FileSystemPathDataFiles未指定,则FileSystemPathDD使用(或者FileSystemPath,如果FileSystemPathDD尚未设置)。如果
FileSystemPathDataFiles为给定数据节点指定 了 目录(包括在 文件[ndbd default]部分中 指定参数的情况config.ini),则启动该数据节点--initial会导致删除目录中的所有文件。 -
表22.171此表提供FileSystemPathUndoFiles数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 文件名 默认 [见文] 范围 ... 重启类型 在
如果指定了此参数,则NDB Cluster Disk Data撤消日志文件将放置在指示的目录中。 这将覆盖为其设置的任何值
FileSystemPathDD。 通过在 用于创建该数据文件ADD UNDO的CREATE LOGFILE GROUP或ALTER LOGFILE GROUP语句 的 子句中 指定路径,可以为给定数据文件覆盖此参数 。 如果FileSystemPathUndoFiles未指定,则FileSystemPathDD使用(或者FileSystemPath,如果FileSystemPathDD尚未设置)。如果
FileSystemPathUndoFiles为给定数据节点指定 了 目录(包括在 文件[ndbd default]部分中 指定参数的情况config.ini),则启动该数据节点--initial会导致删除目录中的所有文件。
有关更多信息,请参见 第22.5.13.1节“NDB集群磁盘数据对象” 。
-
-
磁盘数据对象创建参数。 接下来的两个参数使您 - 在第一次启动集群时 - 可以在不使用SQL语句的情况下创建磁盘数据日志文件组,表空间或两者。
-
表22.172此表提供InitialLogFileGroup数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 串 默认 [见文] 范围 ... 重启类型 小号
此参数可用于指定在执行集群的初始启动时创建的日志文件组。
InitialLogFileGroup如下所示指定:InitialLogFileGroup = [name =
name;] [undo_buffer_size =size;]file-specification-listfile-specification-list:file-specification[;file-specification[; ...]file-specification:filename:size该
name日志文件组是可选的,默认为DEFAULT-LG。 这undo_buffer_size也是可选的; 如果省略,则默认为64M。 每个file-specification对应一个撤消日志文件,并且必须至少指定一个file-specification-list。 撤消日志文件是根据已设定的任何值放置FileSystemPath,FileSystemPathDD和FileSystemPathUndoFiles,就好像他们已经作为的结果被创建CREATE LOGFILE GROUP或ALTER LOGFILE GROUP声明。考虑以下:
InitialLogFileGroup = name = LG1; undo_buffer_size = 128M; undo1.log:250M; undo2.log:150M
这相当于以下SQL语句:
创建LOGFILE GROUP LG1 添加UNDOFILE'undove1.log' INITIAL_SIZE 250M UNDO_BUFFER_SIZE 128M ENGINE NDBCLUSTER; ALTER LOGFILE GROUP LG1 添加UNDOFILE'undove2.log' INITIAL_SIZE 150M ENGINE NDBCLUSTER;在启动数据节点时创建此日志文件组
--initial。初始日志文件组的资源将添加到全局内存池以及值的值
SharedGlobalMemory。此参数(如果使用)应始终
[ndbd default]在config.ini文件 的 部分中 设置 。 未定义在不同数据节点上设置不同值时NDB群集的行为。 -
表22.173此表提供InitialTablespace数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 串 默认 [见文] 范围 ... 重启类型 小号
此参数可用于指定在执行群集的初始启动时创建的NDB群集磁盘数据表空间。
InitialTablespace如下所示指定:InitialTablespace = [name =
name;] [extent_size =size;]file-specification-list该
name表空间是可选的,默认为DEFAULT-TS。 这extent_size也是可选的; 它默认为1M。 在file-specification-list使用相同的语法如图所示与InitialLogfileGroup参数,唯一的区别是,每个file-specification与用于InitialTablespace对应的数据文件。 必须至少指定一个file-specification-list。 数据文件是根据已设定的任何值放置FileSystemPath,FileSystemPathDD和FileSystemPathDataFiles就好像它们是作为一个CREATE TABLESPACE或ALTER TABLESPACE声明 的结果而创建的 。例如,考虑下面的行指定
InitialTablespace在[ndbd default]所述的部分config.ini文件(如InitialLogfileGroup,该参数应该总是在设定[ndbd default]部中,作为NDB簇时的行为不同的值不同的数据节点上设置没有定义):InitialTablespace = name = TS1; extent_size = 8M; data1.dat:2G; data2.dat:4G
这相当于以下SQL语句:
创建TABLESPACE TS1 添加数据文件'data1.dat' EXTENT_SIZE 8M INITIAL_SIZE 2G ENGINE NDBCLUSTER; ALTER TABLESPACE TS1 添加数据文件'data2.dat' INITIAL_SIZE 4G ENGINE NDBCLUSTER;此表空间是在数据节点启动
--initial时创建的,并且可以在此后创建NDB Cluster Disk Data表时使用。
-
磁盘数据和GCP停止错误。
使用诸如
Node之
nodeid
类的磁盘数据表时遇到的错误
因为检测到GCP停止而导致该节点被终止
(错误2303)通常被称为
“
GCP停止错误
”
。
当重做日志没有足够快地刷新到磁盘时会发生这样的错误;
这通常是由于磁盘速度慢和磁盘吞吐量不足。
您可以通过使用更快的磁盘以及将磁盘数据文件放在与数据节点文件系统不同的磁盘上来帮助防止发生这些错误。
减少值
TimeBetweenGlobalCheckpoints
往往会减少为每个全局检查点写入的数据量,因此在尝试编写全局检查点时可以提供一些防止重做日志缓冲区溢出的保护。
但是,减少此值也会缩短编写GCP的时间,因此必须谨慎操作。
除了
DiskPageBufferMemory
前面解释
的考虑因素外,
DiskIOThreadPool
配置参数设置正确
也非常重要
;
其
DiskIOThreadPool
设置得太高,很容易造成GCP停止错误(错误#37227)。
GCP停止可能是由保存或提交超时引起的;
的
TimeBetweenEpochsTimeout
数据节点的配置参数决定提交的超时。
但是,可以通过将此参数设置为0来禁用这两种类型的超时。
配置发送缓冲区内存分配的参数。
发送缓冲区内存是从所有传输器之间共享的内存池动态分配的,这意味着可以根据需要调整发送缓冲区的大小。
(以前,NDB内核为集群中的每个节点使用固定大小的发送缓冲区,该节点在节点启动时分配,并且在节点运行时无法更改。)
TotalSendBufferMemory
和
OverLoadLimit
数据节点配置参数允许设置限制在这个内存分配上。
有关使用这些参数(以及
SendBufferMemory
)的
更多信息
,请参阅
第22.3.3.14节“配置NDB群集发送缓冲区参数”
。
-
此参数采用指定任何一组转运发送缓冲存储器除了分配量
TotalSendBufferMemory,SendBufferMemory或两者。 -
此参数用于确定在此节点上为所有已配置的传输器之间的共享发送缓冲区内存分配的内存总量。
如果设置了此参数,则其最小允许值为256KB; 0表示尚未设置参数。 有关更多详细信息,请参见 第22.3.3.14节“配置NDB集群发送缓冲区参数” 。
另请参见 第22.5.15节“在线添加NDB集群数据节点” 。
重做日志过度提交处理。
当花费太多时间将重做日志刷新到磁盘时,可以控制数据节点对操作的处理。
当给定的重做日志刷新花费的时间超过
RedoOverCommitLimit
秒,超过
RedoOverCommitCounter
几次,导致任何挂起的事务被中止
时,就会发生这种情况
。
发生这种情况时,发送事务的API节点可以处理应该通过排队操作并重新尝试它们或通过中止它们来提交的操作,如下所示:
DefaultOperationRedoProblemAction
。
以下列表中描述了用于设置超时和API节点执行此操作之前可能超过的次数的数据节点配置参数:
-
表22.174此表提供RedoOverCommitCounter数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 数字 默认 3 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
当
RedoOverCommitLimit尝试将给定的重做日志写入磁盘多次或多次时,超过任何未作为结果提交的事务将被中止,并且发起任何这些事务的API节点处理构成这些事务的操作。它的值DefaultOperationRedoProblemAction(通过排队重新尝试的操作或中止它们)。RedoOverCommitCounter默认为3.将其设置为0以禁用限制。 -
表22.175此表提供RedoOverCommitLimit数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 秒 默认 20 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数设置在超时之前尝试将给定的重做日志写入磁盘的上限(以秒为单位)。 数据节点尝试刷新此重做日志但需要更长时间的次数将
RedoOverCommitLimit被保留并与之进行比较RedoOverCommitCounter,并且当刷新时间比该参数的值花费的时间长得多时,任何未提交的事务都是由于刷新超时中止。 发生这种情况时,发起任何这些事务的API节点根据其DefaultOperationRedoProblemAction设置 处理组成这些事务 的操作(它将要重新尝试的操作排队,或者中止它们)。默认情况下,
RedoOverCommitLimit是20秒。 设置为0以禁用检查重做日志刷新超时。
控制重启尝试。
当数据节点无法开始使用
MaxStartFailRetries
和
StartFailRetryDelay
数据节点配置参数
时,可以对数据节点的重启尝试进行细粒度控制
。
MaxStartFailRetries
限制在放弃启动数据节点之前所做的重试总次数,
StartFailRetryDelay
设置重试尝试之间的秒数。
这些参数列在这里:
-
表22.176此表提供StartFailRetryDelay数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
使用此参数可设置启动失败时数据节点重启尝试之间的秒数。 默认值为0(无延迟)。
MaxStartFailRetries除非StopOnError等于0, 否则将忽略 此参数和 。 -
表22.177此表提供MaxStartFailRetries数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 3 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
使用此参数可以限制数据节点在启动时失败时重新尝试的次数。 默认值为3次尝试。
StartFailRetryDelay除非StopOnError等于0, 否则将忽略 此参数和 。
NDB索引统计参数。 以下列表中的参数与NDB索引统计信息生成有关。
-
表22.178此表提供IndexStatAutoCreate数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0,1 重启类型 小号
创建索引时启用(设置等于1)或禁用(设置等于0)自动统计信息收集。 默认情况下禁用。
-
表22.179此表提供IndexStatAutoUpdate数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0,1 重启类型 小号
启用(设置等于1)或禁用(设置等于0)监视索引以进行更改并触发检测到的自动统计信息更新。 触发更新所需的更改量和更改程度由
IndexStatTriggerPct和IndexStatTriggerScale选项 的设置决定 。 -
表22.180此表提供IndexStatSaveSize数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 32768 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 在
允许
NDB系统表和 mysqld 内存缓存 中任何给定索引的已保存统计信息的最大空间(以字节为单位) 。无论任何尺寸限制,始终至少生成一个样品。 此尺寸按比例缩放
IndexStatSaveScale。指定的大小由 大索引
IndexStatSaveSize的值缩放IndexStatTriggerPct,乘以0.01。 这进一步乘以索引大小的基数2的对数。 设置IndexStatTriggerPct等于0将禁用缩放效果。 -
表22.181此表提供IndexStatSaveScale数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 百分比 默认 100 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 在
指定的大小由 大索引
IndexStatSaveSize的值缩放IndexStatTriggerPct,乘以0.01。 这进一步乘以索引大小的基数2的对数。 设置IndexStatTriggerPct等于0将禁用缩放效果。 -
表22.182此表提供IndexStatTriggerPct数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 百分比 默认 100 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 在
触发索引统计信息更新的更新的百分比更改。 该值按比例缩放
IndexStatTriggerScale。 您可以通过设置IndexStatTriggerPct为0来 完全禁用此触发器 。 -
表22.183此表提供IndexStatTriggerScale数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 百分比 默认 100 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 在
IndexStatTriggerPct对于大型索引,按此数量 缩放 0.01倍。 值为0将禁用缩放。 -
表22.184此表提供IndexStatUpdateDelay数据节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 秒 默认 60 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 在
给定索引的自动索引统计信息更新之间的最小延迟(秒)。 将此变量设置为0可禁用任何延迟。 默认值为60秒。
文件中
的
[mysqld]
和
[api]
部分
config.ini
定义MySQL服务器(SQL节点)和用于访问群集数据的其他应用程序(API节点)的行为。
所示参数均不是必需的。
如果未提供计算机或主机名,则任何主机都可以使用此SQL或API节点。
一般来说,一
[mysqld]
节用于表示为集群提供SQL接口的MySQL服务器,一
[api]
节用于
访问集群数据的
mysqld
进程
以外的应用程序
,但这两个名称实际上是同义词;
例如,您可以列出作为节中的SQL节点的MySQL服务器的参数
[api]
。
有关NDB Cluster的MySQL服务器选项的讨论,请参见 第22.3.3.9.1节“NDB集群的MySQL服务器选项” 。 有关与NDB群集相关的MySQL服务器系统变量的信息,请参见 第22.3.3.9.2节“NDB群集系统变量” 。
-
这
Id是一个整数值,用于标识所有集群内部消息中的节点。 允许的值范围是1到255(包括1和255)。 无论节点类型如何,此值对于群集中的每个节点都必须是唯一的。注意无论使用何种NDB Cluster版本,数据节点ID都必须小于49。 如果计划部署大量数据节点,最好将API节点(和管理节点)的节点ID限制为大于48的值。
NodeId是标识API节点时使用的首选参数名称。 (Id继续支持向后兼容性,但现在已弃用,并在使用时生成警告。它也可能在将来删除。) -
指定要连接的数据节点。
-
这
NodeId是一个整数值,用于标识所有集群内部消息中的节点。 允许的值范围是1到255(包括1和255)。 无论节点类型如何,此值对于群集中的每个节点都必须是唯一的。注意无论使用何种NDB Cluster版本,数据节点ID都必须小于49。 如果计划部署大量数据节点,最好将API节点(和管理节点)的节点ID限制为大于48的值。
NodeId是标识管理节点时使用的首选参数名称。 别名,Id在非常旧版本的NDB Cluster中用于此目的,并且继续支持向后兼容性; 它现在已被弃用,并在使用时生成警告,并且在将来的NDB Cluster版本中将被删除。 -
表22.188此表提供ExecuteOnComputer API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 名称 默认 [没有] 范围 ... 重启类型 小号
这是指 配置文件的
Id某个[computer]部分中 定义的计算机(主机)之一 的 集合 。重要不推荐使用此参数,并且在将来的版本中将删除此参数。 请改用
HostName参数。 -
指定此参数定义SQL节点(API节点)所驻留的计算机的主机名。 要指定主机名,请使用此参数或者
ExecuteOnComputer是必需的。如果不
HostName在 文件ExecuteOnComputer的给定[mysql]或[api]部分中 或未 指定config.ini,则SQL或API节点可以使用 来自可以与管理服务器主机建立网络连接的任何主机 的相应 “ 槽 ” 进行连接。 这与数据节点的默认行为不同localhost,HostName除非另有说明 , 否则将采用 此行为 。 -
表22.190此表提供LocationDomainId API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 16 重启类型 小号
将SQL或其他API节点分配 给云中 的特定 可用性域 (也称为可用区)。 通过告知
NDB哪些节点位于哪些可用域中,可以通过以下方式在云环境中提高性能:-
如果在同一节点上找不到请求的数据,则可以将读取定向到同一可用性域中的另一个节点。
-
保证不同可用域中的节点之间的通信使用
NDB传输器的WAN支持,而无需任何进一步的手动干预。 -
传输器的组编号可以基于使用的可用域,使得SQL和其他API节点也尽可能与同一可用性域中的本地数据节点通信。
-
可以从没有数据节点的可用性域中选择仲裁器,或者如果没有找到这样的可用域,则可以从第三可用性域中选择仲裁器。
LocationDomainId取0到16之间的整数值,其中0是默认值; 使用0与保留参数unset相同。 -
-
表22.191此表提供ArbitrationRank API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 0-2 默认 0 范围 0 - 2 重启类型 ñ
此参数定义哪些节点可以充当仲裁者。 管理节点和SQL节点都可以是仲裁者。 值0表示给定节点从不用作仲裁器,值1表示节点作为仲裁器具有高优先级,值2表示低优先级。 正常配置使用管理服务器作为仲裁程序,将其设置
ArbitrationRank为1(管理节点的默认值),将所有SQL节点的值设置为0(SQL节点的默认值)。通过
ArbitrationRank在所有管理和SQL节点上 设置 为0,可以完全禁用仲裁。 您还可以通过覆盖此参数来控制仲裁; 为此,请 在 全局配置文件Arbitration的[ndbd default]部分中 设置 参数config.ini。 -
表22.192此表提供ArbitrationDelay API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 毫秒 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
将此参数设置为除0(默认值)之外的任何其他值意味着仲裁器对仲裁请求的响应将延迟指定的毫秒数。 通常没有必要更改此值。
-
表22.193此表提供BatchByteSize API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 16K 范围 1K - 1M 重启类型 ñ
对于转换为索引的全表扫描或范围扫描的查询,以最佳性能获取正确大小的批处理记录非常重要。 可以根据记录数(
BatchSize)和字节数(BatchByteSize) 来设置适当的大小 。 实际批量大小受两个参数的限制。执行查询的速度可能会有40%以上的变化,具体取决于此参数的设置方式。
此参数以字节为单位。 默认值为16K。
-
此参数以记录数量度量,默认设置为256.最大值为992。
-
表22.195此表提供ExtraSendBufferMemory API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数指定转运发送缓冲存储器除了分配给已使用设置的任何的量
TotalSendBufferMemory,SendBufferMemory或两者。 -
表22.196此表提供HeartbeatThreadPriority API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 串 默认 [没有] 范围 ... 重启类型 小号
使用此参数可以为管理和API节点设置心跳线程的调度策略和优先级。 设置此参数的语法如下所示:
HeartbeatThreadPriority =
policy[,priority]policy: {FIFO | RR}设置此参数时,必须指定策略。 这是 (先进先出)
FIFO或RR(循环赛)之一。 这可选地由优先级(整数)跟随。 -
表22.197此表提供MaxScanBatchSize API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 256K 范围 32K - 16M 重启类型 ñ
批量大小是从每个数据节点发送的每个批次的大小。 大多数扫描是并行执行的,以防止MySQL服务器并行地从多个节点接收太多数据; 此参数设置所有节点上总批量大小的限制。
此参数的默认值设置为256KB。 它的最大尺寸是16MB。
-
表22.198此表提供TotalSendBufferMemory API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 256K - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数用于确定在此节点上为所有已配置的传输器之间的共享发送缓冲区内存分配的内存总量。
如果设置了此参数,则其最小允许值为256KB; 0表示尚未设置参数。 有关更多详细信息,请参见 第22.3.3.14节“配置NDB集群发送缓冲区参数” 。
-
此参数
false默认为。 这会强制断开连接的API节点(包括充当SQL节点的MySQL服务器)使用与群集的新连接,而不是尝试重新使用现有连接,因为重新使用连接会在使用动态分配的节点ID时导致问题。 (缺陷号45921)注意可以使用NDB API覆盖此参数。 有关更多信息,请参阅 Ndb_cluster_connection :: set_auto_reconnect() 和 Ndb_cluster_connection :: get_auto_reconnect() 。
-
DefaultOperationRedoProblemAction表22.200此表提供DefaultOperationRedoProblemAction API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 列举 默认 队列 范围 ABORT,QUEUE 重启类型 小号
当将太多时间刷新到磁盘时, 此参数(以及
RedoOverCommitLimit和RedoOverCommitCounter)控制数据节点对操作的处理。 当给定的重做日志刷新花费的时间超过RedoOverCommitLimit秒,超过RedoOverCommitCounter几次,导致任何挂起的事务被中止 时,就会发生这种情况 。发生这种情况时,节点可以按照以下两种方式之一进行响应
DefaultOperationRedoProblemAction:-
ABORT:来自中止事务的任何挂起操作也将中止。 -
QUEUE:来自已中止的事务的待处理操作排队等待重新尝试。 这是默认值。 当重做日志空间 不足 时( 即 发生 P_TAIL_PROBLEM 错误时 ),待处理操作仍会中止 。
-
-
表22.201此表提供DefaultHashMapSize API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 水桶 默认 3840 范围 0 - 3840 重启类型 ñ
使用的表哈希映射的大小
NDB可使用此参数进行配置。DefaultHashMapSize可以采用三个可能的值中的任何一个(0,240,380)。 这些值及其影响如下表所述。表22.202 DefaultHashMapSize参数值
值 描述/效果 0在集群中的所有数据节点和API节点中使用此参数的最小值集(如果有); 如果未在任何数据或API节点上设置,请使用默认值。 240旧的默认哈希映射大小 3840NDB 8.0中默认使用的哈希映射大小
此参数的最初预期用途是促进旧版NDB Cluster版本的升级和降级,其中哈希映射大小不同,因为此更改不是向后兼容的。 升级到NDB Cluster 8.0或从NDB Cluster 8.0降级时,这不是问题。
-
使用WAN TCP设置作为默认设置。
-
表22.204此表提供ConnectBackoffMaxTime API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在具有许多未启动数据节点的NDB群集中,可以提高此参数的值以规避对尚未开始在群集中运行的数据节点的连接尝试,以及管理节点的中等高流量。 只要API节点未连接到任何新数据节点,
StartConnectBackoffMaxTime就会应用参数 的值 ; 否则,ConnectBackoffMaxTime用于确定连接尝试之间等待的时间长度(以毫秒为单位)。时间流逝 过程中 节点的连接尝试计算经过的时间这个参数时,没有考虑到。 超时以大约100 ms的分辨率应用,从100 ms延迟开始; 对于每次后续尝试,此周期的长度加倍,直到达到
ConnectBackoffMaxTime毫秒,最大为100000毫秒(100秒)。一旦API节点连接到数据节点并且该节点报告(在心跳消息中)它已连接到其他数据节点,对这些数据节点的连接尝试不再受此参数的影响,并且此后每100毫秒进行一次。直到连接 数据节点启动后,可以
HeartbeatIntervalDbApi通知API节点发生这种情况。 -
表22.205此表提供StartConnectBackoffMaxTime API节点配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在具有许多未启动数据节点的NDB群集中,可以提高此参数的值以规避对尚未开始在群集中运行的数据节点的连接尝试,以及管理节点的中等高流量。 只要API节点未连接到任何新数据节点,
StartConnectBackoffMaxTime就会应用参数 的值 ; 否则,ConnectBackoffMaxTime用于确定连接尝试之间等待的时间长度(以毫秒为单位)。时间流逝 过程中 节点的连接尝试计算经过的时间这个参数时,没有考虑到。 超时以大约100 ms的分辨率应用,从100 ms延迟开始; 对于每次后续尝试,此周期的长度加倍,直到达到
StartConnectBackoffMaxTime毫秒,最大为100000毫秒(100秒)。一旦API节点连接到数据节点并且该节点报告(在心跳消息中)它已连接到其他数据节点,对这些数据节点的连接尝试不再受此参数的影响,并且此后每100毫秒进行一次。直到连接 数据节点启动后,可以
HeartbeatIntervalDbApi通知API节点发生这种情况。
API节点调试参数。
您可以使用
ApiVerbose
configuration参数启用给定API节点的调试输出。
此参数采用整数值。
0是默认值,并禁用此类调试;
1启用调试输出到集群日志;
2还增加了
DBDICT
调试输出。
(缺陷号20638450)另见
DUMP 1229
。
您还可以
SHOW
STATUS
在
mysql
客户端中
使用作为NDB Cluster SQL节点运行的MySQL服务器获取信息
,如下所示:
MySQL的> SHOW STATUS LIKE 'ndb%';
+ ----------------------------- + ---------------- +
| Variable_name | 价值|
+ ----------------------------- + ---------------- +
| Ndb_cluster_node_id | 5 |
| Ndb_config_from_host | 198.51.100.112 |
| Ndb_config_from_port | 1186 |
| Ndb_number_of_storage_nodes | 4 |
+ ----------------------------- + ---------------- +
4行(0.02秒)
有关此语句的输出中出现的状态变量的信息,请参见 第22.3.3.9.3节“NDB集群状态变量” 。
要将新的SQL或API节点添加到正在运行的NDB群集的配置中,必须在向
文件
添加新的
[mysqld]
或
[api]
部分
之后执行所有群集节点的滚动重新启动
config.ini
(或者,如果您使用多个管理服务器,则为文件) 。
必须在新的SQL或API节点连接到群集之前完成此操作。
这是 不 必要执行群集的任何重新启动,如果新的SQL或API节点可以使用以前未使用的API槽在群集配置以连接到群集。
该
[system]
部分用于作为整体应用于集群的参数。
该
Name
系统参数与MySQL企业监控器;
ConfigGenerationNumber
并且
PrimaryMGMNode
不用于生产环境。
除了将NDB Cluster与MySQL Enterprise Monitor一起使用外,没有必要
[system]
在
config.ini
文件中
包含一个
部分
。
有关这些参数的更多信息,请参见以下列表:
-
表22.206此表提供ConfigGenerationNumber系统配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
配置生成号。 此参数当前未使用。
-
设置群集的名称。 使用MySQL Enterprise Monitor进行部署时需要此参数; 否则就不用了。
您可以通过检查
Ndb_system_name状态变量 来获取此参数的 值。 在NDB API应用程序中,您还可以使用它来检索它get_system_name()。 -
表22.208此表提供PrimaryMGMNode系统配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
主管理节点的节点ID。 此参数当前未使用。
本节提供有关特定于NDB Cluster的MySQL服务器选项,服务器和状态变量的信息。 有关使用这些的一般信息,以及其他不特定于NDB Cluster的选项和变量,请参见 第5.1节“MySQL服务器” 。
有关群集配置文件(通常命名
config.ini
)中
使用的NDB群集配置参数
,请参见
第22.3节“NDB群集的配置”
。
本节提供 与NDB Cluster相关 的 mysqld 服务器选项的 说明 。 有关 不特定于NDB Cluster的 mysqld 选项的 信息 ,以及有关使用 mysqld 选项的一般信息 ,请参见 第5.1.7节“服务器命令选项” 。
有关与其他NDB集群进程(
ndbd
,
ndb_mgmd
和
ndb_mgm
)
一起使用的命令行选项的信息
,请参见
第22.4.31节“NDB集群程序常用选项 - NDB集群程序常用选项”
。
有关与
NDB
实用程序
一起使用的命令行选项
(例如
ndb_desc
,
ndb_size.pl
和
ndb_show_tables
)的信息,请参见
第22.4节“NDB群集程序”
。
-
表22.209 ndbcluster的类型和值信息
属性 值 名称 ndbcluster命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 默认,范围 FALSE(版本:8.0) 笔记 描述:启用NDB集群(如果此版本的MySQL支持它)
残疾人
--skip-ndbcluster。
该
NDBCLUSTER存储引擎是必要的使用NDB簇。 如果 mysqld 二进制文件包含对NDBCLUSTER存储引擎的 支持,则 默认情况下会禁用引擎。 使用该--ndbcluster选项启用它。 使用--skip-ndbcluster明确的禁止发动机。如果 也使用 该
--ndbcluster选项,则忽略 该 选项(并且 未 启用NDB存储引擎 ) 。 (同时使用此选项既不必要也不可取 。)--initialize--initialize -
--ndb-allow-copying-alter-table=[ON|OFF]表22.210 ndb-allow-copying-alter-table的类型和值信息
属性 值 名称 ndb-allow-copying-alter-table命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 ON(版本:8.0) 笔记 描述:设置为OFF以防止ALTER TABLE在NDB表上使用复制操作
让
ALTER TABLE和其他DDL语句对NDB表 使用复制操作 。 设置为OFF防止这种情况发生; 这样做可以提高关键应用程序的性能。 -
表22.211 ndb-batch-size的类型和值信息
属性 值 名称 ndb-batch-size命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 32768/0-31536000(版本:8.0) 笔记 描述:用于NDB事务批处理的大小(以字节为单位)
这将设置用于NDB事务批处理的大小(以字节为单位)。
-
--ndb-cluster-connection-pool=#表22.212 ndb-cluster-connection-pool的类型和值信息
属性 值 名称 ndb-cluster-connection-pool命令行 是 系统变量 是 状态变量 是 选项文件 是 范围 全球 动态 没有 类型 默认,范围 1/1 - 63(版本:8.0) 笔记 描述:MySQL使用的集群的连接数
通过将此选项设置为大于1的值(默认值), mysqld 进程可以使用与群集的多个连接,从而有效地模仿多个SQL节点。 每个连接都需要 在cluster configuration( )文件中 拥有自己的 部分
[api]或[mysqld]部分config.ini,并根据群集支持的最大API连接数进行计数。假设您有2台集群主机,每台运行一个 启动了 mysqld 进程 的SQL节点
--ndb-cluster-connection-pool=4; 这意味着群集必须有8个API插槽可用于这些连接(而不是2)。 所有这些连接都是在SQL节点连接到群集时设置的,并以循环方式分配给线程。只有在 具有多个CPU,多个核心或两者的主机上 运行 mysqld 时,此选项才有 用。 为获得最佳结果,该值应小于主机上可用的核心总数。 将其设置为大于此值的值可能会严重降低性能。
重要因为每个使用连接池的SQL节点占用多个API节点插槽 - 每个插槽在集群中都有自己的节点ID - 所以在启动任何 采用连接池的 mysqld 进程时, 不得 将节点ID用作集群连接字符串的一部分 。
使用该
--ndb-cluster-connection-pool选项 时在连接字符串中设置节点ID 会导致SQL节点尝试连接到群集时出现节点ID分配错误。 -
--ndb-cluster-connection-pool-nodeids=list表22.213 ndb-cluster-connection-pool-nodeids的类型和值信息
属性 值 名称 ndb-cluster-connection-pool-nodeids命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 /(版本:8.0) 笔记 描述:以逗号分隔的节点ID列表,用于连接MySQL使用的集群; 列表中的节点数必须与为--ndb-cluster-connection-pool设置的值相同
指定用于连接到SQL节点使用的集群的节点ID的逗号分隔列表。 此列表中的节点数必须与为该
--ndb-cluster-connection-pool选项 设置的值相同 。 -
--ndb-blob-read-batch-bytes=bytes表22.214 ndb-blob-read-batch-bytes的类型和值信息
属性 值 名称 ndb-blob-read-batch-bytes命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 65536/0-4294967295(版本:NDB 8.0) 笔记 描述:指定应该批量处理大型BLOB读取的大小(以字节为单位)。 0 =没有限制。
此选项可用于设置
BLOB在NDB Cluster应用程序中 批量处理 数据 的大小(以字节为单位) 。 当该批量大小超过BLOB当前事务中要读取 的 数据 量时,BLOB将立即执行 任何挂起的 读取操作。此选项的最大值为4294967295; 默认值为65536.将其设置为0具有禁用
BLOB读取批处理 的效果 。注意在NDB API应用程序中,您可以
BLOB使用setMaxPendingBlobReadBytes()和getMaxPendingBlobReadBytes()方法 控制 写入批处理 。 -
--ndb-blob-write-batch-bytes=bytes表22.215 ndb-blob-write-batch-bytes的类型和值信息
属性 值 名称 ndb-blob-write-batch-bytes命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 65536/0-4294967295(版本:8.0) 笔记 描述:指定应批量处理大型BLOB写入的大小(以字节为单位)。 0 =没有限制。
此选项可用于设置
BLOB在NDB Cluster应用程序中 批量处理 数据 的大小(以字节为单位) 。 当BLOB要在当前事务中写入 的 数据 量超过此批量大小时 ,BLOB将立即执行 任何挂起的 写入操作。此选项的最大值为4294967295; 默认值为65536.将其设置为0具有禁用
BLOB写入批处理 的效果 。注意在NDB API应用程序中,您可以
BLOB使用setMaxPendingBlobWriteBytes()和getMaxPendingBlobWriteBytes()方法 控制 写入批处理 。 -
--ndb-connectstring=connection_string表22.216 ndb-connectstring的类型和值信息
属性 值 名称 ndb-connectstring命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 默认,范围 (版本:8.0) 笔记 描述:指向分发群集配置的管理服务器
使用
NDBCLUSTER存储引擎时,此选项指定分发群集配置数据的管理服务器。 有关 语法, 请参见 第22.3.3.3节“NDB集群连接字符串” 。 -
--ndb-default-column-format=[FIXED|DYNAMIC]表22.217 ndb-default-column-format的类型和值信息
属性 值 名称 ndb-default-column-format命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 DYNAMIC / FIXED,DYNAMIC(版本:NDB 8.0) 默认,范围 FIXED / FIXED,DYNAMIC(版本:NDB 8.0) 笔记 描述:在向表创建或添加列时,默认情况下为COLUMN_FORMAT和ROW_FORMAT选项使用此值(FIXED或DYNAMIC)。
设置默认值
COLUMN_FORMAT和ROW_FORMAT新表(请参见 第13.1.20节“CREATE TABLE语法” )。 默认是FIXED。 -
--ndb-deferred-constraints=[0|1]表22.218 ndb-deferred-constraints的类型和值信息
属性 值 名称 ndb-deferred-constraints命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 0/0 - 1(版本:8.0) 笔记 描述:指定对唯一索引(支持这些索引)的约束检查应该延迟到提交时间。 通常不需要或使用; 仅用于测试目的。
控制是否将对唯一索引的约束检查推迟到提交时间,此时支持此类检查。
0是默认值。NDB群集或NDB群集复制的操作通常不需要此选项,主要用于测试。
-
表22.219 ndb-schema-dist-timeout的类型和值信息
属性 值 名称 ndb-schema-dist-timeout命令行 是 系统变量 是 选项文件 是 范围 全球 动态 没有 类型:默认,范围 整数:120/5 - 1200(版本:8.0.17) 笔记 描述:在模式分发期间检测超时之前等待多长时间
指定此 mysqld 在将其标记为超时之前等待架构操作完成 的最长时间(以秒为单位) 。
-
--ndb-distribution=[KEYHASH|LINHASH]表22.220 ndb-distribution的类型和值信息
属性 值 名称 ndb-distribution命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 KEYHASH / LINHASH,KEYHASH(版本:8.0) 笔记 描述:NDBCLUSTER中新表的默认分布(KEYHASH或LINHASH,默认为KEYHASH)
控制
NDB表 的默认分配方法 。 可以设置为KEYHASH(键散列)或LINHASH(线性散列)。KEYHASH是默认值。 -
表22.221 ndb-log-apply-status的类型和值信息
属性 值 名称 ndb-log-apply-status命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:使MySQL服务器充当从属服务器,使用自己的服务器ID记录从其直接主服务器接收的mysql.ndb_apply_status更新。 仅在使用--ndbcluster选项启动服务器时有效。
使从属 mysqld
mysql.ndb_apply_status使用自己的服务器ID而不是主服务器ID 将从其直接主 服务器 接收的任何更新记录到 其自己的二进制日志中 的 表中。 在循环或链复制设置中,这允许此类更新传播到mysql.ndb_apply_status配置为当前 mysqld的 从属的任何MySQL服务器 的 表中 。在链复制设置中,使用此选项允许下游(从)群集了解它们相对于所有上游贡献者(主服务器)的位置。
在循环复制设置中,此选项会导致更改
ndb_apply_status表的 完成整个电路,最终传播回原始NDB集群。 这也允许作为主人的集群查看其变化(时期)何时应用于圆中的其他集群。除非使用该
--ndbcluster选项 启动MySQL服务器,否则此选项无效 。 -
--ndb-log-empty-epochs=[ON|OFF]表22.222 ndb-log-empty-epochs的类型和值信息
属性 值 名称 ndb-log-empty-epochs命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:启用时,即使启用了--log-slave-updates,也会将没有更改的时期写入ndb_apply_status和ndb_binlog_index表。
导致没有更改的时期被写入
ndb_apply_status和ndb_binlog_index表,即使--log-slave-updates启用了。默认情况下,此选项被禁用。 禁用
--ndb-log-empty-epochs导致没有更改的纪元事务不会被写入二进制日志,尽管即使是空的纪元仍然写入一行ndb_binlog_index。由于
--ndb-log-empty-epochs=1原因的尺寸ndb_binlog_index表独立于二进制日志的大小的增加,用户应该做好准备来管理这个表的增长,即使他们所期望的集群被闲置的很大一部分时间。 -
--ndb-log-empty-update=[ON|OFF]表22.223 ndb-log-empty-update的类型和值信息
属性 值 名称 ndb-log-empty-update命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:启用后,即使启用了--log-slave-updates,也会导致无法将更改生成的更新写入ndb_apply_status和ndb_binlog_index表。
导致无法将更改生成的更新写入
ndb_apply_status和ndb_binlog_index表,即使--log-slave-updates已启用也是如此。默认情况下,此选项被禁用(
OFF)。 禁用--ndb-log-empty-update会导致更新而不会将更改写入二进制日志。 -
--ndb-log-exclusive-reads=[0|1]表22.224 ndb-log-exclusive-reads的类型和值信息
属性 值 名称 ndb-log-exclusive-reads命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 0(版本:8.0) 笔记 描述:使用独占锁记录主键读取; 允许基于读取冲突解决冲突
使用此选项启动服务器会导致使用独占锁记录主键读取,从而允许基于读取冲突进行NDB群集复制冲突检测和解决。 您还可以通过将
ndb_log_exclusive_reads系统变量 的值 分别 设置 为1或0来 在运行时启用和禁用这些锁 。 0(禁用锁定)是默认值。有关更多信息,请参阅 读取冲突检测和解决方案 。
-
表22.225 ndb-log-orig的类型和值信息
属性 值 名称 ndb-log-orig命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:在mysql.ndb_binlog_index表中记录发起服务器id和epoch
在
ndb_binlog_index表中 记录原始服务器ID和纪元 。注意这使得给定时期可以具有多个行
ndb_binlog_index,每个 行 用于每个始发时期。有关更多信息,请参见 第22.6.4节“NDB集群复制架构和表” 。
-
表22.226 ndb-log-transaction-id的类型和值信息
属性 值 名称 ndb-log-transaction-id命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:在二进制日志中写入NDB事务ID。 需要--log-bin-v1-events = OFF。
使从属 mysqld 在二进制日志的每一行中写入NDB事务ID。 此类日志记录需要使用二进制日志的第2版事件格式; 因此,
--log-bin-use-v1-row-events必须设置FALSE为使用此选项。主线MySQL Server 8.0不支持此选项。 需要使用该
NDB$EPOCH_TRANS()功能 启用NDB群集复制冲突检测和解决 (请参阅 NDB $ EPOCH_TRANS() )。默认值为
FALSE。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
表22.227 ndb-log-update-minimal的类型和值信息
属性 值 名称 ndb-log-update-minimal命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:NDB 8.0) 默认,范围 OFF(版本:NDB 8.0) 默认,范围 OFF(版本:NDB 8.0) 笔记 描述:以最小格式记录更新。
通过仅在前映像中写入主键值,并且仅在后映像中写入更改的列,以最小的方式记录更新。 如果复制到除以外的存储引擎,这可能会导致兼容性问题
NDB。 -
表22.228 ndb-mgmd-host的类型和值信息
属性 值 名称 ndb-mgmd-host命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 默认,范围 localhost:1186(版本:8.0) 笔记 描述:设置主机(和端口,如果需要)以连接到管理服务器
可用于设置要连接到的程序的单个管理服务器的主机和端口号。 如果程序在其连接信息中需要节点ID或对多个管理服务器(或两者)的引用,请改用该
--ndb-connectstring选项。 -
表22.229 ndb-nodeid的类型和值信息
属性 值 名称 ndb-nodeid命令行 是 系统变量 没有 状态变量 是 选项文件 是 范围 全球 动态 没有 类型 默认,范围 / 1 - 63(版本:NDB 8.0) 默认,范围 / 1 - 255(版本:NDB 8.0) 笔记 描述:此MySQL服务器的NDB群集节点ID
在NDB集群中设置此MySQL服务器的节点ID。
无论使用哪两个选项的顺序, 该
--ndb-nodeid选项都会覆盖任何设置的节点ID--ndb-connectstring。此外,如果
--ndb-nodeid使用,则必须在一个[mysqld]或[api]一部分中 找到匹配的节点IDconfig.ini,或者文件中必须有 “ 打开 ”[mysqld]或[api]部分(即,没有NodeId或Id指定 参数 )。 如果将节点ID指定为连接字符串的一部分,也是如此。无论如何确定节点ID,它都显示为
Ndb_cluster_node_id输出中 的全局状态变量的值SHOW STATUS,并且cluster_node_id在connection输出 的 行中显示SHOW ENGINE NDBCLUSTER STATUS。有关NDB Cluster SQL节点的节点ID的更多信息,请参见 第22.3.3.7节“在NDB集群中定义SQL和其他API节点” 。
-
表22.230 ndbinfo的类型和值信息
属性 值 名称 ndbinfo命令行 是 系统变量 没有 选项文件 没有 范围 动态 没有 类型:默认,范围 枚举:ON,OFF,FORCE(版本:8.0.13) 笔记 描述:启用ndbinfo插件(如果支持)
启用
ndbinfo信息数据库 的插件 。 默认情况下,只要NDBCLUSTER启用, 它就会 为 ON 。 -
--ndb-optimization-delay=milliseconds表22.231 ndb-optimization-delay的类型和值信息
属性 值 名称 ndb-optimization-delay命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 是 类型 默认,范围 10/0 - 100000(版本:8.0) 笔记 描述:设置NDB表上OPTIMIZE TABLE处理行集之间等待的毫秒数
设置
OPTIMIZE TABLE表上 的 语句 在行集之间等待的毫秒数NDB。 默认值为10。 -
--ndb-recv-thread-activation-threshold=threshold表22.232 ndb-recv-thread-activation-threshold的类型和值信息
属性 值 名称 ndb-recv-thread-activation-threshold命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 默认,范围 8/0(MIN_ACTIVATION_THRESHOLD) - 16(MAX_ACTIVATION_THRESHOLD)(版本:NDB 8.0) 笔记 描述:接收线程接管集群连接轮询时的激活阈值(在并发活动线程中测量)
当达到此并发活动线程数时,接收线程将接管群集连接的轮询。
-
--ndb-recv-thread-cpu-mask=bitmask表22.233 ndb-recv-thread-cpu-mask的类型和值信息
属性 值 名称 ndb-recv-thread-cpu-mask命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 默认,范围 [空](版本:8.0) 笔记 描述:用于将接收器线程锁定到特定CPU的CPU掩码; 指定为十六进制。 请参阅文档了解详细信
设置CPU掩码以将接收器线程锁定到特定CPU。 这被指定为十六进制位掩码; 例如,
0x33表示每个接收器线程使用一个CPU。 默认情况下,空字符串(没有锁定接收器线程)。 -
ndb-transid-mysql-connection-map=state表22.234 ndb-transid-mysql-connection-map的类型和值信息
属性 值 名称 ndb-transid-mysql-connection-map命令行 是 系统变量 没有 状态变量 没有 选项文件 没有 范围 动态 没有 类型 默认,范围 ON / ON,OFF,FORCE(版本:8.0) 笔记 描述:启用或禁用ndb_transid_mysql_connection_map插件; 也就是说,启用或禁用具有该名称的INFORMATION_SCHEMA表
启用或禁用处理 数据库
ndb_transid_mysql_connection_map中表 的插件INFORMATION_SCHEMA。 所采用的值中的一个ON,OFF或FORCE。ON(默认值)启用插件。OFF禁用插件,这使得ndb_transid_mysql_connection_map无法访问。FORCE如果插件无法加载并启动,则会阻止MySQL Server启动。您可以
ndb_transid_mysql_connection_map通过检查输出来查看表插件是否正在运行SHOW PLUGINS。 -
表22.235 ndb-wait-connected的类型和值信息
属性 值 名称 ndb-wait-connected命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 0/0 - 31536000(版本:8.0) 默认,范围 30/0 - 31536000(版本:NDB 8.0) 默认,范围 0/0 - 31536000(版本:8.0) 默认,范围 30/0 - 31536000(版本:NDB 8.0) 笔记 描述:MySQL服务器在接受MySQL客户端连接之前等待连接到集群管理和数据节点的时间(以秒为单位)
此选项设置MySQL服务器在接受MySQL客户端连接之前等待与NDB群集管理和数据节点建立连接的时间段。 时间以秒为单位指定。 默认值为
30。 -
表22.236 ndb-wait-setup的类型和值信息
属性 值 名称 ndb-wait-setup命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 15/0 - 31536000(版本:NDB 8.0) 默认,范围 15/0 - 31536000(版本:NDB 8.0) 默认,范围 15/0 - 31536000(版本:NDB 8.0) 默认,范围 30/0 - 31536000(版本:NDB 8.0) 默认,范围 15/0 - 31536000(版本:NDB 8.0) 默认,范围 30/0 - 31536000(版本:NDB 8.0) 笔记 描述:MySQL服务器等待NDB引擎设置完成的时间(以秒为单位)
此变量显示MySQL服务器
NDB在超时和NDB视为不可用 之前 等待 存储引擎完成设置的时间段 。 时间以秒为单位指定。 默认值为30。 -
表22.237 server-id-bits的类型和值信息
属性 值 名称 server-id-bits命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 32/7 - 32(版本:8.0) 笔记 描述:设置实际用于标识服务器的server_id中的最低有效位数,允许NDB API应用程序以最高有效位存储应用程序数据。 server_id必须小于此值的2的幂。
此选项指示32位
server_id中实际标识服务器 的最低有效位数 。 表示服务器实际上是由少于32个比特识别使得能够对一些剩余位被用于其它目的,例如存储由使用内的NDB API的事件的API的应用程序生成的用户数据AnyValue的的OperationOptions结构(NDB簇用来AnyValue存储服务器ID)。从
server_id检测复制循环等目的中 提取有效服务器ID时 ,服务器会忽略其余位。 在决定是否应根据服务器ID忽略事件时, 该--server-id-bits选项用于屏蔽server_idIO和SQL线程中的 任何不相关位 。这个数据可以通过 mysqlbinlog 从二进制日志中读取 ,前提是它运行时自己的
--server-id-bits选项设置为32(默认值)。值
server_id必须小于2 ^server_id_bits; 否则, mysqld 拒绝启动。该系统变量仅由NDB Cluster支持。 标准MySQL 8.0服务器不支持它。
-
表22.238 skip-ndbcluster的类型和值信息
属性 值 名称 skip-ndbcluster命令行 是 系统变量 没有 状态变量 没有 选项文件 是 范围 动态 没有 类型 笔记 描述:禁用NDB Cluster存储引擎
禁用
NDBCLUSTER存储引擎。 这是使用NDBCLUSTER存储引擎支持 构建的二进制文件的默认值 ; 仅当--ndbcluster明确给出选项时 ,服务器才为此存储引擎分配内存和其他资源 。 有关 示例 , 请参见 第22.3.1节“NDB集群的快速测试设置” 。
本节提供有关特定于NDB群集和
NDB
存储引擎的
MySQL服务器系统变量的详细信息
。
有关非NDB Cluster特有的系统变量,请参见
第5.1.8节“服务器系统变量”
。
有关使用系统变量的一般信息,请参见
第5.1.9节“使用系统变量”
。
-
表22.239 ndb_autoincrement_prefetch_sz的类型和值信息
属性 值 名称 ndb_autoincrement_prefetch_sz命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 32/1 - 256(版本:8.0) 默认,范围 1/1 - 256(版本:NDB 8.0) 默认,范围 32/1 - 256(版本:NDB 8.0) 默认,范围 1/1 - 256(版本:NDB 8.0) 默认,范围 32/1 - 256(版本:NDB 8.0) 默认,范围 1/1 - 256(版本:NDB 8.0) 默认,范围 32/1 - 256(版本:NDB 8.0) 默认,范围 1/1 - 256(版本:NDB 8.0) 默认,范围 1/1 - 65536(版本:NDB 8.0) 默认,范围 32/1 - 256(版本:NDB 8.0) 默认,范围 1/1 - 65536(版本:NDB 8.0) 默认,范围 1/1 - 65536(版本:NDB 8.0) 笔记 描述:NDB自动增量预取大小
确定自动增量列中间隙的概率。 将其设置
1为最小化此值。 将其设置为高值以进行优化会使插入更快,但会降低在一批插入中使用连续自动增量数的可能性。 最小值和默认值为1.最大值为ndb_autoincrement_prefetch_sz65536。此变量仅影响
AUTO_INCREMENT语句之间获取 的 ID 数 ; 在给定语句中,一次获得至少32个ID。 默认值为1。重要此变量不会影响使用的插入
INSERT ... SELECT。 -
表22.240 ndb_cache_check_time的类型和值信息
属性 值 名称 ndb_cache_check_time命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 0 / - (版本:8.0) 笔记 描述:MySQL查询缓存对集群SQL节点进行检查之间的毫秒数
MySQL查询缓存检查NDB Cluster SQL节点之间经过的毫秒数。 将此值设置为0(默认值和最小值)意味着查询缓存会检查每个查询的验证。
此变量的建议最大值为1000,这意味着每秒执行一次检查。 值越大意味着执行检查并且可能由于不常更新SQL节点上的更新而无效。 通常不希望将其设置为大于2000的值。
注意ndb_cache_check_timeMySQL 5.7中不推荐使用 查询缓存 ; 在MySQL 8.0中删除了查询缓存。 -
表22.241 ndb_clear_apply_status的类型和值信息
属性 值 名称 ndb_clear_apply_status命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 是 类型 默认,范围 ON(版本:8.0) 笔记 描述:导致RESET SLAVE清除ndb_apply_status表中的所有行; 默认为ON
默认情况下,执行
RESET SLAVE会导致NDB Cluster复制从站清除其ndb_apply_status表中的 所有行 。 您可以通过设置禁用此功能ndb_clear_apply_status=OFF。 -
表22.242 ndb_data_node_neighbour的类型和值信息
属性 值 名称 ndb_data_node_neighbour命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 0/0 - 255(版本:NDB 8.0) 笔记 描述:指定与此MySQL服务器“最接近”的集群数据节点,用于事务提示和完全复制的表
设置 “ 最近 ” 数据节点 的ID, 即选择执行事务的首选非本地数据节点,而不是在与SQL或API节点相同的主机上运行的节点。 这用于确保在访问完全复制的表时,我们在此数据节点上访问它,以确保始终使用表的本地副本。 这也可以用于提供交易提示。
在物理上比同一主机上的其他节点更接近并因此具有更高网络吞吐量的节点的情况下,这可以改善数据访问时间。
有关详细 信息, 请参见 第13.1.20.11节“设置NDB_TABLE选项” 。
注意set_data_node_neighbour()提供了 一种 在NDB API应用程序中使用 的等效方法 。 -
表22.243 ndb_default_column_format的类型和值信息
属性 值 名称 ndb_default_column_format命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 DYNAMIC / FIXED,DYNAMIC(版本:NDB 8.0) 默认,范围 FIXED / FIXED,DYNAMIC(版本:NDB 8.0) 笔记 描述:设置用于新NDB表的默认行格式和列格式(FIXED或DYNAMIC)
设置默认值
COLUMN_FORMAT和ROW_FORMAT新表(请参见 第13.1.20节“CREATE TABLE语法” )。 默认是FIXED。 -
表22.244 ndb_deferred_constraints的类型和值信息
属性 值 名称 ndb_deferred_constraints命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 0/0 - 1(版本:8.0) 笔记 描述:指定应延迟约束检查(支持这些检查)。 通常不需要或使用; 仅用于测试目的。
控制是否延迟约束检查,支持这些检查。
0是默认值。NDB群集或NDB群集复制的操作通常不需要此变量,主要用于测试。
-
表22.245 ndb_distribution的类型和值信息
属性 值 名称 ndb_distribution命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 KEYHASH / LINHASH,KEYHASH(版本:8.0) 笔记 描述:NDBCLUSTER中新表的默认分布(KEYHASH或LINHASH,默认为KEYHASH)
控制
NDB表 的默认分配方法 。 可以设置为KEYHASH(键散列)或LINHASH(线性散列)。KEYHASH是默认值。 -
表22.246 ndb_eventbuffer_free_percent的类型和值信息
属性 值 名称 ndb_eventbuffer_free_percent命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 20/1 - 99(版本:8.0) 笔记 描述:在达到ndb_eventbuffer_max_alloc设置的限制之后,在恢复缓冲之前应该在事件缓冲区中可用的可用内存百分比
设置分配给事件缓冲区(ndb_eventbuffer_max_alloc)的最大内存的百分比,该值在达到最大值之后应在事件缓冲区中可用,然后再次开始缓冲。
-
表22.247 ndb_eventbuffer_max_alloc的类型和值信息
属性 值 名称 ndb_eventbuffer_max_alloc命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 0/0 - 4294967295(版本:8.0) 笔记 描述:NDB API可以为缓冲事件分配的最大内存。 默认为0(无限制)。
设置NDB API可为缓冲事件分配的最大内存量(以字节为单位)。 0表示不施加限制,是默认值。
-
表22.248 ndb_extra_logging的类型和值信息
属性 值 名称 ndb_extra_logging命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 0 / - (版本:8.0) 默认,范围 1 / - (版本:NDB 8.0) 笔记 描述:控制MySQL错误日志中NDB群集架构,连接和数据分发事件的日志记录
此变量允许在MySQL错误日志中记录特定于
NDB存储引擎的信息。当此变量设置为0时,
NDB写入MySQL错误日志 的唯一特定信息 与事务处理有关。 如果设置为大于0但小于10的值,NDB则还会记录表模式和连接事件,以及是否正在使用冲突解决方案以及其他NDB错误和信息。 如果该值设置为10或更多,则有关NDB内部的 信息 (例如群集节点之间的数据分发进度)也会写入MySQL错误日志。 默认值为1。 -
表22.249 ndb_force_send的类型和值信息
属性 值 名称 ndb_force_send命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 TRUE(版本:8.0) 笔记 描述:强制立即向NDB发送缓冲区,而不等待其他线程
强制
NDB立即 发送缓冲区 ,而不等待其他线程。 默认为ON。 -
表22.250 ndb_fully_replicated的类型和值信息
属性 值 名称 ndb_fully_replicated命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 OFF(版本:NDB 8.0) 笔记 描述:是否完全复制了新的NDB表
确定是否
NDB完全复制 新 表。 这个设置可以覆盖使用单个表COMMENT="NDB_TABLE=FULLY_REPLICATED=..."中CREATE TABLE或ALTER TABLE陈述; 有关语法和其他信息, 请参见 第13.1.20.11节“设置NDB_TABLE选项” 。 -
表22.251 ndb_index_stat_enable的类型和值信息
属性 值 名称 ndb_index_stat_enable命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 OFF(版本:8.0) 默认,范围 ON(版本:NDB 8.0) 笔记 描述:在查询优化中使用NDB索引统计信息
NDB在查询优化中 使用 索引统计信息 默认是ON。 -
表22.252 ndb_index_stat_option的类型和值信息
属性 值 名称 ndb_index_stat_option命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 loop_enable = 1000ms,loop_idle = 1000ms,loop_busy = 100ms,update_batch = 1,read_batch = 4,idle_batch = 32,check_batch = 8,check_delay = 10m,delete_batch = 8,clean_delay = 1m,error_batch = 4,error_delay = 1m,evict_batch = 8,evict_delay = 1m,cache_limit = 32M,cache_lowpct = 90,zero_total = 0(版本:8.0) 默认,范围 loop_checkon = 1000ms,loop_idle = 1000ms,loop_busy = 100ms,update_batch = 1,read_batch = 4,idle_batch = 32,check_batch = 32,check_delay = 1m,delete_batch = 8,clean_delay = 0,error_batch = 4,error_delay = 1m,evict_batch = 8,evict_delay = 1m,cache_limit = 32M,cache_lowpct = 90(版本:NDB 8.0) 笔记 描述:以逗号分隔的NDB索引统计信息可调选项列表; 列表不应包含空格
此变量用于为NDB索引统计信息生成提供调整选项。 该列表由选项名称和值的逗号分隔的名称 - 值对组成,此列表不得包含任何空格字符。
设置时未使用的选项未
ndb_index_stat_option从默认值更改。 例如,您可以设置ndb_index_stat_option = 'loop_idle=1000ms,cache_limit=32M'。时间值可以选择以
h(小时),m(分钟)或s(秒) 为后缀 。 可以选择使用ms; 指定毫秒值 ; 毫秒值不能使用指定h,m或s。)整数的值可以与后缀K,M或G。可以使用此变量设置的选项名称显示在下表中。 该表还提供了选项的简要说明,默认值以及(如果适用)其最小值和最大值。
表22.253 ndb_index_stat_option选项和值
名称 描述 默认/单位 最小/最大 loop_enable1000毫秒 0 / 4G loop_idle闲暇时睡觉的时间 1000毫秒 0 / 4G loop_busy有更多工作在等待时间 100毫秒 0 / 4G update_batch1 0 / 4G read_batch4 1 / 4G idle_batch32 1 / 4G check_batch8 1 / 4G check_delay检查新统计数据的频率 10米 1 / 4G delete_batch8 0 / 4G clean_delay1米 0 / 4G error_batch4 1 / 4G error_delay1米 1 / 4G evict_batch8 1 / 4G evict_delay从读取时间清除LRU缓存 1米 0 / 4G cache_limit此 mysqld 用于缓存索引统计信息的最大内存量(以字节为单位) ; 超过此值时清理缓存。 32 M 0 / 4G cache_lowpct90 0/100 zero_total将此值设置为1会将所有累计计数器复位 ndb_index_stat_status为0.完成此操作后,此选项值也会重置为0。0 0/1
-
表22.254 ndb_join_pushdown的类型和值信息
属性 值 名称 ndb_join_pushdown命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 TRUE(版本:NDB 8.0) 笔记 描述:允许将联接下推到数据节点
此变量控制是否将
NDB表上的 联接 下推到NDB内核(数据节点)。 以前,使用NDBSQL节点的 多次访问来处理连接 ; 但是,当ndb_join_pushdown启用时,可推送的连接被完整地发送到数据节点,在那里它可以在数据节点之间分布并且在数据的多个副本上并行执行,其中单个合并的结果被返回到 mysqld 。 这可以大大减少SQL节点与处理此类连接所需的数据节点之间的往返次数。默认情况下,
ndb_join_pushdown已启用。NDB下推加入的条件。 为了使连接可以推送,它必须满足以下条件:
-
只能比较列,并且要连接的所有列必须使用 完全相同 的数据类型。
这意味着 无法按下 表达式 ,以及(例如) 列和 列上的连接也无法下推。
t1.a = t2.a +constantINTBIGINT -
不支持显式锁定; 但是,
NDB强制执行存储引擎特有的隐式基于行的锁定。这意味着
FOR UPDATE无法下推 使用连接 。 -
为了使加盟下推,在加入子表必须使用的一个访问
ref,eq_ref或const访问方法,或这些方法的一些组合。外连接子表只能使用
eq_ref。如果推送的连接的根是
eq_ref或者const,则只能eq_ref附加 由连接的子表 。 (连接的表ref很可能成为另一个推送连接的根。)如果查询优化器决定
Using join cache候选子表,则该表不能作为子表推送。 但是,它可能是另一组推送表的根。 -
加入引用通过明确分区表
[LINEAR] HASH,LIST或RANGE目前尚无法下推。
您可以通过检查来查看是否可以推送给定的连接
EXPLAIN; 当连接可以推下来,你可以看到引用pushed join的Extra输出列,如本例所示:mysql>
EXPLAIN- >SELECT e.first_name, e.last_name, t.title, d.dept_name- >FROM employees e- >JOIN dept_emp de ON e.emp_no=de.emp_no- >JOIN departments d ON d.dept_no=de.dept_no- >JOIN titles t ON e.emp_no=t.emp_no\G*************************** 1。排******************** ******* id:1 select_type:SIMPLE 表:d 类型:全部 possible_keys:PRIMARY key:NULL key_len:NULL ref:NULL 行:9 额外:4的父母推动加入@ 1 *************************** 2.排******************** ******* id:1 select_type:SIMPLE 表:de 类型:ref possible_keys:PRIMARY,emp_no,dept_no key:dept_no key_len:4 ref:employees.d.dept_no 行:5305 额外:'d'的孩子被推入加入@ 1 *************************** 3。排******************** ******* id:1 select_type:SIMPLE 表:e 类型:eq_ref possible_keys:PRIMARY 关键:主要 key_len:4 ref:employees.de.emp_no 行:1 额外:'de'的孩子被推入加入@ 1 ****************************排******************** ******* id:1 select_type:SIMPLE 表:t 类型:ref possible_keys:PRIMARY,emp_no key:emp_no key_len:4 ref:employees.de.emp_no 行:19 额外:推入加入@ 1的'e'的孩子 4行(0.00秒)注意如果内连接子表连接
ref, 并且 结果按排序索引排序或分组,则此索引不能提供排序行,这会强制写入已排序的临时文件。有关推送连接性能的另外两个信息源可供使用:
-
状态变量
Ndb_pushed_queries_defined,Ndb_pushed_queries_dropped,Ndb_pushed_queries_executed,和Ndb_pushed_reads。 -
ndbinfo.counters表中 的计数器 属于DBSPJ内核块。 有关这些计数器的信息 , 请参见 第22.5.10.10节“ndbinfo计数器表” 。 另请参阅 “ NDB Cluster API开发人员指南” 中的 “DBSPJ块 ” 。
-
-
表22.255 ndb_log_apply_status的类型和值信息
属性 值 名称 ndb_log_apply_status命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:作为从属服务器的MySQL服务器是否使用自己的服务器ID记录从其直接主服务器接收的mysql.ndb_apply_status更新
一个只读变量,显示服务器是否已使用该
--ndb-log-apply-status选项 启动 。 -
表22.256 ndb_log_bin的类型和值信息
属性 值 名称 ndb_log_bin命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 ON(版本:8.0) 笔记 描述:在二进制日志中写入NDB表的更新。 仅当使用--log-bin启用二进制日志记录时才有效。
导致
NDB要写入二进制日志的表的 更新 。 如果在服务器上尚未启用二进制日志记录,则此变量的设置无效log_bin。 在NDB 8.0.16及更高版本中,ndb_log_bin默认为0(FALSE)。 -
表22.257 ndb_log_binlog_index的类型和值信息
属性 值 名称 ndb_log_binlog_index命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 是 类型 默认,范围 ON(版本:8.0) 笔记 描述:将时期和二进制日志位置之间的映射插入到ndb_binlog_index表中。 默认为ON。 仅在服务器上启用二进制日志记录时有效。
导致将纪元映射到二进制日志中的位置以插入
ndb_binlog_index表中。 如果尚未为使用的服务器启用二进制日志记录,则设置此变量无效log_bin。 (此外,ndb_log_bin不得禁用。)ndb_log_binlog_index默认为1(ON); 通常,在生产环境中永远不需要更改此值。 -
表22.258 ndb_log_empty_epochs的类型和值信息
属性 值 名称 ndb_log_empty_epochs命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:启用后,即使启用了log_slave_updates,也会向ndb_apply_status和ndb_binlog_index表写入没有更改的时期
当此变量设置为0时,没有更改的纪元事务不会写入二进制日志,尽管即使对于空纪元仍然写入一行
ndb_binlog_index。 -
表22.259 ndb_log_empty_update的类型和值信息
属性 值 名称 ndb_log_empty_update命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:启用后,即使启用了log_slave_updates,也会将不产生更改的更新写入ndb_apply_status和ndb_binlog_index表
当此变量设置为
ON(1)时,即使--log-slave-updates启用 了二进制日志,也会将没有更改的更新事务写入二进制日志 。 -
表22.260 ndb_log_exclusive_reads的类型和值信息
属性 值 名称 ndb_log_exclusive_reads命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 0(版本:8.0) 笔记 描述:使用独占锁记录主键读取; 允许基于读取冲突解决冲突
此变量确定是否使用独占锁记录主键读取,这允许基于读取冲突进行NDB群集复制冲突检测和解决。 要启用这些锁定,请将值设置
ndb_log_exclusive_reads为1. 0,这将禁用此类锁定,这是默认值。有关更多信息,请参阅 读取冲突检测和解决方案 。
-
表22.261 ndb_log_orig的类型和值信息
属性 值 名称 ndb_log_orig命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:始发服务器的id和epoch是否记录在mysql.ndb_binlog_index表中。 启动mysqld时使用--ndb-log-orig选项进行设置。
显示是否在
ndb_binlog_index表 中记录了原始服务器ID和纪元 。 使用--ndb-log-orig服务器选项 设置 。 -
表22.262 ndb_log_transaction_id的类型和值信息
属性 值 名称 ndb_log_transaction_id命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 没有 类型 默认,范围 OFF(版本:8.0) 笔记 描述:是否将NDB事务ID写入二进制日志(只读)。
此只读布尔系统变量显示从属 mysqld 是否 在二进制日志中写入NDB事务ID(需要使用 具有 冲突检测功能的 “ 主动 - 主动 ” NDB群集复制
NDB$EPOCH_TRANS())。 要更改设置,请使用该--ndb-log-transaction-id选项。ndb_log_transaction_id主线MySQL Server 8.0不支持。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
表22.263 ndb_metadata_check的类型和值信息
属性 值 名称 ndb_metadata_check命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型:默认,范围 布尔值:ON(版本:8.0.16) 笔记 描述:启用与MySQL数据字典相关的NDB元数据更改的自动检测; 默认启用
从NDB 8.0.16开始, 与MySQL数据字典相比 ,
NDB使用后台线程 每秒 检查元数据更改ndb_metadata_check_interval。 可以通过设置ndb_metadata_check为 禁用此元数据更改检测线程OFF。 默认情况下启用该线程。 -
表22.264 ndb_metadata_check_interval的类型和值信息
属性 值 名称 ndb_metadata_check_interval命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型:默认,范围 整数:60/0 - 31536000(版本:8.0.16) 笔记 描述:执行与MySQL数据字典相关的NDB元数据更改检查的间隔(秒)
在NDB 8.0.16及更高版本中,NDB在后台运行元数据更改检测线程,以确定NDB字典何时相对于MySQL数据字典发生了更改。 默认情况下,此类检查之间的间隔为60秒; 这可以通过设置值来调整
ndb_metadata_check_interval。 要启用或禁用该线程,请使用ndb_metadata_check。 -
表22.265 ndb_optimized_node_selection的类型和值信息
属性 值 名称 ndb_optimized_node_selection命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 ON(版本:8.0) 默认,范围 3/0 - 3(版本:NDB 8.0) 笔记 描述:确定SQL节点如何选择要用作事务协调器的集群数据节点
有两种形式的优化节点选择,如下所述:
-
SQL节点使用 promixity 来确定事务协调器; 也就是说, 选择SQL节点 的 “ 最近 ” 数据节点作为事务协调器。 为此,与SQL节点具有共享存储器连接的数据节点被认为与SQL节点 “ 最接近 ” ; 下一个最接近的(按接近度递减的顺序)是:TCP连接到
localhost; SCI连接; 来自主机以外的TCP连接localhost。 -
SQL线程使用 分发感知 来选择数据节点。 也就是说,容纳由给定事务的第一个语句访问的集群分区的数据节点被用作整个事务的事务协调器。 (仅当事务的第一个语句访问不超过一个集群分区时,这才有效。)
此选项取整数值之一
0,1,2,或3。3是默认值。 这些值会影响节点选择,如下所示:-
0:节点选择未优化。 在SQL线程进入下一个数据节点之前,每个数据节点被用作事务协调器8次。 -
1:接近SQL节点用于确定事务协调器。 -
2:分发感知用于选择事务协调器。 但是,如果事务的第一个语句访问多个集群分区,则SQL节点将恢复为此选项设置为时看到的循环行为0。 -
3:如果可以使用分发感知来确定事务协调器,则使用它; 否则,邻近度用于选择事务协调器。 (这是默认行为。)
接近度确定如下:
-
从为
Group参数 设置的值开始 (默认 值为 55)。 -
对于与其他API节点共享相同主机的API节点,将值递减1.假设默认值为
Group,与API节点在同一主机上的数据节点的有效值为54,对于远程数据节点55。 -
设置
ndb_data_node_neighbour进一步将有效值减小Group50,使该节点被视为最近的节点。 仅当所有数据节点都在主机API节点之外的主机上时才需要这样做,并且希望将其中一个数据节点专用于API节点。 在正常情况下,前面描述的默认调整就足够了。
不经常更改
ndb_data_node_neighbour是不可取的,因为这会更改群集连接的状态,因此可能会中断每个线程的新事务的选择算法,直到它稳定为止。 -
-
表22.266 ndb_read_backup的类型和值信息
属性 值 名称 ndb_read_backup命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:NDB 8.0) 笔记 描述:启用从任何副本读取
为
NDB随后创建的 任何 表 启用从任何副本读取 。 -
ndb_recv_thread_activation_threshold表22.267 ndb_recv_thread_activation_threshold的类型和值信息
属性 值 名称 ndb_recv_thread_activation_threshold命令行 没有 系统变量 没有 状态变量 没有 选项文件 没有 范围 动态 没有 类型 默认,范围 8/0(MIN_ACTIVATION_THRESHOLD) - 16(MAX_ACTIVATION_THRESHOLD)(版本:NDB 8.0) 笔记 描述:接收线程接管集群连接轮询时的激活阈值(在并发活动线程中测量)
当达到此并发活动线程数时,接收线程将接管群集连接的轮询。
此变量的范围是全局的。 它也可以使用该
--ndb-recv-thread-activation-threshold选项 在启动时设置 。 -
表22.268 ndb_recv_thread_cpu_mask的类型和值信息
属性 值 名称 ndb_recv_thread_cpu_mask命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 是 类型 默认,范围 [空](版本:8.0) 笔记 描述:用于将接收器线程锁定到特定CPU的CPU掩码; 指定为十六进制。 请参阅文档了解详细信
用于将接收器线程锁定到特定CPU的CPU掩码。 这被指定为十六进制位掩码。 例如,
0x33表示每个接收器线程使用一个CPU。 空字符串是默认值; 设置ndb_recv_thread_cpu_mask为此值将删除先前设置的任何接收器线程锁。此变量的范围是全局的。 它也可以使用该
--ndb-recv-thread-cpu-mask选项 在启动时设置 。 -
ndb_report_thresh_binlog_epoch_slip表22.269 ndb_report_thresh_binlog_epoch_slip的类型和值信息
属性 值 名称 ndb_report_thresh_binlog_epoch_slip命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 3/0 - 256(版本:8.0) 默认,范围 10/0 - 256(版本:NDB 8.0) 笔记 描述:NDB 7.5.4及更高版本:完全缓冲但尚未被binlog注入器线程消耗的时期数的阈值,当超过时生成BUFFERED_EPOCHS_OVER_THRESHOLD事件缓冲区状态消息; 在NDB 7.5.4之前:在报告二进制日志状态之前滞后的时期数的阈值
这表示在事件缓冲区中完全缓冲但尚未被binlog注入器线程消耗的时期数的阈值。 当超出此滑动程度(滞后)时,将报告事件缓冲区状态消息,并
BUFFERED_EPOCHS_OVER_THRESHOLD提供原因(请参阅参考资料 第22.5.7.3节“群集日志中的事件缓冲区报告”) )。 当从数据节点接收到一个纪元并在事件缓冲器中完全缓冲时,滑动增加; 当binlog注入器线程消耗了一个纪元时,它会减少。 空的纪元被缓冲并排队,因此只有在使用时才启用此计算时才包括在此计算中Ndb::setEventBufferQueueEmptyEpoch()NDB API中 方法 。 -
ndb_report_thresh_binlog_mem_usage表22.270 ndb_report_thresh_binlog_mem_usage的类型和值信息
属性 值 名称 ndb_report_thresh_binlog_mem_usage命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 10/0 - 10(版本:8.0) 笔记 描述:这是在报告二进制日志状态之前剩余可用内存百分比的阈值
这是在报告二进制日志状态之前剩余可用内存百分比的阈值。 例如,值
10(默认值)表示如果从数据节点接收二进制日志数据的可用内存量低于10%,则会向群集日志发送状态消息。 -
表22.271 ndb_row_checksum的类型和值信息
属性 值 名称 ndb_row_checksum命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 整数 默认,范围 1/0 - 1(版本:NDB 8.0) 笔记 描述:启用时,设置行校验和; 默认启用
传统上,
NDB已经创建了具有行校验和的表,这些表以牺牲性能为代价来检查硬件问题。 设置ndb_row_checksum为0表示行校验和 不 用于新表或更改的表,这会对所有类型的查询的性能产生重大影响。 默认情况下,此变量设置为1,以提供向后兼容的行为。 -
表22.272 slave_allow_batching的类型和值信息
属性 值 名称 slave_allow_batching命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 off(版本:8.0) 笔记 描述:为复制从站打开和关闭更新批处理
是否在NDB Cluster复制从属上启用了批量更新。
设置此变量仅在使用
NDB存储引擎 复制时才有效 ; 在MySQL Server 8.0中,它存在但什么都不做。 有关更多信息,请参见 第22.6.6节“启动NDB集群复制(单一复制通道)” 。 -
ndb_show_foreign_key_mock_tables表22.273 ndb_show_foreign_key_mock_tables的类型和值信息
属性 值 名称 ndb_show_foreign_key_mock_tables命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:显示用于支持foreign_key_checks = 0的模拟表
显示
NDB支持 使用的模拟表foreign_key_checks=0。 启用此选项后,在创建和删除表时会显示额外警告。 表的实际(内部)名称可以在输出中看到SHOW CREATE TABLE。 -
表22.274 ndb_slave_conflict_role的类型和值信息
属性 值 名称 ndb_slave_conflict_role命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 是 类型 默认,范围 NONE / NONE,PRIMARY,SECONDARY,PASS(版本:8.0) 笔记 描述:奴隶在冲突检测和解决中的作用。 值是PRIMARY,SECONDARY,PASS或NONE(默认值)之一。 只有在从属SQL线程停止时才能更改。 有关详细信息,请参阅文档
确定此SQL节点(和NDB群集)在循环( “ 主动 - 主动 ” )复制设置中 的角色 。
ndb_slave_conflict_role可以采取的值的任何一个PRIMARY,SECONDARY,PASS,或NULL(缺省值)。 必须先停止从属SQL线程,然后才能进行更改ndb_slave_conflict_role。 此外,它是不可能直接在...之间改变PASS和任一PRIMARY或SECONDARY直接; 在这种情况下,您必须确保SQL线程已停止,然后SET @@GLOBAL.ndb_slave_conflict_role = 'NONE'先 执行 。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
表22.275 ndb_table_no_logging的类型和值信息
属性 值 名称 ndb_table_no_logging命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 会议 动态 是 类型 默认,范围 FALSE(版本:8.0) 笔记 描述:启用此设置时创建的NDB表未检查点到磁盘(尽管创建了表模式文件)。 创建表或使用NDBCLUSTER更改表时生效的设置在表的生命周期内仍然存在。
当此变量设置为
ON或时1,它会导致NDB表不会被检查点到磁盘。 更具体地说,此设置适用于使用ENGINE NDBwhen时 创建或更改的表ndb_table_no_logging,并继续应用表的生命周期,即使ndb_table_no_logging稍后更改。 假设A,B,C,和D是我们创建(或许也是改变),而且我们还更改设置表ndb_table_no_logging如下所示:SET @@ ndb_table_no_logging = 1; 创建表A ... ENGINE NDB; 创建表B ...发动机MYISAM; 创建表C ...发动机MYISAM; ALTER TABLE B ENGINE NDB; SET @@ ndb_table_no_logging = 0; 创建表D ... ENGINE NDB; ALTER TABLE C ENGINE NDB; SET @@ ndb_table_no_logging = 1;
在上一系列事件之后,表格
A并B没有检查点;A创建时ENGINE NDB,B被改变使用NDB,两者都ndb_table_no_logging被启用。 但是,表格C和D记录;C被修改为使用NDB,D并使用ENGINE NDB,同时ndb_table_no_logging被禁用。 设置ndb_table_no_logging回1还是ON不 不会 导致表C或D进行检查点。注意ndb_table_no_logging对NDB表模式文件 的创建没有影响 ; 抑制这些,ndb_table_temporary改为 使用 。 -
表22.276 ndb_table_temporary的类型和值信息
属性 值 名称 ndb_table_temporary命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 会议 动态 是 类型 默认,范围 FALSE(版本:8.0) 笔记 描述:NDB表在磁盘上不是持久的:不会创建任何模式文件,也不会记录表
设置为
ON或时1,此变量会导致NDB表不写入磁盘:这意味着不会创建表模式文件,也不会记录表。注意目前设置此变量无效。 这是一个已知的问题; 见Bug#34036。
-
表22.277 ndb_use_copying_alter_table的类型和值信息
属性 值 名称 ndb_use_copying_alter_table命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 没有 类型 笔记 描述:在NDB Cluster中使用复制ALTER TABLE操作
强制
NDB在线ALTER TABLE操作 出现问题时复制表格 。 默认值为OFF。 -
表22.278 ndb_use_exact_count的类型和值信息
属性 值 名称 ndb_use_exact_count命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 ON(版本:8.0) 默认,范围 OFF(版本:NDB 8.0) 笔记 描述:规划查询时使用确切的行数
强制
NDB在SELECT COUNT(*)查询计划 期间使用记录计数 来加速此类查询。 默认值为OFF,允许整体更快的查询。 -
表22.279 ndb_use_transactions的类型和值信息
属性 值 名称 ndb_use_transactions命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 都 动态 是 类型 默认,范围 ON(版本:8.0) 笔记 描述:强制NDB在SELECT COUNT(*)查询计划期间使用记录计数来加速此类查询
您可以
NDB通过将此变量的值设置为OFF(不推荐) 来禁用 事务支持 。 默认是ON。 -
表22.280 ndb_version的类型和值信息
属性 值 名称 ndb_version命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 没有 类型 默认,范围 (版本:8.0) 笔记 描述:将build和NDB引擎版本显示为整数
NDB引擎版本,作为复合整数。 -
表22.281 ndb_version_string的类型和值信息
属性 值 名称 ndb_version_string命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 没有 类型 默认,范围 (版本:8.0) 笔记 描述:显示构建信息,包括ndb-xyz格式的NDB引擎版本
NDB引擎版本的 格式。ndb-x.y.z -
表22.282 server_id_bits的类型和值信息
属性 值 名称 server_id_bits命令行 是 系统变量 是 状态变量 没有 选项文件 是 范围 全球 动态 没有 类型 默认,范围 32/7 - 32(版本:8.0) 笔记 描述:如果服务器以--server-id-bits选项设置为非默认值启动服务器,则为server_id的有效值
server_id如果服务器启动时的 有效值, 则--server-id-bits选项设置为非默认值。如果值
server_id大于或等于2的幂server_id_bits, mysqld 拒绝启动。该系统变量仅由NDB Cluster支持。
server_id_bits标准MySQL服务器不支持。 -
表22.283 transaction_allow_batching的类型和值信息
属性 值 名称 transaction_allow_batching命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 会议 动态 是 类型 默认,范围 FALSE(版本:8.0) 笔记 描述:允许在事务中批处理语句。 禁用AUTOCOMMIT使用。
设置为
1或时ON,此变量启用同一事务中的语句批处理。 要使用此变量,autocommit必须先将其设置为0或 禁用OFF; 否则,设置transaction_allow_batching无效。将此变量与仅执行写入的事务一起使用是安全的,因为启用它可以导致从 “ 之前 ” 图像 读取 。 您应该
COMMIT在发出之前 确保提交任何挂起的事务( 如果需要, 使用显式 )SELECT。重要transaction_allow_batching只要给定语句的效果可能取决于同一事务中先前语句的结果,就不应该使用它。此变量目前仅支持NDB Cluster。
以下列表中的系统变量都与
ndbinfo
信息数据库相关。
-
表22.284 ndbinfo_database的类型和值信息
属性 值 名称 ndbinfo_database命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 没有 类型 默认,范围 ndbinfo(版本:8.0) 笔记 描述:用于NDB信息数据库的名称; 只读
显示用于
NDB信息数据库 的名称 ; 默认是ndbinfo。 这是一个只读变量,其值在编译时确定; 您可以通过启动服务器来设置它 ,它设置为此变量显示的值,但实际上不会更改用于NDB信息数据库的名称。--ndbinfo-database=name -
表22.285 ndbinfo_max_bytes的类型和值信息
属性 值 名称 ndbinfo_max_bytes命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 0 / - (版本:8.0) 笔记 描述:仅用于调试
仅用于测试和调试。
-
表22.286 ndbinfo_max_rows的类型和值信息
属性 值 名称 ndbinfo_max_rows命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 10 / - (版本:8.0) 笔记 描述:仅用于调试
仅用于测试和调试。
-
表22.287 ndbinfo_offline的类型和值信息
属性 值 名称 ndbinfo_offline命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:将ndbinfo数据库置于脱机模式,其中不从表或视图返回任何行
将
ndbinfo数据库置于脱机模式,即使表和视图实际上不存在,或者它们存在但具有不同的定义,也可以打开它们NDB。 没有从这些表(或视图)返回任何行。 -
表22.288 ndbinfo_show_hidden的类型和值信息
属性 值 名称 ndbinfo_show_hidden命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 OFF(版本:8.0) 笔记 描述:是否在mysql客户端中显示ndbinfo内部基表。 默认为OFF。
是否
ndbinfo在mysql客户端 中显示数据库的基础内部表 。 默认是OFF。 -
表22.289 ndbinfo_table_prefix的类型和值信息
属性 值 名称 ndbinfo_table_prefix命令行 是 系统变量 是 状态变量 没有 选项文件 没有 范围 都 动态 是 类型 默认,范围 ndb $(版本:8.0) 笔记 描述:用于命名ndbinfo内部基表的前缀
用于命名ndbinfo数据库基表的前缀(通常是隐藏的,除非通过设置公开
ndbinfo_show_hidden)。 这是一个只读变量,其默认值为ndb$。 您可以使用该--ndbinfo-table-prefix选项 启动服务器 ,但这只是设置变量而不会更改用于命名隐藏基表的实际前缀; 前缀本身是在编译时确定的。 -
表22.290 ndbinfo_version的类型和值信息
属性 值 名称 ndbinfo_version命令行 没有 系统变量 是 状态变量 没有 选项文件 没有 范围 全球 动态 没有 类型 默认,范围 (版本:8.0) 笔记 描述:ndbinfo引擎的版本; 只读
显示
ndbinfo正在使用 的 引擎 版本 ; 只读。
本节提供有关与NDB群集和
NDB
存储引擎
相关的MySQL服务器状态变量的详细信息
。
有关不特定于NDB Cluster的状态变量,以及有关使用状态变量的一般信息,请参见
第5.1.10节“服务器状态变量”
。
-
MySQL服务器可以询问
NDBCLUSTER存储引擎是否知道具有给定名称的表。 这称为发现。Handler_discover表示使用此机制发现表的次数。 -
Ndb_api_bytes_sent_count_session发送到此客户端会话中的数据节点的数据量(以字节为单位)。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_bytes_sent_count_slave此从站发送到数据节点的数据量(以字节为单位)。
虽然这个变量可以使用读取任一
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)发送到数据节点的数据量(以字节为单位)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_bytes_received_count_session从此客户端会话中的数据节点接收的数据量(以字节为单位)。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_bytes_received_count_slave此从站从数据节点接收的数据量(以字节为单位)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)从数据节点接收的数据量(以字节为单位)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_event_data_count_injectorNDB binlog注入器线程接收的行更改事件的数量。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)收到的行更改事件数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_event_nondata_count_injectorNDB二进制日志注入器线程接收的事件数(行更改事件除外)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)收到的事件数(行更改事件除外)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_event_bytes_count_injectorNDB binlog注入器线程接收的事件的字节数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)接收的事件的字节数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此客户端会话中基于或使用主键的操作数。 这包括对blob表,隐式解锁操作和自动增量操作的操作,以及用户可见的主键操作。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此从属设备基于或使用主键的操作数。 这包括对blob表,隐式解锁操作和自动增量操作的操作,以及用户可见的主键操作。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)基于或使用主键的操作数。 这包括对blob表,隐式解锁操作和自动增量操作的操作,以及用户可见的主键操作。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_pruned_scan_count_session此客户端会话中已扫描到单个分区的扫描数。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_pruned_scan_count_slave此从属设备已扫描到单个分区的扫描次数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)已扫描到单个分区的扫描数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_range_scan_count_session已在此客户端会话中启动的范围扫描数。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_range_scan_count_slave此从站启动的范围扫描数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)启动的范围扫描数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_read_row_count_session在此客户端会话中读取的总行数。 这包括在此客户端会话中通过任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此从属设备已读取的总行数。 这包括由此从属设备执行的任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)已读取的总行数。 这包括由此MySQL服务器(SQL节点)进行的任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_scan_batch_count_session此客户端会话中收到的批次行数。 1批次被定义为来自单个片段的1组扫描结果。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_scan_batch_count_slave此从站接收的批次行数。 1批次被定义为来自单个片段的1组扫描结果。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)接收的批次行数。 1批次被定义为来自单个片段的1组扫描结果。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_table_scan_count_session已在此客户端会话中启动的表扫描数,包括内部表的扫描。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_table_scan_count_slave此从属服务器启动的表扫描数,包括内部表的扫描数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)启动的表扫描数,包括内部表的扫描。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_abort_count_session此客户端会话中的事务数已中止。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_abort_count_slave此从属设备中止的事务数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)中止的事务数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_close_count_session此客户端会话中关闭的事务数。 这个值可能比的总和
Ndb_api_trans_commit_count_session和Ndb_api_trans_abort_count_session,因为有些交易可能已被回滚。虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_close_count_slave此从属关闭的事务数。 这个值可能比的总和
Ndb_api_trans_commit_count_slave和Ndb_api_trans_abort_count_slave,因为有些交易可能已被回滚。虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)关闭的事务数。 该值可能大于总和
Ndb_api_trans_commit_count和Ndb_api_trans_abort_count,因为有些交易可能已被回滚。虽然可以使用其中任何一个读取此变量
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_commit_count_session此客户端会话中提交的事务数。
尽管可以使用
SHOW GLOBAL STATUS或 读取此变量SHOW SESSION STATUS,但它仅与当前会话相关,并且不受此任何其他客户端的影响 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_commit_count_slave此从属服务器提交的事务数。
虽然这个变量可以使用读取任一
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)提交的事务数。
虽然这个变量可以使用读取任一
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_local_read_row_count_session在此客户端会话中读取的总行数。 这包括在此客户端会话中通过任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_local_read_row_count_slave此从属设备已读取的总行数。 这包括由此从属设备执行的任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_local_read_row_count此MySQL服务器(SQL节点)已读取的总行数。 这包括由此MySQL服务器(SQL节点)进行的任何主键,唯一键或扫描操作读取的所有行。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_start_count_session在此客户端会话中启动的事务数。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_trans_start_count_slave此从属服务器启动的事务数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)启动的事务数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此客户端会话中基于或使用唯一键的操作数。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此从属设备基于或使用唯一键的操作次数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)基于或使用唯一键的操作数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_exec_complete_count_session在等待执行操作完成时,此客户端会话中线程被阻止的次数。 这包括所有
execute()调用以及对客户端不可见的blob和自动增量操作的隐式执行。虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_exec_complete_count_slave在等待执行操作完成时,此从属程序阻止线程的次数。 这包括所有
execute()调用以及对客户端不可见的blob和自动增量操作的隐式执行。虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_exec_complete_count在等待执行操作完成时,此MySQL服务器(SQL节点)阻止线程的次数。 这包括所有
execute()调用以及对客户端不可见的blob和自动增量操作的隐式执行。虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_meta_request_count_session在此客户端会话中阻止线程等待基于元数据的信号的次数,例如DDL请求,新纪元和事务记录的占用。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_meta_request_count_slave此从属设备阻止线程等待基于元数据的信号的次数,例如预期的DDL请求,新纪元和事务记录的占用。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_meta_request_count此MySQL服务器(SQL节点)阻止线程等待基于元数据的信号的次数,例如DDL请求,新纪元和事务记录的占用。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_nanos_count_session在此客户端会话中花费的总时间(以纳秒为单位),等待来自数据节点的任何类型的信号。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_nanos_count_slave此从站等待来自数据节点的任何类型信号所花费的总时间(以纳秒为单位)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
此MySQL服务器(SQL节点)等待来自数据节点的任何类型信号所花费的总时间(以纳秒为单位)。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_scan_result_count_session在等待基于扫描的信号(例如,等待扫描的更多结果或等待扫描关闭)时,此客户端会话中线程被阻止的次数。
虽然这个变量可以使用任一被读取
SHOW GLOBAL STATUS或SHOW SESSION STATUS,它仅涉及当前会话,并且不受此的任何其他客户端 的mysqld 。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_scan_result_count_slave在等待基于扫描的信号(例如,等待扫描的更多结果或等待扫描关闭)时,此从属设备阻止线程的次数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。 如果此MySQL服务器不充当复制从属服务器,或者不使用NDB表,则此值始终为0。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
Ndb_api_wait_scan_result_count在等待基于扫描的信号(例如等待扫描的更多结果或等待扫描关闭)时,此MySQL服务器(SQL节点)阻止线程的次数。
虽然这个变量可以使用任意读取
SHOW GLOBAL STATUS或者SHOW SESSION STATUS,它的范围是有效的全球。有关更多信息,请参见 第22.5.17节“NDB API统计计数器和变量” 。
-
如果服务器充当NDB群集节点,则此变量的值为其在群集中的节点ID。
如果服务器不是NDB群集的一部分,则此变量的值为0。
-
如果服务器是NDB群集的一部分,则此变量的值是从中获取其配置数据的群集管理服务器的主机名或IP地址。
如果服务器不是NDB群集的一部分,则此变量的值为空字符串。
-
如果服务器是NDB群集的一部分,则此变量的值是它通过其连接到从中获取其配置数据的群集管理服务器的端口号。
如果服务器不是NDB群集的一部分,则此变量的值为0。
-
显示
NDB$MAX_DELETE_WIN()由于上次 使用 此 mysqld 导致NDB群集复制冲突解决而导致当前SQL节点上的行被拒绝的次数 启动 。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
在NDB群集复制冲突解决中使用时,此变量显示 自上次 启动 此 mysqld 以来 由于 “ 最大时间戳获胜 ” 冲突解决 而未在当前SQL节点上应用行的次数 。
有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
在NDB群集复制冲突解决中使用,此变量显示由于 给定 mysqld 上 的 “ 相同时间戳获胜 ” 冲突解决 而未应用行的次数 自上次重新启动以来 。
有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
在NDB群集复制冲突解决中使用时,此变量显示 自上次重新启动以来 使用
NDB$EPOCH()给定 mysqld 上的冲突解决而 发现冲突的行数 。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
使用时显示在NDB群集复制冲突解决中发现冲突的行数
NDB$EPOCH2()自上次重新启动以来指定为主数据库的主服务器上 。有关更多信息,请参阅 NDB $ EPOCH2() 。
-
在NDB群集复制冲突解决中使用时,此变量显示 自上次重新启动以来 使用
NDB$EPOCH_TRANS()给定 mysqld 上的冲突解决而 发现冲突的行数 。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
在NDB群集复制冲突解决中使用时,此变量显示 自上次重新启动以来 使用
NDB$EPOCH_TRANS2()给定 mysqld 上的冲突解决而 发现冲突的行数 。有关更多信息,请参阅 NDB $ EPOCH2_TRANS() 。
-
Ndb_conflict_last_conflict_epoch这个奴隶上发现冲突的最新纪元。 您可以将此值与
Ndb_slave_max_replicated_epoch; 如果Ndb_slave_max_replicated_epoch大于Ndb_conflict_last_conflict_epoch,则尚未检测到冲突。有关 更多信息 , 请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_reflected_op_discard_count使用NDB群集复制冲突解决时,这是由于在执行期间遇到错误而未在辅助节点上应用的反射操作的数量。
有关 更多信息 , 请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_reflected_op_prepare_count使用NDB群集复制进行冲突解决时,此状态变量包含已定义的已反射操作的数量(即准备在辅助节点上执行)。
请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
在NDB群集复制中使用冲突解决方案时,这将提供已准备好在辅助节点上执行的刷新操作数。
有关 更多信息 , 请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_last_stable_epoch发现由事务冲突函数冲突的行数
有关 更多信息 , 请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_trans_row_conflict_count在NDB群集复制冲突解决中使用,此状态变量显示在给定 mysqld 上由事务冲突函数直接冲突的行数 自上次重新启动以来, 。
目前,NDB Cluster支持的唯一事务冲突检测功能是NDB $ EPOCH_TRANS(),因此该状态变量实际上与
Ndb_conflict_fn_epoch_trans。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_trans_row_reject_count在NDB群集复制冲突解决中使用时,此状态变量显示由于被事务冲突检测功能确定为冲突而重新排列的总行数。 这不仅包括
Ndb_conflict_trans_row_conflict_count冲突事务中的任何行, 还包括 冲突事务中的任何行。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_trans_reject_count在NDB群集复制冲突解决中使用时,此状态变量显示事务冲突检测功能发现冲突的事务数。
有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_trans_detect_iter_count在NDB群集复制冲突解决中使用,它显示了提交纪元事务所需的内部迭代次数。 应该(略微)大于或等于
Ndb_conflict_trans_conflict_commit_count。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
Ndb_conflict_trans_conflict_commit_count在NDB群集复制冲突解决中使用,它显示了在需要事务冲突处理之后提交的纪元事务的数量。
有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
使用删除 - 删除冲突检测时,这是检测到的删除 - 删除冲突的数量,其中应用了删除操作,但指示的行不存在。
-
提供
NDB操作所 产生的 内核 往返次数 。 -
最近承诺的时代
NDB。 -
这个
NDB客户 最近承诺的时代 。 -
自该服务器上次启动以来NDB元数据更改检测线程发现了与MySQL数据字典相关的更改的次数。
-
如果服务器是NDB群集的一部分,则此变量的值是群集中的数据节点数。
如果服务器不是NDB群集的一部分,则此变量的值为0。
-
连接总数下推到NDB内核,以便在数据节点上进行分布式处理。
注意使用
EXPLAIN可以推送的 联接测试 有助于此数字。 -
推送到NDB内核但无法在那里处理的连接数。
-
成功推送到
NDB并在那里执行 的连接数 。 -
通过下推的连接从NDB内核 返回到 mysqld 的行数 。
-
此变量保存
NDBCLUSTER自上次启动NDB群集以来NDBCLUSTER能够使用分区修剪 的扫描数量 。Ndb_scan_count在模式设计中 使用此变量 可以有助于最大化服务器将扫描修剪到单个表分区的能力,从而仅涉及单个数据节点。 -
此变量保存
NDBCLUSTER自上次启动NDB群集以来 执行的扫描总数 。 -
Ndb_slave_max_replicated_epoch关于这个奴隶的最近承诺的时代。 您可以将此值与
Ndb_conflict_last_conflict_epoch; 如果Ndb_slave_max_replicated_epoch是两者中的较大者,则尚未检测到任何冲突。有关更多信息,请参见 第22.6.11节“NDB集群复制冲突解决” 。
-
如果此MySQL服务器连接到NDB群集,则此只读变量显示群集系统名称。 否则,该值为空字符串。
-
使用已在当前会话中启动的提示的事务数。 比较
Ndb_api_trans_start_count_session以获得能够使用提示的所有NDB事务的比例。 在NDB 8.0.17中添加。
TCP / IP是NDB群集中节点之间所有连接的默认传输机制。 通常没有必要定义TCP / IP连接; NDB Cluster自动为所有数据节点,管理节点和SQL或API节点设置此类连接。
有关此规则的例外,请参见 第22.3.3.11节“使用直接连接的NDB集群TCP / IP连接” 。
要覆盖默认连接参数,必须使用
文件
[tcp]
中的
一个或多个
部分
定义连接
config.ini
。
每个
[tcp]
部分明确定义两个NDB Cluster节点之间的TCP / IP连接,并且必须至少包含参数
NodeId1
和
NodeId2
,以及将任何连接参数来覆盖。
也可以通过在
[tcp
default]
部分中
设置这些参数来更改这些参数的默认值
。
所有
[tcp]
的分段
config.ini
文件应列出
最后
,下列文件中的所有其他部分。
但是,
[tcp
default]
部分
不需
要这样做。
此要求是
config.ini
NDB群集管理服务器读取文件
的方式的已知问题
。
此处列出了
可在其中设置的连接参数
[tcp]
和
文件的
[tcp default]
各个部分
config.ini
:
-
为了识别两个节点之间的连接,需要提供他们的节点ID在
[tcp]配置文件为的值的部分NodeId1和NodeId2。 这些Id节点的每个节点 都是相同的唯一 值,如 第22.3.3.7节“在NDB集群中定义SQL和其他API节点”中所述 。 -
为了识别两个节点之间的连接,需要提供他们的节点ID在
[tcp]配置文件为的值的部分NodeId1和NodeId2。 这些Id节点的每个节点 都是相同的唯一 值,如 第22.3.3.7节“在NDB集群中定义SQL和其他API节点”中所述 。 -
的
HostName1和HostName2参数可用于指定要用于两个节点之间的给定TCP连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
的
HostName1和HostName2参数可用于指定要用于两个节点之间的给定TCP连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
表22.295此表提供OverloadLimit TCP配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果发送缓冲区中有多个未发送的字节,则认为连接过载。
此参数可用于确定在认为连接过载之前必须存在于发送缓冲区中的未发送数据量。 有关 更多信息 , 请参见 第22.3.3.14节“配置NDB集群发送缓冲区参数” 。
-
表22.296此表提供SendBufferMemory TCP配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 2M 范围 256K - 4294967039(0xFFFFFEFF) 重启类型 ñ
TCP传输器在执行对操作系统的发送调用之前使用缓冲区来存储所有消息。 当此缓冲区达到64KB时,其内容将被发送; 这些也是在执行了一轮消息时发送的。 要处理临时过载情况,还可以定义更大的发送缓冲区。
如果明确设置此参数,则内存不专用于每个传输器; 相反,使用的值表示
TotalSendBufferMemory单个传输器可以使用 多少内存(在可用内存总量中)的硬限制 。 有关在NDB群集中配置动态传输器发送缓冲区内存分配的更多信息,请参见 第22.3.3.14节“配置NDB群集发送缓冲区参数” 。发送缓冲区的默认大小为2MB,这是大多数情况下建议的大小。 最小大小为64 KB; 理论最大值为4 GB。
-
为了能够回溯分布式消息数据报,有必要识别每个消息。 当此参数设置
Y为时,消息ID通过网络传输。 默认情况下,在生成版本中禁用此功能,并在-debug构建中 启用此功能 。 -
此参数是一个布尔参数(通过将其设置为启用
Y或1,通过将其设置到禁止N或0)。 默认情况下禁用它。 启用后,将计算所有消息的校验和,然后将它们放入发送缓冲区。 此功能可确保在发送缓冲区或传输机制中等待时消息不会损坏。 -
如果此参数
Checksum都已启用,请执行预发送校验和检查,并检查节点之间的所有TCP信号是否存在错误。 如果Checksum未启用则无效。 -
表22.300此表提供ReceiveBufferMemory TCP配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 2M 范围 16K - 4294967039(0xFFFFFEFF) 重启类型 ñ
指定从TCP / IP套接字接收数据时使用的缓冲区大小。
此参数的默认值为2MB。 最小可能值为16KB; 理论最大值为4GB。
-
表22.301此表提供TCP_RCV_BUF_SIZE TCP配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 2G 重启类型 ñ
确定TCP传输器初始化期间接收缓冲区集的大小。 默认值和最小值为0,允许操作系统或平台设置此值。 对于大多数常见用例,建议使用默认值。
-
表22.302此表提供TCP_SND_BUF_SIZE TCP配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 2G 重启类型 ñ
确定TCP传输器初始化期间发送缓冲区集的大小。 默认值和最小值为0,允许操作系统或平台设置此值。 对于大多数常见用例,建议使用默认值。
-
确定TCP传输器初始化期间内存集的大小。 对于大多数常见用例,建议使用默认值。
-
将此参数设置为
TRUE或1绑定,IP_ADDR_ANY以便可以从任何位置进行连接(对于自动生成的连接)。 默认值为FALSE(0)。 -
当
ndb_optimized_node_selection启用时,节点接近在某些情况下,用于选择要连接到的节点。 此参数可用于通过将其设置为较低的值来影响邻近度,该值被解释为 “ 更接近 ” 。 有关更多信息,请参阅系统变量的说明。
使用数据节点之间的直接连接设置集群需要明确指定
[tcp]
在集群部分中
连接的数据节点的交叉IP地址
config.ini
文件
。
在以下示例中,我们设想一个至少包含四个主机的集群,每个主机用于管理服务器,一个SQL节点和两个数据节点。
集群作为一个整体驻留在
172.23.72.*
LAN
的
子网上。
除了通常的网络连接外,这两个数据节点使用标准交叉电缆直接连接,并使用IP地址直接相互通信。
1.1.0.*
地址范围内的
如下所示:
#Management Server [ndb_mgmd] ID = 1 主机名= 172.23.72.20 #SQL节点 的[mysqld] ID = 2 主机名= 172.23.72.21 #Data Nodes [NDBD] ID = 3 主机名= 172.23.72.22 [NDBD] ID = 4 主机名= 172.23.72.23 #TCP / IP连接 [TCP] NodeID1相同= 3 NodeId2 = 4 主机名1 = 1.1.0.1 主机名2 = 1.1.0.2
的
HostName1
和
HostName2
指定的直接连接时参数仅使用。
通过使数据节点绕过以太网设备(如交换机,集线器或路由器),在数据节点之间使用直接TCP连接可以提高集群的整体效率,从而减少集群的延迟。
要以这种方式直接连接两个以上数据节点的最佳优势,您必须在每个数据节点与同一节点组中的每个其他数据节点之间建立直接连接。
NDB群集节点之间的通信通常使用TCP / IP进行处理。
共享存储器(SHM)传输器的特征在于信号通过写入存储器而不是插座来传输。
共享内存传输器(SHM)可以在同一主机上同时运行API节点(通常是SQL节点)和数据节点时,通过否定TCP连接所需的高达20%的开销来提高性能。
NDB群集尝试使用共享内存传输器,并在同一主机上的数据节点和API节点之间自动配置它。
您可以通过将
UseShm
数据节点配置参数
设置为显式启用共享内存连接
1
。
当明确定义共享内存作为连接方法时,还必须
HostName
为数据节点和
HostName
API节点设置,并且这些是相同的。
也可以在同一NDB集群中,在不同主机上使用多个SHM连接,每个主机具有一个API节点和一个数据节点;
有关如何执行此操作的示例,请参阅本节后面的内容。
假设一个集群正在运行一个数据节点,该数据节点具有节点ID 1,而一个节点ID为51的SQL节点位于同一主机上10.0.0.1。 要在这两个节点之间启用SHM连接,所有必要的是确保群集配置文件中包含以下条目:
[NDBD] 的NodeId = 1 主机名= 10.0.0.1 UseShm = 1 的[mysqld] 的NodeId = 51 主机名= 10.0.0.1
刚显示的两个条目是集群所需的任何其他条目和参数设置的补充。 本节稍后将介绍更为完整的示例。
在启动使用SHM连接的数据节点之前,还必须确保托管此类数据节点的每台计算机上的操作系统都有足够的内存分配给共享内存段。
有关此信息,请参阅操作平台的文档。
在多个主机分别运行数据节点和API节点的设置
UseShm
中,可以
[ndbd
default]
通过在配置文件
的
部分中
进行设置来
在
所有此类主机上启用共享内存
。
这将在本节后面的示例中显示。
虽然不是严格要求,但可以通过
[shm default]
在cluster configuration(
config.ini
)文件
的
部分中
设置以下一个或多个参数来完成对集群中所有SHM连接的调优
:
-
ShmSize:共享内存大小 -
ShmSpinTime:睡眠前旋转的时间(以μs为单位) -
SendBufferMemory:从此节点发送的信号的缓冲区大小,以字节为单位。 -
SendSignalId:表示通过传输器发送的每个信号中都包含一个信号ID。 -
Checksum:表示通过传输器发送的每个信号中都包含校验和。 -
PreSendChecksum:在发送信号之前检查校验和; 还必须启用校验和才能使其正常工作
此示例显示了一个简单的设置,其中SHM连接在多个主机上定义,在NDB群集中使用3个按主机名列出的计算机,托管显示的节点类型:
-
10.0.0.0:管理服务器 -
10.0.0.1:数据节点和SQL节点 -
10.0.0.2:数据节点和SQL节点
在这种情况下,每个数据节点使用TCP传输器与管理服务器和其他数据节点通信; 每个SQL节点使用共享内存传输器与其本地数据节点进行通信,并使用TCP传输器与远程数据节点进行通信。 config.ini文件启用了反映此设置的基本配置,其内容显示在此处:
[ndbd默认] DATADIR =/path/to/datadirUseShm = 1 [shm默认] ShmSize = 8M ShmSpintime = 200 SendBufferMemory = 4M [tcp默认] SendBufferMemory = 8M [ndb_mgmd] 的NodeId = 49 主机名= 10.0.0.0 DATADIR =/path/to/datadir[NDBD] 的NodeId = 1 主机名= 10.0.0.1 DATADIR =/path/to/datadir[NDBD] 的NodeId = 2 主机名= 10.0.0.2 DATADIR =/path/to/datadir的[mysqld] 的NodeId = 51 主机名= 10.0.0.1 的[mysqld] 的NodeId = 52 主机名= 10.0.0.2 [API] [API]
影响所有共享内存传输器的参数在该
[shm default]
部分
中设置
;
这些可以在一个或多个
[shm]
部分中
基于每个连接被覆盖
。
每个这样的部分必须使用
NodeId1
和
与给定的SHM连接相关联
NodeId2
;
这些参数所需的值是由传输器连接的两个节点的节点ID。
您还可以使用
HostName1
和
按主机名标识节点
HostName2
,但这些参数不是必需的。
未设置主机名的API节点使用TCP传输器与数据节点进行通信,而不依赖于启动它们的主机;
[tcp default]
配置文件部分中
设置的参数和值
适用于群集中的所有TCP传输器。
为获得最佳性能,您可以为SHM运输车(
ShmSpinTime
参数)
定义旋转时间
;
这会影响数据节点接收器线程和轮询所有者(接收线程或用户线程)
NDB
。
重启类型。 有关本节中参数说明使用的重新启动类型的信息,请参见下表:
表22.304 NDB群集重新启动类型
| 符号 | 重启类型 | 描述 |
|---|---|---|
| ñ | 节点 | 可以使用滚动重新启动来更新该参数(请参见 第22.5.5节“执行NDB群集的滚动重新启动” ) |
| 小号 | 系统 | 必须完全关闭所有群集节点,然后重新启动,以实现此参数的更改 |
| 一世 | 初始 |
必须使用该
--initial
选项
重新启动数据节点
|
-
此参数是一个布尔值(
Y/N),默认情况下 处于 禁用状态。 启用后,将计算所有消息的校验和,然后将其置于发送缓冲区中。此功能可防止在发送缓冲区中等待时消息被破坏。 它还可以检查运输过程中损坏的数据。
-
确定群组邻近度; 较小的值被解释为更接近。 对于大多数情况,默认值就足够了。
-
的
HostName1和HostName2参数可用于指定要用于在两个节点之间一个给定的SHM连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
的
HostName1和HostName2参数可用于指定要用于在两个节点之间一个给定的SHM连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
为了识别两个节点之间的连接,有必要为每个节点提供节点标识符,如
NodeId1和NodeId2。 -
为了识别两个节点之间的连接,有必要为每个节点提供节点标识符,如
NodeId1和NodeId2。 -
标识共享内存连接的服务器端。 默认情况下,这是数据节点的节点ID。
-
表22.312此表提供OverloadLimit共享内存配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果发送缓冲区中有多个未发送的字节,则认为连接过载。 有关更多 信息, 请参见 第22.3.3.14节“配置NDB群集发送缓冲区参数” 和 第22.5.10.44节“ndbinfo传输器表” 。
-
如果此参数
Checksum都已启用,请执行预发送校验和检查,并检查节点之间的所有SHM信号是否存在错误。 如果Checksum未启用则无效。 -
表22.314此表提供SendBufferMemory共享内存配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 整数 默认 2M 范围 256K - 4294967039(0xFFFFFEFF) 重启类型 ñ
使用共享内存连接从此节点发送的信号的共享内存缓冲区的大小(以字节为单位)。
-
为了回溯分布式消息的路径,有必要为每个消息提供唯一标识符。 设置此参数
Y也会导致这些消息ID也通过网络传输。 默认情况下,在生成版本中禁用此功能,并在-debug构建中 启用此功能 。 -
表22.316此表提供ShmKey共享内存配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
在设置共享内存段时,表示为整数的节点ID用于唯一地标识用于通信的共享内存段。 没有默认值。 如果
UseShm启用,则共享内存密钥由自动计算NDB。 -
表22.317此表提供ShmSize共享内存配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 4M 范围 64K - 4294967039(0xFFFFFEFF) 重启类型 ñ
每个SHM连接都有一个共享内存段,其中节点之间的消息由发送方放置并由读取器读取。 该段的大小由
ShmSize。 默认值为4MB。 -
接收时,睡觉前等待的时间,以微秒为单位。
-
表22.319此表提供Signum共享内存配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 [没有] 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
此参数以前用于覆盖操作系统信号编号; 在NDB 8.0中,它不再使用,并且忽略它的任何设置。
[sci]
config.ini
文件中的
部分
明确定义了集群节点之间的SCI(可伸缩相干接口)连接。
在NDB Cluster中使用SCI传输器需要专门的硬件以及专门构建的MySQL二进制文件;
使用NDB 8.0发行版不支持编译此类二进制文件。
NDB
源代码
中存在以下参数
以及
ndb_config
和其他
NDB
程序
的输出
,但目前
无效
:
-
为了识别两个节点之间的连接,有必要为每个节点提供节点标识符,如
NodeId1和NodeId2。 -
为了识别两个节点之间的连接,有必要为每个节点提供节点标识符,如
NodeId1和NodeId2。 -
表22.322此表提供Host1SciId0 SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 [没有] 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
这标识了第一个Cluster节点(标识为
NodeId1) 上的SCI节点ID 。 -
表22.323此表提供Host1SciId1 SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
可以设置SCI传输器以在两个SCI卡之间进行故障转移,然后在这两个SCI卡之间使用单独的网络。 这标识了要在第一节点上使用的节点ID和第二SCI卡。
-
表22.324该表提供Host2SciId0 SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 [没有] 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
这标识第二个Cluster节点(由标识符
NodeId2) 上的SCI节点ID 。 -
表22.325此表提供Host2SciId1 SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
当使用两个SCI卡提供故障转移时,此参数标识要在第二个节点上使用的第二个SCI卡。
-
的
HostName1和HostName2参数可用于指定要用于在两个节点之间一个给定的SCI连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
的
HostName1和HostName2参数可用于指定要用于在两个节点之间一个给定的SCI连接的特定网络接口。 用于这些参数的值可以是主机名或IP地址。 -
表22.328此表提供SharedBufferSize SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 无符号 默认 10M 范围 64K - 4294967039(0xFFFFFEFF) 重启类型 ñ
每个SCI传输器具有用于两个节点之间的通信的共享存储器段。 对于大多数应用程序,将此段的大小设置为默认值1MB应该足够了。 使用较小的值会导致执行许多并行插入时出现问题; 如果共享缓冲区太小,这也可能导致 ndbd 进程 崩溃 。
-
SCI媒体前面的一个小缓冲区在通过SCI网络传输之前存储消息。 默认情况下,此值设置为8KB。 我们的基准测试表明性能最好是64KB,但16KB达到了这个目标的几个百分点,并且将其增加到8KB以上几乎没有任何优势。
-
要跟踪分布式消息,必须唯一地标识每条消息。 当此参数设置
Y为时,消息ID通过网络传输。 默认情况下,在生成版本中禁用此功能,并在-debug构建中 启用此功能 。 -
此参数是布尔值,默认情况下处于禁用状态。 当
Checksum启用时,校验和计算所有的消息它们被放置在发送缓冲之前。 此功能可防止在发送缓冲区中等待时消息被破坏。 它还可以检查运输过程中损坏的数据。 -
表22.332此表提供OverloadLimit SCI配置参数的类型和值信息
属性 值 版本(或更高版本) NDB 8.0.13 类型或单位 字节 默认 0 范围 0 - 4294967039(0xFFFFFEFF) 重启类型 ñ
如果发送缓冲区中有多个未发送的字节,则认为连接过载。 有关 更多信息 , 请参见 第22.3.3.14节“配置NDB集群发送缓冲区参数” 。
该
NDB
核心采用统一发送缓冲区,其内存是由所有转运共享池动态分配。
这意味着可以根据需要调整发送缓冲区的大小。
通过设置以下参数可以完成统一发送缓冲区的配置:
-
TotalSendBufferMemory。 该参数可为所有类型的NDB Cluster节点-即来设定,它可以在被设置
[ndbd],[mgm]和[api](或[mysql]所述的)部分config.ini文件。 它表示由每个节点分配的内存总量(以字节为单位),在所有已配置的传输器中将其设置为使用。 如果设置,其最小值为256KB; 最大值是4294967039。为了与现有配置向后兼容,此参数将所有已配置传输器的最大发送缓冲区大小的总和作为其默认值,再加上每个传输器的额外32KB(一页)。 最大值取决于传输器的类型,如下表所示:
表22.333具有最大发送缓冲区大小的传输器类型
运输车 最大发送缓冲区大小(字节) TCP SendBufferMemory(默认= 2M)SCI SendLimit(默认= 8K)加16KSHM 20K
这使现有配置的运行方式与NDB Cluster 6.3及更早版本的运行方式几乎相同,并且每个运输器具有相同的内存量和发送缓冲区空间。 但是,一个传输器未使用的内存不可用于其他传输器。
-
OverloadLimit。 此参数在
config.ini文件[tcp]部分中使用,表示在认为连接过载之前必须存在于发送缓冲区中的未发送数据量(以字节为单位)。 发生此类过载情况时,影响重载连接的事务将因NDB API错误1218( 在NDB内核中重载发送缓冲区 )而 失败, 直到超载状态通过。 默认值为0,在这种情况下,有效过载限制将根据SendBufferMemory * 0.8给定连接进行 计算 。 此参数的最大值为4G。 -
SendBufferMemory。 此值表示单个传输器可以在指定的整个池中使用的内存量的硬限制
TotalSendBufferMemory。 但是,SendBufferMemory所有配置的传输器 的总和 可能大于TotalSendBufferMemory为给定节点设置 的总和 。 这是一种在使用许多节点时节省内存的方法,只要所有传输器同时不需要最大内存量。
您可以使用该
ndbinfo.transporters
表来监视发送缓冲区内存使用情况,并检测可能对性能产生负面影响的减速和过载情况。
甚至
NDBCLUSTER
在1996年开始
设计之前
,很明显在构建并行数据库时遇到的主要问题之一是网络中节点之间的通信。
出于这个原因,
NDBCLUSTER
从一开始就设计允许使用许多不同的数据传输机制。
在本手册中,我们使用术语“
transporter”
来表示这些。
NDB Cluster代码库提供了四种不同的传输器:
-
TCP / IP使用100 Mbps或千兆以太网 ,如 第22.3.3.10节“NDB群集TCP / IP连接”中所述 。
-
直接(机器对机器)TCP / IP ; 虽然此传输器使用与前一项中提到的相同的TCP / IP协议,但它需要以不同方式设置硬件,并且配置也不同。 因此,它被认为是NDB Cluster的单独传输机制。 有关详细 信息, 请参见 第22.3.3.11节“使用直接连接的NDB集群TCP / IP连接” 。
-
共享内存(SHM) 。 有关SHM的更多信息,请参见 第22.3.3.12节“NDB集群共享内存连接” 。
-
可扩展的相干接口(SCI) 。 有关SCI的更多信息,请参见 第22.3.3.13节“NDB集群中的SCI传输连接” 。
注意在NDB Cluster中使用SCI传输器需要NDB 8.0不具备的专用硬件,软件和MySQL二进制文件。
如今大多数用户都使用以太网上的TCP / IP,因为它无处不在。 TCP / IP也是目前用于NDB Cluster的经过最佳测试的传输器。
我们正在努力确保与 ndbd 进程的 通信以 尽可能大的 “ 块 ”进行 ,因为这有利于所有类型的数据传输。
- 22.4.1 ndbd - NDB集群数据节点守护程序
- 22.4.2 ndbinfo_select_all - 从ndbinfo表中选择
- 22.4.3 ndbmtd - NDB簇数据节点守护进程(多线程)
- 22.4.4 ndb_mgmd - NDB群集管理服务器守护程序
- 22.4.5 ndb_mgm - NDB集群管理客户端
- 22.4.6 ndb_blob_tool - 检查并修复NDB集群表的BLOB和TEXT列
- 22.4.7 ndb_config - 提取NDB群集配置信息
- 22.4.8 ndb_delete_all - 从NDB表中删除所有行
- 22.4.9 ndb_desc - 描述NDB表
- 22.4.10 ndb_drop_index - 从NDB表中删除索引
- 22.4.11 ndb_drop_table - 删除NDB表
- 22.4.12 ndb_error_reporter - NDB错误报告实用程序
- 22.4.13 ndb_import - 将CSV数据导入NDB
- 22.4.14 ndb_index_stat - NDB索引统计工具
- 22.4.15 ndb_move_data - NDB数据复制实用程序
- 22.4.16 ndb_perror - 获取NDB错误消息信息
- 22.4.17 ndb_print_backup_file - 打印NDB备份文件内容
- 22.4.18 ndb_print_file - 打印NDB磁盘数据文件内容
- 22.4.19 ndb_print_frag_file - 打印NDB片段列表文件内容
- 22.4.20 ndb_print_schema_file - 打印NDB模式文件内容
- 22.4.21 ndb_print_sys_file - 打印NDB系统文件内容
- 22.4.22 ndb_redo_log_reader - 检查并打印群集重做日志的内容
- 22.4.23 ndb_restore - 恢复NDB群集备份
- 22.4.24 ndb_select_all - 从NDB表打印行
- 22.4.25 ndb_select_count - 打印NDB表的行计数
- 22.4.26 ndb_setup.py - 为NDB群集启动基于浏览器的自动安装程序
- 22.4.27 ndb_show_tables - 显示NDB表的列表
- 22.4.28 ndb_size.pl - NDBCLUSTER大小要求估算器
- 22.4.29 ndb_top - 查看NDB线程的CPU使用情况信息
- 22.4.30 ndb_waiter - 等待NDB群集到达给定状态
- 22.4.31 NDB群集程序常用选项 - NDB群集程序常用选项
使用和管理NDB集群需要几个专门的程序,我们将在本章中介绍。 我们将在NDB集群中讨论这些程序的用途,如何使用这些程序,以及为每个程序提供哪些启动选项。
这些程序包括NDB Cluster数据,管理和SQL节点进程( ndbd , ndbmtd , ndb_mgmd 和 mysqld )以及管理客户端( ndb_mgm )。
有关 用于启动NDB Cluster Auto-Installer 的程序 ndb_setup.py的 信息 也包含在本节中。 您应该知道 第22.4.26节“ ndb_setup.py - 启动基于浏览器的NDB群集自动安装程序” ,仅包含有关命令行客户端的信息; 有关使用此程序生成的GUI安装程序配置和部署NDB群集的信息,请参阅 NDB群集自动安装程序(NDB 7.5) 。
有关将 mysqld 用作NDB集群过程的信息,请参见 第22.5.4节“NDB集群的MySQL服务器使用情况” 。
NDB
NDB Cluster分发包含
其他
实用程序,诊断程序和示例程序。
这些包括
ndb_restore
,
ndb_show_tables
和
ndb_config
。
本节还介绍了这些程序。
本节的最后一部分包含所有各种NDB Cluster程序通用的选项表。
ndbd 是用于使用NDB Cluster存储引擎处理表中所有数据的进程。 这是使数据节点能够完成分布式事务处理,节点恢复,磁盘检查点,在线备份和相关任务的过程。
在NDB群集中,一组 ndbd 进程协作处理数据。 这些进程可以在同一台计算机(主机)或不同的计算机上执行。 数据节点和群集主机之间的对应关系是完全可配置的。
下表包含特定于NDB Cluster数据节点程序 ndbd的 命令选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndbd ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.334 ndbd程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 本地绑定地址 |
所有NDB 8.0版本 |
|
| 在几秒钟内尝试联系管理服务器之间等待的时间; 0表示不要在两次尝试之间等待 |
所有NDB 8.0版本 |
|
| 设置放弃前重试连接的次数; 0表示仅尝试1次(并且不重试) |
所有NDB 8.0版本 |
|
| 在几秒钟内尝试联系管理服务器之间等待的时间; 0表示不要在两次尝试之间等待 |
所有NDB 8.0版本 |
|
|
|
启动ndbd作为守护进程(默认); 用--nodaemon覆盖 |
所有NDB 8.0版本 |
| 在前台运行ndbd,用于调试目的(隐含--nodaemon) |
所有NDB 8.0版本 |
|
| 执行ndbd的初始启动,包括清理文件系统。 使用此选项之前,请参阅文档 |
所有NDB 8.0版本 |
|
| 执行部分初始启动(需要--nowait-nodes) |
所有NDB 8.0版本 |
|
| 用于将数据节点进程安装为Windows服务。 不适用于非Windows平台。 |
所有NDB 8.0版本 |
|
| 控制日志缓冲区的大小。 在调试时使用,生成许多日志消息; 默认值足以进行正常操作。 |
所有NDB 8.0版本 |
|
| 不要立即启动ndbd; ndbd等待命令从ndb_mgmd开始 |
所有NDB 8.0版本 |
|
| 不要将ndbd作为守护进程启动; 提供测试目的 |
所有NDB 8.0版本 |
|
| 不要等待这些数据节点启动(以逗号分隔的节点ID列表)。 还需要使用--ndb-nodeid。 |
所有NDB 8.0版本 |
|
| 用于删除以前作为Windows服务安装的数据节点进程。 不适用于非Windows平台。 |
所有NDB 8.0版本 |
|
| 使数据日志将额外的调试信息写入节点日志。 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --bind-address=name类型 串 默认值 导致 ndbd 绑定到特定网络接口(主机名或IP地址)。 此选项没有默认值。
-
属性 值 命令行格式 --connect-delay=#弃用 是 类型 数字 默认值 5最低价值 0最大价值 3600确定启动时尝试联系管理服务器之间等待的时间(尝试次数由
--connect-retries选项 控制 )。 默认值为5秒。此选项已弃用,并且可能会在将来的NDB Cluster版本中删除。 请
--connect-retry-delay改用。 -
属性 值 命令行格式 --connect-retries=#类型 数字 默认值 12最低价值 0最大价值 65535设置放弃前重试连接的次数; 0表示仅尝试1次(并且不重试)。 默认值为12次尝试。 尝试之间等待的时间由
--connect-retry-delay选项 控制 。 -
属性 值 命令行格式 --connect-retry-delay=#类型 数字 默认值 5最低价值 0最大价值 4294967295确定在启动时尝试联系管理服务器之间等待的时间(尝试之间的时间由
--connect-retries选项 控制 )。 默认值为5秒。此选项取代了该
--connect-delay选项,该选项现已弃用,并且将在未来的NDB Cluster版本中删除。 -
属性 值 命令行格式 --daemon类型 布尔 默认值 TRUE指示 ndbd 或 ndbmtd 作为守护进程执行。 这是默认行为。
--nodaemon可用于防止进程作为守护程序运行。 -
属性 值 命令行格式 --foreground类型 布尔 默认值 FALSE使 ndbd 或 ndbmtd 作为前台进程执行,主要用于调试目的。 此选项意味着该
--nodaemon选项。 -
属性 值 命令行格式 --initial类型 布尔 默认值 FALSE指示 ndbd 执行初始启动。 初始启动将删除由早期 ndbd 实例为恢复目的而创建的任何文件 。 它还会重新创建恢复日志文件。 在某些操作系统上,此过程可能会花费大量时间。
一
--initial开始是用来 仅 在启动时 的ndbd 非常特殊的情况的过程; 这是因为此选项会导致从NDB Cluster文件系统中删除所有文件,并重新创建所有重做日志文件。 这些情况列在这里:-
执行已更改任何文件内容的软件升级时。
-
使用新版本的 ndbd 重新启动节点时 。
-
作为最后的手段,由于某种原因,节点重启或系统重启失败。 在这种情况下,请注意,由于数据文件的破坏,此节点无法再用于还原数据。
警告为避免最终丢失数据的可能性,建议您 不要同时 使用该
--initial选项StopOnError = 0。 相反, 仅在群集启动后 设置StopOnError为0config.ini,然后正常重新启动数据节点 - 即没有--initial选项。 有关StopOnError此问题的详细说明, 请参阅 参数说明。 (缺陷号24945638)使用此选项可防止
StartPartialTimeout和StartPartitionedTimeout配置参数产生任何影响。重要该选项并 不会 影响以下两种类型的文件:
-
已受受影响的节点创建的备份文件
-
NDB群集磁盘数据文件(请参见 第22.5.13节“NDB群集磁盘数据表” )。
此选项对刚刚从已运行的数据节点启动(或重新启动)的数据节点恢复数据也没有影响。 此数据恢复自动进行,无需用户干预正常运行的NDB群集。
第一次启动集群时(即在创建任何数据节点文件之前),允许使用此选项; 但是, 没有 必要这样做。
-
-
属性 值 命令行格式 --initial-start类型 布尔 默认值 FALSE执行群集的部分初始启动时使用此选项。 应该使用此选项启动每个节点,以及
--nowait-nodes。假设您有一个4节点集群,其数据节点具有ID 2,3,4和5,并且您希望仅使用节点2,4和5执行部分初始启动,即省略节点3:
shell>
ndbd --ndb-nodeid=2 --nowait-nodes=3 --initial-startshell>ndbd --ndb-nodeid=4 --nowait-nodes=3 --initial-startshell>ndbd --ndb-nodeid=5 --nowait-nodes=3 --initial-start使用此选项时,还必须使用该选项指定要启动的数据节点的节点ID
--ndb-nodeid。重要不要混淆了此选项
--nowait-nodes供选择 ndb_mgmd ,可用于实现与多个管理服务器配置集群没有所有管理服务器正在网上启动。 -
属性 值 命令行格式 --install[=name]平台特定 视窗 类型 串 默认值 ndbd导致 ndbd 作为Windows服务安装。 (可选)您可以指定服务的名称; 如果未设置,则服务名称默认为
ndbd。 虽然最好 在 或 配置文件中 指定其他 ndbd 程序选项 ,但可以与它一起使用 。 但是,在这种情况下, 必须首先指定选项,然后才能给出任何其他选项,以便Windows服务安装成功。my.inimy.cnf--install--install通常不建议将此选项与选项一起使用
--initial,因为这会导致每次停止和启动服务时都擦除并重建数据节点文件系统。 至尊还应注意,如果你打算使用任何其他采取 NDBD 影响数据节点,包括启动选项--initial-start,--nostart以及--nowait-nodes与-together--install,你应该绝对确保你完全理解并允许做任何可能的后果所以。该
--install选项对非Windows平台没有影响。 -
属性 值 命令行格式 --logbuffer-size=#类型 整数 默认值 32768最低价值 2048最大价值 4294967295设置数据节点日志缓冲区的大小。 在使用大量额外日志记录进行调试时,如果日志消息太多,则日志缓冲区可能会耗尽空间,在这种情况下,某些日志消息可能会丢失。 在正常操作期间不应发生这种情况。
-
属性 值 命令行格式 --nodaemon类型 布尔 默认值 FALSE阻止 ndbd 或 ndbmtd 作为守护进程执行。 此选项会覆盖该
--daemon选项。 这对于在调试二进制文件时将输出重定向到屏幕很有用。Windows上 ndbd 和 ndbmtd 的默认行为 是在前台运行,在Windows平台上不需要此选项,因为它没有任何效果。
-
属性 值 命令行格式 --nostart类型 布尔 默认值 FALSE指示 ndbd 不自动启动。 使用此选项时, ndbd 连接到管理服务器,从中获取配置数据,并初始化通信对象。 但是,在管理服务器明确要求之前,它实际上并不启动执行引擎。 这可以通过
START在管理客户端中 发出适当的 命令 来完成 (请参见 第22.5.2节“NDB集群管理客户端中的命令” )。 -
--nowait-nodes=node_id_1[,node_id_2[, ...]]属性 值 命令行格式 --nowait-nodes=list类型 串 默认值 此选项采用数据节点列表,群集在启动之前不会等待这些节点。
这可用于以分区状态启动集群。 例如,要启动只有一半数据节点(节点2,3,4和5)在4节点集群中运行的集群,可以使用启动每个 ndbd 进程
--nowait-nodes=3,5。 在这种情况下,群集尽快开始为节点2和4连接,而不会 不 等待StartPartitionedTimeout对节点3和5毫秒来连接,因为它会以其他方式。如果您想要启动与上一个示例中相同的集群而没有一个 ndbd (例如,节点3的主机遇到硬件故障),则启动节点2,4和5
--nowait-nodes=3。 然后,只要节点2,4和5连接,集群就会启动,并且不会等待节点3启动。 -
属性 值 命令行格式 --remove[=name]平台特定 视窗 类型 串 默认值 ndbd导致 以前作为Windows服务安装 的 ndbd 进程被删除。 (可选)您可以指定要卸载的服务的名称; 如果未设置,则服务名称默认为
ndbd。该
--remove选项对非Windows平台没有影响。 -
导致额外的调试输出写入节点日志。
您还可以 在数据节点运行时 使用
NODELOG DEBUG ON和NODELOG DEBUG OFF启用和禁用此额外日志记录。
ndbd
生成一组日志文件,这些文件放在
配置文件中
指定的目录
DataDir
中
config.ini
。
这些日志文件如下所示。
node_id
是并表示节点的唯一标识符。
例如,
ndb_2_error.log
是由节点ID为的数据节点生成的错误日志
2
。
-
ndb_是一个文件,包含所引用的 ndbd 进程遇到 的所有崩溃的记录 。 此文件中的每条记录都包含一个简短的错误字符串以及对此崩溃的跟踪文件的引用。 此文件中的典型条目可能如下所示:node_id_error.log日期/时间:2004年7月30日星期六 - 00:20:01 错误类型:错误 消息:内部程序错误(ndbrequire失败) 故障编号:2341 问题数据:DbtupFixAlloc.cpp 参考对象:DBTUP(行:173) ProgramName:NDB内核 ProcessID:14909 TraceFile:ndb_2_trace.log.2 *** *** EOM
可以在 数据节点错误消息中 找到 可能的 ndbd 退出代码和在数据节点进程过早关闭时生成的 消息的列表 。
重要错误日志文件中的最后一个条目不一定是最新的条目 (也不可能是)。 错误日志中的条目 未按 时间顺序列出; 相反,它们对应于文件中确定的跟踪文件的顺序 (见下文)。 因此,错误日志条目以循环而非顺序的方式被覆盖。
ndb_node_id_trace.log.next -
ndb_是一个跟踪文件,准确描述错误发生之前发生的事情。 此信息对于NDB Cluster开发团队的分析非常有用。node_id_trace.log.trace_id可以配置在覆盖旧文件之前将创建的这些跟踪文件的数量。
trace_id是一个为每个连续的跟踪文件递增的数字。 -
ndb_是跟踪要分配的下一个跟踪文件编号的文件。node_id_trace.log.next -
ndb_是包含 ndbd 进程 输出的任何数据的文件 。 仅当 ndbd 作为守护程序启动时 才会创建此文件 ,这是默认行为。node_id_out.log -
ndb_是一个文件,包含 作为守护程序启动时 ndbd 进程 的进程ID 。 它还可用作锁定文件,以避免启动具有相同标识符的节点。node_id.pid -
ndb_是仅在 ndbd的 调试版本中使用的文件 ,其中可以使用 ndbd 进程中 的数据跟踪所有传入,传出和内部消息 。node_id_signal.log
建议不要使用通过NFS挂载的目录,因为在某些环境中,这可能会导致问题,即
.pid
即使在进程终止后,文件
上的锁
仍然有效。
要启动 ndbd ,可能还需要指定管理服务器的主机名及其正在侦听的端口。 可选地,还可以指定进程要使用的节点ID。
外壳> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
有关此问题的其他信息 , 请参见 第22.3.3.3节“NDB集群连接字符串” 。 第22.4.31节“NDB群集程序通用选项 - NDB群集程序通用选项” 描述了可与 ndbd 一起使用的其他命令行选项 。 有关数据节点配置参数的信息,请参见 第22.3.3.6节“定义NDB集群数据节点” 。
当 ndbd 启动时,它实际上启动了两个进程。 第一个被称为 “ 天使过程 ” ; 它唯一的工作是发现执行过程何时完成,然后重新启动 ndbd 进程(如果配置为执行此操作)。 因此,如果您尝试 使用Unix kill 命令 终止ndbd ,则必须从angel进程开始终止这两个进程。 终止 ndbd 进程 的首选方法 是使用管理客户端并从那里停止进程。
执行过程使用一个线程来读取,写入和扫描数据,以及所有其他活动。 该线程是异步实现的,因此它可以轻松处理数千个并发操作。 另外,一个看门狗线程监督执行线程,以确保它不会挂起无限循环。 线程池处理文件I / O,每个线程能够处理一个打开的文件。 线程也可以由 ndbd 进程中 的传输器用于传输器连接 。 在执行大量操作(包括更新)的多处理器系统中, 如果允许 , ndbd 进程最多可以消耗2个CPU。
对于具有许多CPU的计算机,可以使用 属于不同节点组的 多个 ndbd 进程; 但是,这样的配置仍然被认为是实验性的,并且在生产环境中不支持MySQL 8.0。 请参见 第22.1.7节“NDB集群的已知限制” 。
ndbinfo_select_all
是一个客户端程序,它从
ndbinfo
数据库中的
一个或多个表中选择所有行和列
并非
此程序可以读取
mysql
客户端中
ndbinfo
可用的
所有
表
。
此外,
ndbinfo_select_all
可以显示有关
使用SQL无法访问的
内部表的信息
,包括
和
元数据表。
ndbinfo
tables
columns
要
ndbinfo
使用
ndbinfo_select_all
从一个或多个
表中进行
选择
,需要在调用程序时提供表的名称,如下所示:
外壳> ndbinfo_select_all table_name1 [table_name2] [...]
例如:
外壳> ndbinfo_select_all logbuffers logspaces
== logbuffers ==
node_id log_type log_id log_part总使用率高
5 0 0 0 33554432 262144 0
6 0 0 0 33554432 262144 0
7 0 0 0 33554432 262144 0
8 0 0 0 33554432 262144 0
== logspaces ==
node_id log_type log_id log_part总使用率高
5 0 0 0 268435456 0 0
5 0 0 1 268435456 0 0
5 0 0 2 268435456 0 0
5 0 0 3 268435456 0 0
6 0 0 0 268435456 0 0
6 0 0 1 268435456 0 0
6 0 0 2 268435456 0 0
6 0 0 3 268435456 0 0
7 0 0 0 268435456 0 0
7 0 0 1 268435456 0 0
7 0 0 2 268435456 0 0
7 0 0 3 268435456 0 0
8 0 0 0 268435456 0 0
8 0 0 1 268435456 0 0
8 0 0 2 268435456 0 0
8 0 0 3 268435456 0 0
外壳>
下表包含特定于 ndbinfo_select_all的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndbinfo_select_all ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.335 ndbinfo_select_all程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 设置循环之间的延迟(秒)。 默认值为5。 |
所有NDB 8.0版本 |
|
| 设置执行选择的次数。 默认值为1。 |
所有NDB 8.0版本 |
|
| 表所在的数据库的名称。 |
所有NDB 8.0版本 |
|
| 设置并行度。 |
所有NDB 8.0版本 |
ndbmtd
是
ndbd
的多线程版本
,该过程用于使用
NDBCLUSTER
存储引擎
处理表中的所有数据
。
ndbmtd
旨在用于具有多个CPU核心的主机上。
除非另有说明,否则
ndbmtd的
功能与
ndbd
相同
;
因此,在本节中,我们将重点介绍
ndbmtd
与
ndbd的
不同之处
,您应该参考
第22.4.1节“
ndbd”
- NDB集群数据节点守护程序”
,有关运行适用于数据节点进程的单线程和多线程版本的NDB Cluster数据节点的其他信息。
与 ndbd一起 使用的命令行选项和配置参数 也适用于 ndbmtd 。 有关这些选项和参数的更多信息,请分别参见 第22.4.1节“ ndbd - NDB集群数据节点守护程序” 和 第22.3.3.6节“定义NDB集群数据节点” 。
ndbmtd
也与
ndbd
文件系统兼容
。
换句话说,
可以停止
运行
ndbd
的数据节点
,用
ndbmtd
替换二进制文件
,然后重新启动而不会丢失任何数据。
(但是,在执行此操作时,
MaxNoOfExecutionThreads
如果希望
ndbmtd
以多线程方式运行
,
则
必须确保
在重新启动节点之前将其设置为适当的值
。)同样,
只需通过停止节点和
ndbmtd
二进制文件即可替换为
ndbd
然后启动
ndbd
代替多线程二进制文件。
当在两者之间切换以启动数据节点二进制时,没有必要使用
--initial
。
使用 ndbmtd 与 在两个关键方面 使用 ndbd 不同 :
-
因为 ndbmtd 在单线程模式下默认运行(也就是说,它的行为类似于 ndbd ),所以必须将其配置为使用多个线程。 这可以通过
config.ini在MaxNoOfExecutionThreads配置参数或ThreadConfig配置参数 的 文件中 设置适当的值来完成 。 使用MaxNoOfExecutionThreads更简单,但ThreadConfig提供更多的灵活性。 有关这些配置参数及其用法的更多信息,请参阅 多线程配置参数(ndbmtd) 。 -
跟踪文件由 ndbmtd 进程中的 严重错误生成 ,其方式与 ndbd 失败 生成的方式略有不同 。 在接下来的几段中将更详细地讨论这些差异。
与
ndbd
一样
,
ndbmtd
生成一组日志文件,这些文件放在
配置文件中
指定的目录
DataDir
中
config.ini
。
除跟踪文件外,它们以相同的方式生成,并且与
ndbd
生成的名称相同
。
如果发生严重错误,
ndbmtd会
生成跟踪文件,描述错误发生之前发生的情况。
这些文件可以在数据节点中找到
DataDir
,可用于分析NDB集群开发和支持团队的问题。
为每个
ndbmtd
线程
生成一个跟踪文件
。
这些文件的名称具有以下模式:
ndb_node_id_trace.log.trace_id_tthread_id,
在此模式中,
node_id
代表群集中数据节点的唯一节点ID,
trace_id
是跟踪序列号,并且
thread_id
是线程ID。
例如,如果
ndbmtd
进程作为具有节点ID 3且
MaxNoOfExecutionThreads
等于4
的NDB Cluster数据节点运行
失败,
则会
在数据节点的数据目录中生成四个跟踪文件。
如果是第一次在此节点发生故障,那么这些文件被命名为
ndb_3_trace.log.1_t1
,
ndb_3_trace.log.1_t2
,
ndb_3_trace.log.1_t3
,和
ndb_3_trace.log.1_t4
。
在内部,这些跟踪文件遵循与
ndbd
跟踪文件
相同的格式
。
所述 的ndbd 的是,当数据节点进程关闭生成退出代码和消息过早也使用 ndbmtd 。 有关 这些的列表, 请参阅 数据节点错误消息 。
管理服务器是读取群集配置文件并将此信息分发到请求它的群集中的所有节点的过程。 它还维护集群活动的日志。 管理客户端可以连接到管理服务器并检查群集的状态。
下表包含特定于NDB群集管理服务器程序 ndb_mgmd的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_mgmd ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.336 ndb_mgmd程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 本地绑定地址 |
所有NDB 8.0版本 |
|
| 启用管理服务器配置缓存; 默认为TRUE。 |
所有NDB 8.0版本 |
|
|
|
指定集群配置文件; 在NDB-6.4.0及更高版本中,需要--reload或--initial来覆盖配置缓存(如果存在) |
所有NDB 8.0版本 |
|
|
指定集群管理服务器的配置缓存目录 |
所有NDB 8.0版本 |
|
|
以守护进程模式运行ndb_mgmd(默认) |
所有NDB 8.0版本 |
| 导致管理服务器从配置文件重新加载其配置数据,绕过配置缓存 |
所有NDB 8.0版本 |
|
| 用于将管理服务器进程安装为Windows服务。 不适用于非Windows平台。 |
所有NDB 8.0版本 |
|
| 以交互方式运行ndb_mgmd(在生产中不正式支持;仅用于测试目的) |
所有NDB 8.0版本 |
|
| 在群集日志中编写应用于此节点的消息时使用的名称。 |
所有NDB 8.0版本 |
|
| 从my.cnf文件中读取群集配置数据 |
所有NDB 8.0版本 |
|
| 不提供任何节点ID检查 |
所有NDB 8.0版本 |
|
| 不要将ndb_mgmd作为守护程序运行 |
所有NDB 8.0版本 |
|
| 启动此管理服务器时,请勿等待这些管理节点。 还需要使用--ndb-nodeid。 |
所有NDB 8.0版本 |
|
| 打印完整配置并退出 |
所有NDB 8.0版本 |
|
| 使管理服务器将配置文件与其配置缓存进行比较 |
所有NDB 8.0版本 |
|
| 用于删除以前作为Windows服务安装的管理服务器进程,可选择指定要删除的服务的名称。 不适用于非Windows平台。 |
所有NDB 8.0版本 |
|
| 将其他信息写入日志。 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --bind-address=host类型 串 默认值 [none]使管理服务器绑定到特定网络接口(主机名或IP地址)。 此选项没有默认值。
-
属性 值 命令行格式 --config-cache[=TRUE|FALSE]类型 布尔 默认值 TRUE此选项的默认值为
1(或TRUE,或ON),可用于禁用管理服务器的配置缓存,以便在config.ini每次启动时 读取其配置 (请参见 第22.3.3节“NDB群集配置文件” )。 您可以通过 使用以下任一选项 启动 ndb_mgmd 进程 来执行此操作 :使用刚刚列出的选项之一仅在管理服务器启动时没有存储配置时才有效。 如果管理服务器找到任何配置缓存文件,则 忽略 该
--config-cache选项或--skip-config-cache选项。 因此,要禁用配置缓存,应在 第 一次启动管理服务器时 使用该选项 。 否则 - 也就是说,如果您希望为 已经 存在的管理服务器禁用配置缓存 创建配置缓存 - 您必须停止管理服务器,手动删除任何现有配置缓存文件,然后使用--skip-config-cache(或--config-cache设置等于0OFF,或FALSE) 重新启动管理服务器 。配置缓存文件通常在
mysql-cluster安装目录下指定的目录中创建(除非使用该--configdir选项 覆盖了此位置 )。 每次管理服务器更新其配置数据时,它都会写入新的缓存文件。 使用以下格式按创建顺序依次命名文件:ndb_
node-id_config.bin。seq-numbernode-id是管理服务器的节点ID;seq-number是序列号,与1。例如开始,如果管理服务器的节点ID为5,则前三配置缓存文件会被创建时,被命名为ndb_5_config.bin.1,ndb_5_config.bin.2和ndb_5_config.bin.3。如果你的目的是清除或重新加载,而无需实际禁用缓存配置缓存,你应该开始 ndb_mgmd 与其中一个选项
--reload或--initial代替--skip-config-cache。要重新启用配置缓存,只需重新启动管理服务器,但不 使用先前用于禁用配置缓存 的
--config-cache或--skip-config-cache选项。ndb_mgmd 不检查配置目录(
--configdir)或尝试在--skip-config-cache使用 时创建一个 。 (缺陷号码#13428853) -
--config-file=,filename-ffilename属性 值 命令行格式 --config-file=file类型 文件名 默认值 [none]指示管理服务器应将其用于其配置文件的文件。 默认情况下,管理服务器查找
config.ini与 ndb_mgmd 可执行 文件 位于同一目录中的 文件; 否则必须明确指定文件名和位置。此选项没有默认值,并且被忽略,除非管理服务器被强制读取配置文件,因为 ndb_mgmd 是使用
--reloador--initial选项 启动的 ,或者是因为管理服务器找不到任何配置缓存。 如果 启动了 ndb_mgmd , 也会读取此选项--config-cache=OFF。 有关 更多信息 , 请参见 第22.3.3节“NDB群集配置文件” 。 -
属性 值 命令行格式 --configdir=directory--config-dir=directory类型 文件名 默认值 $INSTALLDIR/mysql-cluster指定集群管理服务器的配置缓存目录。
--config-dir是此选项的别名。 -
属性 值 命令行格式 --daemon类型 布尔 默认值 TRUE指示 ndb_mgmd 作为守护进程启动。 这是默认行为。
在Windows平台上 运行 ndb_mgmd 时,此选项无效 。
-
属性 值 命令行格式 --initial类型 布尔 默认值 FALSE配置数据在内部缓存,而不是在每次启动管理服务器时从集群全局配置文件中读取(请参见 第22.3.3节“NDB集群配置文件” )。 使用该
--initial选项可以通过强制管理服务器删除任何现有缓存文件,然后从群集配置文件重新读取配置数据并构建新缓存来覆盖此行为。这与
--reload选项有 两种不同 。 首先,--reload强制服务器针对缓存检查配置文件,并仅在文件内容与缓存不同时重新加载其数据。 其次,--reload不删除任何现有的缓存文件。如果 使用 但无法找到全局配置文件 来调用 ndb_mgmd
--initial,则管理服务器无法启动。管理服务器启动时,它会检查同一NDB群集中的另一个管理服务器,并尝试使用其他管理服务器的配置数据。 执行具有多个管理节点的NDB群集的滚动重新启动时,此行为会产生影响。 有关 更多信息 , 请参见 第22.5.5节“执行NDB集群的滚动重新启动” 。
与
--config-file选项 一起使用时 ,仅在实际找到配置文件时才清除缓存。 -
属性 值 命令行格式 --install[=name]平台特定 视窗 类型 串 默认值 ndb_mgmd导致 ndb_mgmd 作为Windows服务安装。 (可选)您可以指定服务的名称; 如果未设置,则服务名称默认为
ndb_mgmd。 虽然最好 在 或 配置文件中 指定其他 ndb_mgmd 程序选项 ,但可以将它们一起使用 。 但是,在这种情况下, 必须首先指定选项,然后才能给出任何其他选项,以便Windows服务安装成功。my.inimy.cnf--install--install通常不建议将此选项与选项一起使用
--initial,因为这会导致每次停止和启动服务时都擦除并重建配置缓存。 如果您打算使用 影响管理服务器启动的 任何其他 ndb_mgmd 选项, 也应该小心 ,并且您应该绝对确定您完全理解并允许这样做的任何可能后果。该
--install选项对非Windows平台没有影响。 -
属性 值 命令行格式 --interactive类型 布尔 默认值 FALSE以交互模式 启动 ndb_mgmd ; 也就是说, 只要管理服务器正在运行,就会启动 ndb_mgm 客户端会话。 此选项不会启动任何其他NDB Cluster节点。
-
属性 值 命令行格式 --log-name=name类型 串 默认值 MgmtSrvr提供要在群集日志中用于此节点的名称。
-
属性 值 命令行格式 --mycnf类型 布尔 默认值 FALSE从
my.cnf文件中 读取配置数据 。 -
属性 值 命令行格式 --no-nodeid-checks类型 布尔 默认值 FALSE不要对节点ID执行任何检查。
-
属性 值 命令行格式 --nodaemon类型 布尔 默认值 FALSE指示 ndb_mgmd 不作为守护进程启动。
Windows上 ndb_mgmd 的默认行为 是在前台运行,在Windows平台上不需要此选项。
-
属性 值 命令行格式 --nowait-nodes=list类型 数字 默认值 最低价值 1最大价值 255启动NDB群集时,配置了两个管理节点,每个管理服务器通常会检查其他 ndb_mgmd 是否也可以运行,以及其他管理服务器的配置是否与其自身相同。 但是,有时需要仅使用一个管理节点启动集群(并且可能允许 稍后启动 其他 ndb_mgmd )。 此选项使管理节点绕过对其节点ID传递给此选项的任何其他管理节点的任何检查,允许集群启动,就像配置为仅使用已启动的管理节点一样。
为了便于说明,请考虑
config.ini文件 的以下部分 (我们省略了与此示例无关的大多数配置参数):[NDBD] NodeId = 1 HostName = 198.51.100.101 [NDBD] NodeId = 2 HostName = 198.51.100.102 [NDBD] NodeId = 3 HostName = 198.51.100.103 [NDBD] NodeId = 4 HostName = 198.51.100.104 [ndb_mgmd] NodeId = 10 HostName = 198.51.100.150 [ndb_mgmd] NodeId = 11 HostName = 198.51.100.151 [API] NodeId = 20 HostName = 198.51.100.200 [API] NodeId = 21 HostName = 198.51.100.201
假设您希望仅使用具有节点ID
10并在具有IP地址198.51.100.150的主机上运行 的管理服务器来启动此群集 。 (例如,假设您打算在其他管理服务器上运行的主机由于硬件故障而暂时不可用,并且您正在等待它被修复。)要以这种方式启动集群,请使用命令在198.51.100.150机器上输入以下命令:外壳>
ndb_mgmd --ndb-nodeid=10 --nowait-nodes=11如上例所示,使用时
--nowait-nodes,还必须使用该--ndb-nodeid选项指定此 ndb_mgmd 进程 的节点ID 。然后,您可以按常规方式启动每个群集的数据节点。 如果您希望在以后启动并使用第二个管理服务器以及第一个管理服务器而不重新启动数据节点,则必须使用引用两个管理服务器的连接字符串启动每个数据节点,如下所示:
外壳>
ndbd -c 198.51.100.150,198.51.100.151对于 您希望以连接到此群集的NDB Cluster SQL节点启动的 任何 mysqld 进程 使用的连接字符串,情况也是如此 。 有关 更多信息 , 请参见 第22.3.3.3节“NDB集群连接字符串” 。
与 ndb_mgmd一起 使用时 ,此选项仅影响管理节点相对于其他管理节点的行为。 不要将它与 ndbd 或 ndbmtd
--nowait-nodes使用 的 选项 混淆, 以允许集群以少于其完整数据节点的数量开始; 当与数据节点一起使用时,此选项仅针对其他数据节点影响其行为。可以将多个管理节点ID作为逗号分隔列表传递给此选项。 每个节点ID必须不小于1且不大于255.实际上,对同一个NDB集群使用两个以上的管理服务器是非常罕见的(或者需要这样做); 在大多数情况下,您只需要为启动群集时不希望使用的一个管理服务器的单个节点ID传递给此选项。
注意当您稍后启动 “ 丢失 ” 管理服务器时,其配置必须与群集已在使用的管理服务器的配置相匹配。 否则,它无法通过现有管理服务器执行配置检查,并且无法启动。
-
属性 值 命令行格式 --print-full-config类型 布尔 默认值 FALSE显示有关群集配置的扩展信息。 在命令行上使用此选项, ndb_mgmd 进程将打印有关群集设置的信息,包括群集配置节的详尽列表以及参数及其值。 通常与
--config-file(-f)选项 一起使用 。 -
属性 值 命令行格式 --reload类型 布尔 默认值 FALSE每次启动管理服务器时,NDB Cluster配置数据都会在内部存储,而不是从集群全局配置文件中读取(请参见 第22.3.3节“NDB集群配置文件” )。 使用此选项会强制管理服务器根据群集配置文件检查其内部数据存储,并在发现配置文件与缓存不匹配时重新加载配置。 保留现有配置缓存文件,但不使用。
这与
--initial选项有 两种不同 。 首先,--initial导致删除所有缓存文件。 其次,--initial强制管理服务器重新读取全局配置文件并构造新的缓存。如果管理服务器找不到全局配置文件,则
--reload忽略 该 选项。当
--reload被使用时,管理服务器必须能够与数据节点和它试图读取全局配置文件之前集群中的任何其他管理服务器进行通信; 否则,管理服务器无法启动。 这可能是由于网络环境的变化(例如节点的新IP地址或更改的防火墙配置)而发生的。 在这种情况下,您必须使用--initial强制放弃现有缓存配置并从文件重新加载。 有关 其他信息, 请参见 第22.5.5节“执行NDB集群的滚动重新启动” 。 -
属性 值 命令行格式 --remove[=name]平台特定 视窗 类型 串 默认值 ndb_mgmd删除已作为Windows服务安装的管理服务器进程,可选择指定要删除的服务的名称。 仅适用于Windows平台。
-
属性 值 命令行格式 --verbose类型 布尔 默认值 FALSE删除已作为Windows服务安装的管理服务器进程,可选择指定要删除的服务的名称。 仅适用于Windows平台。
启动管理服务器时,不必严格指定连接字符串。 但是,如果您使用多个管理服务器,则应提供连接字符串,并且群集中的每个节点都应明确指定其节点ID。
有关使用连接字符串的信息 , 请参见 第22.3.3.3节“NDB集群连接字符串” 。 第22.4.4节“ ndb_mgmd - NDB集群管理服务器守护程序” 介绍了 ndb_mgmd的 其他选项 。
ndb_mgmd
在其起始目录
中创建或使用以下文件
DataDir
,这些
config.ini
文件
位于
配置文件中
指定的
文件中。
在下面的列表中,
node_id
是唯一的节点标识符。
-
config.ini是整个群集的配置文件。 该文件由用户创建并由管理服务器读取。 第22.3节“NDB群集的配置” 讨论了如何设置此文件。 -
ndb_是群集事件日志文件。 此类事件的示例包括检查点启动和完成,节点启动事件,节点故障和内存使用级别。 有关描述的集群事件的完整列表,请参见 第22.5节“NDB集群的管理” 。node_id_cluster.log默认情况下,当群集日志的大小达到一百万字节时,文件将重命名为 ,其中 是群集日志文件的序列号。 (例如:如果已存在序列号为1,2和3的文件,则使用该编号命名下一个日志文件 。)您可以使用以下命令更改文件的大小和数量以及群集日志的其他特征。 配置参数。
ndb_node_id_cluster.log.seq_idseq_id4LogDestination -
ndb_是用于文件node_id_out.logstdout和stderr运行管理服务器作为后台进程时。 -
ndb_是将管理服务器作为守护程序运行时使用的进程标识文件。node_id.pid
该 ndb_mgm 实际上不需要管理客户端进程来运行群集。 它的价值在于提供一组命令来检查集群的状态,启动备份和执行其他管理功能。 管理客户端使用C API访问管理服务器。 高级用户还可以使用此API对专用管理进程进行编程,以执行与 ndb_mgm 执行的任务类似的任务 。
要启动管理客户端,必须提供管理服务器的主机名和端口号:
外壳> ndb_mgm [host_name [port_num]]
例如:
外壳> ndb_mgm ndb_mgmd.mysql.com 1186
默认主机名和端口号分别为
localhost
1186和1186。
下表包含特定于NDB群集管理客户端程序 ndb_mgm的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_mgm )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.337 ndb_mgm程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 设置放弃前重试连接的次数; --connect-retries的同义词 |
所有NDB 8.0版本 |
|
| 执行命令并退出 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --connect-retries=#类型 数字 默认值 3最低价值 0最大价值 4294967295此选项指定在放弃之前首次尝试重试连接之后的次数(客户端始终至少尝试连接一次)。 使用每个尝试等待的时间长度
--connect-retry-delay。此选项与该
--try-reconnect选项 同义, 现在不推荐使用 该 选项。此选项的默认值与其他
NDB程序一起 使用时,与默认选项不同 。 有关更多 信息, 请参见 第22.4.31节“NDB群集程序的通用选项 - NDB群集程序常用选项” 。 -
--execute=,command-ecommand属性 值 命令行格式 --execute=name此选项可用于从系统shell向NDB群集管理客户端发送命令。 例如,以下任一项等同
SHOW于在管理客户端中 执行 :外壳>
ndb_mgm -e "SHOW"外壳>ndb_mgm --execute="SHOW"这类似于
--execute或-e选项 如何 与 mysql 命令行客户端一起使用。 请参见 第4.2.2.1节“在命令行上使用选项” 。注意如果使用此选项传递的管理客户机命令包含任何空格字符,则该命令 必须 用引号括起来。 可以使用单引号或双引号。 如果管理客户端命令不包含空格字符,则引号是可选的。
-
属性 值 命令行格式 --try-reconnect=#弃用 是 类型 数字 类型 整数 默认值 12默认值 3最低价值 0最大价值 4294967295如果与管理服务器的连接中断,则节点每5秒尝试重新连接一次,直到成功为止。 通过使用此选项,可以限制
number放弃和报告错误之前 的尝试次数 。此选项已弃用,可能会在将来的版本中删除。 请
--connect-retries改用。
有关使用的其他信息 ndb_mgm 可以发现 第22.5.2,“在NDB集群管理客户端命令” 。
此工具可用于检查和删除
NDB
表
中的孤立BLOB列部件
,以及生成列出任何孤立部件的文件。
它有时用于诊断和修复
NDB
包含
BLOB
或
TEXT
列的
损坏或损坏的
表
。
ndb_blob_tool 的基本语法 如下所示:
ndb_blob_tool [options]table[column,...]
除非你使用的
--help
选项,你必须指定一个动作通过包括一个或多个选项来进行
--check-orphans
,
--delete-orphans
或
--dump-file
。
这些选项导致
ndb_blob_tool
检查孤立的BLOB部件,删除任何孤立的BLOB部件,并分别生成列出孤立的BLOB部件的转储文件,本节稍后将对此进行更详细的描述。
您还必须在调用
ndb_blob_tool
时指定表的名称
。
此外,您可以选择使用表名中的一个或多个(逗号分隔)名称
BLOB
或
TEXT
表格列。
如果未列出任何列,则该工具适用于所有表
BLOB
和
TEXT
列。
如果需要指定数据库,请使用
--database
(
-d
)选项。
该
--verbose
选项在输出中提供有关工具进度的其他信息。
下表包含特定于 ndb_blob_tool的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_blob_tool ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.338 ndb_blob_tool程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 检查孤儿blob部件 |
所有NDB 8.0版本 |
|
| 数据库找到表。 |
所有NDB 8.0版本 |
|
| 删除孤立blob部分 |
所有NDB 8.0版本 |
|
| 将孤立密钥写入指定文件 |
所有NDB 8.0版本 |
|
| 详细输出 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --check-orphans类型 布尔 默认值 FALSE在NDB Cluster表中检查孤立的BLOB部件。
-
属性 值 命令行格式 --database=db_name类型 串 默认值 [none]指定数据库以查找表。
-
属性 值 命令行格式 --delete-orphans类型 布尔 默认值 FALSE从NDB群集表中删除孤立的BLOB部分。
-
属性 值 命令行格式 --dump-file=file类型 文件名 默认值 [none]写一个孤立的BLOB列部分列表
file。 写入文件的信息包括每个孤立BLOB部分的表密钥和BLOB部件号。 -
属性 值 命令行格式 --verbose类型 布尔 默认值 FALSE在工具的输出中提供有关其进度的额外信息。
例
首先,我们
使用
此处显示
的
语句
NDB
在
test
数据库中
创建一个
表
CREATE
TABLE
:
使用测试;
创建表btest(
c0 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c1 TEXT,
c2 BLOB
)ENGINE = NDB;
然后我们使用一系列与此类似的语句在此表中插入几行:
INSERT INTO btest VALUES(NULL,'x',REPEAT('x',1000));
--check-orphans
对此表
运行时
,
ndb_blob_tool会
生成以下输出:
外壳> ndb_blob_tool --check-orphans --verbose -d test btest
连接的
处理2个blob
处理blob#0 c1 NDB $ BLOB_19_1
NDB $ BLOB_19_1:nextResult:res = 1
总份数:0
孤儿部分:0
处理blob#1 c2 NDB $ BLOB_19_2
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 0
NDB $ BLOB_19_2:nextResult:res = 1
总份数:10
孤儿部分:0
断开的
NDBT_ProgramExit:0 - 好的
该工具报告没有
NDB
与列关联的BLOB列部件
c1
,即使它
c1
是
TEXT
列。
这是因为,在一个
NDB
表中,只有a
BLOB
或
TEXT
column值
的前256个字节
是内联存储的,只有多余的(如果有的话)是分开存储的;
因此,如果在这些类型之一的给定列中没有超过256个字节的值,则不会
为此列
BLOB
创建列部分
NDB
。
有关
更多信息
,
请参见
第11.8节“数据类型存储要求”
。
此工具从以下来源之一中提取数据节点,SQL节点和API节点的当前配置信息:NDB群集管理节点或其
config.ini
或
my.cnf
文件。
默认情况下,管理节点是配置数据的源;
要覆盖默认值,请使用
--config-file
或
--mycnf
选项
执行ndb_config
。
通过使用数据节点指定其节点ID,也可以使用数据节点作为源
。
--config_from_node=
node_id
ndb_config
还可以提供可以使用的所有配置参数的脱机转储,以及它们的默认值,最大值和最小值以及其他信息。
转储可以以文本或XML格式生成;
有关详细信息,请参阅
本节后面
的讨论
--configinfo
和
--xml
选项。
您可以过滤通过部分结果(
DB
,
SYSTEM
或
CONNECTIONS
使用其中的一个选项)
--nodes
,
--system
或
--connections
。
下表包含特定于 ndb_config的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_config ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.339 ndb_config程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 设置config.ini文件的路径 |
所有NDB 8.0版本 |
|
| 从具有此ID的节点(必须是数据节点)获取配置数据。 |
所有NDB 8.0版本 |
|
| 使用默认值,最大值和最小值转储有关文本格式的所有NDB配置参数的信息。 与--xml一起使用以获取XML输出。 |
所有NDB 8.0版本 |
|
| 仅打印连接信息([tcp],[tcp default],[sci],[sci default],[shm]或[shm default]部分的群集配置文件)。 不能与--system或--nodes一起使用。 |
所有NDB 8.0版本 |
|
| 仅打印具有非默认值的配置参数 |
所有NDB 8.0版本 |
|
| 现场分离器 |
所有NDB 8.0版本 |
|
| 指定主机 |
所有NDB 8.0版本 |
|
| 从my.cnf文件中读取配置数据 |
所有NDB 8.0版本 |
|
|
|
获取具有此ID的节点的配置 |
所有NDB 8.0版本 |
| 仅打印节点信息(群集配置文件的[ndbd]或[ndbd default]部分)。 不能与--system或--connections一起使用。 |
所有NDB 8.0版本 |
|
| --ndb-connectstring的缩写形式 |
所有NDB 8.0版本 |
|
| 一个或多个查询选项(属性) |
所有NDB 8.0版本 |
|
| 将所有参数和值转储为单个逗号分隔的字符串。 |
所有NDB 8.0版本 |
|
| 行分隔符 |
所有NDB 8.0版本 |
|
| 仅打印SYSTEM部分信息(请参阅ndb_config --configinfo输出)。 不能与--nodes或--connections一起使用。 |
所有NDB 8.0版本 |
|
| 指定节点类型 |
所有NDB 8.0版本 |
|
| 使用--xml和--configinfo以XML格式获取所有NDB配置参数的转储,包括默认值,最大值和最小值。 |
所有NDB 8.0版本 |
-
该
--configinfo选项使 ndb_config 转储NDB群集分发支持的每个NDB群集配置参数的列表,其中 ndb_config 是其中的一部分,包括以下信息:-
每个参数的用途,效果和用法的简要说明
-
config.ini可以使用参数 的 文件 部分 -
参数的数据类型或测量单位
-
适用时,参数的默认值,最小值和最大值
-
NDB Cluster发布版本和构建信息
默认情况下,此输出采用文本格式。 此输出的一部分显示在此处:
外壳>
ndb_config --configinfo****** SYSTEM ****** 名称(字符串) 系统名称(NDB集群) 强制性 PrimaryMGMNode(非负整数) 主ndb_mgmd(MGM)节点的节点标识 默认值:0(最小值:0,最大值:4294967039) ConfigGenerationNumber(非负整数) 配置生成号 默认值:0(最小值:0,最大值:4294967039) ****** D B ****** MaxNoOfSubscriptions(非负整数) 订阅的最大数量(默认为0 == MaxNoOfTables) 默认值:0(最小值:0,最大值:4294967039) MaxNoOfSubscribers(非负整数) 订阅者最多数量(默认为0 == 2 * MaxNoOfTables) 默认值:0(最小值:0,最大值:4294967039) ...将此选项与选项一起使用
--xml以获取XML格式的输出。 -
-
属性 值 命令行格式 --config-file=file_name类型 文件名 默认值 提供管理服务器配置文件(
config.ini) 的路径 。 这可能是相对或绝对路径。 如果管理节点驻留在与 调用 ndb_config的 主机不同的主机上 ,则必须使用绝对路径。 -
属性 值 命令行格式 --config-from-node=#类型 数字 默认值 none最低价值 1最大价值 48从具有此ID的数据节点获取群集的配置数据。
如果具有此ID的节点不是数据节点,则 ndb_config将 失败并显示错误。 (要从管理节点获取配置数据,只需省略此选项。)
-
属性 值 命令行格式 --connections类型 布尔 默认值 FALSE告诉 ndb_config 打印
CONNECTIONS信息只,也就是说,大约在找到的参数的信息[tcp],[tcp default],[sci],[sci default],[shm],或[shm default]群集配置文件的部分(参见 第22.3.3.10“NDB簇TCP / IP连接” , 第22.3.3.13“ “NDB集群中的SCI传输连接” 和 第22.3.3.12节“NDB集群共享内存连接” ,以获取更多信息。 -
属性 值 命令行格式 --diff-default类型 布尔 默认值 FALSE仅打印具有非默认值的配置参数。
-
--fields=,delimiter-fdelimiter属性 值 命令行格式 --fields=string类型 串 默认值 指定
delimiter用于分隔结果中的字段 的 字符串。 默认值为,(逗号字符)。注意如果
delimiter包含空格或转义\n符 (例如 换行符),则必须引用它。 -
属性 值 命令行格式 --host=name类型 串 默认值 指定要获取配置信息的节点的主机名。
注意虽然主机名
localhost通常解析为IP地址127.0.0.1,但对于所有操作平台和配置,这可能不一定适用。 这意味着,它是可能的,当localhost被用于config.ini为 ndb_config--host=localhost如果失败 ndb_config 在不同的主机,其中上运行localhost解析到一个不同的地址(例如,在SUSE Linux的某些版本中,这是127.0.0.2)。 通常,为获得最佳结果,应对与主机相关的所有NDB Cluster配置值使用数字IP地址,或验证所有NDB Cluster主机是否localhost以相同方式 处理 。 -
属性 值 命令行格式 --mycnf类型 布尔 默认值 FALSE从
my.cnf文件中 读取配置数据 。 -
--ndb-connectstring=,connection_string-cconnection_string属性 值 命令行格式 --ndb-connectstring=connectstring--connect-string=connectstring类型 串 默认值 localhost:1186指定用于连接管理服务器的连接字符串。 连接字符串的格式与 第22.3.3.3节“NDB群集连接字符串”中 所述的相同 ,默认为
localhost:1186。 -
属性 值 命令行格式 --ndb-nodeid=#类型 数字 默认值 0指定要获取配置信息的节点的节点ID。
-
属性 值 命令行格式 --nodes类型 布尔 默认值 FALSE告诉 ndb_config 打印仅 与集群配置文件的 一个
[ndbd]或[ndbd default]一部分中 定义的参数相关的信息 (请参见 第22.3.3.6节“定义NDB集群数据节点” )。此选项与
--connectionsand 互斥--system; 只能使用这3个选项中的一个。 -
--query=,query-options-qquery-options属性 值 命令行格式 --query=string类型 串 默认值 这是一个以逗号分隔的 查询选项 列表 - 即要返回的一个或多个节点属性的列表。 这些包括
nodeid(节点ID),类型(节点类型,也就是说,ndbd,mysqld,或ndb_mgmd),并且任何配置参数,其值要被获得。例如,
--query=nodeid,type,datamemory,datadir返回节点ID,节点类型DataMemory,以及DataDir每个节点。注意如果给定参数不适用于某种类型的节点,则返回相应值的空字符串。 有关详细信息,请参阅本节后面的示例。
-
属性 值 命令行格式 --query-all类型 串 默认值 返回所有查询选项的逗号分隔列表(节点属性;请注意,此列表是单个字符串。
-
--rows=,separator-rseparator属性 值 命令行格式 --rows=string类型 串 默认值 指定
separator用于分隔结果中的行 的 字符串。 默认值为空格字符。注意如果
separator包含空格或转义\n符 (例如 换行符),则必须引用它。 -
属性 值 命令行格式 --system类型 布尔 默认值 FALSE告诉 ndb_config
SYSTEM仅 打印 信息。 这包括在运行时无法更改的系统变量; 因此,它们没有集群配置文件的相应部分。 它们可以****** SYSTEM ******在 ndb_config 的输出中 看到(带有前缀 )--configinfo。此选项与
--nodesand 互斥--connections; 只能使用这3个选项中的一个。 -
属性 值 命令行格式 --type=name类型 列举 默认值 [none]有效值 ndbdmysqldndb_mgmd过滤的结果,使得仅配置值施加到指定的节点
node_type(ndbd,mysqld,或ndb_mgmd)被返回。 -
属性 值 命令行格式 --help--usage导致 ndb_config 打印可用选项列表,然后退出。
-
属性 值 命令行格式 --version导致 ndb_config 打印版本信息字符串,然后退出。
-
属性 值 命令行格式 --configinfo --xml类型 布尔 默认值 false原因 ndb_config
--configinfo加入这个选项提供的XML输出。 此示例中显示了此类输出的一部分:外壳>
ndb_config --configinfo --xml<configvariables protocolversion =“1”ndbversionstring =“5.7.26-ndb-7.5.15” ndbversion =“460032”ndbversionmajor =“7”ndbversionminor =“5” ndbversionbuild = “0”> <section name =“SYSTEM”> <param name =“Name”comment =“系统名称(NDB Cluster)”type =“string” 强制性= “真”/> <param name =“PrimaryMGMNode”comment =“主要ndb_mgmd(MGM)节点的节点ID” type =“unsigned”default =“0”min =“0”max =“4294967039”/> <param name =“ConfigGenerationNumber”comment =“配置世代号” type =“unsigned”default =“0”min =“0”max =“4294967039”/> </节> <section name =“MYSQLD”primarykeys =“NodeId”> <param name =“wan”comment =“使用WAN TCP设置为默认值”type =“bool” 默认= “假”/> <param name =“HostName”comment =“此节点的计算机名称” type =“string”default =“”/> <param name =“Id”comment =“NodeId”type =“unsigned”mandatory =“true” min =“1”max =“255”deprecated =“true”/> <param name =“NodeId”comment =“识别应用程序节点的数字(mysqld(API))” type =“unsigned”mandatory =“true”min =“1”max =“255”/> <param name =“ExecuteOnComputer”comment =“HostName”type =“string” 弃用= “真”/> ... </节> ... </ configvariables>注意通常, ndb_config 生成的XML输出的
--configinfo--xml格式为每个元素一行; 出于易读性的原因,我们在前面的示例中添加了额外的空格,以及下一个空格。 这应该对使用此输出的应用程序没有任何影响,因为大多数XML处理器要么忽略非必要的空格,要么可以指示这样做。XML输出还指示何时更改给定参数需要使用该
--initial选项 重新启动数据节点 。 这通过initial="true"相应<param>元素中 存在 属性来显示 。 此外, 还显示 了重启类型(system或node); 如果给定参数需要重新启动系统,则通过restart="system"相应<param>元素中 存在 属性 来指示 。 例如,更改为Diskless参数 设置的值 需要系统初始重启,如此处所示(使用restart和initial突出显示的属性):<param name =“Diskless”comment =“Run wo / disk”type =“bool”default =“false” restart =“system”initial =“true” />目前,
initial对于<param>与不需要初始重启的参数相对应 的 元素 ,XML输出中 不 包含 任何 属性 ; 换句话说,initial="false"是默认值,false如果该属性不存在,则应该假设 该值 。 类似地,默认重启类型是node(即 群集 的在线或 “ 滚动 ” 重启),但restart仅当重启类型为system(意味着必须同时关闭所有集群节点,然后 重新启动)。不推荐使用的参数在
deprecated属性 的XML输出中指示 ,如下所示:<param name =“NoOfDiskPagesToDiskAfterRestartACC”comment =“DiskCheckpointSpeed” type =“unsigned”default =“20”min =“1”max =“4294967039” deprecated =“true” />在这种情况下,
comment指的是一个或多个取代已弃用参数的参数。 与此类似initial,deprecated仅在不推荐使用该参数时指示 该 属性deprecated="true",并且对于未弃用 的参数 ,该 属性 根本不显示。 (缺陷号21127135)从NDB 7.5.0开始,需要的参数用
mandatory="true",如下所示:<param name =“NodeId” comment =“识别应用程序节点的数字(mysqld(API))” type =“unsigned” mandatory =“true” min =“1”max =“255”/>与 仅针对需要初始重启或不推荐使用的参数显示
initialordeprecated属性的 方式大致相同,mandatory仅当实际需要给定参数时才包含 该 属性。重要该
--xml选项只能与--configinfo选项 一起使用 。 使用--xml没有--configinfo失败并出现错误。与此程序用于获取当前配置数据的选项不同,
--configinfo并且 在编译 ndb_config--xml时使用从NDB Cluster源获取的信息 。 因此, 这两个选项 不需要连接到正在运行的NDB群集或访问 或 文件。config.inimy.cnf
将其他
ndb_config
选项(例如
--query
或
--type
)与
--configinfo
(包含或不包含该
--xml
选项
)
组合在一起
。目前,如果您尝试这样做,通常的结果是除了
--configinfo
或
之外的所有其他选项
--xml
都被忽略。
但是,这种行为无法保证并随时更改
。另外,由于
ndb_config
,与使用时
--configinfo
的选项,不访问NDB集群或读取任何文件,试图指定其他选项,如
--ndb-connectstring
或
--config-file
与
--configinfo
无济于事。
例子
-
要获取集群中每个节点的节点ID和类型,请执行以下操作:
外壳>
./ndb_config --query=nodeid,type --fields=':' --rows='\n'1:NDBD 2:NDBD 3:NDBD 4:NDBD 5:ndb_mgmd 6:mysqld的 7:mysqld的 8:mysqld的 9:mysqld的在这个例子中,我们使用
--fields选项用冒号字符(:) 分隔每个节点的ID和类型 ,以及将--rows每个节点的值放在输出中的新行上的选项。 -
生成可供数据,SQL和API节点用于连接到管理服务器的连接字符串:
外壳>
./ndb_config --config-file=usr/local/mysql/cluster-data/config.ini \ --query=hostname,portnumber --fields=: --rows=, --type=ndb_mgmd198.51.100.179:1186 -
此 ndb_config 调用 仅 检查数据节点(使用该
--type选项),并显示每个节点的ID和主机名的值,以及为其DataMemory和DataDir参数 设置的值 :外壳>
./ndb_config --type=ndbd --query=nodeid,host,datamemory,datadir -f ' : ' -r '\n'1:198.51.100.193:83886080:/ usr / local / mysql / cluster-data 2:198.51.100.112:83886080:/ usr / local / mysql / cluster-data 3:198.51.100.176:83886080:/ usr / local / mysql / cluster-data 4:198.51.100.119:83886080:/ usr / local / mysql / cluster-data在这个例子中,我们分别使用短选项
-f和-r设置字段分隔符和行分隔符,以及-q用于传递要获取的参数列表 的短选项 。 -
要从除特定主机之外的任何主机中排除结果,请使用以下
--host选项:外壳>
./ndb_config --host=198.51.100.176 -f : -r '\n' -q id,type3:NDBD 5:ndb_mgmd在此示例中,我们还使用简短格式
-q来确定要查询的属性。同样,您可以使用该
--nodeid选项 将结果限制为具有特定ID的节点 。
ndb_delete_all
删除给定
NDB
表中的
所有行
。
在某些情况下,这可能比
DELETE
甚至
更快
TRUNCATE TABLE
。
用法
ndb_delete_all -c -dconnection_stringtbl_namedb_name
这将从名为
tbl_name
的数据库中指定
的表中删除所有行
db_name
。
它完全等同于
在MySQL中
执行
。
TRUNCATE
db_name.tbl_name
下表包含特定于 ndb_delete_all的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_delete_all )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.340 ndb_delete_all程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
|
|
找到表的数据库的名称 |
所有NDB 8.0版本 |
| 在单个事务中执行删除(可能会用完操作) |
所有NDB 8.0版本 |
|
|
|
运行tup扫描 |
所有NDB 8.0版本 |
|
|
运行磁盘扫描 |
所有NDB 8.0版本 |
ndb_desc
提供一个或多个
NDB
表
的详细描述
。
用法
ndb_desc -c -d [ ]connection_stringtbl_namedb_nameoptionsndb_desc -c -d -tconnection_stringindex_namedb_nametbl_name
可以与 ndb_desc 一起使用的其他选项将 在本节后面列出。
样本输出
MySQL表创建和填充语句:
使用测试;
CREATE TABLE鱼(
id INT(11)NOT NULL AUTO_INCREMENT,
name VARCHAR(20)NOT NULL,
length_mm INT(11)NOT NULL,
weight_gm INT(11)NOT NULL,
PRIMARY KEY pk(id),
UNIQUE KEY uk(姓名)
)ENGINE = NDB;
插入鱼类价值观
(NULL,'guppy',35,2),(NULL,'tuna',2500,150000),
(NULL,'shark',3000,110000),(NULL,'manta ray',1500,50000),
(NULL,'grouper',900,125000),(NULL,'puffer',250,2500);
ndb_desc的 输出 :
外壳> ./ndb_desc -c localhost fish -d test -p
- 鱼 -
版本:2
片段类型:HashMapPartition
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:4
主键数:1
frm数据长度:337
最大行数:0
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
PartitionCount:2
FragmentCount:2
PartitionBalance:FOR_RP_BY_LDM
ExtraRowGciBits:0
ExtraRowAuthorBits:0
TableStatus:已检索
表格选项:
HashMap:DEFAULT-HASHMAP-3840-2
- 属性 -
id Int PRIMARY KEY DISTRIBUTION KEY AT = FIXED ST = MEMORY AUTO_INCR
名称Varchar(20; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY DYNAMIC
length_mm Int NOT NULL AT = FIXED ST = MEMORY DYNAMIC
weight_gm Int NOT NULL AT = FIXED ST = MEMORY DYNAMIC
- 索引 -
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
英国(名称) - OrderedIndex
uk $ unique(name) - UniqueHashIndex
- 每个分区信息 -
分区行计数提交计数Frag固定内存Frag varsized memory Extent_space Free extent_space
0 2 2 32768 32768 0 0
1 4 4 32768 32768 0 0
NDBT_ProgramExit:0 - 好的
有关多个表的信息可以 通过使用它们的名称 在单个 ndb_desc 调用中 获得 ,用空格分隔。 所有表必须位于同一数据库中。
您可以使用
--table
(简短形式
:)
-t
选项
获取有关特定索引的其他信息
,并将索引的名称作为
ndb_desc
的第一个参数提供
,如下所示:
外壳> ./ndb_desc uk -d test -t fish
- 英国 -
版本:2
基准表:鱼
属性数量:1
记录:0
索引类型:OrderedIndex
索引状态:已检索
- 属性 -
名称Varchar(20; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY
- IndexTable 10 / uk -
版本:2
片段类型:FragUndefined
K值:6
最小负载系数:78
最大载荷系数:80
临时表:是的
属性数量:2
主键数:1
frm数据的长度:0
最大行数:0
行校验:1
行GCI:1
SingleUserMode:2
ForceVarPart:0
PartitionCount:2
FragmentCount:2
FragmentCountType:ONE_PER_LDM_PER_NODE
ExtraRowGciBits:0
ExtraRowAuthorBits:0
TableStatus:已检索
表格选项:
- 属性 -
名称Varchar(20; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY
NDB $ TNODE无符号[64]主键分配键AT =固定ST =存储器
- 索引 -
PRIMARY KEY(NDB $ TNODE) - UniqueHashIndex
NDBT_ProgramExit:0 - 好的
以这种方式指定索引时,
--extra-partition-info
和
--extra-node-info
选项无效。
该
Version
输出列包含表的模式对象的版本。
有关解释此值的信息,请参阅
NDB架构对象版本
。
可以使用
NDB_TABLE
嵌入在
CREATE
TABLE
和
ALTER
TABLE
语句中的
注释
设置的三个表属性
在
ndb_desc
输出
中也可见
。
表格
FRAGMENT_COUNT_TYPE
始终显示在
FragmentCountType
列中。
READ_ONLY
并且
FULLY_REPLICATED
,如果设定为1,示出了在
Table options
塔中。
ALTER
TABLE
在
mysql
客户端中
执行以下
语句
后,您可以看到这一点
:
MySQL的>ALTER TABLE fish COMMENT='NDB_TABLE=READ_ONLY=1,FULLY_REPLICATED=1';1排,1警告(0.00秒) MySQL的>SHOW WARNINGS\G+ --------- + ------ + -------------------------------- -------------------------------------------------- ----------------------- + | 等级| 代码| 消息| + --------- + ------ + -------------------------------- -------------------------------------------------- ----------------------- + | 警告| 1296 | 得到错误4503'表属性为FRAGMENT_COUNT_TYPE = ONE_PER_LDM_PER_NODE但不在评论'中来自NDB | + --------- + ------ + -------------------------------- -------------------------------------------------- ----------------------- + 1排(0.00秒)
发出警告是因为
READ_ONLY=1
要求表的片段计数类型是(或设置为)
ONE_PER_LDM_PER_NODE_GROUP
;
NDB
在这种情况下自动设置。
您可以使用以下命令检查
ALTER TABLE
语句是否具有所需的效果
SHOW CREATE
TABLE
:
MySQL的> SHOW CREATE TABLE fish\G
*************************** 1。排******************** *******
表:鱼
创建表:CREATE TABLE`fish`(
`id` int(11)NOT NULL AUTO_INCREMENT,
`name` varchar(20)NOT NULL,
`length_mm` int(11)NOT NULL,
`weight_gm` int(11)NOT NULL,
PRIMARY KEY(`id`),
独特的钥匙`uk`(`name`)
)ENGINE = ndbcluster DEFAULT CHARSET = latin1
COMMENT = 'NDB_TABLE = READ_BACKUP = 1,FULLY_REPLICATED = 1'
1排(0.01秒)
由于
FRAGMENT_COUNT_TYPE
未明确设置,因此其值不会显示在打印的注释文本中
SHOW CREATE TABLE
。
但是,
ndb_desc
显示此属性的更新值。
该
Table options
列显示刚刚启用的二进制属性。
你可以在这里显示的输出中看到这一点(强调文本):
外壳> ./ndb_desc -c localhost fish -d test -p
- 鱼 -
版本:4
片段类型:HashMapPartition
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:4
主键数:1
frm数据长度:380
最大行数:0
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
PartitionCount:1
FragmentCount:1
FragmentCountType:ONE_PER_LDM_PER_NODE_GROUP
ExtraRowGciBits:0
ExtraRowAuthorBits:0
TableStatus:已检索
表选项:readbackup,完全复制
HashMap:DEFAULT-HASHMAP-3840-1
- 属性 -
id Int PRIMARY KEY DISTRIBUTION KEY AT = FIXED ST = MEMORY AUTO_INCR
名称Varchar(20; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY DYNAMIC
length_mm Int NOT NULL AT = FIXED ST = MEMORY DYNAMIC
weight_gm Int NOT NULL AT = FIXED ST = MEMORY DYNAMIC
- 索引 -
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
英国(名称) - OrderedIndex
uk $ unique(name) - UniqueHashIndex
- 每个分区信息 -
分区行计数提交计数Frag固定内存Frag varsized memory Extent_space Free extent_space
NDBT_ProgramExit:0 - 好的
有关这些表属性的更多信息,请参见 第13.1.20.11节“设置NDB_TABLE选项” 。
的
Extent_space
和
Free
extent_space
唯一的列是适用
NDB
具有在磁盘上的列的表;
对于仅具有内存列的表,这些列始终包含该值
0
。
为了说明它们的用法,我们修改了前面的例子。 首先,我们必须创建必要的磁盘数据对象,如下所示:
创建LOGFILE GROUP lg_1
添加UNDOFILE'undo_1.log'
INITIAL_SIZE 16M
UNDO_BUFFER_SIZE 2M
ENGINE NDB;
ALTER LOGFILE GROUP lg_1
添加UNDOFILE'under_2.log'
INITIAL_SIZE 12M
ENGINE NDB;
创建TABLESPACE ts_1
添加数据文件'data_1.dat'
使用LOGFILE GROUP lg_1
INITIAL_SIZE 32M
ENGINE NDB;
ALTER TABLESPACE ts_1
添加数据文件'data_2.dat'
INITIAL_SIZE 48M
ENGINE NDB;
(有关刚刚显示的语句及其创建的对象的更多信息,请参见 第22.5.13.1节“NDB集群磁盘数据对象” ,以及 第13.1.16节“创建日志文件组语法” 和 第13.1.21节,“CREATE TABLESPACE语法” 。)
现在我们可以创建并填充
fish
在磁盘上存储其2列的表的版本(如果表已经存在,则首先删除表的先前版本):
CREATE TABLE鱼(
id INT(11)NOT NULL AUTO_INCREMENT,
name VARCHAR(20)NOT NULL,
length_mm INT(11)NOT NULL,
weight_gm INT(11)NOT NULL,
PRIMARY KEY pk(id),
UNIQUE KEY uk(姓名)
)TABLESPACE ts_1存储磁盘
ENGINE = NDB;
插入鱼类价值观
(NULL,'guppy',35,2),(NULL,'tuna',2500,150000),
(NULL,'shark',3000,110000),(NULL,'manta ray',1500,50000),
(NULL,'grouper',900,125000),(NULL,'puffer',250,2500);
针对此版本的表运行时, ndb_desc 显示以下输出:
外壳> ./ndb_desc -c localhost fish -d test -p
- 鱼 -
版本:1
片段类型:HashMapPartition
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:4
主键数:1
frm数据的长度:346
最大行数:0
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
PartitionCount:2
FragmentCount:2
FragmentCountType:ONE_PER_LDM_PER_NODE
ExtraRowGciBits:0
ExtraRowAuthorBits:0
TableStatus:已检索
表格选项:
HashMap:DEFAULT-HASHMAP-3840-2
- 属性 -
id Int PRIMARY KEY DISTRIBUTION KEY AT = FIXED ST = MEMORY AUTO_INCR
名称Varchar(20; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY
length_mm Int NOT NULL AT = FIXED ST = DISK
weight_gm Int NOT NULL AT = FIXED ST = DISK
- 索引 -
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
英国(名称) - OrderedIndex
uk $ unique(name) - UniqueHashIndex
- 每个分区信息 -
分区行计数提交计数Frag固定内存Frag varsized memory Extent_space Free extent_space
0 2 2 32768 32768 1048576 1044440
1 4 4 32768 32768 1048576 1044400
NDBT_ProgramExit:0 - 好的
这意味着在每个分区上为该表的表空间分配了1048576个字节,其中1044440个字节可用于额外存储。
换句话说,1048576 - 1044440 =每个分区4136个字节当前用于存储来自此表的基于磁盘的列中的数据。
显示的字节数
Free extent_space
仅可用于存储来自
fish
表
的磁盘列数据
;
因此,从
INFORMATION_SCHEMA.FILES
表格中
选择时不可见
。
对于完全复制的表,
ndb_desc
仅显示包含主分区片段副本的节点;
复制片段副本(仅)的节点将被忽略。
与NDB 7.5.4开始,您可以获取这些信息,使用
MySQL的
客户端,从
table_distribution_status
,
table_fragments
,
table_info
,并
table_replicas
在表
ndbinfo
的数据库。
下表包含特定于 ndb_desc的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_desc ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.341 ndb_desc程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 在输出中包含BLOB表的分区信息。 要求也使用-p选项 |
所有NDB 8.0版本 |
|
| 包含表的数据库的名称 |
所有NDB 8.0版本 |
|
| 在输出中包括分区到数据节点映射。 要求也使用-p选项 |
所有NDB 8.0版本 |
|
| 显示有关分区的信息 |
所有NDB 8.0版本 |
|
| 重试连接的次数(每秒一次) |
所有NDB 8.0版本 |
|
| 指定要在其中查找索引的表。 使用此选项时,-p和-n无效并被忽略。 |
所有NDB 8.0版本 |
|
| 使用不合格的表名 |
所有NDB 8.0版本 |
-
使用此选项还需要使用
--extra-partition-info(-p)选项。 -
指定应在其中找到表的数据库。
-
包括有关表分区与它们所在的数据节点之间的映射的信息。 此信息可用于验证分发感知机制并支持更高效的应用程序访问存储在NDB群集中的数据。
使用此选项还需要使用
--extra-partition-info(-p)选项。 -
打印有关表分区的其他信息。
-
在放弃之前尝试多次连接。 每秒进行一次连接尝试。
-
指定要在其中查找索引的表。
-
使用不合格的表名。
在NDB 7.5.3和更高版本中,输出中列出的表索引按ID排序。 以前,这不是确定性的,并且可能因平台而异。 (Bug#81763,Bug#23547742)
ndb_drop_index
从
NDB
表中
删除指定的索引
。
建议您仅将此实用程序用作编写NDB API应用程序的示例
- 有关详细信息,请参阅本节后面的警告。
用法
ndb_drop_index -c -dconnection_stringtable_nameindexdb_name
上面显示的语句删除名为该指数
index
从
table
的
database
。
下表包含特定于 ndb_drop_index的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_drop_index )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
使用NDB API对Cluster表索引执行的操作对MySQL不可见,并使MySQL服务器无法使用该表 。 如果您使用此程序删除索引,然后尝试从SQL节点访问该表,则会出现错误结果,如下所示:
外壳>./ndb_drop_index -c localhost dogs ix -d ctest1丢掉索引犬/ idx ......好的 NDBT_ProgramExit:0 - 好的 外壳>./mysql -u jon -p ctest1输入密码: ******* 读取表信息以完成表和列名称 您可以关闭此功能以使用-A更快地启动 欢迎使用MySQL监视器。命令以;结尾; 或\ g。 您的MySQL连接ID是7到服务器版本:5.7.26-ndb-7.5.15 输入'help;' 或'\ h'寻求帮助。输入'\ c'清除缓冲区。 MySQL的>SHOW TABLES;+ ------------------ + | Tables_in_ctest1 | + ------------------ + | a | | bt1 | | bt2 | | 狗| | 员工| | 鱼| + ------------------ + 6行(0.00秒) mysql> ERROR 1296(HY000):从NDBCLUSTER得到错误4243'索引未找到'SELECT * FROM dogs;
在这种情况下,您
再次将表提供给MySQL的
唯一
选择是删除表并重新创建它。
您可以使用SQL语句
DROP
TABLE
或
ndb_drop_table
实用程序(请参见
第22.4.11节“
ndb_drop_table
- 删除NDB表”
)删除该表。
ndb_drop_table
删除指定的
NDB
表。
(如果您尝试在使用其他存储引擎创建的表上使用此功能
NDB
,则尝试将失败,并显示错误
723:不存在此类表
。)此操作非常快;
在某些情况下,它比
DROP
TABLE
在
NDB
表
上
使用MySQL
语句
快一个数量级
。
用法
ndb_drop_table -c -dconnection_stringtbl_namedb_name
下表包含特定于 ndb_drop_table的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_drop_table ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
在NDB 8.0.17之前,
NDB
使用此实用程序删除
的
表
保留
在MySQL数据字典中,但无法
DROP TABLE
在
mysql
客户端中使用。
在NDB 8.0.17及更高版本中,
可以使用删除
此类
“
孤立
”
表
DROP
TABLE
。
(Bug#29125206,Bug#93672)
ndb_error_reporter 从数据节点和管理节点日志文件创建存档,可用于帮助诊断群集中的错误或其他问题。 强烈建议您在归档NDB群集中的错误报告时使用此实用程序 。
下表包含特定于NDB群集程序 ndb_error_reporter的 命令选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_error_reporter )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.344 ndb_error_reporter程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 超时前连接节点时等待的秒数。 |
所有NDB 8.0版本 |
|
| 禁用远程主机的scp; 仅用于测试。 |
所有NDB 8.0版本 |
|
| 在错误报告中包含文件系统数据; 可以使用大量的磁盘空间 |
所有NDB 8.0版本 |
|
| 跳过具有此ID的节点组中的所有节点。 |
所有NDB 8.0版本 |
用法
ndb_error_reporterpath/to/config-file[username] [options]
此实用程序旨在用于管理节点主机,并且需要管理主机配置文件(通常命名
config.ini
)
的路径
。
(可选)您可以提供能够使用SSH访问群集数据节点的用户的名称,以复制数据节点日志文件。
然后,
ndb_error_reporter
将归档中包含的所有这些文件包含在运行它的同一目录中。
存档已命名
,其中
是日期时间字符串。
ndb_error_report_
YYYYMMDDhhmmss.tar.bz2YYYYMMDDhhmmss
ndb_error_reporter 也接受此处列出的选项:
-
属性 值 命令行格式 --connection-timeout=timeout类型 整数 默认值 0在超时之前尝试连接节点时等待这么多秒。
-
属性 值 命令行格式 --dry-scp类型 布尔 默认值 TRUE不使用远程主机的scp 运行 ndb_error_reporter 。 仅用于测试。
-
属性 值 命令行格式 --fs类型 布尔 默认值 FALSE将数据节点文件系统复制到管理主机并将其包含在存档中。
由于数据节点的文件系统可能非常大,即使被压缩后,我们请您不要 不 使用此选项,Oracle创建发送档案,除非你被特别要求这样做。
-
属性 值 命令行格式 --connection-timeout=timeout类型 整数 默认值 0跳过属于具有提供的节点组ID的节点组的所有节点。
ndb_import
直接
使用NDB API将
CSV格式的数据(例如
mysqldump
生成的数据)
--tab
导入
NDB
。
ndb_import
需要连接到NDB管理服务器(
ndb_mgmd
)才能运行;
它不需要连接到MySQL服务器。
用法
ndb_importdb_namefile_nameoptions
ndb_import
需要两个参数。
db_name
是找到要导入数据的表的数据库的名称;
file_name
是从中读取数据的CSV文件的名称;
如果该文件不在当前目录中,则必须包含该文件的路径。
文件名必须与表的名称相匹配;
文件的扩展名(如果有)不予考虑。
ndb_import
支持的选项
包括用于指定字段分隔符,转义符和行终止符的选项,本节稍后将对此进行介绍。
ndb_import
必须能够连接到NDB集群管理服务器;
因此,必须有一个未使用的
[api]
群集
config.ini
文件中的
插槽
。
要复制使用不同存储引擎的现有表(例如
InnoDB
,作为
NDB
表),请使用
mysql
客户端执行
SELECT INTO
OUTFILE
语句以将现有表导出为CSV文件,然后执行
CREATE TABLE
LIKE
语句以创建具有该表的新表结构作为现有表,然后
ALTER
TABLE ...
ENGINE=NDB
在新表上
执行
;
在此之后,从系统shell调用
ndb_import
将数据加载到新
NDB
表中。
例如,在
InnoDB
名为
myinnodb_table
的数据库中命名
的现有
表
myinnodb
可以导出到
NDB
名为
的
表中
myndb_table
在
myndb
此处显示
的数据库
中,假设您已经以具有适当权限的MySQL用户身份登录:
-
在 mysql 客户端:
MySQL的>
USE myinnodb;的MySQL>SELECT * INTO OUTFILE '/tmp/myndb_table.csv'>FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\'>LINES TERMINATED BY '\n'>FROM myinnodbtable;MySQL的>CREATE DATABASE myndb;MySQL的>USE myndb;MySQL的>CREATE TABLE myndb_table LIKE myinnodb.myinnodb_table;MySQL的>ALTER TABLE myndb_table ENGINE=NDB;MySQL的>EXIT;再见 外壳>一旦创建了目标数据库和表, 就不再需要 运行 mysqld 。 如果您愿意,可以在继续之前 使用 mysqladmin shutdown 或其他方法 停止它 。
-
在系统shell中:
#如果您还不在MySQL bin目录中: 外壳>
cd外壳>path-to-mysql-bin-dirndb_import myndb /tmp/myndb_table.csv --fields-optionally-enclosed-by='"' \--fields-terminated-by="," --fields-escaped-by='\\'输出应该类似于此处显示的内容:
job-1从/tmp/myndb_table.csv导入myndb.myndb_table job-1 [running]从/tmp/myndb_table.csv导入myndb.myndb_table job-1 [success]从/tmp/myndb_table.csv导入myndb.myndb_table job-1在0h0m9s中以2277行/秒的速度导入了19984行 工作总结:已定义:1次运行:1次成功:1次失败:0次 外壳>
下表包含特定于 ndb_import的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_import ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.345 ndb_import程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 转储任何致命错误的核心; 用于调试 |
所有NDB 8.0版本 |
|
| 对于具有隐藏PK的表,请指定自动增量增量。 见mysqld |
所有NDB 8.0版本 |
|
| 对于具有隐藏PK的表,请指定autoincrement offset。 见mysqld |
所有NDB 8.0版本 |
|
| 对于具有隐藏PK的表,请指定预取的自动增量值的数量。 见mysqld |
所有NDB 8.0版本 |
|
| 要创建的群集连接数 |
所有NDB 8.0版本 |
|
| 当工作失败时,继续下一份工作 |
所有NDB 8.0版本 |
|
| 每个数据节点的线程数,执行数据库操作 |
所有NDB 8.0版本 |
|
| 错误插入类型,用于测试目的; 使用“list”获取所有可能的值 |
所有NDB 8.0版本 |
|
| 错误插入延迟(以毫秒为单位); 随机变化被添加 |
所有NDB 8.0版本 |
|
| 与LOAD DATA语句的FIELDS ENCLOSED BY选项相同。 对于CSV输入,这与使用--fields-optional-enclosed-by相同 |
所有NDB 8.0版本 |
|
| 与LOAD DATA语句的FIELDS ESCAPED BY选项相同 |
所有NDB 8.0版本 |
|
| 与LOAD DATA语句的FIELDS OPTIONALLY ENCLOSED BY选项相同 |
所有NDB 8.0版本 |
|
| 与LOAD DATA语句的FIELDS TERMINATED BY选项相同。 |
所有NDB 8.0版本 |
|
| 等待更多事情要睡觉的毫秒数 |
所有NDB 8.0版本 |
|
| 在idlesleep之前重试的次数 |
所有NDB 8.0版本 |
|
| 忽略输入文件中的第一行#行。 用于跳过非数据头。 |
所有NDB 8.0版本 |
|
| 输入类型:随机或csv |
所有NDB 8.0版本 |
|
| 处理输入的线程数。 如果--input-type为csv,则必须为2或更多。 |
所有NDB 8.0版本 |
|
| 保留状态文件 |
所有NDB 8.0版本 |
|
| 与LOAD DATA语句的LINES TERMINATED BY选项相同 |
所有NDB 8.0版本 |
|
| 设置内部日志级别; 用于调试和开发 |
所有NDB 8.0版本 |
|
| 仅导入此数量的输入数据行; default为0,导入所有行 |
所有NDB 8.0版本 |
|
| 如果某些内容发生了变化(状态,被拒绝的行,临时错误),请定期打印正在运行的作业的状 值0禁用。 值1显示所看到的任何变化。 较高的值会将状态打印指数降低到某个预定义的限制。 |
所有NDB 8.0版本 |
|
| 在单个事务中以批处理方式运行数据库操作 |
所有NDB 8.0版本 |
|
| 不要使用分发密钥提示来选择数据节点(TC) |
所有NDB 8.0版本 |
|
| db执行批处理是一组发送到NDB内核的事务和操作。 此选项限制db执行批处理中的NDB操作(包括blob操作)。 因此,它还限制了异步交易的数量。 值0无效 |
所有NDB 8.0版本 |
|
| 执行批处理中的限制字节数(默认值0 =无限制) |
所有NDB 8.0版本 |
|
| 输出类型:ndb是默认值,null用于测试 |
所有NDB 8.0版本 |
|
| 处理输出或中继数据库操作的线程数 |
所有NDB 8.0版本 |
|
| 将I / O缓冲区对齐到给定大小 |
所有NDB 8.0版本 |
|
| I / O缓冲区的大小为页面大小的倍数。 CSV输入工作程序分配一个双倍大小的缓冲区 |
所有NDB 8.0版本 |
|
| 已完成的异步交易的每次轮询超时; 轮询继续,直到所有民意调查完成或发生错误 |
所有NDB 8.0版本 |
|
| 限制数据加载中被拒绝的行数(具有永久错误的行)。 默认值为0表示任何被拒绝的行都会导致致命错误。 超出限制的行也会添加到* .rej |
所有NDB 8.0版本 |
|
| 如果作业中止(临时错误,用户中断),则恢复尚未处理的行 |
所有NDB 8.0版本 |
|
| 限制行队列中的行(默认为0 =无限制); 如果--input-type是随机的,则必须为1或更多 |
所有NDB 8.0版本 |
|
| 限制行队列中的字节数(0 =无限制) |
所有NDB 8.0版本 |
|
| 在哪里写州文件; currect目录是默认的 |
所有NDB 8.0版本 |
|
保存在性能和统计信息
*.sto
和
*.stt
文件
|
所有NDB 8.0版本 |
|
| 临时错误之间休眠的毫秒数 |
所有NDB 8.0版本 |
|
| 每个执行批处理由于临时错误导致事务失败的次数; 0表示任何临时错误都是致命的。 此类错误不会导致任何行写入.rej文件 |
所有NDB 8.0版本 |
|
| 启用详细输出 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --abort-on-error类型 布尔 默认值 FALSE转储任何致命错误的核心; 仅用于调试。
-
属性 值 命令行格式 --ai-increment=#类型 整数 默认值 1最低价值 1最大价值 4294967295对于具有隐藏主键的表,请指定自动增量增量,就像
auto_increment_incrementMySQL服务器中 的 系统变量一样。 -
属性 值 命令行格式 --ai-offset=#类型 整数 默认值 1最低价值 1最大价值 4294967295对于具有隐藏主键的表,请指定自动增量偏移。 与
auto_increment_offset系统变量 类似 。 -
属性 值 命令行格式 --ai-prefetch-sz=#类型 整数 默认值 1024最低价值 1最大价值 4294967295对于具有隐藏主键的表,请指定预取的自动增量值的数量。 行为类似于
ndb_autoincrement_prefetch_szMySQL服务器中 的 系统变量。 -
属性 值 命令行格式 --connections=#类型 整数 默认值 1最低价值 1最大价值 4294967295要创建的群集连接数。
-
属性 值 命令行格式 --continue类型 布尔 默认值 FALSE当作业失败时,继续下一个作业。
-
属性 值 命令行格式 --db-workers=#类型 整数 默认值 4最低价值 1最大价值 4294967295每个数据节点的线程数,执行数据库操作。
-
属性 值 命令行格式 --errins-type=name类型 列举 默认值 [none]有效值 stopjobstopallsighupsigintlist错误插入类型; 使用
list作为name值,以获得所有可能的值。 此选项仅用于测试目的。 -
属性 值 命令行格式 --errins-delay=#类型 整数 默认值 1000最低价值 0最大价值 4294967295错误插入延迟(以毫秒为单位); 随机变化被添加。 此选项仅用于测试目的。
-
属性 值 命令行格式 --fields-enclosed-by=char类型 串 默认值 [none]这与该
FIELDS ENCLOSED BY选项对LOAD DATA语句的 工作方式相同 ,指定要作为引用字段值进行处理的字符。 对于CSV输入,这与--fields-optionally-enclosed-by。 -
属性 值 命令行格式 --fields-escaped-by=name类型 串 默认值 \FIELDS ESCAPED BY以与SQLLOAD DATA语句 选项 相同的方式指定转义字符 。 -
--fields-optionally-enclosed-by=char属性 值 命令行格式 --fields-optionally-enclosed-by=char类型 串 默认值 [none]这与
FIELDS OPTIONALLY ENCLOSED BY选项对LOAD DATA语句的 工作方式相同 ,指定要作为可选引用字段值进行处理的字符。 对于CSV输入,这与--fields-enclosed-by。 -
属性 值 命令行格式 --fields-terminated-by=char类型 串 默认值 \t这与该
FIELDS TERMINATED BY选项对LOAD DATA语句的 工作方式相同 ,指定要作为字段分隔符进行处理的字符。 -
属性 值 命令行格式 --idlesleep=#类型 整数 默认值 1最低价值 1最大价值 4294967295等待执行更多工作的睡眠毫秒数。
-
属性 值 命令行格式 --idlespin=#类型 整数 默认值 0最低价值 0最大价值 4294967295睡觉前重试的次数。
-
属性 值 命令行格式 --ignore-lines=#类型 整数 默认值 0最低价值 0最大价值 4294967295导致ndb_import忽略
#输入文件 的第一 行。 这可以用于跳过不包含任何数据的文件头。 -
属性 值 命令行格式 --input-type=name类型 列举 默认值 csv有效值 randomcsv设置输入类型的类型。 默认是
csv;random仅用于测试目的。 。 -
属性 值 命令行格式 --input-workers=#类型 整数 默认值 4最低价值 1最大价值 4294967295设置处理输入的线程数。
-
属性 值 命令行格式 --keep-state类型 布尔 默认值 false默认情况下,ndb_import
*.rej在完成作业时 会删除所有状态文件(非空 文件 除外 )。 指定此选项(也不需要参数)以强制程序保留所有状态文件。 -
属性 值 命令行格式 --lines-terminated-by=name类型 串 默认值 \n这与
LINES TERMINATED BY选项对LOAD DATA语句的 工作方式相同 ,指定要作为行尾处理的字符。 -
属性 值 命令行格式 --log-level=#类型 整数 默认值 0最低价值 0最大价值 2在给定级别执行内部日志记录。 此选项主要用于内部和开发用途。
在仅NDB的调试版本中,可以使用此选项将日志记录级别设置为最多4个。
-
属性 值 命令行格式 --max-rows=#类型 整数 默认值 0最低价值 0最大价值 4294967295仅导入此数量的输入数据行; 默认值为0,用于导入所有行。
-
属性 值 命令行格式 --monitor=#类型 整数 默认值 2最低价值 0最大价值 4294967295如果某些内容发生了变化(状态,被拒绝的行,临时错误),请定期打印正在运行的作业的状态。 设置为0可禁用此报告。 设置为1会打印出看到的任何更改。 较高的值会降低此状态报告的频率。
-
属性 值 命令行格式 --no-asynch类型 布尔 默认值 FALSE在单个事务中以批处理方式运行数据库操作。
-
属性 值 命令行格式 --no-hint类型 布尔 默认值 FALSE不要使用分发键提示来选择数据节点。
-
属性 值 命令行格式 --opbatch=#类型 整数 默认值 256最低价值 1最大价值 4294967295设置每个执行批处理操作数(包括blob操作)的限制,从而设置异步事务的数量。
-
属性 值 命令行格式 --opbytes=#类型 整数 默认值 0最低价值 0最大价值 4294967295设置每个执行批处理的字节数限制。 使用0表示无限制。
-
属性 值 命令行格式 --output-type=name类型 列举 默认值 ndb有效值 null设置输出类型。
ndb是默认值。null仅用于测试。 -
属性 值 命令行格式 --output-workers=#类型 整数 默认值 2最低价值 1最大价值 4294967295设置处理输出或中继数据库操作的线程数。
-
属性 值 命令行格式 --pagesize=#类型 整数 默认值 4096最低价值 1最大价值 4294967295将I / O缓冲区与给定大小对齐。
-
属性 值 命令行格式 --pagecnt=#类型 整数 默认值 64最低价值 1最大价值 4294967295将I / O缓冲区的大小设置为页面大小的倍数。 CSV输入工作程序分配大小加倍的缓冲区。
-
属性 值 命令行格式 --polltimeout=#类型 整数 默认值 1000最低价值 1最大价值 4294967295为已完成的异步事务设置每个轮询的超时时间; 轮询继续,直到所有民意调查完成,或直到发生错误。
-
属性 值 命令行格式 --rejects=#类型 整数 默认值 0最低价值 0最大价值 4294967295限制数据加载中被拒绝的行数(具有永久错误的行)。 默认值为0,表示任何被拒绝的行都会导致致命错误。 导致超出限制的任何行都将添加到
.rej文件中。此选项施加的限制在当前运行期间有效。 为此目的, 重新启动的运行
--resume被视为 “ 新 ” 运行。 -
属性 值 命令行格式 --resume类型 布尔 默认值 FALSE如果作业中止(由于临时db错误或用户中断),请继续执行尚未处理的任何行。
-
属性 值 命令行格式 --rowbatch=#类型 整数 默认值 0最低价值 0最大价值 4294967295设置每行队列的行数限制。 使用0表示无限制。
-
属性 值 命令行格式 --rowbytes=#类型 整数 默认值 262144最低价值 0最大价值 4294967295设置每行队列的字节数限制。 使用0表示无限制。
-
属性 值 命令行格式 --stats类型 布尔 默认值 false在名为
*.sto和的 文件中保存有关性能和其他内部统计信息的选项的信息*.stt。 这些文件始终保持成功完成(即使--keep-state未指定)。 -
属性 值 命令行格式 --state-dir=name类型 串 默认值 .在哪里写入状态文件(
tbl_name.maptbl_name.rejtbl_name.restbl_name.stt -
属性 值 命令行格式 --tempdelay=#类型 整数 默认值 10最低价值 0最大价值 4294967295临时错误之间休眠的毫秒数。
-
属性 值 命令行格式 --temperrors=#类型 整数 默认值 0最低价值 0最大价值 4294967295每个执行批处理由于临时错误导致事务失败的次数。 默认值为0,这意味着任何临时错误都是致命的。 临时错误不会导致任何行添加到
.rej文件中。 -
属性 值 命令行格式 --verbose类型 布尔 默认值 false启用详细输出。
与此同时
LOAD
DATA
,字段和行格式的选项与用于创建CSV文件的选项非常匹配,无论是使用
SELECT INTO ...
OUTFILE
还是通过其他方式完成。
没有与
LOAD
DATA
声明
STARTING WITH
选项
等效的内容
。
在NDB 7.6.2中添加了 ndb_import 。
ndb_index_stat
提供有关
NDB
表的
索引的每个片段统计信息
。
这包括缓存版本和年龄,每个分区的索引条目数以及索引的内存消耗。
用法
要获取有关给定
NDB
表的
基本索引统计信息
,请使用
(
)选项
调用
此处
所示的
ndb_index_stat
,其中表的名称作为第一个参数,并且包含紧跟在其后面的表的数据库的名称
:
--database
-d
ndb_index_stattable-ddatabase
在这个例子中,我们使用
ndb_index_stat
以获取有关的信息等
NDB
指定的表
mytable
中的
test
数据库:
外壳> ndb_index_stat -d test mytable
表:城市指数:PRIMARY fragCount:2
sampleVersion:3 loadTime:1399585986 sampleCount:1994 keyBytes:7976
query cache:valid:1 sampleCount:1994 totalBytes:27916
以ms为单位的时间:保存:7.133排序:每个样本1.974排序:0.000
NDBT_ProgramExit:0 - 好的
sampleVersion
是从中获取统计数据的缓存的版本号。
使用该
选项
运行
ndb_index_stat
--update
会导致sampleVersion递增。
loadTime
显示上次更新缓存的时间。
这表示自Unix Epoch以来的秒数。
sampleCount
是每个分区找到的索引条目数。
您可以通过将其乘以片段数来估计条目总数(显示为
fragCount
)。
sampleCount
可以与
SHOW
INDEX
or
的基数进行比较
INFORMATION_SCHEMA.STATISTICS
,虽然后两者提供了整个表的视图,而
ndb_index_stat
提供了每片段的平均值。
keyBytes
是索引使用的字节数。
在此示例中,主键是一个整数,每个索引需要四个字节,因此
keyBytes
可以在这种情况下计算,如下所示:
keyBytes = sampleCount *(每个索引4个字节)= 1994 * 4 = 7976
此信息也可以使用相应的列定义获得
INFORMATION_SCHEMA.COLUMNS
(这需要MySQL服务器和MySQL客户端应用程序)。
totalBytes
是表中所有索引消耗的总内存,以字节为单位。
前面示例中显示的计时特定于每次调用 ndb_index_stat 。
该
--verbose
选项提供了一些额外的输出,如下所示:
外壳> ndb_index_stat -d test mytable --verbose
随机种子1337010518
连接的
循环1的1
table:mytable index:PRIMARY fragCount:4
sampleVersion:2 loadTime:1336751773 sampleCount:0 keyBytes:0
读取统计数据
查询缓存已创建
query cache:valid:1 sampleCount:0 totalBytes:0
以ms为单位的时间:保存:20.766排序:0.001
断开的
NDBT_ProgramExit:0 - 好的
外壳>
如果程序的唯一输出是
NDBT_ProgramExit: 0 - OK
,则可能表示尚未存在统计信息。
要强制它们被创建(或者如果已经存在则更新它们),
使用该
选项
调用
ndb_index_stat
--update
,或者
ANALYZE TABLE
在
mysql
客户机中
的表上
执行
。
选项
下表包含特定于NDB群集 ndb_index_stat 实用程序的选项。 表格后面列出了其他说明。 有关大多数NDB Cluster程序(包括 ndb_index_stat )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.346 ndb_index_stat程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 包含该表的数据库的名称。 |
所有NDB 8.0版本 |
|
| 删除给定表的索引统计信息,停止先前配置的任何自动更新。 |
所有NDB 8.0版本 |
|
| 更新给定表的索引统计信息,重新启动先前配置的任何自动更新。 |
所有NDB 8.0版本 |
|
| 打印查询缓存。 |
所有NDB 8.0版本 |
|
| 在第一个键attr上执行许多随机范围查询(必须是int unsigned)。 |
所有NDB 8.0版本 |
|
| 删除NDB内核中的所有统计表和事件(所有统计信息都丢失) |
所有NDB 8.0版本 |
|
| 在NDB内核中创建所有统计表和事件(如果它们都不存在) |
所有NDB 8.0版本 |
|
| 在NDB内核中创建尚不存在的任何统计表和事件。 |
所有NDB 8.0版本 |
|
| 创建NDB内核中尚不存在的任何统计表或事件。 删除任何无效的。 |
所有NDB 8.0版本 |
|
| 验证是否存在NDB系统索引统计信息和事件表。 |
所有NDB 8.0版本 |
|
| 不要将sys- *选项应用于表。 |
所有NDB 8.0版本 |
|
| 不要将sys- *选项应用于事件。 |
所有NDB 8.0版本 |
|
| 打开详细输出 |
所有NDB 8.0版本 |
|
| 设置执行给定命令的次数。 默认值为0。 |
所有NDB 8.0版本 |
ndb_index_stat统计选项。 以下选项用于生成索引统计信息。 它们使用给定的表和数据库。 它们不能与系统选项混合使用(请参阅 ndb_index_stat系统选项 )。
-
属性 值 命令行格式 --database=name类型 串 默认值 [none]最低价值 最大价值 包含要查询的表的数据库的名称。
-
属性 值 命令行格式 --delete类型 布尔 默认值 false最低价值 最大价值 删除给定表的索引统计信息,停止先前配置的任何自动更新。
-
属性 值 命令行格式 --update类型 布尔 默认值 false最低价值 最大价值 更新给定表的索引统计信息,然后重新启动先前配置的任何自动更新。
-
属性 值 命令行格式 --dump类型 布尔 默认值 false最低价值 最大价值 转储查询缓存的内容。
-
属性 值 命令行格式 --query=#类型 数字 默认值 0最低价值 0最大价值 MAX_INT对第一个键属性执行随机范围查询(必须是int unsigned)。
ndb_index_stat系统选项。 以下选项用于生成和更新NDB内核中的统计信息表。 这些选项都不能与统计信息选项混合使用(请参阅 ndb_index_stat统计信息选项 )。
-
属性 值 命令行格式 --sys-drop类型 布尔 默认值 false最低价值 最大价值 删除NDB内核中的所有统计信息表和事件。 这会导致所有统计信息丢失 。
-
属性 值 命令行格式 --sys-create类型 布尔 默认值 false最低价值 最大价值 在NDB内核中创建所有统计表和事件。 仅当先前没有它们存在时,这才有效。
-
属性 值 命令行格式 --sys-create-if-not-exist类型 布尔 默认值 false最低价值 最大价值 创建调用程序时尚不存在的任何NDB系统统计信息表或事件(或两者)。
-
属性 值 命令行格式 --sys-create-if-not-valid类型 布尔 默认值 false最低价值 最大价值 在删除任何无效的NDB系统统计表或事件之后,创建任何尚未存在的NDB系统统计表或事件。
-
属性 值 命令行格式 --sys-check类型 布尔 默认值 false最低价值 最大价值 验证NDB内核中是否存在所有必需的系统统计信息表和事件。
-
属性 值 命令行格式 --sys-skip-tables类型 布尔 默认值 false最低价值 最大价值 不要将任何
--sys-*选项应用于任何统计表。 -
属性 值 命令行格式 --sys-skip-events类型 布尔 默认值 false最低价值 最大价值 不要
--sys-*对任何事件 应用任何 选项。 -
属性 值 命令行格式 --verbose类型 布尔 默认值 false最低价值 最大价值 打开详细输出。
-
属性 值 命令行格式 --loops=#类型 数字 默认值 0最低价值 0最大价值 MAX_INT重复命令次数(用于测试)。
ndb_move_data将 数据从一个NDB表复制到另一个NDB表。
用法
使用源表和目标表的名称调用该程序; 这些中的任何一个或两个都可以选择使用数据库名称进行限定。 两个表都必须使用NDB存储引擎。
ndb_move_dataoptionssourcetarget
下表包含特定于 ndb_move_data的 选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_move_data )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.347 ndb_move_data程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 转储核心永久性错误(调试选项) |
所有NDB 8.0版本 |
|
| 字符集所在的目录 |
所有NDB 8.0版本 |
|
| 找到表的数据库的名称 |
所有NDB 8.0版本 |
|
| 移动所有行后删除源表 |
所有NDB 8.0版本 |
|
| 插入随机临时错误(测试选项) |
所有NDB 8.0版本 |
|
| 忽略源表或目标表中的额外列 |
所有NDB 8.0版本 |
|
| 转换为较小的类型时,允许截断属性数据 |
所有NDB 8.0版本 |
|
| 允许将属性数据转换为更大的类型 |
所有NDB 8.0版本 |
|
| 指定尝试临时错误。 格式为x [,y [,z]],其中x = max尝试(0 =无限制),y =最小延迟(ms),z =最大延迟(ms) |
所有NDB 8.0版本 |
|
| 启用详细消息 |
所有NDB 8.0版本 |
-
属性 值 命令行格式 --abort-on-error类型 布尔 默认值 FALSE转储核心永久性错误(调试选项)。
-
属性 值 命令行格式 --character-sets-dir=name类型 串 默认值 [none]字符集所在的目录。
-
属性 值 命令行格式 --database=dbname类型 串 默认值 TEST_DB找到表的数据库的名称。
-
属性 值 命令行格式 --drop-source类型 布尔 默认值 FALSE移动所有行后删除源表。
-
属性 值 命令行格式 --error-insert类型 布尔 默认值 FALSE插入随机临时错误(测试选项)。
-
属性 值 命令行格式 --exclude-missing-columns类型 布尔 默认值 FALSE忽略源表或目标表中的额外列。
-
属性 值 命令行格式 --lossy-conversions类型 布尔 默认值 FALSE转换为较小的类型时,允许截断属性数据。
-
属性 值 命令行格式 --promote-attributes类型 布尔 默认值 FALSE允许将属性数据转换为更大的类型。
-
属性 值 命令行格式 --staging-tries=x[,y[,z]]类型 串 默认值 0,1000,60000指定尝试临时错误。 格式为x [,y [,z]],其中x = max尝试(0 =无限制),y =最小延迟(ms),z =最大延迟(ms)。
-
属性 值 命令行格式 --verbose类型 布尔 默认值 FALSE启用详细消息。
ndb_perror
显示有关NDB错误的信息,给出其错误代码。
这包括错误消息,错误类型以及错误是永久性还是临时性。
添加到NDB 7.6.4中的MySQL NDB Cluster分发版中,它旨在作为
perror的
替代品
--ndb
。
用法
ndb_perror [options]error_code
ndb_perror 不需要访问正在运行的NDB群集或任何节点(包括SQL节点)。 要查看有关给定NDB错误的信息,请使用错误代码作为参数调用该程序,如下所示:
外壳> ndb_perror 323
NDB错误代码323:节点组ID无效,节点组已存在:永久错误:应用程序错误
要仅显示错误消息,
请
使用
--silent
选项(简短形式
-s
)
调用
ndb_perror
,如下所示:
外壳> ndb_perror -s 323
节点组ID无效,节点组已存在:永久错误:应用程序错误
与 perror 一样 , ndb_perror 接受多个错误代码:
外壳> ndb_perror 321 1001
NDB错误代码321:无效的节点组ID:永久错误:应用程序错误
NDB错误代码1001:非法连接字符串
ndb_perror的 其他程序选项 将在本节后面介绍。
ndb_perror
替换了
perror
--ndb
,自NDB 7.6.4起不推荐使用,并且在将来的MySQL NDB Cluster版本中将被删除。
为了在脚本和其他可能依赖于
perror
获取NDB错误信息的
应用程序中更容易替换
,
ndb_perror
支持自己的
“
虚拟
”
--ndb
选项,它不执行任何操作。
下表包含特定于NDB群集程序 ndb_perror的 所有选项 。 其他说明如下表所示。
其他选项
-
属性 值 命令行格式 --help类型 布尔 默认值 TRUE显示程序帮助文本并退出。
-
属性 值 命令行格式 --ndb类型 布尔 默认值 TRUE为了与应用程序兼容,取决于 使用该程序 选项的 旧版本 perror
--ndb。 与 ndb_perror一起 使用时的选项 不执行任何操作,并被它忽略。 -
属性 值 命令行格式 --silent类型 布尔 默认值 TRUE仅显示错误消息。
-
属性 值 命令行格式 --version类型 布尔 默认值 TRUE打印程序版本信息并退出。
-
属性 值 命令行格式 --verbose类型 布尔 默认值 TRUE详细输出; 禁用
--silent。
ndb_print_backup_file 从群集备份文件中获取诊断信息。
用法
ndb_print_backup_file file_name
file_name
是群集备份文件的名称。
这可以是
群集备份目录中的
任何文件(
.Data
,
.ctl
或
.log
文件)。
这些文件位于子目录下数据节点的备份目录中
,其中
是备份的序列号。
有关群集备份文件及其内容的更多信息,请参见
第22.5.3.1节“NDB群集备份概念”
。
BACKUP-
##
与
ndb_print_schema_file
和
ndb_print_sys_file
(与大多数其他
NDB
旨在在管理服务器主机上运行或连接到管理服务器的实用程序
不同
)一样,
ndb_print_backup_file
必须在群集数据节点上运行,因为它直接访问数据节点文件系统。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
在NDB 8.0.17及更高版本中,此程序还可用于读取撤消日志文件。
其他选项
没有。
ndb_print_file 从NDB Cluster Disk Data文件中获取信息。
用法
ndb_print_file [-v] [-q] file_name+
file_name
是NDB群集磁盘数据文件的名称。
接受多个文件名,以空格分隔。
与
ndb_print_schema_file
和
ndb_print_sys_file
(与大多数其他
NDB
旨在在管理服务器主机上运行或连接到管理服务器的实用程序
不同
)一样,
ndb_print_file
必须在NDB Cluster数据节点上运行,因为它访问数据节点文件系统直。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
其他选项
ndb_print_file 支持以下选项:
-
-v:输出详细。 -
-q:抑制输出(安静模式)。 -
--help,-h,-?:打印帮助信息。
有关更多信息,请参见 第22.5.13节“NDB集群磁盘数据表” 。
ndb_print_frag_file 从集群片段列表文件中获取信息。 它旨在用于帮助诊断数据节点重新启动的问题。
用法
ndb_print_frag_file file_name
file_name
是一个集群片段列表文件的名称,它与模式匹配
,其中
是一个2-9(含)范围内的数字,可以在具有节点ID的数据节点的数据节点文件系统中找到
,在目录中
,
是
或
。
每个片段文件包含属于每个
表
的片段的记录
。
有关群集片段文件的详细信息,请参阅
NDB群集数据节点文件系统目录文件
。
S
X.FragListX
nodeid
ndb_
nodeid_fs/DN/DBDIH/N
1
2
NDB
与
ndb_print_backup_file
,
ndb_print_sys_file
和
ndb_print_schema_file
(与大多数其他
NDB
旨在在管理服务器主机上运行或连接到管理服务器的实用程序
不同
)一样,
ndb_print_frag_file
必须在群集数据节点上运行,因为它访问数据节点文件系统直接。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
其他选项
没有。
样本输出
外壳> ndb_print_frag_file /usr/local/mysqld/data/ndb_3_fs/D1/DBDIH/S2.FragList
文件名:/usr/local/mysqld/data/ndb_3_fs/D1/DBDIH/S2.FragList,大小为8192
noOfPages = 1 noOfWords = 182
表数据
----------
Num Frags:2 NoOfReplicas:2 hashpointer:4294967040
kvalue:6 mask:0x00000000方法:HashMap
存储在记录和检查点,SR存活
------片段与FragId:0 --------
首选主要:2 numStoredReplicas:2 numOldStoredReplicas:0 distKey:0 LogPartId:0
-------存储副本----------
副本节点是:2 initialGci:2 numCrashedReplicas = 0 nextLcpNo = 1
LcpNo [0]:maxGciCompleted:1 maxGciStarted:2 lcpId:1 lcpStatus:有效
LcpNo [1]:maxGciCompleted:0 maxGciStarted:0 lcpId:0 lcpStatus:invalid
-------存储副本----------
副本节点是:3 initialGci:2 numCrashedReplicas = 0 nextLcpNo = 1
LcpNo [0]:maxGciCompleted:1 maxGciStarted:2 lcpId:1 lcpStatus:有效
LcpNo [1]:maxGciCompleted:0 maxGciStarted:0 lcpId:0 lcpStatus:invalid
------片段与FragId:1 --------
首选主要:3 numStoredReplicas:2 numOldStoredReplicas:0 distKey:0 LogPartId:1
-------存储副本----------
副本节点是:3 initialGci:2 numCrashedReplicas = 0 nextLcpNo = 1
LcpNo [0]:maxGciCompleted:1 maxGciStarted:2 lcpId:1 lcpStatus:有效
LcpNo [1]:maxGciCompleted:0 maxGciStarted:0 lcpId:0 lcpStatus:invalid
-------存储副本----------
副本节点是:2 initialGci:2 numCrashedReplicas = 0 nextLcpNo = 1
LcpNo [0]:maxGciCompleted:1 maxGciStarted:2 lcpId:1 lcpStatus:有效
LcpNo [1]:maxGciCompleted:0 maxGciStarted:0 lcpId:0 lcpStatus:invalid
ndb_print_schema_file 从集群模式文件中获取诊断信息。
用法
ndb_print_schema_file file_name
file_name
是群集模式文件的名称。
有关群集架构文件的详细信息,请参阅
NDB群集数据节点文件系统目录文件
。
与
ndb_print_backup_file
和
ndb_print_sys_file
(与大多数其他
NDB
旨在在管理服务器主机上运行或连接到管理服务器的实用程序
不同
)一样,
ndb_print_schema_file
必须在群集数据节点上运行,因为它直接访问数据节点文件系统。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
其他选项
没有。
ndb_print_sys_file 从NDB Cluster系统文件获取诊断信息。
用法
ndb_print_sys_file file_name
file_name
是集群系统文件(sysfile)的名称。
集群系统文件位于数据节点的数据目录(
DataDir
)中;
此目录下的路径到系统文件匹配模式
。
在每种情况下,
代表一个数字(不一定是相同的数字)。
有关更多信息,请参阅
NDB群集数据节点文件系统目录文件
。
ndb_
#_fs/D#/DBDIH/P#.sysfile#
与
ndb_print_backup_file
和
ndb_print_schema_file
(与大多数其他
NDB
旨在在管理服务器主机上运行或连接到管理服务器的实用程序
不同
)一样,
ndb_print_backup_file
必须在群集数据节点上运行,因为它直接访问数据节点文件系统。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
其他选项
没有。
读取重做日志文件,检查其是否有错误,以人类可读格式打印其内容,或两者兼而有之。 ndb_redo_log_reader 主要供NDB Cluster开发人员和支持人员用于调试和诊断问题。
此实用程序仍在开发中,其语法和行为在将来的NDB Cluster版本中可能会发生变化。
在NDB 7.2之前,此实用程序名为 ndbd_redo_log_reader 。
可以在目录中找到
ndb_redo_log_reader
的C ++源文件
/storage/ndb/src/kernel/blocks/dblqh/redoLogReader
。
下表包含特定于NDB群集程序 ndb_redo_log_reader的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_redo_log_reader )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.349 ndb_redo_log_reader程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 打印转储信息 |
所有NDB 8.0版本 |
|
| 仅打印文件描述符 |
所有NDB 8.0版本 |
|
| 打印使用信息 |
所有NDB 8.0版本 |
|
| 提供圈数信息,最大GCI开始并完成 |
所有NDB 8.0版本 |
|
| 从兆字节开始 |
所有NDB 8.0版本 |
|
| 仅显示文件中每兆字节的第一页标题 |
所有NDB 8.0版本 |
|
| 不要检查记录是否有错误 |
所有NDB 8.0版本 |
|
| 不要打印记录 |
所有NDB 8.0版本 |
|
| 从这个页面开始 |
所有NDB 8.0版本 |
|
| 仅显示页面标题 |
所有NDB 8.0版本 |
|
| 从此页面索引开始 |
所有NDB 8.0版本 |
|
| 位移转储 |
所有NDB 8.0版本 |
用法
ndb_redo_log_readerfile_name[options]
file_name
是群集重做日志文件的名称。
重做日志文件位于数据节点的数据目录(
DataDir
)
下的编号目录中
;
此目录下的重做日志文件路径与模式匹配
。
是数据节点的节点ID。
每个
实例
代表一个数字(不一定是相同的数字);
以下数字
在8-39的范围内;
后续数字的范围
根据
配置参数
的值而变化
,默认值为16;
因此,文件名中的数字的默认范围是0-15(含)。
有关更多信息,请参阅
ndb_
nodeid_fs/D#/DBLQH/S#.FragLognodeid
#
D
S
NoOfFragmentLogFiles
NDB群集数据节点文件系统目录文件
。
要读取的文件的名称后面可能跟有以下列出的一个或多个选项:
-
属性 值 命令行格式 -dump类型 布尔 默认值 FALSE打印转储信息。
-
属性 值 命令行格式 -filedescriptors类型 布尔 默认值 FALSE-filedescriptors:仅打印文件描述符。 -
属性 值 命令行格式 --help--help:打印使用信息。 -
属性 值 命令行格式 -lap类型 布尔 默认值 FALSE提供圈数信息,最大GCI开始并完成。
-
属性 值 命令行格式 -mbyte #类型 数字 默认值 0最低价值 0最大价值 15-mbyte:开始兆字节。##是0到15之间的整数,包括0和15。 -
属性 值 命令行格式 -mbyteheaders类型 布尔 默认值 FALSE-mbyteheaders:仅显示文件中每兆字节的第一页标题。 -
属性 值 命令行格式 -noprint类型 布尔 默认值 FALSE-noprint:不要打印日志文件的内容。 -
属性 值 命令行格式 -nocheck类型 布尔 默认值 FALSE-nocheck:不要检查日志文件中的错误。 -
属性 值 命令行格式 -page #类型 整数 默认值 0最低价值 0最大价值 31-page:从这个页面开始。##是0到31范围内的整数,包括0和31。 -
属性 值 命令行格式 -pageheaders类型 布尔 默认值 FALSE-pageheaders:仅显示页面标题。 -
属性 值 命令行格式 -pageindex #类型 整数 默认值 12最低价值 12最大价值 8191-pageindex:从此页面索引开始。##是一个介于12和8191之间的整数。 -
属性 值 命令行格式 -twiddle类型 布尔 默认值 FALSE位移转储。
与
ndb_print_backup_file
和
ndb_print_schema_file
(与大多数
NDB
旨在在管理服务器主机上运行或连接到管理服务器
的
实用程序
不同
)一样,
ndb_redo_log_reader
必须在群集数据节点上运行,因为它直接访问数据节点文件系统。
由于它不使用管理服务器,因此可以在管理服务器未运行时使用此实用程序,甚至在群集完全关闭时也可以使用此实用程序。
群集恢复程序作为单独的命令行实用程序
ndb_restore实现
,通常可以在MySQL
bin
目录中
找到
。
该程序读取由备份创建的文件,并将存储的信息插入数据库。
ndb_restore
必须一次为每个被创建的备份文件的执行
START BACKUP
用于创建备份命令(见
第22.5.3.2,“使用NDB群集管理客户端创建备份”
)。
这等于创建备份时群集中的数据节点数。
在使用 ndb_restore 之前 ,建议群集以单用户模式运行,除非您并行还原多个数据节点。 有关 更多信息 , 请参见 第22.5.8节“NDB集群单用户模式” 。
下表包含特定于NDB群集本机备份还原程序 ndb_restore的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_restore ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.350 ndb_restore程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 将数据附加到制表符分隔的文件 |
所有NDB 8.0版本 |
|
| 备份文件目录的路径 |
所有NDB 8.0版本 |
|
| 使用给定ID从备份还原 |
所有NDB 8.0版本 |
|
| --connectstring的别名。 |
所有NDB 8.0版本 |
|
| 导致备份中的索引被忽略; 可能会减少恢复数据所需的时间。 |
所有NDB 8.0版本 |
|
| 在还原期间不要忽略系统表。 仅限实验; 不适合生产用途 |
所有NDB 8.0版本 |
|
| 要排除的一个或多个数据库的列表(包括未命名的数据库) |
所有NDB 8.0版本 |
|
| 如果为TRUE(缺省值),则不要还原复制ALTER TABLE操作遗留的任何中间表(具有前缀为'#sql-'的名称)。 |
所有NDB 8.0版本 |
|
| 导致从数据库中的表版本中缺少的表的备份版本中的列被忽略。 |
所有NDB 8.0版本 |
|
| 导致数据库中缺少的备份表将被忽略。 |
所有NDB 8.0版本 |
|
| 要排除的一个或多个表的列表(包括那些未命名的同一数据库中的表); 每个表引用必须包含数据库名称 |
所有NDB 8.0版本 |
|
| 字段用指定的字符括起来 |
所有NDB 8.0版本 |
|
| 字段可选地用指示的字符括起来 |
所有NDB 8.0版本 |
|
| 字段由指示的字符终止 |
所有NDB 8.0版本 |
|
| 以十六进制格式打印二进制类型 |
所有NDB 8.0版本 |
|
| 要还原的一个或多个数据库的列表(不包括那些未命名的数据库) |
所有NDB 8.0版本 |
|
| 要还原的一个或多个表的列表(排除那些未命名的同一数据库中的表); 每个表引用必须包含数据库名称 |
所有NDB 8.0版本 |
|
| 行由指示的字符终止 |
所有NDB 8.0版本 |
|
| 从备份还原数据时,允许对列值进行有损转换(键入降级或符号更改) |
所有NDB 8.0版本 |
|
| 如果连接了mysqld并使用二进制日志记录,请不要记录已还原的数据 |
所有NDB 8.0版本 |
|
| 不要还原与磁盘数据相关的对象 |
所有NDB 8.0版本 |
|
| 不要升级尚未调整VAR数据大小的varsize属性的数组类型,也不要更改列属性 |
所有NDB 8.0版本 |
|
| NDBCLUSTER存储引擎的节点组映射。 语法:list of(source_nodegroup,destination_nodegroup) |
所有NDB 8.0版本 |
|
| 进行备份的节点的ID |
所有NDB 8.0版本 |
|
| 恢复数据时要使用的并行事务数 |
所有NDB 8.0版本 |
|
| 在将固定宽度字符串类型提升为可变宽度类型时,允许保留尾随空格(包括填充) |
所有NDB 8.0版本 |
|
| 打印元数据,数据和日志到stdout(相当于--print-meta --print-data --print-log) |
所有NDB 8.0版本 |
|
| 将数据打印到stdout |
所有NDB 8.0版本 |
|
| 打印到标准输出 |
所有NDB 8.0版本 |
|
| 将元数据打印到stdout |
所有NDB 8.0版本 |
|
| 将SQL日志写入stdout; 默认值为FALSE |
所有NDB 8.0版本 |
|
| 打印每个给定秒数的恢复状态 |
所有NDB 8.0版本 |
|
| 从备份还原数据时,允许提升属性 |
所有NDB 8.0版本 |
|
| 导致在备份中找到的有序索引的多线程重建。 使用的线程数由设置BuildIndexThreads参数确定。 |
所有NDB 8.0版本 |
|
| 使用NDB API将表数据和日志还原到NDB Cluster |
所有NDB 8.0版本 |
|
| 将纪元信息恢复到状态表中。 方便MySQL Cluster复制从属设备启动复制。 将更新/插入mysql.ndb_apply_status中ID为0的行。 |
所有NDB 8.0版本 |
|
| 使用NDB API将元数据还原到NDB群集 |
所有NDB 8.0版本 |
|
| 恢复以前移动到NDB的MySQL权限表。 |
所有NDB 8.0版本 |
|
| 还原到名称与原始名称不同的数据库 |
所有NDB 8.0版本 |
|
| 导致备份文件中丢失的blob表被忽略。 |
所有NDB 8.0版本 |
|
| 在恢复数据期间跳过表结构检查 |
所有NDB 8.0版本 |
|
| 在将从较新的MySQL Cluster版本创建的备份还原到旧版本时,会忽略ndb_restore无法识别的架构对象。 |
所有NDB 8.0版本 |
|
| 为给定路径中的每个表创建一个以制表符分隔的.txt文件 |
所有NDB 8.0版本 |
|
| 输出的详细程度 |
所有NDB 8.0版本 |
此实用程序的典型选项如下所示:
ndb_restore [-cconnection_string] -nnode_id-bbackup_id\ [-m] -r --backup_path =/path/to/backup/files
通常,从NDB群集备份还原时,
ndb_restore至少
需要
--nodeid
(简短形式:
-n
),
--backupid
(简短形式
:)
-b
和
--backup_path
选项。
此外,当使用
ndb_restore
还原包含唯一索引的任何表时,必须包含
--disable-indexes
或
--rebuild-indexes
。
(Bug#57782,Bug#11764893)
该
-c
选项用于指定连接字符串,该字符串
指示
ndb_restore
集群管理服务器的位置(请参见
第22.3.3.3节“NDB集群连接字符串”
)。
如果未使用此选项,则
ndb_restore会
尝试连接到管理服务器
localhost:1186
。
此实用程序充当群集API节点,因此需要一个空闲连接
“
插槽
”
才能连接到群集管理服务器。
这意味着
群集
文件中
必须至少有一个
[api]
或
[mysqld]
部分可供其使用
config.ini
。
保持至少一个空的是个好主意
[api]
或
[mysqld]
在部分
config.ini
没有被用于MySQL服务器或其它应用程序出于这个原因,(见
第22.3.3.7,“定义SQL,并在NDB簇其他API节点”
)。
您可以 使用 ndb_mgm 管理客户端中 的 SHOW 命令 验证 ndb_restore 是否已连接到群集 。 您也可以从系统shell完成此操作,如下所示:
外壳> ndb_mgm -e "SHOW"
有关ndb_restore使用的所有选项的更多详细信息,请参见以下列表:
-
属性 值 命令行格式 --append与
--tab&--print-data选项一起使用时,会导致数据附加到具有相同名称的任何现有文件。 -
属性 值 命令行格式 --backup-path=dir_name类型 目录名称 默认值 ./备份目录的路径是必需的; 这是 使用 选项 提供给 ndb_restore 的
--backup_path,并且必须包含与要还原的备份的ID备份对应的子目录。 例如,如果数据节点DataDir是/var/lib/mysql-cluster,则备份目录是/var/lib/mysql-cluster/BACKUP,并且可以在中找到具有ID 3的备份的备份文件/var/lib/mysql-cluster/BACKUP/BACKUP-3。 该路径可以是绝对的或相对于 ndb_restore 可执行文件所在 的目录 ,并且可以选择带有前缀backup_path=。可以使用与创建配置不同的配置将备份还原到数据库。 例如,假设与备份ID备份
12,在集群中具有节点ID两个存储节点创建2和3,要恢复到群集具有四个节点。 然后 ,对于进行备份的群集中的每个存储节点, ndb_restore 必须运行两次。 但是, ndb_restore 无法始终将运行一个MySQL版本的集群所做的备份还原到运行不同MySQL版本的集群。重要无法使用旧版本的 ndb_restore 还原从较新版本的NDB群集创建的 备份 。 您可以将从较新版本的MySQL制作的备份还原到较旧的群集,但必须使用 较新的NDB群集版本中 的 ndb_restore 副本 才能执行此操作。
例如,要恢复运行NDB簇7.5.15运行NDB簇7.4.25集群集群采取集群备份,您必须使用 ndb_restore 自带的NDB簇7.5.15分布。
为了更快速地恢复,只要有足够数量的集群连接可用,就可以并行恢复数据。 也就是说,在并行还原到多个节点时,必须 在 每个并发 ndb_restore 进程 的群集 文件中 都有一个
[api]或 一个[mysqld]部分 。 但是,必须始终在日志之前应用数据文件。config.ini -
属性 值 命令行格式 --backupid=#类型 数字 默认值 none此选项用于指定备份的ID或序列号,与备份 完成时显示 的 消息中 管理客户端 显示的 号码相同 。 (请参见 第22.5.3.2节“使用NDB群集管理客户端创建备份” 。)
Backupbackup_idcompleted重要还原群集备份时,必须确保从具有相同备份ID的备份还原所有数据节点。 使用来自不同备份的文件最多会导致将群集还原到不一致状态,并且可能完全失败。
在NDB 8.0.15及更高版本中,此选项是必需的。
-
属性 值 命令行格式 --connect类型 串 默认值 localhost:1186别名
--ndb-connectstring。 -
属性 值 命令行格式 --disable-indexes在从本机
NDB备份 恢复数据期间禁用索引恢复 。 之后,您可以使用多线程构建索引一次性恢复所有表的索引--rebuild-indexes,这应该比为非常大的表同时重建索引更快。 -
属性 值 命令行格式 --dont-ignore-systab-0通常,在还原表数据和元数据时, ndb_restore会 忽略
NDB备份中存在 的 系统表 的副本 。--dont-ignore-systab-0导致系统表恢复。 此选项仅供实验和开发使用,不建议在生产环境中使用 。 -
属性 值 命令行格式 --exclude-databases=db-list类型 串 默认值 以逗号分隔的一个或多个数据库的列表,不应该恢复。
此选项通常与
--exclude-tables; 有关更多信息和示例,请参阅该选项的说明。 -
--exclude-intermediate-sql-tables[=TRUE|FALSE]属性 值 命令行格式 --exclude-intermediate-sql-tables[=TRUE|FALSE]类型 布尔 默认值 TRUE执行复制
ALTER TABLE操作时, mysqld 创建中间表(其名称以前缀为前缀#sql-)。 何时TRUE,该--exclude-intermediate-sql-tables选项使 ndb_restore 无法恢复可能已从这些操作中遗留下来的表。TRUE默认情况下, 此选项 。 -
属性 值 命令行格式 --exclude-missing-columns可以使用此选项仅还原选定的表列,这会导致 ndb_restore 忽略正在还原的表中缺少的任何列,与备份中找到的那些表的版本相比。 此选项适用于要还原的所有表。 如果您希望此选项仅适用于选定的表或数据库,您可以结合使用它与一个或多个的
--include-*或--exclude-*在本节其他地方所描述的选项的话,那么数据使用一组互补的这些恢复的其他表格选项。 -
属性 值 命令行格式 --exclude-missing-tables可以使用此选项仅还原选定的表,这会导致 ndb_restore 忽略备份中未在目标数据库中找到的任何表。
-
属性 值 命令行格式 --exclude-tables=table-list类型 串 默认值 要排除的一个或多个表的列表; 每个表引用必须包含数据库名称。 经常与
--exclude-databases。 一起使用 。何时使用
--exclude-databases或--exclude-tables仅使用该选项命名的数据库或表格; 所有其他数据库和表都由 ndb_restore 恢复 。此表显示了几个 ndb_restore usng
--exclude-*选项的 调用 (为清晰起见,省略了可能需要的其他选项),以及这些选项对从NDB Cluster备份进行还原的影响:表22.351使用--exclude- *选项对ndb_restore进行了几次调用,以及这些选项对从NDB群集备份进行还原的影响。
选项 结果 --exclude-databases=db1除 db1恢复 之外的所有数据库中的所有表 ; 没有表格db1被恢复--exclude-databases=db1,db2(或--exclude-databases=db1--exclude-databases=db2)除了 db1和db2恢复 所有数据库中的所有表 ; 没有表格db1或db2已恢复--exclude-tables=db1.t1除 t1数据库 外的所有表db1都已恢复; 所有其他表格db1都已恢复; 恢复所有其他数据库中的所有表--exclude-tables=db1.t2,db2.t1(要么--exclude-tables=db1.t2--exclude-tables=db2.t1)数据库中 db1除 表和数据库 外的t2所有表(表db2除外)t1都将恢复; 没有其他表格db1或db2恢复; 恢复所有其他数据库中的所有表
您可以一起使用这两个选项。 例如,由以下原因引起所有数据库中的所有表 除了 数据库
db1和db2,和表t1和t2数据库db3,要恢复:外壳>
ndb_restore [...] --exclude-databases=db1,db2 --exclude-tables=db3.t1,db3.t2(同样,为了清晰和简洁起见,我们已经省略了其他可能必要的选项。)
您可以 根据以下规则一起 使用
--include-*和--exclude-*选项:-
所有
--include-*和--exclude-*选项 的行动 都是累积的。 -
All
--include-*和--exclude-*options按照从右到左传递给ndb_restore的顺序进行评估。 -
如果选项存在冲突,则第一个(最右边)选项优先。 换句话说,与给定数据库或表匹配的第一个选项(从右到左) “ 获胜 ” 。
例如,以下一组选项会导致 ndb_restore 从数据库还原所有表,
db1除了db1.t1从其他任何数据库还原其他表 之外 :--include-databases = db1 --exclude-tables = db1.t1
但是,反转刚刚给出的选项的顺序只会导致数据库中的所有表
db1都被还原(包括db1.t1但不包含任何其他数据库的表),因为--include-databases最右边 的 选项是与数据库的第一个匹配db1,因此需要优先于匹配的任何其他选项db1或其中的任何表db1:--exclude-tables = db1.t1 --include-databases = db1
-
-
属性 值 命令行格式 --fields-enclosed-by=char类型 串 默认值 传递给此选项的字符串包含每个列值(无论数据类型如何;请参阅说明
--fields-optionally-enclosed-by)。 -
--fields-optionally-enclosed-by属性 值 命令行格式 --fields-optionally-enclosed-by类型 串 默认值 传递给该选项的字符串用于发布包含字符数据列的值(如
CHAR,VARCHAR,BINARY,TEXT,或ENUM)。 -
属性 值 命令行格式 --fields-terminated-by=char类型 串 默认值 \t (tab)传递给此选项的字符串用于分隔列值。 默认值是制表符(\ n
\t)。 -
属性 值 命令行格式 --hex如果使用此选项,则所有二进制值都以十六进制格式输出。
-
属性 值 命令行格式 --include-databases=db-list类型 串 默认值 要还原的一个或多个数据库的逗号分隔列表。 经常与
--include-tables; 有关更多信息和示例,请参阅该选项的说明。 -
属性 值 命令行格式 --include-tables=table-list类型 串 默认值 以逗号分隔的要恢复的表列表; 每个表引用必须包含数据库名称。
何时使用
--include-databases或--include-tables仅使用该选项命名的那些数据库或表; 所有其他数据库和表都被 ndb_restore 排除 ,并且不会被还原。下表显示了 使用 选项 的 ndb_restore的 几个调用
--include-*(为清楚起见,省略了可能需要的其他选项),以及这些 调用对 从NDB群集备份进行还原的影响:表22.352使用--include- *选项对ndb_restore进行了几次调用,以及它们对从NDB群集备份进行还原的影响。
选项 结果 --include-databases=db1仅 db1恢复 数据库 中的 表 ; 忽略所有其他数据库中的所有表--include-databases=db1,db2(或--include-databases=db1--include-databases=db2)在数据库中仅有的表 db1和db2恢复; 忽略所有其他数据库中的所有表--include-tables=db1.t1只 恢复 t1数据库中的 表db1; 不会db1还原其他数据库中的任何 其他表--include-tables=db1.t2,db2.t1(或--include-tables=db1.t2--include-tables=db2.t1)只有表 t2数据库db1和表t1数据库db2恢复; 在没有其它表db1,db2或任何其它数据库被恢复
您也可以一起使用这两个选项。 例如,以下原因导致数据库中的所有表
db1以及db2表t1和t2数据库中的 所有表都db3被还原(并且没有其他数据库或表):外壳>
ndb_restore [...] --include-databases=db1,db2 --include-tables=db3.t1,db3.t2(同样,我们在刚刚显示的示例中省略了其他可能需要的选项。)
还可以 使用此处显示的语法,仅使用 任何
--include-*(或--exclude-*)选项 从单个数据库还原选定的数据库或选定的表 :ndb_restore ,[ [,...] | [,] [,...]]
other_optionsdb_namedb_nametbl_nametbl_name换句话说,您可以指定要还原的以下任一项:
-
来自一个或多个数据库的所有表
-
来自单个数据库的一个或多个表
-
-
属性 值 命令行格式 --lines-terminated-by=char类型 串 默认值 \n (linebreak)指定用于结束每行输出的字符串。 默认值为换行符(\ n
\n)。 -
属性 值 命令行格式 --lossy-conversions类型 布尔 默认值 FALSE(如果未使用选项)此选项旨在补充该
--promote-attributes选项。--lossy-conversions从备份恢复数据时, 使用 允许对列值进行有损转换(类型降级或符号更改)。 除了一些例外,管理降级的规则与MySQL复制相同; 有关属性降级当前支持的特定类型转换的信息 , 请参见 第17.4.1.9.2节“具有不同数据类型的列的复制” 。ndb_restore 报告在每个属性和列的有损转换期间执行的任何数据截断。
-
属性 值 命令行格式 --no-binlog此选项可防止任何连接的SQL节点将 ndb_restore 还原的数据写入 其二进制日志。
-
--no-restore-disk-objects,-d属性 值 命令行格式 --no-restore-disk-objects类型 布尔 默认值 FALSE此选项可阻止 ndb_restore 恢复任何NDB群集磁盘数据对象,例如表空间和日志文件组; 有关这些内容的更多信息 , 请参见 第22.5.13节“NDB集群磁盘数据表” 。
-
属性 值 命令行格式 --no-upgrade使用 ndb_restore 还原备份时,
VARCHAR将使用现在使用的可变宽度格式调整使用旧固定格式创建的列的大小并重新创建。 可以通过指定来覆盖此行为--no-upgrade。 -
--ndb-nodegroup-map=map,-z属性 值 命令行格式 --ndb-nodegroup-map=map此选项可用于将从一个节点组获取的备份还原到另一个节点组。 它的参数是表格的列表 。
source_node_group,target_node_group -
属性 值 命令行格式 --nodeid=#类型 数字 默认值 none指定进行备份的数据节点的节点ID。
当从具有备份的数据节点恢复到具有不同数量的数据节点的集群时,此信息有助于识别要还原到给定节点的正确的一组或多组文件。 (在这种情况下,通常需要将多个文件还原到单个数据节点。)有关 其他信息和示例, 请参见 第22.4.23.1节“还原到不同数量的数据节点” 。
在NDB 8.0.15及更高版本中,此选项是必需的。
-
属性 值 命令行格式 --parallelism=#类型 数字 默认值 128最低价值 1最大价值 1024ndb_restore 使用单行事务同时应用多行。 此参数确定 ndb_restore 实例 尝试使用 的并行事务(并发行)数 。 默认情况下,这是128; 最小值为1,最大值为1024。
执行插入的工作在所涉及的数据节点中的线程之间并行化。 该机制用于从
.Data文件 恢复批量数据 - 即数据的模糊快照; 它不用于构建或重建索引。 更改日志是连续应用的; 索引丢弃和构建是DDL操作并单独处理。 还原的客户端没有线程级并行性。 -
--preserve-trailing-spaces,-P属性 值 命令行格式 --preserve-trailing-spaces在将固定宽度字符数据类型提升为其可变宽度等效
CHAR值 时(即,将 列值提升为VARCHAR或将BINARY列值 提升为)时,会导致保留尾随空格VARBINARY。 否则,在将这些列值插入新列时,会从这些列值中删除任何尾随空格。 -
属性 值 命令行格式 --print类型 布尔 默认值 FALSE使 ndb_restore 打印所有数据,元数据和日志
stdout。 相当于用--print-data,--print-meta和--print-log选择在一起。注意使用
--print或任何--print_*选项实际上是执行干运行。 包括这些选项中的一个或多个会导致任何输出重定向到stdout; 在这种情况下, ndb_restore 不会尝试将数据或元数据还原到NDB群集。 -
属性 值 命令行格式 --print-data类型 布尔 默认值 FALSE导致 ndb_restore 将其输出定向到
stdout。 常与一个或多个一起使用--tab,--fields-enclosed-by,--fields-optionally-enclosed-by,--fields-terminated-by,--hex,和--append。TEXT和BLOB列值始终被截断。 这些值被截断为输出中的前256个字节。 使用时,目前无法覆盖此项--print-data。 -
属性 值 命令行格式 --print-log类型 布尔 默认值 FALSE导致 ndb_restore 将其日志输出到
stdout。 -
属性 值 命令行格式 --print-meta类型 布尔 默认值 FALSE打印所有元数据
stdout。 -
属性 值 命令行格式 --print-sql-log类型 布尔 默认值 FALSE将SQL语句记录到
stdout。 使用该选项启用; 通常这种行为被禁用。 该选项在尝试记录所有正在恢复的表是否已明确定义主键之前进行检查; 仅具有由其实现的隐藏主键的表上的查询NDB无法转换为有效的SQL。此选项不适用于具有
BLOB列的表。 -
属性 值 命令行格式 --progress-frequency=#类型 数字 默认值 0最低价值 0最大价值 65535N在备份过程中每秒 打印一次状态报告 。 0(默认值)不会打印状态报告。 最大值为65535。 -
属性 值 命令行格式 --promote-attributesndb_restore 支持有限的 属性提升 ,与MySQL复制支持的方式大致相同; 也就是说,从给定类型的列备份的数据通常可以使用 “ 更大,类似 ” 类型 恢复到列 。 例如,从数据
CHAR(20)列可以被恢复到声明为一列VARCHAR(20),VARCHAR(30)或CHAR(30);MEDIUMINT列中的 数据 可以还原为类型INT或 列BIGINT。 请参见 第17.4.1.9.2节“具有不同数据类型的列的复制” ,对于属性提升当前支持的类型转换表。必须显式启用 ndb_restore的 属性提升 ,如下所示:
-
准备要还原备份的表。 ndb_restore 不能用于重新创建与原始表不同的表; 这意味着您必须手动创建表,或者
ALTER TABLE在还原表元数据之后但在还原数据之前 更改要使用的列 。 -
在恢复表数据时 ,使用 选项(简短格式 ) 调用 ndb_restore 。 如果不使用此选项,则不会发生属性提升; 相反,还原操作失败并显示错误。
--promote-attributes-A
在字符数据类型和/
TEXT或BLOB之间进行转换时,只能在字符类型(CHAR和VARCHAR)和二进制类型(BINARY和VARBINARY)之间进行转换。 例如, 在 ndb_restore 的同一调用 中将 列 提升INT为BIGINT同时 ,无法提升 列 。VARCHARTEXTTEXT不支持使用不同字符集 在 列 之间 进行 转换 ,并且明确禁止。当执行字符或二进制类型转换到
TEXT或BLOB与 ndb_restore ,您可能会注意到它创建并使用一个或多个名为临时表 。 之后不需要这些表,并且通常 在成功还原后 由 ndb_restore 删除 。table_name$STnode_id -
-
属性 值 命令行格式 --rebuild-indexes在还原本机
NDB备份 时启用有序索引的多线程重建 。 使用 此选项 通过 ndb_restore 构建有序索引的线程数 由BuildIndexThreads数据节点配置参数和LDM数控制。必须仅对第一次运行 ndb_restore 使用此选项 ; 这会导致重建所有有序索引,而不会
--rebuild-indexes在还原后续节点时再次 使用 。 在将新行插入数据库之前,应使用此选项; 否则,可能会插入一行,以后在尝试重建索引时导致唯一约束违规。默认情况下,有序索引的构建与LDM的数量并行化。 使用
BuildIndexThreads数据节点配置参数 可以更快地在节点和系统重新启动期间执行的脱机索引构建 ; 此参数对 ndb_restore 删除和重建索引没有影响 ,这是在线执行的。重建唯一索引使用磁盘写入带宽进行重做日志记录和本地检查点。 该带宽量不足会导致重做缓冲区过载或日志过载错误。 在这种情况下,您可以 再次 运行 ndb_restore
--rebuild-indexes; 该过程在发生错误时重新开始。 遇到临时错误时也可以执行此操作。 您可以 无限期地 重复执行 ndb_restore--rebuild-indexes; 您可以通过减少值来阻止此类错误--parallelism。 如果问题是空间不足,可以增加重做日志的大小(FragmentLogFileSize节点配置参数),或者您可以提高执行LCP的速度(MaxDiskWriteSpeed以及相关参数),以便更快地释放空间。 -
属性 值 命令行格式 --restore-data类型 布尔 默认值 FALSE输出
NDB表数据和日志。 -
属性 值 命令行格式 --restore-epoch将纪元信息添加(或恢复)到群集复制状态表。 这对于在NDB群集复制从属设备上启动复制很有用。 使用此选项时,如果列中的
mysql.ndb_apply_statushas0中的id行已存在,则更新 该行 ; 如果该行尚不存在,则插入该行。 (请参见 第22.6.9节“使用NDB集群复制进行NDB集群备份” 。) -
属性 值 命令行格式 --restore-meta类型 布尔 默认值 FALSE此选项使 ndb_restore 打印
NDB表元数据。第一次运行 ndb_restore 还原程序时,还需要还原元数据。 换句话说,您必须重新创建数据库表 - 这可以通过使用
--restore-meta(-m)选项 运行来完成 。 恢复元数据只需要在单个数据节点上完成; 这足以将其恢复到整个群集。在旧版本的NDB Cluster中,使用此选项还原模式的表使用与原始群集上相同数量的分区,即使它与新群集具有不同数量的数据节点也是如此。 在NDB 7.5.2及更高版本中,在恢复元数据时,这不再是一个问题; ndb_restore 现在使用目标集群的默认分区数,除非本地数据管理器线程的数量也与原始集群中的数据节点的数量相同。
注意开始还原备份时,群集应具有空数据库。 (换句话说,您应该
--initial在执行还原之前 启动数据节点 。) -
属性 值 命令行格式 --restore-privilege-tables类型 布尔 默认值 FALSE(如果未使用选项)默认情况下, ndb_restore 不会还原在8.0版之前的NDB Cluster版本中创建的分布式MySQL权限表,该版本不支持在NDB 7.6及更早版本中实现的分配权限。 此选项会导致 ndb_restore 还原它们。
在NDB 8.0.16及更高版本中,此类表不用于访问控制; 作为MySQL服务器升级过程的一部分,服务器会创建
InnoDB这些表本身的副本。 有关更多信息,请参见 第22.2.8节“升级和降级NDB集群” ,以及 第6.2.3节“授权表” 。 -
--rewrite-database=olddb,newdb属性 值 命令行格式 --rewrite-database=olddb,newdb类型 串 默认值 none此选项可以还原到具有与备份中使用的名称不同的名称的数据库。 例如,如果备份是由名为的数据库组成的
products,则可以将其包含的数据还原到名为的数据库inventory,使用此选项如此处所示(省略可能需要的任何其他选项):shell> ndb_restore --rewrite-database = product,inventory
在 ndb_restore 的单个调用中可以多次使用该选项 。 因此,它可以从指定的数据库恢复同时
db1向指定的数据库db2,并从指定的数据库db3到一个名为db4使用--rewrite-database=db1,db2 --rewrite-database=db3,db4。 其他 ndb_restore 选项可以在多次出现之间使用--rewrite-database。如果多个
--rewrite-database选项 之间发生冲突 ,则--rewrite-database使用 的最后一个 选项(从左到右读取)是生效的选项。 例如,if--rewrite-database=db1,db2 --rewrite-database=db1,db3使用,仅--rewrite-database=db1,db3被尊重,并被--rewrite-database=db1,db2忽略。 也可以从多个数据库到一个单一的数据库恢复,所以--rewrite-database=db1,db3 --rewrite-database=db2,db3从数据库中恢复所有表和数据db1,并db2进入数据库db3。重要使用时从多个备份数据库还原到单个目标数据库时
--rewrite-database,不会检查表或其他对象名之间的冲突,并且无法保证还原行的顺序。 这意味着在这种情况下可能会覆盖行并丢失更新。 -
属性 值 命令行格式 --skip-broken-objects此选项使 ndb_restore 在读取本机
NDB备份 时忽略损坏的表 ,并继续还原任何剩余的表(也未损坏)。 目前,该--skip-broken-objects选项仅适用于丢失blob部件表的情况。 -
属性 值 命令行格式 --skip-table-check可以在不恢复表元数据的情况下还原数据。 默认情况下,执行此操作时, 如果在表数据和表模式之间发现不匹配 ,则 ndb_restore会 失败并显示错误; 此选项会覆盖该行为。
放宽 使用 ndb_restore 恢复数据时对列定义不匹配的一些限制 ; 当遇到这些类型的不匹配之一时, ndb_restore 不会像之前那样因错误而停止,而是接受数据并将其插入目标表,同时向用户发出警告,表明正在完成此操作。 发生与否的选项要么这种行为
--skip-table-check或--promote-attributes正在使用中。 列定义中的这些差异具有以下类型:-
不同的
COLUMN_FORMAT设置(FIXED,DYNAMIC,DEFAULT) -
不同的
STORAGE设置(MEMORY,DISK) -
不同的默认值
-
不同的分配密钥设置
-
-
属性 值 命令行格式 --skip-unknown-objects此选项会导致 ndb_restore 忽略在读取本机
NDB备份时 无法识别的任何架构对象 。 这可用于将运行(例如)NDB 7.6的群集的备份还原到运行NDB Cluster 7.5的群集。 -
--tab=dir_name,-Tdir_name属性 值 命令行格式 --tab=dir_name类型 目录名称 --print-data创建转储文件的 原因 ,每个表一个,每个都命名tbl_name.txt.当前目录。 -
属性 值 命令行格式 --verbose=#类型 数字 默认值 1最低价值 0最大价值 255设置输出详细程度的级别。 最小值为0; 最大值为255.默认值为1。
错误报告。
ndb_restore
报告临时和永久错误。
在出现临时错误的情况下,它可以从中恢复,并
Restore successful,
but encountered temporary error, please look at
configuration
在这种情况下进行
报告
。
使用
ndb_restore
初始化NDB集群以用于循环复制后,不会自动创建充当复制从属的SQL节点上的二进制日志,并且必须手动创建它们。
要创建二进制日志,请
SHOW
TABLES
在运行之前在该SQL节点上
发出
语句
START
SLAVE
。
这是NDB群集中的已知问题。
可以从NDB备份还原到具有与进行备份的原始数据节点数不同的数据节点的群集。 以下两节分别讨论了目标群集的数据节点数量少于或多于备份源的情况。
如果较大数量的节点是较小数量的偶数倍,则可以还原到具有比原始数据节点更少的数据节点的群集。 在以下示例中,我们将具有四个数据节点的群集上的备份用于具有两个数据节点的群集。
-
原始群集的管理服务器位于主机上
host10。 原始群集有四个数据节点,节点ID和主机名显示在管理服务器config.ini文件 的以下摘录中 :[ndbd]
NodeId= 2HostName= host2 [NDBD] 的NodeId = 4 HOSTNAME =主机4 [NDBD] 的NodeId = 6 HOSTNAME =主机6 [NDBD] 的NodeId = 8 主机名= host8我们假设每个数据节点最初都是使用 ndbmtd
--ndb-connectstring=host10或等效的。 -
以正常方式执行备份。 有关如何执行此操作的信息 , 请参见 第22.5.3.2节“使用NDB群集管理客户端创建备份” 。
-
此处列出了每个数据节点上备份创建的文件,其中
N是节点ID,B是备份ID。-
BACKUP-B-0.N.Data -
BACKUP-B.N.ctl -
BACKUP-B.N.log
这些文件 位于每个数据节点下。 对于本示例的其余部分,我们假设备份ID为1。
BackupDataDir/BACKUP/BACKUP-B让所有这些文件可用于以后复制到新数据节点(可以通过 ndb_restore 在数据节点的本地文件系统上访问它们 )。 最简单的方法是将它们全部复制到一个位置; 我们假设这就是你所做的。
-
-
目标集群的管理服务器位于主机上
host20,目标有两个数据节点,显示节点ID和主机名,来自以下管理服务器config.ini文件host20:[NDBD] 的NodeId = 3 主机名= host3上 [NDBD] 的NodeId = 5 主机名=主机5
每个数据节点过程对
host3和host5应与启动 ndbmtd-c host20--initial或等同物,以便新的(目标)簇用干净的数据节点的文件系统启动。 -
将两组不同的两个备份文件复制到每个目标数据节点。 对于此示例,将备份文件从节点2和4从原始群集复制到目标群集中的节点3。 这些文件列在这里:
-
BACKUP-1-0.2.Data -
BACKUP-1.2.ctl -
BACKUP-1.2.log -
BACKUP-1-0.6.Data -
BACKUP-1.6.ctl -
BACKUP-1.6.log
然后将备份文件从节点6和8复制到节点5; 这些文件显示在以下列表中:
-
BACKUP-1-0.4.Data -
BACKUP-1.4.ctl -
BACKUP-1.4.log -
BACKUP-1-0.8.Data -
BACKUP-1.8.ctl -
BACKUP-1.8.log
对于本示例的其余部分,我们假设各个备份文件已保存到
/BACKUP-1节点3和5中的每个节点上 的目录中 。 -
-
在两个目标数据节点中的每个节点上,必须从两组备份进行还原。 首先,通过调用恢复从节点2和4到节点3的备份 ndb_restore 上
host3,如下所示:外壳>
ndb_restore -c host20外壳>--nodeid=2--backupid=1--restore-data--backup_path=/BACKUP-1ndb_restore -c host20 --nodeid=4 --backupid=1 --restore-data --backup_path=/BACKUP-1然后通过调用恢复从节点6和8到节点5的备份 ndb_restore 上
host5,如下所示:外壳>
ndb_restore -c host20 --nodeid=6 --backupid=1 --restore-data --backup_path=/BACKUP-1外壳>ndb_restore -c host20 --nodeid=8 --backupid=1 --restore-data --backup_path=/BACKUP-1
为给定的 ndb_restore 命令 指定的节点ID 是原始备份中的节点 的节点ID, 而不是要将其还原到的数据节点 的节点ID 。 使用本节中介绍的方法执行备份时, ndb_restore 将连接到管理服务器,并获取要还原备份的群集中的数据节点列表。 相应地分发恢复的数据,从而在执行备份时不需要知道或计算目标集群中的节点数。
更改每个节点组的LCP线程或LQH线程总数时,应从使用 mysqldump 创建的备份重新创建模式 。
-
创建数据备份 。 您可以通过 从系统shell 调用 ndb_mgm 客户端
START BACKUP命令 来执行此操作 ,如下所示:外壳>
ndb_mgm -e "START BACKUP 1"这假设所需的备份ID为1。
-
创建架构的备份。 仅当每个节点组的LCP线程或LQH线程的总数发生更改时,才需要执行此步骤。
外壳>
mysqldump --no-data --routines --events --triggers --databases > myschema.sql重要NDB使用 ndb_mgm 创建本 机备份后 ,如果执行此操作,则在创建架构备份之前,不得进行任何架构更改。 -
将备份目录复制到新群集。 例如,如果要还原的备份具有ID 1和
BackupDataDir= ,则此节点上的备份路径为 。 在这个目录里面有三个文件,在这里列出:/backups/node_nodeid/backups/node_1/BACKUP/BACKUP-1-
BACKUP-1-0.1.Data -
BACKUP-1.1.ctl -
BACKUP-1.1.log
您应该将整个目录复制到新节点。
如果需要创建模式文件,请将其复制到SQL节点上可由 mysqld 读取的位置 。
-
不需要从特定节点还原备份。
要从刚创建的备份还原,请执行以下步骤:
-
恢复架构 。
-
如果使用 mysqldump 创建了单独的模式备份文件 ,请使用 mysql 客户端 导入此文件 ,类似于此处所示:
外壳>
mysql < myschema.sql导入模式文件时, 除了显示内容之外 ,您可能还需要指定
--user和--password选项(以及可能的其他选项),以便 mysql 客户端能够连接到MySQL服务器。 -
如果你是 不是 需要创建一个模式文件,你可以重新创建使用模式 ndb_restore
--restore-meta(缩写形式-m),类似于下面显示的那样:shell> ndb_restore --nodeid = 1 --backupid = 1 --restore-meta --backup_path = / backups / node_1 / BACKUP / BACKUP-1
ndb_restore 必须能够联系管理服务器;
--ndb-connectstring如果需要,可以 添加 选项以使其成为可能。
-
-
恢复数据 。 每次使用该数据节点的节点ID时,需要对原始集群中的每个数据节点执行一次此操作。 假设最初有4个数据节点,所需的命令集将如下所示:
ndb_restore --nodeid = 1 --backupid = 1 --restore-data --backup_path = / backups / node_1 / BACKUP / BACKUP-1 --disable-indexes ndb_restore --nodeid = 2 --backupid = 1 --restore-data --backup_path = / backups / node_2 / BACKUP / BACKUP-1 --disable-indexes ndb_restore --nodeid = 3 --backupid = 1 --restore-data --backup_path = / backups / node_3 / BACKUP / BACKUP-1 --disable-indexes ndb_restore --nodeid = 4 --backupid = 1 --restore-data --backup_path = / backups / node_4 / BACKUP / BACKUP-1 --disable-indexes
这些可以并行运行。
请务必
--ndb-connectstring根据需要 添加 选项。 -
重建索引 。 这些被
--disable-indexes刚刚显示的命令中使用 的 选项 禁用 。 重新创建索引可避免由于恢复在所有点上不一致而导致的错误。 在某些情况下,重建索引还可以提高性能。 要重建索引,请在单个节点上执行以下命令:外壳>
ndb_restore --nodeid=1 --backupid=1 --backup_path=/backups/node_1/BACKUP/BACKUP-1 --rebuild-indexes如前所述,您可能需要添加该
--ndb-connectstring选项,以便 ndb_restore 可以联系管理服务器。
从NDB Cluster 8.0.16开始,可以使用 具有多个LDM的 ndbmtd 在每个数据节点上进行并行备份 (请参见 第22.5.3.5节“使用带并行数据节点的NDB” )。 接下来的两节将介绍如何恢复以这种方式进行的备份。
并行还原并行备份需要 来自NDB Cluster分发版本8.0.16或更高版本 的 ndb_restore 二进制文件。 该过程与 ndb_restore 程序 描述中的一般用法部分中概述的过程没有实质性的不同 ,并且包括执行 ndb_restore 两次,类似于此处所示:
shell> ndb_restore -n 1 -b 1 -m --backup_path =path/to/backup_dir/ BACKUP / BACKUP-hellbackup_id> ndb_restore -n 1 -b 1 -r --backup_path =path/to/backup_dir/ BACKUP / BACKUP-backup_id
backup_id
是要还原的备份的ID。
在一般情况下,不需要额外的特殊论点;
ndb_restore
始终检查
--backup_path
选项
指示的目录下是否存在并行子目录,
并恢复元数据(串行),然后恢复表数据(并行)。
可以以串行方式恢复在数据节点上使用并行性进行的备份。
为此,调用
ndb_restore
并
--backup_path
指向主备份目录下每个LDM创建的子目录,一次到任何一个子目录以恢复元数据(由哪个子目录包含完整的元数据副本无关紧要)
),然后依次向每个子目录恢复数据。
假设我们要恢复备份ID为100的备份,该备份ID是用四个LDM进行的,那
BackupDataDir
就是
/opt
。
要恢复这种情况下的元数据,我们可以
像这样
调用
ndb_restore
:
shell> ndb_restore -n 1 -b 1 -m --backup_path = opt / BACKUP / BACKUP-100 / BACKUP-100-PART-1-OF-4
要恢复表数据,请执行 ndb_restore 四次,每次依次使用其中一个子目录,如下所示:
shell> ndb_restore -n 1 -b 1 -r --backup_path = opt / BACKUP / BACKUP-100 / BACKUP-100-PART-1-OF-4 shell> ndb_restore -n 1 -b 1 -r --backup_path = opt / BACKUP / BACKUP-100 / BACKUP-100-PART-2-OF-4 shell> ndb_restore -n 1 -b 1 -r --backup_path = opt / BACKUP / BACKUP-100 / BACKUP-100-PART-3-OF-4 shell> ndb_restore -n 1 -b 1 -r --backup_path = opt / BACKUP / BACKUP-100 / BACKUP-100-PART-4-OF-4
您可以使用相同的技术将并行备份还原到不支持并行备份的旧版NDB Cluster(在NDB 8.0.16之前),使用 随旧版本的NDB Cluster软件提供 的 ndb_restore 二进制文件。
ndb_select_all
打印
NDB
表中的
所有行
stdout
。
用法
ndb_select_all -c -d [> ]connection_stringtbl_namedb_namefile_name
下表包含特定于NDB群集本机备份还原程序 ndb_select_all的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_select_all )的 通用选项 ,请参见 第22.4.31节“NDB群集程序的通用选项 - NDB群集程序常用选项” 。
表22.353 ndb_select_all程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 找到表的数据库的名称 |
所有NDB 8.0版本 |
|
| 并行度 |
所有NDB 8.0版本 |
|
|
|
锁定类型 |
所有NDB 8.0版本 |
| 根据提供名称的索引对结果集进行排序 |
所有NDB 8.0版本 |
|
| 按降序对结果集进行排序(需要订单标记) |
所有NDB 8.0版本 |
|
|
|
打印标题(设置为0 | FALSE以禁用输出中的标题) |
所有NDB 8.0版本 |
| 输出以十六进制格式表示的数字 |
所有NDB 8.0版本 |
|
| 设置列分隔符 |
所有NDB 8.0版本 |
|
| 打印磁盘引用(仅对具有非索引列的磁盘数据表有用) |
所有NDB 8.0版本 |
|
| 打印rowid |
所有NDB 8.0版本 |
|
| 在输出中包含GCI |
所有NDB 8.0版本 |
|
| 在输出中包括GCI和行历元 |
所有NDB 8.0版本 |
|
| 按顺序扫描 |
所有NDB 8.0版本 |
|
| 不要打印表列数据 |
所有NDB 8.0版本 |
-
找到表的数据库的名称。 默认值为
TEST_DB。 -
指定并行度。
-
--lock=,lock_type-llock_type在阅读表时使用锁。 可能的值
lock_type是:-
0:读锁定 -
1:读取锁定保持 -
2:独家读锁
此选项没有默认值。
-
-
--order=,index_name-oindex_name根据命名的索引对输出进行排序
index_name。注意这是索引的名称,而不是列的名称; 索引必须在创建时显式命名。
-
按降序对输出进行排序。 此选项只能与
-o(--order)选项 一起使用 。 -
从输出中排除列标题。
-
导致所有数值以十六进制格式显示。 这不会影响字符串或日期时间值中包含的数字的输出。
-
--delimiter=,character-Dcharacter使
character要用作一列分隔符。 此分隔符仅分隔表数据列。默认分隔符是制表符。
-
将磁盘引用列添加到输出。 该列仅对具有非索引列的磁盘数据表非空。
-
添加一
ROWID列,提供有关存储行的片段的信息。 -
GCI向输出 添加一 列,显示上次更新每一行的全局检查点。 有关检查点的更多信息 , 请参见 第22.1节“NDB集群概述” 和 第22.5.6.2节“NDB集群日志事件” 。 -
ROW$GCI64向输出 添加一 列,显示上次更新每一行的全局检查点,以及发生此更新的时期编号。 -
按元组的顺序扫描表。
-
导致任何表数据被省略。
样本输出
MySQL
SELECT
语句的
输出
:
MySQL的> SELECT * FROM ctest1.fish;
+ ---- + ----------- +
| id | 名字|
+ ---- + ----------- +
| 3 | 鲨鱼|
| 6 | 河豚|
| 2 | 金枪鱼|
| 4 | 蝠ray |
| 5 | 石斑鱼|
| 1 | 孔雀鱼|
+ ---- + ----------- +
6行(0.04秒)
等效调用 ndb_select_all的 输出 :
外壳> ./ndb_select_all -c localhost fish -d ctest1
id名称
3 [鲨鱼]
6 [puffer]
2 [金枪鱼]
4 [蝠ray]
5 [石斑鱼]
1 [孔雀鱼]
返回6行
NDBT_ProgramExit:0 - 好的
所有字符串值都用
ndb_select_all
输出中的
方括号(
[
...
]
)
括
起来
。
再举一个例子,考虑如下所示创建和填充的表:
CREATE TABLE狗(
id INT(11)NOT NULL AUTO_INCREMENT,
name VARCHAR(25)NOT NULL,
品种VARCHAR(50)NOT NULL,
PRIMARY KEY pk(id),
KEY ix(姓名)
)
TABLESPACE ts存储磁盘
ENGINE = NDBCLUSTER;
插入狗的价值观
('','Lassie','牧羊犬'),
('','Scooby-Doo','大丹犬'),
('','Rin-Tin-Tin','Alsatian'),
('','Rosscoe','Mutt');
这演示了使用几个额外的 ndb_select_all 选项:
外壳> ./ndb_select_all -d ctest1 dogs -o ix -z --gci --disk
GCI id名称品种DISK_REF
834461 2 [Scooby-Doo] [Great Dane] [m_file_no:0 m_page:98 m_page_idx:0]
834878 4 [Rosscoe] [Mutt] [m_file_no:0 m_page:98 m_page_idx:16]
834463 3 [Rin-Tin-Tin] [阿尔萨斯] [m_file_no:0 m_page:34 m_page_idx:0]
835657 1 [Lassie] [Collie] [m_file_no:0 m_page:66 m_page_idx:0]
返回4行
NDBT_ProgramExit:0 - 好的
ndb_select_count
打印一个或多个
NDB
表中
的行数
。
使用单个表,结果等同于使用MySQL语句获得的结果
。
SELECT COUNT(*) FROM
tbl_name
用法
ndb_select_count [-cconnection_string] -d [,[,...]]db_nametbl_nametbl_name2
下表包含特定于NDB群集本机备份还原程序 ndb_select_count的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_select_count )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.354 ndb_select_count程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
|
|
找到表的数据库的名称 |
所有NDB 8.0版本 |
|
|
并行度 |
所有NDB 8.0版本 |
|
|
锁定类型 |
所有NDB 8.0版本 |
通过在调用此命令时列出由空格分隔的表名,可以从同一数据库中的多个表中获取行计数,如“ 示例输出” 下所示 。
样本输出
外壳> ./ndb_select_count -c localhost -d ctest1 fish dogs
表鱼6条记录
表狗的4条记录
NDBT_ProgramExit:0 - 好的
ndb_setup.py 启动NDB Cluster Auto-Installer并在默认Web浏览器中打开安装程序的Start页面。
此程序旨在作为普通用户调用,而不是与
mysql
系统
root
或其他管理帐户
一起调用
。
本节仅介绍命令行工具的用法和程序选项。 有关使用在 调用 ndb_setup.py 时生成的自动安装程序GUI的信息 ,请参阅 NDB群集自动安装程序(NDB 7.5) 。
用法
所有平台:
ndb_setup.py [ options]
此外,仅在Windows平台上:
setup.bat [ options]
下表包含NDB群集安装和配置程序 ndb_setup.py 支持的所有选项 。 其他说明如下表所示。
表22.355 ndb_setup.py程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 启动时Web浏览器打开的页面。 |
所有NDB 8.0版本 |
|
| 包含允许连接到服务器的客户端证书列表的文件 |
所有NDB 8.0版本 |
|
| 包含标识服务器的X509证书的文件。 (默认值:cfg.pem) |
所有NDB 8.0版本 |
|
| Python日志模块调试级别。 DEBUG,INFO,WARNING(默认),ERROR或CRITICAL之一。 |
所有NDB 8.0版本 |
|
|
|
打印帮助信息 |
所有NDB 8.0版本 |
| 指定包含私钥的文件(如果未包含在--cert文件中) |
所有NDB 8.0版本 |
|
| 不要在浏览器中打开起始页面,只需启动该工具即可 |
所有NDB 8.0版本 |
|
|
|
指定Web服务器使用的端口 |
所有NDB 8.0版本 |
| 记录对此文件的请求。 使用' - '强制记录到stderr。 |
所有NDB 8.0版本 |
|
| 要连接的服务器的名称 |
所有NDB 8.0版本 |
|
| 使用未加密(HTTP)的客户端/服务器连接 |
所有NDB 8.0版本 |
|
| 使用加密(HTTPS)客户端/服务器连接 |
所有NDB 8.0版本 |
-
--browser-start-page=,file-s属性 值 命令行格式 --browser-start-page=filename类型 串 默认值 index.html指定要在浏览器中打开的文件作为安装和配置“开始”页面。 默认是
index.html。 -
属性 值 命令行格式 --ca-certs-file=filename类型 文件名 默认值 [none]指定包含允许连接到服务器的客户端证书列表的文件。 默认值为空字符串,表示不使用客户端身份验证。
-
属性 值 命令行格式 --cert-file=filename类型 文件名 默认值 /usr/share/mysql/mcc/cfg.pem指定包含标识服务器的X509证书的文件。 证书可以自签名。 默认是
cfg.pem。 -
属性 值 命令行格式 --debug-level=level类型 列举 默认值 WARNING有效值 WARNINGDEBUGINFOERRORCRITICAL设置Python日志记录模块调试级别。 这是一个
DEBUG,INFO,WARNING,ERROR,或CRITICAL。WARNING是默认值。 -
属性 值 命令行格式 --help打印帮助信息。
-
属性 值 命令行格式 --key-file=file类型 文件名 默认值 [none]如果X509证书文件(
--cert-file)中 未包含私钥,请指定包含私钥的文件 。 默认值为空字符串,表示不使用此类文件。 -
属性 值 命令行格式 --no-browser启动安装和配置工具,但不要在浏览器中打开“开始”页面。
-
属性 值 命令行格式 --port=#类型 数字 默认值 8081最低价值 1最大价值 65535设置Web服务器使用的端口。 默认值为8081。
-
属性 值 命令行格式 --server-log-file=fileo类型 文件名 默认值 ndb_setup.log有效值 ndb_setup.log-(登录stderr)记录对此文件的请求。 默认是
ndb_setup.log。 要指定日志记录stderr而不是文件,请使用-(短划线字符)作为文件名。 -
属性 值 命令行格式 --server-name=name类型 串 默认值 localhost指定连接时要使用的浏览器的主机名或IP地址。 默认是
localhost。 -
属性 值 命令行格式 --use-http使浏览器使用HTTP连接服务器。 这意味着连接未加密且不以任何方式保护。
-
属性 值 命令行格式 --use-https使浏览器与服务器使用安全(HTTPS)连接。
ndb_show_tables
显示
NDB
集群
中所有
数据库对象
的列表
。
默认情况下,这不仅包括用户创建的表和
NDB
系统表,还包括
NDB
特定索引,内部触发器和NDB群集磁盘数据对象。
下表包含特定于NDB群集本机备份还原程序 ndb_show_tables的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_show_tables ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.356 ndb_show_tables程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 指定找到表的数据库 |
所有NDB 8.0版本 |
|
| 重复输出的次数 |
所有NDB 8.0版本 |
|
| 返回适合MySQL LOAD DATA INFILE语句的输出 |
所有NDB 8.0版本 |
|
| 显示表临时标志 |
所有NDB 8.0版本 |
|
|
|
将输出限制为此类型的对象 |
所有NDB 8.0版本 |
| 不要限定表名 |
所有NDB 8.0版本 |
用法
ndb_show_tables [-c connection_string]
-
指定找到表的数据库的名称。 如果未指定此选项,并且未在
TEST_DB数据库 中找到表 ,则 ndb_show_tables会 发出警告。 -
指定实用程序应执行的次数。 如果未指定此选项,则此值为1,但如果使用该选项,则必须为其提供整数参数。
-
使用此选项会使输出采用适合使用的格式
LOAD DATA。 -
如果指定,则会导致显示临时表。
-
可用于将输出限制为一种类型的对象,由整数类型代码指定,如下所示:
-
1:系统表 -
2:用户创建的表 -
3:唯一哈希索引
任何其他值都会导致
NDB列出 所有 数据库对象(默认值)。 -
-
如果指定,则会导致显示不合格的对象名称。
只能从MySQL访问用户创建的NDB Cluster表;
系统表,如
mysqld
SYSTAB_0
不可见
。
但是,您可以使用
API应用程序(例如
ndb_select_all)
检查系统表的内容
(请参见
第22.4.24节“
ndb_select_all
- 从NDB表打印行”
)。
NDB
这是一个Perl脚本,可用于估计MySQL数据库转换为使用
NDBCLUSTER
存储引擎时
所需的空间量
。
与本节中讨论的其他实用程序不同,它不需要访问NDB集群(事实上,它没有理由这样做)。
但是,它确实需要访问要测试的数据库所在的MySQL服务器。
要求
-
运行MySQL服务器。 服务器实例不必为NDB Cluster提供支持。
-
Perl的工作安装。
-
该
DBI模块,如果它不是您的Perl安装的一部分,可以从CPAN获得。 (许多Linux和其他操作系统发行版为此库提供了自己的包。) -
具有必要权限的MySQL用户帐户。 如果您不希望使用现有帐户,那么使用 -where 创建一个 是要检查的数据库的名称 - 就足够了。
GRANT USAGE ONdb_name.*db_name
ndb_size.pl
也可以在MySQL源代码中找到
storage/ndb/tools
。
下表包含特定于NDB群集程序 ndb_size.pl的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_size.pl )的 通用选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.357 ndb_size.pl程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 要检查的数据库或数据库; 接受以逗号分隔的列表; 默认为ALL(使用服务器上找到的所有数据库) |
所有NDB 8.0版本 |
|
| 将主机和可选端口指定为主机[:port] |
所有NDB 8.0版本 |
|
| 指定要连接的套接字 |
所有NDB 8.0版本 |
|
| 指定MySQL用户名 |
所有NDB 8.0版本 |
|
| 指定MySQL用户密码 |
所有NDB 8.0版本 |
|
| 设置输出格式(文本或HTML) |
所有NDB 8.0版本 |
|
| 跳过以逗号分隔的表列表中的任何表 |
所有NDB 8.0版本 |
|
| 跳过以逗号分隔的数据库列表中的任何数据库 |
所有NDB 8.0版本 |
|
| 将对数据库的所有查询保存到指定的文件中 |
所有NDB 8.0版本 |
|
| 从指定的文件加载所有查询; 没有连接到数据库 |
所有NDB 8.0版本 |
|
| 指定一个表来处理唯一索引大小计算 |
所有NDB 8.0版本 |
用法
perl ndb_size.pl [--database = { db_name| ALL}] [--hostname = host[:port]] [--socket =socket ] \
[--user = user] [--password =password ] \
[--help | -h] [--format = {html | text}] \
[--loadqueries = file_name] [--savequeries = file_name]
默认情况下,此实用程序尝试分析服务器上的所有数据库。
您可以使用该
--database
选项
指定单个数据库
;
通过使用
ALL
数据库的名称
可以使默认行为显式化
。
您还可以使用
--excludedbs
带有逗号分隔的要跳过的数据库名称列表
的
选项
来排除一个或多个数据库
。
同样,您可以通过在可选
--excludetables
选项
后面列出逗号分隔的名称来跳过特定表
。
可以使用
--hostname
;
指定主机名
;
默认是
localhost
。
您可以使用以下命令指定除主机之外的端口
host
:
port
format的值
--hostname
。
默认端口号为3306.如有必要,还可以指定套接字;
默认是
/var/lib/mysql.sock
。
可以使用显示的相应选项指定MySQL用户名和密码。
也可以使用
--format
选项
控制输出的格式
;
这可以采取两种价值观的
html
或
text
与
text
被默认。
此处显示了文本输出的示例:
外壳> ndb_size.pl --database=test --socket=/tmp/mysql.sock
数据库的ndb_size.pl报告:'test'(1个表)
--------------------------------------------------
连接到:DBI:mysql:host = localhost; mysql_socket = / tmp / mysql.sock
包括版本信息:4.1,5.0,5.1
test.t1
-------
列的DataMemory(*表示varsized DataMemory):
列名类型Varsized Key 4.1 5.0 5.1
HIDDEN_NDB_PKEY bigint PRI 8 8 8
c2 varchar(50)Y 52 52 4 *
c1 int(11)4 4 4
- - -
固定尺寸列DM /行64 64 12
Varsize Columns DM / Row 0 0 4
索引的DataMemory:
索引名称类型4.1 5.0 5.1
PRIMARY BTREE 16 16 16
- - -
总索引DM /行16 16 16
索引的IndexMemory:
索引名称4.1 5.0 5.1
主要33 16 16
- - -
索引IM / Row 33 16 16
摘要(对于本表):
4.1 5.0 5.1
固定架空DM /行12 12 16
NULL字节/行4 4 4
DataMemory / Row 96 96 48
(包括开销,位图和索引)
Varsize Overhead DM / Row 0 0 8
Varsize NULL字节/行0 0 4
Avg Varside DM / Row 0 0 16
行号0 0 0
行/ 32kb DM Page 340 340 680
Fixedsize DataMemory(KB)0 0 0
行/ 32kb Varsize DM Page 0 0 2040
Varsize DataMemory(KB)0 0 0
行/ 8kb IM Page 248 512 512
IndexMemory(KB)0 0 0
参数最低要求
------------------------------
*表示大于默认值
参数默认值4.1 5.0 5.1
DataMemory(KB)81920 0 0 0
NoOfOrderedIndexes 128 1 1 1
NoOfTables 128 1 1 1
IndexMemory(KB)18432 0 0 0
NoOfUniqueHashIndexes 64 0 0 0
NoOfAttributes 1000 3 3 3
NoOfTriggers 768 5 5 5
出于调试目的,包含由此脚本运行的查询的Perl数组可以从指定的文件中读取,可以使用保存到文件中
--savequeries
;
可以使用指定在脚本执行期间要读取的包含此类数组的文件
--loadqueries
。
这两个选项都没有默认值。
要以HTML格式生成输出,请使用该
--format
选项并将输出重定向到文件,如下所示:
外壳> ndb_size.pl --database=test --socket=/tmp/mysql.sock --format=html > ndb_size.html
(没有重定向,输出将被发送到
stdout
。)
此脚本的输出包括以下信息:
-
最小值为
DataMemory,IndexMemory,MaxNoOfTables,MaxNoOfAttributes,MaxNoOfOrderedIndexes,和MaxNoOfTriggers,以适应所分析的表所需的配置参数。 -
数据库中定义的所有表,属性,有序索引和唯一哈希索引的内存要求。
-
在
IndexMemory和DataMemory每个表和表行所需。
ndb_top 显示终端中有关NDB群集数据节点上NDB线程的CPU使用情况的运行信息。 每个线程在输出中由两行表示,第一行显示系统统计信息,第二行显示线程的测量统计信息。
从MySQL NDB Cluster 7.6.3开始提供 ndb_top 。
用法
ndb_top [-hhostname] [-tport] [-uuser] [-ppass] [-nnode_id]
ndb_top
连接到作为集群的SQL节点运行的MySQL服务器。
默认情况下,它会尝试连接到
运行on
和端口3306
的
mysqld
localhost
,因为
root
没有指定密码
的MySQL
用户。
您可以分别使用
--host
(
-h
)和
--port
(
-t
)
覆盖默认主机和端口
。
要指定MySQL用户和密码,请使用
--user
(
-u
)和
--passwd
(
-p
)选项。
此用户必须能够读取
ndbinfo
数据库中的
表
(
ndb_top
使用来自
ndbinfo.cpustat
和相关表的信息)。
有关MySQL用户帐户和密码的更多信息,请参见 第6.2节“访问控制和帐户管理” 。
输出可以是纯文本或ASCII图形;
您可以分别使用
--text
(
-x
)和
--graph
(
-g
)选项
指定它
。
这两种显示模式提供相同的信息;
它们可以同时使用。
必须至少使用一种显示模式。
默认情况下(
--color
或
-c
选项)
支持并启用图表的彩色显示
。
启用颜色支持后,图形显示屏将OS用户时间显示为蓝色,OS系统时间显示为绿色,空闲时间显示为空白。
对于测量负载,蓝色用于执行时间,黄色用于发送时间,红色用于发送缓冲区完全等待所花费的时间,空白用于空闲时间。
图表显示中显示的百分比是所有非空闲线程的百分比总和。
颜色目前不可配置;
您可以使用灰度代替
--skip-color
。
排序视图(
--sort
,
-r
)基于测量的负载的最大值和OS报告的负载。
可以使用
--measured-load
(
-m
)和
--os-load
(
)
启用和禁用这些显示
-o
)选项
。
必须启用至少一个这些负载的显示。
程序尝试从具有
--node-id
(
-n
)选项
给出的节点ID的数据节点获取统计信息
;
如果未指定,则为1.
ndb_top
无法提供有关其他类型节点的信息。
视图根据终端窗口的高度和宽度进行调整; 支持的最小宽度为76个字符。
一旦启动,
ndb_top会
持续运行,直到被迫退出;
你可以退出程序
Ctrl-C
。
显示每秒更新一次;
要设置不同的延迟间隔,请使用
--sleep-time
(
-s
)。
ndb_top 可在Mac OS X,Linux和Solaris上使用。 Windows平台目前不支持它。
下表包含特定于NDB群集程序 ndb_top的 所有选项 。 其他说明如下表所示。
表22.358 ndb_top程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
|
|
以彩色显示ASCII图形; 使用--skip-colors来禁用 |
所有NDB 8.0版本 |
|
|
使用图表显示数据; 使用--skip-graphs禁用 |
所有NDB 8.0版本 |
|
|
显示程序使用信息 |
所有NDB 8.0版本 |
| 要连接的MySQL服务器的主机名或IP地址 |
所有NDB 8.0版本 |
|
| 通过螺纹显示测量的载荷 |
所有NDB 8.0版本 |
|
| 监视具有此节点ID的节点 |
所有NDB 8.0版本 |
|
| 显示操作系统测量的负载 |
所有NDB 8.0版本 |
|
| 使用此密码连接 |
所有NDB 8.0版本 删除:NDB 7.6.4 |
|
| 使用此密码连接 |
所有NDB 8.0版本 |
|
|
|
连接到MySQL服务器时使用的端口号 |
所有NDB 8.0版本 |
| 在显示刷新之间等待的时间,以秒为单位 |
所有NDB 8.0版本 |
|
|
|
用于连接的套接字文件。 |
所有NDB 8.0版本 |
|
|
按用途排序线程; 使用--skip-sort来禁用 |
所有NDB 8.0版本 |
|
|
使用文本显示数据 |
所有NDB 8.0版本 |
| 以此MySQL用户身份连接 |
所有NDB 8.0版本 |
在NDB 7.6.6或更高版本,
ndb_top
还支持常见的
NDB
程序选项
--defaults-file
,
--defaults-extra-file
,
--print-defaults
,
--no-defaults
,和
--defaults-group-suffix
。
(Bug#86614,Bug#26236298)
其他选项
-
属性 值 命令行格式 --color类型 布尔 默认值 TRUE以彩色显示ASCII图形; 使用
--skip-colors禁用。 -
属性 值 命令行格式 --graph类型 布尔 默认值 TRUE使用图表显示数据; 使用
--skip-graphs禁用。 这个选项或--text必须是真的; 两种选择都可能是真的。 -
属性 值 命令行格式 --help类型 布尔 默认值 TRUE显示程序使用信息。
-
属性 值 命令行格式 --host[=name]类型 串 默认值 localhost要连接的MySQL服务器的主机名或IP地址。
-
属性 值 命令行格式 --measured-load类型 布尔 默认值 FALSE通过螺纹显示测量的载荷。 这个选项或
--os-load必须是真的; 两种选择都可能是真的。 -
属性 值 命令行格式 --node-id[=#]类型 整数 默认值 1观察具有此节点ID的数据节点。
-
属性 值 命令行格式 --os-load类型 布尔 默认值 TRUE显示操作系统测量的负载。 这个选项或
--measured-load必须是真的; 两种选择都可能是真的。 -
属性 值 命令行格式 --passwd[=password]类型 布尔 默认值 NULL使用此密码连接。
NDB 7.6.4中不推荐使用此选项。 它在NDB 7.6.6中被删除,在那里它被
--password选项 替换 。 (缺陷#26907833) -
属性 值 命令行格式 --password[=password]类型 布尔 默认值 NULL使用此密码连接。
在NDB 7.6.6中添加了此选项,作为
--passwd先前使用 的 选项 的替代 。 (缺陷#26907833) -
--port[=#],-t(NDB 7.6.6和更高版本:-P)属性 值 命令行格式 --port[=#]类型 整数 默认值 3306连接到MySQL服务器时使用的端口号。
从NDB 7.6.6开始,此选项的简短形式是
-P,并-t作为--text选项 的缩写形式重新用作 。 (缺陷#26907833) -
属性 值 命令行格式 --sleep-time[=seconds]类型 整数 默认值 1在显示刷新之间等待的时间,以秒为单位。
-
属性 值 命令行格式 --socket类型 路径名称 默认值 [none]使用指定的套接字文件进行连接。
在NDB 7.6.6中添加。 (Bug#86614,Bug#26236298)
-
属性 值 命令行格式 --sort类型 布尔 默认值 TRUE按用途排序线程; 使用
--skip-sort禁用。 -
--text,-x(NDB 7.6.6和更高版本:-t)属性 值 命令行格式 --text类型 布尔 默认值 FALSE使用文本显示数据。 这个选项或
--graph必须是真的; 两种选择都可能是真的。从NDB 7.6.6开始,此选项的简短形式 是删除
-t支持-x。 (缺陷#26907833) -
属性 值 命令行格式 --user[=name]类型 串 默认值 root以此MySQL用户身份连接。
样本输出。
下图显示
ndb_top
在Linux系统的终端窗口中运行,其中
ndbmtd
数据节点处于中等负载下。
这里,使用
ndb_top
调用程序
以提供文本和图形输出:
-n8
-x
ndb_waiter
重复(每100毫秒)打印出所有集群数据节点的状态,直到集群达到给定状态或
--timeout
超出限制,然后退出。
默认情况下,它等待群集实现
STARTED
状态,其中所有节点都已启动并连接到群集。
这可以使用
--no-contact
和
重写
--not-started
选项
。
此实用程序报告的节点状态如下:
下表包含特定于NDB群集本机备份还原程序 ndb_waiter的选项 。 其他说明如下表所示。 有关大多数NDB Cluster程序(包括 ndb_waiter ) 通用的选项 ,请参见 第22.4.31节“NDB群集程序常用选项 - NDB群集程序常用选项” 。
表22.359 ndb_waiter程序的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 等待群集达到NO CONTACT状态 |
所有NDB 8.0版本 |
|
| 等待群集达到NOT STARTED状态 |
所有NDB 8.0版本 |
|
| 等待群集进入单用户模式 |
所有NDB 8.0版本 |
|
| 等待这么多秒,然后退出群集是否已达到所需状态; 默认为2分钟(120秒) |
所有NDB 8.0版本 |
|
| 不等待的节点列表。 |
所有NDB 8.0版本 |
|
| 要等待的节点列表。 |
所有NDB 8.0版本 |
用法
ndb_waiter [-c connection_string]
其他选项
-
ndb_waiter 不会等待
STARTED状态, 而是 继续运行,直到群集NO_CONTACT在退出之前 达到 状态。 -
ndb_waiter 不会等待
STARTED状态, 而是 继续运行,直到群集NOT_STARTED在退出之前 达到 状态。 -
--timeout=,seconds-tseconds是时候等了。 如果在该秒数内未达到所需状态,则程序退出。 默认值为120秒(1200个报告周期)。
-
程序等待群集进入单用户模式。
-
使用此选项时,ndb_waiter不会等待列出其ID的节点。 该列表以逗号分隔; 范围可以用短划线表示,如下所示:
外壳>
ndb_waiter --nowait-nodes=1,3,7-9重要不要 不 与一起使用此选项
--wait-nodes选项。 -
使用此选项时, ndb_waiter 仅等待列出其ID的节点。 该列表以逗号分隔; 范围可以用短划线表示,如下所示:
外壳>
ndb_waiter --wait-nodes=2,4-6,10重要不要 不 与一起使用此选项
--nowait-nodes选项。
样本输出。
此处显示的是
ndb_waiter
在针对4节点群集运行时
的输出
,其中两个节点已关闭,然后再次手动启动。
...
省略
重复报告(由...表示
)。
外壳> ./ndb_waiter -c localhost
在(localhost)连接到mgmsrv
状态节点1已启动
状态节点2 NO_CONTACT
状态节点3已启动
状态节点4 NO_CONTACT
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2未知
状态节点3已启动
状态节点4 NO_CONTACT
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2启动
状态节点3已启动
状态节点4 NO_CONTACT
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2启动
状态节点3已启动
状态节点4未知
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2启动
状态节点3已启动
状态节点4启动
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2已启动
状态节点3已启动
状态节点4启动
等待群集进入状态STARTED
...
状态节点1已启动
状态节点2已启动
状态节点3已启动
状态节点4已启动
等待群集进入状态STARTED
NDBT_ProgramExit:0 - 好的
如果未指定连接字符串,则
ndb_waiter
尝试连接到管理
localhost
,然后报告
Connecting to mgmsrv at (null)
。
所有NDB Cluster程序都接受本节中描述的选项,但以下情况除外:
早期NDB Cluster版本的用户应注意,其中一些选项已更改,以使它们彼此一致,并且还与
mysqld一致
。
您可以将该
--help
选项与任何NDB Cluster程序一起使用 -
ndb_print_backup_file
,
ndb_print_schema_file
和
ndb_print_sys_file除外
- 以查看程序支持的选项列表。
下表中的选项对于所有NDB Cluster可执行文件都是通用的(本节前面提到的除外)。
表22.360所有MySQL NDB Cluster程序通用的命令行选项
| 格式 | 描述 | 添加,已弃用或已删除 |
|---|---|---|
| 安装字符集的目录 |
所有NDB 8.0版本 |
|
| 设置放弃前重试连接的次数 |
所有NDB 8.0版本 |
|
| 在几秒钟内尝试联系管理服务器之间等待的时间 |
所有NDB 8.0版本 |
|
| 在错误上写入核心(在调试版本中默认为TRUE) |
所有NDB 8.0版本 |
|
| 启用调试调用的输出。 只能用于启用调试的版本 |
所有NDB 8.0版本 |
|
| 读取全局选项文件后读取此文件 |
所有NDB 8.0版本 |
|
| 从此文件中读取默认选项 |
所有NDB 8.0版本 |
|
| 还要读取名称以此后缀结尾的组 |
所有NDB 8.0版本 |
|
|
|
显示帮助消息并退出 |
所有NDB 8.0版本 |
| 从登录文件中读取此路径 |
所有NDB 8.0版本 |
|
|
|
设置连接字符串以连接到ndb_mgmd。 语法:[nodeid = <id>;] [host =] <hostname> [:<port>]。 覆盖NDB_CONNECTSTRING或my.cnf中指定的条目。 |
所有NDB 8.0版本 |
| 设置主机(和端口,如果需要)以连接到管理服务器 |
所有NDB 8.0版本 |
|
| 设置此节点的节点标识 |
所有NDB 8.0版本 |
|
| 以更优化的方式选择事务的节点 |
所有NDB 8.0版本 |
|
| 不要从登录文件以外的任何选项文件中读取默认选项 |
所有NDB 8.0版本 |
|
| 打印程序参数列表并退出 |
所有NDB 8.0版本 |
|
| 输出版本信息并退出 |
所有NDB 8.0版本 |
有关各个NDB Cluster程序的特定选项,请参见 第22.4节“NDB群集程序” 。
有关 NDB群集 的 mysqld 选项 , 请参见 第22.3.3.9.1节“NDB群集的MySQL服务器选项” 。
-
属性 值 命令行格式 --character-sets-dir=dir_name类型 目录名称 默认值 告诉程序在哪里可以找到字符集信息。
-
属性 值 命令行格式 --connect-retries=#类型 数字 默认值 12最低价值 0最大价值 4294967295此选项指定在放弃之前首次尝试重试连接之后的次数(客户端始终至少尝试连接一次)。 使用每个尝试等待的时间长度
--connect-retry-delay。 -
属性 值 命令行格式 --connect-retry-delay=#类型 数字 默认值 5最低价值 1最低价值 0最大价值 4294967295此选项指定在放弃之前每次尝试连接时等待的时间长度。 尝试连接的次数由设置
--connect-retries。 -
属性 值 命令行格式 --core-file类型 布尔 默认值 FALSE如果程序死了,写一个核心文件。 核心文件的名称和位置取决于系统。 (对于在Linux上运行的NDB Cluster程序节点,默认位置是程序的工作目录 - 对于数据节点,这是节点的
DataDir。)对于某些系统,可能存在限制或限制。 例如, 在启动服务器之前 可能需要执行 ulimit -c unlimited 。 有关详细信息,请参阅系统文档。如果使用 configure
--debug选项 构建NDB Cluster ,则 默认启用。 对于常规构建, 默认情况下禁用。--core-file--core-file -
属性 值 命令行格式 --debug=options类型 串 默认值 d:t:O,/tmp/ndb_restore.trace此选项仅可用于使用调试启用的版本。 它用于以与 mysqld 进程 相同的方式启用调试调用的输出 。
-
--defaults-extra-file=filename属性 值 命令行格式 --defaults-extra-file=filename类型 串 默认值 [none]读取全局选项文件后读取此文件。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
属性 值 命令行格式 --defaults-file=filename类型 串 默认值 [none]从此文件中读取默认选项。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
属性 值 命令行格式 --defaults-group-suffix类型 串 默认值 [none]还要读取名称以此后缀结尾的组。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
属性 值 命令行格式 --help--usage打印一个简短列表,其中包含可用命令选项的说明。
-
属性 值 命令行格式 --login-path=path类型 串 默认值 [none]从登录文件中读取此路径。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
--ndb-connectstring=, ,connection_string--connect-string=connection_string-cconnection_string属性 值 命令行格式 --ndb-connectstring=connectstring--connect-string=connectstring类型 串 默认值 localhost:1186此选项采用NDB Cluster连接字符串,该字符串指定要连接的应用程序的管理服务器,如下所示:
外壳>
ndbd --ndb-connectstring="nodeid=2;host=ndb_mgmd.mysql.com:1186"有关更多信息,请参见 第22.3.3.3节“NDB集群连接字符串” 。
-
属性 值 命令行格式 --ndb-mgmd-host=host[:port]类型 串 默认值 localhost:1186可用于设置要连接到的程序的单个管理服务器的主机和端口号。 如果程序在其连接信息中需要节点ID或对多个管理服务器(或两者)的引用,请改用该
--ndb-connectstring选项。 -
属性 值 命令行格式 --ndb-nodeid=#类型 数字 默认值 0设置此节点的NDB群集节点ID。 允许值的范围取决于节点的类型(数据,管理或API)和NDB Cluster软件版本 。 有关更多 信息, 请参见 第22.1.7.2节“NDB群集与标准MySQL限制的限制和差异” 。
-
属性 值 命令行格式 --no-defaults类型 布尔 默认值 TRUE不要从登录文件以外的任何选项文件中读取默认选项。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
--ndb-optimized-node-selection属性 值 命令行格式 --ndb-optimized-node-selection类型 布尔 默认值 TRUE优化事务的节点选择。 默认情况下启用。
-
属性 值 命令行格式 --print-defaults类型 布尔 默认值 TRUE打印程序参数列表并退出。
有关此选项和其他选项文件选项的其他信息,请参见 第4.2.2.3节“影响选项文件处理的命令行选项” 。
-
属性 值 命令行格式 --version打印可执行文件的NDB Cluster版本号。 版本号是相关的,因为并非所有版本都可以一起使用,并且NDB群集启动过程会验证所使用的二进制文件的版本是否可以在同一群集中共存。 在执行在线(滚动)软件升级或NDB群集降级时,这也很重要。
有关 更多信息 , 请参见 第22.5.5节“执行NDB集群的滚动重新启动” 。
- 22.5.1 NDB集群启动阶段摘要
- 22.5.2 NDB集群管理客户端中的命令
- 22.5.3 NDB集群的在线备份
- 22.5.4 NDB集群的MySQL服务器使用情况
- 22.5.5执行NDB集群的滚动重新启动
- 22.5.6在NDB集群中生成的事件报告
- 22.5.7 NDB集群日志消息
- 22.5.8 NDB集群单用户模式
- 22.5.9快速参考:NDB集群SQL语句
- 22.5.10 ndbinfo:NDB群集信息数据库
- 22.5.11 NDB集群的INFORMATION_SCHEMA表
- 22.5.12 NDB群集安全问题
- 22.5.13 NDB群集磁盘数据表
- 22.5.14在NDB集群中使用ALTER TABLE进行在线操作
- 22.5.15在线添加NDB集群数据节点
- 22.5.16分布式MySQL权限(不支持)
- 22.5.17 NDB API统计计数器和变量
管理NDB集群涉及许多任务,第一个任务是配置和启动NDB集群。 第22.3节“NDB群集的配置” 和 第22.4节“NDB群集程序” 对此进行了介绍 。
接下来的几节将介绍正在运行的NDB集群的管理。
有关与NDB群集的管理和部署相关的安全性问题的信息,请参见 第22.5.12节“NDB群集安全性问题” 。
主要有两种主动管理正在运行的NDB集群的方法。
第一种方法是使用输入管理客户端的命令,从而可以检查群集状态,更改日志级别,启动和停止备份以及停止和启动节点。
第二种方法涉及研究集群日志的内容
;
这通常位于管理服务器的
目录中,但可以使用该
选项
覆盖此位置
。
(回想一下,它
表示正在记录其活动的节点的唯一标识符。)群集日志包含由
ndbd
生成的事件报告
。
也可以将群集日志条目发送到Unix系统日志。
ndb_
node_id_cluster.logDataDir
LogDestination
node_id
还可以使用该
SHOW
ENGINE NDB
STATUS
语句
从SQL节点监视集群操作的某些方面
。
有关NDB群集操作的更多详细信息可通过使用
ndbinfo
数据库
的SQL界面实时获得
。
有关更多信息,请参见
第22.5.10节“ndbinfo:NDB集群信息数据库”
。
NDB统计计数器使用
mysql
客户端
提供改进的监视
。
在NDB内核中实现的这些计数器与由
Ndb
对象
执行或影响
对象的
操作有关
,例如启动,关闭和中止事务;
主键和唯一键操作;
表,范围和修剪扫描;
阻塞线程等待各种操作完成;
以及NDB Cluster发送和接收的数据和事件。
每当进行NDB API调用或数据发送到数据节点或由数据节点接收时,计数器由NDB内核递增。
mysqld
将NDB API统计计数器公开为系统状态变量,可以从其所有名称(
Ndb_api_
)的
公共前缀中识别
。
这些变量的值可以在
mysql
客户端中从
SHOW
STATUS
语句
的输出中
读取,也可以
通过查询
SESSION_STATUS
表或
GLOBAL_STATUS
表(在
INFORMATION_SCHEMA
数据库中)
来读取
。
通过比较执行作用于
NDB
表
的SQL语句之前和之后的状态变量的值
,您可以观察在NDB API级别上对应于此语句的操作,这对于NDB的监视和性能调整是有益的。簇。
MySQL Cluster Manager提供了一个高级命令行界面,可简化许多其他复杂的NDB群集管理任务,例如启动,停止或重新启动具有大量节点的NDB群集。 MySQL Cluster Manager客户端还支持用于获取和设置大多数节点配置参数的值的命令,以及 与NDB Cluster相关的 mysqld 服务器选项和变量。 有关 更多信息, 请参阅“ MySQL™Cluster Manager 1.4.7用户手册” 。
本节简要概述了启动NDB Cluster数据节点时涉及的步骤。
可以
在“
内部指南”的
NDB Cluster Start Phase中
找到更完整的信息
。
NDB
这些阶段
node_id
STATUSstart_phase
列中
报告
ndbinfo.nodes
。
开始类型。 有几种不同的启动类型和模式,如下面的列表所示:
设置和初始化(阶段-1)。 在启动之前, 必须初始化 每个数据节点( ndbd 进程)。 初始化包括以下步骤:
-
获取节点ID
-
获取配置数据
-
分配用于节点间通信的端口
-
根据从配置文件中获取的设置分配内存
当数据节点或SQL节点首次连接到管理节点时,它会保留群集节点ID。 为确保没有其他节点分配相同的节点ID,此ID将保留,直到该节点已设法连接到群集,并且至少有一个 ndbd 报告此节点已连接。 节点ID的保留由相关节点和 ndb_mgmd 之间的连接保护 。
初始化每个数据节点后,可以继续进行集群启动过程。 此处列出了群集在此过程中经历的各个阶段:
-
0期 的
NDBFS和NDBCNTR块启动(见 NDB内核模块 )。 在使用--initial选项 启动的那些数据节点上清除数据节点文件系统 。 -
阶段1. 在此阶段,
NDB启动 所有剩余的 内核块。 建立NDB群集连接,建立块间通信,并启动心跳。 在节点重新启动的情况下,还会检查API节点连接。注意当一个或多个节点在阶段1中挂起而其余节点在阶段2中挂起时,这通常表示网络问题。 这种问题的一个可能原因是具有多个网络接口的一个或多个群集主机。 导致此情况的另一个常见问题是阻塞群集节点之间通信所需的TCP / IP端口。 在后一种情况下,这通常是由于防火墙配置错误造成的。
-
第2阶段 的
NDBCNTR核心模块检查所有现有节点的状态。 选择主节点,并初始化集群模式文件。 -
第3阶段 的
DBLQH和DBTC内核模块建立它们之间的通信。 确定启动类型; 如果这是重新启动,则DBDIH块获得执行重新启动的权限。 -
阶段4. 对于初始启动或初始节点重新启动,将创建重做日志文件。 这些文件的数量等于
NoOfFragmentLogFiles。对于系统重启:
-
读取模式或模式。
-
从本地检查点读取数据。
-
应用所有重做信息,直到达到最新的可恢复全局检查点。
对于节点重新启动,找到重做日志的尾部。
-
-
阶段5. 数据节点启动的大多数数据库相关部分在此阶段执行。 对于初始启动或系统重新启动,将执行本地检查点,然后执行全局检查点。 在此阶段开始定期检查内存使用情况,并执行任何所需的节点接管。
-
阶段6. 在此阶段,定义并设置节点组。
-
阶段7. 仲裁器节点被选中并开始起作用。 设置下一个备份ID,以及备份磁盘写入速度。 达到此开始阶段的节点标记为
Started。 现在,API节点(包括SQL节点)可以连接到群集。 -
阶段8. 如果这是系统重新启动,则重建所有索引(按
DBDIH)。 -
阶段9. 重置节点内部启动变量。
-
第100阶段(已废除)。 以前,在节点重启或初始节点重启期间,API节点可以连接到节点并开始接收事件。 目前,这个阶段是空的。
-
阶段101. 此时,在节点重启或初始节点重启时,事件传递将切换到加入集群的节点。 新加入的节点负责将其主要数据传递给订户。 该阶段也称为
SUMA切换阶段 。
完成此过程以进行初始启动或系统重新启动后,将启用事务处理。 对于节点重新启动或初始节点重新启动,启动过程的完成意味着该节点现在可以充当事务协调器。
除了中央配置文件之外,还可以通过管理客户端 ndb_mgm 提供的命令行界面来控制集群 。 这是正在运行的集群的主要管理界面。
第22.5.6节“在NDB集群中生成的事件报告” 中给出了事件日志的命令 ; 第22.5.3节“NDB集群的在线备份” 中提供了用于创建备份和从中还原的命令 。
将ndb_mgm与MySQL Cluster Manager一起使用。
MySQL Cluster Manager处理启动和停止进程并在内部跟踪它们的状态,因此
对于受MySQL Cluster Manager控制的NDB Cluster,
没有必要使用
ndb_mgm
来执行这些任务。
建议
不要
使用
NDB Cluster发行版附带
的
ndb_mgm
命令行客户端来执行涉及启动或停止节点的操作。
这些措施包括但不限于
START
,
STOP
,
RESTART
,和
SHUTDOWN
命令。
有关更多信息,请参阅
MySQL Cluster Manager进程命令
。
管理客户端具有以下基本命令。
在下面的列表中,
node_id
表示数据节点ID或关键字
ALL
,表示该命令应该应用于所有集群的数据节点。
-
显示有关所有可用命令的信息。
-
连接到连接字符串指示的管理服务器。 如果客户端已连接到此服务器,则客户端将重新连接。
-
显示有关群集状态的信息。 可能的节点状态值包括
UNKNOWN,NO_CONTACT,NOT_STARTED,STARTING,STARTED,SHUTTING_DOWN,和RESTARTING。 此命令的输出还指示群集何时处于单用户模式(状态SINGLE USER MODE),并且在NDB 8.0.17及更高版本中,指示当此模式生效时,哪个API或SQL节点具有独占访问权限。 -
在线显示由
node_id(或所有数据节点) 标识的 数据节点。ALL START仅适用于所有数据节点,不会影响管理节点。重要要使用此命令使数据节点联机,必须已使用
--nostart或 启动数据节点-n。 -
停止标识的数据或管理节点
node_id。注意ALL STOP仅用于停止所有数据节点,不会影响管理节点。受此命令影响的节点将断开与群集的连接,并且其关联的 ndbd 或 ndb_mgmd 进程将终止。
该
-a选项会立即停止节点,而无需等待任何挂起事务的完成。通常,
STOP如果结果导致不完整的集群,则会失败。 该-f选项强制节点关闭而不检查此情况。 如果使用此选项且结果是不完整的群集,则群集会立即关闭。警告使用该
-a选项还会禁用在STOP调用 时执行的安全检查, 以确保停止节点不会导致群集不完整。 换句话说,在使用-a带STOP命令 的 选项 时应特别小心 ,因为此选项使群集可以进行强制关闭,因为它不再拥有存储在其中的所有数据的完整副本NDB。 -
node_idRESTART [-n] [-i] [-a] [-f]重新启动由
node_id(或所有数据节点) 标识的 数据节点。使用
-i选项RESTART可使数据节点执行初始重启; 也就是说,删除并重新创建节点的文件系统。 效果与停止数据节点进程然后使用 系统shell中的 ndbd 再次启动它的效果相同--initial。注意使用此选项时,不会删除备份文件和磁盘数据文件。
使用该
-n选项会导致重新启动数据节点进程,但在START发出 适当的 命令 之前,数据节点实际上不会处于联机状态 。 此选项的效果与停止数据节点然后使用 系统shell中的 ndbd--nostart或 ndbd 再次启动它相同-n。使用该
-a原因导致依赖此节点的所有当前事务被中止。 当节点重新加入群集时,不会执行GCP检查。通常,
RESTART如果使节点脱机会导致群集不完整,则会失败。 该-f选项强制节点重新启动而不检查此情况。 如果使用此选项并且结果是不完整的群集,则重新启动整个群集。 -
显示由
node_id(或所有数据节点) 标识的数据节点的状态信息 。此命令的输出还指示群集何时处于单用户模式。
-
显示
report-type由所标识的数据节点node_id或使用的所有数据节点 的类型报告ALL。目前,有三个可接受的值
report-type:-
BackupStatus提供有关正在进行的群集备份的状态报告 -
MemoryUsage显示每个数据节点正在使用多少数据内存和索引内存,如下例所示:ndb_mgm>
ALL REPORT MEMORY节点1:数据使用率为5%(177个32K页,共3200个) 节点1:索引使用率为0%(108个8K页,共12832个) 节点2:数据使用率为5%(177个32K页,共3200个) 节点2:索引使用率为0%(108个8K页,共12832个)此信息也可从
ndbinfo.memoryusage表中获得。 -
EventLog报告来自一个或多个数据节点的事件日志缓冲区的事件。
report-type不区分大小写并且 “ 模糊 ” ; 因为MemoryUsage,你可以使用MEMORY(如前面的例子所示),memory甚至简单地MEM(或mem)。 您可以BackupStatus以类似的方式 缩写 。 -
-
ENTER SINGLE USER MODEnode_id进入单用户模式,只
node_id允许 由节点ID标识的MySQL服务器 访问数据库。从NDB 8.0.17开始, ndb_mgm 客户端清楚地确认已发出此命令并已生效,如下所示:
ndb_mgm>
ENTER SINGLE USER MODE 100输入单用户模式 仅为API节点100授予访问权限。同样在NDB 8.0.17及更高版本中,在单用户模式下具有独占访问权限的API或SQL节点在
SHOW命令 的输出中 指示,如下所示:ndb_mgm>
SHOW群集配置 --------------------- [ndbd(NDB)] 2个节点 id = 5 @ 127.0.0.1(mysql-8.0.17 ndb-8.0.17,单用户模式,Nodegroup:0,*) id = 6 @ 127.0.0.1(mysql-8.0.17 ndb-8.0.17,单用户模式,节点组:0) [ndb_mgmd(MGM)] 1个节点 id = 50 @ 127.0.0.1(mysql-8.0.17 ndb-8.0.17) [mysqld(API)] 2个节点 id = 100 @ 127.0.0.1(mysql-8.0.17 ndb-8.0.17,允许单个用户) id = 101(未连接,接受来自任何主机的连接)注意所有数据和管理节点必须运行NDB Cluster软件的8.0.17版才能启用此功能。
-
退出单用户模式,启用所有SQL节点(即所有正在运行的 mysqld 进程)以访问数据库。
注意EXIT SINGLE USER MODE即使不在单用户模式下 也可以使用 ,尽管在这种情况下命令没有效果。 -
终止管理客户端。
此命令不会影响连接到群集的任何节点。
-
关闭所有群集数据节点和管理节点。 要在完成此操作后退出管理客户端,请使用
EXIT或QUIT。该命令 没有 关闭连接到群集的任何SQL节点或API的节点。
-
CREATE NODEGROUPnodeid[,nodeid, ...]创建新的NDB群集节点组并使数据节点加入它。
在将新数据节点在线添加到NDB群集之后使用此命令,并使它们加入新节点组,从而开始完全参与群集。 该命令将逗号分隔的节点ID列表作为其唯一参数 - 这些节点ID是刚刚添加和启动的节点的ID,用于加入新节点组。 节点数必须与已经属于集群的每个节点组中的节点数相同(每个NDB集群节点组必须具有相同数量的节点)。 换句话说,如果NDB群集具有2个节点组,每个节点组包含2个数据节点,则新节点组还必须具有2个数据节点。
此命令创建的新节点组的节点组ID是自动确定的,并且始终是集群中下一个最高的未使用节点组ID; 无法手动设置。
有关更多信息,请参见 第22.5.15节“在线添加NDB集群数据节点” 。
-
删除给定的NDB群集节点组
nodegroup_id。此命令可用于从NDB群集中删除节点组。
DROP NODEGROUP将要删除的节点组的节点组ID作为其唯一参数。DROP NODEGROUP仅用于从该节点组中删除受影响的节点组中的数据节点。 它不会停止数据节点,将它们分配给不同的节点组,也不会从群集的配置中删除它们。 管理客户机SHOW命令 的输出中指示不属于节点组的数据节点,而不是no nodegroup节点组ID,如下所示(使用粗体文本表示):id = 3 @ 10.100.2.67(8.0.17-ndb-8.0.17,无节点组)DROP NODEGROUP仅当要删除的节点组中的所有数据节点完全没有任何表数据和表定义时才起作用。 由于目前无法使用 ndb_mgm 或 mysql 客户端从特定数据节点或节点组中删除所有数据,这意味着该命令仅在以下两种情况下成功:-
发行后
CREATE NODEGROUP在 ndb_mgm 客户端,但在此之前发出任何ALTER TABLE ... REORGANIZE PARTITION语句中的 MySQL的 客户端。 -
删除所有
NDBCLUSTER表后使用DROP TABLE。TRUNCATE TABLE不能用于此目的,因为这只删除表数据; 数据节点继续存储NDBCLUSTER表的定义,直到DROP TABLE发出导致表元数据被删除 的 语句。
有关更多信息
DROP NODEGROUP,请参见 第22.5.15节“在线添加NDB集群数据节点” 。 -
-
将 ndb_mgm 显示的提示更改为 字符串文字
prompt。prompt不应该引用(除非您希望提示包含引号)。 与 mysql 客户端 的情况不同 ,无法识别特殊字符序列和转义。 如果在没有参数的情况下调用,该命令会将提示重置为默认值(ndb_mgm>)。这里显示了一些示例:
ndb_mgm>
PROMPT mgm#1:mgm#1:SHOW群集配置 ...PROMPT mymgm >mgm #1:mymgm>PROMPT 'mymgm:''mymgm:'PROMPT mymgm:mymgm:PROMPTndb_mgm>EXIT乔恩@ valhaj:〜/ bin中>请注意,
prompt字符串中的 前导空格和空格 不会被修剪。 尾随空格被删除。 -
node_idNODELOG DEBUG {ON|OFF}在节点日志中切换调试日志记录,就好像已使用该
--verbose选项 启动受影响的数据节点 。NODELOG DEBUG ON开始调试记录;NODELOG DEBUG OFF切换调试注销。
附加命令。 ndb_mgm 客户端中 提供的许多其他命令在 别处描述,如以下列表所示:
-
START BACKUP用于在 ndb_mgm 客户端中 执行联机备份 ; 该ABORT BACKUP命令用于取消正在进行的备份。 有关更多信息,请参见 第22.5.3节“NDB集群的在线备份” 。 -
该
CLUSTERLOG命令用于执行各种日志记录功能。 有关 更多信息和示例, 请参见 第22.5.6节“在NDB集群中生成的事件报告” 。NODELOG DEBUG如本节前面所述,激活或停用节点日志中的调试打印输出。 -
对于测试和诊断工作,客户端支持
DUMP可用于在集群上执行内部命令的命令。 除非MySQL支持人员指示这样做,否则不应在生产环境中使用它。 有关更多信息,请参阅 MySQL NDB Cluster Internals Manual 。
接下来的几节将介绍如何准备,然后使用 ndb_mgm 管理客户端 中的此功能创建NDB群集备份 。 为了区分这种类型的备份和使用 mysqldump 进行的备份 ,我们有时将其称为 “ 本机 ” NDB群集备份。 (有关使用 mysqldump 创建备份的信息 ,请参见 第4.5.4节“ mysqldump - 数据库备份程序” 。)NDB群集备份的恢复是使用 随NDB群集分发提供 的 ndb_restore 实用程序 完成的 。 有关的信息 ndb_restore 及其在还原NDB群集备份中的 用法, 请参见 第22.4.23节“ ndb_restore - 还原NDB群集备份” 。
从NDB 8.0.16开始,可以使用多个LDM创建备份,以实现数据节点上的并行性。 请参见 第22.5.3.5节“使用并行数据节点建立NDB” 。
备份是给定时间的数据库快照。 备份包括三个主要部分:
-
元数据。 所有数据库表的名称和定义
-
表记录。 在进行备份时实际存储在数据库表中的数据
-
交易日志。 一个顺序记录,说明数据存储在数据库中的方式和时间
这些部分中的每一个都保存在参与备份的所有节点上。 在备份期间,每个节点将这三个部分保存到磁盘上的三个文件中:
-
BACKUP-backup_id.node_id.ctl包含控制信息和元数据的控制文件。 每个节点将相同的表定义(对于集群中的所有表)保存到其自己的此文件版本中。
-
BACKUP-backup_id-0.node_id.data包含表记录的数据文件,基于每个片段保存。 也就是说,不同的节点在备份期间保存不同的片段。 每个节点保存的文件都以一个标题开头,该标题表明记录所属的表。 在记录列表后面有一个包含所有记录校验和的页脚。
-
BACKUP-backup_id.node_id.log包含已提交事务记录的日志文件。 仅存储在备份中的表上的事务存储在日志中。 备份中涉及的节点保存不同的记录,因为不同的节点托管不同的数据库片段。
在刚刚显示的列表中,
backup_id
代表备份标识符,并且
node_id
是创建文件的节点的唯一标识符。
备份文件的位置由
BackupDataDir
参数
确定
。
在开始备份之前,请确保已正确配置群集以执行备份。 (请参见 第22.5.3.3节“NDB集群备份的配置” 。)
该
START BACKUP
命令用于创建备份:
开始备份[backup_id] [wait_option] [snapshot_option]wait_option: 等待{开始| 已完成} | NOWAITsnapshot_option: SNAPSHOTSTART | SNAPSHOTEND
连续备份是按顺序自动识别的,因此
backup_id
,大于或等于1的整数是可选的;
如果省略,则使用下一个可用值。
如果使用现有
backup_id
值,则备份将失败,并显示“
备份失败:文件已存在
”错误
。
如果使用,
backup_id
必须
START
BACKUP
在使用任何其他选项之前立即执行。
所述
wait_option
可用于确定何时控制返回给管理客户端一个后
START BACKUP
发出命令,如示于下列表中:
WAIT COMPLETED
是默认值。
A
snapshot_option
可用于确定备份
START BACKUP
是在发出时还是在完成
时匹配集群的状态
。
SNAPSHOTSTART
备份开始时备份与群集状态匹配;
SNAPSHOTEND
备份在备份完成时反映群集的状态。
SNAPSHOTEND
是默认值,并且与先前NDB Cluster版本中的行为相匹配。
如果使用
SNAPSHOTSTART
with选项
START BACKUP
,并且
CompressedBackup
启用
了
参数,则仅压缩数据和控制文件 - 不压缩日志文件。
如果同时使用a
wait_option
和a
snapshot_option
,则可以按任何顺序指定它们。
例如,假设没有现有备份4作为其ID,则以下所有命令均有效:
开始备份等待启动SNAPSHOTSTART 启动备份SNAPSHOTSTART等待启动 启动备份4等待已完成的SNAPSHOTSTART 开始备份SNAPSHOTEND等待完成 启动备份4 NOWAIT SNAPSHOTSTART
创建备份的过程包括以下步骤:
-
启动管理客户端( ndb_mgm ),如果它尚未运行。
-
执行
START BACKUP命令。 这会产生几行输出,指示备份的进度,如下所示:ndb_mgm>
START BACKUP等待完成,这可能需要几分钟 节点2:备份1从节点1开始 节点2:备份1从节点1开始完成 StartGCP:177 StopGCP:180 #Records:7362 #LogRecords:0 数据:453648字节日志:0字节 ndb_mgm> -
备份
backup_id从节点开始node_idbackup_id是此特定备份的唯一标识符。 如果尚未配置,则此标识符将保存在群集日志中。node_id是与数据节点协调备份的管理服务器的标识符。 此时,在备份过程中,群集已收到并处理了备份请求。 这并不意味着备份已经完成。 此处显示了此语句的示例:节点2:备份1从节点1开始
-
管理客户端使用这样的消息指示备份已启动:
备份
backup_id从节点node_id完成 开始与备份已启动的通知的情况一样,
backup_id是此特定备份的唯一标识符,并且node_id是正在协调备份与数据节点的管理服务器的节点ID。 此输出附带其他信息,包括相关的全局检查点,备份的记录数和数据大小,如下所示:节点2:备份1从节点1开始完成 StartGCP:177 StopGCP:180 #Records:7362 #LogRecords:0 数据:453648字节日志:0字节
也可以通过
使用
or
选项
调用
ndb_mgm
从系统shell执行备份
,如下例所示:
-e
--execute
外壳> ndb_mgm -e "START BACKUP 6 WAIT COMPLETED SNAPSHOTSTART"
START BACKUP
以这种方式
使用
时,必须指定备份ID。
默认情况下,会
在每个数据节点
的
BACKUP
子目录
中创建群集备份
DataDir
。
可以单独覆盖一个或多个数据节点,也可以
config.ini
使用
BackupDataDir
配置参数
覆盖
文件
中的所有群集数据节点
。
为给定备份创建的备份文件
backup_id
存储在
备份目录
中指定的子目录
中。
BACKUP-
backup_id
-
启动管理客户端。
-
执行以下命令:
ndb_mgm>
ABORT BACKUPbackup_id该数字
backup_id是备份启动时(在消息中 ) 管理客户端响应中包含的备份的标识符 。Backupbackup_idstarted from nodemanagement_node_id -
管理客户端将确认中止请求 。
Abort of backupbackup_idordered注意此时,管理客户端尚未收到群集数据节点对此请求的响应,并且备份尚未实际中止。
-
备份中止后,管理客户端将以类似于此处所示的方式报告此事实:
节点1:从5开始的备份3已中止。 错误:1321 - 备份由用户请求中止:永久错误:用户定义的错误 节点3:从5开始的备份3已中止。 错误:1323 - 1323:永久错误:内部错误 节点2:从5开始的备份3已中止。 错误:1323 - 1323:永久错误:内部错误 节点4:从5开始的备份3已中止。 错误:1323 - 1323:永久错误:内部错误
在此示例中,我们显示了具有4个数据节点的集群的示例输出,其中要中止的备份的序列号是
3,并且集群管理客户端连接到的管理节点具有节点ID5。 完成其中止备份的第一个节点报告中止的原因是由于用户的请求。 (其余节点报告由于未指定的内部错误而导致备份中止。)注意无法保证群集节点以
ABORT BACKUP任何特定顺序 响应 命令。这些 消息表示备份已终止,并且已从群集文件系统中删除与此备份相关的所有文件。
Backupbackup_idstarted from nodemanagement_node_idhas been aborted
也可以使用以下命令从系统shell中止正在进行的备份:
外壳> ndb_mgm -e "ABORT BACKUP backup_id"
如果在
发出
ID
backup_id
时
没有
运行
ID的备份
ABORT BACKUP
,则管理客户端不响应,也不在群集日志中指示发送了无效的中止命令。
五个配置参数对备份至关重要:
-
在将数据写入磁盘之前用于缓冲数据的内存量。
-
在将这些记录写入磁盘之前用于缓冲日志记录的内存量。
-
在数据节点中为备份分配的总内存。 这应该是为备份数据缓冲区和备份日志缓冲区分配的内存总和。
-
写入磁盘的块的默认大小。 这适用于备份数据缓冲区和备份日志缓冲区。
-
写入磁盘的块的最大大小。 这适用于备份数据缓冲区和备份日志缓冲区。
有关这些参数的更多详细信息,请参见 备份参数 。
您还可以使用
BackupDataDir
配置参数
设置备份文件的位置
。
默认是
。
FileSystemPath/BACKUP/BACKUP-
backup_id
如果在发出备份请求时返回错误代码,则最可能的原因是内存或磁盘空间不足。 您应该检查是否有足够的内存分配给备份。
如果你已设置
BackupDataBufferSize
并且
BackupLogBufferSize
它们的总和大于4MB,那么你也必须设置
BackupMemory
。
您还应确保备份目标的硬盘驱动器分区上有足够的空间。
NDB
不支持可重复读取,这可能会导致恢复过程出现问题。
虽然备份过程
“
很热
”
,但从备份恢复NDB群集并不是一个100%
“
热门
”的
过程。
这是因为在恢复过程期间,正在运行的事务从恢复的数据中获得不可重复的读取。
这意味着在还原过程中数据的状态不一致。
从NDB 8.0.16开始,可以在数据节点上并行执行多个本地数据管理器(LDM)的备份。
为此,集群中的所有数据节点都必须使用多个LDM,并且每个数据节点必须使用相同数量的LDM。
这意味着所有数据节点必须运行
ndbmtd
(
ndbd
是单线程的,因此总是只有一个LDM),并且必须将它们配置为在进行备份之前使用多个LDM;
默认情况下,ndbmtd以单线程模式运行。
你可以使它们通过选择适当的设置用于多线程数据节点的配置参数中的一个来使用多个的LDM这个
MaxNoOfExecutionThreads
或
ThreadConfig
。
请记住,更改这些参数需要重新启动群集;
这可以是滚动重启。
根据LDM的数量和其他因素,您可能还需要增加
NoOfFragmentLogParts
。
如果您使用的是大型磁盘数据表,则可能还需要增加
DiskPageBufferMemory
。
与单线程的备份,你还想要或需要作出调整设置
BackupDataBufferSize
,
BackupMemory
以及与备份(请参阅其他配置参数
备份参数
)。
一旦所有数据节点都使用多个LDM,您就可以使用
START
BACKUP
NDB管理客户端中
的
命令进行
并行备份
,就像数据节点运行
ndbd
(或
单线程模式下的
ndbmtd
)一样;
不需要其他语法或特殊语法,您可以根据需要或任意组合指定备份ID,等待选项或快照选项。
使用多个LDM的备份
在每个数据节点上
的目录下
(
每个LDM下面创建一个子目录,每个LDM一个
);
这些子目录是命名的
,
依此类推,最多
,
用于此备份的备份ID
在哪里,
是
每个数据节点的LDM数。
每个子目录包含通常的备份文件
,
和
,其中
是该数据的节点的节点ID。
BACKUP/BACKUP-
backup_id/BackupDataDir
BACKUP-
backup_id-PART-1-OF-N/BACKUP-
backup_id-PART-2-OF-N/BACKUP-
backup_id-PART-N-OF-N/backup_id
N
BACKUP-
backup_id-0.node_id.DataBACKUP-
backup_id.node_id.ctlBACKUP-backup_id.node_id.log
node_id
在NDB 8.0.16及更高版本中, ndb_restore会 自动检查刚才描述的子目录是否存在; 如果找到它们,它会尝试并行恢复备份。 有关还原使用多个LDM执行的备份的信息,请参见 第22.4.23.2节“从并行执行的备份还原” 。
mysqld
是传统的MySQL服务器进程。
要与NDB Cluster一起使用,
需要构建
mysqld
并支持
NDB
存储引擎,因为它位于
https://dev.mysql.com/downloads/中
提供的预编译二进制文件中
。
如果从源代码构建MySQL,则必须
使用
包含支持
的
选项
调用
CMake
。
-DWITH_NDBCLUSTER=1
NDB
有关从源代码编译NDB Cluster的更多信息,请参见 第22.2.2.4节“在Linux上从源代码构建NDB集群” 和 第22.2.3.2节“在Windows上从源代码编译和安装NDB集群” 。
(有关 mysqld 选项和变量的信息,除了本节中讨论的与NDB Cluster相关的信息之外,请参见 第22.3.3.9节“用于NDB群集的MySQL服务器选项和变量” 。)
如果
mysqld
二进制文件是使用Cluster支持构建的,则
NDBCLUSTER
默认情况下仍会禁用存储引擎。
您可以使用以下两种方法之一来启用此引擎:
-
使用
--ndbcluster开始时作为命令行启动选项 的mysqld 。 -
插入包含
ndbcluster在 文件[mysqld]部分中 的行my.cnf。
验证服务器是否在
NDBCLUSTER
启用存储引擎的
情况下运行的简单方法
是
SHOW
ENGINES
在MySQL监视器(
mysql
)中
发出
语句
。
您应该将值
YES
视为
Support
行中
的
值
NDBCLUSTER
。
如果您
NO
在此行中
看到
或者输出中没有显示此行,则表明您没有运行
NDB
启用MySQL的版本。
如果您
DISABLED
在此行中
看到
,则需要以上述两种方式之一启用它。
要读取群集配置数据,MySQL服务器至少需要三条信息:
-
MySQL服务器自己的集群节点ID
-
管理服务器的主机名或IP地址(MGM节点)
-
可以连接到管理服务器的TCP / IP端口号
节点ID可以动态分配,因此不必严格指定它们。
所述
mysqld的
参数
ndb-connectstring
被用来启动时要么指定命令行上的连接字符串
的mysqld
或
my.cnf
。
连接字符串包含可以找到管理服务器的主机名或IP地址,以及它使用的TCP / IP端口。
在以下示例中,
ndb_mgmd.mysql.com
是管理服务器所在的主机,管理服务器在端口1186上侦听群集消息:
外壳> mysqld --ndbcluster --ndb-connectstring=ndb_mgmd.mysql.com:1186
有关 连接字符串 的更多信息, 请参见 第22.3.3.3节“NDB集群连接字符串” 。
有了这些信息,MySQL服务器将成为集群的完全参与者。 (我们经常 将以这种方式运行 的 mysqld 进程称为SQL节点。)它将完全了解所有集群数据节点及其状态,并将建立与所有数据节点的连接。 在这种情况下,它能够使用任何数据节点作为事务协调器并读取和更新节点数据。
您可以在
mysql
客户端中
看到
MySQL服务器是否使用连接到集群
SHOW
PROCESSLIST
。
如果MySQL服务器连接到群集,并且您具有该
PROCESS
权限,则输出的第一行如下所示:
mysql> SHOW PROCESSLIST \ G.
*************************** 1。排******************** *******
Id:1
用户:系统用户
主办:
D b:
命令:守护进程
时间:1
状态:从ndbcluster等待事件
信息:NULL
参加一个NDB集群中,
mysqld的
进程必须启动
两个
选项
--ndbcluster
和
--ndb-connectstring
(或它们的等价物
my.cnf
)。
如果
仅使用该
选项
启动
mysqld
--ndbcluster
,或者如果它无法联系群集,则无法使用
NDB
表,
也无法创建任何新表,无论存储引擎如何
。
后一种限制是一种安全措施,旨在防止创建具有相同名称的表
NDB
SQL节点未连接到群集时的表。
如果您希望在
mysqld
进程未参与NDB群集的
情况下
使用其他存储引擎创建表
,则必须在
没有
该
--ndbcluster
选项的
情况下
重新启动服务器
。
本节讨论如何执行 NDB群集安装 的 滚动重新启动 ,因为它涉及依次停止和启动(或重新启动)每个节点,以便群集本身保持运行。 这通常是作为 滚动升级 或 滚动降级的 一部分完成的 ,其中群集的高可用性是强制性的,并且不允许整个群集的停机时间。 在我们提到升级的地方,此处提供的信息通常也适用于降级。
可能需要滚动重启的原因有很多。 这些将在接下来的几段中描述。
配置更改。 要更改群集的配置,例如将SQL节点添加到群集,或将配置参数设置为新值。
NDB Cluster软件升级或降级。 将群集升级到较新版本的NDB Cluster软件(或将其降级到较旧版本)。 这通常被称为 “ 滚动升级 ” (或 “ 滚动降级 ” ,当还原为旧版本的NDB群集时)。
更改节点主机。 在运行一个或多个NDB Cluster节点进程的硬件或操作系统中进行更改。
系统重置(群集重置)。 要重置群集,因为它已达到不良状态。 在这种情况下,通常需要重新加载一个或多个数据节点的数据和元数据。 这可以通过以下三种方式之一完成:
-
使用该 选项 启动每个数据节点进程( ndbd 或可能 ndbmtd )
--initial,这将强制数据节点清除其文件系统并从其他数据节点重新加载所有NDB Cluster数据和元数据。 -
在执行重新启动之前 使用 ndb_mgm 客户端
START BACKUP命令 创建备份 。 升级后,使用 ndb_restore 还原节点 。有关更多 信息, 请参见 第22.5.3节“NDB群集的联机备份” 和 第22.4.23节“ ndb_restore - 还原NDB群集备份” 。
资源恢复。
通过连续
INSERT
和
DELETE
操作
释放先前分配给表的内存
,以供其他NDB Cluster表重用。
执行滚动重启的过程可以概括如下:
-
停止所有集群管理节点( ndb_mgmd 进程),重新配置它们,然后重新启动它们。 (请参阅 使用多个管理服务器滚动重新启动 。)
-
停止,重新配置,然后依次重新启动每个群集数据节点( ndbd 进程)。
可以通过 在上一步骤之后为 ndb_mgm 客户端
RESTART中的每个数据节点 发出一些节点配置参数来更新 ; 其他人要求使用shell命令(例如 在大多数Unix系统上 执行 kill )或管理客户端 命令 完全停止数据节点 ,然后根据需要通过调用 ndbd 或 ndbmtd 可执行文件 从系统shell再次启动 。STOP注意在Windows上,您还可以使用 SC STOP 和 SC START 命令
NET STOP和NET START命令,或Windows Service Manager来停止和启动已作为Windows服务安装的节点(请参见 第22.2.3.4节“将NDB群集进程安装为Windows服务”) )。所需的重新启动类型在每个节点配置参数的文档中指出。 请参见 第22.3.3节“NDB集群配置文件” 。
-
停止,重新配置,然后依次重新启动每个群集SQL节点( mysqld 进程)。
NDB Cluster支持一些灵活的升级节点订单。 升级NDB群集时,您可以在升级管理节点,数据节点或两者之前升级API节点(包括SQL节点)。 换句话说,您可以按任何顺序升级API和SQL节点。 这符合以下规定:
-
此功能仅用作在线升级的一部分。 来自不同NDB Cluster版本的节点二进制文件的混合既不打算也不支持在生产环境中连续,长期使用。
-
在升级任何数据节点之前,必须升级所有管理节点。 无论升级群集的API和SQL节点的顺序如何,这都是正确的。
-
在升级所有管理节点和数据节点之前,不得使用 特定于 “ 新 ” 版本的 功能 。
这也适用于可能适用的任何MySQL服务器版本更改,以及NDB引擎版本更改,因此在计划升级时不要忘记考虑这一点。 (对于NDB群集的在线升级,这是正确的。)
另请参阅Bug#48528和Bug#49163。
在节点重新启动期间,任何API节点都不可能执行模式操作(例如数据定义语句)。
使用多个管理服务器重新启动滚动。 在执行具有多个管理节点的NDB群集的滚动重新启动时,应记住 ndb_mgmd 检查是否正在运行任何其他管理节点,如果是,则尝试使用该节点的配置数据。 要防止这种情况发生,并强制 ndb_mgmd 重新读取其配置文件,请执行以下步骤:
执行滚动重新启动以更新群集的配置时,可以使用
表
的
config_generation
列
ndbinfo.nodes
来跟踪使用新配置成功重新启动的数据节点。
请参见
第22.5.10.28节“ndbinfo节点表”
。
在本节中,我们将讨论NDB Cluster提供的事件日志类型以及记录的事件类型。
NDB Cluster提供两种类型的事件日志:
-
的 群集日志 ,其包括所有群集节点生成的事件。 群集日志是建议用于大多数用途的日志,因为它在单个位置提供整个群集的日志记录信息。
默认情况下,群集日志将保存到 管理服务器中 名为 (其中 是管理服务器的节点ID)的文件中 。
ndb_node_id_cluster.lognode_idDataDir群集日志记录信息也可以发送到
stdout或者syslog除了或代替的设施被保存到文件中,如通过对所设置的值来确定DataDir和LogDestination配置参数。 有关这些参数的详细信息 , 请参见 第22.3.3.5节“定义NDB群集管理服务器” 。 -
节点日志 是每个节点的本地 日志 。
节点事件日志记录生成的输出将写入节点中的文件 ( 节点的节点ID) 。 为管理节点和数据节点生成节点事件日志。
ndb_node_id_out.lognode_idDataDir节点日志仅用于应用程序开发期间或用于调试应用程序代码。
可以将两种类型的事件日志设置为记录不同的事件子集。
每个可报告事件可根据三个不同标准进行区分:
-
类别 :这可以是以下值中的任何一个:
STARTUP,SHUTDOWN,STATISTICS,CHECKPOINT,NODERESTART,CONNECTION,ERROR,或INFO。 -
优先级 :这是由数字中的一个表示从0至15包容性,其中0表示 “ 最重要的 ” 和15个 “ 最重要的。 ”
-
严重级别 :这可以是下列任一值:
ALERT,CRITICAL,ERROR,WARNING,INFO,或DEBUG。
可以在这些属性上过滤群集日志和节点日志。
群集日志中使用的格式如下所示:
2007-01-26 19:35:55 [MgmSrvr] INFO - 节点1:数据使用率为2%(60个32K页,总计2560个) 2007-01-26 19:35:55 [MgmSrvr] INFO - 节点1:索引使用率为1%(24个8K页,共2336页) 2007-01-26 19:35:55 [MgmSrvr] INFO - 节点1:资源0分钟:0最大值:639当前:0 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点2:数据使用率为2%(76个32K页,共计2560个) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点2:索引使用率为1%(24个8K页,共2336页) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点2:资源0分钟:0最大值:639当前:0 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点3:数据使用率为2%(58个32K页,共2560页) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点3:索引使用率为1%(25个8K页,共2336页) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点3:资源0分钟:0最大值:639当前:0 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点4:数据使用率为2%(74个32K页,共2560页) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点4:索引使用率为1%(25个8K页,共2336页) 2007-01-26 19:35:55 [MgmSrvr]信息 - 节点4:资源0分钟:0最大值:639当前:0 2007-01-26 19:39:42 [MgmSrvr]信息 - 节点4:节点9已连接 2007-01-26 19:39:42 [MgmSrvr] INFO - 节点1:节点9已连接 2007-01-26 19:39:42 [MgmSrvr] INFO - 节点1:节点9:API 8.0.17-ndb-8.0.17 2007-01-26 19:39:42 [MgmSrvr] INFO - 节点2:节点9已连接 2007-01-26 19:39:42 [MgmSrvr]信息 - 节点2:节点9:API 8.0.17-ndb-8.0.17 2007-01-26 19:39:42 [MgmSrvr]信息 - 节点3:节点9已连接 2007-01-26 19:39:42 [MgmSrvr] INFO - 节点3:节点9:API 8.0.17-ndb-8.0.17 2007-01-26 19:39:42 [MgmSrvr] INFO - 节点4:节点9:API 8.0.17-ndb-8.0.17 2007-01-26 19:59:22 [MgmSrvr] ALERT - 节点2:节点7断开连接 2007-01-26 19:59:22 [MgmSrvr] ALERT - 节点2:节点7断开连接
群集日志中的每一行都包含以下信息:
-
格式化 的时间戳 。
YYYY-MM-DDHH:MM:SS -
正在执行日志记录的节点类型。 在群集日志中,始终如此
[MgmSrvr]。 -
事件的严重性。
-
报告事件的节点的ID。
-
事件的描述。 日志中出现的最常见事件类型是群集中不同节点之间的连接和断开连接,以及何时发生检查点。 在某些情况下,描述可能包含状态信息。
ndb_mgm
支持许多与集群日志和节点日志相关的管理命令。
在下面的列表中,
node_id
表示存储节点ID或关键字
ALL
,表示该命令应该应用于所有集群的数据节点。
-
CLUSTERLOG ON打开群集登录。
-
CLUSTERLOG OFF关闭群集注销。
-
CLUSTERLOG INFO提供有关群集日志设置的信息。
-
node_idCLUSTERLOGcategory=threshold记录
category优先级小于或等于的事件threshold在群集日志。 -
CLUSTERLOG FILTERseverity_level切换指定事件的群集日志记录
severity_level。
下表介绍了群集日志类别阈值的默认设置(适用于所有数据节点)。 如果事件的优先级值低于或等于优先级阈值,则会在群集日志中报告该事件。
每个数据节点报告事件,并且可以在不同节点上将阈值设置为不同的值。
表22.361群集日志类别,具有默认阈值设置
| 类别 | 默认阈值(所有数据节点) |
|---|---|
STARTUP |
7 |
SHUTDOWN |
7 |
STATISTICS |
7 |
CHECKPOINT |
7 |
NODERESTART |
7 |
CONNECTION |
7 |
ERROR |
15 |
INFO |
7 |
该
STATISTICS
类别可以提供大量有用的数据。
有关
更多信息
,
请参见
第22.5.6.3节“在NDB集群管理客户端中使用CLUSTERLOG STATISTICS”
。
阈值用于过滤每个类别中的事件。
例如,
STARTUP
除非阈值为,否则不会记录优先级为3
的
事件
STARTUP
设置为3或更高,
。
如果阈值为3,则仅发送优先级为3或更低的事件。
下表显示了事件严重性级别。
这些对应于Unix
syslog
级别,除了
LOG_EMERG
和
之外
LOG_NOTICE
,未使用或映射。
表22.362事件严重性级别
| 严重级别值 | 严重 | 描述 |
|---|---|---|
| 1 | ALERT |
应立即更正的条件,例如损坏的系统数据库 |
| 2 | CRITICAL |
关键条件,例如设备错误或资源不足 |
| 3 | ERROR |
应该纠正的条件,例如配置错误 |
| 4 | WARNING |
条件不是错误,但可能需要特殊处理 |
| 五 | INFO |
信息性消息 |
| 6 | DEBUG |
调试用于
NDBCLUSTER
开发的
消息
|
可以打开或关闭事件严重性级别(使用
CLUSTERLOG FILTER
- 见上文)。
如果启用了严重性级别,则会记录优先级小于或等于类别阈值的所有事件。
如果关闭严重性级别,则不会记录属于该严重性级别的事件。
事件日志中报告的事件报告具有以下格式:
datetime[string]severity-message
例如:
2005-07-24 09:19:30 [NDB] INFO - 节点4开始阶段4完成
本节讨论所有可报告事件,按类别和每个类别中的严重性级别排序。
在事件描述中,GCP和LCP分别表示 “ 全局检查点 ” 和 “ 本地检查点 ” 。
连接事件
这些事件与群集节点之间的连接相关联。
表22.363与群集节点之间的连接关联的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
Connected |
8 | INFO |
数据节点已连接 |
Disconnected |
8 | ALERT |
数据节点断开连接 |
CommunicationClosed |
8 | INFO |
SQL节点或数据节点连接已关闭 |
CommunicationOpened |
8 | INFO |
SQL节点或数据节点连接打开 |
ConnectedApiVersion |
8 | INFO |
使用API版本连接 |
检查点事件
此处显示的日志消息与检查点相关联。
表22.364与检查点关联的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
GlobalCheckpointStarted |
9 | INFO |
GCP启动:REDO日志写入磁盘 |
GlobalCheckpointCompleted |
10 | INFO |
GCP完成了 |
LocalCheckpointStarted |
7 | INFO |
LCP启动:写入磁盘的数据 |
LocalCheckpointCompleted |
7 | INFO |
LCP正常完成 |
LCPStoppedInCalcKeepGci |
0 | ALERT |
LCP停了下来 |
LCPFragmentCompleted |
11 | INFO |
片段上的LCP已完成 |
UndoLogBlocked |
7 | INFO |
UNDO日志被阻止; 缓冲区附近溢出 |
RedoStatus |
7 | INFO |
重做状态 |
STARTUP活动
生成以下事件以响应节点或群集的启动及其成功或失败。 它们还提供有关启动过程进度的信息,包括有关日志记录活动的信息。
表22.365与节点或集群启动相关的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
NDBStartStarted |
1 | INFO |
启动数据节点启动阶段(所有节点启动) |
NDBStartCompleted |
1 | INFO |
开始阶段完成,所有数据节点 |
STTORRYRecieved |
15 | INFO |
完成重启后收到的块 |
StartPhaseCompleted |
4 | INFO |
数据节点启动阶段
X
已完成
|
CM_REGCONF |
3 | INFO |
节点已成功包含在集群中; 显示节点,管理节点和动态ID |
CM_REGREF |
8 | INFO |
节点已被拒绝包含在群集中; 由于配置错误,无法建立通信或其他问题,无法包含在群集中 |
FIND_NEIGHBOURS |
8 | INFO |
显示邻居数据节点 |
NDBStopStarted |
1 | INFO |
数据节点关闭已启动 |
NDBStopCompleted |
1 | INFO |
数据节点关闭完成 |
NDBStopForced |
1 | ALERT |
强制关闭数据节点 |
NDBStopAborted |
1 | INFO |
无法正常关闭数据节点 |
StartREDOLog |
4 | INFO |
新的重做日志开始了;
GCI保持
X
最新的可恢复GCI
Y
|
StartLog |
10 | INFO |
新日志开始;
日志部分
X
,启动MB
Y
,停止MB
Z
|
UNDORecordsExecuted |
15 | INFO |
撤消已执行的记录 |
StartReport |
4 | INFO |
报告开始了 |
LogFileInitStatus |
7 | INFO |
日志文件初始化状态 |
LogFileInitCompStatus |
7 | INFO |
日志文件完成状态 |
StartReadLCP |
10 | INFO |
开始阅读本地检查点 |
ReadLCPComplete |
10 | INFO |
读取本地检查点已完成 |
RunRedo |
8 | INFO |
运行重做日志 |
RebuildIndex |
10 | INFO |
重建索引 |
NODERESTART活动
重新启动节点时会生成以下事件,并与节点重新启动过程的成功或失败有关。
表22.366与重新启动节点相关的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
NR_CopyDict |
7 | INFO |
完成了字典信息的复制 |
NR_CopyDistr |
7 | INFO |
完成复制分发信息 |
NR_CopyFragsStarted |
7 | INFO |
开始复制片段 |
NR_CopyFragDone |
10 | INFO |
完成复制片段 |
NR_CopyFragsCompleted |
7 | INFO |
完成复制所有片段 |
NodeFailCompleted |
8 | ALERT |
节点故障阶段已完成 |
NODE_FAILREP |
8 | ALERT |
报告节点已失败 |
ArbitState |
6 | INFO |
报告是否找到仲裁员;
在寻找仲裁员时有七种不同的可能结果,如下所示:
|
ArbitResult |
2 | ALERT |
报告仲裁员结果;
仲裁尝试有八种不同的可能结果,如下所示:
|
GCP_TakeoverStarted |
7 | INFO |
GCP接管开始了 |
GCP_TakeoverCompleted |
7 | INFO |
GCP接管完成 |
LCP_TakeoverStarted |
7 | INFO |
LCP收购开始了 |
LCP_TakeoverCompleted |
7 | INFO |
LCP接管完成(state =
X
)
|
ConnectCheckStarted |
6 | INFO |
连接检查已开始 |
ConnectCheckCompleted |
6 | INFO |
连接检查已完成 |
NodeFailRejected |
6 | ALERT |
节点故障阶段失败 |
统计事件
以下事件具有统计性质。 它们提供诸如事务数量和其他操作,各个节点发送或接收的数据量以及内存使用情况等信息。
表22.367统计性事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
TransReportCounters |
8 | INFO |
报告事务统计信息,包括事务数,提交,读取,简单读取,写入,并发操作,属性信息和中止 |
OperationReportCounters |
8 | INFO |
运营数量 |
TableCreated |
7 | INFO |
报告创建的表的数量 |
JobStatistic |
9 | INFO |
平均内部作业调度统计 |
ThreadConfigLoop |
9 | INFO |
线程配置循环数 |
SendBytesStatistic |
9 | INFO |
发送到节点的平均字节数
X
|
ReceiveBytesStatistic |
9 | INFO |
从节点接收的平均字节数
X
|
MemoryUsage |
五 | INFO |
数据和索引内存使用率(80%,90%和100%) |
MTSignalStatistics |
9 | INFO |
多线程信号 |
SCHEMA活动
这些事件与NDB Cluster架构操作有关。
表22.368与NDB集群模式操作相关的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
CreateSchemaObject |
8 | INFO |
架构被反对创建 |
AlterSchemaObject |
8 | INFO |
架构对象已更新 |
DropSchemaObject |
8 | INFO |
架构对象已删除 |
错误事件
这些事件与群集错误和警告有关。 这些中的一个或多个的存在通常表示发生了重大故障或故障。
表22.369与群集错误和警告有关的事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
TransporterError |
2 | ERROR |
运输车错误 |
TransporterWarning |
8 | WARNING |
运输车警告 |
MissedHeartbeat |
8 | WARNING |
节点
X
错过了心跳号码
Y
|
DeadDueToHeartbeat |
8 | ALERT |
由于心跳错过,
节点被
X
宣布为
“
死
”
|
WarningEvent |
2 | WARNING |
一般警告事件 |
SubscriptionStatus |
4 | WARNING |
订阅状态的变化 |
信息事件
这些事件提供有关群集状态和与群集维护相关的活动(如日志记录和心跳传输)的一般信息。
表22.370信息事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
SentHeartbeat |
12 | INFO |
发送心跳 |
CreateLogBytes |
11 | INFO |
创建日志:日志部分,日志文件,大小(MB) |
InfoEvent |
2 | INFO |
一般信息活动 |
EventBufferStatus |
7 | INFO |
事件缓冲状态 |
EventBufferStatus2 |
7 | INFO |
改进了事件缓冲状态信息 |
SentHeartbeat
只有在
VM_TRACE
启用
NDB Cluster的情况下编译时,事件才可用
。
SINGLEUSER活动
这些事件与进入和退出单用户模式相关联。
备份事件
这些事件提供有关正在创建或还原的备份的信息。
表22.372备份事件
| 事件 | 优先 | 严重程度 | 描述 |
|---|---|---|---|
BackupStarted |
7 | INFO |
备份开始了 |
BackupStatus |
7 | INFO |
备份状态 |
BackupCompleted |
7 | INFO |
备份完成 |
BackupFailedToStart |
7 | ALERT |
备份无法启动 |
BackupAborted |
7 | ALERT |
备份由用户中止 |
RestoreStarted |
7 | INFO |
开始从备份恢复 |
RestoreMetaData |
7 | INFO |
恢复元数据 |
RestoreData |
7 | INFO |
恢复数据 |
RestoreLog |
7 | INFO |
恢复日志文件 |
RestoreCompleted |
7 | INFO |
完成从备份恢复 |
SavedEvent |
7 | INFO |
活动已保存 |
该
NDB
管理客户端的
CLUSTERLOG STATISTICS
命令可以提供许多可在其输出的统计数据。
提供有关集群状态信息的计数器由事务协调器(TC)和本地查询处理程序(LQH)以5秒的报告间隔更新,并写入集群日志。
事务协调员统计信息。 每个事务都有一个事务协调器,可通过以下方法之一选择:
-
以循环方式
-
通过通信接近
-
通过在事务启动时提供数据放置提示
您可以使用
ndb_optimized_node_selection
系统变量
确定从给定SQL节点启动的事务使用哪种TC选择方法
。
同一事务中的所有操作都使用相同的事务协调器,该协调器报告以下统计信息:
-
Trans计数。 这是使用此TC作为事务协调器的最后一个间隔中启动的数字事务。 在报告间隔结束时,这些事务中的任何一个都可能已提交,已中止或未提交。
注意事务不在TC之间迁移。
-
提交计数。 这是使用此TC作为在上一个报告间隔中提交的事务协调器的事务数。 由于在此报告间隔中提交的某些事务可能已在先前的报告间隔中启动,因此可能
Commit count大于Trans count。 -
读数。 这是使用此TC作为在上一个报告间隔中启动的事务协调器的主键读取操作的数量,包括简单读取。 此计数还包括作为唯一索引操作的一部分执行的读取。 唯一索引读取操作为隐藏的唯一索引表生成2个主键读取操作-1,对于发生读取的表生成1个主键读取操作。
-
简单的读数。 这是使用此TC作为在上一个报告间隔中启动的事务协调器的简单读取操作的数量。
-
写数。 这是使用此TC作为在上一个报告间隔中启动的事务协调器的主键写入操作的数量。 这包括所有插入,更新,写入和删除,以及作为唯一索引操作的一部分执行的写入。
注意唯一索引更新操作可以在索引表和基表上生成多个PK读写操作。
-
AttrInfoCount。 这是使用此TC作为事务协调器的主键操作的上一报告间隔中接收的32位数据字的数量。 对于读取,这与请求的列数成比例。 对于插入和更新,这与写入的列数和数据大小成比例。 对于删除操作,通常为零。
唯一索引操作会生成多个PK操作,因此会增加此计数。 但是, 此处 不会 计算 发送以描述PK操作本身的数据字以及发送的密钥信息 。 发送用于描述要读取扫描列或描述ScanFilters的列的属性信息也不计入其中
AttrInfoCount。 -
并发运营。 这是使用此TC作为事务协调器的主键或扫描操作的数量,这些操作在上一个报告间隔期间启动但未完成。 操作在启动时递增此计数器,并在完成时递减计数器; 这发生在事务提交之后。 脏读写 - 以及失败的操作 - 递减此计数器。
该最大值
Concurrent Operations可以具有是操作一个TC块可以支持的最大数量; 目前,这是(2 * MaxNoOfConcurrentOperations) + 16 + MaxNoOfConcurrentTransactions。 (有关这些配置参数的更多信息,请参见 第22.3.3.6节“定义NDB集群数据节点”的“ 事务参数” 部分 。) -
中止计数。 这是使用此TC作为在上一个报告间隔期间中止的事务协调器的事务数。 由于在上一个报告间隔中中止的某些事务可能已在先前的报告间隔中启动,
Abort count因此有时可能大于Trans count。 -
扫描。 这是使用此TC作为在上一个报告间隔期间启动的事务协调器的表扫描数。 这不包括范围扫描(即有序索引扫描)。
-
范围扫描。 这是使用此TC作为在上一个报告间隔中启动的事务协调器的有序索引扫描的数量。
-
本地读取。 这是在同时保存记录主副本的节点上使用事务协调器执行的主键读取操作的数量。 该计数也可以从 表中 的
LOCAL_READS计数器 获得ndbinfo.counters。 -
本地写道。 这包含在同时保存记录主副本的节点上使用事务协调器执行的主键读取操作的数量。 该计数也可以从 表中 的
LOCAL_WRITES计数器 获得ndbinfo.counters。
本地查询处理程序统计信息(Operations)。 每个本地查询处理程序块有1个集群事件(即每个数据节点进程1个)。 操作记录在LQH中,它们所操作的数据驻留在LQH中。
单个事务可以对存储在多个LQH块中的数据进行操作。
该
Operations
统计提供此LQH块在最后的报告间隔进行本地操作的数量,并包括所有类型的读写操作(插入,更新,写入和删除操作)。
这还包括用于复制写入的操作。
例如,在2副本群集中,对主副本的写入记录在主LQH中,对备份的写入将记录在备份LQH中。
唯一的密钥操作可能导致多个本地操作;
然而,这并
不
包括如表扫描或有序索引扫描,这不被计数的结果而产生的局部操作。
进程调度程序统计信息 除了事务协调器和本地查询处理程序报告的统计信息之外,每个 ndbd 进程还有一个调度程序,它还提供与NDB集群性能相关的有用指标。 该调度程序在无限循环中运行; 在每个循环期间,调度程序执行以下任务:
-
将任何来自套接字的传入消息读入作业缓冲区。
-
检查是否有任何定时消息要执行; 如果是这样,也将它们放入作业缓冲区。
-
执行(在循环中)作业缓冲区中的任何消息。
-
发送通过在作业缓冲区中执行消息生成的任何分布式消息。
-
等待任何新的传入消息。
进程调度程序统计信息包括以下内容
-
平均循环计数器。 这是从前面的列表开始的第三步中执行的循环数。 随着TCP / IP缓冲区利用率的提高,此统计信息的大小会增加。 您可以使用它来监视添加新数据节点进程时的性能变化。
-
平均发送大小和平均接收大小。 通过这些统计信息,您可以评估节点之间的写入和读取效率。 值以字节为单位给出。 值越高意味着发送或接收的每字节成本越低; 最大值为64K。
要记录所有群集日志统计信息,可以在
NDB
管理客户端中
使用以下命令
:
ndb_mgm> ALL CLUSTERLOG STATISTICS=15
将阈值设置为
STATISTICS
15会导致群集日志变得非常冗长,并且增长速度非常快,与群集节点数量和NDB群集中的活动量成正比。
有关与日志记录和报告相关的NDB群集管理客户端命令的更多信息,请参见 第22.5.6.1节“NDB群集日志记录管理命令” 。
本节包含有关写入群集日志以响应不同群集日志事件的消息的信息。
它提供有关
NDB
运输车错误的
其他更具体的信息
。
下表列出了最常见的
NDB
群集日志消息。
有关群集日志,日志事件和事件类型的信息,请参见
第22.5.6节“在NDB群集中生成的事件报告”
。
这些日志消息也对应于MGM API中的日志事件类型;
有关Cluster API开发人员感兴趣的相关信息,
请参阅
Ndb_logevent_type类型
。
表22.373常见的NDB集群日志消息
| 日志消息 | 描述 | 活动名称 | 事件类型 | 优先 | 严重 |
|---|---|---|---|---|---|
Node |
具有节点ID的数据节点
node_id
已连接到管理服务器(节点
mgm_node_id
)。
|
Connected |
Connection |
8 | INFO |
Node |
具有节点ID的数据节点
data_node_id
已与管理服务器(节点
mgm_node_id
)
断开连接
。
|
Disconnected |
Connection |
8 | ALERT |
Node |
具有节点ID的API节点或SQL节点
api_node_id
不再与数据节点通信
data_node_id
。
|
CommunicationClosed |
Connection |
8 | INFO |
Node |
具有节点ID的API节点或SQL节点
api_node_id
现在正在与数据节点通信
data_node_id
。
|
CommunicationOpened |
Connection |
8 | INFO |
Node |
具有节点ID的API节点
使用
API版本
api_node_id
连接到管理节点
(通常与MySQL版本号相同)。
mgm_node_id
NDB
version
|
ConnectedApiVersion |
Connection |
8 | INFO |
Node |
gci
已启动
带有ID的全局检查点
;
node
node_id
是负责此全局检查点的主服务器。
|
GlobalCheckpointStarted |
Checkpoint |
9 | INFO |
Node |
gci
已完成
具有该ID的全球检查点
;
node
node_id
是负责此全局检查点的主服务器。
|
GlobalCheckpointCompleted |
Checkpoint |
10 | INFO |
Node |
lcp
已在节点上启动
具有序列ID的本地检查
点
node_id
。
可以使用的最新GCI具有索引
current_gci
,并且可以从中恢复群集的最旧GCI具有索引
old_gci
。
|
LocalCheckpointStarted |
Checkpoint |
7 | INFO |
Node |
lcp
节点
node_id
上
具有序列ID的本地检查点
已完成。
|
LocalCheckpointCompleted |
Checkpoint |
8 | INFO |
Node |
节点无法确定最近可用的GCI。 | LCPStoppedInCalcKeepGci |
Checkpoint |
0 | ALERT |
Node |
已将表片段检查点到节点上的磁盘
node_id
。
正在进行的GCI具有索引
started_gci
,并且已完成的最新GCI具有索引
completed_gci
。
|
LCPFragmentCompleted |
Checkpoint |
11 | INFO |
Node |
撤消日志记录被阻止,因为日志缓冲区接近溢出。 | UndoLogBlocked |
Checkpoint |
7 | INFO |
Node |
node_id
运行
NDB
版本的
数据节点
version
正在开始其启动过程。
|
NDBStartStarted |
StartUp |
1 | INFO |
Node |
node_id
运行
NDB
版本的
数据节点
version
已成功启动。
|
NDBStartCompleted |
StartUp |
1 | INFO |
Node |
节点已收到指示群集重新启动已完成的信号。 | STTORRYRecieved |
StartUp |
15 | INFO |
Node |
该节点已完成启动阶段
phase
一的
type
开始。
有关启动阶段的列表,请参见
第22.5.1节“NDB集群启动阶段摘要”
。
(
type
是的一个
initial
,
system
,
node
,
initial node
,或
<Unknown>
。)
|
StartPhaseCompleted |
StartUp |
4 | INFO |
Node |
节点
president_id
已被选为
“
总统
”
。
own_id
并且
dynamic_id
应始终
node_id
与报告节点
的ID(
)
相同
。
|
CM_REGCONF |
StartUp |
3 | INFO |
Node |
报告节点(ID
node_id
)无法接受节点
president_id
作为总裁。
该
cause
问题给出的一个
Busy
,
Election with wait = false
,
Not president
,
Election
without selecting new candidate
,或
No
such cause
。
|
CM_REGREF |
StartUp |
8 | INFO |
Node |
节点已在群集(节点
id_1
和节点
id_2
)中
发现其相邻节点
。
node_id
,
own_id
并且
dynamic_id
应该始终如一;
如果不是,则表示群集节点严重错误配置。
|
FIND_NEIGHBOURS |
StartUp |
8 | INFO |
Node |
节点已收到关闭信号。
的
type
关闭的或者是
Cluster
或
Node
。
|
NDBStopStarted |
StartUp |
1 | INFO |
Node
[
] [
]
,
Initiated by signal
|
该节点已关闭。
该报告可以包括
action
,其如果存在的话是一个
restarting
,
no
start
或
initial
。
该报告还可能包括对
NDB
议定书
的提及
signal
;
有关可能的信号,请参阅
操作和信号
。
|
NDBStopCompleted |
StartUp |
1 | INFO |
Node
[
,
action
]
.
[
] [
] [
[
]]
Occurred
during startphase
Initiated by
Caused by error
(extra info
|
该节点已被强制关闭。
的
action
(之一
restarting
,
no
start
或
initial
)随后被采取,如果有的话,也有报道。
如果在节点启动时发生关闭,则报告将包括
start_phase
节点失败的时间段。
如果这是
signal
发送到节点
的结果,
则还会提供此信息(
有关详细信息,
请参阅
操作和信号
)。
如果导致失败的错误已知,则还包括此错误;
有关
NDB
错误消息和分类的
详细信息
,请参阅
NDB Cluster API错误
。
|
NDBStopForced |
StartUp |
1 | ALERT |
Node |
用户中止了节点关闭过程。 | NDBStopAborted |
StartUp |
1 | INFO |
Node |
这将报告节点启动期间引用的全局检查点。
之前的重做日志
keep_pos
被删除。
last_pos
是参与的数据节点的最后一个全局检查点;
restore_pos
是实际用于还原所有数据节点的全局检查点。
|
StartREDOLog |
StartUp |
4 | INFO |
startup_message
[
单独列出;
见下文。
]
|
在不同情况下可以记录许多可能的启动消息。 这些是单独列出的; 请参见 第22.5.7.2节“NDB集群日志启动消息” 。 | StartReport |
StartUp |
4 | INFO |
Node |
已完成将数据字典信息复制到重新启动的节点。 | NR_CopyDict |
NodeRestart |
8 | INFO |
Node |
已完成将数据分发信息复制到重新启动的节点。 | NR_CopyDistr |
NodeRestart |
8 | INFO |
Node |
node_id
已开始
将片段复制到起始数据节点
|
NR_CopyFragsStarted |
NodeRestart |
8 | INFO |
Node |
fragment_id
表
table_id
中的
片段
已复制到数据节点
node_id
|
NR_CopyFragDone |
NodeRestart |
10 | INFO |
Node |
node_id
已完成
将所有表片段复制到重新启动数据节点
|
NR_CopyFragsCompleted |
NodeRestart |
8 | INFO |
Node |
数据节点
node1_id
检测到
数据节点
的故障
node2_id
|
NodeFailCompleted |
NodeRestart |
8 | ALERT |
All nodes completed failure of Node
|
所有(剩余的)数据节点都检测到数据节点的故障
node_id
|
NodeFailCompleted |
NodeRestart |
8 | ALERT |
Node failure of
|
数据节点的故障
node_id
已在被检测
的内核块,其中块是1
,
,
,或
;
有关更多信息,请参阅
NDB内核块
blockNDB
DBTC
DBDICT
DBDIH
DBLQH
|
NodeFailCompleted |
NodeRestart |
8 | ALERT |
Node |
数据节点已失败。
它在故障时的状态由仲裁状态代码描述
state_code
:可以在文件中找到可能的状态代码值
include/kernel/signaldata/ArbitSignalData.hpp
。
|
NODE_FAILREP |
NodeRestart |
8 | ALERT |
President restarts arbitration thread
[state=
或
或
或
或
或
或
Prepare arbitrator node
Receive arbitrator node
Started arbitrator node
Lost arbitrator node
Lost arbitrator node
Lost arbitrator node
|
这是关于集群中仲裁的现状和进展的报告。
node_id
是选择作为仲裁程序的管理节点或SQL节点的节点ID。
state_code
是一个仲裁状态代码,见于
include/kernel/signaldata/ArbitSignalData.hpp
。
发生错误时,
error_message
还会
ArbitSignalData.hpp
提供
一个
也定义
为的错误
。
ticket_id
是仲裁员选择参与其选择的所有节点时发出的唯一标识符;
这用于确保请求仲裁的每个节点都是参与选择过程的节点之一。
|
ArbitState |
NodeRestart |
6 | INFO |
Arbitration check lost - less than 1/2 nodes left
或
Arbitration check won - all node groups and more
than 1/2 nodes left
或
Arbitration
check won - node group majority
或
Arbitration check lost - missing node
group
或
Network partitioning -
arbitration required
或
或
或
或
或
Arbitration won
- positive reply from node
Arbitration lost - negative reply from
node
Network partitioning - no arbitrator
available
Network partitioning - no
arbitrator configured
Arbitration
failure -
|
该消息报告仲裁结果。
如果仲裁失败,
则提供
error_message
仲裁和仲裁
state_code
;
两者的定义见于
include/kernel/signaldata/ArbitSignalData.hpp
。
|
ArbitResult |
NodeRestart |
2 | ALERT |
Node |
此节点正在尝试承担下一个全局检查点的责任(即,它正在成为主节点) | GCP_TakeoverStarted |
NodeRestart |
7 | INFO |
Node |
此节点已成为主节点,并承担下一个全局检查点的责任 | GCP_TakeoverCompleted |
NodeRestart |
7 | INFO |
Node |
此节点正在尝试承担下一组本地检查点的责任(即,它正在成为主节点) | LCP_TakeoverStarted |
NodeRestart |
7 | INFO |
Node |
该节点已成为主节点,并承担了下一组本地检查点的责任 | LCP_TakeoverCompleted |
NodeRestart |
7 | INFO |
Node |
此交易活动报告大约每10秒发布一次 | TransReportCounters |
Statistic |
8 | INFO |
Node |
此节点执行的操作数,大约每10秒提供一次 | OperationReportCounters |
Statistic |
8 | INFO |
Node |
已创建具有所示表ID的表 | TableCreated |
Statistic |
7 | INFO |
Node |
JobStatistic |
Statistic |
9 | INFO |
|
Mean send size to Node = |
此节点将
bytes
每个
发送的平均
字节数发送到节点
node_id
|
SendBytesStatistic |
Statistic |
9 | INFO |
Mean receive size to Node = |
bytes
每次从节点接收数据时,
此节点都会接收平均
数据
node_id
|
ReceiveBytesStatistic |
Statistic |
9 | INFO |
Node
/
Node
|
DUMP
1000
在集群管理客户端中发出命令
时生成此报告
;
有关详细信息,请参阅
DUMP 1000
,在
MySQL的NDB簇内幕手册
|
MemoryUsage |
Statistic |
五 | INFO |
Node |
与节点通信时发生传输器错误
node2_id
;
对于转运错误代码和消息的列表,请参阅
NDB运输车错误
,在
MySQL的NDB簇内幕手册
|
TransporterError |
Error |
2 | ERROR |
Node |
在与节点通信时警告潜在的运输者问题
node2_id
;
有关传输程序错误代码和消息的列表,请参阅
NDB传输程序错误
,以获取更多信息
|
TransporterWarning |
Error |
8 | WARNING |
Node |
此节点错过了节点的心跳
node2_id
|
MissedHeartbeat |
Error |
8 | WARNING |
Node |
此节点已从节点错过至少3个心跳
node2_id
,因此声明该节点
“
已死
”
|
DeadDueToHeartbeat |
Error |
8 | ALERT |
Node |
此节点已向节点发送心跳
node2_id
|
SentHeartbeat |
Info |
12 | INFO |
Node |
在重度事件缓冲区使用期间可以看到此报告,例如,在相对较短的时间段内应用许多更新时; 报告显示了字节数和使用的事件缓冲区内存百分比,分配的字节数和仍然可用的百分比,以及最新的缓冲和消耗时期; 有关更多信息,请参见 第22.5.7.3节“群集日志中的事件缓冲区报告” | EventBufferStatus2 |
Info |
7 | INFO |
Node
,
,
Node
Node
|
进入和退出单用户模式时,这些报告将写入群集日志;
API_node_id
是具有对集群的独占访问权限的API或SQL的节点ID(有关更多信息,请参见
第22.5.8节“NDB集群单用户模式”
);
该消息
表明发生了错误,在正常操作中永远不应该看到
Unknown single user report
|
SingleUser |
Info |
7 | INFO |
Node |
已使用具有以下管理节点的管理节点启动备份
mgm_node_id
;
START BACKUP
发出命令
时,此消息也会显示在集群管理客户端中
;
有关更多信息,请参见
第22.5.3.2节“使用NDB群集管理客户端创建备份”
|
BackupStarted |
Backup |
7 | INFO |
Node |
backup_id
已完成
具有ID的备份
;
有关更多信息,请参见
第22.5.3.2节“使用NDB群集管理客户端创建备份”
|
BackupCompleted |
Backup |
7 | INFO |
Node |
备份无法启动; 有关错误代码,请参阅 MGM API错误 | BackupFailedToStart |
Backup |
7 | ALERT |
Node |
备份在启动后终止,可能是由于用户干预 | BackupAborted |
Backup |
7 | ALERT |
以下列表中提供了带有描述的可能启动消息:
-
Initial start, waiting for %s to connect, nodes [ all: %s connected: %s no-wait: %s ] -
Waiting until nodes: %s connects, nodes [ all: %s connected: %s no-wait: %s ] -
Waiting %u sec for nodes %s to connect, nodes [ all: %s connected: %s no-wait: %s ] -
Waiting for non partitioned start, nodes [ all: %s connected: %s missing: %s no-wait: %s ] -
Waiting %u sec for non partitioned start, nodes [ all: %s connected: %s missing: %s no-wait: %s ] -
Initial start with nodes %s [ missing: %s no-wait: %s ] -
Start with all nodes %s -
Start with nodes %s [ missing: %s no-wait: %s ] -
Start potentially partitioned with nodes %s [ missing: %s no-wait: %s ] -
Unknown startreport: 0x%x [ %s %s %s %s ]
NDB
对从数据节点接收的事件使用一个或多个内存缓冲区。
Ndb
订阅表事件的
每个
对象
都有一个这样的缓冲区
,这意味着每个
mysqld
通常有两个缓冲区
执行二进制日志记录
(一个缓冲区用于模式事件,一个缓冲区用于数据事件)。
每个缓冲区包含由事件组成的时期。
这些事件包括操作类型(插入,更新,删除)和行数据(图像之前和之后加上元数据)。
NDB
在集群日志中生成消息以描述这些缓冲区的状态。
尽管这些报告显示在群集日志中,但它们引用API节点上的缓冲区(与大多数其他群集日志消息不同,这些消息由数据节点生成)。
群集日志中的事件缓冲区日志记录报告使用此处显示的格式:
节点node_id:事件缓冲区状态(object_id): used =bytes_used(percent_used%的%) alloc =bytes_allocated(percent_alloc最大%)max =bytes_availablelatest_consumed_epoch =latest_consumed_epochlatest_buffered_epoch =latest_buffered_epochreport_reason =report_reason
此处列出了构成此报告的字段,并附有说明:
-
node_id:报告发起的节点的ID。 -
object_id:Ndb报告发起 的 对象的 ID 。 -
bytes_used:缓冲区使用的字节数。 -
percent_used:使用的分配字节的百分比。 -
bytes_allocated:分配给此缓冲区的字节数。 -
percent_alloc:使用的可用字节百分比; 如果ndb_eventbuffer_max_alloc等于0(无限制), 则不打印 。 -
bytes_available:可用字节数; 如果ndb_eventbuffer_max_alloc为0(无限制),则为0。 -
latest_consumed_epoch:最近消耗完成的时代。 (在NDB API应用程序中,这是通过调用完成的nextEvent()。) -
latest_buffered_epoch:最近缓冲(完全)在事件缓冲区中的纪元。 -
report_reason:报告的原因。 可能的原因将在本节后面部分中介绍。
报告的可能原因在以下列表中描述:
-
ENOUGH_FREE_EVENTBUFFER:事件缓冲区有足够的空间。LOW_FREE_EVENTBUFFER:事件缓冲区的可用空间不足。可以通过设置
ndb_report_thresh_binlog_mem_usage服务器变量 来调整触发这些报告的阈值可用百分比级别 。 -
BUFFERED_EPOCHS_OVER_THRESHOLD:缓冲的纪元数是否超过配置的阈值。 此数字是整个收到的最新纪元与最近消耗的纪元之间的差异(在NDB API应用程序中,这是通过调用nextEvent()或 完成nextEvent2())。 报告每秒生成一次,直到缓冲的纪元数低于阈值,可以通过设置ndb_report_thresh_binlog_epoch_slip服务器变量 来调整 。 您还可以通过调用来调整NDB API应用程序中的阈值setEventBufferQueueEmptyEpoch()。 -
PARTIALLY_DISCARDING:事件缓冲区内存已耗尽 -ndb_eventbuffer_max_alloc即已使用 100% 。 即使使用率超过100%,任何部分缓冲的时期也会被缓冲完成,但是所有接收到的新时期都将被丢弃。 这意味着事件流中出现了间隙。 -
COMPLETELY_DISCARDING:没有缓冲时期。 -
PARTIALLY_BUFFERING:间隙后的缓冲区可用百分比已上升到阈值,可以 使用 服务器系统变量 在 mysql 客户端中 设置,也可以ndb_eventbuffer_free_percent通过调用在NDB API应用程序中设置set_eventbuffer_free_percent()。 新纪元被缓冲。 由于间隙而无法完成的时期被丢弃。 -
COMPLETELY_BUFFERING:收到的所有时期都被缓冲,这意味着有足够的事件缓冲存储器。 事件流中的差距已经关闭。
本节列出了在传输程序错误的情况下写入群集日志的错误代码,名称和消息。
表22.374传输器错误生成的错误代码
| 错误代码 | 错误名称 | 错误文字 |
|---|---|---|
| 为0x00 | TE_NO_ERROR | 没错 |
| 0×01 | TE_ERROR_CLOSING_SOCKET | 在关闭套接字时发现错误 |
| 0×02 | TE_ERROR_IN_SELECT_BEFORE_ACCEPT | 接受之前发现错误。 运输商将重试 |
| ×03 | TE_INVALID_MESSAGE_LENGTH | 消息中发现错误(消息长度无效) |
| 0×04 | TE_INVALID_CHECKSUM | 消息(校验和)中发现错误 |
| 0×05 | TE_COULD_NOT_CREATE_SOCKET | 创建套接字时发现错误(无法创建套接字) |
| 0×06 | TE_COULD_NOT_BIND_SOCKET | 绑定服务器套接字时发现错误 |
| 0×07 | TE_LISTEN_FAILED | 收听服务器套接字时发现错误 |
| 0x08的 | TE_ACCEPT_RETURN_ERROR | 接受期间发现错误(接受返回错误) |
| 0x0B中 | TE_SHM_DISCONNECT | 远程节点已断开连接 |
| 0x0c | TE_SHM_IPC_STAT | 无法检查shm段 |
| 0X0D | TE_SHM_UNABLE_TO_CREATE_SEGMENT | 无法创建shm段 |
| 为0x0E | TE_SHM_UNABLE_TO_ATTACH_SEGMENT | 无法附加shm段 |
| 为0x0F | TE_SHM_UNABLE_TO_REMOVE_SEGMENT | 无法删除shm段 |
| 为0x10 | TE_TOO_SMALL_SIGID | Sig ID太小了 |
| 为0x11 | TE_TOO_LARGE_SIGID | Sig ID太大了 |
| 0×12 | TE_WAIT_STACK_FULL | 等待堆栈已满 |
| 0×13 | TE_RECEIVE_BUFFER_FULL | 接收缓冲区已满 |
| 0×14 | TE_SIGNAL_LOST_SEND_BUFFER_FULL | 发送缓冲区已满,尝试强制发送失败 |
| 为0x15 | TE_SIGNAL_LOST | 发送失败原因不明(信号丢失) |
| 0x16 | TE_SEND_BUFFER_FULL | 发送缓冲区已满,但已经解决了一段时间 |
| 0x0017 | TE_SCI_LINK_ERROR | 此节点与交换机之间没有链接 |
| 为0x18 | TE_SCI_UNABLE_TO_START_SEQUENCE | 无法启动序列,因为系统资源已被删除或未创建任何序列 |
| 0x19 | TE_SCI_UNABLE_TO_REMOVE_SEQUENCE | 无法删除序列 |
| 0X1A | TE_SCI_UNABLE_TO_CREATE_SEQUENCE | 无法创建序列,因为系统资源是免除的。 必须重启 |
| 0x1b | TE_SCI_UNRECOVERABLE_DATA_TFX_ERROR | 试图在冗余链路上发送数据但失败了 |
| 为0x1C | TE_SCI_CANNOT_INIT_LOCALSEGMENT | 无法初始化本地细分 |
| 0x1d | TE_SCI_CANNOT_MAP_REMOTESEGMENT | 无法映射远程段 |
| 0X1E | TE_SCI_UNABLE_TO_UNMAP_SEGMENT | 无法释放此段使用的资源(步骤1) |
| 为0x1F | TE_SCI_UNABLE_TO_REMOVE_SEGMENT | 无法释放此细分使用的资源(步骤2) |
| 为0x20 | TE_SCI_UNABLE_TO_DISCONNECT_SEGMENT | 无法断开与远程网段的连接 |
| 为0x21 | TE_SHM_IPC_PERMANENT | shm ipc永久错误 |
| 为0x22 | TE_SCI_UNABLE_TO_CLOSE_CHANNEL | 无法关闭sci通道和分配的资源 |
单用户模式 使数据库管理员可以将对数据库系统的访问限制为单个API节点,例如MySQL服务器(SQL节点)或 ndb_restore 的实例 。 进入单用户模式时,将正常关闭与所有其他API节点的连接,并中止所有正在运行的事务。 不允许新的交易开始。
群集进入单用户模式后,只有指定的API节点被授予对数据库的访问权限。
您可以使用
ndb_mgm
客户端中
的
ALL STATUS
命令
查看群集何时进入单用户模式。
您还可以检查
表
的
列
(
有关更多信息,
请参见
第22.5.10.28节“ndbinfo节点表”
)。
status
ndbinfo.nodes
例:
ndb_mgm> ENTER SINGLE USER MODE 5
执行此命令并且集群已进入单用户模式后,其节点ID
5
成为集群唯一允许用户
的API节点
。
上述命令中指定的节点必须是API节点; 尝试指定任何其他类型的节点将被拒绝。
调用上述命令时,将中止在指定节点上运行的所有事务,关闭连接,并且必须重新启动服务器。
该命令
EXIT SINGLE USER MODE
将群集的数据节点的状态从单用户模式更改为正常模式。
API节点 - 例如MySQL服务器 - 等待连接(即,等待群集准备就绪并可用),再次被允许连接。
表示为单用户节点的API节点在状态更改期间和之后继续运行(如果仍然连接)。
例:
ndb_mgm> EXIT SINGLE USER MODE
在单用户模式下运行时,有两种推荐的方法可以处理节点故障:
-
方法1:
-
完成所有单用户模式事务
-
发出
EXIT SINGLE USER MODE命令 -
重新启动集群的数据节点
-
-
方法2:
在进入单用户模式之前重新启动存储节点。
本节讨论几个可用于管理和监视连接到NDB群集的MySQL服务器的SQL语句,并在某些情况下提供有关群集本身的信息。
-
SHOW ENGINE NDB STATUS,SHOW ENGINE NDBCLUSTER STATUS此语句的输出包含有关服务器与群集的连接,NDB群集对象的创建和使用以及NDB群集复制的二进制日志记录的信息。
有关 用法示例和更多详细信息 , 请参见 第13.7.6.15节“SHOW ENGINE语法” 。
-
此语句可用于确定是否在MySQL服务器中启用了群集支持,如果是,则确定它是否处于活动状态。
有关 更多详细信息, 请参见 第13.7.6.16节“显示发动机语法” 。
注意本声明不支持
LIKE条款。 但是,您可以使用LIKE过滤INFORMATION_SCHEMA.ENGINES表的 查询 ,如下一项中所述。 -
SELECT * FROM INFORMATION_SCHEMA.ENGINES [WHERE ENGINE LIKE 'NDB%']这相当于
SHOW ENGINES,但使用 数据库 的ENGINES表INFORMATION_SCHEMA。 与SHOW ENGINES语句 的情况不同 ,可以使用LIKE子句 过滤结果 ,并选择特定列以获取可能在脚本中使用的信息。 例如,以下查询显示服务器是否使用NDB支持 构建 ,如果是,则是否已启用:mysql>
SELECT SUPPORT FROM INFORMATION_SCHEMA.ENGINES- >WHERE ENGINE LIKE 'NDB%';+ --------- + | 支持| + --------- + | 启用| + --------- +有关 更多信息 , 请参见 第25.9节“INFORMATION_SCHEMA ENGINES表” 。
-
此语句提供与
NDB存储引擎 相关的大多数服务器系统变量 及其值的列表,如下所示:MySQL的>
SHOW VARIABLES LIKE 'NDB%';+ ------------------------------- + ------- + | Variable_name | 价值| + ------------------------------- + ------- + | ndb_autoincrement_prefetch_sz | 32 | | ndb_cache_check_time | 0 | | ndb_extra_logging | 0 | | ndb_force_send | ON | | ndb_index_stat_cache_entries | 32 | | ndb_index_stat_enable | 关闭| | ndb_index_stat_update_freq | 20 | | ndb_report_thresh_binlog_epoch_slip | 3 | | ndb_report_thresh_binlog_mem_usage | 10 | | ndb_use_copying_alter_table | 关闭| | ndb_use_exact_count | ON | | ndb_use_transactions | ON | + ------------------------------- + ------- +有关 更多信息 , 请参见 第5.1.8节“服务器系统变量” 。
-
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES WHERE VARIABLE_NAME LIKE 'NDB%';此语句相当于
SHOW前一项中描述 的 命令,并提供几乎相同的输出,如下所示:mysql>
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES- >WHERE VARIABLE_NAME LIKE 'NDB%';+ ------------------------------- + ----------- ----- + | VARIABLE_NAME | VARIABLE_VALUE | + ------------------------------- + ----------- ----- + | NDB_AUTOINCREMENT_PREFETCH_SZ | 32 | | NDB_CACHE_CHECK_TIME | 0 | | NDB_EXTRA_LOGGING | 0 | | NDB_FORCE_SEND | ON | | NDB_INDEX_STAT_CACHE_ENTRIES | 32 | | NDB_INDEX_STAT_ENABLE | 关闭| | NDB_INDEX_STAT_UPDATE_FREQ | 20 | | NDB_REPORT_THRESH_BINLOG_EPOCH_SLIP | 3 | | NDB_REPORT_THRESH_BINLOG_MEM_USAGE | 10 | | NDB_USE_COPYING_ALTER_TABLE | 关闭| | NDB_USE_EXACT_COUNT | ON | | NDB_USE_TRANSACTIONS | ON | + ------------------------------- + ----------- ----- +与
SHOW命令 的情况不同 ,可以选择单个列。 例如:mysql>
SELECT VARIABLE_VALUE- >FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES- >WHERE VARIABLE_NAME = 'ndb_force_send';+ ---------------- + | VARIABLE_VALUE | + ---------------- + | ON | + ---------------- +有关详细 信息, 请参阅 INFORMATION_SCHEMA GLOBAL_VARIABLES和SESSION_VARIABLES表 以及 第5.1.8节“服务器系统变量” 。
-
此语句一目了然地显示MySQL服务器是否充当集群SQL节点,如果是,它提供MySQL服务器的集群节点ID,与其连接的集群管理服务器的主机名和端口,以及集群中的数据节点数量,如下所示:
MySQL的>
SHOW STATUS LIKE 'NDB%';+ -------------------------- + ---------------- + | Variable_name | 价值| + -------------------------- + ---------------- + | Ndb_cluster_node_id | 10 | | Ndb_config_from_host | 198.51.100.103 | | Ndb_config_from_port | 1186 | | Ndb_number_of_data_nodes | 4 | + -------------------------- + ---------------- +如果MySQL服务器是使用群集支持构建的,但它没有连接到群集,则此语句的输出中的所有行都包含零或空字符串:
MySQL的>
SHOW STATUS LIKE 'NDB%';+ -------------------------- + ------- + | Variable_name | 价值| + -------------------------- + ------- + | Ndb_cluster_node_id | 0 | | Ndb_config_from_host | | | Ndb_config_from_port | 0 | | Ndb_number_of_data_nodes | 0 | + -------------------------- + ------- +另请参见 第13.7.6.35节“显示状态语法” 。
-
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_STATUS WHERE VARIABLE_NAME LIKE 'NDB%';此语句提供与
SHOW前一项中讨论 的 命令 类似的输出 。 但是,与使用的情况不同SHOW STATUS,可以使用SELECTSQL中的值来提取脚本中的值以用于监视和自动化目的。有关 详细信息, 请参阅 INFORMATION_SCHEMA GLOBAL_STATUS和SESSION_STATUS表 。
您还可以在
ndbinfo
信息数据库中
查询
有关许多NDB群集操作的实时数据
的表
。
请参见
第22.5.10节“ndbinfo:NDB集群信息数据库”
。
- 22.5.10.1 ndbinfo arbitrator_validity_detail表
- 22.5.10.2 ndbinfo arbitrator_validity_summary表
- 22.5.10.3 ndbinfo块表
- 22.5.10.4 ndbinfo cluster_locks表
- 22.5.10.5 ndbinfo cluster_operations表
- 22.5.10.6 ndbinfo cluster_transactions表
- 22.5.10.7 ndbinfo config_nodes表
- 22.5.10.8 ndbinfo config_params表
- 22.5.10.9 ndbinfo config_values表
- 22.5.10.10 ndbinfo计数器表
- 22.5.10.11 ndbinfo cpustat表
- 22.5.10.12 ndbinfo cpustat_50ms表
- 22.5.10.13 ndbinfo cpustat_1sec表
- 22.5.10.14 ndbinfo cpustat_20sec表
- 22.5.10.15 ndbinfo dict_obj_info表
- 22.5.10.16 ndbinfo dict_obj_types表
- 22.5.10.17 ndbinfo disk_write_speed_base表
- 22.5.10.18 ndbinfo disk_write_speed_aggregate表
- 22.5.10.19 ndbinfo disk_write_speed_aggregate_node表
- 22.5.10.20 ndbinfo diskpagebuffer表
- 22.5.10.21 ndbinfo error_messages表
- 22.5.10.22 ndbinfo locks_per_fragment表
- 22.5.10.23 ndbinfo日志缓冲表
- 22.5.10.24 ndbinfo日志空间表
- 22.5.10.25 ndbinfo成员资格表
- 22.5.10.26 ndbinfo memoryusage表
- 22.5.10.27 ndbinfo memory_per_fragment表
- 22.5.10.28 ndbinfo节点表
- 22.5.10.29 ndbinfo operations_per_fragment表
- 22.5.10.30 ndbinfo进程表
- 22.5.10.31 ndbinfo资源表
- 22.5.10.32 ndbinfo restart_info表
- 22.5.10.33 ndbinfo server_locks表
- 22.5.10.34 ndbinfo server_operations表
- 22.5.10.35 ndbinfo server_transactions表
- 22.5.10.36 ndbinfo table_distribution_status表
- 22.5.10.37 ndbinfo table_fragments表
- 22.5.10.38 ndbinfo table_info表
- 22.5.10.39 ndbinfo table_replicas表
- 22.5.10.40 ndbinfo tc_time_track_stats表
- 22.5.10.41 ndbinfo threadblocks表
- 22.5.10.42 ndbinfo线程表
- 22.5.10.43 ndbinfo threadstat表
- 22.5.10.44 ndbinfo传输器表
ndbinfo
是一个包含特定于NDB Cluster的信息的数据库。
此数据库包含许多表,每个表提供有关NDB群集节点状态,资源使用情况和操作的不同类型的数据。 您可以在接下来的几个部分中找到有关每个表的更多详细信息。
ndbinfo
包含在MySQL服务器中的NDB Cluster支持;
不需要特殊的编译或配置步骤;
这些表是由MySQL服务器连接到集群时创建的。
您可以使用以下命令验证
ndbinfo
给定MySQL Server实例中的支持是否处于活动状态
SHOW
PLUGINS
;
如果
ndbinfo
支持已启用,您应该看到一个包含一行
ndbinfo
在
Name
列,并
ACTIVE
在
Status
列,如下所示(强调文本):
MySQL的> SHOW PLUGINS;
+ ---------------------------------- + -------- + ----- --------------- + --------- + --------- +
| 名称| 状态| 输入| 图书馆| 许可证|
+ ---------------------------------- + -------- + ----- --------------- + --------- + --------- +
| binlog | ACTIVE | 存储引擎| NULL | GPL |
| mysql_native_password | ACTIVE | 认证| NULL | GPL |
| sha256_password | ACTIVE | 认证| NULL | GPL |
| MRG_MYISAM | ACTIVE | 存储引擎| NULL | GPL |
| 记忆| ACTIVE | 存储引擎| NULL | GPL |
| CSV | ACTIVE | 存储引擎| NULL | GPL |
| MyISAM | ACTIVE | 存储引擎| NULL | GPL |
| InnoDB | ACTIVE | 存储引擎| NULL | GPL |
| INNODB_TRX | ACTIVE | 信息模式| NULL | GPL |
| INNODB_LOCKS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_LOCK_WAITS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMP | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMP_RESET | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMPMEM | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMPMEM_RESET | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMP_PER_INDEX | ACTIVE | 信息模式| NULL | GPL |
| INNODB_CMP_PER_INDEX_RESET | ACTIVE | 信息模式| NULL | GPL |
| INNODB_BUFFER_PAGE | ACTIVE | 信息模式| NULL | GPL |
| INNODB_BUFFER_PAGE_LRU | ACTIVE | 信息模式| NULL | GPL |
| INNODB_BUFFER_POOL_STATS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_TEMP_TABLE_INFO | ACTIVE | 信息模式| NULL | GPL |
| INNODB_METRICS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_DEFAULT_STOPWORD | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_DELETED | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_BEING_DELETED | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_CONFIG | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_INDEX_CACHE | ACTIVE | 信息模式| NULL | GPL |
| INNODB_FT_INDEX_TABLE | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_TABLES | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_TABLESTATS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_INDEXES | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_COLUMNS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_FIELDS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_FOREIGN | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_FOREIGN_COLS | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_TABLESPACES | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_DATAFILES | ACTIVE | 信息模式| NULL | GPL |
| INNODB_SYS_VIRTUAL | ACTIVE | 信息模式| NULL | GPL |
| PERFORMANCE_SCHEMA | ACTIVE | 存储引擎| NULL | GPL |
| ndbCluster | ACTIVE | 存储引擎| NULL | GPL |
| ndbinfo | ACTIVE | 存储引擎| NULL | GPL |
| ndb_transid_mysql_connection_map | ACTIVE | 信息模式| NULL | GPL |
| BLACKHOLE | ACTIVE | 存储引擎| NULL | GPL |
| 存档| ACTIVE | 存储引擎| NULL | GPL |
| 分区| ACTIVE | 存储引擎| NULL | GPL |
| ngram | ACTIVE | FTPARSER | NULL | GPL |
+ ---------------------------------- + -------- + ----- --------------- + --------- + --------- +
46行(0.00秒)
您也可以通过检查
SHOW
ENGINES
包含
ndbinfo
在
Engine
列和列
YES
中的
行
的输出来执行此操作
Support
,如此处所示(强调文本):
MySQL的> SHOW ENGINES\G
*************************** 1。排******************** *******
引擎:ndbcluster
支持:是的
注释:集群,容错表
交易:YES
XA:没有
保存点:没有
*************************** 2.排******************** *******
引擎:CSV
支持:是的
评论:CSV存储引擎
交易:NO
XA:没有
保存点:没有
*************************** 3。排******************** *******
引擎:InnoDB
支持:默认
注释:支持事务,行级锁定和外键
交易:YES
XA:是的
保存点:是
****************************排******************** *******
发动机:BLACKHOLE
支持:是的
评论:/ dev / null存储引擎(你写的东西都消失了)
交易:NO
XA:没有
保存点:没有
****************************排******************** *******
引擎:MyISAM
支持:是的
评论:MyISAM存储引擎
交易:NO
XA:没有
保存点:没有
*************************** 6.排******************** *******
发动机:MRG_MYISAM
支持:是的
评论:收集相同的MyISAM表
交易:NO
XA:没有
保存点:没有
*************************** 7.排******************** *******
引擎:存档
支持:是的
评论:归档存储引擎
交易:NO
XA:没有
保存点:没有
*************************** 8.排******************** *******
引擎:ndbinfo
支持:是的
评论:NDB Cluster系统信息存储引擎
交易:NO
XA:没有
保存点:没有
*************************** 9。排******************** *******
引擎:PERFORMANCE_SCHEMA
支持:是的
评论:性能架构
交易:NO
XA:没有
保存点:没有
*************************** 10.排******************** *******
发动机:记忆
支持:是的
注释:基于哈希,存储在内存中,对临时表有用
交易:NO
XA:没有
保存点:没有
10行(0.00秒)
如果
ndbinfo
启用了支持,则可以
ndbinfo
使用
mysql
或其他MySQL客户端中的
SQL语句进行
访问
。
例如,您可以看到
ndbinfo
输出中列出的
SHOW DATABASES
,如此处所示(强调文本):
MySQL的> SHOW DATABASES;
+ -------------------- +
| 数据库|
+ -------------------- +
| information_schema |
| mysql |
| ndbinfo |
| performance_schema |
| sys |
+ -------------------- +
5行(0.04秒)
如果
mysqld
进程未使用该
--ndbcluster
选项
启动
,
ndbinfo
则不可用且不显示
SHOW DATABASES
。
如果
mysqld
以前连接到NDB群集但群集变得不可用(由于诸如群集关闭,网络连接丢失等事件),
ndbinfo
并且其表仍然可见,但尝试访问任何表(除了
blocks
或之外)
config_params
)
来自NDBINFO的Got错误157'连接到NDB失败'失败
。
除了
blocks
和
config_params
表之外,我们称之为
ndbinfo
“
表
”
的实际上是从内部
NDB
表
生成的视图,这些
表通常对MySQL服务器不可见。
所有
ndbinfo
表都是只读的,并在查询时按需生成。
由于其中许多是由数据节点并行生成的,而其他特定于给定SQL节点,因此无法保证它们提供一致的快照。
此外,
ndbinfo
表格
不支持按下连接
;
因此
ndbinfo
,即使查询使用了
WHERE
子句
,连接大型
表也可能需要将大量数据传输到请求API节点
。
ndbinfo
表不包含在查询缓存中。
(Bug#59831)
您可以
ndbinfo
使用
USE
语句
选择
数据库
,然后发出
SHOW
TABLES
语句以获取表的列表,就像对于任何其他数据库一样,如下所示:
MySQL的>USE ndbinfo;数据库已更改 MySQL的>SHOW TABLES;+ --------------------------------- + | Tables_in_ndbinfo | + --------------------------------- + | arbitrator_validity_detail | | arbitrator_validity_summary | | 块| | cluster_locks | | cluster_operations | | cluster_transactions | | config_nodes | | config_params | | config_values | | 柜台| | cpustat | | cpustat_1sec | | cpustat_20sec | | cpustat_50ms | | dict_obj_info | | dict_obj_types | | disk_write_speed_aggregate | | disk_write_speed_aggregate_node | | disk_write_speed_base | | diskpagebuffer | | error_messages | | locks_per_fragment | | logbuffers | | 日志空间| | 会员资格| | memory_per_fragment | | memoryusage | | 节点| | operations_per_fragment | | 流程| | 资源| | restart_info | | server_locks | | server_operations | | server_transactions | | table_distribution_status | | table_fragments | | table_info | | table_replicas | | tc_time_track_stats | | threadblocks | | 线程| | threadstat | | 运输商| + --------------------------------- + 44行(0.00秒)
在NDB 8.0中,所有
ndbinfo
表都使用
NDB
存储引擎;
然而,一个
ndbinfo
条目仍然出现在的输出
SHOW
ENGINES
和
SHOW
PLUGINS
如先前所描述。
您可以
SELECT
像通常期望的那样对这些表
执行
语句:
MySQL的> SELECT * FROM memoryusage;
+ --------- + --------------------- + -------- + -------- ---- + ------------ + ------------- +
| node_id | memory_type | 用过| used_pages | 总计| total_pages |
+ --------- + --------------------- + -------- + -------- ---- + ------------ + ------------- +
| 5 | 数据存储器| 753664 | 23 | 1073741824 | 32768 |
| 5 | 索引记忆| 163840 | 20 | 1074003968 | 131104 |
| 5 | 长消息缓冲区| 2304 | 9 | 67108864 | 262144 |
| 6 | 数据存储器| 753664 | 23 | 1073741824 | 32768 |
| 6 | 索引记忆| 163840 | 20 | 1074003968 | 131104 |
| 6 | 长消息缓冲区| 2304 | 9 | 67108864 | 262144 |
+ --------- + --------------------- + -------- + -------- ---- + ------------ + ------------- +
6行(0.02秒)
可以使用更复杂的查询,例如
SELECT
使用该
memoryusage
表的
以下两个
语句
:
MySQL的>SELECT SUM(used) as 'Data Memory Used, All Nodes'>FROM memoryusage>WHERE memory_type = 'Data memory';+ ----------------------------- + | 使用的数据存储器,所有节点| + ----------------------------- + | 6460 | + ----------------------------- + 1排(0.37秒) MySQL的>SELECT SUM(max) as 'Total IndexMemory Available'>FROM memoryusage>WHERE memory_type = 'Index memory';+ ----------------------------- + | Total IndexMemory可用| + ----------------------------- + | 25664 | + ----------------------------- + 1排(0.33秒)
ndbinfo
表和列名称区分大小写(因为
ndbinfo
数据库本身
的名称
)。
这些标识符为小写。
尝试使用错误的lettercase会导致错误,如下例所示:
MySQL的>SELECT * FROM nodes;+ --------- + -------- + --------- + ------------- + | node_id | 正常运行时间| 状态| start_phase | + --------- + -------- + --------- + ------------- + | 1 | 13602 | 开始了| 0 | | 2 | 16 | 开始了| 0 | + --------- + -------- + --------- + ------------- + 2行(0.04秒) mysql> ERROR 1146(42S02):表'ndbinfo.Nodes'不存在SELECT * FROM Nodes;
mysqldump
ndbinfo
完全
忽略
数据库,并从任何输出中排除它。
即使使用
--databases
或
--all-databases
选项
也是如此
。
NDB Cluster还维护
INFORMATION_SCHEMA
信息数据库中的
FILES
表,包括包含有关用于NDB Cluster Disk Data存储的文件的信息的
ndb_transid_mysql_connection_map
表,
以及
表,其中显示了事务,事务协调器和NDB Cluster API节点之间的关系。
有关更多信息,请参见表的说明或
第22.5.11节“NDB集群的INFORMATION_SCHEMA表”
。
该
arbitrator_validity_detail
表显示了集群中的每个数据节点都具有仲裁程序的视图。
它是
membership
表格的
一个子集
。
下表提供了有关表中列的信息
arbitrator_validity_detail
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.375 arbitrator_validity_detail表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此节点的节点ID |
arbitrator |
整数 | 仲裁员的节点ID |
arb_ticket |
串 | 用于跟踪仲裁的内部标识符 |
arb_connected |
Yes
要么
No
|
此节点是否连接到仲裁程序 |
arb_state |
枚举(见文) | 仲裁状态 |
节点ID与 ndb_mgm -e“SHOW” 报告的节点ID相同 。
所有节点应显示相同的
值
arbitrator
和
arb_ticket
值以及相同的
arb_state
值。
可能的
arb_state
值是
ARBIT_NULL
,
ARBIT_INIT
,
ARBIT_FIND
,
ARBIT_PREP1
,
ARBIT_PREP2
,
ARBIT_START
,
ARBIT_RUN
,
ARBIT_CHOOSE
,
ARBIT_CRASH
,和
UNKNOWN
。
arb_connected
显示当前节点是否连接到
arbitrator
。
该
arbitrator_validity_summary
表提供了仲裁器关于集群数据节点的复合视图。
下表提供了有关表中列的信息
arbitrator_validity_summary
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.376 arbitrator_validity_summary表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
arbitrator |
整数 | 仲裁员的节点ID |
arb_ticket |
串 | 用于跟踪仲裁的内部标识符 |
arb_connected |
Yes
要么
No
|
此仲裁程序是否已连接到群集 |
consensus_count |
整数 | 将此节点视为仲裁程序的数据节点数 |
在正常操作中,此表在任何可观的时间长度内应该只有1行。 如果它超过1行的时间超过一会儿,那么并非所有节点都连接到仲裁器,或者所有节点都已连接,但不同意同一仲裁器。
该
arbitrator
列显示仲裁员的节点ID。
arb_ticket
是此仲裁员使用的内部标识符。
arb_connected
显示此节点是否作为仲裁程序连接到群集。
该
blocks
表是一个静态表,它只包含所有NDB内核块的名称和内部ID(请参阅
NDB内核块
)。
它用于
ndbinfo
映射块编号
的其他
表(大多数实际上是视图)用于生成人类可读输出的块名称。
下表提供了有关表中列的信息
blocks
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
要获取所有块名称的列表,只需执行即可
SELECT block_name FROM ndbinfo.blocks
。
虽然这是一个静态表,但其内容可能因不同的NDB Cluster版本而异。
该
cluster_locks
表提供有关当前锁定请求的信息,这些锁定请求持有和等待
NDB
NDB群集中的表的
锁定
,并且作为配对表
cluster_operations
。
从
cluster_locks
表中
获得的信息
可用于调查失速和死锁。
下表提供了有关表中列的信息
cluster_locks
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.378 cluster_locks表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 报告节点的ID |
block_instance |
整数 | 报告LDM实例的ID |
tableid |
整数 | 包含此行的表的ID |
fragmentid |
整数 | 包含锁定行的片段的ID |
rowid |
整数 | 锁定行的ID |
transid |
整数 | 交易ID |
mode |
串 | 锁定请求模式 |
state |
串 | 锁定状态 |
detail |
串 | 这是否是第一次在行锁定队列中保持锁定 |
op |
串 | 操作类型 |
duration_millis |
整数 | 等待或持有锁定的毫秒数 |
lock_num |
整数 | 锁定对象的ID |
waiting_for |
整数 | 等待此ID的锁定 |
表ID(
tableid
列)在内部分配,与其他
ndbinfo
表
中使用的相同
。
它也显示在
ndb_show_tables
的输出中
。
事务ID(
transid
列)是NDB API为请求或持有当前锁的事务生成的标识符。
该
mode
列显示锁定模式;
这始终是
S
(表示共享锁)或
X
(独占锁)之一。
如果事务在给定行上持有独占锁,则该行上的所有其他锁具有相同的事务ID。
该
state
列显示锁定状态。
它的值始终是
H
(保持)或
W
(等待)之一。
等待锁定请求等待由不同事务持有的锁定。
当
detail
列包含
*
(星号字符)时,这意味着此锁是受影响行的锁定队列中的第一个保持锁;
否则,此列为空。
此信息可用于帮助识别锁定请求列表中的唯一条目。
该
op
列显示了请求锁定的操作类型。
这始终是一个值
READ
,
INSERT
,
UPDATE
,
DELETE
,
SCAN
,或
REFRESH
。
该
duration_millis
列显示此锁定请求等待或持有锁定的毫秒数。
当为等待请求授予锁定时,将重置为0。
锁ID(
lockid
列)对于此节点和块实例是唯一的。
锁状态显示在
lock_state
列中;
如果是这样
W
,则锁定等待被授予,并且该
waiting_for
列显示此请求正在等待的锁定对象的锁定ID。
否则,该
waiting_for
列为空。
waiting_for
只能引用锁在同一行,所确定
node_id
,
block_instance
,
tableid
,
fragmentid
,和
rowid
。
该
cluster_operations
表从本地数据管理(LQH)块的角度提供NDB集群中所有活动的每操作(有状态主键op)视图(请参阅
DBLQH块
)。
下表提供了有关表中列的信息
cluster_operations
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.379 cluster_operations表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 报告LQH块的节点ID |
block_instance |
整数 | LQH块实例 |
transid |
整数 | 交易ID |
operation_type |
串 | 操作类型(参见可能值的文本) |
state |
串 | 操作状态(参见可能值的文本) |
tableid |
整数 | 表ID |
fragmentid |
整数 | 片段ID |
client_node_id |
整数 | 客户端节点ID |
client_block_ref |
整数 | 客户端块参考 |
tc_node_id |
整数 | 事务协调器节点ID |
tc_block_no |
整数 | 事务协调器块号 |
tc_block_instance |
整数 | 事务协调器块实例 |
事务ID是唯一的64位数字,可以使用NDB API的
getTransactionId()
方法获得。
(目前,MySQL服务器不公开正在进行的事务的NDB API事务ID。)
所述
operation_type
列可以采取的值的任一个
READ
,
READ-SH
,
READ-EX
,
INSERT
,
UPDATE
,
DELETE
,
WRITE
,
UNLOCK
,
REFRESH
,
SCAN
,
SCAN-SH
,
SCAN-EX
,或
<unknown>
。
该
state
柱可以具有的值中的任何一个
ABORT_QUEUED
,
ABORT_STOPPED
,
COMMITTED
,
COMMIT_QUEUED
,
COMMIT_STOPPED
,
COPY_CLOSE_STOPPED
,
COPY_FIRST_STOPPED
,
COPY_STOPPED
,
COPY_TUPKEY
,
IDLE
,
LOG_ABORT_QUEUED
,
LOG_COMMIT_QUEUED
,
LOG_COMMIT_QUEUED_WAIT_SIGNAL
,
LOG_COMMIT_WRITTEN
,
LOG_COMMIT_WRITTEN_WAIT_SIGNAL
,
LOG_QUEUED
,
PREPARED
,
PREPARED_RECEIVED_COMMIT
,
SCAN_CHECK_STOPPED
,
SCAN_CLOSE_STOPPED
,
SCAN_FIRST_STOPPED
,
SCAN_RELEASE_STOPPED
,
SCAN_STATE_USED
,
SCAN_STOPPED
,
SCAN_TUPKEY
,
STOPPED
,
TC_NOT_CONNECTED
,
WAIT_ACC
,
WAIT_ACC_ABORT
,
WAIT_AI_AFTER_ABORT
,
WAIT_ATTR
,
WAIT_SCAN_AI
,
WAIT_TUP
,
WAIT_TUPKEYINFO
,
WAIT_TUP_COMMIT
,或
WAIT_TUP_TO_ABORT
。
(如果MySQL服务器在
ndbinfo_show_hidden
启用时
运行
,您可以通过从
ndb$dblqh_tcconnect_state
表中
选择来查看此状态列表,该
表通常是隐藏的。)
您可以
NDB
通过检查
ndb_show_tables
的输出从其表ID中
获取
表
的名称
。
它
fragid
与
ndb_desc
--extra-partition-info
(简短格式
-p
)
的输出中看到的分区号相同
。
在
client_node_id
和中
client_block_ref
,
client
指的是NDB Cluster API或SQL节点(即,NDB API客户端或连接到群集的MySQL Server)。
的
block_instance
和
tc_block_instance
柱提供,分别为
DBLQH
和
DBTC
块实例号。
您可以将这些与块名一起使用,以从
threadblocks
表中
获取有关特定线程的信息
。
该
cluster_transactions
表显示有关NDB群集中所有正在进行的事务的信息。
下表提供了有关表中列的信息
cluster_transactions
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.380 cluster_transactions表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 事务协调器的节点ID |
block_instance |
整数 | TC块实例 |
transid |
整数 | 交易ID |
state |
串 | 操作状态(参见可能值的文本) |
count_operations |
整数 | 事务中的有状态主键操作数(包括带锁的读操作以及DML操作) |
outstanding_operations |
整数 | 操作仍在本地数据管理块中执行 |
inactive_seconds |
整数 | 花在等待API的时间 |
client_node_id |
整数 | 客户端节点ID |
client_block_ref |
整数 | 客户端块参考 |
事务ID是唯一的64位数字,可以使用NDB API的
getTransactionId()
方法获得。
(目前,MySQL服务器不公开正在进行的事务的NDB API事务ID。)
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
该
state
柱可以具有的值中的任何一个
CS_ABORTING
,
CS_COMMITTING
,
CS_COMMIT_SENT
,
CS_COMPLETE_SENT
,
CS_COMPLETING
,
CS_CONNECTED
,
CS_DISCONNECTED
,
CS_FAIL_ABORTED
,
CS_FAIL_ABORTING
,
CS_FAIL_COMMITTED
,
CS_FAIL_COMMITTING
,
CS_FAIL_COMPLETED
,
CS_FAIL_PREPARED
,
CS_PREPARE_TO_COMMIT
,
CS_RECEIVING
,
CS_REC_COMMITTING
,
CS_RESTART
,
CS_SEND_FIRE_TRIG_REQ
,
CS_STARTED
,
CS_START_COMMITTING
,
CS_START_SCAN
,
CS_WAIT_ABORT_CONF
,
CS_WAIT_COMMIT_CONF
,
CS_WAIT_COMPLETE_CONF
,
CS_WAIT_FIRE_TRIG_REQ
。
(如果MySQL服务器在
ndbinfo_show_hidden
启用时
运行
,您可以通过选择来查看此状态列表
ndb$dbtc_apiconnect_state
表,通常是隐藏的。)
在
client_node_id
和中
client_block_ref
,
client
指的是NDB Cluster API或SQL节点(即,NDB API客户端或连接到群集的MySQL Server)。
该
tc_block_instance
列提供
DBTC
块实例编号。
您可以将其与块名一起使用,以从
threadblocks
表中
获取有关特定线程的信息
。
该
config_nodes
表显示了在NDB Cluster
config.ini
文件中
配置的节点
。
对于每个节点,该表显示一行,其中包含节点ID,节点类型(管理节点,数据节点或API节点)以及配置节点运行的主机的名称或IP地址。
此表未指示给定节点是否实际正在运行,或者它当前是否已连接到群集。
有关连接到NDB群集的节点的信息可以从
nodes
和
processes
表中获取。
下表提供了有关表中列的信息
config_nodes
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.381 config_params表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 节点的ID |
node_type |
串 | 节点的类型 |
node_hostname |
串 | 节点所在主机的名称或IP地址 |
该
node_id
列显示该节点的
config.ini
文件中
使用的节点ID
;
如果未指定,则显示将自动分配给此节点的节点ID。
该
node_type
列显示以下三个值之一:
-
MGM:管理节点。 -
NDB:数据节点。 -
API:API节点; 这包括SQL节点。
该
node_hostname
列显示
config.ini
文件中
指定的节点主机
。
如果
HostName
尚未在群集配置文件中设置
,则API节点可以为空
。
如果
HostName
尚未在配置文件中为数据节点设置,
localhost
则在此处使用。
localhost
如果
HostName
尚未为管理节点指定,
也会使用
。
该
config_params
表是一个静态表,它提供有关NDB群集配置参数的名称和内部ID号以及其他信息。
下表提供了有关表中列的信息
config_params
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
此表还可以与
config_values
表
一起使用,
以获取有关节点配置参数的实时信息。
表22.382 config_params表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
param_number |
整数 | 参数的内部ID号 |
param_name |
串 | 参数的名称 |
param_description |
串 | 参数的简要说明 |
param_type |
串 | 参数的数据类型 |
param_default |
串 | 参数的默认值(如果有) |
param_min |
串 | 参数的最大值(如果有) |
param_max |
串 | 参数的最小值(如果有) |
param_mandatory |
整数 | 如果参数是必需的,则为1,否则为0 |
param_status |
串 | 目前尚未使用 |
该表是只读的。
虽然这是一个静态表,但其内容可能因NDB群集安装而异,因为受支持的参数可能因软件版本,群集硬件配置和其他因素之间的差异而有所不同。
该
config_values
表提供有关节点配置参数值的当前状态的信息。
表中的每一行对应于给定节点上参数的当前值。
表22.383 config_params表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 集群中节点的ID |
config_param |
整数 | 参数的内部ID号 |
config_value |
串 | 参数的当前值 |
此表的
config_param
列和
config_params
表的
param_number
列使用相同的参数标识符。
通过连接这些列上的两个表,可以获得有关所需节点配置参数的详细信息。
此处显示的查询提供了群集中每个数据节点上所有参数的当前值,按节点ID和参数名称排序:
SELECT v.node_id AS'Node Id',
p.param_name AS'参数',
v.config_value AS'价值'
FROM config_values v
JOIN config_params p
ON v.config_param = p.param_number
在哪里p.param_name不喜欢'\ _ \ _ _%'
ORDER BY v.node_id,p.param_name;
在用于简单测试的小示例集群上运行时,上一个查询的部分输出:
+ --------- + --------------------------------------- --- + ---------------- + | 节点ID | 参数| 价值| + --------- + --------------------------------------- --- + ---------------- + | 2 | 仲裁| 1 | | 2 | 仲裁时间| 7500 | | 2 | BackupDataBufferSize | 16777216 | | 2 | BackupDataDir | / home / jon / data | | 2 | BackupDiskWriteSpeedPct | 50 | | 2 | BackupLogBufferSize | 16777216 | ... | 3 | TotalSendBufferMemory | 0 | | 3 | TransactionBufferMemory | 1048576 | | 3 | TransactionDeadlockDetectionTimeout | 1200 | | 3 | TransactionInactiveTimeout | 4294967039 | | 3 | TwoPassInitialNodeRestartCopy | 0 | | 3 | UndoDataBuffer | 16777216 | | 3 | UndoIndexBuffer | 2097152 | + --------- + --------------------------------------- --- + ---------------- + 248行(0.02秒)
该
WHERE
子句筛选出名称以双下划线(
__
)
开头的参数
;
这些参数保留用于NDB开发人员的测试和其他内部使用,不适用于生产NDB集群。
通过发出正确的查询,您可以获得更具体,更详细或两者的输出。
本实施例提供的所有类型的关于可用的信息
NodeId
,
NoOfReplicas
,
HostName
,
DataMemory
,
IndexMemory
,和
TotalSendBufferMemory
参数作为当前设置为集群中的所有数据节点:
SELECT p.param_name AS名称,
v.node_id AS Node,
p.param_type AS类型,
p.param_default AS'默认',
p.param_min AS最小值,
p.param_max AS最大值,
CASE p.param_mandatory当1'''''''''''''''''''''''''''''''
v.config_value AS Current
FROM config_params p
JOIN config_values v
ON p.param_number = v.config_param
在哪里p。PARAM_NAME
IN('NodeId','NoOfReplicas','HostName',
'DataMemory','IndexMemory','TotalSendBufferMemory')\ G.
在具有用于简单测试的2个数据节点的小型NDB群集上运行时,此查询的输出如下所示:
*************************** 1。排******************** *******
名称:NodeId
节点:2
输入:unsigned
默认:
最低:1
最大值:48
要求:Y
目前:2
*************************** 2.排******************** *******
名称:HostName
节点:2
输入:string
默认值:localhost
最低:
最大值:
要求:N
当前:127.0.0.1
*************************** 3。排******************** *******
名称:TotalSendBufferMemory
节点:2
输入:unsigned
默认值:0
最低:262144
最大值:4294967039
要求:N
目前:0
****************************排******************** *******
名称:NoOfReplicas
节点:2
输入:unsigned
默认值:2
最低:1
最大值:4
要求:N
目前:2
****************************排******************** *******
名称:DataMemory
节点:2
输入:unsigned
默认值:102760448
最低:1048576
最大值:1099511627776
要求:N
当前:524288000
*************************** 6.排******************** *******
名称:NodeId
节点:3
输入:unsigned
默认:
最低:1
最大值:48
要求:Y
目前:3
*************************** 7.排******************** *******
名称:HostName
节点:3
输入:string
默认值:localhost
最低:
最大值:
要求:N
当前:127.0.0.1
*************************** 8.排******************** *******
名称:TotalSendBufferMemory
节点:3
输入:unsigned
默认值:0
最低:262144
最大值:4294967039
要求:N
目前:0
*************************** 9。排******************** *******
名称:NoOfReplicas
节点:3
输入:unsigned
默认值:2
最低:1
最大值:4
要求:N
目前:2
*************************** 10.排******************** *******
名称:DataMemory
节点:3
输入:unsigned
默认值:102760448
最低:1048576
最大值:1099511627776
要求:N
当前:524288000
10行(0.01秒)
该
counters
表提供事件的运行总计,例如特定内核块和数据节点的读取和写入。
计数从最近的节点启动或重启开始;
节点启动或重新启动会重置该节点上的所有计数器。
并非所有内核块都具有所有类型的计数器。
下表提供了有关表中列的信息
counters
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.384计数器表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 数据节点ID |
block_name |
串 | 相关NDB内核块的名称(请参阅 NDB内核块 )。 |
block_instance |
整数 | 阻止实例 |
counter_id |
整数 | 计数器的内部ID号; 通常是1到10之间的整数,包括1和10。 |
counter_name |
串 | 柜台的名称。 请参阅文本以获取各个计数器的名称以及与每个计数器关联的NDB内核块。 |
val |
整数 | 计数器的价值 |
每个计数器都与特定的NDB内核块相关联。
该
OPERATIONS
计数器与相关
DBLQH
(本地查询处理)的内核模块(见
的DBLQH块
)。
主键读取计为一个操作,主键更新也是如此。
对于读取,
DBLQH
每个操作中
有一个操作
DBTC
。
对于写入,每个副本计数一次操作。
的
ATTRINFO
,
TRANSACTIONS
,
COMMITS
,
READS
,
LOCAL_READS
,
SIMPLE_READS
,
WRITES
,
LOCAL_WRITES
,
ABORTS
,
TABLE_SCANS
,和
RANGE_SCANS
计数器与DBTC(事务协调员)内核块(参见相关
的DBTC块
)。
LOCAL_WRITES
并且
LOCAL_READS
是在一个节点中使用事务协调器的主键操作,该节点还包含记录的主副本。
该
READS
计数器包括所有读取。
LOCAL_READS
仅包括与此事务协调器位于同一节点上的主副本的读取。
SIMPLE_READS
仅包括那些读操作是给定事务的开始和结束操作的读操作。
简单读取不包含锁定但是是事务的一部分,因为它们观察到包含它们的事务所做的未提交的更改,而不是任何其他未提交的事务。
从TC块的角度来看,
这种读取是
“
简单的
”
;
因为它们没有锁,所以它们不耐用,而且一次
DBTC
已经将它们路由到相关的LQH区块,它没有任何状态。
ATTRINFO
保持解释程序发送到数据节点的次数。
有关
内核中
消息的
更多信息,
请参阅
NDB协议消息
。
ATTRINFO
NDB
的
LOCAL_TABLE_SCANS_SENT
,
READS_RECEIVED
,
PRUNED_RANGE_SCANS_RECEIVED
,
RANGE_SCANS_RECEIVED
,
LOCAL_READS_SENT
,
CONST_PRUNED_RANGE_SCANS_RECEIVED
,
LOCAL_RANGE_SCANS_SENT
,
REMOTE_READS_SENT
,
REMOTE_RANGE_SCANS_SENT
,
READS_NOT_FOUND
,
SCAN_BATCHES_RETURNED
,
TABLE_SCANS_RECEIVED
,和
SCAN_ROWS_RETURNED
柜台与关联
DBSPJ
(选择下推加入)内核模块(见
的DBSPJ块
)。
该
block_name
和
block_instance
列分别提供适用的NDB内核模块名称和实例号。
您可以使用它们从
threadblocks
表中
获取有关特定线程的信息
。
许多计数器在解决此类问题时提供有关传输器过载和发送缓冲区大小调整的信息。 对于每个LQH实例,以下列表中的每个计数器都有一个实例:
-
LQHKEY_OVERLOAD:由于传输器过载而在LQH块实例处拒绝的主键请求数 -
LQHKEY_OVERLOAD_TC:LQHKEY_OVERLOADTC节点传输器过载 的实例计数 -
LQHKEY_OVERLOAD_READER:LQHKEY_OVERLOADAPI读取器(只读)节点重载 的实例计数 。 -
LQHKEY_OVERLOAD_NODE_PEER:LQHKEY_OVERLOAD下一个备份数据节点(仅写入)重载 的实例计数 -
LQHKEY_OVERLOAD_SUBSCRIBER:LQHKEY_OVERLOAD事件订阅者(仅写入)的重载 实例的计数 。 -
LQHSCAN_SLOWDOWNS:由于扫描API传输器过载而导致碎片扫描批量大小减少的实例计数。
该
cpustat
表提供了每秒针对
NDB
内核中
运行的每个线程收集的每线程CPU统计信息
。
下表提供了有关表中列的信息
cpustat
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.385 cpustat表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 线程正在运行的节点的ID |
thr_no |
整数 | 线程ID(特定于此节点) |
OS_user |
整数 | OS用户时间 |
OS_system |
整数 | OS系统时间 |
OS_idle |
整数 | OS空闲时间 |
thread_exec |
整数 | 线程执行时间 |
thread_sleeping |
整数 | 线程睡眠时间 |
thread_send |
整数 | 线程发送时间 |
thread_buffer_full |
整数 | 线程缓冲全职 |
elapsed_time |
整数 | 经过的时间 |
该
cpustat_50ms
表提供了
NDB
内核中
运行的每个线程每50毫秒获得的原始每线程CPU数据
。
与
cpustat_1sec
和
类似
cpustat_20sec
,此表显示每个线程20个测量集,每个测量集引用一个指定持续时间的周期。
因此,
cpsustat_50ms
提供1秒的历史。
下表提供了有关表中列的信息
cpustat_50ms
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.386 cpustat_50ms表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 线程正在运行的节点的ID |
thr_no |
整数 | 线程ID(特定于此节点) |
OS_user_time |
整数 | OS用户时间 |
OS_system_time |
整数 | OS系统时间 |
OS_idle_time |
整数 | OS空闲时间 |
exec_time |
整数 | 线程执行时间 |
sleep_time |
整数 | 线程睡眠时间 |
send_time |
整数 | 线程发送时间 |
buffer_full_time |
整数 | 线程缓冲全职 |
elapsed_time |
整数 | 经过的时间 |
该
cpustat-1sec
表提供了
NDB
内核中
运行的每个线程每秒获得的原始每线程CPU数据
。
与
cpustat_50ms
和
类似
cpustat_20sec
,此表显示每个线程20个测量集,每个测量集引用一个指定持续时间的周期。
从而,
cpsustat_1sec
提供20秒的历史。
下表提供了有关表中列的信息
cpustat_1sec
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.387 cpustat_1sec表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 线程正在运行的节点的ID |
thr_no |
整数 | 线程ID(特定于此节点) |
OS_user_time |
整数 | OS用户时间 |
OS_system_time |
整数 | OS系统时间 |
OS_idle_time |
整数 | OS空闲时间 |
exec_time |
整数 | 线程执行时间 |
sleep_time |
整数 | 线程睡眠时间 |
send_time |
整数 | 线程发送时间 |
buffer_full_time |
整数 | 线程缓冲全职 |
elapsed_time |
整数 | 经过的时间 |
该
cpustat_20sec
表为每个运行的线程提供每20秒获得的原始每线程CPU数据
NDB
内核中
。
与
cpustat_50ms
和
类似
cpustat_1sec
,此表显示每个线程20个测量集,每个测量集引用一个指定持续时间的周期。
因此,
cpsustat_20sec
提供400秒的历史。
下表提供了有关表中列的信息
cpustat_20sec
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.388 cpustat_20sec表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 线程正在运行的节点的ID |
thr_no |
整数 | 线程ID(特定于此节点) |
OS_user_time |
整数 | OS用户时间 |
OS_system_time |
整数 | OS系统时间 |
OS_idle_time |
整数 | OS空闲时间 |
exec_time |
整数 | 线程执行时间 |
sleep_time |
整数 | 线程睡眠时间 |
send_time |
整数 | 线程发送时间 |
buffer_full_time |
整数 | 线程缓冲全职 |
elapsed_time |
整数 | 经过的时间 |
该
dict_obj_info
表提供有关
NDB
数据字典(
DICT
)对象(如表和索引)的信息。
(该
dict_obj_types
可以查询
表以获取所有类型的列表。)此信息包括对象的类型,状态,父对象(如果有)和完全限定名称。
下表提供了有关表中列的信息
dict_obj_info
。
对于每列,该表显示名称,数据类型和简要说明。
表22.389 dict_obj_info表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
type |
整数 |
DICT
对象
类型
;
加入
dict_obj_types
获取名称
|
id |
整数 | 对象标识符 |
version |
整数 | 对象版本 |
state |
整数 | 对象状态 |
parent_obj_type |
整数 |
父对象的类型(
dict_obj_types
类型ID);
0表示该对象没有父对象
|
parent_obj_id |
整数 | 父对象ID(例如基表); 0表示该对象没有父对象 |
fq_name |
串 |
完全限定的对象名称;
对于一个表,它具有一个形式
,对于一个主键,表单是
,并且对于一个唯一的键是
sys/def/
sys/def/
|
该
dict_obj_types
表是一个静态表,列出了NDB内核中使用的可能的字典对象类型。
这些是
Object::Type
NDB API中
定义的相同类型
。
下表提供了有关表中列的信息
dict_obj_types
。
对于每列,该表显示名称,数据类型和简要说明。
该
disk_write_speed_base
表提供有关LCP,备份和还原操作期间磁盘写入速度的基本信息。
下表提供了有关表中列的信息
disk_write_speed_base
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.391 disk_write_speed_base表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
| NODE_ID | 整数 | 该节点的节点ID |
| thr_no | 整数 | 此LDM线程的线程ID |
| millis_ago | 整数 | 自本报告期结束以来的毫秒数 |
| millis_passed | 整数 | 在此报告期间经过了几毫秒 |
| backup_lcp_bytes_written | 整数 | 在此期间由本地检查点和备份进程写入磁盘的字节数 |
| redo_bytes_written | 整数 | 在此期间写入REDO日志的字节数 |
| target_disk_write_speed | 整数 | 每个LDM线程的实际磁盘写入速度(基础数据) |
该
disk_write_speed_aggregate
表提供有关LCP,备份和还原操作期间磁盘写入速度的聚合信息。
下表提供了有关表中列的信息
disk_write_speed_aggregate
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.392 disk_write_speed_aggregate表中的列
| 列名称 | 类型 | 描述 |
|---|---|---|
| NODE_ID | 整数 | 该节点的节点ID |
| thr_no | 整数 | 此LDM线程的线程ID |
| backup_lcp_speed_last_sec | 整数 | 最后一秒备份和LCP进程写入磁盘的字节数 |
| redo_speed_last_sec | 整数 | 在最后一秒写入REDO日志的字节数 |
| backup_lcp_speed_last_10sec | 整数 | 备份和每秒LCP进程写入磁盘的字节数,在过去10秒内取平均值 |
| redo_speed_last_10sec | 整数 | 每秒写入REDO日志的字节数,在过去10秒内取平均值 |
| std_dev_backup_lcp_speed_last_10sec | 整数 | 通过备份和每秒LCP进程写入磁盘的字节数的标准偏差,在过去10秒内取平均值 |
| std_dev_redo_speed_last_10sec | 整数 | 写入每秒REDO日志的字节数的标准偏差,在过去10秒内取平均值 |
| backup_lcp_speed_last_60sec | 整数 | 备份和每秒LCP进程写入磁盘的字节数,在过去60秒内取平均值 |
| redo_speed_last_60sec | 整数 | 每秒写入REDO日志的字节数,在过去10秒内取平均值 |
| std_dev_backup_lcp_speed_last_60sec | 整数 | 通过备份和每秒LCP进程写入磁盘的字节数的标准偏差,在过去60秒内取平均值 |
| std_dev_redo_speed_last_60sec | 整数 | 写入每秒REDO日志的字节数的标准偏差,在过去60秒内取平均值 |
| slowdowns_due_to_io_lag | 整数 | 自上次节点启动以来,由于REDO日志I / O延迟,磁盘写入速度变慢的秒数 |
| slowdowns_due_to_high_cpu | 整数 | 自上次节点启动以来由于CPU使用率过高而导致磁盘写入速度变慢的秒数 |
| disk_write_speed_set_to_min | 整数 | 自上次节点启动以来磁盘写入速度设置为最小值的秒数 |
| current_target_disk_write_speed | 整数 | 每个LDM线程的实际磁盘写入速度(聚合) |
该
disk_write_speed_aggregate_node
表提供了每个节点的有关LCP,备份和还原操作期间磁盘写入速度的聚合信息。
下表提供了有关表中列的信息
disk_write_speed_aggregate_node
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.393 disk_write_speed_aggregate_node表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
| NODE_ID | 整数 | 该节点的节点ID |
| backup_lcp_speed_last_sec | 整数 | 最后一秒备份和LCP进程写入磁盘的字节数 |
| redo_speed_last_sec | 整数 | 在最后一秒写入REDO日志的字节数 |
| backup_lcp_speed_last_10sec | 整数 | 备份和每秒LCP进程写入磁盘的字节数,在过去10秒内取平均值 |
| redo_speed_last_10sec | 整数 | 每秒写入REDO日志的字节数,在过去10秒内取平均值 |
| backup_lcp_speed_last_60sec | 整数 | 备份和每秒LCP进程写入磁盘的字节数,在过去60秒内取平均值 |
| redo_speed_last_60sec | 整数 | 备份和每秒LCP进程写入磁盘的字节数,在过去60秒内取平均值 |
该
diskpagebuffer
表提供有关NDB Cluster Disk Data表的磁盘页面缓冲区使用情况的统计信息。
下表提供了有关表中列的信息
diskpagebuffer
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.394 diskpagebuffer表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 数据节点ID |
block_instance |
整数 | 阻止实例 |
pages_written |
整数 | 写入磁盘的页数。 |
pages_written_lcp |
整数 | 本地检查点写入的页数。 |
pages_read |
整数 | 从磁盘读取的页数 |
log_waits |
整数 | 等待将日志写入磁盘的页写入次数 |
page_requests_direct_return |
整数 | 缓冲区中可用页面的请求数 |
page_requests_wait_queue |
整数 | 必须等待页面在缓冲区中可用的请求数 |
page_requests_wait_io |
整数 | 必须从磁盘上的页面读取的请求数(页面在缓冲区中不可用) |
您可以将此表与NDB Cluster Disk Data表一起使用,以确定是否
DiskPageBufferMemory
足够大以允许从缓冲区而不是从磁盘读取数据;
最小化磁盘搜索有助于提高此类表的性能。
您可以
DiskPageBufferMemory
使用诸如此之类的查询
来确定读取的比例与读取
的总数,该查询以百分比形式获得此比率:
选择
NODE_ID,
100 * page_requests_direct_return /
(page_requests_direct_return + page_requests_wait_io)
AS hit_ratio
FROM ndbinfo.diskpagebuffer;
此查询的结果应类似于此处显示的结果,群集中的每个数据节点都有一行(在此示例中,群集有4个数据节点):
+ --------- + ----------- + | node_id | hit_ratio | + --------- + ----------- + | 5 | 97.6744 | | 6 | 97.6879 | | 7 | 98.1776 | | 8 | 98.1343 | + --------- + ----------- + 4行(0.00秒)
hit_ratio
接近100%的值表示只从磁盘而不是从缓冲区进行非常少量的读取,这意味着磁盘数据读取性能接近最佳水平。
如果这些值中的任何一个小于95%,则这是一个强烈的指示,表明
DiskPageBufferMemory
需要在
config.ini
文件中
增加
设置
。
更改
DiskPageBufferMemory
需要在生效之前滚动重新启动所有群集的数据节点。
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
使用此信息,您可以获取有关各个线程的磁盘页面缓冲区度量标准的信息;
LIMIT 1
此处显示了用于将输出限制为单个线程
的示例查询
:
的MySQL>SELECT>node_id, thr_no, block_name, thread_name, pages_written,>pages_written_lcp, pages_read, log_waits,>page_requests_direct_return, page_requests_wait_queue,>page_requests_wait_io>FROM ndbinfo.diskpagebuffer>INNER JOIN ndbinfo.threadblocks USING (node_id, block_instance)>INNER JOIN ndbinfo.threads USING (node_id, thr_no)>WHERE block_name = 'PGMAN' LIMIT 1\G*************************** 1。排******************** ******* node_id:1 thr_no:1 block_name:PGMAN thread_name:rep pages_written:0 pages_written_lcp:0 pages_read:1 log_waits:0 page_requests_direct_return:4 page_requests_wait_queue:0 page_requests_wait_io:1 1排(0.01秒)
该
error_messages
表提供了有关的信息
下表提供了有关表中列的信息
error_messages
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.395 error_messages表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
error_code |
整数 | 数字错误代码 |
error_description |
串 | 错误描述 |
error_status |
串 | 错误状态代码 |
error_classification |
整数 | 错误分类代码 |
error_code
是一个数字NDB错误代码。
这是可以提供给
ndb_perror
或
perror
的相同错误代码
--ndb
。
error_description
提供导致错误的条件的基本描述。
该
error_status
列提供与错误相关的状态信息。
此列中列出了此列的可能值:
-
No error -
Illegal connect string -
Illegal server handle -
Illegal reply from server -
Illegal number of nodes -
Illegal node status -
Out of memory -
Management server not connected -
Could not connect to socket -
Start failed -
Stop failed -
Restart failed -
Could not start backup -
Could not abort backup -
Could not enter single user mode -
Could not exit single user mode -
Failed to complete configuration change -
Failed to get configuration -
Usage error -
Success -
Permanent error -
Temporary error -
Unknown result -
Temporary error, restart node -
Permanent error, external action needed -
Ndbd file system error, restart node initial -
Unknown
error_classification列显示错误分类。 有关分类代码及其含义的信息, 请参阅 NDB错误分类 。
该
locks_per_fragment
表提供有关锁定声明请求计数的信息,以及基于每个片段的这些请求的结果,作为
operations_per_fragment
和的
表
,
memory_per_fragment
。
此表还显示自创建片段或表或自最近重新启动以来等待锁成功和未成功所花费的总时间。
下表提供了有关表中列的信息
locks_per_fragment
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.396 locks_per_fragment表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
fq_name |
串 | 完全限定的表名 |
parent_fq_name |
串 | 父对象的完全限定名称 |
type |
串 | 表类型; 查看可能值的文本 |
table_id |
整数 | 表ID |
node_id |
整数 | 报告节点ID |
block_instance |
整数 | LDM实例ID |
fragment_num |
整数 | 片段标识符 |
ex_req |
整数 | 独占锁定请求已启动 |
ex_imm_ok |
整数 | 立即授予独占锁定请求 |
ex_wait_ok |
整数 | 等待后授予的独占锁定请求 |
ex_wait_fail |
整数 | 未授予独占锁定请求 |
sh_req |
整数 | 共享锁请求已启动 |
sh_imm_ok |
整数 | 立即授予共享锁请求 |
sh_wait_ok |
整数 | 等待后授予共享锁请求 |
sh_wait_fail |
整数 | 未授予共享锁请求 |
wait_ok_millis |
整数 | 等待授予的锁定请求所花费的时间(以毫秒为单位) |
wait_fail_millis |
整数 | 等待失败的锁请求所花费的时间(以毫秒为单位) |
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
fq_name
是
database
/
schema
/
name
格式
的完全限定数据库对象名称
,例如
test/def/t1
或
sys/def/10/b$unique
。
parent_fq_name
是此对象的父对象(表)的完全限定名称。
table_id
是由表生成的表的内部ID
NDB
。
这与其他
ndbinfo
表中
显示的内部表ID相同
;
它在
ndb_show_tables
的输出中也可见
。
该
type
列显示表的类型。
这始终是一个
System table
,
User
table
,
Unique hash index
,
Hash index
,
Unique ordered
index
,
Ordered index
,
Hash
index trigger
,
Subscription
trigger
,
Read only constraint
,
Index trigger
,
Reorganize
trigger
,
Tablespace
,
Log
file group
,
Data file
,
Undo file
,
Hash map
,
Foreign key definition
,
Foreign key
parent trigger
,
Foreign key child
trigger
,或
Schema transaction
。
在所有的列中显示的值
ex_req
,
ex_req_imm_ok
,
ex_wait_ok
,
ex_wait_fail
,
sh_req
,
sh_req_imm_ok
,
sh_wait_ok
,和
sh_wait_fail
代表请求的累积数量,因为表或片段的创建,或因为此节点的最后重新启动,无论这些后来发生。
对于
wait_ok_millis
和
wait_fail_millis
列中
显示的时间值也是如此
。
每个锁定请求都被视为正在进行中,或者以某种方式完成(即成功或失败)。 这意味着以下关系是正确的:
ex_req> =(ex_req_imm_ok + ex_wait_ok + ex_wait_fail) sh_req> =(sh_req_imm_ok + sh_wait_ok + sh_wait_fail)
当前正在进行的请求数是当前未完成请求的数量,可以在此处找到:
[正在进行独占锁定请求] =
ex_req - (ex_req_imm_ok + ex_wait_ok + ex_wait_fail)
[正在进行共享锁请求] =
sh_req - (sh_req_imm_ok + sh_wait_ok + sh_wait_fail)
等待失败表示中止事务,但中止可能是也可能不是由锁等待超时引起的。 您可以在等待锁定时获取中止总数,如下所示:
[等待锁定时中止] = ex_wait_fail + sh_wait_fail
该
logbuffer
表提供有关NDB Cluster日志缓冲区使用情况的信息。
下表提供了有关表中列的信息
logbuffers
。
对于每列,该表显示名称,数据类型和简要说明。
表22.397 logbuffers表中的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此数据节点的ID。 |
log_type |
串 |
日志类型。
一:
REDO
,
DD-UNDO
,
BACKUP-DATA
,或
BACKUP-LOG
。
|
log_id |
整数 | 日志ID。 |
log_part |
整数 | 日志部件号。 |
total |
整数 | 此日志可用的总空间。 |
used |
整数 | 此日志使用的空间。 |
logbuffers
执行NDB备份时,可以使用反映两种其他日志类型的表行。
其中一行具有日志类型
BACKUP-DATA
,该
类型
显示备份期间将片段复制到备份文件时使用的数据缓冲区数量。
另一行具有日志类型
BACKUP-LOG
,该
类型
显示备份期间用于记录备份开始后所做更改的日志缓冲区数量。
对于集群中的每个数据节点,表中
log_type
显示
了这些
行中的
每一
行
logbuffers
。
除非当前正在执行NDB备份,否则这些行不存在。
此表提供有关NDB Cluster日志空间使用情况的信息。
下表提供了有关表中列的信息
logspaces
。
对于每列,该表显示名称,数据类型和简要说明。
表22.398日志空间表中的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此数据节点的ID。 |
log_type |
串 |
日志类型;
其中之一:
REDO
或
DD-UNDO
。
|
log_id |
整数 | 日志ID。 |
log_part |
整数 | 日志部件号。 |
total |
整数 | 此日志可用的总空间。 |
used |
整数 | 此日志使用的空间。 |
该
membership
表描述了每个数据节点具有集群中所有其他节点的视图,包括节点组成员资格,总统节点,仲裁程序,仲裁程序后继程序,仲裁程序连接状态和其他信息。
下表提供了有关表中列的信息
membership
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.399成员资格表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此节点的节点ID |
group_id |
整数 | 该节点所属的节点组 |
left node |
整数 | 上一节点的节点ID |
right_node |
整数 | 下一个节点的节点ID |
president |
整数 | 总统的节点ID |
successor |
整数 | 总统继任者的节点ID |
succession_order |
整数 | 此节点成功担任总统的顺序 |
Conf_HB_order |
整数 | - |
arbitrator |
整数 | 仲裁员的节点ID |
arb_ticket |
串 | 用于跟踪仲裁的内部标识符 |
arb_state |
枚举(见文) | 仲裁状态 |
arb_connected |
Yes
要么
No
|
此节点是否连接到仲裁程序 |
connected_rank1_arbs |
节点ID列表 | 连接第1级的仲裁员 |
connected_rank2_arbs |
节点ID列表 | 连接第1级的仲裁员 |
节点ID和节点组ID与 ndb_mgm -e“SHOW” 报告的相同 。
left_node
并且
right_node
根据连接圆中所有数据节点的模型定义,按照节点ID的顺序,类似于时钟刻度盘上数字的顺序,如下所示:

在这个例子中,我们有8个数据节点,编号为5,6,7,8,12,13,14和15,顺时针顺序排列。 我们 从圆圈的内部 确定 “ 左 ” 和 “ 右 ” 。 节点5左侧的节点是节点15,节点5右侧的节点是节点6.您可以通过运行以下查询并观察输出来查看所有这些关系:
mysql>SELECT node_id,left_node,right_node- >FROM ndbinfo.membership;+ --------- + ----------- ------------ + + | node_id | left_node | right_node | + --------- + ----------- ------------ + + | 5 | 15 | 6 | | 6 | 5 | 7 | | 7 | 6 | 8 | | 8 | 7 | 12 | | 12 | 8 | 13 | | 13 | 12 | 14 | | 14 | 13 | 15 | | 15 | 14 | 5 | + --------- + ----------- ------------ + + 8行(0.00秒)
该名称 “ 左 ” 和 “ 右 ” 是在事件日志中以同样的方式使用。
该
president
节点是当前节点查看的负责设置仲裁器的节点(请参阅
NDB群集启动阶段
)。
如果总统失败或断开连接,则当前节点期望
successor
列中
显示其ID的节点
成为新的总统。
该
succession_order
列显示当前节点将自身视为具有的继承队列中的位置。
在普通的NDB集群中,所有数据节点都应该看到与其相同的节点
president
和相同的节点(除了总统)
successor
。
此外,现任总统应该把自己视为
1
继承的顺序,
successor
节点应该看作自己
2
,等等。
所有节点应显示相同的
arb_ticket
值以及相同的
arb_state
值。
可能的
arb_state
值是
ARBIT_NULL
,
ARBIT_INIT
,
ARBIT_FIND
,
ARBIT_PREP1
,
ARBIT_PREP2
,
ARBIT_START
,
ARBIT_RUN
,
ARBIT_CHOOSE
,
ARBIT_CRASH
,和
UNKNOWN
。
arb_connected
显示此节点是否连接到显示为此节点的节点
arbitrator
。
的
connected_rank1_arbs
和
connected_rank2_arbs
列,每列显示具有一个0以上仲裁列表
ArbitrationRank
等于1,或至2中。
管理节点和API节点都有资格成为仲裁者。
查询此表提供的信息类似于
ndb_mgm
客户端中
的
ALL REPORT
MemoryUsage
命令
提供的信息
,或者记录的信息
。
ALL DUMP
1000
下表提供了有关表中列的信息
memoryusage
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.400 memoryusage表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此数据节点的节点ID。 |
memory_type |
串 |
其中一个
Data memory
,
Index memory
或
Long message buffer
。
|
used |
整数 | 此数据节点当前用于数据存储器或索引存储器的字节数。 |
used_pages |
整数 | 此数据节点当前用于数据存储器或索引存储器的页数; 看文字。 |
total |
整数 | 可用于此数据节点的数据存储器或索引存储器的总字节数; 看文字。 |
total_pages |
整数 | 此数据节点上可用于数据存储器或索引存储器的内存页总数; 看文字。 |
该
total
列表示特定数据节点上给定资源(数据存储器或索引存储器)可用的内存总量(以字节为单位)。
此数字应大约等于
config.ini
文件中
相应配置参数的设置
。
假设群集具有节点ID 2个数据节点
5
和
6
,并且
config.ini
文件包含以下内容:
[ndbd默认] DataMemory = 1G IndexMemory = 1G
还假设
LongMessageBuffer
配置参数的值允许采用其默认值(64 MB)。
以下查询显示大致相同的值:
mysql> SELECT node_id,memory_type,total
> FROM ndbinfo.memoryusage;
+ --------- + --------------------- + ------------ +
| node_id | memory_type | 总计|
+ --------- + --------------------- + ------------ +
| 5 | 数据存储器| 1073741824 |
| 5 | 索引记忆| 1074003968 |
| 5 | 长消息缓冲区| 67108864 |
| 6 | 数据存储器| 1073741824 |
| 6 | 索引记忆| 1074003968 |
| 6 | 长消息缓冲区| 67108864 |
+ --------- + --------------------- + ------------ +
6行(0.00秒)
在这种情况下,
total
索引内存
的
列值略高于
IndexMemory
由于内部舍入而
设置的值
。
对于
used_pages
和
total_pages
列,资源以页面形式测量,大小为32K,
DataMemory
而8K
IndexMemory
。
对于长消息缓冲存储器,页面大小为256字节。
该
memory_per_fragment
表提供有关各个片段的内存使用情况的信息。
下表提供了有关表中列的信息
memory_per_fragment
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.401 memory_per_fragment表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
| fq_name | 串 | 这个片段的名称 |
| parent_fq_name | 串 | 此片段的父级名称 |
| 类型 | 串 | 对象类型; 查看可能值的文本 |
| 的table_id | 整数 | 此表的表ID |
| NODE_ID | 整数 | 此节点的节点ID |
| block_instance | 整数 | 内核块实例ID |
| fragment_num | 整数 | 片段ID(数量) |
| fixed_elem_alloc_bytes | 整数 | 为固定大小的元素分配的字节数 |
| fixed_elem_free_bytes | 整数 | 分配给固定大小元素的页面中剩余的空闲字节数 |
| fixed_elem_size_bytes | 整数 | 每个固定大小元素的长度,以字节为单位 |
| fixed_elem_count | 整数 | 固定大小的元素数量 |
| fixed_elem_free_count | 十进制 | 固定大小元素的可用行数 |
| var_elem_alloc_bytes | 整数 | 为可变大小元素分配的字节数 |
| var_elem_free_bytes | 整数 | 分配给可变大小元素的页面中剩余的空闲字节数 |
| var_elem_count | 整数 | 可变大小元素的数量 |
| hash_index_alloc_bytes | 整数 | 分配给哈希索引的字节数 |
在
type
从该表中列显示用于该片段(字典对象类型
Object::Type
中,NDB API中),并且可以在下面的列表中显示的值中的任何一个:
-
系统表
-
用户表
-
唯一哈希索引
-
哈希指数
-
唯一有序索引
-
有序索引
-
哈希索引触发器
-
订阅触发器
-
只读约束
-
索引触发器
-
重组触发器
-
表空间
-
日志文件组
-
数据文件
-
撤消文件
-
哈希地图
-
外键定义
-
外键父触发器
-
外键子触发器
-
架构事务
您也可以通过
在
mysql
客户端中
执行来获取此列表
。
SELECT
* FROM
ndbinfo.dict_obj_types
该
block_instance
列提供NDB内核块实例编号。
您可以使用它来从
threadblocks
表中
获取有关特定线程的信息
。
该表包含有关数据节点状态的信息。 对于在群集中运行的每个数据节点,此表中的相应行提供节点的节点ID,状态和正常运行时间。 对于正在启动的节点,它还会显示当前的启动阶段。
下表提供了有关表中列的信息
nodes
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.402节点表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 数据节点在集群中的唯一节点ID。 |
uptime |
整数 | 自上次启动节点以来的时间,以秒为单位。 |
status |
串 | 数据节点的当前状态; 查看可能值的文本。 |
start_phase |
整数 | 如果数据节点正在启动,则为当前启动阶段。 |
config_generation |
整数 | 此数据节点上使用的群集配置文件的版本。 |
该
uptime
列显示自上次启动或重新启动以来此节点运行的时间(以秒为单位)。
这是一个
BIGINT
价值。
该图包括启动节点实际需要的时间;
换句话说,这个计数器开始运行
首次调用
ndbd
或
ndbmtd
的时刻
;
因此,即使对于尚未完成启动的节点,也
uptime
可能显示非零值。
该
status
列显示节点的当前状态。
这是一个:
NOTHING
,
CMVMI
,
STARTING
,
STARTED
,
SINGLEUSER
,
STOPPING_1
,
STOPPING_2
,
STOPPING_3
,或
STOPPING_4
。
状态为时
STARTING
,您可以在
start_phase
列中看到
当前的启动阶段
(请参阅本节后面的内容)。
当群集处于单用户模式时,将
SINGLEUSER
显示在
status
所有数据节点
的
列中(请参见
第22.5.8节“NDB群集单用户模式”
)。
看到其中一个
STOPPING
状态并不一定意味着节点正在关闭,但可能意味着它正在进入一个新的状态。
例如,如果您将群集置于单用户模式,您有时可以看到数据节点
STOPPING_2
在状态更改之前
简要地报告其状态
SINGLEUSER
。
该
start_phase
列使用与
ndb_mgm
客户端
node_id
STATUS0
。
有关具有描述的NDB Cluster启动阶段列表,请参见
第22.5.1节“NDB集群启动阶段摘要”
。
该
config_generation
列显示哪个版本的群集配置对每个数据节点有效。
在执行群集的滚动重新启动以便更改配置参数时,这非常有用。
例如,从以下
SELECT
语句
的输出中
,您可以看到节点3尚未使用最新版本的集群配置(
6
),尽管节点1,2和4正在这样做:
MySQL的>USE ndbinfo;数据库已更改 MySQL的>SELECT * FROM nodes;+ --------- + -------- + --------- + ------------- + ------ ------------- + | node_id | 正常运行时间| 状态| start_phase | config_generation | + --------- + -------- + --------- + ------------- + ------ ------------- + | 1 | 10462 | 开始了| 0 | 6 | | 2 | 10460 | 开始了| 0 | 6 | | 3 | 10457 | 开始了| 0 | 5 | | 4 | 10455 | 开始了| 0 | 6 | + --------- + -------- + --------- + ------------- + ------ ------------- + 2行(0.04秒)
因此,对于刚刚显示的情况,您应该重新启动节点3以完成群集的滚动重新启动。
此表中不考虑已停止的节点。 假设您有一个包含4个数据节点的NDB集群(节点ID 1,2,3和4),并且所有节点都正常运行,则此表包含4行,每个数据节点1个:
MySQL的>USE ndbinfo;数据库已更改 MySQL的>SELECT * FROM nodes;+ --------- + -------- + --------- + ------------- + ------ ------------- + | node_id | 正常运行时间| 状态| start_phase | config_generation | + --------- + -------- + --------- + ------------- + ------ ------------- + | 1 | 11776 | 开始了| 0 | 6 | | 2 | 11774 | 开始了| 0 | 6 | | 3 | 11771 | 开始了| 0 | 6 | | 4 | 11769 | 开始了| 0 | 6 | + --------- + -------- + --------- + ------------- + ------ ------------- + 4行(0.04秒)
如果关闭其中一个节点,则只有仍在运行的节点在此
SELECT
语句
的输出中
表示,如下所示:
ndb_mgm> 2 STOP
节点2:节点关闭已启动
节点2:节点关闭完成。
节点2已关闭。
MySQL的> SELECT * FROM nodes;
+ --------- + -------- + --------- + ------------- + ------ ------------- +
| node_id | 正常运行时间| 状态| start_phase | config_generation |
+ --------- + -------- + --------- + ------------- + ------ ------------- +
| 1 | 11807 | 开始了| 0 | 6 |
| 3 | 11802 | 开始了| 0 | 6 |
| 4 | 11800 | 开始了| 0 | 6 |
+ --------- + -------- + --------- + ------------- + ------ ------------- +
3排套装(0.02秒)
该
operations_per_fragment
表提供有关对单个片段和片段副本执行的操作的信息,以及这些操作的一些结果。
下表提供了有关表中列的信息
operations_per_fragment
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.403 operations_per_fragment表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
| fq_name | 串 | 这个片段的名称 |
| parent_fq_name | 串 | 此片段的父级名称 |
| 类型 | 串 | 对象类型; 查看可能值的文本 |
| 的table_id | 整数 | 此表的表ID |
| NODE_ID | 整数 | 此节点的节点ID |
| block_instance | 整数 | 内核块实例ID |
| fragment_num | 整数 | 片段ID(数量) |
| tot_key_reads | 整数 | 此片段副本的密钥读取总数 |
| tot_key_inserts | 整数 | 此片段副本的密钥插入总数 |
| tot_key_updates | 整数 | 此片段副本的密钥更新总数 |
| tot_key_writes | 整数 | 此片段副本的密钥写入总数 |
| tot_key_deletes | 整数 | 此片段副本的密钥删除总数 |
| tot_key_refs | 整数 | 拒绝关键业务的数量 |
| tot_key_attrinfo_bytes | 整数 |
所有
attrinfo
属性的
总大小
|
| tot_key_keyinfo_bytes | 整数 |
所有
keyinfo
属性的
总大小
|
| tot_key_prog_bytes | 整数 |
attrinfo
属性
携带的所有解释程序的总大小
|
| tot_key_inst_exec | 整数 | 解释程序为关键操作执行的指令总数 |
| tot_key_bytes_returned | 整数 | 从键读取操作返回的所有数据和元数据的总大小 |
| tot_frag_scans | 整数 | 在此片段副本上执行的扫描总数 |
| tot_scan_rows_examined | 整数 | 扫描检查的总行数 |
| tot_scan_rows_returned | 整数 | 返回给客户端的总行数 |
| tot_scan_bytes_returned | 整数 | 返回给客户端的数据和元数据的总大小 |
| tot_scan_prog_bytes | 整数 | 扫描操作的解释程序的总大小 |
| tot_scan_bound_bytes | 整数 | 有序索引扫描中使用的所有边界的总大小 |
| tot_scan_inst_exec | 整数 | 扫描执行的指令总数 |
| tot_qd_frag_scans | 整数 | 扫描此片段副本的次数已排队 |
| conc_frag_scans | 整数 | 此片段副本上当前处于活动状态的扫描数(排队扫描除外) |
| conc_qd_frag_scans | 整数 | 当前为此片段副本排队的扫描数 |
| tot_commits | 整数 | 提交给此片段副本的行更改总数 |
在
fq_name
包含此片段副本所属的架构对象的全名。
目前有以下格式:
-
基表: -
DbName/def/TblName -
BLOB表: -DbName/def/NDB$BLOB_BaseTblId_ColNo -
有序索引: -
sys/def/BaseTblId/IndexName -
独特指数: -
sys/def/BaseTblId/IndexName$unique
mysqld
$unique
添加了唯一索引显示
的
后缀
;
对于由不同NDB API客户端应用程序创建的索引,这可能不同,或者不存在。
刚显示的完全限定对象名称的语法是一个内部接口,在将来的版本中可能会有所变化。
考虑
t1
由以下SQL语句创建和修改的表:
创建数据库mydb; 使用mydb; CREATE TABLE t1( INT NOT NULL, b INT NOT NULL, t TEXT NOT NULL, 主要关键(b) )ENGINE = ndbcluster; 创建独特的索引ix1 ON t1(b)使用哈希;
如果
t1
分配了表ID 11,则会生成
fq_name
此处显示
的
值:
-
基表:
mydb/def/t1 -
BLOB表:mydb/def/NDB$BLOB_11_2 -
有序索引(主键):
sys/def/11/PRIMARY -
独特指数:
sys/def/11/ix1$unique
对于索引或
BLOB
表,该
parent_fq_name
列包含
fq_name
相应基表的列。
对于基表,此列始终为
NULL
。
的
type
列显示用于该片段的架构对象类型,它可以采取的值的任何一个
System table
,
User table
,
Unique hash index
,或
Ordered
index
。
BLOB
表格显示为
User table
。
该
table_id
列的值是在任何给定时间唯一的,但如果相应的对象已被删除可重复使用。
使用
ndb_show_tables
实用程序
可以看到相同的ID
。
该
block_instance
列显示此片段副本所属的LDM实例。
您可以使用它来从
threadblocks
表中
获取有关特定线程的信息
。
第一个这样的实例总是编号为0。
由于通常有两个副本,并且假设是这样,每个
fragment_num
值应该在表中出现两次,在同一节点组的两个不同数据节点上。
由于
NDB
不使用有序索引单键访问,计数
tot_key_reads
,
tot_key_inserts
,
tot_key_updates
,
tot_key_writes
,和
tot_key_deletes
没有被有序索引操作递增。
使用时
tot_key_writes
,您应该记住,如果密钥存在,此上下文中的写入操作会更新行,否则会插入新行。
(一种用法是在
SQL语句
的
NDB
实现中
REPLACE
。)
该
tot_key_refs
列显示LDM拒绝的关键操作数。
通常,这种拒绝是由于重复的密钥(插入),
密钥未找到
错误(更新,删除和读取),或者操作被用作匹配密钥的行的谓词的解释程序拒绝。
的
attrinfo
和
keyinfo
通过所计数的属性
tot_key_attrinfo_bytes
和
tot_key_keyinfo_bytes
列是一个属性
LQHKEYREQ
信号(见
的NDB通信协议
)中使用由LDM启动的键操作。
一个
attrinfo
典型地含有元组字段值(插入和更新)或投影规格(读取);
keyinfo
包含在此架构对象中定位给定元组所需的主键或唯一键。
显示的值
tot_frag_scans
包括完整扫描(检查每一行)和子集扫描。
BLOB
永远不会扫描
唯一索引和
表,因此与其他扫描相关的计数一样,此值对于这些的碎片副本为0。
tot_scan_rows_examined
可能会显示小于给定片段副本中的总行数,因为有序索引扫描可能受边界限制。
此外,客户端可以选择在检查所有可能匹配的行之前结束扫描;
例如,当使用包含
LIMIT
or
EXISTS
子句
的SQL语句时会发生这种情况
。
tot_scan_rows_returned
总是小于或等于
tot_scan_rows_examined
。
tot_scan_bytes_returned
包括,在推入连接的情况下,投影返回到
DBSPJ
NDB内核中
的
块。
tot_qd_frag_scans
可以通过
MaxParallelScansPerFragment
数据节点配置参数
的设置来实现,该
参数限制了可以在单个片段副本上并发执行的扫描的数量。
该表包含有关NDB群集节点进程的信息;
每个节点由表中的行表示。
此表中仅显示连接到群集的节点。
您可以从
nodes
和
config_nodes
表中
获取有关已配置但未连接到群集的节点的信息
。
下表提供了有关表中列的信息
processes
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.404节点表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 节点在集群中的唯一节点ID |
node_type |
串 | 节点类型(管理,数据或API节点;请参阅文本) |
node_version |
串 |
NDB
在此节点上运行
的
软件程序的
版本
。
|
process_id |
整数 | 此节点的进程ID |
angel_process_id |
整数 | 此节点的天使进程的进程ID |
process_name |
串 | 可执行文件的名称 |
service_URI |
串 | 此节点的服务URI(参见文本) |
node_id
是分配给群集中此节点的ID。
该
node_type
列显示以下三个值之一:
-
MGM:管理节点。 -
NDB:数据节点。 -
API:API或SQL节点。
对于随NDB Cluster分发一起提供的可执行文件,
node_version
显示软件Cluster版本字符串,例如
8.0.17-ndb-8.0.17
。
process_id
是主机操作系统使用进程显示应用程序(如
Linux上的
top)
或Windows平台上的任务管理器
显示的节点可执行文件的进程ID
。
angel_process_id
是节点的angel进程的系统进程ID,它确保在出现故障时自动重新启动数据节点或SQL。
对于SQL节点以外的管理节点和API节点,此列的值为
NULL
。
该
process_name
列显示正在运行的可执行文件的名称。
对于管理节点,这是
ndb_mgmd
。
对于数据节点,这是
ndbd
(单线程)或
ndbmtd
(多线程)。
对于SQL节点,这是
mysqld
。
对于其他类型的API节点,它是连接到集群的可执行程序的名称;
NDB API应用程序可以为此设置自定义值
Ndb_cluster_connection::set_name()
。
service_URI
显示服务网络地址。
对于管理节点和数据节点,使用的方案是
ndb://
。
对于SQL节点,这是
mysql://
。
默认情况下,SQL节点以外的API节点
ndb://
用于该方案;
NDB API应用程序可以使用它将其设置为自定义值
Ndb_cluster_connection::set_service_uri()
。
无论节点类型如何,该方案后面都是NDB传输器用于所讨论节点的IP地址。
对于管理节点和SQL节点,此地址包括端口号(管理节点通常为1186,SQL节点为3306)。
如果使用
bind_address
系统变量集
启动SQL节点
,则使用此地址而不是传输器地址,除非绑定地址设置为
*
,
0.0.0.0
或
::
。
附加路径信息可以包括在
service_URI
反映各种配置选项的SQL节点
的
值中。
例如,
mysql://198.51.100.3/tmp/mysql.sock
表示SQL节点已启动
--skip-networking
,并
mysql://198.51.100.3:3306/?server-id=1
显示已为此SQL节点启用了复制。
此表提供有关数据节点资源可用性和使用情况的信息。
这些资源有时称为 超级池 。
下表提供了有关表中列的信息
resources
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.405资源表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此数据节点的唯一节点ID。 |
resource_name |
串 | 资源名称; 看文字。 |
reserved |
整数 | 为此资源保留的金额。 |
used |
整数 | 此资源实际使用的金额。 |
max |
整数 | 自上次启动节点以来使用的此资源的最大数量。 |
该
resource_name
可以是下表中显示的名称之一:
表22.406 ndbinfo.resources表资源名称和描述
| 资源名称 | 描述 |
|---|---|
RESERVED |
由系统保留; 不能被覆盖。 |
DISK_OPERATIONS |
如果分配了日志文件组,则使用撤消日志缓冲区的大小来设置此资源的大小。
该资源仅用于为撤消日志文件组分配撤消日志缓冲区;
只有一个这样的团体。
根据需要进行整体分配
CREATE LOGFILE GROUP
。
|
DISK_RECORDS |
为磁盘数据操作分配的记录。 |
DATA_MEMORY |
用于主内存元组,索引和哈希索引。 如果已设置IndexMemory,则DataMemory和IndexMemory的总和加上8页,每页32 KB。 不能过度分配。 |
JOBBUFFER |
用于通过NDB调度程序分配作业缓冲区; 无法进行过度分配。 对于可以通信的所有线程,每个线程大约2 MB,并且在两个方向上都有1 MB缓冲区。 对于大型配置,这会消耗几GB。 |
FILE_BUFFERS |
由
DBLQH
内核块中
的重做日志处理程序使用
;
无法进行过度分配。
大小为
NoOfFragmentLogParts
*
RedoBuffer
,每个日志文件部分加1 MB。
|
TRANSPORTER_BUFFERS |
用于
ndbmtd
发送缓冲区
;
总和
TotalSendBufferMemory
和
ExtraSendBufferMemory
。
此资源最多可以分配25%。
TotalSendBufferMemory
通过对每个节点的发送缓冲区内存求和来计算,其默认值为2 MB。
因此,在具有四个数据节点和八个API节点的系统中,数据节点具有12 * 2MB的发送缓冲存储器。
ExtraSendBufferMemory
由
ndbmtd
使用,
每个线程相当于2 MB额外内存。
因此,使用4个LDM线程,2个TC线程,1个主线程,1个复制线程和2个接收线程,
ExtraSendBufferMemory
是10 * 2 MB。
可以通过设置
SharedGlobalMemory
数据节点配置参数
来执行此资源的分配
。
|
DISK_PAGE_BUFFER |
用于磁盘页面缓冲区;
由
DiskPageBufferMemory
配置参数
确定
。
不能过度分配。
|
QUERY_MEMORY |
由
DBSPJ
内核块使用。
|
SCHEMA_TRANS_MEMORY |
最小值为2 MB; 可以进行过度分配以使用任何剩余的可用内存。 |
该
restart_info
表包含有关节点重新启动操作的信息。
表中的每个条目对应于具有给定节点ID的数据节点的实时节点重启状态报告。
仅显示任何给定节点的最新报告。
下表提供了有关表中列的信息
restart_info
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.407 restart_info表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 群集中的节点ID |
node_restart_status |
VARCHAR(256) |
节点状态;
查看值的文本。
这些中的每一个对应于可能的值
node_restart_status_int
。
|
node_restart_status_int |
整数 | 节点状态码; 查看值的文本。 |
secs_to_complete_node_failure |
整数 | 完成节点故障处理的时间(秒) |
secs_to_allocate_node_id |
整数 | 从节点故障完成到节点ID分配的时间(以秒为单位) |
secs_to_include_in_heartbeat_protocol |
整数 | 从心跳协议中分配节点ID到包含的时间(以秒为单位) |
secs_until_wait_for_ndbcntr_master |
整数 |
从包含在心跳协议中直到等待
NDBCNTR
主服务开始的
时间(以秒为单位)
|
secs_wait_for_ndbcntr_master |
整数 |
等待
NDBCNTR
主人
接受
启动的
时间(以秒
为单位)
|
secs_to_get_start_permitted |
整数 | 从接收到从master启动的权限到所有节点都已接受此节点的启动所用的时间(以秒为单位) |
secs_to_wait_for_lcp_for_copy_meta_data |
整数 | 在复制元数据之前等待LCP完成所花费的时间(以秒为单位) |
secs_to_copy_meta_data |
整数 | 将元数据从主节点复制到新起始节点所需的时间(以秒为单位) |
secs_to_include_node |
整数 | 以秒为单位的时间等待GCP并将所有节点包含在协议中 |
secs_starting_node_to_request_local_recovery |
整数 | 节点刚开始等待请求本地恢复的时间(以秒为单位) |
secs_for_local_recovery |
整数 | 节点刚开始本地恢复所需的时间(以秒为单位) |
secs_restore_fragments |
整数 | 从LCP文件恢复片段所需的时间(以秒为单位) |
secs_undo_disk_data |
整数 | 在磁盘数据部分记录上执行撤消日志所需的时间(以秒为单位) |
secs_exec_redo_log |
整数 | 在所有已还原的片段上执行重做日志所需的时间(以秒为单位) |
secs_index_rebuild |
整数 | 在已还原的片段上重建索引所需的时间(以秒为单位) |
secs_to_synchronize_starting_node |
整数 | 从活动节点同步起始节点所需的时间(以秒为单位) |
secs_wait_lcp_for_restart |
整数 | 完成重启之前LCP启动和完成所需的时间(以秒为单位) |
secs_wait_subscription_handover |
整数 | 等待切换复制订阅所花费的时间(以秒为单位) |
total_restart_secs |
整数 | 从节点故障到节点再次启动的总秒数 |
下表显示了
node_restart_status_int
对应的状态名称和消息(
node_restart_status
)的
定义值
:
表22.408 restart_info表中使用的状态代码和消息
| 列名称 | 类型 | 描述 |
|---|---|---|
| 0 | ALLOCATED_NODE_ID |
Allocated node id |
| 1 | INCLUDED_IN_HB_PROTOCOL |
Included in heartbeat protocol |
| 2 | NDBCNTR_START_WAIT |
Wait for NDBCNTR master to permit us to start |
| 3 | NDBCNTR_STARTED |
NDBCNTR master permitted us to start |
| 4 | START_PERMITTED |
All nodes permitted us to start |
| 五 | WAIT_LCP_TO_COPY_DICT |
Wait for LCP completion to start copying metadata |
| 6 | COPY_DICT_TO_STARTING_NODE |
Copying metadata to starting node |
| 7 | INCLUDE_NODE_IN_LCP_AND_GCP |
Include node in LCP and GCP protocols |
| 8 | LOCAL_RECOVERY_STARTED |
Restore fragments ongoing |
| 9 | COPY_FRAGMENTS_STARTED |
Synchronizing starting node with live nodes |
| 10 | WAIT_LCP_FOR_RESTART |
Wait for LCP to ensure durability |
| 11 | WAIT_SUMA_HANDOVER |
Wait for handover of subscriptions |
| 12 | RESTART_COMPLETED |
Restart completed |
| 13 | NODE_FAILED |
Node failed, failure handling in progress |
| 14 | NODE_FAILURE_COMPLETED |
Node failure handling completed |
| 15 | NODE_GETTING_PERMIT |
All nodes permitted us to start |
| 16 | NODE_GETTING_INCLUDED |
Include node in LCP and GCP protocols |
| 17 | NODE_GETTING_SYNCHED |
Synchronizing starting node with live nodes |
| 18 | NODE_GETTING_LCP_WAITED |
[没有] |
| 19 | NODE_ACTIVE |
Restart completed |
| 20 | NOT_DEFINED_IN_CLUSTER |
[没有] |
| 21 | NODE_NOT_RESTARTED_YET |
Initial state |
状态编号0到12仅适用于主节点; 表中显示的其余部分适用于所有重新启动的数据节点。 状态号13和14定义节点故障状态; 当没有关于给定节点的重启的信息可用时,出现图20和21。
另请参见 第22.5.1节“NDB集群启动阶段摘要” 。
该
server_locks
表在结构上与
cluster_locks
表
类似
,并提供了后一个表中找到的信息的子集,但它特定于它所在的SQL节点(MySQL服务器)。
(该
cluster_locks
表提供有关集群中所有锁的信息。)更确切地说,
server_locks
包含有关属于当前
mysqld
实例
的线程请求的锁的信息
,并作为伴随表
server_operations
。
这可能有助于将锁定模式与特定的MySQL用户会话,查询或用例相关联。
下表提供了有关表中列的信息
server_locks
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.409 server_locks表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
mysql_connection_id |
整数 | MySQL连接ID |
node_id |
整数 | 报告节点的ID |
block_instance |
整数 | 报告LDM实例的ID |
tableid |
整数 | 包含此行的表的ID |
fragmentid |
整数 | 包含锁定行的片段的ID |
rowid |
整数 | 锁定行的ID |
transid |
整数 | 交易ID |
mode |
串 | 锁定请求模式 |
state |
串 | 锁定状态 |
detail |
串 | 这是否是第一次在行锁定队列中保持锁定 |
op |
串 | 操作类型 |
duration_millis |
整数 | 等待或持有锁定的毫秒数 |
lock_num |
整数 | 锁定对象的ID |
waiting_for |
整数 | 等待此ID的锁定 |
该
mysql_connection_id
列显示MySQL连接或线程ID,如下所示
SHOW PROCESSLIST
。
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
将
tableid
被分配给由表
NDB
;
在其他
ndbinfo
表中以及在
ndb_show_tables
的输出中
,该表使用相同的ID
。
transid
列中
显示的事务ID
是NDB API为请求或持有当前锁的事务生成的标识符。
该
mode
列显示锁定模式,它始终是
S
(共享锁定)或
X
(独占锁定)之一。
如果事务对给定行具有独占锁定,则该行上的所有其他锁定具有相同的事务ID。
该
state
列显示锁定状态。
它的值始终是
H
(保持)或
W
(等待)之一。
等待锁定请求等待由不同事务持有的锁定。
该
detail
列指示此锁是否是受影响行的锁定队列中的第一个保持锁,在这种情况下它包含
*
(星号字符);
否则,此列为空。
此信息可用于帮助识别锁定请求列表中的唯一条目。
该
op
列显示了请求锁定的操作类型。
这始终是一个值
READ
,
INSERT
,
UPDATE
,
DELETE
,
SCAN
,或
REFRESH
。
该
duration_millis
列显示此锁定请求等待或持有锁定的毫秒数。
当为等待请求授予锁定时,将重置为0。
锁ID(
lockid
列)对于此节点和块实例是唯一的。
如果
lock_state
列的值为
W
,则此锁等待被授予,并且该
waiting_for
列显示此请求正在等待的锁对象的锁ID。
否则,
waiting_for
是空的。
waiting_for
可以仅指在同一行上的锁(通过
node_id
,
block_instance
,
tableid
,
fragmentid
,和
rowid
)。
该
server_operations
表包含
NDB
当前SQL节点(MySQL Server)当前所涉及的
所有正在进行的
操作的
条目
。它实际上是该
cluster_operations
表
的子集
,其中未显示其他SQL和API节点的操作。
下表提供了有关表中列的信息
server_operations
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.410 server_operations表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
mysql_connection_id |
整数 | MySQL服务器连接ID |
node_id |
整数 | 节点ID |
block_instance |
整数 | 阻止实例 |
transid |
整数 | 交易ID |
operation_type |
串 | 操作类型(参见可能值的文本) |
state |
串 | 操作状态(参见可能值的文本) |
tableid |
整数 | 表ID |
fragmentid |
整数 | 片段ID |
client_node_id |
整数 | 客户端节点ID |
client_block_ref |
整数 | 客户端块参考 |
tc_node_id |
整数 | 事务协调器节点ID |
tc_block_no |
整数 | 事务协调器块号 |
tc_block_instance |
整数 | 事务协调器块实例 |
它
mysql_connection_id
与输出中显示的连接或会话ID相同
SHOW PROCESSLIST
。
它是从
INFORMATION_SCHEMA
表中
获得的
NDB_TRANSID_MYSQL_CONNECTION_MAP
。
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
事务ID(
transid
)是唯一的64位数字,可以使用NDB API的
getTransactionId()
方法获得。
(目前,MySQL服务器不公开正在进行的事务的NDB API事务ID。)
所述
operation_type
列可以采取的值的任一个
READ
,
READ-SH
,
READ-EX
,
INSERT
,
UPDATE
,
DELETE
,
WRITE
,
UNLOCK
,
REFRESH
,
SCAN
,
SCAN-SH
,
SCAN-EX
,或
<unknown>
。
该
state
柱可以具有的值中的任何一个
ABORT_QUEUED
,
ABORT_STOPPED
,
COMMITTED
,
COMMIT_QUEUED
,
COMMIT_STOPPED
,
COPY_CLOSE_STOPPED
,
COPY_FIRST_STOPPED
,
COPY_STOPPED
,
COPY_TUPKEY
,
IDLE
,
LOG_ABORT_QUEUED
,
LOG_COMMIT_QUEUED
,
LOG_COMMIT_QUEUED_WAIT_SIGNAL
,
LOG_COMMIT_WRITTEN
,
LOG_COMMIT_WRITTEN_WAIT_SIGNAL
,
LOG_QUEUED
,
PREPARED
,
PREPARED_RECEIVED_COMMIT
,
SCAN_CHECK_STOPPED
,
SCAN_CLOSE_STOPPED
,
SCAN_FIRST_STOPPED
,
SCAN_RELEASE_STOPPED
,
SCAN_STATE_USED
,
SCAN_STOPPED
,
SCAN_TUPKEY
,
STOPPED
,
TC_NOT_CONNECTED
,
WAIT_ACC
,
WAIT_ACC_ABORT
,
WAIT_AI_AFTER_ABORT
,
WAIT_ATTR
,
WAIT_SCAN_AI
,
WAIT_TUP
,
WAIT_TUPKEYINFO
,
WAIT_TUP_COMMIT
,或
WAIT_TUP_TO_ABORT
。
(如果MySQL服务器在
ndbinfo_show_hidden
启用时
运行
,您可以通过从
ndb$dblqh_tcconnect_state
表中
选择来查看此状态列表,该
表通常是隐藏的。)
您可以
NDB
通过检查
ndb_show_tables
的输出从其表ID中
获取
表
的名称
。
它
fragid
与
ndb_desc
--extra-partition-info
(简短格式
-p
)
的输出中看到的分区号相同
。
在
client_node_id
和中
client_block_ref
,
client
指的是NDB Cluster API或SQL节点(即,NDB API客户端或连接到群集的MySQL Server)。
在
block_instance
与
tc_block_instance
列提供NDB内核块实例号。
您可以使用它们从
threadblocks
表中
获取有关特定线程的信息
。
该
server_transactions
表是表的子集
cluster_transactions
,但仅包括当前SQL节点(MySQL Server)作为参与者的那些事务,同时包括相关的连接ID。
下表提供了有关表中列的信息
server_transactions
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.411 server_transactions表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
mysql_connection_id |
整数 | MySQL服务器连接ID |
node_id |
整数 | 事务协调器节点ID |
block_instance |
整数 | 事务协调器块实例 |
transid |
整数 | 交易ID |
state |
串 | 操作状态(参见可能值的文本) |
count_operations |
整数 | 事务中的有状态操作数 |
outstanding_operations |
整数 | 操作仍由本地数据管理层执行(LQH块) |
inactive_seconds |
整数 | 花在等待API的时间 |
client_node_id |
整数 | 客户端节点ID |
client_block_ref |
整数 | 客户端块参考 |
它
mysql_connection_id
与输出中显示的连接或会话ID相同
SHOW PROCESSLIST
。
它是从
INFORMATION_SCHEMA
表中
获得的
NDB_TRANSID_MYSQL_CONNECTION_MAP
。
block_instance
是指内核块的实例。
与块名称一起,此数字可用于在
threadblocks
表中
查找给定实例
。
事务ID(
transid
)是唯一的64位数字,可以使用NDB API的
getTransactionId()
方法获得。
(目前,MySQL服务器不公开正在进行的事务的NDB API事务ID。)
该
state
柱可以具有的值中的任何一个
CS_ABORTING
,
CS_COMMITTING
,
CS_COMMIT_SENT
,
CS_COMPLETE_SENT
,
CS_COMPLETING
,
CS_CONNECTED
,
CS_DISCONNECTED
,
CS_FAIL_ABORTED
,
CS_FAIL_ABORTING
,
CS_FAIL_COMMITTED
,
CS_FAIL_COMMITTING
,
CS_FAIL_COMPLETED
,
CS_FAIL_PREPARED
,
CS_PREPARE_TO_COMMIT
,
CS_RECEIVING
,
CS_REC_COMMITTING
,
CS_RESTART
,
CS_SEND_FIRE_TRIG_REQ
,
CS_STARTED
,
CS_START_COMMITTING
,
CS_START_SCAN
,
CS_WAIT_ABORT_CONF
,
CS_WAIT_COMMIT_CONF
,
CS_WAIT_COMPLETE_CONF
,
CS_WAIT_FIRE_TRIG_REQ
。
(如果MySQL服务器在
ndbinfo_show_hidden
启用时
运行
,您可以通过选择来查看此状态列表
ndb$dbtc_apiconnect_state
表,通常是隐藏的。)
在
client_node_id
和中
client_block_ref
,
client
指的是NDB Cluster API或SQL节点(即,NDB API客户端或连接到群集的MySQL Server)。
该
block_instance
列提供
DBTC
内核块实例编号。
您可以使用它来从
threadblocks
表中
获取有关特定线程的信息
。
该
table_distribution_status
表提供有关表的表分发进度的信息
NDB
。
下表提供了有关列的信息
table_distribution_status
。
对于每列,该表显示名称,数据类型和简要说明。
表22.412 table_distribution_status表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 节点ID |
table_id |
整数 | 表ID |
tab_copy_status |
串 |
将表分发数据复制到磁盘的状态;
之一
IDLE
,
SR_PHASE1_READ_PAGES
,
SR_PHASE2_READ_TABLE
,
SR_PHASE3_COPY_TABLE
,
REMOVE_NODE
,
LCP_READ_TABLE
,
COPY_TAB_REQ
,
COPY_NODE_STATE
,
ADD_TABLE_MASTER
,
ADD_TABLE_SLAVE
,
INVALIDATE_NODE_LCP
,
ALTER_TABLE
,
COPY_TO_SAVE
,或
GET_TABINFO
|
tab_update_status |
串 |
表分布数据的更新状态;
之一
IDLE
,
LOCAL_CHECKPOINT
,
LOCAL_CHECKPOINT_QUEUED
,
REMOVE_NODE
,
COPY_TAB_REQ
,
ADD_TABLE_MASTER
,
ADD_TABLE_SLAVE
,
INVALIDATE_NODE_LCP
,或
CALLBACK
|
tab_lcp_status |
串 |
表LCP的状态;
其中一个
ACTIVE
(等待执行本地检查点),
WRITING_TO_FILE
(检查点已执行但尚未写入磁盘),或
COMPLETED
(检查点已执行并持久保存到磁盘)
|
tab_status |
串 |
表内部状态;
之一
ACTIVE
(表中存在),
CREATING
(
正被创建的表),或
DROPPING
(表正被删除)
|
tab_storage |
串 |
表可恢复性;
其中一个
NORMAL
(完全可以通过重做日志记录和检查点
NOLOGGING
恢复
),
(可以从节点崩溃中恢复,在集群崩溃后为空)或
TEMPORARY
(不可恢复)
|
tab_partitions |
整数 | 表中的分区数 |
tab_fragments |
整数 |
表中的片段数量;
通常相同
tab_partitions
;
对于完全复制的表等于
tab_partitions * [number of node
groups]
|
current_scan_count |
整数 | 当前活动扫描数 |
scan_count_wait |
整数 |
可以完成之前等待执行的当前扫描次数
ALTER
TABLE
。
|
is_reorg_ongoing |
整数 | 表是否正在重组(如果为真,则为1) |
该
table_fragments
表提供有关表的碎片,分区,分发和(内部)复制的信息
NDB
。
下表提供了有关列的信息
table_fragments
。
对于每列,该表显示名称,数据类型和简要说明。
表22.413 table_fragments表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 |
节点ID(
DIH
主)
|
table_id |
整数 | 表ID |
partition_id |
整数 | 分区ID |
fragment_id |
整数 | 片段ID(与分区ID相同,除非完全复制表) |
partition_order |
整数 | 分区中的片段顺序 |
log_part_id |
整数 | 记录片段的部件ID |
no_of_replicas |
整数 | 副本数量 |
current_primary |
整数 | 当前主节点ID |
preferred_primary |
整数 | 首选主节点ID |
current_first_backup |
整数 | 当前的第一个备份节点ID |
current_second_backup |
整数 | 当前的第二个备份节点ID |
current_third_backup |
整数 | 当前的第三个备份节点ID |
num_alive_replicas |
整数 | 当前活动副本的数量 |
num_dead_replicas |
整数 | 当前死亡复制品的数量 |
num_lcp_replicas |
整数 | 要检查点的副本数量 |
该
table_info
表提供有关对各个
NDB
表
有效的日志记录,检查点,分发和存储选项的信息
。
下表提供了有关列的信息
table_info
。
对于每列,该表显示名称,数据类型和简要说明。
表22.414 table_info表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
table_id |
整数 | 表ID |
logged_table |
整数 | 是否记录表(1)或不记录(0) |
row_contains_gci |
整数 | 表行是否包含GCI(1为true,0 false) |
row_contains_checksum |
整数 | 表行是否包含校验和(1个true,0 false) |
read_backup |
整数 | 如果读取备份副本,则为1,否则为0 |
fully_replicated |
整数 | 如果表完全复制,则为1,否则为0 |
storage_type |
串 |
表存储类型;
一个
MEMORY
或
DISK
|
hashmap_id |
整数 | Hashmap ID |
partition_balance |
串 |
用于表的分区余额(片段计数类型);
之一
FOR_RP_BY_NODE
,
FOR_RA_BY_NODE
,
FOR_RP_BY_LDM
,或
FOR_RA_BY_LDM
|
create_gci |
整数 | 创建表的GCI |
该
table_replicas
表提供有关
NDB
表片段和片段副本
的复制,分发和检查点的信息
。
下表提供了有关列的信息
table_replicas
。
对于每列,该表显示名称,数据类型和简要说明。
表22.415 table_replicas表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 |
获取数据的节点的ID(
DIH
主)
|
table_id |
整数 | 表ID |
fragment_id |
整数 | 片段ID |
initial_gci |
整数 | 表的初始GCI |
replica_node_id |
整数 | 存储副本的节点的ID |
is_lcp_ongoing |
整数 | 如果LCP在此片段上正在进行,则为1,否则为0 |
num_crashed_replicas |
整数 | 崩溃的副本实例数 |
last_max_gci_started |
整数 | 最近的GCI始于最近的LCP |
last_max_gci_completed |
整数 | 在最近的LCP中完成了最高的GCI |
last_lcp_id |
整数 | 最近的LCP的ID |
prev_lcp_id |
整数 | 以前LCP的ID |
prev_max_gci_started |
整数 | 在之前的LCP中开始了最高的GCI |
prev_max_gci_completed |
整数 | 在之前的LCP中完成了最高的GCI |
last_create_gci |
整数 | 上次创建最后崩溃的副本实例的GCI |
last_replica_gci |
整数 | 最后崩溃的副本实例的最后一个GCI |
is_replica_alive |
整数 | 如果此副本处于活动状态,则为1,否则为0 |
该
tc_time_track_stats
表提供
DBTC
通过API节点访问从数据节点中
的
块(TC)实例
获得的时间跟踪信息
NDB
。
每个TC实例跟踪它代表API节点或其他数据节点进行的一系列活动的延迟;
这些活动包括事务,事务错误,密钥读取,密钥写入,唯一索引操作,任何类型的失败密钥操作,扫描,失败扫描,片段扫描和失败的片段扫描。
为每个活动维护一组计数器,每个计数器覆盖小于或等于上限的一系列延迟。
在每个活动结束时,确定其等待时间并且适当的计数器递增。
tc_time_track_stats
将此信息显示为行,并为以下每个实例添加一行:
-
数据节点,使用其ID
-
TC块实例
-
其他通信数据节点或API节点,使用其ID
-
上限值
每行包含每种活动类型的值。 这是此活动发生的次数,延迟在行指定的范围内(即,延迟不超过上限)。
下表提供了有关列的信息
tc_time_track_stats
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.416 tc_time_track_stats表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 请求节点ID |
block_number |
整数 | TC块号 |
block_instance |
整数 | TC块实例编号 |
comm_node_id |
整数 | 通信API或数据节点的节点ID |
upper_bound |
整数 | 间隔的上限(以微秒为单位) |
scans |
整数 | 根据从打开到关闭的成功扫描持续时间,跟踪请求它们的API或数据节点。 |
scan_errors |
整数 | 基于从打开到关闭的扫描失败的持续时间,针对请求它们的API或数据节点进行跟踪。 |
scan_fragments |
整数 | 基于从打开到关闭的成功片段扫描的持续时间,跟踪执行它们的数据节点 |
scan_fragment_errors |
整数 | 基于从打开到关闭的失败片段扫描的持续时间,跟踪执行它们的数据节点 |
transactions |
整数 |
基于从开始到发送提交的成功事务的持续时间
ACK
,针对请求它们的API或数据节点
进行
跟踪。
无国籍交易不包括在内。
|
transaction_errors |
整数 | 基于从开始到失败的失败事务的持续时间,针对请求它们的API或数据节点进行跟踪。 |
read_key_ops |
整数 | 基于带锁的成功主键读取的持续时间。 跟踪请求它们的API或数据节点以及执行它们的数据节点。 |
write_key_ops |
整数 | 基于成功主键写入的持续时间,针对请求它们的API或数据节点以及执行它们的数据节点进行跟踪。 |
index_key_ops |
整数 | 基于成功的唯一索引键操作的持续时间,针对请求它们的API或数据节点以及执行基表读取的数据节点进行跟踪。 |
key_op_errors |
整数 | 基于所有不成功的密钥读取或写入操作的持续时间,针对请求它们的API或数据节点以及执行它们的数据节点进行跟踪。 |
该
block_instance
列提供
DBTC
内核块实例编号。
您可以将其与块名称一起使用,以从
threadblocks
表中
获取有关特定线程的信息
。
该
threadblocks
表关联数据节点,线程和
NDB
内核块
实例
。
下表提供了有关表中列的信息
threadblocks
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.417 threadblocks表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 节点ID |
thr_no |
整数 | 线程ID |
block_name |
串 | 阻止名称 |
block_instance |
整数 | 阻止实例编号 |
的值
block_name
在此表是在找到的值中的一个
block_name
从选择时的列
ndbinfo.blocks
表。
尽管对于给定的NDB Cluster版本,可能值列表是静态的,但列表可能因版本而异。
该
block_instance
列提供内核块实例编号。
该
threads
表提供有关在
NDB
内核中
运行的线程的信息
。
下表提供了有关表中列的信息
threads
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.418线程表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 线程正在运行的节点的ID |
thr_no |
整数 | 线程ID(特定于此节点) |
thread_name |
串 | 线程名称(线程类型) |
thread_description |
串 | 线程(类型)描述 |
此处显示了来自双节点示例集群的示例输出,包括线程描述:
MySQL的> SELECT * FROM threads;
+ --------- + -------- + ------------- + ---------------- -------------------------------------------------- +
| node_id | thr_no | thread_name | thread_description |
+ --------- + -------- + ------------- + ---------------- -------------------------------------------------- +
| 5 | 0 | 主要| 主线程,架构和分发处理|
| 5 | 1 | rep | rep线程,异步复制和代理块处理|
| 5 | 2 | ldm | ldm线程,处理一组数据分区|
| 5 | 3 | recv | 接收线程,执行接收和轮询新接收|
| 6 | 0 | 主要| 主线程,架构和分发处理|
| 6 | 1 | rep | rep线程,异步复制和代理块处理|
| 6 | 2 | ldm | ldm线程,处理一组数据分区|
| 6 | 3 | recv | 接收线程,执行接收和轮询新接收|
+ --------- + -------- + ------------- + ---------------- -------------------------------------------------- +
8行(0.01秒)
该
threadstat
表提供了
NDB
内核中
运行的线程的统计信息的粗略快照
。
下表提供了有关表中列的信息
threadstat
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.419 threadstat表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 节点ID |
thr_no |
整数 | 线程ID |
thr_nm |
串 | 线程名称 |
c_loop |
串 | 主循环中的循环数 |
c_exec |
串 | 执行的信号数 |
c_wait |
串 | 等待额外输入的次数 |
c_l_sent_prioa |
整数 | 发送给自己节点的优先级A信号数 |
c_l_sent_priob |
整数 | 发送给自己节点的优先级B信号数 |
c_r_sent_prioa |
整数 | 发送到远程节点的优先级A信号数 |
c_r_sent_priob |
整数 | 发送到远程节点的优先级B信号数 |
os_tid |
整数 | 操作系统线程ID |
os_now |
整数 | 操作系统时间(毫秒) |
os_ru_utime |
整数 | OS用户CPU时间(μs) |
os_ru_stime |
整数 | OS系统CPU时间(μs) |
os_ru_minflt |
整数 | OS页面回收(软页面错误) |
os_ru_majflt |
整数 | 操作系统页面错误(硬页面错误) |
os_ru_nvcsw |
整数 | OS自愿上下文切换 |
os_ru_nivcsw |
整数 | OS非自愿上下文切换 |
os_time
使用系统
gettimeofday()
调用。
的的值
os_ru_utime
,
os_ru_stime
,
os_ru_minflt
,
os_ru_majflt
,
os_ru_nvcsw
,和
os_ru_nivcsw
使用该系统获得的列
getrusage()
呼叫,或等同物。
由于此表包含在给定时间点进行的计数,因此为了获得最佳结果,必须定期查询此表并将结果存储在一个或多个中间表中。 MySQL服务器的事件调度程序可用于自动执行此类监视。 有关更多信息,请参见 第24.4节“使用事件调度程序” 。
该表包含有关NDB传输器的信息。
下表提供了有关表中列的信息
transporters
。
对于每列,该表显示名称,数据类型和简要说明。
其他信息可在表格后面的注释中找到。
表22.420转运蛋白表的列
| 列名称 | 类型 | 描述 |
|---|---|---|
node_id |
整数 | 此数据节点在群集中的唯一节点ID |
remote_node_id |
整数 | 远程数据节点的节点ID |
status |
串 | 连接状态 |
remote_address |
串 | 远程主机的名称或IP地址 |
bytes_sent |
整数 | 使用此连接发送的字节数 |
bytes_received |
整数 | 使用此连接接收的字节数 |
connect_count |
整数 | 在此传输器上建立连接的次数 |
overloaded |
布尔值(0或1) | 如果此传输器当前过载,则为1,否则为0 |
overload_count |
整数 | 自连接以来此传输器已进入过载状态的次数 |
slowdown |
布尔值(0或1) | 如果此运输车处于减速状态,则为1,否则为0 |
slowdown_count |
整数 | 自连接以来此运输装置进入减速状态的次数 |
对于群集中的每个正在运行的数据节点,该
transporters
表显示一行,显示该节点与群集中所有节点(
包括其自身)
的每个节点的状态
。
该信息被显示在表中的
状态
列,它可以有以下值中的任何一个:
CONNECTING
,
CONNECTED
,
DISCONNECTING
,或
DISCONNECTED
。
已配置但当前未连接到群集的API和管理节点的连接显示为status
DISCONNECTED
。
node_id
当前未连接的数据节点的
行
未显示在此表中。
(这是
ndbinfo.nodes
表
中断开的节点的类似遗漏
。
它
remote_address
是ID在
remote_node_id
列中
显示的节点的主机名或地址
。
在
bytes_sent
从这个节点和
bytes_received
由该节点是数字,分别由使用此连接,因为它建立了节点发送和接收的字节。
对于状态为
CONNECTING
或的
节点,
DISCONNECTED
始终显示这些列
0
。
假设您有一个由2个数据节点,2个SQL节点和1个管理节点组成的5节点集群,如
ndb_mgm
客户端中
SHOW
命令
的输出所示
:
ndb_mgm> SHOW
连接到Management Server:localhost:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 10.100.10.1(8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 10.100.10.2(8.0.17-ndb-8.0.17,节点组:0)
[ndb_mgmd(MGM)] 1个节点
id = 10 @ 10.100.10.10(8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 20 @ 10.100.10.20(8.0.17-ndb-8.0.17)
id = 21 @ 10.100.10.21(8.0.17-ndb-8.0.17)
transporters
表-5中
有10行
用于第一个数据节点,5表示第二个 - 假设所有数据节点都在运行,如下所示:
mysql>SELECT node_id, remote_node_id, status- >FROM ndbinfo.transporters;+ --------- + ---------------- + --------------- + | node_id | remote_node_id | 状态| + --------- + ---------------- + --------------- + | 1 | 1 | 断开连接| | 1 | 2 | 已连接| | 1 | 10 | 已连接| | 1 | 20 | 已连接| | 1 | 21 | 已连接| | 2 | 1 | 已连接| | 2 | 2 | 断开连接| | 2 | 10 | 已连接| | 2 | 20 | 已连接| | 2 | 21 | 已连接| + --------- + ---------------- + --------------- + 10行(0.04秒)
如果关闭使用该命令在这个集群中的数据的一个节点
2 STOP
在
ndb_mgm
客户端,然后重复前面的查询(再次使用
MySQL的
客户端),该表目前只显示5行1列从剩余的管理每个连接节点到另一个节点,包括它自身和当前处于脱机状态的数据节点,并显示当前离线的数据节点
CONNECTING
的每个剩余连接的状态,如下所示:
mysql>SELECT node_id, remote_node_id, status- >FROM ndbinfo.transporters;+ --------- + ---------------- + --------------- + | node_id | remote_node_id | 状态| + --------- + ---------------- + --------------- + | 1 | 1 | 断开连接| | 1 | 2 | 连接| | 1 | 10 | 已连接| | 1 | 20 | 已连接| | 1 | 21 | 已连接| + --------- + ---------------- + --------------- + 5行(0.02秒)
的
connect_count
,
overloaded
,
overload_count
,
slowdown
,和
slowdown_count
计数器被重置上连接,并且所述远程节点断开连接之后仍保持它们的值。
在
bytes_sent
和
bytes_received
柜台也被重置连接,因此保留下断开(直到下一次连接它们进行复位),它们的值。
当此传输器的发送缓冲区包含多于
字节(默认值为80%
,即0.8 * 2097152 = 1677721字节)
时
,
会发生
由
和
列
引用
的
过载
状态
。
当给定的传输器处于过载状态时,尝试使用此传输器的任何新事务都会失败,并显示错误1218(
在NDB内核中重载发送缓冲区
)。
这会影响扫描和主键操作。
overloaded
overload_count
OVerloadLimit
SendBufferMemory
当传输器的发送缓冲区包含超过60%的过载限制(默认情况下等于0.6 * 2097152 = 1258291字节)时,会发生此表的列
和
列
引用
的
减速
状态
。
在此状态下,使用此传输器的任何新扫描都会减小其批量大小,以最大限度地减少传输器上的负载。
slowdown
slowdown_count
发送缓冲区减速或过载的常见原因包括:
-
将数据节点(ndbd或ndbmtd)与参与二进制日志记录的SQL节点放在同一主机上
-
每个事务或事务批处理的行数很多
-
配置问题如不足
SendBufferMemory -
RAM不足或网络连接不良等硬件问题
另请参见 第22.3.3.14节“配置NDB群集发送缓冲区参数” 。
两个
INFORMATION_SCHEMA
表提供了在管理NDB群集时特别有用的信息。
该
FILES
表提供有关NDB Cluster Disk Data文件的信息。
该
ndb_transid_mysql_connection_map
表提供了事务,事务协调器和API节点之间的映射。
可以从
ndbinfo
数据库中
的表中获取有关NDB集群事务,操作,线程,块和其他性能方面的其他统计信息和其他数据
。
有关这些表的信息,请参见
第22.5.10节“ndbinfo:NDB集群信息数据库”
。
本节讨论在设置和运行NDB Cluster时要考虑的安全注意事项。
本节涉及的主题包括以下内容:
-
NDB群集和网络安全问题
-
与安全运行NDB Cluster相关的配置问题
-
NDB群集和MySQL权限系统
-
适用于NDB Cluster的MySQL标准安全程序
在本节中,我们将讨论与NDB Cluster相关的基本网络安全问题。 记住NDB Cluster “ 开箱即用 ” 并不安全 是非常重要的 ; 您或您的网络管理员必须采取适当的步骤,以确保您的群集不会通过网络受到危害。
群集通信协议本质上是不安全的,并且在群集中的节点之间的通信中不使用加密或类似的安全措施。 由于网络速度和延迟会对群集的效率产生直接影响,因此也不建议对节点之间的网络连接采用SSL或其他加密方式,因为此类方案将有效地降低通信速度。
确实没有使用身份验证来控制对NDB群集的API节点访问。 与加密一样,强加身份验证要求的开销会对群集性能产生负面影响。
此外,访问群集时,不会检查以下任一项的源IP地址:
-
使用 由 文件中的 空 或 部分 创建的 “ 空闲插槽 ”的 SQL或API节点
[mysqld][api]config.ini这意味着,如果文件中有任何空
[mysqld]或[api]部分config.ini,则任何知道管理服务器主机名(或IP地址)和端口的API节点(包括SQL节点)都可以连接到集群并无限制地访问其数据。 ( 有关此问题及相关问题的详细信息 , 请参见 第22.5.12.2节“NDB群集和MySQL权限” 。)注意您可以通过
HostName为 文件 中的 所有 部分[mysqld]和[api]部分 指定 参数 来对集群的SQL和API节点访问进行一些控制config.ini。 但是,这也意味着,如果您希望从先前未使用的主机将API节点连接到群集,则需要将[api]包含其主机名 的 部分 添加 到该config.ini文件中。本章其他地方 有关
HostName参数的 更多信息 。 有关使用 API节点的 配置示例 , 另请参见 第22.3.1节“NDB群集的快速测试设置”HostName。 -
任何 ndb_mgm 客户端
这意味着给予管理服务器的主机名(或IP地址)和端口(如果不是标准端口)的任何群集管理客户端都可以连接到群集并执行任何管理客户端命令。 这包括诸如
ALL STOP和之类的 命令SHUTDOWN。
出于这些原因,有必要在网络级别上保护群集。 Cluster最安全的网络配置是将群集节点之间的连接与任何其他网络通信隔离开来的配置。 这可以通过以下任何方法来完成:
-
将群集节点保持在与任何公共网络物理分离的网络上。 这个选项是最可靠的; 但是,它实施起来最昂贵。
我们在此处展示了使用这种物理隔离网络的NDB群集设置示例:
此设置有两个网络,一个用于群集管理服务器和数据节点的专用(实心框),以及一个用于SQL节点的公用(虚线框)。 (我们展示了使用千兆交换机连接的管理和数据节点,因为这提供了最佳性能。)两个网络都受到硬件防火墙的保护,有时也称为 基于网络的防火墙 。
这种网络设置是最安全的,因为没有数据包可以从网络外部到达集群的管理或数据节点 - 并且没有任何集群的内部通信可以到达外部 - 无需通过SQL节点,只要SQL节点不允许任何要转发的数据包。 当然,这意味着必须保护所有SQL节点免受黑客攻击。
重要关于潜在的安全漏洞,SQL节点与任何其他MySQL服务器没有什么不同。 有关 可用于保护MySQL服务器的技术的说明, 请参见 第6.1.3节“使MySQL对攻击者安全” 。
-
使用一个或多个软件防火墙(也称为 基于主机的防火墙 )来控制哪些数据包从网络中不需要访问它的部分传递到集群。 在这种类型的设置中,必须在群集中的每个主机上安装软件防火墙,否则可以从本地网络外部访问。
基于主机的选项实现起来最便宜,但纯粹依赖于软件来提供保护,因此最难保持安全。
这种类型的NDB集群网络设置如下所示:
使用这种类型的网络设置意味着有两个NDB群集主机区域。 每个群集主机必须能够与群集中的所有其他计算机进行通信,但只有那些托管SQL节点(虚线框)的人才可以与外部进行任何联系,而那些包含数据节点和管理的区域必须将节点(实心框)与不属于群集的任何计算机隔离。 使用这些应用程序的集群和用户应用程序必须 不能 被允许具有管理和数据节点主机的直接访问。
要实现此目的,您必须根据每个群集主机上运行的节点类型设置软件防火墙,以限制下表中显示的类型的流量:
表22.421基于主机的防火墙群集配置中的节点类型
节点类型 允许的流量 SQL或API节点 -
它源自管理或数据节点的IP地址(使用任何TCP或UDP端口)。
-
它源自群集所在的网络,位于应用程序正在使用的端口上。
数据节点或管理节点 -
它源自管理或数据节点的IP地址(使用任何TCP或UDP端口)。
-
它源自SQL或API节点的IP地址。
应拒绝除表中显示的给定节点类型之外的任何流量。
配置防火墙的细节因防火墙应用程序和防火墙应用程序而异,超出了本手册的范围。 iptables 是一种非常常见且可靠的防火墙应用程序,它通常与 APF一起 用作前端,使配置更容易。 如果您选择实施此类型的NDB群集网络设置,或者 下一个项目中讨论 的 “ 混合 ” 类型, 您可以(并且应该)查阅您使用的软件防火墙的文档 。
-
-
也可以使用前两种方法的组合,使用硬件和软件来保护集群 - 即使用基于网络和基于主机的防火墙。 在安全级别和成本方面,这是前两个方案之间的关系。 这种类型的网络设置使群集保持在硬件防火墙之后,但允许传入的数据包通过连接所有群集主机的路由器到达SQL节点。
此处显示了使用硬件和软件防火墙组合的NDB群集的一种可能的网络部署:
在这种情况下,您可以在硬件防火墙中设置规则以拒绝除SQL节点和API节点之外的任何外部流量,然后仅允许应用程序所需的端口上的流量。
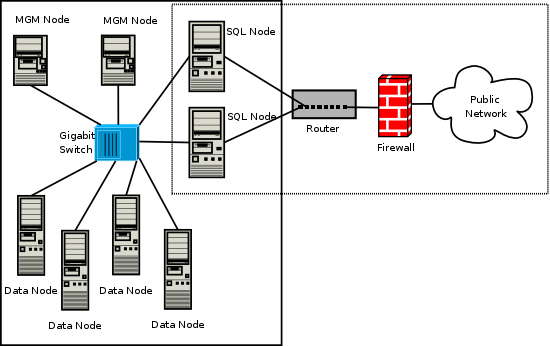
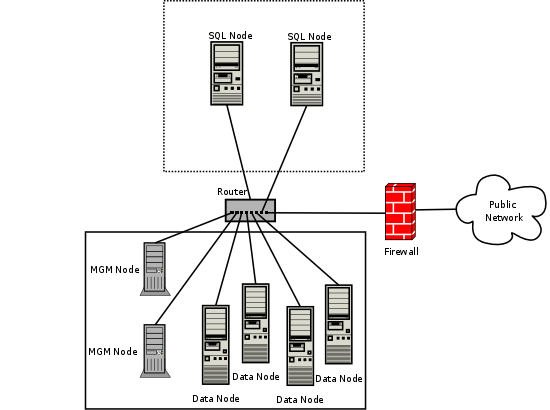
无论您使用何种网络配置,请记住,从保持群集安全的角度来看,您的目标仍然是相同的 - 以防止任何不必要的流量到达群集,同时确保群集中节点之间的最有效通信。
由于NDB群集需要为节点之间的通信打开大量端口,因此建议使用隔离网络。 这是防止不需要的流量到达群集的最简单方法。
如果您希望远程管理NDB集群(即从本地网络外部),建议的方法是使用 ssh 或其他安全登录shell来访问SQL节点主机。 然后,您可以从此主机运行管理客户端,以便从群集自己的本地网络中安全地访问管理服务器。
即使理论上可以这样做, 也不 建议使用 ndb_mgm 直接从运行群集的本地网络外部管理群集。 由于管理客户端和管理服务器之间既不进行身份验证也不进行加密,这代表了一种管理群集的极不安全的方法,并且几乎肯定会迟早受到损害。
在本节中,我们将讨论MySQL权限系统如何与NDB群集相关联,以及这对于保持NDB群集安全的影响。
标准MySQL权限适用于NDB群集表。
这包括
在数据库,表和列级别上授予的
所有MySQL权限类型(
SELECT
权限,
UPDATE
权限,
DELETE
权限等)。
与任何其他MySQL服务器一样,用户和权限信息存储在
mysql
系统数据库中。
用于授予和撤销
NDB
表,包含此类表的数据库以及此类表中的列的
特权的SQL语句
在所有方面都与
用于涉及任何(其他)MySQL存储引擎的数据库对象相关
的
GRANT
和
REVOKE
语句
相同
。
同样的事情也是如此
CREATE
USER
和
DROP
USER
陈述。
请务必记住,默认情况下,MySQL授权表使用
MyISAM
存储引擎。
因此,这些表通常不会在充当NDB集群中的SQL节点的MySQL服务器之间复制或共享。
换句话说,默认情况下,用户及其权限的更改不会在SQL节点之间自动传播。
如果您愿意,可以在NDB Cluster SQL节点上启用MySQL用户和权限的自动分发;
有关详细信息
,
请参见
第22.5.16节“分布式MySQL权限(不支持)”
。
相反,因为MySQL无法拒绝权限(权限可以首先被撤销或不被授予,但不会被拒绝),对于
NDB
具有权限的用户的一个SQL节点上
的
表
没有特殊保护
。另一个SQL节点;
(即使你没有使用自动分配用户权限也是如此。这个的确定例子是MySQL
root
帐户,它可以对任何数据库对象执行任何操作。结合空
文件
[mysqld]
或
文件的
[api]
部分
config.ini
,这个帐户可以是特别危险。要了解原因,请考虑以下情况:
-
该
config.ini文件至少包含一个空[mysqld]或[api]部分。 这意味着NDB群集管理服务器不会检查MySQL服务器(或其他API节点)从中访问NDB群集的主机。 -
没有防火墙,或者防火墙无法防止从网络外部的主机访问NDB群集。
-
NDB群集管理服务器的主机名或IP地址是已知的,或者可以从网络外部确定。
如果这些条件成立,则任何地方的任何人都可以启动MySQL服务器
并访问此NDB群集。
使用MySQL
帐户,此人可以执行以下操作:
--ndbcluster
--ndb-connectstring=
management_hostroot
-
执行元数据语句,例如
SHOW DATABASESstatement(获取NDB服务器上 所有 数据库 的列表 )或 语句,以获取 给定数据库 中所有 表 的列表SHOW TABLES FROMsome_ndb_databaseNDB -
-
SELECT * FROM从任何表中读取所有数据some_table -
DELETE FROM删除表中的所有数据some_table -
DESCRIBE或者 确定表模式some_tableSHOW CREATE TABLEsome_table -
UPDATE用 “ 垃圾 ” 数据 填充表格列 ; 与简单地删除所有数据相比,这实际上可能造成更大的损害some_tableSETcolumn1=some_value更阴险的变体可能包括以下陈述:
UPDATE
some_tableSETan_int_column=an_int_column+ 1要么
UPDATE
some_tableSETa_varchar_column= REVERSE(a_varchar_column)这种恶意言论仅受到攻击者想象力的限制。
唯一可以避免这种混乱的表是那些使用存储引擎创建的表
NDB,而不是 “ 流氓 ” SQL节点 可见 。可以以其身份登录的用户也可以
root访问INFORMATION_SCHEMA数据库及其表,从而获取有关数据库,表,存储例程,计划事件以及存储元数据的任何其他数据库对象的信息INFORMATION_SCHEMA。root除非您使用分布式权限,否则对不同NDB Cluster SQL节点上 的 帐户 使用不同的密码也是一个非常好的主意 。 -
总之,如果可以从本地网络外部直接访问,则无法拥有安全的NDB群集。
永远不要将MySQL root帐户密码留空 。 当将MySQL作为NDB Cluster SQL节点运行时,将其作为独立(非群集)MySQL服务器运行时也是如此,并且应该在将MySQL服务器配置为SQL之前作为MySQL安装过程的一部分完成NDB群集中的节点。
如果您希望使用NDB Cluster的分布式权限功能,则不应简单地转换
mysql
数据库中
的系统表以
NDB
手动
使用
存储引擎。
使用为此目的提供的存储过程;
请参见
第22.5.16节“分布式MySQL权限(不支持)”
。
否则,如果需要
mysql
在SQL节点之间
同步
系统表,则可以使用标准MySQL复制来执行此操作,或者使用脚本在MySQL服务器之间复制表条目。
摘要。 关于NDB群集的MySQL权限系统需要记住的最重要的要点如下:
-
在一个SQL节点上建立的用户和权限不会自动存在,也不会在群集中的其他SQL节点上生效。 相反,删除群集中一个SQL节点上的用户或权限不会从任何其他SQL节点中删除用户或权限。
-
您可以使用SQL脚本及其包含的存储过程在SQL节点之间分发MySQL用户和权限,这些脚本是在NDB Cluster分发中为此目的而提供的。
-
一旦MySQL用户被授予
NDB来自NDB集群中一个SQL节点 的 表的 特权 ,该用户就可以 “ 看到 ” 该表中的任何数据,无论数据来自哪个SQL节点,即使您没有使用权限分发。
在本节中,我们将讨论适用于运行NDB Cluster的MySQL标准安全过程。
通常,安全运行MySQL的任何标准过程也适用于将MySQL服务器作为NDB集群的一部分运行。
首先,您应该始终以
mysql
操作系统用户
身份运行MySQL服务器
;
这与在标准(非群集)环境中运行MySQL没有什么不同。
该
mysql
系统帐户应该被唯一和明确的规定。
幸运的是,这是新MySQL安装的默认行为。
您可以
使用系统命令
验证
mysqld
进程是否以
mysql
操作系统用户
身份运行,
如下所示:
外壳> ps aux | grep mysql
根10467 0.0 0.1 3616 1380 pts / 3 S 11:53 0:00
/ bin / sh ./mysqld_safe --ndbcluster --ndb-connectstring = localhost:1186
mysql 10512 0.2 2.5 58528 26636 pts / 3 Sl 11:53 0:00
/ usr / local / mysql / libexec / mysqld --basedir = / usr / local / mysql \
--datadir = / usr / local / mysql / var --user = mysql --ndbcluster \
--ndb-connectstring = localhost:1186 --pid-file = / usr / local / mysql / var / mothra.pid \
--log误差=的/ usr /本地/ MySQL的的/ var / mothra.err
jon 10579 0.0 0.0 2736 688 pts / 0 S + 11:54 0:00 grep mysql
如果
mysqld
进程正在运行
mysql
,则应立即将其关闭并以
mysql
用户
身份重新启动
。
如果系统上不存在该
mysql
用户,则应创建用户帐户,该用户应该是该
mysql
用户组的
一部分
;
在这种情况下,您还应确保此系统上的MySQL数据目录(使用
mysqld
--datadir
选项
设置
)由
用户
拥有
,并且SQL节点的
文件包含
在该
部分中。
或者,您可以使用启动MySQL服务器进程
mysql
my.cnf
user=mysql
[mysqld]
--user=mysql
在命令行上,但最好使用该
my.cnf
选项,因为您可能忘记使用命令行选项,因此
无意中
将
mysqld
作为另一个用户运行。
该
mysqld_safe的
启动脚本强制MySQL作为运行
mysql
用户。
切勿 以系统root用户身份 运行 mysqld 。 这样做意味着MySQL可能会读取系统上的任何文件,因此MySQL应该被攻击者破坏。
如前一节所述(参见 第22.5.12.2节“NDB集群和MySQL权限” ),您应该在运行MySQL服务器后立即为其设置root密码。 您还应该删除默认安装的匿名用户帐户。 您可以使用以下语句完成这些任务:
外壳>mysql -u rootmysql>UPDATE mysql.user- > - >SET Password=PASSWORD('secure_password')WHERE User='root';mysql>DELETE FROM mysql.user- >WHERE User='';MySQL的>FLUSH PRIVILEGES;
执行
DELETE
语句
时要非常小心,
不要忽略该
WHERE
子句,否则可能会删除
所有
MySQL用户。
确保在
FLUSH PRIVILEGES
修改
mysql.user
表后立即
运行
语句
,以便更改立即生效。
如果没有
FLUSH PRIVILEGES
,则更改在下次重新启动服务器之前不会生效。
许多NDB群集实用程序(如
ndb_show_tables
,
ndb_desc
和
ndb_select_all)
也可以在不进行身份验证的情况下工作,并且可以显示表名,模式和数据。
默认情况下,它们安装在具有权限的Unix风格系统上
wxr-xr-x
(755),这意味着它们可以由任何可以访问该
mysql/bin
目录的
用户执行
。
有关这些实用程序的详细信息 , 请参见 第22.4节“NDB群集程序” 。
NDB Cluster支持
NDB
在磁盘上而不是在RAM中
存储非索引的
表
列
。
列数据和日志记录元数据保存在数据文件和撤消日志文件中,概念化为表空间和日志文件组,如下一节所述 - 请参见
第22.5.13.1节“NDB集群磁盘数据对象”
。
NDB群集磁盘数据性能可能受许多配置参数的影响。 有关这些参数及其影响的信息,请参阅 磁盘数据配置参数 以及 磁盘数据和GCP停止错误 。
通过将数据节点文件系统与撤消日志文件和表空间数据文件分离,可以大大提高使用磁盘数据存储的NDB群集的性能,这可以使用符号链接完成。 有关更多信息,请参见 第22.5.13.2节“将符号链接与磁盘数据对象一起使用” 。
NDB群集磁盘数据存储使用以下对象实现:
-
表空间 :充当其他磁盘数据对象的容器。 表空间包含一个或多个数据文件以及一个或多个撤消日志文件组。
-
数据文件 :存储列数据。 数据文件直接分配给表空间。
-
撤消日志文件 :包含回滚事务所需的撤消信息。 分配给撤消日志文件组。
-
日志文件组 :包含一个或多个撤消日志文件。 分配给表空间。
撤消日志文件和数据文件是每个数据节点的文件系统中的实际文件;
默认情况下它们被放置在
在
在NDB簇指定
文件,并且其中
是数据节点的节点ID。
通过在创建撤消日志或数据文件时指定绝对路径或相对路径作为文件名的一部分,可以将这些放置在其他位置。
创建这些文件的语句将在本节后面显示。
ndb_
node_id_fsDataDir
config.ini
node_id
撤消日志文件仅由磁盘数据表使用,并且不需要或仅由
NDB
存储在内存中
的
表
使用
。
NDB群集表空间和日志文件组未实现为文件。
虽然并非所有磁盘数据对象都实现为文件,但它们都共享相同的命名空间。
这意味着
必须唯一地命名
每个磁盘数据对象
(而不仅仅是给定类型的每个磁盘数据对象)。
例如,您不能将表空间和日志文件组都命名为
dd1
。
假设您已经设置了包含所有节点(包括管理和SQL节点)的NDB群集,则在磁盘上创建NDB群集表的基本步骤如下:
-
创建日志文件组,并为其分配一个或多个撤消日志文件(撤消日志文件有时也称为 undofile )。
-
创建一个表空间; 将日志文件组以及一个或多个数据文件分配给表空间。
-
创建使用此表空间进行数据存储的磁盘数据表。
这些任务中的每一个都可以使用 mysql 客户端或其他MySQL客户端应用程序 中的SQL语句来完成 ,如下面的示例所示。
-
我们创建一个名为
lg_1using 的日志文件组CREATE LOGFILE GROUP。 此日志文件组是要由两个撤消日志文件,这是我们的名字undo_1.log和undo_2.log,其初始大小分别为16 MB和12 MB。 (撤消日志文件的默认初始大小为128 MB。)或者,您也可以指定日志文件组的撤消缓冲区的大小,或允许其采用默认值8 MB。 在此示例中,我们将UNDO缓冲区的大小设置为2 MB。 必须使用撤消日志文件创建日志文件组; 所以我们添加undo_1.log到lg_1在此CREATE LOGFILE GROUP声明:创建LOGFILE GROUP lg_1 添加UNDOFILE'undo_1.log' INITIAL_SIZE 16M UNDO_BUFFER_SIZE 2M ENGINE NDBCLUSTER;要添加
undo_2.log到日志文件组,请使用以下ALTER LOGFILE GROUP语句:ALTER LOGFILE GROUP lg_1 添加UNDOFILE'under_2.log' INITIAL_SIZE 12M ENGINE NDBCLUSTER;一些注意事项:
-
.log此处使用 的 文件扩展名不是必需的。 我们仅使用它来使日志文件易于识别。 -
每一个
CREATE LOGFILE GROUP和ALTER LOGFILE GROUP声明必须包含一个ENGINE选项。 此选项唯一允许的值是NDBCLUSTER和NDB。重要在任何给定时间,同一NDB群集中最多只能存在一个日志文件组。
-
使用撤消日志文件添加到日志文件组时 ,会 在群集中每个数据节点 的 目录中 创建 一个具有该名称的文件 ,其中 是数据节点的节点ID。 每个撤消日志文件都具有SQL语句中指定的大小。 例如,如果NDB群集有4个数据节点,则 刚刚显示 的 语句创建4个撤消日志文件,每个在4个数据节点的数据目录中各1个; 这些文件中的每一个都被命名
ADD UNDOFILE 'filename'filenamendb_node_id_fsDataDirnode_idALTER LOGFILE GROUPundo_2.log每个文件的大小为12 MB。 -
UNDO_BUFFER_SIZE受可用系统内存量的限制。 -
有关这些语句的更多信息 , 请参见 第13.1.16节“CREATE LOGFILE GROUP语法” 和 第13.1.6节“ALTER LOGFILE GROUP语法” 。
-
-
现在我们可以创建一个表空间 - 一个抽象容器,用于磁盘数据表用于存储数据的文件。 表空间与特定的日志文件组相关联; 创建新表空间时,必须指定用于撤消日志记录的日志文件组。 您还必须至少指定一个数据文件; 创建表空间后,可以向表空间添加更多数据文件。 也可以从表空间中删除数据文件(请参阅本节后面的示例)。
假设我们希望创建一个名为的表空间
ts_1, 该表空间lg_1用作其日志文件组。 我们希望表空间包含两个数据文件,命名为data_1.dat和data_2.dat,其初始大小分别为32 MB和48 MB。 (默认值为INITIAL_SIZE128 MB。)我们可以使用两个SQL语句执行此操作,如下所示:创建TABLESPACE ts_1 添加数据文件'data_1.dat' 使用LOGFILE GROUP lg_1 INITIAL_SIZE 32M ENGINE NDBCLUSTER; ALTER TABLESPACE ts_1 添加数据文件'data_2.dat' INITIAL_SIZE 48M;该
CREATE TABLESPACE语句创建一个ts_1包含数据文件 的表空间data_1.dat,并ts_1与日志文件组 关联lg_1。 在ALTER TABLESPACE将第二数据文件(data_2.dat)。一些注意事项:
-
与
.log本示例中用于撤消日志文件的.dat文件扩展名一样,文件扩展名 没有特殊意义 ; 它仅用于方便识别。 -
使用时将数据文件添加到表空间时 ,会 在群集中每个数据节点 的 目录中 创建 一个具有名称的文件 ,其中 是数据节点的节点ID。 每个数据文件的大小都在SQL语句中指定。 例如,如果NDB集群有4个数据节点,则 刚刚显示 的 语句创建4个数据文件,每个数据文件在4个数据节点的数据目录中各1个; 每个文件都被命名 ,每个文件的大小为48 MB。
ADD DATAFILE 'filename'filenamendb_node_id_fsDataDirnode_idALTER TABLESPACEdata_2.dat -
CREATE TABLESPACE陈述必须包含一个ENGINE条款; 只能在表空间中创建使用与表空间相同的存储引擎的表。 因为ALTER TABLESPACE,一个ENGINE条款被接受但被弃用,并在将来的版本中被删除。 对于NDB表空间,此选项的唯一允许值为NDBCLUSTER和NDB。 -
有关
CREATE TABLESPACE和ALTER TABLESPACE语句的 更多信息 ,请参见 第13.1.21节“CREATE TABLESPACE语法” 和 第13.1.10节“ALTER TABLESPACE语法” 。
-
-
现在可以使用表空间中的文件创建一个表,其未编制索引的列存储在磁盘上
ts_1:CREATE TABLE dt_1( member_id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, last_name VARCHAR(50)NOT NULL, first_name VARCHAR(50)NOT NULL, dob DATE NOT NULL, 加入DATE NOT NULL, INDEX(last_name,first_name) ) TABLESPACE ts_1存储磁盘 ENGINE NDBCLUSTER;TABLESPACE ts_1 STORAGE DISK告诉NDB存储引擎使用表空间ts_1来存储磁盘上的数据。一旦表
ts_1已经创建如图所示,您可以执行INSERT,SELECT,UPDATE,和DELETE它的语句,就像你会与任何其他MySQL表。还可以通过
STORAGE在CREATE TABLEor或ALTER TABLE语句中 使用 子句作为列定义的一部分 来指定单个列是存储在磁盘上还是存储在内存中 。STORAGE DISK导致列存储在磁盘上,并STORAGE MEMORY导致使用内存存储。 有关 更多信息 , 请参见 第13.1.20节“CREATE TABLE语法” 。
您可以
NDB
通过查询
数据库中
的
FILES
表
来获取有关
磁盘数据文件和撤消刚刚创建的日志文件
的
INFORMATION_SCHEMA
信息,如下所示:
MySQL的>SELECTFILE_NAME AS File, FILE_TYPE AS Type,TABLESPACE_NAME AS Tablespace, TABLE_NAME AS Name,LOGFILE_GROUP_NAME AS 'File group',FREE_EXTENTS AS Free, TOTAL_EXTENTS AS TotalFROM INFORMATION_SCHEMA.FILESWHERE ENGINE='ndbcluster';+ -------------- + ---------- + ------------ + ------ + --- --------- + ------ + --------- + | 档案| 输入| 表空间| 名称| 文件组| 免费| 总计| + -------------- + ---------- + ------------ + ------ + --- --------- + ------ + --------- + | ./undo_1.log | UNDO LOG | lg_1 | NULL | lg_1 | 0 | 4194304 | | ./undo_2.log | UNDO LOG | lg_1 | NULL | lg_1 | 0 | 3145728 | | ./data_1.dat | DATAFILE | ts_1 | NULL | lg_1 | 32 | 32 | | ./data_2.dat | DATAFILE | ts_1 | NULL | lg_1 | 48 | 48 | + -------------- + ---------- + ------------ + ------ + --- --------- + ------ + --------- + 4行(0.00秒)
有关更多信息和示例,请参见 第25.11节“INFORMATION_SCHEMA文件表” 。
隐式存储在磁盘上的列的索引。
对于
dt_1
刚才显示的示例中定义的
表
,只有
dob
和
joined
列存储在磁盘上。
这是因为对索引
id
,
last_name
以及
first_name
属于这些列列等数据存储在RAM中。
只有非索引列可以保存在磁盘上;
索引和索引列数据继续存储在内存中。
在设计磁盘数据表时,必须牢记使用索引和保存RAM之间的权衡。
您不能将索引添加到已明确声明的列
STORAGE DISK
,而不先将其存储类型更改为
MEMORY
;
任何这样做的尝试都会因错误而失败。
可以索引
隐式
使用磁盘存储的
列
;
完成此操作后,列的存储类型将
MEMORY
自动
更改为
。
通过
“
含蓄
”
,我们指的是它的存储类型未声明的,但它是一列从父表继承。
在以下CREATE TABLE语句中(使用
ts_1
先前定义
的表空间
),列
c2
和
c3
隐式使用磁盘存储:
mysql>CREATE TABLE ti (- >c1 INT PRIMARY KEY,- >c2 INT,- >c3 INT,- >c4 INT- >)- >STORAGE DISK- >TABLESPACE ts_1- >ENGINE NDBCLUSTER;查询OK,0行受影响(1.31秒)
因为
c2
,
c3
和
c4
它们本身没有声明
STORAGE DISK
,所以可以索引它们。
在这里,我们
分别
为
c2
和
添加索引
c3
,
CREATE
INDEX
并且
ALTER TABLE
:
MySQL的>CREATE INDEX i1 ON ti(c2);查询正常,0行受影响(2.72秒) 记录:0重复:0警告:0 MySQL的>ALTER TABLE ti ADD INDEX i2(c3);查询OK,0行受影响(0.92秒) 记录:0重复:0警告:0
SHOW CREATE TABLE
确认已添加索引。
MySQL的> SHOW CREATE TABLE ti\G
*************************** 1。排******************** *******
表:ti
创建表:CREATE TABLE`ti`(
`c1` int(11)NOT NULL,
`c2` int(11)DEFAULT NULL,
`c3` int(11)DEFAULT NULL,
`c4` int(11)DEFAULT NULL,
PRIMARY KEY(`c1`),
KEY`i1`(`c2`),
KEY`i2`(`c3`)
)/ *!50100 TABLESPACE`ts_1`存储磁盘* / ENGINE = ndbcluster DEFAULT CHARSET = latin1
1排(0.00秒)
你可以看到使用 ndb_desc ,索引列(强调文本)现在使用内存而不是磁盘存储:
外壳> ./ndb_desc -d test t1
- t1 -
版本:33554433
片段类型:HashMapPartition
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:4
主键数:1
frm数据的长度:317
最大行数:0
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
PartitionCount:4
FragmentCount:4
PartitionBalance:FOR_RP_BY_LDM
ExtraRowGciBits:0
ExtraRowAuthorBits:0
TableStatus:已检索
表格选项:
HashMap:DEFAULT-HASHMAP-3840-4
- 属性 -
c1 Int主键分配键AT =固定ST =存储器
c2 Int NULL AT = FIXED ST = MEMORY
c3 Int NULL AT =固定ST = MEMORY
c4 Int NULL AT = FIXED ST = DISK
- 索引 -
PRIMARY KEY(c1) - UniqueHashIndex
i2(c3) - OrderedIndex
PRIMARY(c1) - OrderedIndex
i1(c2) - OrderedIndex
NDBT_ProgramExit:0 - 好的
表现说明。 如果将磁盘数据文件保存在与数据节点文件系统不同的物理磁盘上,则使用磁盘数据存储的群集的性能将大大提高。 必须对集群中的每个数据节点执行此操作才能获得任何明显的好处。
您可以使用绝对和相对文件系统路径与
ADD UNDOFILE
和
ADD
DATAFILE
;
相对路径是根据数据节点的数据目录计算的。
您还可以使用符号链接指向其他磁盘上的目录;
有关更多信息和示例
,
请参见
第22.5.13.2节“对磁盘数据对象使用符号链接”
。
必须按特定顺序创建日志文件组,表空间和使用这些表的任何磁盘数据表。 删除这些对象也是如此,并遵循以下约束:
-
只要任何表空间使用日志文件组,就不能删除它。
-
只要表空间包含任何数据文件,就无法删除它。
-
只要存在任何使用表空间的表,就不能从表空间中删除任何数据文件。
-
删除与创建文件的表空间不同的创建的文件是不可能的。
例如,要删除本节中到目前为止创建的所有对象,可以使用以下语句:
MySQL的>DROP TABLE dt_1;mysql>ALTER TABLESPACE ts_1- >DROP DATAFILE 'data_2.dat'- >ENGINE NDBCLUSTER;mysql>ALTER TABLESPACE ts_1- >DROP DATAFILE 'data_1.dat'- >ENGINE NDBCLUSTER;mysql>DROP TABLESPACE ts_1- >ENGINE NDBCLUSTER;mysql>DROP LOGFILE GROUP lg_1- >ENGINE NDBCLUSTER;
这些语句必须按所示顺序执行,除了两个
ALTER TABLESPACE ... DROP
DATAFILE
语句可以按任何顺序执行。
通过将数据节点文件系统与任何表空间文件(撤消日志文件和数据文件)分离,并将它们放在不同的磁盘上,可以大大提高使用磁盘数据存储的NDB群集的性能。
在NDB Cluster的早期版本中,在NDB Cluster中没有直接支持这一点,但是可以使用本节所述的符号链接实现这种分离。
NDB群集支持数据节点配置参数
FileSystemPathDD
,
FileSystemPathDataFiles
并且
FileSystemPathUndoFiles
这使得不必使用符号链接。
有关这些参数的详细信息,请参阅
磁盘数据文件系统参数
。
集群中的每个数据节点都在文件中
定义
的数据节点下的
目录中创建文件系统
。
在这个例子中,我们假定每个数据节点主机具有3个磁盘,别名为
,
,和
,和该群集的
包括以下内容:
ndb_
node_id_fsDataDir
config.ini
/data0
/data1
/data2
config.ini
[ndbd默认] DataDir = / data0
我们的目标是将所有磁盘数据日志文件放入
每个数据节点主机上
/data1
,并将所有磁盘数据数据文件放入其中
/data2
。
在此示例中,我们假设群集的数据节点主机都使用Linux操作系统。 对于其他平台,您可能需要将操作系统的命令替换为此处显示的命令。
要完成此操作,请执行以下步骤:
-
在数据节点文件系统下,创建指向其他驱动器的符号链接:
shell>
cd /data0/ndb_2_fsshell>lsD1 D10 D11 D2 D8 D9 LCP shell>ln -s /data0 dnlogsshell>ln -s /data1 dndata您现在应该有两个符号链接:
外壳>
ls -l --hide=D*lrwxrwxrwx 1用户组30 2007-03-19 13:58 dndata - > / data1 lrwxrwxrwx 1用户组30 2007-03-19 13:59 dnlogs - > / data2我们仅针对节点ID为2的数据节点显示此信息; 但是,您必须为 每个 数据节点 执行此操作 。
-
现在,在 mysql 客户端中,使用符号链接创建日志文件组和表空间,如下所示:
mysql>
CREATE LOGFILE GROUP lg1- >ADD UNDOFILE 'dnlogs/undo1.log'- >INITIAL_SIZE 150M- >UNDO_BUFFER_SIZE = 1M- >ENGINE=NDBCLUSTER;mysql>CREATE TABLESPACE ts1- >ADD DATAFILE 'dndata/data1.log'- >USE LOGFILE GROUP lg1- >INITIAL_SIZE 1G- >ENGINE=NDBCLUSTER;验证文件是否已创建并正确放置,如下所示:
shell>
cd /data1shell>ls -l总计2099304 -rw-rw-r-- 1个用户组157286400 2007-03-19 14:02 undo1.dat shell>cd /data2shell>ls -l总计2099304 -rw-rw-r-- 1个用户组1073741824 2007-03-19 14:02 data1.dat -
如果在一台主机上运行多个数据节点,则必须注意避免让它们尝试为磁盘数据文件使用相同的空间。 您可以通过在每个数据节点文件系统中创建符号链接来简化此操作。 假设您正在使用
/data0两个数据节点文件系统,但您希望为两个节点启用磁盘数据文件/data1。 在这种情况下,您可以执行类似于此处所示的操作:shell>
cd /data0shell>ln -s /data1/dn2 ndb_2_fs/ddshell>ln -s /data1/dn3 ndb_3_fs/ddshell>ls -l --hide=D* ndb_2_fslrwxrwxrwx 1用户组30 2007-03-19 14:22 dd - > / data1 / dn2 外壳>ls -l --hide=D* ndb_3_fslrwxrwxrwx 1个用户组30 2007-03-19 14:22 dd - > / data1 / dn3 -
现在,您可以使用符号链接创建日志文件组和表空间,如下所示:
mysql>
CREATE LOGFILE GROUP lg1- >ADD UNDOFILE 'dd/undo1.log'- >INITIAL_SIZE 150M- >UNDO_BUFFER_SIZE = 1M- >ENGINE=NDBCLUSTER;mysql>CREATE TABLESPACE ts1- >ADD DATAFILE 'dd/data1.log'- >USE LOGFILE GROUP lg1- >INITIAL_SIZE 1G- >ENGINE=NDBCLUSTER;验证文件是否已创建并正确放置,如下所示:
shell>
cd /data1shell>lsdn2 dn3 外壳>ls dn2undo1.log data1.log 外壳>ls dn3undo1.log data1.log
-
可变长度的磁盘数据表列占用固定的空间量。 对于每一行,这等于存储该列的最大可能值所需的空间。
有关计算这些值的一般信息,请参见 第11.8节“数据类型存储要求” 。
您可以通过查询
INFORMATION_SCHEMA.FILES表 来获取数据文件中可用空间量和撤消日志文件的估计值 。 有关更多信息和示例,请参见 第25.11节“INFORMATION_SCHEMA文件表” 。注意该
OPTIMIZE TABLE语句对磁盘数据表没有任何影响。 -
磁盘数据表中的每一行使用内存中的8个字节指向存储在磁盘上的数据。 这意味着,在某些情况下,将内存中列转换为基于磁盘的格式实际上可能会导致更大的内存使用量。 例如,将
CHAR(4)列从基于内存的格式 转换为 基于磁盘的格式会将DataMemory每行 的 使用量从4字节增加到8字节。
使用该
--initial
选项
启动集群
不会
删除磁盘数据文件。
在执行群集的初始重新启动之前,必须手动删除它们。
通过确保
DiskPageBufferMemory
足够大小
的磁盘搜索次数,可以提高磁盘数据表的性能
。
您可以查询该
diskpagebuffer
表以帮助确定是否需要增加此参数的值。
MySQL NDB Cluster 8.0使用
ALTER
TABLE
MySQL Server(
ALGORITHM=DEFAULT|INPLACE|COPY
)
使用的标准
语法
支持在线表模式更改
,并在其他地方进行了描述。
一些旧版本的NDB Cluster使用特定
NDB
于在线
ALTER
TABLE
操作
的语法
。
此语法已被删除。
在
NDB
表的
可变宽度列上添加和删除索引的操作
在线进行。
在线操作是非复制的;
也就是说,它们不需要重新创建索引。
它们不会锁定被更改的表以防止NDB集群中的其他API节点访问(但请参阅
本节后面
的NDB在线操作的限制
)。
对于
NDB
具有多个API节点的NDB集群中的表更改,
此类操作不需要单用户模式
;
在线DDL操作期间,事务可以继续不间断。
ALGORITHM=INPLACE
可用于执行在线
ADD COLUMN
,
ADD INDEX
(包括
CREATE INDEX
语句)和
DROP INDEX
对
NDB
表的
操作
。
NDB
还支持
在线重命名
表。
目前,您无法
NDB
在线
向
表中
添加基于磁盘的列
。
这意味着,如果要将内存中的列添加到
NDB
使用表级
STORAGE DISK
选项
的表中
,则必须将新列声明为显式使用基于内存的存储。
例如 - 假设您已经创建了表空间
ts1
-suppose,您可以
t1
按如下方式
创建表
:
的MySQL>CREATE TABLE t1 (>c1 INT NOT NULL PRIMARY KEY,>c2 VARCHAR(30)>)>TABLESPACE ts1 STORAGE DISK>ENGINE NDB;查询OK,0行受影响(1.73秒) 记录:0重复:0警告:0
您可以在线向此表添加新的内存列,如下所示:
MySQL的>ALTER TABLE t1>ADD COLUMN c3 INT COLUMN_FORMAT DYNAMIC STORAGE MEMORY,>ALGORITHM=INPLACE;查询正常,0行受影响(1.25秒) 记录:0重复:0警告:0
如果
STORAGE MEMORY
省略
该
选项,则
此语句失败
:
的MySQL>ALTER TABLE t1>ADD COLUMN c4 INT COLUMN_FORMAT DYNAMIC,> ERROR 1846(0A000):不支持算法= INPLACE。原因:ALGORITHM=INPLACE;添加列或添加/重新组织在线不支持的分区。尝试 算法= COPY。
如果省略该
COLUMN_FORMAT DYNAMIC
选项,则会自动使用动态列格式,但会发出警告,如下所示:
MySQL的>ALTER ONLINE TABLE t1 ADD COLUMN c4 INT STORAGE MEMORY;查询正常,0行受影响,1警告(1.17秒) 记录:0重复:0警告:0 MySQL的>SHOW WARNINGS\G*************************** 1。排******************** ******* 等级:警告 代码:1478 消息:不支持带有STORAGE DISK的DYNAMIC列c4,列将 变得固定 MySQL的>SHOW CREATE TABLE t1\G*************************** 1。排******************** ******* 表:t1 创建表:CREATE TABLE`t1`( `c1` int(11)NOT NULL, `c2` varchar(30)DEFAULT NULL, `c3` int(11)/ *!50606 STORAGE MEMORY * / / *!50606 COLUMN_FORMAT DYNAMIC * / DEFAULT NULL, `c4` int(11)/ *!50606 STORAGE MEMORY * / DEFAULT NULL, 主键(`c1`) )/ *!50606 TABLESPACE ts_1存储磁盘* / ENGINE = ndbcluster DEFAULT CHARSET = latin1 1排(0.03秒)
在
STORAGE
和
COLUMN_FORMAT
关键字仅在NDB集群支持;
在任何其他版本的MySQL中,尝试在
CREATE
TABLE
或
ALTER
TABLE
语句中
使用这些关键字中的任何一个都会
导致错误。
也可以
在
表
上
ALTER TABLE ...
REORGANIZE PARTITION, ALGORITHM=INPLACE
使用没有
选项
的语句
。
这可用于在已在线添加到群集的新数据节点之间重新分配NDB群集数据。
这并
没有
执行任何碎片整理,这需要一个
或空
语句。
有关更多信息,请参见
第22.5.15节“在线添加NDB集群数据节点”
。
partition_names INTO
(partition_definitions)NDB
OPTIMIZE TABLE
ALTER TABLE
NDB在线运营的局限性
DROP COLUMN
不支持
在线
操作。
在线
ALTER
TABLE
,
CREATE
INDEX
或
DROP
INDEX
添加列或添加或删除索引的语句受以下限制:
-
一个给定的网络
ALTER TABLE可以使用只有一个ADD COLUMN,ADD INDEX或DROP INDEX。 可以在一个语句中在线添加一个或多个列; 在一个语句中只能在线创建或删除一个索引。 -
正在修改的表是不是就比上一个网上的另外一个API节点锁定 , 或 操作(或 或 语句)运行。 但是,在 执行联机操作时 ,该表将锁定源自 同一 API节点 上的任何其他操作 。
ALTER TABLEADD COLUMNADD INDEXDROP INDEXCREATE INDEXDROP INDEX -
要更改的表必须具有显式主键; 由
NDB存储引擎 创建的隐藏主键 不足以实现此目的。 -
表格使用的存储引擎无法在线更改。
-
与NDB Cluster Disk Data表一起使用时,无法在线更改列的存储类型(
DISK或MEMORY)。 这意味着,当您以在线执行操作的方式添加或删除索引,并且希望更改一列或多列的存储类型时,必须ALGORITHM=COPY在添加或删除索引的语句中 使用 。
要在线添加的列不能使用
BLOB
或
TEXT
键入,并且必须满足以下条件:
-
列必须是动态的; 也就是说,必须可以使用它来创建它们
COLUMN_FORMAT DYNAMIC。 如果省略该COLUMN_FORMAT DYNAMIC选项,则会自动使用动态列格式。 -
列必须允许
NULL值,除了以外没有任何显式默认值NULL。 在线添加的列会自动创建DEFAULT NULL,如下所示:MySQL的>
CREATE TABLE t2 (>c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY>) ENGINE=NDB;查询OK,0行受影响(1.44秒) 的MySQL>ALTER TABLE t2>ADD COLUMN c2 INT,>ADD COLUMN c3 INT,>ALGORITHM=INPLACE;查询正常,0行受影响,2警告(0.93秒) MySQL的>SHOW CREATE TABLE t1\G*************************** 1。排******************** ******* 表:t1 创建表:CREATE TABLE`t2`( `c1` int(11)NOT NULL AUTO_INCREMENT, `c2` int(11)DEFAULT NULL, `c3` int(11)DEFAULT NULL, 主键(`c1`) )ENGINE = ndbcluster DEFAULT CHARSET = latin1 1排(0.00秒) -
必须在任何现有列之后添加列。 如果您尝试在任何现有列之前在线添加列或使用该
FIRST关键字,则该语句将失败并显示错误。 -
现有的表列无法在线重新排序。
对于
表
ALTER
TABLE
上的
在线
操作
NDB
,固定格式列在联机添加时或在线创建或删除索引时会转换为动态,如此处所示(
为了清楚起见,
重复显示的
语句
CREATE TABLE
和
ALTER
TABLE
语句):
MySQL的>CREATE TABLE t2 (>c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY>) ENGINE=NDB;查询OK,0行受影响(1.44秒) 的MySQL>ALTER TABLE t2>ADD COLUMN c2 INT,>ADD COLUMN c3 INT,>ALGORITHM=INPLACE;查询正常,0行受影响,2警告(0.93秒) MySQL的>SHOW WARNINGS;*************************** 1。排******************** ******* 等级:警告 代码:1478 消息:将FIXED字段'c2'转换为DYNAMIC以启用在线ADD COLUMN *************************** 2.排******************** ******* 等级:警告 代码:1478 消息:将FIXED字段'c3'转换为DYNAMIC以启用在线ADD COLUMN 2行(0.00秒)
只有在线添加的列必须是动态的。
现有的列不必是;
这包括表的主键,也可以是
FIXED
,如下所示:
MySQL的>CREATE TABLE t3 (>c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY COLUMN_FORMAT FIXED>) ENGINE=NDB;查询OK,0行受影响(2.10秒) MySQL的>ALTER TABLE t3 ADD COLUMN c2 INT, ALGORITHM=INPLACE;查询正常,0行受影响,1警告(0.78秒) 记录:0重复:0警告:0 MySQL的>SHOW WARNINGS;*************************** 1。排******************** ******* 等级:警告 代码:1478 消息:将FIXED字段'c2'转换为DYNAMIC以启用在线ADD COLUMN 1排(0.00秒)
通过重命名操作
不会将列转换
FIXED
为
DYNAMIC
列格式。
有关更多信息
COLUMN_FORMAT
,请参见
第13.1.20节“CREATE TABLE语法”
。
的
KEY
,
CONSTRAINT
和
IGNORE
关键字都以支持
ALTER
TABLE
using语句
ALGORITHM=INPLACE
。
不允许
MAX_ROWS
使用在线
ALTER TABLE
语句
设置
为0
。
您必须使用复制
ALTER TABLE
来执行此操作。
(Bug#21960004)
本节介绍如何 “ 在线 ” 添加NDB群集数据节点 - 即,无需完全关闭群集并在此过程中重新启动它。
目前,您必须将新数据节点作为新节点组的一部分添加到NDB群集。 此外,无法在线更改副本数(或每个节点组的节点数)。
本节提供有关在线添加NDB群集节点的行为和当前限制的一般信息。
数据的重新分配。
在线添加新节点的能力包括重组
NDBCLUSTER
表数据和索引的方法,以便通过
ALTER
TABLE ... REORGANIZE PARTITION
语句
将它们分布在所有数据节点上,包括新节点
。
支持内存和磁盘数据表的表重组。
此重新分发当前不包含唯一索引(仅重新分配有序索引)。
NDBCLUSTER
在添加新数据节点之前已经存在的表
的重新分发
不是自动的,但可以使用
mysql
或其他MySQL客户端应用程序中的
简单SQL语句来完成
。
但是,添加到添加新节点组之后创建的表的所有数据和索引将自动分布在所有群集数据节点中,包括作为新节点组的一部分添加的节点。
部分开始。 可以在不启动所有新数据节点的情况下添加新节点组。 还可以将新节点组添加到降级群集 - 即仅部分启动的群集,或者一个或多个数据节点未运行的群集。 在后一种情况下,群集必须具有足够的节点才能在添加新节点组之前运行。
对持续运营的影响。
使用NDB Cluster数据的正常DML操作不会通过创建或添加新节点组或通过表重组来阻止。
但是,无法与表重组同时执行DDL - 也就是说,在
ALTER
TABLE ...
REORGANIZE PARTITION
执行
语句时不能发出其他DDL语句
。
此外,在执行
ALTER TABLE ...
REORGANIZE PARTITION
(或执行任何其他DDL语句)期间,无法重新启动集群数据节点。
失败处理。 处理节点组和表重组期间的数据节点故障,如下表所示:
表22.422节点组创建和表重组期间的数据节点故障处理
| 失败期间 | “ 旧 ” 数据节点 失败 | “ 新 ” 数据节点 失败 | 系统错误 |
|---|---|---|---|
| 节点组创建 |
|
|
|
| 表重组 |
|
|
|
删除节点组。
所述
ndb_mgm
客户端支持一
DROP NODEGROUP
命令,但是也可以删除一个节点组仅当节点组中没有数据节点包含任何数据。
由于目前无法
“
清空
”
特定数据节点或节点组,因此该命令仅适用于以下两种情况:
-
发行后
CREATE NODEGROUP在 ndb_mgm 客户端,但在此之前发出任何ALTER TABLE ... REORGANIZE PARTITION语句中的 MySQL的 客户端。 -
删除所有
NDBCLUSTER表后使用DROP TABLE。TRUNCATE TABLE不起作用,因为数据节点继续存储表定义。
在本节中,我们列出了将新数据节点添加到NDB群集所需的基本步骤。 无论是 对数据节点进程 使用 ndbd 还是 ndbmtd 二进制文件, 此过程都适用 。 有关更详细的示例,请参见 第22.5.15.3节“在线添加NDB集群数据节点:详细示例” 。
假设您已经有一个正在运行的NDB群集,则在线添加数据节点需要执行以下步骤:
-
编辑群集配置
config.ini文件,添加[ndbd]与要添加的节点对应的 新 部分。 在群集使用多个管理服务器的情况下,需要对config.ini管理服务器使用的 所有 文件 进行这些更改 。您必须注意,
config.ini文件中 添加的任何新数据节点的 节点ID不会与现有节点使用的节点ID重叠。 如果您有使用动态分配的节点ID的API节点,并且这些ID与您要用于新数据节点的节点ID匹配,则可以强制任何此类API节点 “ 迁移 ” ,如此过程稍后所述。 -
执行所有NDB Cluster管理服务器的滚动重新启动。
-
执行所有现有NDB Cluster数据节点的滚动重新启动。
--initial重新启动现有数据节点时 不必(或通常甚至需要) 。如果您使用的动态分配ID的API节点与您希望分配给新数据节点的任何节点ID匹配,则必须重新启动所有API节点(包括SQL节点),然后才能在此步骤中重新启动任何数据节点进程。 这会导致具有先前未明确分配的节点ID的任何API节点放弃这些节点ID并获取新节点ID。
-
对连接到NDB群集的任何SQL或API节点执行滚动重新启动。
-
启动新数据节点。
可以以任何顺序启动新数据节点。 它们也可以同时启动,只要它们在所有现有数据节点的滚动重新启动完成后启动,并且在继续下一步之前启动。
-
CREATE NODEGROUP在NDB集群管理客户端中 执行一个或多个 命令,以创建新数据节点所属的新节点组或节点组。 -
在所有数据节点(包括新节点)之间重新分配集群的数据。 通常,这是通过
ALTER TABLE ... ALGORITHM=INPLACE, REORGANIZE PARTITION在 mysql 客户端中为每个NDBCLUSTER表 发出一个 语句 来完成的 。例外 :对于使用该
MAX_ROWS选项 创建的表 ,此语句不起作用; 相反,用于ALTER TABLE ... ALGORITHM=INPLACE MAX_ROWS=...重组这些表。 您还应该记住,不建议使用MAX_ROWS以这种方式设置分区数,而应该使用PARTITION_BALANCE; 有关更多信息 , 请参见 第13.1.20.11节“设置NDB_TABLE选项” 。注意只需对添加新节点组时已存在的表执行此操作。 添加新节点组后创建的表中的数据将自动分发; 但是,添加到
tbl新节点之前存在的 任何给定表 中的 数据 不会使用新节点进行分发,直到该表重新组织为止。 -
ALTER TABLE ... REORGANIZE PARTITION ALGORITHM=INPLACE重新组织分区但不回收 “ 旧 ” 节点 上释放的空间 。 您可以通过为每个NDBCLUSTER表OPTIMIZE TABLE为 mysql 客户端 发出 一个 语句 来完成此操作 。这适用于内存
NDB表的 可变宽度列使用的空间 。OPTIMIZE TABLE内存表的固定宽度列不支持; 磁盘数据表也不支持它。
您可以添加所需的所有节点,然后
CREATE
NODEGROUP
连续
发出几个
命令以将新节点组添加到群集。
在本节中,我们提供了一个详细的示例,说明如何在线添加新的NDB Cluster数据节点,从在单个节点组中具有2个数据节点的NDB群集开始,并以在2个节点组中具有4个数据节点的群集结束。
开始配置。
出于说明的目的,我们假设最小配置,并且群集使用
config.ini
仅包含以下信息
的
文件:
[ndbd默认] DataMemory = 100M IndexMemory = 100M NoOfReplicas = 2 DataDir = / usr / local / mysql / var / mysql-cluster [NDBD] Id = 1 HostName = 198.51.100.1 [NDBD] Id = 2 HostName = 198.51.100.2 [MGM] HostName = 198.51.100.10 Id = 10 [API] ID = 20 HostName = 198.51.100.20 [API] ID = 21 HostName = 198.51.100.21
我们在数据节点ID和其他节点之间的序列中留下了空白。 这使得以后更容易将尚未使用的节点ID分配给新添加的数据节点。
我们还假设您已使用适当的命令行启动集群
my.cnf
,并且
SHOW
在管理客户端
中运行
的生成类似于此处所示的输出:
- NDB群集 - 管理客户端 -
ndb_mgm> SHOW
连接到Management Server:198.51.100.10:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 198.51.100.1(8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 198.51.100.2(8.0.17-ndb-8.0.17,Nodegroup:0)
[ndb_mgmd(MGM)] 1个节点
id = 10 @ 198.51.100.10(8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 20 @ 198.51.100.20(8.0.17-ndb-8.0.17)
id = 21 @ 198.51.100.21(8.0.17-ndb-8.0.17)
最后,我们假设集群包含一个
NDBCLUSTER
如下所示创建的表:
使用n;
CREATE TABLE ips(
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
country_code CHAR(2)NOT NULL,
类型CHAR(4)NOT NULL,
ip_address VARCHAR(15)NOT NULL,
地址BIGINT UNSIGNED DEFAULT NULL,
date BIGINT UNSIGNED DEFAULT NULL
)ENGINE NDBCLUSTER;
本节后面显示的内存使用情况和相关信息是在向此表中插入大约50000行后生成的。
在此示例中,我们显示了 用于数据节点进程 的单线程 ndbd 。 您也可以应用此示例,如果您使用多线程 ndbmtd , 则将 ndbmtd 替换 为 ndbd, 无论它出现在 后面 的步骤中。
第1步:更新配置文件。
在文本编辑器中打开集群全局配置文件,并添加
[ndbd]
与2个新数据节点对应的部分。
(我们给这些数据节点ID 3和4,并假设它们将分别在地址198.51.100.3和198.51.100.4的主机上运行。)添加新节之后,
config.ini
文件
的内容
应该看起来就像这里显示的那样,文件的添加以粗体显示:
[ndbd默认]
DataMemory = 100M
IndexMemory = 100M
NoOfReplicas = 2
DataDir = / usr / local / mysql / var / mysql-cluster
[NDBD]
Id = 1
HostName = 198.51.100.1
[NDBD]
Id = 2
HostName = 198.51.100.2
[NDBD]
Id = 3
HostName = 198.51.100.3
[NDBD]
Id = 4
HostName = 198.51.100.4
[MGM]
HostName = 198.51.100.10
Id = 10
[API]
ID = 20
HostName = 198.51.100.20
[API]
ID = 21
HostName = 198.51.100.21
完成必要的更改后,保存文件。
第2步:重新启动管理服务器。 重新启动集群管理服务器要求您发出单独的命令以停止管理服务器,然后再次启动它,如下所示:
-
使用management client
STOP命令 停止管理服务器 ,如下所示:ndb_mgm>
10 STOP节点10已关闭。 断开连接以允许Management Server关闭 外壳> -
由于关闭管理服务器会导致管理客户端终止,因此必须从系统shell启动管理服务器。 为简单起见,我们假设它
config.ini与管理服务器二进制文件位于同一目录中,但实际上,您必须提供配置文件的正确路径。 你还必须提供--reload或--initial选项,以便管理服务器从文件而不是其配置缓存中读取新配置。 如果shell的当前目录也与管理服务器二进制文件所在的目录相同,则可以调用管理服务器,如下所示:外壳>
ndb_mgmd -f config.ini --reload2008-12-08 17:29:23 [MgmSrvr] INFO - NDB集群管理服务器。8.0.17-NDB-8.0.17 2008-12-08 17:29:23 [MgmSrvr] INFO - 从'config.ini'读取集群配置
如果
SHOW
在重新启动
ndb_mgm
进程
后
检查
管理客户端中
的输出
,您现在应该看到如下内容:
- NDB群集 - 管理客户端 -
ndb_mgm> SHOW
连接到Management Server:198.51.100.10:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 198.51.100.1(8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 198.51.100.2(8.0.17-ndb-8.0.17,Nodegroup:0)
id = 3(未连接,接受198.51.100.3的连接)
id = 4(未连接,接受198.51.100.4的连接)
[ndb_mgmd(MGM)] 1个节点
id = 10 @ 198.51.100.10(8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 20 @ 198.51.100.20(8.0.17-ndb-8.0.17)
id = 21 @ 198.51.100.21(8.0.17-ndb-8.0.17)
步骤3:执行现有数据节点的滚动重启。
此步骤可以使用
RESTART
命令
在集群管理客户端内完全完成
,如下所示:
ndb_mgm>1 RESTART节点1:节点关闭已启动 节点1:节点关闭完成,重启,无启动。 节点1正在重新启动 ndb_mgm>节点1:启动启动(版本8.0.17) 节点1:已启动(版本8.0.17) ndb_mgm>2 RESTART节点2:节点关闭已启动 节点2:节点关闭完成,重启,无启动。 节点2正在重新启动 ndb_mgm>节点2:启动启动(版本8.0.17) ndb_mgm>节点2:已启动(版本8.0.17)
发出每个
X
RESTARTNode
X: Started
(version ...)
您可以通过检查
mysql
客户端中
的
ndbinfo.nodes
表
来验证是否已使用更新的配置重新启动所有现有数据节点
。
步骤4:执行所有群集API节点的滚动重新启动。
使用
mysqladmin shutdown
和
mysqld_safe
(或其他启动脚本)
关闭并重新启动充当集群中SQL节点的每个MySQL服务器
。
这应该与此处显示的类似,其中
password
是
root
给定MySQL服务器实例
的MySQL
密码:
外壳>mysqladmin -uroot -p081208 20:19:56来自pid文件的mysqld_safe mysqld /usr/local/mysql/var/tonfisk.pid结束了 外壳>passwordshutdownmysqld_safe --ndbcluster --ndb-connectstring=198.51.100.10 &081208 20:20:06 mysqld_safe记录到'/usr/local/mysql/var/tonfisk.err'。 081208 20:20:06 mysqld_safe用数据库启动mysqld守护进程 来自/ usr / local / mysql / var
当然,确切的输入和输出取决于MySQL在系统上的安装方式和位置,以及您选择启动它的选项(以及是否在
my.cnf
文件
中指定了部分或全部这些选项
)。
步骤5:执行新数据节点的初始启动。
从每个主机上的系统shell为新数据节点启动数据节点,如下所示,使用以下
--initial
选项:
外壳> ndbd -c 198.51.100.10 --initial
与重新启动现有数据节点的情况不同,您可以同时启动新数据节点; 在开始另一个之前你不需要等待一个人完成开始。
等到两个新数据节点都已启动,然后再继续下一步
。
新数据节点启动后,您可以在管理客户端
SHOW
命令
的输出中看到
它们还不属于任何节点组(如此处以粗体显示):
ndb_mgm> SHOW
连接到Management Server:198.51.100.10:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 198.51.100.1(8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 198.51.100.2(8.0.17-ndb-8.0.17,Nodegroup:0)
id = 3 @ 198.51.100.3(8.0.17-ndb-8.0.17,无节点组)
id = 4 @ 198.51.100.4(8.0.17-ndb-8.0.17,无节点组)
[ndb_mgmd(MGM)] 1个节点
id = 10 @ 198.51.100.10(8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 20 @ 198.51.100.20(8.0.17-ndb-8.0.17)
id = 21 @ 198.51.100.21(8.0.17-ndb-8.0.17)
步骤6:创建新节点组。
您可以通过
CREATE
NODEGROUP
在集群管理客户端中
发出
命令
来执行此操作
。
此命令将要包含在新节点组中的数据节点的节点ID的逗号分隔列表作为其参数,如下所示:
ndb_mgm> CREATE NODEGROUP 3,4
节点组1已创建
通过
SHOW
再次
发出
,您可以验证数据节点3和4是否已加入新节点组(再次以粗体显示):
ndb_mgm> SHOW
连接到Management Server:198.51.100.10:1186
群集配置
---------------------
[ndbd(NDB)] 2个节点
id = 1 @ 198.51.100.1(8.0.17-ndb-8.0.17,Nodegroup:0,*)
id = 2 @ 198.51.100.2(8.0.17-ndb-8.0.17,Nodegroup:0)
id = 3 @ 198.51.100.3(8.0.17-ndb-8.0.17,节点组:1)
id = 4 @ 198.51.100.4(8.0.17-ndb-8.0.17,节点组:1)
[ndb_mgmd(MGM)] 1个节点
id = 10 @ 198.51.100.10(8.0.17-ndb-8.0.17)
[mysqld(API)] 2个节点
id = 20 @ 198.51.100.20(8.0.17-ndb-8.0.17)
id = 21 @ 198.51.100.21(8.0.17-ndb-8.0.17)
第7步:重新分发群集数据。
创建节点组时,现有数据和索引不会自动分发到新节点组的数据节点,您可以通过
REPORT
在管理客户端中
发出相应的
命令
来查看
:
ndb_mgm> ALL REPORT MEMORY
节点1:数据使用率为5%(177个32K页,共3200个)
节点1:索引使用率为0%(108个8K页,共12832个)
节点2:数据使用率为5%(177个32K页,共3200个)
节点2:索引使用率为0%(108个8K页,共12832个)
节点3:数据使用率为0%(0 32K页,共3200页)
节点3:索引使用率为0%(总共12832的0 8K页)
节点4:数据使用率为0%(0 32K页,共3200页)
节点4:索引使用率为0%(总共12832的0 8K页)
通过使用
带有
选项的
ndb_desc
-p
,这会导致输出包含分区信息,您可以看到该表仍然只使用了2个分区(在
Per partition info
输出
的
部分中,此处以粗体文本显示):
外壳> ndb_desc -c 198.51.100.10 -d n ips -p
- ips -
版本:1
片段类型:9
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:6
主键数:1
frm数据的长度:340
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
FragmentCount:2
TableStatus:已检索
- 属性 -
id Bigint PRIMARY KEY DISTRIBUTION KEY AT = FIXED ST = MEMORY AUTO_INCR
country_code Char(2; latin1_swedish_ci)NOT NULL AT = FIXED ST = MEMORY
type char(4; latin1_swedish_ci)NOT NULL AT = FIXED ST = MEMORY
ip_address Varchar(15; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY
地址Bigunsigned NULL AT = FIXED ST = MEMORY
date Bigunsigned NULL AT = FIXED ST = MEMORY
- 索引 -
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
- 每个分区信息 -
分区行计数提交计数Frag固定内存Frag varsized memory
0 26086 26086 1572864 557056
1 26329 26329 1605632 557056
NDBT_ProgramExit:0 - 好的
通过对每个
NDB
表
执行
mysql
客户端中
的
ALTER
TABLE ... ALGORITHM=INPLACE, REORGANIZE PARTITION
语句,
可以使数据在所有数据节点之间重新分配
。
ALTER TABLE ... ALGORITHM=INPLACE, REORGANIZE
PARTITION
不适用于使用该
MAX_ROWS
选项
创建的表
。
相反,用于
ALTER TABLE ... ALGORITHM=INPLACE,
MAX_ROWS=...
重新组织此类表。
请记住,不建议使用
MAX_ROWS
用于设置每个表的分区数,而应该使用
PARTITION_BALANCE
;
有关更多信息
,
请参见
第13.1.20.11节“设置NDB_TABLE选项”
。
发出语句后
ALTER TABLE ips
ALGORITHM=INPLACE, REORGANIZE PARTITION
,您可以看到使用
ndb_desc
表示此表的数据现在使用4个分区存储,如下所示(输出的相关部分以粗体显示):
外壳> ndb_desc -c 198.51.100.10 -d n ips -p
- ips -
版本:16777217
片段类型:9
K值:6
最小负载系数:78
最大载荷系数:80
临时表:没有
属性数量:6
主键数:1
frm数据的长度:341
行校验:1
行GCI:1
SingleUserMode:0
ForceVarPart:1
FragmentCount:4
TableStatus:已检索
- 属性 -
id Bigint PRIMARY KEY DISTRIBUTION KEY AT = FIXED ST = MEMORY AUTO_INCR
country_code Char(2; latin1_swedish_ci)NOT NULL AT = FIXED ST = MEMORY
type char(4; latin1_swedish_ci)NOT NULL AT = FIXED ST = MEMORY
ip_address Varchar(15; latin1_swedish_ci)NOT NULL AT = SHORT_VAR ST = MEMORY
地址Bigunsigned NULL AT = FIXED ST = MEMORY
date Bigunsigned NULL AT = FIXED ST = MEMORY
- 索引 -
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
- 每个分区信息 -
分区行计数提交计数Frag固定内存Frag varsized memory
0 12981 52296 1572864 557056
1 13236 52515 1605632 557056
2 13105 13105 819200 294912
3 13093 13093 819200 294912
NDBT_ProgramExit:0 - 好的
通常,
与分区标识符列表和一组分区定义一起使用,以为已经显式分区的表创建新的分区方案。
在这方面,它用于将数据重新分配到新的NDB群集节点组是一个例外。
以这种方式使用时,不会出现其他关键字或标识符
。
ALTER
TABLE
table_name
[ALGORITHM=INPLACE,] REORGANIZE PARTITIONREORGANIZE
PARTITION
有关更多信息,请参见 第13.1.9节“ALTER TABLE语法” 。
此外,对于每个表,该
ALTER
TABLE
语句后面应该有一个
OPTIMIZE TABLE
回收浪费的空间。
您可以
NDBCLUSTER
使用针对该
INFORMATION_SCHEMA.TABLES
表
的以下查询
获取所有
表的
列表:
SELECT TABLE_SCHEMA,TABLE_NAME
来自INFORMATION_SCHEMA.TABLES
WHERE ENGINE ='NDBCLUSTER';
在
INFORMATION_SCHEMA.TABLES.ENGINE
一个NDB簇表值始终是
NDBCLUSTER
,不管是否
CREATE TABLE
使用语句创建(或表
ALTER
TABLE
使用现有的表从不同的存储引擎转换语句)使用
NDB
或
NDBCLUSTER
在其
ENGINE
选项。
在输出中执行这些语句之后,您可以看到
ALL REPORT MEMORY
数据和索引现在在所有集群数据节点之间重新分配,如下所示:
ndb_mgm> ALL REPORT MEMORY
节点1:数据使用率为5%(176 32K页,共3200页)
节点1:索引使用率为0%(76个8K页,共12832页)
节点2:数据使用率为5%(176个32K页,总计3200个)
节点2:索引使用率为0%(76个8K页,共12832页)
节点3:数据使用率为2%(80个32K页,共3200个)
节点3:索引使用率为0%(总共12832个,共51个8K页)
节点4:数据使用率为2%(80个32K页,共3200个)
节点4:索引使用率为0%(总共12832个50个8K页)
由于一次只能对
NDBCLUSTER
表执行
一次DDL操作
,因此必须等到每个
ALTER
TABLE ...
REORGANIZE PARTITION
语句完成后才能发出下一个语句。
没有必要为
添加新数据节点
后
创建
ALTER
TABLE ...
REORGANIZE PARTITION
的
NDBCLUSTER
表
发出
语句
;
添加到这些表的数据自动分布在所有数据节点中。
但是,在
添加新节点
之前
存在的表中,
使用新节点分配现有数据和新数据,直到使用这些表进行重组
。
NDBCLUSTER
ALTER TABLE ...
REORGANIZE PARTITION
替代程序,无需重新启动。 首次启动集群时,可以通过配置额外数据节点而不是启动它们来避免滚动重启的需要。 我们像以前一样假设您希望从一个节点组中的两个数据节点 - 节点1和2开始,然后通过添加由节点3和4组成的第二个节点组将集群扩展到四个数据节点:
[ndbd默认] DataMemory = 100M IndexMemory = 100M NoOfReplicas = 2 DataDir = / usr / local / mysql / var / mysql-cluster [NDBD] Id = 1 HostName = 198.51.100.1 [NDBD] Id = 2 HostName = 198.51.100.2 [NDBD] Id = 3 HostName = 198.51.100.3 节点组= 65536 [NDBD] Id = 4 HostName = 198.51.100.4 节点组= 65536 [MGM] HostName = 198.51.100.10 Id = 10 [API] ID = 20 HostName = 198.51.100.20 [API] ID = 21 HostName = 198.51.100.21
可以配置稍后联机的数据节点(节点3和4)
NodeGroup = 65536
,在这种情况下,节点1和2可以各自启动,如下所示:
外壳> ndbd -c 198.51.100.10 --initial
配置的数据节点
NodeGroup = 65536
由管理服务器处理,就像
--nowait-nodes=3,4
在等待由
StartNoNodeGroupTimeout
数据节点配置参数
的设置确定的一段时间之后
使用已启动节点1和2一样
。
默认情况下,这是15秒(15000毫秒)。
StartNoNodegroupTimeout
对于集群中的所有数据节点必须相同;
因此,您应始终将其设置在
文件
的
[ndbd
default]
部分中
config.ini
,而不是单个数据节点中。
准备好添加第二个节点组时,只需执行以下附加步骤:
-
启动数据节点3和4,为每个新节点调用一次数据节点进程:
外壳>
ndbd -c 198.51.100.10 --initial -
CREATE NODEGROUP在管理客户端中 发出适当的 命令:ndb_mgm>
CREATE NODEGROUP 3,4 -
在 mysql 客户端中, 为每个现有 表 发布
ALTER TABLE ... REORGANIZE PARTITION和OPTIMIZE TABLE声明NDBCLUSTER。 (如本节其他部分所述,在完成此操作之前,现有的NDB Cluster表不能使用新节点进行数据分发。)
NDB Cluster 8.0不再支持在以前版本中实现的NDB群集中所有SQL节点上分发MySQL用户和权限。 有关此更改对先前版本的NDB 8.0升级的影响的信息,请参见 第22.2.8节“升级和降级NDB群集” 。
有关在NDB 7.6分布式权限和更早的信息,请参阅 分布式MySQL的权限为NDB簇 ,在 MySQL的NDB簇7.5和NDB簇7.6 。
可以使用与由
Ndb
对象
执行或影响
对象的
动作相关的多种类型的统计计数器
。
此类行动包括启动和关闭(或中止)交易;
主键和唯一键操作;
表,范围和修剪扫描;
等待各种操作完成时线程被阻塞;
和发送和接收的数据和事件
NDBCLUSTER
。
每当进行NDB API调用或数据发送到数据节点或由数据节点接收时,计数器在NDB内核内递增。
mysqld
将这些计数器公开为系统状态变量;
它们的值可以在输出中读取
SHOW
STATUS
,或者通过查询
INFORMATION_SCHEMA.SESSION_STATUS
或
来读取
INFORMATION_SCHEMA.GLOBAL_STATUS
表。
通过比较对
NDB
表
操作的语句之前和之后的值
,您可以观察在API级别上执行的相应操作,从而执行语句的成本。
您可以使用以下
SHOW
STATUS
语句
列出所有这些状态变量
:
MySQL的> SHOW STATUS LIKE 'ndb_api%';
+ -------------------------------------------- + ---- ------ +
| Variable_name | 价值|
+ -------------------------------------------- + ---- ------ +
| Ndb_api_wait_exec_complete_count_session | 0 |
| Ndb_api_wait_scan_result_count_session | 0 |
| Ndb_api_wait_meta_request_count_session | 0 |
| Ndb_api_wait_nanos_count_session | 0 |
| Ndb_api_bytes_sent_count_session | 0 |
| Ndb_api_bytes_received_count_session | 0 |
| Ndb_api_trans_start_count_session | 0 |
| Ndb_api_trans_commit_count_session | 0 |
| Ndb_api_trans_abort_count_session | 0 |
| Ndb_api_trans_close_count_session | 0 |
| Ndb_api_pk_op_count_session | 0 |
| Ndb_api_uk_op_count_session | 0 |
| Ndb_api_table_scan_count_session | 0 |
| Ndb_api_range_scan_count_session | 0 |
| Ndb_api_pruned_scan_count_session | 0 |
| Ndb_api_scan_batch_count_session | 0 |
| Ndb_api_read_row_count_session | 0 |
| Ndb_api_trans_local_read_row_count_session | 0 |
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
| Ndb_api_wait_exec_complete_count_slave | 0 |
| Ndb_api_wait_scan_result_count_slave | 0 |
| Ndb_api_wait_meta_request_count_slave | 0 |
| Ndb_api_wait_nanos_count_slave | 0 |
| Ndb_api_bytes_sent_count_slave | 0 |
| Ndb_api_bytes_received_count_slave | 0 |
| Ndb_api_trans_start_count_slave | 0 |
| Ndb_api_trans_commit_count_slave | 0 |
| Ndb_api_trans_abort_count_slave | 0 |
| Ndb_api_trans_close_count_slave | 0 |
| Ndb_api_pk_op_count_slave | 0 |
| Ndb_api_uk_op_count_slave | 0 |
| Ndb_api_table_scan_count_slave | 0 |
| Ndb_api_range_scan_count_slave | 0 |
| Ndb_api_pruned_scan_count_slave | 0 |
| Ndb_api_scan_batch_count_slave | 0 |
| Ndb_api_read_row_count_slave | 0 |
| Ndb_api_trans_local_read_row_count_slave | 0 |
| Ndb_api_wait_exec_complete_count | 2 |
| Ndb_api_wait_scan_result_count | 3 |
| Ndb_api_wait_meta_request_count | 27 |
| Ndb_api_wait_nanos_count | 45612023 |
| Ndb_api_bytes_sent_count | 992 |
| Ndb_api_bytes_received_count | 9640 |
| Ndb_api_trans_start_count | 2 |
| Ndb_api_trans_commit_count | 1 |
| Ndb_api_trans_abort_count | 0 |
| Ndb_api_trans_close_count | 2 |
| Ndb_api_pk_op_count | 1 |
| Ndb_api_uk_op_count | 0 |
| Ndb_api_table_scan_count | 1 |
| Ndb_api_range_scan_count | 0 |
| Ndb_api_pruned_scan_count | 0 |
| Ndb_api_scan_batch_count | 0 |
| Ndb_api_read_row_count | 1 |
| Ndb_api_trans_local_read_row_count | 1 |
| Ndb_api_event_data_count | 0 |
| Ndb_api_event_nondata_count | 0 |
| Ndb_api_event_bytes_count | 0 |
+ -------------------------------------------- + ---- ------ +
60行(0.02秒)
这些状态变量也可以从
数据库的
表
SESSION_STATUS
和
GLOBAL_STATUS
表中获得
INFORMATION_SCHEMA
,如下所示:
mysql>SELECT * FROM INFORMATION_SCHEMA.SESSION_STATUS- >WHERE VARIABLE_NAME LIKE 'ndb_api%';+ -------------------------------------------- + ---- ------------ + | VARIABLE_NAME | VARIABLE_VALUE | + -------------------------------------------- + ---- ------------ + | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SESSION | 2 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SESSION | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SESSION | 1 | | NDB_API_WAIT_NANOS_COUNT_SESSION | 8144375 | | NDB_API_BYTES_SENT_COUNT_SESSION | 68 | | NDB_API_BYTES_RECEIVED_COUNT_SESSION | 84 | | NDB_API_TRANS_START_COUNT_SESSION | 1 | | NDB_API_TRANS_COMMIT_COUNT_SESSION | 1 | | NDB_API_TRANS_ABORT_COUNT_SESSION | 0 | | NDB_API_TRANS_CLOSE_COUNT_SESSION | 1 | | NDB_API_PK_OP_COUNT_SESSION | 1 | | NDB_API_UK_OP_COUNT_SESSION | 0 | | NDB_API_TABLE_SCAN_COUNT_SESSION | 0 | | NDB_API_RANGE_SCAN_COUNT_SESSION | 0 | | NDB_API_PRUNED_SCAN_COUNT_SESSION | 0 | | NDB_API_SCAN_BATCH_COUNT_SESSION | 0 | | NDB_API_READ_ROW_COUNT_SESSION | 1 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SESSION | 1 | | NDB_API_EVENT_DATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_NONDATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_BYTES_COUNT_INJECTOR | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SLAVE | 0 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SLAVE | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SLAVE | 0 | | NDB_API_WAIT_NANOS_COUNT_SLAVE | 0 | | NDB_API_BYTES_SENT_COUNT_SLAVE | 0 | | NDB_API_BYTES_RECEIVED_COUNT_SLAVE | 0 | | NDB_API_TRANS_START_COUNT_SLAVE | 0 | | NDB_API_TRANS_COMMIT_COUNT_SLAVE | 0 | | NDB_API_TRANS_ABORT_COUNT_SLAVE | 0 | | NDB_API_TRANS_CLOSE_COUNT_SLAVE | 0 | | NDB_API_PK_OP_COUNT_SLAVE | 0 | | NDB_API_UK_OP_COUNT_SLAVE | 0 | | NDB_API_TABLE_SCAN_COUNT_SLAVE | 0 | | NDB_API_RANGE_SCAN_COUNT_SLAVE | 0 | | NDB_API_PRUNED_SCAN_COUNT_SLAVE | 0 | | NDB_API_SCAN_BATCH_COUNT_SLAVE | 0 | | NDB_API_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | + -------------------------------------------- + ---- ------------ + 60行(0.00秒) mysql>SELECT * FROM INFORMATION_SCHEMA.GLOBAL_STATUS- >WHERE VARIABLE_NAME LIKE 'ndb_api%';+ -------------------------------------------- + ---- ------------ + | VARIABLE_NAME | VARIABLE_VALUE | + -------------------------------------------- + ---- ------------ + | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SESSION | 2 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SESSION | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SESSION | 1 | | NDB_API_WAIT_NANOS_COUNT_SESSION | 8144375 | | NDB_API_BYTES_SENT_COUNT_SESSION | 68 | | NDB_API_BYTES_RECEIVED_COUNT_SESSION | 84 | | NDB_API_TRANS_START_COUNT_SESSION | 1 | | NDB_API_TRANS_COMMIT_COUNT_SESSION | 1 | | NDB_API_TRANS_ABORT_COUNT_SESSION | 0 | | NDB_API_TRANS_CLOSE_COUNT_SESSION | 1 | | NDB_API_PK_OP_COUNT_SESSION | 1 | | NDB_API_UK_OP_COUNT_SESSION | 0 | | NDB_API_TABLE_SCAN_COUNT_SESSION | 0 | | NDB_API_RANGE_SCAN_COUNT_SESSION | 0 | | NDB_API_PRUNED_SCAN_COUNT_SESSION | 0 | | NDB_API_SCAN_BATCH_COUNT_SESSION | 0 | | NDB_API_READ_ROW_COUNT_SESSION | 1 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SESSION | 1 | | NDB_API_EVENT_DATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_NONDATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_BYTES_COUNT_INJECTOR | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SLAVE | 0 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SLAVE | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SLAVE | 0 | | NDB_API_WAIT_NANOS_COUNT_SLAVE | 0 | | NDB_API_BYTES_SENT_COUNT_SLAVE | 0 | | NDB_API_BYTES_RECEIVED_COUNT_SLAVE | 0 | | NDB_API_TRANS_START_COUNT_SLAVE | 0 | | NDB_API_TRANS_COMMIT_COUNT_SLAVE | 0 | | NDB_API_TRANS_ABORT_COUNT_SLAVE | 0 | | NDB_API_TRANS_CLOSE_COUNT_SLAVE | 0 | | NDB_API_PK_OP_COUNT_SLAVE | 0 | | NDB_API_UK_OP_COUNT_SLAVE | 0 | | NDB_API_TABLE_SCAN_COUNT_SLAVE | 0 | | NDB_API_RANGE_SCAN_COUNT_SLAVE | 0 | | NDB_API_PRUNED_SCAN_COUNT_SLAVE | 0 | | NDB_API_SCAN_BATCH_COUNT_SLAVE | 0 | | NDB_API_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | + -------------------------------------------- + ---- ------------ + 60行(0.00秒)
每个
Ndb
对象都有自己的计数器。
NDB API应用程序可以读取计数器的值以用于优化或监视。
对于同时使用多个
Ndb
对象的
多线程客户端,
还可以
Ndb
从属于给定对象的
所有
对象
获得计数器的总和视图
Ndb_cluster_connection
。
暴露了四组这些计数器。
一套仅适用于当前会话;
其他3个是全球性的。
尽管它们的值可以作为
mysql
客户端
中的会话或全局状态变量获得
。
这意味着指定
SESSION
or
GLOBAL
关键字
SHOW
STATUS
对NDB API统计状态变量报告的值没有影响,并且无论从表的等效列
SESSION_STATUS
还是
GLOBAL_STATUS
表中
获取值,每个变量的值都是相同
的
。
-
会话计数器(特定于会话)
会话计数器与
Ndb(仅)当前会话使用 的 对象 相关 。 其他MySQL客户端使用此类对象不会影响这些计数。为了最大限度地减少与标准MySQL会话变量的混淆,我们将与这些NDB API会话计数器对应的变量称为 “
_session变量 ” ,并带有前导下划线。 -
奴隶柜台(全球)
这组计数器与
Ndb复制从属SQL线程使用 的 对象(如果有)相关。 如果此 mysqld 不充当复制从属,或者不使用NDB表,则所有这些计数都为0。我们将相关的状态变量称为 “
_slave变量 ” (带有前导下划线)。 -
喷油器计数器(全球)
注入器计数器涉及
Ndb用于通过二进制日志注入器线程侦听集群事件 的 对象。 即使不写二进制日志, 连接到NDB集群的 mysqld 进程也会继续监听某些事件,例如架构更改。我们将与NDB API注入器计数器对应的状态变量称为 “
_injector变量 ” (带有前导下划线)。 -
服务器(全局)计数器(全局)
这组计数器涉及
Ndb此 mysqld 当前使用的 所有 对象 。 这包括所有MySQL客户端应用程序,从属SQL线程(如果有),binlog注入器和NDB实用程序线程。我们将与这些计数器对应的状态变量称为 “ 全局变量 ” 或 “ mysqld -level变量 ” 。
可以通过为子串附加滤波获得用于特定的一组变量的值
session
,
slave
或
injector
在变量名(连同公共前缀
Ndb_api
)。
对于
_session
变量,这可以如下所示完成:
MySQL的> SHOW STATUS LIKE 'ndb_api%session';
+ -------------------------------------------- + ---- ----- +
| Variable_name | 价值|
+ -------------------------------------------- + ---- ----- +
| Ndb_api_wait_exec_complete_count_session | 2 |
| Ndb_api_wait_scan_result_count_session | 0 |
| Ndb_api_wait_meta_request_count_session | 1 |
| Ndb_api_wait_nanos_count_session | 8144375 |
| Ndb_api_bytes_sent_count_session | 68 |
| Ndb_api_bytes_received_count_session | 84 |
| Ndb_api_trans_start_count_session | 1 |
| Ndb_api_trans_commit_count_session | 1 |
| Ndb_api_trans_abort_count_session | 0 |
| Ndb_api_trans_close_count_session | 1 |
| Ndb_api_pk_op_count_session | 1 |
| Ndb_api_uk_op_count_session | 0 |
| Ndb_api_table_scan_count_session | 0 |
| Ndb_api_range_scan_count_session | 0 |
| Ndb_api_pruned_scan_count_session | 0 |
| Ndb_api_scan_batch_count_session | 0 |
| Ndb_api_read_row_count_session | 1 |
| Ndb_api_trans_local_read_row_count_session | 1 |
+ -------------------------------------------- + ---- ----- +
18行(0.50秒)
要获取NDB API
mysqld
-level状态变量的列表,请过滤以开头
ndb_api
和结尾的
变量名称
_count
,如下所示:
mysql>SELECT * FROM INFORMATION_SCHEMA.SESSION_STATUS- >WHERE VARIABLE_NAME LIKE 'ndb_api%count';+ ------------------------------------ + ------------ ---- + | VARIABLE_NAME | VARIABLE_VALUE | + ------------------------------------ + ------------ ---- + | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | + ------------------------------------ + ------------ ---- + 21行(0.09秒)
并非所有计数器都反映在所有4组状态变量中。
对于事件计数器
DataEventsRecvdCount
,
NondataEventsRecvdCount
和
EventBytesRecvdCount
,只有
_injector
和
mysqld
-level NDB API状态变量可用:
MySQL的> SHOW STATUS LIKE 'ndb_api%event%';
+ -------------------------------------- + ------- +
| Variable_name | 价值|
+ -------------------------------------- + ------- +
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
| Ndb_api_event_data_count | 0 |
| Ndb_api_event_nondata_count | 0 |
| Ndb_api_event_bytes_count | 0 |
+ -------------------------------------- + ------- +
6行(0.00秒)
_injector
任何其他NDB API计数器都没有实现状态变量,如下所示:
MySQL的> SHOW STATUS LIKE 'ndb_api%injector%';
+ -------------------------------------- + ------- +
| Variable_name | 价值|
+ -------------------------------------- + ------- +
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
+ -------------------------------------- + ------- +
3组(0.00秒)
状态变量的名称可以很容易地与相应计数器的名称相关联。 每个NDB API统计计数器在下表中列出,其中包含描述以及与此计数器对应的任何MySQL服务器状态变量的名称。
表22.423 NDB API统计计数器
| 柜台名称 | 描述 |
状态变量(按统计类型):
|
|---|---|---|
WaitExecCompleteCount |
等待执行操作完成时阻塞线程的次数。
包括所有
execute()
调用以及blob操作的隐式执行和客户端不可见的自动递增。
|
|
WaitScanResultCount |
等待基于扫描的信号时线程被阻塞的次数,例如等待其他结果或扫描关闭。 | |
WaitMetaRequestCount |
线程被阻塞等待基于元数据的信号的次数; 在等待DDL操作或启动(或结束)纪元时,可能会发生这种情况。 | |
WaitNanosCount |
等待来自数据节点的某种类型信号所花费的总时间(以纳秒为单位)。 | |
BytesSentCount |
发送到数据节点的数据量(以字节为单位) | |
BytesRecvdCount |
从数据节点接收的数据量(以字节为单位) | |
TransStartCount |
已开始的交易数量。 | |
TransCommitCount |
提交的交易数量。 | |
TransAbortCount |
交易次数中止。 | |
TransCloseCount |
交易次数中止。
(此值可以比的总和
TransCommitCount
和
TransAbortCount
)。
|
|
PkOpCount |
基于或使用主键的操作数。 此计数包括blob-part表操作,隐式解锁操作和自动递增操作,以及MySQL客户端通常可见的主键操作。 | |
UkOpCount |
基于或使用唯一键的操作数。 | |
TableScanCount |
已启动的表扫描数。 这包括扫描内部表格。 | |
RangeScanCount |
已启动的范围扫描数。 | |
PrunedScanCount |
已修剪到单个分区的扫描数。 | |
ScanBatchCount |
收到的批次行数。 ( 此上下文中的 批处理 是来自单个片段的一组扫描结果。) | |
ReadRowCount |
已读取的总行数。 包括使用主键,唯一键和扫描操作读取的行。 | |
TransLocalReadRowCount |
从正在运行事务的数据同一节点读取的行数。 | |
DataEventsRecvdCount |
收到的行更改事件数。 | |
NondataEventsRecvdCount |
收到的事件数,而不是行更改事件。 | |
EventBytesRecvdCount |
收到的事件的字节数。 |
要查看所有已提交事务的计数 - 即所有
TransCommitCount
计数器状态变量 - 您可以过滤
SHOW
STATUS
子字符串
的结果
trans_commit_count
,如下所示:
MySQL的> SHOW STATUS LIKE '%trans_commit_count%';
+ ------------------------------------ + ------- +
| Variable_name | 价值|
+ ------------------------------------ + ------- +
| Ndb_api_trans_commit_count_session | 1 |
| Ndb_api_trans_commit_count_slave | 0 |
| Ndb_api_trans_commit_count | 2 |
+ ------------------------------------ + ------- +
3组(0.00秒)
从此可以确定在当前的 mysql 客户端会话中 已提交1个事务 ,并且 自上次重新启动以来 已在此 mysqld 上提交了2个事务 。
通过
_session
在执行语句之前和之后
比较相应
状态变量
的值,您可以查看给定SQL语句如何增加各种NDB API计数器
。
在此示例中,在获取初始值之后
SHOW
STATUS
,我们在
test
数据库中
创建
一个
NDB
名为
的
表,
该
表
t
具有单个列:
MySQL的>SHOW STATUS LIKE 'ndb_api%session%';+ -------------------------------------------- + ---- ---- + | Variable_name | 价值| + -------------------------------------------- + ---- ---- + | Ndb_api_wait_exec_complete_count_session | 2 | | Ndb_api_wait_scan_result_count_session | 0 | | Ndb_api_wait_meta_request_count_session | 3 | | Ndb_api_wait_nanos_count_session | 820705 | | Ndb_api_bytes_sent_count_session | 132 | | Ndb_api_bytes_received_count_session | 372 | | Ndb_api_trans_start_count_session | 1 | | Ndb_api_trans_commit_count_session | 1 | | Ndb_api_trans_abort_count_session | 0 | | Ndb_api_trans_close_count_session | 1 | | Ndb_api_pk_op_count_session | 1 | | Ndb_api_uk_op_count_session | 0 | | Ndb_api_table_scan_count_session | 0 | | Ndb_api_range_scan_count_session | 0 | | Ndb_api_pruned_scan_count_session | 0 | | Ndb_api_scan_batch_count_session | 0 | | Ndb_api_read_row_count_session | 1 | | Ndb_api_trans_local_read_row_count_session | 1 | + -------------------------------------------- + ---- ---- + 18行(0.00秒) MySQL的>USE test;数据库已更改 MySQL的>CREATE TABLE t (c INT) ENGINE NDBCLUSTER;查询OK,0行受影响(0.85秒)
现在您可以执行一个新
SHOW
STATUS
语句并观察更改,如下所示(输出中突出显示已更改的行):
MySQL的> SHOW STATUS LIKE 'ndb_api%session%';
+ -------------------------------------------- + ---- ------- +
| Variable_name | 价值|
+ -------------------------------------------- + ---- ------- +
| Ndb_api_wait_exec_complete_count_session | 8 |
| Ndb_api_wait_scan_result_count_session | 0 |
| Ndb_api_wait_meta_request_count_session | 17 |
| Ndb_api_wait_nanos_count_session | 706871709 |
| Ndb_api_bytes_sent_count_session | 2376 |
| Ndb_api_bytes_received_count_session | 3844 |
| Ndb_api_trans_start_count_session | 4 |
| Ndb_api_trans_commit_count_session | 4 |
| Ndb_api_trans_abort_count_session | 0 |
| Ndb_api_trans_close_count_session | 4 |
| Ndb_api_pk_op_count_session | 6 |
| Ndb_api_uk_op_count_session | 0 |
| Ndb_api_table_scan_count_session | 0 |
| Ndb_api_range_scan_count_session | 0 |
| Ndb_api_pruned_scan_count_session | 0 |
| Ndb_api_scan_batch_count_session | 0 |
| Ndb_api_read_row_count_session | 2 |
| Ndb_api_trans_local_read_row_count_session | 1 |
+ -------------------------------------------- + ---- ------- +
18行(0.00秒)
类似地,您可以看到NDB API统计信息计数器中的更改,这是通过插入行来实现的
t
:插入行,然后运行
SHOW
STATUS
上一个示例中使用
的相同
语句,如下所示:
MySQL的>INSERT INTO t VALUES (100);查询正常,1行受影响(0.00秒) MySQL的>SHOW STATUS LIKE 'ndb_api%session%';+ -------------------------------------------- + ---- ------- + | Variable_name | 价值| + -------------------------------------------- + ---- ------- + | Ndb_api_wait_exec_complete_count_session | 11 | | Ndb_api_wait_scan_result_count_session | 6 | | Ndb_api_wait_meta_request_count_session | 20 | | Ndb_api_wait_nanos_count_session | 707370418 | | Ndb_api_bytes_sent_count_session | 2724 | | Ndb_api_bytes_received_count_session | 4116 | | Ndb_api_trans_start_count_session | 7 | | Ndb_api_trans_commit_count_session | 6 | | Ndb_api_trans_abort_count_session | 0 | | Ndb_api_trans_close_count_session | 7 | | Ndb_api_pk_op_count_session | 8 | | Ndb_api_uk_op_count_session | 0 | | Ndb_api_table_scan_count_session | 1 | | Ndb_api_range_scan_count_session | 0 | | Ndb_api_pruned_scan_count_session | 0 | | Ndb_api_scan_batch_count_session | 0 | | Ndb_api_read_row_count_session | 3 | | Ndb_api_trans_local_read_row_count_session | 2 | + -------------------------------------------- + ---- ------- + 18行(0.00秒)
我们可以从这些结果中做出一些观察:
-
虽然我们创建
t时没有明确的主键,但是执行了5次主键操作( “ 之前 ” 和 “ 之后 ” 值 的差异Ndb_api_pk_op_count_session,或者6减1)。 这反映了隐藏主键的创建,该主键是使用NDB存储引擎 的所有表的功能 。 -
通过比较连续值
Ndb_api_wait_nanos_count_session,我们可以看到实现该CREATE TABLE语句 的NDB API操作 等待的时间要长得多(706871709 - 820705 = 706051004纳秒,或大约0.7秒)来自数据节点的响应INSERT(707370418 - 706871709 = 498709) ns或大约.0005秒)。 在 mysql 客户端中 为这些语句报告的执行时间 与这些数字大致相关。在没有足够的(纳秒)的时间分辨率平台,小的变化在价值
WaitNanosCount由于SQL语句非常迅速执行NDB API计数器可能并不总是可见的值Ndb_api_wait_nanos_count_session,Ndb_api_wait_nanos_count_slave或Ndb_api_wait_nanos_count。 -
该
INSERT语句增加了ReadRowCount和TransLocalReadRowCountNDB API统计计数器,正如Ndb_api_read_row_count_session和和 的增加值所反映的那样Ndb_api_trans_local_read_row_count_session。
NDB Cluster支持 异步复制 ,通常简称为 “ 复制 ” 。 本节介绍如何设置和管理作为NDB群集运行的一组计算机复制到第二台计算机或一组计算机的配置。 我们假设读者对标准MySQL复制有一些熟悉,如本手册其他部分所述。 (参见 第17章, 复制 )。
NDB Cluster不支持使用GTID进行复制;
NDB
存储引擎
也不支持半同步复制
。
正常(非群集)复制涉及
“
主
”
服务器和
“
从
”
服务器,主服务器是要复制的操作和数据的源,而
从
服务器是这些服务器的接收者。
在NDB群集中,复制在概念上非常相似,但在实践中可能更复杂,因为它可能会扩展到涵盖许多不同的配置,包括在两个完整群集之间复制。
虽然NDB集群本身依赖于
NDB
存储引擎来实现集群功能,但是没有必要将其
NDB
用作从属副本的复制表的
存储引擎
(请参阅
从NDB到其他存储引擎的复制)
)。
但是,为了获得最大可用性,可以(并且更可取)从一个NDB集群复制到另一个NDB集群,我们将讨论这种情况,如下图所示:
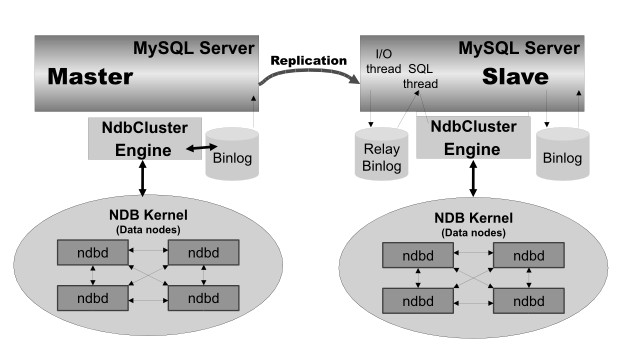
在此方案中,复制过程是记录主群集的连续状态并将其保存到从属群集的过程。
此过程由称为NDB二进制日志注入器线程的特殊线程完成,该线程在每个MySQL服务器上运行并生成二进制日志(
binlog
)。
此线程确保生成二进制日志的集群中的所有更改(而不仅仅是通过MySQL服务器实现的更改)都以正确的序列化顺序插入到二进制日志中。
我们将MySQL复制主服务器和复制从服务器称为复制服务器或复制节点,并将它们之间的数据流或通信线称为
复制通道
。
有关使用NDB群集和NDB群集复制执行时间点恢复的信息,请参见 第22.6.9.2节“使用NDB群集复制进行时间点恢复” 。
NDB API _slave状态变量。
NDB API计数器可以在NDB Cluster复制从站上提供增强的监视功能。
这些实现为NDB统计
_slave
状态变量,如
连接到作为NDB集群复制中的从属服务器的MySQL服务器
的
mysql
客户端会话
SHOW
STATUS
中的
SESSION_STATUS
或
GLOBAL_STATUS
表
的查询结果或结果中
所示
。
通过比较执行影响复制的语句之前和之后的这些状态变量的值
NDB
在表中,您可以观察从站在NDB API级别上执行的相应操作,这在监视或排除NDB群集复制故障时非常有用。
第22.5.17节“NDB API统计计数器和变量”
提供了其他信息。
从NDB复制到非NDB表。
可以将
NDB
表从作为主服务器的NDB集群
复制
到使用其他MySQL存储引擎的表,例如
InnoDB
或者
MyISAM
在从属
mysqld
上
复制
表
。
这取决于许多条件;
有关详细信息,
请参阅
从NDB复制到其他存储引擎
,以及
从NDB复制到非事务存储引擎
。
在本节中,我们使用以下缩写或符号来指代主群集和从群集,以及在群集或群集节点上运行的流程和命令:
表22.424本节中使用的缩写,指的是主集群和从集群,以及在节点上运行的进程和命令
| 符号或缩写 | 说明(指...) |
|---|---|
M |
用作(主)复制主机的群集 |
S |
该集群充当(主)复制从属 |
shell |
要在主群集上发出Shell命令 |
mysql |
MySQL客户机命令在作为主集群上的SQL节点运行的单个MySQL服务器上发出 |
mysql |
要在参与复制主群集的所有SQL节点上发出MySQL客户端命令 |
shell |
Shell命令将在从属群集上发布 |
mysql |
MySQL客户端命令在作为从属群集上的SQL节点运行的单个MySQL服务器上发出 |
mysql |
在参与复制从属群集的所有SQL节点上发出MySQL客户端命令 |
C |
主复制通道 |
C' |
辅助复制通道 |
M' |
辅助复制主机 |
S' |
辅助复制从属 |
复制通道需要两个MySQL服务器充当复制服务器(主服务器和从服务器各一个)。 例如,这意味着在具有两个复制通道的复制设置(为冗余提供额外通道)的情况下,总共将有四个复制节点,每个群集两个。
如本节所述,NDB群集的复制以及后续复制依赖于基于行的复制。
这意味着复制主MySQL服务器必须与
--binlog-format=ROW
或
一起运行
--binlog-format=MIXED
,如
第22.6.6节“启动NDB集群复制(单一复制通道)”中所述
。
有关基于行的复制的一般信息,请参见
第17.2.1节“复制格式”
。
如果您尝试使用NDB群集复制
--binlog-format=STATEMENT
,则复制无法正常工作,因为
ndb_binlog_index
主服务器
epoch
上的
ndb_apply_status
表和从服务器上的表
的
列
未更新(请参见
第22.6.4节“NDB集群复制架构和表”
)。
相反,只有充当复制主服务器的MySQL服务器上的更新才会传播到从服务器,并且不会复制主群集上任何其他SQL节点的更新。
--binlog-format
NDB 8.0中选项
的默认值为
MIXED
。
在任一集群中用于复制的每个MySQL服务器必须在参与任一集群的所有MySQL复制服务器中唯一标识(您不能在主集群和从集群上共享相同ID的复制服务器)。
这可以通过使用
选项
启动每个SQL节点来完成
,其中
是一个唯一的整数。
尽管不是绝对必要,但为了本讨论的目的,我们将假设所有NDB Cluster二进制文件具有相同的发行版本。
--server-id=
idid
在MySQL Replication中,所 涉及的 两个MySQL服务器( mysqld 进程)必须在所使用的复制协议版本和它们支持的SQL功能集之间相互兼容(参见 第17.4.2节“复制”)。 MySQL版本之间的兼容性“ )。 由于NDB群集和MySQL Server 8.0发行版中的二进制文件之间的差异,NDB群集复制还要求两个 mysqld 二进制文件都来自NDB群集分发。 确保 mysqld 的最简单,最简单的方法 服务器兼容是对所有主和从 mysqld 二进制文件 使用相同的NDB Cluster分发 。
我们假设从服务器或集群专用于主服务器的复制,并且没有其他数据存储在主服务器上。
NDB
必须使用MySQL服务器和客户端创建要复制的
所有
表。
使用NDB API(例如,使用
Dictionary::createTable()
)
创建的表和其他数据库对象
对MySQL服务器不可见,因此不会被复制。
可以复制NDB API应用程序对使用MySQL服务器创建的现有表的更新。
可以使用基于语句的复制来复制NDB集群。 但是,在这种情况下,以下限制适用:
-
必须将作为主服务器的集群上的数据行的所有更新定向到单个MySQL服务器。
-
无法使用多个同时进行的MySQL复制过程来复制群集。
-
仅复制在SQL级别所做的更改。
这些是基于语句的复制的其他限制,而不是基于行的复制; 有关两种复制格式之间差异的更多具体信息, 请参见 第17.2.1.1节“基于语句和基于行的复制的优点和缺点” 。
本节讨论在使用NDB Cluster 8.0进行复制时的已知问题。
失去主从连接。
复制主SQL节点和复制从属SQL节点之间,或复制主SQL节点与主群集中的数据节点之间可能会发生连接丢失。
在后一种情况下,这不仅可能由于物理连接丢失(例如,网络电缆损坏)而发生,而是由于数据节点事件缓冲区的溢出;
如果SQL节点响应太慢,则群集可能会丢弃它(通过调整
MaxBufferedEpochs
和
TimeBetweenEpochs
配置参数,
这在某种程度上是可控的
)。
如果发生这种情况,
则可以将新数据插入主集群,而不必记录在复制主机的二进制日志中
。
因此,为了保证高可用性,维护备份复制通道,监视主通道以及在必要时故障转移到辅助复制通道以保持从属群集与主节点同步非常重要。
NDB Cluster不是为自己执行此类监视而设计的;
为此,需要外部应用程序。
复制主机
在连接或重新连接到主群集时
发出
“
间隙
”
事件。
(间隙事件是一种
“
事件事件
”
,表示发生的事件会影响数据库的内容,但不能轻易地表示为一组更改。事件的示例是服务器崩溃,数据库重新同步,(某些事件)
)软件更新,以及(某些)硬件更改。)当从属设备遇到复制日志中的间隙时,它会停止并显示错误消息。
此消息在输出中可用
SHOW SLAVE STATUS
,并指示由于复制流中注册的事件导致SQL线程已停止,并且需要手动干预。
有关
在此类情况下应执行的操作的详细信息
,
请参见
第22.6.8节“使用NDB集群复制实现故障切换”
。
由于NDB Cluster不是单独设计用于监视复制状态或提供故障转移,因此如果从属服务器或群集需要高可用性,则必须设置多个复制行,监视 主复制行上的 主 mysqld ,以及如果必要,准备故障转移到次要线路。 这必须手动完成,或者可能通过第三方应用程序完成。 有关实现此类设置的信息,请参见 第22.6.7节“为NDB集群复制使用两个复制通道” 和 第22.6.8节“使用NDB集群复制实现故障转移” 。
但是,如果要从独立的MySQL服务器复制到NDB群集,则通常一个通道就足够了。
循环复制。 NDB群集复制支持循环复制,如下一个示例所示。 复制设置涉及三个编号为1,2和3的NDB群集,其中群集1充当群集2的复制主群集,群集2充当群集3的主群集,群集3充当群集1的主群集,因此完成圆圈。 每个NDB集群有两个SQL节点,其中SQL节点A和B属于集群1,SQL节点C和D属于集群2,SQL节点E和F属于集群3。
只要满足以下条件,就支持使用这些群集进行循环复制:
-
所有主服务器和从服务器上的SQL节点都是相同的
-
使用该
--log-slave-updates选项 启动充当复制主服务器和从服务器的所有SQL节点
这种循环复制设置如下图所示:

在此方案中,群集1中的SQL节点A复制到群集2中的SQL节点C; SQL节点C复制到集群3中的SQL节点E; SQL节点E复制到SQL节点A.换句话说,复制行(由图中的弯曲箭头指示)直接连接用作复制主服务器和从服务器的所有SQL节点。
还应该可以设置循环复制,其中并非所有主SQL节点都是从属节点,如下所示:
在这种情况下,每个群集中的不同SQL节点将用作复制主服务器和从服务器。
但是,您
不能使用
启动任何SQL节点
--log-slave-updates
。
这种类型的NDB集群循环复制方案应该是可能的,其中复制线(图中的曲线箭头再次表示)是不连续的,但应该注意它尚未经过彻底测试,因此必须仍被认为是实验性的。
的
NDB
存储引擎使用
幂等执行模式
,这抑制重复键和以其他方式分解NDB簇的圆形复制其他错误。
这相当于将全局
slave_exec_mode
系统变量
设置
为
IDEMPOTENT
,但这在NDB群集复制中不是必需的,因为NDB群集会自动设置此变量并忽略任何显式设置它的尝试。
NDB群集复制和主键。
在节点发生故障的
NDB
情况下,由于在这种情况下可能会插入重复的行,因此仍然可能发生没有主键
的
表的
复制错误
。
因此,强烈建议所有
NDB
正在复制的表都具有主键。
NDB群集复制和唯一密钥。
在旧版本的NDB Cluster中,更新
NDB
表
的唯一键列值的操作
可能会在复制时导致重复键错误。
NDB
通过推迟唯一键检查直到执行了所有表行更新后,才能
解决
表
之间的复制问题
。
目前仅支持以这种方式推迟约束
NDB
。
因此,当从
NDB
诸如
MyISAM
或
InnoDB
仍然不支持
的不同存储引擎
复制时,唯一密钥的更新
。
在没有延迟检查唯一密钥更新的情况下进行复制时遇到的问题可以使用
NDB
表
来说明,
例如
t
,在主服务器上创建并填充(并复制到不支持延迟唯一密钥更新的从服务器),如下所示:
CREATE TABLE t(
p INT PRIMARY KEY,
c INT,
独特的钥匙u(c)
)ENGINE NDB;
插入到t
VALUES(1,1),(2,2),(3,3),(4,4),(5,5);
以下
UPDATE
语句在
t
master
上
成功,因为受影响的行按
ORDER BY
选项
确定的顺序处理,
在整个表上执行:
UPDATE t SET c = c - 1 ORDER BY p;
但是,同一语句因从属服务器上的重复键错误或其他约束违规而失败,因为行更新的顺序一次是针对一个分区完成的,而不是针对整个表进行的。
NDB
创建时,
每个
表都由key隐式分区。
有关
更多信息
,
请参见
第23.2.5节“KEY Partitioning”
。
GTID不受支持。
使用全局事务ID的复制与
NDB
存储引擎
不兼容,
不受支持。
启用GTID可能会导致NDB群集复制失败。
不支持多线程从站。
NDB簇不支持多线程的奴隶,并设置相关的系统变量,例如
slave_parallel_workers
,
slave_checkpoint_group
和
slave_checkpoint_group
(或等值
的mysqld
启动选项)没有任何影响。
这是因为如果在同一时期内写入,则从属设备可能无法将在一个数据库中发生的事务与在另一个数据库中发生的事务分开。
此外,
由于需要更新
表
,因此
NDB
存储引擎
处理的每个事务都
涉及至少两个数据库 - 目标数据库和
mysql
系统数据库
mysql.ndb_apply_status
(请参见
第22.6.4节“NDB集群复制架构和表”
)。
这反过来又打破了多线程的要求,即事务特定于给定的数据库。
使用--initial重新启动。
使用该
--initial
选项
重新启动集群
会导致GCI序列和纪元号重新开始
0
。
(这通常适用于NDB群集,并且不限于涉及群集的复制方案。)在这种情况下,应该重新启动复制中涉及的MySQL服务器。
在此之后,您应该使用
RESET
MASTER
和
RESET
SLAVE
语句分别清除invalid
ndb_binlog_index
和
ndb_apply_status
tables。
从NDB复制到其他存储引擎。
NDB
考虑到此处列出的限制,可以使用从属服务器上的不同存储引擎将主服务器上的表
复制到
表中:
-
不支持多主复制和循环复制(主服务器和从服务器上的表必须使用
NDB存储引擎才能工作)。 -
使用不对从属表执行二进制日志记录的存储引擎需要特殊处理。
-
将非事务存储引擎用于从属表也需要特殊处理。
-
主 mysqld 必须以
--ndb-log-update-as-write=0或 开头--ndb-log-update-as-write=OFF。
接下来的几段提供了有关上述每个问题的其他信息。
将NDB复制到其他存储引擎时不支持多个主服务器。
对于从
NDB
不同存储引擎的
复制,
两个数据库之间的关系必须是简单的主从数据库。
这意味着NDB Cluster和其他存储引擎之间不支持循环或主 - 主复制。
此外,在
NDB
不同存储引擎
之间复制时,无法配置多个复制通道
。
(但是,NDB Cluster数据库
可以
同时复制到多个从属NDB Cluster数据库。)如果master使用
NDB
表,则仍然可以让多个MySQL Server维护所有更改的二进制日志;
但是,对于从站更改主站(故障转移),必须在从站上明确定义新的主从关系。
将NDB复制到不执行二进制日志记录的从属存储引擎。 如果您尝试从NDB群集复制到使用不处理其自己的二进制日志记录的存储引擎的从属服务器,则复制过程将因错误 而无法进行二进制日志记录...由于不止一个引擎,因此无法以原子方式写入语句涉及并且至少有一个引擎是自记录的 (错误 1595 )。 可以通过以下方式之一解决此问题:
-
关闭从站上的二进制日志记录。 这可以通过设置来完成
sql_log_bin = 0。 -
更改用于mysql.ndb_apply_status表的存储引擎。 导致此表使用不处理自己的二进制日志记录的引擎也可以消除冲突。 这可以通过发出诸如
ALTER TABLE mysql.ndb_apply_status ENGINE=MyISAM奴隶之 类的声明来完成 。NDB在从站上 使用非 存储引擎 时这样做是安全 的,因为您不需要担心保持多个从属SQL节点同步。 -
过滤掉对从属的mysql.ndb_apply_status表的更改。 这可以通过启动从属SQL节点来完成
--replicate-ignore-table=mysql.ndb_apply_status。 如果需要通过复制忽略其他表,则可能希望使用适当的--replicate-wild-ignore-table选项。
你应该
不
禁止复制或二进制日志
mysql.ndb_apply_status
或更改复制从一个NDB簇到另一个时使用此表的存储引擎。
有关
详细信息,
请参阅
复制和二进制日志过滤规则以及NDB群集之间的复制
。
从NDB复制到非事务性存储引擎。
从复制
NDB
到非事务性存储引擎(例如
MyISAM
,复制
INSERT ...
ON DUPLICATE KEY UPDATE
语句)
时,您可能会遇到不必要的重复键错误
。
您可以通过使用来抑制这些
--ndb-log-update-as-write=0
,这会强制将更新记录为写入(而不是更新)。
复制和二进制日志过滤规则,以及NDB群集之间的复制。
如果你正在使用任何选项
--replicate-do-*
,
--replicate-ignore-*
,
--binlog-do-db
,或
--binlog-ignore-db
过滤被复制数据库或表,必须注意不要挡住或复制的二进制日志
mysql.ndb_apply_status
,这是需要NDB集群之间的复制正常工作。
特别是,您必须牢记以下内容:
-
使用 (没有其他 或 选项)意味着 只 复制 数据库 中的 表 。 在这种情况下,你也应该使用 , 或 以保证 填充的奴隶。
--replicate-do-db=db_name--replicate-do-*--replicate-ignore-*db_name--replicate-do-db=mysql--binlog-do-db=mysql--replicate-do-table=mysql.ndb_apply_statusmysql.ndb_apply_status使用 (并且没有其他 选项)意味着 仅 将对 数据库 中的 表的 更改 写入二进制日志。 在这种情况下,你也应该使用 , 或 以保证 填充的奴隶。
--binlog-do-db=db_name--binlog-do-dbdb_name--replicate-do-db=mysql--binlog-do-db=mysql--replicate-do-table=mysql.ndb_apply_statusmysql.ndb_apply_status -
使用
--replicate-ignore-db=mysql意味着不会mysql复制数据库中的 表 。 在这种情况下,您还应该使用--replicate-do-table=mysql.ndb_apply_status以确保mysql.ndb_apply_status复制。使用
--binlog-ignore-db=mysql意味着不会将对mysql数据库中的 表的更改 写入二进制日志。 在这种情况下,您还应该使用--replicate-do-table=mysql.ndb_apply_status以确保mysql.ndb_apply_status复制。
您还应该记住,每个复制规则都需要以下内容:
-
它自己的
--replicate-do-*或--replicate-ignore-*选项,并且多个规则不能在单个复制过滤选项中表示。 有关这些规则的信息,请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。 -
它自己
--binlog-do-db或--binlog-ignore-db选项,并且多个规则不能在单个二进制日志过滤选项中表示。 有关这些规则的信息,请参见 第5.4.4节“二进制日志” 。
如果要将NDB群集复制到使用其他存储引擎的从属群集
NDB
,则之前给出的注意事项可能不适用,如本节其他部分所述。
NDB群集复制和IPv6。 目前,NDB API和MGM API不支持IPv6。 但是,MySQL服务器(包括那些充当NDB群集中的SQL节点的服务器)可以使用IPv6来联系其他MySQL服务器。 这意味着您可以使用IPv6在NDB群集之间进行复制,以连接主SQL从节点,如下图中的虚线箭头所示:
但是,源自 NDB群集的 所有连接( 在 上图中由实线箭头表示)必须使用IPv4。 换句话说,必须使用IPv4可以相互访问所有NDB Cluster数据节点,管理服务器和管理客户端。 此外,SQL节点必须使用IPv4与群集通信。
由于目前在NDB和MGM API中不支持IPv6,因此使用这些API编写的任何应用程序也必须使用IPv4建立所有连接。
属性提升和降级。
NDB群集复制包括对属性提升和降级的支持。
后者的实现区分有损和无损类型转换,并且可以通过设置
slave_type_conversions
全局服务器系统变量
来控制它们在从属上的使用
。
有关NDB群集中属性提升和降级的详细信息,请参阅 基于行的复制:属性提升和降级 。
NDB
,
InnoDB
或者
MyISAM
,不会将对虚拟列的更改写入二进制日志;
但是,这对NDB群集复制或
NDB
其他存储引擎
之间的复制没有不利影响
。
记录对存储的生成列的更改。
NDB Cluster中的复制在
mysql
每个MySQL Server实例上
使用
数据库
中的许多专用表,在
被复制的集群和复制从属服务器(无论从服务器是单个服务器还是集群)中充当SQL节点。
这些表是在MySQL安装过程中创建的,包括一个用于存储二进制日志索引数据的表。
由于该
ndb_binlog_index
表是每个MySQL服务器的本地表,并且不参与群集,因此它使用
InnoDB
存储引擎。
这意味着它必须在每个
mysqld上
单独创建
参与主集群。
(但是,二进制日志本身包含要复制的集群中所有MySQL服务器的更新。)此表定义如下:
CREATE TABLE`ndb_binlog_index`(
`Position` BIGINT(20)UNSIGNED NOT NULL,
`File` VARCHAR(255)NOT NULL,
`epoch` BIGINT(20)UNSIGNED NOT NULL,
`inserts` INT(10)UNSIGNED NOT NULL,
`updates` INT(10)UNSIGNED NOT NULL,
`deletes` INT(10)UNSIGNED NOT NULL,
`schemaops` INT(10)UNSIGNED NOT NULL,
`orig_server_id` INT(10)UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20)UNSIGNED NOT NULL,
`gci` INT(10)UNSIGNED NOT NULL,
`next_position` bigint(20)unsigned NOT NULL,
`next_file` varchar(255)NOT NULL,
PRIMARY KEY(`epoch`,`orig_server_id`,`orig_epoch`)
)ENGINE = InnoDB DEFAULT CHARSET = latin1;
如果要从旧版本(NDB 7.5.2之前)升级,请执行MySQL升级过程并确保升级系统表。
(从MySQL 8.0.16开始,使用
--upgrade=FORCE
选项
启动服务器
。在MySQL 8.0.16之前,
在启动服务器后
使用
和
选项
调用
mysql_upgrade
。)系统表升级会导致
对该表执行语句。
为了向后兼容,继续支持
使用
此表
的
存储引擎。
--force
--upgrade-system-tables
ALTER
TABLE ... ENGINE=INNODB
MyISAM
ndb_binlog_index
转换为后可能需要额外的磁盘空间
InnoDB
。
如果这成为一个问题,您可以通过使用
InnoDB
此表
的
表空间,将其更改
ROW_FORMAT
为
COMPRESSED
或两者
来节省空间
。
有关更多信息,请参见
第13.1.21节“CREATE TABLESPACE语法”
和
第13.1.20节“CREATE TABLE语法”
,以及
第15.6.3节“表空间”
。
此表的大小取决于每个二进制日志文件的纪元数和二进制日志文件的数量。
每个二进制日志文件的历元数通常取决于每个历元生成的二进制日志的数量和二进制日志文件的大小,较小的历元导致每个文件具有更多的历元。
您应该知道空的纪元产生对
ndb_binlog_index
表的
插入
,即使
--ndb-log-empty-epochs
选项是
OFF
,这意味着每个文件的条目数取决于文件使用的时间长度;
那是,
[每个文件的纪元数] = [每个文件花费的时间] / TimeBetweenEpochs
繁忙的NDB群集定期写入二进制日志,并且可能比安静的日志文件更快地旋转二进制日志文件。
这意味着
“
安静
”的
NDB群集
--ndb-log-empty-epochs=ON
实际上
ndb_binlog_index
每个文件
的
行数可以比具有大量活动
的
行多得多。
当
使用该
选项
启动
mysqld时
--ndb-log-orig
,
orig_server_id
和
orig_epoch
列分别存储事件源自的服务器的ID以及事件发生在源服务器上的时期,这在使用多个主服务器的NDB集群复制设置中很有用。
该
SELECT
语句用于在多主机设置中查找最接近从机的最高应用时期的二进制日志位置(请参见
第22.6.10节“NDB集群复制:多主机和循环复制”)
)使用这两列没有索引的列。
尝试进行故障转移时,这可能会导致性能问题,因为查询必须执行表扫描,尤其是在主服务器运行时
--ndb-log-empty-epochs=ON
。
您可以通过向这些列添加索引来改进多主故障转移时间,如下所示:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup使用BTREE(orig_server_id,orig_epoch);
从单个主服务器复制到单个从服务器时,添加此索引不会带来任何好处,因为在这种情况下用于获取二进制日志位置的查询不会使用
orig_server_id
或
orig_epoch
。
有关使用
和
列的
更多信息
,
请参见
第22.6.8节“使用NDB集群复制实现故障转移”
。
next_position
next_file
下图显示了NDB Cluster复制主服务器,其二进制日志注入器线程和
mysql.ndb_binlog_index
表的关系。

另一个名为的表
ndb_apply_status
用于记录从主服务器复制到从服务器的操作。
与此情况不同
ndb_binlog_index
,此表中的数据并非特定于(从属)群集中的任何一个SQL节点,因此
ndb_apply_status
可以使用
NDBCLUSTER
存储引擎,如下所示:
CREATE TABLE`ndb_apply_status`(
`server_id` INT(10)UNSIGNED NOT NULL,
`epoch` BIGINT(20)UNSIGNED NOT NULL,
`log_name` VARCHAR(255)CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20)UNSIGNED NOT NULL,
`end_pos` BIGINT(20)UNSIGNED NOT NULL,
PRIMARY KEY(`server_id`)使用HASH
)ENGINE = NDBCLUSTER DEFAULT CHARSET = latin1;
该
ndb_apply_status
表仅在从属服务器上填充,这意味着在主服务器上,该表永远不会包含任何行;
因此,没有必要允许
DataMemory
或
IndexMemory
分配到
ndb_apply_status
那里。
因为此表是从源自主服务器的数据填充的,所以应该允许它复制;
任何复制过滤或二进制日志过滤规则无意中阻止从属服务器更新
ndb_apply_status
或主服务器写入二进制日志可能会阻止集群之间的复制正常运行。
有关此类过滤规则可能引发的问题的详细信息,请参阅
NDB群集之间复制的复制和二进制日志过滤规则
。
将
ndb_binlog_index
和
ndb_apply_status
表在创建
mysql
数据库,因为他们不应该由用户显式复制。
用户干预通常不需要创建或维持任一这些表的,因为这两个
ndb_binlog_index
和
ndb_apply_status
由保持
NDB
二进制日志(二进制日志)喷射器线程。
这使主
mysqld
进程
保持
更新为
NDB
存储引擎
执行的更改
。
该
二进制日志注入线程
直接从接收事件
的存储引擎。
该
NDB
NDB
NDB
inject负责捕获集群中的所有数据事件,并确保更改,插入或删除数据的所有事件都记录在
ndb_binlog_index
表中。
从I / O线程将事件从主站的二进制日志传输到从站的中继日志。
但是,建议检查这些表的存在性和完整性,作为准备NDB群集进行复制的初始步骤。
通过
mysql.ndb_binlog_index
直接在主服务器上
查询
表,
可以查看二进制日志中记录的事件数据
。
这也可以使用
SHOW BINLOG EVENTS
复制主服务器或从属MySQL服务器上
的
语句
来完成
。
(参见
第13.7.6.2节“显示BINLOG事件语法”
。)
您还可以从输出中获取有用的信息
SHOW
ENGINE NDB
STATUS
。
在对
NDB
表
执行模式更改时
,应用程序应等到
ALTER
TABLE
语句在发出语句的MySQL客户端连接中返回,然后再尝试使用表的更新定义。
如果
ndb_apply_status
从属服务器上不存在
该
表,则
ndb_restore将
重新创建该表。
NDB群集复制的冲突解决需要存在其他
mysql.ndb_replication
表。
目前,必须手动创建此表。
有关如何执行此操作的信息,请参见
第22.6.11节“NDB集群复制冲突解决”
。
准备NDB群集以进行复制包括以下步骤:
-
检查所有MySQL服务器的版本兼容性(请参见 第22.6.2节“NDB群集复制的一般要求” )。
-
使用适当的权限在主群集上创建从属帐户:
mysql
M>GRANT REPLICATION SLAVE- > - >ON *.* TO 'slave_user'@'slave_host'IDENTIFIED BY 'slave_password';在上一个语句中,
slave_user是从属帐户用户名,slave_host是复制从属的主机名或IP地址,slave_password是分配给该帐户的密码。例如,要创建具有名称的从属用户帐户,
myslave从名为的主机登录rep-slave并使用密码53cr37,请使用以下GRANT语句:mysql
M>GRANT REPLICATION SLAVE- >ON *.* TO 'myslave'@'rep-slave'- >IDENTIFIED BY '53cr37';出于安全原因,最好使用唯一的用户帐户 - 不用于任何其他目的 - 用于复制从帐户。
-
配置从站以使用主站。 使用MySQL Monitor,可以使用以下
CHANGE MASTER TO语句 完成 :mysql
S>CHANGE MASTER TO- > - > - > - >MASTER_HOST='master_host',MASTER_PORT=master_port,MASTER_USER='slave_user',MASTER_PASSWORD='slave_password';在前面的语句中,
master_host是复制主机的主机名或IP地址,master_port是从站用于连接到主站的端口,slave_user是 为主 站上的从站设置的用户名 , 是为其slave_password设置的密码上一步中的该用户帐户。例如,要
rep-master使用上一步中创建的复制从属帐户 告诉从属服务器从主机名为的MySQL服务器 进行复制,请使用以下语句:mysql
S>CHANGE MASTER TO- >MASTER_HOST='rep-master',- >MASTER_PORT=3306,- >MASTER_USER='myslave',- >MASTER_PASSWORD='53cr37';有关可与此语句一起使用的选项的完整列表,请参见 第13.4.2.1节“将语言更改为语法” 。
要提供复制备份功能,还需要 在启动复制过程之前向
--ndb-connectstring从属my.cnf文件 添加 选项 。 有关详细 信息, 请参见 第22.6.9节“使用NDB集群复制进行NDB集群备份” 。有关可以
my.cnf为复制从站 设置的其他选项 ,请参见 第17.1.6节“复制和二进制日志记录选项和变量” 。 -
如果主群集已在使用中,您可以创建主群集的备份并将其加载到从站上,以减少从站与主站同步所需的时间。 如果从站也在运行NDB Cluster,则可以使用 第22.6.9节“使用NDB集群复制进行NDB集群备份”中 所述的备份和还原过程来完成此操作 。
ndb-connectstring =
management_host[:port]如果您 未 在复制从站上使用NDB Cluster,则可以在复制主机上使用此命令创建备份:
贝壳
M>mysqldump --master-data=1然后通过将转储文件复制到从站将结果数据转储导入到从站。 在此之后,您可以使用 mysql 客户端将dumpfile中的数据导入slave数据库,如下所示,其中
dump_file是使用 master上的 mysqldump 生成的文件db_name的名称 ,并且 是要复制的数据库的名称:贝壳
S>mysql -u root -pdb_name<dump_file有关与 mysqldump 一起使用的选项的完整列表 ,请参见 第4.5.4节“ mysqldump - 数据库备份程序” 。
注意如果以这种方式将数据复制到从属设备,则应确保
--skip-slave-start从命令行上的选项 启动从属设备 ,或者包含skip-slave-start在从属my.cnf文件中以防止它尝试连接到主服务器以开始复制之前所有数据都已加载。 数据加载完成后,请按照接下来两节中列出的其他步骤进行操作。 -
确保充当复制主服务器的每个MySQL服务器都配置了唯一的服务器ID,并使用行格式启用了二进制日志记录。 (请参见 第17.2.1节“复制格式” 。)这些选项可以在主服务器的
my.cnf文件中 设置,也可以在 启动master mysqld 进程 时在命令行上设置 。 有关 后一选项的信息, 请参见 第22.6.6节“启动NDB集群复制(单一复制通道)” 。
本节概述了使用单个复制通道启动NDB群集复制的过程。
-
通过发出以下命令启动MySQL复制主服务器:
贝壳
M>mysqld --ndbcluster --server-id=id\--log-bin &在前面的语句中,
id是此服务器的唯一ID(请参见 第22.6.2节“NDB群集复制的一般要求” )。 这将启动服务器的 mysqld 进程,并使用正确的日志记录格式启用二进制日志记录。注意您也可以启动master
--binlog-format=MIXED,在这种情况下,在群集之间复制时会自动使用基于行的复制。STATEMENTNDB群集复制不支持基于二进制日志记录(请参见 第22.6.2节“NDB群集复制的常规要求” )。 -
启动MySQL复制从服务器,如下所示:
贝壳
S>mysqld --ndbcluster --server-id=id&在刚才显示的命令中,
id是从服务器的唯一ID。 无需在复制从站上启用日志记录。注意您应该使用
--skip-slave-start此命令 的 选项,否则您应该包含skip-slave-start在从属服务器的my.cnf文件中,除非您希望立即开始复制。 使用此选项后,复制开始将延迟,直到START SLAVE发出 相应的 语句,如下面的步骤4中所述。 -
必须将从服务器与主服务器的复制二进制日志同步。 如果以前没有在主服务器上运行二进制日志记录,请在从服务器上运行以下语句:
mysql
S>CHANGE MASTER TO- >MASTER_LOG_FILE='',- >MASTER_LOG_POS=4;这指示从站开始从日志的起始点读取主站的二进制日志。 否则 - 也就是说,如果使用备份从主服务器加载数据 - 请参见 第22.6.8节“使用NDB集群复制实现故障转移” ,以获取有关如何获取正确值
MASTER_LOG_FILE以及MASTER_LOG_POS在这种情况下 使用的正确值的信息 。 -
最后,您必须通过从 复制从属服务器上的 mysql 客户端 发出此命令来指示从服务器开始应用复制 :
mysql
S>START SLAVE;这也启动了从主设备到从设备的复制数据传输。
也可以使用两个复制通道,其方式类似于下一节中描述的过程; 第22.6.7节“为NDB集群复制使用两个复制通道” 中介绍了它与使用单个复制通道之间的区别 。
通过启用
批量更新,
还可以提高群集复制性能
。
这可以通过
slave_allow_batching
在从属
mysqld
进程
上
设置
系统变量
来实现
。
通常,更新会在收到后立即应用。
但是,使用批处理会导致更新以32 KB批次应用,这可能会导致更高的吞吐量和更少的CPU使用率,尤其是在个别更新相对较小的情况下。
奴隶批处理基于每个时期; 属于多个事务的更新可以作为同一批次的一部分发送。
即使更新总数小于32 KB,也会在到达纪元的末尾时应用所有未完成的更新。
可以在运行时打开和关闭批处理。 要在运行时激活它,您可以使用以下两种语句之一:
SET GLOBAL slave_allow_batching = 1; SET GLOBAL slave_allow_batching = ON;
如果特定批处理导致问题(例如其效果似乎未正确复制的语句),则可以使用以下任一语句停用从属批处理:
SET GLOBAL slave_allow_batching = 0; SET GLOBAL slave_allow_batching = OFF;
您可以通过适当的
SHOW
VARIABLES
语句
检查当前是否正在使用从属批处理
,如下所示:
MySQL的> SHOW VARIABLES LIKE 'slave%';
+ --------------------------- + ------- +
| Variable_name | 价值|
+ --------------------------- + ------- +
| slave_allow_batching | ON |
| slave_compressed_protocol | 关闭|
| slave_load_tmpdir | / tmp |
| slave_net_timeout | 3600 |
| slave_skip_errors | 关闭|
| slave_transaction_retries | 10 |
+ --------------------------- + ------- +
6行(0.00秒)
在更完整的示例场景中,我们设想两个复制通道来提供冗余,从而防止单个复制通道可能出现故障。 这需要总共四个复制服务器,两个主集群主服务器和两个从服务器集群服务器。 出于以下讨论的目的,我们假设分配了唯一标识符,如下所示:
表22.425文中描述的NDB群集复制服务器
| 服务器ID | 描述 |
|---|---|
| 1 | 主 - 主复制通道( M ) |
| 2 | 主 - 辅助复制通道( M' ) |
| 3 | 从属 - 主要复制通道( S ) |
| 4 | 从属 - 辅助复制通道( S' ) |
使用两个通道设置复制与设置单个复制通道没有根本区别。
首先,
必须启动主复制主服务器和辅助复制主服务器
的
mysqld
进程,然后是主
从服务器的
mysqld
进程。
然后,可以通过
START
SLAVE
在每个从属上
发出
语句
来启动复制过程
。
这些命令及其发布顺序如下所示:
-
启动主复制主机:
贝壳
M>mysqld --ndbcluster --server-id=1 \--log-bin & -
启动辅助复制主机:
贝壳
M'>mysqld --ndbcluster --server-id=2 \--log-bin & -
启动主复制从属服务器:
贝壳
S>mysqld --ndbcluster --server-id=3 \--skip-slave-start & -
启动辅助复制从属:
贝壳
S'>mysqld --ndbcluster --server-id=4 \--skip-slave-start & -
最后,通过
START SLAVE在主从服务器上 执行 语句 来启动主通道上的复制, 如下所示:mysql
S>START SLAVE;警告此时仅启动主要通道。 仅在主复制通道发生故障时才启动辅助复制通道,如 第22.6.8节“使用NDB集群复制实现故障转移”中所述 。 同时运行多个复制通道可能会导致在复制从属服务器上创建不需要的重复记录。
如前所述,没有必要在复制从属上启用二进制日志记录。
如果主群集复制过程失败,则可以切换到辅助复制通道。 以下过程描述了完成此操作所需的步骤。
-
获取最新全局检查点(GCP)的时间。 也就是说,您需要从
ndb_apply_status从属群集上的表中 确定最新的纪元 ,可以使用以下查询找到该 纪元 :mysql
S'>SELECT @latest:=MAX(epoch)- >FROM mysql.ndb_apply_status;在循环复制拓扑中,在每个主机上运行主服务器和从服务器时,在使用时
ndb_log_apply_status=1,NDB集群纪元将写入从属二进制日志中。 这意味着该ndb_apply_status表包含此主机上从站的信息,以及充当在此主机上运行的主站的从站的任何其他主机的信息。在这种情况下,您需要确定此从属设备上的最新纪元,以排除此从属设备的二进制日志中 用于设置此从属设备
IGNORE_SERVER_IDS的CHANGE MASTER TO语句 选项 中未列出的任何其他从属设备的任何历元记录 。 排除这些时期的原因是mysql.ndb_apply_status表中的服务器IDIGNORE_SERVER_IDS与用于准备此从属主服务器的CHANGE MASTER TO语句 一致的 列表中的行也被认为是来自本地服务器,除了那些具有从属服务器的服务器自己的服务器ID。 您可以Replicate_Ignore_Server_Ids从输出中 检索此列表SHOW SLAVE STATUS。 我们假设您已经获得此列表并ignore_server_ids在此处显示的查询中 替换它 ,这与查询的先前版本一样,将最大的纪元选择为名为的变量@latest:mysql
S'>SELECT @latest:=MAX(epoch)- >FROM mysql.ndb_apply_status- >WHERE server_id NOT IN (ignore_server_ids);在某些情况下,使用要包括的服务器ID列表以及 前一查询 的 条件 可能更简单或更有效(或两者) 。
server_id INserver_id_listWHERE -
使用从步骤1中显示的查询中获取的信息,从
ndb_binlog_index主群集上的表中 获取相应的记录 。您可以使用以下查询从主
ndb_binlog_index表中 获取所需的记录 :mysql
M'>SELECT- >@file:=SUBSTRING_INDEX(next_file, '/', -1),- >@pos:=next_position- >FROM mysql.ndb_binlog_index- >WHERE epoch >= @latest- >ORDER BY epoch ASC LIMIT 1;这些是自主复制通道失败以来保存在主服务器上的记录。 我们在
@latest这里 使用了一个用户变量 来表示在步骤1中获得的值。当然,一个 mysqld 实例 不可能 直接访问在另一个服务器实例上设置的用户变量。 必须 手动或在应用程序代码 中将 这些值 “ 插入 ” 第二个查询。重要您必须确保 在执行之前 启动 了从属 mysqld 。 否则,复制可能会因重复的DDL错误而停止。
--slave-skip-errors=ddl_exist_errorsSTART SLAVE -
现在,可以通过在辅助从属服务器上运行以下查询来同步辅助通道:
mysql
S'>CHANGE MASTER TO- >MASTER_LOG_FILE='@file',- >MASTER_LOG_POS=@pos;我们再次使用用户变量(在这种情况下
@file和@pos)来表示在步骤2中获得并在步骤3中应用的值; 实际上,必须手动插入这些值,或者使用可以访问所涉及的两个服务器的应用程序代码。注意@file是一个字符串值,例如'/var/log/mysql/replication-master-bin.00001',因此在SQL或应用程序代码中使用时必须引用。 然而,所代表的值@pos必须 不能 被引用。 虽然MySQL通常会尝试将字符串转换为数字,但这种情况是个例外。 -
您现在可以通过在辅助从属 mysqld 上发出适当的命令来在辅助通道上启动复制 :
mysql
S'>START SLAVE;
辅助复制通道处于活动状态后,您可以调查主要修复和效果修复的失败。 执行此操作所需的确切操作将取决于主要通道失败的原因。
仅当主复制通道发生故障时才会启动辅助复制通道。 同时运行多个复制通道可能会导致在复制从属服务器上创建不需要的重复记录。
如果故障被限制为单个服务器,但应(在理论上)可以从复制
M
到
S'
,或从
M'
到
S
;
但是,这还没有经过测试。
本节讨论使用NDB群集复制进行备份和还原。 我们假设已经配置了复制服务器,如前所述(请参见 第22.6.5节“为复制准备NDB集群” 和紧随其后的部分)。 这已经完成,进行备份然后从中恢复的过程如下:
-
有两种不同的方法可以启动备份。
-
方法A. 此方法要求在启动复制过程之前先在主服务器上启用群集备份过程。 这可以通过包括在以下行来完成
[mysql_cluster]的部分my.cnf file,其中management_host是的IP地址或主机名NDB进行主群集管理服务器,并且port是管理服务器的端口号:ndb-connectstring =
management_host[:port]注意仅在未使用默认端口(1186)时才需要指定端口号。 有关 NDB集群中 端口和端口分配的更多信息 , 请参见 第22.2.4节“NDB集群的初始配置” 。
贝壳
M>ndb_mgm -e "START BACKUP" -
方法B. 如果
my.cnf文件未指定在何处查找管理主机,则可以通过将此信息NDB作为START BACKUP命令的 一部分 传递给 管理客户端 来启动备份过程 。 这可以如此处所示完成,其中management_host和port是管理服务器的主机名和端口号:贝壳
M>ndb_mgmmanagement_host:port-e "START BACKUP"在前面概述的场景中(请参见 第22.6.5节“为复制准备NDB群集” ),这将按如下方式执行:
贝壳
M>ndb_mgm rep-master:1186 -e "START BACKUP"
-
-
将群集备份文件复制到正在联机的从站。 为主群集 运行 ndbd 进程的 每个系统 都将具有位于其上的群集备份文件,并且 必须将 所有 这些文件复制到从属服务器以确保成功还原。 只要MySQL和NDB二进制文件在该目录中具有读取权限,就可以将备份文件复制到从属管理主机所在的计算机上的任何目录中。 在这种情况下,我们假设这些文件已被复制到目录中
/var/BACKUPS/BACKUP-1。从集群不必具有与 主集合 相同数量的 ndbd 进程(数据节点); 但是,强烈建议这个数字是相同的。 这 是 必要的,从与启动
--skip-slave-start选项,以防止复制过程中过早启动。 -
在从属群集上创建主群集上存在的要复制到从属的任何数据库。
重要甲
CREATE DATABASE(或CREATE SCHEMA相应于要复制的每个数据库)语句必须从集群中的每个节点SQL上执行。 -
在MySQL监视器中使用以下语句重置从属群集:
mysql
S>RESET SLAVE; -
您现在可以 依次 使用 ndb_restore 命令为每个备份文件启动 复制从站上的集群还原过程 。 对于第一个,有必要包括
-m恢复群集元数据 的 选项:贝壳
S>ndb_restore -cslave_host:port-nnode-id\-bbackup-id-m -rdirdir是备份文件放置在复制从站上的目录的路径。 对于 ndb_restore 对应于剩余的备份文件的命令时,-m应选择 不 使用。要从具有四个数据节点的主集群进行恢复(如 第22.6节“NDB集群复制” 中的图所示 ),其中备份文件已复制到目录
/var/BACKUPS/BACKUP-1,在从站上执行的正确命令序列可能看起来如此像这样:shell
S> shell > shell > shell >ndb_restore -c rep-slave:1186 -n 2 -b 1 -m \-r ./var/BACKUPS/BACKUP-1Sndb_restore -c rep-slave:1186 -n 3 -b 1 \-r ./var/BACKUPS/BACKUP-1Sndb_restore -c rep-slave:1186 -n 4 -b 1 \-r ./var/BACKUPS/BACKUP-1Sndb_restore -c rep-slave:1186 -n 5 -b 1 -e \-r ./var/BACKUPS/BACKUP-1重要为了将纪元写入从属,需要在此示例中 最终调用 ndb_restore 中 的
-e(或--restore-epoch)选项 。 如果没有此信息,从站将无法与主站正确同步。 (请参见 第22.4.23节“ ndb_restore - 还原NDB群集备份” 。)mysql.ndb_apply_status -
现在,您需要从
ndb_apply_statusslave上 的 表中 获取最新的纪元 (如 第22.6.8节“使用NDB集群复制实现故障转移”中所述 ):mysql
S>SELECT @latest:=MAX(epoch)FROM mysql.ndb_apply_status; -
使用
@latest上一步中获得的纪元值,您可以 使用此处显示的查询 从主 表@pos中的正确二进制日志文件中 获取正确的起始位置 :@filemysql.ndb_binlog_indexmysql
M>SELECT- >@file:=SUBSTRING_INDEX(File, '/', -1),- >@pos:=Position- >FROM mysql.ndb_binlog_index- >WHERE epoch >= @latest- >ORDER BY epoch ASC LIMIT 1;如果当前没有复制流量,您可以通过
SHOW MASTER STATUS在主服务器上 运行 并使用Position列中 的值 来获取此信息 ,该文件的名称后缀为File列中 显示的所有文件的最大值 。 但是,在这种情况下,您必须确定并在下一步中手动提供它,或者使用脚本解析输出。 -
使用上一步中获得的值,您现在可以
CHANGE MASTER TO在slave的 mysql 客户端中 发出相应的 语句 :mysql
S>CHANGE MASTER TO- >MASTER_LOG_FILE='@file',- >MASTER_LOG_POS=@pos; -
既然从属设备 “ 知道 ” 从哪个二进制日志文件开始从主设备读取数据,您可以使从设备开始使用此标准MySQL语句进行复制:
mysql
S>START SLAVE;
要在第二个复制通道上执行备份和还原,只需重复这些步骤,在适当的情况下将主要主服务器和从属服务器的主机名和ID替换为主要主服务器和从属服务器复制服务器的主机名和ID,然后运行前面的步骤对他们的陈述。
有关执行群集备份和从备份还原群集的其他信息,请参见 第22.5.3节“NDB群集的联机备份” 。
可以自动执行上一节中描述的大部分过程(请参见
第22.6.9节“使用NDB集群复制进行NDB集群备份”
)。
以下Perl脚本
reset-slave.pl
用作如何执行此操作的示例。
#!/ user / bin / perl -w
#file:reset-slave.pl
#版权所有©2005 MySQL AB
#这个程序是免费软件; 您可以重新分发和/或修改
#根据发布的GNU通用公共许可证的条款
#自由软件基金会; 许可证的第2版,或
#(根据您的选择)任何更高版本。
#该程序的发布是希望它有用,
#但没有任何保证; 甚至没有暗示的保证
#适应性或特定用途的适用性。见
#GNU通用公共许可证了解更多详情。
#您应该已收到GNU通用公共许可证的副本
#以及该计划; 如果没有,请写信给:
#Free Software Foundation,Inc。
#59 Temple Place,Suite 330
#Boston,MA 02111-1307 USA
#
#版本1.1
########################包括######################### ######
使用DBI;
######################## Globals ######################### #######
我的$ m_host ='';
我的$ m_port ='';
我的$ m_user ='';
我的$ m_pass ='';
我的$ s_host ='';
我的$ s_port ='';
我的$ s_user ='';
我的$ s_pass ='';
我的$ dbhM ='';
我的$ dbhS ='';
####################### Sub Prototypes ######################### #
sub CollectCommandPromptInfo;
sub ConnectToDatabases;
sub DisconnectFromDatabases;
sub GetSlaveEpoch;
sub GetMasterInfo;
sub UpdateSlave;
######################## Program Main ######################## ###
CollectCommandPromptInfo;
ConnectToDatabases;
GetSlaveEpoch;
GetMasterInfo;
UpdateSlave;
DisconnectFromDatabases;
#################收集命令提示信息##################
sub CollectCommandPromptInfo
{
###检查用户是否提供了正确数量的命令行参数
死“用法:\ n
reset-slave> master MySQL host <> master MySQL port <\ n
>主用户<>主传递<>从属MySQL主机<\ n
> slave MySQL port <> slave user <> slave pass <\ n
必须传递所有8个参数。使用BLANK作为NULL密码\ n“
除非@ARGV == 8;
$ m_host = $ ARGV [0];
$ m_port = $ ARGV [1];
$ m_user = $ ARGV [2];
$ m_pass = $ ARGV [3];
$ s_host = $ ARGV [4];
$ s_port = $ ARGV [5];
$ s_user = $ ARGV [6];
$ s_pass = $ ARGV [7];
if($ m_pass eq“BLANK”){$ m_pass ='';}
if($ s_pass eq“BLANK”){$ s_pass ='';}
}
###############建立与两个数据库的连接#############
sub ConnectToDatabases
{
###连接到主群集和从群集数据库
###连接到master
$ dbhM
= DBI-> connect(
“DBI:mysql的:数据库MySQL的=;主持人= $ m_host;港口= $ m_port”
“$ m_user”,“$ m_pass”)
或死“无法连接到Master Cluster MySQL进程!
错误:$ DBI :: errstr \ n“;
###连接到奴隶
$ dbhS
= DBI-> connect(
“DBI:mysql的:数据库MySQL的=;主持人= $ s_host”
“$ s_user”,“$ s_pass”)
或死“无法连接到Slave Cluster MySQL进程!
错误:$ DBI :: errstr \ n“;
}
################断开与两个数据库的连接################
sub DisconnectFromDatabases
{
###与master断开连接
$ dbhM->断开
或警告“断开连接失败:$ DBI :: errstr \ n”;
###断开与奴隶的联系
$ dbhS->断开
或警告“断开连接失败:$ DBI :: errstr \ n”;
}
######################找到最后一个好的GCI ##################
sub GetSlaveEpoch
{
$ sth = $ dbhS-> prepare(“SELECT MAX(epoch)
来自mysql.ndb_apply_status;“)
或死“准备从奴隶选择纪元时出错:”,
$ dbhS-> errstr;
$ sth->执行
或死“从奴隶错误中选择纪元:”,$ sth-> errstr;
$ sth-> bind_col(1,\ $ epoch);
$ sth->获取;
打印“\ tSlave Epoch = $ epoch \ n”;
$ sth->完成;
}
#######在二进制日志中找到最后一个GCI的位置########
sub GetMasterInfo
{
$ sth = $ dbhM-> prepare(“SELECT
SUBSTRING_INDEX(文件,'/', - 1),位置
来自mysql.ndb_binlog_index
在哪里epoch> $ epoch
按时代顺序ASC LIMIT 1;“)
或死“准备从主错误中选择:”,$ dbhM-> errstr;
$ sth->执行
或者死于“从主错误中选择:”,$ sth-> errstr;
$ sth-> bind_col(1,\ $ binlog);
$ sth-> bind_col(2,\ $ binpos);
$ sth->获取;
打印“\ tMaster二进制日志= $ binlog \ n”;
打印“\ tMaster二进制日志位置= $ binpos \ n”;
$ sth->完成;
}
##########将从属设置为从该位置处理#########
sub UpdateSlave
{
$ sth = $ dbhS-> prepare(“CHANGE MASTER TO
MASTER_LOG_FILE = '$二进制日志',
MASTER_LOG_POS = $ binpos;“)
或死“准备改变主要错误:”,$ dbhS-> errstr;
$ sth->执行
或死“奴隶错误改变主人:”,$ sth-> errstr;
$ sth->完成;
打印“\ tSlave已更新。您现在可以启动奴隶。\ n”;
}
#end reset-slave.pl
时间点
恢复 - 即在给定时间点之后恢复数据更改 - 在恢复完整备份之后执行,该完整备份将服务器返回到进行备份时的状态。
使用NDB群集和NDB群集复制执行NDB群集表的时间点恢复可以使用本机
NDB
数据备份(通过
CREATE
BACKUP
在
ndb_mgm
客户端中
发出
)和恢复
ndb_binlog_index
表(来自使用
mysqldump
进行的转储
)来完成。
要执行NDB群集的时间点恢复,必须按照此处显示的步骤操作:
-
NDB使用 ndb_mgm 客户端中 的START BACKUP命令 备份 群集中的 所有 数据库 (请参见 第22.5.3节“NDB群集的联机备份” )。 -
稍后,在还原群集之前,请对
mysql.ndb_binlog_index表 进行备份 。 使用 mysqldump 进行此任务 可能最简单 。 此时还备份二进制日志文件。此备份应定期更新 - 甚至可能每小时更新一次 - 具体取决于您的需求。
-
( 发生灾难性故障或错误 。)
-
找到上次已知的良好备份。
-
清除数据节点文件系统(使用 ndbd
--initial或 ndbmtd--initial)。注意NDB群集磁盘数据表空间和日志文件不会被删除
--initial。 您必须手动删除它们。 -
使用
DROP TABLE或TRUNCATE TABLE与mysql.ndb_binlog_index表格 一起 使用 。 -
执行 ndb_restore ,恢复所有数据。
--restore-epoch运行 ndb_restore 时 必须包含该 选项 ,以便ndb_apply_status正确填充 该 表。 (有关 更多信息, 请参见 第22.4.23节“ ndb_restore - 还原NDB群集备份” 。) -
如有必要,从 mysqldump
ndb_binlog_index的输出中 恢复 表 并从备份中恢复二进制日志文件。 -
找到最近应用的纪元 - 即 表中 的最大
epoch列值ndb_apply_status- 作为用户变量@LATEST_EPOCH(强调):SELECT @LATEST_EPOCH:= MAX(纪元) FROM mysql.ndb_apply_status; -
找到最新的二进制日志文件(
@FIRST_FILE)及位置(Position该文件对应于中列的值)@LATEST_EPOCH在ndb_binlog_index表:SELECT Position,@ FIRST_FILE:= File 来自mysql.ndb_binlog_index 在哪里epoch> @LATEST_EPOCH ORDER BY epoch ASC LIMIT 1;
-
使用 mysqlbinlog ,从给定文件重放二进制日志事件并定位到失败点。 (参见 第4.6.8节“ mysqlbinlog - 处理二进制日志文件的实用程序” 。)
有关 二进制日志,复制和增量恢复的详细信息 , 另请参见 第7.5节“使用二进制日志进行时间点(增量)恢复” 。
可以在多主复制中使用NDB Cluster,包括在多个NDB群集之间进行循环复制。
循环复制示例。 在接下来的几段中,我们将考虑复制设置的示例,其中涉及三个编号为1,2和3的NDB群集,其中群集1充当群集2的复制主服务器,群集2充当群集3的主服务器和群集3充当集群1的主节点。每个集群具有两个SQL节点,其中SQL节点A和B属于集群1,SQL节点C和D属于集群2,SQL节点E和F属于集群3。
只要满足以下条件,就支持使用这些群集进行循环复制:
-
所有主服务器和从服务器上的SQL节点都是相同的
-
使用该
--log-slave-updates选项 启动充当复制主服务器和从服务器的所有SQL节点
这种循环复制设置如下图所示:
在此方案中,群集1中的SQL节点A复制到群集2中的SQL节点C; SQL节点C复制到集群3中的SQL节点E; SQL节点E复制到SQL节点A.换句话说,复制行(由图中的弯曲箭头指示)直接连接用作复制主服务器和从服务器的所有SQL节点。
也可以设置循环复制,使得并非所有主SQL节点都是从属节点,如下所示:
在这种情况下,每个群集中的不同SQL节点将用作复制主服务器和从服务器。
但是,您
不能使用
启动任何SQL节点
--log-slave-updates
。
这种类型的NDB集群循环复制方案应该是可能的,其中复制线(图中的曲线箭头再次表示)是不连续的,但应该注意它尚未经过彻底测试,因此必须仍被认为是实验性的。
使用NDB本机备份和还原来初始化从属NDB群集。
设置循环复制时,可以使用
BACKUP
一个NDB群集上
的管理客户端
命令
初始化从群集,
以创建备份,然后使用
ndb_restore
在另一个NDB群集上应用此备份
。
但是,这不会在充当复制从属的第二个NDB Cluster的SQL节点上自动创建二进制日志。
为了创建二进制日志,必须
SHOW
TABLES
在该SQL节点上
发出一个
语句;
这应该在跑步之前完成
START
SLAVE
。
这是我们打算在将来的版本中解决的已知问题。
多主故障转移示例。 在本节中,我们将讨论多主NDB群集复制设置中的故障转移,其中三个NDB群集具有服务器ID 1,2和3.在此方案中,群集1复制到群集2和3; 群集2也复制到群集3.此关系如下所示:
换句话说,数据从集群1复制到集群3到2个不同的路由:直接和通过集群2。
并非所有参与多主机复制的MySQL服务器都必须充当主机和从机,并且给定的NDB集群可能会为不同的复制通道使用不同的SQL节点。 这种情况如下所示:
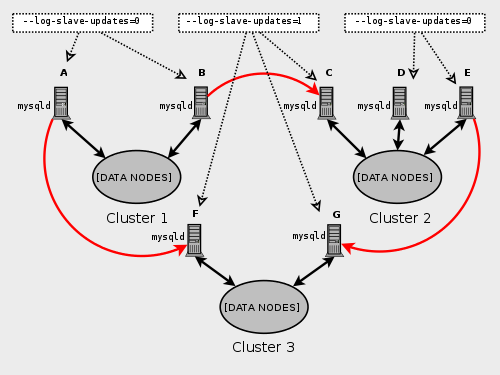
必须使用该
--log-slave-updates
选项
运行充当复制从站的MySQL服务器
。
上图中还显示了
哪个
mysqld
进程需要此选项。
使用该
--log-slave-updates
选项对不作为复制从属服务器运行的服务器没有影响。
当其中一个复制集群出现故障时,就会出现故障转移的需要。 在此示例中,我们考虑群集1丢失服务的情况,因此群集3从群集1丢失2个更新源。由于NDB群集之间的复制是异步的,因此无法保证群集3的更新直接源自群集1比通过群集2接收的更新。您可以通过确保群集3针对群集1的更新赶上群集2来处理此问题。就MySQL服务器而言,这意味着您需要从MySQL复制任何未完成的更新服务器C到服务器F.
在服务器C上,执行以下查询:
mysqlC> SELECT @latest:= MAX(epoch)
- > FROM mysql.ndb_apply_status
- > WHERE server_id = 1;
mysqlC> SELECT
- > @file:= SUBSTRING_INDEX(File,'/', - 1),
- > @pos:=位置
- > FROM mysql.ndb_binlog_index
- > WHERE orig_epoch> = @latest
- > AND orig_server_id = 1
- > ORDER BY epoch ASC LIMIT 1;
您可以通过向
ndb_binlog_index
表中
添加适当的索引来提高此查询的性能,从而显着加快故障转移时间
。
有关
更多信息
,
请参见
第22.6.4节“NDB集群复制架构和表”
。
复制
服务器C
的值
@file
并
@pos
手动从服务器C
复制
到服务器F(或让您的应用程序执行等效操作)。
然后,在服务器F上,执行以下
CHANGE MASTER
TO
语句:
mysqlF> CHANGE MASTER TO
- > MASTER_HOST ='serverC'
- > MASTER_LOG_FILE ='@ file',
- > MASTER_LOG_POS = @ pos;
完成此操作后,您可以
START
SLAVE
在MySQL服务器F上
发出
声明,并且源自服务器B的任何缺失更新都将复制到服务器F.
该
CHANGE MASTER TO
语句还支持一个
IGNORE_SERVER_IDS
选项,
该
选项采用逗号分隔的服务器ID列表,并导致忽略源自相应服务器的事件。
有关更多信息,请参见
第13.4.2.1节“更改主语法”
和
第13.7.6.34节“显示从动语句语法”
。
有关此选项如何与
ndb_log_apply_status
变量
相互作用的信息
,请参见
第22.6.8节“使用NDB集群复制实现故障转移”
。
当使用涉及多个主设备的复制设置(包括循环复制)时,不同的主设备可能会尝试使用不同的数据更新从设备上的同一行。 NDB群集复制中的冲突解决方法通过允许使用用户定义的解析列来确定是否应在从属服务器上应用给定主服务器上的更新来提供解决此类冲突的方法。
通过NDB簇(支持某些类型的冲突解决的
NDB$OLD()
,
NDB$MAX()
,
NDB$MAX_DELETE_WIN()
)实现这种用户定义的列作为
“
时间戳
”
列(虽然它的类型不能为
TIMESTAMP
,因为在本节后面解释)。
这些类型的冲突解决方案始终是逐行应用的,而不是事务性的。
基于时代的冲突解决功能
NDB$EPOCH()
和
NDB$EPOCH_TRANS()
比较复制纪元的顺序(因此这些函数是事务性的)。
当发生冲突时,可以使用不同的方法来比较从站上的分辨率列值,如本节后面所述;
使用的方法可以基于每个表进行设置。
您还应该记住,应用程序有责任确保使用相关值正确填充分辨率列,以便在确定是否应用更新时,解析功能可以做出适当的选择。
要求。 解决冲突的准备工作必须在主人和奴隶身上进行。 以下列表中描述了这些任务:
-
在写入二进制日志的主服务器上,您必须确定发送了哪些列(所有列或仅有已更新的列)。 这是通过应用 mysqld 启动选项
--ndb-log-updated-only(本节稍后介绍)或基于每个表的表中的条目mysql.ndb_replication(参见 ndb_replication系统表 ) 整体上为MySQL服务器完成的 。注意如果要复制具有非常大的列(例如 列
TEXT或BLOB列)的表,--ndb-log-updated-only则还可以用于减少主从备份日志的大小并避免由于超出而导致的可能的复制失败max_allowed_packet。有关此问题的详细信息 , 请参见 第17.4.1.20节“复制和max_allowed_packet” 。
-
在从属服务器上,您必须确定要应用哪种类型的冲突解决方案( “ 最新时间戳获胜 ” , “ 相同时间戳获胜 ” , “ 主要获胜 ” , “ 主要获胜,完成交易 ” 或无)。 这是使用
mysql.ndb_replication系统表在每个表的基础上完成的(请参阅 ndb_replication系统表 )。 -
NDB Cluster还支持读取冲突检测,即检测一个群集中给定行的读取与另一个群集中同一行的更新或删除之间的冲突。 这需要通过
ndb_log_exclusive_reads在从站上 设置 等于1 获得的独占读锁 。 冲突读取读取的所有行都记录在例外表中。 有关更多信息,请参阅 读取冲突检测和解决方案 。
使用函数
NDB$OLD()
时
NDB$MAX()
,以及
NDB$MAX_DELETE_WIN()
基于时间戳的冲突解决方案,我们经常将用于确定更新的列称为
“
时间戳
”
列。
但是,此列的数据类型永远不会
TIMESTAMP
;
相反,它的数据类型应该是
INT
(
INTEGER
)或
BIGINT
。
在
“
时间戳
”
栏也应
UNSIGNED
和
NOT NULL
。
本节后面讨论
的
NDB$EPOCH()
和
NDB$EPOCH_TRANS()
函数通过比较在主NDB群集和辅助NDB群集上应用的复制时期的相对顺序来工作,而不使用时间戳。
主列控制。
我们可以根据
“
之前
”
和
“
之后
”
图像
看到更新操作
- 也就是说,应用更新之前和之后的表的状态。
通常,当用主键更新表时,
“
之前
”
图像不是很有意义;
但是,当我们需要在每次更新的基础上确定是否在复制从站上使用更新的值时,我们需要确保将两个映像都写入主服务器的二进制日志。
这是通过
mysqld
--ndb-log-update-as-write
选项
完成的
,如本节后面所述。
记录完整或部分行(--ndb-log-updated-only选项)
| 属性 | 值 |
|---|---|
| 命令行格式 | --ndb-log-updated-only[={OFF|ON}] |
| 系统变量 | ndb_log_updated_only |
| 范围 | 全球 |
| 动态 | 是 |
SET_VAR
提示适用
|
没有 |
| 类型 | 布尔 |
| 默认值 | ON |
出于解决冲突的目的,有两种记录行的基本方法,由
mysqld
--ndb-log-updated-only
选项
的设置决定
:
-
记录完整的行
-
仅记录已更新的列数据 - 即已设置其值的列数据,无论该值是否实际更改。 这是默认行为。
通常只需记录更新的列就足够了,而且效率更高;
但是,如果需要记录完整行,可以通过设置
--ndb-log-updated-only
为
0
或来完成
OFF
。
--ndb-log-update-as-write选项:将更改的数据记录为更新
| 属性 | 值 |
|---|---|
| 命令行格式 | --ndb-log-update-as-write[={OFF|ON}] |
| 系统变量 | ndb_log_update_as_write |
| 范围 | 全球 |
| 动态 | 是 |
SET_VAR
提示适用
|
没有 |
| 类型 | 布尔 |
| 默认值 | ON |
MySQL服务器
--ndb-log-update-as-write
选项
的设置
确定是否使用
“
之前
”
图像
执行日志记录
。
因为冲突解决是在MySQL服务器的更新处理程序中完成的,所以必须控制主服务器上的日志记录,以便更新是更新而不是写入;
也就是说,更新被视为现有行的更改而不是新行的写入(即使这些更换现有行)。
默认情况下,此选项处于启用状态;
换句话说,更新被视为写入。
(也就是说,默认情况下,更新
write_row
在二进制日志中
写为
事件,而不是
update_row
事件。)
要关闭该选项,请
使用
或
启动master
mysqld
。
在使用不同的存储引擎从NDB表复制到表时,必须执行此操作;
有关详细信息,
请参阅
从NDB复制到其他存储引擎
,以及
从NDB复制到非事务存储引擎
。
--ndb-log-update-as-write=0
--ndb-log-update-as-write=OFF
冲突解决控制。
通常在可能发生冲突的服务器上启用冲突解决。
与日志记录方法选择类似,它由表中的条目启用
mysql.ndb_replication
。
ndb_replication系统表。
要启用冲突解决,必须
在主服务器,从服务器或两者上
ndb_replication
的
mysql
系统数据库中
创建一个
表
,具体取决于要使用的冲突解决方案类型和方法。
此表用于基于每个表控制日志记录和冲突解决功能,并且每个表在复制中涉及一行。
ndb_replication
在要解决冲突的服务器上创建并填充控制信息。
在简单的主从设置中,数据也可以在从设备上本地更改,这通常是从设备。
在更复杂的主 - 主(双向)复制模式中,这通常是所涉及的所有主数据。
每行
mysql.ndb_replication
对应于正在复制的表,并指定如何记录和解决该表的冲突(即,使用哪个冲突解决功能,如果有)。
该
mysql.ndb_replication
表
的定义
如下所示:
CREATE TABLE mysql.ndb_replication(
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
主键使用HASH(db,table_name,server_id)
)ENGINE = NDB
PARTITION BY KEY(db,table_name);
此表中的列将在接下来的几段中介绍。
D b。
包含要复制的表的数据库的名称。
您可以使用其中一个或两个通配符,
_
并将其
%
作为数据库名称的一部分。
匹配类似于为
LIKE
运营商
实施的匹配
。
TABLE_NAME。
要复制的表的名称。
表名称可以包含通配符的一个或两个
_
和
%
。
匹配类似于为
LIKE
运营商
实施的匹配
。
SERVER_ID。 表所在的MySQL实例(SQL节点)的唯一服务器ID。
binlog_type。 要使用的二进制日志记录的类型。 确定如下表所示:
表22.426 binlog_type值,包含内部值和描述
| 值 | 内在价值 | 描述 |
|---|---|---|
| 0 | NBT_DEFAULT |
使用服务器默认 |
| 1 | NBT_NO_LOGGING |
请勿在二进制日志中记录此表 |
| 2 | NBT_UPDATED_ONLY |
仅记录更新的属性 |
| 3 | NBT_FULL |
记录完整行,即使没有更新(MySQL服务器默认行为) |
| 4 | NBT_USE_UPDATE |
(
仅
用于生成
NBT_UPDATED_ONLY_USE_UPDATE
和
NBT_FULL_USE_UPDATE
值 - 不用于单独使用)
|
| 五 | [ 未使用 ] | --- |
| 6 | NBT_UPDATED_ONLY_USE_UPDATE
(等于
NBT_UPDATED_ONLY | NBT_USE_UPDATE
)
|
即使值未更改,也请使用更新的属性 |
| 7 | NBT_FULL_USE_UPDATE
(等于
NBT_FULL |
NBT_USE_UPDATE
)
|
即使值未更改,也请使用整行 |
conflict_fn。 要应用的冲突解决功能。 必须将此函数指定为以下列表中显示的函数之一:
这些功能将在接下来的几段中介绍。
NDB $ OLD(列)。
如果
column_name
主设备和从设备
的值
相同,则应用更新;
否则,更新不会应用于从站,并且会将异常写入日志。
这由以下伪代码说明:
if(master_old_column_value==slave_current_column_value) 应用更新(); 其他 log_exception();
此功能可用于 “ 相同值赢 ” 冲突解决。 这种类型的冲突解决方案可确保不会从错误的主服务器对从服务器应用更新。
此函数使用 主控器 “ 之前 ” 图像中 的列值 。
NDB $ MAX(列)。 如果 来自主服务器的给定行 的 “ timestamp ” 列值高于从服务器上的列,则应用它; 否则它不会应用于从属设备。 这由以下伪代码说明:
如果(master_new_column_value>slave_current_column_value) 应用更新();
此功能可用于 “ 最大时间戳获胜 ” 冲突解决。 这种类型的冲突解决方案可确保在发生冲突时,最近更新的行的版本是持久存在的版本。
此功能使用 主控器 “ after ” 图像中 的列值 。
NDB $ MAX_DELETE_WIN()。
这是一个变种
NDB$MAX()
。
由于没有时间戳可用于删除操作,因此删除使用
NDB$MAX()
实际上被处理为
NDB$OLD
。
但是,对于某些用例,这不是最佳选择。
因为
NDB$MAX_DELETE_WIN()
,如果
添加或更新来自主服务器的现有行的给定行
的
“
timestamp
”
列值高于从服务器上的行,则应用它。
但是,删除操作被视为始终具有较高的值。
这在以下伪代码中说明:
if((master_new_column_value>slave_current_column_value) ||operation.type==“删除”) 应用更新();
此功能可用于 “ 最大时间戳,删除胜利 ” 冲突解决方案。 此类冲突解决方案可确保在发生冲突时,已删除或(最近)更新的行的版本是持续存在的版本。
与此同时
NDB$MAX()
,主
“
后
”
图像
的列值
是此函数使用的值。
NDB $ EPOCH()和NDB $ EPOCH_TRANS()。
该
NDB$EPOCH()
函数跟踪从属NDB群集上应用复制的纪元的顺序,该顺序与源自从属的更改有关。
此相对排序用于确定源自从站的更改是否与本地发起的任何更改同时发生,因此可能存在冲突。
以下描述中的大部分内容
NDB$EPOCH()
也适用于
NDB$EPOCH_TRANS()
。
文中注明了任何例外情况。
NDB$EPOCH()
是非对称的,在一个NDB群集中以双群集循环复制配置(有时称为
“
主动 - 主动
”
复制)运行。
我们在这里指的是它作为主要运行的集群,而另一个作为辅助集群。
主服务器上的从服务器负责检测和处理冲突,而辅助服务器上的从服务器不参与任何冲突检测或处理。
当主服务器上的从服务器检测到冲突时,它会将事件注入其自己的二进制日志中以补偿这些事件; 这可确保辅助NDB群集最终与主数据库重新对齐,从而防止主数据库和辅助数据库发生分歧。 这种补偿和重新调整机制要求主NDB集群始终赢得与次要的任何冲突 - 即主要的更改始终使用,而不是在发生冲突时使用次要更改。 这种 “ 主要永远胜利 ” 规则具有以下含义:
-
一旦在主服务器上提交,更改数据的操作将完全持久,并且不会因冲突检测和解决而撤消或回滚。
-
从主数据中读取的数据完全一致。 在主节点(本地或从节点)上提交的任何更改将不会在以后还原。
-
如果主服务器确定它们存在冲突,则稍后可以恢复在辅助服务器上更改数据的操作。
-
在辅助节点上读取的各个行始终是自洽的,每一行始终反映辅助节点提交的状态或主节点提交的状态。
-
在辅助节点上读取的行集在给定的单个时间点可能不一定是一致的。 因为
NDB$EPOCH_TRANS(),这是一种暂时的状态; 因为NDB$EPOCH(),它可以是持久状态。 -
假设一段足够长的时间没有任何冲突,辅助NDB集群(最终)上的所有数据都与主数据一致。
NDB$EPOCH()
并且
NDB$EPOCH_TRANS()
不需要任何用户架构修改或应用程序更改来提供冲突检测。
但是,必须仔细考虑所使用的模式以及所使用的访问模式,以验证整个系统的行为是否在指定的限制范围内。
每个
NDB$EPOCH()
和
NDB$EPOCH_TRANS()
函数都可以使用一个可选参数;
这是用于表示纪元的低32位的位数,应设置为不小于
CEIL(LOG2(TimeBetweenGlobalCheckpoints/TimeBetweenEpochs),1)
对于这些配置参数(2000和100毫秒,分别地)的默认值,这给5个比特的值,所以默认值(6)应是足够的,除非其它值被用于
TimeBetweenGlobalCheckpoints
,
TimeBetweenEpochs
或两者。
值太小会导致误报,而太大的值可能会导致数据库中浪费的空间过多。
双方
NDB$EPOCH()
并
NDB$EPOCH_TRANS()
插入了冲突行到相关的例外表中的条目,前提是这些表根据在本节别处描述的相同例外表架构规则被定义(见
NDB $ OLD(列)
)。
在创建要使用它的表之前,您需要创建任何异常表。
正如在本节中讨论的其他冲突检测功能,
NDB$EPOCH()
并且
NDB$EPOCH_TRANS()
是由包括在相关的条目激活
mysql.ndb_replication
表(参照
该ndb_replication系统表
)。
在此方案中,主NDB群集和辅助NDB群集的角色完全由
mysql.ndb_replication
表条目
决定
。
由于冲突检测算法使用
NDB$EPOCH()
且
NDB$EPOCH_TRANS()
不对称,因此必须为主从站和辅助从站的
server_id
条目
使用不同的值
。
DELETE
单独的操作
之间的冲突
不足以使用
NDB$EPOCH()
或
触发冲突
NDB$EPOCH_TRANS()
,并且时期内的相对位置无关紧要。
(缺陷#18459944)
冲突检测状态变量。
可以使用多个状态变量来监视冲突检测。
您可以看到
NDB$EPOCH()
自从此从属服务器上次从
Ndb_conflict_fn_epoch
系统状态变量
的当前值重新启动以来
在冲突中找到了多少行
。
Ndb_conflict_fn_epoch_trans
提供直接在冲突中找到的行数
NDB$EPOCH_TRANS()
。
Ndb_conflict_fn_epoch2
并
Ndb_conflict_fn_epoch2_trans
表示在冲突中的行数
NDB$EPOCH2()
和
NDB$EPOCH2_TRANS()
分别。
实际重新排列的行数,包括因其成员资格而受影响的行数或与其他冲突行相同的事务依赖性,由下式给出
Ndb_conflict_trans_row_reject_count
。
有关更多信息,请参见 第22.3.3.9.3节“NDB集群状态变量” 。
NDB $ EPOCH()的限制。
当使用
NDB$EPOCH()
执行冲突检测
时,当前适用以下限制
:
-
使用NDB Cluster epoch边界检测冲突,粒度与
TimeBetweenEpochs(默认值:100毫秒) 成比例 。 最小冲突窗口是两个群集上相同数据的并发更新始终报告冲突的最短时间。 这总是一个非零的时间长度,并且大致成比例2 * (latency + queueing + TimeBetweenEpochs)。 这意味着 - 假设TimeBetweenEpochs群集之间 的默认值 和忽略群集之间的任何延迟(以及任何排队延迟) - 最小冲突窗口大小约为200毫秒。 在查看预期的应用程序 “ 竞赛 ” 时应考虑此最小窗口 图案。 -
使用
NDB$EPOCH()和NDB$EPOCH_TRANS()函数的 表需要额外的存储空间 ; 每行需要1到32位额外空间,具体取决于传递给函数的值。 -
删除操作之间的冲突可能导致主要和次要之间的分歧。 当同时在两个群集上删除行时,可以检测到冲突,但不会记录冲突,因为删除了该行。 这意味着将不会检测到任何后续重新对齐操作的传播期间的进一步冲突,这可能导致分歧。
删除应该是外部序列化的,或仅路由到一个群集。 或者,应使用此类删除以及其后的任何插入以事务方式更新单独的行,以便可以跨行删除跟踪冲突。 这可能需要更改应用程序。
-
当使用 或 用于冲突检测 时,当前仅支持 循环 “ 主动 - 主动 ” 配置中的 两个NDB群集 。
NDB$EPOCH()NDB$EPOCH_TRANS()
NDB $ EPOCH_TRANS()。
NDB$EPOCH_TRANS()
扩展
NDB$EPOCH()
功能。
使用
“
主要赢取所有
”
规则(请参阅
NDB $ EPOCH()和NDB $ EPOCH_TRANS()
)
以相同的方式检测和处理冲突,
但是在发生冲突的同一事务中更新任何其他行的额外条件也被视为冲突。
换句话说,在
NDB$EPOCH()
二级中
NDB$EPOCH_TRANS()
重新
排列单个冲突行的位置,
重新
排列
冲突的事务。
此外,任何可检测地依赖于冲突事务的事务也被视为冲突,这些依赖性由辅助集群的二进制日志的内容确定。 由于二进制日志仅包含数据修改操作(插入,更新和删除),因此仅使用重叠数据修改来确定事务之间的依赖关系。
NDB$EPOCH_TRANS()
受到与之相同的条件和限制
NDB$EPOCH()
,并且还要求使用版本2二进制日志行事件(
--log-bin-use-v1-row-events
等于0),这会在二进制日志中为每个事件添加2个字节的存储开销。
此外,所有事务ID必须记录在辅助二进制日志(
--ndb-log-transaction-id
选项)中,这会增加进一步的变量开销(每行最多13个字节)。
请参阅 NDB $ EPOCH()和NDB $ EPOCH_TRANS() 。
状态信息。
服务器状态变量
Ndb_conflict_fn_max
提供
自上次
启动
mysqld
以来
由于
“
最大时间戳获胜
”
冲突解决
而未在当前SQL节点上应用行的次数的计数
。
自上次重新启动以来,
给定
mysqld
上
的
“
相同时间戳获胜
”
冲突解决方案
未应用行的次数
由全局状态变量给出
。
除了递增之外
,未使用的行的主键也会插入到
异常表中
,如本节后面所述。
Ndb_conflict_fn_old
Ndb_conflict_fn_old
NDB $ EPOCH2()。
该
NDB$EPOCH2()
函数类似于
NDB$EPOCH()
,除了
NDB$EPOCH2()
提供使用循环复制(
“
master-master
”
)拓扑的
删除 - 删除处理
。
在这种情况下,初级和次级的作用通过设置分配给所述两个主
ndb_slave_conflict_role
系统变量为适当的值上的每个主站(每个通常是一个
PRIMARY
,
SECONDARY
)。
完成此操作后,辅助设备所做的修改将由主设备反映到辅助设备,然后有条件地应用它们。
NDB $ EPOCH2_TRANS()。
NDB$EPOCH2_TRANS()
扩展
NDB$EPOCH2()
功能。
以相同的方式检测和处理冲突,并将主要和次要角色分配给复制群集,但是在发生冲突的同一事务中更新的任何其他行的额外条件也被视为冲突。
也就是说,
NDB$EPOCH2()
重新调整辅助中的各个冲突行,同时
NDB$EPOCH_TRANS()
重新调整冲突的事务。
哪里
NDB$EPOCH()
和
NDB$EPOCH_TRANS()
使用每行(每个上次修改的纪元)指定的元数据,在主服务器上确定从辅助服务器传入的复制行是否与本地提交的更改同时发生;
并发更改被视为冲突,后续异常表更新和次要重新对齐。
在主数据库上删除行时会出现问题,因此不再有任何最后修改的历元可用于确定是否存在任何复制操作冲突,这意味着未检测到冲突的删除操作。
这可能导致分歧,例如在一个集群上删除,与另一个集群同时删除和插入;
这就是为什么删除操作在使用时只能路由到一个群集的原因
NDB$EPOCH()
和
NDB$EPOCH_TRANS()
。
NDB$EPOCH2()
绕过刚才描述的问题 - 通过忽略任何删除 - 删除冲突来存储有关PRIMARY上已删除行的信息,并避免任何潜在的结果分歧。
这是通过反映成功应用于辅助节点并从辅助节点复制到辅助节点的任何操作来实现的。
在返回辅助节点时,它可以用于重新应用辅助节点上的操作,该操作由源自主节点的操作删除。
在使用时
NDB$EPOCH2()
,您应该记住,辅助应用从主要删除,删除新行,直到它被反射操作还原。
理论上,后续插入或更新次要与从主要删除冲突,但在这种情况下,我们选择忽略这一点并允许次要
“
赢
”
,以防止集群之间的分歧。
换句话说,删除后,主服务器不检测冲突,而是立即采用辅助服务器的以下更改。
因此,辅助状态可以在其进展到最终(稳定)状态时重新访问多个先前提交的状态,并且其中一些可能是可见的。
您还应该知道,将所有操作从辅助服务器反映到主服务器会增加主服务器日志日志的大小,以及对带宽,CPU使用率和磁盘I / O的需求。
反射操作在辅助节点上的应用取决于辅助节点上目标行的状态。
可以通过检查
Ndb_conflict_reflected_op_prepare_count
和
Ndb_conflict_reflected_op_discard_count
状态变量
来跟踪是否在辅助设备上应用反射的更改
。
应用的更改数量只是这两个值之间的差异(请注意,
Ndb_conflict_reflected_op_prepare_count
总是大于或等于
Ndb_conflict_reflected_op_discard_count
)。
当且仅当满足以下两个条件时才应用事件:
-
行的存在 - 即是否存在 - 与事件的类型一致。 对于删除和更新操作,该行必须已存在。 对于插入操作,该行必须 不 存在。
-
该行最后由主要修改。 可以通过执行反射操作来完成修改。
如果不满足这两个条件,则辅助设备将丢弃反射操作。
冲突解决异常表。
要使用
NDB$OLD()
冲突解决功能,还需要创建
NDB
与要使用此类冲突解决方案的
每个
表相
对应的异常表
。
使用
NDB$EPOCH()
或
时也是如此
NDB$EPOCH_TRANS()
。
此表的名称是要应用冲突解决方案的表的名称,并
$EX
附加
字符串
。
(例如,如果原始表
mytable
的名称
是
,则应该是相应的异常表名称的名称
mytable$EX
。)创建例外表的语法如下所示:
CREATE TABLEoriginal_table$ EX( [NDB $] server_id INT UNSIGNED, [NDB $] master_server_id INT UNSIGNED, [NDB $] master_epoch BIGINT UNSIGNED, [NDB $]统计INT UNSIGNED, [NDB $ OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW','DELETE_ROW', 'REFRESH_ROW','READ_ROW')NOT NULL,] [NDB $ CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST','ROW_ALREADY_EXISTS', 'DATA_IN_CONFLICT','TRANS_IN_CONFLICT')NOT NULL,] [NDB $ ORIG_TRANSID BIGINT UNSIGNED NOT NULL,]original_table_pk_columns, [orig_table_column|orig_table_column$ OLD |orig_table_column$新] [additional_columns,] PRIMARY KEY([NDB $] server_id,[NDB $] master_server_id,[NDB $] master_epoch,[NDB $] count) )ENGINE = NDB;
前四列是必需的。
前四列的名称和与原始表的主键列匹配的列并不重要;
然而,我们建议为了清楚和一致的原因,您使用这里显示的名字
server_id
,
master_server_id
,
master_epoch
,和
count
列,并使用相同的名称作为原始表匹配那些在原表的主键列。
如果例外表使用一个或多个可选列
NDB$OP_TYPE
,
NDB$CFT_CAUSE
或
NDB$ORIG_TRANSID
本节稍后讨论,则还必须使用前缀命名每个必需列
NDB$
。
如果需要,
NDB$
即使您没有定义任何可选列
,也可以使用
前缀来命名所需的列,但在这种情况下,必须使用前缀命名所有四个必需列。
在这些列之后,构成原始表主键的列应按照用于定义原始表的主键的顺序进行复制。 复制原始表的主键列的列的数据类型应与原始列的列相同(或大于)。 可以使用主键列的子集。
无论采用哪种NDB Cluster版本,例外表都必须使用
NDB
存储引擎。
(
NDB$OLD()
与异常表一起
使用的示例将
在本节后面显示。)
可以选择在复制的主键列之后定义附加列,但不能在其中任何列之前定义;
任何这样的额外列不能
NOT NULL
。
NDB Cluster支持三个额外的,预定义的可选列
NDB$OP_TYPE
,
NDB$CFT_CAUSE
和
NDB$ORIG_TRANSID
,这在接下来的几个段落中。
NDB$OP_TYPE
:此列可用于获取导致冲突的操作类型。
如果您使用此列,请按此处所示进行定义:
NDB $ OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW','DELETE_ROW',
'REFRESH_ROW','READ_ROW')NOT NULL
的
WRITE_ROW
,
UPDATE_ROW
和
DELETE_ROW
操作类型代表用户启动的操作。
REFRESH_ROW
操作是通过冲突解决生成的操作,用于补偿从检测到冲突的集群发送回原始集群的事务。
READ_ROW
操作是由独占行锁定义的用户启动的读取跟踪操作。
NDB$CFT_CAUSE
:您可以定义一个可选列
NDB$CFT_CAUSE
,它提供已注册冲突的原因。
此列(如果使用)的定义如下所示:
NDB $ CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST','ROW_ALREADY_EXISTS',
'DATA_IN_CONFLICT','TRANS_IN_CONFLICT')NOT NULL
ROW_DOES_NOT_EXIST
可以报告为原因
UPDATE_ROW
和
WRITE_ROW
操作;
ROW_ALREADY_EXISTS
可以报告
WRITE_ROW
事件。
DATA_IN_CONFLICT
在基于行的冲突函数检测到冲突时报告;
TRANS_IN_CONFLICT
当事务冲突函数拒绝属于完整事务的所有操作时,将报告。
NDB$ORIG_TRANSID
:
NDB$ORIG_TRANSID
列(如果使用)包含原始事务的ID。
此列应定义如下:
NDB $ ORIG_TRANSID BIGINT UNSIGNED NOT NULL
NDB$ORIG_TRANSID
是由64位生成的值
NDB
。
此值可用于将来自相同或不同异常表的属于同一冲突事务的多个异常表条目相关联。
其不是原始表的主键的一部分附加参考列可以命名
colname$OLDcolname$NEWcolname$OLDDELETE_ROW
事件的
操作
。
colname$NEWWRITE_ROW
事件,
UPDATE_ROW
事件或两种类型的事件的操作。
如果冲突操作不为给定的非主键引用列提供值,则exception表行包含
NULL
该列或该列的已定义缺省值。
在
mysql.ndb_replication
为复制设置数据表时读取表,因此必须在
创建要复制的表
mysql.ndb_replication
之前
插入与要复制的表对应的行
。
例子
以下示例假定您已经有一个正常工作的NDB集群复制设置,如 第22.6.5节“为复制准备NDB集群” 和 第22.6.6节“启动NDB集群复制(单个复制通道)”中所述 。
NDB $ MAX()示例。
假设您希望
在表上
启用
“
最大时间戳获胜
”
冲突解决方案
test.t1
,使用列
mycol
作为
“
时间戳
”
。
这可以使用以下步骤完成:
-
请确保您已经启动了主 的mysqld 用
--ndb-log-update-as-write=OFF。 -
在master上,执行以下
INSERT语句:INSERT INTO mysql.ndb_replication VALUES('test','t1',0,NULL,'NDB $ MAX(mycol)');在其中插入0
server_id表示访问此表的所有SQL节点都应使用冲突解决方案。 如果只想对特定的 mysqld 使用冲突解决方案 ,请使用实际的服务器ID。插入
NULL到所述binlog_type列具有作为插入0(相同的效果NBT_DEFAULT); 使用服务器默认值。 -
创建
test.t1表:CREATE TABLE test.t1(columnsmycol INT UNSIGNED,columns)ENGINE = NDB;现在,当对此表进行更新时,将应用冲突解决方案,并将具有最大值的行的版本
mycol写入从属。
其他
binlog_type
选项 - 例如
NBT_UPDATED_ONLY_USE_UPDATE
应该用于使用
ndb_replication
表而不是使用命令行选项
来控制主服务器上的日志记录
。
NDB $ OLD()示例。
假设
NDB
正在复制此处定义
的
表,并且您希望
为此表的更新
启用
“
相同时间戳获胜
”
冲突解决方案:
CREATE TABLE test.t2(
INT UNSIGNED NOT NULL,
b CHAR(25)NOT NULL,
columns,
mycol INT UNSIGNED NOT NULL,
columns,
PRIMARY KEY pk(a,b)
)ENGINE = NDB;
按所示顺序,需要执行以下步骤:
-
首先 - 在 创建 之前
test.t2- 您必须在mysql.ndb_replication表中 插入一行 ,如下所示:INSERT INTO mysql.ndb_replication VALUES('test','t2',0,NULL,'NDB $ OLD(mycol)');该
binlog_type列的 可能值 显示在本节的前面部分中。 该值'NDB$OLD(mycol)'应插入conflict_fn列中。 -
为其创建适当的例外表
test.t2。 此处显示的表创建语句包括所有必需的列; 必须在这些列之后以及在表的主键定义之前声明任何其他列。CREATE TABLE test.t2 $ EX( server_id INT UNSIGNED, master_server_id INT UNSIGNED, master_epoch BIGINT UNSIGNED, 算INT UNSIGNED, INT UNSIGNED NOT NULL, b CHAR(25)NOT NULL, [additional_columns,] PRIMARY KEY(server_id,master_server_id,master_epoch,count) )ENGINE = NDB;我们可以包含其他列,以获取有关给定冲突的类型,原因和原始事务ID的信息。 我们也不需要为原始表中的所有主键列提供匹配列。 这意味着您可以像这样创建例外表:
CREATE TABLE test.t2 $ EX( NDB $ server_id INT UNSIGNED, NDB $ master_server_id INT UNSIGNED, NDB $ master_epoch BIGINT UNSIGNED, NDB $ count INT UNSIGNED, INT UNSIGNED NOT NULL, NDB $ OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW','DELETE_ROW', 'REFRESH_ROW','READ_ROW')NOT NULL, NDB $ CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST','ROW_ALREADY_EXISTS', 'DATA_IN_CONFLICT','TRANS_IN_CONFLICT')NOT NULL, NDB $ ORIG_TRANSID BIGINT UNSIGNED NOT NULL, [additional_columns,] PRIMARY KEY(NDB $ server_id,NDB $ master_server_id,NDB $ master_epoch,NDB $ count) )ENGINE = NDB;注意该
NDB$前缀是必需的四个必需列,因为我们包括列的至少一个NDB$OP_TYPE,NDB$CFT_CAUSE或NDB$ORIG_TRANSID在表定义。 -
test.t2如前所示 创建表 。
对于要使用其执行冲突解决的每个表,必须遵循这些步骤
NDB$OLD()
。
对于每个这样的表,必须有相应的行
mysql.ndb_replication
,并且在与要复制的表相同的数据库中必须有一个例外表。
阅读冲突检测和解决方案。
NDB Cluster还支持跟踪读取操作,这使得循环复制设置可以管理一个集群中给定行的读取与另一个集群中同一行的更新或删除之间的冲突。
此示例使用
employee
和
department
表来模拟一个场景,在该场景中,员工在主群集(我们在下文中称为群集
A
)
上从一个部门移动到另一个部门,
而从属群集(以下称
B
)更新员工的员工数量交叉交易中的部门。
已使用以下SQL语句创建数据表:
#员工表
CREATE TABLE员工(
id INT PRIMARY KEY,
名称VARCHAR(2000),
dept INT NOT NULL
)ENGINE = NDB;
#部门表
CREATE TABLE部门(
id INT PRIMARY KEY,
名称VARCHAR(2000),
成员INT
)ENGINE = NDB;
这两个表的内容包括以下
SELECT
语句
的(部分)输出中显示的行
:
MySQL的>SELECT id, name, dept FROM employee;+ --------------- + ------ + | id | 名字| 部门| + ------ + -------- + ------ + ... | 998 | 迈克| 3 | | 999 | 乔| 3 | | 1000 | 玛丽| 3 | ... + ------ + -------- + ------ + MySQL的>SELECT id, name, members FROM department;+ ----- + ------------- + --------- + | id | 名字| 成员| + ----- + ------------- + --------- + ... | 3 | 旧项目| 24 | ... + ----- + ------------- + --------- +
我们假设我们已经在使用包含四个必需列的异常表(这些列用于此表的主键),操作类型和原因的可选列以及使用SQL语句创建的原始表的主键列如下所示:
CREATE TABLE员工$ EX(
NDB $ server_id INT UNSIGNED,
NDB $ master_server_id INT UNSIGNED,
NDB $ master_epoch BIGINT UNSIGNED,
NDB $ count INT UNSIGNED,
NDB $ OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW','DELETE_ROW',
'REFRESH_ROW','READ_ROW')NOT NULL,
NDB $ CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST',
'ROW_ALREADY_EXISTS',
'DATA_IN_CONFLICT',
'TRANS_IN_CONFLICT')NOT NULL,
id INT NOT NULL,
PRIMARY KEY(NDB $ server_id,NDB $ master_server_id,NDB $ master_epoch,NDB $ count)
)ENGINE = NDB;
假设在两个集群上发生了两个同时发生的事务。 在集群 A上 ,我们创建一个新部门,然后使用以下SQL语句将员工编号999移动到该部门:
BEGIN;INSERTINTO部门VALUES(4,“新项目”,1);UPDATE员工SET dept = 4 WHERE id = 999; 承诺;
同时,在集群
B上
,另一个事务从中读取
employee
,如下所示:
开始;
SELECT name FROM employee WHERE id = 999;
UPDATE部门SET成员=成员 - 1 WHERE id = 3;
承诺;
冲突解决机制通常不会检测到冲突的事务,因为冲突发生在read(
SELECT
)和更新操作之间。
您可以通过
在从属群集上
执行来规避此问题
。
以这种方式获取独占读锁会导致在主服务器上读取的任何行被标记为需要在从属群集上进行冲突解决。
如果我们在记录这些事务之前以这种方式启用独占读取,
则跟踪
集群
B
上的读取
并将其发送到集群
A
以进行解析;
将检测到员工行上的冲突,并且
中止
群集
B
上的事务
。
SET
ndb_log_exclusive_reads
= 1
冲突在例外表(在集群
A上
)中作为
READ_ROW
操作注册(
有关操作类型的说明,
请参阅
冲突解决例外表
),如下所示:
MySQL的> SELECT id, NDB$OP_TYPE, NDB$CFT_CAUSE FROM employee$EX;
+ ------- + ------------- + ------------------- +
| id | NDB $ OP_TYPE | NDB $ CFT_CAUSE |
+ ------- + ------------- + ------------------- +
...
| 999 | READ_ROW | TRANS_IN_CONFLICT |
+ ------- + ------------- + ------------------- +
读取操作中找到的任何现有行都会被标记。 这意味着异常表中可能会记录由同一冲突产生的多个行,如检查群集 A 上的更新 与 同时事务中同一表中 群集 B 上的多行读取 之间的冲突所示 。 在集群 A 上执行的事务 如下所示:
开始;
插入部门VALUES(4,“新项目”,0);
UPDATE员工SET dept = 4 WHERE dept = 3;
SELECT COUNT(*)INTO @count FROM employee WHERE dept = 4;
UPDATE部门SET成员= @count WHERE id = 4;
承诺;
同时,包含此处显示的语句的事务在集群 B 上运行 :
SET ndb_log_exclusive_reads = 1; #如果尚未启用,则必须设置
...
开始;
SELECT COUNT(*)INTO @count FROM employee WHERE dept = 3 FOR UPDATE;
UPDATE部门SET成员= @count WHERE id = 3;
承诺;
在这种情况下,
将读取
WHERE
与第二个事务中的条件
匹配的所有三行
SELECT
,并在例外表中标记,如下所示:
MySQL的> SELECT id, NDB$OP_TYPE, NDB$CFT_CAUSE FROM employee$EX;
+ ------- + ------------- + ------------------- +
| id | NDB $ OP_TYPE | NDB $ CFT_CAUSE |
+ ------- + ------------- + ------------------- +
...
| 998 | READ_ROW | TRANS_IN_CONFLICT |
| 999 | READ_ROW | TRANS_IN_CONFLICT |
| 1000 | READ_ROW | TRANS_IN_CONFLICT |
...
+ ------- + ------------- + ------------------- +
读取跟踪仅基于现有行执行。 基于给定条件跟踪的读取仅与 找到 的任何行冲突 ,而不与在交错事务中插入 的任何行冲突 。 这类似于在NDB Cluster的单个实例中执行独占行锁定的方式。
NDB Cluster版本的更改与本参考手册分开记录; 您可以在 NDB 8.0发行说明中 找到每个NDB Cluster 8.0发行版中的更改的 发行说明 ,以及 NDB 7.6发行说明中的 每个NDB Cluster 7.6发行 版的发行说明 。
您可以从 NDB Cluster发行说明 获取旧版 NDB Cluster的发行说明 。